【xxl-job】XXL-Job源码深度剖析:分布式任务调度的艺术与实践
XXL-Job源码深度剖析
- 核心概念
- 1、调度中心
- 2、执行器
- 3、任务
- 来个Demo
- 1、搭建调度中心
- 2、执行器和任务添加
- 3、创建执行器和任务
- 从执行器启动说起
- 1、初始化JobHandler
- 2、创建一个Http服务器
- 3、注册到调度中心
- 任务触发原理⭐⭐⭐
- 1、任务如何触发?
- 调度线程scheduleThread
- 时间轮线程ringThread
- 2、快慢线程池的异步触发任务优化
- 3、如何选择执行器实例?
- 4、执行器如何去执行任务?
- 5、任务执行结果的回调
- 最后
今天来扒一扒轻量级的分布式任务调度平台Xxl-Job背后的架构原理
核心概念
这篇文章着重于XXL-Job的源码分析,关于XXL-Job的概念和使用移步文章《xxl-job入门》。
1、调度中心
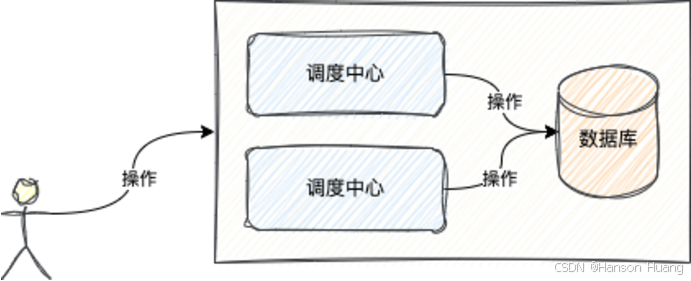
调度中心是一个单独的Web服务,主要是用来触发定时任务的执行
它提供了一些页面操作,我们可以很方便地去管理这些定时任务的触发逻辑
调度中心依赖数据库,所以数据都是存在数据库中的
调度中心也支持集群模式,但是它们所依赖的数据库必须是同一个
所以同一个集群中的调度中心实例之间是没有任何通信的,数据都是通过数据库共享的
2、执行器
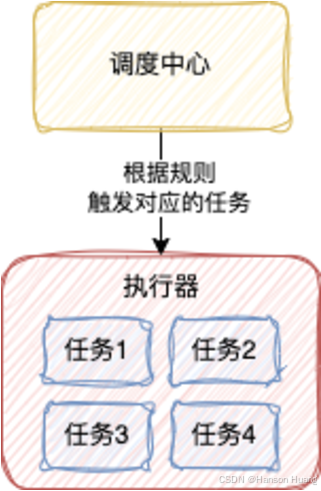
执行器是用来执行具体的任务逻辑的
执行器你可以理解为就是平时开发的服务,一个服务实例对应一个执行器实例
每个执行器有自己的名字,为了方便,你可以将执行器的名字设置成服务名
3、任务
任务什么意思就不用多说了
一个执行器中也是可以有多个任务的
总的来说,
调用中心是用来控制定时任务的触发逻辑,而执行器是具体执行任务的,这是一种任务和触发逻辑分离的设计思想,这种方式的好处就是使任务更加灵活,可以随时被调用,还可以被不同的调度规则触发。
来个Demo
快速讲一讲Xxl-Job搭建
1、搭建调度中心
调度中心搭建很简单,先下载源码
https://github.com/xuxueli/xxl-job.git
然后改一下数据库连接信息,执行一下在项目源码中的/doc/db下的sql文件
启动可以打成一个jar包,或者本地启动就是可以的
启动完成之后,访问下面这个地址就可以访问到控制台页面了
http://localhost:8080/xxl-job-admin/toLogin
用户名密码默认是 admin/123456
2、执行器和任务添加
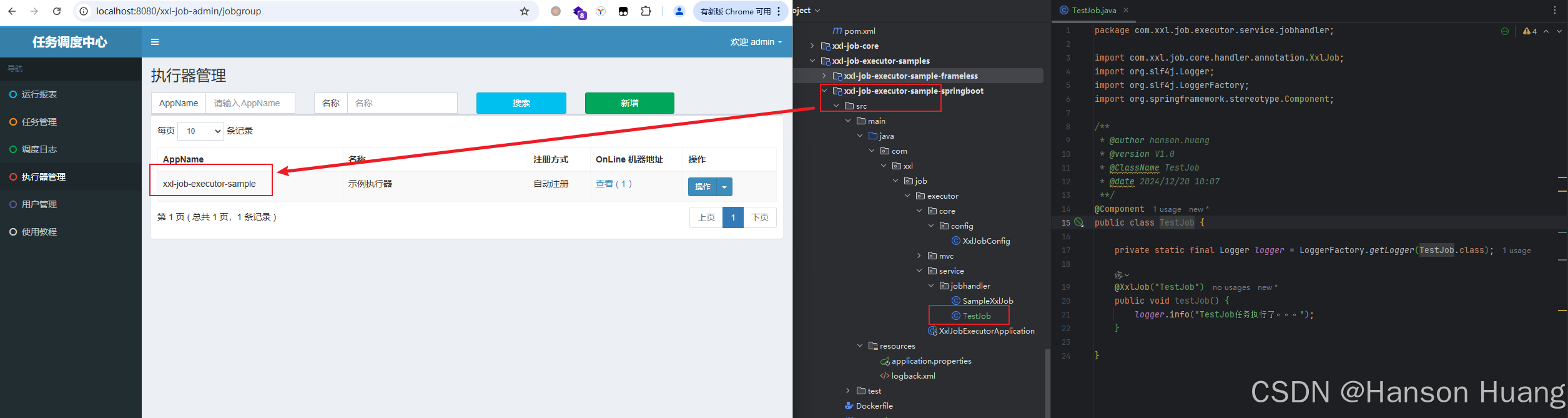
执行器用源码中自带的示例执行器,也可以自己仿写一个,保持AppName与服务名保持一致即可
任务添加
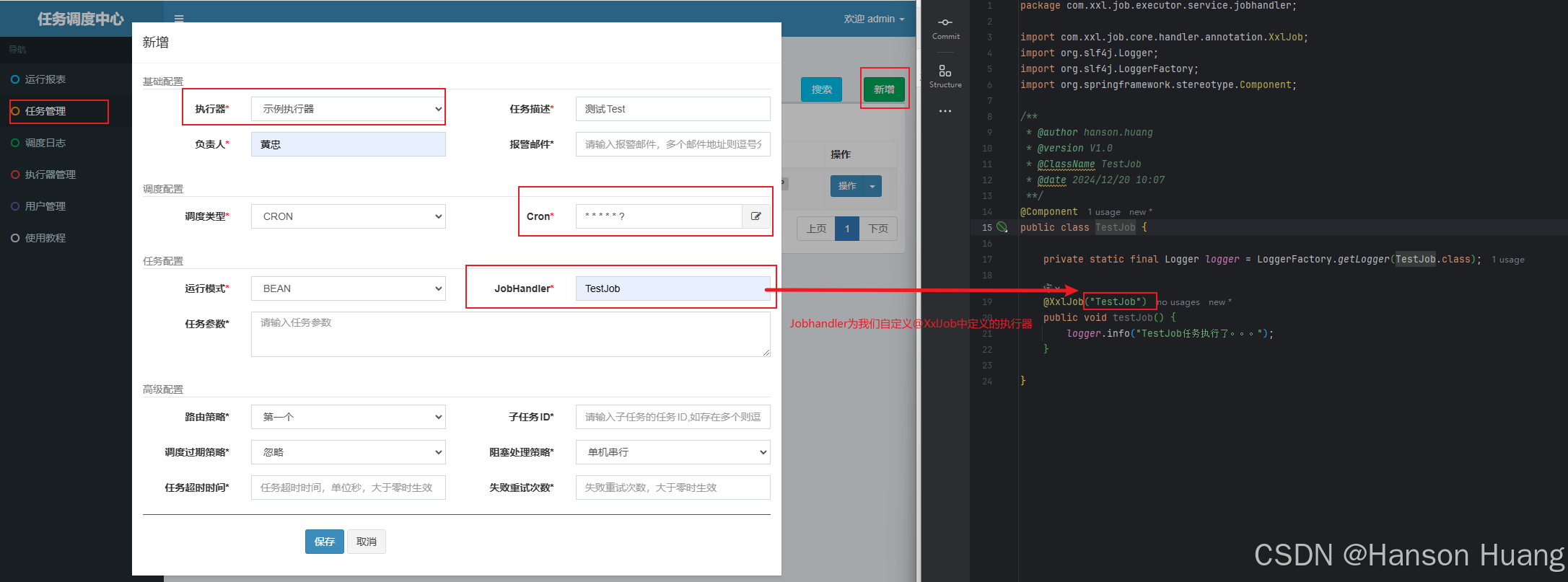
执行器选择我们刚刚添加的,指定任务名称为TestJob,corn表达式的意思是每秒执行一次
创建完之后需要启动一下任务,默认是关闭状态,也就不会执行
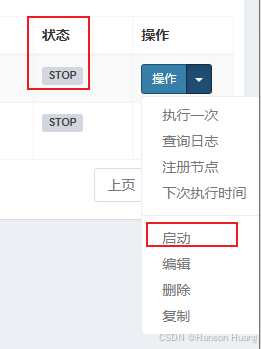
创建执行器和任务其实就是CRUD,并没有复杂的业务逻辑
按照如上配置的整个Demo的意思就是
每隔1s,执行一次xxl-job-executor-sample这个执行器中的TestJob任务
3、创建执行器和任务
可以按照源码中xxl-job-executor-sample仿写
引入依赖,下面是源码中示例执行器maven
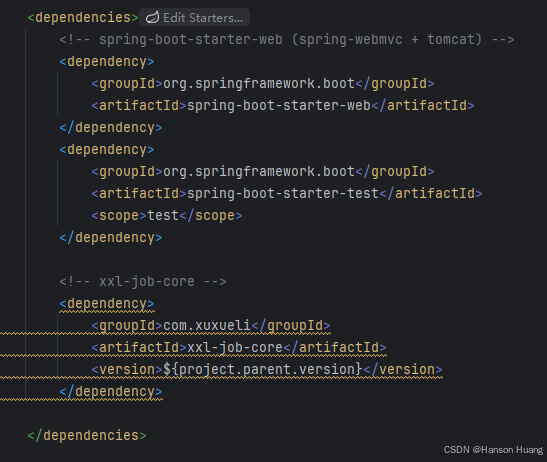
<!-- spring-boot-starter-web (spring-webmvc + tomcat) -->
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId>
</dependency><!-- xxl-job-core -->
<dependency><groupId>com.xuxueli</groupId><artifactId>xxl-job-core</artifactId><version>${project.parent.version}</version>
</dependency>
配置文件:
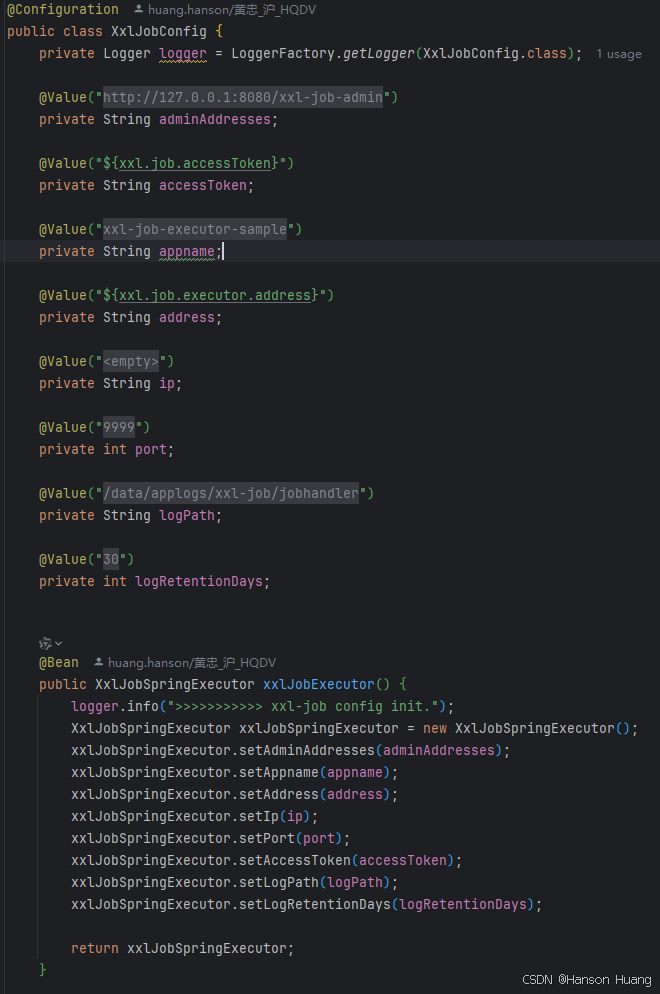
XxlJobSpringExecutor这个类的作用,后面会着重讲
通过@XxlJob指定一个名为TestJob的任务,这个任务名需要跟前面页面配置的对应上
@Component
public class TestJob {private static final Logger logger = LoggerFactory.getLogger(TestJob.class);@XxlJob("TestJob")public void testJob() {logger.info("TestJob任务执行了。。。");}
}
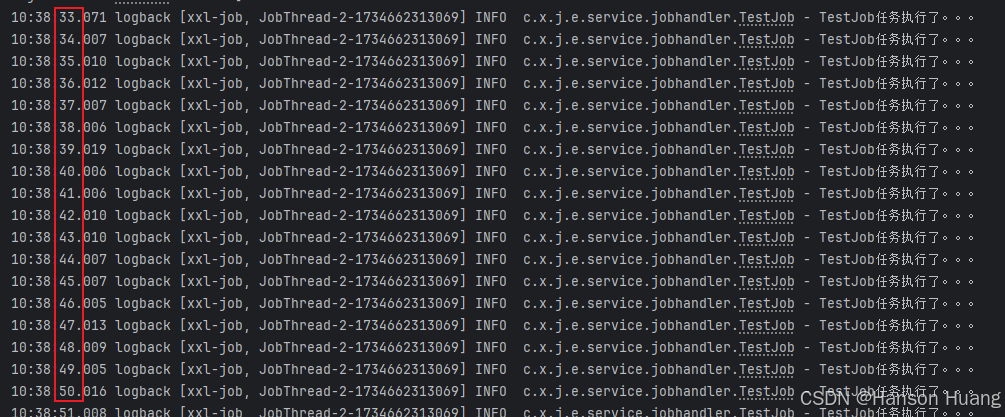
所以如果顺利的话,每隔1s钟就会打印一句TestJob任务执行了。。。
启动项目,注意修改一下端口,因为调用中心默认也是8080,本地起会端口冲突
最终执行结果如下,符合预期
讲完概念和使用部分,接下来就来好好讲一讲Xxl-Job核心的实现原理
从执行器启动说起
前面Demo中使用到了一个很重要的一个类
com.xxl.job.core.executor.impl.XxlJobSpringExecutor
这个类就是整个执行器启动的入口
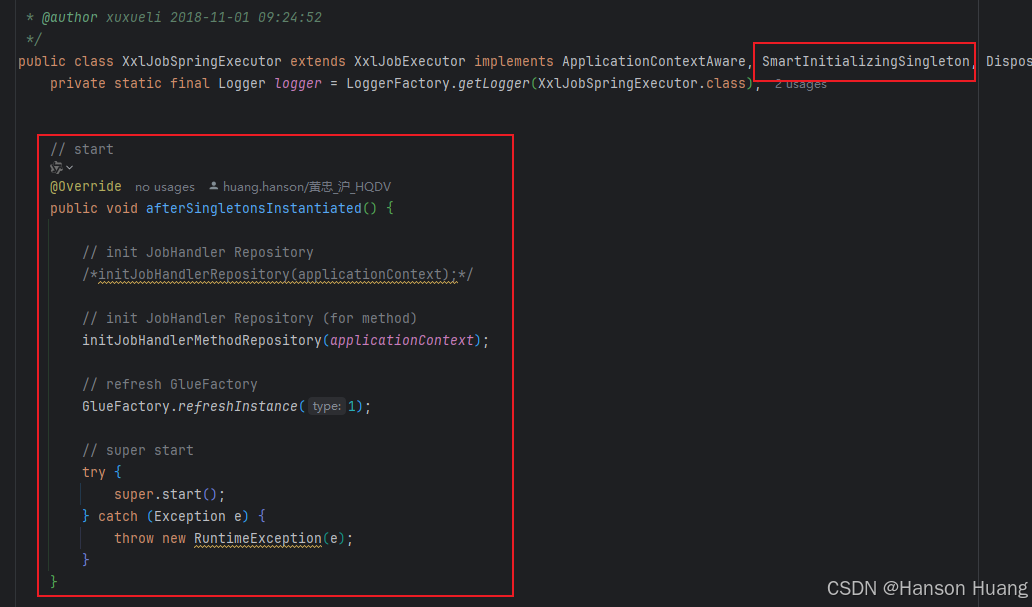
这个类实现了SmartInitializingSingleton接口
所以经过Bean的生命周期,一定会调用afterSingletonsInstantiated这个方法的实现
这个方法干了很多初始化的事,这里我挑三个重要的讲,其余的等到具体的功能的时候再提
1、初始化JobHandler
JobHandler是个什么?
所谓的JobHandler其实就是一个定时任务的封装
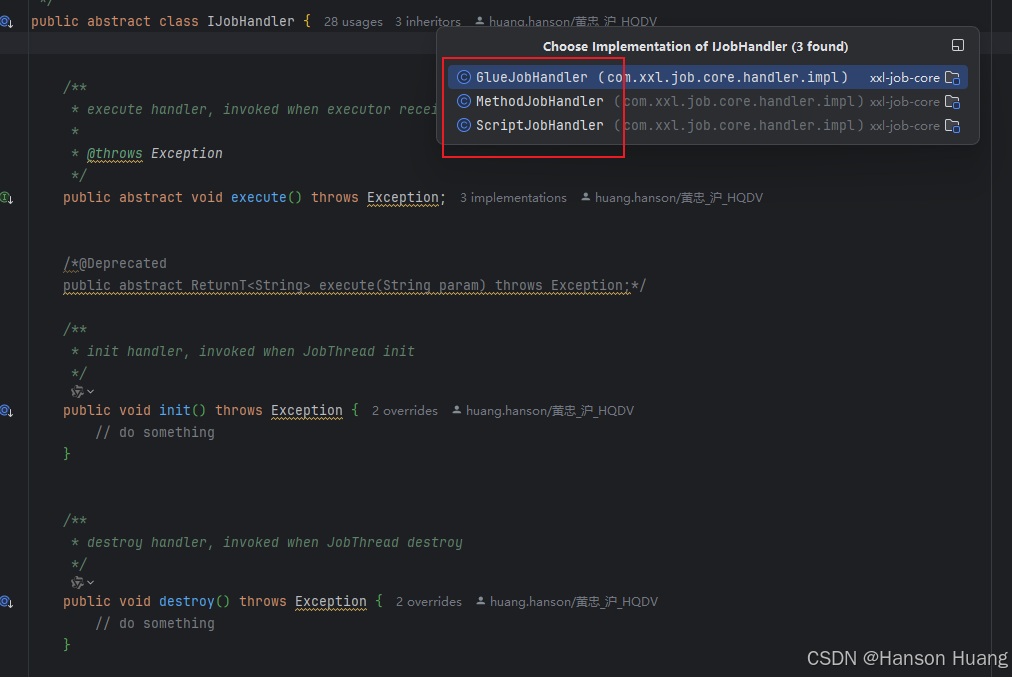
一个定时任务会对应一个JobHandler对象
当执行器执行任务的时候,就会调用JobHandler的execute方法
JobHandler有三种实现:
- MethodJobHandler
- GlueJobHandler
- ScriptJobHandler
MethodJobHandler是通过反射来调用方法执行任务
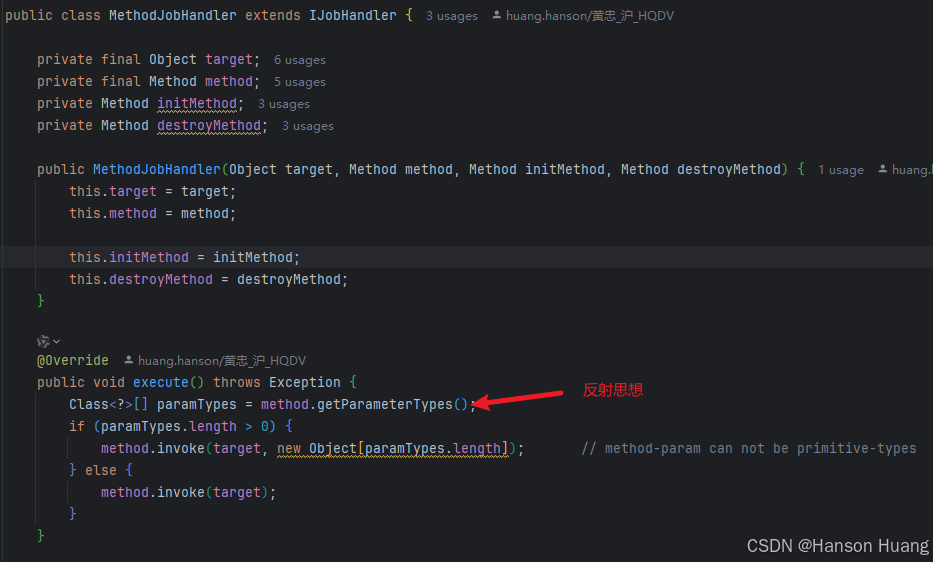
所以MethodJobHandler的任务的实现就是一个方法,刚好我们demo中的例子任务其实就是一个方法
所以Demo中的任务最终被封装成一个MethodJobHandler
GlueJobHandler比较有意思,它支持动态修改任务执行的代码
当你在创建任务的时候,需要指定运行模式为GLUE(Java)
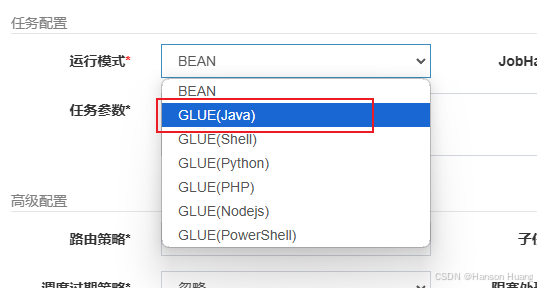
之后需要在操作按钮点击GLUE IDE编写Java代码
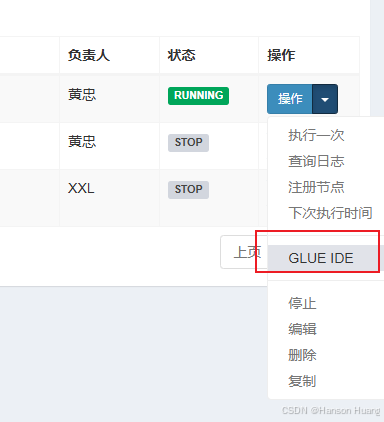

