python进阶-05-利用Selenium来实现动态爬虫
python进阶-05-利用Selenium来实现动态爬虫
一.说明
这是python进阶部分05,我们上一篇文章学习了Scrapy来爬取网站,但是很多网站需要登录才能爬取有用的信息,或者网站的静态部分是一个空壳,内容是js动态加载的,或者人机验证,请求拦截转发等,那么这种情况Scrapy来爬取就很费劲,有人说我们可以分析登录接口,js加载内容实现爬取我们需要的内容,哼哼你想多了,请求内容经过服务器转发给你加过包的!所以还是不行,那就没有办法来抓取我们想要的数据了么?
有,就是Selenium动态爬取网页信息,Selenium会启动和控制浏览器直接实现自动登录,Selenium直接运行在浏览器中从而可以直接爬取js加载完的信息。
那么Selenium这么强大有没有什么缺陷?也是有的,效率不高!
但省事啊,就跟Python一样!人生苦短,我用Python,好,继续开始我们的日拱一卒,让我们彻底掌握这一技术!。
二.安装
要使用Selenium,就得先安装,但是Selenium安装不仅仅需要安装Selenium python库,还要在python虚拟环境中安装对应的浏览器驱动!所以安装Selenium分别为 安装Selenium Python库 下载和安装浏览器及对应浏览器的驱动 。
-
下载Selenium库
pip install selenium -i http://pypi.doubanio.com/simple --trusted-host pypi.doubanio.com -
下载对应浏览器和驱动
-
Chrome的驱动chromedriver
#谷歌浏览器驱动官方 https://chromedriver.storage.googleapis.com/index.html # 谷歌浏览器官方开发者文档 # https://developer.chrome.com/docs/chromedriver/downloads?hl=zh-cn #谷歌浏览器历史版本下载 https://downzen.com/en/windows/google-chrome/versions/?page=1 #禁用谷歌浏览器更新,大家可看下面的文章,在此不进行重复说明 #chrome://version/ 查看浏览器版本和安装文件夹 https://blog.csdn.net/weixin_65228312/article/details/141724054
通过测试发现chromedriver下载的均为支持最新版本的谷歌浏览器,大家安装最新浏览器即可!
如果驱动不支持 会提示您应该安装的浏览器版本,安装指定浏览器版本,和禁用浏览器更新即可。
-
Firefox的驱动geckodriver下载地址
https://github.com/mozilla/geckodriver/releases/
-
IE/微软Edge的驱动IEdriver下载地址
https://www.nuget.org/packages/Selenium.WebDriver.IEDriver/
-
-
为了帮助大家快速理解,我已经准备了一套Firefox浏览器和对应驱动geckodriver,一套谷歌131版本的浏览器驱动,在我的资源里面,大家可以直接下,下载地址如下
#Firefox的驱动geckodriver https://download.csdn.net/download/Lookontime/90059540 #Chrome的驱动chromedriver https://download.csdn.net/download/Lookontime/90091812 -
如何安装,浏览器直接安装,
geckodriver.exe驱动文件放到 我们的虚拟python环境的Scripts中即可#直接复制到虚拟环境 Scripts中即可,如果没有装虚拟环境的小伙 直接将驱动放到python跟目录下 F:\python_demo_07\my_venv\Scripts
三.启动selenium驱动浏览器的方法
-
启动谷歌浏览器来爬取内容
from selenium import webdriver from selenium.webdriver.common.keys import Keys #提供键盘按键的支持,如回车键 RETURNbrowser = webdriver.Chrome(executable_path="F:/python_demo_07/my_venv/Scripts/chromedriver.exe") browser.get('http://www.myurlhub.com') elem = browser.find_element_by_name("q") #获取节点 elem.clear() #清除搜索框中的默认文本 elem.send_keys("pycon") #输入 "pycon" elem.send_keys(Keys.RETURN) #模拟按下键盘的回车键 RETURN,触发搜索 assert "No results found." not in driver.page_source #断言页面标题中包含 "Python"。如果不包含,则抛出异常 browser.close() #关闭浏览器窗口 -
启动Firefox
from selenium import webdriver browser = webdriver.Firefox(executable_path="F:/python_demo_07/my_venv/Scripts/geckodriver.exe") browser.get('http://www.myurlhub.com') -
启动IE(不推荐 古老项目可能需要吧)
from selenium import webdriver browser = webdriver.Ie(executable_path="F:/python_demo_07/my_venv/Scripts/IEDriver .exe") browser.get('http://www.myurlhub.com')
四.selenium的详细用法
4.1 声明浏览器对象
from selenium import webdriver
browser = webdriver.Chrome()
browser = webdriver.Firefox()
browser = webdriver.Safari()
browser = webdriver.Edge()
browser = webdriver.PhantomJS()
4.2 访问页面
from selenium import webdriver
browser = webdriver.Chrome(executable_path="F:/python_demo_07/my_venv/Scripts/chromedriver.exe")
browser.get('http://www.myurlhub.com')
print(browser.page_source) #打印页面源代码
browser.close() #关闭浏览器窗口
4.3 查找单个元素
from selenium import webdriver
from selenium.webdriver.common.by import By #
browser = webdriver.Chrome(executable_path="F:/python_demo_07/my_venv/Scripts/chromedriver.exe")
browser.get('http://www.myurlhub.com')
# 1. 根据 ID 查找元素
element_by_id = browser.find_element(By.ID, "element_id")
element_by_id = browser.find_element_by_id("element_id")# 2. 根据 name 属性查找元素
element_by_name = browser.find_element(By.NAME, "element_name")# 3. 根据 class 名称查找元素
element_by_class_name = browser.find_element(By.CLASS_NAME, "class_name")
element_by_class_name = browser.find_element_by_css_selector("#class_name")
# 4. 根据标签名查找元素
element_by_tag_name = browser.find_element(By.TAG_NAME, "tag_name")# 5. 使用 CSS 选择器查找元素
element_by_css = browser.find_element(By.CSS_SELECTOR, ".class_name #element_id")# 6. 使用 XPath 查找元素
element_by_xpath = browser.find_element(By.XPATH, "//div[@class='class_name']")
browser.close() #关闭浏览器窗口
4.4 查找多个元素
from selenium import webdriver
from selenium.webdriver.common.by import By# 启动 Chrome 浏览器
browser = webdriver.Chrome(executable_path="F:/python_demo_07/my_venv/Scripts/chromedriver.exe")# 打开指定网址
browser.get('http://www.myurlhub.com')# 1. 根据 class 名查找多个元素
elements_by_class_name = browser.find_elements(By.CLASS_NAME, "class_name")
element_by_class_name = browser.find_element_by_css_selector("#class_name")
# 2. 根据标签名查找多个元素
elements_by_tag_name = browser.find_elements(By.TAG_NAME, "tag_name")# 3. 使用 CSS 选择器查找多个元素
elements_by_css = browser.find_elements(By.CSS_SELECTOR, ".class_name #element_id")# 4. 使用 XPath 查找多个元素
elements_by_xpath = browser.find_elements(By.XPATH, "//div[@class='class_name']")# 输出查找到的元素个数
print(f"找到 {len(elements_by_class_name)} 个元素")4.5元素的交互操作
from selenium import webdriver
from selenium.webdriver.common.by import By# 启动 Chrome 浏览器
browser = webdriver.Chrome(executable_path="F:/python_demo_07/my_venv/Scripts/chromedriver.exe")# 打开指定网址
browser.get('http://www.myurlhub.com')#点击按钮
button = browser.find_element(By.ID, "submit_button")
button.click() # 点击按钮#输入文本
input_box = browser.find_element(By.NAME, "username")
input_box.send_keys("my_username") # 输入文本#清除文本框内容
input_box.clear() # 清空输入框#获取元素文本
paragraph = browser.find_element(By.TAG_NAME, "p")
print(paragraph.text) # 输出段落的文本内容#获取元素属性
link = browser.find_element(By.LINK_TEXT, "Python")
href = link.get_attribute("href") # 获取链接的 href 属性
print(href)#提交表单
form = browser.find_element(By.ID, "search_form")
form.submit() # 提交表单#悬停操作from selenium.webdriver.common.action_chains import ActionChains #引入动作链element = browser.find_element(By.ID, "hover_element")
actions = ActionChains(browser)
actions.move_to_element(element).perform() # 悬停在元素上#拖放操作
source = browser.find_element(By.ID, "drag_source")
target = browser.find_element(By.ID, "drop_target")actions = ActionChains(browser)
actions.drag_and_drop(source, target).perform() # 拖放操作#键盘操作
