数据库事务:确保数据一致性的关键机制
1. 什么是数据库事务
- 定义:事务(Transaction)是数据库管理系统中的一个逻辑工作单元,用于确保一组相关操作要么全部成功执行,要么全部不执行,从而维护数据的一致性和完整性。
- 重要性:在多用户环境下,当多个事务并发执行时,为了保证数据的完整性和一致性,事务的概念变得至关重要。例如,在银行转账系统中,从一个账户扣款并给另一个账户加款这两个操作必须同时成功或者同时失败,否则就会导致资金账目混乱。
2. 事务四个特性(ACID特性)
2.1. 原子性(Atomicity)
2.1.1. 定义
原子性保证事务是一个不可分割的工作单元,其中的操作要么全部完成,要么全部不执行。如果事务中的任何部分失败,则整个事务将被撤销。
2.1.2. 实现原理
- 日志记录(Logging):数据库系统在执行事务时会将所有操作记录到一个日志文件中。这些日志条目包括事务的开始、每个操作及其参数、以及事务的结束。
- 两阶段提交(Two-Phase Commit, 2PC):用于分布式系统中的事务管理,确保所有参与节点要么全部成功提交,要么全部回滚。
- 回滚机制(Rollback Mechanism):如果事务中的某个操作失败,系统会根据日志中的信息撤销之前的所有操作,恢复到事务开始前的状态。
2.1.3. 示例
假设有一个事务包含三个操作:INSERT INTO users (name, age) VALUES (‘Alice’, 25)、UPDATE accounts SET balance = balance + 100 WHERE user_id = 1 和 DELETE FROM logs WHERE user_id = 1。如果在执行第三个操作时发生了错误,那么数据库会根据日志将前两个操作撤销,使数据库状态回到事务开始之前,就像这个事务从未执行过一样。
2.2. 一致性(Consistency)
2.2.1. 定义
一致性确保事务必须使数据库从一个一致状态转换到另一个一致状态。事务执行前后,数据库的完整性约束没有被破坏。
2.2.2. 实现原理
- 约束检查(Constraint Checking):数据库系统在事务执行过程中会检查并验证所有相关的完整性约束(如主键、外键、唯一性约束等),以确保数据始终处于一致状态。
- 触发器(Triggers):可以定义触发器来自动执行某些操作,以维护数据的一致性。例如,在插入或更新数据时自动更新相关表的数据。
- 事务验证(Transaction Validation):在事务提交前,系统会验证事务是否满足所有的业务规则和完整性约束。
2.2.3. 示例
在一个学生成绩管理系统中,规定学生的成绩范围为0 - 100分。如果一个事务试图将某个学生的成绩更新为120分,那么该事务将违反域完整性约束,DBMS会拒绝执行此操作,以确保数据的一致性。
2.3. 隔离性(Isolation)
2.3.1. 定义
多个事务并发执行时,一个事务的执行不应影响其他事务的执行。每个事务都应在独立的环境中运行,就像它是唯一正在运行的事务一样。
2.3.2. 实现原理
- 锁机制(Locking):通过加锁来防止多个事务同时访问和修改同一数据项。常见的锁类型包括行级锁、表级锁、读锁和写锁。
- 多版本并发控制(Multi-Version Concurrency Control, MVCC):为每个事务提供数据的不同版本视图,允许多个事务并发读取而不互相干扰。MVCC通过保存旧版本的数据快照来实现这一点。
- 隔离级别(Isolation Levels):数据库系统提供了不同的隔离级别,允许用户根据需求选择合适的隔离程度。常见的隔离级别包括:
- 读未提交(Read Uncommitted):最低隔离级别,允许脏读。
- 读已提交(Read Committed):不允许脏读,但允许不可重复读。
- 可重复读(Repeatable Read):不允许脏读和不可重复读,但允许幻读。
- 串行化(Serializable):最高隔离级别,完全避免了脏读、不可重复读和幻读。
2.4. 持久性(Durability)
2.4.1. 定义
持久性确保一旦事务提交,它对数据库所做的更改将是永久性的,即使系统发生故障也不会丢失。
2.4.2. 实现原理
- 日志持久化(Log Persistence):所有事务的操作都会先记录到日志文件中,并且在事务提交后立即将日志刷入磁盘。即使系统崩溃,也可以通过重做日志恢复数据。
- 检查点(Checkpointing):定期创建检查点,将内存中的数据同步到磁盘,减少恢复时间。
- 双重缓冲(Double Buffering):使用双重缓冲技术确保数据在写入磁盘时不会丢失。
2.4.3. 示例
在一个在线支付系统中,当用户完成一笔支付后,涉及到更新用户的余额信息等操作。假设在事务提交后,服务器突然断电,由于采用了持久性机制,数据库可以根据日志恢复支付操作,确保用户的余额信息不会丢失,支付业务能够正常完成。
3. 数据库事务操作
在数据库管理系统中,事务可以分为显式事务(Explicit Transactions)和隐式事务(Implicit Transactions)。
3.1. 显式事务(Explicit Transactions)
1. 定义:显式事务是由用户显式地通过SQL语句开始和结束的事务。用户明确地使用 BEGIN TRANSACTION、COMMIT 和 ROLLBACK 等语句来控制事务的边界。
2. 特点:
- 用户控制:开发者明确地定义事务的开始和结束。
- 灵活性:可以包含任意数量的操作,并且可以根据需要进行回滚。
- 性能优化:可以更好地控制事务的粒度,减少锁的持有时间,提高并发性能。
3. SQL语句:
- 开始事务:BEGIN TRANSACTION 或 START TRANSACTION
- 提交事务:COMMIT
- 回滚事务:ROLLBACK
4. 示例:
-- 开始事务
START TRANSACTION;-- 执行SQL操作
INSERT INTO account (id, balance) VALUES (1, 1000);
UPDATE account SET balance = balance - 100 WHERE id = 1;
INSERT INTO transaction_log (account_id, amount) VALUES (1, -100);-- 提交事务
COMMIT;-- 或者回滚事务
-- ROLLBACK;
3.2. 隐式事务(Implicit Transactions)
1. 定义:隐式事务是由数据库自动管理的事务。每个单独的SQL语句被视为一个独立的事务,自动提交或回滚。
2. 特点:
- 自动管理:数据库自动处理事务的开始和结束。
- 简单性:对于简单的操作,隐式事务简化了事务管理。
- 限制性:每个SQL语句都是一个独立的事务,无法包含多个操作。
3. SQL语句:
- 自动提交:每个SQL语句执行后自动提交。
- 自动回滚:某些错误可能导致SQL语句自动回滚。
4. 示例:
-- 插入操作自动提交
INSERT INTO account (id, balance) VALUES (1, 1000);-- 更新操作自动提交
UPDATE account SET balance = balance - 100 WHERE id = 1;-- 插入操作自动提交
INSERT INTO transaction_log (account_id, amount) VALUES (1, -100);
3.3. 显式事务和隐式事务的比较
| 特性 | 显式事务 (Explicit Transactions) | 隐式事务 (Implicit Transactions) |
|---|---|---|
| 控制方式 | 用户显式控制事务的开始和结束 | 数据库自动管理事务的开始和结束 |
| 事务边界 | 开发者定义事务的开始和结束点 | 每个SQL语句被视为一个独立的事务 |
| 灵活性 | 可以包含多个操作,根据需要进行回滚 | 每个操作都是独立的,无法包含多个操作 |
| 性能 | 可以更好地控制事务的粒度,减少锁的持有时间,提高并发性能 | 每个操作自动提交,可能增加锁的持有时间,影响并发性能 |
| 适用场景 | 复杂的事务操作,需要确保多个操作的原子性 | 简单的操作,每个操作独立,不需要复杂的事务控制 |
3.4. Savepoint
1. 定义:Savepoint 是事务中的一个标记点,允许用户在事务中设置一个保存点,并在需要时回滚到该保存点,而不影响事务中其他部分的操作。这为事务提供了更灵活的回滚机制。
2. 特点:
- 细粒度回滚:可以回滚到事务中的特定点,而不是整个事务。
- 提高灵活性:允许在事务中进行部分回滚,而不影响其他操作。
- 性能优化:减少不必要的回滚操作,提高事务处理效率。
3. SQL语句:
- 设置保存点:SAVEPOINT savepoint_name
- 回滚到保存点:ROLLBACK TO SAVEPOINT savepoint_name
- 释放保存点:RELEASE SAVEPOINT savepoint_name
4. 示例:
-- 开始事务
START TRANSACTION;-- 执行一些操作
INSERT INTO account (id, balance) VALUES (1, 1000);-- 设置保存点
SAVEPOINT savepoint1;-- 执行更多操作
UPDATE account SET balance = balance - 100 WHERE id = 1;-- 设置另一个保存点
SAVEPOINT savepoint2;-- 执行更多操作
INSERT INTO transaction_log (account_id, amount) VALUES (1, -100);-- 回滚到 savepoint2
ROLLBACK TO SAVEPOINT savepoint2;-- 释放 savepoint1
RELEASE SAVEPOINT savepoint1;-- 提交事务
COMMIT;
详细步骤:
1)开始事务:START TRANSACTION;
2)插入操作:INSERT INTO account (id, balance) VALUES (1, 1000);
3)设置保存点 savepoint1:SAVEPOINT savepoint1;
4)更新操作:UPDATE account SET balance = balance - 100 WHERE id = 1;
5)设置保存点 savepoint2:SAVEPOINT savepoint2;
6)插入操作:INSERT INTO transaction_log (account_id, amount) VALUES (1, -100);
7)回滚到 savepoint2:ROLLBACK TO SAVEPOINT savepoint2;(注意:这将撤销插入到 transaction_log 的操作,但保留 savepoint1 之前的更新操作。)
8)释放 savepoint1:RELEASE SAVEPOINT savepoint1;
9)提交事务:COMMIT;
代码示例(Java + JDBC):
