Cypher进阶(函数、索引)
文章目录
- Cypher进阶
- Aggregation
- count()函数
- 统计函数
- collect()函数
- unwind
- foreach
- merge
- union
- load csv
- call
- 函数
- 断言函数
- all()
- any()
- ~~exists()~~
- is not null
- none()
- single()
- 标量函数
- coalesce()
- startNode()/endNode()
- id()
- length()
- size()
- 列表函数
- nodes()
- keys()
- range()
- reduce()
- 数学函数
- 数值函数
- 对数函数
- 字符串函数
- 索引
- 创建索引
- 查看索引
- 删除索引
- 使用索引
Cypher进阶
- 构造需要使用到的图
create (A:Person {name:"A",age:13})
create (B:Person {name:"B",age:33,eyes:"blue"})
create (C:Person {name:"C",age:44,eyes:"blue"})
create (D1:Person {name:"D",eyes:"broen"})
create (D2:Person {name:"D"})
create (A)-[:knows]->(B)
create (A)-[:knows]->(C)
create (A)-[:knows]->(D1)
create (B)-[:knows]->(D2)
create (C)-[:knows]->(D2)

match (n:Person) return n

Aggregation
- Cypher 支持使用聚合(Aggregation)来计算聚在一起的数据,类似 SQL 中的 group by。聚合函数有多个输入值,然后基于它们计算出一个聚合值。例如,avg 函数计算多个数值的平均值。min 函数用于找到一组值中最小的那个值。
count()函数
- count用于计算行的数量.
- 查询A的标签以及好友数量
match (n {name:"A"})-->(x) return labels(n), n.age, count(*)

- 查询A相关的关系数量
match (n {name:"A"}) -[r]->() return type(r),count(*)

- 查询A的好友数量
match (n {name:"A"})-->(x) return count(x)

- 查询给空属性的节点数量
match (n:Person) return count(n.age)
- 查询朋友数量,去重以及未去重情况
match (me:Person)-->(friend:Person)-->(friend_of_friend:Person)
where me.name="A"
return count(distinct friend_of_friend),count(friend_of_friend)

统计函数
match(n:Person) return sum(n.age) //求和
match(n:Person) return avg(n.age) //平均值
match(n:Person) return max(n.age) //最大值
match(n:Person) return min(n.age) //最小值
collect()函数
- collect()将所有值收集起来放入到一个集合中,排除null值
match (n:Person) return collect(n.age)

unwind
- unwind将列表展开为一个行的序列
unwind [1,2,3,null] as x return x, 'val' as y

- 将列表展开并且去重后形成新的列表
with [1,1,2,2] as coll unwind coll as x with distinct x return collect(x) as setOfVals

- 将a、b两个列表连接形成新的列表,再将其展开进行操作,然后去重,最后收集
with [1,2,2] as a,[3,4] as b
unwind(a+b) as x
with distinct x
return collect(x) as y

- 嵌套列表的展开操作
with [[1,2],[3,4],5] as nested
unwind nested as x
unwind x as y
return collect(y)
[1, 2, 3, 4, 5]

foreach
- foreach主要用于更新列表中的数据,或者来自路径的组件、聚合的结果。
- 再foreach括号内,可以执行任何的更新命令,包括create,create unique,delete,foreach。如果希望对列表中的每个元素执行额外的match命令,使用unwind命令更合适。
- 构造数据
create (A:Person {name:"A"})
create (B:Person {name:"B"})
create (C:Person {name:"C"})
create (D:Person {name:"D"})
create (A)-[:knows]->(B)
create (B)-[:knows]->(C)
create (C)-[:knows]->(D)


