两种分类代码:独热编码与标签编码
目录
一、说明
二、理解分类数据
2.1 分类数据的类型:名义数据与序数数据
2.2 为什么需要编码
三、什么是独热编码?
3.1 工作原理:独热编码背后的机制
3.2 应用:独热编码的优势
四、什么是标签编码?
4.1 工作原理:标签编码的实际应用
4.2 示例:标签编码分步指南
4.3 应用:当标签编码合适时
五、比较:独热编码与标签编码
5.1 复杂性:维度灾难与内存效率
5.2 序数数据与名义数据:选择正确的编码
5.3 对算法的影响:当数字关系很重要时
5.4 内存和计算效率:权衡
六、何时使用独热编码与标签编码
七、One Hot 和标签编码的替代方案
八、结论
一、说明
当你深入研究机器学习时,你遇到的第一个障碍就是如何处理非数字数据。这就是编码的作用所在——将分类数据转换成机器学习算法可以理解的东西。但问题是:并非所有编码都是平等的。
您可能听说过独热编码和标签编码——它们是转换分类数据时最常用的两种技术。但知道何时使用其中一种而不是另一种吗?这才是真正的挑战。一种是扩展数据集,而另一种是压缩数据集——但会产生后果。
在这篇文章中,我们将探讨这两种方法。我将带您了解每种方法的区别、应用以及优缺点。到最后,您不仅会了解何时使用独热编码以及何时选择标签编码,而且还会知道每种方法如何影响模型的性能。
准备好了吗?让我们开始吧。
二、理解分类数据
在讨论编码方法之前,让我们先确保我们对分类数据有相同的理解。简而言之,分类数据是任何代表类别的数据——例如颜色、动物类型,甚至是人的教育水平。这些不是我们可以在机器学习模型中直接处理的数字,但它们包含我们不能忽视的宝贵信息。
2.1 分类数据的类型:名义数据与序数数据
事情变得有趣了:并非所有分类数据都一样。有名义数据和序数数据。
- 名义数据是纯粹的描述性数据。可以把它想象成不按任何顺序命名事物——比如“红色”、“蓝色”和“绿色”。一个并不比另一个“大”,它们只是不同而已。
- 另一方面,序数数据具有固有顺序。想象一下调查结果,例如“低”、“中”和“高”——尽管我们仍在处理类别,但其中存在自然的递进。
在独热编码和标签编码之间进行选择时,这种区别非常重要。为什么?因为错误的编码可能会扰乱算法对数据的解释。
2.2 为什么需要编码
现在,你可能会想:“为什么要费心对分类数据进行编码?” 事情是这样的:机器学习算法使用数字。它们不“理解”单词或标签——它们需要数字表示。如果没有编码,你的算法就无法处理或从分类特征中学习。
例如,如果你正在训练一个模型来预测一套房子是否会出售,而你的特征之一是“街区”,那么这就是分类数据。你需要对其进行编码,否则你的模型就会忽略这些信息——或者更糟的是,会误解它。
三、什么是独热编码?
您可能听说过机器学习讨论中经常提到的“独热编码”一词。但它到底是什么意思呢?嗯,这是一种将类别转换为机器学习模型可以理解的格式(二进制向量)的方法。可以将其视为在编码世界中为每个类别分配一个特殊的位置。
3.1 工作原理:独热编码背后的机制
具体过程如下:对于数据中的每个唯一类别,独热编码都会创建一个新的二进制列。因此,您不再拥有一个包含多个分类值的列,而是拥有多个列 — 每个列代表一个类别。
让我们举个例子。假设你有一个数据集,其中有一列“水果”,其中包含三个类别:“苹果”、“香蕉”和“橙子”。在独热编码中,这三个类别将转换为三个单独的列。如下所示:

在此设置中,每个水果类别都由一个二进制向量表示,其中一个类别标记为“1”,其他类别标记为“0”。这样,您的模型就不会意外地假设类别之间存在关系(因为毕竟苹果并不“大于”香蕉)。
示例:逐步应用独热编码
让我们通过一个更现实的例子进一步分解。假设您正在处理一个数据集,其中包含一个“国家/地区”列,其中包含“美国”、“加拿大”和“墨西哥”等值。以下是应用独热编码的方法:
- 步骤 1:确定独特类别(在本例中为三个:美国、加拿大和墨西哥)。
- 第 2 步:对于每个唯一类别,创建一个二进制列。
- 步骤 3:将 1 分配给每一行的相应列,将 0 分配给所有其他行。
编码后,“国家”列将转换为:

