处理 **5万字(约7.5万-10万token,中文1字≈1.5-2token)** 的上下文
处理 5万字(约7.5万-10万token,中文1字≈1.5-2token) 的上下文,对模型的长文本处理能力和显存要求较高。以下是不同规模模型的适用性分析及推荐:
一、模型规模与上下文能力的关系
| 模型类型 | 参数量 | 最大上下文长度(token) | 是否支持5万字(约10万token) | 典型模型示例 | 资源需求 |
|---|---|---|---|---|---|
| 小型模型 | 1B-7B | 4k-32k | ❌ 不支持 | Mistral-7B、Llama-3-8B | 单卡GPU(如RTX 3090) |
| 中型模型 | 13B-34B | 32k-128k | ✅ 支持 | Yi-34B、Qwen-14B | 多卡GPU或云服务 |
| 大型闭源模型 | 100B+ | 128k-200k+ | ✅ 支持 | GPT-4、Claude-3、Gemini-1.5 Pro | 仅API调用 |
| 长文本专用模型 | 7B-70B | 200k-1M+ | ✅ 支持 | Longformer、BigBird、Yi-200k | 高显存或分布式训练 |
二、推荐模型及选择逻辑
1. 闭源API方案(无需本地部署)
-
GPT-4 Turbo
- 上下文窗口:128k token
- 支持5万字(约10万token),但需注意中文token膨胀问题(可能接近上限)。
- 优势:推理质量高,API调用简单。
- 成本:约$0.03/1k输入token + $0.06/1k输出token。
-
Claude-3 Opus
- 上下文窗口:200k token
- 轻松处理5万字(中文约7.5万token),剩余容量充足。
- 优势:长文本理解能力强,适合复杂分析。
- 成本:约$0.075/1k输入token + $0.225/1k输出token。
2. 开源本地部署方案
-
Yi-34B-200k
- 参数量:34B
- 上下文窗口:200k token
- 支持5万字,显存需求约80GB(需多卡A100或量化版+显存优化)。
- 优势:开源可定制,适合中文长文本。
- 缺点:需高性能硬件。
-
Qwen-14B-128k
- 参数量:14B
- 上下文窗口:128k token
- 勉强支持5万字(中文可能接近上限),显存需求约30GB(需A100/A6000)。
- 优势:阿里云优化中文场景,支持工具调用。
-
Longformer (12B)
- 参数量:12B
- 上下文窗口:16k-64k(可通过稀疏注意力扩展)
- 需分块处理或压缩文本,适合长文档摘要。
- 优势:显存占用低(单卡24G可运行)。
3. 低成本妥协方案
- Mistral-7B-32k
- 参数量:7B
- 上下文窗口:32k token
- 需将文本分块(如每块8k token),分多次处理再整合结果。
- 显存需求:约16GB(可量化至8bit+RTX 4090)。
三、关键技术挑战与解决方案
| 问题 | 解决方案 |
|---|---|
| 显存不足 | - 使用量化(4/8bit) - 分块处理+缓存复用(如KV Cache优化) - 启用FlashAttention-2加速 |
| 长文本质量下降 | - 选择长文本专用架构(如RoPE扩展、NTK-aware插值) - 增加位置编码密度 |
| 推理速度慢 | - 启用vLLM/PagedAttention加速 - 使用TensorRT-LLM部署 |
| 中文token效率低 | - 改用字粒度分词(如Qwen) - 扩展词表(如Yi-200k中文优化) |
四、实际部署建议
-
优先级排序
- 质量优先 → 闭源API(Claude-3 > GPT-4)
- 可控性优先 → Yi-34B-200k(需硬件)
- 低成本优先 → Mistral-7B分块处理 + RAG增强
-
显存估算公式
显存占用 ≈ 参数量(B) × 2(16bit) × 1.2(缓存) + 上下文长度 × 每token内存 示例:Yi-34B-200k ≈ 34×2×1.2 + 200k×0.1MB ≈ 81.6GB + 20GB ≈ 102GB(需多卡A100) -
分块处理技巧
- 按章节/段落切分,保留重叠区域(如每块末尾保留500token上下文)
- 用Embedding模型筛选关键段落(如BM25+语义检索)
五、总结
- 最佳选择:Claude-3 Opus(API调用)或 Yi-34B-200k(本地部署)。
- 替代方案:GPT-4 Turbo(接近上限)或 Qwen-14B-128k(需压缩文本)。
- 低成本路线:Mistral-7B分块处理 + 检索增强生成(RAG)。
可根据预算、硬件条件和质量要求灵活选择。若需具体部署代码或调优方案,可进一步说明需求!
相关文章:
** 的上下文)
处理 **5万字(约7.5万-10万token,中文1字≈1.5-2token)** 的上下文
处理 5万字(约7.5万-10万token,中文1字≈1.5-2token) 的上下文,对模型的长文本处理能力和显存要求较高。以下是不同规模模型的适用性分析及推荐: 一、模型规模与上下文能力的关系 模型类型参数量最大上下文长度&#…...

