【图像分类】基于PyTorch搭建LSTM实现MNIST手写数字体识别(双向LSTM,附完整代码和数据集)
写在前面:
首先感谢兄弟们的关注和订阅,让我有创作的动力,在创作过程我会尽最大能力,保证作品的质量,如果有问题,可以私信我,让我们携手共进,共创辉煌。
在https://blog.csdn.net/AugustMe/article/details/128969138文章中,我们使用了基于PyTorch搭建LSTM实现MNIST手写数字体识别,LSTM是单向的,现在我们使用双向LSTM试一试效果,和之前的单向LSTM模型稍微有差别,请注意查看代码的变化。
1.导入依赖库
这些依赖库是必须导入的,用于后续代码的构建:
import torch
from torch import nn, optim
from torch.autograd import Variable
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
from PIL import Image
import numpy as np
依赖库的版本信息:
torch: 1.8.0+cpu
numpy: 1.19.3
matplotlib: 3.2.1
pillow: 7.2.0
2.数据集
训练模型肯定少不了数据集,本教程使用我们以比较熟悉的 mnist 数据集,该数据集是手写数字数据集,每一张图片得大小为28×28,训练集60000张,测试集10000张,mnist数据集下载代码如下:
# 训练集
train_data = datasets.MNIST(root="./", # 存放位置train = True, # 载入训练集transform=transforms.ToTensor(), # 把数据变成tensor类型download = True # 下载)
# 测试集
test_data = datasets.MNIST(root="./",train = False,transform=transforms.ToTensor(),download = True)
这个mnist下载成功与否,还和你的网络有关系,有时候网络不好,可能会导致下载失败。如果你下载不下来,可以联系我,我将数据集打包发给你。
下载得到的数据集存放如下:

3.数据导入
数据下载成功后,加载下载得到的数据集,核心代码如下:
# 批次大小
batch_size = 32
# 装载训练集
train_loader = DataLoader(dataset=train_data, batch_size=batch_size, shuffle=True)
# 装载测试集
test_loader = DataLoader(dataset=test_data, batch_size=batch_size, shuffle=False)
我们查看一下数据集中的图片,核心代码为:
# batch_size设为 1 时查看
for i, data in enumerate(train_loader):inputs, labels = dataprint(inputs.shape)print(labels.shape)img = inputs.view((28,28))print(img.shape)# plt.imshow(img)plt.imshow(img, cmap='gray')break
plt.imshow(img, cmap=‘gray’)