每个国家现在都有自己的列,并且不对它们之间的任何序数关系做出任何假设。
3.2 应用:独热编码的优势
你可能会想:我到底在哪里使用独热编码?好吧,事情是这样的——独热编码在分类任务中被广泛使用,尤其是当算法不能很好地处理分类数据时。算法如下:
- 逻辑回归:独热编码至关重要,因为该算法将分类变量视为独立变量。
- 神经网络:神经网络喜欢独热编码,因为它简化了输入,让网络专注于数值数据中的模式。
- K-Means 聚类:在这里,算法计算点之间的距离,如果没有独热编码,它可能会误解分类值。
独热编码功能强大,但有一个缺点——最终可能会产生太多列,尤其是当您有很多类别时。但我们稍后会谈到这一点。
四、什么是标签编码?
现在,让我们来谈谈标签编码——将分类数据转换为可用数据的另一种方法。与创建多个二进制列的独热编码不同,标签编码为每个类别分配一个唯一的整数。
4.1 工作原理:标签编码的实际应用
在标签编码中,您无需创建单独的列,而是将每个类别映射到一个数字。例如,让我们以之前的相同“水果”数据集为例:

这里,“苹果”变成 0,“香蕉”变成 1,“橙子”变成 2。很简单,对吧?这里的关键区别在于,所有类别都打包到一列中,从而避免了使用独热编码时出现的列爆炸问题。
4.2 示例:标签编码分步指南
让我们看一个不同的例子。假设您有一个数据集,其中有一列“汽车品牌”,其中包含“丰田”、“本田”和“福特”。当您应用标签编码时:
- 步骤 1:确定独特类别 — 丰田、本田、福特。
- 第 2 步:为每个类别分配一个唯一的整数。
经过标签编码后,该列变为:

