【多模态LLM】英伟达NVLM多模态大模型训练细节和数据集
前期笔者介绍了OCR-free的多模态大模型,可以参考:【多模态&文档智能】OCR-free感知多模态大模型技术链路及训练数据细节,其更偏向于训练模型对于密集文本的感知能力。本文看一看英伟达出品的多模态大模型NVLM-1.0系列,虽然暂未开源,但该文章给出了NVLM的详细细节,值得一读。
NVLM-1.0方法

NVLM-1.0包括三种不同的架构:
- NVLM-D,一种解码器架构;
- NVLM-X,一种基于交叉注意力(X-attention)的架构;
- NVLM-H,一种混合架构。
共享视觉路径
所有NVLM模型共享一个视觉路径。使用InternViT-6B-448px-V1-5作为默认的视觉编码器,并在整个训练阶段保持其冻结状态。该视觉编码器以固定的448x448像素分辨率处理图像,生成1024个输出标记。采用动态高分辨率(DHR)方法来处理不同分辨率的图像输入。具体的如下图,图像被分割成最多6个瓦片(tile),每个瓦片对应448x448像素。然后,每个瓦片被送入InternViT-6B进行处理,生成1024个标记。这些标记通过下采样操作减少到256个标记,这么做可以降低处理开销。


上述两张图都是动态DHR的处理过程,围绕图像的预处理,包括归一化、缩放、裁剪、根据宽高比动态处理等操作,构建了一套完整的流程,代码逻辑如下:
import torch
from PIL import Image
import torchvision.transforms as T
from torchvision.transforms.functional import InterpolationModeIMAGENET_MEAN = (0.485, 0.456, 0.406)
IMAGENET_STD = (0.229, 0.224, 0.225)def build_transform(input_size):MEAN, STD = IMAGENET_MEAN, IMAGENET_STDtransform = T.Compose([T.Lambda(lambda img: img.convert('RGB') if img.mode != 'RGB' else img),T.Resize((input_size, input_size), interpolation=InterpolationMode.BICUBIC),T.ToTensor(),T.Normalize(mean=MEAN, std=STD)])return transformdef find_closest_aspect_ratio(aspect_ratio, target_ratios, width, height, image_size):best_ratio_diff = float('inf')best_ratio = (1, 1)area = width * heightfor ratio in target_ratios:target_aspect_ratio = ratio[0] / ratio[1]ratio_diff = abs(aspect_ratio - target_aspect_ratio)if ratio_diff < best_ratio_diff:best_ratio_diff = ratio_diffbest_ratio = ratioelif ratio_diff == best_ratio_diff:if area > 0.5 * image_size * image_size * ratio[0] * ratio[1]:best_ratio = ratioreturn best_ratiodef dynamic_preprocess(image, min_num=1, max_num=6, image_size=448, use_thumbnail=True):orig_width, orig_height = image.sizeaspect_ratio = orig_width / orig_heighttarget_ratios = set((i, j) for n in range(min_num, max_num + 1) for i in range(1, n + 1) for j in range(1, n + 1) ifi * j <= max_num and i * j >= min_num)target_ratios = sorted(target_ratios, key=lambda x: x[0] * x[1])target_aspect_ratio = find_closest_aspect_ratio(aspect_ratio, target_ratios, orig_width, orig_height, image_size)target_width = image_size * target_aspect_ratio[0]target_height = image_size * target_aspect_ratio[1]blocks = target_aspect_ratio[0] * target_aspect_ratio[1]resized_img = image.resize((target_width, target_height))processed_images = []for i in range(blocks):box = ((i % (target_width // image_size)) * image_size,(i // (target_width // image_size)) * image_size,((i % (target_width // image_size)) + 1) * image_size,((i // (target_width // image_size)) + 1) * image_size)split_img = resized_img.crop(box)processed_images.append(split_img)assert len(processed_images) == blocksif use_thumbnail and len(processed_images) != 1:thumbnail_img = image.resize((image_size, image_size))processed_images.append(thumbnail_img)return processed_imagesdef load_image(image_file, input_size=448, max_num=6):image = Image.open(image_file).convert('RGB')transform = build_transform(input_size=input_size)images = dynamic_preprocess(image, image_size=input_size, use_thumbnail=True, max_num=max_num)pixel_values = [transform(image) for image in images]pixel_values = torch.stack(pixel_values)return pixel_values文中引入了三种tile标签:
- 无标签:简单连接,没有tile标签,这是InternVL-1.5的设计。
- 一维扁平化tile tag:<tile_1>、<tile_2>、…、<tile_6>、<tile_global>。
- 二维网格tag:<tile_x0_y0>、<tile_x1_y0>、…、<tile_xW_yH>、<tile_global>,其中<tile_xi_yj>的{i:j}可以是{1:1, 1:2, 1:3, 1:4, 1:5, 1:6, 2:1, 2:2, 2:3, 3:1, 3:2, 4:1, 5:1, 6:1}中的任何一个。
- 二维边界框标签: (x0, y0), (x1, y1) 、…、 (xW, yH), (xW+1, yH+1) ,其中(xi, yj)和(xi+1, yj+1)分别是整个高分辨率图像中该特定tile的(左、上)和(右、下)坐标。
实验可以看到,其中DHR + 1-D tag取得了最佳的性能。