import java.sql.*;public class SavepointExample {public static void main(String[] args) {String url = "jdbc:mysql://localhost:3306/test";String user = "root";String password = "root";try (Connection conn = DriverManager.getConnection(url, user, password)) {// 关闭自动提交模式conn.setAutoCommit(false);try {// 开始事务conn.setAutoCommit(false);// 执行一些操作Statement stmt = conn.createStatement();stmt.executeUpdate("INSERT INTO account (id, balance) VALUES (1, 1000)");// 设置保存点Savepoint savepoint1 = conn.setSavepoint("savepoint1");// 执行更多操作stmt.executeUpdate("UPDATE account SET balance = balance - 100 WHERE id = 1");// 设置另一个保存点Savepoint savepoint2 = conn.setSavepoint("savepoint2");// 执行更多操作stmt.executeUpdate("INSERT INTO transaction_log (account_id, amount) VALUES (1, -100)");// 回滚到 savepoint2conn.rollback(savepoint2);// 释放 savepoint1conn.releaseSavepoint(savepoint1);// 提交事务conn.commit();System.out.println("事务提交成功");} catch (SQLException e) {// 回滚事务conn.rollback();System.out.println("事务回滚");e.printStackTrace();} finally {// 恢复自动提交模式conn.setAutoCommit(true);}} catch (SQLException e) {e.printStackTrace();}}
}
3.5. 只读事务
1. 定义:只读事务是指在事务期间不允许对数据库进行任何修改操作。只读事务可以提高并发性能,因为数据库管理系统可以对只读操作进行优化,减少锁的使用。
2. 特点:
- 提高并发性能:只读事务不会修改数据,减少了锁的争用。
- 数据一致性:确保事务期间数据不会被其他事务修改。
- 简化事务管理:只读事务不需要回滚操作,简化了事务管理。
3. SQL语句:
- 设置只读事务:在某些数据库中,可以通过特定的语法设置只读事务。例如,在某些数据库中可以使用 SET TRANSACTION READ ONLY。
4. 示例:
-- 开始只读事务
SET TRANSACTION READ ONLY;
START TRANSACTION;-- 执行只读操作
SELECT * FROM account WHERE id = 1;-- 提交事务
COMMIT;
详细步骤:
1)设置只读事务:SET TRANSACTION READ ONLY;
2)开始事务:START TRANSACTION;
3)执行只读操作:SELECT * FROM account WHERE id = 1;
4)提交事务:COMMIT;
代码示例(Java + JDBC):
import java.sql.*;public class ReadOnlyTransactionExample {public static void main(String[] args) {String url = "jdbc:mysql://localhost:3306/test";String user = "root";String password = "root";try (Connection conn = DriverManager.getConnection(url, user, password)) {// 关闭自动提交模式conn.setAutoCommit(false);try {// 设置只读事务conn.setReadOnly(true);// 开始事务conn.setAutoCommit(false);// 执行只读操作Statement stmt = conn.createStatement();ResultSet rs = stmt.executeQuery("SELECT * FROM account WHERE id = 1");while (rs.next()) {int id = rs.getInt("id");int balance = rs.getInt("balance");System.out.println("id = " + id + ", balance = " + balance);}// 提交事务conn.commit();System.out.println("事务提交成功");} catch (SQLException e) {// 回滚事务conn.rollback();System.out.println("事务回滚");e.printStackTrace();} finally {// 恢复自动提交模式conn.setAutoCommit(true);// 恢复可写模式conn.setReadOnly(false);}} catch (SQLException e) {e.printStackTrace();}}
}
4. 数据库隔离级别
数据库隔离级别定义了事务之间如何隔离,以确保数据的一致性和完整性。SQL标准定义了四个隔离级别,每个级别都提供了不同程度的隔离性,同时也带来了不同的并发性能和数据一致性问题。数据库隔离级别从低到高依次为:读未提交(Read Uncommitted)、读已提交(Read Committed)、可重复读(Repeatable Read)、串行化(Serializable)。以下是详细的隔离级别及其产生的问题。
4.1. 读未提交(Read Uncommitted)
4.1.1. 定义
事务可以读取其他事务未提交的数据。
4.1.2. 特点
- 最低隔离级别:允许事务读取未提交的数据。
- 并发性能最高:由于不需要等待其他事务提交,可以立即读取数据。
4.1.3. 产生的问题
脏读(Dirty Read):事务读取了其他事务未提交的数据,如果其他事务回滚,读取的数据将不一致。
脏读示例:
1. 数据库初始状态
假设有一个表 account,包含以下数据:
id balance 1 1000.00 2. 流程图
事务A 事务B BEGIN;
UPDATE account SET balance = 500 WHERE id = 1;BEGIN;
SELECT balance FROM account WHERE id = 1;SELECT balance FROM account WHERE id = 1; ROLLBACK; 3. 详细步骤
1)事务A开始并更新数据
事务A 开始执行,并更新 account 表中 id = 1 的 balance 为 500。
-- 事务A BEGIN; UPDATE account SET balance = 500 WHERE id = 1;2)事务B开始并读取数据
事务B 开始执行,并读取 account 表中 id = 1 的 balance。
-- 事务B BEGIN; SELECT balance FROM account WHERE id = 1;事务B 读取到的 balance 是 500,这是事务A未提交的数据。
3)事务A回滚
事务A 回滚,撤销之前的操作,将 balance 恢复为 1000。
-- 事务A ROLLBACK;4)事务B再次读取数据
事务B 再次读取 account 表中 id = 1 的 balance。
-- 事务B SELECT balance FROM account WHERE id = 1;事务B 读取到的 balance 是 1000,与之前读取到的 500 不一致。
4. 脏读问题分析
- 初始状态:balance 为 1000。
- 事务A更新数据:将 balance 更新为 500,但未提交。
- 事务B读取数据:读取到事务A未提交的 balance 值 500。
- 事务A回滚:balance 恢复为 1000。
- 事务B再次读取数据:读取到 balance 为 1000,与之前读取到的 500 不一致。
5. 代码示例
以下是使用Java和JDBC的代码示例,展示脏读的问题:
import java.sql.*;public class DirtyReadExample {public static void main(String[] args) {String url = "jdbc:mysql://localhost:3306/test";String user = "root";String password = "root";try (Connection connA = DriverManager.getConnection(url, user, password);Connection connB = DriverManager.getConnection(url, user, password)) {// 设置事务隔离级别为读未提交connA.setTransactionIsolation(Connection.TRANSACTION_READ_UNCOMMITTED);connB.setTransactionIsolation(Connection.TRANSACTION_READ_UNCOMMITTED);// 事务A开始并更新数据connA.setAutoCommit(false);Statement stmtA = connA.createStatement();stmtA.executeUpdate("UPDATE account SET balance = 500 WHERE id = 1");System.out.println("事务A更新数据,balance = 500");// 事务B开始并读取数据connB.setAutoCommit(false);Statement stmtB = connB.createStatement();ResultSet rsB = stmtB.executeQuery("SELECT balance FROM account WHERE id = 1");if (rsB.next()) {int balance = rsB.getInt("balance");System.out.println("事务B读取数据,balance = " + balance);}// 事务A回滚connA.rollback();System.out.println("事务A回滚");// 事务B再次读取数据rsB = stmtB.executeQuery("SELECT balance FROM account WHERE id = 1");if (rsB.next()) {int balance = rsB.getInt("balance");System.out.println("事务B再次读取数据,balance = " + balance);}// 提交事务BconnB.commit();} catch (SQLException e) {e.printStackTrace();}} }输出结果:
事务A更新数据,balance = 500 事务B读取数据,balance = 500 事务A回滚 事务B再次读取数据,balance = 10006. 总结
通过上述流程和代码示例,可以看出脏读的问题在于事务B读取了事务A未提交的数据,而事务A最终回滚,导致事务B读取的数据不一致。选择合适的隔离级别(如读已提交或更高)可以避免脏读问题。
4.2. 读已提交(Read Committed)
4.2.1. 定义
事务只能读取其他事务已经提交的数据。
4.2.2. 特点
- 避免脏读:事务只能读取已提交的数据。
- 并发性能较高:允许事务在其他事务提交后读取数据。
