深度学习笔记之BERT(五)TinyBERT
深度学习笔记之TinyBERT
- 引言
- 回顾:DistilBERT模型
- TinyBERT模型结构
- TinyBERT模型策略
- Transformer层蒸馏
- 嵌入层蒸馏
- 预测层蒸馏
- TinyBERT模型的训练
- 效果展示
引言
上一节介绍了 DistilBERT \text{DistilBERT} DistilBERT模型,本节将继续介绍优化性更强的知识蒸馏 BERT \text{BERT} BERT模型—— TinyBERT \text{TinyBERT} TinyBERT模型。
回顾:DistilBERT模型
DistilBERT \text{DistilBERT} DistilBERT模型是一种基于 BERT-base \text{BERT-base} BERT-base的知识蒸馏版本,其模型结构表示如下。单从模型结构的角度观察,学生模型神经元的维度没有发生变化 ( 768 ) (768) (768),仅是 Encoder \text{Encoder} Encoder层数减少为 BERT-base \text{BERT-base} BERT-base的一半;并且各层的初始化继承了一部分 BERT-base \text{BERT-base} BERT-base:从教师模型的 Encoder \text{Encoder} Encoder层中每两层选择一层作为学生模型 Encoder \text{Encoder} Encoder层的初始化。

DistilBERT \text{DistilBERT} DistilBERT训练出的学生模型( param:66M \text{param:66M} param:66M)依然可以达到 BERT-base \text{BERT-base} BERT-base模型几乎 97 97 97%的准确度。能够达到这个效果离不开 DistilBERT \text{DistilBERT} DistilBERT的三个核心策略:
- 掩码语言模型策略 ( Masked Language Model ) (\text{Masked Language Model}) (Masked Language Model):根据 RoBERTa \text{RoBERTa} RoBERTa中的描述,摒弃掉下句预测 ( Next Sentence Prediction,NSP ) (\text{Next Sentence Prediction,NSP}) (Next Sentence Prediction,NSP)策略,并使用动态掩码替代静态掩码作为 BERT \text{BERT} BERT模型的训练策略;
- 蒸馏策略 ( Distillation loss ) (\text{Distillation loss}) (Distillation loss):通过使用 Softmax \text{Softmax} Softmax温度函数将教师模型 BERT-base \text{BERT-base} BERT-base与学生模型 DistilBERT \text{DistilBERT} DistilBERT输出层的解空间尽可能地相似:
其中N N N表示教师模型和学生模型的输出层维度,在DistilBERT \text{DistilBERT} DistilBERT模型中,两者的维度相同,均为768 768 768。
T ( x ) = ( t 1 , t 2 , ⋯ , t N ) S ( x ) = ( s 1 , s 2 , ⋯ , s N ) L c r o s s = − ∑ i = 1 N t i ∗ log ( s i ) \begin{aligned} & \mathcal T(x) = (t_1,t_2,\cdots,t_N) \\ & \mathcal S(x) = (s_1,s_2,\cdots,s_{N}) \\ & \mathcal L_{cross} = -\sum_{i=1}^{N} t_i * \log (s_i) \end{aligned} T(x)=(t1,t2,⋯,tN)S(x)=(s1,s2,⋯,sN)Lcross=−i=1∑Nti∗log(si) - 余弦嵌入策略 ( Cosine Embedding loss ) (\text{Cosine Embedding loss}) (Cosine Embedding loss):通过计算输出层分布向量之间夹角的余弦值 cos [ T ( x ) , S ( x ) ] \cos [\mathcal T(x),\mathcal S(x)] cos[T(x),S(x)],当该值为 1 1 1时,对应的 L c o s i n e \mathcal L_{cosine} Lcosine达到最小。此时两向量的方向为同一方向,教师和学生模型输出的解空间已被对齐:
L c o s i n e = 1 − cos [ T ( x ) , S ( x ) ] \mathcal L_{cosine} = 1 - \cos[\mathcal T(x),\mathcal S(x)] Lcosine=1−cos[T(x),S(x)]
总结:
在 ALBERT \text{ALBERT} ALBERT模型中介绍过,虽然 ALBERT \text{ALBERT} ALBERT也是 BERT \text{BERT} BERT的简化版本,但它们的解空间并不相同;