这样,您将获得一列代表类别的数值。这种方法高效且易于实现,但也存在风险 — 标签编码引入了隐含顺序。模型可能会认为“本田”(1) 在某种程度上大于“丰田”(0) 或“福特”(2),但事实并非如此。
4.3 应用:当标签编码合适时
标签编码非常适合序数数据(具有明确的顺序或排名,例如“低”、“中”和“高”)。标签编码也更常用于自然处理分类数据而无需大量转换的算法中,例如:
- 决策树:随机森林和决策树等算法可以处理标签编码数据,而不会误解类别之间的数字关系。
- 排名问题:如果您处理的是序数数据,例如客户评级或调查回复,标签编码可能是一个简单的选择。
如果您拥有大量类别,并且想要避免独热编码带来的维数灾难,标签编码尤其有用。但是,您必须谨慎处理非序数数据,因为它可能会导致您的模型得出关于类别之间关系的错误结论。
到目前为止,您已经对独热编码和标签编码有了扎实的理解,但关键问题仍然存在:什么时候应该使用其中一种?请继续关注,因为我们接下来将解决这个问题。
五、比较:独热编码与标签编码
现在我们已经分解了独热编码和标签编码的机制,您可能会想:“好吧,但我什么时候应该使用其中一种呢?”让我们进行详细的比较,以便您可以为您的数据集和机器学习模型做出最佳决策。
5.1 复杂性:维度灾难与内存效率
问题是:独热编码和标签编码在复杂性方面存在很大差异。
- 独热编码:虽然它在保持类别独立性方面做得很好,但它会显著增加数据集的维度。想象一下,您正在使用“城市”这样的特征,并且您的数据中有 1,000 个不同的城市。独热编码将创建 1,000 个新的二进制列 - 哎呀!这种列的激增不仅会增加内存使用量,还会导致我们所说的维数灾难。您添加的维度(或列)越多,算法就越难找到模式,这可能会导致模型性能下降。
- 标签编码:另一方面,标签编码的内存效率更高。无论有多少类别,标签编码只需要一个列即可表示任何分类特征。但是,标签编码可能会因隐含的序数关系而引入偏差,这一点很重要。您的模型可能会错误地将“1”视为大于“0”,这可能会扭曲预测,尤其是在数字距离很重要的线性回归等算法中。
5.2 序数数据与名义数据:选择正确的编码
现在,让我们讨论一下分类数据的类型以及它的重要性。
- 标签编码是处理序数数据(即具有自然顺序的数据)的首选。想想教育水平:“高中”、“大学”和“研究生”。在这种情况下,标签编码是有意义的,因为存在固有的排名,并且数值不会混淆模型。
- 处理名义数据时,独热编码效果显著,因为类别之间没有固有顺序。例如,如果您对“颜色”(例如,红色、蓝色、绿色)进行编码,则应用标签编码会暗示某种层次结构 - 例如“蓝色”在某种程度上比“红色”更好或“更大”,但事实并非如此。这就是独热编码能够独立处理每个类别的能力真正发挥作用的地方。
5.3 对算法的影响:当数字关系很重要时
事情变得有点棘手。有些算法对标签编码引入的数字关系很敏感,而其他算法则不敏感。
- 标签编码可能会导致将数值解释为距离的算法出现问题。以线性回归为例:如果您对“城市”等特征使用标签编码,算法可能会将“纽约”(编码为 0)解释为比“芝加哥”(编码为 2)更接近“洛杉矶”(编码为 1),这是没有意义的。同样的问题也出现在K 均值聚类中,它严重依赖于点之间的距离。
- 另一方面,独热编码非常适合基于距离的算法,如 K 均值和神经网络。神经网络尤其受益于独热编码,因为它可以帮助网络独立处理每个类别,从而防止其对类别之间的关系做出任何假设。
5.4 内存和计算效率:权衡
在处理大型数据集时,独热编码和标签编码之间的选择通常归结为内存使用量和计算复杂性之间的权衡。
- 独热编码:正如我之前提到的,独热编码会导致大量的列,特别是当你的分类特征有许多唯一类别时。这种维度的增加不仅会消耗更多内存,还会减慢计算速度——算法必须更加努力地处理所有这些额外的列。
- 标签编码:如果内存效率是首要考虑因素,尤其是在大型数据集中,标签编码是更具吸引力的选择。它非常精简,每个特征只需要一列,因此可扩展性更强。但请记住,如果您的数据不是有序的,则可能会引入偏差。
六、何时使用独热编码与标签编码
那么,如何决定使用哪种方法呢?让我们来分析一下。
算法兼容性
- 对于能够处理高维数据并从独立类别中受益的算法,请使用独热编码。独热编码最理想的一些关键算法包括:
- 神经网络:独热编码简化了神经网络的输入,使其能够专注于数字模式。
- K-Means 聚类:由于 K-means 依赖于距离,因此最好采用独热编码,因为它可以避免数字关系。
- 逻辑回归:在逻辑回归中,分类特征必须独立,而独热编码可以保留这一点。
- 当您使用对分类特征具有鲁棒性的算法或处理序数数据时,请使用标签编码。 通常应用标签编码的一些算法包括:
- 决策树和随机森林:这些基于树的方法自然能够处理标签编码数据,而无需假设类别之间的关系。
- XGBoost:与决策树一样,XGBoost 可以处理标签编码而不会误解数值。
数据集特征