from selenium.webdriver.common.keys import Keysinput_box = browser.find_element(By.NAME, "query")
input_box.send_keys("selenium" + Keys.ENTER) # 输入文本并回车#切换到 iframe
iframe = browser.find_element(By.TAG_NAME, "iframe")
browser.switch_to.frame(iframe) # 切换到 iframe4.6 执行JavaScript 脚本
#执行简单 JavaScript 脚本
browser.execute_script("alert('Hello from Selenium!');")
#操作 DOM 元素
element = browser.find_element(By.ID, "my_element")
browser.execute_script("arguments[0].style.backgroundColor = 'yellow';", element)
#获取js执行结果
title = browser.execute_script("return document.title;")
print(title) # 输出页面标题
#滚动页面
# 滚动到页面底部
browser.execute_script("window.scrollTo(0, document.body.scrollHeight);")# 滚动到特定元素
element = browser.find_element(By.ID, "target_element")
browser.execute_script("arguments[0].scrollIntoView(true);", element)
#添加动态内容
browser.execute_script("document.body.innerHTML += '<p>Added by Selenium</p>';")
#处理窗口大小和位置
# 调整窗口大小
browser.execute_script("window.resizeTo(1024, 768);")# 获取窗口位置
position = browser.execute_script("return window.screenX, window.screenY;")
print(position)4.7 获取元素信息
element = browser.find_element(By.ID, "my_element")
print(element.text) # 输出元素的文本内容element = browser.find_element(By.NAME, "username")
value = element.get_attribute("value") # 获取输入框的值
print(value)href = element.get_attribute("href") # 获取链接的 href 属性
print(href)element = browser.find_element(By.CLASS_NAME, "button")
color = element.value_of_css_property("color") # 获取按钮的文字颜色
print(color)element = browser.find_element(By.ID, "my_element")
print(element.tag_name) # 输出标签名,如 'div'、'input'element = browser.find_element(By.ID, "my_element")
print(element.size) # 输出元素的宽度和高度 {'width': 100, 'height': 50}
print(element.location) # 输出元素的位置 {'x': 50, 'y': 100}element = browser.find_element(By.ID, "my_element")
print(element.is_displayed()) # 检查元素是否可见
print(element.is_enabled()) # 检查元素是否启用
print(element.is_selected()) # 检查复选框或单选按钮是否选中element = browser.find_element(By.ID, "my_element")
print(element.is_displayed()) # 检查元素是否可见
print(element.is_enabled()) # 检查元素是否启用
print(element.is_selected()) # 检查复选框或单选按钮是否选中element = browser.find_element(By.ID, "my_element")
print(element.get_attribute("outerHTML")) # 输出元素的完整 HTML
print(element.get_attribute("innerHTML")) # 输出元素内部的 HTML4.8 等待
等待的目的是确保操作的元素已经出现在页面上,避免因加载延迟导致的异常,Selenium 中等待分为隐式等待和显式等待
4.8.1 隐式等待
对整个 WebDriver 会话生效,隐式等待会在查找元素时,等待一定的时间。如果在超时时间内找到了元素,就继续执行;如果超时,抛出 NoSuchElementException
from selenium import webdriverbrowser = webdriver.Chrome()
browser.implicitly_wait(10) # 设置隐式等待时间为10秒browser.get("http://example.com")
element = browser.find_element(By.ID, "my_element") # 如果元素在10秒内加载完成,立即返回4.8.2 显式等待
显式等待会针对特定条件或特定元素等待指定时间。可以结合条件使用,比如等待元素可见、可点击等。
Selenium 提供了一些常见的等待条件,配合显式等待使用:
presence_of_element_located: 等待元素出现在 DOM 中,但不一定可见。visibility_of_element_located: 等待元素出现在 DOM 中并可见。element_to_be_clickable: 等待元素可以被点击。text_to_be_present_in_element: 等待某元素的文本出现。alert_is_present: 等待弹窗出现。
#等待元素点击
from selenium.webdriver.common.by import By
from selenium.webdriver.common.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as ECbrowser = webdriver.Chrome()browser.get("http://example.com")# 等待最多10秒,直到元素可被点击
element = WebDriverWait(browser, 10).until(EC.element_to_be_clickable((By.ID, "my_element"))
)
element.click() # 点击元素#等待元素可见
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC# 等待元素可见,最多 10 秒
element = WebDriverWait(browser, 10).until(EC.visibility_of_element_located((By.CLASS_NAME, "visible-element"))
)
element2 = WebDriverWait(self.driver, 10).until(EC.presence_of_element_located((By.CSS_SELECTOR, 'p img'))
)
print(element.text) # 输出元素文本#等待文本出现在元素中,等待元素中出现特定文本 "Success"。
element = WebDriverWait(browser, 10).until(EC.text_to_be_present_in_element((By.ID, "status"), "Success")
)
print("Text found!")#等待多个元素加载完成
elements = WebDriverWait(browser, 10).until(EC.presence_of_all_elements_located((By.TAG_NAME, "li"))
)
for element in elements:print(element.text)#等待按钮变为可点击状态
button = WebDriverWait(browser, 10).until(EC.element_to_be_clickable((By.CSS_SELECTOR, ".submit-button"))
)
button.click() # 点击按钮#等待 iframe 可切换
iframe = WebDriverWait(browser, 10).until(EC.frame_to_be_available_and_switch_to_it((By.TAG_NAME, "iframe"))
)
print("Switched to iframe")
iframe = WebDriverWait(browser, 10).until(EC.frame_to_be_available_and_switch_to_it((By.TAG_NAME, "iframe"))
)
print("Switched to iframe")# 等待 alert 弹窗出现
alert = WebDriverWait(browser, 10).until(EC.alert_is_present())
alert.accept() # 接受 alert 弹窗#等待元素属性变化 等待元素的 class 属性变为 "completed"。
element = browser.find_element(By.ID, "progress")
WebDriverWait(browser, 10).until(lambda driver: element.get_attribute("class") == "completed"
)
print("Progress completed!")#等待页面标题变更
WebDriverWait(browser, 10).until(EC.title_contains("Dashboard"))
print("Page loaded with expected title!")#等待特定元素不可见
WebDriverWait(browser, 10).until(EC.invisibility_of_element_located((By.ID, "loading-spinner"))
)
print("Spinner disappeared!")#等待文件下载完成(JavaScript 控制按钮触发下载)点击下载按钮后,通过检查页面的 cookie 确认文件下载完成。
download_button = WebDriverWait(browser, 10).until(EC.element_to_be_clickable((By.ID, "download-btn"))
)
download_button.click()WebDriverWait(browser, 20).until(lambda driver: "file_downloaded=true" in driver.execute_script("return document.cookie")
)
print("File download completed!")4.9 浏览器的前进和后退,刷新等操作
from selenium import webdriver
import timebrowser = webdriver.Chrome()# 打开两个页面
browser.get("https://www.example.com")
time.sleep(2) # 等待页面加载
browser.get("https://www.google.com")
time.sleep(2)# 后退到第一个页面
browser.back()
print("后退到:", browser.current_url)# 前进到第二个页面
browser.forward()
print("前进到:", browser.current_url)# 刷新页面
browser.refresh()
print("页面已刷新")4.10 cookies处理(了解即可 selenium 不需要操作cookies)
from selenium import webdriverbrowser = webdriver.Chrome()# 打开网站
browser.get("https://www.example.com")# 添加 Cookie
browser.add_cookie({"name": "my_cookie", "value": "cookie_value"})# 获取所有 Cookies