NVLM-D: 解码器架构
NVLM-D模型类似于之前的解码器架构多模态LLMs(如:)。通过一个两层MLP将预训练的视觉编码器连接到LLM。训练NVLM-D涉及两个阶段:预训练和SFT。在预训练阶段,MLP需要先进行训练,同时保持视觉编码器和LLM主干冻结。在SFT阶段,MLP和LLM都被训练以学习新的视觉-语言任务,而视觉编码器保持冻结状态。为了防止LLM在多模态SFT训练期间退化文本性能,引入了一个高质量的文本SFT数据集。
NVLM-X: 基于X-attention的模型
NVLM-X使用门控交叉注意力来处理图像token。与Flamingo模型不同,NVLM-X不使用感知重采样器,而是直接通过交叉注意力层处理图像标记。在SFT阶段,解冻LLM主干,并混合高质量文本SFT数据集以保持强大的文本性能。
NVLM-H: 混合模型
NVLM-H结合了解码器架构和基于X-attention的架构的优点。将图像token分为两部分:缩略图token和常规瓦片token。缩略图标记通过自注意力层处理,而常规瓦片标记通过交叉注意力层处理。这种设计提高了高分辨率图像的处理能力,同时显著提高了计算效率。
模型配置和训练方法
所有NVLM模型的训练过程包括两个阶段:预训练和监督微调(SFT)。在预训练阶段,冻结LLM主干和视觉编码器,只训练模态对齐模块。在SFT阶段,保持视觉编码器冻结,同时训练LLM和模态对齐模块。
LLM和视觉模型选择
- LLM:对于NVLM-D、NVLM-X和NVLM-H 72B模型,使用Qwen2-72B-Instruct作为LLM。为了计算效率,还使用了较小的Nous-Hermes-2-Yi-34B进行更快的消融研究和实验。
- 视觉编码器:所有NVLM模型都使用InternViT-6B-448px-V1-5作为视觉编码器。
模态对齐模块
- NVLM-D: 使用两层MLP将视觉编码器和背景语言模型连接起来。隐藏维度为12800→20480→7168(34B模型)和12800→29568→8192(72B模型)。
- NVLM-X: 图像特征首先通过一层MLP投影到背景语言模型的隐藏维度,然后插入门控X-attention层。具体配置为12800→7168(34B模型)和12800→8192(72B模型)。
- NVLM-H: 使用两层MLP和X-attention层作为模态对齐模块。缩略图图像标记直接输入到背景语言模型解码器中,而常规图像块则通过X-attention层进行处理。
训练超参数
-
预训练阶段

-
SFT阶段

训练数据
-
预训练数据集

-
SFT数据集

-
文本SFT数据集
包括ShareGPT、SlimOrca、EvolInstruct、GPTeacher、AlpacaGPT4、UltraInteract、OrcaMathWordProblems、MathInstruct、MetaMath、GlaiveCodeAssistant、Magicoder、WizardCoder、GlaiveCodeAssistant等。并使用OpenAI模型GPT-4o和GPT-4o-mini进一步优化响应质量,并进行数据去污染,确保不包含基准测试数据集中的提示。
-
SFT数据构建格式


