九. Redis 持久化-RDB(详细讲解说明,一个配置一个说明分析,步步讲解到位)
九. Redis 持久化-RDB(详细讲解说明,一个配置一个说明分析,步步讲解到位)
文章目录
- 九. Redis 持久化-RDB(详细讲解说明,一个配置一个说明分析,步步讲解到位)
- 1. RDB 概述
- 2. RDB 持久化执行流程
- 3. RDB 的详细配置
- 4. RDB 备份&恢复
- 5. RDB 持久化小结(优势 和 劣势)
- 6. 最后:
Redis 持久化-RDB:官网文档地址: https://redis.io/docs/latest/operate/oss_and_stack/management/persistence/
Redis 关于持久化方案:有两种:
- RDB(Redis DataBase)
- AOF(Append Of File)
这里我们主要介绍 RDB 持久化方案,AOF 持久化方案,在下一篇文章当中。
1. RDB 概述
RDB 是什么 ?:
在指定的时间间隔内将内存当中的数据集快照写入到磁盘当中,也就是 Snapshot 快照,恢复时将快照文件当中的内容读取到内存 当中。
2. RDB 持久化执行流程
RDB 及其执行流程:

对上图的解读:
具体流程如下:
- Redis 客户端执行 bgsave 命令或者自动触发 bgsave 命令。
- 主进程判断当前是否已经存在正在执行的子进程 ,如果存在,那么主进程直接返回。
- 如果不存在,正在执行的子进程 ,那么就 fork 一个新的子进程进行持久化数据,fork 过程是阻塞的,fork 操作完成后主进程即可执行其它操作。
- 子进程先将数据写入到 临时的
rdb文件中 ,待快照数据写入完成后,再原子替换旧的rdb文件。- 同时发送信号给主进程,通知主进程
rdb持久化完成,主进程更新相关的统计信息。
小结:
- 整个过程中,主进程是不进行任何 IO 操作的,这就确保了极高的性能。
- 如果需要进行大规模数据的恢复,且对于数据恢复的完整性不是非常敏感,那 RDB 方式要比 AOF 方式更加的高效。
- RDB的缺点是最后一次持久化的数据可能丢失。
如果你是正常关闭 Redis ,仍然会进行持久化,不会造成数据丢失。
如果是 Redis 异常终止/宕机 ,就可能造成数据丢失。
后面在讲解快照配置的时候,进行说明。
Fork&Copy-On-Write:
-
Fork 的作用是复制一个与当前进程一样的进程。新进程的所有数据(变量,环境变量,程序计数器等)数值都和原进程一致,但是是一个全新的进程,并作为原进程的子进程。
-
在 Linux 程序中,fork() 会产生一个和父进程完全相同的子进程,但子进程在此后都会 exec 系统调用,出于效率考虑,Linux 中引入了 “写时复制技术 即:copy-on-write” ,有兴趣的可以移步至🌟🌟🌟 https://blog.csdn.net/Code_beeps/article/details/92838520 一位网友的解读。
-
一般情况父进程和子进程会共用一段物理内存,只有进程空间的各段的内容要发送变化时,才会将父进程的内容复制一份给子进程。
3. RDB 的详细配置
- 默认快照配置:
Redis 当中的快照的文件是名为 dump.rdb 文件,这是默认的。
在 /etc/redis.conf 中配置文件名称当中,存在这个 dump.rdb 的配置。

如何配置
默认为 Redis 启动时命令行所在的目录下:
意思就是:默认会将 “dump.rdb” 快照文件存储到 Redis 启动时命令行所在的目录下

重点: 进入到/usr/local/bin 目录下, 启动 Redis, 这个那么这里的 ./ 所指的路径就是 /usr/local/bin , 如果你在 /root/ 目录下启动 Redis , 那么这里 ./ 所指的就是 /root/ 下了路径 , 这点请大家注意。

