端到端自动驾驶大模型:视觉-语言-动作模型 VLA
模型框架定义、模型快速迭代能力是考查智驾团队出活能力的两个核心指标。在展开讨论Vision-Language-Action Models(VLA)之前,咱们先来讨论端到端自动驾驶大模型设计。
目录
1. 端到端自动驾驶大模型设计
1.1 模型输入设计
1.2 模型输出设计
1.3 实现难点分析
2 VLA相关工作
2.1 视觉语言模型VLM
2.2 通用机器人策略
2.3 视觉-语言-动作模型VLA
2.4 谷歌RT-2
2.5 斯坦福OpenVLA
3 OpenVLA 模型
3.1 VLM模型
3.2 VLA训练过程
3.3 训练数据集
3.4 图形分辨率
3.5 视觉编码器微调
3.6 训练轮数、学习率
3.7 训练硬件设施
3.8 Parameter微调
4.写在最后
1. 端到端自动驾驶大模型设计
1.1 模型输入设计
先看看之前在100多人的一个自动驾驶群里的讨论发言:

1.2 模型输出设计
接着上面话题,端到端自动驾驶模型输出的设计应该包括三方面:
- 第一种感知信息,包括Occupancy占用、道路结构网络等(实时构建4D全场景地图,这一步的实现,还顺带实现可以不用高精地图);
- 第二种是驾驶场景描述信息,包括各种动态场景描述和交通参与者行为描述。当前,大家为了快速实现自动驾驶,人为编辑了很多场景及分类,按照各种ODD场景匹配各种驾驶元动作,这使得智能上限很低。增加了场景理解的一些描述信息,能有效的监督大模型能够真正理解场景和交通参与者意图,大大提升自动驾驶智能的上限。
- 第三个信息则是在感知万物、知晓常识的基础上,实现未来轨迹推理,直接输出驾驶Action。当前普遍做法是感知的输出,作为下一环轨迹规划的输入,这严格说来不是真正意义上的端到端。
1.3 实现难点分析

如果认定强化学习可以实现超人类司机的能力,则坚定采用强化学习这一套逻辑。
那强化学习特别有针对性的数据集从哪里来?
咱们马上会想到现场采集、生成式AIGC等。AIGC生成感知数据不算难(这环节难点在于运动数据精度),最难的点在模仿老司机行为。也许这环节解决了,个人认为机器人开车超过人类应该没问题。
鉴于前面推理,这样看来,自动驾驶模型应该是一个Vision-Language-Action(VLA)大模型,即模型容量足够大,在开放数据集下感知万物,同时有常识能推理,最后给出优雅的Action。
当前大模型的底层核心框架仍然是transformer的天下,这种耗资源的算法急需被替换,这能加速自动驾驶大模型的商业化落地进程。总之堆人(动不动需要几千人)、堆资源(需要几万颗GPU)的方式不符合商业逻辑。
本专题由 深圳季连科技有限公司 AIgraphX 自动驾驶大模型团队编辑。下面内容来自网络,侵权即删。文中如有错误的地方,也请在留言区告知。
2 VLA相关工作
2.1 视觉语言模型VLM
视觉语言模型Vision Language Models(VLMs)在互联网规模的数据上进行训练,从输入图像和语言提示生成自然语言,已被用于从视觉问答到物体定位的无数应用。最近VLM的关键进展之一是模型架构,它将预训练视觉编码器与预训练语言模型的特征连接起来,直接建立在计算机视觉和自然语言建模的基础上,以创建强大的多模态模型。新开源的VLMs已经融合了一种更简单的“patch-as-token”方法,将来自预训练视觉转换器的patch特征被视为token,然后投影到语言模型的输入空间中。这种简单性使得大规模语言模型VLM的训练变得很容易。
2.2 通用机器人策略
机器人技术最近的一个趋势是在大型不同机器人数据集上训练多任务“通才”机器人策略,涵盖许多不同的机器人实例。值得注意的是,Octo算法训练了一个通才策略,该策略可以控制多个机器人开箱即用,并允许对新机器人设置进行灵活的微调。
2.3 视觉-语言-动作模型VLA
许多工作已经探索了VLM在机器人中的应用,例如,用于视觉状态表示、目标检测、高级规划,以及提供反馈信号,其他将VLM直接集成到端到端视觉运动操控策略中。最近的一些工作已经探索了使用大型预训练VLM模型来预测机器人的动作。这种模型通常被称为视觉语言动作模型Vision-Language-Action Models(VLAs),因为它们将机器人控制动作直接融合到VLM主干中。
这有三个关键好处:
- 它在大型互联网规模的视觉语言数据集上执行视觉和语言对齐;
- 使用通用架构,而不是对机器人控制定制,允许我们利用现代VLM可扩展基础设施,并以最小代码修改量扩展到训练十亿参数策略;
- 它为机器人从VLM的快速改进提供了直接途径。
2.4 谷歌RT-2
Robotic Transformer 2(RT-2)是由谷歌 DeepMind 推出的视觉-语言-动作(VLA)技术,它为人类提供了通过纯语言命令来优化机器人控制的能力。RT-2可以从网络和机器人的数据中学习,并将这些知识转化为机器人控制通用指令,帮助机器人在未曾见过的现实环境中完成各种复杂任务,同时提高机器人适应性和推理能力。

