记6(人工神经网络
目录
- 1、M-P神经元
- 2、感知机
- 3、Delta法则
- 4、前馈型神经网络(Feedforward Neural Networks)
- 5、鸢尾花数据集——单层前馈型神经网络:
- 6、多层神经网络:增加隐含层
- 7、实现异或运算(01、10为1,00、11为0)
- 8、线性不可分问题
- 9、万能近似定理
- 10、超参数与验证集
- 11、误差反向传播算法(Backpropagation, BP)
1、M-P神经元
- M-P神经元:1943,McCulloch,Pitts
x1,x2,x3…模拟神经元的树突,接受信号,wi表示权重,对输入xi加权求和后与θ比较得到z,再传入阶跃函数得到输出y。但是不具备学习能力。

2、感知机
模型和上图一样,输入层xi不需要计算,只有输出层发生计算,层数只有一层。
具备学习能力,有多个解,受权值初始值和错误样本顺序影响。
线性二分类器,对非线性问题无法收敛。

单个感知机实现二分类问题,多个感知机(就是多个输出)能实现多分类问题(就是前面所说的softmax回归) :

3、Delta法则
就是前面的逻辑回归,用step()函数或sigmoid()函数,逻辑回归可以看做是单层神经网络
4、前馈型神经网络(Feedforward Neural Networks)
每层只与前一层神经元相连;同一层之间没有连接;各层间没有反馈,不存在跨层连接
全连接网络(Full Connnected Network):前一层(左边)的节点都与后一层(右边)的节点连接,且后一层的节点都接受来自前一层的所有输入。
5、鸢尾花数据集——单层前馈型神经网络:
- 设计:
结构:单层前馈型神经网络
激活函数:softmax函数;
损失函数:交叉熵损失函数;
- 实现:如下图,输入是训练集的120条数据,含4条属性/数据,输出是3个标签(独热编码表示为1*3向量),将之前的模型参数W(Y=WX)的第一行参数分离出来,即Y=WX+B(以便实现多层神经网络时更加方便直观)。使用独热编码(见上一篇笔记)