与此相反, DistilBERT \text{DistilBERT} DistilBERT中除了继承了 BERT \text{BERT} BERT中的掩码语言模型策略外,剩余的两条策略均是围绕牢牢绑定教师模型与学生模型的解空间而设计。
重新观察学生模型 DistilBERT \text{DistilBERT} DistilBERT,它能够达到如此精炼的模型结构 ( param:110M -> 66M ) (\text{param:110M -> 66M}) (param:110M -> 66M),但依然保持极高的准确性,没有出现欠拟合的情况。这至少意味着: DistilBERT \text{DistilBERT} DistilBERT模型中的神经元被利用得更加充分。
在这种情况下,是否可以百尺竿头更进一步呢 ? TinyBERT ?\text{ TinyBERT} ? TinyBERT模型给了我们一个更精进的答案。
TinyBERT模型结构
相比于 DistilBERT \text{DistilBERT} DistilBERT模型中 Encoder \text{Encoder} Encoder层数减半的严肃操作, TinyBERT \text{TinyBERT} TinyBERT模型可以自定义学生模型的层数。并且还可以设置隐藏层单元中神经元的维度,从而使模型更加精简。那么它是如何实现在如此精简的模型结构下,不仅没有欠拟合,而且还能保持优秀的训练结果呢 ? ? ? 自然是依靠更加严苛的策略作为约束。
TinyBERT \text{TinyBERT} TinyBERT模型的教师-学生模型结构表示如下:

