【Java】位图 布隆过滤器
位图
初识位图
位图, 实际上就是将二进制位作为哈希表的一个个哈希桶的数据结构, 由于二进制位只能表示 0 和 1, 因此通常用于表示数据是否存在.
如下图所示, 这个位图就用于标识 0 ~ 14 中有什么数字存在

可以看到, 我们这里相当于是把下标作为了 key-value 的一员. 但是这样同样也使得位图这个数据结构非常有局限性, 因为下标只能是整数. 因此通常来说, 位图都是用于存储整数是否存在的.
那么位图这么有局限性, 我们为何要使用它呢?
实际上, 我们可以看到, 存储一个数字是否存在, 我们只需要消耗 1 个比特位, 而如果我们使用正常的一个哈希表的键值对来存储的话, 首先是一个整型就是 4 个字节, 其次就是一个 boolean 类型, 我们暂定为 1 字节大小. 而这样相当于就占了 5 个字节, 总共为 40 个比特位.
那么结论也很明显了, 位图存储一个数据是否存在, 只需要消耗 1 比特空间, 相较于直接使用哈希表键值对存储, 大大提升了空间的使用效率.
实现思路
首先要实现位图, 我们肯定需要一个能很好操作比特位的数据类型, 那么在这一点上, 只要是整型都可以轻易的做到, 因此 byte, short, int, long 都是可行的
但是如果只使用单个数, 那肯定是不够的, 以 int 为例, 单个 int 就只有 32 位, 那假如说要存 100 个数字呢? 因此这里最好我们使用一个数组来操作. 我们这里就采用 byte 数组来实现(因为画图好画)
那么由于 byte 是 8 位, 因此我们就可以知道 byte[0] (这里没有数组名因此这样简称) 对应着的是前 8 位, 代表着 0 ~ 7 这八个数字. 而 byte[1] 则往后对应, 对应着 8 ~ 15, 后续同理… 后续我们通过使用 num / 8 就可以轻松的获取到对应下标

但是接下来另一个问题来了, 我们如何操作到位图中的每一个位呢? 如果是最简单的思路, 其实就是靠数字 1 来操作, 因为数字 1 的二进制位为 0000 0001 其中这个单独的 1 位置可以非常便于我们操作, 并且相较于其他的数字可读性非常的高.
那么此时我们会发现一个问题, 假如我想要令 byte[0] 中代表 0 的一位为 1, 那么此时我们还需要通过左移 1 来实现, 如下图所示

这样有没有问题呢? 当然没有, 不过依旧是比较的反直觉, 明明我们修改的数应该是 0 但是却反而需要通过移位来做, 因此我们这里就采用在每一个数字里面里面, 下标都是逆序的设计方式