- softmax函数:tf.nn.softmax(tf.matmul(X_train,W)+b)
- 自然顺序码转化为独热编码(需要先转换为浮点数):tf.one_hot(tf.constant(y_test,dtype=tf.int32),3)
- 交叉熵损失函数:tf.keras.losses.categorical_crossentropy(y_true,y_pred)
y_true:独热编码的标签值
y_pred:softmax函数的输出值
输出是一个一维张量,其中的每个元素是每个样品的交叉熵损失,因此需要用求平均值函数- 设置运行时分配显存(如果出现错误:Blast GEMMlaunch failed:):
gpus=tf.config.experimental.list_physical_devices('GPU')
for gpu in gpus:tf.config.experimental.set_memory_growth(gpu,True)
返回张量最大值的索引:tf.argmax(input_tensor,axis=0)(见TensorFlow笔记3)
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
#读取文件,详见Python笔记10
train_path=tf.keras.utils.get_file("iris.csv", origin=None) #获取文件的绝对路径
df_iris=pd.read_csv(train_path,header=0) #结果是panda的二维数据表
iris=np.array(df_iris) #将二维数据表类型转化为二维数组类型,shape=(150,6),与视频中不一样,索引号为0的是序号
x=iris[:,1:5] #索引号1~4列属性:花瓣长度和宽度,x.shape=(150, 2)
y=iris[:,5] #train_y.shape=(150,)x_svv=np.concatenate((np.stack(x[y=='setosa']), #选取2种花,以及其前2种属性np.stack(x[y=='versicolor']),np.stack(x[y=='virginica'])),axis=0)
y_svv=np.concatenate((np.zeros(np.where(y=='setosa')[0].size), #元组只有一个元素(数组)np.ones(np.where(y=='versicolor')[0].size),2*np.ones(np.where(y=='virginica')[0].size),),axis=0)np.random.seed(612)
iris_rand=np.concatenate((x_svv,np.expand_dims(y_svv,axis=1)),axis=1)
np.random.shuffle(iris_rand) #打乱数组,并选前面120条数据为训练集,后面30条做测试集
x_train=tf.constant(iris_rand[:120,0:4],dtype=tf.float32) #转化为float32张量
y_train=tf.constant(iris_rand[:120,4],dtype=tf.int64) #转化为int32张量
x_test=tf.constant(iris_rand[120:,0:4],dtype=np.float32)
y_test=tf.constant(iris_rand[120:,4],dtype=tf.int64)X_train=x_train-tf.reduce_mean(x_train,axis=0) #中心化, x_train.dtype=dtype('O'),是object
X_test=x_test-tf.reduce_mean(x_test,axis=0)
Y_train=tf.one_hot(y_train,3) #转化为独热编码Y_train.shape=TensorShape([120, 3])
Y_test=tf.one_hot(y_test,3)learn_rate=0.5 #超参数——学习率
iter=50 #迭代次数
display_step=10 #设置每迭代10次输出结果,方便查看
np.random.seed(612)
W=tf.Variable(np.random.randn(4,3),dtype=tf.float32) #W列向量,4行3列
B=tf.Variable(np.zeros([3]),dtype=tf.float32) #B列向量,长度为3的一维张量cce_train=[] #保存交叉熵损失
cce_test=[]
acc_train=[] #保存准确率
acc_test=[]#训练模型
for i in range(0,iter+1):with tf.GradientTape() as tape:#softmax函数,PRED_train是120*3的张量,每行3个元素表属于某个样品的预测概率PRED_train=tf.nn.softmax(tf.matmul(X_train,W)+B) #shape=TensorShape([120, 3])Loss_train=tf.reduce_mean(tf.keras.losses.categorical_crossentropy(y_true=Y_train, y_pred=PRED_train))PRED_test=tf.nn.softmax(tf.matmul(X_test,W)+B)Loss_test=tf.reduce_mean(tf.keras.losses.categorical_crossentropy(y_true=Y_test, y_pred=PRED_test))#准确率,求PRED_train的每一行3个元素的max,即属于对应标签的概率最大,再与真实值y_train比较,求得准确率Accuracy_train=tf.reduce_mean(tf.cast(tf.equal(tf.argmax(PRED_train,axis=1),y_train),tf.float32))Accuracy_test=tf.reduce_mean(tf.cast(tf.equal(tf.argmax(PRED_test,axis=1),y_test),tf.float32)) cce_train.append(Loss_train)cce_test.append(Loss_test)acc_train.append(Accuracy_train)acc_test.append(Accuracy_test)grads=tape.gradient(Loss_train,[W,B])W.assign_sub(learn_rate*grads[0]) #dL_dWB.assign_sub(learn_rate*grads[1]) #dL_dBif i%display_step==0:print("i:%i,\tTrainAcc:%f,TrainLoss:%f\tTestAcc:%f,TestLoss:%f" %(i,Accuracy_train,Loss_train,Accuracy_test,Loss_test))#可视化,图1准确率,图2损失函数
plt.figure(figsize=(10,3))
plt.subplot(121)
plt.plot(cce_train,color="blue",label="train")
plt.plot(cce_test,color="red",label="test")
plt.xlabel("Iteration")
plt.ylabel("Loss")
plt.subplot(122)
plt.plot(acc_train,color="blue",label="train")
plt.plot(acc_test,color="red",label="test")
plt.xlabel("Iteration")
plt.ylabel("Accuracy")
plt.tight_layout() #自动调整子图
plt.show()输出:训练集和测试集损失都在下降,可以继续训练
i:0, TrainAcc:0.291667,TrainLoss:2.102095 TestAcc:0.366667,TestLoss:1.757901
i:10, TrainAcc:0.891667,TrainLoss:0.338472 TestAcc:0.933333,TestLoss:0.447548
i:20, TrainAcc:0.933333,TrainLoss:0.271075 TestAcc:0.900000,TestLoss:0.405325
i:30, TrainAcc:0.958333,TrainLoss:0.234893 TestAcc:0.833333,TestLoss:0.384106
i:40, TrainAcc:0.958333,TrainLoss:0.210969 TestAcc:0.766667,TestLoss:0.370561
i:50, TrainAcc:0.966667,TrainLoss:0.193312 TestAcc:0.766667,TestLoss:0.360828

