大模型语料库的构建过程 包括知识图谱构建 垂直知识图谱构建 输入到sql构建 输入到cypher构建 通过智能体管理数据生产组件
以下是大模型语料库的构建过程:
一、文档切分语料库构建
-
数据来源确定:
- 首先,需要确定语料库的数据来源。这些来源可以是多种多样的,包括但不限于:
- 网络资源:利用网络爬虫技术从各种网站(如新闻网站、学术网站、博客、社交媒体平台等)收集文本数据。例如,可以使用 Python 的
requests和BeautifulSoup库来爬取网页内容,设定不同的网址和规则,收集各类文章、帖子、评论等信息。 - 现有文档存储:整合企业内部的文档库、图书馆的数字资源、电子书籍、研究报告、学术论文等,这些文档可以以不同的格式存在,如 PDF、DOCX、TXT 等。
- 开放数据集:利用一些公开的数据集,像 Common Crawl 提供的大规模文本数据,以增加语料库的广度和多样性。
- 网络资源:利用网络爬虫技术从各种网站(如新闻网站、学术网站、博客、社交媒体平台等)收集文本数据。例如,可以使用 Python 的
- 首先,需要确定语料库的数据来源。这些来源可以是多种多样的,包括但不限于:
-
文档格式转换与清洗:
- 对于不同格式的文档,需要将其转换为统一的纯文本格式,以便后续处理。
- 对于 PDF 文档,使用
PyPDF2或pdfplumber等 Python 库将其转换为纯文本,去除不必要的格式信息。 - 对于 DOCX 格式的文档,可使用
python-docx库提取文本内容。 - 对于 HTML 内容,使用
BeautifulSoup库去除 HTML 标签和脚本,仅保留文本信息。
- 对于 PDF 文档,使用
- 对转换后的纯文本进行清洗,使用正则表达式和字符串处理函数去除无关信息,例如删除多余的空格、特殊字符、广告信息、版权声明等,确保文本内容的简洁性和一致性。
- 对于不同格式的文档,需要将其转换为统一的纯文本格式,以便后续处理。
-
文档切分操作:
- 将长文档按照语义单元进行切分,常见的切分方式有:
- 按段落切分:根据段落标记(如
\n\n)将文档拆分成段落,使每个段落成为一个独立的语料单元,以保证每个单元具有相对独立的语义。 - 按句子切分:利用自然语言处理工具(如
nltk或spaCy)的句子分割功能,将段落进一步拆分成句子,确保语料单元的细化和易于处理。
- 按段落切分:根据段落标记(如
- 将切分好的语料单元存储在数据库(如 MongoDB 或 Elasticsearch)或文件系统中,并为每个语料单元添加元数据,包括来源、时间戳、文档类型等信息,方便后续管理和检索。
- 将长文档按照语义单元进行切分,常见的切分方式有:
二、基于文档向量聚簇向量库构建
- 文档向量化:
- 利用 BGE(BAAI General Embedding)相关技术对切分好的语料单元进行向量化。
- 首先,安装并导入
sentence-transformers库,它提供了方便的接口来使用 BGE 模型。 - 加载预训练的 BGE 模型,如
BAAI/bge-base-en或BAAI/bge-large-en等,通过以下代码实现:
- 首先,安装并导入
- 利用 BGE(BAAI General Embedding)相关技术对切分好的语料单元进行向量化。
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('BAAI/bge-base-en')
- 将语料单元列表作为输入,使用模型将其编码为向量,示例代码如下:
sentences = ["This is a sample sentence", "Another sentence for embedding"]
sentence_embeddings = model.encode(sentences)
- 存储生成的向量,可以使用向量数据库,如 Faiss 或 Annoy 进行存储。以下是使用 Faiss 的简单示例:
import faiss
import numpy as np
d = sentence_embeddings.shape[1] # 向量维度
index = faiss.IndexFlatL2(d) # 构建一个 L2 距离的索引
index.add(sentence_embeddings.astype(np.float32)) # 添加向量到索引中
- 对于较长的语料单元,可以采用截断、采样或其他文本摘要技术,确保输入到 BGE 模型的长度在合理范围内。
- 聚类操作:
- 选择合适的聚类算法,如 K-Means、DBSCAN 或层次聚类。以 K-Means 为例,使用
scikit-learn库实现:
- 选择合适的聚类算法,如 K-Means、DBSCAN 或层次聚类。以 K-Means 为例,使用
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters=5, random_state=0).fit(sentence_embeddings)
cluster_labels = kmeans.labels_
- 确定聚类的数量可以使用肘部法则(Elbow Method)或轮廓系数(Silhouette Coefficient)进行评估。例如,使用肘部法则的代码如下:
sse = []
for k in range(1, 11):kmeans = KMeans(n_clusters=k, random_state=0).fit(sentence_embeddings)sse.append(kmeans.inertia_)
import matplotlib.pyplot as plt
plt.plot(range(1, 11), sse)
plt.xlabel('Number of clusters')
plt.ylabel('SSE')
plt.show()
- 存储聚类结果,将簇的信息存储在数据库中,包括簇中心向量、簇内语料单元的索引等,以便后续的分析和检索。
三、基于大模型指令的通用知识图谱语料库构建
- 实体和关系抽取:
- 从切分好的语料库中选取语料单元,使用大模型(如 GPT-3、BERT 或其微调版本)进行实体和关系抽取。通过精心设计的提示,引导大模型完成任务,例如:
import openai
openai.api_key = "your_api_key"
for corpus in corpus_list:prompt = f"从以下文本中提取所有的实体和关系:{corpus}"response = openai.Completion.create(engine="text-davinci-02",prompt=prompt,max_tokens=100)extracted_info = response.choices[0].text.strip()# 解析提取的信息,将其存储在结构化数据中,如 JSON 或 RDF 格式
