Dijkstra算法解析
Dijkstra算法,用于求解图中从一个起点到其他所有节点的最短路径。解决单源最短路径问题的有效方法。
条件
有向
带权路径
时间复杂度 O(n平方)
方法步骤
1 把图上的点分为两个集合 要求的起点 和除了起点之外的点 。能直达的写上权值 不能直达的写上无穷 自己到自己的距离是0
2 在除起点以外的中找权值最小的顶点,这个顶点加入起点所在的集合。由于新顶点的并入,可以把新顶点作为中转点,再重新计算起点到所有除已经并入顶点的距离,找最小的继续并入,直到所有顶点并入起点所在的集合。
以下是对代码的详细解析和注释:
代码解析
全局变量定义
#define N 1005 // 定义最大顶点数为1005
int n, m; // n表示顶点数,m表示边数
bool str[N]; // 用于标记是否已确定最短路径
int dis[N]; // 存储从起始点到各个顶点的最短距离
int g[N][N]; // 邻接矩阵,存储图的结构-
N:定义图中最大顶点数为1005。 -
n和m:分别表示图中的顶点数和边数。 -
str:布尔数组,用于标记某个顶点是否已经确定了最短路径。 -
dis:数组,存储从起点到每个顶点的最短距离。 -
g:邻接矩阵,g[i][j]表示从顶点i到顶点j的距离。
Dijkstra算法实现
void dijkstra() {// 初始化dis数组为一个很大的值(这里选择0x3f3f3f3f)memset(dis, 0x3f3f3f3f, sizeof(dis));// 起始点到自身的距离为0dis[1] = 0;for (int i = 1; i <= n; ++i) {int temp = -1; // 选择未确定的顶点// 寻找当前未确定的最小距离顶点for (int j = 1; j <= n; ++j)if (!str[j] && (temp == -1 || dis[j] < dis[temp]))temp = j;// 更新与该顶点相邻的其他顶点的距离for (int j = 1; j <= n; ++j)dis[j] = min(dis[j], dis[temp] + g[temp][j]);// 标记该顶点已经确定了最短路径str[temp] = true;}// 输出结果for (int i = 1; i <= n; ++i) {if (dis[i] == 0x3f3f3f3f)cout << "-1" << " "; // 如果没有到该顶点的路径则输出-1elsecout << dis[i] << " "; // 否则输出最短距离}
}-
初始化:
-
memset(dis, 0x3f3f3f3f, sizeof(dis));:将dis数组初始化为一个很大的值(0x3f3f3f3f),表示初始时从起点到其他顶点的距离是无穷大。 -
dis[1] = 0;:将起点到自身的距离设置为0。
-
-
主循环:
-
for (int i = 1; i <= n; ++i):循环n次,每次找到一个未确定最短路径的顶点。 -
int temp = -1;:初始化当前未确定的最短距离顶点为 -1。 -
for (int j = 1; j <= n; ++j):遍历所有顶点,找到未确定最短路径的顶点中距离最短的顶点temp。-
if (!str[j] && (temp == -1 || dis[j] < dis[temp])):如果顶点j未确定最短路径且距离更短,则更新temp。
-
-
for (int j = 1; j <= n; ++j):更新与顶点temp相邻的其他顶点的距离。-
dis[j] = min(dis[j], dis[temp] + g[temp][j]);:如果通过temp到达j的距离更短,则更新dis[j]。
-
-
str[temp] = true;:标记顶点temp已经确定了最短路径。
-
-
结果输出:
-
遍历
dis数组,输出从起点到每个顶点的最短距离。 -
如果
dis[i]仍然是0x3f3f3f3f,表示没有路径到达顶点i,输出-1。 -
否则输出
dis[i]。
-
主函数