6、多层神经网络:增加隐含层

7、实现异或运算(01、10为1,00、11为0)
采用2个感知机:一个感知机相当于一根直线,下图第1个感知机实现与运算(11–>1,其他–>0),第2个感知机实现或非运算(见下图红色横线处)

再进行叠加(对h1、h2进行或非运算),得到异或运算的模型(每个神经元,即感知机,有3个参数):

也可以使用以下运算(先进行或运算OR、或非运算NAND,再进行与运算AND):

8、线性不可分问题
可以转化为多个线性问题,每个线性问题用一个感知机(一个神经元下图第3图的橙色圈)表示一条直线,再用一个神经元将其组合起来(下图第3图绿色圈):

下图中1个四边形,1个六变形。需要用2个隐含层(下图红色框),用4个神经元(黄色圈)区分4边形,用6个神经元(橙色圈)区分6边形,再将2个图形组合起来(绿色圈)

9、万能近似定理
在前馈型神经网络中,只要有一个隐含层,并且这个隐含层中有足够多的神经元,就可以逼近任意一个连续的函数或空间分布
- 多隐含层神经网络:能够表示非连续的函数或空间区域、减少泛化误差、减少每层神经元的数量

10、超参数与验证集
例如:有2个超参数a、b,a∈{1,2,3},b∈{4,5,6,7},那么就有3*4种组合。使用同一个训练集训练每一种组合得到各种组合的模型,使用同一个验证集测试其误差(防止模型的过拟合),去除误差较大的模型,确定模型超参数,再在测试集评估模型的泛化能力。
11、误差反向传播算法(Backpropagation, BP)
误差反向传播算法(Backpropagation, BP):利用链式法则,反向传播损失函数的梯度信息,计算出损失函数对网络中所有模型参数的梯度(它计算的只是梯度,其本身不是学习算法,将梯度传递给其他算法,如梯度下降法,来学习更新模型的参数)
举个栗子:下面神经网络,输入值x=1时,真实值y=0.8,4个模型参数wh、bh、w0、b0,重复下面4个步骤:

step1:设置模型参数初始值:wh=0.2, bh=0.1, w0=0.3, b0=0.2
step2:正向计算预测值(即是计算预测值y0):
y h = 1 1 + e − ( 0.2 ∗ 1 + 0.1 ) = 0.57 y_h=\dfrac{1}{1+e^{-(0.2*1+0.1)}}=0.57 yh=1+e−(0.2∗1+0.1)1=0.57
y 0 = 1 1 + e − ( 0.3 ∗ 0.57 + 0.2 ) = 0.59 y_0=\dfrac{1}{1+e^{-(0.3*0.57+0.2)}}=0.59 y0=1+e−(0.3∗0.57+0.2)1=0.59
step3:计算误差:Loss=0.5*(y-y0)²=0.02205
step4:误差反向传播:

- 可以用TensorFlow自带求导自动求偏导,也可手动求,下面手动对w求偏导数的过程(用求导的链式求导即可):(图中有问题的:dLoss/dw0少了一个负号!!!)

同理,更新参数b0(和上面对w0求偏导比较,只有dz0/db0不同):

同理,更新隐含层模型参数wh、bh:


如果隐含层有多个神经元,那么误差反向传播,则按照权值wi按比例反向传播:

如果输出层有多个神经元,和上面同理:

相关文章:
记6(人工神经网络
目录 1、M-P神经元2、感知机3、Delta法则4、前馈型神经网络(Feedforward Neural Networks)5、鸢尾花数据集——单层前馈型神经网络:6、多层神经网络:增加隐含层7、实现异或运算(01、10为1,00、11为0)8、线性…...

stm32硬件实现与w25qxx通信
使用的型号为stm32f103c8t6与w25q64。 STM32CubeMX配置与引脚衔接 根据stm32f103c8t6引脚手册,采用B12-B15四个引脚与W25Q64连接,实现SPI通信。 W25Q64SCK(CLK)PB13MOSI(DI)PB15MISO(DO)PB14CS(…...