- 循环设置节点的属性marked=true
match p=(begin)-[*]->(end) where begin.name='A' and end.name='D' foreach (n in nodes(p) | set n.marked=true)
merge
- merge或者匹配已存在的节点并绑定到它,或者创建新的然后绑定到它。它有点像match和create的组合。
- 当在整个模式上使用merge时,要么是整个模式匹配到,要么是整个模式被创建。merge不能部分地应用于模式,如果希望部分匹配,可以将模式拆分为多个merge语句。
//删除数据
match (n) detach delete n
//构造数据
CREATE (A:Person {bornIn: 'New York', name: 'Charlie Sheen', chauffeurName: 'John Brown'})
CREATE (B:Person {bornIn: 'New York', name: 'Oliver Stone', chauffeurName: 'Bill White'})
CREATE (C:Person {chauffeurName: 'John Brown', bornIn: 'New Jersey', name: 'Michael Douglas'})
CREATE (D:Person {bornIn: 'Ohio', name: 'Martin Sheen', chauffeurName: 'Bob Brown'})
CREATE (E:Person {bornIn: 'New York', name: 'Rob Reiner', chauffeurName: 'Ted Green'})
CREATE (M1:Movie {title: 'Wall Street'})
CREATE (M2:Movie {title: 'The American President'})CREATE (A)-[:ACTED_IN]->(M1)
CREATE (A)-[:FATHER]->(D)
CREATE (B)-[:ACTED_IN]->(M1)
CREATE (C)-[:ACTED_IN]->(M1)
CREATE (C)-[:ACTED_IN]->(M2)
CREATE (D)-[:ACTED_IN]->(M1)
CREATE (D)-[:ACTED_IN]->(M2)
CREATE (E)-[:ACTED_IN]->(M2)RETURN *


-
节点未完全匹配,所以会创建节点
merge (robert:Critic) return robert,labels(robert) merge (charlie {name:"Charlie Sheen", age: 10}) return charlie{"identity": 29,"labels": [],"properties": {"name": "Charlie Sheen","age": 10},"elementId": "4:c4c1679d-3dad-4695-b164-654c5485fd8c:29" } -
匹配到节点,不会创建新的节点
merge (michael:Person {name:"Michael Douglas"}) return michael.name, michael.bornIn

-
按照Person的出生地创建city节点,重新执行不会创建city节点
match (person:Person) merge (city:City {name: person.bornIn}) return person.name,person.bornIn,city╒═════════════════╤═════════════╤════════════════════════════╕ │person.name │person.bornIn│city │ ╞═════════════════╪═════════════╪════════════════════════════╡ │"Charlie Sheen" │"New York" │(:City {name: "New York"}) │ ├─────────────────┼─────────────┼────────────────────────────┤ │"Oliver Stone" │"New York" │(:City {name: "New York"}) │ ├─────────────────┼─────────────┼────────────────────────────┤ │"Michael Douglas"│"New Jersey" │(:City {name: "New Jersey"})│ ├─────────────────┼─────────────┼────────────────────────────┤ │"Martin Sheen" │"Ohio" │(:City {name: "Ohio"}) │ ├─────────────────┼─────────────┼────────────────────────────┤ │"Rob Reiner" │"New York" │(:City {name: "New York"}) │ └─────────────────┴─────────────┴────────────────────────────┘ -
当创建节点时执行 on create中的内容
merge (keanu:Person {name:"keanu Reeves"}) on create set keanu.created=timestamp() return keanu.name,keanu.created╒══════════════╤═════════════╕ │keanu.name │keanu.created│ ╞══════════════╪═════════════╡ │"keanu Reeves"│1738637550446│ └──────────────┴─────────────┘ -
当匹配到节点时,设置属性
merge (person:Person) on match set person.found=true return person.name,person.found╒═════════════════╤════════════╕ │person.name │person.found│ ╞═════════════════╪════════════╡ │"Charlie Sheen" │true │ ├─────────────────┼────────────┤ │"Oliver Stone" │true │ ├─────────────────┼────────────┤ │"Michael Douglas"│true │ ├─────────────────┼────────────┤ │"Martin Sheen" │true │ ├─────────────────┼────────────┤ │"Rob Reiner" │true │ ├─────────────────┼────────────┤ │"keanu Reeves" │true │ └─────────────────┴────────────┘ -
已经存在的节点,不执行create set,会执行match set
merge (keanu:Person {name:"Keanu Reeves"}) on create set keanu.created =timestamp() on match set keanu.lastSeen =timestamp() return keanu.name,keanu.created,keanu.lastSeen╒══════════════╤═════════════╤══════════════╕ │keanu.name │keanu.created│keanu.lastSeen│ ╞══════════════╪═════════════╪══════════════╡ │"Keanu Reeves"│1738675666030│null │ └──────────────┴─────────────┴──────────────┘ -
匹配或创建关系
match (charlie:Person {name:"Charlie Sheen"}),(wallStreet:Movie {title:"Wall Street"}) merge (charlie)-[r:ACTED_IN]->(wallStreet) return charlie.name, type(r),wallStreet.title╒═══════════════╤══════════╤════════════════╕ │charlie.name │type(r) │wallStreet.title│ ╞═══════════════╪══════════╪════════════════╡ │"Charlie Sheen"│"ACTED_IN"│"Wall Street" │ └───────────────┴──────────┴────────────────┘ -
merge可以和match与merge子句一起使用
match (person:Person) merge (city:City {name:person.bornIn}) merge (person)-[r:BORN_IN]->(city) return person.name,person.bornIn,city
union
- union是将多个查询结果组合起来。
create (A:Actor {name:"Anthony Hopkins"}) create (B:Actor {name:"Hitchcock"}) create (C:Actor {name:"Helen Mirren"}) create (M:Movie {title:"Hitchcock"}) create (A)-[:KNOWS]-> (C) create (A)-[:ACTS_IN]->(M) create (C)-[:ACTS_IN]->(M)