plt.imshow(img):
4.双向LSTM网络
Long Short-Term Memory (LSTM) 是一种特殊的循环神经网络,它能够处理较长的序列,并且能够记忆长期的依赖关系。LSTM 的结构包括输入门、输出门、遗忘门和记忆细胞,它们共同组成了一个“门控循环单元”,可以控制信息的流动,从而实现长期依赖关系的学习。LSTM 在自然语言处理、语音识别、机器翻译等领域有着广泛的应用。
基于pytorch深度学习框架搭建LSTM网络模型,使用了双向LSTM,一层:
这里面模型和之前的文章稍有不同,注意 output,(h_n,c_n)三个值的输出。
# 定义网络结构
class LSTM(nn.Module):def __init__(self):super(LSTM,self).__init__() # 初始化self.lstm = nn.LSTM(input_size = 28, # 表示输入特征的大小hidden_size = 64, # 隐藏层的特征维度num_layers = 1, # 表示lstm隐藏层的层数batch_first = True, # lstm默认格式input(seq_len,batch,feature)# 等于True表示input和output变成(batch,seq_len,feature)bidirectional = True # True则为双向lstm默认为False)self.out = torch.nn.Linear(in_features=64*2, out_features=10)self.softmax = torch.nn.Softmax(dim=1) # 映射到0-1之间def forward(self,x):# (batch, seq_len, feature)x = x.view(-1, 28, 28)# output:(batch,seq_len,hidden_size)包含每个序列的输出结果# 虽然lstm的batch_first为True,但是h_n,c_n的第0个维度还是num_layers# h_n :[num_layers,batch,hidden_size]只包含最后一个序列的输出结果# c_n:[num_layers,batch,hidden_size]只包含最后一个序列的输出结果output,(h_n,c_n) = self.lstm(x) # x输入到lstmoutput_in_last_timestep = output[:,-1,:] # 获取下一个输入x = self.out(output_in_last_timestep) # 输入到outx = self.softmax(x) # 输入到softmaxreturn x
特别说明:
LSTM中存在维度的变化,一定要注意,下面以实例进行讲解,请看下面的代码和注释。
h_n包含的是句子的最后一个单词的隐藏状态,c_n包含的是句子的最后一个单词的细胞状态,所以它们都与句子的长度seq_length无关。output[:,-1,:]与h_n是相等的,因为output[-1]包含的正是batch_size个句子中每一个句子的最后一个单词的隐藏状态,注意LSTM中的隐藏状态其实就是输出,cell state细胞状态才是LSTM中一直隐藏的,记录着信息,output与h_n的关系。
实验代码,仅供参考:
# -*- coding: utf-8 -*-
"""
Created on Fri Feb 10 15:25:40 2023@author: augustqi维度变化:
https://blog.csdn.net/qq_54867493/article/details/128790652
"""import torch
import torch.nn as nninput_x = torch.randn(1, 28, 28)
print(input_x.shape)input_x_ = input_x.view(-1, 28, 28)
print(input_x_.shape)lstm = nn.LSTM(input_size = 28, # 输入数据的特征维数,通常就是embedding_dim(词向量的维度)hidden_size = 64, # 隐藏层的特征维度num_layers = 1, # 表示lstm循环神经网络的层数batch_first = True, # lstm默认格式input(seq_len,batch,feature)# 等于True表示input和output变成(batch,seq_len,feature)bidirectional = True # True则为双向lstm默认为False)linear = torch.nn.Linear(in_features=64*2, out_features=10)softmax = torch.nn.Softmax(dim=1)output, (h_n, c_n) = lstm(input_x_)'''
output的维度:(batch, seq_len, num_directions*hidden_size)
hn的维度:(num_directions*num_layer, batch_size, hidden_size)
cn的维度:同hn
'''print(output)
# 如果bidirectional=True, num_directions=2; 如果bidirectional=False, num_directions=1
print(output.shape) # [seq_length, batch_size, num_directions * hidden_size]print(output[:,-1,:])
