day05_Spark SQL
文章目录
- day05_Spark SQL课程笔记
- 一、今日课程内容
- 二、Spark SQL 基本介绍(了解)
- 1、什么是Spark SQL
- **为什么 Spark SQL 是“SQL与大数据之间的桥梁”?**
- **实际意义**
- 为什么要学习Spark SQL呢?
- **为什么 Spark SQL 像“瑞士军刀”?**
- 2、Spark SQL 与 HIVE异同
- 3、Spark SQL的数据结构对比
- 三、Spark SQL的入门案例(掌握)
- 四、DataFrame详解(熟悉)
- 1.DataFrame基本介绍
- 2.DataFrame的构建方式
- 2.1 createDataFrame()创建
- 2.1.1 基于列表
- 2.1.2 基于RDD普通方式
- 2.1.3 基于RDD反射方式
- 2.2 toDF()创建
- 2.3 read读取外部文件
- 2.3.1 Text方式读取
- 2.3.2 CSV方式读取
- 2.3.3 JSON方式读取
- 3.DataFrame的相关API
- 3.1 SQL相关的API
- 3.2 DSL相关的API
- 4.Spark SQL词频统计
- 01_sparkSession和sparkContext区别联系.py
- 结果
- 02_[掌握]spark_sql词频统计.py
- 结果
- 03_createDataFrame方式基于列表方式创建df.py
- 结果
- 04_createDataFrame方式基于RDD创建df.py
- 结果
- 05_createDataFrame方式基于RDD反射创建df.py
- 结果
- 06_toDF方式把RDD转换为df.py
- 结果
- 07_read传统api方式读取text_csv_json.py
- 结果
- 08_read简写api方式读取text_csv_json.py
- 结果
- 09_spark_sql词频统计_多种方式.py
- 结果
day05_Spark SQL课程笔记
一、今日课程内容
- 1- Spark SQL的基本介绍(了解)
- 2- Spark SQL的入门案例(了解)
- 3- DataFrame详解(掌握)
- 4- Spark SQL的综合案例(熟悉)

今日目的:掌握DataFrame详解
二、Spark SQL 基本介绍(了解)
https://spark.apache.org/sql

1、什么是Spark SQL
Spark SQL是Spark多种组件中其中一个,主要是用于处理大规模的**【结构化数据】**
什么是结构化数据: 一份数据, 每一行都有固定的列, 每一列的类型都是一致的 我们将这样的数据称为结构化的数据
例如: mysql的表数据1 张三 202 李四 153 王五 184 赵六 12
简单来说:Spark SQL是Spark中用于处理结构化数据的模块,就像是“SQL与大数据之间的桥梁”,让用户能够用熟悉的SQL语句查询和分析大规模数据。
具体而言:
- 核心功能:
- DataFrame API:提供类似于Pandas DataFrame的API,支持结构化数据处理。
- SQL查询:用户可以直接使用标准SQL语句查询数据,无需编写复杂的分布式计算代码。
- 数据源集成:支持从多种数据源(如Hive、Parquet、JSON、JDBC)读取数据,并将结果写回到这些数据源。
- 优化引擎:内置Catalyst优化器,能够自动优化查询计划,提升执行效率。
- 应用场景:
- 在数据仓库中,使用Spark SQL查询和分析海量数据,生成报表和洞察。
- 在ETL任务中,使用Spark SQL清洗和转换数据,提升数据处理效率。
- 在实时分析中,结合Structured Streaming,使用Spark SQL处理实时数据流。
实际生产场景:
- 在电商平台中,使用Spark SQL分析用户行为数据,生成个性化推荐。
- 在金融领域,使用Spark SQL处理交易数据,进行风险分析和预测。
总之:Spark SQL结合了SQL的易用性和Spark的分布式计算能力,为结构化数据处理提供了高效、灵活的工具,广泛应用于数据分析和处理任务。
为什么 Spark SQL 是“SQL与大数据之间的桥梁”?
-
连接 SQL 与分布式计算
- SQL:传统SQL用于查询关系型数据库,适合小规模数据处理。
- 大数据:分布式计算框架(如Spark)用于处理海量数据,但需要编写复杂代码。
- Spark SQL:让用户能够用熟悉的SQL语句直接查询大规模数据,无需编写复杂的分布式计算代码,从而在SQL的易用性和大数据的处理能力之间架起桥梁。
-
统一数据访问
- SQL:通常只能访问关系型数据库。
- Spark SQL:支持多种数据源(如Hive、Parquet、JSON、JDBC等),将不同数据源的数据统一为结构化数据,方便用SQL查询。
-
高性能优化
- SQL:传统SQL引擎在处理大数据时性能有限。
- Spark SQL:通过Catalyst优化器和Tungsten引擎,自动优化查询计划,利用分布式计算和内存加速,提升大数据查询性能。
-
降低大数据处理门槛
- SQL:数据分析师和开发者熟悉SQL,但可能不熟悉分布式计算。
- Spark SQL:让这些用户无需学习复杂的分布式编程,直接用SQL处理大数据,降低了大数据处理的门槛。
-
支持复杂场景
- SQL:适合简单的查询和分析。
- Spark SQL:不仅支持标准SQL,还提供DataFrame API,支持复杂的数据处理逻辑(如ETL、机器学习数据准备),并可与Structured Streaming结合,处理实时数据流。
实际意义
Spark SQL通过将SQL的易用性与大数据的分布式计算能力结合,让用户能够轻松处理海量数据,同时保持高性能和灵活性,真正成为“SQL与大数据之间的桥梁”。
为什么要学习Spark SQL呢?
1- 会 SQL的人, 一定比会大数据的人多
2- Spark SQL 既可以编写SQL语句, 也可以编写代码, 甚至可以混合使用
3- Spark SQL 可以 和 HIVE进行集成, 集成后, 可以替换掉HIVE原有MR的执行引擎, 提升效率
简单来说:学习Spark SQL就像是“掌握了一把万能钥匙”,能够轻松处理和分析大规模结构化数据,为数据驱动的业务决策提供强大支持。
具体而言:
- 高效处理大数据:Spark SQL基于Spark引擎,能够分布式处理TB甚至PB级数据,远超传统数据库的性能。
- SQL的易用性:使用标准SQL语句查询数据,降低学习成本,尤其适合熟悉SQL的数据分析师和开发人员。
- 多数据源支持:支持从Hive、Parquet、JSON、JDBC等多种数据源读取数据,满足复杂的数据集成需求。
- 与Spark生态无缝集成:Spark SQL可以与Spark的其他模块(如MLlib、GraphX、Structured Streaming)无缝集成,支持从数据清洗到机器学习、实时分析的完整流程。
- 优化性能:内置Catalyst优化器和Tungsten引擎,能够自动优化查询计划,提升执行效率。
实际生产场景:
- 在数据仓库中,使用Spark SQL快速查询和分析海量数据,生成业务报表。
- 在实时分析中,结合Structured Streaming,使用Spark SQL处理实时数据流,支持实时决策。
- 在机器学习中,使用Spark SQL清洗和准备数据,为模型训练提供高质量的数据输入。
总之:学习Spark SQL能够让你在大数据时代游刃有余,无论是数据分析、实时处理还是机器学习,都能找到用武之地,为职业发展和技术能力提升带来巨大价值。
Spark SQL特点:
1- 融合性: 既可以使用标准SQL语言, 也可以编写代码, 同时支持混合使用2- 统一的数据访问: 可以通过统一的API来对接不同的数据源3- HIVE的兼容性: Spark SQL可以和HIVE进行整合, 整合后替换执行引擎为Spark, 核心: 基于HIVE的metastore来处理4- 标准化连接: Spark SQL也是支持 JDBC/ODBC的连接方式
简单来说:Spark SQL的特点就像是“瑞士军刀”,集成了SQL的易用性、Spark的分布式计算能力和强大的优化引擎,为结构化数据处理提供了高效、灵活的工具。
具体而言:
- 统一的数据访问:支持从多种数据源(如Hive、Parquet、JSON、JDBC)读取数据,并将结果写回到这些数据源。
- SQL与DataFrame API:既支持标准SQL查询,又提供DataFrame API,适合不同开发习惯的用户。
- 高性能优化:内置Catalyst优化器和Tungsten引擎,能够自动优化查询计划,提升执行效率。
- 与Spark生态无缝集成:可以与Spark的其他模块(如MLlib、GraphX、Structured Streaming)无缝集成,支持从数据清洗到机器学习、实时分析的完整流程。
- Hive兼容性:完全兼容Hive,支持HiveQL查询和Hive元数据访问,方便从Hive迁移到Spark SQL。
- 结构化数据处理:专门为结构化数据设计,支持复杂的数据类型(如嵌套结构、数组、Map等)。
- 实时数据处理:结合Structured Streaming,支持实时数据流的SQL查询和分析。
实际生产场景:
- 在数据仓库中,使用Spark SQL快速查询和分析海量数据,生成业务报表。
- 在实时分析中,结合Structured Streaming,使用Spark SQL处理实时数据流,支持实时决策。
- 在机器学习中,使用Spark SQL清洗和准备数据,为模型训练提供高质量的数据输入。
总之:Spark SQL凭借其强大的功能和灵活的接口,成为大数据处理领域的利器,无论是数据分析、实时处理还是机器学习,都能发挥重要作用。
为什么 Spark SQL 像“瑞士军刀”?
-
多功能性
- 瑞士军刀:集多种工具于一身,应对不同任务。
- Spark SQL:集成SQL查询、DataFrame API、流处理等功能,适应多种数据处理场景。
-
灵活性
- 瑞士军刀:工具切换灵活,适应不同需求。
- Spark SQL:支持多种数据源(如Hive、Parquet、JSON等)和开发方式(SQL或API),满足不同开发习惯。
-
高效性
- 瑞士军刀:设计精巧,使用效率高。
- Spark SQL:通过Catalyst优化器和Tungsten引擎,自动优化查询计划,利用列式存储和内存计算加速处理。
-
广泛适用性
- 瑞士军刀:适用于多种场景。
- Spark SQL:覆盖批处理、实时流处理、机器学习等,适用于数据仓库、实时分析、数据湖等多种场景。
-
易用性
- 瑞士军刀:操作简单,易于使用。
- Spark SQL:兼容Hive,支持标准SQL,降低大数据处理门槛。
SparkSQL发展历史:
● 2014年 1.0正式发布
● 2015年 1.3 发布DataFrame数据结构, 沿用至今
● 2016年 1.6 发布Dataset数据结构(带泛型的DataFrame), 适用于支持泛型的语言(Java\Scala)
● 2016年 2.0 统一了Dataset 和 DataFrame, 以后只有Dataset了, Python用的DataFrame就是 没有泛型的Dataset
注意: 2019年 3.0 发布, 性能大幅度提升,SparkSQL变化不大

