YOLO目标检测4
一. 参考资料
《YOLO目标检测》 by 杨建华博士
本篇文章的主要内容来自于这本书,只是作为学习记录进行分享。

二. 环境搭建
(1) ubuntu20.04 anaconda安装方法
(2) 搭建yolo训练环境
# 首先,我们建议使用Anaconda来创建一个conda的虚拟环境
conda create -n yolo python=3.6
# 然后, 请激活已创建的虚拟环境
conda activate yolo
# 接着,配置环境:
pip install -r requirements.txt
# 项目作者所使用的环境配置:PyTorch = 1.9.1
Torchvision = 0.10.1
# 为了能够正常运行该项目的代码,请确保您的torch版本为1.x系列。三. YOLOv1代码解读
3.1 YOLOv1整体框架
# YOLO_Tutorial/models/yolov1/yolov1.py
# --------------------------------------------------------
...class YOLOv1(nn.Module):def __init__(self, cfg, device, input_size, num_classes,
trainable, conf_thresh, nms_thresh):super(YOLOv1, self).__init__()self.cfg=cfg # 模型配置文件self.device=device # 设备、CUDA或CPUself.num_classes=num_classes # 类别的数量self.trainable=trainable # 训练的标记self.conf_thresh=conf_thresh # 得分阈值self.nms_thresh=nms_thresh # NMS阈值self.stride=32 # 网络的最大步长# >>>>>>>>>>>>>>>>>>>> 主干网络 <<<<<<<<<<<<<<<<<<<<<# TODO: 构建我们的backbone网络# self.backbone=?# >>>>>>>>>>>>>>>>>>>> 颈部网络 <<<<<<<<<<<<<<<<<<<<<# TODO: 构建我们的neck网络# self.neck=?# >>>>>>>>>>>>>>>>>>>> 检测头 <<<<<<<<<<<<<<<<<<<<<# TODO: 构建我们的detection head 网络# self.head=?# >>>>>>>>>>>>>>>>>>>> 预测层 <<<<<<<<<<<<<<<<<<<<<# TODO: 构建我们的预测层# self.pred=?def create_grid(self, input_size):# TODO: 用于生成网格坐标矩阵def decode_boxes(self, pred):# TODO: 解算边界框坐标def nms(self, bboxes, scores):# TODO: 非极大值抑制操作def postprocess(self, bboxes, scores):# TODO: 后处理, 包括得分阈值筛选和NMS操作@torch.no_grad()def inference(self, x):# TODO: YOLOv1前向推理def forward(self, x, targets=None):# TODO: YOLOv1的主体运算函数3.2 YOLOv1主干网络
作者改进的YOLOv1使用较轻量的ResNet-18作为主干网络。由于PyTorch官方已提供了ResNet的源码和相应的预训练模型,因此,这里就不需要我们自己去搭建ResNet的网络和训练了。为了方便调用和查看,ResNet的代码文件放在项目中models/yolov1/yolov1_backbone.py文件下,感兴趣的读者可以打开该文件来查看ResNet网络的代码。在确定了主干网络后,我们只需在YOLOv1框架中编写代码即可调用ResNet-18网络,如代码4-5所示。
# >>>>>>>>>>>>>>>>>>>>主干网络<<<<<<<<<<<<<<<<<<<<<
# TODO:构建我们的backbone网络
self.backbone,feat_dim=build_backbone(cfg['backbone'],trainable&cfg['pretrained'])在代码4-5中,cfg是模型的配置文件,feat_dim变量是主干网络输出的特征图的通道数,这在后续的代码会使用到。我们通过trainable&cfg['pretrained']的组合来决定是否加载预训练权重。代码4-6展示了模型的配置文件所包含的一些参数,包括网络结构的参数、损失函数所需的权重参数、优化器参数以及一些训练配置参数等,每个参数的含义都已标注在注释中。