print(output[:,-1,:].shape)print(h_n)
print(h_n.shape) # [num_directions * num_layers, batch, hidden_size]print(c_n)
print(c_n.shape) # c_n.shape = h_n.shapeprint(h_n[-1,:,:])
print(h_n[-1,:,:].shape) linear_out = linear(h_n[-1,:,:])softmax_out = softmax(linear_out)linear_out_2 = linear(output[:,-1,:])
softmax_out_2 = softmax(linear_out_2)"""
h_n包含的是句子的最后一个单词的隐藏状态,c_n包含的是句子的最后一个单词的细胞状态,
所以它们都与句子的长度seq_length无关。
output[:,-1,:]与h_n是相等的,因为output[-1]包含的正是batch_size个句子中每一个句子的最后一个单词的隐藏状态,
注意LSTM中的隐藏状态其实就是输出,cell state细胞状态才是LSTM中一直隐藏的,记录着信息,output与h_n的关系。"""
5.模型训练
训练代码如下,主要包括定义模型、定义损失函数、定义优化器,训练时的超参数,详情如下:
# 定义模型
model = LSTM()
# 定义代价函数
mse_loss = nn.CrossEntropyLoss() # 交叉熵
# 定义优化器
optimizer = optim.Adam(model.parameters(),lr=0.001) # AdamEpoch = 30
loss_train_list = []
loss_test_list = []
# 训练
for epoch in range(Epoch):# 模型的训练状态model.train()correct_train = 0loss_train = 0for i, data in enumerate(train_loader):# 获得一个批次的数据和标签inputs, labels = data# 获得模型预测结果(64,10)out = model(inputs)# 获得最大值,以及最大值所在的位置_, predicted = torch.max(out, 1)# 预测正确的数量correct_train += (predicted==labels).sum()# 交叉熵代价函数out(batch,C:类别的数量),labels(batch)loss = mse_loss(out, labels)loss_train += loss.item() # loss.data, tensor(1.4612)# 梯度清零optimizer.zero_grad()# 计算梯度loss.backward()# 修改权值optimizer.step() loss_train_list.append(loss_train/len(train_data))print("Epoch:{}/{}, Train acc:{:.4f}, Loss:{:.6f}".format(epoch+1, Epoch, (correct_train.item()/len(train_data)), (loss_train/len(train_data))))
6.模型测试
每训练完一个epoch,就使用测试集测试一下模型,输出测试精度和损失情况:
# 模型的测试状态
model.eval()
correct_test = 0 # 测试集准确率
loss_test = 0
for i, data in enumerate(test_loader):# 获得一个批次的数据和标签inputs, labels = data# 获得模型预测结果(64,10)out = model(inputs)# 获得最大值,以及最大值所在的位置_,predicted = torch.max(out, 1)# 预测正确的数量correct_test += (predicted==labels).sum()loss = mse_loss(out, labels)loss_test += loss.item() # loss.data, tensor(1.4612)loss_test_list.append(loss_test/len(test_data))
print("Test acc:{:.4f}, Loss:{:.6f}".format(correct_test.item()/len(test_data), loss_test/len(test_data)))
7.损失可视化
训练30个epoch,终端输出情况:
Epoch:1/30, Train acc:0.7438, Loss:0.054061
Test acc:0.8521, Loss:0.050427
Epoch:2/30, Train acc:0.8615, Loss:0.050059
Test acc:0.9322, Loss:0.047967
Epoch:3/30, Train acc:0.9387, Loss:0.047655
Test acc:0.9546, Loss:0.047182
Epoch:4/30, Train acc:0.9506, Loss:0.047248
Test acc:0.9618, Loss:0.046989
Epoch:5/30, Train acc:0.9620, Loss:0.046881
Test acc:0.9593, Loss:0.047013
