JAVA基础-深入理解Java内存模型(一)-- 重排序与先行发生原则(happens-before)
深入理解Java内存模型(一)-- 重排序
很棒的一个关于Java内存模型系列文章,首先感谢作者,转载自深入理解java内存模型系列文章 ,为了方便阅读,做了一些内容整合和重排版。
提纲
Java线程之间的通信对程序员完全黑盒,内存可见性问题很容易困扰Java程序员,本文试图揭开Java内存模型神秘的面纱。本文大致分三部分:
- 重排序与顺序一致性;
- 三个同步原语(lock,volatile,final)的内存语义,重排序规则及在处理器中的实现;
- Java内存模型的设计目标,及其与处理器内存模型和顺序一致性内存模型的关系。
Java内存模型
在Java中,所有实例域、静态域和数组元素存储在堆内存中,堆内存在线程之间共享(本文使用“共享变量”这个术语代指实例域,静态域和数组元素)。
局部变量(Local variables),方法定义参数(Java语言规范称之为formal method parameters)和异常处理器参数(exception handler parameters)不会在线程之间共享,它们不会有内存可见性问题,也不受内存模型的影响。
Java线程之间的通信由Java内存模型(本文简称为JMM)控制,JMM决定一个线程对共享变量的写入何时对另一个线程可见。从抽象的角度来看,JMM定义了线程和主内存之间的抽象关系:线程之间的共享变量存储在主内存(main memory)中,每个线程都有一个私有的本地内存(local memory),本地内存中存储了该线程以读/写共享变量的副本。本地内存是JMM的一个抽象概念,并不真实存在。它涵盖了缓存,写缓冲区,寄存器以及其他的硬件和编译器优化。Java内存模型的抽象示意图如下:

从上图来看,线程A与线程B之间如要通信的话,必须要经历下面2个步骤:
-
首先,线程A把本地内存A中更新过的共享变量刷新到主内存中去。
-
然后,线程B到主内存中去读取线程A之前已更新过的共享变量。
下面通过示意图来说明这两个步骤

如上图所示,本地内存A和B有主内存中共享变量 x 的副本。假设初始时,这三个内存中的 x 值都为0。线程A在执行时,把更新后的 x 值(假设值为1)临时存放在自己的本地内存A中。当线程A和线程B需要通信时,线程A首先会把自己本地内存中修改后的 x 值刷新到主内存中,此时主内存中的 x 值变为了 1。随后,线程B到主内存中去读取线程A更新后的 x 值,此时线程B的本地内存的 x 值也变为了1。
从整体来看,这两个步骤实质上是线程A在向线程B发送消息,而且这个通信过程必须要经过主内存。JMM通过控制主内存与每个线程的本地内存之间的交互,来为Java程序员提供内存可见性保证。
重排序
在执行程序时为了提高性能,编译器和处理器常常会对指令做重排序。重排序分三种类型:
-
编译器优化的重排序。编译器在不改变单线程程序语义的前提下,可以重新安排语句的执行顺序。
-
指令级并行的重排序。现代处理器采用了指令级并行技术(Instruction-Level Parallelism, ILP)来将多条指令重叠执行。如果不存在数据依赖性,处理器可以改变语句对应机器指令的执行顺序。
-
内存系统的重排序。由于处理器使用缓存和读/写缓冲区,这使得加载和存储操作看上去可能是在乱序执行。 从Java源代码到最终实际执行的指令序列,会分别经历下面三种重排序:

上述的 1 属于编译器重排序, 2 和 3 属于处理器重排序。这些重排序都可能会导致多线程程序出现内存可见性问题。
- 对于编译器,JMM的编译器重排序规则会禁止特定类型的编译器重排序(不是所有的编译器重排序都要禁止)。
- 对于处理器重排序,JMM的处理器重排序规则会要求 Java编译器 在生成指令序列时,插入特定类型的内存屏障(memory barriers,intel称之为memory fence)指令,通过内存屏障指令来禁止特定类型的处理器重排序(不是所有的处理器重排序都要禁止)。
JMM属于语言级的内存模型,它确保在不同的编译器和不同的处理器平台之上,通过禁止特定类型的编译器重排序和处理器重排序,为程序员提供一致的内存可见性保证。
处理器重排序与内存屏障指令
现代的处理器使用写缓冲区来临时保存向内存写入的数据:
- 写缓冲区可以保证指令流水线持续运行,它可以避免由于处理器停顿下来等待向内存写入数据而产生的延迟。
- 通过以批处理的方式刷新写缓冲区,以及合并写缓冲区中对同一内存地址的多次写,可以减少对内存总线的占用。
虽然写缓冲区有这么多好处,但每个处理器上的写缓冲区,仅仅对它所在的处理器可见。这个特性会对内存操作的执行顺序产生重要的影响:处理器对内存的读/写操作的执行顺序,不一定与内存实际发生的读/写操作顺序一致!为了具体说明,请看下面示例:
初始状态:a = b = 0
| Processor A | Processor B |
| a = 1; //A1 x = b; //A2 | b = 2; //B1 y = a; //B2 |
假设处理器A和处理器B按程序的顺序并行执行内存访问,最终却可能得到x = y = 0的结果。具体的原因如下图所示:

把流程按照顺序展示一下:
- (A1,B1)阶段:处理器A和处理器B可以同时把共享变量(a,b)写入自己的写缓冲区,
- (A2,B2)阶段:处理器A和处理器B从内存中读取另一个共享变量(b,a)
- (A3,B3)阶段:处理器A和处理器B把自己写缓存区中保存的脏数据(a,b)刷新到共享内存中。
当以这种时序执行时,程序就可以得到x = y = 0的结果。 从内存操作实际发生的顺序来看,直到处理器A执行A3来刷新自己的写缓存区,写操作A1才算真正执行了。虽然处理器A执行内存操作的顺序为:A1->A2,但内存操作实际发生的顺序却是:A2->A1。此时,处理器A的内存操作顺序被重排序了(处理器B的情况和处理器A一样,这里就不赘述了)。
这里的关键是,由于写缓冲区仅对自己的处理器可见,它会导致处理器执行内存操作的顺序可能会与内存实际的操作执行顺序不一致。由于现代的处理器都会使用写缓冲区,因此现代的处理器都会允许对写-读操作重排序。 下面是常见处理器允许的重排序类型的列表:
| Load-Load | Load-Store | Store-Store | Store-Load | 数据依赖 | |
| sparc-TSO | N | N | N | Y | N |
| x86 | N | N | N | Y | N |
| ia64 | Y | Y | Y | Y | N |
| PowerPC | Y | Y | Y | Y | N |
上表单元格中的“N”表示处理器不允许两个操作重排序,“Y”表示允许重排序。
从上表我们可以看出:常见的处理器都允许Store-Load重排序;常见的处理器都不允许对存在数据依赖的操作做重排序。sparc-TSO和x86拥有相对较强的处理器内存模型,它们仅允许对写-读操作做重排序(因为它们都使用了写缓冲区)。
- 注1:sparc-TSO是指以TSO(Total Store Order)内存模型运行时,sparc处理器的特性。
- 注2:上表中的x86包括x64及AMD64。
- 注3:由于ARM处理器的内存模型与PowerPC处理器的内存模型非常类似,本文将忽略它。
- 注4:数据依赖性后文会专门说明。
为了保证内存可见性,Java编译器在生成指令序列的适当位置会插入内存屏障指令来禁止特定类型的处理器重排序。JMM把内存屏障指令分为下列四类:
| 屏障类型 | 指令示例 | 说明 |
| LoadLoad Barriers | Load1; LoadLoad; Load2 | 确保Load1数据的装载,之前于Load2及所有后续装载指令的装载。 |
| StoreStore Barriers | Store1; StoreStore; Store2 | 确保Store1数据对其他处理器可见(刷新到内存),之前于Store2及所有后续存储指令的存储。 |
| LoadStore Barriers | Load1; LoadStore; Store2 | 确保Load1数据装载,之前于Store2及所有后续的存储指令刷新到内存。 |
| StoreLoad Barriers | Store1; StoreLoad; Load2 | 确保Store1数据对其他处理器变得可见(指刷新到内存),之前于Load2及所有后续装载指令的装载。StoreLoad Barriers会使该屏障之前的所有内存访问指令(存储和装载指令)完成之后,才执行该屏障之后的内存访问指令。 |
StoreLoad Barriers是一个“全能型”的屏障,它同时具有其他三个屏障的效果。现代的多处理器大都支持该屏障(其他类型的屏障不一定被所有处理器支持)。执行该屏障开销会很昂贵,因为当前处理器通常要把写缓冲区中的数据全部刷新到内存中(buffer fully flush)。
happens-before
从JDK5开始,java使用新的JSR -133内存模型(本文除非特别说明,针对的都是JSR- 133内存模型)。JSR-133使用happens-before的概念来阐述操作之间的内存可见性。在JMM中,如果一个操作执行的结果需要对另一个操作可见,那么这两个操作之间必须要存在happens-before关系。这里提到的两个操作既可以是在一个线程之内,也可以是在不同线程之间。
与程序员密切相关的happens-before规则如下(划重点!!!!):
- 程序顺序规则:一个线程中的每个操作,happens- before 于该线程中的任意后续操作。
- 监视器锁规则:对一个监视器锁的解锁,happens- before 于随后对这个监视器锁的加锁。
- volatile变量规则:对一个volatile域的写,happens- before 于任意后续对这个volatile域的读。
- 传递性:如果A happens- before B,且B happens- before C,那么A happens- before C。
注意,两个操作之间具有happens-before关系,并不意味着前一个操作必须要在后一个操作之前执行!happens-before仅仅要求前一个操作(执行的结果)对后一个操作可见,且前一个操作按顺序排在第二个操作之前(the first is visible to and ordered before the second)。happens- before的定义很微妙,后文会具体说明happens-before为什么要这么定义。
happens-before与JMM的关系如下图所示:

如上图所示,一个happens-before规则通常对应于多个编译器和处理器重排序规则。对于Java程序员来说,happens-before规则简单易懂,它避免Java程序员为了理解JMM提供的内存可见性保证而去学习复杂的重排序规则以及这些规则的具体实现。
数据依赖性
如果两个操作访问同一个变量,且这两个操作中有一个为写操作,此时这两个操作之间就存在数据依赖性。数据依赖分下列三种类型:
| 名称 | 代码示例 | 说明 |
| 写后读 | a = 1;b = a; | 写一个变量之后,再读这个位置。 |
| 写后写 | a = 1;a = 2; | 写一个变量之后,再写这个变量。 |
| 读后写 | a = b;b = 1; | 读一个变量之后,再写这个变量。 |
上面三种情况,只要重排序两个操作的执行顺序,程序的执行结果将会被改变。
前面提到过,编译器和处理器可能会对操作做重排序。编译器和处理器在重排序时,会遵守数据依赖性,编译器和处理器不会改变存在数据依赖关系的两个操作的执行顺序。
注意,这里所说的数据依赖性仅针对单个处理器中执行的指令序列和单个线程中执行的操作,不同处理器之间和不同线程之间的数据依赖性不被编译器和处理器考虑。
as-if-serial语义
as-if-serial语义的意思指:不管怎么重排序(编译器和处理器为了提高并行度),(单线程)程序的执行结果不能被改变。编译器,runtime 和处理器都必须遵守as-if-serial语义。
为了遵守as-if-serial语义,编译器和处理器不会对存在数据依赖关系的操作做重排序,因为这种重排序会改变执行结果。但是,如果操作之间不存在数据依赖关系,这些操作可能被编译器和处理器重排序。为了具体说明,请看下面计算圆面积的代码示例:
double pi = 3.14; //A
double r = 1.0; //B
double area = pi * r * r; //C
上面三个操作的数据依赖关系如下图所示:

如上图所示,A和C之间存在数据依赖关系,同时B和C之间也存在数据依赖关系。因此在最终执行的指令序列中,C不能被重排序到A和B的前面(C排到A和B的前面,程序的结果将会被改变)。但A和B之间没有数据依赖关系,编译器和处理器可以重排序A和B之间的执行顺序。下图是该程序的两种执行顺序:

as-if-serial语义把单线程程序保护了起来,遵守as-if-serial语义的编译器,runtime 和处理器共同为编写单线程程序的程序员创建了一个幻觉:单线程程序是按程序的顺序来执行的。as-if-serial语义使单线程程序员无需担心重排序会干扰他们,也无需担心内存可见性问题。
程序顺序规则
根据happens- before的程序顺序规则,上面计算圆的面积的示例代码存在三个happens- before关系:
- A happens- before B;
- B happens- before C;
- A happens- before C;
这里的第3个happens- before关系,是根据happens- before的传递性推导出来的。
这里A happens- before B,但实际执行时B却可以排在A之前执行(看上面的重排序后的执行顺序)。在第一章提到过,如果A happens- before B,JMM并不要求A一定要在B之前执行。JMM仅仅要求前一个操作(执行的结果)对后一个操作可见,且前一个操作按顺序排在第二个操作之前。这里操作A的执行结果不需要对操作B可见;而且重排序操作A和操作B后的执行结果,与操作A和操作B按happens- before顺序执行的结果一致。在这种情况下,JMM会认为这种重排序并不非法(not illegal),JMM允许这种重排序。
在计算机中,软件技术和硬件技术有一个共同的目标:在不改变程序执行结果的前提下,尽可能的开发并行度。编译器和处理器遵从这一目标,从happens- before的定义我们可以看出,JMM同样遵从这一目标。
重排序对多线程的影响
现在让我们来看看,重排序是否会改变多线程程序的执行结果。请看下面的示例代码:
class ReorderExample {
int a = 0;
boolean flag = false;public void writer() {a = 1; //1flag = true; //2
}Public void reader() {if (flag) { //3int i = a * a; //4……}
}
}
flag变量是个标记,用来标识变量a是否已被写入。这里假设有两个线程A和B,A首先执行writer()方法,随后B线程接着执行reader()方法。线程B在执行操作4时,能否看到线程A在操作1对共享变量a的写入?
答案是:不一定能看到。
由于操作1和操作2没有数据依赖关系,编译器和处理器可以对这两个操作重排序;同样,操作3和操作4没有数据依赖关系,编译器和处理器也可以对这两个操作重排序。让我们先来看看,当操作1和操作2重排序时,可能会产生什么效果?请看下面的程序执行时序图:

如上图所示,操作1和操作2做了重排序。程序执行时,线程A首先写标记变量flag,随后线程B读这个变量。由于条件判断为真,线程B将读取变量a。此时,变量a还根本没有被线程A写入,在这里多线程程序的语义被重排序破坏了!
※注:本文统一用红色的虚箭线表示错误的读操作,用绿色的虚箭线表示正确的读操作。
下面再让我们看看,当操作3和操作4重排序时会产生什么效果(借助这个重排序,可以顺便说明控制依赖性)。下面是操作3和操作4重排序后,程序的执行时序图:

在程序中,操作3和操作4存在控制依赖关系。当代码中存在控制依赖性时,会影响指令序列执行的并行度。为此,编译器和处理器会采用猜测(Speculation)执行来克服控制相关性对并行度的影响。以处理器的猜测执行为例,执行线程B的处理器可以提前读取并计算a*a,然后把计算结果临时保存到一个名为重排序缓冲(reorder buffer ROB)的硬件缓存中。当接下来操作3的条件判断为真时,就把该计算结果写入变量i中。
从图中我们可以看出,猜测执行实质上对操作3和4做了重排序。重排序在这里破坏了多线程程序的语义!
在单线程程序中,对存在控制依赖的操作重排序,不会改变执行结果(这也是as-if-serial语义允许对存在控制依赖的操作做重排序的原因);但在多线程程序中,对存在控制依赖的操作重排序,可能会改变程序的执行结果。
顺序一致性
数据竞争
当程序未正确同步时,就会存在数据竞争。java 内存模型规范对数据竞争的定义如下:
- 在一个线程中写一个变量,
- 在另一个线程读同一个变量,
- 而且写和读没有通过同步来排序。
当代码中包含数据竞争时,程序的执行往往产生违反直觉的结果(前一章的示例正是如此)。如果一个多线程程序能正确同步,这个程序将是一个没有数据竞争的程序。
JMM 对正确同步的多线程程序的内存一致性做了如下保证:
如果程序是正确同步的,程序的执行将具有顺序一致性(sequentially consistent)–即程序的执行结果与该程序在顺序一致性内存模型中的执行结果相同(马上我们将会看到,这对于程序员来说是一个极强的保证)。这里的同步是指广义上的同步,包括对常用同步原语(lock,volatile 和 final)的正确使用。
顺序一致性内存模型
顺序一致性内存模型是一个被计算机科学家理想化了的理论参考模型,它为程序员提供了极强的内存可见性保证。顺序一致性内存模型有两大特性:
- 一个线程中的所有操作必须按照程序的顺序来执行。
- (不管程序是否同步)所有线程都只能看到一个单一的操作执行顺序。在顺序一致性内存模型中,每个操作都必须原子执行且立刻对所有线程可见。
顺序一致性内存模型为程序员提供的视图如下:

在概念上,顺序一致性模型有一个单一的全局内存,这个内存通过一个左右摆动的开关可以连接到任意一个线程。同时,每一个线程必须按程序的顺序来执行内存读 / 写操作。从上图我们可以看出,在任意时间点最多只能有一个线程可以连接到内存。当多个线程并发执行时,图中的开关装置能把所有线程的所有内存读 / 写操作串行化。
为了更好的理解,下面我们通过两个示意图来对顺序一致性模型的特性做进一步的说明。
假设有两个线程 A 和 B 并发执行。其中 A 线程有三个操作,它们在程序中的顺序是:A1->A2->A3。B 线程也有三个操作,它们在程序中的顺序是:B1->B2->B3。
假设这两个线程使用监视器来正确同步:A 线程的三个操作执行后释放监视器,随后 B 线程获取同一个监视器。那么程序在顺序一致性模型中的执行效果将如下图所示:

现在我们再假设这两个线程没有做同步,下面是这个未同步程序在顺序一致性模型中的执行示意图:

未同步程序在顺序一致性模型中虽然整体执行顺序是无序的,但所有线程都只能看到一个一致的整体执行顺序。以上图为例,线程 A 和 B 看到的执行顺序都是:B1->A1->A2->B2->A3->B3。之所以能得到这个保证是因为顺序一致性内存模型中的每个操作必须立即对任意线程可见。
但是,在 JMM 中就没有这个保证。未同步程序在 JMM 中不但整体的执行顺序是无序的,而且所有线程看到的操作执行顺序也可能不一致。比如,在当前线程把写过的数据缓存在本地内存中,且还没有刷新到主内存之前,这个写操作仅对当前线程可见;从其他线程的角度来观察,会认为这个写操作根本还没有被当前线程执行。只有当前线程把本地内存中写过的数据刷新到主内存之后,这个写操作才能对其他线程可见。在这种情况下,当前线程和其它线程看到的操作执行顺序将不一致。
同步程序的顺序一致性效果
下面我们对前面的示例程序 ReorderExample 用监视器来同步,看看正确同步的程序如何具有顺序一致性。
请看下面的示例代码:
Class SynchronizedExample {
int a = 0;
boolean flag = false;public synchronized void writer() {a = 1;flag = true;
}public synchronized void reader() {if (flag) {int i = a;……}
}
}
上面示例代码中,假设 A 线程执行 writer() 方法后,B 线程执行 reader() 方法。这是一个正确同步的多线程程序。根据 JMM 规范,该程序的执行结果将与该程序在顺序一致性模型中的执行结果相同。下面是该程序在两个内存模型中的执行时序对比图:

在顺序一致性模型中,所有操作完全按程序的顺序串行执行。而在 JMM 中,临界区内的代码可以重排序(但 JMM 不允许临界区内的代码“逸出”到临界区之外,那样会破坏监视器的语义)。JMM 会在退出监视器和进入监视器这两个关键时间点做一些特别处理,使得线程在这两个时间点具有与顺序一致性模型相同的内存视图(具体细节后文会说明)。虽然线程 A 在临界区内做了重排序,但由于监视器的互斥执行的特性,这里的线程 B 根本无法“观察”到线程 A 在临界区内的重排序。这种重排序既提高了执行效率,又没有改变程序的执行结果。
从这里我们可以看到 JMM 在具体实现上的基本方针:在不改变(正确同步的)程序执行结果的前提下,尽可能的为编译器和处理器的优化打开方便之门。
未同步程序的执行特性
对于未同步或未正确同步的多线程程序,JMM 只提供最小安全性:线程执行时读取到的值要么是之前某个线程写入的值,要么是默认值(0,null,false)。
JMM 保证线程读操作读取到的值不会无中生有(out of thin air)的冒出来。为了实现最小安全性,JVM 在堆上分配对象时,首先会清零内存空间,然后才会在上面分配对象(JVM 内部会同步这两个操作)。因此,在以清零的内存空间(pre-zeroed memory)分配对象时,域的默认初始化已经完成了。
JMM 不保证未同步程序的执行结果与该程序在顺序一致性模型中的执行结果一致。因为未同步程序在顺序一致性模型中执行时,整体上是无序的,其执行结果无法预知。保证未同步程序在两个模型中的执行结果一致毫无意义。
和顺序一致性模型一样,未同步程序在 JMM 中的执行时,整体上也是无序的,其执行结果也无法预知。同时,未同步程序在这两个模型中的执行特性有下面几个差异:
- 顺序一致性模型保证单线程内的操作会按程序的顺序执行,而 JMM 不保证单线程内的操作会按程序的顺序执行(比如上面正确同步的多线程程序在临界区内的重排序)。这一点前面已经讲过了,这里就不再赘述。
- 顺序一致性模型保证所有线程只能看到一致的操作执行顺序,而 JMM 不保证所有线程能看到一致的操作执行顺序。这一点前面也已经讲过,这里就不再赘述。
- JMM 不保证对 64 位的 long 型和 double 型变量的读 / 写操作具有原子性,而顺序一致性模型保证对所有的内存读 / 写操作都具有原子性。
第 3 个差异与处理器总线的工作机制密切相关。在计算机中,数据通过总线在处理器和内存之间传递。每次处理器和内存之间的数据传递都是通过一系列步骤来完成的,这一系列步骤称之为总线事务(bus transaction)。总线事务包括读事务(read transaction)和写事务(write transaction)。读事务从内存传送数据到处理器,写事务从处理器传送数据到内存,每个事务会读 / 写内存中一个或多个物理上连续的字。这里的关键是,总线会同步试图并发使用总线的事务。在一个处理器执行总线事务期间,总线会禁止其它所有的处理器和 I/O 设备执行内存的读 / 写。下面让我们通过一个示意图来说明总线的工作机制:

如上图所示,假设处理器 A,B 和 C 同时向总线发起总线事务,这时总线仲裁(bus arbitration)会对竞争作出裁决,这里我们假设总线在仲裁后判定处理器 A 在竞争中获胜(总线仲裁会确保所有处理器都能公平的访问内存)。此时处理器 A 继续它的总线事务,而其它两个处理器则要等待处理器 A 的总线事务完成后才能开始再次执行内存访问。假设在处理器 A 执行总线事务期间(不管这个总线事务是读事务还是写事务),处理器 D 向总线发起了总线事务,此时处理器 D 的这个请求会被总线禁止。
总线的这些工作机制可以把所有处理器对内存的访问以串行化的方式来执行;在任意时间点,最多只能有一个处理器能访问内存。这个特性确保了单个总线事务之中的内存读 / 写操作具有原子性。
在一些 32 位的处理器上,如果要求对 64 位数据的读 / 写操作具有原子性,会有比较大的开销。为了照顾这种处理器,java 语言规范鼓励但不强求 JVM 对 64 位的 long 型变量和 double 型变量的读 / 写具有原子性。当 JVM 在这种处理器上运行时,会把一个 64 位 long/ double 型变量的读 / 写操作拆分为两个 32 位的读 / 写操作来执行。这两个 32 位的读 / 写操作可能会被分配到不同的总线事务中执行,此时对这个 64 位变量的读 / 写将不具有原子性。
当单个内存操作不具有原子性,将可能会产生意想不到后果。请看下面示意图:
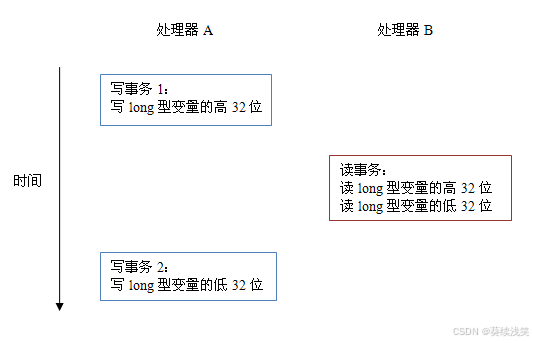
如上图所示,假设处理器 A 写一个 long 型变量,同时处理器 B 要读这个 long 型变量。处理器 A 中 64 位的写操作被拆分为两个 32 位的写操作,且这两个 32 位的写操作被分配到不同的写事务中执行。同时处理器 B 中 64 位的读操作被拆分为两个 32 位的读操作,且这两个 32 位的读操作被分配到同一个的读事务中执行。当处理器 A 和 B 按上图的时序来执行时,处理器 B 将看到仅仅被处理器 A“写了一半“的无效值。
相关文章:
JAVA基础-深入理解Java内存模型(一)-- 重排序与先行发生原则(happens-before)
深入理解Java内存模型(一)-- 重排序 很棒的一个关于Java内存模型系列文章,首先感谢作者,转载自深入理解java内存模型系列文章 ,为了方便阅读,做了一些内容整合和重排版。 提纲 Java线程之间的通信对程序…...

【Lambda】java之lambda表达式stream流式编程操作集合
java之lambda表达式&stream流式编程操作集合 1 stream流概念1.1 中间操作1.1.1 无状态操作1.1.2 有状态操作 1.2 终端操作1.2.1 非短路操作1.2.2 短路操作 2 steam流的生成2.1 方式一:数组转为stream流2.2 方式二:集合转为steam流2.3 方式三…...
家具购物小程序+php
基于微信小程序的家具购物小程序的设计与实现 摘要 随着信息技术在管理上越来越深入而广泛的应用,管理信息系统的实施在技术上已逐步成熟。本文介绍了基于微信小程序的家具购物小程序的设计与实现的开发全过程。通过分析基于微信小程序的家具购物小程序的设计与实…...