编程题-最接近的三数之和
题目: 给你一个长度为 n 的整数数组 nums 和 一个目标值 target。请你从 nums 中选出三个整数,使它们的和与 target 最接近。 返回这三个数的和。 假定每组输入只存在恰好一个解。 解法一(排序双指针): 题目要求找…...

索引的底层数据结构、B+树的结构、为什么InnoDB使用B+树而不是B树呢
索引的底层数据结构 MySQL中常用的是Hash索引和B树索引 Hash索引:基于哈希表实现的,查找速度非常快,但是由于哈希表的特性,不支持范围查找和排序,在MySQL中支持的哈希索引是自适应的,不能手动创建 B树的…...

【工欲善其事】利用 DeepSeek 实现复杂 Git 操作:从原项目剥离出子版本树并同步到新的代码库中
文章目录 利用 DeepSeek 实现复杂 Git 操作1 背景介绍2 需求描述3 思路分析4 实现过程4.1 第一次需求确认4.2 第二次需求确认4.3 第三次需求确认4.4 V3 模型:中间结果的处理4.5 方案验证,首战告捷 5 总结复盘 利用 DeepSeek 实现复杂 Git 操作 1 背景介绍…...

网络编程套接字(中)
文章目录 🍏简单的TCP网络程序服务端创建套接字服务端绑定服务端监听服务端获取连接服务端处理请求客户端创建套接字客户端连接服务器客户端发起请求服务器测试单执行流服务器的弊端 🍐多进程版的TCP网络程序捕捉SIGCHLD信号让孙子进程提供服务 …...
)
前端学习-事件委托(三十)
目录 前言 课前思考 for循环注册事件 语法 事件委托 1.事件委托的好处是什么? 2.事件委托是委托给了谁,父元素还是子元素 3.如何找到真正触发的元素 示例代码 总结 前言 才子佳人,自是白衣卿相 课前思考 1.如果同时给多个元素注册事件&…...

线程池以及在QT中的接口使用
文章目录 前言线程池架构组成**一、任务队列(Task Queue)****二、工作线程组(Worker Threads)****三、管理者线程(Manager Thread)** 系统协作流程图解 一、QRunnable二、QThreadPool三、线程池的应用场景W…...

c语言操作符(详细讲解)
目录 前言 一、算术操作符 一元操作符: 二元操作符: 二、赋值操作符 代码例子: 三、比较操作符 相等与不相等比较操作符: 大于和小于比较操作符: 大于等于和小于等于比较操作符: 四、逻辑操作符 逻辑与&…...

【自然语言处理(NLP)】深度学习架构:Transformer 原理及代码实现
文章目录 介绍Transformer核心组件架构图编码器(Encoder)解码器(Decoder) 优点应用代码实现导包基于位置的前馈网络残差连接后进行层规范化编码器 Block编码器解码器 Block解码器训练预测 个人主页:道友老李 欢迎加入社…...

JavaScript 入门教程
JavaScript 入门教程 JavaScript 入门教程引言学习 JavaScript 的好处常见的 JavaScript 框架和库 安装开发环境下载并安装 Node.js 和 npm安装常用开发工具(如 VS Code)配置本地开发环境 基础语法入门数据类型变量与常量运算符算术运算符比较运算符 条件…...