2、Spark SQL 与 HIVE异同
相同点:
1- 都是分布式SQL计算引擎
2- 都可以处理大规模的结构化数据
3- 都可以建立Yarn集群之上运行
不同点:
1- Spark SQL是基于内存计算, 而HIVE SQL是基于磁盘进行计算的
2- Spark SQL没有元数据管理服务(自己维护), 而HIVE SQL是有metastore的元数据管理服务的
3- Spark SQL底层执行Spark RDD程序, 而HIVE SQL底层执行是MapReduce
4- Spark SQL可以编写SQL也可以编写代码,但是HIVE SQL仅能编写SQL语句
简单来说:Spark SQL和Hive都是用于处理大规模结构化数据的工具,但Spark SQL更像是“高性能跑车”,而Hive则是“可靠的卡车”,两者各有优劣,适合不同的场景。
具体而言:
- 相同点:
- SQL支持:两者都支持标准SQL查询,降低了使用门槛。
- 大数据处理:都适用于处理大规模结构化数据,支持TB甚至PB级数据。
- Hive兼容性:Spark SQL完全兼容Hive,支持HiveQL查询和Hive元数据访问。
- 不同点:
- 执行引擎:
- Spark SQL基于Spark引擎,采用内存计算,适合迭代计算和实时处理。
- Hive基于MapReduce引擎,采用磁盘计算,适合离线批处理。
- 性能:
- Spark SQL的性能通常优于Hive,尤其是在复杂查询和迭代计算场景中。
- Hive在处理超大规模数据时稳定性更高,但速度较慢。
- 实时性:
- Spark SQL支持实时数据处理(通过Structured Streaming)。
- Hive主要用于离线批处理,实时性较差。
- 易用性:
- Spark SQL提供DataFrame API,支持多种编程语言(如Python、Scala、Java),开发更灵活。
- Hive主要依赖SQL,扩展性较弱。
实际生产场景:
- 在需要快速迭代和实时分析的场景中,如用户行为分析,Spark SQL更为适合。
- 在超大规模离线批处理场景中,如历史数据归档,Hive更为稳定可靠。
总之:Spark SQL和Hive各有优势,选择时需根据业务需求、数据规模和性能要求综合考虑。两者也可以结合使用,发挥各自的优势。
3、Spark SQL的数据结构对比

说明:pandas的DataFrame: 二维表 处理单机结构数据SparkCore的RDD: 处理任何的数据结构 处理大规模的分布式数据SparkSQL的DataFrame: 二维表 处理大规模的分布式结构数据

RDD(Resilient Distributed Dataset)是Spark中最基本的抽象,代表了一个不可变、分布式的数据集合。RDD支持并行操作,可以在集群中的多个节点上进行处理。RDD具有容错性,即使在节点故障时也能够自动恢复。但是RDD只提供了基本的功能,对于结构化数据的处理能力有限。DataFrame是Spark SQL中的一个概念,它是一种以列为主的分布式数据集合,类似于关系型数据库中的表格。DataFrame具有数据结构化的特点,每一列都有相应的数据类型,而且可以使用SQL语句进行查询和操作。DataFrame也支持大部分RDD的操作,但是在处理结构化数据方面更加方便。DataSet是Spark 2.0引入的一种新的API,它是DataFrame的一个扩展,提供了类型安全的数据操作。DataSet在编译时检查数据类型,可以避免一些运行时的错误。与DataFrame相比,DataSet更加适用于需要强类型支持的场景,但是在灵活性和易用性方面可能略逊于DataFrame。由于Python不支持泛型, 所以无法使用Dataset类型, 客户端仅支持DataFrame类型
三、Spark SQL的入门案例(掌握)