代码必须得实现IJobHandler接口,之后任务执行的时候就会执行execute方法的实现
如果你需要修改任务的逻辑,只需要重新编辑即可,不需要重启服务
ScriptJobHandler,通过名字也可以看出,是专门处理一些脚本的
运行模式除了BEAN和GLUE(Java)之外,其余都是脚本模式
而本节的主旨,所谓的初始化JobHandler就是指,执行器启动的时候会去Spring容器中找到加了@XxlJob注解的Bean,例如上文中提到的TestJob
解析注解,然后封装成一个MethodJobHandler对象,最终存到XxlJobSpringExecutor成员变量的一个本地的Map缓存中
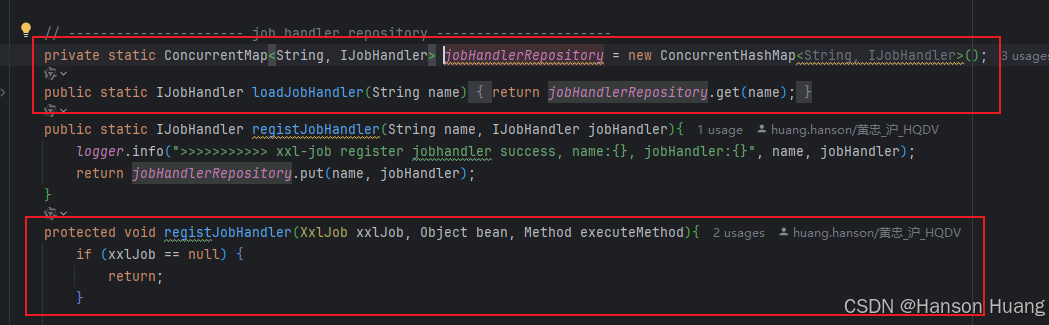
缓存key就是任务的名字
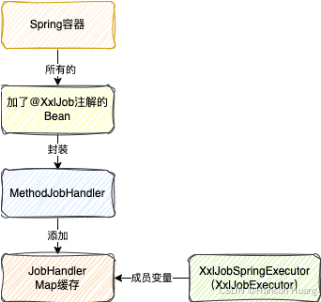
至于GlueJobHandler和ScriptJobHandler都是任务触发时才会创建
除了上面这几种,你也自己实现JobHandler,手动注册到JobHandler的缓存中,也是可以通过调度中心触发的
2、创建一个Http服务器
除了初始化JobHandler之外,执行器还会创建一个Http服务器
这个服务器端口号就是通过XxlJobSpringExecutor配置的端口,demo中就是设置的是9999,底层是基于Netty实现的
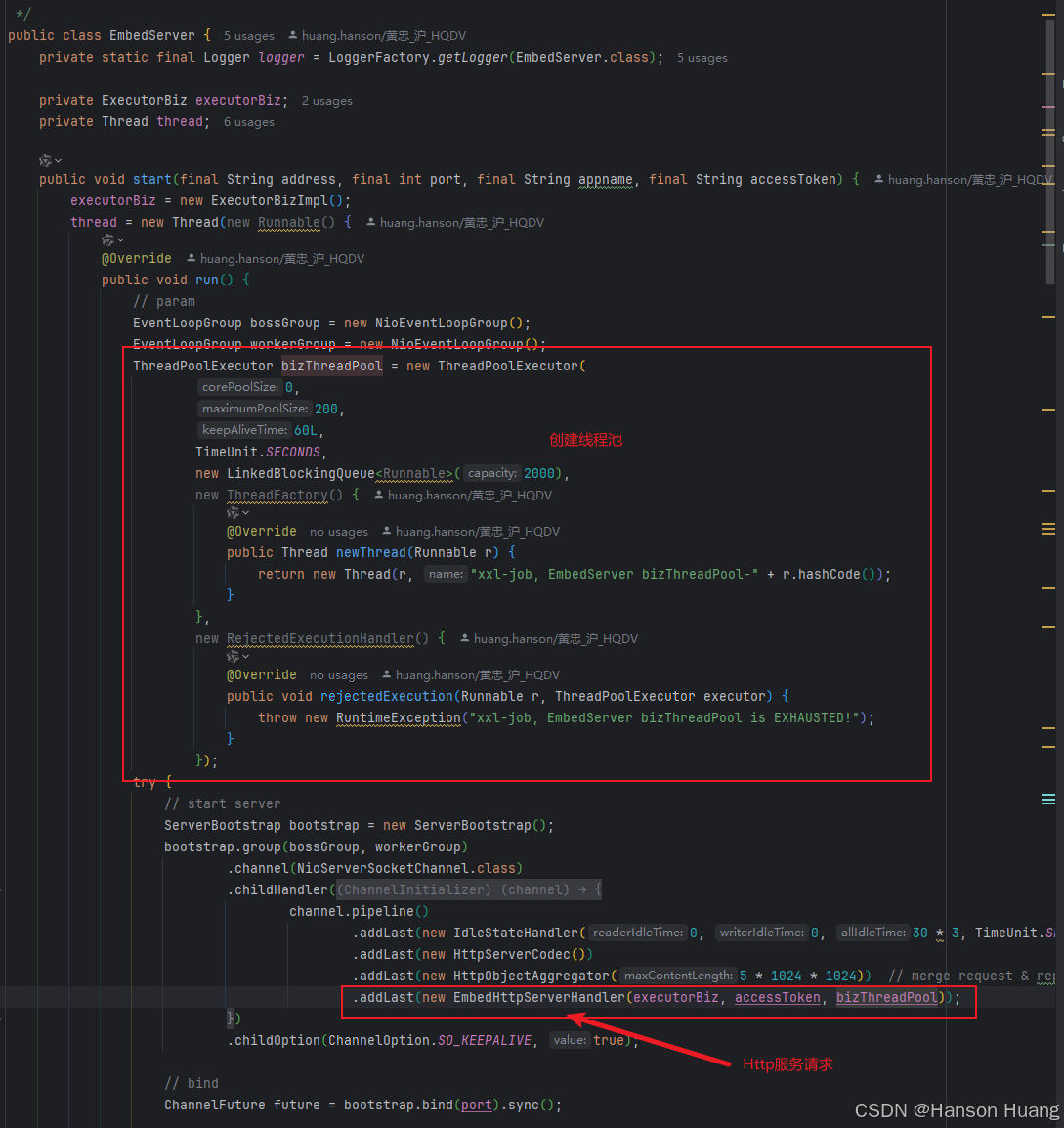
这个Http服务端会接收来自调度中心的请求
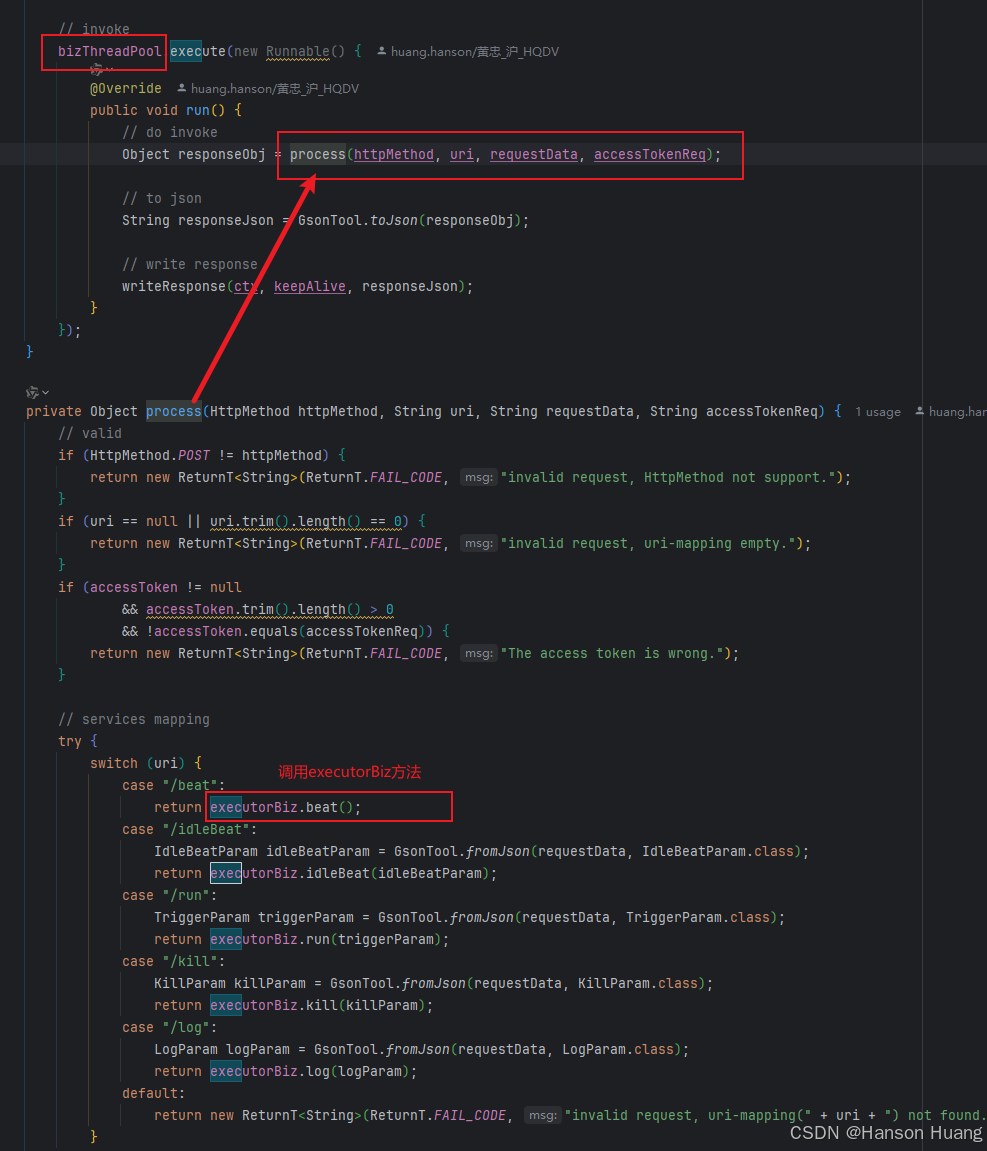
当执行器接收到调度中心的请求时,会把请求交给ExecutorBizImpl来处理
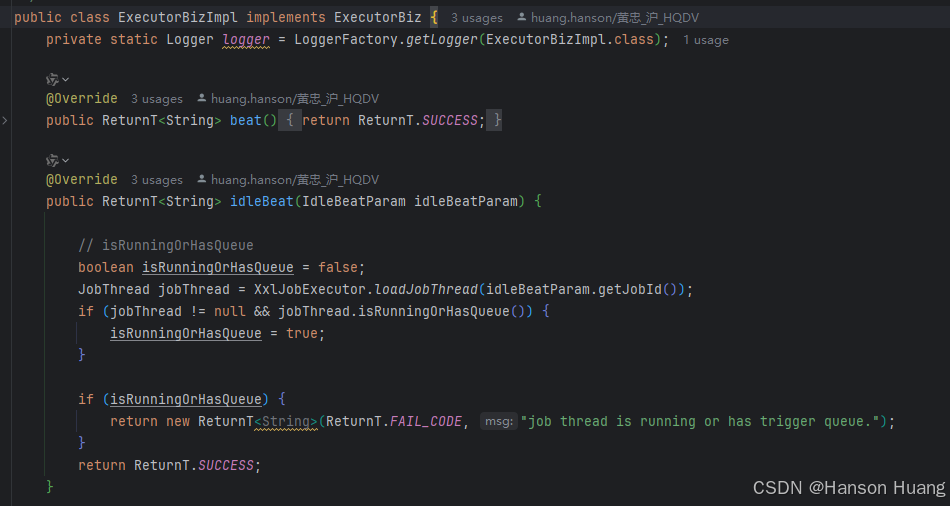
这个类非常重要,所有调度中心的请求都是这里处理的
ExecutorBizImpl实现了ExecutorBiz接口
当你翻源码的时候会发现,ExecutorBiz还有一个ExecutorBizClient实现
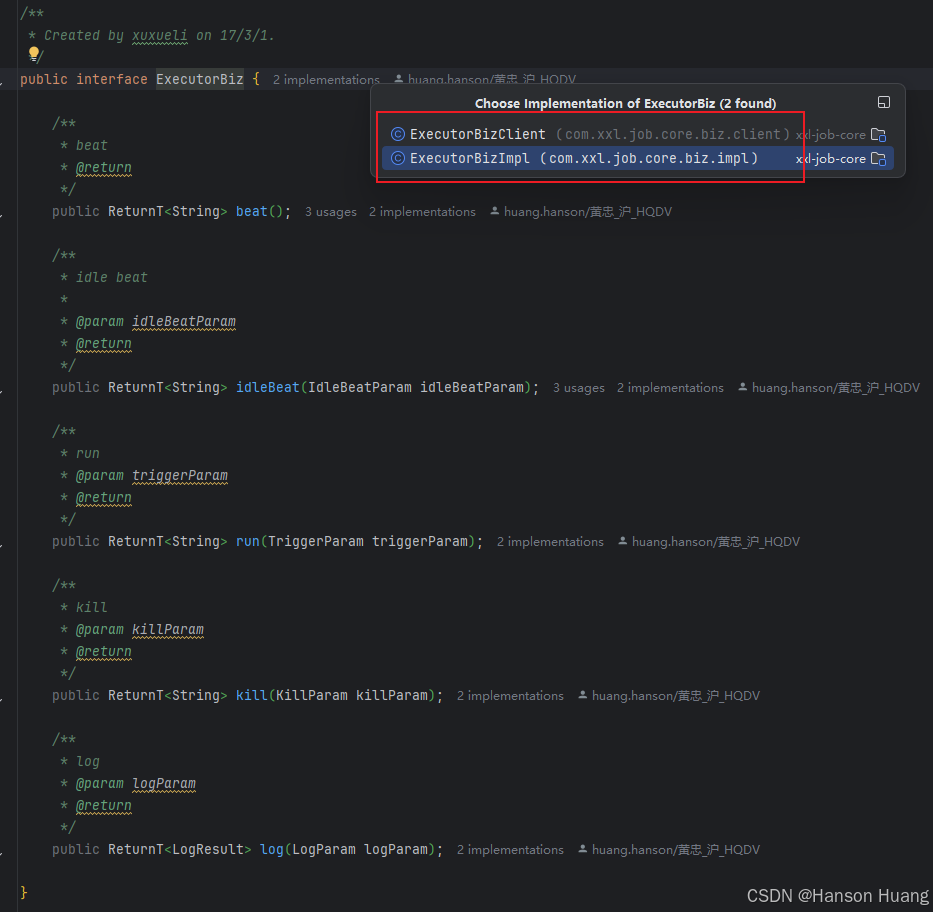
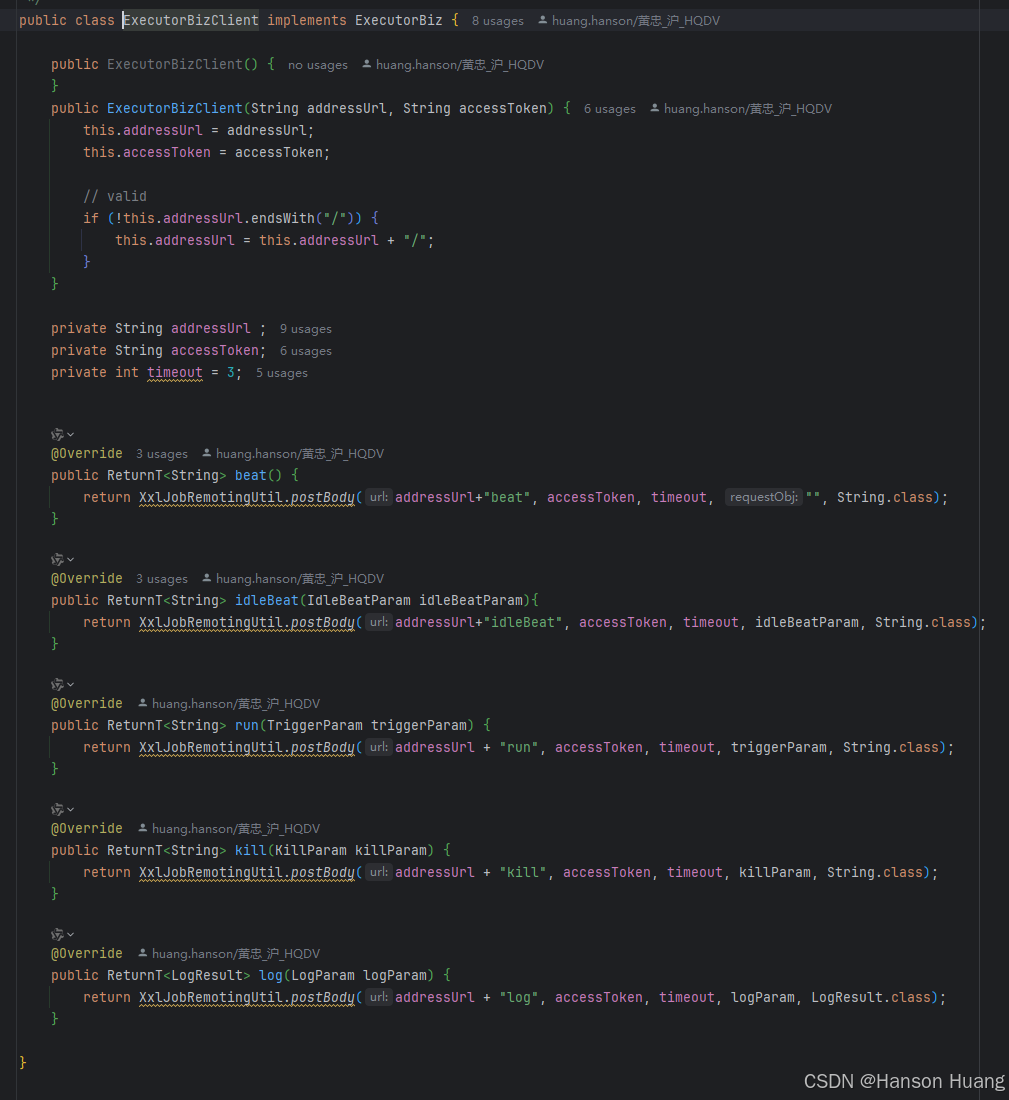
ExecutorBizClient的实现就是发送http请求,所以这个实现类是在调度中心使用的,用来访问执行器提供的http接口
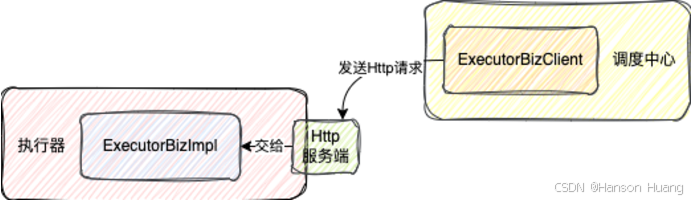
3、注册到调度中心
当执行器启动的时候,会启动一个注册线程,这个线程会往调度中心注册当前执行器的信息,包括两部分数据
- 执行器的名字,也就是设置的
appname - 执行器所在机器的
ip和端口,这样调度中心就可以访问到这个执行器提供的Http接口
前面提到每个服务实例都会对应一个执行器实例,所以调用中心会保存每个执行器实例的地址
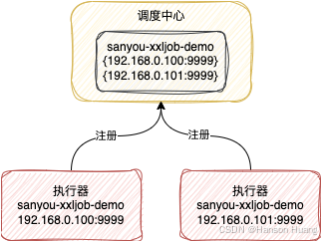
这里你可以把调度中心的功能类比成注册中心
任务触发原理⭐⭐⭐
弄明白执行器启动时干了哪些事,接下来讲一讲Xxl-Job最最核心的功能,那就是任务触发的原理
任务触发原理我会分下面5个小点来讲解
- 任务如何触发?
- 快慢线程池的异步触发任务优化
- 如何选择执行器实例?
- 执行器如何去执行任务?
- 任务执行结果的回调
1、任务如何触发?
源码:
com.xxl.job.admin.core.thread.JobScheduleHelper
调度线程scheduleThread
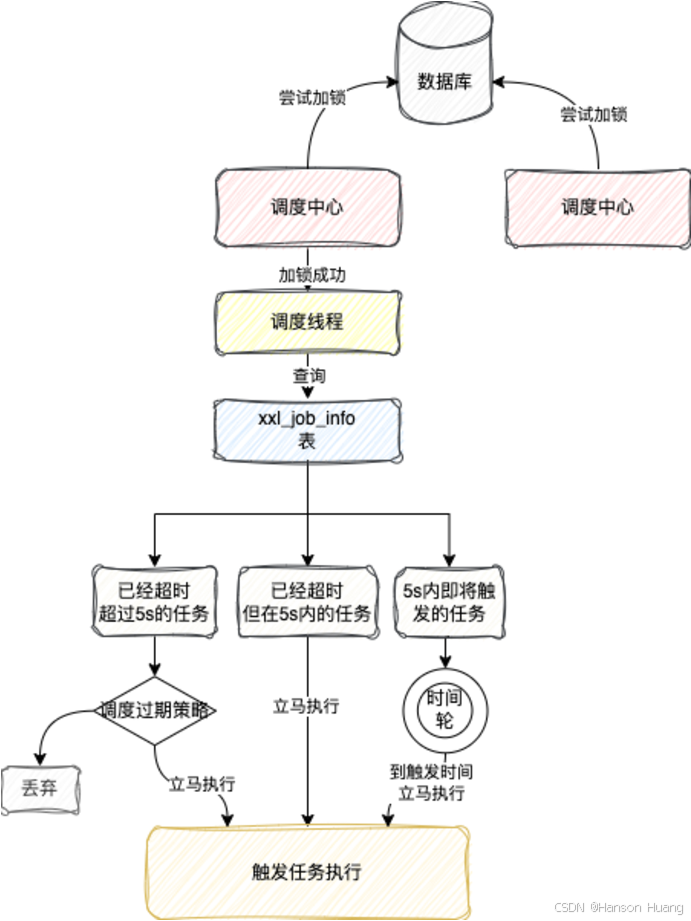
调度中心在启动的时候,会开启一个线程,这个线程的作用就是来计算任务触发时机,这里我把这个线程称为调度线程
这个调度线程会去查询xxl_job_info这张表
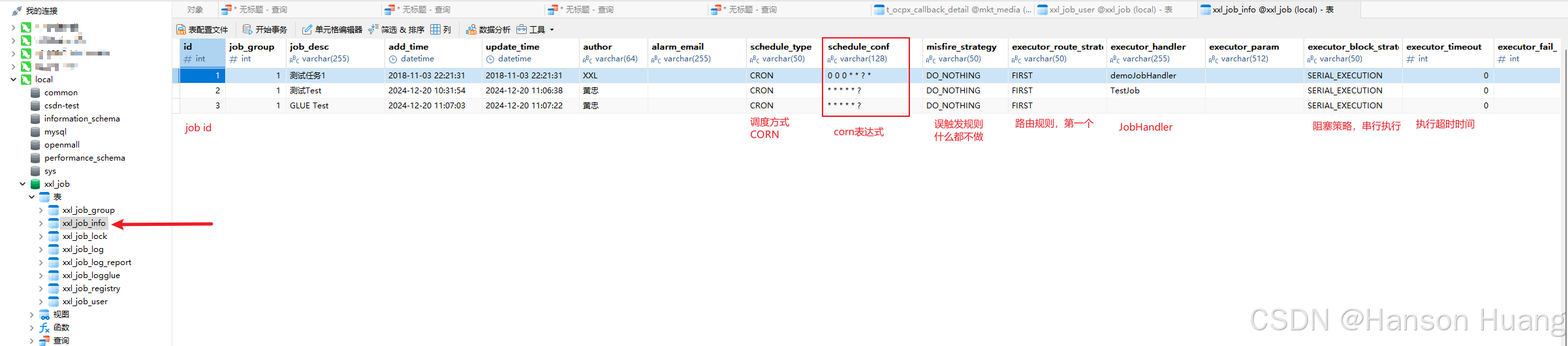
这张表存了任务的一些基本信息和任务下一次执行的时间
调度线程会去查询下一次执行的时间 <= 当前时间 + 5s的任务
这个5s是XxlJob写死的,被称为预读时间,提前读出来,保证任务能准时触发
举个例子,假设当前时间是2024-12-20 08:00:10,这里的查询就会查出下一次任务执行时间在2024-12-20 08:00:15之前执行的任务