那么这样的默认配置就存在一个问题,那就是,如果我们每次去到不同的目录下启动 redis 的化,那么这个
dump.rdb(快照存储我们信息/数据的文件) 就会存储到不同的目录下,这样就导致了,如果该目录下没有我们之前执行存储的数据的dump.rdb文件的话,我们Redis 就无法读取到该存有我们之前dump.rdb数据的文件,也就无法恢复我们之前存储操作的数据了。演示:
我们创建两个目录:分别是: test01,和 test02 在 test01 目录下执行 set k1 "test01" 同时查看该目录下是否生成 dump.rdb(快照文件) 在 test02 目录下执行 set k2 "test02" 同时查看该目录下是否生成 dump.rdb(快照文件)[root@localhost home]# mkdir test01 # 创建目录

[root@localhost test01]# redis-cli 127.0.0.1:6379> keys * (error) NOAUTH Authentication required. 127.0.0.1:6379> auth rainbowsea OK 127.0.0.1:6379> keys * (empty array) 127.0.0.1:6379> set k1 "test01" OK 127.0.0.1:6379> keys * 1) "k1"


同理执行:test02


怎么解决这个,Redis 在不同的目录下,导致数据存储快照不同,数据没有跟上?
我们可以自定义配置好这个 dump.rdb 文件的存放路径,不是默认的dir./(根据启动Redis目录不同而变化) ,而是一直配置在一个固定的路径下。就可以解决这个问题了。
这里我们将其配置到 /root/ 目录下,这样我们每次生成的 dump.rdb 文件就一直是在同一个路径的目录下了
dir /root/

注意:需要关闭 Redis 服务,重新启动 Redis 服务,配置才会生效 。
[root@localhost test02]# redis-server /etc/redis.conf [root@localhost test02]# redis-cli


- save 和 bgsave
127.0.0.1:6379> save
127.0.0.1:6379> bgsave

默认的快照配置: 如图:同样是在 `/etc/redis.conf文件当中配置的。


注意理解这个时间段的概念.:

如果我们没有开启 save 的注释 那么在退出,Redis 时 也会进行备份 更新 dump.rdb 文件的。
- save : save 时只管保存,其它不管,全部阻塞。手动保存,不建议。
- bgsave: Redis 会在后台异步进行快照操作,快照同时还可以响应客户端请求。
- 可以通过 lastave 命令获取最后一次成功执行快照的时间(unix 时间戳),可以使用工具转换。https://tool.lu/timestamp/
- flushall
- 执行 flushall 命令,也会产生 dump.rdb 文件,数据为空。
Redis Flushall命令用于清空整个 Redis 服务器的数据(删除所有数据库的所有 key )


- Save
格式:save 秒钟 写操作次数, 如图


RDB 是整个内存的压缩过的 Snapshot,RDB 的数据结构,可以配置复合的快照触发条件 。
禁用:给 save 传空字符串,可以看文档:
- stop-writes-on-bgsave-error

意思是:当 Redis 无法写入磁盘的话(比如磁盘满了), 直接关掉 Redis 的写操作。推荐 yes
- rdbcompression

该配置的意思是:
- 对于存储到磁盘中的快照,可以设置是否进行压缩存储。如果是的话,redis 会采用 LZF 算法进行压缩。
- 如果你不想消耗 CPU 来进行压缩的话,可以设置为关闭此功能,默认 yes。
- rdbchecksum

该配置的意思是:
- 在存储快照后,还可以让 redis 使用 CRC64算法来进行数据校验,保证文件是完整的。
- 但是这样做会增加大约 10% 的性能消耗,如果希望获取到最大的性能提升,可以关闭此功能,推荐 yes 打开。
-
动态停止 RDB:
-
动态停止RDB:
redis-cli config set save "",就是给 save 属性赋值为""空字符串,表示禁用保护策略。这里使用命令是让 客户端在此刻,启动的客户端停止 RDB,一旦退出了该客户端就,该配置就失效了。RDB 持久化策略又启动了。
示例演示:
需求: 如果 Redis 的 key 在 30 秒内, 有 5 个 key 变化, 就自动进行 RDB 备份.