- 连接演员与电影的查询结果
match (n:Actor) return n.name as name union all match (n:Movie) return n.title as name╒═════════════════╕ │name │ ╞═════════════════╡ │"Anthony Hopkins"│ ├─────────────────┤ │"Hitchcock" │ ├─────────────────┤ │"Helen Mirren" │ ├─────────────────┤ │"Hitchcock" │ └─────────────────┘
load csv
- load csv用于从csv文件中导入数据。
//artists.csv
1,ABBA,1992
2,Roxette,1986
3,Europe,1979
4,The Cardigans,1992
load csv from 'https://xxx/csv/artists.csv' as line
create (:Artist {name line[1],year: toInteger(line[2])})
- csv文件包含头标题
//artists.csv
Id,Name,Yeat
1,ABBA,1992
2,Roxette,1986
3,Europe,1979
4,The Cardigans,1992
load csv from 'https://xxx/csv/artists.csv' as line
create (:Artist {name: line.name,year: toInteger(line.Year)})
- 加载大量数据,使用periodic commit可以使neo4j每1000(默认)条提交一次
using periodic commit
load csv from 'https://xxx'
create (:Artist {name line[1],year: toInteger(line[2])})//自定义提交频率
using periodic commit 500
load csv from 'https://xxx'
create (:Artist {name line[1],year: toInteger(line[2])})
- linenumber()获取行号
load csv form 'https://xxx' as line
return linenumber() as number ,line
call
- call语句用于调用数据库中的过程。
- 使用call语句调用过程。调用过程时,需要指定所需要的参数。可以通过在过程名的后面使用逗号分隔的列表来显式地指定,也可以使用查询参数来作为过程调用的实参。后者仅适用于在单独的过程调用中作为参数,即整个查询语句只包含一个单一的 CALL 调用。
- 大多数的过程返回固定列的记录流,类似于 Cypher 查询返回的记录流。YIELD 子句用于显式地选择返回结果集中的哪些部分并绑定到一个变量以供后续的查询引用。在一个更大的查询内部,过程调用返回的结果可以显式地使用 YTELD 引入一个 WHERE 子句来过滤结果(类似 WITH… WHERE…。
- Neo4j 支持 VOID 过程。VOID 过程既没有声明任何结果字段,也不返回任何结果记录。调用 VOID 过程可能有一个副作用,就是它既不允许也不需要使用 YIELD。在一个大的查询中调用 VOID 过程,就像 WITH*在记录流的作用那样简单地传递输入的每一个结果。
- 查询当前数据库中的标签
call db.labels()
╒═══════╕
│label │
╞═══════╡
│"Movie"│
├───────┤
│"Actor"│
└───────┘
- 复杂查询中调用过程`
call db.labels() yield label return(label) as labelNumbers
╒════════════╕
│labelNumbers│
╞════════════╡
│"Movie" │
├────────────┤
│"Actor" │
└────────────┘
- where设置条件
call db.labels() yield label where label contains "Person" return label╒═══════╕ │label │ ╞═══════╡ │"Movie"│ └───────┘
函数
断言函数
- 断言函数是对给定的输入返回true或false的布尔函数
CREATE (p1:Person {name: 'Alice', eyes: 'brown', age: 31})
CREATE (p2:Person {eyes: 'brown', age: 61})
CREATE (p3:Person {name: 'Charlie', eyes: 'green', age: 53})
CREATE (p4:Person {name: 'Bob', eyes: 'blue', age: 25})
CREATE (p5:Person {name: 'Daniel', eyes: 'brown', age: 54})
CREATE (p6:Person {array:['one', 'two', 'three'], name: 'Eskil', eyes: 'blue', age: 41})CREATE (p1)-[:KNOWS]->(p3)
CREATE (p1)-[:KNOWS]->(p4)
CREATE (p3)-[:KNOWS]->(p5)
CREATE (p4)-[:KNOWS]->(p5)
CREATE (p4)-[:MARRIED]->(p6)