可以看到此时在 byte[0] 里面, 下标就是从 7 依次减到 0, 而在 byte[1] 里面, 下标从 15 减到 8. 随后如果我们要修改 0 对应的数字, 需要左移的位就是 0 % 8, 其他的同理
当然, 这部分的设计是完全偏向于个人喜好的, 如果想要实现刚开始的顺序记录, 也不是不可以. 不过此处后续将会采用内部下标逆序的设计方式来书写代码, 感兴趣的可以自行实现顺序的版本.
位的基本操作
由于要操作位图, 相关的位操作我们必须要提前了解下, 这样才会便于我们后续代码的书写. 当然这里介绍的是具体的位相关操作, 如果对二进制位没有基本了解以及位运算也没有基本了解的, 需要自行先去了解一下相关内容
前提要求, 下面的所有第 x 位指的是从右往左, 从 0 开始来计数的
例如 0000 0001
其中 1 在第 0 位
- 给定一个数 n, 确定它的二进制中第 x 位是 0 还是 1
这个其实非常简单, 直接用一个 1 按位与即可, 要么把 1 左移 x 位后按位与, 要么把 n 右移 x 位后按位与
(1 << x) & n == 1 或 (n >> x) & n == 1
这个操作主要用于位图的查找功能
- 将一个数 n 的二进制中的第 x 位修改为 1
要把第 x 位修改为 1, 使用一个 1 左移 x 位后, 采用按位或操作即可
n |= (1 << x)
这个操作主要用于位图的记录功能
- 将一个数 n 的二进制中的第 x 位修改为 0
这个要修改为 0, 其实还是要用 1 左移 x 位, 不过要再取一次反, 然后采用按位与的操作
n &= (~(1 << x))
这个操作主要用于位图的删除功能
位图实现
其实目前所有的基础知识都介绍完了, 尤其是上面的三个基础操作, 接下来实现代码应该是非常简单的
初始化
public class MyBitSet {private byte[] bits;private static final int DEFAULT_SIZE = 8;public MyBitSet() {this(DEFAULT_SIZE);}public MyBitSet(int size) {bits = new byte[size / 8 + 1];}
}
存储元素
// 将某个数存入位图
public void set(int index) {int byteIndex = index / 8;// 扩容if(byteIndex >= bits.length){bits = Arrays.copyOf(bits, byteIndex + 1);}int bitIndex = index % 8;bits[byteIndex] |= (byte) (1 << bitIndex);
}
查找元素
// 查看某个数在位图中是否存在
public boolean get(int index) {int byteIndex = index / 8;int bitIndex = index % 8;return (bits[byteIndex] & (1 << bitIndex)) != 0;
}
删除元素
// 将某个数从位图中清除
public void clear(int index) {int byteIndex = index / 8;int bitIndex = index % 8;bits[byteIndex] &= (byte) ~(1 << bitIndex);
}
位图应用
位图由于其只能存储整数以及占用空间小的特性, 通常可以用于在海量的整数中去记录一个数是否存在, 另外其还可以用于做去重 + 排序的工作
public class Main {public static void main(String[] args) {int[] arr = {1, 5, 4, 7, 8, 9, 4, 22, 3, 1};MyBitSet bitSet = new MyBitSet(100);// 添加元素for (int i : arr) {bitSet.set(i);}// 遍历for (int i = 0; i < 100; i++) {if (bitSet.get(i)) {System.out.print(i + " ");}}}
}
同时它也可以实现一些基本的集合功能, 例如求交集
public BitSet and(MyBitSet other) {// 获取两个 BitSet 中较大的长度int size = Math.max(bits.length, other.bits.length) * 8;// 创建一个 BitSet 来存储结果BitSet result = new BitSet(size);for (int i = 0; i < size; i++) {// 如果两个 BitSet 的对应位置都为 1,则将结果 BitSet 的对应位置设为 1if (get(i) && other.get(i)) {result.set(i);}}return result;
}
测试代码
public class Main {public static void main(String[] args) {int[] set1 = {1, 5, 4, 7, 8, 9, 4, 22, 3, 1};int[] set2 = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};MyBitSet bitSet1 = new MyBitSet(100);MyBitSet bitSet2 = new MyBitSet(100);for (int i = 0; i < set1.length; i++) {bitSet1.set(set1[i]);}for (int i = 0; i < set2.length; i++) {bitSet2.set(set2[i]);}BitSet and = bitSet1.and(bitSet2);for (int i = 0; i < 100; i++) {if(and.get(i)){System.out.print(i + " ");}}}
}
BitSet 使用
Java 也提供了位图相关实现, 即 BitSet. 使用非常简单, 使用 get(), set() 方法即可
public class Main {public static void main(String[] args) {BitSet bitSet = new BitSet(8);int[] arr1 = {1, 2, 4, 5, 22, 6, 9, 4};for (int i = 0; i < arr1.length; i++) {bitSet.set(arr1[i]);}System.out.println(bitSet);}
}
布隆过滤器
初识布隆过滤器
前面我们提到如果面对着海量数据, 哈希表就会过度占用空间, 位图则只能用于处理整型. 那么有没有什么办法可以即节省空间, 又能处理海量数据呢?
此时有人可能就想了, 那为何我们不能把一个东西进行哈希, 计算出哈希值后放到对应的位图里面呢?
但是这种做法忽略了哈希表的一个重要特点, 就是会发生哈希冲突, 倘若发生哈希冲突, 那么此时位图是很难进行处理的.
其实布隆过滤器, 就相当于是我们上面这个思路的拓展, 它对一个元素, 会采用多个不同的哈希函数来进行哈希, 最后将位图中的多个位进行记录.
那此时可能有人还是要问了: 这个似乎也没有完全解决冲突问题, 那这个思路岂不是还有问题?
实际上, 布隆过滤器本身设计出来就是作为一个概率型数据结构存在的, 在判断某一个元素是否存在于容器中的时候, 会存在一定的误判率. 不过这个是可以通过调整哈希函数的个数以及容器的大小来调整误判概率的. 具体如何计算是一个数学问题, 我们这里就不多讨论了.
误判相关
实际上, 布隆过滤器的原理还是非常简单的, 无非就是用多个哈希函数去计算出下标然后丢到位图里面. 但是我们仍旧没有弄明白, 为何布隆过滤器会有误判, 误判会导致什么结果?
实际上, 为什么会有误判这个点非常好理解, 其实就是位图没法处理哈希冲突的一种体现. 我们以极端情况来看, 假设只使用一个哈希函数, 对 zhangsan 这个名字进行哈希, 得到的下标是 10, 我们将其存储到位图中.