save 30 5





4. RDB 备份&恢复
Redis 可以充当缓存,对项目进行优化,因此重要/敏感的数据建议在 MySQL要保存一份。
从设计层面来说,Redis 的内存数据,都是可以重新获取的(可能来自程序,也可能来自MySQL)
因此我们这里说的备份&恢复 :主要是给大家说明一下 Redis 启动时,初始化数据是从 dump.rdb 来的 整个机制。
演示:
这里我们演示的是:
将我们已经的
dump.rdb备份文件复制拷贝(备份)一份,复制后之后,再将原来的dump.rdb文件删除了(模拟文件损坏了,或者是执行 flushall 删除库)。再将我们拷贝备份的 dum.rdb 文件,复制过去,然后重启 redis 读取 dump.rdb 备份文件当中的数据,进行一个数据上的恢复。
config get dir 查询 rdb 文件的目录
127.0.0.1:6379> config get dir

将 dump.rdb 进行备份 如果有必要可以写 shell 脚本来定时备份 [参考韩顺平老师 Linux 课程定时
,备份 Mysql 数据库视频地址 https://www.bilibili.com/video/BV1Sv411r7vd?p=105 ] 。
[root@localhost ~]# cp /root/dump.rdb /root/dump.rdb.bak



127.0.0.1:6379> flushall


注意:这里得关闭一下服务器

[root@localhost ~]# rm /root/dump.rdb # 删除文件夹



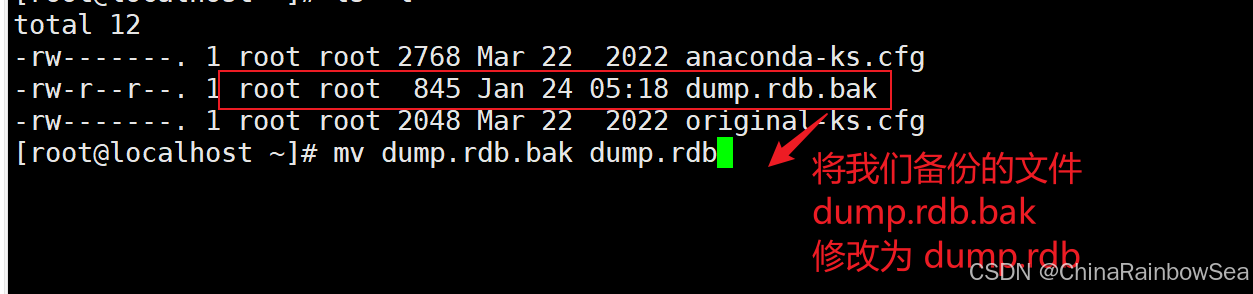
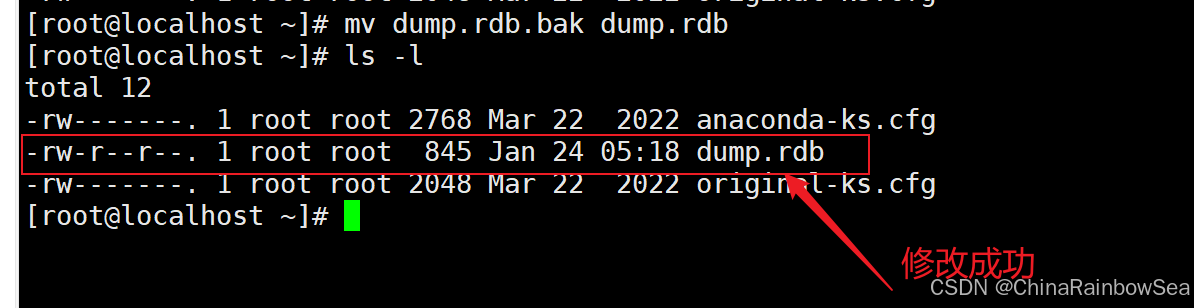
关闭 Redis 服务器,重新启动 Redis 服务器,让它读取到我们配置的dump.rdb 备份文件,恢复我们的数据信息。