print("所有 Cookies:", browser.get_cookies())# 获取指定 Cookie
print("单个 Cookie:", browser.get_cookie("my_cookie"))# 删除指定 Cookie
browser.delete_cookie("my_cookie")# 删除所有 Cookies
browser.delete_all_cookies()
# 刷新页面以使添加和删除cookie 生效
browser.refresh()browser.quit()4.11 JWT令牌处理(了解即可 selenium 不需要操作JWT 和发送请求)
#方式一 from selenium import webdriver
from selenium.webdriver.common.by import By# 初始化浏览器
browser = webdriver.Chrome()# 打开目标页面(需与 JWT 的域匹配)
browser.get("https://www.example.com")# 添加 JWT 令牌到 Cookie
jwt_token = "your_jwt_token_here"
browser.add_cookie({"name": "Authorization", # 一般服务端会使用这个名称,但请根据具体情况修改"value": f"Bearer {jwt_token}","domain": "www.example.com", # 确保域名与当前页面匹配"path": "/"
})# 刷新页面或访问需要 JWT 身份验证的页面
browser.refresh()# 验证是否登录成功
print("Current URL:", browser.current_url)#方式二browser.execute_script("""fetch('https://www.example.com/protected', {method: 'GET',headers: {'Authorization': 'Bearer your_jwt_token_here'}}).then(response => response.json()).then(data => console.log(data));
""")4.12 切换页面操作
#页面切换
from selenium import webdriver
import timebrowser = webdriver.Chrome()# 打开第一个页面
browser.get("https://www.example.com")
print("当前窗口句柄:", browser.current_window_handle)# 打开新标签页
browser.execute_script("window.open('https://www.google.com');")
time.sleep(2) # 等待页面加载# 获取所有窗口句柄
handles = browser.window_handles
print("所有窗口句柄:", handles)# 切换到新标签页(第二个窗口)
browser.switch_to.window(handles[1])
print("当前窗口句柄:", browser.current_window_handle)
print("当前页面 URL:", browser.current_url)# 切换回第一个窗口
browser.switch_to.window(handles[0])
print("当前窗口句柄:", browser.current_window_handle)
print("当前页面 URL:", browser.current_url)browser.quit()#iframe 切换
from selenium import webdriverbrowser = webdriver.Chrome()
browser.get("https://www.example.com")# 切换到 iframe
iframe = browser.find_element_by_tag_name("iframe")
browser.switch_to.frame(iframe)# 在 iframe 内部执行操作
element = browser.find_element_by_id("inner_element")
element.click()# 切换回主页面
browser.switch_to.default_content()# 继续在主页面操作
browser.quit()五.案例一 爬取翻译内容(技术文章仅用于学习与研究目的,不得用于违法行为,如需要翻译接口请购买正版翻译接口)
别看百度翻译很简单,其实我们直接Requests百度翻译或者Scrapy 会发现当字符超过一定长度,就无法获取结果,因为页面结果是js动态生成的!
针对这种情况,就需要分析页面结构,隐藏接口等情况,才能爬取,且翻译的字符超过一定数量接口就会改变,导致我们在做百度翻译,失败!
但是现在不同的!这时候就适合用selenium技术!不用哪些花里胡哨的的操作!
但是利用selenium技术,爬取页面内容会很慢,如需翻译接口,请购买百度翻译接口,本文主要是用来解释selenium技术。
1.开发环境
python 3.6.8
火狐浏览器:65.0.2 (64 位)
#Firefox的驱动geckodriver
https://download.csdn.net/download/Lookontime/90059540
1.我们新建一个FastAPI接口,创建和启用FastAPI接口,看我的这篇文章:
https://blog.csdn.net/Lookontime/article/details/143696629
2.在项目文件夹中创建main.py 代码如下
#main.pyfrom fastapi import FastAPI
from api.crawler import fanyi
app = FastAPI()# 包含用户相关的所有路由
app.include_router(fanyi.router, prefix="/crawler", tags=["CrawlerAPI"])
3.创建api文件夹 用作FastAPI路由
api文件夹下新建:__init__.py 文件 及crawler文件夹,其中__init__.py无任何内容
crawler文件夹下新建:fanyi.py和params.py 文件
代码如下:
params.py 文件
#params.py
from pydantic import BaseModel
from typing import List, Optional
class FanyiParams(BaseModel):query: strlang: str = 'en2zh'ext_channel: str = 'DuSearch'
fanyi.py文件
#fanyi.py
from fastapi import APIRouter, HTTPException
from selenium import webdriver
from .params import *
#确保页面加载完成,避免异步调用导致异常
from selenium import webdriver
from selenium.webdriver.firefox.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as ECrouter = APIRouter()@router.post("/baidu_fanyi")
def baidu_fanyi(params:FanyiParams):try:# 设置 Firefox 的无头模式options = Options()options.headless = True # 启用无头模式,避免打开实际浏览器browser = webdriver.Firefox(executable_path="F:/python_demo_07/my_venv/Scripts/geckodriver.exe", options=options)browser.get(f'https://fanyi.baidu.com/mtpe-individual/multimodal?query={params.query}&lang={params.lang}&ext_channel={params.ext_channel}')# 等待页面中某个元素加载完成WebDriverWait(browser, 10).until(EC.presence_of_element_located((By.ID, 'trans-selection')))fanyi = browser.find_element(By.ID, "trans-selection")fanyi_text = fanyi.textprint("翻译结果",fanyi_text)browser.close() # html = browser.page_source # 获取完整 HTML 内容 return fanyi_textexcept Exception as e:print(f"发生错误: {e}")return {"error": "无法获取翻译结果"}
4.启动FastAPI
(my_venv) PS F:\python_demo_07> uvicorn main:app --port 8082
但是很抱歉截止文章发布前,这种原生的selenium应用已经无法爬取翻译内容了
5.升级selenium
开发环境,这次我们用谷歌浏览器
python 3.12.6
谷歌浏览器:131.0.6778.109
#Chrome的驱动chromedriver
https://download.csdn.net/download/Lookontime/90091812插件:undetected_chromedriver
pip install undetected_chromedriver -i http://pypi.doubanio.com/simple --trusted-host pypi.doubanio.com
因为selenium很容易被检测到是selenium驱动的浏览器,所以我们需要让浏览器检测不到
代码替换如下:
from fastapi import APIRouter, HTTPExceptionfrom .params import *
#确保页面加载完成,避免异步调用导致异常
import undetected_chromedriver as uc
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as ECrouter = APIRouter()@router.post("/baidu_fanyi")
def baidu_fanyi(params:FanyiParams):try:# 设置 无头模式options = uc.ChromeOptions()# 添加无头模式选项options.add_argument('--headless')# 添加其他必要参数options.add_argument('--disable-gpu') # 禁用 GPUoptions.add_argument('--no-sandbox') # 避免沙盒模式问题(可选)options.add_argument('--disable-dev-shm-usage') # 防止共享内存问题(可选)options.add_argument('--window-size=1920,1080') # 设置窗口大小options.add_argument('--disable-blink-features=AutomationControlled') # 禁用自动化控制检测browser = uc.Chrome(executable_path="F:/开发源码/python_demo_07/my_venv_3_12_6/Scripts/chromedriver.exe", options=options)browser.get(f'https://fanyi.baidu.com/mtpe-individual/multimodal?query={params.query}&lang={params.lang}&ext_channel={params.ext_channel}')# 等待页面中某个元素加载完成WebDriverWait(browser, 10).until(EC.presence_of_element_located((By.ID, 'trans-selection')))fanyi = browser.find_element(By.ID, "trans-selection")fanyi_text = fanyi.textprint("翻译结果",fanyi_text)browser.close() # html = browser.page_source # 获取完整 HTML 内容 return fanyi_textexcept Exception as e:print(f"发生错误: {e}")return {"error": "无法获取翻译结果"}ok这次我们又可以了
六.案例二 利用selenium技术爬取壁纸(技术文章仅用于学习与研究目的,不得用于违法行为,如需要壁纸请购买)