- 对大模型的输出进行解析和验证,将提取的实体和关系存储在结构化的数据格式中,确保信息的准确性和完整性。
- 知识图谱构建:
- 将提取的实体作为节点,关系作为边,使用图数据库(如 Neo4j)构建通用知识图谱。以下是使用
py2neo库的示例:
- 将提取的实体作为节点,关系作为边,使用图数据库(如 Neo4j)构建通用知识图谱。以下是使用
from py2neo import Graph
graph = Graph("bolt://localhost:7687", auth=("neo4j", "password"))
# 假设 entity1 和 entity2 是提取的两个实体,relation 是它们之间的关系
graph.run("CREATE (e1:Entity {name: $name1})-[r:RELATION {type: $relation}]->(e2:Entity {name: $name2})", name1=entity1, relation=relation, name2=entity2)
- 对知识图谱进行扩充和优化,可以继续使用大模型的能力,通过生成性任务来推断新的实体和关系。例如,使用以下提示让大模型根据已有的信息推断更多内容:
prompt = "根据以下实体和关系,推断新的实体和关系:[已有实体和关系列表]"
response = openai.Completion.create(engine="text-davinci-02",prompt=prompt,max_tokens=100
)
- 将新推断的实体和关系添加到知识图谱中,以不断丰富知识图谱的内容。
四、基于垂直领域专家经验的大模型指令构建的垂直领域知识图谱语料库
-
领域数据收集与筛选:
- 针对特定的垂直领域(如医疗、金融、法律等)收集数据,来源可以包括:
- 专业数据库:如医疗领域的 PubMed、金融领域的 Bloomberg 等,从这些专业数据库中提取特定领域的数据。
- 企业内部数据:从企业的业务系统、数据库中收集与该领域相关的信息。
- 专业网站和报告:从行业网站、专业报告、期刊中获取最新的信息。
- 对收集的数据进行筛选和整理,结合垂直领域专家的经验,确保数据的相关性和专业性。
- 针对特定的垂直领域(如医疗、金融、法律等)收集数据,来源可以包括:
-
实体和关系抽取:
- 与通用知识图谱的构建类似,但会使用更具领域针对性的大模型或对大模型进行微调。首先,使用垂直领域专家提供的知识和经验来设计更精确的提示,引导大模型进行实体和关系抽取。例如,对于医疗领域:
import openai
openai.api_key = "your_api_key"
for medical_corpus in medical_corpus_list:prompt = f"从以下医疗文本中提取医疗实体和关系:{medical_corpus}"response = openai.Completion.create(engine="text-davinci-02",prompt=prompt,max_tokens=100)extracted_info = response.choices[0].text.strip()# 解析提取的信息,将其存储在结构化数据中,如 JSON 或 RDF 格式
- 对大模型的输出进行解析和验证,可邀请领域专家对结果进行审核,确保提取信息的准确性和专业性。
- 知识图谱构建与融合:
- 将提取的垂直领域实体和关系构建成垂直领域知识图谱,使用图数据库存储,如 Neo4j。
- 将垂直领域知识图谱与通用知识图谱进行融合,可以通过共享的实体或关系将两者连接起来,形成一个更完整的知识图谱。
五、根据输入生成 Cypher 语料库构建
-
问题收集:
- 从用户的问题、问答系统、客服记录等渠道收集自然语言问题,将这些问题存储在数据库(如 PostgreSQL、MySQL)或文件系统中,并添加问题的来源、时间、领域等元数据。
-
Cypher 语句生成:
- 使用大模型将自然语言问题转换为 Cypher 查询语句,使用特定的提示引导大模型完成转换,例如:
import openai
openai.api_key = "your_api_key"
for question in question_list:prompt = f"将以下自然语言问题转换为 Cypher 查询:{question}"response = openai.Completion.create(engine="text-davinci-02",prompt=prompt,max_tokens=100)cypher_query = response.choices[0].text.strip()# 存储自然语言问题和对应的 Cypher 查询,建立映射关系
- 对生成的 Cypher 查询语句进行验证和优化,可以使用 Neo4j 的 Cypher 解释器检查语句的语法和语义是否正确,对于错误或不合理的语句,使用大模型重新生成或人工修改。
六、根据输入生成 SQL 数据集
-
结构化数据确定:
- 确定需要使用 SQL 进行查询的数据来源,这些数据通常存储在关系型数据库中,如企业的业务数据库、数据仓库等,包含不同的表和字段,例如用户信息表、销售数据表、库存表等。
-
SQL 语句生成:
- 使用大模型将自然语言问题转换为 SQL 语句,使用相应的提示引导大模型完成任务,例如:
import openai
openai.api_key = "your_api_key"
for question in question_list:prompt = f"将以下自然语言问题转换为 SQL 查询:{question}"response = openai.Completion.create(engine="text-davinci-02",prompt=prompt,max_tokens=100)sql_query = response.choices[0].text.strip()# 存储自然语言问题和对应的 SQL 查询,建立映射关系
- 对生成的 SQL 语句进行验证和优化,使用数据库的 SQL 解释器(如 MySQL 的 `EXPLAIN` 语句)检查语句的可行性和性能,对于错误或不合理的语句,使用大模型重新生成或人工修改。
代码解释
- 文档切分部分:
- 使用各种工具将不同格式的文档转换为纯文本,并将长文本按段落或句子切分,方便后续处理和存储。
- 文档向量聚簇部分:
sentence-transformers库加载 BGE 模型,将语料单元转换为向量表示,使用faiss存储向量,使用scikit-learn的KMeans进行聚类操作,通过肘部法则确定聚类数量。
- 知识图谱部分:
- 利用大模型进行实体和关系抽取,使用