【狂热算法篇】探秘图论之Dijkstra 算法:穿越图的迷宫的最短路径力量(通俗易懂版)
羑悻的小杀马特.-CSDN博客羑悻的小杀马特.擅长C/C题海汇总,AI学习,c的不归之路,等方面的知识,羑悻的小杀马特.关注算法,c,c语言,青少年编程领域.https://blog.csdn.net/2401_82648291?typebbshttps://blog.csdn.net/2401_82648291?typebbshttps://blog.csdn.net/2401_8264829…...

springboot 启动原理
目标: SpringBootApplication注解认识了解SpringBoot的启动流程 了解SpringFactoriesLoader对META-INF/spring.factories的反射加载认识AutoConfigurationImportSelector这个ImportSelector starter的认识和使用 目录 SpringBoot 启动原理SpringBootApplication 注…...

浅析DDOS攻击及防御策略
DDoS(分布式拒绝服务)攻击是一种通过大量计算机或网络僵尸主机对目标服务器发起大量无效或高流量请求,耗尽其资源,从而导致服务中断的网络攻击方式。这种攻击方式利用了分布式系统的特性,使攻击规模更大、影响范围更广…...

Linux网络 HTTPS 协议原理
概念 HTTPS 也是一个应用层协议,不过 是在 HTTP 协议的基础上引入了一个加密层。因为 HTTP的内容是明文传输的,明文数据会经过路由器、wifi 热点、通信服务运营商、代理服务器等多个物理节点,如果信息在传输过程中被劫持,传输的…...

Idea插件开发
相关操作 执行插件 导出插件 然后到 /build/distributions 目录下面去找...

Java 有很多常用的库
1. 常用工具类库 Apache Commons:提供了大量常用的工具类,如: commons-lang3:字符串、数字、日期等常用工具类。commons-io:IO 操作,文件读写、流处理等。commons-collections4:集合类扩展。 G…...

pytorch实现文本摘要
人工智能例子汇总:AI常见的算法和例子-CSDN博客 import numpy as npfrom modelscope.hub.snapshot_download import snapshot_download from transformers import BertTokenizer, BertModel import torch# 下载模型到本地目录 model_dir snapshot_download(tians…...

C++基础day1
前言:谢谢阿秀,指路阿秀的学习笔记 一、基础语法 1.构造和析构: 类的构造函数是一种特殊的函数,在创建一个新的对象时调用。类的析构函数也是一种特殊的函数,在删除所创建的对象时调用。 构造顺序:父类->子类 析…...

从TinyZero的数据与源码来理解DeepSeek-R1-Zero的强化学习训练过程
1. 引入 TinyZero(参考1)是伯克利的博士生复现DeepSeek-R1-Zero的代码参仓库,他使用veRL来运行RL强化学习方法,对qwen2.5的0.5B、1.5B、3B等模型进行训练,在一个数字游戏数据集上,达到了较好的推理效果。 …...

爬虫基础(四)线程 和 进程 及相关知识点
目录 一、线程和进程 (1)进程 (2)线程 (3)区别 二、串行、并发、并行 (1)串行 (2)并行 (3)并发 三、爬虫中的线程和进程 &am…...

【自开发工具介绍】SQLSERVER的ImpDp和ExpDp工具01
1、开发背景 大家都很熟悉,Oracle提供了Impdp和ExpDp工具,功能很强大,可以进行db的导入导出的处理。但是对于Sqlserver数据库只是提供了简单的图形化的导出导入工具,在实际的开发和生产环境不太可能让用户在图形化的界面选择移行…...

队列—学习
1. 手写队列的实现 使用数组实现队列是一种常见的方法。队列的基本操作包括入队(enqueue)和出队(dequeue)。队列的头部和尾部分别用 head 和 tail 指针表示。 代码实现 const int N 10000; // 定义队列容量,确保够…...

SpringBoot的配置(配置文件、加载顺序、配置原理)
文章目录 SpringBoot的配置(配置文件、加载顺序、配置原理)一、引言二、配置文件1、配置文件的类型1.1、配置文件的使用 2、多环境配置 三、加载顺序四、配置原理五、使用示例1、配置文件2、配置类3、控制器 六、总结 SpringBoot的配置(配置文件、加载顺序、配置原理) 一、引言…...