这次我们测试selenium技术的壁纸网站是https://pic.netbian.com/new/ 我看很多大佬已经拿这个网站实验过了,但是现在想爬这个网站是有点难度了,因为网站加了一个人机验证,我们通过selenium会被认为是机器人,就拒绝我们访问!如果用Scrapy 那更不行了。。。好!看我们搞定!
6.1开发环境
python 3.12.6
谷歌浏览器:131.0.6778.109
#Chrome的驱动chromedriver
https://download.csdn.net/download/Lookontime/90091812插件:undetected_chromedriver
pip install undetected_chromedriver -i http://pypi.doubanio.com/simple --trusted-host pypi.doubanio.com
6.2修改params.py 文件
#params.py文件
from pydantic import BaseModel
from typing import List, Optional
class FanyiParams(BaseModel):query: strlang: str = 'en2zh'ext_channel: str = 'DuSearch'# lang: Optional[str] = 'zh2en'# ext_channel: Optional[str] = 'DuSearch'class BiziParams(BaseModel):keyboard: str
6.3新增servers类库
- 在主目录在新增servers文件夹
- servers文件夹下新增
__init__.py文件内容为空 - servers文件夹下新增seleniumHelper文件夹
- seleniumHelper文件夹 新增
index.py文件
#index.py
import base64
from io import BytesIO
import os
from pathlib import Path
import re
import time
from PIL import Image#确保页面加载完成,避免异步调用导致异常
import undetected_chromedriver as uc
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as ECclass seleniumInit:def __init__(self):options = uc.ChromeOptions()options.add_argument('--disable-gpu')self.driver = uc.Chrome(executable_path="F:/开发源码/python_demo_07/my_venv_3_12_6/Scripts/chromedriver.exe", options=options)self.keyboard = Nonedef start_requests(self,keyboard='手机'):self.keyboard = keyboard# 初始页面只需要加载一次并输入关键词url = "https://pic.netbian.com/new/"self.driver.get(url)WebDriverWait(self.driver, 10).until(EC.presence_of_element_located((By.NAME, 'keyboard')))input_box = self.driver.find_element(By.NAME, "keyboard")input_box.clear()input_box.send_keys(keyboard + Keys.RETURN)# 等待页面跳转到搜索结果页WebDriverWait(self.driver, 10).until(EC.presence_of_element_located((By.CLASS_NAME, 'nextpage')))# 从搜索结果开始解析self.parse_with_selenium(self.driver.current_url)def parse_with_selenium(self, url):self.driver.get(url)WebDriverWait(self.driver, 10).until(EC.presence_of_element_located((By.XPATH, "//a[@target='_blank']")))next_page_element = self.driver.find_element(By.XPATH, "//li[@class='nextpage']/a")next_page_href = next_page_element.get_attribute('href')a_list = self.driver.find_elements(By.XPATH, "//a[@target='_blank']")hrefs = [a.get_attribute('href') for a in a_list if a.get_attribute('href')]for href in hrefs:if href.startswith('https://pic.netbian.com/tupian'):print(f"发现链接: {href}")self.get_img(href)# 处理下一页try:if next_page_href:self.parse_with_selenium(next_page_href)except Exception:print("没有下一页")def get_img(self, url):self.driver.get(url)WebDriverWait(self.driver, 10).until(EC.presence_of_element_located((By.CSS_SELECTOR, 'a#img img')))img_element = self.driver.find_element(By.CSS_SELECTOR, 'a#img img')img_src = img_element.get_attribute('src')if img_src:# 确保 URL 是完整的img_url = img_src if img_src.startswith('http') else f"https://pic.netbian.com{img_src}"print('准备下载图片:', img_url)# 下载并保存图片# 设置保存图片的文件夹路径save_folder = f"F:/ImageFiles/{self.keyboard}/" # 你可以根据需要修改这个路径if not os.path.exists(save_folder):os.makedirs(save_folder) # 如果文件夹不存在,则创建# 合成完整的文件路径file_name = img_url.split('/')[-1]file_path = os.path.join(save_folder, file_name)js = "let c = document.createElement('canvas');let ctx = c.getContext('2d');" \"let img = document.querySelector('a#img img'); /*找到图片*/ " \"c.height=img.naturalHeight;c.width=img.naturalWidth;" \"ctx.drawImage(img, 0, 0,img.naturalWidth, img.naturalHeight);" \"let base64String = c.toDataURL();return base64String;"base64_str = self.driver.execute_script(js)img = self.base64_to_image(base64_str)print("最终img",img)# 转换为RGB模式(如果是RGBA)if img.mode == 'RGBA':img = img.convert('RGB')img.save(file_path, format='JPEG')time.sleep(6)print(f'图片已保存: {file_name}')def base64_to_image(self,base64_str):base64_data = re.sub('^data:image/.+;base64,', '', base64_str)byte_data = base64.b64decode(base64_data)image_data = BytesIO(byte_data)img = Image.open(image_data)return img
6.4 修改fanyi.py文件添加一个接口
#fanyi.py
from fastapi import APIRouter, HTTPExceptionfrom .params import *
#确保页面加载完成,避免异步调用导致异常
import undetected_chromedriver as uc
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from servers.seleniumHelper.index import seleniumInitrouter = APIRouter()@router.post("/baidu_fanyi")
def baidu_fanyi(params:FanyiParams):try:# 设置 无头模式options = uc.ChromeOptions()# 添加无头模式选项options.add_argument('--headless')# 添加其他必要参数options.add_argument('--disable-gpu') # 禁用 GPUoptions.add_argument('--no-sandbox') # 避免沙盒模式问题(可选)options.add_argument('--disable-dev-shm-usage') # 防止共享内存问题(可选)options.add_argument('--window-size=1920,1080') # 设置窗口大小options.add_argument('--disable-blink-features=AutomationControlled') # 禁用自动化控制检测browser = uc.Chrome(executable_path="F:/开发源码/python_demo_07/my_venv_3_12_6/Scripts/chromedriver.exe", options=options)browser.get(f'https://fanyi.baidu.com/mtpe-individual/multimodal?query={params.query}&lang={params.lang}&ext_channel={params.ext_channel}')# 等待页面中某个元素加载完成WebDriverWait(browser, 10).until(EC.presence_of_element_located((By.ID, 'trans-selection')))fanyi = browser.find_element(By.ID, "trans-selection")fanyi_text = fanyi.textprint("翻译结果",fanyi_text)browser.close() # html = browser.page_source # 获取完整 HTML 内容 return fanyi_textexcept Exception as e:print(f"发生错误: {e}")return {"error": "无法获取翻译结果"}# 2.爬取壁纸
@router.post("/iciba_fanyi")
def iciba_fanyi(params:BiziParams):sInit = seleniumInit()sInit.start_requests(params.keyboard)return "爬取完成"
总结下这个网站我是看csdn上有个大佬爬过,所以我也就试试用来测试技术,技术文章仅用于学习与研究目的,不得用于违法行为,如需要壁纸请购买,支持正版,而且正版的壁纸清晰度很高,这部分不能是爬取到的。
但是发现这个网站加了机器人 加了图片请求转换,等待,所以开发的思路就是不能用原生selenium,否则机器人检测我们过不去,等我们千辛万苦绕过机器人时,发现请求图片被后端进行转换了并不能给你图片信息,这个时候就需要用js来实现复制图片。
代码地址:
https://download.csdn.net/download/Lookontime/90097745
七.总结
Python 进阶中的selenium就介绍到这里,再次声明文章只是为了研究selenium技术。
创作整理不易,请大家多多关注 多多点赞,有写的不对的地方欢迎大家补充,我来整理,再次感谢!
相关文章:
python进阶-05-利用Selenium来实现动态爬虫
python进阶-05-利用Selenium来实现动态爬虫 一.说明 这是python进阶部分05,我们上一篇文章学习了Scrapy来爬取网站,但是很多网站需要登录才能爬取有用的信息,或者网站的静态部分是一个空壳,内容是js动态加载的,或者人机验证&…...