- 大型数据集:如果您处理的是高基数特征(具有许多唯一类别的特征,如邮政编码或产品 ID),标签编码可能更有效,因为它可以节省内存并降低计算复杂度。但请记住,您只应在不存在引入序数偏差的风险时使用它。
- 小型数据集:在较小的数据集中,过度拟合的风险会增加,尤其是使用独热编码时。独热编码创建的额外列可能会导致您的模型记住数据而不是进行泛化。标签编码可能更适合维度不是问题的小数据集。
实际场景
让我们将其应用到实际应用中。
- 案例研究 1:预测客户流失
假设您正在为一家电信公司构建客户流失预测模型。您有一个包含 50 个不同区域的“客户区域”特征。在这种情况下,独热编码可能会导致 50 个额外的列,从而减慢您的算法速度。由于区域之间没有序数关系,您可以坚持使用独热编码或使用 PCA 等技术降低维度。 - 案例研究 2:按客户满意度对产品进行排名
现在,假设您正在开发一个模型,该模型根据客户满意度评级(如“低”、“中”和“高”)对产品进行排名。在这里,标签编码是有意义的,因为评级有固有的顺序,而决策树等算法不会误解数值。
所以,归根结底,你需要了解你的数据集,并理解你选择的算法如何处理分类数据。有了这些知识,你就可以自信地决定独热编码或标签编码是否最适合你的模型性能。
七、One Hot 和标签编码的替代方案
随着你对机器学习世界的深入了解,你可能会发现传统的独热编码和标签编码不太适合。幸运的是,有几种替代方案可以帮助你更有效地处理分类数据。让我们探索其中几种替代方案,以便你扩展你的工具包。
频率编码
首先是频率编码。该技术涉及用数据集中相应的频率(或计数)替换每个类别。它很简单,对于大型分类变量特别有用。
- 工作原理:例如,如果您有一个像“城市”这样的特征,其中包含“纽约”、“洛杉矶”和“芝加哥”等类别,那么您可以将每个城市替换为其在数据集中出现的次数。因此,如果“纽约”出现 300 次,“洛杉矶”出现 200 次,“芝加哥”出现 100 次,则您的新编码值将分别为 300、200 和 100。
- 权衡:这种方法可以让你免于独热编码带来的维度灾难。然而,你可能会担心它的潜在缺点:由于频率编码将类别简化为单个数值,它可能会掩盖频率较低的类别的独特特征。这意味着,虽然你获得了效率,但如果某些类别对你的模型很重要,你可能会失去一些预测能力。
目标编码
接下来,我们来谈谈目标编码。这种方法的潜在优势可能会让你感到惊讶,尤其是在监督学习任务中。
- 它是什么:目标编码将每个类别替换为该类别的目标变量的平均值。例如,如果您预测房价,并且您的分类特征是“街区”,则目标编码将用该街区的平均房价替换每个街区。如果“市中心”的平均价格为 500,000 美元,“郊区”的平均价格为 300,000 美元,那么这些就是您的新值。
- 优点:在特定情况下,这种方法可以胜过独热编码和标签编码,尤其是当分类特征与目标变量有很强的关系时。通过捕捉这种关系,您的模型可能会做出更明智的预测。但是,这种技术需要谨慎处理以避免数据泄露,尤其是在处理小型数据集时。使用交叉验证可以帮助您降低这种风险,方法是确保仅基于训练数据计算目标均值。
二进制编码
最后,我们来探讨一下二进制编码。这种方法通常被视为独热编码和标签编码之间的折衷,结合了两者的特点,同时追求效率。
- 工作原理:二进制编码首先将类别转换为整数,类似于标签编码。然后,它将这些整数转换为二进制代码。例如,如果您有三个类别,“红色”、“蓝色”和“绿色”,标签编码将分别分配给它们 0、1 和 2。然后二进制编码会将这些整数转换为二进制,结果如下:
- 红色:00
- 蓝色:01
- 绿色:10
- 每个类别由比独热编码更少的列来表示,但比标签编码更清晰地表示。
- 为什么要使用它?:此方法可以节省内存,同时仍保持类别之间的区别。它对于高基数特征特别有用,其中独热编码会创建太多列,但您仍然希望避免标签编码可能引入的偏差。
八、结论
总结一下对编码技术的探索,很明显,在独热编码和标签编码之间做出选择并不总是那么简单。您已经了解到每种方法都有其优点和缺点,了解这些细微差别可以显著影响模型的性能。
您可能会想:“那么,我应该使用哪种编码?”答案通常取决于数据的性质、您计划实现的算法以及您的具体用例。
- 对于不存在序数关系的名义数据,独热编码非常有用,可确保您的模型独立处理类别。
- 对于可以处理数值可能暗示的隐式关系的序数数据和算法来说,标签编码是一个很好的选择。
在继续机器学习之旅时,不要忘记探索频率编码、目标编码和二进制编码等替代方案。每种方法都有其适用之处,尝试这些方法可以得到更好、更高效的模型。
归根结底,编码的世界是广阔的,精通这些技术将使您能够应对数据科学项目中的各种挑战。继续尝试,保持好奇心,让您的见解指导您找到最适合您的数据集的编码策略!
相关文章:
两种分类代码:独热编码与标签编码
目录 一、说明 二、理解分类数据 2.1 分类数据的类型:名义数据与序数数据 2.2 为什么需要编码 三、什么是独热编码? 3.1 工作原理:独热编码背后的机制 3.2 应用:独热编码的优势 四、什么是标签编码? 4.1 工作原理&…...

