大数据挖掘--两个角度理解相似度计算理论
文章目录
- 0 相似度计算可以转换成什么问题
- 1 集合相似度的应用
- 1.1 集合相似度
- 1.1文档相似度
- 1.2 协同过滤
- 用户-用户协同过滤
- 物品-物品协同过滤
- 1.2 文档的shingling--将文档表示成集合
- 1.2.1 k-shingling
- 1.2.2 基于停用词的 shingling
- 1.3 最小哈希签名
- 1.4 局部敏感哈希算法(LSH)
- 1.5 最小哈希签名和局部敏感哈希(LSH)的概念结合示例
- 最小哈希签名步骤:
- 局部敏感哈希 (LSH) 步骤:
- 2 距离测度的应用
- 2.1 距离测度
- 1. 欧氏距离 (Euclidean Distance)
- 2. 余弦距离 (Cosine Distance)
- 3. 编辑距离 (Edit Distance)
- 4. 海明距离 (Hamming Distance)
- 3 LSH函数家族
0 相似度计算可以转换成什么问题
相似度计算是数据分析和机器学习领域中一项关键任务,它可以帮助我们理解和分析不同对象之间的相似性。然而,相似度计算本身可以通过转换成其他类型的问题来更加有效地处理和解决。
首先,我们来看一种常见的相似度度量——Jaccard相似度。Jaccard相似度将相似度计算视为集合之间的比较问题。具体来说,它关注两个集合之间的交集相对于并集的大小。这种方法特别适合用于需要比较集合相似性的场景,比如在文本分析中,我们可以将文档表示为一组词的集合,Jaccard相似度帮助我们评估两份文档的相似程度。通过计算交集和并集,我们将相似度问题转化为集合运算问题,这种方法简洁而有效,尤其在需要处理大量数据时,利用集合操作的高效性可以显著提高计算速度。
另一方面,相似度计算也可以转换为距离测度的问题。在这种情况下,我们将对象视为几何空间中的点,计算这些点之间的距离来推断相似性。欧氏距离是一种直观的衡量方式,它通过计算两点之间的直线距离来评估它们的接近程度。这种方法在需要空间可视化的场合中非常有用。此外,还有曼哈顿距离,它通过计算路径总长来反映两点的差异,这在某些离散空间中表现出色。余弦相似度则提供了另一种转换视角,通过考察向量之间的夹角来确定它们的相似性,这在高维向量空间中,尤其在文本分析和推荐系统中,被广泛使用。
1 集合相似度的应用
1.1 集合相似度
1.1文档相似度
在文本分析中,我们常常需要衡量两篇文档之间的相似性,这可以通过集合相似度来实现。一个常用的方法是Jaccard相似度。假设有两个文档 A A A 和 B B B,我们可以将它们表示为词的集合,分别记为 S A S_A SA 和 S B S_B SB。Jaccard相似度计算公式如下:
J ( S A , S B ) = ∣ S A ∩ S B ∣ ∣ S A ∪ S B ∣ J(S_A, S_B) = \frac{|S_A \cap S_B|}{|S_A \cup S_B|} J(SA,SB)=∣SA∪SB∣∣SA∩SB∣
其中, ∣ S A ∩ S B ∣ |S_A \cap S_B| ∣SA∩SB∣ 是两个集合的交集的大小, ∣ S A ∪ S B ∣ |S_A \cup S_B| ∣SA∪SB∣ 是两个集合的并集的大小。Jaccard相似度的值在 0 到 1 之间,值越大表示两个文档越相似。
算法:在实际应用中,计算文档相似度时,我们可以进行如下步骤:
- 将每个文档转换为词集合。
- 计算每对文档集合的交集和并集大小。
- 应用Jaccard公式计算相似度。
这种方法简单高效,特别适合于初步的文本聚类和分类问题。
1.2 协同过滤
在推荐系统中,协同过滤是一种广泛使用的方法。这里我们主要探讨基于集合相似度的协同过滤,包括用户-用户和物品-物品协同过滤。
用户-用户协同过滤
在用户-用户协同过滤中,我们通过比较用户之间的兴趣相似性来进行推荐。假设我们有用户 u i u_i ui 和 u j u_j uj,它们的兴趣集合分别为 I i I_i Ii 和 I j I_j Ij。我们可以使用Jaccard相似度来计算用户相似性:
J ( I i , I j ) = ∣ I i ∩ I j ∣ ∣ I i ∪ I j ∣ J(I_i, I_j) = \frac{|I_i \cap I_j|}{|I_i \cup I_j|} J(Ii,Ij)=∣Ii∪Ij∣∣Ii∩Ij∣
通过计算用户之间的Jaccard相似度,我们可以为用户推荐那些相似用户喜欢的物品。
物品-物品协同过滤
类似地,在物品-物品协同过滤中,我们比较物品之间的相似性。假设有物品 p a p_a pa 和 p b p_b pb,它们的用户集合分别为 U a U_a Ua 和 U b U_b Ub,我们计算物品的Jaccard相似度:
J ( U a , U b ) = ∣ U a ∩ U b ∣ ∣ U a ∪ U b ∣ J(U_a, U_b) = \frac{|U_a \cap U_b|}{|U_a \cup U_b|} J(Ua,Ub)=∣Ua∪Ub∣∣Ua∩Ub∣
物品相似性可以帮助我们推荐用户可能喜欢的其他相似物品。
算法:协同过滤的基本步骤包括:
- 构建用户-物品矩阵。
- 根据需要选择用户-用户或物品-物品的相似度计算。
- 计算相似度矩阵。
- 根据相似度为用户生成推荐列表。
通过利用集合相似度,我们能够有效地实现协同过滤,使推荐系统更加智能化和个性化。这些方法不仅提高了推荐的准确性,还提升了用户的参与感和满意度。
1.2 文档的shingling–将文档表示成集合
在文本处理和分析过程中,将文档转换为集合的形式可以帮助我们更好地进行相似度分析和其他文本操作。其中,shingling 是一种将文档转化为集合的方法,通过将文档分割为一系列短的连续子序列(或称为“片段”)来实现。以下是关于 k-shingling 和基于停用词的 shingling 的详细介绍。
1.2.1 k-shingling
k-shingling 是一种将文档转化为子序列集合的方法,通过将文档中的文本分割为长度为 k 的连续子字符串(或子词)来实现。每一个长度为 k 的子串称为一个“shingle”。这种方法的核心在于选择合适的 k 值,以确保文档可以被合理地分割。
步骤:
-
选择 k 值:通常,k 的选择取决于具体应用和文档长度。较小的 k 值可以捕捉到更多的局部信息,而较大的 k 值更能反映文档的全局结构。
-
生成 shingles:从文档中提取所有可能的 k-shingles。对于每一个连续的 k 个字符或词,记录为一个 shingle。
-
构建集合:将所有提取的 shingles 组成一个集合。此集合可以用来比较不同文档的相似性。
示例:对于字符串 “The quick brown fox” 和 k = 2,可能的 shingles 为 {“Th”, “he”, "e “, " q”, “qu”, “ui”, “ic”, “ck”, "k “, " b”, “br”, “ro”, “ow”, “wn”, "n “, " f”, “fo”, “ox”}。
1.2.2 基于停用词的 shingling
基于停用词的 shingling 是一种改进的 shingling 方法,它通过忽略文档中的停用词(例如 “the”, “is”, “at”, “on” 等),来生成更具意义的 shingles。这种方法可以帮助减少噪声,提高文档相似度计算的精确度。
步骤:
-
移除停用词:在进行 shingling 之前,首先从文档中移除常见的停用词。这可以通过预定义的停用词列表实现。
-
生成 shingles:在移除停用词后,使用类似 k-shingling 的方法生成 shingles。这样生成的 shingles 更能体现文档的核心内容。
-
构建集合:将生成的 shingles 组成一个集合,用于进一步的相似度计算。
优点:通过忽略停用词,基于停用词的 shingling 能够更专注于文档的主题词汇,减少不必要的干扰。
好的,以下是关于如何使用最小哈希签名将大文档压缩成小的签名,以及如何利用局部敏感哈希(LSH)算法处理这些签名,以保持文档间的相似度。
1.3 最小哈希签名
最小哈希签名是一种将大集合(如文档中的术语集合)压缩成较小的签名的技术,同时保留集合之间的相似度。这是通过一组哈希函数实现的,它们将集合中的元素映射到整数,并选取最小的数值作为签名。
步骤:
-
选择哈希函数:选择一组不同的哈希函数 h 1 , h 2 , … , h n h_1, h_2, \ldots, h_n h1,h2,…,hn。每个哈希函数将文档中的shingle(子字符串)映射到一个整数。
-
生成签名:对于每个文档和每个哈希函数,计算所有shingle的哈希值,并记录最小的哈希值。重复此过程n次(使用n个不同的哈希函数),形成一个长度为n的签名向量。
-
保持相似度:两个文档的最小哈希签名相同元素的比例,接近于这两个文档的Jaccard相似度,即 J ( A , B ) = ∣ A ∩ B ∣ ∣ A ∪ B ∣ J(A, B) = \frac{|A \cap B|}{|A \cup B|} J(A,B)=∣A∪B∣∣A∩B∣。
1.4 局部敏感哈希算法(LSH)
LSH 是一种用于快速查找相似文档的算法,特别适用于处理最小哈希签名。这种方法通过将签名分段,并使用哈希函数将相似的签名段映射到相同的桶中,从而实现高效的近似最近邻搜索。