int main() {// 初始化邻接矩阵g为一个很大的值memset(g, 0x3f3f3f3f, sizeof(g));// 输入顶点数n和边数mcin >> n >> m;while (m--) { // 处理每一条边的输入int x, y, z;cin >> x >> y >> z;// 更新邻接矩阵g中的权值g[x][y] = min(g[x][y], z);}// 调用dijkstra函数求解dijkstra();return 0;
}-
初始化邻接矩阵:
-
memset(g, 0x3f3f3f3f, sizeof(g));:将邻接矩阵g初始化为一个很大的值(0x3f3f3f3f),表示初始时图中没有边。
-
-
输入图的边:
-
cin >> n >> m;:读取顶点数n和边数m。 -
while (m--):循环m次,读取每一条边的信息。-
cin >> x >> y >> z;:读取边的起点x、终点y和权重z。 -
g[x][y] = min(g[x][y], z);:更新邻接矩阵g中的权值,如果有多条边连接同一对顶点,只保留权重最小的那条边。
-
-
-
调用Dijkstra算法:
-
dijkstra();:调用dijkstra函数求解最短路径。
-
-
输出结果:
-
dijkstra函数会输出从起点到每个顶点的最短距离。
-
示例输入和输出
示例输入
5 7
1 2 4
1 3 3
2 4 2
3 2 1
3 4 5
4 5 1
2 5 7示例输出
0 2 3 4 5
解释
-
顶点 1 到顶点 2 的最短距离为 2(1 -> 3 -> 2)。
-
顶点 1 到顶点 3 的最短距离为 3(1 -> 3)。
-
顶点 1 到顶点 4 的最短距离为 4(1 -> 3 -> 2 -> 4)。
-
顶点 1 到顶点 5 的最短距离为 5(1 -> 3 -> 2 -> 4 -> 5)。
关键点总结
-
邻接矩阵:使用二维数组
g[N][N]表示图的结构,g[i][j]表示从顶点i到顶点j的距离。 -
选择最短距离顶点:通过遍历所有顶点,找到未确定最短路径的顶点中距离最短的顶点。
-
更新邻接顶点的距离:通过当前顶点更新其邻接顶点的距离。
-
标记顶点:使用布尔数组
str标记顶点是否已经确定了最短路径。
Dijkstra算法详细步骤解析
1. 初始化
在算法开始之前,需要进行以下初始化操作:
-
初始化距离数组
dis:-
将
dis数组中的所有元素初始化为一个很大的值(如0x3f3f3f3f),表示从起点到其他顶点的距离初始为无穷大。 -
将起点的距离设置为 0,即
dis[start] = 0。
-
-
初始化访问标记数组
str:-
将
str数组中的所有元素初始化为false,表示所有顶点初始时都未被访问过。
-
-
初始化邻接矩阵
g:-
将邻接矩阵
g中的所有元素初始化为一个很大的值(如0x3f3f3f3f),表示初始时图中没有边。
-
2. 主循环
Dijkstra算法的核心是一个主循环,该循环执行 n 次(n 为顶点数),每次找到一个未访问的最短距离顶点,并更新其邻接顶点的距离。
-
选择未访问的最短距离顶点:
-
遍历所有顶点,找到未访问的顶点中距离最短的顶点
u。 -
如果所有顶点都已被访问过,或者没有找到未访问的顶点,则退出循环。
-
-
更新邻接顶点的距离:
-
遍历顶点
u的所有邻接顶点v,如果通过u到达v的距离更短,则更新dis[v]。 -
具体来说,如果
dis[u] + g[u][v] < dis[v],则更新dis[v] = dis[u] + g[u][v]。
-
-
标记顶点为已访问:
-
将顶点
u标记为已访问,即str[u] = true,避免重复处理。
-
3. 结果输出
在主循环结束后,dis 数组中存储了从起点到每个顶点的最短距离。遍历 dis 数组,输出结果:
-
如果
dis[i]仍然是初始的大值(如0x3f3f3f3f),表示没有路径到达顶点i,输出-1。 -
否则,输出
dis[i],表示从起点到顶点i的最短距离。
示例执行过程
假设图的结构如下:
-
顶点数
n = 5 -
边数
m = 7 -
边的权重如下:
-
1 -> 2: 4
-
1 -> 3: 3
-
2 -> 4: 2
-
3 -> 2: 1
-
3 -> 4: 5
-
4 -> 5: 1