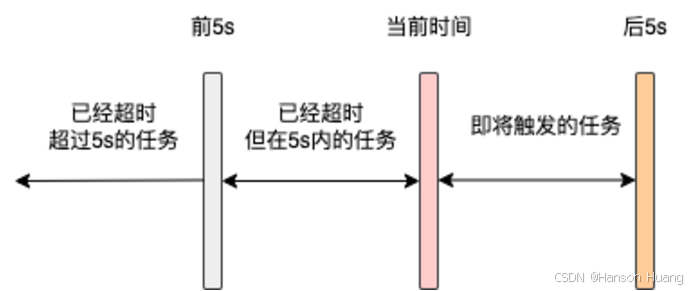
查询到任务之后,调度线程会去将这些任务根据执行时间划分为三个部分:
- 当前时间已经超过任务下一次执行时间
5s以上,也就是需要在2024-12-20 08:00:05(不包括05s)之前的执行的任务 - 当前时间已经超过任务下一次执行时间,但是但不足
5s,也就是在2024-12-20 08:00:05和2024-12-20 08:00:10(不包括10s)之间执行的任务 - 还未到触发时间,但是一定是
5s内就会触发执行的
对于第一部分的已经超过5s以上时间的任务,会根据任务配置的调度过期策略来选择要不要执行
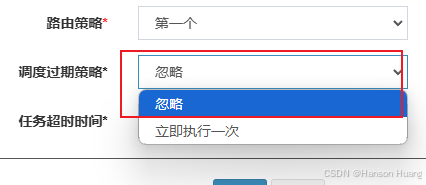
调度过期策略就两种,就是字面意思
- 直接忽略这个已经过期的任务
- 立马执行一次这个过期的任务
对于第二部分的超时时间在5s以内的任务,就直接立马执行一次,之后如果判断任务下一次执行时间就在5s内,会直接放到一个时间轮里面,等待下一次触发执行
对于第三部分任务,由于还没到执行时间,所以不会立马执行,也是直接放到时间轮里面,等待触发执行
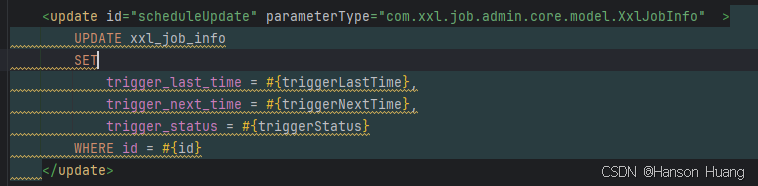
当这批任务处理完成之后,不论是前面是什么情况,调度线程都会去重新计算每个任务的下一次触发时间,然后更新xxl_job_info这张表的下一次执行时间
到此,一次调度的计算就算完成了
之后调度线程还会继续重复上面的步骤,查任务,调度任务,更新任务下次执行时间,一直死循环下去,这就实现了任务到了执行时间就会触发的功能
这里在任务触发的时候还有一个很有意思的细节
由于调度中心可以是集群的形式,每个调度中心实例都有调度线程,那么如何保证任务在同一时间只会被其中的一个调度中心触发一次?
我猜你第一时间肯定想到分布式锁,但是怎么加呢?
XxlJob实现就比较有意思了,它是基于八股文中常说的通过数据库来实现的分布式锁的,基于MySQL数据库的分布式锁移步文章《优雅的使用MySQL实现分布式锁》
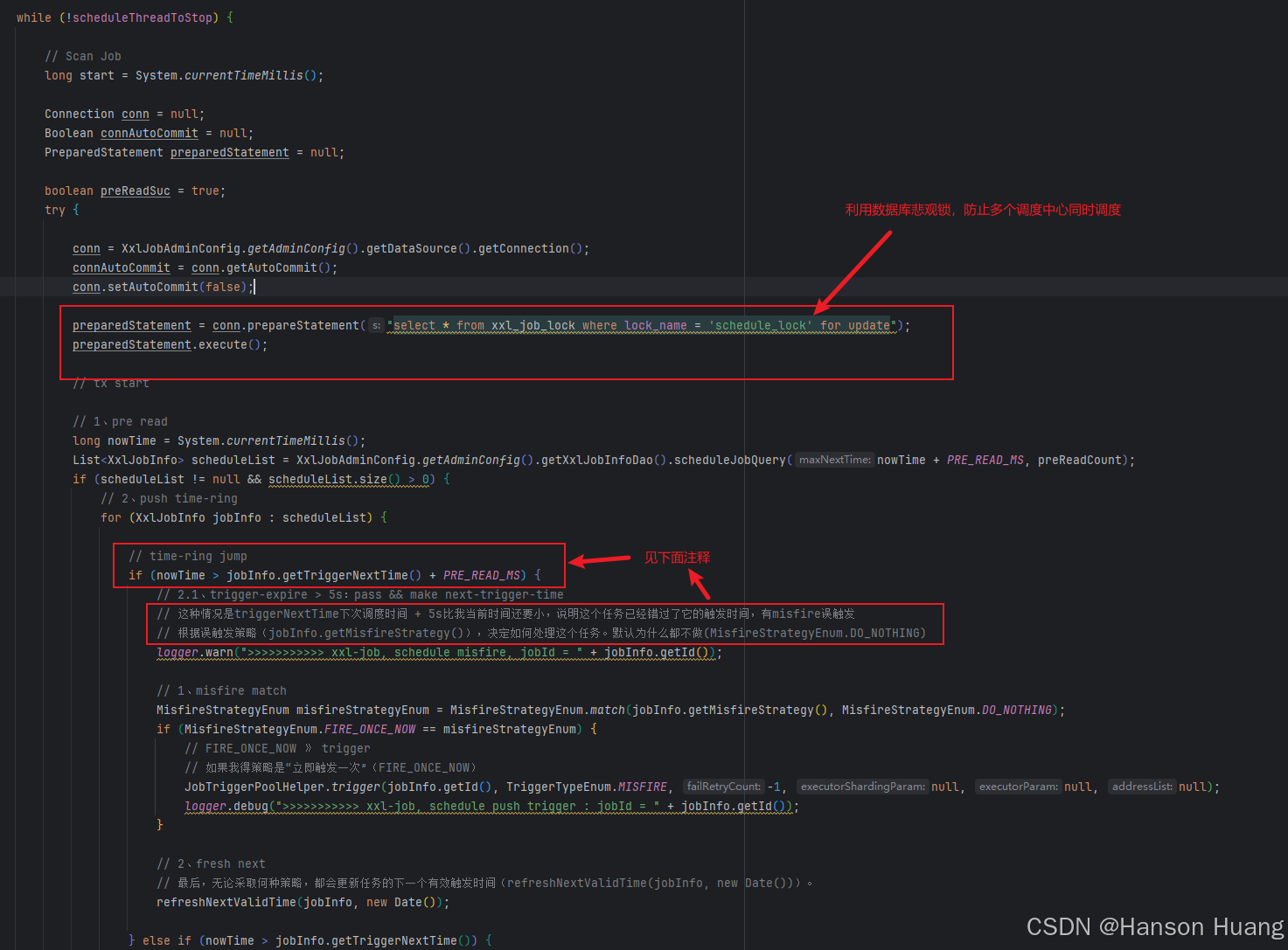
在调度之前,调度线程会尝试执行下面这句sql