随后我们尝试在里面查找 lisi 这个数据, 但是假设其计算的哈希下标也是 10, 那么此时访问 10 发现结果是 1, 就发生误判了

针对多个哈希函数, 其实也是同样的道理, 无非就是访问的点多了, 概率会更低而已.
那么现在我们已知了, 布隆过滤器返回 true 的时候, 是有可能误判的, 那么当其返回 false 的时候有没有可能会误判呢?
其实是不会的, 因为返回 true 会误判的本质是, 那个位置发生了哈希冲突, 且有某一个元素占用了那个位置, 那么只要有元素占用了那个位置, 就一定会返回 true. 而返回 false 则不满足有元素占用的那个条件, 因此返回 false 是不会发生误判的.
综上所述, 布隆过滤器会在返回 true 的时候概率发生误判, 而 false 则一定不会发生误判.
布隆过滤器实现
初始化
public class MyBloomFilter {// 位图private BitSet bitSet;// 标记当前容量, 主要用于给哈希 -> 下标的映射private int size;// 采用 HashMap 类似设计, 便于进行哈希 -> 下标的映射private static final int DEFAULT_SIZE = 1 << 25;// 随机种子, 用于实现不同的哈希函数, 这里是随便写的private static final int[] seeds = new int[]{5, 7, 11, 13};// 哈希函数及其实现private MyHash[] func;static class MyHash {int seed;public MyHash(int seed) {this.seed = seed;}public int hash(Object key) {int h;// 直接使用 key.hashCode() * seed 来实现简单的哈希随机函数return (key == null) ? 0 : (h = key.hashCode() * seed) ^ (h >>> 16);}}public MyBloomFilter() {bitSet = new BitSet(DEFAULT_SIZE);func = new MyHash[seeds.length];size = DEFAULT_SIZE;for (int i = 0; i < seeds.length; i++) {func[i] = new MyHash(seeds[i]);}}
}
增加和查找
非常简单的两个方法, 无非就是多次调用哈希函数并且计算下标, 最后存储/读取位图而已
public void add(Object key) {if (key == null) return;for (MyHash f : func) {bitSet.set(f.hash(key) & (size - 1));}
}public boolean contains(Object key) {if (key == null) return false;for (MyHash f : func) {if(!bitSet.get(f.hash(key) & (size - 1))) return false;}return true;
}
优缺点
优点:
- 添加和查询的时间复杂度低, 具体时间复杂度与哈希函数有关
- 不存储元素本身, 需要保密的场景下有一些优势
- 允许有误判率的情况下, 时间和空间效率都很高
- 使用相同哈希函数计算的布隆过滤器可以支持集合运算
缺点:
- 存在误判率(可以通过添加白名单来进行兜底, 对可能进行误判的数据进行存储)
- 传统的布隆过滤器不支持删除操作, 因为可能会影响其他元素. 如果需要实现可以给每一个位加一个计数器, 不过数据量过多的情况可能会导致计数器发生溢出
- 不能获取到元素本身
使用场景
- 去重场景, 例如网页爬虫去重 URL, 分布式系统日志去重等
- 过滤场景, 记录并且过滤垃圾邮件
- 解决缓存击穿问题:
- 背景: 系统访问缓存时, 如果发现缓存中没有相应数据, 那么就会尝试请求数据库来查找数据. 那么此时攻击者可以借助这个特性, 大量仿造不存在的数据对数据库进行攻击, 使得数据库服务器崩溃.
- 解决方案: 使用布隆过滤器记录下数据库中的所有数据, 经过缓存前先进行一轮判断, 发现返回 false 直接不响应即可(因为布隆过滤器返回 false 一定代表不存在). 若返回 true, 则才允许尝试访问后续的其他资源.
使用布隆过滤器
虽然 Java 没有提供官方的布隆过滤器实现, 但是第三方库还是有一些实现的, 下面我们简单使用一个
首先使用 Maven 创建项目, 并且引入下面的依赖
<dependency><groupId>com.google.guava</groupId><artifactId>guava</artifactId><version>19.0</version>
</dependency>
然后可以通过下面的代码创建一个布隆过滤器, 其中第一个参数主要是将对象转为字节数组, 提供给布隆过滤器用于进行哈希运算的, 由于我们这里只是简单使用, 因此不详细介绍了
public class Main {public static void main(String[] args) {// 期望的误判率double fpp = 0.001;// 预计要插入多少数据int size = 100000;// 创建布隆过滤器BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), size, fpp);}
}
接下来我们来简单测试下这个东西的误判率
public class Main {public static void main(String[] args) {// 期望的误判率double fpp = 0.001;// 预计要插入多少数据int size = 100000;// 创建布隆过滤器BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), size, fpp);// 存 0 ~ 100000for (int i = 0; i <= size; i++) {bloomFilter.put(i);}// 通过 100000 ~ 200000 的数据,看看有多少个是误判的int count = 0;for (int i = 100000; i <= 200000; i++){if (bloomFilter.mightContain(i)) {count++;}}System.out.println("误判率:" + count + " / " + (200000 - 100000) + " = " + (double) count / (200000 - 100000));}
}
运行可以发现误判率基本大差不差, 是符合预期的