SparkSession 和 SparkContext 是 Apache Spark 中两个重要的组件,它们在 Spark 应用程序中扮演着不同的角色。SparkContext:SparkContext 是 Spark 1.x 版本中最重要的入口点,在 Spark 2.x 版本中,它已经被 SparkSession 取代,但在一些旧的代码和文档中仍然可能会看到它的存在。SparkContext 是 Spark 应用程序与 Spark 集群通信的主要入口点。它负责与集群管理器(如 YARN、Mesos 或 Spark 自带的 Standalone)通信,以便分配资源和执行任务。SparkContext 提供了创建 RDD(弹性分布式数据集)的功能,RDD 是 Spark 中基本的数据抽象,代表了分布在集群中的不可变的数据集。SparkSession:在 Spark 2.x 中,SparkSession 被引入来取代 SparkContext,并提供了更多功能和简化的 API。,它是 Spark 应用程序中的入口点,封装了 SparkContext。SparkSession 提供了一种统一的入口点,用于读取数据、执行查询、进行数据处理等各种 Spark 任务。SparkSession 提供了 DataFrame 和 Dataset API,这两种 API 提供了更高级别、更易于使用的抽象,用于处理结构化数据。与 SparkContext 不同,SparkSession 可以与 Hive 集成,允许在 Spark 应用程序中执行 SQL 查询,并访问 Hive 中的表和数据。总之,SparkContext 是 Spark 1.x 版本中的主要入口点,负责与集群通信和管理资源,而 SparkSession 是 Spark 2.x 中的主要入口点,提供了更多的功能和简化的 API,用于执行各种 Spark 任务,并且可以与 Hive 集成。还可以通过SparkSession对象还是可以得到SparkContext对象。入门体验
# 导包
import os
from pyspark.sql import SparkSession# 绑定指定的python解释器os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'# 创建main函数
if __name__ == '__main__':# 1.创建SparkContext对象spark = SparkSession.builder.appName('pyspark_demo').master('local[*]').getOrCreate()sc = spark.sparkContext# print(spark,type(spark))# print(sc,type(sc))# 2.验证是否能生成rddtextRDD = sc.textFile('file:///export/data/spark_project/spark_sql/data/uniqlo.csv')# collect: 搜集数据触发任务展示数据 count:获取数据条数 type:查看类型# print(textRDD.collect())print(textRDD.count())print(type(textRDD)) # <class 'pyspark.rdd.RDD'># 验证是否能生成DataFramedf = spark.read.csv('file:///export/data/spark_project/spark_sql/data/uniqlo.csv')# show: 展示数据 count:获取数据条数 type:查看类型# print(df.show())print(df.count())print(type(df)) # <class 'pyspark.sql.dataframe.DataFrame'># 3.关闭资源sc.stop()spark.stop()
四、DataFrame详解(熟悉)
1.DataFrame基本介绍

DataFrame表示的是一个二维的表。二维表,必然存在行、列等表结构描述信息表结构描述信息(元数据Schema): StructType对象
字段: StructField对象,可以描述字段名称、字段数据类型、是否可以为空
行: Row对象
列: Column对象,包含字段名称和字段值在一个StructType对象下,由多个StructField组成,构建成一个完整的元数据信息
如何构建表结构信息数据:

2.DataFrame的构建方式
方式1: 使用SparkSession的createDataFrame(data,schema)函数创建data参数1.基于List列表数据进行创建2.基于RDD弹性分布式数据集进行创建3.基于pandas的DataFrame数据进行创建schema参数1: 字符串格式一 :“字段名1 字段类型,字段名2 字段类型”格式二(推荐):“字段名1:字段类型,字段名2:字段类型”2: List格式: ["字段名1","字段名2"] 3: DataType(推荐,用的最多)格式一:schema=StructType().add('字段名1',字段类型).add('字段名2',字段类型)格式二:schema=StructType([StructField('字段名1',类型),StructField('字段名1',类型)])方式2: 使用DataFrame的toDF(colNames)函数创建DataFrame的toDF方法是一个在Apache Spark的DataFrame API中用来创建一个新的DataFrame的方法。这个方法可以将一个RDD转换为DataFrame,或者将一个已存在的DataFrame转换为另一个DataFrame。在Python中,你可以使用toDF方法来指定列的名字。如果你不指定列的名字,那么默认的列的名字会是_1, _2等等。 格式: rdd.toDF([列名])方式3: 使用SparkSession的read()函数创建在 Spark 中,SparkSession 的 read 是用于读取数据的入口点之一,它提供了各种方法来读取不同格式的数据并将其加载到 Spark 中进行处理。统一API格式: spark.read.format('text|csv|json|parquet|orc|...') : 读取外部文件的方式.option('k','v') : 选项 可以设置相关的参数 (可选).schema(StructType | String) : 设置表的结构信息.load('加载数据路径') : 读取外部文件的路径, 支持 HDFS 也支持本地简写API格式:注意: 以上所有的外部读取方式,都有简单的写法。spark内置了一些常用的读取方案的简写格式: spark.read.文件读取方式('加载数据路径')注意: parquet:是Spark中常用的一种列式存储文件格式和Hive中的ORC差不多, 他俩都是列存储格式2.1 createDataFrame()创建
场景:一般用在开发和测试中。因为只能处理少量的数据
2.1.1 基于列表
# 导包
import os
from pyspark.sql import SparkSession# 绑定指定的python解释器
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'# 创建main函数
if __name__ == '__main__':# 1.创建SparkContext对象spark = SparkSession.builder.appName('pyspark_demo').master('local[*]').getOrCreate()# 2.创建DF对象data = [(1, '张三', 18), (2, '李四', 28), (3, '王五', 38)]df1 = spark.createDataFrame(data,schema=['id','name','age'])# 展示数据df1.show()# 查看结构信息df1.printSchema()print('---------------------------------------------------------')df2 = spark.createDataFrame(data,schema='id int,name string,age int')# 展示数据df2.show()# 查看结构信息df2.printSchema()print('---------------------------------------------------------')df3 = spark.createDataFrame(data,schema='id:int,name:string,age:int')# 展示数据df3.show()# 查看结构信息df3.printSchema()# 3.关闭资源spark.stop()
2.1.2 基于RDD普通方式
场景:RDD可以存储任意结构的数据;而DataFrame只能处理二维表数据。在使用Spark处理数据的初期,可能输入进来的数据是半结构化或者是非结构化的数据,那么我可以先通过RDD对数据进行ETL处理成结构化数据,再使用开发效率高的SparkSQL来对后续数据进行处理分析。
Schema选择StructType对象来定义DataFrame的“表结构”转换RDD
# 导包
import os
from pyspark.sql import SparkSession# 绑定指定的python解释器
from pyspark.sql.types import StructType, StringType, StructFieldos.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'# 创建main函数
if __name__ == '__main__':# 1.创建SparkContext对象spark = SparkSession.builder.appName('pyspark_demo').master('local[*]').getOrCreate()sc = spark.sparkContext# 2.读取生成rddtextRDD = sc.textFile('file:///export/data/spark_project/spark_sql/data/data1.txt')print(type(textRDD)) # <class 'pyspark.rdd.RDD'>etlRDD = textRDD.map(lambda line:line.split(',')).map(lambda l:(l[0],l[1]))# 3.定义schema结构信息schema1 = StructType().add('name',StringType(),True).add('age',StringType(),True)schema2 = StructType([StructField('name',StringType(),True),StructField('age',StringType(),True)])schema3 = ['name','age']schema4 = 'name string,age string'schema5 = 'name:string,age:string'# 4.创建DF对象dfpeople = spark.createDataFrame(etlRDD,schema5)# 5.df展示结构信息dfpeople.show()dfpeople.printSchema()# 6.拓展: 创建临时视图,方便sql查询dfpeople.createTempView('peoples')r = spark.sql('select * from peoples')r.show()# 7.关闭资源sc.stop()spark.stop()2.1.3 基于RDD反射方式
Schema使用反射方法来推断Schema模式Spark SQL 可以将 Row 对象的 RDD 转换为 DataFrame,从而推断数据类型。
# 导包
import os
from pyspark.sql import SparkSession# 绑定指定的python解释器
from pyspark.sql.types import StructType, StringType, StructField, Rowos.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'# 创建main函数
if __name__ == '__main__':# 1.创建SparkContext对象spark = SparkSession.builder.appName('pyspark_demo').master('local[*]').getOrCreate()sc = spark.sparkContext# 2.读取生成rdd# 3.定义schema结构信息textRDD = sc.textFile('file:///export/data/spark_project/spark_sql/data/data1.txt')etlRDD_schema = textRDD.map(lambda line:line.split(',')).map(lambda l:Row(name=l[0],age=l[1]))# 4.创建DF对象dfpeople = spark.createDataFrame(etlRDD_schema)# 5.df展示结构信息dfpeople.show()dfpeople.printSchema()# 6.拓展: 创建临时视图,方便sql查询dfpeople.createTempView('peoples')r = spark.sql('select * from peoples')r.show()# 7.关闭资源sc.stop()spark.stop()
2.2 toDF()创建
schema模式编码在字符串中,toDF参数用于指定列的名字。如果你不指定列的名字,那么默认的列的名字会是_1, _2等等。
# 导包
import os
from pyspark.sql import SparkSession# 绑定指定的python解释器
from pyspark.sql.types import StructType, StringType, StructField, Rowos.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'# 创建main函数
if __name__ == '__main__':# 1.创建SparkContext对象spark = SparkSession.builder.appName('pyspark_demo').master('local[*]').getOrCreate()sc = spark.sparkContext# 2.读取生成rdd# 3.定义schema结构信息textRDD = sc.textFile('file:///export/data/spark_project/spark_sql/data/data1.txt')etlRDD = textRDD.map(lambda line:line.split(','))# 4.创建DF对象dfpeople = etlRDD.toDF(['name','age'])# 5.df展示结构信息dfpeople.show()dfpeople.printSchema()# 6.拓展: 创建临时视图,方便sql查询dfpeople.createTempView('peoples')r = spark.sql('select * from peoples')r.show()# 7.关闭资源sc.stop()spark.stop()
2.3 read读取外部文件
复杂API
统一API格式:
spark.read.format('text|csv|json|parquet|orc|avro|jdbc|.....') # 读取外部文件的方式.option('k','v') # 选项 可以设置相关的参数 (可选).schema(StructType | String) # 设置表的结构信息.load('加载数据路径') # 读取外部文件的路径, 支持 HDFS 也支持本地
简写API
请注意: 以上所有的外部读取方式,都有简单的写法。spark内置了一些常用的读取方案的简写
格式: spark.read.读取方式()例如: df = spark.read.csv(path='file:///export/data/_03_spark_sql/data/stu.txt',header=True,sep=' ',inferSchema=True,encoding='utf-8',)
2.3.1 Text方式读取
text方式读取文件:1- 不管文件中内容是什么样的,text会将所有内容全部放到一个列中处理2- 默认生成的列名叫value,数据类型string3- 我们只能够在schema中修改字段value的名称,其他任何内容不能修改
# 导包
import os
from pyspark.sql import SparkSession# 绑定指定的python解释器
from pyspark.sql.types import StructType, StringType, StructField, Rowos.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'# 创建main函数
if __name__ == '__main__':# 1.创建SparkContext对象spark = SparkSession.builder.appName('pyspark_demo').master('local[*]').getOrCreate()# 2.读取数据# 注意: 读取text文件默认只有1列,且列名交value,可以通过schema修改df = spark.read\.format('text')\.schema('info string')\.load('file:///export/data/spark_project/spark_sql/data/data1.txt')# 5.df展示结构信息df.show()df.printSchema()# 6.拓展: 创建临时视图,方便sql查询df.createTempView('peoples')r = spark.sql('select * from peoples')r.show()# 6.关闭资源spark.stop()
2.3.2 CSV方式读取
csv格式读取外部文件:1- 复杂API和简写API都必须掌握2- 相关参数作用说明:2.1- path:指定读取的文件路径。支持HDFS和本地文件路径2.2- schema:手动指定元数据信息2.3- sep:指定字段间的分隔符2.4- encoding:指定文件的编码方式2.5- header:指定文件中的第一行是否是字段名称2.6- inferSchema:根据数据内容自动推断数据类型。但是,推断结果可能不精确
# 导包
import os
from pyspark.sql import SparkSession# 绑定指定的python解释器
from pyspark.sql.types import StructType, StringType, StructField, Rowos.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'# 创建main函数
if __name__ == '__main__':# 1.创建SparkContext对象spark = SparkSession.builder.appName('pyspark_demo').master('local[*]').getOrCreate()# 2.读取数据# 注意: csv文件可以识别多个列,可以使用schema指定列名,类型# 原始方式# df = spark.read\# .format('csv')\# .schema('name string,age int')\# .option('sep',',')\# .option('encoding','utf8')\# .option('header',False)\# .load('file:///export/data/spark_project/spark_sql/data/data1.txt')# 简化方式df = spark.read.csv(schema='name string,age int',sep=',',encoding='utf8',header=False,path='file:///export/data/spark_project/spark_sql/data/data1.txt')# 5.df展示结构信息df.show()df.printSchema()# 6.拓展: 创建临时视图,方便sql查询df.createTempView('peoples')r = spark.sql('select * from peoples')r.show()# 7.关闭资源spark.stop()2.3.3 JSON方式读取
json读取数据:
1- 需要手动指定schema信息。如果手动指定的时候,字段名称与json中的key名称不一致,会解析不成功,以null值填充
2- csv/json中schema的结构,如果是字符串类型,那么字段名称和字段数据类型间,只能以空格分隔
json的数据内容
{'id': 1,'name': '张三','age': 20}
{'id': 2,'name': '李四','age': 23,'address': '北京'}
{'id': 3,'name': '王五','age': 25}
{'id': 4,'name': '赵六','age': 29}
代码实现
# 导包
import os
from pyspark.sql import SparkSession# 绑定指定的python解释器
from pyspark.sql.types import StructType, StringType, StructField, Rowos.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'# 创建main函数
if __name__ == '__main__':# 1.创建SparkContext对象spark = SparkSession.builder.appName('pyspark_demo').master('local[*]').getOrCreate()# 2.读取数据# 注意: json的key和schema指定的字段名不一致,会用null补充,如果没有数据也是用null补充# 简化方式df = spark.read.json(schema='id int,name string,age int,address string',encoding='utf8',path='file:///export/data/spark_project/spark_sql/data/data2.txt')# 5.df展示结构信息df.show()df.printSchema()# 6.拓展: 创建临时视图,方便sql查询df.createTempView('peoples')r = spark.sql('select * from peoples')r.show()# 关闭资源spark.stop()
3.DataFrame的相关API
操作DataFrame一般有二种操作方案:一种为【DSL方式】,另一种为【SQL方式】
SQL方式: 通过编写SQL语句完成统计分析操作
DSL方式: 特定领域语言,使用DataFrame特有的API完成计算操作,也就是代码形式从使用角度来说: SQL可能更加的方便一些,当适应了DSL写法后,你会发现DSL要比SQL更好用
从Spark角度来说: 更推荐使用DSL方案,此种方案更加利于Spark底层的优化处理
3.1 SQL相关的API
- 创建一个视图/表
df.createTempView('视图名称'): 创建一个临时的视图(表名)
df.createOrReplaceTempView('视图名称'): 创建一个临时的视图(表名),如果视图存在,直接替换
注意: 临时视图仅能在当前这个Spark Session的会话中使用df.createGlobalTempView('视图名称'): 创建一个全局视图,运行在一个Spark应用中多个spark会话中都可以使用。在使用的时候必须通过 global_temp.视图名称 方式才可以加载到。较少使用
- 执行SQL语句
spark.sql('书写SQL')
3.2 DSL相关的API
官网链接: https://spark.apache.org/docs/3.1.2/api/python/reference/pyspark.sql.html#dataframe-apis
- select():类似于SQL中select, SQL中select后面可以写什么, 这样同样也一样
- distinct(): 去重后返回一个新的DataFrame
- withColumn(参数1,参数2):用来产生新列。参数1是新列的名称;参数2是新列数据的来源
- withColumnRenamed(参数1,参数2):给字段重命名操作。参数1是旧字段名,参数2是新字段名
- alias(): 返回设置了别名的新DataFrame
- agg():执行聚合操作。如果有多个聚合,聚合之间使用逗号分隔即可,比较通用
- where()和filter():用于对数据进行过滤操作, 一般在spark SQL中主要使用where
- groupBy():使用指定的列对DataFrame进行分组,方便后期对它们进行聚合
- orderBy():返回按指定列排序的新DataFrame
- limit() : 返回指定数目的结果集
- show():用于展示DF中数据, 默认仅展示前20行
- 参数1:设置默认展示多少行 默认为20
- 参数2:是否为阶段列, 默认仅展示前20个字符数据, 如果过长, 不展示(一般不设置)
- printSchema():用于打印当前这个DF的表结构信息
DSL主要支持以下几种传递的方式: str | Column对象 | 列表str格式: '字段'Column对象: DataFrame含有的字段 df['字段']执行过程新产生: F.col('字段')列表: ['字段1','字段2'...][df['字段1'],df['字段2']]
为了能够支持在编写Spark SQL的DSL时候,在DSL中使用SQL函数,专门提供一个SQL的函数库。直接加载使用
链接: https://spark.apache.org/docs/3.1.2/api/sql/index.html
导入这个函数库: import pyspark.sql.functions as F
通过F调用对应的函数即可,常见函数如下:F.explode()F.split()F.count()F.sum()F.avg()F.max()F.min()...
4.Spark SQL词频统计
准备一个words.txt的文件,words.txt文件的内容如下:
hadoop hive hadoop sqoop hive
sqoop hadoop zookeeper hive hue
hue sqoop hue zookeeper hive
spark oozie spark hadoop oozie
hive oozie spark hadoop
需求分析:
1- 扫描文件将每行内容切分得到单个的单词
2- 组织DataFrame的数据结构,分别利用SQL风格和DSL风格完成每个单词个数统计
3- 要求最后结果有两列:一列是单词,一列是次数