-
2 -> 5: 7
-
初始化
-
dis数组:[0, 0x3f3f3f3f, 0x3f3f3f3f, 0x3f3f3f3f, 0x3f3f3f3f] -
str数组:[false, false, false, false, false] -
g邻接矩阵:[[0x3f3f3f3f, 4, 3, 0x3f3f3f3f, 0x3f3f3f3f],[0x3f3f3f3f, 0x3f3f3f3f, 0x3f3f3f3f, 2, 0x3f3f3f3f],[0x3f3f3f3f, 1, 0x3f3f3f3f, 5, 0x3f3f3f3f],[0x3f3f3f3f, 0x3f3f3f3f, 0x3f3f3f3f, 0x3f3f3f3f, 1],[0x3f3f3f3f, 7, 0x3f3f3f3f, 0x3f3f3f3f, 0x3f3f3f3f] ]
第1次循环
-
选择未访问的最短距离顶点:
-
遍历所有顶点,找到未访问的顶点中距离最短的顶点
u = 1(起点)。
-
-
更新邻接顶点的距离:
-
遍历顶点
1的邻接顶点2和3:-
dis[2] = min(dis[2], dis[1] + g[1][2]) = min(0x3f3f3f3f, 0 + 4) = 4 -
dis[3] = min(dis[3], dis[1] + g[1][3]) = min(0x3f3f3f3f, 0 + 3) = 3
-
-
-
标记顶点为已访问:
-
str[1] = true
-
第2次循环
-
选择未访问的最短距离顶点:
-
遍历所有顶点,找到未访问的顶点中距离最短的顶点
u = 3(dis[3] = 3)。
-
-
更新邻接顶点的距离:
-
遍历顶点
3的邻接顶点2和4:-
dis[2] = min(dis[2], dis[3] + g[3][2]) = min(4, 3 + 1) = 4 -
dis[4] = min(dis[4], dis[3] + g[3][4]) = min(0x3f3f3f3f, 3 + 5) = 8
-
-
-
标记顶点为已访问:
-
str[3] = true
-
第3次循环
-
选择未访问的最短距离顶点:
-
遍历所有顶点,找到未访问的顶点中距离最短的顶点
u = 2(dis[2] = 4)。
-
-
更新邻接顶点的距离:
-
遍历顶点
2的邻接顶点4和5:-
dis[4] = min(dis[4], dis[2] + g[2][4]) = min(8, 4 + 2) = 6 -
dis[5] = min(dis[5], dis[2] + g[2][5]) = min(0x3f3f3f3f, 4 + 7) = 11
-
-
-
标记顶点为已访问:
-
str[2] = true
-
第4次循环
-
选择未访问的最短距离顶点:
-
遍历所有顶点,找到未访问的顶点中距离最短的顶点
u = 4(dis[4] = 6)。
-
-
更新邻接顶点的距离:
-
遍历顶点
4的邻接顶点5:-
dis[5] = min(dis[5], dis[4] + g[4][5]) = min(11, 6 + 1) = 7
-
-
-
标记顶点为已访问:
-
str[4] = true
-
第5次循环
-
选择未访问的最短距离顶点:
-
遍历所有顶点,找到未访问的顶点中距离最短的顶点
u = 5(dis[5] = 7)。
-
-
更新邻接顶点的距离:
-
顶点
5没有邻接顶点,无需更新。
-
-
标记顶点为已访问:
-
str[5] = true
-
结果输出
遍历 dis 数组,输出从起点到每个顶点的最短距离:
-
dis[1] = 0 -
dis[2] = 4 -
dis[3] = 3 -
dis[4] = 6 -
dis[5] = 7
关键点总结
-
选择未访问的最短距离顶点:
-
每次选择未访问的顶点中距离最短的顶点,确保每一步都选择当前最优的顶点进行处理。
-
-
更新邻接顶点的距离:
-
通过当前顶点更新其邻接顶点的距离,确保每一步都更新到最新的最短距离。
-
-
标记顶点为已访问:
-
避免重复处理已访问的顶点,提高算法的效率。
-
-
结果输出:
-
最终输出从起点到每个顶点的最短距离,如果没有路径到达某个顶点,则输出
-1
-
相关文章:

Dijkstra算法解析
Dijkstra算法,用于求解图中从一个起点到其他所有节点的最短路径。解决单源最短路径问题的有效方法。 条件 有向 带权路径 时间复杂度 O(n平方) 方法步骤 1 把图上的点分为两个集合 要求的起点 和除了起点之外的点 。能直达的写上权值 不…...

C++ Primer 多维数组
欢迎阅读我的 【CPrimer】专栏 专栏简介:本专栏主要面向C初学者,解释C的一些基本概念和基础语言特性,涉及C标准库的用法,面向对象特性,泛型特性高级用法。通过使用标准库中定义的抽象设施,使你更加适应高级…...

maven mysql jdk nvm node npm 环境安装
安装JDK 1.8 11 环境 maven环境安装 打开网站 下载 下载zip格式 解压 自己创建一个maven库 以后在idea 使用maven时候重新设置一下 这三个地方分别设置 这时候maven才算设置好 nvm 管理 npm nodejs nvm下载 安装 Releases coreybutler/nvm-windows GitHub 一键安装且若有…...

SQL Server中RANK()函数:处理并列排名与自然跳号
RANK()是SQL Server的窗口函数,为结果集中的行生成排名。当出现相同值时,后续排名会跳过被占用的名次,形成自然间隔。与DENSE_RANK()的关键区别在于是否允许排名值连续。 语法: RANK() OVER ([PARTITION BY 分组列]ORDER BY 排序…...

如何运行Composer安装PHP包 安装JWT库
1. 使用Composer Composer是PHP的依赖管理工具,它允许你轻松地安装和管理PHP包。对于JWT,你可以使用firebase/php-jwt这个库,这是由Firebase提供的官方库。 安装Composer(如果你还没有安装的话): 访问Co…...

最新功能发布!AllData数据中台核心菜单汇总
🔥🔥 AllData大数据产品是可定义数据中台,以数据平台为底座,以数据中台为桥梁,以机器学习平台为中层框架,以大模型应用为上游产品,提供全链路数字化解决方案。 ✨奥零数据科技官网:http://www.aolingdata.com ✨AllData开源项目:https://github.com/alldatacenter/…...

【OS】AUTOSAR架构下的Interrupt详解(上篇)
目录 前言 正文 1.中断概念分析 1.1 中断处理API 1.2 中断级别 1.3 中断向量表 1.4 二类中断的嵌套 1.4.1概述 1.4.2激活 1.5一类中断 1.5.1一类中断的实现 1.5.2一类中断的嵌套 1.5.3在StartOS之前的1类ISR 1.5.4使用1类中断时的注意事项 1.6中断源的初始化 1.…...

大数据挖掘--两个角度理解相似度计算理论
文章目录 0 相似度计算可以转换成什么问题1 集合相似度的应用1.1 集合相似度1.1文档相似度1.2 协同过滤用户-用户协同过滤物品-物品协同过滤 1.2 文档的shingling--将文档表示成集合1.2.1 k-shingling1.2.2 基于停用词的 shingling 1.3 最小哈希签名1.4 局部敏感哈希算法&#…...

Win10微软商店重新安装指南
Win10微软商店重新安装指南 在使用Windows 10操作系统的过程中,微软商店(Microsoft Store)作为官方提供的应用下载平台,一直是用户获取和安装各类应用程序的重要渠道。然而,有时用户可能会遇到微软商店无法找到或误删的情况,这无疑给软件的安装和管理带来了不便。本文将…...

操作系统和中间件的信息收集
在浏览器中收集操作系统与中间件信息时,主要通过客户端JavaScript(用于操作系统/浏览器信息)和服务器端脚本(用于中间件信息)实现。以下是分步指南: 一、客户端操作系统信息收集(JavaScript&am…...

项目集成Spring Security授权部分
一、需求分析 业务背景 当前项目采用前后端分离架构,后端需要对接口访问进行严格控制,防止未授权访问。鉴于系统需要支持高并发与分布式部署,采用无状态认证方式显得尤为重要。 核心需求 无状态认证:使用 JWT 作为令牌࿰…...