海量数据处理相关问题
- 给一个超过 100G 大小的日志文件, 文件中存储着 IP 地址, 如何找到出现次数最多 / Top-K 的 IP 地址?
这种问题, 说是几百 G 的数据, 本质上是希望告诉你, 这个数据是无法存储到内存中的, 也就是说把这些数据直接存储到内存中是不可行的, 我们需要进行预处理.
那么针对这种大文件的处理, 核心思路无非就一个, 拆小文件, 但是这里也有两种拆法:
- 无脑拆分, 直接拆成能够装入内存中的大小, 随后遍历每一个文件进行全局计数.
- 哈希拆分, 通过对 IP 地址进行哈希操作, 保证每一个 IP 地址都能够被映射到同一个文件中. 最后分别统计出每一个文件出现次数最多的即可, 就不需要全局计数了. (假如是 Top-k 问题, 则需要对应选出每个文件 Top-k 的 IP 数, 随后进行下比较即可)
当然, 这里的哈希拆分我们需要注意, 哈希函数必须要合理, 使得每一个文件大小是均匀的, 否则可能会导致某一个文件过大无法放入内存进行处理.
- 给定两个文件, 分别有 100 亿个整数, 如何求其的交集, 并集, 差集?
- 哈希拆分: 依旧是老套路, 通过哈希把相同数字塞同一个文件里面, 随后对每一个小文件进行对应集合操作
- 位图:
- 使用两个位图来记录数据
- 将两个位图中的所有位进行与操作, 得到交集
- 将两个位图中的所有位进行或操作, 得到并集
- 将两个位图中的所有位进行异或操作, 得到差集
- 给定 100 亿个整数, 设计算法找出只出现过一次的整数
- 哈希拆分思路: 依旧是通过哈希来把相同数字放到同一个文件中, 随后查看每一个小文件即可. 同样的, 这里也需要保证哈希函数设计合理, 使得每一个文件大小均匀. 这也是为什么不能采用区间划分, 因为可能某一些数字出现很多, 从而导致数字集中在一个文件里面
- 双位图思路:
位图, 是可以用于处理海量整数数据的记录的, 但是问题就在于它只能记录一个数是否出现, 即只能表示有和无这两个信息. 而如今这个情景需要我们记录三个信息: 1. 无 2. 有一次 3. 有一次以上
那么有没有什么办法可以让位图可以多记录一些信息呢? 当然有, 一个位图不够, 那么就用两个.
此时相当于一个数对应着两个位, 此时可以表示的情况就有 00 01 10 11 四种情况了, 用于记录三种情况绰绰有余. 并且其实这两个位可以用于做二进制计数, 分别对应 0 1 2 3
- 单位图思路:
那么继承上面的双位图思路, 我们能否使用单个位图呢? 答案当然也是可以的, 但是一个位还是不够用, 因此我们可以给每一个数字分两个位, 随后记录方式和上面一样.
- 给定 100 亿个整数, 设计算法找出出现次数不超过两次的整数
这个问题实际上是上面问题的拓展, 但是核心思路都是一致的
- 哈希拆分思路: 依旧是通过哈希来把相同数字放到同一个文件中, 随后查看每一个小文件即可.
- 位图思路: 采用两个位图/单位图的两个位, 来进行二进制计数, 记录出现次数为 01 和 10 的即可(即对应出现次数为 1 和 2 的)
- 给两个 100G 文件, 如何近似的求其交集?
这里由于并不要求我们精准的求出交集, 所以我们除了采用经典的哈希拆分思路还可以借助布隆过滤器来做.
思路也非常的简单, 首先把第一个文件里面的数据丢到布隆过滤器中, 随后遍历第二个文件来在布隆过滤器中查找是否存在即可.
相关文章:
【Java】位图 布隆过滤器
位图 初识位图 位图, 实际上就是将二进制位作为哈希表的一个个哈希桶的数据结构, 由于二进制位只能表示 0 和 1, 因此通常用于表示数据是否存在. 如下图所示, 这个位图就用于标识 0 ~ 14 中有什么数字存在 可以看到, 我们这里相当于是把下标作为了 key-value 的一员. 但是这…...