就是这个sql
select * from xxl_job_lock where lock_name = 'schedule_lock' for update
一旦执行成功,说明当前调度中心成功抢到了锁,接下来就可以执行调度任务了
当调度任务执行完之后再去关闭连接,从而释放锁
由于每次执行之前都需要去获取锁,这样就保证在调度中心集群中,同时只有一个调度中心执行调度任务
现在来看看源码,详细说说上面过程
首先定义两个线程调度线程scheduleThread和时间轮线程ringThread,定义了一个map缓存时间轮,key为1-59的描述,value为当前秒数需要执行的job的id集合
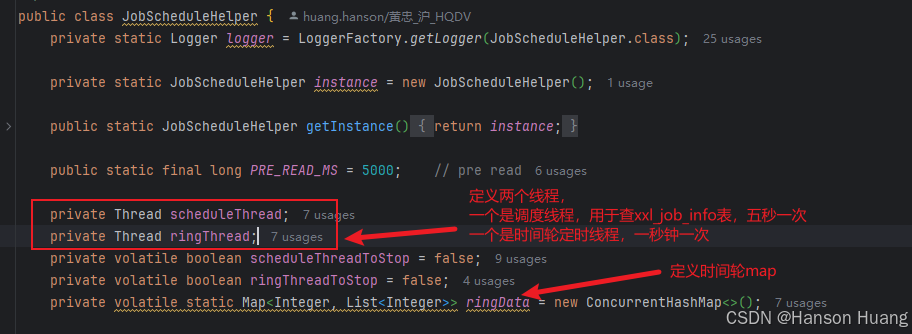
来看调度线程scheduleThread
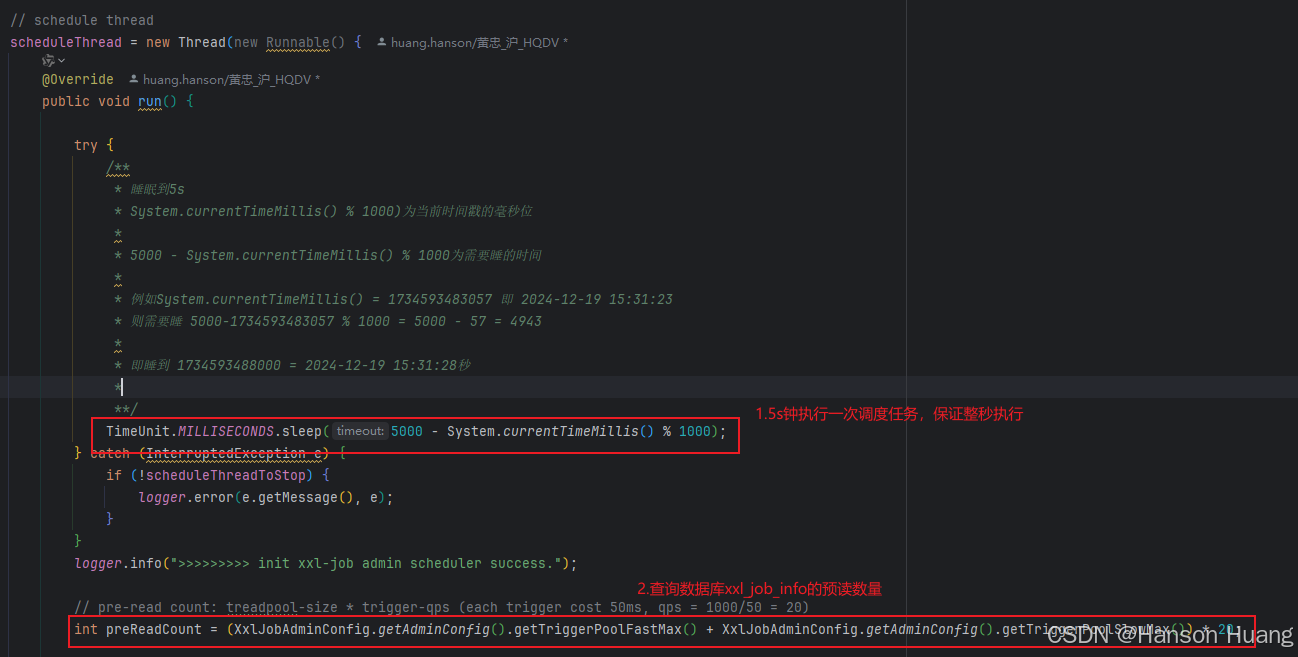
在开始阶段,做了调度线程做了两件非常重要的事情
- 将调度时间控制在5s钟执行一次,具体如何控制时间逻辑可以看注释
- 将每次插表预读的数量控制在
6000,这个6000怎么来的?每秒钟每个线程处理一个任务花费的时间大概是50ms,那么一个线程的qps就是1000/50=20条任务,后面我们会创建两个线程池(快慢线程池去执行这些任务,后面具体再说),快线程池最大线程池数为200,慢线程池数最大线数为100,所以每批次最大的预读条数就是(200+100)*20=6000
其次再接着看,调度中心可以部署在多台服务器上,需要共享同一个数据库,源码中使用使用select * from xxl_job_lock where lock_name = 'schedule_lock' for update,MySQL的悲观锁保证每次只有一个调度中心来执行调度任务
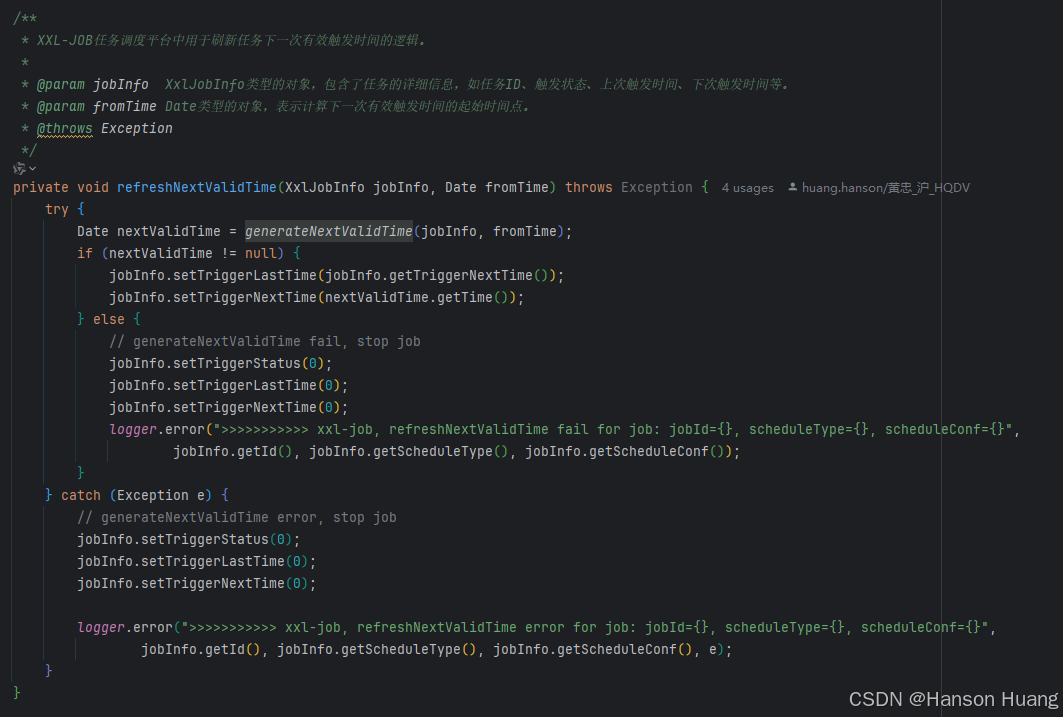
第一种情况:nowTime > jobInfo.getTriggerNextTime() + PRE_READ_MS
nowTime > jobInfo.getTriggerNextTime() + PRE_READ_MS就是上述提到的第一种情况,这种情况是triggerNextTime下次调度时间 + 5s比我当前时间还要小,说明这个任务已经错过了它的触发时间,有misfire误触发 根据误触发策略(jobInfo.getMisfireStrategy()),决定如何处理这个任务。默认为什么都不做(MisfireStrategyEnum.DO_NOTHING)
接下来无论是那种策略,都需要更新下一次触发时间
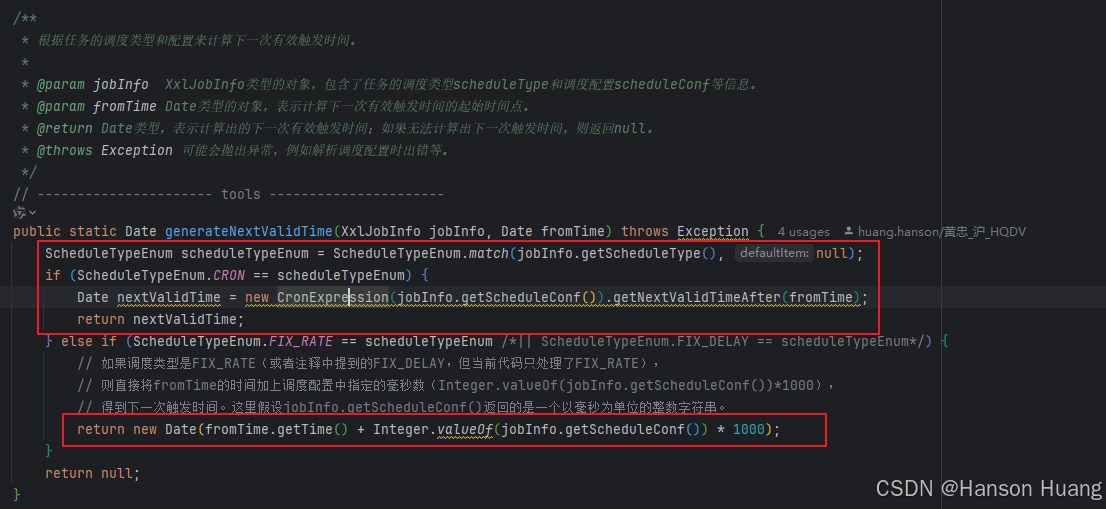
其中generateNextValidTime的逻辑就是根据调度类型计算下一次触发时间
- CRON:根据CRON表达是和当前时间戳计算出下一次触发的事时间
- FIX_RATE:用当前时间加上固定速率*1000
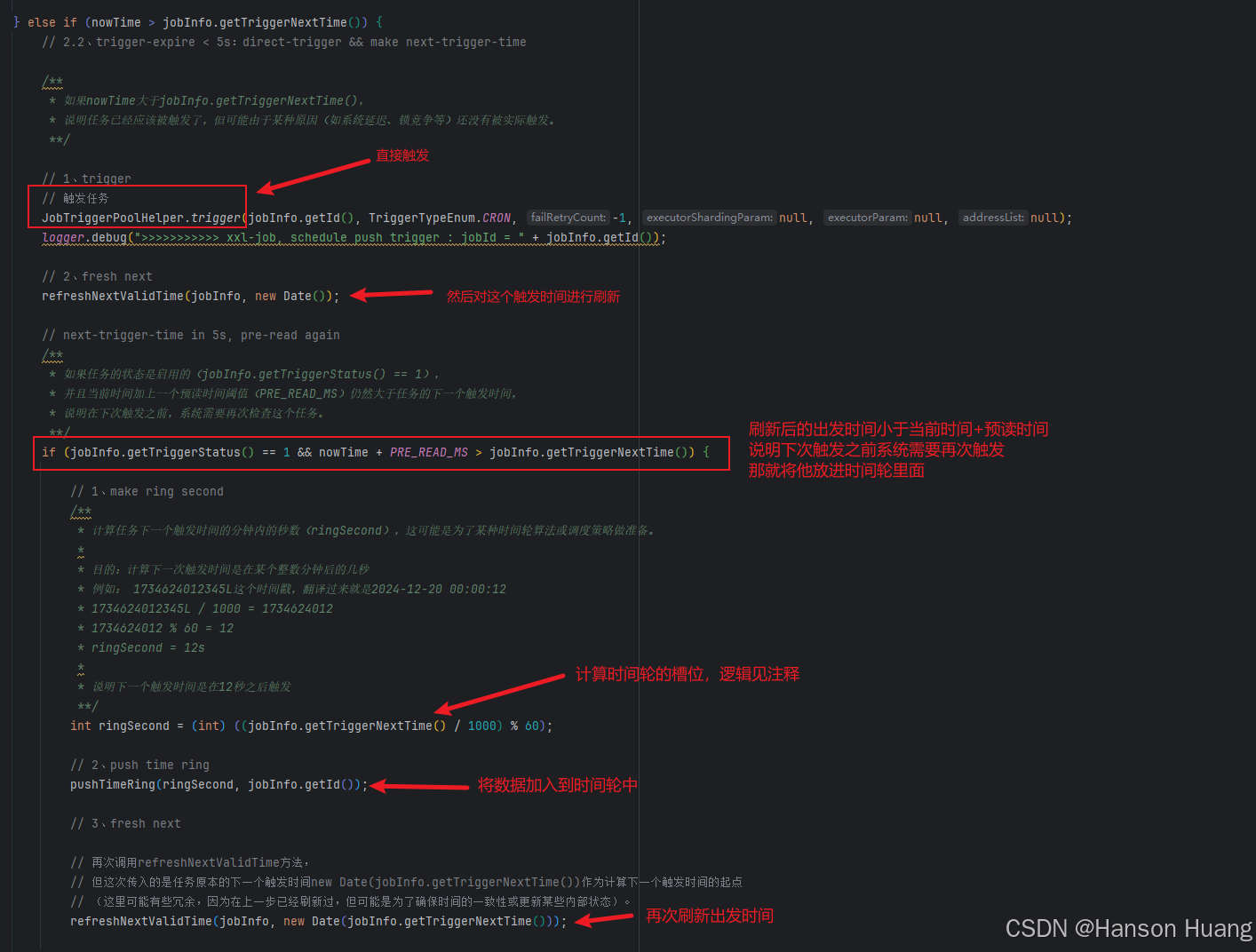
第二种情况:nowTime > jobInfo.getTriggerNextTime()
当nowTime > jobInfo.getTriggerNextTime()时,先将这个任务进行触发,然后更新这个人物的下一次触发时间,再判断我下次预读的数据中,这条任务是否需要触发,如果需要触发这次就直接将他放进时间轮中,然后再次更新触发时间
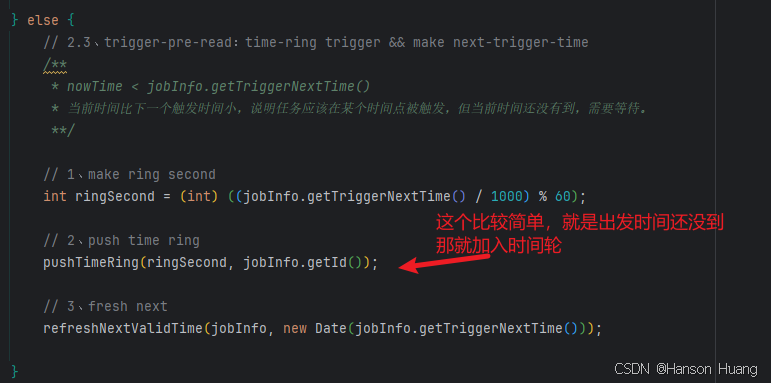
第三种情况:nowTime < jobInfo.getTriggerNextTime()
这个情况比较简单,就是触发时间还没到,那就将这个任务放在时间轮中
在预读数据全部执行完以后,更新xxl_job_info表状态

