大模型训练(6):张量并行
0 英文缩写
- Pipeline Parallelism(PP)流水线并行
- Tensor Parallel(TP)张量并行
- Data Parallelism(DP)数据并行
- Distributed Data Parallelism(DDP)分布式数据并行
- Zero Redundancy Optimizer(ZeRO)零冗余优化器
- Artificial General Intelligence(AGI)通用人工智慧
- FWD前传
- BWD后传
- multi-layer perceptron(MLP)多层感知机
- Large Language Model(LLM)大语言模型
- FeedForward Network(FFN)前馈网络
- Rectified Linear Unit(ReLU)线性整流函数
1 背景
在之前的内容中,我们已经介绍过流水线并行(PP)、数据并行(DP,DDP和ZeRO)。今天我们将要介绍最重要,也是目前基于Transformer 做大模型预训练最基本的并行范式:来自NVIDIA的张量并行(TP)有的地方也叫张量模型并行。它的基本思想就是把模型的参数纵向切开,工作负载放到不同的GPU上进行独立计算,然后再对结果做聚合。TP主要通过实现Megatron,NVIDIA Megatron 是一个基于PyTorch 的框架,主要用于训练基于Transformer 架构的巨型语言模型,可以说没有它就没有AGI。
- 此篇文章主要介绍TP的原理和实现方式
- 后续文章会陆续介绍
- Megatron 的混合并行部分
- 部分 Megatron 的设计思想和细节(结合源码)
如果对Transformer的设计不了解也没关系,在这篇文章里都会给出图解介绍,不过还是建议大家在阅读前面的文章
2 矩阵乘法切分
作出如下设:
- 输入数据为 X X X,维度 ( b , s , h ) (b,s,h) (b,s,h)
- 参数为 W W W,维度 ( h , h ′ ) (h, h') (h,h′)
b:batch_size,表示批量大小s:sequence_length,表示输入序列的长度h:hidden_size,表示每个token向量的维度h':参数W的hidden_size
则每次forward的过程如下:

为画图方便,图中所绘是b=3时的情况。
假设现在W太大,导致单卡装不下。我们需要把 W W W切开放到不同的卡上,则我们面临三个主要问题:
- 怎么切分 W W W
- 切完 W W W后,怎么做FWD
- 做完FWD后,怎么做BWD,进而求出梯度,更新权重
一般来说,我们可以沿着 W W W的行(h维度),或者列(h'维度)切分 W W W。下面我们分别介绍这两种切割办法,并说明它们是如何做FWD和BWD的。
2.1 按行切分权重
2.1.1 行切分前传
我们用 N N N来表示GPU的数量。有几块GPU,就把 W W W按行维度切成几份。下图展示了 N = 2 N=2 N=2时的切割方式:

W W W按照行维度切开后, X X X的h维度和它不对齐了,这可怎么做矩阵乘法呢?很简单,再把 X X X按列切开就行了,分别算出来多个结果矩阵的部分结果,然后在进行求和归并,如下图所示:

2.1.2 行切分后传
做完FWD,取得预测值 Y Y Y,进而可计算出损失 L L L,接下来就能BWD了。我们重画一下FWD的过程,并在其中加入BWD的部分,整体流程图如下:

-
f和g:分别表示两个算子,每个算子都包含一组这个算子对应的FWD + BWD操作- 注意
f和g不是前后传算子,可以理解为- 在前传中
f算子表现为:基于TP的矩阵分割乘算子(上文已经介绍) - 在前传中
g算子表现为:基于TP的矩阵多个部分结果求和(上文已经介绍) - 在后传中
g算子表现为:假定要求 L L L对 W i W_i Wi 求梯度,则可根据链式求导法则推出 ∂ L ∂ W i = ∂ L ∂ Y ∗ ∂ Y ∂ Y i ∗ ∂ Y i ∂ W i = ∂ L ∂ Y ∗ ∂ Y i ∂ W i \frac{\partial L}{\partial W_i}=\frac{\partial L}{\partial Y}∗\frac{\partial Y}{\partial Y_i}∗\frac{\partial Y_i}{\partial W_i}=\frac{\partial L}{\partial Y}∗\frac{\partial Y_i}{\partial W_i} ∂Wi∂L=∂Y∂L∗∂Yi∂Y∗∂Wi∂Yi=∂Y∂L∗∂Wi∂Yi ,(因为 Y = Y 1 + Y 2 Y=Y_1+Y_2 Y=Y1+Y2 所以 Y Y Y对 Y i Y_i Yi的求导是1),也就是说,只要把 ∂ L ∂ Y \frac{\partial L}{\partial Y} ∂Y∂L 同时广播到两块GPU上,两块GPU就可以独立计算各自权重的梯度了。 - 在后传中
f算子表现为:在上图中,模型只有一层,计算过程比较简单。但是当模型存在多层时,梯度要从上一层向下一层传播。比如图中,梯度要继续往 X X X的上一级传递,就需要先传播到 X X X,得到 ∂ L ∂ X \frac{\partial L}{\partial X} ∂X∂L 然后才能往下一层继续传递。这就是f的backward的作用。这里也易推出, ∂ L ∂ X = c o n c a t ( ∂ L ∂ X 1 , ∂ L ∂ X 2 ) \frac{\partial L}{\partial X} = concat(\frac{\partial L}{\partial X_1},\frac{\partial L}{\partial X_2}) ∂X∂L=concat(∂X1∂L,∂X2∂L)
- 在前传中
- 注意
-
图中的每一行,表示单独在一块GPU上计算的过程(举例是 N = 2 N=2 N=2,即为切分到两个GPU,实际上也可以很多)
2.2 按列切分权重
2.2.1 列切分前传
按列切分权重后,FWD计算图如下:
注意不同于按行切分,按列切分的前传计算出来的子结果矩阵不需要通加法进行归并,计算出来的结果都已经完备,仅需要通过拼接即可形成完整结果

