Elasticsearch:使用阿里 infererence API 及 semantic text 进行向量搜索

在之前的文章 “Elasticsearch 开放推理 API 新增阿里云 AI 搜索支持”,它详细描述了如何使用 Elastic inference API 来针对阿里的密集向量模型,稀疏向量模型, 重新排名及 completion 进行展示。在那篇文章里,它使用了很多的英文的例子。我觉得阿里的模型更适合中文字来进行展示。我们知道 Elastic 的开箱即用的稀疏向量模型 ELSER 只适合英文。目前它不支持中文。恰好阿里的稀疏向量模型填补了这个空白。稀疏向量可以开箱即用。对于很多不是很精通人工智能的开发者来说,这无疑是个福音,而且它使用的资源很小。
更多阅读,请参阅 “阿里云 AI 搜索推理服务”。
稀疏向量
根据文档,我们使用如下的命令来创建稀疏向量的推理 API 端点:
PUT _inference/sparse_embedding/alibabacloud_ai_search_sparse
{"service": "alibabacloud-ai-search","service_settings": {"api_key": "<api_key>","service_id": "ops-text-sparse-embedding-001","host": "default-j01.platform-cn-shanghai.opensearch.aliyuncs.com","workspace": "default"}
}在上面,我们需要从阿里云获得 api_key 来进行。运行上面的命令:

我们接下来可以通过如下的方式来测试(如下信息由地址获得):
POST _inference/alibabacloud_ai_search_sparse
{"input": "阿里巴巴(中国)有限公司成立于2007年03月26日,法定代表人蒋芳"
}上面的命令显示的结果为:

我们从上面的显示结果可以看出来,它和我们之前的 Elastic ELSER 输出是不同的。这里应该是 unicode。

上面的命令和下面的命令是一样的:
POST _inference/sparse_embedding/alibabacloud_ai_search_sparse
{"input": "阿里巴巴(中国)有限公司成立于2007年03月26日,法定代表人蒋芳"
}
因为每个 endpoint 在 Elasticsearch 创建时,都会自动检测并识别出它是什么类型的模型,所以上面路径中的 sparse_embedding 是可以省去的。
密集向量
同样,根据文档,我们使用如下的命令来创密集向量的推理 API 端点:
PUT _inference/text_embedding/alibabacloud_ai_search_embeddings
{"service": "alibabacloud-ai-search","service_settings": {"api_key": "<api_key>","service_id": "ops-text-embedding-001","host": "default-j01.platform-cn-shanghai.opensearch.aliyuncs.com","workspace": "default"}
}运行上面的命令,我们可以看到:

我们可以使用如下的命令来生成密集向量:
POST _inference/alibabacloud_ai_search_embeddings
{"input": "阿里巴巴(中国)有限公司成立于2007年03月26日,法定代表人蒋芳"
}
密集向量是一个浮点数的数组。我们在生成的时候,其实还是可以对它进行标量量化,这样可以节省内存消耗,并提高搜索的速度。更多有关向量量化的信息,请阅读文章 “Elasticsearch:dense vector 数据类型及标量量化”。
完成 - completion
我们甚至可以针对搜索的结果运用大模型来得到一个 completion 的结果,比如,我们使用如下的命令来生成一个 completion 的推理 API 端点:
PUT _inference/completion/alibabacloud_ai_search_completion
{"service": "alibabacloud-ai-search","service_settings": {"host" : "default-j01.platform-cn-shanghai.opensearch.aliyuncs.com","api_key": "{{API_KEY}}","service_id": "ops-qwen-turbo","workspace" : "default"}
}
我们可以通过如下的例子来展示 completion:
POST _inference/completion/alibabacloud_ai_search_completion
{"input": "阿里巴巴(中国)有限公司是什么时候成立的?"
}
这个结果是结合大模型而生成的。大模型提供了一个基于在大模型训练时得到的结果。
重新排名 - rerank
同样,我们可以按照如下的命令来生成一个 rerank 的推理 API 端点:
PUT _inference/rerank/alibabacloud_ai_search_rerank
{"service": "alibabacloud-ai-search","service_settings": {"api_key": "<api_key>","service_id": "ops-bge-reranker-larger","host": "default-j01.platform-cn-shanghai.opensearch.aliyuncs.com","workspace": "default"}
}
我们可以使用如下的例子来进行展示:
POST _inference/alibabacloud_ai_search_rerank
{"query": "阿里巴巴(中国)有限公司是哪一年成立的?","input": ["阿里巴巴是全球领先的B2B电子商务网上贸易平台","阿里巴巴(中国)有限公司成立于2007年03月26日,法定代表人蒋芳"]
}在上面的 input 里,我们列举了两个文档。我们可以通过 rerank 端点来针对这两个文档重新进行排序。假如我们想搜索的文字是 “阿里巴巴(中国)有限公司是哪一年成立的?”。那么 rerank 返回来的结果是:

从上面,我们可以看出来,第二个文档比第一个文档更为贴近,也就是它的相关度更高。
RAG 应用
在很多情况下,我们企业有很多的业务数据或者私有数据每时每刻都在生成,而大模型的知识仅限于在它生成的时候,所以很多的时候,大模型有很多的知识是不知道的。如果我们不对大模型的回答进行限制,那么它可能给出的答案就是错误的,从而产生幻觉。在实际的应用中,我们通常把业务或私有数据保存于像 Elasticsearch 这样的向量数据库中。在搜索时,我们首先搜索 Elasticsearch,并把搜索的结果发送给大模型做为 prompt 的一部分,这样就可以解决幻觉的问题。

首先,我们来创建一个稀疏向量索引:
PUT alibaba_sparse
{"mappings": {"properties": {"inference_field": {"type": "semantic_text","inference_id": "alibabacloud_ai_search_sparse"}}}
}
请注意在上面,我们使用了 semantic_text 字段。它使用于密集向量及稀疏向量,并且它还可以自动帮我们的文档进行分片。

有关分片的更多知识,请阅读文章 “Elasticsearch:检索增强生成背后的重要思想”。
然后,我们写入如下的两个文档:
PUT alibaba_sparse/_bulk
{"index": {"_id": "1"}}
{"inference_field": "阿里巴巴(中国)有限公司成立于2007年03月26日,法定代表人蒋芳"}
{"index": {"_id": "2"}}
{"inference_field": "百度是拥有强大互联网基础的领先AI公司。百度愿景是:成为最懂用户,并能帮助人们成长的全球顶级高科技公司。于2000年1月1日在中关村创建了百度公司"}我们通过如下的命令来进行搜索:
GET alibaba_sparse/_search
{"query": {"semantic": {"field": "inference_field","query": "百度公司是哪年成立的?"}}
}上面搜索的结果为:

很显然,含有百度的文档排在第一的位置。这个就是我们所说的向量搜索。
在实际的很多例子中,我们有时想得到一个唯一的答案,甚至这个答案是推理出来的,而不原始的文档。这个时候我们就需要用到大模型,也就是使用 completion 这个推理端点。
我们首先来做如下的搜索:
GET alibaba_sparse/_search
{"query": {"semantic": {"field": "inference_field","query": "阿里巴巴公司的法人是谁?"}}
}
这次只有一个文档被列出来了。我们在下面使用 completion 端点:
POST _inference/completion/alibabacloud_ai_search_completion
{"input": "<|system|>你是一个知识渊博的人.</s><|user|>CONTEXT:阿里巴巴(中国)有限公司成立于2007年03月26日,法定代表人蒋芳QUESTION: 阿里巴巴公司的法人是谁?</s><|assistant|>"
}在上面,我们把上面搜索的结果文档 “阿里巴巴(中国)有限公司成立于2007年03月26日,法定代表人蒋芳” 作为 context 的一部分,并把搜索的问题也一并提交。我们使用 completion 端点 API 来查看结果:

上面显示的结果是 “阿里巴巴公司的法定代表人是蒋芳”。很显然这个和之前的直接使用 completion 而没有 context 的结果是完全不同的:
POST _inference/completion/alibabacloud_ai_search_completion
{"input": "阿里巴巴法定代表是谁?"
}
我们可以这么理解,有了从 Elasticsearch 向量数据库(实时业务数据或私有数据)中搜索来的结果并提供给大模型,大模型可以根据这些上下文,得到更为贴近答案的搜索结果。这个在实际的使用中避免幻觉!
另外一个例子:
POST _inference/completion/alibabacloud_ai_search_completion
{"input": "<|system|>你是一个知识渊博的人.</s><|user|>CONTEXT:阿里巴巴(中国)有限公司成立于2007年03月26日,法定代表人蒋芳QUESTION: 阿里巴巴(中国)有限公司是什么时候成立的?</s><|assistant|>"
}