all()
- 判断是否一个断言使用于列表中的所有元素
- 语言L:
all(variable in list where predicate) - 返回结果中不包含年龄小于30岁的人
match p=(a)-[*1..3]->(b)
where a.name='Alice' and b.name='Daniel' and all(x in nodes(p) where x.age>30)
return p

any()
- 判断是否一个断言适用于列表中的一个元素
- 语法:
any(variable in list where predicate)
match (a)
where a.name='Eskil' and any(x in a.array where x='one')
return a.name,a.array
╒═══════╤═══════════════════════╕
│a.name │a.array │
╞═══════╪═══════════════════════╡
│"Eskil"│["one", "two", "three"]│
└───────┴───────────────────────┘
exists()
- 判断是否存在该模式或者节点中是否存储属性
- 匹配所有包含name属性的节点以及包含了married关系的标记为true
match (n)
where exists(n.name)
return n.name as name,exists((n)-[:MARRIED]->()) as is_married
The property existence syntax `... exists(variable.property)` is no longer supported. Please use `variable.property IS NOT NULL`
is not null
MATCH (n)
WHERE n.name IS NOT NULL
RETURN n.name AS name, EXISTS((n)-[:MARRIED]->()) AS is_married
╒═════════╤══════════╕
│name │is_married│
╞═════════╪══════════╡
│"Alice" │false │
├─────────┼──────────┤
│"Charlie"│false │
├─────────┼──────────┤
│"Bob" │true │
├─────────┼──────────┤
│"Daniel" │false │
├─────────┼──────────┤
│"Eskil" │false │
└─────────┴──────────┘
none()
- none():如果断言不适用于列表中的任何元素,则返回true
- 语法:
none(variable in list where predicate)
match p=(n)-[*1..3]->(b)
where n.name="Alice" and none(x in nodes(p) where x.age=25)
return p

single()
- 如果断言只适用于列表中的某一个元素,返回true
- 语法:
none(variable in list where predicate)
- 匹配节点中只包含eyes='blue’的节点
match p=(n)-->(b)
where n.name="Alice" and single(var in nodes(p) where var.eyes="blue")
return p

标量函数
- 清空并构造数据
//删除数据
match (n) detach delete n
//构造数据
CREATE (p1:Developer {name: 'Alice', eyes: 'brown', age: 38})
CREATE (p2:Developer {name: 'Charlie', eyes: 'green', age: 53})
CREATE (p3:Developer {name: 'Bob', eyes: 'blue', age: 25})
CREATE (p4:Developer {name: 'Daniel', eyes: 'brown', age: 54})
CREATE (p5:Developer {name: 'Eskil', eyes: 'blue', age: 41, array: ['one', 'two', 'three']})CREATE (p1)-[:KNOWS]->(p2)
CREATE (p1)-[:KNOWS]->(p3)
CREATE (p2)-[:KNOWS]->(p4)
CREATE (p3)-[:KNOWS]->(p4)
CREATE (p3)-[:MARRIED]->(p5)