py2neo将提取的信息存储在 Neo4j 图数据库中,通过大模型的生成能力对知识图谱进行扩充。
- 利用大模型进行实体和关系抽取,使用
- Cypher 和 SQL 生成部分:
- 利用大模型将自然语言问题转换为 Cypher 或 SQL 语句,使用数据库的解释器对生成的语句进行验证和优化。
使用说明
- 在使用大模型时,要根据不同的任务设计合理的提示,引导大模型准确完成任务。
- 对于存储的数据,根据数据的特点选择合适的存储方式,如向量数据库存储向量、图数据库存储知识图谱、关系型数据库存储问题和语句映射等。
- 对大模型的输出要进行严格的验证和优化,保证最终结果的准确性和有效性。
- 定期更新和维护语料库,根据新的数据和领域的发展,更新聚类结果、知识图谱和生成的语句。
通过以上步骤,可以逐步构建一个功能完善的大模型语料库,为大模型在不同领域和应用场景中的使用提供全面的数据支持。
以下是一个面向数据集构建的智能体协调管理底层数据加工组件的设计,该组件可以对上述大模型语料库构建过程中的数据进行二次加工:
一、总体架构
该智能体协调管理底层数据加工组件主要由以下几个部分组成:
- 数据输入模块:负责接收来自不同来源的原始数据,包括文档语料库、向量数据、知识图谱数据等。
- 智能体控制器:根据数据的类型和加工需求,调度不同的加工模块进行数据的二次加工,并协调不同模块之间的工作。
- 数据加工模块:包含多个专门的加工模块,如实体关系加工模块、聚类优化模块、Cypher/SQL 语句优化模块等,分别对不同类型的数据进行二次加工。
- 数据存储模块:存储经过二次加工的数据,并提供数据的检索和更新功能。
- 监控与评估模块:对加工过程和结果进行监控和评估,以便持续优化加工过程。
二、模块详细设计
数据输入模块
-
功能:
- 从文件系统、数据库(如 MongoDB、Elasticsearch、Neo4j、MySQL 等)或外部数据源接收原始数据。
- 对输入的数据进行格式检查和初步的预处理,确保数据的一致性和可用性。
-
实现示例(以 Python 为例):
import json
import pymongo
from neo4j import GraphDatabasedef fetch_document_corpus():client = pymongo.MongoClient("mongodb://localhost:27017/")db = client["corpus_db"]collection = db["document_corpus"]return list(collection.find())def fetch_vector_data():# 假设向量数据存储在文件中with open("vector_data.json", "r") as f:return json.load(f)def fetch_knowledge_graph():driver = GraphDatabase.driver("bolt://localhost:7687", auth=("neo4j", "password"))with driver.session() as session:result = session.run("MATCH (n) RETURN n")return [record for record in result]def fetch_sql_data():connection = pymysql.connect(host="localhost",user="root",password="password",database="sql_corpus_db")cursor = connection.cursor()cursor.execute("SELECT * FROM sql_queries")return cursor.fetchall()def fetch_cypher_data():driver = GraphDatabase.driver("bolt://localhost:7687", auth=("neo4j", "password"))with driver.session() as session:result = session.run("MATCH (n:Query) RETURN n.cypher_query")return [record["cypher_query"] for record in result]
智能体控制器
-
功能:
- 分析输入数据的类型和特征,决定调用哪些数据加工模块进行处理。
- 协调不同加工模块的工作顺序和资源分配,确保数据的流畅加工。
- 处理加工过程中的异常和错误,进行相应的调整和重新调度。
-
实现示例(以 Python 为例):
class DataProcessingAgentController:def __init__(self):self.processing_modules = []def register_module(self, module):self.processing_modules.append(module)def process_data(self, data):for module in self.processing_modules:if module.can_process(data):try:processed_data = module.process(data)self.store_data(processed_data)except Exception as e:print(f"Error processing data with module {module}: {e}")self.handle_error(module, data)def store_data(self, data):# 调用数据存储模块存储数据passdef handle_error(self, module, data):# 处理异常,可能重新调度模块或调整数据处理流程pass
数据加工模块
实体关系加工模块
-
功能:
- 对于从大模型中提取的实体和关系数据,进行进一步的清理、验证和优化。
- 利用外部知识资源或规则,对实体和关系进行补充和完善。
- 解决实体和关系中的歧义或错误信息。
-
实现示例(以 Python 为例):