有关如何构建提示(prompt),请参阅我之前的文章 “为生成式人工智能制作 prompt 三明治”。
按照同样的方法,我们来创建一个密集向量的索引:
PUT alibaba_dense
{"mappings": {"properties": {"inference_field": {"type": "semantic_text","inference_id": "alibabacloud_ai_search_embeddings"}}}
}我们按照同样的方法来写入文档:
PUT alibaba_dense/_bulk
{"index": {"_id": "1"}}
{"inference_field": "阿里巴巴(中国)有限公司成立于2007年03月26日,法定代表人蒋芳"}
{"index": {"_id": "2"}}
{"inference_field": "百度是拥有强大互联网基础的领先AI公司。百度愿景是:成为最懂用户,并能帮助人们成长的全球顶级高科技公司。于2000年1月1日在中关村创建了百度公司"}
我们来对这个密集向量索引 alibaba_dense 来进行搜索:
GET alibaba_dense/_search
{"query": {"semantic": {"field": "inference_field","query": "Alibaba 的法人是谁?"}}
}
很显然,在我们的搜索中,我们并没有使用 “阿里巴巴”,我们查询的是 Alibaba。在向量空间里 “阿里巴巴” 等同于 “Alibaba”。同样地,
GET alibaba_dense/_search
{"query": {"semantic": {"field": "inference_field","query": "Baidu 是什么样的公司?"}}
}上面的搜索的结果是:

很显然,含有 “百度” 的文档排名为第一尽管我们搜索的是 “Baidu”。
好的,今天的分享就到这里。
相关文章:
Elasticsearch:使用阿里 infererence API 及 semantic text 进行向量搜索
在之前的文章 “Elasticsearch 开放推理 API 新增阿里云 AI 搜索支持”,它详细描述了如何使用 Elastic inference API 来针对阿里的密集向量模型,稀疏向量模型, 重新排名及 completion 进行展示。在那篇文章里,它使用了很多的英文…...

Linux WEB服务器的部署及优化
1.用户常用关于web的信息 1.1.什么是www www是world wide web的缩写,及万维网,也就是全球信息广播的意思。 通常说的上网就是使用www来查询用户所需要的信息。 www可以结合文字、图形、影像以及声音等多媒体,超链接的方式将信息以Internet…...

人工智能大模型LLM开源资源汇总(持续更新)
说明 目前是大范围整理阶段,所以存在大量机翻说明,后续会逐渐补充和完善资料,减少机翻并增加说明。 Github上的汇总资源(大部分英文) awesome-production-machine-learning 此存储库包含一系列精选的优秀开源库&am…...

目标跟踪算法:SORT、卡尔曼滤波、匈牙利算法
目录 1 目标检测 2 卡尔曼滤波 3《从放弃到精通!卡尔曼滤波从理论到实践》视频简单学习笔记 3.1 入门 3.2 进阶 3.2.1 状态空间表达式 3.2.2 高斯分布 3.3 放弃 3.4 精通 4 匈牙利算法 5 《【运筹学】-指派问题(匈牙利算法)》视…...

Java版-图论-拓扑排序与有向无环图
拓扑排序 拓扑排序说明 对一个有向无环图(Directed Acyclic Graph简称DAG)G进行拓扑排序,是将G中所有顶点排成一个线性序列,使得图中任意一对顶点u和v,若边<u,v>∈E(G),则u在线性序列中出现在v之前。通常,这样的线性序列称为满足拓扑次序(Topological Order)的序列…...

GTC2024 回顾 | 优阅达携手 HubSpot 亮相上海,赋能企业数字营销与全球业务增长
从初创企业入门到成长型企业拓展,再到 AI 驱动智能化运营,HubSpot 为企业的每步成长提供了全方位支持。 2024 年 11 月下旬,备受瞩目的 GTC2024 全球流量大会(上海)成功举办。本次大会汇聚了全国内多家跨境出海领域企业…...

eclipse启动的时候,之前一切很正常,但突然报Reason: Failed to determine a suitable driver class的解决
1、之前项目都是启动正常的,然后运行以后发现启动不了了,还会报错: 2、这个Reason: Failed to determine a suitable driver class,说是没有合适的驱动class spring:datasource:url: jdbc:sqlserver://192.168.1.101:1433;databa…...

_tkinter.TclError: can‘t find package tkdnd Unable to load tkdnd library.解决办法
Traceback (most recent call last): File “tkinterdnd2\TkinterDnD.py”, line 55, in _require _tkinter.TclError: can’t find package tkdnd During handling of the above exception, another exception occurred: Traceback (most recent call last): File “1.导入总表…...
VBA高级应用30例应用在Excel中的ListObject对象:向表中添加注释
《VBA高级应用30例》(版权10178985),是我推出的第十套教程,教程是专门针对高级学员在学习VBA过程中提高路途上的案例展开,这套教程案例与理论结合,紧贴“实战”,并做“战术总结”,以…...

folly库Conv类型转换源码解析
1,普通类型转换 例子1: bool boolV = true;EXPECT_EQ(to<bool>(boolV), true);int intV = 42;EXPECT_EQ(to<int>(intV), 42);float floatV = 4.2f;EXPECT_EQ(to<float>(floatV), 4.2f);double doubleV = 0.42;EXPECT_EQ(to<double>(doubleV), 0.42)…...