51单片机——共阴数码管实验
数码管中有8位数字,从右往左分别为LED1、LED2、...、LED8,如下图所示 如何实现点亮单个数字,用下图中的ABC来实现 P2.2管脚控制A,P2.3管脚控制B,P2.4管脚控制C //定义数码管位选管脚 sbit LSAP2^2; sbit LSBP2^3; s…...

【开源社区openEuler实践】rust_shyper
title: 探索 Rust_Shyper:系统编程的新前沿 date: ‘2024-12-30’ category: blog tags: Rust_ShyperRust 语言系统编程性能与安全 sig: Virt archives: ‘2024-12’ author:way_back summary: Rust_Shyper 作为基于 Rust 语言的创新项目,在系统编程领域…...

LiteFlow 流程引擎引入Spring boot项目集成pg数据库
文章目录 官网地址简要项目引入maven 所需jar包配置 PostgreSQL 数据库表使用LiteFlow配置 yml 文件通过 代码方式使用 liteflow数据库sql 数据在流程中周转 官网地址 https://liteflow.cc/ 简要 如果你要对复杂业务逻辑进行新写或者重构,用LiteFlow最合适不过。…...

阻抗(Impedance)、容抗(Capacitive Reactance)、感抗(Inductive Reactance)
阻抗(Impedance)、容抗(Capacitive Reactance)、感抗(Inductive Reactance) 都是交流电路中描述电流和电压之间关系的参数,但它们的含义、单位和作用不同。下面是它们的定义和区别: …...

旷视科技Java面试题及参考答案
讲一下进程间的通讯方式(如管道、消息队列、共享内存、Socket 等),各有什么特点? 管道(Pipe) 管道是最早出现的进程间通信方式之一,主要用于具有亲缘关系(父子进程)的进程之间通信。 特点: 半双工通信,数据只能单向流动。例如,在一个简单的父子进程通信场景中,父进…...
;不生效解决方案)
reactor的Hooks.enableAutomaticContextPropagation();不生效解决方案
1. pom中需要先增加如下的内容 <dependency><groupId>io.micrometer</groupId><artifactId>context-propagation</artifactId><version>1.1.2</version> </dependency> 2. 注意,要看idea是否将context-propagati…...

DS复习提纲模版
数组的插入删除 int SeqList::list_insert(int i, int item) { //插入if (i < 1 || i > size 1 || size > maxsize) {return 0; // Invalid index or list is full}for (int j size-1; j > i-1; j--) { // Shift elements to the rightlist[j1] list[j];}li…...

蓝桥杯备赛:C++基础,顺序表和vector(STL)
目录 一.C基础 1.第一个C程序: 2.头文件: 3.cin和cout初识: 4.命名空间: 二.顺序表和vector(STL) 1.顺序表的基本操作: 2.封装静态顺序表: 3.动态顺序表--vector:…...

【LLM】概念解析 - Tensorflow/Transformer/PyTorch
背景 本文将从算法原理、适用范围、强项、知名大模型的应用、python 调用几个方面,对深度学习框架 TensorFlow、PyTorch 和基于深度学习的模型 Transformer 进行比较。主要作用是基础概念扫盲。 一、 算法原理对比 Transformer Transformer 是一种基于深度学习的…...

对一段已知行情用python中画出K线图~
1. 已知行情: 2024/09/05 ~ 2025/1/3 date open high low close 0 2024-09-05 2785.2635 2796.0186 2777.4710 2788.3141 1 2024-09-06 2791.7645 2804.0932 2765.6394 2765.8066 2 2024-09-09 2754.7237 2756.5560 2726.9667 2736.…...

Rocky Linux下安装meld
背景介绍: meld是一款Linux系统下的用于 文件夹和文件的比对软件,非常常用; 故障现象: 输入安装命令后,sudo yum install meld,报错。 12-31 22:12:17 ~]$ sudo yum install meld Last metadata expirat…...

DVWA靶场Insecure CAPTCHA(不安全验证)漏洞所有级别通关教程及源码审计
目录 Insecure CAPTCHA(不安全验证)low源码审计 medium源码审计 high源码审计 impossible源码审计 Insecure CAPTCHA(不安全验证) Insecure CAPTCHA(不安全验证)漏洞指的是在实现 CAPTCHA(完全自动化公共图灵测试区分计算机和人类࿰…...

JavaScript HTML DOM 实例
JavaScript HTML DOM 实例 JavaScript 的 HTML DOM(文档对象模型)允许您通过脚本来控制 HTML 页面。DOM 是 HTML 文档的编程接口,它将 Web 页面与编程语言连接起来,使得开发者可以改变页面中的内容、结构和样式。在这篇文章中,我们将通过一系列实例来探讨如何使用 JavaSc…...