代码实现:
# 导包
import os
from pyspark.sql import SparkSession,functions as F# 绑定指定的python解释器
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'# 创建main函数
if __name__ == '__main__':# 1.创建spark对象# appName:应用程序名称 master:提交模式# getOrCreate:在builder构建器中获取一个存在的SparkSession,如果不存在,则创建一个新的spark = SparkSession.builder.appName('sparksql_demo').master('local[*]').getOrCreate()# 2.通过read读取外部文件方式创建DF对象df = spark.read\.format('text')\.schema('words string')\.load('file:///export/data/spark_project/spark_sql/data/data3.txt')print(type(df))# 需求: 从data3.txt读取所有单词,然后统计每个单词出现的次数# 3.SQL风格# 方式1: 使用子查询方式# 先创建临时视图,然后通过sql语句查询展示df.createTempView('words_tb')qdf = spark.sql("select words,count(1) as cnt from (select explode(split(words,' ')) as words from words_tb) t group by words")print(type(qdf))qdf.show()# # 方式2: 使用侧视图# qdf = spark.sql(# "select t.words,count(1) as cnt from words_tb lateral view explode(split(words,' ')) t as words group by t.words"# )print(type(qdf))qdf.show()# 4.DSL风格# 方式1: 分组后直接用count()统计df.select(F.explode(F.split('words', ' ')).alias('words')).groupBy('words').count().show()# 方式1升级版:通过withColumnRenamed修改字段名df.select(F.explode(F.split('words', ' ')).alias('words')).groupBy('words').count().withColumnRenamed('count','cnt').show()# 方式2: 分组后用agg函数df.select(F.explode(F.split('words', ' ')).alias('words')).groupBy('words').agg(F.count('words').alias('cnt')).show()# 方式3: 直接使用withColumdf.withColumn('words',F.explode(F.split('words', ' '))).groupBy('words').agg(F.count('words').alias('cnt')).show()# 5.释放资源spark.stop()
01_sparkSession和sparkContext区别联系.py
# 导包
import os
from pyspark.sql import SparkSession# 解决JAVA_HOME 未设置问题
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'if __name__ == '__main__':# 1.先创建spark session对象spark = SparkSession.builder.appName("spark_demo").master("local[*]").getOrCreate()# 注意: 如果操作sparksql直接用spark对象即可,如果还有操作rdd的操作,需要获取sc对象sc = spark.sparkContext# 此处就可以写python 代码了...# 使用sc对象读取本地文件,测试返回的是不是RDD对象result1 = sc.textFile("file:///export/data/spark_project/05_saprk_sql/resources/uniqlo.csv")print(type(result1)) # <class 'pyspark.rdd.RDD'>print(result1.count())print(result1.take(10))# 使用spark对象读取本地文件,测试返回的是不是DataFrame对象result2 = spark.read.csv("file:///export/data/spark_project/05_saprk_sql/resources/uniqlo.csv")print(type(result2)) # <class 'pyspark.sql.dataframe.DataFrame'>print(result2.count())# 注意: show默认是展示20条数据result2.show(10)# 注意: 最后一定释放资源sc.stop()spark.stop()结果

02_[掌握]spark_sql词频统计.py
# 导包
import os
from pyspark.sql import SparkSession# 解决JAVA_HOME 未设置问题
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'if __name__ == '__main__':# 先创建spark session对象spark = SparkSession.builder.appName("spark_demo").master("local[*]").getOrCreate()# 用sparksql读取存储了多个单词的文件,最后计算词频df = spark.read.text("file:///export/data/spark_project/05_saprk_sql/resources/data3.txt")# TODO: 把df对象转换为临时表df.createTempView("words_table")# 如何使用sparkSQL去用sql语句查询词频spark.sql("""with t1 as (select explode(split(value,' ')) as wordfrom words_table)select word,count(*) as cnt from t1 group by word""").show()# 注意: 最后一定释放资源spark.stop()结果

03_createDataFrame方式基于列表方式创建df.py
# 导包
import os
from pyspark.sql import SparkSession# 解决JAVA_HOME 未设置问题
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'if __name__ == '__main__':# 1.先创建spark session对象spark = SparkSession.builder.appName("spark_demo").master("local[*]").getOrCreate()# 注意: 如果操作sparksql直接用spark对象即可,如果还有操作rdd的操作,需要获取sc对象sc = spark.sparkContext# 演示基于列表创建df# 1.先有列表data = [("zhangsan", 18), ("lisi", 19), ("wangwu", 20)]# 2.1创建df# 注意: schema可以不指定,默认列名是_1,_2...df1 = spark.createDataFrame(data)# 3.1验证df数据df1.show()df1.printSchema()print('---------------------------------------------------------------')# 2.2创建df# 注意: schema可以不指定,默认列名是_1,_2...# 指定schema的多种方式,以下任选一个传到createDataFrame方法()即可schema1 = ["name", "age"]schema2 = "name:string,age:int"schema3 = "name string,age int"df2 = spark.createDataFrame(data, schema3)# 3.2验证df数据df2.show()df2.printSchema()# 注意: 最后一定释放资源sc.stop()spark.stop()结果