【GIS教程】使用GDAL-Python将tif转为COG并在ArcGIS Js前端加载-附完整代码
目录 一、数据格式 二、COG特点 三、使用GDAL生成COG格式的数据 四、使用ArcGIS Maps SDK for JavaScript加载COG格式数据 一、数据格式 COG(Cloud optimized GeoTIFF)是一种GeoTiff格式的数据。托管在 HTTP 文件服务器上,可以代替geose…...
与cad交互)
VB.net进行CAD二次开发(二)与cad交互
开发过程遇到了一个问题:自制窗口与控件与CAD的交互。 启动类,调用非模式窗口 Imports Autodesk.AutoCAD.Runtime Public Class Class1 //CAD启动界面 <CommandMethod("US")> Public Sub UiStart() Dim myfrom As Form1 New…...

【NLP 11、Adam优化器】
祝你先于春天, 翻过此间铮铮山峦 —— 24.12.8 一、Adam优化器的基本概念 定义 Adam(Adaptive Moment Estimation)是一种基于梯度的优化算法,用于更新神经网络等机器学习模型中的参数。它结合了动量法(Momentum&…...
51单片机应用开发(进阶)---串口接收字符命令
实现目标 1、巩固UART知识; 2、掌握串口接收字符数据; 3、具体实现目标:(1)上位机串口助手发送多字符命令,单片机接收命令作相应的处理(如:openled1 即打开LED1;closeled1 即关…...

redis 怎么样删除list
在 Redis 中,可以使用以下方法删除列表或列表中的元素: 1. 删除整个列表 使用 DEL 命令删除一个列表键: DEL mylist这个命令会删除键 mylist 及其值(无论 mylist 是一个列表还是其他类型的键)。 2. 删除列表中的部分…...

【数据结构——内排序】快速排序(头歌实践教学平台习题)【合集】
目录😋 任务描述 测试说明 我的通关代码: 测试结果: 任务描述 本关任务:实现快速排序算法。 测试说明 平台会对你编写的代码进行测试: 测试输入示例: 10 6 8 7 9 0 1 3 2 4 5 (说明:第一行是元素个数&a…...
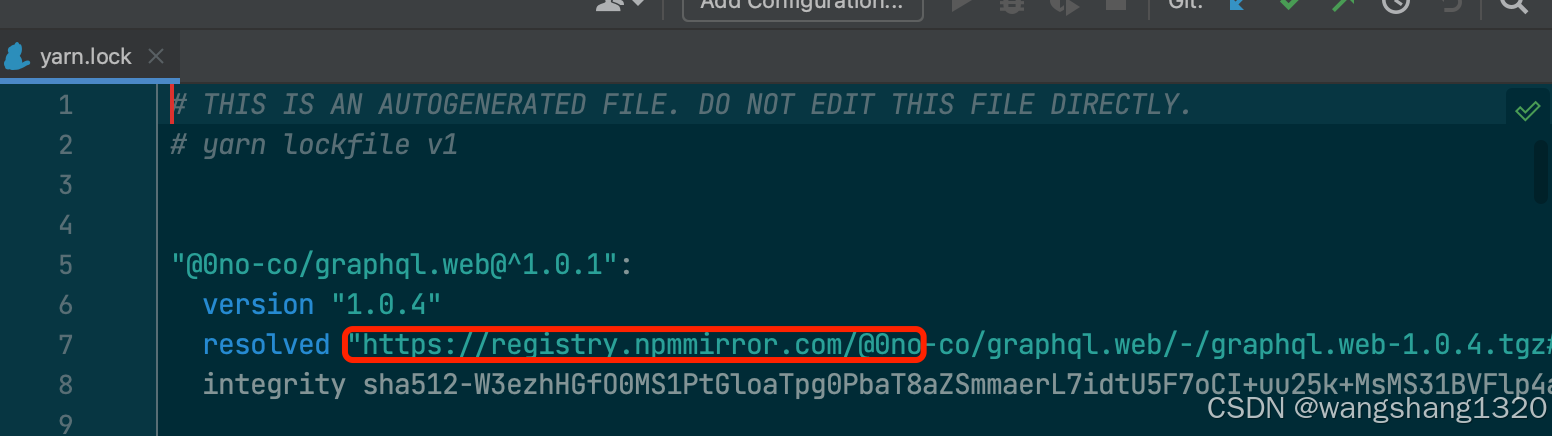
npm或yarn包配置地址源
三种方法 1.配置.npmrc 文件 在更目录新增.npmrc文件 然后写入需要访问的包的地址 2.直接yarn.lock文件里面修改地址 简单粗暴 3.yarn install 的时候添加参数 设置包的仓库地址 yarn config set registry https://registry.yarnpkg.com 安装:yarn install 注意…...

STUN服务器用于内网NAT的方案
在内网中部署 STUN 服务器的场景通常用于处理多层 NAT 或内网客户端之间的通信需求,尤其是在大企业或学校等复杂网络环境下。通过 STUN 服务器,可以帮助客户端设备检测和适配 NAT 转换规则,进而支持 WebRTC 或其他实时通信技术的正常运行。 …...
Linux 简单命令总结
1. 简单命令 1.1. ls 列出该目录下的所有子目录与文件,后面还可以跟上一些选项 常用选项: ・-a 列出目录下的所有文件,包括以。开头的隐含文件。 ・-d 将目录象文件一样显示,而不是显示其下的文件。如:ls -d 指定目…...

Vue.js组件开发:提升你的前端工程能力
Vue.js 是一个用于构建用户界面的渐进式框架,它允许开发者通过组件化的方式创建可复用且易于管理的代码。在 Vue.js 中开发组件是一个直观且高效的过程,下面我将概述如何创建和使用 Vue 组件,并提供一些最佳实践。 1. 创建基本组件 首先&am…...