# YOLO_Tutorial/config/mode1_config/yolov1_config.py
# --------------------------------------------------------
...yolov1_cfg={# input'trans_type': 'ssd', # 使用SSD风格的数据增强'multi_scale': [0.5, 1.5], # 多尺度的范围# model'backbone': 'resnet18', # 使用ResNet-18作为主干网络'pretrained': True, # 加载预训练权重'stride': 32, # P5 # 网络的最大输出步长# neck'neck': 'sppf', # 使用SPP作为颈部网络'expand_ratio': 0.5, # SPP的模型参数'pooling_size': 5, # SPP的模型参数'neck_act': 'lrelu', # SPP的模型参数'neck_norm': 'BN', # SPP的模型参数'neck_depthwise': False, # SPP的模型参数# head'head': 'decoupled_head', # 使用解耦检测头'head_act': 'lrelu', # 检测头所需的参数'head_norm': 'BN', # 检测头所需的参数'num_cls_head': 2, # 解耦检测头的类别分支所包含的卷积层数'num_reg_head': 2, # 解耦检测头的回归分支所包含的卷积层数'head_depthwise': False, # 检测头所需的参数# loss weight'loss_obj_weight': 1.0, # obj损失的权重'loss_cls_weight': 1.0, # cls损失的权重'loss_box_weight': 5.0, # box损失的权重# training configuration'no_aug_epoch': -1, # 关闭马赛克增强和混合增强的节点# optimizer'optimizer': 'sgd', # 使用SGD优化器'momentum': 0.937, # SGD优化器的momentum参数'weight_decay': 5e-4, # SGD优化器的weight_decay参数'clip_grad': 10, # 梯度剪裁参数# model EMA'ema_decay': 0.9999, # 模型EMA参数'ema_tau': 2000, # 模型EMA参数# lr schedule'scheduler': 'linear', # 使用线性学习率衰减策略'lr0': 0.01, # 初始学习率'lrf': 0.01, # 最终的学习率=lr0 * lrf'warmup_momentum': 0.8, # Warmup阶段, 优化器的momentum参数的初始值'warmup_bias_lr': 0.1, # Warmup阶段, 优化器为模型的bias参数设置的学习率初始值
}3.3 YOLOv1颈部网络
作者改进的YOLOv1选择SPP模块作为颈部网络。SPP网络的结构非常简单,仅由若干不同尺寸的核的最大池化层所组成,实现起来也非常地简单,相关代码我们已经在前面展示了。而在YOLOv1中,我们直接调用相关的函数来使用SPP即可,如代码4-7所示。
# >>>>>>>>>>>>>>>>>>>> 颈部网络 <<<<<<<<<<<<<<<<<<<<<
# TODO: 构建我们的颈部网络
self.neck=build_neck(cfg, feat_dim, out_dim=512)
head_dim=self.neck.out_dim3.4 YOLOv1检测头
有关检测头的代码和预测层相关的代码已经在前面介绍过了,这里,我们只需要调用相关的函数来使用解耦检测头,然后再使用卷积创建预测层,如代码4-8所示。
# >>>>>>>>>>>>>>>>>>>> 检测头 <<<<<<<<<<<<<<<<<<<<<
# TODO: 构建我们的detection head 网络
## 检测头
self.head=build_head(cfg, head_dim, head_dim, num_classes)# >>>>>>>>>>>>>>>>>>>> 预测层 <<<<<<<<<<<<<<<<<<<<<
# TODO: 构建我们的预测层
self.obj_pred=nn.Conv2d(head_dim, 1, kernel_size=1)
self.cls_pred=nn.Conv2d(head_dim, num_classes, kernel_size=1)
self.reg_pred=nn.Conv2d(head_dim, 4, kernel_size=1)3.5 YOLOv1前向推理函数
在上述所示的推理代码中,作者对pred操作执行了view操作,将和
两个维度合并到一起,由于这之后不会再有任何卷积操作了,而仅仅是要计算损失,因此,将输出张量的维度从
调整为
的目的仅是方便后续的损失计算和后处理,而不会造成其他不必要的负面影响。