P1226 【模板】快速幂
题目描述 给你三个整数 𝑎,𝑏,𝑝求 𝑎𝑏 mod 𝑝 输入格式 输入只有一行三个整数,分别代表 𝑎,𝑏,𝑝 输出格式 输出一行一个字符串 a^b mod ps…...

【C++】求第二大的数详细解析
博客主页: [小ᶻ☡꙳ᵃⁱᵍᶜ꙳] 本文专栏: C 文章目录 💯前言💯题目描述💯输入描述💯解题思路分析1. 题目核心要求2. 代码实现与解析3. 核心逻辑逐步解析定义并初始化变量遍历并处理输入数据更新最大值与次大值输…...
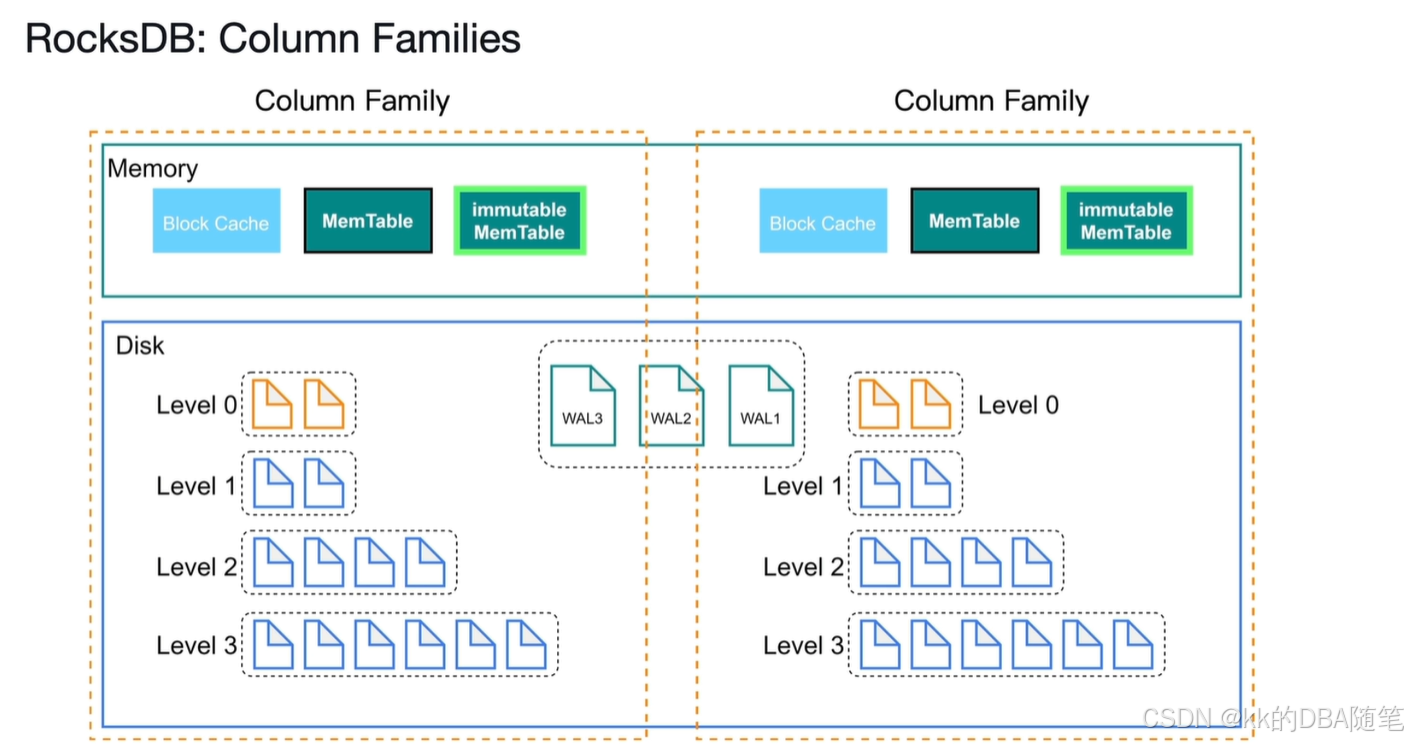
从零开始学TiDB(3)TiKV 持久化机制
如图,每个TiKV有两个rocksdb实例,rocksdbKV复制存储键值对,rocksdb raft负责存储复制的日志 。 每个region及其副本构成了raft group。这个OB的Zone其实有点类似,在OB中每个Unit及其副本构成了paxos组,在TiDB中叫raft…...