04_createDataFrame方式基于RDD创建df.py
# 导包
import os
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StringType, StructField# 解决JAVA_HOME 未设置问题
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'if __name__ == '__main__':# 1.先创建spark session对象spark = SparkSession.builder.appName("spark_demo").master("local[*]").getOrCreate()# 注意: 如果操作sparksql直接用spark对象即可,如果还有操作rdd的操作,需要获取sc对象sc = spark.sparkContext# 1.先用sc读取data1.txt文件生成rdd对象rdd = sc.textFile("file:///export/data/spark_project/05_saprk_sql/resources/data1.txt")# 注意: rdd需要提前切割数据rdd = rdd.map(lambda x: x.split(","))print(type(rdd))print(rdd.collect())# 2.再基于rdd对象创建df# 指定schema的多种方式,以下任选一个传到createDataFrame方法()即可schema1 = ["name", "age"]schema2 = "name:string,age:string"schema3 = "name string,age string"schema4 = StructType().add("name", StringType()).add("age", StringType())schema5 = StructType([StructField("name", StringType()), StructField("age", StringType())])df = spark.createDataFrame(rdd, schema1)# 3.验证df数据df.show()df.printSchema()# 注意: 最后一定释放资源sc.stop()spark.stop()结果

05_createDataFrame方式基于RDD反射创建df.py
# 导包
import os
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StringType, StructField, Row# 解决JAVA_HOME 未设置问题
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'if __name__ == '__main__':# 1.先创建spark session对象spark = SparkSession.builder.appName("spark_demo").master("local[*]").getOrCreate()# 注意: 如果操作sparksql直接用spark对象即可,如果还有操作rdd的操作,需要获取sc对象sc = spark.sparkContext# 1.先用sc读取data1.txt文件生成rdd对象rdd = sc.textFile("file:///export/data/spark_project/05_saprk_sql/resources/data1.txt")# 注意: rdd需要提前切割数据# 注意: Row()的功能是将数据转换为Row对象指定属性和类型rdd = rdd.map(lambda x: x.split(",")).map(lambda x: Row(name=x[0], age=int(x[1])))print(type(rdd))print(rdd.collect())# 2.再基于rdd对象创建df# 不指定schema,通过反射默认获取rdd中Row对象的属性作为df的schemadf = spark.createDataFrame(rdd)# 3.验证df数据df.show()df.printSchema()# 注意: 最后一定释放资源sc.stop()spark.stop()结果

06_toDF方式把RDD转换为df.py
# 导包
import os
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StringType, StructField, Row# 解决JAVA_HOME 未设置问题
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'if __name__ == '__main__':# 1.先创建spark session对象spark = SparkSession.builder.appName("spark_demo").master("local[*]").getOrCreate()# 注意: 如果操作sparksql直接用spark对象即可,如果还有操作rdd的操作,需要获取sc对象sc = spark.sparkContext# 1.先用sc读取data1.txt文件生成rdd对象rdd = sc.textFile("file:///export/data/spark_project/05_saprk_sql/resources/data1.txt")# 注意: rdd需要提前切割数据rdd = rdd.map(lambda x: x.split(","))print(type(rdd))print(rdd.collect())# 2.再把rdd对象直接转换为dfdf = rdd.toDF(["name", "age"])# 3.验证df数据df.show()df.printSchema()# 注意: 最后一定释放资源sc.stop()spark.stop()结果

07_read传统api方式读取text_csv_json.py
# 导包
import os
from pyspark.sql import SparkSession# 解决JAVA_HOME 未设置问题
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'if __name__ == '__main__':# 先创建spark session对象spark = SparkSession.builder.appName("spark_demo").master("local[*]").getOrCreate()# 注意: 如果操作sparksql直接用spark对象即可,如果还有操作rdd的操作,需要获取sc对象sc = spark.sparkContext# 需求: 读取data1.txt# text文件直接读取一行,不分割,默认是列数据,所以需要指定schema一列接收df1 = (spark.read.format('text').schema('info string').load('file:///export/data/spark_project/05_saprk_sql/resources/data1.txt'))df1.show()df1.printSchema()print('--------------------------------------------------------------------------------------------------')# 注意: csv默认按照','逗号分隔,而数据正好是逗号',',所以即使不指定sep参数也能用schema指定两列接收df2 = (spark.read.format('csv').schema('name string,age int').option('sep', ',').option('encoding', 'utf8').option('header', 'False').load('file:///export/data/spark_project/05_saprk_sql/resources/data1.txt'))df2.show()df2.printSchema()print('--------------------------------------------------------------------------------------------------')# 注意: json文件默认按照{k:v}格式,默认k作为列名,v作为列值,即使要指定schema,列名也要和k一致,否则都是nulldf3 = (spark.read.format('json').schema('id int,name string,age int,address string').option('encoding', 'utf8').load('file:///export/data/spark_project/05_saprk_sql/resources/data2.txt'))df3.show()df3.printSchema()# 注意: 最后一定释放资源sc.stop()spark.stop()结果

08_read简写api方式读取text_csv_json.py
# 导包
import os
from pyspark.sql import SparkSession# 解决JAVA_HOME 未设置问题
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'if __name__ == '__main__':# 先创建spark session对象spark = SparkSession.builder.appName("spark_demo").master("local[*]").getOrCreate()# 注意: 如果操作sparksql直接用spark对象即可,如果还有操作rdd的操作,需要获取sc对象sc = spark.sparkContext# 需求: 读取data1.txt# text简写方式没有schema参数,默认列名是valuedf1 = spark.read.text(paths='file:///export/data/spark_project/05_saprk_sql/resources/data1.txt')df1.show()df1.printSchema()print('--------------------------------------------------------------------------------------------------')# 注意: csv默认按照','逗号分隔,而数据正好是逗号',',所以即使不指定sep参数也能用schema指定两列接收df2 = spark.read.csv(path='file:///export/data/spark_project/05_saprk_sql/resources/data1.txt',schema='name string,age int',sep=',',encoding='utf8',header='False')df2.show()df2.printSchema()print('--------------------------------------------------------------------------------------------------')# 注意: json文件默认按照{k:v}格式,默认k作为列名,v作为列值,即使要指定schema,列名也要和k一致,否则都是nulldf3 = spark.read.json(path='file:///export/data/spark_project/05_saprk_sql/resources/data2.txt',schema='id int,name string,age int,address string',encoding='utf8')df3.show()df3.printSchema()# 注意: 最后一定释放资源sc.stop()spark.stop()结果