def forward(self, x):if not self.trainable:return self.inference(x)else:# 主干网络feat=self.backbone(x)# 颈部网络feat=self.neck(feat)# 检测头cls_feat, reg_feat=self.head(feat)# 预测层obj_pred=self.obj_pred(cls_feat)cls_pred=self.cls_pred(cls_feat)reg_pred=self.reg_pred(reg_feat)fmp_size=obj_pred.shape[-2:]# 对pred 的size做一些调整, 便于后续的处理# [B, C, H, W] -> [B, H, W, C] -> [B, H*W, C]obj_pred=obj_pred.permute(0, 2, 3, 1).contiguous().flatten(1, 2)cls_pred=cls_pred.permute(0, 2, 3, 1).contiguous().flatten(1, 2)reg_pred=reg_pred.permute(0, 2, 3, 1).contiguous().flatten(1, 2)# 解耦边界框box_pred=self.decode_boxes(reg_pred, fmp_size)# 网络输出outputs={"pred_obj": obj_pred, # (Tensor) [B, M, 1]"pred_cls": cls_pred, # (Tensor) [B, M, C]"pred_box": box_pred, # (Tensor) [B, M, 4]"stride": self.stride, # (Int)"fmp_size": fmp_size # (List) [fmp_h, fmp_w]}return outputs另外,在测试阶段,我们只需要推理当前输入图像,无须计算损失,所以我们单独实现了一个inference函数,如代码4-10所示。
@torch.no_grad()
def inference(self, x):# 主干网络feat=self.backbone(x)# 颈部网络feat=self.neck(feat)# 检测头cls_feat, reg_feat=self.head(feat)# 预测层obj_pred=self.obj_pred(cls_feat)cls_pred=self.cls_pred(cls_feat)reg_pred=self.reg_pred(reg_feat)fmp_size=obj_pred.shape[-2:]# 对pred 的size做一些调整, 便于后续的处理# [B, C, H, W] -> [B, H, W, C] -> [B, H*W, C]obj_pred=obj_pred.permute(0, 2, 3, 1).contiguous().flatten(1, 2)cls_pred=cls_pred.permute(0, 2, 3, 1).contiguous().flatten(1, 2)reg_pred=reg_pred.permute(0, 2, 3, 1).contiguous().flatten(1, 2)# 测试时, 默认batch是1# 因此, 我们不需要用batch这个维度, 用[0]将其取走obj_pred=obj_pred[0] # [H*W, 1]cls_pred=cls_pred[0] # [H*W, NC]reg_pred=reg_pred[0] # [H*W, 4]# 每个边界框的得分scores=torch.sqrt(obj_pred.sigmoid() * cls_pred.sigmoid())# 解算边界框, 并归一化边界框: [H*W, 4]bboxes=self.decode_boxes(reg_pred, fmp_size)# 将预测放在CPU处理上, 以便进行后处理scores=scores.cpu().numpy()bboxes=bboxes.cpu().numpy()# 后处理bboxes, scores, labels=self.postprocess(bboxes, scores)return bboxes, scores, labels在上面的用于推理的代码中,装饰器@torch.no_grad()表示该inference函数不会存在任何梯度,因为推理阶段不会涉及反向传播,无须计算变量的梯度。在这段代码中,多了一个后处理postprocess函数的调用,将在后续进行说明。
至此,我们搭建完了YOLOv1的网络,只需将上面的单独实现分别对号入座地加入YOLOv1的网络框架里。最后,我们就可以获得网络的3个预测分支的输出。但是,这里还遗留下了以下3个问题尚待处理。
(1) 如何有效地计算出边界框的左上角点坐标和右下角点坐标。
(2) 如何计算3个分支的损失。
(3) 如何对预测结果进行后处理。
3.6 YOLOv1的后处理
(1) 求解预测边界框的坐标
对于某一处的网格,YOLOv1输出的边界框的中心点偏移量预测为
和
,宽和高的对数映射预测为
和
,我们使用公式(4-6)即可解算出边界框的中心点坐标
和
与宽高
和
其中,是Sigmoid函数。从公式中可以看出,为了计算预测的边界框的中心点坐标,我们需要获得网格的坐标
,因为我们的YOLOv1也是在每个网格预测偏移量,从而获得精确的边界框中心点坐标。直接的方法就是遍历每一个网格,以获取网格坐标,然后加上此处预测的偏移量即可获得此处预测出的边界框中心点坐标,但是这种for循环操作的效率不高。在一般情况下,能用矩阵运算来实现的操作就尽量避免使用for循环,因为不论是GPU还是CPU,矩阵运算都是可以并行处理的,开销更小,因此,这里我们采用一个讨巧的等价方法。
在计算边界框坐标之前,先生成一个保存网格所有坐标的矩阵,其中
和
是输出的特征图的空间尺寸,2是网格的横纵坐标。
就是输出特征图上
处的网格坐标
,即
,
,如图4-7所示。