【专业标题】数字时代的影像保卫战:照片误删拯救全指南
在智能手机普及率达98%的今天,每个人的数字相册都承载着价值连城的记忆资产。照片误删事件却如同数字时代的隐形杀手,全球每分钟有超过5000张珍贵影像因此消失。当我们发现重要照片不翼而飞时,那种心脏骤停般的恐慌感,正是数据时代…...

深度剖析八大排序算法
欢迎并且感谢大家指出我的问题,由于本人水平有限,有些内容写的不是很全面,只是把比较实用的东西给写下来,如果有写的不对的地方,还希望各路大牛多多指教!谢谢大家!🥰 在计算机科学领…...

JVM_程序计数器的作用、特点、线程私有、本地方法的概述
①. 程序计数器 ①. 作用 (是用来存储指向下一条指令的地址,也即将要执行的指令代码。由执行引擎读取下一条指令) ②. 特点(是线程私有的 、不会存在内存溢出) ③. 注意:在物理上实现程序计数器是在寄存器实现的,整个cpu中最快的一个执行单元 ④. 它是唯一一个在java虚拟机规…...

【Numpy核心编程攻略:Python数据处理、分析详解与科学计算】2.20 傅里叶变换:从时域到频域的算法实现
2.20 傅里叶变换:从时域到频域的算法实现 目录 #mermaid-svg-zrRqIme9IEqP6JJE {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-zrRqIme9IEqP6JJE .error-icon{fill:#552222;}#mermaid-svg-zrRqIme9IEqP…...
PAT甲级1052、Linked LIst Sorting
题目 A linked list consists of a series of structures, which are not necessarily adjacent in memory. We assume that each structure contains an integer key and a Next pointer to the next structure. Now given a linked list, you are supposed to sort the stru…...

git error: invalid path
git clone GitHub - guanpengchn/awesome-books: :books: 开发者推荐阅读的书籍 在windows上想把这个仓库拉取下来,发现本地git仓库创建 但只有一个.git隐藏文件夹,其他文件都处于删除状态。 问题: Cloning into awesome-books... remote:…...

优选算法合集————双指针(专题二)
好久都没给大家带来算法专题啦,今天给大家带来滑动窗口专题的训练 题目一:长度最小的子数组 题目描述: 给定一个含有 n 个正整数的数组和一个正整数 target 。 找出该数组中满足其和 ≥ target 的长度最小的 连续子数组 [numsl, numsl1, …...
)
Ubuntu下Tkinter绑定数字小键盘上的回车键(PySide6类似)
设计了一个tkinter程序,在Win下绑定回车键,直接绑定"<Return>"就可以使用主键盘和小键盘的回车键直接“提交”,到了ubuntu下就不行了。经过搜索,发现ubuntu下主键盘和数字小键盘的回车键,名称不一样。…...