4.2.3. 产生的问题
不可重复读(Non-repeatable Read):事务在同一个查询中多次读取同一数据时,数据可能被其他事务修改,导致结果不一致。
不可重复读示例:
1. 数据库初始状态
假设有一个表 account,包含以下数据:
id balance 1 1000.00 2. 流程图
事务A 事务B BEGIN;
SELECT balance FROM account WHERE id = 1;BEGIN;
UPDATE account SET balance = 500 WHERE id = 1;
COMMIT;SELECT balance FROM account WHERE id = 1; 3. 详细步骤
1)事务A开始并读取数据
事务A 开始执行,并读取 account 表中 id = 1 的 balance。
-- 事务A BEGIN; SELECT balance FROM account WHERE id = 1;事务A 读取到的 balance 是 1000。
2)事务B开始并更新数据
事务B 开始执行,并更新 account 表中 id = 1 的 balance 为 500。
-- 事务B BEGIN; UPDATE account SET balance = 500 WHERE id = 1; COMMIT;3)事务A再次读取数据
事务A 再次读取 account 表中 id = 1 的 balance。
-- 事务A SELECT balance FROM account WHERE id = 1;事务A 读取到的 balance 是 500,与之前读取到的 1000 不一致。
4. 不可重复读问题分析
- 初始状态:balance 为 1000。
- 事务A读取数据:读取到 balance 为 1000。
- 事务B更新数据:将 balance 更新为 500 并提交。
- 事务A再次读取数据:读取到 balance 为 500,与之前读取到的 1000 不一致。
5. 代码示例
import java.sql.*;public class NonRepeatableReadExample {public static void main(String[] args) {String url = "jdbc:mysql://localhost:3306/test";String user = "root";String password = "root";try (Connection connA = DriverManager.getConnection(url, user, password);Connection connB = DriverManager.getConnection(url, user, password)) {// 设置事务隔离级别为读已提交connA.setTransactionIsolation(Connection.TRANSACTION_READ_COMMITTED);connB.setTransactionIsolation(Connection.TRANSACTION_READ_COMMITTED);// 事务A开始并读取数据connA.setAutoCommit(false);Statement stmtA = connA.createStatement();ResultSet rsA = stmtA.executeQuery("SELECT balance FROM account WHERE id = 1");if (rsA.next()) {int balance = rsA.getInt("balance");System.out.println("事务A第一次读取数据,balance = " + balance);}// 事务B开始并更新数据connB.setAutoCommit(false);Statement stmtB = connB.createStatement();stmtB.executeUpdate("UPDATE account SET balance = 500 WHERE id = 1");connB.commit();System.out.println("事务B更新数据,balance = 500");// 事务A再次读取数据rsA = stmtA.executeQuery("SELECT balance FROM account WHERE id = 1");if (rsA.next()) {int balance = rsA.getInt("balance");System.out.println("事务A第二次读取数据,balance = " + balance);}// 提交事务AconnA.commit();} catch (SQLException e) {e.printStackTrace();}} }输出结果:
事务A第一次读取数据,balance = 1000 事务B更新数据,balance = 500 事务A第二次读取数据,balance = 5006. 总结
通过上述流程和代码示例,可以看出不可重复读的问题在于事务A在同一个查询中多次读取同一数据时,数据被事务B修改,导致结果不一致。选择合适的隔离级别(如可重复读或更高)可以避免不可重复读问题。
4.3. 可重复读(Repeatable Read)
4.3.1. 定义
事务在同一个查询中多次读取同一数据时,数据保持一致,即使其他事务修改了这些数据。
4.3.2. 特点
- 避免脏读和不可重复读:事务在读取数据后,其他事务对该数据的修改不会影响当前事务的后续读取。
- 并发性能适中:通过锁或多版本并发控制(MVCC)实现。
4.3.3. 产生的问题
幻读(Phantom Read):事务在同一个查询中多次读取同一范围的数据时,数据集可能被其他事务插入或删除,导致结果不一致。
幻读示例:
1. 数据库初始状态
假设有一个表 account,包含以下数据:
id balance 1 1000.00 2 2000.00 2. 流程图
事务A 事务B BEGIN;
SELECT * FROM account WHERE balance > 1500;BEGIN;
INSERT INTO account (id, balance) VALUES (3, 3000);
COMMIT;SELECT * FROM account WHERE balance > 1500; 3. 详细步骤
1)事务A开始并读取数据
事务A 开始执行,并读取 account 表中 balance > 1500 的所有记录。
-- 事务A BEGIN; SELECT * FROM account WHERE balance > 1500;事务A 读取到的记录是:
id balance 2 2000.00 2)事务B开始并插入数据
事务B 开始执行,并插入一条新的记录 id = 3,balance = 3000。
-- 事务B BEGIN; INSERT INTO account (id, balance) VALUES (3, 3000); COMMIT;3)事务A再次读取数据
事务A 再次读取 account 表中 balance > 1500 的所有记录。
-- 事务A SELECT * FROM account WHERE balance > 1500;事务A 读取到的记录是:
id balance 2 2000.00 3 3000.00 4. 幻读问题分析
- 初始状态:表中有两条记录,id = 1 和 id = 2,balance 分别为 1000 和 2000。
- 事务A读取数据:读取到 balance > 1500 的记录,即 id = 2,balance = 2000。
- 事务B插入数据:插入一条新的记录 id = 3,balance = 3000。
- 事务A再次读取数据:读取到 balance > 1500 的记录,包括 id = 2 和 id = 3,出现了新的记录 id = 3,即幻读。
5. 代码示例
import java.sql.*;public class PhantomReadExample {public static void main(String[] args) {String url = "jdbc:mysql://localhost:3306/test";String user = "root";String password = "root";try (Connection connA = DriverManager.getConnection(url, user, password);Connection connB = DriverManager.getConnection(url, user, password)) {// 设置事务隔离级别为可重复读connA.setTransactionIsolation(Connection.TRANSACTION_REPEATABLE_READ);connB.setTransactionIsolation(Connection.TRANSACTION_REPEATABLE_READ);// 事务A开始并读取数据connA.setAutoCommit(false);Statement stmtA = connA.createStatement();ResultSet rsA = stmtA.executeQuery("SELECT * FROM account WHERE balance > 1500");System.out.println("事务A第一次读取数据:");while (rsA.next()) {int id = rsA.getInt("id");int balance = rsA.getInt("balance");System.out.println("id = " + id + ", balance = " + balance);}// 事务B开始并插入数据connB.setAutoCommit(false);Statement stmtB = connB.createStatement();stmtB.executeUpdate("INSERT INTO account (id, balance) VALUES (3, 3000)");connB.commit();System.out.println("事务B插入数据,id = 3, balance = 3000");// 事务A再次读取数据rsA = stmtA.executeQuery("SELECT * FROM account WHERE balance > 1500");System.out.println("事务A第二次读取数据:");while (rsA.next()) {int id = rsA.getInt("id");int balance = rsA.getInt("balance");System.out.println("id = " + id + ", balance = " + balance);}// 提交事务AconnA.commit();} catch (SQLException e) {e.printStackTrace();}} }输出结果:
事务A第一次读取数据: id = 2, balance = 2000 事务B插入数据,id = 3, balance = 3000 事务A第二次读取数据: id = 2, balance = 2000 id = 3, balance = 30006. 总结
通过上述流程和代码示例,可以看出幻读的问题在于事务A在同一个查询中多次读取同一范围的数据时,数据集被事务B插入了新的记录,导致结果不一致。选择合适的隔离级别(如串行化)可以避免幻读问题。
4.4. 串行化(Serializable)
4.4.1. 定义
事务完全串行化执行,即一个事务在另一个事务提交之前必须等待。