5. k8s二进制集群之ETCD集群部署
下载etcd安装包创建etcd配置文件准备证书文件和etcd存储目录ETCD证书文件安装(分别对应指定节点)创建证书服务的配置文件启动etcd集群验证etcd集群状态继续上一篇文章《k8s二进制集群之ETCD集群证书生成》下面介绍一下etcd证书生成配置。 下载etcd安装包 https://github.com…...

MV结构下设置Qt表格的代理
目录 预备知识 模型 关联 刷新 示例 代理 模型 界面 结果 完整资料见: 所谓MV结构,是“model-view”(模型-视图)的简称。也就是说,表格的数据保存在model中,而视图由view实现。在我前面的很多博客…...

二维数组 C++ 蓝桥杯
1.稀疏矩阵 #include<iostream> using namespace std;const int N 1e4 10; int a[N][N];int main() {int n, m; cin >> n >> m;for (int i 1; i < n; i) {for (int j 1; j < m; j) {cin >> a[i][j];}}for (int j m; j > 1; j--) {for (i…...

【Linux】文件描述符
初识文件 之前我们认识到当我们进行创建出一个空文件在磁盘上也是占用一部分空间的,因为文件的组成是由文件内容和文件属性共同构成。 文件内容属性,那我们对文件进行操作无外乎就是对内容和属性两个方面进行操作。 文件在磁盘上进行存储,…...

大语言模型的个性化综述 ——《Personalization of Large Language Models: A Survey》
摘要: 本文深入解读了论文“Personalization of Large Language Models: A Survey”,对大语言模型(LLMs)的个性化领域进行了全面剖析。通过详细阐述个性化的基础概念、分类体系、技术方法、评估指标以及应用实践,揭示了…...

AI 编程工具—Cursor进阶使用 Agent模式
AI 编程工具—Cursor进阶使用 Agent模式 我们在使用Cursor 的是有,在Composer 模式下,提交的是有两种模式 Normal 模式,也就是默认的模式Agent 模式Agent 模式可以帮我们生成代码文件,执行程序,安装依赖,并且完成一些列的工作 这里有个点很重要就是在Agent 模式下,Cur…...

【AI大模型】DeepSeek API大模型接口实现
目录 一、DeepSeek发展历程 2023 年:创立与核心技术突破 2024 年:开源生态与行业落地 2025 年:多模态与全球化布局 性能对齐 OpenAI-o1 正式版 二、API接口调用 1.DeepSeek-V3模型调用 2.DeepSeek-R1模型调用 三、本地化部署接口调…...

Qt展厅播放器/多媒体播放器/中控播放器/帧同步播放器/硬解播放器/监控播放器
一、前言说明 音视频开发除了应用在安防监控、视频网站、各种流媒体app开发之外,还有一个小众的市场,那就是多媒体展厅场景,这个场景目前处于垄断地位的软件是HirenderS3,做的非常早而且非常全面,都是通用的需求&…...

Kafka分区策略实现
引言 Kafka 的分区策略决定了生产者发送的消息会被分配到哪个分区中,合理的分区策略有助于实现负载均衡、提高消息处理效率以及满足特定的业务需求。 轮询策略(默认) 轮询策略是 Kafka 默认的分区策略(当消息没有指定键时&…...

网络编程(Modbus进阶)
思维导图 Modbus RTU(先学一点理论) 概念 Modbus RTU 是工业自动化领域 最广泛应用的串行通信协议,由 Modicon 公司(现施耐德电气)于 1979 年推出。它以 高效率、强健性、易实现的特点成为工业控制系统的通信标准。 包…...

遍历 Map 类型集合的方法汇总
1 方法一 先用方法 keySet() 获取集合中的所有键。再通过 gey(key) 方法用对应键获取值 import java.util.HashMap; import java.util.Set;public class Test {public static void main(String[] args) {HashMap hashMap new HashMap();hashMap.put("语文",99);has…...

【Zephyr 系列 10】实战项目:打造一个蓝牙传感器终端 + 网关系统(完整架构与全栈实现)
🧠关键词:Zephyr、BLE、终端、网关、广播、连接、传感器、数据采集、低功耗、系统集成 📌目标读者:希望基于 Zephyr 构建 BLE 系统架构、实现终端与网关协作、具备产品交付能力的开发者 📊篇幅字数:约 5200 字 ✨ 项目总览 在物联网实际项目中,**“终端 + 网关”**是…...