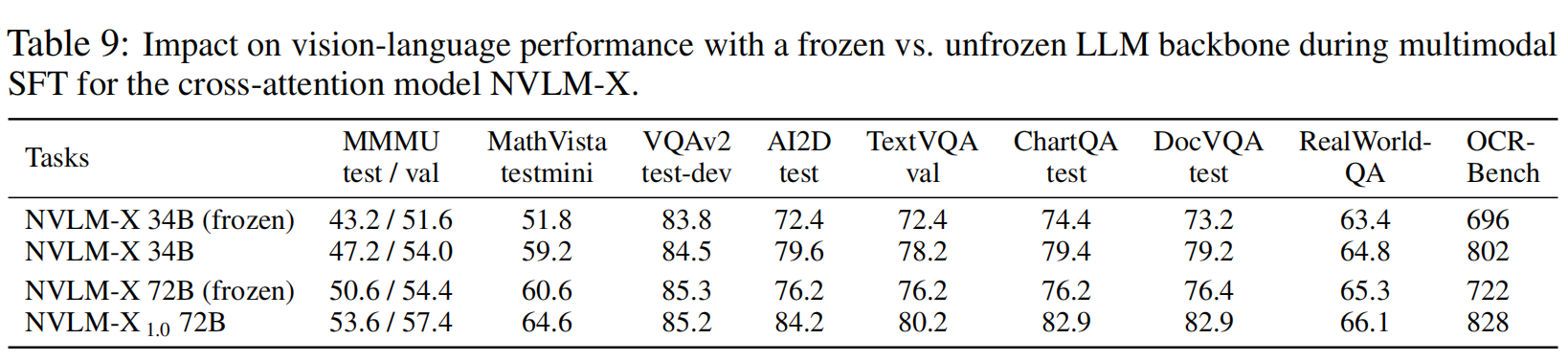
实验结果
重点关注多模态推理、视觉上下文中的数学推理、自然图像理解、场景-文本阅读、图表理解、文档理解、现实世界感知和OCR能力。


参考文献
- NVLM: Open Frontier-Class Multimodal LLMs,https://arxiv.org/pdf/2409.11402
相关文章:
【多模态LLM】英伟达NVLM多模态大模型训练细节和数据集
前期笔者介绍了OCR-free的多模态大模型,可以参考:【多模态&文档智能】OCR-free感知多模态大模型技术链路及训练数据细节,其更偏向于训练模型对于密集文本的感知能力。本文看一看英伟达出品的多模态大模型NVLM-1.0系列,虽然暂未…...

HTTP详解——HTTP基础
HTTP 基本概念 HTTP 是超文本传输协议 (HyperText Transfer Protocol) 超文本传输协议(HyperText Transfer Protocol) HTTP 是一个在计算机世界里专门在 两点 之间 传输 文字、图片、音视频等 超文本 数据的 约定和规范 1. 协议 约定和规范 2. 传输 两点之间传输…...