5. RDB 持久化小结(优势 和 劣势)
优势:
- 适合大规模的数据恢复
- 对数据完整性和一致性要求不高更适合使用
- 节省磁盘空间
- 恢复速度快

劣势:
- 虽然 Redis 在 fork 时使用了写时拷贝技术(Cop-On-Write) ,但是如果数据庞大时还是比较消耗性能。
- 在备份周期在一定间隔时间做一次备份,所以如果 Redis 意外 down 掉 的话(如果正常关闭 Redis仍然会进行 RDB 备份,不会丢失数据),就会丢失最后一次快照后的所有修改。
6. 最后:
“在这个最后的篇章中,我要表达我对每一位读者的感激之情。你们的关注和回复是我创作的动力源泉,我从你们身上吸取了无尽的灵感与勇气。我会将你们的鼓励留在心底,继续在其他的领域奋斗。感谢你们,我们总会在某个时刻再次相遇。”
相关文章:

九. Redis 持久化-RDB(详细讲解说明,一个配置一个说明分析,步步讲解到位)
九. Redis 持久化-RDB(详细讲解说明,一个配置一个说明分析,步步讲解到位) 文章目录 九. Redis 持久化-RDB(详细讲解说明,一个配置一个说明分析,步步讲解到位)1. RDB 概述2. RDB 持久化执行流程3. RDB 的详细配置4. RDB 备份&恢…...

mac连接linux服务器
1、mac连接linux服务器 # ssh -p 22 root192.168.1.152、mac指定密码连接linux服务器 (1) 先安装sshpass,下载后解压执行 ./configure && make && makeinstall https://sourceforge.net/projects/sshpass/ (2) 连接linux # sshpass -p \/\\\[\!\\wen12\$ s…...

oracle: 表分区>>范围分区,列表分区,散列分区/哈希分区,间隔分区,参考分区,组合分区,子分区/复合分区/组合分区
分区表 是将一个逻辑上的大表按照特定的规则划分为多个物理上的子表,这些子表称为分区。 分区可以基于不同的维度,如时间、数值范围、字符串值等,将数据分散存储在不同的分区 中,以提高数据管理的效率和查询性能,同时…...

使用Pygame制作“走迷宫”游戏
1. 前言 迷宫游戏是最经典的 2D 游戏类型之一:在一个由墙壁和通道构成的地图里,玩家需要绕过障碍、寻找通路,最终抵达出口。它不但简单易实现,又兼具可玩性,还能在此基础上添加怪物、道具、机关等元素。本篇文章将展示…...

AJAX案例——图片上传个人信息操作
黑马程序员视频地址: AJAX-Day02-11.图片上传https://www.bilibili.com/video/BV1MN411y7pw?vd_source0a2d366696f87e241adc64419bf12cab&spm_id_from333.788.videopod.episodes&p26 图片上传 <!-- 文件选择元素 --><input type"file"…...

Day35-【13003】短文,什么是双端队列?栈和队列的互相模拟,以及解决队列模拟栈时出栈时间开销大的方法
文章目录 第三节进一步讨论栈和队列双端队列栈和队列的相互模拟使用栈来模拟队列类型定义入队出队判空,判满 使用队列来模拟栈类型定义初始化清空操作判空,判满栈长度输出入栈出栈避免出栈时间开销大的方法 第三节进一步讨论栈和队列 双端队列 假设你芷…...

力扣 55. 跳跃游戏
🔗 https://leetcode.cn/problems/jump-game 题目 给一个数组 nums,最开始在 index 0,每次可以跳跃的区间是 0-nums[i]判断是否可以跳到数组末尾 思路 题解是用贪心,实际上模拟也可以过遍历可以到达的下标,判断其可…...

深入剖析 HTML5 新特性:语义化标签和表单控件完全指南
系列文章目录 01-从零开始学 HTML:构建网页的基本框架与技巧 02-HTML常见文本标签解析:从基础到进阶的全面指南 03-HTML从入门到精通:链接与图像标签全解析 04-HTML 列表标签全解析:无序与有序列表的深度应用 05-HTML表格标签全面…...