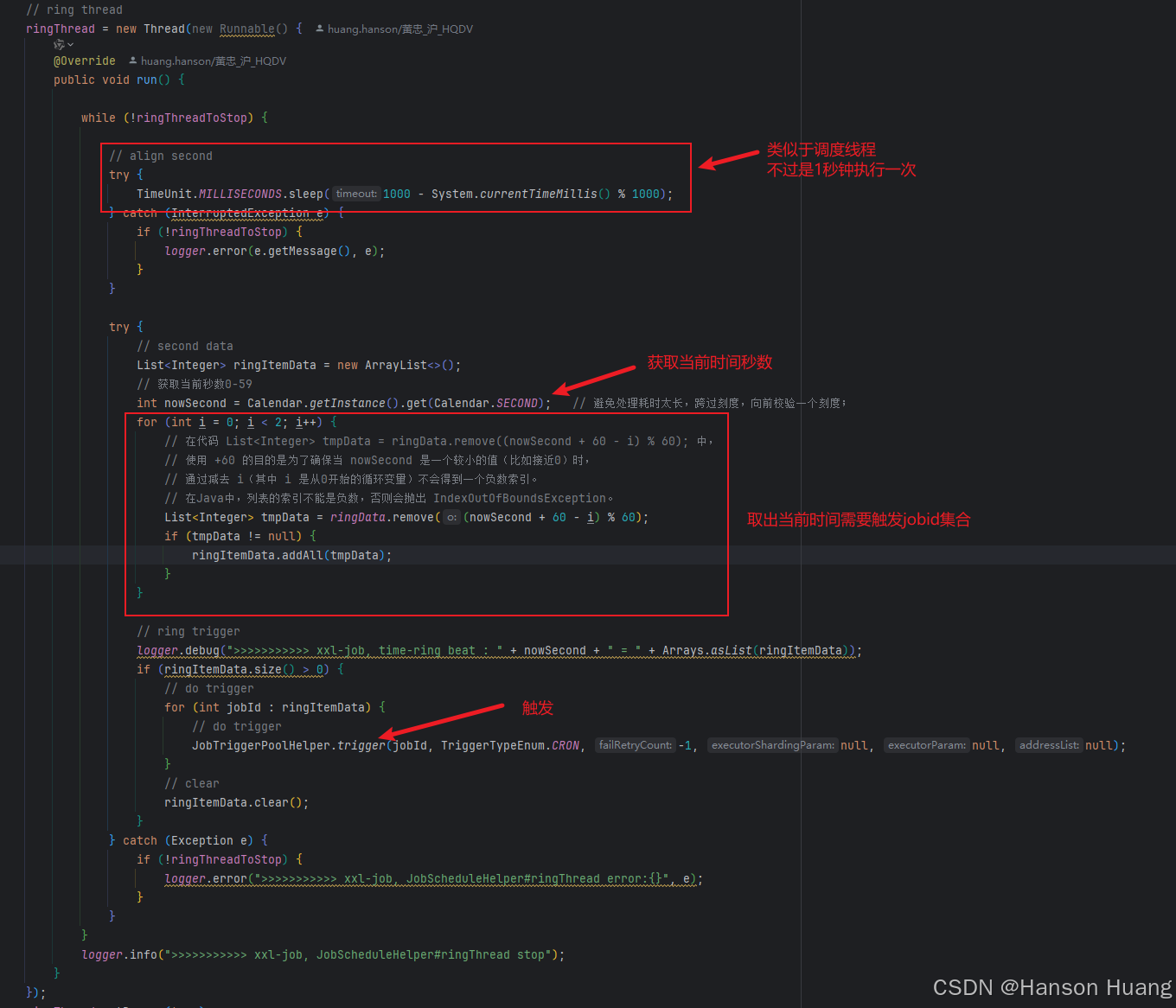
时间轮线程ringThread
时间轮原理移步文章《【时间轮】通过xxl-job剖析时间轮》
ringThread线程每隔一秒执行一次,根据当前时间去取需要触发的任务id,然后进行触发
最后画一张图来总结一下这一小节
2、快慢线程池的异步触发任务优化
当任务达到了触发条件,并不是由调度线程直接去触发执行器的任务执行
调度线程会将这个触发的任务交给线程池去执行
所以上图中的最后一部分触发任务执行其实是线程池异步去执行的
那么,为什么要使用线程池异步呢?
主要是因为触发任务,需要通过Http接口调用具体的执行器实例去触发任务
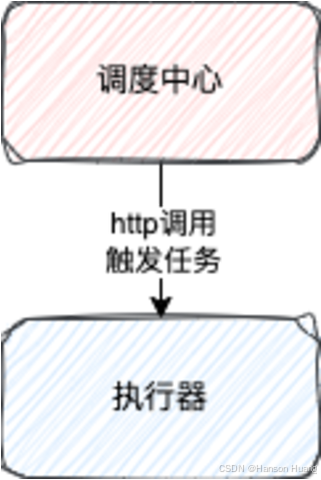
这一过程必然会耗费时间,如果调度线程去做,就会耽误调度的效率
所以就通过异步线程去做,调度线程只负责判断任务是否需要执行
并且,Xxl-Job为了进一步优化任务的触发,将这个触发任务执行的线程池划分成快线程池和慢线程池两个线程池
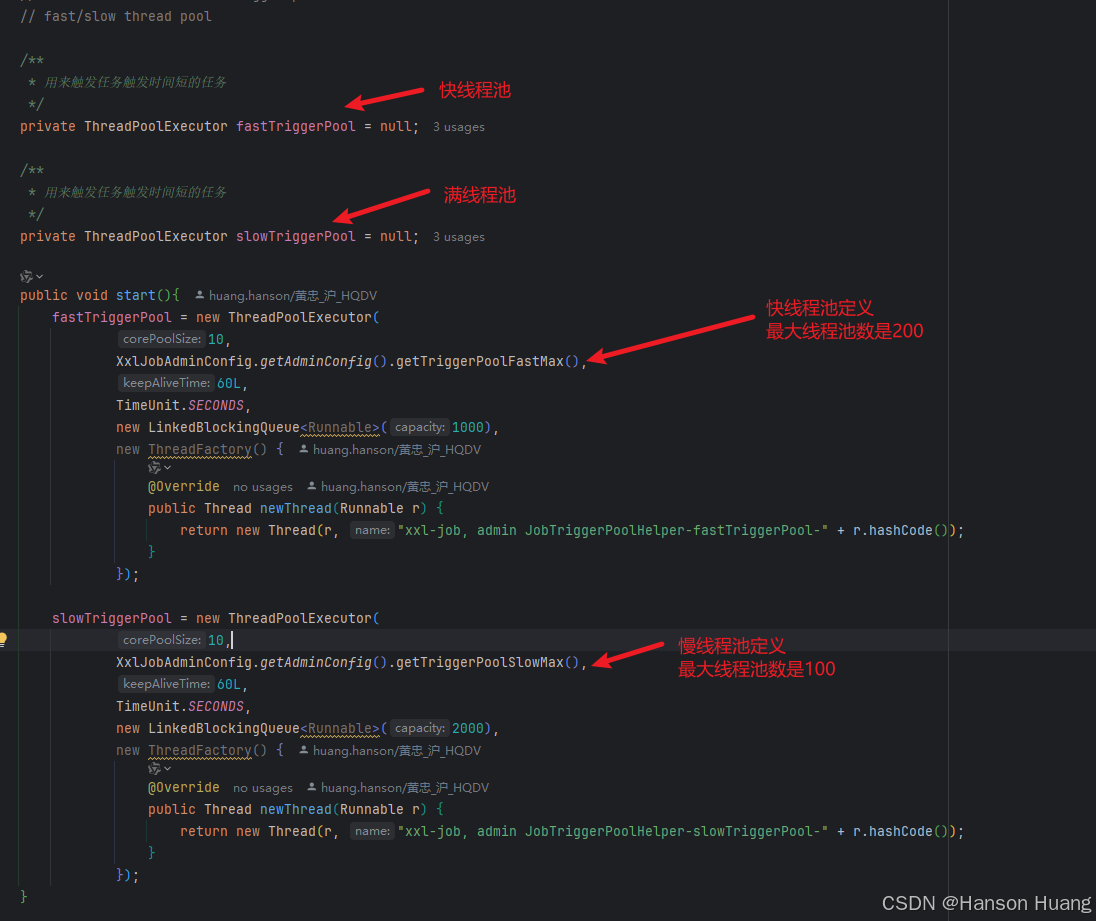
那为什么要设置成两个线程池呢,一个线程池不能解决吗?怎么区分任务的快慢呢?
为什么要设置两个线程,试想一下,现在有一批很慢的任务,执行时间可能是几秒以上,但是corn表达式是1s中执行一次,如果用一个线程池会阻塞后面的任务,像这种任务就可以用慢线程池来执行
怎么区别快慢任务呢?来看源码:
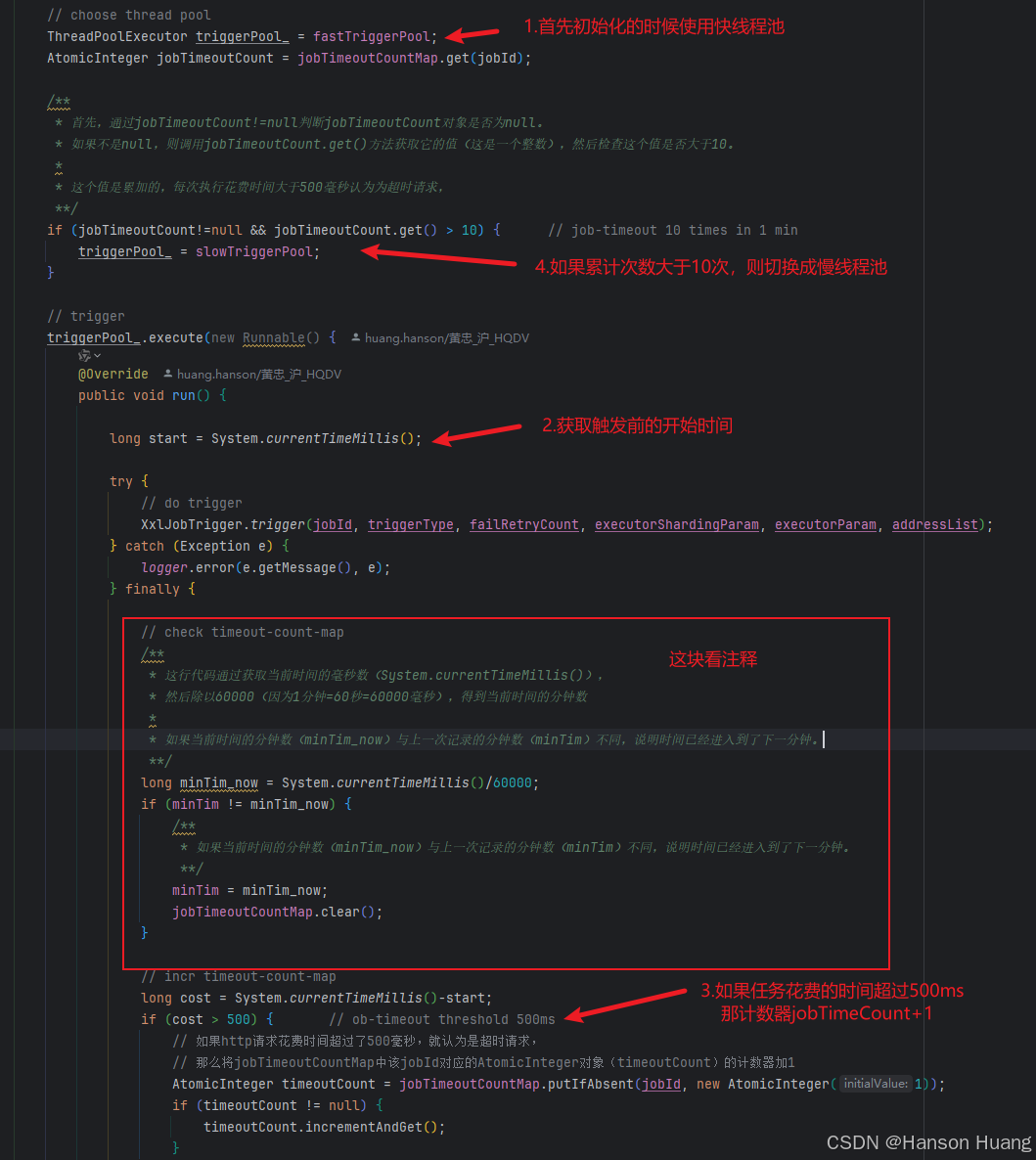
在调用执行器的Http接口触发任务执行的时候,Xxl-Job会去记录每个任务的触发所耗费的时间
注意并不是任务执行时间,只是整个Http请求耗时时间,这是因为执行器执行任务是异步执行的,所以整个时间不包括任务执行时间,这个后面会详细说
当任务一次触发的时间超过500ms,那么这个任务的慢次数就会加1
如果这个任务一分钟内触发的慢次数超过10次,接下来就会将触发任务交给慢线程池去执行
所以快慢线程池就是避免那种频繁触发并且每次触发时间还很长的任务阻塞其它任务的触发的情况发生
3、如何选择执行器实例?
上一节说到,当任务需要触发的时候,调度中心会向执行器发送Http请求,执行器去执行具体的任务
那么问题来了
由于一个执行器会有很多实例,那么应该向哪个实例请求?
这其实就跟任务配置时设置的路由策略有关了
从图上可以看出xxljob支持多种路由策略
除了分片广播,其余的具体的算法实现都是通过ExecutorRouter的实现类来实现的
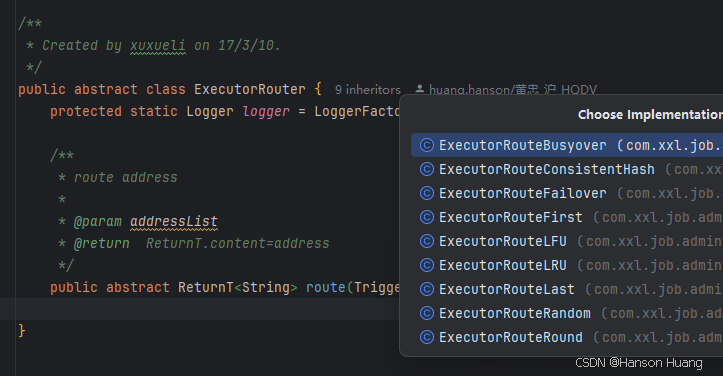
这里简单讲一讲各种算法的原理,有兴趣的小伙伴可以去看看内部的实现细节
第一个、最后一个、轮询、随机都很简单,没什么好说的
一致性Hash讲起来比较复杂,你可以先看看这篇文章,再去查看Xxl-Job的代码实现
https://blog.csdn.net/weixin_45683778/article/details/136694740
最不经常使用(LFU:Least Frequently Used):Xxl-Job内部会有一个缓存,统计每个任务每个地址的使用次数,每次都选择使用次数最少的地址,这个缓存每隔24小时重置一次
最近最久未使用(LRU:Least Recently Used):将地址存到LinkedHashMap中,它利用LinkedHashMap可以根据元素访问(get/put)顺序来给元素排序的特性,快速找到最近最久未使用(未访问)的节点
故障转移:调度中心都会去请求每个执行器,只要能接收到响应,说明执行器正常,那么任务就会交给这个执行器去执行