coalesce()
- coalesce():返回表达式列表中的第一个非空的值,如果所有的实参数都为空,则返回null
- 语法:
coalesce(espression [, expression]*) - 查询Alice的hairColor,eyes属性,由于hairColor不存在,则返回eyes
match (a) where a.name="Alice" return coalesce(a.hairColor,a.eyes)
╒════════════════════════════╕
│coalesce(a.hairColor,a.eyes)│
╞════════════════════════════╡
│"brown" │
└────────────────────────────┘
startNode()/endNode()
- startNode():返回一个关系中的开始节点
- endNode():返回一个关系中的结束节点
match (x {name:"Alice"})-[r]-()
return startNode(r)
╒══════════════════════════════════════════════════╕
│startNode(r) │
╞══════════════════════════════════════════════════╡
│(:Developer {name: "Alice",eyes: "brown",age: 38})│
├──────────────────────────────────────────────────┤
│(:Developer {name: "Alice",eyes: "brown",age: 38})│
└──────────────────────────────────────────────────┘
match (x {name:"Alice"})-[r]-()
return endNode(r)
╒════════════════════════════════════════════════════╕
│endNode(r) │
╞════════════════════════════════════════════════════╡
│(:Developer {name: "Charlie",eyes: "green",age: 53})│
├────────────────────────────────────────────────────┤
│(:Developer {name: "Bob",eyes: "blue",age: 25}) │
└────────────────────────────────────────────────────┘
id()
- id():返回关系或节点的ID
match (m) return id(m)
╒═════╕
│id(m)│
╞═════╡
│65 │
├─────┤
│66 │
├─────┤
│67 │
├─────┤
│68 │
├─────┤
│69 │
└─────┘
length()
- length():返回路径的长度
match p=(a)-->(b)-->(c)
where a.name="Alice"
return p,length(p)
╒══════════════════════════════════════════════════════════════════════╤═════════╕
│p │length(p)│
╞══════════════════════════════════════════════════════════════════════╪═════════╡
│(:Developer {name: "Alice",eyes: "brown",age: 38})-[:KNOWS]->(:Develop│2 │
│er {name: "Charlie",eyes: "green",age: 53})-[:KNOWS]->(:Developer {nam│ │
│e: "Daniel",eyes: "brown",age: 54}) │ │
├──────────────────────────────────────────────────────────────────────┼─────────┤
│(:Developer {name: "Alice",eyes: "brown",age: 38})-[:KNOWS]->(:Develop│2 │
│er {name: "Bob",eyes: "blue",age: 25})-[:KNOWS]->(:Developer {name: "D│ │
│aniel",eyes: "brown",age: 54}) │ │
├──────────────────────────────────────────────────────────────────────┼─────────┤
│(:Developer {name: "Alice",eyes: "brown",age: 38})-[:KNOWS]->(:Develop│2 │
│er {name: "Bob",eyes: "blue",age: 25})-[:MARRIED]->(:Developer {array:│ │
│ ["one", "two", "three"],name: "Eskil",eyes: "blue",age: 41}) │ │
└──────────────────────────────────────────────────────────────────────┴─────────┘
size()
- 返回列表中元素的个数或字符串的长度
match (a)
where size(a.name)>6
return size(a.name)
╒════════════╕
│size(a.name)│
╞════════════╡
│7 │
└────────────┘
列表函数
- 列表函数返回列表中的元素
CREATE (p1:Developer:Person {name: 'Alice', eyes: 'brown', age: 38})
CREATE (p2 {name: 'Charlie', eyes: 'green', age: 53})
CREATE (p3 {name: 'Bob', eyes: 'blue', age: 25})
CREATE (p4 {name: 'Daniel', eyes: 'brown', age: 54})
CREATE (p5 {name: 'Eskil', eyes: 'blue', age: 41, array: ['one', 'two', 'three']})CREATE (p1)-[:KNOWS]->(p2)
CREATE (p1)-[:KNOWS]->(p3)
CREATE (p2)-[:KNOWS]->(p4)
CREATE (p3)-[:KNOWS]->(p4)
CREATE (p3)-[:MARRIED]->(p5)