class EntityRelationProcessingModule:def can_process(self, data):# 判断数据是否为实体和关系数据return "entities" in data and "relations" in datadef process(self, data):entities = data["entities"]relations = data["relations"]# 进行实体和关系的优化处理optimized_entities = self.optimize_entities(entities)optimized_relations = self.optimize_relations(relations)return {"entities": optimized_entities, "relations": optimized_relations}def optimize_entities(self, entities):# 对实体进行清理和优化,例如去除重复、添加语义信息等cleaned_entities = []seen_entities = set()for entity in entities:if entity["name"] not in seen_entities:seen_entities.add(entity["name"])cleaned_entities.append(entity)return cleaned_entitiesdef optimize_relations(self, relations):# 对关系进行清理和优化,例如去除错误关系、添加缺失关系等optimized_relations = []for relation in relations:if self.is_valid_relation(relation):optimized_relations.append(relation)return optimized_relationsdef is_valid_relation(self, relation):# 检查关系的有效性,例如检查源节点和目标节点是否存在等return True
聚类优化模块
-
功能:
- 对基于文档向量的聚类结果进行优化,提高聚类的质量。
- 利用新的数据和算法对聚类结果进行更新和调整。
-
实现示例(以 Python 为例):
from sklearn.cluster import KMeans
import numpy as npclass ClusteringOptimizationModule:def can_process(self, data):# 判断数据是否为聚类数据return "cluster_labels" in data and "vectors" in datadef process(self, data):vectors = np.array(data["vectors"])cluster_labels = data["cluster_labels"]# 使用新的聚类算法或参数进行优化optimized_clusters = self.recluster(vectors, cluster_labels)return {"cluster_labels": optimized_clusters, "vectors": vectors}def recluster(self, vectors, cluster_labels):# 使用 K-Means 重新聚类kmeans = KMeans(n_clusters=len(set(cluster_labels)), random_state=0).fit(vectors)return kmeans.labels_
Cypher/SQL 语句优化模块
-
功能:
- 对大模型生成的 Cypher 和 SQL 语句进行语法检查和优化。
- 根据知识图谱和数据库结构,对语句进行性能优化。
- 利用专家规则和历史执行数据,对语句进行调整和改进。
-
实现示例(以 Python 为例):
class CypherSQLStatementOptimizationModule:def can_process(self, data):# 判断数据是否为 Cypher 或 SQL 语句return "cypher_queries" in data or "sql_queries" in datadef process(self, data):if "cypher_queries" in data:optimized_cypher = self.optimize_cypher(data["cypher_queries"])data["cypher_queries"] = optimized_cypherif "sql_queries" in data:optimized_sql = self.optimize_sql(data["sql_queries"])data["sql_queries"] = optimized_sqlreturn datadef optimize_cypher(self, cypher_queries):optimized_queries = []for query in cypher_queries:# 进行 Cypher 语句的优化,例如添加索引建议等optimized_query = self.syntax_check_cypher(query)optimized_queries.append(optimized_query)return optimized_queriesdef optimize_sql(self, sql_queries):optimized_queries = []for query in sql_queries:# 进行 SQL 语句的优化,例如添加索引建议等optimized_query = self.syntax_check_sql(query)optimized_queries.append(optimized_query)return optimized_queriesdef syntax_check_cypher(self, query):# 使用 Neo4j 的解释器进行语法检查和优化return querydef syntax_check_sql(self, query):# 使用数据库的 SQL 解释器进行语法检查和优化return query
数据存储模块
- 功能:
- 将经过二次加工的数据存储到相应的存储系统中,如更新文档语料库、更新知识图谱、存储优化后的 Cypher 和 SQL 语句等。
- 实现示例(以 Python 为例):