MySQL教程之:输入查询
如上一节所述,确保您已连接到服务器。这样做本身不会选择任何要使用的数据库,但没关系。在这一点上,了解一下如何发出查询比直接创建表、加载数据和从中检索数据更重要。本节介绍输入查询的基本原则,使用几个查询,您可…...
docker+ffmpeg+nginx+rtmp 拉取摄像机视频
1、构造程序容器镜像 app.py import subprocess import json import time import multiprocessing import socketdef check_rtmp_server(host, port, timeout5):try:with socket.create_connection((host, port), timeout):print(f"RTMP server at {host}:{port} is avai…...
不同音频振幅dBFS计算方法
1. 振幅的基本概念 振幅是描述音频信号强度的一个重要参数。它通常表示为信号的幅度值,幅度越大,声音听起来就越响。为了更好地理解和处理音频信号,通常会将振幅转换为分贝(dB)单位。分贝是一个对数单位,能…...
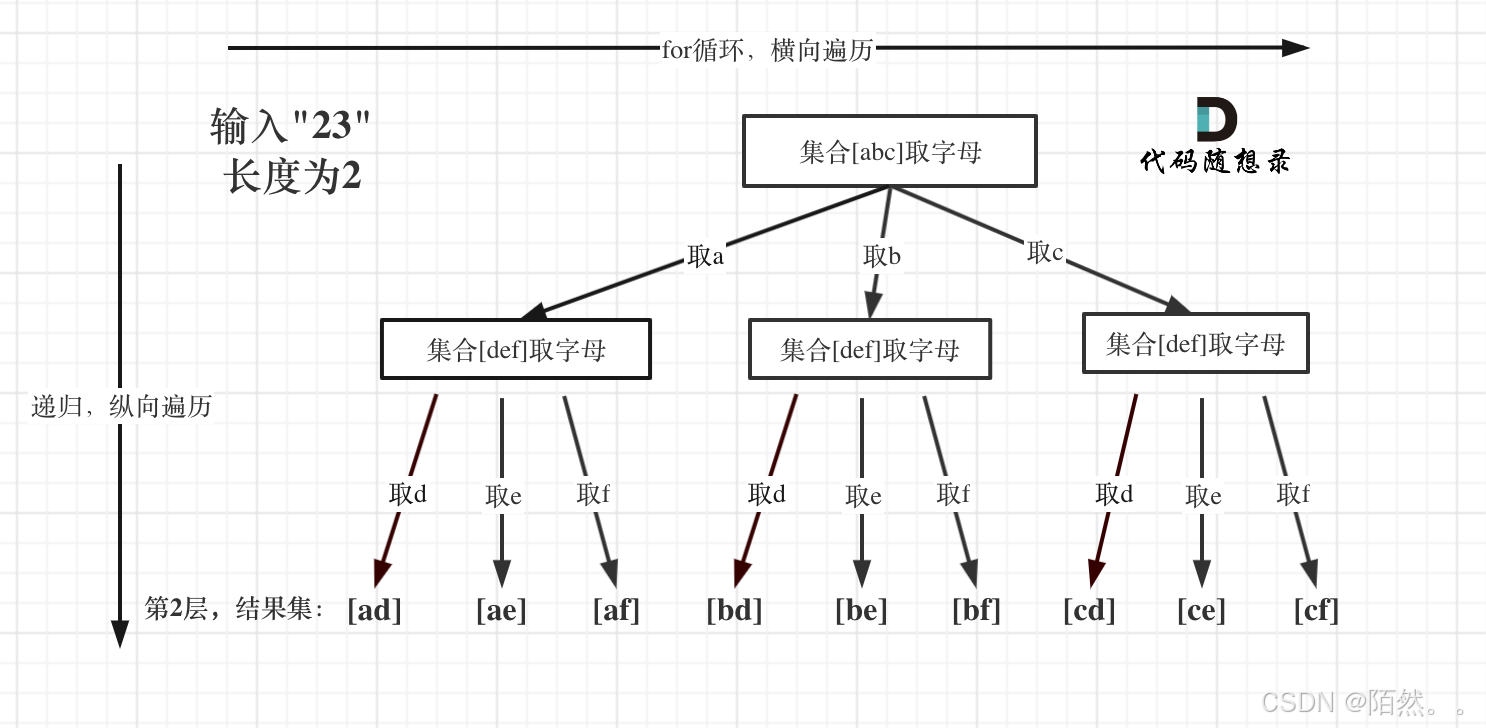
【17. 电话号码的字母组合 中等】
题目: 给定一个仅包含数字 2-9 的字符串,返回所有它能表示的字母组合。答案可以按 任意顺序 返回。 给出数字到字母的映射如下(与电话按键相同)。注意 1 不对应任何字母。 示例 1: 输入:digits “23”…...
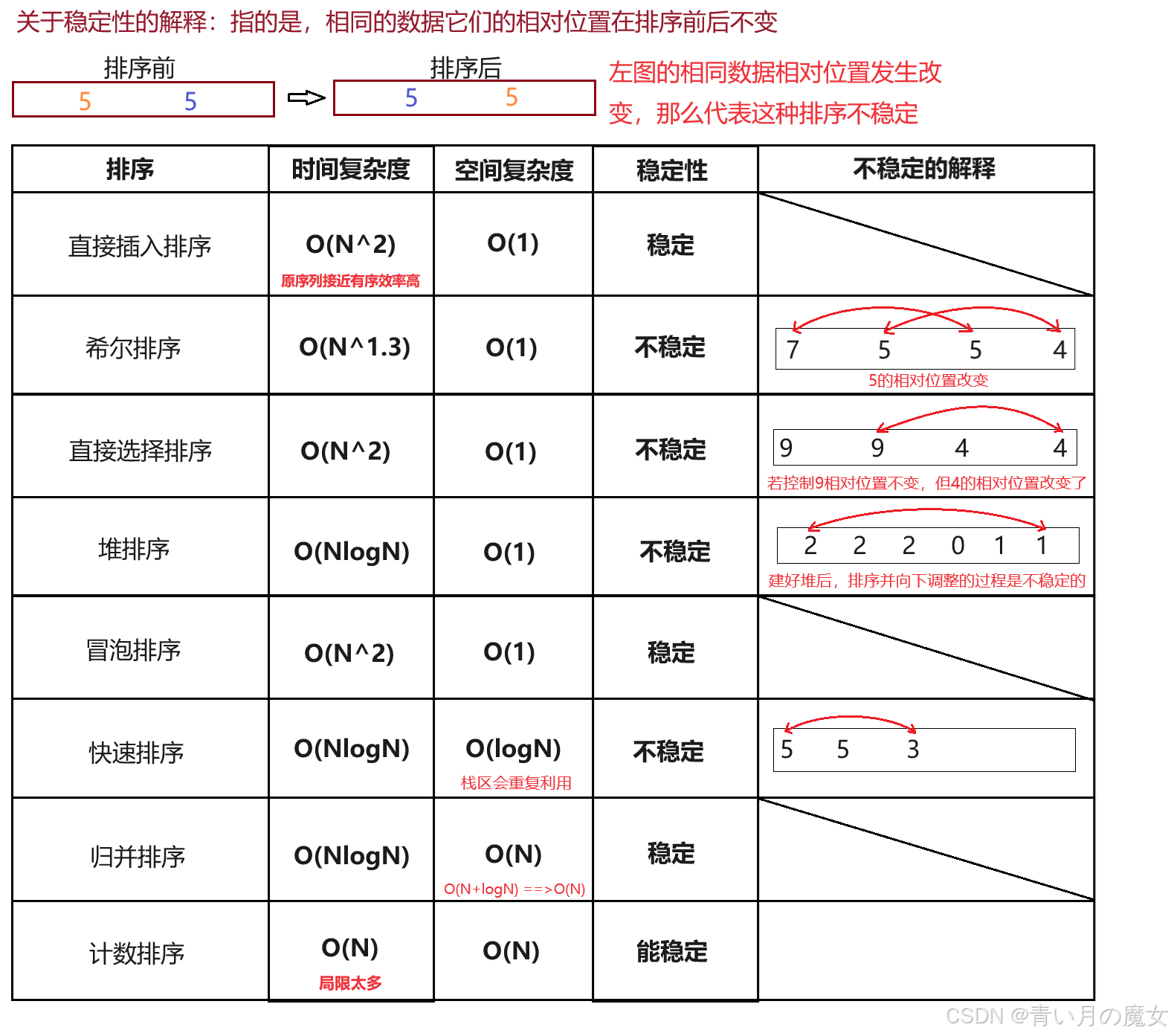
数据结构初阶---排序
一、排序相关概念与运用 1.排序相关概念 排序:所谓排序,就是使一串记录,按照其中的某个或某些关键字的大小,递增或递减的排列起来的操作。 稳定性:假定在待排序的记录序列中,存在多个具有相同的关键字的…...
【从0-1实现一个前端脚手架】
目录 介绍为什么需要脚手架?一个脚手架应该具备哪些功能? 脚手架实现初始化项目相关依赖实现脚手架 发布 介绍 为什么需要脚手架? 脚手架本质就是一个工具,作用是能够让使用者专注于写代码,它可以让我们只用一个命令…...
AI文章管理系统(自动生成图文分发到分站)
最近帮一个网上的朋友做了一套AI文章生成系统。他的需求是这样: 1、做一个服务端转接百度文心一言的生成文章的API接口。 2、服务端能注册用户,用户在服务端注册充值后可以获取一个令牌,这个令牌填写到客户端,客户端就可以根据客…...