所以,在清楚了G矩阵的含义后,我们便可以编写相应的代码来生成G矩阵,如代码4-11所示。
def create_grid(self, input_size):# 输入图像的宽和高w, h=input_size, input_size# 特征图的宽和高ws, hs=w // self.stride, h // self.stride# 生成网格的x坐标和y坐标grid_y, grid_x=torch.meshgrid([torch.arange(hs), torch.arange(ws)])# 将x和y两部分的坐标拼起来:[H, W, 2]grid_xy=torch.stack([grid_x, grid_y], dim=-1).float()# [H, W, 2] -> [HW, 2]grid_xy=grid_xy.view(-1, 2).to(self.device)return grid_xy注意,为了后续解算边界框的方便,将grid_xy的维度调整成的形式,因为在讲解YOLOv1的前向推理的代码时,输出的txtytwth_pred的维度被调整为
的形式,这里我们为了保持维度一致,也做了同样的处理。在得到了G矩阵之后,我们就可以很容易计算边界框的位置参数了,包括边界框的中心点坐标、宽、高、左上角点坐标和右下角点坐标,代码4-12展示了这一计算过程。
def decode_boxes(self, pred, fmp_size):"""将txtytwth转换为常用的x1y1x2y2形式"""# 生成网格坐标矩阵grid_cell=self.create_grid(fmp_size)# 计算预测边界框的中心点坐标、宽和高pred_ctr=(torch.sigmoid(pred[..., :2]) + grid_cell) * self.stridepred_wh=torch.exp(pred[..., 2:]) * self.stride# 将所有边界框的中心点坐标、宽和高换算成x1y1x2y2形式pred_x1y1=pred_ctr - pred_wh * 0.5pred_x2y2=pred_ctr + pred_wh * 0.5pred_box=torch.cat([pred_x1y1, pred_x2y2], dim=-1)return pred_box最终,我们会得到边界框的左上和右下角点坐标。
3.7 后处理
当我们得到了边界框的位置参数后,我们还需要对预测结果做进一步的后处理,滤除那些得分低的边界框和检测到同一目标的冗余框。因此,后处理的主要作用可以总结为两点:
(1)滤除得分低的低质量边界框;
(2)滤除对同一目标的冗余检测结果,即非极大值抑制(NMS)处理。在清楚了后处理的逻辑和目的后,我们就可以编写相应的代码了,如代码4-13所示。
def postprocess(self, bboxes, scores):# 将得分最高的类别作为预测的类别标签labels=np.argmax(scores, axis=1)# 预测标签所对应的得分scores=scores[(np.arange(scores.shape[0]), labels)]# 阈值筛选keep=np.where(scores >=self.conf_thresh)bboxes=bboxes[keep]scores=scores[keep]labels=labels[keep]# 非极大值抑制keep=np.zeros(len(bboxes), dtype=np.int)for i in range(self.num_classes):inds=np.where(labels==i)[0]if len(inds)==0:continuec_bboxes=bboxes[inds]c_scores=scores[inds]c_keep=self.nms(c_bboxes, c_scores)keep[inds[c_keep]]=1keep=np.where(keep > 0)bboxes=bboxes[keep]scores=scores[keep]labels=labels[keep]return bboxes, scores, labels我们采用十分经典的基于Python语言实现的代码作为本文的非极大值抑制。在入门阶段,希望读者能够将这段代码烂熟于心,这毕竟是此领域的必备算法之一。相关代码如代码4-14所示。
def nms(self, bboxes, scores):"""Pure Python NMS baseline."""x1=bboxes[:, 0] #xminy1=bboxes[:, 1] #yminx2=bboxes[:, 2] #xmaxy2=bboxes[:, 3] #ymaxareas=(x2 - x1) * (y2 - y1)order=scores.argsort()[::-1]keep=[]while order.size > 0:i=order[0]keep.append(i)# 计算交集的左上角点和右下角点的坐标xx1=np.maximum(x1[i], x1[order[1:]])yy1=np.maximum(y1[i], y1[order[1:]])xx2=np.minimum(x2[i], x2[order[1:]])yy2=np.minimum(y2[i], y2[order[1:]])# 计算交集的宽和高w=np.maximum(1e-10, xx2 - xx1)h=np.maximum(1e-10, yy2 - yy1)# 计算交集的面积inter=w * h# 计算交并比iou=inter / (areas[i] + areas[order[1:]] - inter)# 滤除超过NMS阈值的边界框inds=np.where(iou <=self.nms_thresh)[0]order=order[inds + 1]return keep经过后处理后,我们得到了最终的3个输出变量:
(1)变量bboxes,包含每一个边界框的左上角坐标和右下角坐标;
(2)变量scores,包含每一个边界框的得分;
(3)变量labels,包含每一个边界框的类别预测。
至此,我们填补了之前留下来的空白,只需要将上面实现的每一个函数放置到YOLOv1的代码框架中,即可组成最终的模型代码。读者可以打开项目中的models/yolov1/yolov1.py文件来查看完整的YOLOv1的模型代码。
四.代码
https://github.com/Tipriest/Lessons/tree/master/YOLO/YOLO_Tutorialhttps://github.com/Tipriest/Lessons/tree/master/YOLO/YOLO_Tutorialhttps://github.com/Tipriest/Lessons/tree/master/YOLO/YOLO_Tutorialhttps://github.com/Tipriest/Lessons/tree/master/YOLO/YOLO_Tutorialhttps://github.com/Tipriest/Lessons/tree/master/YOLO/YOLO_Tutorialhttps://github.com/Tipriest/Lessons/tree/master/YOLO/YOLO_Tutorial![]() https://github.com/Tipriest/Lessons/tree/master/YOLO/YOLO_Tutorial
https://github.com/Tipriest/Lessons/tree/master/YOLO/YOLO_Tutorial
相关文章:
YOLO目标检测4
一. 参考资料 《YOLO目标检测》 by 杨建华博士 本篇文章的主要内容来自于这本书,只是作为学习记录进行分享。 二. 环境搭建 (1) ubuntu20.04 anaconda安装方法 (2) 搭建yolo训练环境 # 首先,我们建议使用Anaconda来创建一个conda的虚拟环境 conda cre…...