4.4.2. 特点
- 避免脏读、不可重复读和幻读:事务完全隔离,效果等同于顺序执行。
- 并发性能最低:事务之间完全串行化,导致并发性能较差。
4.4.3. 产生的问题
性能下降:由于事务之间完全隔离,系统并发性能较低。
4.4.4. 示例
-- 事务A
BEGIN;
SELECT * FROM table_name WHERE column1 > 10; -- 第一次读取-- 事务B
BEGIN;
INSERT INTO table_name (column1) VALUES (15);
-- 事务B必须等待事务A提交或回滚-- 事务A
SELECT * FROM table_name WHERE column1 > 10; -- 第二次读取,结果一致
COMMIT;
4.5. 不同隔离级别的比较
为了更好地理解不同隔离级别如何解决这些问题,以下是各个隔离级别的比较:
| 隔离级别 | 脏读(Dirty Read) | 不可重复读(Non-repeatable Read) | 幻读(Phantom Read) |
|---|---|---|---|
| 读未提交 | 允许 | 允许 | 允许 |
| 读已提交 | 禁止 | 允许 | 允许 |
| 可重复读 | 禁止 | 禁止 | 允许 |
| 串行化 | 禁止 | 禁止 | 禁止 |
选择合适的隔离级别可以根据具体的应用需求来平衡并发性能和数据一致性。
5. 锁类型
5.1. 排他锁(X锁)
- 定义:排他锁(Exclusive Lock, X锁)用于确保只有一个事务可以修改数据项。其他事务在此期间无法对该数据项加任何类型的锁。
- 用途:用于写操作,如插入、更新和删除。
- 示例:
-- 加共享锁
SELECT * FROM table_name WHERE id = 1 LOCK IN SHARE MODE;
5.2. 共享锁(S锁)
- 定义:共享锁(Shared Lock, S锁)允许多个事务同时读取同一数据项,但不允许其他事务对该数据项加排他锁。
- 用途:用于读操作,如查询。
- 示例:
-- 加排他锁
SELECT * FROM table_name WHERE id = 1 FOR UPDATE;
5.3. 锁的相容性矩阵
| 请求锁 \ 当前锁 | 无锁 | S锁 | X锁 |
|---|---|---|---|
| 无锁 | 是 | 是 | 是 |
| S锁 | 是 | 是 | 否 |
| X锁 | 是 | 否 | 否 |
6. 死锁
6.1. 定义
**死锁(Deadlock)**是指两个或多个事务互相等待对方持有的资源(如锁),从而导致所有这些事务都无法继续执行的状态。在数据库系统中,死锁通常发生在多个事务竞争共享资源时,每个事务都持有某些资源并等待其他事务释放它们所需的资源。
6.2. 死锁的形成条件
根据Coffman条件,死锁的发生需要满足以下四个必要条件:
- 互斥条件(Mutual Exclusion):资源一次只能被一个事务占用,不能同时被多个事务共享。
- 占有并等待条件(Hold and Wait):一个事务已经持有了某些资源,并且正在等待获取其他事务持有的资源。
- 不可剥夺条件(No Preemption):资源不能被强制剥夺,只有持有资源的事务可以主动释放资源。
- 循环等待条件(Circular Wait):存在一个事务等待环,即事务T1等待事务T2持有的资源,事务T2等待事务T3持有的资源,……,事务Tn等待事务T1持有的资源。
6.3. 示例
假设有一个简单的银行转账系统,包含两个账户A和B。有两个事务T1和T2分别进行转账操作:
| 事务 | 操作 |
|---|---|
| T1 | BEGIN; LOCK TABLE account A IN EXCLUSIVE MODE; – 获取账户A的排他锁。UPDATE account SET balance = balance - 100 WHERE id = A; |
| T2 | BEGIN; LOCK TABLE account B IN EXCLUSIVE MODE; – 获取账户B的排他锁。UPDATE account SET balance = balance + 100 WHERE id = B; |
| T1 | LOCK TABLE account B IN EXCLUSIVE MODE; |
| T2 | LOCK TABLE account A IN EXCLUSIVE MODE; |
在这个例子中:
- T1先锁住了账户A,然后尝试锁住账户B。
- T2先锁住了账户B,然后尝试锁住账户A。
结果是T1等待T2释放账户B的锁,而T2等待T1释放账户A的锁,形成了死锁。
6.4. 死锁的检测与预防
6.4.1. 死锁检测
死锁检测是指通过定期检查系统状态来发现是否存在死锁。常见的检测方法包括:
- 超时法(Timeout Method):如果一个事务等待某个资源的时间超过了预设的阈值,则认为该事务可能陷入了死锁,系统会终止该事务。
- 等待图法(Wait-for Graph):构建一个有向图,节点表示事务,边表示事务之间的等待关系。如果图中存在环,则说明存在死锁。
6.4.2. 死锁预防
死锁预防是指通过限制事务的行为来避免死锁的发生。常见的预防策略包括:
- 一次性加锁(All-or-Nothing Locking):事务在开始时一次性请求所有需要的锁,而不是逐步请求。这样可以避免部分加锁后等待其他锁的情况。
- 顺序加锁(Lock Ordering):规定所有事务必须按照某种全局顺序加锁。例如,所有事务必须先锁账户A再锁账户B,这样可以避免循环等待。
- 超时机制(Timeout Mechanism):设置一个合理的超时时间,当事务等待资源的时间超过这个时间时,自动回滚该事务,以避免长时间等待导致死锁。
6.4.3. 死锁解除
一旦检测到死锁,系统需要采取措施解除死锁。常见的解除方法包括:
- 回滚事务(Rollback Transactions):选择一个或多个事务进行回滚,释放其持有的锁,使其他事务能够继续执行。通常会选择代价最小的事务进行回滚。
- 优先级调度(Priority Scheduling):为事务分配优先级,优先处理高优先级的事务,低优先级的事务可能会被回滚以解除死锁。
6.5. 死锁的处理策略
- 超时法:
- 优点:实现简单,不需要复杂的图结构。
- 缺点:可能会误判正常的长等待为死锁,导致不必要的事务回滚。
- 等待图法:
- 优点:能够准确检测死锁,适用于大多数并发控制场景。
- 缺点:需要额外的开销来维护等待图,增加了系统的复杂性。
- 预防策略:
- 优点:从根本上避免死锁的发生,减少了死锁检测和解除的开销。
- 缺点:可能会影响系统的灵活性和性能,因为需要对事务的行为进行严格限制。
- 回滚策略:
- 优点:能够在检测到死锁后快速解决问题,保证系统的正常运行。
- 缺点:回滚事务可能导致数据不一致或业务逻辑失败,需要额外的补偿机制。
6.6. 死锁的处理策略
在数据库系统中,死锁是一个常见的问题,特别是在高并发环境下。为了应对死锁,数据库管理系统通常会采用以下几种方式:
- 自动检测和解除:大多数现代数据库系统(如MySQL、PostgreSQL、Oracle等)内置了死锁检测机制,能够在检测到死锁后自动选择一个事务进行回滚。
- 用户配置:允许用户通过配置参数调整死锁检测和解除的策略,例如设置超时时间和回滚优先级。
- 优化查询和事务设计:通过优化SQL查询和事务设计,减少锁的竞争和持有时间,降低死锁发生的概率。
7. 两段锁协议(Two-Phase Locking, 2PL)
7.1. 定义
两段锁协议(2PL)是一种并发控制协议,用于确保数据库事务的可串行化调度。根据该协议,每个事务的执行过程被划分为两个阶段:扩展阶段(Growing Phase) 和 收缩阶段(Shrinking Phase)。
7.2. 阶段划分
7.2.1. 扩展阶段(Growing Phase)
- 特点:在这个阶段中,事务可以申请获得任何数据项上的任何类型的锁(S锁或X锁),但不能释放任何锁。
- 操作:
- 事务开始时进入扩展阶段。
- 在此期间,事务可以根据需要对数据项加锁。
- 一旦事务进入收缩阶段,则不能再申请新的锁。
7.2.2. 收缩阶段(Shrinking Phase)
- 特点:在这个阶段中,事务可以释放任何数据项上的任何类型的锁,但不能申请新的锁。
- 操作:
- 当事务不再需要获取新锁时,进入收缩阶段。
- 在此期间,事务可以逐步释放已经持有的锁。
- 事务结束时,所有锁必须被释放。
7.3. 可串行化保证
通过将事务的操作严格划分为两个阶段,2PL能够确保事务的调度是可串行化的。即,多个事务并发执行的结果等价于某个顺序执行这些事务的结果。这有助于维护数据库的一致性和隔离性。
可串行化 vs 串行化:
- 串行化:事务一个接一个地执行,没有并发。
- 可串行化:虽然事务可以并发执行,但其最终结果等价于某些串行执行的顺序。换句话说,尽管事务是并发执行的,但从外部观察,它们的效果与某种顺序执行相同。
7.4. 类型
- 严格的两段锁协议(Strict Two-Phase Locking, Strict 2PL)
- 定义:在标准2PL的基础上,要求事务在提交或回滚之前不释放任何锁。
- 优点:防止“脏读”和“不可重复读”,提供更强的一致性保证。
- 缺点:可能降低并发性能,因为锁持有时间更长。
- 强两段锁协议(Strong Two-Phase Locking, Strong 2PL)
- 定义:不仅要求事务遵守2PL规则,还要求在事务提交前不允许其他事务对该数据项加锁。
- 优点:进一步增强了数据一致性。
- 缺点:并发性能受到更大限制。
7.5. 示例
假设我们有一个包含两个事务 ( T1 ) 和 ( T2 ) 的银行转账系统,涉及三个账户 ( A )、( B ) 和 ( C )。我们将逐步展示这两个事务如何遵循2PL执行。
1. 初始状态
- 账户 ( A ) 有 100 元。
- 账户 ( B ) 有 200 元。
- 账户 ( C ) 有 300 元。
事务 ( T1 ) :将账户 ( A ) 中的 50 元转到账户 ( B )。
事务 ( T2 ):将账户 ( B ) 中的 100 元转到账户 ( C )。
2. 执行过程
事务 ( T1 ):
1)进入扩展阶段:
- ( T1 ) 加S锁(共享锁)在账户 ( A ) 上。
- ( T1 ) 加X锁(排他锁)在账户 ( B ) 上。
- ( T1 ) 读取账户 ( A ) 的余额(100 元)。
- ( T1 ) 更新账户 ( A ) 的余额为 50 元。
- ( T1 ) 更新账户 ( B ) 的余额为 250 元。
2)进入收缩阶段:
- ( T1 ) 提交事务。
- ( T1 ) 解放账户 ( B ) 上的 X 锁。
- ( T1 ) 解放账户 ( A ) 上的 S 锁。
事务 ( T2 ):
1)进入扩展阶段:
- ( T2 ) 加S锁(共享锁)在账户 ( B ) 上。
- ( T2 ) 加X锁(排他锁)在账户 ( C ) 上。
- ( T2 ) 读取账户 ( B ) 的余额(250 元)。
- ( T2 ) 更新账户 ( B ) 的余额为 150 元。
- ( T2 ) 更新账户 ( C ) 的余额为 400 元。
2)进入收缩阶段:
- ( T2 ) 提交事务。
- ( T2 ) 解放账户 ( C ) 上的 X 锁。
- ( T2 ) 解放账户 ( B ) 上的 S 锁。
3. 关键点分析
1)扩展阶段和收缩阶段的划分:
- 在扩展阶段,事务 ( T1 ) 和 ( T2 ) 分别加锁并进行操作。
- 在收缩阶段,事务提交后逐步释放锁。
2)防止冲突:
- 如果 ( T1 ) 和 ( T2 ) 同时尝试对账户 ( B ) 加锁,则会发生冲突。根据2PL规则,一个事务必须在另一个事务释放锁之后才能继续操作。