【Leetcode 每日一题】3270. 求出数字答案
问题背景 给你三个 正 整数 n u m 1 num_1 num1, n u m 2 num_2 num2 和 n u m 3 num_3 num3。 数字 n u m 1 num_1 num1, n u m 2 num_2 num2 和 n u m 3 num_3 num3 的数字答案 k e y key key 是一个四位数,定义如下&…...
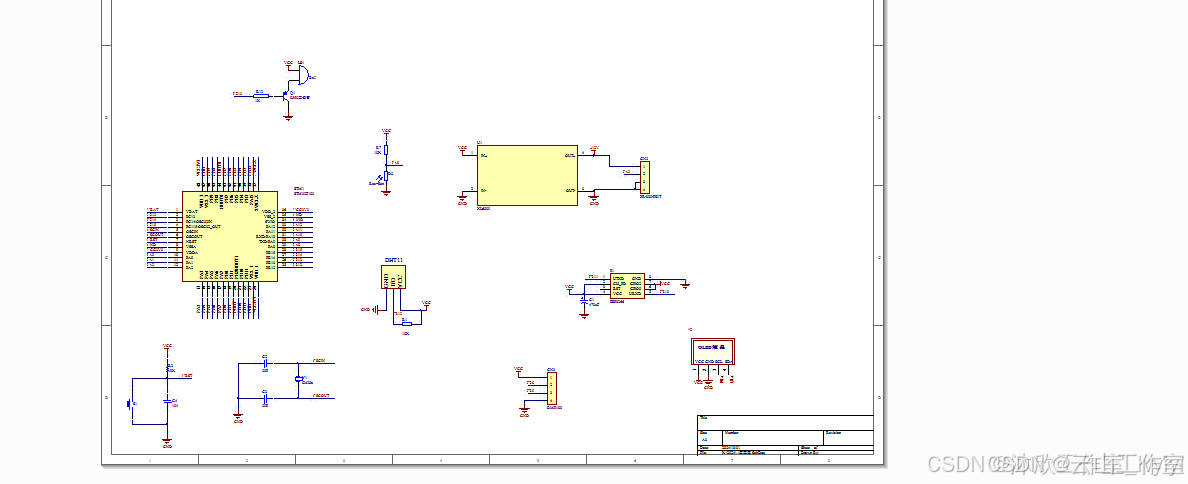
基于单片机的无线气象仪系统设计(论文+源码)
1系统方案设计 如图2.1所示为无线气象仪系统设计框架。系统设计采用STM32单片机作为主控制器,结合DHT11温湿度传感器、光敏传感器、BMP180气压传感器、PR-3000-FS-N01风速传感器实现气象环境的温度、湿度、光照、气压、风速等环境数据的检测,并通过OLED1…...