步骤:
-
分段签名:将最小哈希签名分成若干段,每段包含若干个哈希值。例如,每个签名被分成b个段,每段包含r个哈希值。
-
映射到桶:对每个段,使用一个哈希函数将其映射到一个哈希桶。相似的文档由于签名段的相似性,很可能被映射到同一个桶中。
-
查找相似文档:当需要查找与某个文档相似的文档时,可以仅查找与其签名段映射到相同桶中的文档,这大大缩小了查找范围。
优势:通过结合最小哈希签名和 LSH,能够有效地处理和比较大规模文档集合。最小哈希签名减少了需要处理的数据量,而 LSH 提供了快速的相似性检索机制,使得处理大规模数据集的效率得以提升。
1.5 最小哈希签名和局部敏感哈希(LSH)的概念结合示例
假设我们有两个文档,它们的 shingle 集合如下:
- 文档 A: {“shingle1”, “shingle2”, “shingle3”}
- 文档 B: {“shingle2”, “shingle3”, “shingle4”}
我们应用三组不同的哈希函数 h 1 ( x ) h_1(x) h1(x), h 2 ( x ) h_2(x) h2(x), h 3 ( x ) h_3(x) h3(x),假设这些函数的输出如下:
- h 1 ( " s h i n g l e 1 " ) = 5 h_1("shingle1") = 5 h1("shingle1")=5, h 1 ( " s h i n g l e 2 " ) = 3 h_1("shingle2") = 3 h1("shingle2")=3, h 1 ( " s h i n g l e 3 " ) = 7 h_1("shingle3") = 7 h1("shingle3")=7, h 1 ( " s h i n g l e 4 " ) = 6 h_1("shingle4") = 6 h1("shingle4")=6
- h 2 ( " s h i n g l e 1 " ) = 2 h_2("shingle1") = 2 h2("shingle1")=2, h 2 ( " s h i n g l e 2 " ) = 9 h_2("shingle2") = 9 h2("shingle2")=9, h 2 ( " s h i n g l e 3 " ) = 1 h_2("shingle3") = 1 h2("shingle3")=1, h 2 ( " s h i n g l e 4 " ) = 4 h_2("shingle4") = 4 h2("shingle4")=4
- h 3 ( " s h i n g l e 1 " ) = 8 h_3("shingle1") = 8 h3("shingle1")=8, h 3 ( " s h i n g l e 2 " ) = 6 h_3("shingle2") = 6 h3("shingle2")=6, h 3 ( " s h i n g l e 3 " ) = 5 h_3("shingle3") = 5 h3("shingle3")=5, h 3 ( " s h i n g l e 4 " ) = 3 h_3("shingle4") = 3 h3("shingle4")=3
最小哈希签名步骤:
-
计算最小哈希签名:
- 对于文档 A:
- h 1 h_1 h1: 最小值是 3 (来自 “shingle2”)
- h 2 h_2 h2: 最小值是 1 (来自 “shingle3”)
- h 3 h_3 h3: 最小值是 5 (来自 “shingle3”)
- 对于文档 B:
- h 1 h_1 h1: 最小值是 3 (来自 “shingle2”)
- h 2 h_2 h2: 最小值是 1 (来自 “shingle3”)
- h 3 h_3 h3: 最小值是 3 (来自 “shingle4”)
- 对于文档 A:
-
生成最小哈希签名:
- 文档 A 的签名: (3, 1, 5)
- 文档 B 的签名: (3, 1, 3)
-
比较签名:通过比较签名发现,文档 A 和 B 在三个哈希函数中有两个值相同,签名相同位置的值相同比例为 2/3。
局部敏感哈希 (LSH) 步骤:
-
分段签名:
- 将签名分成两段,每段包含一组哈希值:
- 文档 A: (3, 1) 和 (5)
- 文档 B: (3, 1) 和 (3)
- 将签名分成两段,每段包含一组哈希值:
-
映射到桶:
- 使用哈希函数对每一段进行哈希,映射到哈希桶:
- 段 (3, 1) 的两文档都被映射到同一个桶,因此它们可能相似。
- 段 (5) 和 (3) 被映射到不同的桶。