浅析CDN安全策略防范
CDN(内容分发网络)信息安全策略是保障内容分发网络在提供高效服务的同时,确保数据传输安全、防止恶意攻击和保护用户隐私的重要手段。以下从多个方面详细介绍CDN的信息安全策略: 1. 数据加密 数据加密是CDN信息安全策略的核心之…...
344.反转字符串、541.反转字符串 II)
代码随想录刷题day22|(字符串篇)344.反转字符串、541.反转字符串 II
目录 一、题目思路 二、相关题目 三、总结与知识点 3.1 字符数组转换成字符串 一、题目思路 344反转字符串比较容易,双指针即可在空间复杂度为O(1)的基础上解决; 541反转字符串II :其中for循环中 i 每次的取值,不是 i&#…...

python学opencv|读取图像(五十三)原理探索:使用cv.matchTemplate()函数实现最佳图像匹配
【1】引言 前序学习进程中,已经探索了使用cv.matchTemplate()函数实现最佳图像匹配的技巧,并且成功对两个目标进行了匹配。 相关文章链接为:python学opencv|读取图像(五十二)使用cv.matchTemplate()函数实现最佳图像…...

win10部署本地deepseek-r1,chatbox,deepseek联网(谷歌网页插件Page Assist)
win10部署本地deepseek-r1,chatbox,deepseek联网(谷歌网页插件Page Assist) 前言一、本地部署DeepSeek-r1step1 安装ollamastep2 下载deepseek-r1step2.1 找到模型deepseek-r1step2.2 cmd里粘贴 后按回车,进行下载 ste…...

冯·诺依曼体系结构
目录 冯诺依曼体系结构推导 内存提高冯诺依曼体系结构效率的方法 你使用QQ和朋友聊天时,整个数据流是怎么流动的(不考虑网络情况) 与冯诺依曼体系结构相关的一些知识 冯诺依曼体系结构推导 计算机的存在就是为了解决问题,而解…...

本地部署 DeepSeek-R1 模型
文章目录 霸屏的AIDeepSeek是什么?安装DeepSeek安装图形化界面总结 霸屏的AI 最近在刷视频的时候,总是突然突然出现一个名叫 DeepSeek 的玩意,像这样: 这样: 这不经激起我的一顿好奇心,这 DeepSeek 到底是个…...

Mybatis——sql映射文件中的增删查改
映射文件内的增删查改 准备工作 准备一张数据表,用于进行数据库的相关操作。新建maven工程, 导入mysql-connector-java和mybatis依赖。新建一个实体类,类的字段要和数据表的数据对应编写接口编写mybatis主配置文件 public class User {priva…...

【开源免费】基于Vue和SpringBoot的流浪宠物管理系统(附论文)
本文项目编号 T 182 ,文末自助获取源码 \color{red}{T182,文末自助获取源码} T182,文末自助获取源码 目录 一、系统介绍二、数据库设计三、配套教程3.1 启动教程3.2 讲解视频3.3 二次开发教程 四、功能截图五、文案资料5.1 选题背景5.2 国内…...

nth_element函数——C++快速选择函数
目录 1. 函数原型 2. 功能描述 3. 算法原理 4. 时间复杂度 5. 空间复杂度 6. 使用示例 8. 注意事项 9. 自定义比较函数 11. 总结 nth_element 是 C 标准库中提供的一个算法,位于 <algorithm> 头文件中,用于部分排序序列。它的主要功能是将…...

未来机器人的大脑:如何用神经网络模拟器实现更智能的决策?
编辑:陈萍萍的公主一点人工一点智能 未来机器人的大脑:如何用神经网络模拟器实现更智能的决策?RWM通过双自回归机制有效解决了复合误差、部分可观测性和随机动力学等关键挑战,在不依赖领域特定归纳偏见的条件下实现了卓越的预测准…...

测试微信模版消息推送
进入“开发接口管理”--“公众平台测试账号”,无需申请公众账号、可在测试账号中体验并测试微信公众平台所有高级接口。 获取access_token: 自定义模版消息: 关注测试号:扫二维码关注测试号。 发送模版消息: import requests da…...

地震勘探——干扰波识别、井中地震时距曲线特点
目录 干扰波识别反射波地震勘探的干扰波 井中地震时距曲线特点 干扰波识别 有效波:可以用来解决所提出的地质任务的波;干扰波:所有妨碍辨认、追踪有效波的其他波。 地震勘探中,有效波和干扰波是相对的。例如,在反射波…...
)
Java 语言特性(面试系列1)
一、面向对象编程 1. 封装(Encapsulation) 定义:将数据(属性)和操作数据的方法绑定在一起,通过访问控制符(private、protected、public)隐藏内部实现细节。示例: public …...