Epoch:6/30, Train acc:0.9638, Loss:0.046818
Test acc:0.9630, Loss:0.046920
Epoch:7/30, Train acc:0.9647, Loss:0.046787
Test acc:0.9664, Loss:0.046818
Epoch:8/30, Train acc:0.9680, Loss:0.046681
Test acc:0.9700, Loss:0.046682
Epoch:9/30, Train acc:0.9698, Loss:0.046619
Test acc:0.9686, Loss:0.046729
Epoch:10/30, Train acc:0.9736, Loss:0.046505
Test acc:0.9710, Loss:0.046664
Epoch:11/30, Train acc:0.9761, Loss:0.046428
Test acc:0.9711, Loss:0.046657
Epoch:12/30, Train acc:0.9768, Loss:0.046398
Test acc:0.9771, Loss:0.046465
Epoch:13/30, Train acc:0.9784, Loss:0.046350
Test acc:0.9783, Loss:0.046434
Epoch:14/30, Train acc:0.9796, Loss:0.046312
Test acc:0.9773, Loss:0.046442
Epoch:15/30, Train acc:0.9809, Loss:0.046278
Test acc:0.9794, Loss:0.046393
Epoch:16/30, Train acc:0.9808, Loss:0.046270
Test acc:0.9789, Loss:0.046409
Epoch:17/30, Train acc:0.9807, Loss:0.046278
Test acc:0.9766, Loss:0.046474
Epoch:18/30, Train acc:0.9816, Loss:0.046243
Test acc:0.9793, Loss:0.046388
Epoch:19/30, Train acc:0.9840, Loss:0.046169
Test acc:0.9799, Loss:0.046367
Epoch:20/30, Train acc:0.9846, Loss:0.046152
Test acc:0.9823, Loss:0.046316
Epoch:21/30, Train acc:0.9853, Loss:0.046132
Test acc:0.9833, Loss:0.046268
Epoch:22/30, Train acc:0.9862, Loss:0.046103
Test acc:0.9814, Loss:0.046317
Epoch:23/30, Train acc:0.9850, Loss:0.046141
Test acc:0.9804, Loss:0.046343
Epoch:24/30, Train acc:0.9865, Loss:0.046091
Test acc:0.9815, Loss:0.046316
Epoch:25/30, Train acc:0.9873, Loss:0.046067
Test acc:0.9833, Loss:0.046262
Epoch:26/30, Train acc:0.9879, Loss:0.046048
Test acc:0.9813, Loss:0.046331
Epoch:27/30, Train acc:0.9870, Loss:0.046073
Test acc:0.9837, Loss:0.046250
Epoch:28/30, Train acc:0.9891, Loss:0.046014
Test acc:0.9830, Loss:0.046271
Epoch:29/30, Train acc:0.9875, Loss:0.046061
Test acc:0.9821, Loss:0.046299
Epoch:30/30, Train acc:0.9888, Loss:0.046023
Test acc:0.9815, Loss:0.046324
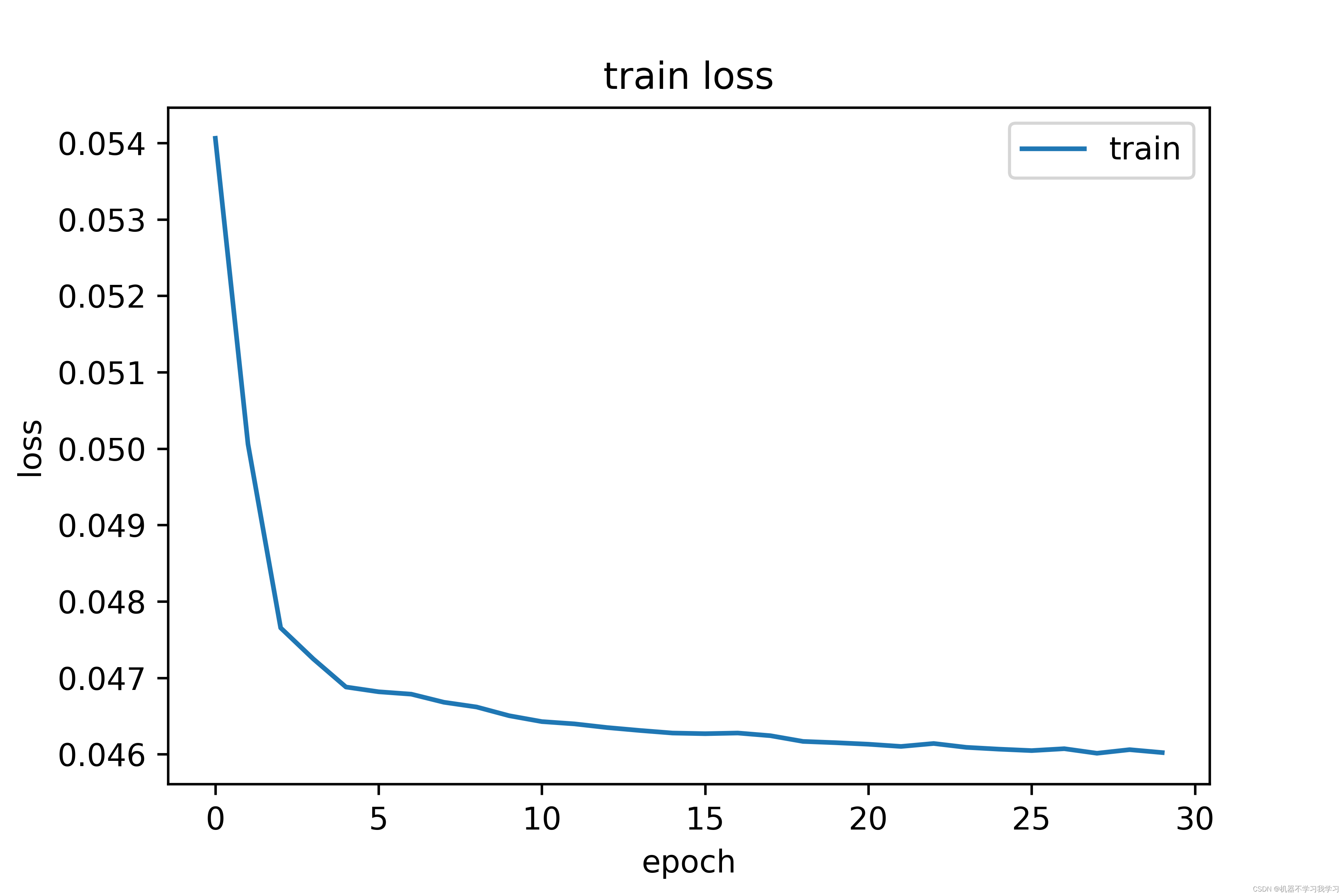
训练集上损失曲线图:
测试集上损失曲线图:
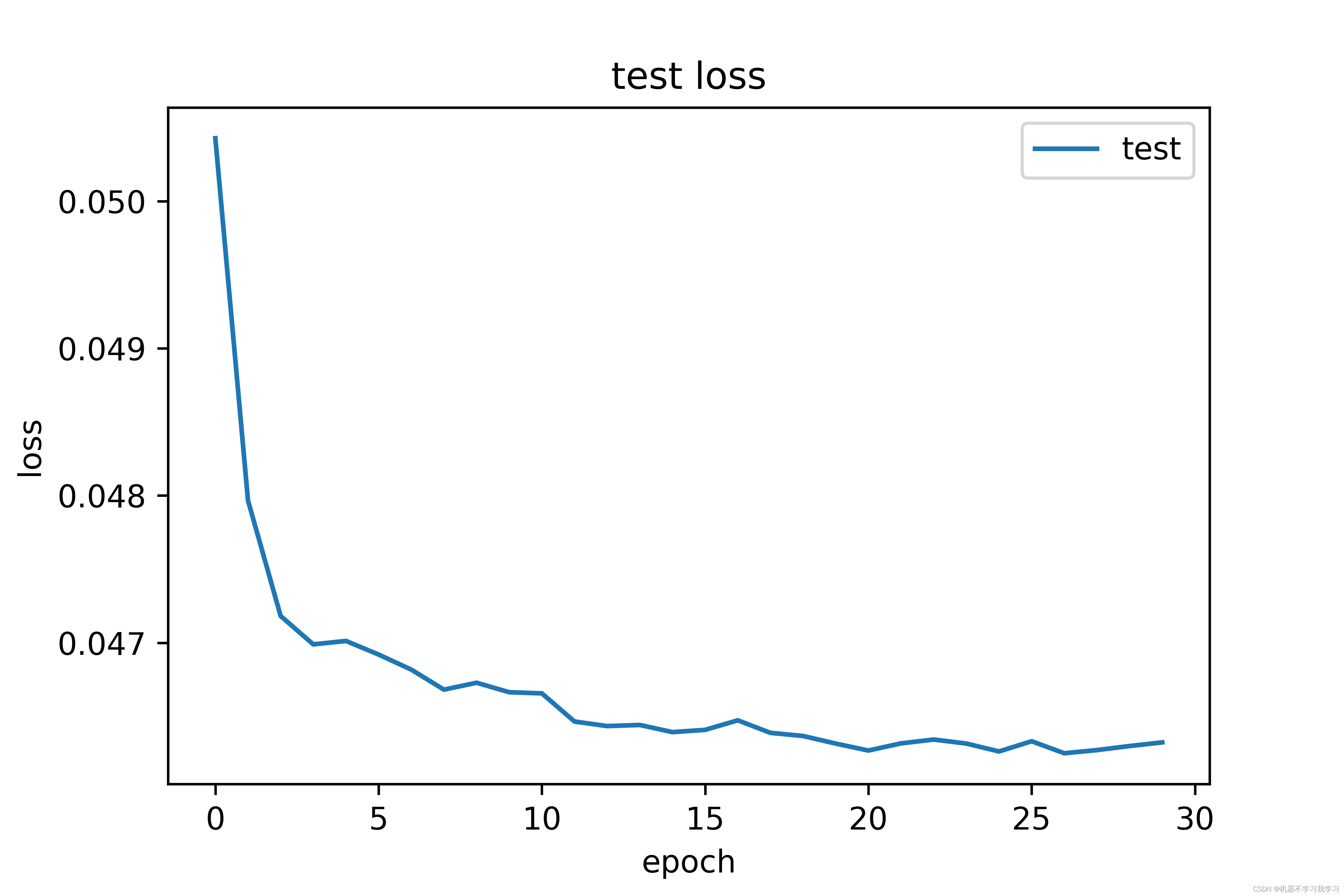
训练30个epoch后,模型在测试集上的精度达到98.15%,效果还不错。训练集上的损失和测试集上的损失都在下降并逐渐收敛。
参考资料
1.https://blog.csdn.net/AugustMe/article/details/128969138
相关文章:
【图像分类】基于PyTorch搭建LSTM实现MNIST手写数字体识别(双向LSTM,附完整代码和数据集)
写在前面: 首先感谢兄弟们的关注和订阅,让我有创作的动力,在创作过程我会尽最大能力,保证作品的质量,如果有问题,可以私信我,让我们携手共进,共创辉煌。 在https://blog.csdn.net/A…...
【Linux】多线程编程 - 同步/条件变量/信号量
目录 一.线程同步 1.什么是线程同步 2.为什么需要线程同步 3.如何实现线程同步 二.条件变量 1.常见接口以及使用 2.wiat/signal中的第二个参数mutex的意义 3.代码验证 三.POSIX信号量 1.概念 2.常见接口以及使用 四.条件变量vsPOSIX信号量 一.线程同步 1.什么是线…...