使用 Pandas 读取 JSON 数据的五种常见结构解析
文章目录 引言JSON 数据的五种常见结构1. split 结构2. records 结构3. index 结构4. columns 结构5. values 结构 引言 在日常生活中,我们经常与各种数据打交道,无论是从网上购物的订单信息到社交媒体上的动态更新。JSON(JavaScript Object…...

C++鼠标轨迹算法(鼠标轨迹模拟真人移动)
一.简介 鼠标轨迹算法是一种模拟人类鼠标操作的程序,它能够模拟出自然而真实的鼠标移动路径。 鼠标轨迹算法的底层实现采用C/C语言,原因在于C/C提供了高性能的执行能力和直接访问操作系统底层资源的能力。 鼠标轨迹算法具有以下优势: 模拟…...
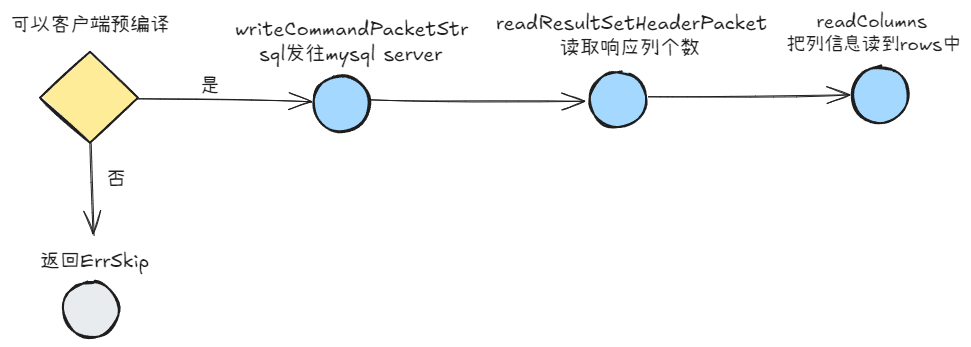
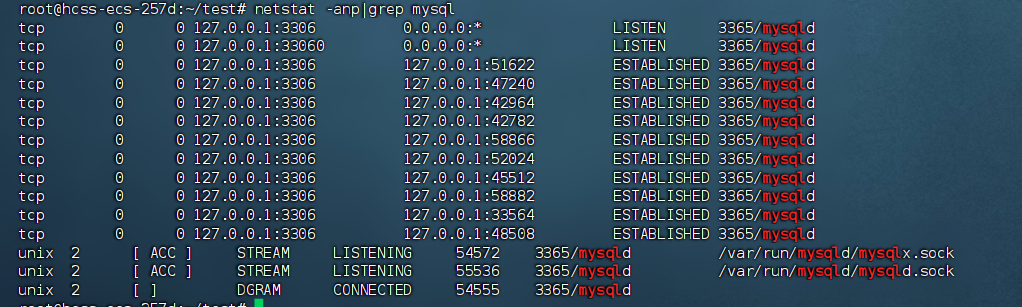
Go mysql驱动源码分析
文章目录 前言注册驱动连接器创建连接交互协议读写数据读数据写数据 mysqlConncontext超时控制 查询发送查询请求读取查询响应 Exec发送exec请求读取响应 预编译客户端预编译服务端预编译生成prepareStmt执行查询操作执行Exec操作 事务读取响应query响应exec响应 总结 前言 go…...
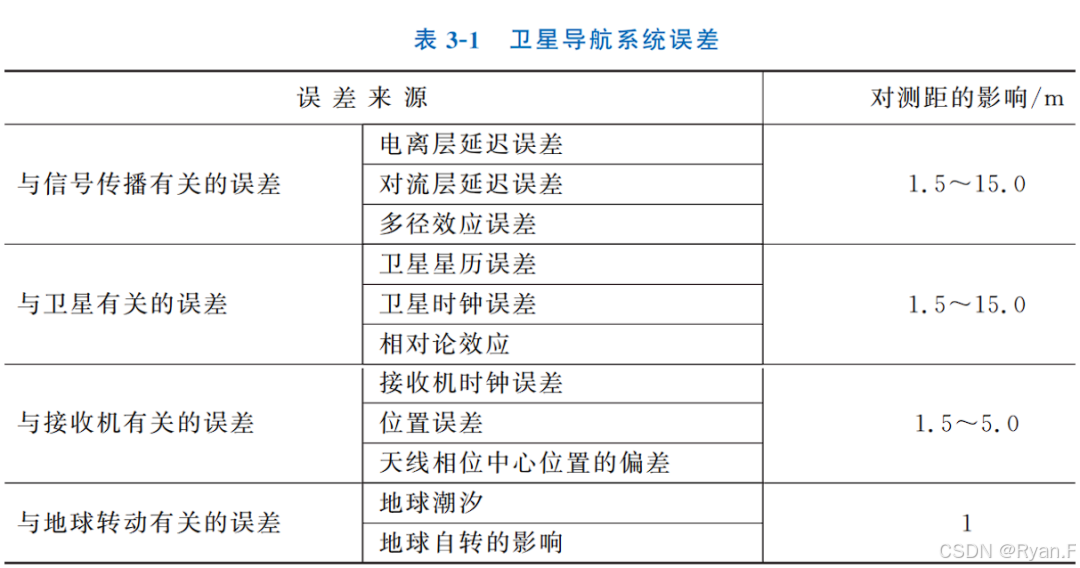
GNSS误差源及差分定位
GNSS误差源: (一)卫星星历误差 由星历信息所得出的卫星位置坐标与实际位置坐标的偏差就是星历误差。星历信息是由 GPS 地面部分测量计算后传入空间部分的。由于卫星在运动中要受到各种摄动力的作用, 而地面部分又很难精确测量这些作用力,…...

pg数据类型
1、数值类型: smallint 2 字节 小范围整数 -32768 到 32767 integer 4 字节 常用的整数 -2147483648 到 2147483647 bigint 8 字节 大范围整数 -9223372036854775808 到 9223372036854775807 decimal 可变长 用户指定的精度&#x…...