十三先天记
没有一刻,只有当下在我心里。我像星星之间的空间一样空虚。他们是我看到的第一件事,我知道的第一件事。 在接下来的时间里,我意识到我是谁,我是谁。我知道星星在我上方,星球的固体金属体在我脚下。这个支持我的世界是泰…...

【论文阅读笔记】“万字”关于深度学习的图像和视频阴影检测、去除和生成的综述笔记 | 2024.9.3
论文“Unveiling Deep Shadows: A Survey on Image and Video Shadow Detection, Removal, and Generation in the Era of Deep Learning”内容包含第1节简介、第2-5节分别对阴影检测、实例阴影检测、阴影去除和阴影生成进行了全面的综述。第6节深入讨论了阴影分析࿰…...

Android AOP:aspectjx
加入引用 在整个项目的 build.gradle 中,添加 classpath "com.hujiang.aspectjx:gradle-android-plugin-aspectjx:2.0.10" 可以看到测试demo的 gradle 版本是很低的。 基于 github 上的文档,可以看到原版只支持到 gradle 4.4 。后续需要使…...

前端【11】HTML+CSS+jQUery实战项目--实现一个简单的todolist
前端【8】HTMLCSSjavascript实战项目----实现一个简单的待办事项列表 (To-Do List)-CSDN博客 学过jQUery可以极大简化js代码的编写,基于之前实现的todolist小demo,了解如何使用 jQuery 来实现常见的动态交互功能。 修改后的js代码 关键点解析 动态添加…...

2025课题推荐——USBL与DVL数据融合的实时定位系统
准确的定位技术是现代海洋探测、海洋工程和水下机器人操作的基础。超短基线(USBL)和多普勒速度计(DVL)是常用的水下定位技术,但单一技术难以应对复杂环境。因此,USBL与DVL的数据融合以构建实时定位系统&…...