def store_document_corpus(corpus):client = pymongo.MongoClient("mongodb://localhost:27017/")db = client["corpus_db"]collection = db["document_corpus"]collection.insert_many(corpus)def store_knowledge_graph(entities, relations):driver = GraphDatabase.driver("bolt://localhost:7687", auth=("neo4j", "password"))with driver.session() as session:for entity in entities:session.run("CREATE (e:Entity {name: $name, properties: $properties})", name=entity["name"], properties=entity.get("properties", {}))for relation in relations:session.run("MATCH (a:Entity {name: $source}), (b:Entity {name: $target}) ""CREATE (a)-[r:RELATION {type: $type}]->(b)", source=relation["source"], target=relation["target"], type=relation["type"])def store_sql_queries(queries):connection = pymysql.connect(host="localhost",user="root",password="password",database="sql_corpus_db")cursor = connection.cursor()for query in queries:cursor.execute("INSERT INTO optimized_sql_queries (query) VALUES (%s)", (query,))connection.commit()def store_cypher_queries(queries):driver = GraphDatabase.driver("bolt://localhost:7687", auth=("neo4j", "password"))with driver.session() as session:for query in queries:session.run("CREATE (q:Query {cypher_query: $query})", query=query)
监控与评估模块
-
功能:
- 监控数据加工过程中的关键指标,如加工时间、加工成功率、错误率等。
- 对加工结果进行评估,如聚类质量评估、语句执行性能评估等。
- 根据评估结果,为智能体控制器提供优化建议。
-
实现示例(以 Python 为例):
import timeclass MonitoringEvaluationModule:def start_monitoring(self, start_time):end_time = time.time()processing_time = end_time - start_timeprint(f"Processing time: {processing_time}")def evaluate_clustering(self, cluster_labels, vectors):# 使用轮廓系数等指标评估聚类质量passdef evaluate_statements(self, statements, execution_results):# 根据执行结果评估语句性能pass
三、组件使用示例
# 初始化智能体控制器
controller = DataProcessingAgentController()# 注册数据加工模块
controller.register_module(EntityRelationProcessingModule())
controller.register_module(ClusteringOptimizationModule())
controller.register_module(CypherSQLStatementOptimizationModule())# 从不同来源获取数据
document_corpus = fetch_document_corpus()
vector_data = fetch_vector_data()
knowledge_graph = fetch_knowledge_graph()
sql_data = fetch_sql_data()
cypher_data = fetch_cypher_data()# 对数据进行处理
controller.process_data({"document_corpus": document_corpus})
controller.process_data({"vector_data": vector_data})
controller.process_data({"knowledge_graph": knowledge_graph})
controller.process_data({"sql_data": sql_data})
controller.process_data({"cypher_data": cypher_data})
代码解释
-
数据输入模块:
- 包含多个函数,用于从不同的数据源(如 MongoDB、Neo4j、文件系统等)获取不同类型的数据,为后续的加工处理提供原始数据。
-
智能体控制器:
DataProcessingAgentController类负责协调各个数据加工模块,根据数据类型调度相应的模块进行处理,并处理异常情况和存储结果。
-
数据加工模块:
- 每个加工模块都有
can_process方法,用于判断是否可以处理该类型的数据,process方法用于实际的数据加工操作。 EntityRelationProcessingModule对实体和关系数据进行清理和优化,确保数据的质量和准确性。ClusteringOptimizationModule对聚类结果进行重新聚类或优化,提高聚类的效果。CypherSQLStatementOptimizationModule对 Cypher 和 SQL 语句进行语法和性能优化。
- 每个加工模块都有
-
数据存储模块:
- 不同的存储函数将经过二次加工的数据存储到相应的存储系统中,确保数据的更新和持久化。
-
监控与评估模块:
- 对加工过程和结果进行监控和评估,为整个加工过程的优化提供依据。
使用说明
- 在使用该组件时,首先要确保各个数据源的连接信息(如数据库地址、用户名、密码等)正确配置。
- 根据需要添加或修改数据加工模块,以适应不同的数据和加工需求。
- 对于存储模块,根据实际的存储系统和数据结构,调整存储函数的实现细节。
- 监控和评估模块可以根据具体的评估指标和业务需求进行细化和扩展,以更好地指导加工过程的优化。
通过这样的智能体协调管理底层数据加工组件,可以对大模型语料库构建过程中的数据进行全面、系统的二次加工,提高数据的质量和可用性,为大模型的训练和应用提供更好的数据支持。
相关文章:

大模型语料库的构建过程 包括知识图谱构建 垂直知识图谱构建 输入到sql构建 输入到cypher构建 通过智能体管理数据生产组件
以下是大模型语料库的构建过程: 一、文档切分语料库构建 数据来源确定: 首先,需要确定语料库的数据来源。这些来源可以是多种多样的,包括但不限于: 网络资源:利用网络爬虫技术从各种网站(如新闻…...

阿里云ECS服务器域名解析
阿里云ECS服务器域名解析,以前添加两条A记录类型,主机记录分别为www和,这2条记录都解析到服务器IP地址。 1.进入阿里云域名控制台,找到域名 ->“解析设置”->“添加记录” 2.添加一条记录类型为A,主机记录为www,…...

牛客周赛71:A:JAVA
链接:登录—专业IT笔试面试备考平台_牛客网 来源:牛客网 题目描述 \hspace{15pt}对于给定的两个正整数 nnn 和 kkk ,是否能构造出 kkk 对不同的正整数 (x,y)(x,y)(x,y) ,使得 xynxynxyn 。 \hspace{15pt}我们认为两对正整数 (…...
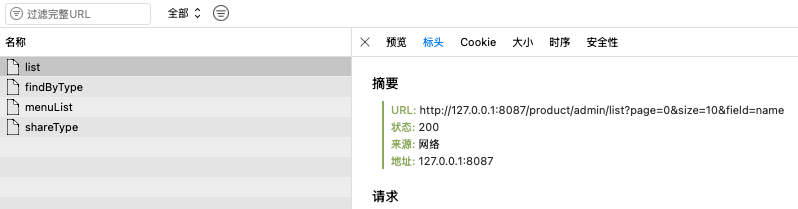
查询产品所涉及的表有(product、product_admin_mapping)
文章目录 1、ProductController2、AdminCommonService3、ProductApiService4、ProductCommonService5、ProductSqlService1. 完整SQL分析可选部分(条件筛选): 2. 涉及的表3. 总结4. 功能概述 查询指定管理员下所有产品所涉及的表?…...
算法基础学习Day5(双指针、动态窗口)
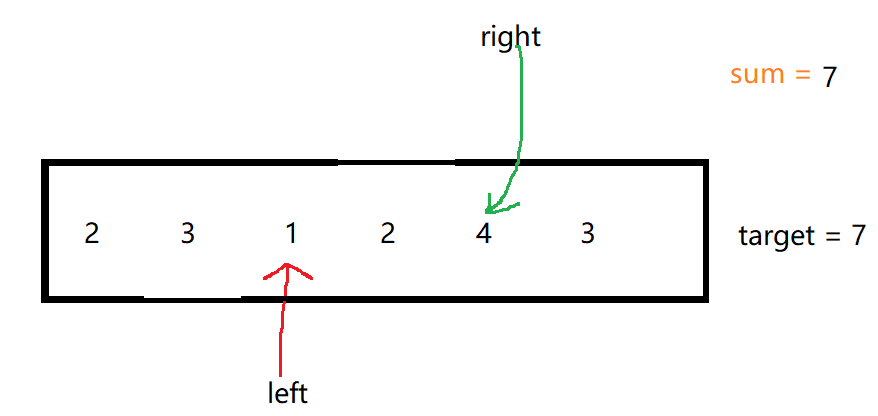
文章目录 1.题目2.题目解答1.四数之和题目及题目解析算法学习代码提交 2.长度最小的子数组题目及题目解析滑动窗口的算法学习方法一:单向双指针(暴力解法)方法二:同向双指针(滑动窗口) 代码提交 1.题目 18. 四数之和 - 力扣(LeetCode&#x…...
docker 部署 mysql 9.0.1
docker 如何部署 mysql 9 ,请看下面步骤: 1. 先看 mysql 官网 先点进去 8 版本的 Reference Manual 。 选择 9.0 版本的。 点到这里来看, 这里有一些基础的安装步骤,可以看一下。 - Basic Steps for MySQL Server Deployment wit…...