【数据库】Mysql精简回顾复习
一、概念 数据库(DB):数据存储的仓库数据库管理系统(DBMS):操纵和管理数据库的大型软件SQL:操作关系型数据库的编程语言,是一套标准关系型数据库(RDBMS)&…...

深入理解 HTTP 的 GET、POST 方法与 Request 和 Response
HTTP 协议是构建 Web 应用的基石,GET 和 POST 是其中最常用的请求方法。无论是前端开发、后端开发,还是接口测试,对它们的深入理解都显得尤为重要。在本文中,我们将介绍 GET 和 POST 方法,以及 Request 和 Response 的…...

MySQL 中联合索引相比单索引性能提升在哪?
首先我们要清楚所以也是要占用磁盘空间的,随着表中数据量越来越多,索引的空间也是随之提升的,因而单表不建议定义过多的索引,所以使用联合索引可以在一定程度上可以减少索引的空间占用其次,使用联合索引的情况下&#…...
第34天:安全开发-JavaEE应用反射机制攻击链类对象成员变量方法构造方法
时间轴: Java反射相关类图解: 反射: 1、什么是 Java 反射 参考: https://xz.aliyun.com/t/9117 Java 提供了一套反射 API ,该 API 由 Class 类与 java.lang.reflect 类库组成。 该类库包含了 Field 、 Me…...

C++笔记之数据单位与C语言变量类型和范围
C++笔记之数据单位与C语言变量类型和范围 code review! 文章目录 C++笔记之数据单位与C语言变量类型和范围一、数据单位1. 数据单位表:按单位的递增顺序排列2. 关于换算关系的说明3. 一般用法及注意事项4. 扩展内容5. 理解和使用建议二、C 语言变量类型和范围基本数据类型标准…...

算法-拆分数位后四位数字的最小和
力扣题目2160. 拆分数位后四位数字的最小和 - 力扣(LeetCode) 给你一个四位 正 整数 num 。请你使用 num 中的 数位 ,将 num 拆成两个新的整数 new1 和 new2 。new1 和 new2 中可以有 前导 0 ,且 num 中 所有 数位都必须使用。 …...

Python 管理 GitHub Secrets 和 Workflows
在现代软件开发中,自动化配置管理变得越来越重要。本文将介绍如何使用 Python 脚本来管理 GitHub 仓库的 Secrets 和 Workflows,这对于需要频繁更新配置或管理多个仓库的团队来说尤为有用。我们将分三个部分进行讨论:设置 GitHub 权限、创建 GitHub Secret 和创建 GitHub Wo…...