2.2.2 列切分后传

f和g:分别表示两个算子,每个算子都包含一组这个算子对应的FWD + BWD操作- 注意
f和g不是前后传算子,可以理解为- 在前传中
f算子表现为:基于TP的矩阵分割乘算子(上文已经介绍) - 在前传中
g算子表现为:基于TP的矩阵多个子结果拼接(上文已经介绍) - 在后传中
g算子表现为:假定要求 L L L对 W i W_i Wi 求梯度,则可根据链式求导法则推出 ∂ L ∂ W i = ∂ L ∂ Y i ∗ ∂ Y i ∂ W i \frac{\partial L}{\partial W_i}=\frac{\partial L}{\partial Y_i}∗\frac{\partial Y_i}{\partial W_i} ∂Wi∂L=∂Yi∂L∗∂Wi∂Yi - 在后传中
f算子表现为:同上文需要得到 ∂ L ∂ X \frac{\partial L}{\partial X} ∂X∂L 然后才能往下一层继续传递。因为对于损失 L L L,这种切分并行方式中, X X X既参与了 X W 1 XW_1 XW1的计算,也参与了 X W 2 XW_2 XW2的计算。因此有 ∂ L ∂ X = ∂ L ∂ X 1 + ∂ L ∂ X 2 \frac{\partial L}{\partial X}=\frac{\partial L}{\partial X}_1+\frac{\partial L}{\partial X}_2 ∂X∂L=∂X∂L1+∂X∂L2 。其中 ∂ L ∂ X i \frac{\partial L}{\partial X}_i ∂X∂Li 这个 i i i不是对 X X X的下标,而是表示第 i i i块GPU上计算得到的对 X X X的梯度。
- 在前传中
- 注意
- 图中的每一行,表示单独在一块GPU上计算的过程(举例是 N = 2 N=2 N=2,即为切分到两个GPU,实际上也可以很多)
2.3 总结
- 分别介绍
按行和按列切分权重的方法,在Megatron-LM中,权重的切分操作就是由按行和按列两种切分方式进行的 - 两种切分方式的每一种分别对应的两个切分基础算子组合而成的(可以理解为共计4个)
- 接下来,针对Transformer模型,我们依次来看在不同的部分里,Megatron-LM是怎么做切分的
3 MLP层
3.0 简单介绍
简单看一下MLP层,我们可以通过在网络中加入一个或多个隐藏层来克服线性模型的限制, 使其能处理更普遍的函数关系类型。 要做到这一点,最简单的方法是将许多全连接层堆叠在一起。 每一层都输出到上面的层,直到生成最后的输出。 我们可以把前L−1层看作表示,把最后一层看作线性预测器。 这种架构通常称为MLP。 下面,我们以图的方式描述了多层感知机

这个多层感知机有4个输入,3个输出,其隐藏层包含5个隐藏单元。 输入层不涉及任何计算,因此使用此网络产生输出只需要实现隐藏层和输出层的计算。 因此,这个多层感知机中的层数为2。 注意,这两个层都是全连接的。 每个输入都会影响隐藏层中的每个神经元, 而隐藏层中的每个神经元又会影响输出层中的每个神经元。
MLP 在 LLM 中扮演着关键角色,它是 Transformer 架构中不可或缺的组成部分(一般作为 FFN 组件),通常位于自注意力层之后,通过其两层全连接结构和非线性激活函数,有效地增强了模型的非线性表达能力。
MLP 处理和转换自注意力层的输出,并帮助模型学习更复杂的模式和关系,从而提升整体性能。其较宽的中间层设计进一步增强了模型的表达能力,而高度可并行化的特性则确保了大规模模型训练和推理的计算效率。
Transformer中的 MLP 层比较简单,是一个两层的全连接层,第一层的激活函数为 ReLU,第二层不使用激活函数,对应的公式如下。
Z = L i n e a r ( R e L U ( L i n e a r ( X ) ) ) = L i n e a r ( Y ) Z= Linear(ReLU(Linear(X))) = Linear(Y) Z=Linear(ReLU(Linear(X)))=Linear(Y)