其中索引 0 0 0表示嵌入层, 1 1 1表示第一个 Encoder \text{Encoder} Encoder,以此类推。最后 N+1,M+1 \text{N+1,M+1} N+1,M+1分别表示教师、学生模型的预测层。
该蒸馏结构与 DistilBERT \text{DistilBERT} DistilBERT之间没有太大区别,只不过没有 DistilBERT \text{DistilBERT} DistilBERT中的初始化操作。教师与学生模型中各层的迁移过程可以表示为如下式子:
n = G ( m ) n = \mathcal G(m) n=G(m)
其表达的含义是:将教师模型中的第 n n n层迁移到学生模型的第 m m m层。例如:
- 0 = G ( 0 ) 0 = \mathcal G(0) 0=G(0)表示将教师模型的嵌入层知识迁移到学生模型的嵌入层;
- N + 1 = G ( M + 1 ) N+1 = \mathcal G(M+1) N+1=G(M+1)表示将教师模型的预测层知识迁移到学生模型的预测层;
- n = G ( m ) n = \mathcal G(m) n=G(m)表示将教师模型的第 n n n个 Encoder \text{Encoder} Encoder层知识迁移到学生模型的第 m m m个 Encoder \text{Encoder} Encoder层。
TinyBERT模型策略
那么 TinyBERT \text{TinyBERT} TinyBERT是如何制定策略的呢 ? ? ? 主要围绕三个部分制定策略:
- Transformer \text{Transformer} Transformer层 ( Encoder ) (\text{Encoder}) (Encoder)
- 嵌入层 ( Embedding Layer ) (\text{Embedding Layer}) (Embedding Layer)
- 预测层 ( Predict Layer ) (\text{Predict Layer}) (Predict Layer)
Transformer层蒸馏
在 Transformer \text{Transformer} Transformer层也就是编码器层,需要使用多头注意力机制计算注意力矩阵,再使用 FeedForward Network \text{FeedForward Network} FeedForward Network进行一个前馈计算,并将最终计算得到的隐藏状态特征作为该编码器的输出。在 TinyBERT \text{TinyBERT} TinyBERT中除了将教师模型中 Encoder \text{Encoder} Encoder内的注意力矩阵迁移到学生模型相应的 Encoder \text{Encoder} Encoder中,也同时将相应的隐藏状态特征迁移到学生模型中。因而 Transformer \text{Transformer} Transformer层蒸馏包括两次知识蒸馏:
- 基于注意力的蒸馏
通过最小化对应学生 Encoder \text{Encoder} Encoder和教师 Encoder \text{Encoder} Encoder内注意力矩阵的均方误差来训练对应学生 Encoder \text{Encoder} Encoder层:其中h h h表示注意力机制头的数量;A i S \mathcal A_i^{\mathcal S} AiS表示学生Encoder \text{Encoder} Encoder内第i i i个头的注意力矩阵;A i T \mathcal A_i^{\mathcal T} AiT表示教师Encoder \text{Encoder} Encoder内第i i i个头的注意力矩阵;MSE \text{MSE} MSE表示均方误差操作。个人疑问:当学生模型隐藏层维度变化的时候A i S , A i T \mathcal A_i^{\mathcal S},\mathcal A_i^{\mathcal T} AiS,AiT是一样大的吗?但书中并没有解释。
L a t t n = 1 h ∑ i = 1 h MSE ( A i S , A i T ) \mathcal L_{attn} = \frac{1}{h} \sum_{i=1}^{h} \text{MSE}(\mathcal A_i^{\mathcal S}, \mathcal A_i^{\mathcal T}) Lattn=h1i=1∑hMSE(AiS,AiT)
需要注意的是,这里的注意力矩阵 A i S , A i T \mathcal A_i^{\mathcal S},\mathcal A_i^{\mathcal T} AiS,AiT使用的是执行 Layer Norm \text{Layer Norm} Layer Norm映射前的矩阵,这样做的目的是保证信息的完整性,并且更快地收敛。
- 基于隐藏状态的蒸馏
隐藏状态是当前 Encoder \text{Encoder} Encoder的输出,我们同样需要将教师 Encoder \text{Encoder} Encoder的隐藏层知识迁移到学生 Encoder \text{Encoder} Encoder的隐藏层状态中:
其中H S \mathcal H_{\mathcal S} HS表示学生Encoder \text{Encoder} Encoder内的隐藏层状态;H T \mathcal H_{\mathcal T} HT表示教师Encoder \text{Encoder} Encoder内的隐藏层状态。同样使用均方误差使H S \mathcal H_{\mathcal S} HS向H T \mathcal H_{\mathcal T} HT方向拟合。
L h i d n = MSE ( H S , H T ) \mathcal L_{hidn} = \text{MSE}(\mathcal H_{\mathcal S},\mathcal H_{\mathcal T}) Lhidn=MSE(HS,HT)
但需要注意的是:当学生 Encoder \text{Encoder} Encoder隐藏层维度发生变化时, H S \mathcal H_{\mathcal S} HS和 H T \mathcal H_{\mathcal T} HT两者之间的维度之间存在差异,因而需要训练一个新的权重矩阵 W h \mathcal W_{h} Wh使两者处于同一级别的维度空间:
相当于作用在损失函数上的权重矩阵,反向传播过程中同样存在梯度更新。
L h i d n = MSE ( H S W h , H T ) \mathcal L_{hidn} = \text{MSE}(\mathcal H_{\mathcal S}\mathcal W_h, \mathcal H_{\mathcal T}) Lhidn=MSE(HSWh,HT)
嵌入层蒸馏
关于嵌入层的蒸馏与隐藏状态的蒸馏相似,当学生模型设置的隐藏层维度与教师模型维度不同时,两者对应的 Embedding \text{Embedding} Embedding也不同。同样在损失函数中添加一个新的权重参数 W E \mathcal W_{\mathcal E} WE,使两个 Embedding \text{Embedding} Embedding处于同一级别的维度空间:
其中 E S \mathcal E_{\mathcal S} ES表示学生模型的 Embedding \text{Embedding} Embedding矩阵; E T \mathcal E_{\mathcal T} ET表示教师模型的 Embedding \text{Embedding} Embedding矩阵。 MSE \text{MSE} MSE表示均方误差。
L e m b = MSE ( E S W E , E T ) \mathcal L_{emb} = \text{MSE}(\mathcal E_{\mathcal S} \mathcal W_{\mathcal E} ,\mathcal E_{\mathcal T}) Lemb=MSE(ESWE,ET)
预测层蒸馏
在预测层蒸馏部分,迁移的是输出层的知识信息。这里和 DistilBERT \text{DistilBERT} DistilBERT模型关于预测层的损失类似。对于教师模型的输出 Z T \mathcal Z^{\mathcal T} ZT和学生模型的输出 Z S \mathcal Z^{\mathcal S} ZS:
- 使用 Softmax \text{Softmax} Softmax温度函数分别获取对应的软目标 P T \mathcal P^{\mathcal T} PT和软预测 P S \mathcal P^{\mathcal S} PS结果:
同理,Z T \mathcal Z^{\mathcal T} ZT对应的软目标结果P T \mathcal P^{\mathcal T} PT不再赘述。
{ P i S = exp ( Z i S / T ) ∑ j exp ( Z j S ) / T P S = ( P 1 S , P 2 S , ⋯ , P N S ) \begin{cases} \begin{aligned} \mathcal P_{i}^{\mathcal S} = \frac{\exp(\mathcal Z_i^{\mathcal S} / \mathcal T)}{\sum_{j} \exp(\mathcal Z_j^{\mathcal S}) / \mathcal T} \end{aligned} \\ \quad \\ \mathcal P^{\mathcal S} = (\mathcal P_1^{\mathcal S},\mathcal P_{2}^{\mathcal S},\cdots,\mathcal P_{N}^{\mathcal S}) \end{cases} ⎩ ⎨ ⎧PiS=∑jexp(ZjS)/Texp(ZiS/T)PS=(P1S,P2S,⋯,PNS) - 再使用交叉熵损失函数对 P S \mathcal P^{\mathcal S} PS与 P T \mathcal P^{\mathcal T} PT进行描述:
L p r e d = − P T ⋅ log ( P S ) \mathcal L_{pred} = - \mathcal P^{\mathcal T} \cdot \log \left(\mathcal P^{\mathcal S} \right) Lpred=−PT⋅log(PS)
最终, TinyBERT \text{TinyBERT} TinyBERT包含所有层的损失函数表示如下:
这里 [ S m , T G ( m ) ] [\mathcal S_{m},\mathcal T_{\mathcal G(m)}] [Sm,TG(m)]表示学生模型的第 m m m层与教师模型第 G ( m ) \mathcal G(m) G(m)之间的迁移关系。
L [ S m , T G ( m ) ] = { L e m b ( S 0 , T 0 ) m = 0 L h i d n ( S m , T G ( m ) ) M ≥ m > 0 L p r e d ( S M + 1 , T N + 1 ) m = M + 1 \mathcal L \left[ \mathcal S_{m},\mathcal T_{\mathcal G(m)}\right]= \begin{cases} \mathcal L_{emb}(\mathcal S_0,\mathcal T_0) \quad m = 0 \\ \mathcal L_{hidn}(\mathcal S_m,\mathcal T_{\mathcal G(m)}) \quad M \geq m > 0 \\ \mathcal L_{pred} (\mathcal S_{M+1},\mathcal T_{N+1}) \quad m = M + 1 \end{cases} L[Sm,TG(m)]=⎩ ⎨ ⎧Lemb(S0,T0)m=0Lhidn(Sm,TG(m))M≥m>0Lpred(SM+1,TN+1)m=M+1
可以看出:
- TinyBERT \text{TinyBERT} TinyBERT损失函数数量是不确定的。它取决于设计学生模型 ( TinyBERT ) (\text{TinyBERT}) (TinyBERT)的层的数量;
- 相比于 DistilBERT \text{DistilBERT} DistilBERT, TinyBERT \text{TinyBERT} TinyBERT需要为削减隐藏层状态维度和层数付出相应的代价——设计的策略需要与教师模型关系更加紧密,并精确到注意力矩阵和隐藏层状态,从而得到一个与教师模型关联更加紧密的、学生模型的解空间。
TinyBERT模型的训练
在文章中作者描述的训练流程表示如下:

在 TinyBERT \text{TinyBERT} TinyBERT模型中,使用两个阶段进行训练:
- 通用蒸馏:在该阶段,使用 BERT-base \text{BERT-base} BERT-base预训练模型作为教师,并使用 BERT-base \text{BERT-base} BERT-base的训练集对学生模型 ( TinyBERT ) (\text{TinyBERT}) (TinyBERT)进行蒸馏。并将该模型称作通用 TinyBERT \text{TinyBERT} TinyBERT模型。
- 特定任务蒸馏:在微调阶段,将基于一项具体任务对通用 TinyBERT \text{TinyBERT} TinyBERT模型进行微调 ( fine-tuning ) (\text{fine-tuning}) (fine-tuning)。具体微调过程方式为:
- 使用预训练 BERT-base \text{BERT-base} BERT-base模型针对具体任务进行微调,并将这个微调后的 BERT-base \text{BERT-base} BERT-base模型作为教师;
- 将上述经过通用蒸馏得到的通用 TinyBERT \text{TinyBERT} TinyBERT模型作为学生,经过蒸馏,得到的 TinyBERT \text{TinyBERT} TinyBERT模型称作微调的 TinyBERT \text{TinyBERT} TinyBERT模型。
效果展示
论文中关于 TinyBERT \text{TinyBERT} TinyBERT对于各下游任务中,与各模型比较结果如下:

其中, DistilBERT 4 \text{DistilBERT}_4 DistilBERT4表示学生模型包含 4 4 4层 Encoder \text{Encoder} Encoder,其他同理。可以发现:
- 相比于 DistilBERT 4 \text{DistilBERT}_4 DistilBERT4, TinyBERT 4 \text{TinyBERT}_4 TinyBERT4使用不到其 30 30 30%,但准确率却远高于 DistilBERT \text{DistilBERT} DistilBERT模型;
- TinyBERT 6 \text{TinyBERT}_6 TinyBERT6参数数量是 BERT-base \text{BERT-base} BERT-base的 60 60 60%左右,但其准确性基本与 BERT-base \text{BERT-base} BERT-base持平。
Reference \text{Reference} Reference:
论文链接
《BERT基础教程——Transformer大模型实战》
相关文章:
深度学习笔记之BERT(五)TinyBERT
深度学习笔记之TinyBERT 引言回顾:DistilBERT模型TinyBERT模型结构TinyBERT模型策略Transformer层蒸馏嵌入层蒸馏预测层蒸馏 TinyBERT模型的训练效果展示 引言 上一节介绍了 DistilBERT \text{DistilBERT} DistilBERT模型,本节将继续介绍优化性更强的知…...

【时间序列预测】基于PyTorch实现CNN_BiLSTM算法
文章目录 1. CNN与BiLSTM2. 完整代码实现3. 代码结构解读3.1 CNN Layer3.2 BiLSTM Layer3.3 Output Layer3.4 forward Layer 4. 应用场景5. 总结 本文将详细介绍如何使用Pytorch实现一个结合卷积神经网络(CNN)和双向长短期记忆网络(BiLSTM&am…...