ES优化方案
ES优化&联合HBASE: 【Elasticsearch】优秀实践-ESHbase的实现_少加点香菜的博客-CSDN博客_sceshbase ES写入性能优化方案 ElasticSearch 调优笔记_index.refresh_interval_六月飞雪的博客-CSDN博客 es如何提升写入性能_婲落ヽ紅顏誶的博客-CSDN博客_es写入性…...
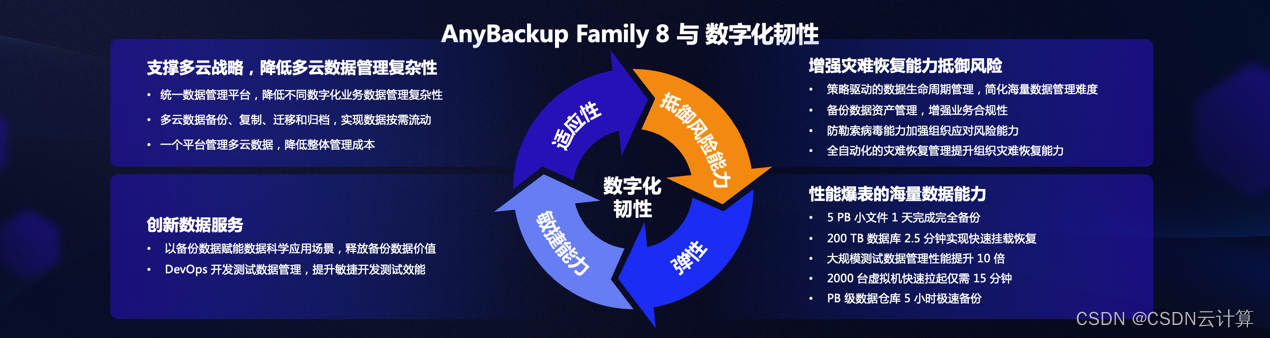
从数据备份保护到完整生命周期管理平台,爱数全新发布 AnyBackup Family 8
编辑 | 宋慧 出品 | CSDN 云计算 从2003年创业,开始做数据备份技术,爱数已经走过了近20年的时间。现在,数据的价值被越来越多的业界与用户看到,数据分析应用赛道近年一直持续火热。而现在的爱数在做的,已经从数据的备…...