Elasticsearch+Kibana+IK分词器+拼音分词器安装
目录 ES报错 Kibanaik分词器拼音分词器 安装都比较简单,可以参考这几篇博客 ES 如何在 Linux,MacOS 及 Windows 上进行安装 Elasticsearch 报错 ES启动报错error downloading geoip database [GeoLite2-ASN.mmdb] Kibana KIBANA的安装教程ÿ…...
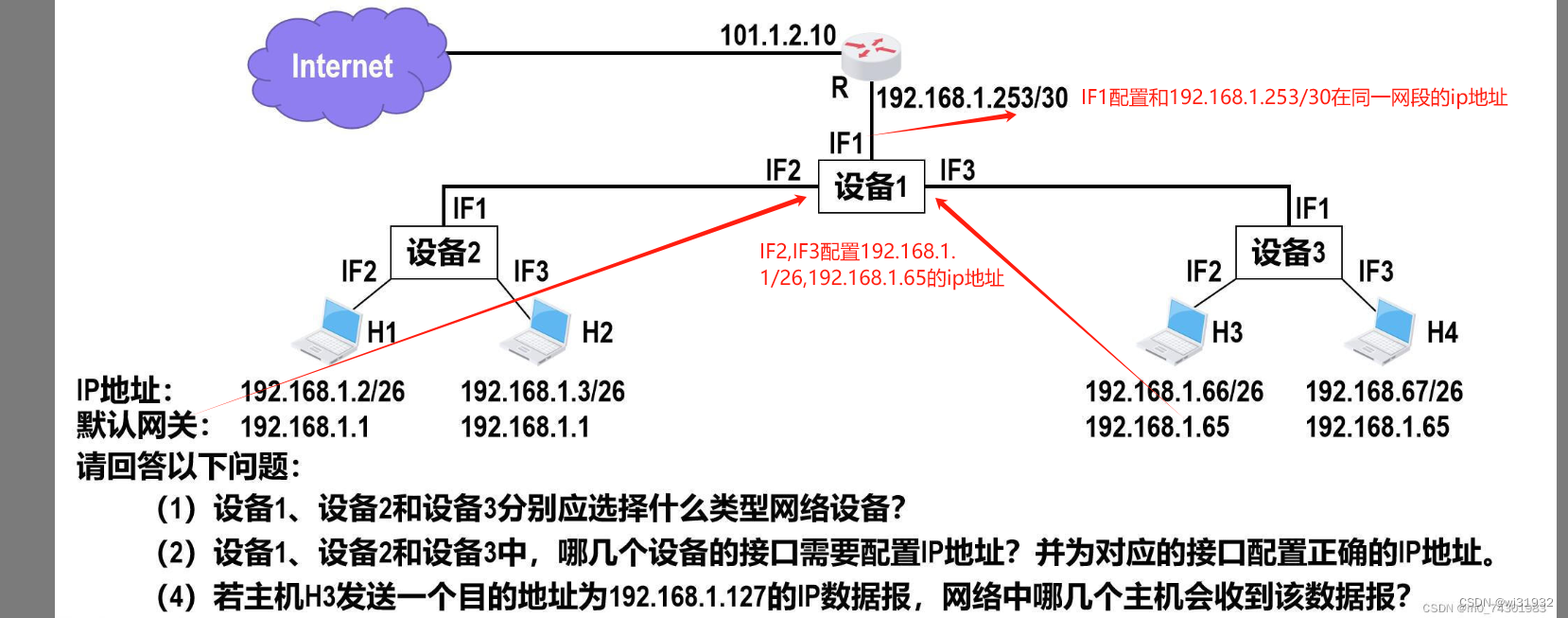
子网划分实例
看到有人问这个问题: 想了一下,这是一个子网划分的问题: 处理方法如图: 这是一个子网划分的问题 设备1用三层交换机,端口设置为路由模式,设备2和设备3为傻瓜交换机模式 设备2和设备3下挂设备都是26为掩码&…...