- 例如,如果 ( T2 ) 在 ( T1 ) 还未提交时尝试对账户 ( B ) 加锁,则 ( T2 ) 必须等待 ( T1 ) 提交并释放锁。
7.6. 优点与缺点
优点:
- 确保可串行化:通过严格的阶段划分,确保事务的调度是可串行化的。
- 防止数据不一致:避免了丢失更新、脏读和不可重复读等问题。
缺点:
- 并发性能较低:由于锁持有时间较长,可能导致其他事务等待,影响并发性能。
- 可能发生死锁:如果多个事务相互等待对方释放锁,可能会导致死锁。
死锁示例:
1. 场景:
假设有一个简单的数据库,包含两个数据项 A 和 B,并且有两个事务 T1 和 T2 需要访问这些数据项。
事务 T1 的操作:
1)获取 A 的 S 锁。
2)获取 B 的 X 锁。
3)执行一些操作。
4)释放 A 的锁。
5)释放 B 的锁。事务 T2 的操作:
1)获取 B 的 S 锁。
2)获取 A 的 X 锁。
3)执行一些操作。
4)释放 B 的锁。
5)释放 A 的锁。2. 时间线示例:
1)初始状态:A 和 B 均未被锁定。
2)时间点 t1:
- T1 开始执行,并获取 A 的 S 锁。
- 状态:A (S, T1),B (无锁)
3)时间点 t2:
- T2 开始执行,并获取 B 的 S 锁。
- 状态:A (S, T1), B (S, T2)
4)时间点 t3:
- T1 尝试获取 B 的 X 锁,但由于 B 已经被 T2 锁定,T1 阻塞。
- 状态:A (S, T1), B (S, T2)
5)时间点 t4:
- T2 尝试获取 A 的 X 锁,但由于 A 已经被 T1 锁定,T2 阻塞。
- 状态:A (S, T1), B (S, T2)
此时,T1 和 T2 都在等待对方释放锁,从而形成死锁。
3. 示例代码
为了更清晰地展示上述死锁情况,以下是伪代码示例:
public class TwoPhaseLockingExample {public static void main(String[] args) {final Object A = new Object();final Object B = new Object();Thread t1 = new Thread(() -> {synchronized (A) {System.out.println("T1: Locked A");try {Thread.sleep(100); // 模拟其他操作} catch (InterruptedException e) {e.printStackTrace();}synchronized (B) {System.out.println("T1: Locked B");// 执行操作System.out.println("T1: Releasing B");}System.out.println("T1: Releasing A");}});Thread t2 = new Thread(() -> {synchronized (B) {System.out.println("T2: Locked B");try {Thread.sleep(100); // 模拟其他操作} catch (InterruptedException e) {e.printStackTrace();}synchronized (A) {System.out.println("T2: Locked A");// 执行操作System.out.println("T2: Releasing A");}System.out.println("T2: Releasing B");}});t1.start();t2.start();} }运行上述代码,您会看到 T1 和 T2 进入死锁状态。通过日志输出可以看到它们分别持有不同的锁并等待对方释放锁。
8. 三级封锁协议
8.1. 定义
三级封锁协议是数据库系统中用于确保事务隔离性的三种不同级别的封锁规则。每级封锁协议都对事务加锁提出了不同的要求,以保证不同程度的数据一致性和并发性。
8.2. 一级封锁协议(1PL)
8.2.1. 定义
一级封锁协议(One-Phase Locking Protocol, 1PL)是数据库管理系统中最基本的并发控制协议之一。它要求事务在修改数据项之前必须获得排他锁(X锁),并在事务结束时释放所有锁。该协议主要用于防止丢失更新问题。
8.2.2. 规则
- 加锁规则:事务在修改数据项之前必须获得排他锁(X锁)。
- 解锁规则:所有锁必须在事务结束时释放,即事务提交或回滚后才能释放锁。
8.2.3. 示例
假设我们有两个事务 ( T1 ) 和 ( T2 ),它们分别对账户 ( A ) 进行操作:
关键点分析:
1)加X锁:
- ( T1 ) 在更新账户 ( A ) 之前加了X锁,并且在提交之前一直持有该锁。
- ( T2 ) 尝试对账户 ( A ) 加X锁时,必须等待 ( T1 ) 提交或回滚后才能继续。
2)更新操作:
- ( T1 ) 和 ( T2 ) 分别对账户 ( A ) 进行更新操作,但 ( T2 ) 必须等待 ( T1 ) 完成并释放锁。
3)提交与解锁:
- ( T1 ) 提交事务后释放X锁,此时 ( T2 ) 才能获取X锁并进行更新操作。
4)等待过程:
- 明确展示了 ( T2 ) 在尝试加X锁时进入等待状态,直到 ( T1 ) 提交或回滚。
8.2.4. 优缺点
优点:
- 简单易实现:只需要关注更新操作,不需要复杂的锁管理机制。对于简单的应用场景,1PL易于实现和维护。
- 防止丢失更新:确保了更新操作的一致性,避免了数据覆盖问题。
- 较低的开销:相比于更严格的封锁协议,1PL的锁管理开销较低,因为它只涉及更新操作的X锁管理,对读取操作没有特殊要求。
缺点:
- 并发性能较低:由于所有更新操作都需要加X锁,可能会导致其他事务长时间等待,影响并发性能。
- 不能防止脏读和不可重复读:对于读取操作没有限制,因此无法防止事务读取未提交的数据(脏读)或在同一事务中多次读取同一数据项时结果不一致(不可重复读)。
- 潜在的死锁风险:如果多个事务对多个数据项进行复杂的加锁操作,可能会形成循环等待,导致死锁。虽然可以通过死锁检测或预防机制来解决,但这增加了系统的复杂性。
8.2.5. 实际应用
一级封锁协议适用于对一致性要求不高、但对性能要求较高的场景。例如,在一些简单的应用程序中,可能只需要确保更新操作的一致性,而对读取操作的隔离性要求不高。具体应用场景包括:
- 批处理系统:主要进行批量更新操作,读取较少。
- 日志记录系统:确保写入操作的一致性。
- 简单数据库应用:如小型企业的库存管理系统或任务调度系统。
- 历史数据分析:以读取为主,更新较少。
- 嵌入式系统:资源有限,对性能和开销有较高要求。
8.3. 二级封锁协议(2PL)
8.3.1. 定义
二级封锁协议(Two-Phase Locking Protocol, 2PL)是一种用于数据库管理系统中控制并发事务的协议。它确保事务在读取或修改数据项之前获得适当的锁,并且在事务结束前不释放任何锁,以保证数据的一致性和隔离性。
8.3.2. 规则
- 加锁规则:
- 事务在读取数据项之前必须获得共享锁(S锁)。
- 事务在修改数据项之前必须获得排他锁(X锁)。
- 解锁规则:
- 所有锁必须在事务结束前保持不变,即事务不能在提交或回滚之前释放任何锁。
8.3.3. 示例
假设我们有两个事务 ( T1 ) 和 ( T2 ),它们分别对账户 ( A ) 进行操作:
关键点分析:
1)加S锁:
- ( T1 ) 在读取账户 ( A ) 之前加了S锁,并在读取完成后立即释放该锁。
- ( T2 ) 尝试对账户 ( A ) 加S锁时,必须等待 ( T1 ) 释放S锁后才能继续。
2)加X锁:
- ( T1 ) 在更新账户 ( A ) 之前加了X锁,并且在提交之前一直持有该锁。
- ( T2 ) 尝试对账户 ( A ) 加X锁时,必须等待 ( T1 ) 提交或回滚后才能继续。
3)等待过程:
- ( T2 ) 在尝试加S锁时进入等待状态,直到 ( T1 ) 释放S锁。
- ( T2 ) 在尝试加X锁时进入等待状态,直到 ( T1 ) 提交并释放X锁。
8.3.4. 优缺点
优点:
- 防止丢失更新:确保了更新操作的一致性,避免了数据覆盖问题。
- 防止脏读:确保事务只能读取已经提交的数据,提高了数据的一致性和可靠性。
- 相对简单的实现:相比于更严格的三级封锁协议,2PL的实现较为简单,容易理解和维护。
- 较高的并发性能:允许多个事务同时持有共享锁(S锁),从而提高读操作的并发性能。
缺点:
- 无法防止不可重复读:如果一个事务在同一事务中多次读取同一数据项,可能会因为其他事务的更新而导致结果不一致。
- 并发性能受限:对于频繁的写操作,由于X锁需要持有到事务结束,可能会导致其他事务长时间等待,影响并发性能。
- 潜在的死锁风险:如果多个事务对多个数据项进行复杂的加锁操作,可能会形成循环等待,导致死锁。
8.3.5. 实际应用
二级封锁协议适用于对一致性要求较高且读多写少的场景。具体应用场景包括:
- 在线交易系统:确保账户余额等关键数据的一致性。
- 银行系统:确保转账、存款和取款操作的高度一致性和隔离性。
- 电子商务平台:确保商品库存管理的准确性,避免超卖等问题。
- 医疗信息系统:确保患者记录和诊断数据的一致性和隔离性。
- 物流管理系统:确保订单处理和库存管理的数据一致性。
8.4. 三级封锁协议(3PL)
8.4.1. 定义
三级封锁协议(Three-Phase Locking Protocol, 3PL)是数据库管理系统中用于控制并发事务的一种高级机制。它在二级封锁协议的基础上进一步加强了锁的管理,确保事务在读取数据项时只能加共享锁(S锁),并且在事务结束前不能释放任何锁。这有效地解决了不可重复读和幻读问题。
8.4.2. 规则
- 加锁规则:
- 事务在读取数据项之前必须获得共享锁(S锁)。
- 事务在修改数据项之前必须获得排他锁(X锁)。
- 解锁规则:
- 所有锁必须在事务结束前保持不变,即事务不能在提交或回滚之前释放任何锁。
- 事务在读取数据项时不能加排他锁(X锁),只能加共享锁(S锁)。
8.4.3. 示例
假设我们有两个事务 ( T1 ) 和 ( T2 ),它们分别对账户 ( A ) 进行操作:
关键点分析:
1)加S锁:
- ( T1 ) 在读取账户 ( A ) 之前加了S锁,并且在整个事务期间保持该锁。
- ( T2 ) 尝试对账户 ( A ) 加S锁时,必须等待 ( T1 ) 提交或回滚后才能继续。
2)加X锁:
- ( T1 ) 在更新账户 ( A ) 之前加了X锁,并且在提交之前一直持有该锁。
- ( T2 ) 在 ( T1 ) 提交后才能获取S锁进行读取操作。
3)等待过程:
- ( T2 ) 在尝试加S锁时进入等待状态,直到 ( T1 ) 提交或回滚。
- ( T2 ) 在 ( T1 ) 提交后才能获取S锁进行读取操作。
8.4.4. 优缺点
优点:
- 防止丢失更新:确保了更新操作的一致性,避免了数据覆盖问题。
- 防止脏读:确保事务只能读取已经提交的数据,提高了数据的一致性和可靠性。
- 防止不可重复读:确保事务在同一事务中多次读取同一数据项时,结果是一致的。
- 高一致性保障:提供了最强的一致性保证,适用于对数据一致性要求极高的场景。
缺点:
- 并发性能较低:由于读取操作也需要持有S锁到事务结束,可能会导致其他事务长时间等待,影响并发性能。
- 复杂度增加:需要更复杂的锁管理机制,增加了系统的复杂度。
- 潜在的死锁风险:如果多个事务对多个数据项进行复杂的加锁操作,可能会形成循环等待,导致死锁。
8.4.5. 实际应用
三级封锁协议适用于对数据一致性要求极高的场景。具体应用场景包括:
- 金融系统:如账务处理、证券交易等,需要确保数据的高度一致性和隔离性。
- 航空订票系统:确保航班座位分配的准确性和一致性。
- 医疗信息系统:确保患者记录和诊断数据的高度一致性和隔离性。
- 分布式数据库系统:确保跨节点数据的一致性和隔离性。
相关文章:

数据库事务:确保数据一致性的关键机制
1. 什么是数据库事务 定义:事务(Transaction)是数据库管理系统中的一个逻辑工作单元,用于确保一组相关操作要么全部成功执行,要么全部不执行,从而维护数据的一致性和完整性。重要性:在多用户环…...

词作词汇积累:错付、大而无当、语焉不详、愈演愈烈
错付 1、基本介绍 【错付】是错误地付出或投入,特别是在感情、信任或资源方面。 【错付】代表投入的东西没有得到应有的回报,或者投入的对象并不值得。 2、实例实操 1. 她将所有的爱与关怀都【错付】给了那个不懂珍惜的人。2. 多年的努力似乎【错付…...

selenium学习笔记
一.搭建环境 1.安装chrome #下载chrome wget https://dl.google.com/linux/direct/google-chrome-stable_current_amd64.deb#安装chrome apt --fix-broken install ./google-chrome-stable_current_amd64.deb2.安装chromedriver 首先先查看版本:google-chrome --…...

asp.net core webapi 并发请求时 怎么保证实时获取的用户信息是此次请求的?
对于并发请求,每个请求会被分配到一个独立的线程或线程池工作线程上。通过 HttpContext 或 AsyncLocal,每个线程都能独立地获取到它自己的上下文数据。由于这些数据是与当前请求相关的,因此在并发请求时不会互相干扰。 在并发请求时…...

