【AI知识】过拟合、欠拟合和正则
一句话总结: 过拟合和欠拟合是机器学习中的两个相对的概念,正则化是用于解决过拟合的方法。
1. 欠拟合: 指模型在训练数据上表现不佳,不能充分捕捉数据的潜在规律,导致在训练集和测试集上的误差都很高。欠拟合意味着模型太简单,无法有效地学习数据中的重要特征,导致其预测能力差。
-
欠拟合的表现: 训练误差较高 / 测试误差较高 / 模型复杂度过低
-
欠拟合的原因:
-
模型过于简单,无法捕捉数据中的复杂模式。
-
模型使用的特征(输入变量)太少,或没有选择合适的特征,导致可能无法捕捉到数据中的重要信息。
-
训练时间过短,模型还没充分从数据中学习到有用的模式,如迭代次数过少或训练轮次不足。
-
过度正则化也可能导致欠拟合,正则化是为了防止过拟合,但如果正则化过强,可能会使模型变得过于简单。
-
如果数据中噪声过大,且模型没有足够的能力来拟合这些噪声的规律时,也可能会表现出欠拟合的现象。
-
-
如何解决欠拟合: 增加模型的复杂度 / 增加特征 / 训练时间增加 / 减少正则化强度 / 数据增强
2. 过拟合(Overfitting): 指的是模型在训练数据上表现得非常好,但在新的、未见过的数据(如测试集或验证集)上表现不佳的现象。即模型对训练数据的拟合程度过高,捕捉了数据中的噪声、细节和偶然性,而没有学习到数据的普遍规律,从而失去了对新数据的泛化能力。
-
过拟合的表现: 训练集表现很好,测试集表现差 / 模型的复杂度过高,能够拟合数据的每个小波动和噪声
-
过拟合的原因:
- 当模型的参数太多,或者模型的复杂度过高时,它会能够很好地拟合训练集中的所有数据点,包括数据中的噪声和细节。-
训练数据量太少,缺乏足够的数据来支持模型的泛化,使得模型无法学习到数据的普遍规律,容易出现过拟合。
-
训练时间过长,模型可能会开始“记住”训练数据,而不是学习数据的普遍规律,从而出现过拟合。
-
训练数据中的噪声(如错误的标签、输入的异常值等)可能会导致模型过拟合,模型会尝试拟合噪声,而不是学习有意义的模式。
-
缺乏正则化,正则化是控制模型复杂度的一种方法,如果没有适当的正则化,模型容易过度拟合训练数据。
-
-
如何解决过拟合:
-
使用简单的模型,减少参数量。
-
增加训练数据量,更多的数据有助于模型学习到更稳定的模式,而不是记住训练数据中的噪声。
-
数据增强(Data Augmentation),如果增加数据量不容易实现,可以通过数据增强来生成更多的训练数据。数据增强技术通过对现有数据进行旋转、平移、裁剪、缩放、翻转等操作,来增加数据集的多样性,在图像处理任务中非常常见。
-
正则化(Regularization),如L1/L2 正则化,Dropout。
-
交叉验证(Cross-validation),通过将数据集分成多个子集,进行多次训练和验证,模型在不同的验证集上的表现可以帮助评估是否出现过拟合。
-
早停(Early Stopping),在训练过程中,如果模型在验证集上的性能开始下降,说明模型可能开始过拟合训练数据。早停技术会在模型表现不再提升时停止训练,从而防止过拟合。
-
集成方法(Ensemble Methods),通过组合多个模型的结果来构建一个更强的模型,常用的方法如随机森林。
-
降维(Dimensionality Reduction)技术,如主成分分析(PCA)可以通过减少输入数据的维度来降低模型的复杂度,防止模型学习到数据中的噪声。
3. 正则化(Regularization): 是机器学习中用于防止模型过拟合的一种技术,目标是限制模型的复杂性。它通过对模型的参数施加限制或惩罚,避免模型在训练数据上过度“记忆”,而是学到一些更一般化的规律,从而提高模型的泛化能力。通常,正则化方法会在损失函数中增加一个正则化项,使得损失函数不仅考虑模型的预测误差,还考虑模型的复杂度。
常见的正则化方法:
-
L1 正则化(Lasso): 通过在损失函数中增加参数权重的绝对值和来限制模型的复杂度。L1 正则化的损失函数如下,其中, w i w_i wi是模型的参数,λ 是正则化超参数,控制正则化的强度。