- 使用哈希函数对每一段进行哈希,映射到哈希桶:
-
查找相似文档:
- 由于文档 A 和 B 在 (3, 1) 段中被映射到同一个桶,因此 LSH 会识别文档 B 作为文档 A 的相似候选者。
通过结合最小哈希签名和 LSH,我们大幅度降低了计算复杂度。最小哈希签名帮助我们压缩文档,同时保留相似度信息,而 LSH 则通过分段签名和桶映射,快速聚合可能相似的文档以进行进一步的精细比较。这种方法尤其适用于需要快速处理和比较的大规模数据集。
2 距离测度的应用
2.1 距离测度
1. 欧氏距离 (Euclidean Distance)
- 定义:欧氏距离是两点间的“直线”距离,用于度量两个点在欧几里得空间中的距离。对于两个n维向量 A = ( a 1 , a 2 , . . . , a n ) A = (a_1, a_2, ..., a_n) A=(a1,a2,...,an) 和 B = ( b 1 , b 2 , . . . , b n ) B = (b_1, b_2, ..., b_n) B=(b1,b2,...,bn),其计算公式为:
Euclidean Distance = ∑ i = 1 n ( a i − b i ) 2 \text{Euclidean Distance} = \sqrt{\sum_{i=1}^{n} (a_i - b_i)^2} Euclidean Distance=∑i=1n(ai−bi)2 - 应用:常用于几何空间中的距离计算,如图像处理、聚类分析(如k-means算法)。
2. 余弦距离 (Cosine Distance)
- 定义:余弦距离实际上测量的是两个向量之间的夹角余弦值,表示两个向量的方向相似度。计算公式为:
Cosine Similarity = A ⋅ B ∥ A ∥ ∥ B ∥ \text{Cosine Similarity} = \frac{A \cdot B}{\|A\| \|B\|} Cosine Similarity=∥A∥∥B∥A⋅B
余弦距离则为 1 − Cosine Similarity 1 - \text{Cosine Similarity} 1−Cosine Similarity。 - 应用:适用于文本分析和信息检索,因为它关注的是向量的方向而不是大小,比如在文档相似性计算中。
3. 编辑距离 (Edit Distance)
- 定义:编辑距离,又称Levenshtein距离,是将一个字符串转换成另一个字符串所需的最小编辑操作次数(包括插入、删除、替换的操作)。
- 应用:广泛用于拼写检查、DNA序列比对和自然语言处理中。
4. 海明距离 (Hamming Distance)
- 定义:海明距离用于衡量两个等长字符串之间的差异,即在相同位置上不同字符的数量。
- 应用:主要用于编码理论和信息技术中的错误检测和纠正,例如校验和比较二进制字符串。
3 LSH函数家族
| 算法 | 定义 | 中心思想 | 核心公式 | 优点 | 缺点 | 应用场景 |
|---|---|---|---|---|---|---|
| MinHash LSH | 用于集合相似性的LSH方法 | 通过最小哈希签名计算集合的Jaccard相似度 | h ( A ) = min ( { h i ( x ) ∣ x ∈ A } ) h(A) = \min(\{h_i(x) \mid x \in A\}) h(A)=min({hi(x)∣x∈A}) | 高效处理集合相似性,减少计算量 | 需要预计算最小哈希签名 | 文档去重,集合相似性计算 |
| SimHash | 用于文本和文档相似性的LSH方法 | 将高维向量降维为短签名,保留方向信息 | s = sign ( ∑ w i x i ) s = \text{sign}(\sum w_i x_i) s=sign(∑wixi) | 适合处理高维数据,方向不变性 | 不适合处理完全不同的文本 | 文本检索,文档相似性计算 |
| p-stable LSH | 用于欧氏距离的LSH方法 | 基于p-stable分布投影到低维空间 | h ( x ) = ⌊ a ⋅ x + b r ⌋ h(x) = \lfloor \frac{a \cdot x + b}{r} \rfloor h(x)=⌊ra⋅x+b⌋ | 准确近似欧氏距离,适合高维数值数据 | 投影精度依赖于维度选择 | 图像检索,数值数据相似性计算 |
| Bit Sampling LSH | 用于汉明距离的LSH方法 | 从二进制字符串中随机选择位作为特征 | 直接位选择 | 简单高效,直接操作二进制数据 | 仅适合固定长度的二进制数据 | 二进制数据比较,错误检测和校验 |
相关文章:

大数据挖掘--两个角度理解相似度计算理论
文章目录 0 相似度计算可以转换成什么问题1 集合相似度的应用1.1 集合相似度1.1文档相似度1.2 协同过滤用户-用户协同过滤物品-物品协同过滤 1.2 文档的shingling--将文档表示成集合1.2.1 k-shingling1.2.2 基于停用词的 shingling 1.3 最小哈希签名1.4 局部敏感哈希算法&#…...

Win10微软商店重新安装指南
Win10微软商店重新安装指南 在使用Windows 10操作系统的过程中,微软商店(Microsoft Store)作为官方提供的应用下载平台,一直是用户获取和安装各类应用程序的重要渠道。然而,有时用户可能会遇到微软商店无法找到或误删的情况,这无疑给软件的安装和管理带来了不便。本文将…...

操作系统和中间件的信息收集
在浏览器中收集操作系统与中间件信息时,主要通过客户端JavaScript(用于操作系统/浏览器信息)和服务器端脚本(用于中间件信息)实现。以下是分步指南: 一、客户端操作系统信息收集(JavaScript&am…...

项目集成Spring Security授权部分
一、需求分析 业务背景 当前项目采用前后端分离架构,后端需要对接口访问进行严格控制,防止未授权访问。鉴于系统需要支持高并发与分布式部署,采用无状态认证方式显得尤为重要。 核心需求 无状态认证:使用 JWT 作为令牌࿰…...

5. k8s二进制集群之ETCD集群部署
下载etcd安装包创建etcd配置文件准备证书文件和etcd存储目录ETCD证书文件安装(分别对应指定节点)创建证书服务的配置文件启动etcd集群验证etcd集群状态继续上一篇文章《k8s二进制集群之ETCD集群证书生成》下面介绍一下etcd证书生成配置。 下载etcd安装包 https://github.com…...

MV结构下设置Qt表格的代理
目录 预备知识 模型 关联 刷新 示例 代理 模型 界面 结果 完整资料见: 所谓MV结构,是“model-view”(模型-视图)的简称。也就是说,表格的数据保存在model中,而视图由view实现。在我前面的很多博客…...

二维数组 C++ 蓝桥杯
1.稀疏矩阵 #include<iostream> using namespace std;const int N 1e4 10; int a[N][N];int main() {int n, m; cin >> n >> m;for (int i 1; i < n; i) {for (int j 1; j < m; j) {cin >> a[i][j];}}for (int j m; j > 1; j--) {for (i…...

【Linux】文件描述符
初识文件 之前我们认识到当我们进行创建出一个空文件在磁盘上也是占用一部分空间的,因为文件的组成是由文件内容和文件属性共同构成。 文件内容属性,那我们对文件进行操作无外乎就是对内容和属性两个方面进行操作。 文件在磁盘上进行存储,…...

大语言模型的个性化综述 ——《Personalization of Large Language Models: A Survey》
摘要: 本文深入解读了论文“Personalization of Large Language Models: A Survey”,对大语言模型(LLMs)的个性化领域进行了全面剖析。通过详细阐述个性化的基础概念、分类体系、技术方法、评估指标以及应用实践,揭示了…...