阿里云ACP云计算备考笔记 (5)——弹性伸缩
目录 第一章 概述 第二章 弹性伸缩简介 1、弹性伸缩 2、垂直伸缩 3、优势 4、应用场景 ① 无规律的业务量波动 ② 有规律的业务量波动 ③ 无明显业务量波动 ④ 混合型业务 ⑤ 消息通知 ⑥ 生命周期挂钩 ⑦ 自定义方式 ⑧ 滚的升级 5、使用限制 第三章 主要定义 …...

跨链模式:多链互操作架构与性能扩展方案
跨链模式:多链互操作架构与性能扩展方案 ——构建下一代区块链互联网的技术基石 一、跨链架构的核心范式演进 1. 分层协议栈:模块化解耦设计 现代跨链系统采用分层协议栈实现灵活扩展(H2Cross架构): 适配层…...

网站指纹识别
网站指纹识别 网站的最基本组成:服务器(操作系统)、中间件(web容器)、脚本语言、数据厍 为什么要了解这些?举个例子:发现了一个文件读取漏洞,我们需要读/etc/passwd,如…...

Python+ZeroMQ实战:智能车辆状态监控与模拟模式自动切换
目录 关键点 技术实现1 技术实现2 摘要: 本文将介绍如何利用Python和ZeroMQ消息队列构建一个智能车辆状态监控系统。系统能够根据时间策略自动切换驾驶模式(自动驾驶、人工驾驶、远程驾驶、主动安全),并通过实时消息推送更新车…...
 Module Federation:Webpack.config.js文件中每个属性的含义解释)
MFE(微前端) Module Federation:Webpack.config.js文件中每个属性的含义解释
以Module Federation 插件详为例,Webpack.config.js它可能的配置和含义如下: 前言 Module Federation 的Webpack.config.js核心配置包括: name filename(定义应用标识) remotes(引用远程模块࿰…...
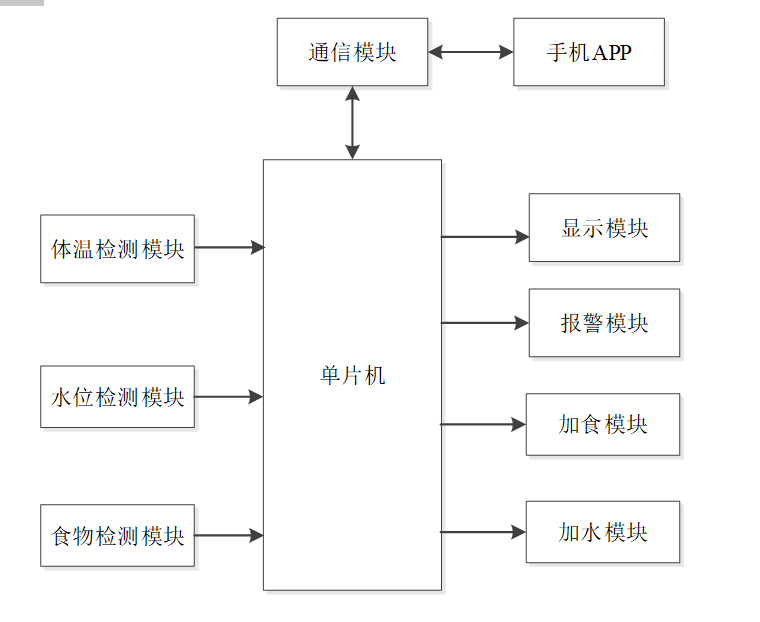
基于单片机的宠物屋智能系统设计与实现(论文+源码)
本设计基于单片机的宠物屋智能系统核心是实现对宠物生活环境及状态的智能管理。系统以单片机为中枢,连接红外测温传感器,可实时精准捕捉宠物体温变化,以便及时发现健康异常;水位检测传感器时刻监测饮用水余量,防止宠物…...