关于小标join大表,操作不当会导致笛卡尔积,数据倾斜
以前总是说笛卡尔积,笛卡尔积,没碰到过,今天在跑流程调度时,就碰到笛卡尔积了,本来,就是查询几个编码的信息,然后由于使用的是with tmp as,没使用where in ,所以跑的很慢 现象&#…...

SpringMVC全局异常处理
一、Java中的异常 定义:异常是程序在运行过程中出现的一些错误,使用面向对象思想把这些错误用类来描述,那么一旦产生一个错误,即创建某一个错误的对象,这个对象就是异常对象。 类型: 声明异常࿱…...

出海服务器可以用国内云防护吗
随着企业国际化进程的加速,越来越多的企业选择将业务部署到海外服务器上,以便更贴近国际市场。然而,海外服务器也面临着来自全球各地的安全威胁和网络攻击。当出海服务器遭受攻击时,是否可以借助国内的云服务器来进行有效的防护呢…...

从零开始的使用SpringBoot和WebSocket打造实时共享文档应用
在现代应用中,实时协作已经成为了非常重要的功能,尤其是在文档编辑、聊天系统和在线编程等场景中。通过实时共享文档,多个用户可以同时对同一份文档进行编辑,并能看到其他人的编辑内容。这种功能广泛应用于 Google Docs、Notion 等…...

Ant Design Pro实战--day01
下载nvm https://nvm.uihtm.com/nvm-1.1.12-setup.zip 下载node.js 16.16.0 //非此版本会报错 nvm install 16.16.0 安装Ant Design pro //安装脚手架 npm i ant-design/pro-cli -g //下载项目 pro create myapp //选择版本 simple 安装依赖 npm install 启动umi yarn add u…...

pcl点云库离线版本构建
某天在摸鱼的小邓接到任务需要进行点云数据的去噪,在万能的github中发现如下pcl库非常好使,so有了此, 1.下载vs2017连接如下: ed2k://|file|mu_visual_studio_community_2017_version_15.1_x86_x64_10254689.exe|1037144|12F5C1…...

字节高频算法面试题:小于 n 的最大数
问题描述(感觉n的位数需要大于等于2,因为n的位数1的话会有点问题,“且无重复”是指nums中存在重复,但是最后返回的小于n最大数是可以重复使用nums中的元素的): 思路: 先对nums倒序排序 暴力回…...

ElasticSearch常见面试题汇总
一、ElasticSearch基础: 1、什么是Elasticsearch: Elasticsearch 是基于 Lucene 的 Restful 的分布式实时全文搜索引擎,每个字段都被索引并可被搜索,可以快速存储、搜索、分析海量的数据。 全文检索是指对每一个词建立一个索引…...

Spring Boot如何实现防盗链
一、什么是盗链 盗链是个什么操作,看一下百度给出的解释:盗链是指服务提供商自己不提供服务的内容,通过技术手段绕过其它有利益的最终用户界面(如广告),直接在自己的网站上向最终用户提供其它服务提供商的…...

工作中常用springboot启动后执行的方法
前言: 工作中难免会遇到一些,程序启动之后需要提前执行的需求。 例如: 初始化缓存:在启动时加载必要的缓存数据。定时任务创建或启动:程序启动后创建或启动定时任务。程序启动完成通知:程序启动完成后通…...