AI 编程工具—Cursor进阶使用 Agent模式
AI 编程工具—Cursor进阶使用 Agent模式 我们在使用Cursor 的是有,在Composer 模式下,提交的是有两种模式 Normal 模式,也就是默认的模式Agent 模式Agent 模式可以帮我们生成代码文件,执行程序,安装依赖,并且完成一些列的工作 这里有个点很重要就是在Agent 模式下,Cur…...

【AI大模型】DeepSeek API大模型接口实现
目录 一、DeepSeek发展历程 2023 年:创立与核心技术突破 2024 年:开源生态与行业落地 2025 年:多模态与全球化布局 性能对齐 OpenAI-o1 正式版 二、API接口调用 1.DeepSeek-V3模型调用 2.DeepSeek-R1模型调用 三、本地化部署接口调…...

Qt展厅播放器/多媒体播放器/中控播放器/帧同步播放器/硬解播放器/监控播放器
一、前言说明 音视频开发除了应用在安防监控、视频网站、各种流媒体app开发之外,还有一个小众的市场,那就是多媒体展厅场景,这个场景目前处于垄断地位的软件是HirenderS3,做的非常早而且非常全面,都是通用的需求&…...

Kafka分区策略实现
引言 Kafka 的分区策略决定了生产者发送的消息会被分配到哪个分区中,合理的分区策略有助于实现负载均衡、提高消息处理效率以及满足特定的业务需求。 轮询策略(默认) 轮询策略是 Kafka 默认的分区策略(当消息没有指定键时&…...

【归属地】批量号码归属地查询按城市高速的分流,基于WPF的解决方案
在现代商业活动中,企业为了提高营销效果和资源利用效率,需要针对不同地区的市场特点开展精准营销。通过批量号码归属地查询并按城市分流,可以为企业的营销决策提供有力支持。 短信营销:一家连锁餐饮企业计划开展促销活动…...

为AI聊天工具添加一个知识系统 之78 详细设计之19 正则表达式 之6
本文要点 要点 本项目设计的正则表达式 是一个 动态正则匹配框架。它是一个谓词系统:谓词 是运动,主语是“维度”,表语是 语言处理。主语的一个 双动结构。 Reg三大功能 语法验证、语义检查和 语用检验,三者 :语义约…...

使用Java操作Redis数据类型的详解指南
SEO Meta Description: 详细介绍如何使用Java操作Redis的各种数据类型,包括字符串、哈希、列表、集合和有序集合,提供代码示例和最佳实践。 介绍 Redis是一种开源的内存数据结构存储,用作数据库、缓存和消息代理。它支持多种数据结构&#…...

一表总结 Java 的3种设计模式与6大设计原则
设计模式通常分为三大类:创建型、结构型和行为型。 创建型模式:主要用于解决对象创建问题结构型模式:主要用于解决对象组合问题行为型模式:主要用于解决对象之间的交互问题 创建型模式 创建型模式关注于对象的创建机制…...

Hive on Spark优化
文章目录 第1章集群环境概述1.1 集群配置概述1.2 集群规划概述 第2章 Yarn配置2.1 Yarn配置说明2.2 Yarn配置实操 第3章 Spark配置3.1 Executor配置说明3.1.1 Executor CPU核数配置3.1.2 Executor内存配置3.1.3 Executor个数配置 3.2 Driver配置说明3.3 Spark配置实操 第4章 Hi…...
)
Java集合面试总结(题目来源JavaGuide)
问题1:说说 List,Set,Map 三者的区别? 在 Java 中,List、Set 和 Map 是最常用的集合框架(Collection Framework)接口,它们的主要区别如下: 1. List(列表) 特点…...
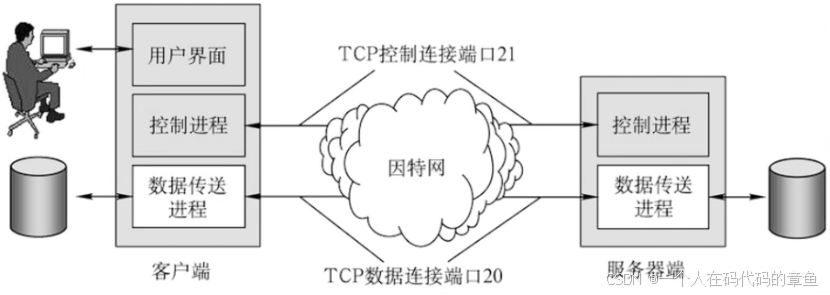
计算机网络 应用层 笔记1(C/S模型,P2P模型,FTP协议)
应用层概述: 功能: 常见协议 应用层与其他层的关系 网络应用模型 C/S模型: 优点 缺点 P2P模型: 优点 缺点 DNS系统: 基本功能 系统架构 域名空间: DNS 服务器 根服务器: 顶级域…...