滑动窗口详解:解决无重复字符的最长子串问题
滑动窗口详解:解决无重复字符的最长子串问题 在算法面试中,“无重复字符的最长子串”问题是一个经典题目,不仅考察基础数据结构的运用,还能够反映你的逻辑思维能力。而在解决这个问题时,滑动窗口(Sliding …...

第05章 11 动量剖面可视化代码一则
在计算流体力学(CFD)中,动量剖面(Momentum Profiles)通常用于描述流体在流动方向上的动量分布。在 VTK 中,可以通过读取速度场数据,并计算和展示动量剖面来可视化呈现速度场信息。 示例代码 以…...

MySQL的复制
一、概述 1.复制解决的问题是让一台服务器的数据与其他服务器保持同步,即主库的数据可以同步到多台备库上,备库也可以配置成另外一台服务器的主库。这种操作一般不会增加主库的开销,主要是启用二进制日志带来的开销。 2.两种复制方式…...

Cpp::IO流(37)
文章目录 前言一、C语言的输入与输出二、什么是流?三、C IO流C标准IO流C文件IO流以写方式打开文件以读方式打开文件 四、stringstream的简单介绍总结 前言 芜湖,要结束喽! 一、C语言的输入与输出 C语言中我们用到的最频繁的输入输出方式就是 …...

基于OpenCV实现的答题卡自动判卷系统
一、图像预处理 🌄 二、查找答题卡轮廓 📏 三、透视变换 🔄 四、判卷与评分 🎯 五、主函数 六、完整代码+测试图像集 总结 🌟 在这篇博客中,我将分享如何使用Python结合OpenCV库开发一个答题卡自动判卷系统。这个系统能够自动从扫描的答题卡中提取信…...

如何将电脑桌面默认的C盘设置到D盘?详细操作步骤!
将电脑桌面默认的C盘设置到D盘的详细操作步骤! 本博文介绍如何将电脑桌面(默认为C盘)设置在D盘下。 首先,在D盘建立文件夹Desktop,完整的路径为D:\Desktop。winR,输入Regedit命令。(或者单击【…...

二十三种设计模式-享元模式
享元模式(Flyweight Pattern)是一种结构型设计模式,旨在通过共享相同对象来减少内存使用,尤其适合在大量重复对象的情况下。 核心概念 享元模式的核心思想是将对象的**可共享部分(内部状态)提取出来进行共…...

算法【有依赖的背包】
有依赖的背包是指多个物品变成一个复合物品(互斥),每件复合物品不要和怎么要多种可能性展开。时间复杂度O(物品个数 * 背包容量),额外空间复杂度O(背包容量)。 下面通过题目加深理解。 题目一 测试链接:[NOIP2006 提…...

A7. Jenkins Pipeline自动化构建过程,可灵活配置多项目、多模块服务实战
服务容器化构建的环境配置构建前需要解决什么下面我们带着问题分析构建的过程:1. 如何解决jenkins执行环境与shell脚本执行环境不一致问题?2. 构建之前动态修改项目的环境变量3. 在通过容器打包时避免不了会产生比较多的不可用的镜像资源,这些资源要是不及时删除掉时会导致服…...

飞牛NAS新增虚拟机功能,如果使用虚拟机网卡直通安装ikuai软路由(如何解决OVS网桥绑定失败以及打开ovs后无法访问飞牛nas等问题)
文章目录 📖 介绍 📖🏡 演示环境 🏡📒 飞牛NAS虚拟机安装爱快教程 📒🛠️ 前期准备🌐 网络要求💾 下载爱快镜像🚀 开始安装💻 开启IOMMU直通🌐 配置网络🚨 解决OVS网桥绑定失败以及打开ovs后无法访问飞牛nas等问题➕ 创建虚拟机🎯 安装ikuai💻 进…...

蓝桥杯例题四
每个人都有无限潜能,只要你敢于去追求,你就能超越自己,实现梦想。人生的道路上会有困难和挑战,但这些都是成长的机会。不要被过去的失败所束缚,要相信自己的能力,坚持不懈地努力奋斗。成功需要付出汗水和努…...

八股——Java基础(四)
目录 一、泛型 1. Java中的泛型是什么 ? 2. 使用泛型的好处是什么? 3. Java泛型的原理是什么 ? 什么是类型擦除 ? 4.什么是泛型中的限定通配符和非限定通配符 ? 5. List和List 之间有什么区别 ? 6. 可以把List传递给一个接受List参数的方法吗? 7. Arra…...