上海亚商投顾:创业板指震荡调整 机器人概念股再度爆发
上海亚商投顾前言:无惧大盘涨跌,解密龙虎榜资金,跟踪一线游资和机构资金动向,识别短期热点和强势个股。 一.市场情绪 沪指昨日冲高回落,深成指、创业板指盘中跌超1%,尾盘跌幅有所收窄。机器人概念股逆势爆…...
:初始化 Initializer)
【C++ 20进阶(2):初始化 Initializer
【C 20进阶(2):初始化 Initializer】 原文:https://blog.csdn.net/weixin_44259356/article/details/144377955 引言 本篇文章为系列文章将着重介绍C20新特性,一是希望可以和大家交流分享,二是也便于自己…...

【重生之我在B站学MySQL】
MySQL笔记 文章目录 MySQL的三层结构SQL语句分类sql语句数据库操作创建数据库查看、删除数据库 表操作创建表mysql常用数据类型(列类型)查询表、插入值创建表练习创建一个员工表emp 修改表mysql约束primary key(主键)not null(非空)unique(唯一)foreign key(外键)check自增长 索…...

Python实现中国象棋
探索中国象棋 Python 代码实现:从规则逻辑到游戏呈现 中国象棋,这款源远流长的棋类游戏,承载着深厚的文化底蕴与策略智慧。如今,借助 Python 与 Pygame 库,我们能够在数字世界中复刻其魅力,深入探究代码背后…...
LBS 开发微课堂|通过openGL ES轻松实现建筑物渲染及动画
为了让广大开发者 更深入地了解 百度地图开放平台的 技术能力 轻松掌握满满的 技术干货 更加简单地接入 位置服务 我们特别推出了 “位置服务(LBS)开发微课堂” 系列技术案例 第五期的主题是 通过openGL ES轻松实现 建筑物渲染及动画 对于…...
的区别为何前者取出的是空,后者取出的是正确的值)
map1[item.id]和map1.get(item.id)的区别为何前者取出的是空,后者取出的是正确的值
在 JavaScript 中,map1[item.id] 和 map1.get(item.id) 用于从 Map 对象中获取值,但它们的工作方式有所不同: map1[item.id]:这种方式用于普通对象(Object),它将 item.id 作为键来获取对应的值…...

window端sqlplus连接linux_oracle11g
1. 环境配置回顾 下载 Oracle Instant Client:根据查询到的版本到链接: oracle官网下载对应版本的三个文件(比如我这里查询到的版本是12.2.0.1.0): instantclient-basic-windows.x64-12.2.0.1.0.zip instantclient-sqlplus-win…...