nodes()
- nodes():用于返回路径中所有的节点
match p=(a)-->(b)-->(c)
where a.name="Alice" and c.name="Eskil"
return nodes(p)
╒══════════════════════════════════════════════════════════════════════╕
│nodes(p) │
╞══════════════════════════════════════════════════════════════════════╡
│[(:Developer:Person {name: "Alice",eyes: "brown",age: 38}), ({name: "B│
│ob",eyes: "blue",age: 25}), ({array: ["one", "two", "three"],name: "Es│
│kil",eyes: "blue",age: 41})] │
└──────────────────────────────────────────────────────────────────────┘
keys()
- keys():返回节点或关系的所有属性的名称
match (a) where a.name="Alice" return keys(a)╒═══════════════════════╕ │keys(a) │ ╞═══════════════════════╡ │["age", "eyes", "name"]│ └───────────────────────┘
range()
- range():返回某个范围内的数值。值之间的默认步长为1,范围包含起始边界值
- 语法:
range(start,end[, step])return range(0,10), range(2,18,3)╒══════════════════════════════════╤═════════════════════╕ │range(0,10) │range(2,18,3) │ ╞══════════════════════════════════╪═════════════════════╡ │[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10]│[2, 5, 8, 11, 14, 17]│ └──────────────────────────────────┴─────────────────────┘
reduce()
- reduce():对列表中的每个元素执行一个表达式,将表达式结构存入一个累加器。
- 语法:
reduce(accumulator=initial, variable in list | expression)
match p=(a)-->(b)-->(c)
where a.name="Alice" and b.name="Bob" and c.name="Daniel"
return reduce(totalAge=0, n in nodes(p) | totalAge+n.age) as reduction
╒═════════╕
│reduction│
╞═════════╡
│117 │
└─────────┘
数学函数
数值函数
- abs():返回实参的绝对值。
- ceil(): 返回大于或等于实参的最小整数。
- floor(): 返回小于或等于实参的最大整数。
- round(): 返回距离表达式值最近的整数。
- rand(): 返回 [0, 1) 之间的一个随机数,返回的数值在整个区间遵循均匀分布。
- sign(): 返回一个数值的正负。
- 如果值为 0,返回 0。
- 如果值为负数,返回 -1。
- 如果值为正数,返回 1。
match (a),(e)
where a.name="Alice" and e.name="Eskil"
return a.age,e.age,abs(a.age-e.age)
╒═════╤═════╤════════════════╕
│a.age│e.age│abs(a.age-e.age)│
╞═════╪═════╪════════════════╡
│38 │41 │3 │
└─────┴─────┴────────────────┘
对数函数
- e():获取e
- exp():返回以自然常数e为底的指数
- log10():返回表达式的常用对数(以10为底)
- sqrt():返回值的平方根
return e(),exp(2),log(27),log10(100),sqrt(169)
╒═════════════════╤════════════════╤═════════════════╤══════════╤═════════╕
│e() │exp(2) │log(27) │log10(100)│sqrt(169)│
╞═════════════════╪════════════════╪═════════════════╪══════════╪═════════╡
│2.718281828459045│7.38905609893065│3.295836866004329│2.0 │13.0 │
└─────────────────┴────────────────┴─────────────────┴──────────┴─────────┘
字符串函数
| 函数名 | 定义 | 功能 | 语法 | 示例 | 结果 |
|---|---|---|---|---|---|
toString() | 将值转换为字符串 | 用于非字符串类型(如数字、布尔值)转字符串 | toString(expression) | RETURN toString(123) | "123" |
split() | 按分隔符拆分字符串 | 将字符串分割为列表 | split(字符串, 分隔符) | RETURN split("A,B,C", ",") | ["A", "B", "C"] |
trim() | 去除字符串两端空格 | 清理字符串前后空格 | trim(字符串) | RETURN trim(" Hello ") | "Hello" |
toUpper() | 转换为大写 | 将字符串全部转为大写 | toUpper(字符串) | RETURN toUpper("neo4j") | "NEO4J" |
toLower() | 转换为小写 | 将字符串全部转为小写 | toLower(字符串) | RETURN toLower("NEO4J") | "neo4j" |
substring() | 截取子字符串 | 从指定位置截取字符串 | substring(字符串, 起始位置[, 长度]) | RETURN substring("Neo4j", 2, 3) | "o4j" (从索引2开始) |
replace() | 替换字符串中的子串 | 替换匹配的子串 | replace(原字符串, 旧值, 新值) | RETURN replace("Hello World", "World", "Neo4j") | "Hello Neo4j" |
size() | 计算字符串长度 | 返回字符串的字符数 | size(字符串) | RETURN size("Neo4j") | 5 |
索引
- 数据库的索引就是为了加快检索数据效率而引入的冗余信息。他的代价是需要额外的存储空间和写入变得缓慢。
- Cypher允许所有节点的某个属性上有特定的标签。索引一旦创建,它将自己管理并当图发生变化时自动更新。一旦索引创建并生效后,Neo4j将自动开始使用索引。
创建索引
- 使用
create index for可以在拥有某个标签的所有节点的某个属性上创建索引。 - 语法:
CREATE INDEX person_name_index FOR (p:Person) ON (p.name);- CREATE INDEX 是创建索引的关键字。
- person_name_index 是索引的名称,可以自定义。
- FOR (p:Person) 表示这个索引是针对标签为 Person 的节点。
- ON (p.name) 表示是基于节点的 name 属性创建索引。
CREATE INDEX person_name_index FOR (p:Person) ON (p.name);
Added 1 index, completed after 79 ms.
查看索引
show index
╒═══╤═══════════════════╤════════╤═════════════════╤════════╤══════════════╤═════════════╤══════════╤══════════════════╤════════════════╤════════════════════════════════╤═════════╕
│id │name │state │populationPercent│type │entityType │labelsOrTypes│properties│indexProvider │owningConstraint│lastRead │readCount│
╞═══╪═══════════════════╪════════╪═════════════════╪════════╪══════════════╪═════════════╪══════════╪══════════════════╪════════════════╪════════════════════════════════╪═════════╡
│2 │"index_f7700477" │"ONLINE"│100.0 │"LOOKUP"│"RELATIONSHIP"│null │null │"token-lookup-1.0"│null │"2025-02-01T13:51:02.983000000Z"│1 │
├───┼───────────────────┼────────┼─────────────────┼────────┼──────────────┼─────────────┼──────────┼──────────────────┼────────────────┼────────────────────────────────┼─────────┤
│1 │"person_name_index"│"ONLINE"│100.0 │"RANGE" │"NODE" │["Person"] │["name"] │"range-1.0" │null │"2025-02-05T04:27:27.362000000Z"│149 │
└───┴───────────────────┴────────┴─────────────────┴────────┴──────────────┴─────────────┴──────────┴──────────────────┴────────────────┴────────────────────────────────┴─────────┘
删除索引
- drop index可以删除某个标签的所有节点的某个属性上的索引。
DROP INDEX person_name_index;
使用索引
- 通常不需要在查询中指出使用哪个索引。Cypher自行决定。
match (person:Person {name:"Alice"}) return person╒═════════════════════════════════════════════════════════╕ │person │ ╞═════════════════════════════════════════════════════════╡ │(:Developer:Person {name: "Alice",eyes: "brown",age: 38})│ └─────────────────────────────────────────────────────────┘
相关文章:
Cypher进阶(函数、索引)
文章目录 Cypher进阶Aggregationcount()函数统计函数collect()函数 unwindforeachmergeunionload csvcall 函数断言函数all()any()~~exists()~~is not nullnone()single() 标量函数coalesce()startNode()/endNode()id()length()size() 列表函数nodes()keys()range()reduce() 数…...