2.5 斯坦福OpenVLA
24年6月,Stanford联合UC Berkeley、TRI、Deepmind 和 MIT发布了论文“OpenVLA: An Open-Source Vision-Language-Action Model”。

OpenVLA,一个7B参数的开源视觉语言动作模型(VLA),在Open X-Embodiment 970 k机器人数据集上进行了训练。OpenVLA为通用机器人动作策略设定了一个新的状态。它支持开箱即用控制多个机器人,并可以通过高效的参数微调快速适应新机器人领域。OpenVLA权重和PyTorch训练管道是完全开源的,可以从HuggingFace下载和微调该模型。
OpenVLA构建在Llama 2语言模型之上,并结合了视觉编码器,融合了DINOv2和SigLIP的预训练特征。作为增加的数据多样性和新模型组件的产物,OpenVLA在通才操作方面表现出了强大的性能,在29个任务和多个机器人实例中,绝对任务成功率超过RT-2-X(55B)等封闭模型16.5%,参数减少了7倍。进一步实验表明,可以有效地微调OpenVLA以适应新的设置,在涉及多个对象和强语言基础能力的多任务环境中具有特别强的泛化结果,并且比从头开始的模仿学习方法(如扩散策略)高出20.4%。
3 OpenVLA 模型

Figure 5: OpenVLA model architecture. Given an image observation and a language instruction, the model predicts 7-dimensional robot control actions. The architecture consists of three key components: (1) a vision encoder that concatenates Dino V2 and SigLIP features, (2) a projector that maps visual features to the language embedding space, and (3) the LLM backbone, a Llama 2 7B-parameter large language model.
3.1 VLM模型
VLM模型架构由三个主要部分组成(见图5):
- Visual Encoder,将图像输入映射为image patch embeddings。
- Projector,将视觉编码器的output embeddings映射到语言模型的输入空间。
- Large Language Model Backbone,大型语言模型(LLM)主干。
VLM是一个典型的端到端训练模型。本方案以Prismatic-7B VLM模型为基础。
Prismatic遵循上述相同的标准架构,具有600m参数的视觉编码器,一个2层MLP Projector和一个7B参数的Llama 2语言模型主干。值得注意的是,Prismatic使用了两个视觉编码器,由SigLIP和DinoV2模型组成。输入图像patch分别通过两个编码器传递,结果特征向量按通道连接。
与更常用的视觉编码器(如CLIP或仅SigLIP编码器)相比,DinoV2特征已被证明有助于改进空间推理,这对机器人控制尤其有帮助。
SigLIP、DinoV2和Llama 2没有公布有关它们的训练数据的细节,这些数据可能分别由数万亿个来自互联网的图像-文本、纯图像和纯文本数据组成。
Prismatic VLM使用LLaVA 1.5数据混合在这些组件之上进行了微调,利用包含来自开源数据集的约1M图像-文本和纯文本数据样本。
3.2 VLA训练过程
为了训练OpenVLA,我们对预训练的Prismatic - 7B VLM主干进行微调,用于机器人动作预测(见图5)。我们将动作预测问题表述为“视觉语言”任务,其中输入观察图像和自然语言任务指令被映射到预测机器人动作串。
3.3 训练数据集
构建OpenVLA训练数据集的目标是捕获大量不同的机器人embodiments, scenes, and tasks。这使得最终模型能够控制各种机器人开箱即用,并允许对新机器人设置进行有效的微调。我们利用Open X-Embodiment数据集作为基础来管理我们的训练数据集。