作用和特点:-
稀疏性(Sparsity): L1 正则化的一个重要特点是它能够产生稀疏模型。即,通过惩罚权重的绝对值,L1 正则化可以将某些权重压缩为零,从而自动进行特征选择。这意味着一些特征会被“丢弃”,使得模型变得更加简单和高效。
-
特征选择: L1 正则化适用于特征数很多的情况,尤其是当很多特征可能与输出无关时。通过将不相关特征的权重置为零,L1 正则化有效地选择了最重要的特征。
-
缺点: 对特征之间的共线性不够鲁棒。如果数据中的特征高度相关,L1 正则化通常会选择其中一个特征,而忽略其他相关特征。
-
-
L2 正则化(Ridge): 通过在损失函数中增加参数权重的平方和来限制模型复杂度。L2 正则化的损失函数如下,其中, w i w_i wi是模型的参数,λ 是正则化超参数,控制正则化的强度。

作用和特点:- 权重的平滑: L2 正则化的作用是将权重的绝对值尽可能地减小,但不会完全使其为零。它鼓励模型权重较小且均匀分布,从而防止某些特征对模型的影响过大,避免过拟合。
- 不产生稀疏解: 与 L1 正则化不同,L2 正则化不会使得某些权重变为零,而是使所有权重都较小,模型的复杂度得到控制。
- 对特征间共线性鲁棒: 在特征高度相关的情况下,L2 正则化通常会均匀地分配权重,而不是选择其中一个特征。
- 缺点: 不具备特征选择功能。与 L1 正则化不同,L2 正则化不会将不相关的特征的权重压缩为零,因此无法自动进行特征选择。
-
Dropout: 是一种常用的神经网络正则化方法。它通过在训练过程中随机“丢弃”一部分神经元(即将其输出设置为零)来防止神经网络过拟合。
Dropout 使得神经网络在每次训练时都使用不同的子网络进行训练,从而防止网络对特定神经元的依赖,增强了模型的泛化能力。 -
早停(Early Stopping): 在训练过程中监控验证集的误差,当验证集误差停止改善时,提前停止训练。这可以防止模型在训练数据上训练过长时间,从而避免过拟合。
-
数据增强(Data Augmentation): 主要用于图像、文本等领域。通过对训练数据进行一系列变换(如旋转、缩放、裁剪、翻转等),生成新的数据样本,从而增加训练集的多样性,降低模型对训练数据的过度依赖,从而防止过拟合。
-
相关文章:
【AI知识】过拟合、欠拟合和正则
一句话总结: 过拟合和欠拟合是机器学习中的两个相对的概念,正则化是用于解决过拟合的方法。 1. 欠拟合: 指模型在训练数据上表现不佳,不能充分捕捉数据的潜在规律,导致在训练集和测试集上的误差都很高。欠拟合意味着模…...

MacOS编译webRTC源码小tip
简单记录一下,本人在编译webRTC时,碰到了一下比较烦人的问题,在MacOS终端下,搭建科学上网之后,chromium的depot_tools仓库成功拉下来了,紧接着,使用fetch以及gclient sync始终都返回curl相关的网…...
:文件压缩及解压缩命令)
Linux基础命令(三):文件压缩及解压缩命令
文件压缩及解压缩命令 tar — 打包和压缩 tar 是一个用于打包文件的工具,常常用来将多个文件或目录打包成一个单独的文件。它本身不进行压缩,但可以与压缩工具(如 gzip 或 bzip2)一起使用。 用法: 打包文件࿰…...

目标跟踪算法:ByteTrack、卡尔曼滤波、匈牙利算法、高置信度检测目标、低置信度检测目标
目录 1 ByteTrack特点 2 ByteTrack和SORT区别----个人通俗理解 3 ByteTrack算法原理 4 ByteTrack整体流程图 上一篇博客我复习了下SORT跟踪算法,这一篇博客我再复习下ByteTrack跟踪算法,ByteTrack里面也是用了卡尔曼滤波和匈牙利算法&#x…...