【java】finalize方法
目录 1. 说明2. 调用过程3. 注意事项 1. 说明 1.finalize方法是Java中Object类的一个方法。2.finalize方法用于在对象被垃圾回收之前执行一些清理工作。3.当JVM(Java虚拟机)确定一个对象不再被引用、即将被回收时,会调用该对象的finalize方法…...

HNU_多传感器(专选)_作业4(构建单层感知器实现分类)
1. (论述题)(共1题,100分) 假设平面坐标系上有四个点,要求构建单层感知器实现分类。 (3,3),(4,3) 两个点的标签为1; (1,1),(0,2) 两个点的标签为-1。 思路:要分类的数据是2维数据,需要2个输入…...

RocketMQ延迟消息机制
两种延迟消息 RocketMQ中提供了两种延迟消息机制 指定固定的延迟级别 通过在Message中设定一个MessageDelayLevel参数,对应18个预设的延迟级别指定时间点的延迟级别 通过在Message中设定一个DeliverTimeMS指定一个Long类型表示的具体时间点。到了时间点后…...

dedecms 织梦自定义表单留言增加ajax验证码功能
增加ajax功能模块,用户不点击提交按钮,只要输入框失去焦点,就会提前提示验证码是否正确。 一,模板上增加验证码 <input name"vdcode"id"vdcode" placeholder"请输入验证码" type"text&quo…...

Frozen-Flask :将 Flask 应用“冻结”为静态文件
Frozen-Flask 是一个用于将 Flask 应用“冻结”为静态文件的 Python 扩展。它的核心用途是:将一个 Flask Web 应用生成成纯静态 HTML 文件,从而可以部署到静态网站托管服务上,如 GitHub Pages、Netlify 或任何支持静态文件的网站服务器。 &am…...

Cloudflare 从 Nginx 到 Pingora:性能、效率与安全的全面升级
在互联网的快速发展中,高性能、高效率和高安全性的网络服务成为了各大互联网基础设施提供商的核心追求。Cloudflare 作为全球领先的互联网安全和基础设施公司,近期做出了一个重大技术决策:弃用长期使用的 Nginx,转而采用其内部开发…...

Spring数据访问模块设计
前面我们已经完成了IoC和web模块的设计,聪明的码友立马就知道了,该到数据访问模块了,要不就这俩玩个6啊,查库势在必行,至此,它来了。 一、核心设计理念 1、痛点在哪 应用离不开数据(数据库、No…...
相比,优缺点是什么?适用于哪些场景?)
Redis的发布订阅模式与专业的 MQ(如 Kafka, RabbitMQ)相比,优缺点是什么?适用于哪些场景?
Redis 的发布订阅(Pub/Sub)模式与专业的 MQ(Message Queue)如 Kafka、RabbitMQ 进行比较,核心的权衡点在于:简单与速度 vs. 可靠与功能。 下面我们详细展开对比。 Redis Pub/Sub 的核心特点 它是一个发后…...

怎么让Comfyui导出的图像不包含工作流信息,
为了数据安全,让Comfyui导出的图像不包含工作流信息,导出的图像就不会拖到comfyui中加载出来工作流。 ComfyUI的目录下node.py 直接移除 pnginfo(推荐) 在 save_images 方法中,删除或注释掉所有与 metadata …...

【Linux】Linux安装并配置RabbitMQ
目录 1. 安装 Erlang 2. 安装 RabbitMQ 2.1.添加 RabbitMQ 仓库 2.2.安装 RabbitMQ 3.配置 3.1.启动和管理服务 4. 访问管理界面 5.安装问题 6.修改密码 7.修改端口 7.1.找到文件 7.2.修改文件 1. 安装 Erlang 由于 RabbitMQ 是用 Erlang 编写的,需要先安…...
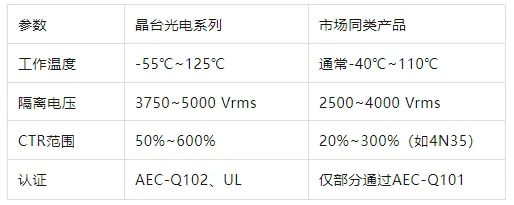
高抗扰度汽车光耦合器的特性
晶台光电推出的125℃光耦合器系列产品(包括KL357NU、KL3H7U和KL817U),专为高温环境下的汽车应用设计,具备以下核心优势和技术特点: 一、技术特性分析 高温稳定性 采用先进的LED技术和优化的IC设计,确保在…...

__VUE_PROD_HYDRATION_MISMATCH_DETAILS__ is not explicitly defined.
这个警告表明您在使用Vue的esm-bundler构建版本时,未明确定义编译时特性标志。以下是详细解释和解决方案: 问题原因: 该标志是Vue 3.4引入的编译时特性标志,用于控制生产环境下SSR水合不匹配错误的详细报告1使用esm-bundler…...