实时数仓:基于数据湖的实时数仓与数据治理架构
设计一个基于数据湖的实时数仓与数据治理架构,需要围绕以下几个核心方面展开:实时数据处理、数据存储与管理、数据质量治理、数据权限管理以及数据消费。以下是一个参考架构方案: 一、架构整体概览 核心组成部分 数据源层 数据来源ÿ…...
)
STM32 拓展 RTC案例1:使用闹钟唤醒待机模式 (HAL库)
需求描述 执行完毕正常代码之后,让MCU进入待机模式,设置闹钟,自动让MCU从待机模式中被唤醒。可以用led点亮熄灭显示是否唤醒。 应用场景:比如设计一个野外温度自动采集的设备,规定每小时采集一次温度,就可…...

ESP32S3使用串口0作为LOG输出
配置 配置串口,在内存保护这个选项里Memory protection 修改内存申请函数 测试代码 uint8_t buf1 heap_caps_malloc(320*240 * sizeof(lv_color_t), MALLOC_CAP_SPIRAM); ESP_LOGI("Test", "%d", buf1);sprintf(buffer, " Biggest / …...

Linux:深入了解fd文件描述符
目录 1. 文件分类 2. IO函数 2.1 fopen读写模式 2.2 重定向 2.3 标准文件流 3. 系统调用 3.1 open函数认识 3.2 open函数使用 3.3 close函数 3.4 write函数 3.5 read函数 4. fd文件描述符 4.1 标准输入输出 4.2 什么是文件描述符 4.3 语言级文件操作 1. 文件分类…...

springboot 集成 etcd
springboot 集成 etcd 往期内容 ETCD 简介docker部署ETCD 前言 好久不见各位小伙伴们,上两期内容中,我们对于分布式kv存储中间件有了简单的认识,完成了docker-compose 部署etcd集群以及可视化工具 etcd Keeper,既然有了认识&a…...

03_Redis基本操作
1.Redis查询命令 1.1 官网命查询命令 为了便于学习Redis,官方将其用于操作不同数据类型的命令进行了分类整理。你可以通过访问Redis官方网站上的命令参考页面https://redis.io/commands来查阅这些分组的命令,这有助于更系统地理解和使用Redis的各项功能。 1.2 HELP查询命令…...

pycharm-pyspark 环境安装
1、环境准备:java、scala、pyspark、python-anaconda、pycharm vi ~/.bash_profile export SCALA_HOME/Users/xunyongsun/Documents/scala-2.13.0 export PATH P A T H : PATH: PATH:SCALA_HOME/bin export SPARK_HOME/Users/xunyongsun/Documents/spark-3.5.4-bin…...

Unity + Firebase + GoogleSignIn 导入问题
我目前使用 Unity版本:2021.3.33f1 JDK版本为:1.8 Gradle 版本为:6.1.1 Firebase 版本: 9.6.0 Google Sign In 版本为: 1.0.1 问题1 :手机点击登录报错 apk转化成zip,解压,看到/lib/armeabi-v…...

web-app uniapp监测屏幕大小的变化对数组一行展示数据作相应处理
web-app uniapp监测屏幕大小的变化对数组一行展示数据作相应处理 1.uni.getSystemInfoSync().screenWidth; 获取屏幕宽度 2.uni.onWindowResize() 实时监测屏幕宽度变化 3.根据宽度的大小拿到每行要展示的数量itemsPerRow 4.为了确保样式能够根据 items…...

2025年VGC大众汽车科技社招入职测评综合能力英语口语SHL历年真题汇总、考情分析
早在1978年,大众汽车集团就开始了与中国的联系。1984年,集团在华的第一家合资企业—上汽大众汽车有限公司奠基成立;1991年,一汽-大众汽车有限公司成立;2017年,大众汽车(安徽)有限公司…...

Linux中配置Java环境变量
基本工作 1.官网下载java 1.8地址(需要注册一个oracle账户): Java Downloads | Oracle 点击上面的链接,滚动页面到最下面就可以看到下载界面,如下图 选择适合自己系统的版本。 本文选用 jdk-8u431-linux-x64.tar.g…...

完全自定义Qt翻译功能,不使用Qt Linguist的.ts 和 .qm类型翻译
这篇文章展示了集成Qt Linguist 的功能。 但是有时候Qt的翻译功能比较繁琐,我们简单项目只需要使用本地化功能,将中文字符串导入到项目中,避免编码格式问题导致的乱码。 只需要使用一个简单的json或者其他格式的本地文件作为映射的key/value.…...

551 灌溉
常规解法: #include<bits/stdc.h> using namespace std; int n,m,k,t; const int N105; bool a[N][N],b[N][N]; int cnt; //设置滚动数组来存贮当前和下一状态的条件 //处理传播扩散问题非常有效int main() {cin>>n>>m>>t;for(int i1;i&l…...

php函数性能优化中应注意哪些问题
PHP 函数性能优化中的注意事项 在 PHP 应用中优化函数性能对于提升整体运行效率至关重要。以下是一些需要注意的关键问题: 1. 避免内联变量 将变量内联到函数调用中会增加不必要的开销。例如: function sum($a, $b) {return $a $b; }// 不要这样做&…...

安科瑞 Acrel-1000DP 分布式光伏监控系统在工业厂房分布式光伏发电项目中的应用
吕梦怡 18706162527 摘 要:常规能源以煤、石油、天然气为主,不仅资源有限,而且会造成严重的大气污染,开发清洁的可再生能源已经成为当今发展的重要任务,“节能优先,效率为本”的分布式发电能源符合社会发…...
鼠标自动移动防止锁屏的办公神器 —— 定时执行专家
目录 ◆ 如何设置 ◇ 方法1:使用【执行Nircmd命令】任务 ◇ 方法2:使用【模拟键盘输入】任务 ◆ 定时执行专家介绍 ◆ 定时执行专家最新版下载 ◆ 如何设置 ◇ 方法1:使用【执行Nircmd命令】任务 1、点击工具栏第一个图标【新建任务】&…...