力扣-图论-3【算法学习day.53】
前言 ###我做这类文章一个重要的目的还是给正在学习的大家提供方向和记录学习过程(例如想要掌握基础用法,该刷哪些题?)我的解析也不会做的非常详细,只会提供思路和一些关键点,力扣上的大佬们的题解质量是非…...

Linux上的C语言编程实践
说明: 这是个人对该在Linux平台上的C语言学习网站笨办法学C上的每一个练习章节附加题的解析和回答 ex1: 在你的文本编辑器中打开ex1文件,随机修改或删除一部分,之后运行它看看发生了什么。 vim ex1.c打开 ex1.c 文件。假如我们删除 return 0…...

芝法酱学习笔记(1.3)——SpringBoot+mybatis plus+atomikos实现多数据源事务
一、前言 1.1 业务需求 之前我们在讲解注册和登录的时候,有一个重要的技术点忽略了过去。那就是多数据源的事务问题。 按照我们的业务需求,monitor服务可能涉及同时对监控中心数据库和企业中心数据库进行操作,而我们希望这样的操作在一个事…...

【计算机网络】实验12:网际控制报文协议ICMP的应用
实验12 网际控制报文协议ICMP的应用 一、实验目的 验证ping命令和tracert命令的工作原理。 二、实验环境 Cisco Packet Tracer模拟器 三、实验过程 1.构建网络拓扑并进行信息标注,将所需要配置的IP地址写在对应的主机或者路由器旁边,如图1所示。 图…...

Docker 离线安装指南
参考文章 1、确认操作系统类型及内核版本 Docker依赖于Linux内核的一些特性,不同版本的Docker对内核版本有不同要求。例如,Docker 17.06及之后的版本通常需要Linux内核3.10及以上版本,Docker17.09及更高版本对应Linux内核4.9.x及更高版本。…...

在软件开发中正确使用MySQL日期时间类型的深度解析
在日常软件开发场景中,时间信息的存储是底层且核心的需求。从金融交易的精确记账时间、用户操作的行为日志,到供应链系统的物流节点时间戳,时间数据的准确性直接决定业务逻辑的可靠性。MySQL作为主流关系型数据库,其日期时间类型的…...

STM32+rt-thread判断是否联网
一、根据NETDEV_FLAG_INTERNET_UP位判断 static bool is_conncected(void) {struct netdev *dev RT_NULL;dev netdev_get_first_by_flags(NETDEV_FLAG_INTERNET_UP);if (dev RT_NULL){printf("wait netdev internet up...");return false;}else{printf("loc…...

最新SpringBoot+SpringCloud+Nacos微服务框架分享
文章目录 前言一、服务规划二、架构核心1.cloud的pom2.gateway的异常handler3.gateway的filter4、admin的pom5、admin的登录核心 三、code-helper分享总结 前言 最近有个活蛮赶的,根据Excel列的需求预估的工时直接打骨折,不要问我为什么,主要…...

页面渲染流程与性能优化
页面渲染流程与性能优化详解(完整版) 一、现代浏览器渲染流程(详细说明) 1. 构建DOM树 浏览器接收到HTML文档后,会逐步解析并构建DOM(Document Object Model)树。具体过程如下: (…...

【Java_EE】Spring MVC
目录 Spring Web MVC 编辑注解 RestController RequestMapping RequestParam RequestParam RequestBody PathVariable RequestPart 参数传递 注意事项 编辑参数重命名 RequestParam 编辑编辑传递集合 RequestParam 传递JSON数据 编辑RequestBody …...

uniapp中使用aixos 报错
问题: 在uniapp中使用aixos,运行后报如下错误: AxiosError: There is no suitable adapter to dispatch the request since : - adapter xhr is not supported by the environment - adapter http is not available in the build 解决方案&…...

Spring AI与Spring Modulith核心技术解析
Spring AI核心架构解析 Spring AI(https://spring.io/projects/spring-ai)作为Spring生态中的AI集成框架,其核心设计理念是通过模块化架构降低AI应用的开发复杂度。与Python生态中的LangChain/LlamaIndex等工具类似,但特别为多语…...

Springboot社区养老保险系统小程序
一、前言 随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱,社区养老保险系统小程序被用户普遍使用,为方…...

USB Over IP专用硬件的5个特点
USB over IP技术通过将USB协议数据封装在标准TCP/IP网络数据包中,从根本上改变了USB连接。这允许客户端通过局域网或广域网远程访问和控制物理连接到服务器的USB设备(如专用硬件设备),从而消除了直接物理连接的需要。USB over IP的…...