联想Y7000 2024版本笔记本 RTX4060安装ubuntu22.04双系统及深度学习环境配置
目录 1..制作启动盘 2.Windows 磁盘分区,删除原来ubuntu的启动项 3.四个设置 4.安装ubuntu 5.ubuntu系统配置 1..制作启动盘 先下载镜像文件,注意版本对应。Rufus - 轻松创建 USB 启动盘 用rufus制作时,需要注意选择正确的分区类型和系统类型。不然安装的系统会有问题…...
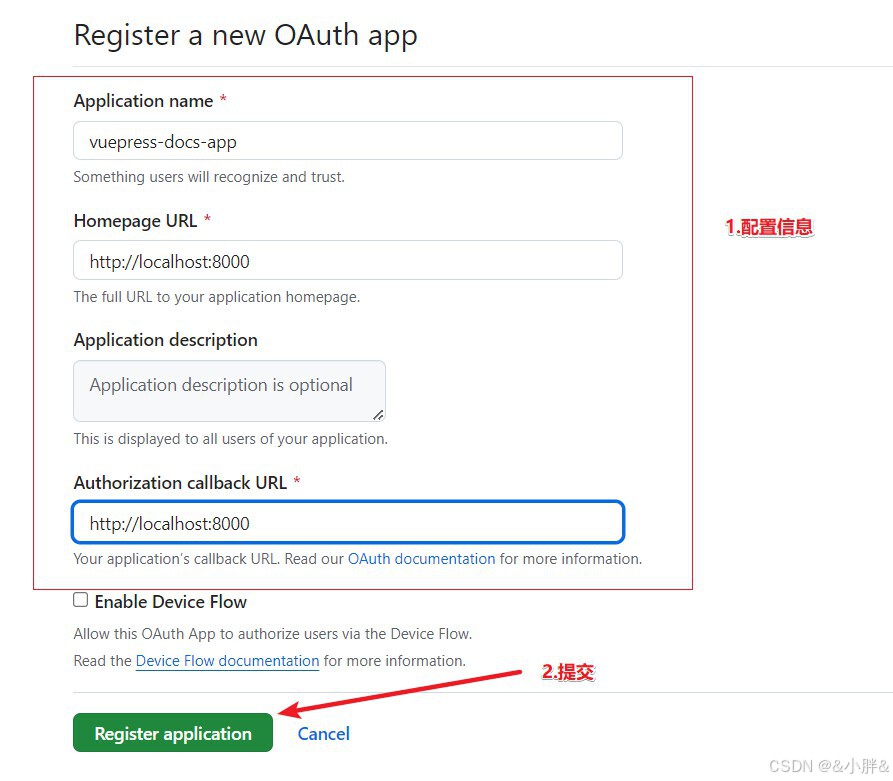
VuePress学习
1.介绍 VuePress 由两部分组成:第一部分是一个极简静态网站生成器 (opens new window),它包含由 Vue 驱动的主题系统和插件 API,另一个部分是为书写技术文档而优化的默认主题,它的诞生初衷是为了支持 Vue 及其子项目的文档需求。…...

一次“okhttp访问间隔60秒,提示unexpected end of stream“的问题排查过程
一、现象 okhttp调用某个服务,如果第二次访问间隔上一次访问时间超过60s,返回错误:"unexpected end of stream"。 二、最终定位原因: 空闲连接如果超过60秒,服务端会主动关闭连接。此时客户端恰巧访问了这…...

SQL最佳实践:避免使用COUNT=0
如果你遇到类似下面的 SQL 查询: SELECT * FROM customer c WHERE 0 (SELECT COUNT(*)FROM orders oWHERE o.customer_id c.customer_id);意味着有人没有遵循 SQL 最佳实践。该语句的作用是查找没有下过订单的客户,其中子查询使用了 COUNT 函数统计客…...