完整的OpenX数据集由70多个独立的机器人数据集组成,其中包含超过2M个机器人轨迹,这些数据集在大型社区的努力下汇集成一个连贯且易于使用的数据格式。为了使对这些数据的训练可行,我们对原始数据集OpenX应用了多个数据管理步骤。
- 限制训练数据集仅包含至少一个第三人称摄像机的操作数据集,并使用单臂末端执行器控制。
- 对通过第一轮过滤的所有数据集利用Octo数据混合权重。Octo启发式地降低或删除多样性较小的数据集,并增加具有较大任务和场景多样性的数据集的权重。
- 还尝试将一些额外的数据集合并到我们的训练混合数据中。这些数据集是自Octo发布以来添加到OpenX数据集的,包括DROID数据集,尽管混合权重为10%。在实践中,我们发现在整个训练过程中,未来可能需要更大的混合权重或模型来适应其多样性。
3.4 图形分辨率
输入图像的分辨率对VLA训练的计算要求有显著影响,因为更高分辨率的图像导致更多的image patch tokens,从而导致更长的上下文长度,从而二次增加训练计算量。
比较了224 × 224px和384 × 384px分别率,发现后者训练时间长增加了3倍,但性能没有明显增长。因此,OpenVLA模型最终选择了224 × 224px分辨率。
3.5 视觉编码器微调
先前对VLM的研究发现,在VLM训练期间冻结视觉编码器通常会导致更高的性能。直观地说,冻结视觉编码器可以更好地保留从互联网规模的预训练中学到的鲁棒特征。然而,我们发现在VLA训练期间微调视觉编码器对于良好的VLA性能至关重要。我们猜测,预训练的视觉主干可能无法捕捉到场景重要部分的足够细粒度的空间细节,从而无法实现机器人的精确控制。
3.6 训练轮数、学习率
典型的LLM或VLM最多在训练数据集上完成一两个epoch。相比之下,我们发现对于VLA训练来说,在训练数据集中迭代多次是很重要的,性能会不断提高,直到训练动作令牌的准确率超过95%。我们最后完成了27个epoch。
我们在VLA训练上使用过多个数量级的学习率,最终2e-5的固定学习率(与VLM预训练期间使用的学习率相同)获得了最佳结果,而且发现学习率warmup不会带来好处。
3.7 训练硬件设施
用64个A100 GPU训练了14天,总共21,500个A100小时,批量大小设置为2048。
在推理过程中,OpenVLA在bfloat16精度加载时需要15GB的GPU内存,并且在一个NVIDIA RTX 4090 GPU 以6Hz的速度运行。
3.8 Parameter微调
具体来说,我们比较了以下几种微调方法:
- 在微调期间,完全微调更新所有权重;
- 只微调OpenVLA的transformer骨干和令牌嵌入矩阵的最后一层;
- Freezes视觉编码器,但微调所有其他权重;
- Sandwich微调,Unfreezes视觉编码器、令牌嵌入矩阵和最后一层;
- LoRA,采用流行的低秩自适应技术,将多个秩值应用于模型的所有线性层。
4.写在最后
随着Nerf、3DGS技术的发展,感知道路结构的技术逐渐成熟,这减少了对百度、高德等高清地图的依赖,即使在普通导航地图区域也能感知标准的道路结构,大大提升了自动驾驶系统实用性。目标、障碍物检测和道路结构感知逐渐统一,但决策规划仍以Rule-based为主,导致算法迭代需要大量人力,代码复杂且泛化能力有限。
随着Tesla V13版本的发布,基于强化学习的决策规划算法有潜力超越经过大量人力资源精心打磨的规则式算法,而且感知和规划可以融合为一个AI模型,即端到端自动驾驶大模型。
相关文章:
端到端自动驾驶大模型:视觉-语言-动作模型 VLA
模型框架定义、模型快速迭代能力是考查智驾团队出活能力的两个核心指标。在展开讨论Vision-Language-Action Models(VLA)之前,咱们先来讨论端到端自动驾驶大模型设计。 目录 1. 端到端自动驾驶大模型设计 1.1 模型输入设计 1.2 模型输出设计 1.3 实现难点分析 …...

druid与pgsql结合踩坑记
最近项目里面突然出现一个怪问题,数据库是pgsql,jdbc连接池是alibaba开源的druid,idea里面直接启动没问题,打完包放在centos上和windows上cmd窗口都能直接用java -jar命令启动,但是放到国产信创系统上就是报错…...