OpenLayers 可视化之热力图
注:当前使用的是 ol 5.3.0 版本,天地图使用的key请到天地图官网申请,并替换为自己的key 热力图(Heatmap)又叫热点图,是一种通过特殊高亮显示事物密度分布、变化趋势的数据可视化技术。采用颜色的深浅来显示…...

python打卡day49
知识点回顾: 通道注意力模块复习空间注意力模块CBAM的定义 作业:尝试对今天的模型检查参数数目,并用tensorboard查看训练过程 import torch import torch.nn as nn# 定义通道注意力 class ChannelAttention(nn.Module):def __init__(self,…...

(十)学生端搭建
本次旨在将之前的已完成的部分功能进行拼装到学生端,同时完善学生端的构建。本次工作主要包括: 1.学生端整体界面布局 2.模拟考场与部分个人画像流程的串联 3.整体学生端逻辑 一、学生端 在主界面可以选择自己的用户角色 选择学生则进入学生登录界面…...

MySQL 隔离级别:脏读、幻读及不可重复读的原理与示例
一、MySQL 隔离级别 MySQL 提供了四种隔离级别,用于控制事务之间的并发访问以及数据的可见性,不同隔离级别对脏读、幻读、不可重复读这几种并发数据问题有着不同的处理方式,具体如下: 隔离级别脏读不可重复读幻读性能特点及锁机制读未提交(READ UNCOMMITTED)允许出现允许…...

Swift 协议扩展精进之路:解决 CoreData 托管实体子类的类型不匹配问题(下)
概述 在 Swift 开发语言中,各位秃头小码农们可以充分利用语法本身所带来的便利去劈荆斩棘。我们还可以恣意利用泛型、协议关联类型和协议扩展来进一步简化和优化我们复杂的代码需求。 不过,在涉及到多个子类派生于基类进行多态模拟的场景下,…...

汽车生产虚拟实训中的技能提升与生产优化
在制造业蓬勃发展的大背景下,虚拟教学实训宛如一颗璀璨的新星,正发挥着不可或缺且日益凸显的关键作用,源源不断地为企业的稳健前行与创新发展注入磅礴强大的动力。就以汽车制造企业这一极具代表性的行业主体为例,汽车生产线上各类…...

python如何将word的doc另存为docx
将 DOCX 文件另存为 DOCX 格式(Python 实现) 在 Python 中,你可以使用 python-docx 库来操作 Word 文档。不过需要注意的是,.doc 是旧的 Word 格式,而 .docx 是新的基于 XML 的格式。python-docx 只能处理 .docx 格式…...

Matlab | matlab常用命令总结
常用命令 一、 基础操作与环境二、 矩阵与数组操作(核心)三、 绘图与可视化四、 编程与控制流五、 符号计算 (Symbolic Math Toolbox)六、 文件与数据 I/O七、 常用函数类别重要提示这是一份 MATLAB 常用命令和功能的总结,涵盖了基础操作、矩阵运算、绘图、编程和文件处理等…...

leetcodeSQL解题:3564. 季节性销售分析
leetcodeSQL解题:3564. 季节性销售分析 题目: 表:sales ---------------------- | Column Name | Type | ---------------------- | sale_id | int | | product_id | int | | sale_date | date | | quantity | int | | price | decimal | -…...

C# 求圆面积的程序(Program to find area of a circle)
给定半径r,求圆的面积。圆的面积应精确到小数点后5位。 例子: 输入:r 5 输出:78.53982 解释:由于面积 PI * r * r 3.14159265358979323846 * 5 * 5 78.53982,因为我们只保留小数点后 5 位数字。 输…...