3.1 MLP层的张量并行计算方法
MLP层构造最简单,所以我们先来看它。MLP层计算过程如下图:

其中,GeLU是激活函数,A和B分别为两个线性层。在Transformer里,一般设 h ′ = 4 h h' = 4h h′=4h。假设现在有 N N N块GPU,我们要把MLP层的权重并行拆到上面做计算,要怎么拆分呢?Megatron提供的拆分办法如下:

在MLP层中,对A采用列切割,对B采用行切割。
f算子的FWD计算:把输入 X X X拷贝到2块GPU上,每块GPU即可独立做forward计算g算子的FWD计算:每块GPU上的FWD的计算完毕,取得 Z 1 Z_1 Z1和 Z 2 Z_2 Z2后,GPU间做一次AllReduce,相加结果产生 Z Z Z。g算子的BWD计算:只需要把 ∂ L ∂ Z \frac{\partial L}{\partial Z} ∂Z∂L 拷贝到两块GPU上,两块GPU就能各自独立做梯度计算。f算子的BWD计算:当前层的梯度计算完毕,需要传递到下一层继续做梯度计算时,我们需要求得 ∂ L ∂ X \frac{\partial L}{\partial X} ∂X∂L 。则此时两块GPU做一次AllReduce,把各自的梯度 ∂ L ∂ X 1 \frac{\partial L}{\partial X}_1 ∂X∂L1 和 ∂ L ∂ X 2 \frac{\partial L}{\partial X}_2 ∂X∂L2 相加即可。
为什么我们对 A A A采用列切割,对 B B B采用行切割呢?这样设计的原因是,我们尽量保证各GPU上的计算相互独立,减少通讯量。对 A A A来说,需要做一次GeLU的计算,而GeLU函数是非线形的,它的性质如下:

也就意味着,如果对A采用行切割,得到的 Y 1 Y_1 Y1和 Y 2 Y_2 Y2分别是结果 Y Y Y的归并前结果,想要得到 Y Y Y需要进行 Y 1 + Y 2 = Y Y_1+Y_2=Y Y1+Y2=Y,所以我们必须在做GeLU前,做一次AllReduce,对 Y i Y_i Yi进行归并,这样就会产生额外通讯量。但是如果对 A A A采用列切割,那每块GPU就可以继续独立计算了,虽然 Y 1 Y_1 Y1和 Y 2 Y_2 Y2是 Y Y Y的部分子矩阵,但是他是独立解耦与其他GPU数据的。一旦确认好 A A A做列切割,那么也就相应定好 B B B需要做行切割了。
3.2 MLP层的通讯量分析
由2.1的分析可知,MLP层做FWD时产生一次AllReduce,做BWD时产生一次AllReduce。在之前的文章里我们讲过,AllReduce的过程分为两个阶段,Reduce-Scatter和All-Gather,每个阶段的通讯量都相等。现在我们设每个阶段的通讯量为 Φ \Phi Φ ,则**一次AllReduce产生的通讯量为 2 Φ 2\Phi 2Φ 。MLP层的总通讯量为 4 Φ 4\Phi 4Φ **。
根据上面的计算图,我们也易知, Φ = s ∗ h ∗ b \Phi = s * h*b Φ=s∗h∗b
4 Self-Attention层
现在,我们来看稍微复杂一点的self-attention层切割方式(Transformer中Encode和Decoder之间还有做cross-attention,但计算逻辑和self-attention一致,因此这里只拿self-attention举例)。
首先,我们快速过一下multi-head attention层的参数构造。
4.0 Multi-head Attention的计算方法
当head数量为1时,self-attention层的计算方法如下:

seq_len,d_model分别为本文维度说明中的s和h,也即序列长度和每个token的向量维度- W Q W_Q WQ, W K W_K WK, W V W_V WV 即attention层需要做训练的三块权重。
k_dim,v_dim满足:k_dim=v_dim=d_model/num_heads=h/num_heads
理清了单头,我们来看多头的情况,下图展示了当num_heads = 2时attention层的计算方法。即对每一块权重,我们都沿着列方向(k_dim)维度切割一刀。此时每个head上的 W Q W_Q WQ, W K W_K WK, W V W_V WV 的维度都变成(d_model, k_dim/2)。每个head上单独做矩阵计算,最后将计算结果concat起来即可。整个流程如下:

4.1 Self-Attention层的张量并行计算方法
可以发现,attention的多头计算简直是为张量并行量身定做的,因为每个头上都可以独立计算,最后再将结果concat起来。也就是说,可以把每个mutil-head的子头的权重参数放到一块GPU上。则整个过程可以画成:

对三个参数矩阵 W Q W_Q WQ, W K W_K WK, W V W_V WV,按照列切割,每个头放到一块GPU上,做并行计算。对线性层 B B B,按照行切割。切割的方式和MLP层基本一致,其FWD与BWD原理也一致,这里不再赘述。
最后,在实际应用中,并不一定按照一个head占用一块GPU来切割权重,我们也可以一个多个head占用一块GPU,这依然不会改变单块GPU上独立计算的目的。所以实际设计时,我们尽量保证head总数能被GPU个数整除。
4.2 Self-Attention层的通讯量分析
类比于MLP层,self-attention层在FWD中做一次AllReduce,在BWD中做一次AllReduce。总通讯量也是 4 Φ 4\Phi 4Φ ,其中 Φ = b ∗ s ∗ h \Phi=b∗s∗h Φ=b∗s∗h
写到这里,我们可以把self-attention层拼接起来看整体的计算逻辑和通讯量:

5 Embedding层
讲完了中间的计算层,现在我们来看输入和输出层。首先看来自输入层的Embeddng。
5.1 输入层Embedding计算模式与并行模式
我们知道Embedding层一般由两个部分组成:
- word embedding:维度
(v, h),其中v表示词表大小。 - positional embedding:维度
(max_s, h),其中max_s表示模型允许的最大序列长度。
对positional embedding来说,max_s本身不会太长,因此每个GPU上都拷贝一份,对显存的压力也不会太大。但是对word embedding来说,词表的大小就很客观了,因此需要把word embedding拆分到各个GPU上,具体的做法如下:

我们来详细说明下这张图。对于输入 X X X,过word embedding的过程,就是等于用token的序号去word embedding中查找对应词向量的过程。例如,输入数据为[0, 212, 7, 9],数据中的每一个元素代表词序号,我们要做的就是去word embedding中的0,212,7,9行去把相应的词向量找出来。
假设词表中有300个词,现在我们将word embedding拆分到两块GPU上,第一块GPU维护词表[0, 150),第二块GPU维护词表[150, 299)。当输入 X X X去GPU上查找时,能找到的词,就正常返回词向量,找到不到就把词向量中的全部全素都置0。按此方式查找完毕后,每块GPU上的数据做一次AllReduce,就能得到最终的输入。
例如例子中,第一块GPU的查找结果为[ok, 0, ok, ok],第二块为[0, ok, 0, 0],两个向量一相加,变为[ok, ok, ok, ok]
5.2 输出层Embedding计算模式与并行模式
输出层中,同样有一个word embedding,把输入再映射回词表里,得到每一个位置的词。一般来说,输入层和输出层共用一个word embeding。其计算过程如下:

需要注意的是,我们必须时刻保证输入层和输出层共用一套word embedding。而在backward的过程中,我们在输出层时会对word embedding计算一次梯度,在输入层中还会对word embedding计算一次梯度。在用梯度做word embedding权重更新时,我们必须保证用两次梯度的总和进行更新。
当模型的输入层到输入层都在一块GPU上时(即流水线并行深度=1),我们不必担心这点(实践中大部分用Megatron做并行的项目也是这么做的)。但若模型输入层和输出层在不同的GPU上时,我们就要保证在权重更新前,两块GPU上的word embedding梯度做了一次AllReduce。现在看得有些迷糊没关系~在本系列下一篇的源码解读里,我们会来分析这一步。
6 Cross-entropy层
终于,我们来到了计算损失函数的一层。回顾一下5.2中,输出层过完embedding后的样子:

正常来说,我们需要对 Y 1 Y_1 Y1和 Y 2 Y_2 Y2做一次All-Gather,把它们concat起来形成 Y Y Y,然后对 Y Y Y的每一行做softmax,就可得到对于当前位置来说,每个词出现的概率。接着,再用此概率和真值组做cross-entropy即可。
但是All-Gather会产生额外的通讯量 b ∗ s ∗ v b∗s∗v b∗s∗v 。当词表 v v v 很大时,这个通讯开销也不容忽视。针对这种情况,可以做如下优化:

- 每块GPU上,我们可以先按行求和,得到各自GPU上的 s u m G P U i ( e ) sum_{GPU_i}(e) sumGPUi(e)
- 将每块GPU上结果做AllReduce,得到每行最终的 s u m ( e ) sum(e) sum(e),也就softmax中的分母。此时的通讯量为 b ∗ s b∗s b∗s
- 在每块GPU上,即可计算各自维护部分的 e / s u m ( e ) e/sum(e) e/sum(e),将其与真值做cross-entropy,得到每行的loss,按行加总起来以后得到GPU上scalar Loss。
- 将GPU上的scalar Loss做AllReduce,得到总Loss。此时通讯量为N
这样,我们把原先的通讯量从 b ∗ s ∗ v b∗s∗v b∗s∗v 大大降至 b ∗ s + N b∗s+N b∗s+N
7 张量并行 + 数据并行
到这里为止,我们基本把张量并行的计算架构说完了。在实际应用中,对Transformer类的模型,采用最经典方法是张量并行 + 数据并行,并在数据并行中引入ZeRO做显存优化。具体的架构如下:

其中,node表示一台机器,一般我们在同一台机器的GPU间做张量并行。在不同的机器上做数据并行。图中颜色相同的部分,为一个数据并行组。凭直觉,我们可以知道这么设计大概率和两种并行方式的通讯量有关。具体来说,它与TP和DP模式下每一层的通讯量有关,也与TP和DP的backward计算方式有关。我们分别来看这两点。
7.1 TP与DP通讯量
首先,我们来分析两者的通讯量。我们关注Transformer中每一层的通讯情况。
在张量并行中,我们设每次通讯数据量为 Φ T P = b ∗ s ∗ h \Phi_{TP}=b∗s∗h ΦTP=b∗s∗h ,从上面分析中我们知道每层做4次AllReduce,其通讯总量为 8 Φ T P 8\Phi_{TP} 8ΦTP。通讯总量为 8 ∗ b ∗ s ∗ h 8∗b∗s∗h 8∗b∗s∗h 。
在数据并行中,设每次通讯量为 Φ D P \Phi_{DP} ΦDP ,从先前的文章中,我们知道每层做1次AllReduce(先不考虑ZeRO拆分权重的情况),其通讯总量为 2 Φ D P 2\Phi_{DP} 2ΦDP 。其中,通讯的主要是梯度,则 Φ D P = h ∗ h \Phi_{DP}=h∗h ΦDP=h∗h ,总通讯量为 2 ∗ h ∗ h 2∗h∗h 2∗h∗h 。
因此,我们要比较的就是 8 ∗ b ∗ s ∗ h 8∗b∗s∗h 8∗b∗s∗h 和 2 ∗ h ∗ h 2∗h∗h 2∗h∗h 。忽略常数和共同项,我们最终比较的是:b∗s VS h
在实际应用中,前者可能会比后者大一些,但量级基本在 105 左右。因此,从通讯量上来说,有差异但不会显著(主要还是和模型设计相关)。不过按照常理,通讯量大的,尽量放在一台机器里(机器内的带宽大,通讯时间也会小)。通讯量相对小的,可以考虑在不同机器间做并行
7.2 TP与DP计算backward的方式
回顾上文,我们知道TP在从上一层往下一层做backward的过程中,所有GPU间需要做一次AllReduce的。例如下图:

而对DP来说,本层算完梯度以后,就正常把本层的梯度发出去,和属于一个DP组的GPU做AllReduce,同时继续往下一层做backward。下一层也是同理。也就是在DP组中,下一层不依赖上一层的梯度聚合结果。因此在DP组中对带宽的要求就没那么高了。所以可以放到机器间做DP。例如下图:

8 实验效果
在讲完Megatron整体的设计后,现在我们可以更好来解读实验效果了。在原始论文中,采用32台DGX-2H,每台里有16张 Telsa V100 SXM3 32GB的GPU,总共512块GPU。在这个硬件配置上,训练不同大小的GPT2模型。核心实验数据如下:

每一行表示模型的不同大小,Model parallel列表示只用TP并行时消耗的GPU卡数,其对应的单卡效率为蓝色柱状图部分。model + data parallel列表示TP + DP并行时消耗的GPU卡数,单卡计算效率为绿色柱状图部分。
8.1 纯TP实验效果
我们先来看纯TP部分。表格中的第一行是整个实验的基线,它设计了一个可以装在单卡里的GPT模型。此时不涉及卡间的通信,因此GPU的计算效率为100%。
然后,调大GPT模型到需要用2卡做TP。此时因为涉及卡间的通信,所以GPU的计算效率略有下降。从蓝色柱状图可以看出,随着模型的增大,需要的GPU数量变多,通讯量增大,单卡的计算效率是在下降的。从1卡增加到8卡,我们可以发现需要的GPU数量和模型大小是成正比的。例如当参数量从1.2B增加到8.3B时,需要的GPU数量也对应增加8倍。
但是,到了8以后呢?在这篇论文里,最大只做到了8卡。可是一台机器明明有16张卡,为啥不能再做到一个16B左右的模型呢?回想上一篇ZeRO部分对显存消耗的分析,当模型增大时,不仅是参数变多,还有例如activation这样的中间结果,也在占据大头显存。因此需要的GPU数量渐渐不再和模型大小成正比了。如果不引入显存优化,一台机器装不下16B的模型。
8.2 TP + DP实验效果
再来看TP + DP的结果。表格的第一行是TP + DP的基线。前面说过第一行的模型大小是可以塞进单卡里的。因此,这行中,是在每台机器中选2块GPU,一共选择64块GPU,每个GPU上都放置了一个完整的模型,GPU间做纯数据并行。其单卡计算效率为绿色柱状图第1条,96%。
在第二行中,模型大小上升,单卡已装不下完整模型。因此在每台机器中,选择4块GPU,每2块GPU组成一个TP组,因此一台机器上共2个TP组。所有机器上共64个TP组,占据128卡。这些TP组间做数据并行。以此类推模型大小再往上走时的实验配置。
不难发现,蓝色柱状图和绿色柱状图是一一对应的关系。分别表示单个模型在1卡、2卡、4卡、8卡上时的单卡效率。在引入数据并行的前提下(跨机),绿色的单卡效率并没有下降很多。这个原因我们在6.2中解释过:因为DP组内做backward计算梯度时,下一层的计算不需要依赖上一层的梯度AllReduce结果。你算你的,我发我的,对计算通讯比不会产生太大影响。
最后呢,一台DGX-2H的售价大概是40w刀,这里的硬件成本就有40 * 32 = 1280w刀。要么怎么说Megatron,注定生于NVIDIA家呢?
8.3 GPU效率计算
最后,在实验这块,咱们再来说说柱状图的weak scaling指标是怎么算出来的。毕竟在论文一开头,也摆出了一堆指标,乍一看还确实比较迷糊。
首先,在单卡装下一个模型的情况下,单GPU每秒计算量是39TeraFlOPs(可以近似理解成做矩阵乘法及加法的次数),不涉及通讯,是基线,因此计算效率为100%。
上到512卡的TP + DP后,512卡上总计每秒计算量为15100TeraFlops,因为涉及到通讯,GPU肯定不是每时每刻都在计算的,那么我们到底利用了多少GPU的算力呢?
假设512卡间无任何通讯影响,则理论算力应该为:39 * 512 = 19968TeraFlops,实际算力为15100TeraFlops。则算力利用比 = 15100/19968 = 76%。这就是文章中贯穿的76%这一指标的由来,它体现了即使做分布式训练,GPU的计算能力也不会被通信浪费掉太多,这也是Megatron的卖点之一。
Last 参考
- https://arxiv.org/pdf/1909.08053.pdf
- https://github.com/NVIDIA/Megatron-LM
- https://github.com/THUDM/CodeGeeX
- https://zhuanlan.zhihu.com/p/366906920
- 图解大模型训练之:张量模型并行(TP),Megatron-LM - 知乎
相关文章:
大模型训练(6):张量并行
0 英文缩写 Pipeline Parallelism(PP)流水线并行Tensor Parallel(TP)张量并行Data Parallelism(DP)数据并行Distributed Data Parallelism(DDP)分布式数据并行Zero Redundancy Opti…...