使用arcpy列表函数
本节将以ListFeatureClasses()为例,学习如何使用arcpy中的列表函数. 操作方法: 1.打开IDLE,新建脚本窗口 2.导入arcpy模块 3.设置工作空间 arcpy.env.workspace "<>" 4.调用ListFeatureClasses()函数,并将返回的值赋值给fcList变量 fcList arcpy.ListFe…...

基于联合概率密度与深度优化的反潜航空深弹命中概率模型研究摘要
前言:项目题材来自数学建模2024年的D题,文章内容为笔者和队友原创,提供一个思路。 摘要 随着现代军事技术的发展,深水炸弹在特定场景下的反潜作战效能日益凸显,如何最大化的发挥深弹威力也成为重要研究课题。本文针对评估深弹投掷落点对命中潜艇概率的影响进行分析,综合利…...

【PyQt】pyqt小案例实现简易文本编辑器
pyqt小案例实现简易文本编辑器 分析 实现了一个简单的文本编辑器,使用PyQt5框架构建。以下是代码的主要功能和特点: 主窗口类 (MyWindow): 继承自 QWidget 类。使用 .ui 文件加载用户界面布局。设置窗口标题、状态栏消息等。创建菜单栏及其子菜单项&…...

二叉树03(数据结构初阶)
文章目录 一:实现链式结构二叉树1.1前中后序遍历1.1.1遍历规则1.1.2代码实现 1.2结点个数以及高度等1.2.1二叉树结点个数1.2.2二叉树叶子结点个数1.2.3二叉树第k层结点个数1.2.4二叉树的深度/高度1.2.5 二叉树查找值为x的结点1.2.6二叉树的销毁 1.3层序遍历1.4判断是…...

ComfyUI工作流 图像反推生成人像手办人像参考(SDXL版)
文章目录 图像反推生成人像手办人像参考SD模型Node节点工作流程效果展示开发与应用图像反推生成人像手办人像参考 本工作流旨在通过利用 Stable Diffusion XL(SDXL)模型和相关辅助节点,实现高效的人像参考生成和手办设计。用户可通过加载定制的模型、LORA 调整和控制节点对…...

【01】共识机制
BTF共识 拜占庭将军问题 拜占庭将军问题是一个共识问题 起源 Leslie Lamport在论文《The Byzantine Generals Problem》提出拜占庭将军问题。 核心描述 军中可能有叛徒,却要保证进攻一致,由此引申到计算领域,发展成了一种容错理论。随着…...

sentinel的限流原理
Sentinel 的限流原理基于 流量统计 和 流量控制策略,通过动态规则对系统资源进行保护。其核心设计包括以下几个关键点: 流量统计模型:滑动时间窗口 Sentinel 使用 滑动时间窗口算法 统计单位时间内的请求量,相比传统的固定时间窗…...

ZOJ 1007 Numerical Summation of a Series
原题目链接 生成该系列值的表格 对于x 的 2001 个值,x 0.000、0.001、0.002、…、2.000。表中的所有条目的绝对误差必须小于 0.5e-12(精度为 12 位)。此问题基于 Hamming (1962) 的一个问题,当时的大型机按今天的微型计算机标准来…...

『 C 』 `##` 在 C 语言宏定义中的作用解析
文章目录 ## 运算符的基本概念可变参数宏与 ## 的应用可变参数宏简介## 处理可变参数的两种情况可变参数列表为空可变参数列表不为空 示例代码验证 在 C 和 C 编程里,宏定义是个很有用的工具。今天咱们就来聊聊 ## 这个预处理器连接运算符在宏定义中的作用ÿ…...
:用于信号分离或降维)
独立成分分析 (ICA):用于信号分离或降维
人工智能例子汇总:AI常见的算法和例子-CSDN博客 独立成分分析 (Independent Component Analysis, ICA) 是一种用于信号分离和降维的统计方法,常用于盲源分离 (Blind Source Separation, BSS) 问题,例如音频信号分离或脑电信号 (EEG) 处理。…...

为什么会有函数调用参数带标签的写法?Swift函数调用的参数传递需要加前缀是否是冗余?函数调用?函数参数?
为什么会有函数调用参数带标签的写法? ObjC函数参数形式与众不同,实参前会加前缀,尤其参数很多的情况,可读性很强。例如: [person setAge: 29 setSex:1 setClass: 35]; 这种参数前面加前缀描述也被叫标签(Label). 注意࿰…...