09_spark_sql词频统计_多种方式.py
# 导包
import os
from pyspark.sql import SparkSession
from pyspark.sql import functions as F# 解决JAVA_HOME 未设置问题
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'if __name__ == '__main__':# 先创建spark session对象spark = SparkSession.builder.appName("spark_demo").master("local[*]").getOrCreate()# 1.加载数据默认返回df对象# 细节: text方式默认一列, 默认列名是valuedf = spark.read.text("file:///export/data/spark_project/05_saprk_sql/resources/data3.txt")df.show()# 2.把df转为sql临时表df.createOrReplaceTempView("words_table")# 3.1 sql方式# 方式1:子查询方式spark.sql("""select word,count(1) as cntfrom(select explode(split(value,' ')) as wordfrom words_table) tgroup by word""").show()print('----------------------------------------------------------------------------')# 方式2:侧视图方式spark.sql("""select word,count(1) as cntfrom words_table lateral view explode(split(value,' ')) cst as wordgroup by word""").show()print('============================================================================')# 3.2 dsl方式# 方式1: 分组后直接用count聚合+withColumnRenamed重名df.select(F.explode(F.split("value", " ")).alias("word")).groupby('word').count().withColumnRenamed("count", "cnt").show()print('----------------------------------------------------------------------------')# 对方式方式1优化df.select(F.explode(F.split("value", " ")).alias("word")).groupby('word').agg(F.count("word").alias("cnt")).show()print('----------------------------------------------------------------------------')# 方式2: withcolumn先产生新列.然后再分组聚合df.withColumn("word",F.explode(F.split("value", " "))).groupby('word').agg(F.count("word").alias("cnt")).show()# 注意: 最后一定释放资源spark.stop()结果

相关文章:
day05_Spark SQL
文章目录 day05_Spark SQL课程笔记一、今日课程内容二、Spark SQL 基本介绍(了解)1、什么是Spark SQL**为什么 Spark SQL 是“SQL与大数据之间的桥梁”?****实际意义**为什么要学习Spark SQL呢?**为什么 Spark SQL 像“瑞士军刀”࿱…...

Java线程的异常处理:确保线程安全运行
哈喽,各位小伙伴们,你们好呀,我是喵手。运营社区:C站/掘金/腾讯云/阿里云/华为云/51CTO;欢迎大家常来逛逛 今天我要给大家分享一些自己日常学习到的一些知识点,并以文字的形式跟大家一起交流,互…...
nvim 打造成可用的IDE(2)
上一个 文章写的太长了, 后来再写东西 就一卡一卡的,所以新开一个。 主要是关于 bufferline的。 之前我的界面是这样的。 这个图标很不舒服有。 后来发现是在这里进行配置。 我也不知道,这个配置 我是从哪 抄过来的。 测试结果࿱…...

如何当前正在运行的 Elasticsearch 集群信息
要查看当前正在运行的 Elasticsearch 集群信息,可以通过以下几种方法: 1. 使用 _cluster/health API _cluster/health API 返回集群的健康状态、节点数量、分片状态等信息。可以用 curl 命令直接访问: curl -X GET "http://localhost…...

PHP Filesystem:深入解析与实战应用
PHP Filesystem:深入解析与实战应用 引言 PHP作为一种流行的服务器端编程语言,提供了强大的文件系统操作功能。本文将深入探讨PHP的Filesystem函数,这些函数允许开发者访问和操作服务器上的文件系统。无论是进行基本的文件操作,还是实现复杂的文件管理系统,PHP的Filesys…...
pdf提取文本,表格以及转图片:spire.pdf
文章目录 🐒个人主页:信计2102罗铠威🏅JavaEE系列专栏📖前言:🎀 1. pdfbox1.1导入pdfbox 的maven依赖1.1 提取文本1.2 提取文本表格(可自行加入逻辑处理)1.3 pdf转换成图片代码&…...

jQuery UI 主题
关于“jQuery UI 主题”,我找到了一些有用的信息。 首先,jQuery UI 主题允许开发人员无缝集成UI小部件到他们网站或应用程序的外观和感观。每个插件通过CSS定义样式,包含两层样式信息:标准的jQuery UI CSS框架样式和具体的插件样…...

C# GDI+的DrawString无法绘制Tab键的现象
【啰嗦2句】 现在用C#的人很少了吧?GDI更少了吧?所以这个问题估计也冷门。没关系,分享给特定需要的人也不错。 【问题现象】 工作中开发了一个报告编辑器,实现图文排版等功能,用着没什么问题,直到有一天…...
C# GID+绘制不透明和半透明的线条
绘制线条时,必须将 Pen 对象传递给 DrawLine 类的 Graphics 方法。 Pen 构造函数的参数之一是 Color 对象。 若要绘制不透明的线条,请将颜色的 alpha 分量设置为 255。 若要绘制半透明的线条,请将 alpha 分量设置为从 1 到 254 的任何值。 在…...

L4-Prompt-Delta
Paper List PromptPapers:https://github.com/thunlp/PromptPapersDeltaPapers: https://github.com/thunlp/DeltaPapers Programming Toolkit OpemPrompt: https://github.com/thunlp/OpenPromptOpenDelta: https://github.com/thunlp/OpenDelta 一、传统微调方法࿱…...
)
Qt 自定义控件(Qt绘图)
一、QPaintEvent绘图事件1、QPaintEvent是Qt框架中一个重要的事件类,专门用于处理绘图事件。 2、当Qt视图组件需要重绘自己的一部分时,就会产生QPaintEvent事件。 3、Qt视图组件重绘自己,通常发生在以下情况: (1)、窗口第一次显示时: 当窗…...
electron 上怎么用node 调用 c++ 提供的方法
背景 在 Electron 上调用 C 代码的场景主要出现在需要执行高性能、低延迟的任务,或者需要与现有的本地 C 库集成时。这些场景往往涉及底层系统交互、性能优化或跨平台兼容性需求。 我们都知道c 的性能和安全性都比JavaScript 要高,但我认为在 Electron …...
Chromium 132 编译指南 Windows 篇 - Git 初始化设置 (四)
1. 引言 在 Chromium 编译指南系列的前几篇文章中,我们已经完成了编译环境的基础设置和关键环境变量的配置。本篇将重点介绍 Git 的安装与初始化配置,这是获取和管理 Chromium 源代码的重要前提。 2. 安装 Git 在 Windows 环境下,Git 并不…...

day03-前端Web-Vue3.0基础
目录 前言1. Vue概述2. 快速入门2.1 需求2.2 步骤2.3 实现 3. Vue指令3.1 介绍3.2 v-for3.2.1 介绍3.2.2 演示3.2.3 v-for的key3.2.4 案例-列表渲染 3.3 v-bind3.3.1 介绍3.3.2 演示3.3.3 案例-图片展示 3.4 v-if & v-show3.4.1 介绍3.4.2 案例-性别职位展示 3.6 v-model3.…...
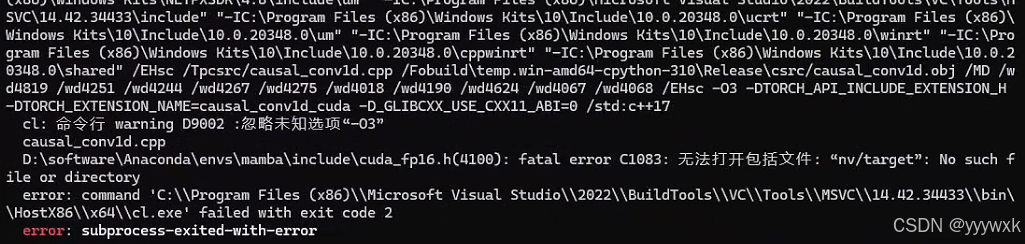
Windows 下Mamba2 / Vim / Vmamba 环境安装问题记录及解决方法终极版(无需绕过triton)
导航 安装教程导航 Mamba 及 Vim 安装问题参看本人博客:Mamba 环境安装踩坑问题汇总及解决方法(初版)Linux 下Mamba 及 Vim 安装问题参看本人博客:Mamba 环境安装踩坑问题汇总及解决方法(重置版)Windows …...
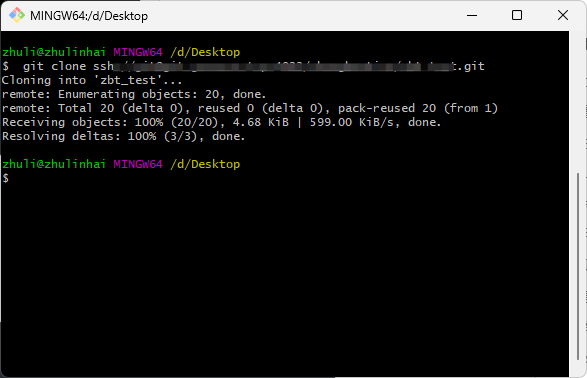
GitLab本地服务器配置ssh和克隆项目
1. 本地安装好git git链接:https://git-scm.com/downloads/win 无脑点击下一步安装即可,打开Git Bash命令终端如下: 2. 配置本地用户名和邮箱 git config --global user.name "你的名字" git config --global user.email "你的邮箱&quo…...