忙碌转移:调度中心也会去请求每个执行器,判断执行器是不是正在执行当前需要执行的任务(任务执行时间过长,导致上一次任务还没执行完,下一次又触发了),如果在执行,说明忙碌,不能用,否则就可以用
分片广播:XxlJob给每个执行器分配一个编号,从0开始递增,然后向所有执行器触发任务,告诉每个执行器自己的编号和总共执行器的数据
我们可以通过XxlJobHelper#getShardIndex获取到编号,XxlJobHelper#getShardTotal获取到执行器的总数据量
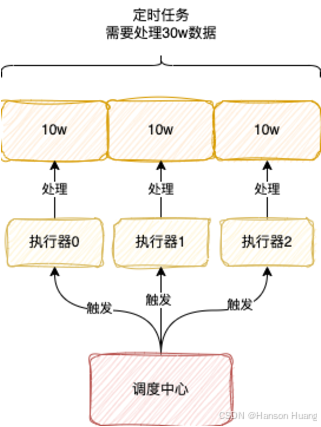
分片广播就是将任务量分散到各个执行器,每个执行器只执行一部分任务,加快任务的处理
举个例子,比如你现在需要处理30w条数据,有3个执行器,此时使用分片广播,那么此时可将任务分成3分,每份10w条数据,执行器根据自己的编号选择对应的那份10w数据处理
当选择好了具体的执行器实例之后,调用中心就会携带一些触发的参数,发送Http请求,触发任务
4、执行器如何去执行任务?
相信你一定记得我前面在说执行器启动是会创建一个Http服务器的时候提到这么一句
当执行器接收到调度中心的请求时,会把请求交给
ExecutorBizImpl来处理
所以前面提到的故障转移和忙碌转移请求执行器进行判断,最终执行器也是交给ExecutorBizImpl处理的
执行器处理触发请求是这个ExecutorBizImpl的run方法实现的
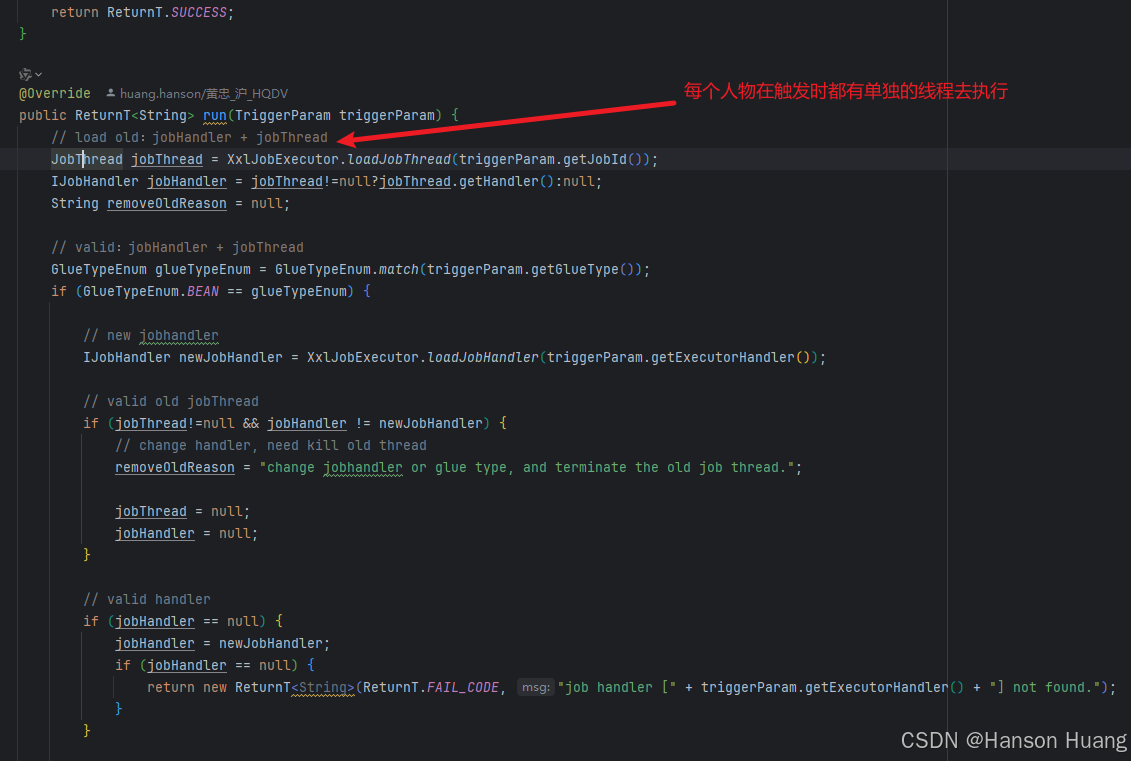
当执行器接收到请求,在正常情况下,执行器会去为这个任务创建一个单独的线程,这个线程被称为JobThread
每个任务在触发的时候都有单独的线程去执行,保证不同的任务执行互不影响
之后任务并不是直接交给线程处理的,而是直接放到一个内存队列中,线程直接从队列中获取任务
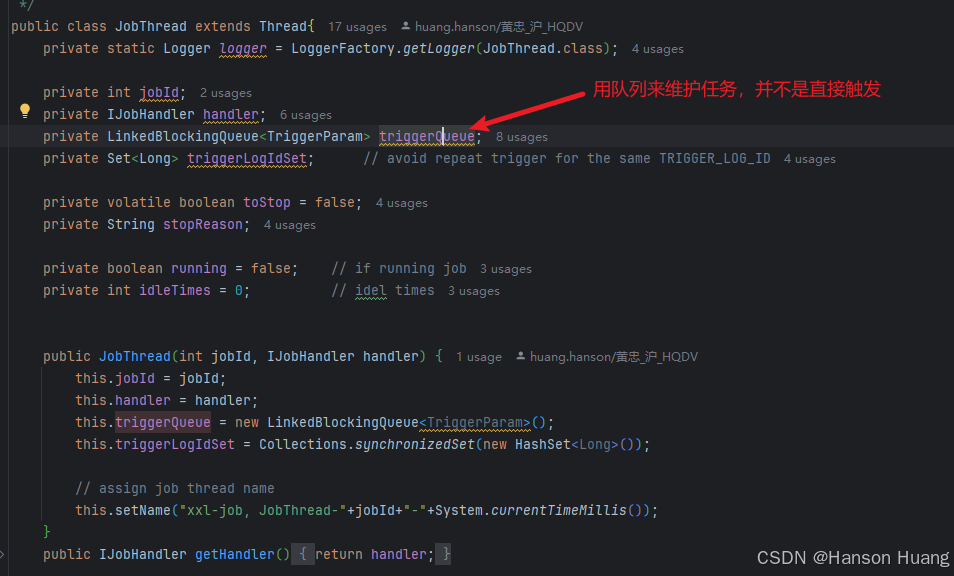
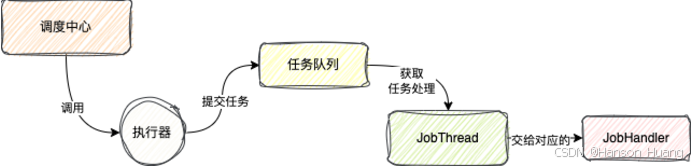
这里我相信你一定有个疑惑
为什么不直接处理,而是交给队列,从队列中获取任务呢?
那就得讲讲不正常的情况了
如果调度中心选择的执行器实例正在处理定时任务,那么此时该怎么处理呢?
这时就跟阻塞处理策略有关了
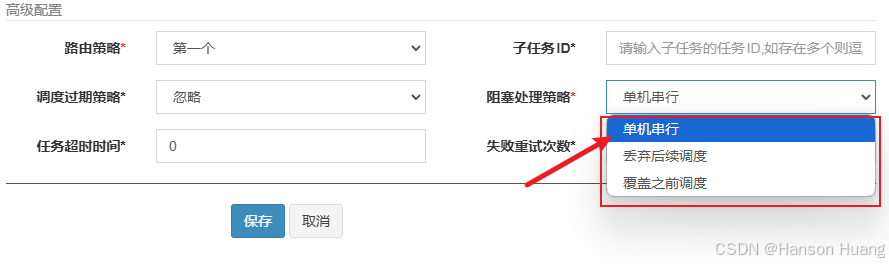
阻塞处理策略总共有三种:
- 单机串行
- 丢弃后续调度
- 覆盖之前调度
单机串行的实现就是将任务放到队列中,由于队列是先进先出的,所以就实现串行,这也是为什么放在队列的原因
丢弃调度的实现就是执行器什么事都不用干就可以了,自然而然任务就丢了
覆盖之前调度的实现就很暴力了,他是直接重新创建一个JobThread来执行任务,并且尝试打断之前的正在处理任务的JobThread,丢弃之前队列中的任务
打断是通过Thread#interrupt方法实现的,所以正在处理的任务还是有可能继续运行,并不是说一打断正在运行的任务就终止了
这里需要注意的一点就是,阻塞处理策略是对于单个执行器上的任务来生效的,不同执行器实例上的同一个任务是互不影响的
比如说,有一个任务有两个执行器A和B,路由策略是轮询
任务第一次触发的时候选择了执行器实例A,由于任务执行时间长,任务第二次触发的时候,执行器的路由到了B,此时A的任务还在执行,但是B感知不到A的任务在执行,所以此时B就直接执行了任务
所以此时你配置的什么阻塞处理策略就没什么用了
如果业务中需要保证定时任务同一时间只有一个能运行,需要把任务路由到同一个执行器上,比如路由策略就选择第一个
5、任务执行结果的回调
当任务处理完成之后,执行器会将任务执行的结果发送给调度中心