[定昌linux系统]如何安装jdk8
1:下载jdk8 的 arm64 的版本,由于官方下载需要gmail,我的gmail 密码忘了,所以从csdn上下载了一份,地址: https://download.csdn.net/download/qq_27742163/88533548?utm_mediumdistribute.pc_relevant_download.none…...
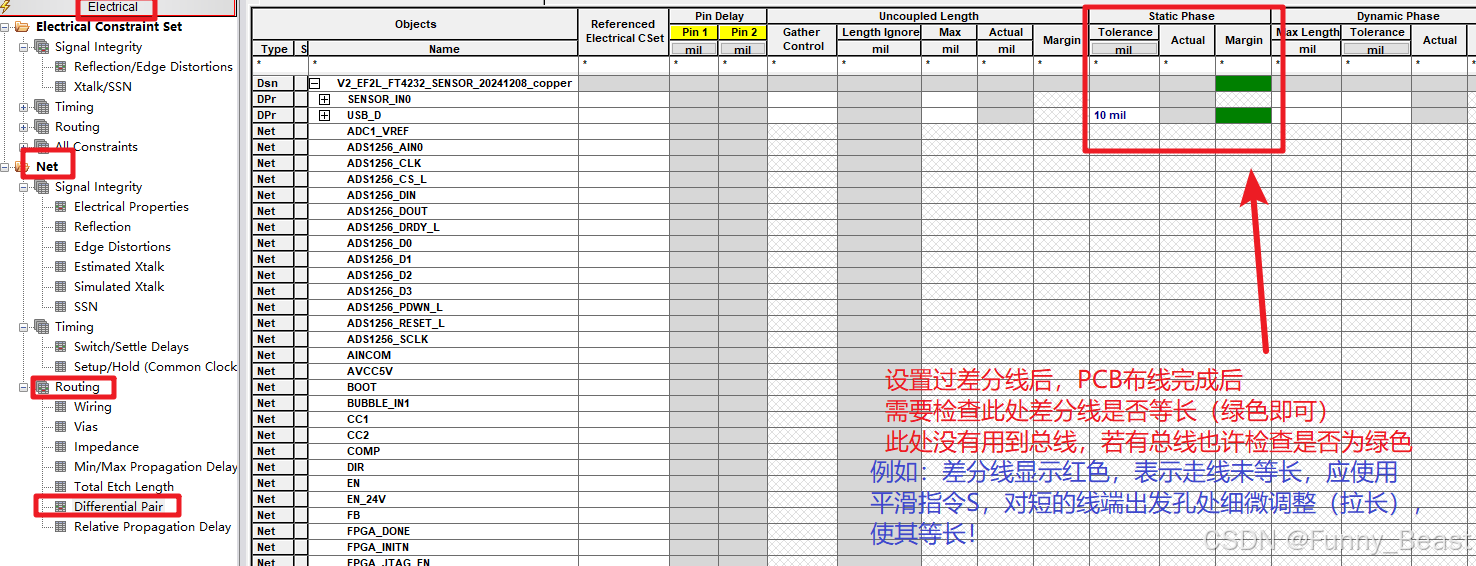
【Cadence32】PCB多层板电源、地平面层创建心得➕CM约束管理器Analyze分析显示设置➕“DP”报错DRC
【转载】Cadence Design Entry HDL 使用教程 【Cadence01】Cadence PCB Edit相对延迟与绝对延迟的显示问题 【Cadence02】Allegro引脚焊盘Pin设置为透明 【Cadence03】cadence不小心删掉钢网层怎么办? 【Cadence04】一般情况下Allegro PCB设计时的约束规则设置&a…...

基于SpringBoot+Vue的新闻管理系统
系统展示 用户前台界面 管理员后台界面 系统背景 随着互联网技术的飞速发展,信息传播速度不断加快,新闻媒体行业面临着巨大的机遇与挑战。传统的新闻媒体正在逐渐向数字化转型,而新闻管理系统作为数字化新闻媒体的核心组成部分,其…...
图的割点、割边(Tarjan算法)
深度优先搜索的利用。 在一个无向连通图中,如果删掉某个顶点后,图不再连通(即任意两点之间不能互相到达),我们称这样的顶点为割点。 在一个无向连通图中,如果删掉某条边后,图不在连通࿰…...