Win10和11 git/Android Studio遇到filename too long问题的解决
1、打开windows长文件、长路径支持: 可以参考这篇文章: 修改注册表方法: 使用Admin登陆machine,在run中输入regedit并回车; 找到路径 ’Computer -> HKEY_LOCAL_MACHINE -> SYSTEM -> CurrentControlSet -&g…...
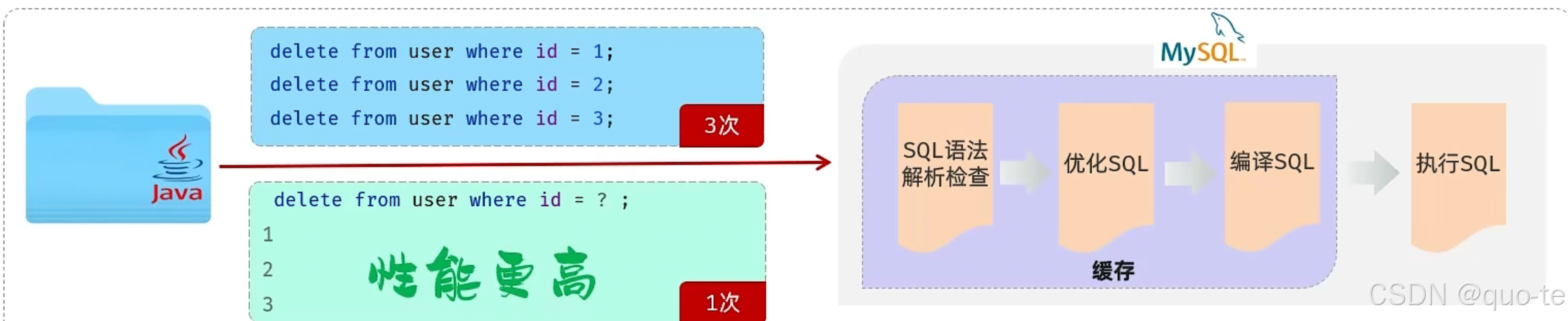
【JavaWeb学习Day11】
java程序操作数据库(JDBC) JDBC:(Java DataBase Connectivity),就是使用Java语言操作关系型数据库的一套API。 本质: 1.sun公司官方定义的一套操作所有关系型数据库的规范、即接口。 2.各个数据库厂商去…...

rom定制系列------小米max3安卓12 miui14批量线刷 默认开启usb功能选项 插电自启等
小米Max3是小米公司于2018年7月19日发布的机型。此机型后在没有max新型号。采用全金属一体机身设计,配备6.9英寸全面屏.八核处理器骁龙636,后置双摄像头1200万500万像素,前置800万像素.机型代码 :nitrogen.官方最终版为稳定版12.5…...

CES 2025|美格智能高算力AI模组助力“通天晓”人形机器人震撼发布
当地时间1月7日,2025年国际消费电子展(CES 2025)在美国拉斯维加斯正式开幕。美格智能合作伙伴阿加犀联合高通在展会上面向全球重磅发布人形机器人原型机——通天晓(Ultra Magnus)。该人形机器人内置美格智能基于高通QC…...

基于uniapp+WebSocket实现聊天对话、消息监听、消息推送、聊天室等功能,多端兼容
基于 UniApp + WebSocket实现多端兼容的实时通讯系统,涵盖WebSocket连接建立、消息收发机制、多端兼容性配置、消息实时监听等功能,适配微信小程序、H5、Android、iOS等终端 目录 技术选型分析WebSocket协议优势UniApp跨平台特性WebSocket 基础实现连接管理消息收发连接…...

DIY|Mac 搭建 ESP-IDF 开发环境及编译小智 AI
前一阵子在百度 AI 开发者大会上,看到基于小智 AI DIY 玩具的演示,感觉有点意思,想着自己也来试试。 如果只是想烧录现成的固件,乐鑫官方除了提供了 Windows 版本的 Flash 下载工具 之外,还提供了基于网页版的 ESP LA…...

在WSL2的Ubuntu镜像中安装Docker
Docker官网链接: https://docs.docker.com/engine/install/ubuntu/ 1、运行以下命令卸载所有冲突的软件包: for pkg in docker.io docker-doc docker-compose docker-compose-v2 podman-docker containerd runc; do sudo apt-get remove $pkg; done2、设置Docker…...

C++八股 —— 单例模式
文章目录 1. 基本概念2. 设计要点3. 实现方式4. 详解懒汉模式 1. 基本概念 线程安全(Thread Safety) 线程安全是指在多线程环境下,某个函数、类或代码片段能够被多个线程同时调用时,仍能保证数据的一致性和逻辑的正确性…...

MySQL账号权限管理指南:安全创建账户与精细授权技巧
在MySQL数据库管理中,合理创建用户账号并分配精确权限是保障数据安全的核心环节。直接使用root账号进行所有操作不仅危险且难以审计操作行为。今天我们来全面解析MySQL账号创建与权限分配的专业方法。 一、为何需要创建独立账号? 最小权限原则…...

服务器--宝塔命令
一、宝塔面板安装命令 ⚠️ 必须使用 root 用户 或 sudo 权限执行! sudo su - 1. CentOS 系统: yum install -y wget && wget -O install.sh http://download.bt.cn/install/install_6.0.sh && sh install.sh2. Ubuntu / Debian 系统…...

网站指纹识别
网站指纹识别 网站的最基本组成:服务器(操作系统)、中间件(web容器)、脚本语言、数据厍 为什么要了解这些?举个例子:发现了一个文件读取漏洞,我们需要读/etc/passwd,如…...

【电力电子】基于STM32F103C8T6单片机双极性SPWM逆变(硬件篇)
本项目是基于 STM32F103C8T6 微控制器的 SPWM(正弦脉宽调制)电源模块,能够生成可调频率和幅值的正弦波交流电源输出。该项目适用于逆变器、UPS电源、变频器等应用场景。 供电电源 输入电压采集 上图为本设计的电源电路,图中 D1 为二极管, 其目的是防止正负极电源反接, …...

08. C#入门系列【类的基本概念】:开启编程世界的奇妙冒险
C#入门系列【类的基本概念】:开启编程世界的奇妙冒险 嘿,各位编程小白探险家!欢迎来到 C# 的奇幻大陆!今天咱们要深入探索这片大陆上至关重要的 “建筑”—— 类!别害怕,跟着我,保准让你轻松搞…...

uniapp 字符包含的相关方法
在uniapp中,如果你想检查一个字符串是否包含另一个子字符串,你可以使用JavaScript中的includes()方法或者indexOf()方法。这两种方法都可以达到目的,但它们在处理方式和返回值上有所不同。 使用includes()方法 includes()方法用于判断一个字…...