本地快速部署DeepSeek-R1模型——2025新年贺岁
一晃年初六了,春节长假余额马上归零了。今天下午在我的电脑上成功部署了DeepSeek-R1模型,抽个时间和大家简单分享一下过程: 概述 DeepSeek模型 是一家由中国知名量化私募巨头幻方量化创立的人工智能公司,致力于开发高效、高性能…...

MVC 文件夹:架构之美与实际应用
MVC 文件夹:架构之美与实际应用 引言 MVC(Model-View-Controller)是一种设计模式,它将应用程序分为三个核心组件:模型(Model)、视图(View)和控制器(Controller)。这种架构模式不仅提高了代码的可维护性和可扩展性,而且使得开发流程更加清晰。本文将深入探讨MVC文…...

Redis --- 秒杀优化方案(阻塞队列+基于Stream流的消息队列)
下面是我们的秒杀流程: 对于正常的秒杀处理,我们需要多次查询数据库,会给数据库造成相当大的压力,这个时候我们需要加入缓存,进而缓解数据库压力。 在上面的图示中,我们可以将一条流水线的任务拆成两条流水…...

如何确认设备文件 /dev/fb0 对应的帧缓冲设备是开发板上的LCD屏?如何查看LCD屏的属性信息?
要判断 /dev/fb0 是否对应的是 LCD 屏幕,可以通过以下几种方法: 方法 1:使用 fbset 命令查看帧缓冲设备的属性信息 Linux 的 帧缓冲设备(Framebuffer) 通常在 /dev/fbX 下,/dev/fb0 一般是主屏幕ÿ…...

C++多线程编程——基于策略模式、单例模式和简单工厂模式的可扩展智能析构线程
1. thread对象的析构问题 在 C 多线程标准库中,创建 thread 对象后,必须在对象析构前决定是 detach 还是 join。若在 thread 对象销毁时仍未做出决策,程序将会终止。 然而,在创建 thread 对象后、调用 join 前的代码中ÿ…...

AI与SEO关键词的完美结合如何提升网站流量与排名策略
内容概要 在当今数字营销环境中,内容的成功不仅依赖于高质量的创作,还包括高效的关键词策略。AI与SEO关键词的结合,正是这一趋势的重要体现。 AI技术在SEO中的重要性 在数字营销领域,AI技术的引入为SEO策略带来了前所未有的变革。…...

保姆级教程Docker部署Kafka官方镜像
目录 一、安装Docker及可视化工具 二、单节点部署 1、创建挂载目录 2、运行Kafka容器 3、Compose运行Kafka容器 4、查看Kafka运行状态 三、集群部署 在Kafka2.8版本之前,Kafka是强依赖于Zookeeper中间件的,这本身就很不合理,中间件依赖…...

解析PHP文件路径相关常量
PHP文件路径相关常量包括以下几个常量: __FILE__:表示当前文件的绝对路径,包括文件名。 __DIR__:表示当前文件所在的目录的绝对路径,不包括文件名。 dirname(__FILE__):等同于__DIR__,表示当前…...

WPS计算机二级•幻灯片的配色、美化与动画
听说这是目录哦 配色基础颜色语言❤️使用配色方案🩷更改PPT的颜色🧡PPT动画添加的原则💛PPT绘图工具💚自定义设置动画💙使用动画刷复制动画效果🩵制作文字打字机效果💜能量站😚 配色…...

C#,shell32 + 调用控制面板项(.Cpl)实现“新建快捷方式对话框”(全网首发)
Made By 于子轩,2025.2.2 不管是使用System.IO命名空间下的File类来创建快捷方式文件,或是使用Windows Script Host对象创建快捷方式,亦或是使用Shell32对象创建快捷方式,都对用户很不友好,今天小编为大家带来一种全新…...

单纯信息展示的站点是否可以用UML建模
凌钦亮 More options Aug 7 2010, 10:36 am 现在社会上大量的网站需求都还只是用于单纯的企业信息展示,那此种网站是否有必要用UML 建模呢?业务用例图的一个个用例是用来卖的,但是他只有信息展示这个需 求,我是否在划分业务用例…...