如上图所示,这整个过程也是异步化的
- JobThread会将任务执行的结果发送到一个内存队列中
- 执行器启动的时候会开启一个处发送任务执行结果的线程:TriggerCallbackThread
- 这个线程会不停地从队列中获取所有的执行结果,将执行结果批量发送给调度中心
- 调用中心接收到请求时,会根据执行的结果修改这次任务的执行状态和进行一些后续的事,比如失败了是否需要重试,是否有子任务需要触发等等
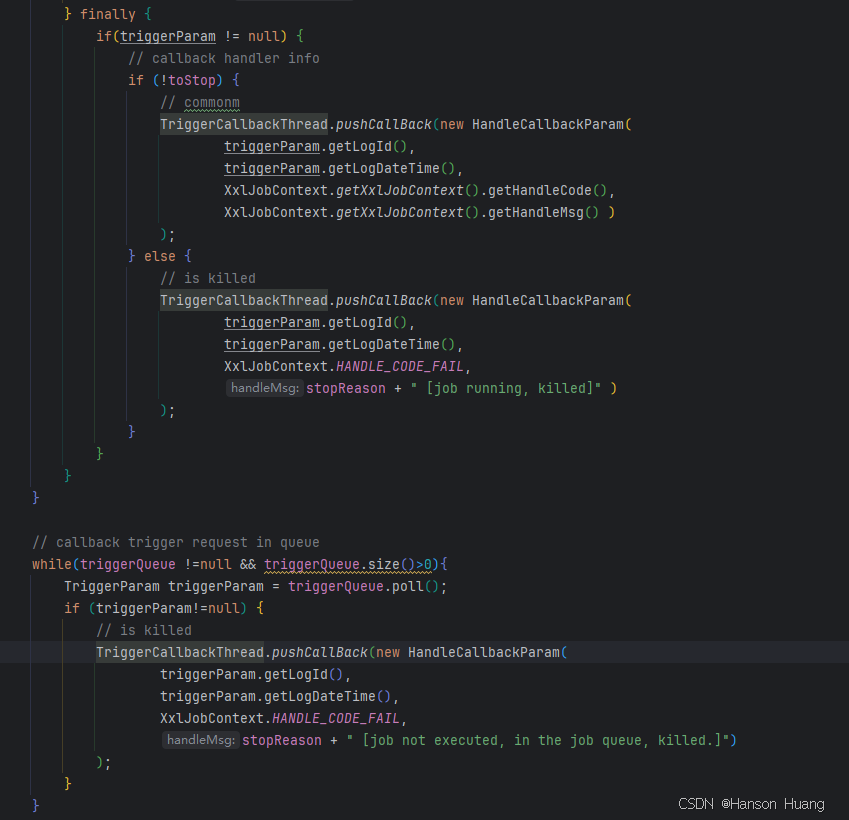
到此,一次任务的就算真正处理完成了
最后
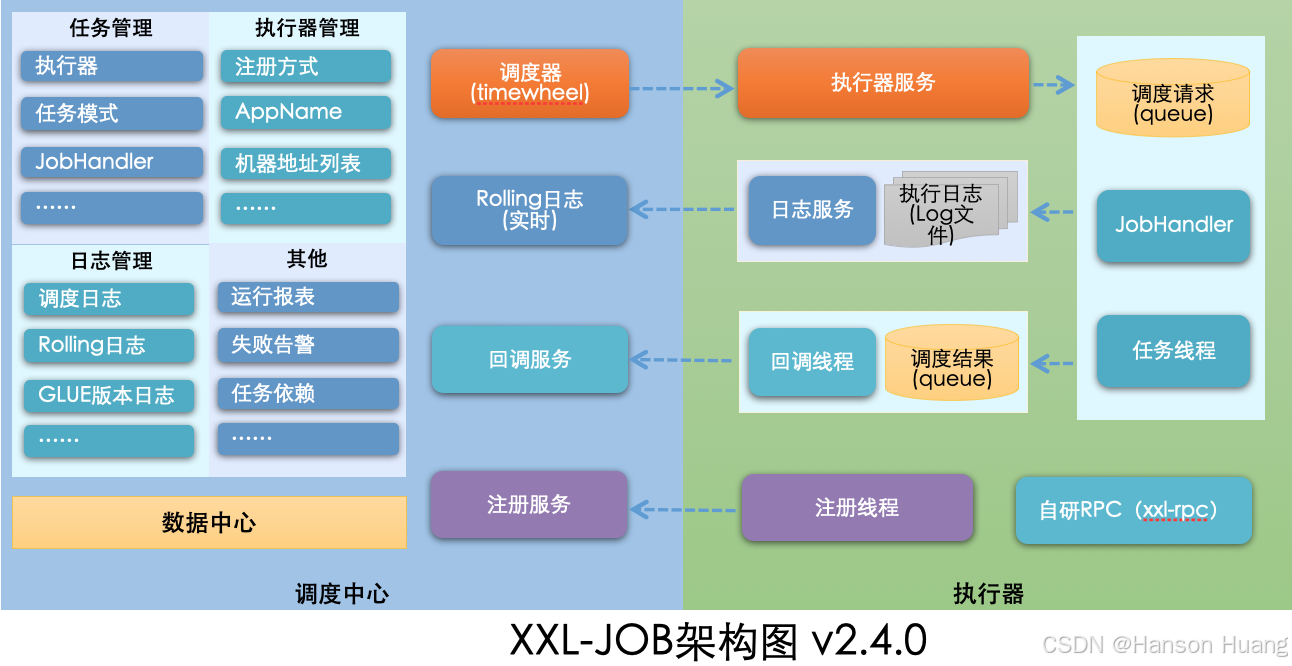
最后我从官网捞了一张Xxl-Job架构图
创作不易,不妨点赞、收藏、关注支持一下,各位的支持就是我创作的最大动力❤️