指令的修饰符
指令的修饰符 参考文献: Vue的快速上手 Vue指令上 Vue指令下 Vue指令的综合案例 文章目录 指令的修饰符指令修饰符 结语 博客主页: He guolin-CSDN博客 关注我一起学习,一起进步,一起探索编程的无限可能吧!让我们一起努力&…...

C# 正则表达式完全指南
C# 正则表达式完全指南 C#通过 System.Text.RegularExpressions 命名空间提供强大的正则表达式支持。本指南将详细介绍C#中正则表达式的使用方法、性能优化和最佳实践。 1. 基础知识 1.1 命名空间导入 using System.Text.RegularExpressions;1.2 基本使用 public class Re…...

基于距离变化能量开销动态调整的WSN低功耗拓扑控制开销算法matlab仿真
目录 1.程序功能描述 2.测试软件版本以及运行结果展示 3.核心程序 4.算法仿真参数 5.算法理论概述 6.参考文献 7.完整程序 1.程序功能描述 通过动态调整节点通信的能量开销,平衡网络负载,延长WSN生命周期。具体通过建立基于距离的能量消耗模型&am…...

微软PowerBI考试 PL300-选择 Power BI 模型框架【附练习数据】
微软PowerBI考试 PL300-选择 Power BI 模型框架 20 多年来,Microsoft 持续对企业商业智能 (BI) 进行大量投资。 Azure Analysis Services (AAS) 和 SQL Server Analysis Services (SSAS) 基于无数企业使用的成熟的 BI 数据建模技术。 同样的技术也是 Power BI 数据…...

蓝桥杯 2024 15届国赛 A组 儿童节快乐
P10576 [蓝桥杯 2024 国 A] 儿童节快乐 题目描述 五彩斑斓的气球在蓝天下悠然飘荡,轻快的音乐在耳边持续回荡,小朋友们手牵着手一同畅快欢笑。在这样一片安乐祥和的氛围下,六一来了。 今天是六一儿童节,小蓝老师为了让大家在节…...

系统设计 --- MongoDB亿级数据查询优化策略
系统设计 --- MongoDB亿级数据查询分表策略 背景Solution --- 分表 背景 使用audit log实现Audi Trail功能 Audit Trail范围: 六个月数据量: 每秒5-7条audi log,共计7千万 – 1亿条数据需要实现全文检索按照时间倒序因为license问题,不能使用ELK只能使用…...

2021-03-15 iview一些问题
1.iview 在使用tree组件时,发现没有set类的方法,只有get,那么要改变tree值,只能遍历treeData,递归修改treeData的checked,发现无法更改,原因在于check模式下,子元素的勾选状态跟父节…...

Python爬虫(一):爬虫伪装
一、网站防爬机制概述 在当今互联网环境中,具有一定规模或盈利性质的网站几乎都实施了各种防爬措施。这些措施主要分为两大类: 身份验证机制:直接将未经授权的爬虫阻挡在外反爬技术体系:通过各种技术手段增加爬虫获取数据的难度…...
)
【RockeMQ】第2节|RocketMQ快速实战以及核⼼概念详解(二)
升级Dledger高可用集群 一、主从架构的不足与Dledger的定位 主从架构缺陷 数据备份依赖Slave节点,但无自动故障转移能力,Master宕机后需人工切换,期间消息可能无法读取。Slave仅存储数据,无法主动升级为Master响应请求ÿ…...

Caliper 配置文件解析:config.yaml
Caliper 是一个区块链性能基准测试工具,用于评估不同区块链平台的性能。下面我将详细解释你提供的 fisco-bcos.json 文件结构,并说明它与 config.yaml 文件的关系。 fisco-bcos.json 文件解析 这个文件是针对 FISCO-BCOS 区块链网络的 Caliper 配置文件,主要包含以下几个部…...

免费PDF转图片工具
免费PDF转图片工具 一款简单易用的PDF转图片工具,可以将PDF文件快速转换为高质量PNG图片。无需安装复杂的软件,也不需要在线上传文件,保护您的隐私。 工具截图 主要特点 🚀 快速转换:本地转换,无需等待上…...

用 Rust 重写 Linux 内核模块实战:迈向安全内核的新篇章
用 Rust 重写 Linux 内核模块实战:迈向安全内核的新篇章 摘要: 操作系统内核的安全性、稳定性至关重要。传统 Linux 内核模块开发长期依赖于 C 语言,受限于 C 语言本身的内存安全和并发安全问题,开发复杂模块极易引入难以…...