【xxl-job】XXL-Job源码深度剖析:分布式任务调度的艺术与实践
XXL-Job源码深度剖析 核心概念1、调度中心2、执行器3、任务 来个Demo1、搭建调度中心2、执行器和任务添加3、创建执行器和任务 从执行器启动说起1、初始化JobHandler2、创建一个Http服务器3、注册到调度中心 任务触发原理⭐⭐⭐1、任务如何触发?调度线程scheduleThr…...

图漾相机-ROS1_SDK_ubuntu版本编译(新版本)
文章目录 官网编译文档链接官网SDK下载链接1、下载 Camport ROS1 SDK1.下载git2、下载链接 2、准备编译工作1、安装 catkin2、配置环境变量3. 将Camport3中的linux库文件拷贝到 user/lib目录下4、修改lunch文件制定相机(可以放在最后可以参考在线文档)**…...

项目二十三:电阻测量(需要简单的外围检测电路,将电阻转换为电压)测量100,1k,4.7k,10k,20k的电阻阻值,由数码管显示。要求测试误差 <10%
资料查找: 01 方案选择 使用单片机测量电阻有多种方法,以下是一些常见的方法及其原理: 串联分压法(ADC) 原理:根据串联电路的分压原理,通过测量已知电阻和待测电阻上的电压,计算出…...

【NLP 17、NLP的基础——分词】
我始终相信,世间所有的安排都有它的道理;失之东隅,收之桑榆 —— 24.12.20 一、中文分词的介绍 1.为什么讲分词? ① 分词是一个被长期研究的任务,通过了解分词算法的发展,可以看到NLP的研究历程 ② 分词…...

uniapp blob格式转换为video .mp4文件使用ffmpeg工具
前言 介绍一下这三种对象使用场景 您前端一旦涉及到文件或图片上传Q到服务器,就势必离不了 Blob/File /base64 三种主流的类型它们之间 互转 也成了常态 Blob - FileBlob -Base64Base64 - BlobFile-Base64Base64 _ File uniapp 上传文件 现在已获取到了blob格式的…...

【无标题】 [蓝桥杯 2024 省 B] 好数
[蓝桥杯 2024 省 B] 好数 好数 一个整数如果按从低位到高位的顺序,奇数位(个位、百位、万位……)上的数字是奇数,偶数位(十位、千位、十万位……)上的数字是偶数,我们就称之为“好数”。 给定一…...

Leecode刷题C语言之同位字符串连接的最小长度
执行结果:通过 执行用时和内存消耗如下: bool check(char *s, int m) {int n strlen(s), count0[26] {0};for (int j 0; j < n; j m) {int count1[26] {0};for (int k j; k < j m; k) {count1[s[k] - a];}if (j > 0 && memcmp(count0, cou…...

Pytorch | 利用BIM/I-FGSM针对CIFAR10上的ResNet分类器进行对抗攻击
Pytorch | 利用BIM/I-FGSM针对CIFAR10上的ResNet分类器进行对抗攻击 CIFAR数据集BIM介绍基本原理算法流程特点应用场景 BIM代码实现BIM算法实现攻击效果 代码汇总bim.pytrain.pyadvtest.py 之前已经针对CIFAR10训练了多种分类器: Pytorch | 从零构建AlexNet对CIFAR1…...

音频进阶学习八——傅里叶变换的介绍
文章目录 前言一、傅里叶变换1.傅里叶变换的发展2.常见的傅里叶变换3.频域 二、欧拉公式1.实数、虚数、复数2.对虚数和复数的理解3.复平面4.复数和三角函数5.复数的运算6.欧拉公式 三、积分运算1.定积分2.不定积分3.基本的积分公式4.积分规则线性替换法分部积分法 5.定积分计算…...

将4G太阳能无线监控的视频接入电子监控大屏,要考虑哪些方面?
随着科技的飞速发展,4G太阳能无线监控系统以其独特的优势在远程监控领域脱颖而出。这种系统结合了太阳能供电的环保特性和4G无线传输的便捷性,为各种环境尤其是无电或电网不稳定的地区提供了一种高效、可靠的视频监控解决方案。将这些视频流接入大屏显示…...

使用docker拉取镜像很慢或者总是超时的问题
在拉取镜像的时候比如说mysql镜像,在拉取 时总是失败: 像这种就是网络的原因,因为你是连接到了外网去进行下载的,这个时候可以添加你的访问镜像源。也就是daemon.json文件,如果你没有这个文件可以输入 vim /etc/dock…...