Go 微服务开发框架 DMicro 的设计思路
Go 微服务开发框架 DMicro 的设计思路 DMicro 源码地址: Gitee:dmicro: dmicro是一个高效、可扩展且简单易用的微服务框架。包含drpc,dserver等 背景 DMicro 诞生的背景,是因为我写了 10 来年的 PHP,想在公司内部推广 Go, 公司内部的组件及 rpc 协议都…...

浅谈功能测试
1.功能测试流程 1.1 功能测试流程 # 功能测试大致按照以下流程进行: (1).需求分析与评审(2).测试计划与测试方案(3).测试用例设计(4).测试用例评审(5).执行用例(6).缺陷跟踪及报告产出 1.2 功能测试流程详解 (1).需求分析与评审 功能测试应从需求出发, 功能测试就是尽量覆…...

UDP的详细解析
UDP的详细解析 文章目录UDP的详细解析UDP 概述UDP的首部格式检验和的计算抓包测试参考TCP/IP运输层的两个主要协议都是互联网的正式标准,即:用户数据报协议UDP (User Datagram Protocol)传输控制协议TCP (Transmission Control Protocol) 按照OSI的术语…...

史上最详细JUC教程之Synchronized与锁升级详解
在Java早期版本中,synchronized属于重量级锁,效率低下,因为监视器锁(monitor)是依赖于底层的操作系统的Mutex Lock来实现的,挂起线程和恢复线程都需要转入内核态去完成,阻塞或唤醒一个Java线程需…...
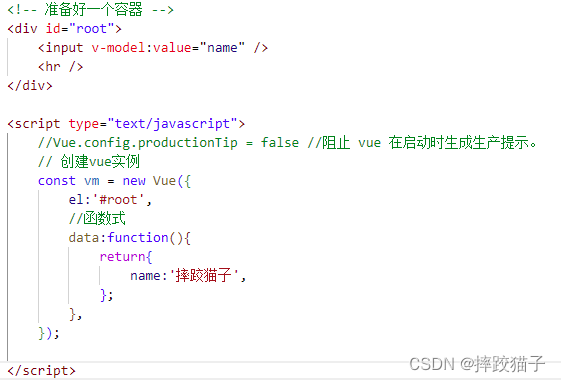
Vue|初识Vue
Vue是一款用于构建用户界面的JavaScript框架。它基于标准HTML、CSS和JavaScript构建,并提供了一套声明式的、组件化的编程模型,帮助开发者高效地开发用户界面。 初识Vue1. Vue简介2. 开发准备3. 模板语法3.1 差值语法3.2 指令语法4. 数据绑定4.1 单向数据…...
在职阿里6年,一个29岁女软件测试工程师的心声
简单的先说一下,坐标杭州,14届本科毕业,算上年前在阿里巴巴的面试,一共有面试了有6家公司(因为不想请假,因此只是每个晚上去其他公司面试,所以面试的公司比较少)其中成功的有4家&…...

(C语言)自定义类型,枚举与联合
问:1. 结构体在自引用的时候不能怎么样?可以怎么样?2. Solve the problems:自定义一个学生结构体类型,要包含姓名,性别,年龄,六科成绩,家乡(也为结构体&#…...