软件架构和软件体系结构的关系
软件架构(Software Architecture)和软件体系结构(Software System Architecture)这两个术语在日常使用中经常被交替使用,但它们在严格意义上有所区别: 1. **软件架构**: - 软件架构主要关注软件…...

C++并发:在线程间共享数据
1 线程间共享数据的问题 1.1 条件竞争 条件竞争:在并发编程中:操作由两个或多个线程负责,它们争先让线程执行各自的操作,而结果取决于它们执行的相对次序,这样的情况就是条件竞争。 诱发恶性条件竞争的典型场景是&am…...

GaussDB逻辑解码技术原理深度解析
GaussDB逻辑解码技术原理深度解析 一、背景介绍 在数字化转型的大潮中,异构数据库之间的数据同步需求日益增长。异构数据库同步指的是将不同类型、不同结构的数据库之间的数据进行同步处理,以确保数据在不同数据库之间的一致性。华为云提供的DRS服务&a…...

JAVA构造方法练习
要求在Student类中,(task1)添加一个有name和ID两个参数的构造方法,对成员变量name和ID进行初始化,(task2)实例化一个Student对象,学生姓名:Yaoming,ID&#x…...

Pytorch 三小时极限入门教程
一、引言 在当今的人工智能领域,深度学习占据了举足轻重的地位。而 Pytorch 作为一款广受欢迎的深度学习框架,以其简洁、灵活的特性,吸引了大量开发者投身其中。无论是科研人员探索前沿的神经网络架构,还是工程师将深度学习技术落…...

Rockect基于Dledger的Broker主从同步原理
1.前言 此文章是在儒猿课程中的学习笔记,感兴趣的想看原来的课程可以去咨询儒猿课堂 这篇文章紧挨着上一篇博客来进行编写,有些不清楚的可以看下上一篇博客: RocketMQ原理简述(二)-CSDN博客 2.Broker的高可用 如果…...

【kafka】Golang实现分布式Masscan任务调度系统
要求: 输出两个程序,一个命令行程序(命令行参数用flag)和一个服务端程序。 命令行程序支持通过命令行参数配置下发IP或IP段、端口、扫描带宽,然后将消息推送到kafka里面。 服务端程序: 从kafka消费者接收…...

工业安全零事故的智能守护者:一体化AI智能安防平台
前言: 通过AI视觉技术,为船厂提供全面的安全监控解决方案,涵盖交通违规检测、起重机轨道安全、非法入侵检测、盗窃防范、安全规范执行监控等多个方面,能够实现对应负责人反馈机制,并最终实现数据的统计报表。提升船厂…...

循环冗余码校验CRC码 算法步骤+详细实例计算
通信过程:(白话解释) 我们将原始待发送的消息称为 M M M,依据发送接收消息双方约定的生成多项式 G ( x ) G(x) G(x)(意思就是 G ( x ) G(x) G(x) 是已知的)࿰…...

LeetCode - 394. 字符串解码
题目 394. 字符串解码 - 力扣(LeetCode) 思路 使用两个栈:一个存储重复次数,一个存储字符串 遍历输入字符串: 数字处理:遇到数字时,累积计算重复次数左括号处理:保存当前状态&a…...

macOS多出来了:Google云端硬盘、YouTube、表格、幻灯片、Gmail、Google文档等应用
文章目录 问题现象问题原因解决办法 问题现象 macOS启动台(Launchpad)多出来了:Google云端硬盘、YouTube、表格、幻灯片、Gmail、Google文档等应用。 问题原因 很明显,都是Google家的办公全家桶。这些应用并不是通过独立安装的…...

九天毕昇深度学习平台 | 如何安装库?
pip install 库名 -i https://pypi.tuna.tsinghua.edu.cn/simple --user 举个例子: 报错 ModuleNotFoundError: No module named torch 那么我需要安装 torch pip install torch -i https://pypi.tuna.tsinghua.edu.cn/simple --user pip install 库名&#x…...

HDFS分布式存储 zookeeper
hadoop介绍 狭义上hadoop是指apache的一款开源软件 用java语言实现开源框架,允许使用简单的变成模型跨计算机对大型集群进行分布式处理(1.海量的数据存储 2.海量数据的计算)Hadoop核心组件 hdfs(分布式文件存储系统)&a…...