为什么需要建设工程项目管理?工程项目管理有哪些亮点功能?
在建筑行业,项目管理的重要性不言而喻。随着工程规模的扩大、技术复杂度的提升,传统的管理模式已经难以满足现代工程的需求。过去,许多企业依赖手工记录、口头沟通和分散的信息管理,导致效率低下、成本失控、风险频发。例如&#…...

sqlserver 根据指定字符 解析拼接字符串
DECLARE LotNo NVARCHAR(50)A,B,C DECLARE xml XML ( SELECT <x> REPLACE(LotNo, ,, </x><x>) </x> ) DECLARE ErrorCode NVARCHAR(50) -- 提取 XML 中的值 SELECT value x.value(., VARCHAR(MAX))…...

土地利用/土地覆盖遥感解译与基于CLUE模型未来变化情景预测;从基础到高级,涵盖ArcGIS数据处理、ENVI遥感解译与CLUE模型情景模拟等
🔍 土地利用/土地覆盖数据是生态、环境和气象等诸多领域模型的关键输入参数。通过遥感影像解译技术,可以精准获取历史或当前任何一个区域的土地利用/土地覆盖情况。这些数据不仅能够用于评估区域生态环境的变化趋势,还能有效评价重大生态工程…...

【OSG学习笔记】Day 16: 骨骼动画与蒙皮(osgAnimation)
骨骼动画基础 骨骼动画是 3D 计算机图形中常用的技术,它通过以下两个主要组件实现角色动画。 骨骼系统 (Skeleton):由层级结构的骨头组成,类似于人体骨骼蒙皮 (Mesh Skinning):将模型网格顶点绑定到骨骼上,使骨骼移动…...

k8s业务程序联调工具-KtConnect
概述 原理 工具作用是建立了一个从本地到集群的单向VPN,根据VPN原理,打通两个内网必然需要借助一个公共中继节点,ktconnect工具巧妙的利用k8s原生的portforward能力,简化了建立连接的过程,apiserver间接起到了中继节…...

深入解析C++中的extern关键字:跨文件共享变量与函数的终极指南
🚀 C extern 关键字深度解析:跨文件编程的终极指南 📅 更新时间:2025年6月5日 🏷️ 标签:C | extern关键字 | 多文件编程 | 链接与声明 | 现代C 文章目录 前言🔥一、extern 是什么?&…...

RNN避坑指南:从数学推导到LSTM/GRU工业级部署实战流程
本文较长,建议点赞收藏,以免遗失。更多AI大模型应用开发学习视频及资料,尽在聚客AI学院。 本文全面剖析RNN核心原理,深入讲解梯度消失/爆炸问题,并通过LSTM/GRU结构实现解决方案,提供时间序列预测和文本生成…...
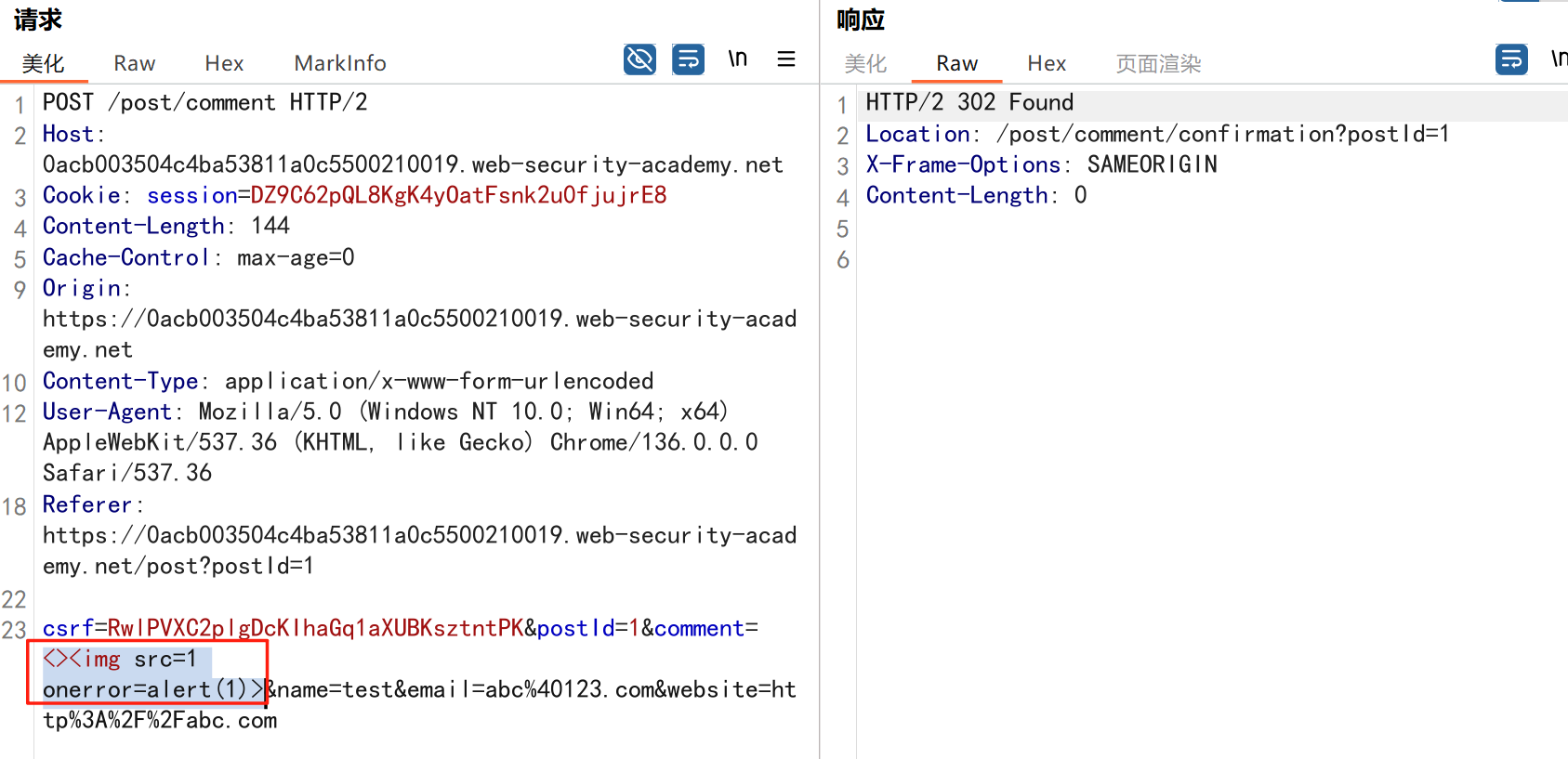
渗透实战PortSwigger靶场:lab13存储型DOM XSS详解
进来是需要留言的,先用做简单的 html 标签测试 发现面的</h1>不见了 数据包中找到了一个loadCommentsWithVulnerableEscapeHtml.js 他是把用户输入的<>进行 html 编码,输入的<>当成字符串处理回显到页面中,看来只是把用户输…...

基于江科大stm32屏幕驱动,实现OLED多级菜单(动画效果),结构体链表实现(独创源码)
引言 在嵌入式系统中,用户界面的设计往往直接影响到用户体验。本文将以STM32微控制器和OLED显示屏为例,介绍如何实现一个多级菜单系统。该系统支持用户通过按键导航菜单,执行相应操作,并提供平滑的滚动动画效果。 本文设计了一个…...

《Offer来了:Java面试核心知识点精讲》大纲
文章目录 一、《Offer来了:Java面试核心知识点精讲》的典型大纲框架Java基础并发编程JVM原理数据库与缓存分布式架构系统设计二、《Offer来了:Java面试核心知识点精讲(原理篇)》技术文章大纲核心主题:Java基础原理与面试高频考点Java虚拟机(JVM)原理Java并发编程原理Jav…...