如何本地部署DeepSeek?DeepThink R1 本地部署全攻略:零基础小白指南。
🚀 离线运行 AI,免费使用 OpenAI 级别推理模型 本教程将手把手教你如何在本地部署 DeepThink R1 AI 模型,让你无需联网就能运行强大的 AI 推理任务。无论你是AI 新手还是资深开发者,都可以轻松上手! 📌 目录…...
mastery lies beyond poetry)
陆游的《诗人苦学说》:从藻绘到“功夫在诗外”(中英双语)mastery lies beyond poetry
陆游的《诗人苦学说》:从藻绘到“功夫在诗外” 今天看万维钢的《万万没想到》一书,看到陆游的功夫在诗外的句子,特意去查找这首诗的原文。故而有此文。 我国学人还往往过分强调“功夫在诗外”这句陆游的名言,认为提升综合素质是一…...

Golang —协程池(panjf2000/ants/v2)
Golang —协程池(panjf2000/ants/v2) 1 ants1.1 基本信息1.2 ants 是如何运行的(流程图) 1 ants 1.1 基本信息 代码地址:github.com/panjf2000/ants/v2 介绍:ants是一个高性能的 goroutine 池,…...

在 crag 中用 LangGraph 进行评分知识精炼-下
在上一次给大家展示了基本的 Rag 检索过程,着重描述了增强检索中的知识精炼和补充检索,这些都是 crag 的一部分,这篇内容结合 langgraph 给大家展示通过检索增强生成(Retrieval-Augmented Generation, RAG)的工作流&am…...

基于springboot+vue的哈利波特书影音互动科普网站
开发语言:Java框架:springbootJDK版本:JDK1.8服务器:tomcat7数据库:mysql 5.7(一定要5.7版本)数据库工具:Navicat11开发软件:eclipse/myeclipse/ideaMaven包:…...
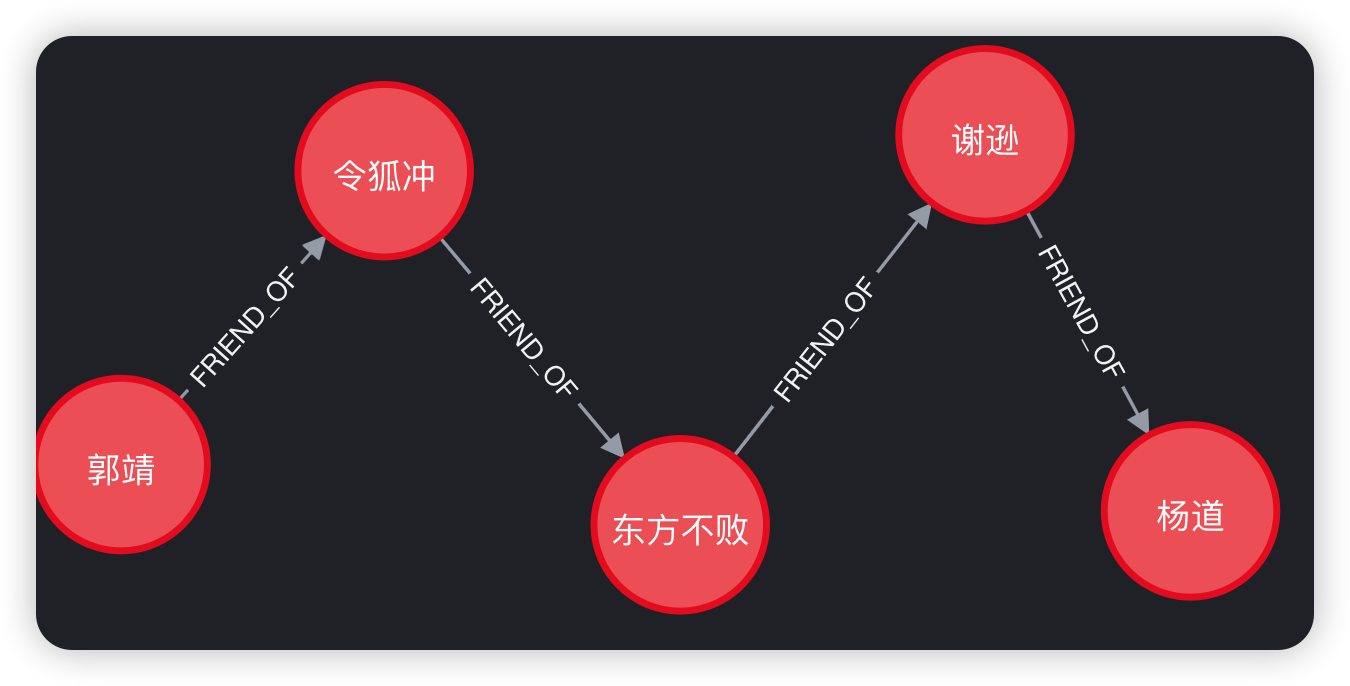
Cypher入门
文章目录 Cypher入门创建数据查询数据matchoptional matchwhere分页with 更新数据删除数据实例:好友推荐 Cypher入门 Cypher是Neo4j的查询语言。 创建数据 在Neo4j中使用create命令创建节点、关系、属性数据。 create (n {name:$value}) return n //创建节点&am…...