UE4 骨骼网格体合并及规范
实现代码 // Fill out your copyright notice in the Description page of Project Settings.#pragma once#include "CoreMinimal.h" #include "SkeletalMeshMerge.h" #include "Kismet/BlueprintFunctionLibrary.h" #include "AceMeshCom…...

Java版企业电子招标采购系统源业码Spring Cloud + Spring Boot +二次开发+ MybatisPlus + Redis
功能描述 1、门户管理:所有用户可在门户页面查看所有的公告信息及相关的通知信息。主要板块包含:招标公告、非招标公告、系统通知、政策法规。 2、立项管理:企业用户可对需要采购的项目进行立项申请,并提交审批,查看所…...

通过源码⼀步⼀步分析 ArrayList 扩容机制
ArrayList 是 Java 中常用的集合类,它底层实现是基于数组的。为了处理元素的动态增加,ArrayList 会在容量不足时进行扩容。以下是通过源码逐步分析 ArrayList 扩容机制的过程。 1. ArrayList 类的基本结构 ArrayList 继承自 AbstractList,实…...

源码分析之Openlayers中默认Controls控件渲染原理
概述 Openlayers 中默认的三类控件是Zoom、Rotate和Attribution 源码分析 defaults方法 Openlayers 默认控件的集成封装在defaults方法中,该方法会返回一个Collection的实例,Collection是一个基于数组封装了一些方法,主要涉及到数组项的添…...

中间件的分类与实践:从消息到缓存
目录 一. 中间件的基本概念 二. 中间件的主要类型 (1)消息中间件(Message-Oriented Middleware, MOM): (2)数据库中间件: (3)Web中间件: &a…...

京东e卡 h5st 4.96
声明: 本文章中所有内容仅供学习交流使用,不用于其他任何目的,抓包内容、敏感网址、数据接口等均已做脱敏处理,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关! 有相关问题请第一时间头像私信联系我删…...
)
《CSS 知识点》滚动条仅在 hover 时才显示(宽度不改变)
很简单! 滚动条的滑动小方块背景色默认透明,仅在hover时设置背景色; 滚动条的轨道背景色默认透明,仅在hover时设置背景色; /*滚动条的滑动小方块*/ ::-webkit-scrollbar-thumb {background: transparent; } /*hover…...

手里有病理切片+单细胞测序的数据,如何开展医工交叉的研究?
小罗碎碎念 这一期推文研究一个问题:病理如何与单细胞结合? 病理与单细胞的结合,时常出现在今年的各大顶刊中。 关于这一领域的研究,其实19年就开始了。我把部分低质量的文献做了剔除,但是也基本能反应这一领域的受关注…...

力矩扭矩传感器介绍
在机械臂(机器人臂)末端使用的力矩扭矩传感器主要用于测量机械臂末端执行器(例如机械手爪、抓取装置等)所受的扭矩和力。这些传感器对机械臂的控制系统至关重要,能够提供精确的力反馈信息,帮助实现更高效、…...

【Appium】AttributeError: ‘NoneType‘ object has no attribute ‘to_capabilities‘
目录 1、报错内容 2、解决方案 (1)检查 (2)报错原因 (3)解决步骤 3、解决结果 1、报错内容 在PyCharm编写好脚本后,模拟器和appium也是连接成功的,但是运行脚本时报错&…...

模型参数、模型存储精度、参数与显存
模型参数量衡量单位 M:百万(Million) B:十亿(Billion) 1 B 1000 M 1B 1000M 1B1000M 参数存储精度 模型参数是固定的,但是一个参数所表示多少字节不一定,需要看这个参数以什么…...

Oracle查询表空间大小
1 查询数据库中所有的表空间以及表空间所占空间的大小 SELECTtablespace_name,sum( bytes ) / 1024 / 1024 FROMdba_data_files GROUP BYtablespace_name; 2 Oracle查询表空间大小及每个表所占空间的大小 SELECTtablespace_name,file_id,file_name,round( bytes / ( 1024 …...