算法学习(十四)—— 二叉树的深度搜索(DFS)
目录 关于dfs 部分OJ题详解 2331. 计算布尔二叉树的值 129. 求根节点到叶节点数字之和 814. 二叉树剪枝 98. 验证二叉搜索树 230. 二叉搜索树中第K小的元素 257. 二叉树的所有路径 关于dfs 算法学习(十二)—— 递归,搜索,…...

【vue2】封装自定义的日历组件(三)之基础添加月份的加减定位到最新月份的第一天
我们在切换月份的时候,希望高亮显示在每个月的第一天上面,这样的效果我们要怎么来实现,其实也很简单,我们先看下实现的效果 实现效果 代码实现 原理就是获取到每月的第一天日期,然后再跟整个的数据进行对比ÿ…...

LabVIEW偏心圆筒流变仪测控系统
偏心圆筒流变仪是一种专门研究聚合物熔体在复杂流场中特殊流变行为的先进设备。通过结合硬件控制与LabVIEW软件开发,本系统实现了对流变仪功能的精准控制与数据采集,进一步提高了聚合物加工过程的研究精度和效率。 项目背景 传统的流变测量设备多集中于…...

Runloop
假设你的项目中有关tableView,然后还有一个定时器timer在执行,定时器代码如下: var num 0override func viewDidLoad() {super.viewDidLoad()let timer Timer(timeInterval: 1,target: self,selector: #selector(self.run),userInfo: nil,r…...
)
SpringBoot的Bean类三种注入方式(附带LomBok注入)
SpringBoot的Bean类三种注入方式(附带LomBok注入) 在 Spring Boot 中,Bean 的注入方式主要包括构造函数注入(Constructor Injection)、字段注入(Field Injection)以及 Setter 方法注入…...

开源向量数据库介绍说明
开源向量数据库 Milvus 特点:分布式、高性能,支持亿级向量检索。 支持的数据类型:文本、图像、音频、视频等。 使用场景:推荐系统、语义搜索、图像搜索。 数据存储后端:支持多种后端,如 SQLite、MySQL、Pos…...

【前端】深度解析 JavaScript 中的 new 关键字与构造函数
博客主页: [小ᶻ☡꙳ᵃⁱᵍᶜ꙳] 本文专栏: 前端 文章目录 💯前言💯构造函数的核心特性💯new 关键字的执行机制💯实例代码与详细解析代码示例代码逐步解析 💯new 的内部执行模拟执行过程的详细解析 &am…...

2024年华中杯数学建模C题基于光纤传感器的平面曲线重建算法建模解题全过程文档及程序
2024年华中杯数学建模 C题 基于光纤传感器的平面曲线重建算法建模 原题再现 光纤传感技术是伴随着光纤及光通信技术发展起来的一种新型传感器技术。它是以光波为传感信号、光纤为传输载体来感知外界环境中的信号,其基本原理是当外界环境参数发生变化时,…...

使用 `typing_extensions.TypeAlias` 简化类型定义:初学者指南
使用 typing_extensions.TypeAlias 简化类型定义:初学者指南 什么是 TypeAlias?安装 typing_extensions示例代码:如何使用 TypeAlias示例 1:为简单类型定义别名示例 2:为复杂类型定义别名示例 3:结合 Union…...

如何快速批量把 PDF 转为 JPG 或其它常见图像格式?
在某些特定场景下,将 PDF 转换为 JPG 图片格式却具有不可忽视的优势。例如,当我们需要在不支持 PDF 查看的设备或软件中展示文档内容时,JPG 图片能够轻松被识别和打开;此外,对于一些网络分享或社交媒体发布的需求&…...

如何在组织中塑造和强化绩效文化?
在组织中塑造和强化绩效文化是一个系统性的工程。 一、明确绩效目标与期望 设定清晰目标 组织应根据自身战略规划,将长期目标分解为具体、可衡量、可实现、相关联、有时限(SMART)的短期和中期绩效目标。例如,一家连锁餐饮企业的…...