PG与ORACLE的差距
首先必须是XID 64,一个在极端环境下会FREEZE的数据库无论如何都无法承担关键业务系统的重任的,我们可以通过各种配置,提升硬件的性能,通过各种IT管控措施来尽可能避免在核心系统上面临FREEZE的风险,不过并不是每个企业…...
- LED驱动(传统模式))
树莓派3B+驱动开发(2)- LED驱动(传统模式)
github主页:https://github.com/snqx-lqh 本项目github地址:https://github.com/snqx-lqh/RaspberryPiDriver 本项目硬件地址:https://oshwhub.com/from_zero/shu-mei-pai-kuo-zhan-ban 欢迎交流 笔记说明 如我在驱动开发总览中说的那样&…...
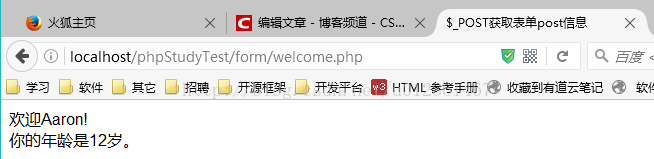
超详细搭建PhpStorm+PhpStudy开发环境
刚开始接触PHP开发,搭建开发环境是第一步,网上下载PhpStorm和PhpStudy软件,怎样安装和激活就不详细说了,我们重点来看一看怎样搭配这两个开发环境。 前提:现在假设你已经安装完PhpStorm和PhpStudy软件。 我的PhpStor…...

分析比对vuex和store模式
在 Vue 中,Vuex 和 store 模式 是两个不同的概念,它们紧密相关,主要用于管理应用的状态。下面我会详细介绍这两个概念,并通过例子帮助你更好地理解。 1. Vuex 是什么? Vuex 是 Vue.js 的一个状态管理库,用…...

C# 网络编程--基础核心内容
在现今软件开发中,网络编程是非常重要的一部分,本文简要介绍下网络编程的概念和实践。 C#网络编程的主要内容包括以下几个方面: : 上图引用大佬的图,大家也关注一下,有技术有品质,有国有家,情…...
)
【C++游戏程序】easyX图形库还原游戏《贪吃蛇大作战》(三)
承接上一篇文章:【C游戏程序】easyX图形库还原游戏《贪吃蛇大作战》(二),我们这次来补充一些游戏细节,以及增加吃食物加长角色长度等设定玩法,也是本游戏的最后一篇文章。 一.玩家边界检测 首先是用来检测…...

uni-app H5端使用注意事项 【跨端开发系列】
🔗 uniapp 跨端开发系列文章:🎀🎀🎀 uni-app 组成和跨端原理 【跨端开发系列】 uni-app 各端差异注意事项 【跨端开发系列】uni-app 离线本地存储方案 【跨端开发系列】uni-app UI库、框架、组件选型指南 【跨端开…...

SpringBoot中的@Configuration注解
在Spring Boot中,Configuration注解扮演着非常重要的角色,它是Spring框架中用于定义配置类的一个核心注解。以下是Configuration注解的主要作用: 定义配置类: 使用Configuration注解的类表示这是一个配置类,Spring容器…...

十二、路由、生命周期函数
router路由 页面路由指的是在应用程序中实现不同页面之间的跳转,以及数据传递。通过 Router 模块就可以实现这个功能 2.1创建页面 之前是创建的文件,使用路由的时候需要创建页面,步骤略有不同 方法 1:直接右键新建Page(常用)方法 2:单独添加页面并配置2.1.1直接右键新建…...

【蓝桥杯每日一题】X 进制减法
X 进制减法 2024-12-6 蓝桥杯每日一题 X 进制减法 贪心 进制转换 题目大意 进制规定了数字在数位上逢几进一。 XX 进制是一种很神奇的进制, 因为其每一数位的进制并不固定!例如说某 种 XX 进制数, 最低数位为二进制, 第二数位为十进制, 第三数位为八进制, 则 XX 进制…...

《蓝桥杯比赛规划》
大家好啊!我是NiJiMingCheng 我的博客:NiJiMingCheng 这节课我们来分享蓝桥杯比赛规划,好的规划会给我们的学习带来良好的收益,废话少说接下来就让我们进入学习规划吧,加油哦!!! 一、…...