Go支付中台方案:多平台兼容与多项目对接
一、中台的概念 中台是一种企业级的架构模式,它处于前台应用和后台资源之间,将企业核心能力进行整合、封装,形成一系列可复用的业务能力组件。这些组件就像乐高积木一样,可以被不同的前台业务快速调用,从而避免重复开…...

MySQL触发器的使用详解
MySQL触发器的使用详解 MySQL触发器是一种特殊的存储过程,它与表操作紧密相关,并且在特定事件(如INSERT、UPDATE或DELETE)发生时自动执行。触发器的主要目的是确保数据完整性、实现复杂的业务逻辑以及记录审计信息。它们可以在事…...

关于NLP交互式系统的一些基础入门
【1】What 基于自然语言处理(NLP)的交互式系统是指能够理解、解析并生成人类自然语言的计算机程序。这些系统旨在通过文本或语音与用户进行交流,以提供信息、解决问题或执行任务。以下是关于这类系统的一些关键点: 核心技术&…...
)
如何在HTML中修改光标的位置(全面版)
如何在HTML中修改光标的位置(全面版) 在Web开发中,控制光标位置是一个重要的技巧,尤其是在表单处理、富文本编辑器开发或格式化输入的场景中。HTML中的光标位置操作不仅适用于表单元素(如<input>和<textarea…...

PHP8 动态属性被弃用兼容方案
PHP 类中可以动态设置和获取没有声明过的类属性。这些属性不遵循具体的规则,并且需要使用 __get() 和 __set() 魔术方法对动态属性如何读写进行有效控制。 class User {private int $uid; }$user new User(); $user->name Foo; 上述代码中,User 类…...
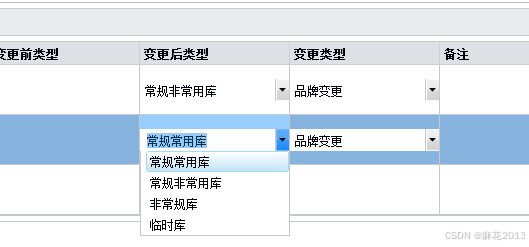
WPF表格控件的列利用模块适配动态枚举类
将枚举列表转化到类内部赋值,在初始化表格行加载和双击事件时,触发类里面的枚举列表的赋值 <c1:Column Header"变更类型" Binding"{Binding ChangeType, ModeTwoWay, ValidatesOnExceptionsTrue, ValidatesOnDataErrorsTrue, NotifyOn…...
【sgUploadImage】自定义组件:基于elementUI的el-upload封装的上传图片、相片组件,适用于上传缩略图、文章封面
sgUploadImage源码 <template><div :class"$options.name"><ul class"uploadImages"><liclass"uploadImage"v-loading"loadings[i]"v-for"(a, i) in uploadImages":key"i"click"click…...

从WWDC看苹果产品发展的规律
WWDC 是苹果公司一年一度面向全球开发者的盛会,其主题演讲展现了苹果在产品设计、技术路线、用户体验和生态系统构建上的核心理念与演进脉络。我们借助 ChatGPT Deep Research 工具,对过去十年 WWDC 主题演讲内容进行了系统化分析,形成了这份…...

DockerHub与私有镜像仓库在容器化中的应用与管理
哈喽,大家好,我是左手python! Docker Hub的应用与管理 Docker Hub的基本概念与使用方法 Docker Hub是Docker官方提供的一个公共镜像仓库,用户可以在其中找到各种操作系统、软件和应用的镜像。开发者可以通过Docker Hub轻松获取所…...

CocosCreator 之 JavaScript/TypeScript和Java的相互交互
引擎版本: 3.8.1 语言: JavaScript/TypeScript、C、Java 环境:Window 参考:Java原生反射机制 您好,我是鹤九日! 回顾 在上篇文章中:CocosCreator Android项目接入UnityAds 广告SDK。 我们简单讲…...

python如何将word的doc另存为docx
将 DOCX 文件另存为 DOCX 格式(Python 实现) 在 Python 中,你可以使用 python-docx 库来操作 Word 文档。不过需要注意的是,.doc 是旧的 Word 格式,而 .docx 是新的基于 XML 的格式。python-docx 只能处理 .docx 格式…...

linux 下常用变更-8
1、删除普通用户 查询用户初始UID和GIDls -l /home/ ###家目录中查看UID cat /etc/group ###此文件查看GID删除用户1.编辑文件 /etc/passwd 找到对应的行,YW343:x:0:0::/home/YW343:/bin/bash 2.将标红的位置修改为用户对应初始UID和GID: YW3…...

NLP学习路线图(二十三):长短期记忆网络(LSTM)
在自然语言处理(NLP)领域,我们时刻面临着处理序列数据的核心挑战。无论是理解句子的结构、分析文本的情感,还是实现语言的翻译,都需要模型能够捕捉词语之间依时序产生的复杂依赖关系。传统的神经网络结构在处理这种序列依赖时显得力不从心,而循环神经网络(RNN) 曾被视为…...

用docker来安装部署freeswitch记录
今天刚才测试一个callcenter的项目,所以尝试安装freeswitch 1、使用轩辕镜像 - 中国开发者首选的专业 Docker 镜像加速服务平台 编辑下面/etc/docker/daemon.json文件为 {"registry-mirrors": ["https://docker.xuanyuan.me"] }同时可以进入轩…...

关键领域软件测试的突围之路:如何破解安全与效率的平衡难题
在数字化浪潮席卷全球的今天,软件系统已成为国家关键领域的核心战斗力。不同于普通商业软件,这些承载着国家安全使命的软件系统面临着前所未有的质量挑战——如何在确保绝对安全的前提下,实现高效测试与快速迭代?这一命题正考验着…...

C++ 设计模式 《小明的奶茶加料风波》
👨🎓 模式名称:装饰器模式(Decorator Pattern) 👦 小明最近上线了校园奶茶配送功能,业务火爆,大家都在加料: 有的同学要加波霸 🟤,有的要加椰果…...

C# 表达式和运算符(求值顺序)
求值顺序 表达式可以由许多嵌套的子表达式构成。子表达式的求值顺序可以使表达式的最终值发生 变化。 例如,已知表达式3*52,依照子表达式的求值顺序,有两种可能的结果,如图9-3所示。 如果乘法先执行,结果是17。如果5…...