CVE-2023-38831 漏洞复现:win10 压缩包挂马攻击剖析
目录 前言 漏洞介绍 漏洞原理 产生条件 影响范围 防御措施 复现步骤 环境准备 具体操作 前言 在网络安全这片没有硝烟的战场上,新型漏洞如同隐匿的暗箭,时刻威胁着我们的数字生活。其中,CVE - 2023 - 38831 这个关联 Win10 压缩包挂…...

【自然语言处理(NLP)】深度循环神经网络(Deep Recurrent Neural Network,DRNN)原理和实现
文章目录 介绍深度循环神经网络(DRNN)原理和实现结构特点工作原理符号含义公式含义 应用领域优势与挑战DRNN 代码实现 个人主页:道友老李 欢迎加入社区:道友老李的学习社区 介绍 **自然语言处理(Natural Language Pr…...

3.3.1_1 检错编码(奇偶校验码)
从这节课开始,我们会探讨数据链路层的差错控制功能,差错控制功能的主要目标是要发现并且解决一个帧内部的位错误,我们需要使用特殊的编码技术去发现帧内部的位错误,当我们发现位错误之后,通常来说有两种解决方案。第一…...
)
IGP(Interior Gateway Protocol,内部网关协议)
IGP(Interior Gateway Protocol,内部网关协议) 是一种用于在一个自治系统(AS)内部传递路由信息的路由协议,主要用于在一个组织或机构的内部网络中决定数据包的最佳路径。与用于自治系统之间通信的 EGP&…...

uni-app学习笔记二十二---使用vite.config.js全局导入常用依赖
在前面的练习中,每个页面需要使用ref,onShow等生命周期钩子函数时都需要像下面这样导入 import {onMounted, ref} from "vue" 如果不想每个页面都导入,需要使用node.js命令npm安装unplugin-auto-import npm install unplugin-au…...

java调用dll出现unsatisfiedLinkError以及JNA和JNI的区别
UnsatisfiedLinkError 在对接硬件设备中,我们会遇到使用 java 调用 dll文件 的情况,此时大概率出现UnsatisfiedLinkError链接错误,原因可能有如下几种 类名错误包名错误方法名参数错误使用 JNI 协议调用,结果 dll 未实现 JNI 协…...

工程地质软件市场:发展现状、趋势与策略建议
一、引言 在工程建设领域,准确把握地质条件是确保项目顺利推进和安全运营的关键。工程地质软件作为处理、分析、模拟和展示工程地质数据的重要工具,正发挥着日益重要的作用。它凭借强大的数据处理能力、三维建模功能、空间分析工具和可视化展示手段&…...

Python爬虫(一):爬虫伪装
一、网站防爬机制概述 在当今互联网环境中,具有一定规模或盈利性质的网站几乎都实施了各种防爬措施。这些措施主要分为两大类: 身份验证机制:直接将未经授权的爬虫阻挡在外反爬技术体系:通过各种技术手段增加爬虫获取数据的难度…...

【JavaSE】绘图与事件入门学习笔记
-Java绘图坐标体系 坐标体系-介绍 坐标原点位于左上角,以像素为单位。 在Java坐标系中,第一个是x坐标,表示当前位置为水平方向,距离坐标原点x个像素;第二个是y坐标,表示当前位置为垂直方向,距离坐标原点y个像素。 坐标体系-像素 …...