C++算法练习day70——53.最大子序和
题目来源:. - 力扣(LeetCode) 题目思路分析 题目:寻找最大子数组和(也称为最大子序和)。 给定一个整数数组 nums,找到一个具有最大和的连续子数组(子数组最少包含一个元素&#x…...

import是如何“占领满屏“
import是如何“占领满屏“的? 《拒绝使用模块重导(Re-export)》 模块重导是一种通用的技术。在腾讯、字节、阿里等各大厂的组件库中都有大量使用。 如:字节的arco-design组件库中的组件:github.com/arco-design… …...

ceph /etc/ceph-csi-config/config.json: no such file or directory
环境 rook-ceph 部署的 ceph。 问题 kubectl describe pod dragonfly-redis-master-0Warning FailedMount 7m59s (x20 over 46m) kubelet MountVolume.MountDevice failed for volume "pvc-c63e159a-c940-4001-bf0d-e6141634cc55" : rpc error: cod…...

OpenWrt Argon主题定制指南:从零开始的界面改造与个性化方案
OpenWrt Argon主题定制指南:从零开始的界面改造与个性化方案 【免费下载链接】luci-theme-argon Argon is a clean and tidy OpenWrt LuCI theme that allows users to customize their login interface with images or videos. It also supports automatic and man…...

DSM 7.2.2系统Video Station解决方案完全指南
DSM 7.2.2系统Video Station解决方案完全指南 【免费下载链接】Video_Station_for_DSM_722 Script to install Video Station in DSM 7.2.2 项目地址: https://gitcode.com/gh_mirrors/vi/Video_Station_for_DSM_722 当你升级到群晖DSM 7.2.2系统后,是否发现…...
参数自适应控制的T型三电平逆变器并离网切换模型研究(Simulink仿真实现))
基于虚拟同步机(VSG)参数自适应控制的T型三电平逆变器并离网切换模型研究(Simulink仿真实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

【stm32简单外设篇】- 震动传感器
一、适用场景 适用场景:防盗/防移动报警(机箱/设备被碰撞报警)、机械振动监测(异常振幅提示)、敲击触发(敲击开关)、跌落检测、简单冲击计数、测试台/生产线故障检测、嵌入式中断与 ADC 采样练习…...

光源追踪系统毕设效率优化实战:从单线程渲染到并行加速的架构演进
最近在忙毕业设计,做了一个基于物理的光源追踪系统。说实话,刚开始的时候,渲染一张简单的测试图都要等上十几分钟,调试起来简直让人崩溃。效率问题成了整个项目最大的拦路虎。今天就来聊聊,我是怎么一步步把这个“慢吞…...

Phi-4-reasoning-vision-15B轻量级调优:temperature=0时OCR结果确定性验证
Phi-4-reasoning-vision-15B轻量级调优:temperature0时OCR结果确定性验证 1. 引言 你有没有遇到过这种情况?用AI模型识别一张图片里的文字,第一次识别得挺准,第二次再试,结果却变了几个字。这种不确定性在需要精确结…...

REFramework松散文件加载器性能优化指南:从卡顿到流畅的技术演进
REFramework松散文件加载器性能优化指南:从卡顿到流畅的技术演进 【免费下载链接】REFramework REFramework 是 RE 引擎游戏的 mod 框架、脚本平台和工具集,能安装各类 mod,修复游戏崩溃、卡顿等问题,还有开发者工具,让…...

科研绘图还在啃软件?Paperxie AI:一句话生成学术图表,流程图 / CAD 图全搞定
paperxie科研绘图https://www.paperxie.cn/drawinghttps://www.paperxie.cn/drawing 在学术圈流传着这样一句话:「论文写得好,不如图画得巧」。一张清晰规范的图表,不仅能让审稿人眼前一亮,更是科研成果可视化的核心载体。但现实是…...

三部六层电梯仿真群控联动系统:基于西门子S7-1200 PLC与博图v15.1及以上版本实现方...
三部六层电梯,基于西门子1200,博图v15.1版本及以上,群控联动带算法,可直接仿真运行,不用下载到实物,需要报告另加, 清单如下: Wincc组态 Plc程序 图纸真实i Q Io表 内部变量m 主讲程…...

基于单片机的瓦斯监测系统设计
收藏关注不迷路!! 🌟文末获取源码数据库🌟 感兴趣的可以先收藏起来,还有大家在毕设选题(免费咨询指导选题),项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多…...