【力扣】238.除自身以外数组的乘积
AC截图 题目 思路 前缀积 前缀积指的是对于一个给定的数组arr,构建一个新的数组prefixProduct,其中prefixProduct[i]表示原数组从第一个元素到第i个元素(包括i)的所有元素的乘积。形式化来说: prefixProduct[0] ar…...

Nacos 的介绍和使用
1. Nacos 的介绍和安装 与 Eureka 一样,Nacos 也提供服务注册和服务发现的功能,Nacos 还支持更多元数据的管理, 同时具备配置管理功能,功能更丰富。 1.1. windows 下的安装和启动方式 下载地址:Release 2.2.3 (May …...

DeepSeek最新图像模型Janus-Pro论文阅读
目录 论文总结 摘要 1. 引言 2. 方法 2.1 架构 2.2 优化的训练策略 2.4 模型扩展 3. 实验 3.1 实施细节 3.2 评估设置 3.3 与最新技术的比较 3.4 定性结果 4. 结论 论文总结 Janus-Pro是DeepSeek最新开源的图像理解生成模型,Janus-Pro在多模态理解和文…...

【仿12306项目】基于SpringCloud,使用Sentinal对抢票业务进行限流
文章目录 一. 常见的限流算法1. 静态窗口限流2. 动态窗口限流3. 漏桶限流4. 令牌桶限流5. 令牌大闸 二. Sentinal简介三. 代码演示0. 限流场景1. 引入依赖2. 定义资源3. 定义规则4. 启动测试 四. 使用Sentinel控台监控流量1. Sentinel控台1.8.6版本下载地址2. 文档说明…...

【赵渝强老师】Spark RDD的依赖关系和任务阶段
Spark RDD彼此之间会存在一定的依赖关系。依赖关系有两种不同的类型:窄依赖和宽依赖。 窄依赖:如果父RDD的每一个分区最多只被一个子RDD的分区使用,这样的依赖关系就是窄依赖;宽依赖:如果父RDD的每一个分区被多个子RD…...

【B站保姆级视频教程:Jetson配置YOLOv11环境(六)PyTorchTorchvision安装】
Jetson配置YOLOv11环境(6)PyTorch&Torchvision安装 文章目录 1. 安装PyTorch1.1安装依赖项1.2 下载torch wheel 安装包1.3 安装 2. 安装torchvisiion2.1 安装依赖2.2 编译安装torchvision2.2.1 Torchvisiion版本选择2.2.2 下载torchvisiion到Downloa…...

Verilog语言学习总结
Verilog语言学习! 目录 文章目录 前言 一、Verilog语言是什么? 1.1 Verilog简介 1.2 Verilog 和 C 的区别 1.3 Verilog 学习 二、Verilog基础知识 2.1 Verilog 的逻辑值 2.2 数字进制 2.3 Verilog标识符 2.4 Verilog 的数据类型 2.4.1 寄存器类型 2.4.2 …...

【阅读笔记】LED显示屏非均匀度校正
一、背景 发光二极管(LED)显示屏具有色彩鲜艳、图像清晰、亮度高、驱动电压低、功耗小、耐震动、价格低廉和使用寿命长等优势。LED显示图像的非均匀度是衡量LED显示屏显示质量的指标,非均匀度过高,会导致LED显示图像出现明暗不均…...
:创建不同线程的子任务、子任务链式调用与异常处理)
【Java异步编程】CompletableFuture基础(1):创建不同线程的子任务、子任务链式调用与异常处理
文章目录 1. 三种实现接口2. 链式调用:保证链的顺序性与异步性3. CompletableFuture创建CompletionStage子任务4. 处理异常a. 创建回调钩子b. 调用handle()方法统一处理异常和结果 5. 如何选择线程池:不同的业务选择不同的线程池 CompletableFuture是JDK…...