linux之kylin系统nginx的安装
一、nginx的作用 1.可做高性能的web服务器 直接处理静态资源(HTML/CSS/图片等),响应速度远超传统服务器类似apache支持高并发连接 2.反向代理服务器 隐藏后端服务器IP地址,提高安全性 3.负载均衡服务器 支持多种策略分发流量…...

C++初阶-list的底层
目录 1.std::list实现的所有代码 2.list的简单介绍 2.1实现list的类 2.2_list_iterator的实现 2.2.1_list_iterator实现的原因和好处 2.2.2_list_iterator实现 2.3_list_node的实现 2.3.1. 避免递归的模板依赖 2.3.2. 内存布局一致性 2.3.3. 类型安全的替代方案 2.3.…...
使用rpicam-app通过网络流式传输视频)
树莓派超全系列教程文档--(62)使用rpicam-app通过网络流式传输视频
使用rpicam-app通过网络流式传输视频 使用 rpicam-app 通过网络流式传输视频UDPTCPRTSPlibavGStreamerRTPlibcamerasrc GStreamer 元素 文章来源: http://raspberry.dns8844.cn/documentation 原文网址 使用 rpicam-app 通过网络流式传输视频 本节介绍来自 rpica…...

安宝特方案丨XRSOP人员作业标准化管理平台:AR智慧点检验收套件
在选煤厂、化工厂、钢铁厂等过程生产型企业,其生产设备的运行效率和非计划停机对工业制造效益有较大影响。 随着企业自动化和智能化建设的推进,需提前预防假检、错检、漏检,推动智慧生产运维系统数据的流动和现场赋能应用。同时,…...

spring:实例工厂方法获取bean
spring处理使用静态工厂方法获取bean实例,也可以通过实例工厂方法获取bean实例。 实例工厂方法步骤如下: 定义实例工厂类(Java代码),定义实例工厂(xml),定义调用实例工厂ÿ…...

高危文件识别的常用算法:原理、应用与企业场景
高危文件识别的常用算法:原理、应用与企业场景 高危文件识别旨在检测可能导致安全威胁的文件,如包含恶意代码、敏感数据或欺诈内容的文档,在企业协同办公环境中(如Teams、Google Workspace)尤为重要。结合大模型技术&…...

SpringCloudGateway 自定义局部过滤器
场景: 将所有请求转化为同一路径请求(方便穿网配置)在请求头内标识原来路径,然后在将请求分发给不同服务 AllToOneGatewayFilterFactory import lombok.Getter; import lombok.Setter; import lombok.extern.slf4j.Slf4j; impor…...

高防服务器能够抵御哪些网络攻击呢?
高防服务器作为一种有着高度防御能力的服务器,可以帮助网站应对分布式拒绝服务攻击,有效识别和清理一些恶意的网络流量,为用户提供安全且稳定的网络环境,那么,高防服务器一般都可以抵御哪些网络攻击呢?下面…...

【学习笔记】深入理解Java虚拟机学习笔记——第4章 虚拟机性能监控,故障处理工具
第2章 虚拟机性能监控,故障处理工具 4.1 概述 略 4.2 基础故障处理工具 4.2.1 jps:虚拟机进程状况工具 命令:jps [options] [hostid] 功能:本地虚拟机进程显示进程ID(与ps相同),可同时显示主类&#x…...

【网络安全】开源系统getshell漏洞挖掘
审计过程: 在入口文件admin/index.php中: 用户可以通过m,c,a等参数控制加载的文件和方法,在app/system/entrance.php中存在重点代码: 当M_TYPE system并且M_MODULE include时,会设置常量PATH_OWN_FILE为PATH_APP.M_T…...