MODBUS TCP转CANopen 技术赋能高效协同作业
在现代工业自动化领域,MODBUS TCP和CANopen两种通讯协议因其稳定性和高效性被广泛应用于各种设备和系统中。而随着科技的不断进步,这两种通讯协议也正在被逐步融合,形成了一种新型的通讯方式——开疆智能MODBUS TCP转CANopen网关KJ-TCPC-CANP…...

初学 pytest 记录
安装 pip install pytest用例可以是函数也可以是类中的方法 def test_func():print()class TestAdd: # def __init__(self): 在 pytest 中不可以使用__init__方法 # self.cc 12345 pytest.mark.api def test_str(self):res add(1, 2)assert res 12def test_int(self):r…...

Linux C语言网络编程详细入门教程:如何一步步实现TCP服务端与客户端通信
文章目录 Linux C语言网络编程详细入门教程:如何一步步实现TCP服务端与客户端通信前言一、网络通信基础概念二、服务端与客户端的完整流程图解三、每一步的详细讲解和代码示例1. 创建Socket(服务端和客户端都要)2. 绑定本地地址和端口&#x…...

在QWebEngineView上实现鼠标、触摸等事件捕获的解决方案
这个问题我看其他博主也写了,要么要会员、要么写的乱七八糟。这里我整理一下,把问题说清楚并且给出代码,拿去用就行,照着葫芦画瓢。 问题 在继承QWebEngineView后,重写mousePressEvent或event函数无法捕获鼠标按下事…...
集成 Mybatis-Plus 和 Mybatis-Plus-Join)
纯 Java 项目(非 SpringBoot)集成 Mybatis-Plus 和 Mybatis-Plus-Join
纯 Java 项目(非 SpringBoot)集成 Mybatis-Plus 和 Mybatis-Plus-Join 1、依赖1.1、依赖版本1.2、pom.xml 2、代码2.1、SqlSession 构造器2.2、MybatisPlus代码生成器2.3、获取 config.yml 配置2.3.1、config.yml2.3.2、项目配置类 2.4、ftl 模板2.4.1、…...

Chromium 136 编译指南 Windows篇:depot_tools 配置与源码获取(二)
引言 工欲善其事,必先利其器。在完成了 Visual Studio 2022 和 Windows SDK 的安装后,我们即将接触到 Chromium 开发生态中最核心的工具——depot_tools。这个由 Google 精心打造的工具集,就像是连接开发者与 Chromium 庞大代码库的智能桥梁…...

微服务通信安全:深入解析mTLS的原理与实践
🔥「炎码工坊」技术弹药已装填! 点击关注 → 解锁工业级干货【工具实测|项目避坑|源码燃烧指南】 一、引言:微服务时代的通信安全挑战 随着云原生和微服务架构的普及,服务间的通信安全成为系统设计的核心议题。传统的单体架构中&…...
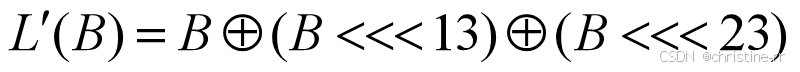
密码学基础——SM4算法
博客主页:christine-rr-CSDN博客 专栏主页:密码学 📌 【今日更新】📌 对称密码算法——SM4 目录 一、国密SM系列算法概述 二、SM4算法 2.1算法背景 2.2算法特点 2.3 基本部件 2.3.1 S盒 2.3.2 非线性变换 编辑…...

[特殊字符] 手撸 Redis 互斥锁那些坑
📖 手撸 Redis 互斥锁那些坑 最近搞业务遇到高并发下同一个 key 的互斥操作,想实现分布式环境下的互斥锁。于是私下顺手手撸了个基于 Redis 的简单互斥锁,也顺便跟 Redisson 的 RLock 机制对比了下,记录一波,别踩我踩过…...

React父子组件通信:Props怎么用?如何从父组件向子组件传递数据?
系列回顾: 在上一篇《React核心概念:State是什么?》中,我们学习了如何使用useState让一个组件拥有自己的内部数据(State),并通过一个计数器案例,实现了组件的自我更新。这很棒&#…...