XML Schema 数值数据类型
XML Schema 数值数据类型 引言 XML Schema 是一种用于描述 XML 文档结构的语言。它定义了 XML 文档中数据的有效性和结构。在 XML Schema 中,数值数据类型是非常重要的一部分,它定义了 XML 文档中可以包含的数值类型。本文将详细介绍 XML Schema 中常用的数值数据类型,以及…...

Window获取界面空闲时间
GetLastInputInfo是一种Windows API函数,用于获取上次输入操作的时间。 该函数通过LASTINPUTINFO结构返回最后一次输入事件的时间。 原型如下 BOOL WINAPI GetLastInputInfo(PLASTINPUTINFO plii);那么可以利用GetLastInputInfo来得到界面没有操作的时长 uint…...

Java进阶(vue基础)
目录 1.vue简单入门 ?1.1.创建一个vue程序 1.2.使用Component模板(组件) 1.3.引入AXOIS ?1.4.vue的Methods(方法) 和?compoted(计算) 1.5.插槽slot 1.6.创建自定义事件? 2.Vue脚手架安装? 3.Element-UI的…...

Mac电脑上好用的压缩软件
在Mac电脑上,有许多优秀的压缩软件可供选择,这些软件不仅支持多种压缩格式,还提供了便捷的操作体验和强大的功能。以下是几款被广泛推荐的压缩软件: BetterZip 功能特点:BetterZip 是一款功能强大的压缩和解压缩工具&a…...