Redis数据库笔记
Spring cache 缓存的介绍 在springboot中如何使用redis的缓存 1、使用Cacheable的例子【一般都是在查询的方法上】 /*** 移动端的套餐查询* value 就是缓存的名称* key 就是缓存id ,就是一个缓存名称下有多个缓存,根据id来区分* 这个id一般就是多个查询…...
U盘出现USBC乱码文件的全面解析与恢复指南
一、乱码现象初探:USBC乱码文件的神秘面纱 在数字时代,U盘已成为我们日常生活中不可或缺的数据存储工具。然而,当U盘中的文件突然变成乱码,且文件名前缀显示为“USBC”时,这无疑给用户带来了极大的困扰。这些乱码文件…...

多线程 - 自旋锁
个人主页:C忠实粉丝 欢迎 点赞👍 收藏✨ 留言✉ 加关注💓本文由 C忠实粉丝 原创 多线程 - 自旋锁 收录于专栏[Linux学习] 本专栏旨在分享学习Linux的一点学习笔记,欢迎大家在评论区交流讨论💌 目录 概述 原理 优点与…...
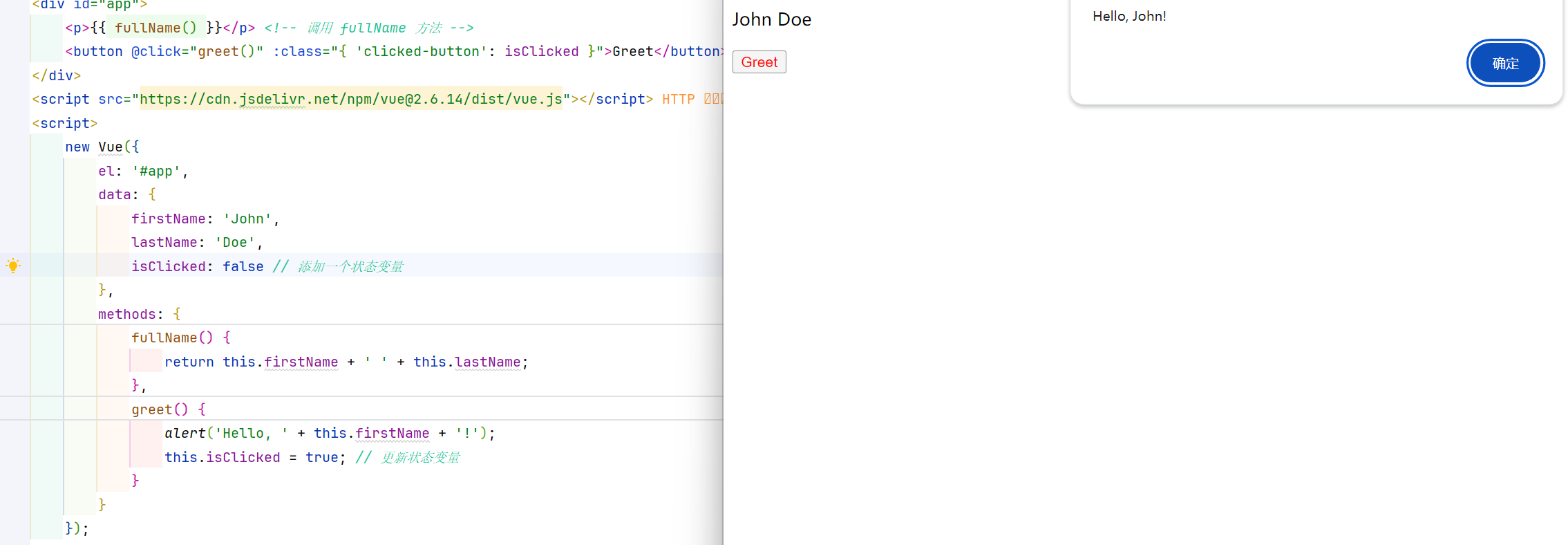
vue2 - Day02 -计算属性(computed)、侦听器(watch)和方法(methods)
在 Vue.js 中,计算属性(computed)、侦听器(watch)和方法(methods)都是响应式的数据处理方式 文章目录 1. 方法(Methods)1.1. 是什么1.2. 怎么用示例: 1.3. 特…...

Linux C 程序 【05】异步写文件
1.开发背景 Linux 系统提供了各种外设的控制方式,其中包括文件的读写,存储文件的介质可以是 SSD 固态硬盘或者是 EMMC 等。 其中常用的写文件方式是同步写操作,但是如果是写大文件会对 CPU 造成比较大的负荷,采用异步写的方式比较…...