CMake控制VS2022项目文件分组
我们可以通过 CMake 控制源文件的组织结构,使它们在 VS 解决方案资源管理器中以“组”(Filter)的形式进行分类展示。 🎯 目标 通过 CMake 脚本将 .cpp、.h 等源文件分组显示在 Visual Studio 2022 的解决方案资源管理器中。 ✅ 支持的方法汇总(共4种) 方法描述是否推荐…...

PAN/FPN
import torch import torch.nn as nn import torch.nn.functional as F import mathclass LowResQueryHighResKVAttention(nn.Module):"""方案 1: 低分辨率特征 (Query) 查询高分辨率特征 (Key, Value).输出分辨率与低分辨率输入相同。"""def __…...

Python Einops库:深度学习中的张量操作革命
Einops(爱因斯坦操作库)就像给张量操作戴上了一副"语义眼镜"——让你用人类能理解的方式告诉计算机如何操作多维数组。这个基于爱因斯坦求和约定的库,用类似自然语言的表达式替代了晦涩的API调用,彻底改变了深度学习工程…...

WPF八大法则:告别模态窗口卡顿
⚙️ 核心问题:阻塞式模态窗口的缺陷 原始代码中ShowDialog()会阻塞UI线程,导致后续逻辑无法执行: var result modalWindow.ShowDialog(); // 线程阻塞 ProcessResult(result); // 必须等待窗口关闭根本问题:…...
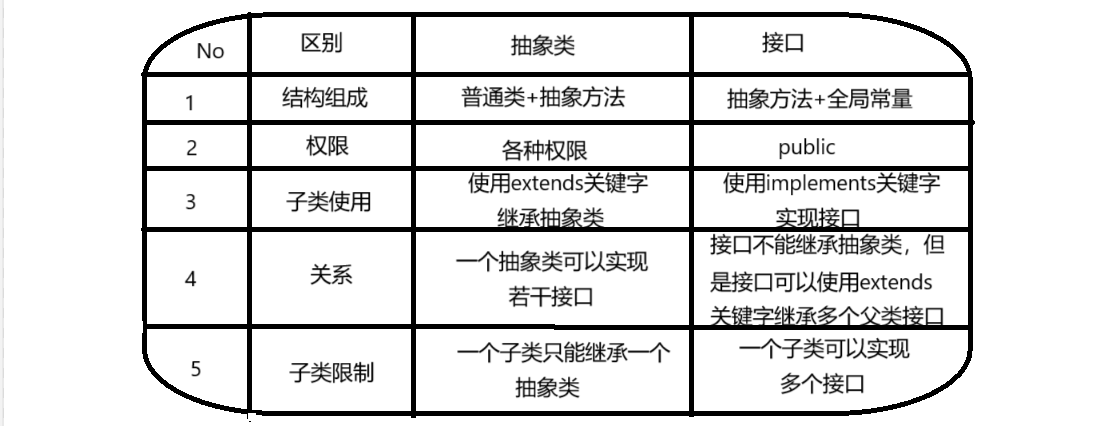
抽象类和接口(全)
一、抽象类 1.概念:如果⼀个类中没有包含⾜够的信息来描绘⼀个具体的对象,这样的类就是抽象类。 像是没有实际⼯作的⽅法,我们可以把它设计成⼀个抽象⽅法,包含抽象⽅法的类我们称为抽象类。 2.语法 在Java中,⼀个类如果被 abs…...

LCTF液晶可调谐滤波器在多光谱相机捕捉无人机目标检测中的作用
中达瑞和自2005年成立以来,一直在光谱成像领域深度钻研和发展,始终致力于研发高性能、高可靠性的光谱成像相机,为科研院校提供更优的产品和服务。在《低空背景下无人机目标的光谱特征研究及目标检测应用》这篇论文中提到中达瑞和 LCTF 作为多…...

vue3 daterange正则踩坑
<el-form-item label"空置时间" prop"vacantTime"> <el-date-picker v-model"form.vacantTime" type"daterange" start-placeholder"开始日期" end-placeholder"结束日期" clearable :editable"fal…...