node.js服务端笔记文档学会写接口,学习分类:path、包、模块化、fs、express、中间件、jwt、开发模式、cors。
node.js 学习笔记 node.js服务端笔记文档学会写接口,path、包、模块化、fs、express、中间件、JWT、开发模式、cors。 gitee:代码接口笔记 1什么是node.js nodejs 是基于ChromeV8,引擎的一个javaScript 运行环境。node.js 无法使用DOM和BO…...
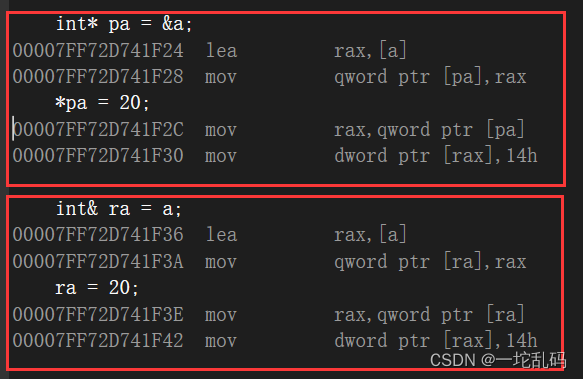
初始C++(三):引用
文章目录一.引用的概念二.引用的使用1.引用作为输出型参数2. 引用作为函数返回值3.const引用三.引用的一些小问题四.引用和指针五.引用和指针的区别一.引用的概念 引用的作用是给一个已经存在的变量取别名,编译器不会为引用变量开空间,引用变量和被他引…...
【前端】参考C站动态发红包界面,高度还原布局和交互
最近有些小伙伴咨询博主说前端布局好难,其实都是熟能生巧! 模仿C站动态发红包界面,cssdiv实现布局,纯javascript实现交互效果 目录 1、界面效果 2、界面分析 2.1、整体结构 2.2、标题 2.3、表单 2.4、按钮 3、代码实现 3.…...

VR全景带你浪漫“狂飙”情人节,见证甜蜜心动
当情人节遇上VR,足以让情侣过一个难忘的情人节。马上情人节就要到了,大家是不是还在绞尽脑汁的想着,如何和另一半过一个浪漫的情人节呢?老套的剧情已经不能吸引人了,让我们看看VR全景给情人节带来了哪些不同的体验吧&a…...
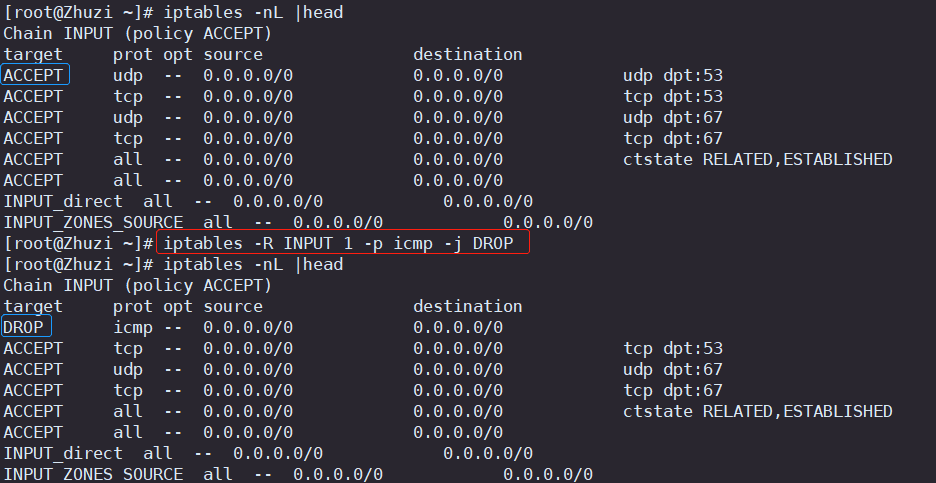
Linux系统安全之iptables防火墙
目录 一.iptables防火墙基本介绍 二.iptables的四表五链 三.iptables的配置 1.iptables的安装 2.iptables防火墙的配置方法 四.添加、查看、删除规则 1.查看(fliter)表中的所有链 iptables -L 2.使用数字形式(fliter)表所有链 查看输出结果 iptables -nL 3.清空表中所…...

【C#基础】C# 变量与常量的使用
序号系列文章1【C#基础】C# 程序通用结构2【C#基础】C# 基础语法解析3【C#基础】C# 数据类型总结文章目录前言一. 变量(variable)1,变量定义及初始化2,变量的类别3,接收输出变量二. 常量(constantÿ…...
[ 常用工具篇 ] CobaltStrike(CS神器)基础(一) -- 安装及设置监听器详解
🍬 博主介绍 👨🎓 博主介绍:大家好,我是 _PowerShell ,很高兴认识大家~ ✨主攻领域:【渗透领域】【数据通信】 【通讯安全】 【web安全】【面试分析】 🎉点赞➕评论➕收藏 养成习…...
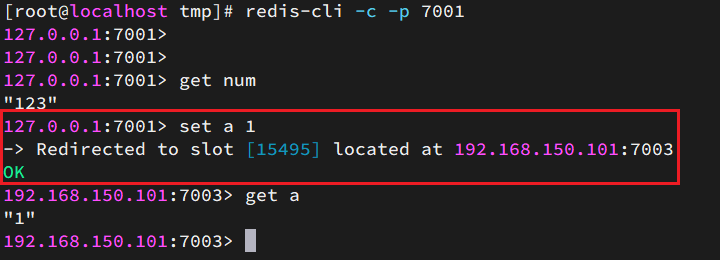
Redis集群
Redis集群 本章是基于CentOS7下的Redis集群教程,包括: 单机安装RedisRedis主从Redis分片集群 1.单机安装Redis 首先需要安装Redis所需要的依赖: yum install -y gcc tcl然后将课前资料提供的Redis安装包上传到虚拟机的任意目录ÿ…...