FinRobot:一个使用大型语言模型的金融应用开源AI代理平台
“FinRobot: An Open-Source AI Agent Platform for Financial Applications using Large Language Models” 论文地址:https://arxiv.org/pdf/2405.14767 Github地址:https://github.com/AI4Finance-Foundation/FinRobot 摘要 在金融领域与AI社区间&a…...

中南大学无人机智能体的全面评估!BEDI:用于评估无人机上具身智能体的综合性基准测试
作者:Mingning Guo, Mengwei Wu, Jiarun He, Shaoxian Li, Haifeng Li, Chao Tao单位:中南大学地球科学与信息物理学院论文标题:BEDI: A Comprehensive Benchmark for Evaluating Embodied Agents on UAVs论文链接:https://arxiv.…...

YSYX学习记录(八)
C语言,练习0: 先创建一个文件夹,我用的是物理机: 安装build-essential 练习1: 我注释掉了 #include <stdio.h> 出现下面错误 在你的文本编辑器中打开ex1文件,随机修改或删除一部分,之后…...

linux arm系统烧录
1、打开瑞芯微程序 2、按住linux arm 的 recover按键 插入电源 3、当瑞芯微检测到有设备 4、松开recover按键 5、选择升级固件 6、点击固件选择本地刷机的linux arm 镜像 7、点击升级 (忘了有没有这步了 估计有) 刷机程序 和 镜像 就不提供了。要刷的时…...

srs linux
下载编译运行 git clone https:///ossrs/srs.git ./configure --h265on make 编译完成后即可启动SRS # 启动 ./objs/srs -c conf/srs.conf # 查看日志 tail -n 30 -f ./objs/srs.log 开放端口 默认RTMP接收推流端口是1935,SRS管理页面端口是8080,可…...

鸿蒙中用HarmonyOS SDK应用服务 HarmonyOS5开发一个生活电费的缴纳和查询小程序
一、项目初始化与配置 1. 创建项目 ohpm init harmony/utility-payment-app 2. 配置权限 // module.json5 {"requestPermissions": [{"name": "ohos.permission.INTERNET"},{"name": "ohos.permission.GET_NETWORK_INFO"…...

Rust 异步编程
Rust 异步编程 引言 Rust 是一种系统编程语言,以其高性能、安全性以及零成本抽象而著称。在多核处理器成为主流的今天,异步编程成为了一种提高应用性能、优化资源利用的有效手段。本文将深入探讨 Rust 异步编程的核心概念、常用库以及最佳实践。 异步编程基础 什么是异步…...

LLM基础1_语言模型如何处理文本
基于GitHub项目:https://github.com/datawhalechina/llms-from-scratch-cn 工具介绍 tiktoken:OpenAI开发的专业"分词器" torch:Facebook开发的强力计算引擎,相当于超级计算器 理解词嵌入:给词语画"…...

智能分布式爬虫的数据处理流水线优化:基于深度强化学习的数据质量控制
在数字化浪潮席卷全球的今天,数据已成为企业和研究机构的核心资产。智能分布式爬虫作为高效的数据采集工具,在大规模数据获取中发挥着关键作用。然而,传统的数据处理流水线在面对复杂多变的网络环境和海量异构数据时,常出现数据质…...

C# 求圆面积的程序(Program to find area of a circle)
给定半径r,求圆的面积。圆的面积应精确到小数点后5位。 例子: 输入:r 5 输出:78.53982 解释:由于面积 PI * r * r 3.14159265358979323846 * 5 * 5 78.53982,因为我们只保留小数点后 5 位数字。 输…...

【数据分析】R版IntelliGenes用于生物标志物发现的可解释机器学习
禁止商业或二改转载,仅供自学使用,侵权必究,如需截取部分内容请后台联系作者! 文章目录 介绍流程步骤1. 输入数据2. 特征选择3. 模型训练4. I-Genes 评分计算5. 输出结果 IntelliGenesR 安装包1. 特征选择2. 模型训练和评估3. I-Genes 评分计…...