ESXI虚拟机中部署docker会降低服务器性能
在 8 核 16GB 的 ESXi 虚拟机中部署 Docker 的性能影响分析 在 ESXi 虚拟机中运行 Docker 容器时,性能影响主要来自以下几个方面: 虚拟化开销:ESXi 虚拟化层和 Docker 容器化层的叠加。资源竞争:虚拟机与容器之间对 CPU、内存、…...
ASP.NET Core与配置系统的集成
目录 配置系统 默认添加的配置提供者 加载命令行中的配置。 运行环境 读取方法 User Secrets 注意事项 Zack.AnyDBConfigProvider 案例 配置系统 默认添加的配置提供者 加载现有的IConfiguration。加载项目根目录下的appsettings.json。加载项目根目录下的appsettin…...

中间件的概念及基本使用
什么是中间件 中间件是ASP.NET Core的核心组件,MVC框架、响应缓存、身份验证、CORS、Swagger等都是内置中间件。 广义上来讲:Tomcat、WebLogic、Redis、IIS;狭义上来讲,ASP.NET Core中的中间件指ASP.NET Core中的一个组件。中间件…...

SpringBoot 整合 Mybatis:注解版
第一章:注解版 导入配置: <groupId>org.mybatis.spring.boot</groupId><artifactId>mybatis-spring-boot-starter</artifactId><version>1.3.1</version> </dependency> 步骤: 配置数据源见 Druid…...

18.[前端开发]Day18-王者荣耀项目实战(一)
01-06 项目实战 1 代码规范 2 CSS编写顺序 3 组件化开发思想 组件化开发思路 项目整体思路 – 各个击破 07_(掌握)王者荣耀-top-整体布局完成 完整代码 01_page_top1.html <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8…...
)
Kafka 使用说明(kafka官方文档中文)
文章来源:kafka -- 南京筱麦软件有限公司 第 1 步:获取 KAFKA 下载最新的 Kafka 版本并提取它: $ tar -xzf kafka_{{scalaVersion}}-{{fullDotVersion}}.tgz $ cd kafka_{{scalaVersion}}-{{fullDotVersion}} 第 2 步:启动 KAFKA 环境 注意:您的本地环境必须安装 Java 8+。…...

基于多智能体强化学习的医疗AI中RAG系统程序架构优化研究
一、引言 1.1 研究背景与意义 在数智化医疗飞速发展的当下,医疗人工智能(AI)已成为提升医疗服务质量、优化医疗流程以及推动医学研究进步的关键力量。医疗 AI 借助机器学习、深度学习等先进技术,能够处理和分析海量的医疗数据,从而辅助医生进行疾病诊断、制定治疗方案以…...

Airflow:深入理解Apache Airflow Task
Apache Airflow是一个开源工作流管理平台,支持以编程方式编写、调度和监控工作流。由于其灵活性、可扩展性和强大的社区支持,它已迅速成为编排复杂数据管道的首选工具。在这篇博文中,我们将深入研究Apache Airflow 中的任务概念,探…...

multisim入门学习设计电路
文章目录 1.软件的安装2.电路基本设计2.1二极管的简介2.2最终的设计效果2.3设计流程介绍 3.如何测试电路 1.软件的安装 我是参考的下面的这个文章,文章的链接放在下面,亲测是有效的,如果是小白的话,可以参考一下: 【…...

【算法精练】二分查找算法总结
目录 前言 1. 二分查找(基础版) 2. 寻找左右端点 循环判断条件 求中间点 总结 前言 说起二分查找,也是一种十分常见的算法,最常听说的就是:二分查找只能在数组有序的场景下使用;其实也未必,…...
使用rpicam-app通过网络流式传输视频)
树莓派超全系列教程文档--(62)使用rpicam-app通过网络流式传输视频
使用rpicam-app通过网络流式传输视频 使用 rpicam-app 通过网络流式传输视频UDPTCPRTSPlibavGStreamerRTPlibcamerasrc GStreamer 元素 文章来源: http://raspberry.dns8844.cn/documentation 原文网址 使用 rpicam-app 通过网络流式传输视频 本节介绍来自 rpica…...

c#开发AI模型对话
AI模型 前面已经介绍了一般AI模型本地部署,直接调用现成的模型数据。这里主要讲述讲接口集成到我们自己的程序中使用方式。 微软提供了ML.NET来开发和使用AI模型,但是目前国内可能使用不多,至少实践例子很少看见。开发训练模型就不介绍了&am…...

AI书签管理工具开发全记录(十九):嵌入资源处理
1.前言 📝 在上一篇文章中,我们完成了书签的导入导出功能。本篇文章我们研究如何处理嵌入资源,方便后续将资源打包到一个可执行文件中。 2.embed介绍 🎯 Go 1.16 引入了革命性的 embed 包,彻底改变了静态资源管理的…...