00---C++入门
1. C关键字(C98) C总计63个关键字,C语言32个关键字 2. 命名空间 在C/C中,变量、函数和后面要学到的类都是大量存在的,这些变量、函数和类的名称将都存在于全局作用域中,可能会导致很多冲突。使用命名空间的目的是对标识符的名称进…...

Python爬虫实战:研究MechanicalSoup库相关技术
一、MechanicalSoup 库概述 1.1 库简介 MechanicalSoup 是一个 Python 库,专为自动化交互网站而设计。它结合了 requests 的 HTTP 请求能力和 BeautifulSoup 的 HTML 解析能力,提供了直观的 API,让我们可以像人类用户一样浏览网页、填写表单和提交请求。 1.2 主要功能特点…...

基于Uniapp开发HarmonyOS 5.0旅游应用技术实践
一、技术选型背景 1.跨平台优势 Uniapp采用Vue.js框架,支持"一次开发,多端部署",可同步生成HarmonyOS、iOS、Android等多平台应用。 2.鸿蒙特性融合 HarmonyOS 5.0的分布式能力与原子化服务,为旅游应用带来…...
-----深度优先搜索(DFS)实现)
c++ 面试题(1)-----深度优先搜索(DFS)实现
操作系统:ubuntu22.04 IDE:Visual Studio Code 编程语言:C11 题目描述 地上有一个 m 行 n 列的方格,从坐标 [0,0] 起始。一个机器人可以从某一格移动到上下左右四个格子,但不能进入行坐标和列坐标的数位之和大于 k 的格子。 例…...

Python如何给视频添加音频和字幕
在Python中,给视频添加音频和字幕可以使用电影文件处理库MoviePy和字幕处理库Subtitles。下面将详细介绍如何使用这些库来实现视频的音频和字幕添加,包括必要的代码示例和详细解释。 环境准备 在开始之前,需要安装以下Python库:…...

MySQL 8.0 OCP 英文题库解析(十三)
Oracle 为庆祝 MySQL 30 周年,截止到 2025.07.31 之前。所有人均可以免费考取原价245美元的MySQL OCP 认证。 从今天开始,将英文题库免费公布出来,并进行解析,帮助大家在一个月之内轻松通过OCP认证。 本期公布试题111~120 试题1…...

【Oracle】分区表
个人主页:Guiat 归属专栏:Oracle 文章目录 1. 分区表基础概述1.1 分区表的概念与优势1.2 分区类型概览1.3 分区表的工作原理 2. 范围分区 (RANGE Partitioning)2.1 基础范围分区2.1.1 按日期范围分区2.1.2 按数值范围分区 2.2 间隔分区 (INTERVAL Partit…...

DeepSeek 技术赋能无人农场协同作业:用 AI 重构农田管理 “神经网”
目录 一、引言二、DeepSeek 技术大揭秘2.1 核心架构解析2.2 关键技术剖析 三、智能农业无人农场协同作业现状3.1 发展现状概述3.2 协同作业模式介绍 四、DeepSeek 的 “农场奇妙游”4.1 数据处理与分析4.2 作物生长监测与预测4.3 病虫害防治4.4 农机协同作业调度 五、实际案例大…...

智能AI电话机器人系统的识别能力现状与发展水平
一、引言 随着人工智能技术的飞速发展,AI电话机器人系统已经从简单的自动应答工具演变为具备复杂交互能力的智能助手。这类系统结合了语音识别、自然语言处理、情感计算和机器学习等多项前沿技术,在客户服务、营销推广、信息查询等领域发挥着越来越重要…...

Linux 中如何提取压缩文件 ?
Linux 是一种流行的开源操作系统,它提供了许多工具来管理、压缩和解压缩文件。压缩文件有助于节省存储空间,使数据传输更快。本指南将向您展示如何在 Linux 中提取不同类型的压缩文件。 1. Unpacking ZIP Files ZIP 文件是非常常见的,要在 …...

Java求职者面试指南:计算机基础与源码原理深度解析
Java求职者面试指南:计算机基础与源码原理深度解析 第一轮提问:基础概念问题 1. 请解释什么是进程和线程的区别? 面试官:进程是程序的一次执行过程,是系统进行资源分配和调度的基本单位;而线程是进程中的…...