Liveweb视频汇聚平台支持WebRTC协议赋能H.265视频流畅传输
随着科技的飞速发展和网络技术的不断革新,视频监控已经广泛应用于社会各个领域,成为现代安全管理的重要组成部分。在视频监控领域,视频编码技术的选择尤为重要,它不仅关系到视频的质量,还直接影响到视频的传输效率和兼…...

SQL组合查询
本文讲述如何利用 UNION 操作符将多条 SELECT 语句组合成一个结果集。 1. 组合查询 多数 SQL 查询只包含从一个或多个表中返回数据的单条 SELECT 语句。但是,SQL 也允许执行多个查询(多条 SELECT 语句),并将结果作为一个查询结果…...

《Playwright:微软的自动化测试工具详解》
Playwright 简介:声明内容来自网络,将内容拼接整理出来的文档 Playwright 是微软开发的自动化测试工具,支持 Chrome、Firefox、Safari 等主流浏览器,提供多语言 API(Python、JavaScript、Java、.NET)。它的特点包括&a…...

【第二十一章 SDIO接口(SDIO)】
第二十一章 SDIO接口 目录 第二十一章 SDIO接口(SDIO) 1 SDIO 主要功能 2 SDIO 总线拓扑 3 SDIO 功能描述 3.1 SDIO 适配器 3.2 SDIOAHB 接口 4 卡功能描述 4.1 卡识别模式 4.2 卡复位 4.3 操作电压范围确认 4.4 卡识别过程 4.5 写数据块 4.6 读数据块 4.7 数据流…...

连锁超市冷库节能解决方案:如何实现超市降本增效
在连锁超市冷库运营中,高能耗、设备损耗快、人工管理低效等问题长期困扰企业。御控冷库节能解决方案通过智能控制化霜、按需化霜、实时监控、故障诊断、自动预警、远程控制开关六大核心技术,实现年省电费15%-60%,且不改动原有装备、安装快捷、…...

Vue2 第一节_Vue2上手_插值表达式{{}}_访问数据和修改数据_Vue开发者工具
文章目录 1.Vue2上手-如何创建一个Vue实例,进行初始化渲染2. 插值表达式{{}}3. 访问数据和修改数据4. vue响应式5. Vue开发者工具--方便调试 1.Vue2上手-如何创建一个Vue实例,进行初始化渲染 准备容器引包创建Vue实例 new Vue()指定配置项 ->渲染数据 准备一个容器,例如: …...

涂鸦T5AI手搓语音、emoji、otto机器人从入门到实战
“🤖手搓TuyaAI语音指令 😍秒变表情包大师,让萌系Otto机器人🔥玩出智能新花样!开整!” 🤖 Otto机器人 → 直接点明主体 手搓TuyaAI语音 → 强调 自主编程/自定义 语音控制(TuyaAI…...
)
Angular微前端架构:Module Federation + ngx-build-plus (Webpack)
以下是一个完整的 Angular 微前端示例,其中使用的是 Module Federation 和 npx-build-plus 实现了主应用(Shell)与子应用(Remote)的集成。 🛠️ 项目结构 angular-mf/ ├── shell-app/ # 主应用&…...

GruntJS-前端自动化任务运行器从入门到实战
Grunt 完全指南:从入门到实战 一、Grunt 是什么? Grunt是一个基于 Node.js 的前端自动化任务运行器,主要用于自动化执行项目开发中重复性高的任务,例如文件压缩、代码编译、语法检查、单元测试、文件合并等。通过配置简洁的任务…...

Ubuntu Cursor升级成v1.0
0. 当前版本低 使用当前 Cursor v0.50时 GitHub Copilot Chat 打不开,快捷键也不好用,当看到 Cursor 升级后,还是蛮高兴的 1. 下载 Cursor 下载地址:https://www.cursor.com/cn/downloads 点击下载 Linux (x64) ,…...
Linux部署私有文件管理系统MinIO
最近需要用到一个文件管理服务,但是又不想花钱,所以就想着自己搭建一个,刚好我们用的一个开源框架已经集成了MinIO,所以就选了这个 我这边对文件服务性能要求不是太高,单机版就可以 安装非常简单,几个命令就…...

图解JavaScript原型:原型链及其分析 | JavaScript图解
忽略该图的细节(如内存地址值没有用二进制) 以下是对该图进一步的理解和总结 1. JS 对象概念的辨析 对象是什么:保存在堆中一块区域,同时在栈中有一块区域保存其在堆中的地址(也就是我们通常说的该变量指向谁&…...