屋顶变身“发电站” ,中天合创屋面分布式光伏发电项目顺利并网!
5月28日,中天合创屋面分布式光伏发电项目顺利并网发电,该项目位于内蒙古自治区鄂尔多斯市乌审旗,项目利用中天合创聚乙烯、聚丙烯仓库屋面作为场地建设光伏电站,总装机容量为9.96MWp。 项目投运后,每年可节约标煤3670…...
基础光照(Basic Lighting))
C++.OpenGL (10/64)基础光照(Basic Lighting)
基础光照(Basic Lighting) 冯氏光照模型(Phong Lighting Model) #mermaid-svg-GLdskXwWINxNGHso {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-GLdskXwWINxNGHso .error-icon{fill:#552222;}#mermaid-svg-GLd…...

视觉slam十四讲实践部分记录——ch2、ch3
ch2 一、使用g++编译.cpp为可执行文件并运行(P30) g++ helloSLAM.cpp ./a.out运行 二、使用cmake编译 mkdir build cd build cmake .. makeCMakeCache.txt 文件仍然指向旧的目录。这表明在源代码目录中可能还存在旧的 CMakeCache.txt 文件,或者在构建过程中仍然引用了旧的路…...

七、数据库的完整性
七、数据库的完整性 主要内容 7.1 数据库的完整性概述 7.2 实体完整性 7.3 参照完整性 7.4 用户定义的完整性 7.5 触发器 7.6 SQL Server中数据库完整性的实现 7.7 小结 7.1 数据库的完整性概述 数据库完整性的含义 正确性 指数据的合法性 有效性 指数据是否属于所定…...

uniapp 开发ios, xcode 提交app store connect 和 testflight内测
uniapp 中配置 配置manifest 文档:manifest.json 应用配置 | uni-app官网 hbuilderx中本地打包 下载IOS最新SDK 开发环境 | uni小程序SDK hbulderx 版本号:4.66 对应的sdk版本 4.66 两者必须一致 本地打包的资源导入到SDK 导入资源 | uni小程序SDK …...
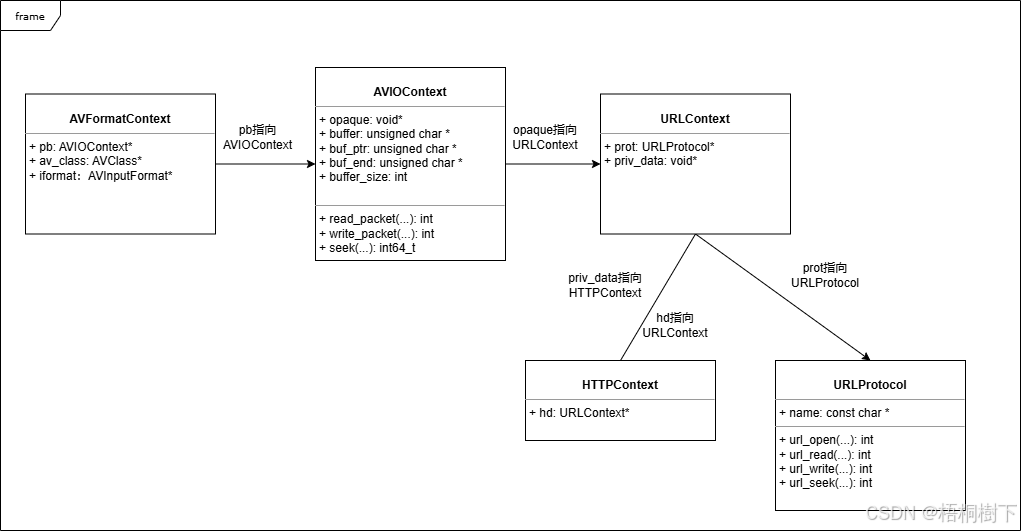
FFmpeg avformat_open_input函数分析
函数内部的总体流程如下: avformat_open_input 精简后的代码如下: int avformat_open_input(AVFormatContext **ps, const char *filename,ff_const59 AVInputFormat *fmt, AVDictionary **options) {AVFormatContext *s *ps;int i, ret 0;AVDictio…...

如何通过git命令查看项目连接的仓库地址?
要通过 Git 命令查看项目连接的仓库地址,您可以使用以下几种方法: 1. 查看所有远程仓库地址 使用 git remote -v 命令,它会显示项目中配置的所有远程仓库及其对应的 URL: git remote -v输出示例: origin https://…...

数据分析六部曲?
引言 上一章我们说到了数据分析六部曲,何谓六部曲呢? 其实啊,数据分析没那么难,只要掌握了下面这六个步骤,也就是数据分析六部曲,就算你是个啥都不懂的小白,也能慢慢上手做数据分析啦。 第一…...