【深度学习新浪潮】什么是credit assignment problem?
Credit Assignment Problem(信用分配问题) 是机器学习,尤其是强化学习(RL)中的核心挑战之一,指的是如何将最终的奖励或惩罚准确地分配给导致该结果的各个中间动作或决策。在序列决策任务中,智能体执行一系列动作后获得一个最终奖励,但每个动作对最终结果的贡献程度往往…...

node.js的初步学习
那什么是node.js呢? 和JavaScript又是什么关系呢? node.js 提供了 JavaScript的运行环境。当JavaScript作为后端开发语言来说, 需要在node.js的环境上进行当JavaScript作为前端开发语言来说,需要在浏览器的环境上进行 Node.js 可…...
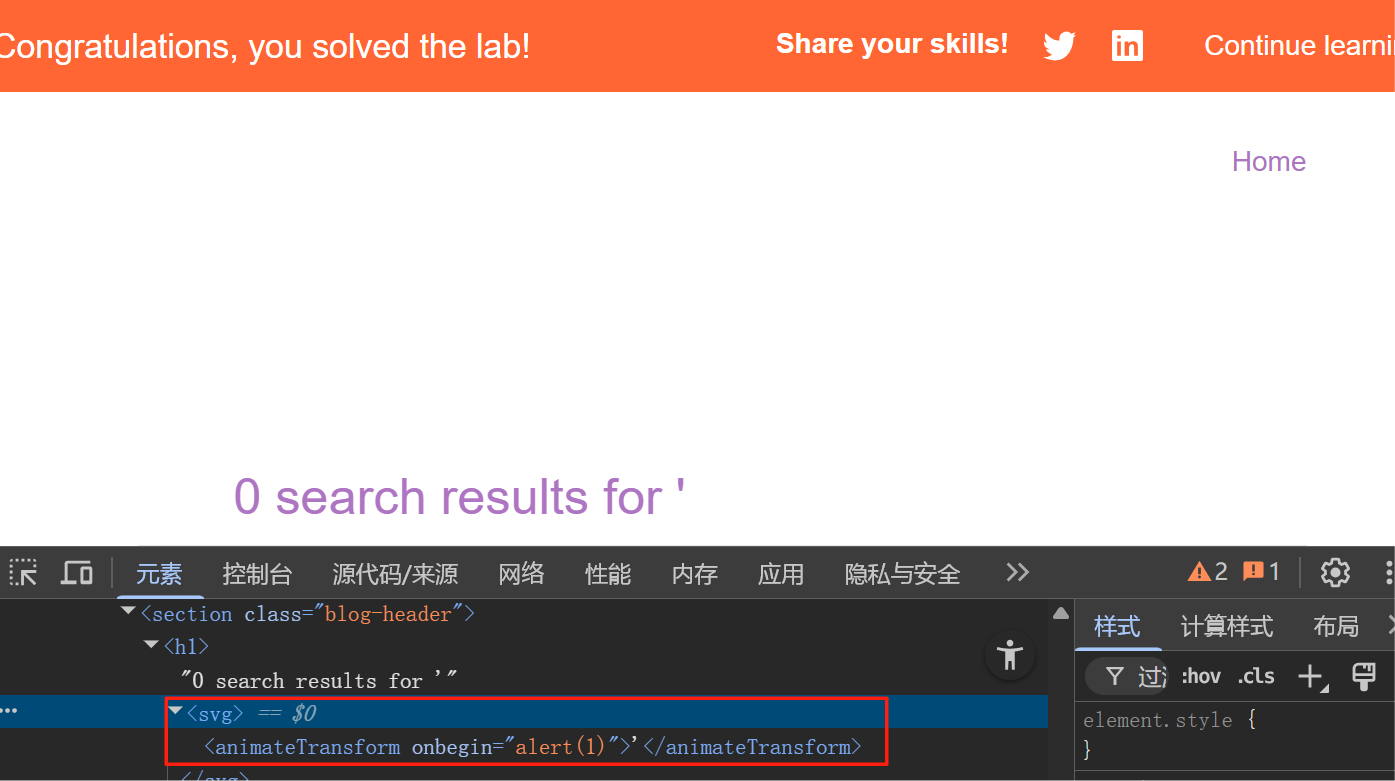
渗透实战PortSwigger Labs指南:自定义标签XSS和SVG XSS利用
阻止除自定义标签之外的所有标签 先输入一些标签测试,说是全部标签都被禁了 除了自定义的 自定义<my-tag onmouseoveralert(xss)> <my-tag idx onfocusalert(document.cookie) tabindex1> onfocus 当元素获得焦点时(如通过点击或键盘导航&…...