uniapp 开发ios, xcode 提交app store connect 和 testflight内测
uniapp 中配置 配置manifest 文档:manifest.json 应用配置 | uni-app官网 hbuilderx中本地打包 下载IOS最新SDK 开发环境 | uni小程序SDK hbulderx 版本号:4.66 对应的sdk版本 4.66 两者必须一致 本地打包的资源导入到SDK 导入资源 | uni小程序SDK …...
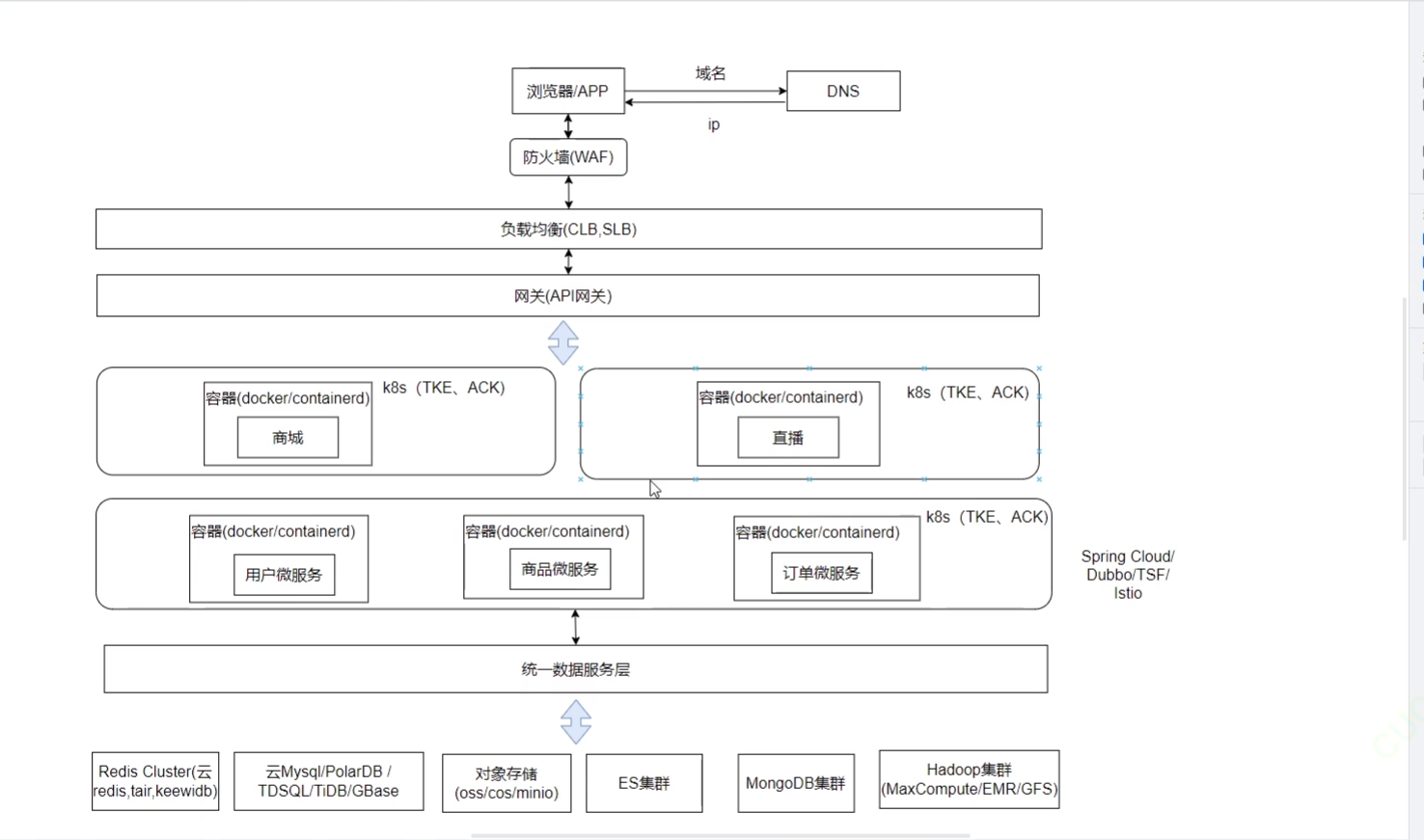
《Docker》架构
文章目录 架构模式单机架构应用数据分离架构应用服务器集群架构读写分离/主从分离架构冷热分离架构垂直分库架构微服务架构容器编排架构什么是容器,docker,镜像,k8s 架构模式 单机架构 单机架构其实就是应用服务器和单机服务器都部署在同一…...

第八部分:阶段项目 6:构建 React 前端应用
现在,是时候将你学到的 React 基础知识付诸实践,构建一个简单的前端应用来模拟与后端 API 的交互了。在这个阶段,你可以先使用模拟数据,或者如果你的后端 API(阶段项目 5)已经搭建好,可以直接连…...