OllyDbg、CE简单介绍
基础知识: 想要破解软件,需要一些基础知识: 文件格式:Windows对应PE、Linux对应ELF、IOS对应Mash-0。文件格式是指操作系统规定的每个段(代码段、数据段、堆、栈)的大小、顺序等信息。 汇编语言࿱…...

日语AI面试高效通关秘籍:专业解读与青柚面试智能助攻
在如今就业市场竞争日益激烈的背景下,越来越多的求职者将目光投向了日本及中日双语岗位。但是,一场日语面试往往让许多人感到步履维艰。你是否也曾因为面试官抛出的“刁钻问题”而心生畏惧?面对生疏的日语交流环境,即便提前恶补了…...
)
云计算——弹性云计算器(ECS)
弹性云服务器:ECS 概述 云计算重构了ICT系统,云计算平台厂商推出使得厂家能够主要关注应用管理而非平台管理的云平台,包含如下主要概念。 ECS(Elastic Cloud Server):即弹性云服务器,是云计算…...

Qt Widget类解析与代码注释
#include "widget.h" #include "ui_widget.h"Widget::Widget(QWidget *parent): QWidget(parent), ui(new Ui::Widget) {ui->setupUi(this); }Widget::~Widget() {delete ui; }//解释这串代码,写上注释 当然可以!这段代码是 Qt …...

(二)原型模式
原型的功能是将一个已经存在的对象作为源目标,其余对象都是通过这个源目标创建。发挥复制的作用就是原型模式的核心思想。 一、源型模式的定义 原型模式是指第二次创建对象可以通过复制已经存在的原型对象来实现,忽略对象创建过程中的其它细节。 📌 核心特点: 避免重复初…...

2025季度云服务器排行榜
在全球云服务器市场,各厂商的排名和地位并非一成不变,而是由其独特的优势、战略布局和市场适应性共同决定的。以下是根据2025年市场趋势,对主要云服务器厂商在排行榜中占据重要位置的原因和优势进行深度分析: 一、全球“三巨头”…...

处理vxe-table 表尾数据是单独一个接口,表格tableData数据更新后,需要点击两下,表尾才是正确的
修改bug思路: 分别把 tabledata 和 表尾相关数据 console.log() 发现 更新数据先后顺序不对 settimeout延迟查询表格接口 ——测试可行 升级↑:async await 等接口返回后再开始下一个接口查询 ________________________________________________________…...

MySQL 知识小结(一)
一、my.cnf配置详解 我们知道安装MySQL有两种方式来安装咱们的MySQL数据库,分别是二进制安装编译数据库或者使用三方yum来进行安装,第三方yum的安装相对于二进制压缩包的安装更快捷,但是文件存放起来数据比较冗余,用二进制能够更好管理咱们M…...
集成 Mybatis-Plus 和 Mybatis-Plus-Join)
纯 Java 项目(非 SpringBoot)集成 Mybatis-Plus 和 Mybatis-Plus-Join
纯 Java 项目(非 SpringBoot)集成 Mybatis-Plus 和 Mybatis-Plus-Join 1、依赖1.1、依赖版本1.2、pom.xml 2、代码2.1、SqlSession 构造器2.2、MybatisPlus代码生成器2.3、获取 config.yml 配置2.3.1、config.yml2.3.2、项目配置类 2.4、ftl 模板2.4.1、…...

Golang——6、指针和结构体
指针和结构体 1、指针1.1、指针地址和指针类型1.2、指针取值1.3、new和make 2、结构体2.1、type关键字的使用2.2、结构体的定义和初始化2.3、结构体方法和接收者2.4、给任意类型添加方法2.5、结构体的匿名字段2.6、嵌套结构体2.7、嵌套匿名结构体2.8、结构体的继承 3、结构体与…...

C# 表达式和运算符(求值顺序)
求值顺序 表达式可以由许多嵌套的子表达式构成。子表达式的求值顺序可以使表达式的最终值发生 变化。 例如,已知表达式3*52,依照子表达式的求值顺序,有两种可能的结果,如图9-3所示。 如果乘法先执行,结果是17。如果5…...