OPENCV形态学基础之二腐蚀
一.腐蚀的原理 (图1) 数学表达式:dst(x,y) erode(src(x,y)) min(x,y)src(xx,yy) 腐蚀也是图像形态学的基本功能之一,腐蚀跟膨胀属于反向操作,膨胀是把图像图像变大,而腐蚀就是把图像变小。腐蚀后的图像变小变暗淡。 腐蚀…...

AGain DB和倍数增益的关系
我在设置一款索尼CMOS芯片时,Again增益0db变化为6DB,画面的变化只有2倍DN的增益,比如10变为20。 这与dB和线性增益的关系以及传感器处理流程有关。以下是具体原因分析: 1. dB与线性增益的换算关系 6dB对应的理论线性增益应为&…...

解读《网络安全法》最新修订,把握网络安全新趋势
《网络安全法》自2017年施行以来,在维护网络空间安全方面发挥了重要作用。但随着网络环境的日益复杂,网络攻击、数据泄露等事件频发,现行法律已难以完全适应新的风险挑战。 2025年3月28日,国家网信办会同相关部门起草了《网络安全…...

「全栈技术解析」推客小程序系统开发:从架构设计到裂变增长的完整解决方案
在移动互联网营销竞争白热化的当下,推客小程序系统凭借其裂变传播、精准营销等特性,成为企业抢占市场的利器。本文将深度解析推客小程序系统开发的核心技术与实现路径,助力开发者打造具有市场竞争力的营销工具。 一、系统核心功能架构&…...

HTML前端开发:JavaScript 获取元素方法详解
作为前端开发者,高效获取 DOM 元素是必备技能。以下是 JS 中核心的获取元素方法,分为两大系列: 一、getElementBy... 系列 传统方法,直接通过 DOM 接口访问,返回动态集合(元素变化会实时更新)。…...

鸿蒙HarmonyOS 5军旗小游戏实现指南
1. 项目概述 本军旗小游戏基于鸿蒙HarmonyOS 5开发,采用DevEco Studio实现,包含完整的游戏逻辑和UI界面。 2. 项目结构 /src/main/java/com/example/militarychess/├── MainAbilitySlice.java // 主界面├── GameView.java // 游戏核…...
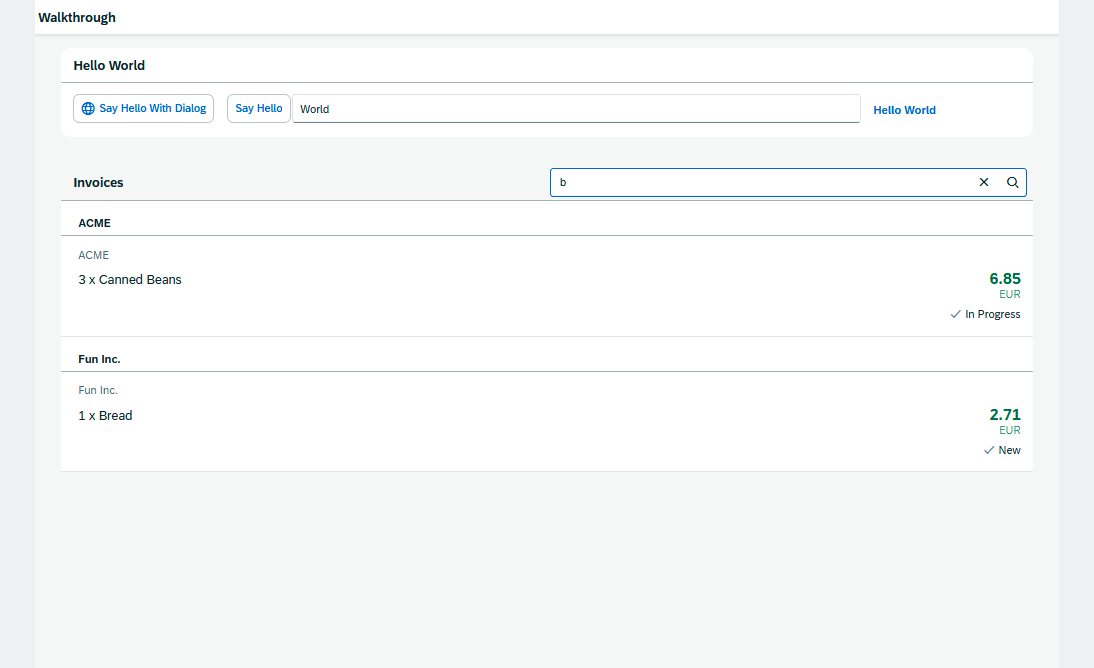
SAP学习笔记 - 开发24 - 前端Fiori开发 Filtering(过滤器),Sorting and Grouping(排序和分组)
上一章讲了SAP Fiori开发的表达式绑定,自定义格式化等内容。 SAP学习笔记 - 开发23 - 前端Fiori开发 Expression Binding(表达式绑定),Custom Formatters(自定义格式化)-CSDN博客 本章继续讲SAP Fiori开发…...