相关文章:
【xxl-job】XXL-Job源码深度剖析:分布式任务调度的艺术与实践
XXL-Job源码深度剖析 核心概念1、调度中心2、执行器3、任务 来个Demo1、搭建调度中心2、执行器和任务添加3、创建执行器和任务 从执行器启动说起1、初始化JobHandler2、创建一个Http服务器3、注册到调度中心 任务触发原理⭐⭐⭐1、任务如何触发?调度线程scheduleThr…...

图漾相机-ROS1_SDK_ubuntu版本编译(新版本)
文章目录 官网编译文档链接官网SDK下载链接1、下载 Camport ROS1 SDK1.下载git2、下载链接 2、准备编译工作1、安装 catkin2、配置环境变量3. 将Camport3中的linux库文件拷贝到 user/lib目录下4、修改lunch文件制定相机(可以放在最后可以参考在线文档)**…...

项目二十三:电阻测量(需要简单的外围检测电路,将电阻转换为电压)测量100,1k,4.7k,10k,20k的电阻阻值,由数码管显示。要求测试误差 <10%
资料查找: 01 方案选择 使用单片机测量电阻有多种方法,以下是一些常见的方法及其原理: 串联分压法(ADC) 原理:根据串联电路的分压原理,通过测量已知电阻和待测电阻上的电压,计算出…...

【NLP 17、NLP的基础——分词】
我始终相信,世间所有的安排都有它的道理;失之东隅,收之桑榆 —— 24.12.20 一、中文分词的介绍 1.为什么讲分词? ① 分词是一个被长期研究的任务,通过了解分词算法的发展,可以看到NLP的研究历程 ② 分词…...

uniapp blob格式转换为video .mp4文件使用ffmpeg工具
前言 介绍一下这三种对象使用场景 您前端一旦涉及到文件或图片上传Q到服务器,就势必离不了 Blob/File /base64 三种主流的类型它们之间 互转 也成了常态 Blob - FileBlob -Base64Base64 - BlobFile-Base64Base64 _ File uniapp 上传文件 现在已获取到了blob格式的…...

【无标题】 [蓝桥杯 2024 省 B] 好数
[蓝桥杯 2024 省 B] 好数 好数 一个整数如果按从低位到高位的顺序,奇数位(个位、百位、万位……)上的数字是奇数,偶数位(十位、千位、十万位……)上的数字是偶数,我们就称之为“好数”。 给定一…...

Leecode刷题C语言之同位字符串连接的最小长度
执行结果:通过 执行用时和内存消耗如下: bool check(char *s, int m) {int n strlen(s), count0[26] {0};for (int j 0; j < n; j m) {int count1[26] {0};for (int k j; k < j m; k) {count1[s[k] - a];}if (j > 0 && memcmp(count0, cou…...

Pytorch | 利用BIM/I-FGSM针对CIFAR10上的ResNet分类器进行对抗攻击
Pytorch | 利用BIM/I-FGSM针对CIFAR10上的ResNet分类器进行对抗攻击 CIFAR数据集BIM介绍基本原理算法流程特点应用场景 BIM代码实现BIM算法实现攻击效果 代码汇总bim.pytrain.pyadvtest.py 之前已经针对CIFAR10训练了多种分类器: Pytorch | 从零构建AlexNet对CIFAR1…...

音频进阶学习八——傅里叶变换的介绍
文章目录 前言一、傅里叶变换1.傅里叶变换的发展2.常见的傅里叶变换3.频域 二、欧拉公式1.实数、虚数、复数2.对虚数和复数的理解3.复平面4.复数和三角函数5.复数的运算6.欧拉公式 三、积分运算1.定积分2.不定积分3.基本的积分公式4.积分规则线性替换法分部积分法 5.定积分计算…...

将4G太阳能无线监控的视频接入电子监控大屏,要考虑哪些方面?
随着科技的飞速发展,4G太阳能无线监控系统以其独特的优势在远程监控领域脱颖而出。这种系统结合了太阳能供电的环保特性和4G无线传输的便捷性,为各种环境尤其是无电或电网不稳定的地区提供了一种高效、可靠的视频监控解决方案。将这些视频流接入大屏显示…...

使用docker拉取镜像很慢或者总是超时的问题
在拉取镜像的时候比如说mysql镜像,在拉取 时总是失败: 像这种就是网络的原因,因为你是连接到了外网去进行下载的,这个时候可以添加你的访问镜像源。也就是daemon.json文件,如果你没有这个文件可以输入 vim /etc/dock…...

Redis数据库笔记
Spring cache 缓存的介绍 在springboot中如何使用redis的缓存 1、使用Cacheable的例子【一般都是在查询的方法上】 /*** 移动端的套餐查询* value 就是缓存的名称* key 就是缓存id ,就是一个缓存名称下有多个缓存,根据id来区分* 这个id一般就是多个查询…...
U盘出现USBC乱码文件的全面解析与恢复指南
一、乱码现象初探:USBC乱码文件的神秘面纱 在数字时代,U盘已成为我们日常生活中不可或缺的数据存储工具。然而,当U盘中的文件突然变成乱码,且文件名前缀显示为“USBC”时,这无疑给用户带来了极大的困扰。这些乱码文件…...

多线程 - 自旋锁
个人主页:C忠实粉丝 欢迎 点赞👍 收藏✨ 留言✉ 加关注💓本文由 C忠实粉丝 原创 多线程 - 自旋锁 收录于专栏[Linux学习] 本专栏旨在分享学习Linux的一点学习笔记,欢迎大家在评论区交流讨论💌 目录 概述 原理 优点与…...
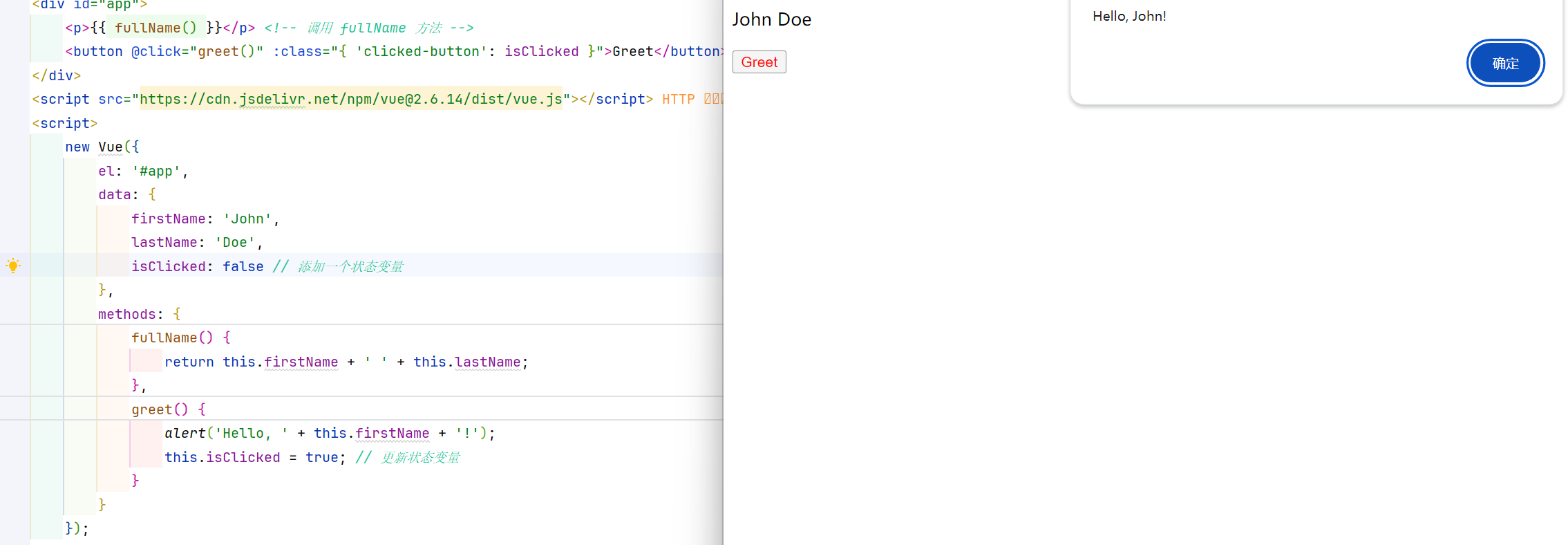
vue2 - Day02 -计算属性(computed)、侦听器(watch)和方法(methods)
在 Vue.js 中,计算属性(computed)、侦听器(watch)和方法(methods)都是响应式的数据处理方式 文章目录 1. 方法(Methods)1.1. 是什么1.2. 怎么用示例: 1.3. 特…...

Linux C 程序 【05】异步写文件
1.开发背景 Linux 系统提供了各种外设的控制方式,其中包括文件的读写,存储文件的介质可以是 SSD 固态硬盘或者是 EMMC 等。 其中常用的写文件方式是同步写操作,但是如果是写大文件会对 CPU 造成比较大的负荷,采用异步写的方式比较…...

Liveweb视频汇聚平台支持WebRTC协议赋能H.265视频流畅传输
随着科技的飞速发展和网络技术的不断革新,视频监控已经广泛应用于社会各个领域,成为现代安全管理的重要组成部分。在视频监控领域,视频编码技术的选择尤为重要,它不仅关系到视频的质量,还直接影响到视频的传输效率和兼…...

SQL组合查询
本文讲述如何利用 UNION 操作符将多条 SELECT 语句组合成一个结果集。 1. 组合查询 多数 SQL 查询只包含从一个或多个表中返回数据的单条 SELECT 语句。但是,SQL 也允许执行多个查询(多条 SELECT 语句),并将结果作为一个查询结果…...

方正畅享全媒体新闻采编系统 screen.do SQL注入漏洞复现
0x01 产品简介 方正畅享全媒体新闻生产系统是以内容资产为核心的智能化融合媒体业务平台,融合了报、网、端、微、自媒体分发平台等全渠道内容。该平台由协调指挥调度、数据资源聚合、融合生产、全渠道发布、智能传播分析、融合考核等多个平台组成,贯穿新闻生产策、采、编、发…...

【机器学习】【集成学习——决策树、随机森林】从零起步:掌握决策树、随机森林与GBDT的机器学习之旅
这里写目录标题 一、引言机器学习中集成学习的重要性 二、决策树 (Decision Tree)2.1 基本概念2.2 组成元素2.3 工作原理分裂准则 2.4 决策树的构建过程2.5 决策树的优缺点(1)决策树的优点(2)决策树的缺点(3࿰…...

【Python】 -- 趣味代码 - 小恐龙游戏
文章目录 文章目录 00 小恐龙游戏程序设计框架代码结构和功能游戏流程总结01 小恐龙游戏程序设计02 百度网盘地址00 小恐龙游戏程序设计框架 这段代码是一个基于 Pygame 的简易跑酷游戏的完整实现,玩家控制一个角色(龙)躲避障碍物(仙人掌和乌鸦)。以下是代码的详细介绍:…...

springboot 百货中心供应链管理系统小程序
一、前言 随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱,百货中心供应链管理系统被用户普遍使用,为方…...

RocketMQ延迟消息机制
两种延迟消息 RocketMQ中提供了两种延迟消息机制 指定固定的延迟级别 通过在Message中设定一个MessageDelayLevel参数,对应18个预设的延迟级别指定时间点的延迟级别 通过在Message中设定一个DeliverTimeMS指定一个Long类型表示的具体时间点。到了时间点后…...
)
React Native 导航系统实战(React Navigation)
导航系统实战(React Navigation) React Navigation 是 React Native 应用中最常用的导航库之一,它提供了多种导航模式,如堆栈导航(Stack Navigator)、标签导航(Tab Navigator)和抽屉…...

shell脚本--常见案例
1、自动备份文件或目录 2、批量重命名文件 3、查找并删除指定名称的文件: 4、批量删除文件 5、查找并替换文件内容 6、批量创建文件 7、创建文件夹并移动文件 8、在文件夹中查找文件...

MongoDB学习和应用(高效的非关系型数据库)
一丶 MongoDB简介 对于社交类软件的功能,我们需要对它的功能特点进行分析: 数据量会随着用户数增大而增大读多写少价值较低非好友看不到其动态信息地理位置的查询… 针对以上特点进行分析各大存储工具: mysql:关系型数据库&am…...

CentOS下的分布式内存计算Spark环境部署
一、Spark 核心架构与应用场景 1.1 分布式计算引擎的核心优势 Spark 是基于内存的分布式计算框架,相比 MapReduce 具有以下核心优势: 内存计算:数据可常驻内存,迭代计算性能提升 10-100 倍(文档段落:3-79…...

dedecms 织梦自定义表单留言增加ajax验证码功能
增加ajax功能模块,用户不点击提交按钮,只要输入框失去焦点,就会提前提示验证码是否正确。 一,模板上增加验证码 <input name"vdcode"id"vdcode" placeholder"请输入验证码" type"text&quo…...

学校招生小程序源码介绍
基于ThinkPHPFastAdminUniApp开发的学校招生小程序源码,专为学校招生场景量身打造,功能实用且操作便捷。 从技术架构来看,ThinkPHP提供稳定可靠的后台服务,FastAdmin加速开发流程,UniApp则保障小程序在多端有良好的兼…...

Java - Mysql数据类型对应
Mysql数据类型java数据类型备注整型INT/INTEGERint / java.lang.Integer–BIGINTlong/java.lang.Long–––浮点型FLOATfloat/java.lang.FloatDOUBLEdouble/java.lang.Double–DECIMAL/NUMERICjava.math.BigDecimal字符串型CHARjava.lang.String固定长度字符串VARCHARjava.lang…...