Ubuntn24.04安装
1.镜像下载 https://cn.ubuntu.com/download Ubuntu 24.04.1 (Noble Numbat) 进入下载即可 2.安装系统 打开虚拟机 选择语言 输入用户名和密码 安装ssh 安装完成重启即可。 3.可能出现的问题 关于Ubuntu系统虚拟机出现频繁闪屏,移动和屏幕适应大小问题_vmware安…...

基于ansible部署elk集群
ansible部署 ELK部署 ELK常见架构 (1)ElasticsearchLogstashKibana:这种架构是最常见的一种,也是最简单的一种架构,这种架构通过Logstash收集日志,运用Elasticsearch分析日志,最后通过Kibana中…...

解锁.NET Fiddle:在线编程的神奇之旅
在.NET 开发的广袤领域中,快速验证想法、测试代码片段以及便捷地分享代码是开发者们日常工作中不可或缺的环节。而.NET Fiddle 作为一款卓越的在线神器,正逐渐成为众多.NET 开发者的得力助手。它打破了传统开发模式中对本地开发环境的依赖,让…...

记录pve中使用libvirt创建虚拟机
pve中创建虚拟机 首先在pve网页中创建一个linux虚拟机,我用的是debian系统,过程省略 注意虚拟机cpu类型要设置为host 检查是否支持虚拟化 ssh分别进入pve和debian虚拟机 检查cpu是否支持虚拟化 egrep --color vmx|svm /proc/cpuinfo # 结果高亮显示…...

【HTML性能优化】提升网站加载速度:GZIP、懒加载与资源合并
系列文章目录 01-从零开始学 HTML:构建网页的基本框架与技巧 02-HTML常见文本标签解析:从基础到进阶的全面指南 03-HTML从入门到精通:链接与图像标签全解析 04-HTML 列表标签全解析:无序与有序列表的深度应用 05-HTML表格标签全面…...

三维空间全局光照 | 及各种扫盲
Lecture 6 SH for diffuse transport Lecture 7关于 SH for glossy transport 三维空间全局光照 diffuse case和glossy case的区别 在Lambertian模型中,BRDF是一个常数 diffuse case 跟outgoing point无关 glossy case 跟outgoing point有关 (Gloss…...
——SQL性能判断标准及索引误区(1))
数据库开发常识(10.6)——SQL性能判断标准及索引误区(1)
10.6. 数据库开发常识 作为一名专业数据库开发人员,不但需要掌握数据库开发相关的语法和功能实现,还要掌握专业数据库开发的常识。这样,才能在保量完成工作任务的同时,也保质的完成工作任务,避免了为应用的日后维护埋…...

网络爬虫js逆向之某音乐平台案例
【注意!!!】 前言: - 本章主要讲解某音乐平台的js逆向知识 - 使用关键字搜定位加密入口 - 通过多篇文章【文字案例】的形式系统化进行描述 - 本文章全文进行了脱敏处理 - 详细代码不进行展示,需要则私聊作者 爬虫js逆向…...

Spark--算子执行原理
一、sortByKey SortByKey是一个transformation算子,但是会触发action,因为在sortByKey方法内部,会对每个分区进行采样,构建分区规则(RangePartitioner)。 内部执行流程 1、创建RangePartitioner part&…...
)
事件驱动架构(EDA)
事件驱动架构(Event-Driven Architecture, EDA)是一种软件架构模式,其中系统的行为由事件的产生和处理驱动。在这种架构中,系统的组件通过事件进行交互,而不是通过直接的调用或者请求响应方式。 关键概念 事件&#x…...

C++ 入门速通-第5章【黑马】
内容来源于:黑马 集成开发环境:CLion 先前学习完了C第1章的内容: C 入门速通-第1章【黑马】-CSDN博客 C 入门速通-第2章【黑马】-CSDN博客 C 入门速通-第3章【黑马】-CSDN博客 C 入门速通-第4章【黑马】-CSDN博客 下面继续学习第5章&…...

2025春招,深度思考MyBatis面试题
大家好,我是V哥,2025年的春招马上就是到来,正在准备求职的朋友过完年,也该收收心,好好思考一下自己哪些技术点还需要补一补了,今天 V 哥要跟大家聊的是MyBatis框架的问题,站在一个高级程序员的角…...

排序算法--冒泡排序
冒泡排序虽然简单,但在实际应用中效率较低,适合小规模数据或教学演示。 // 冒泡排序函数 void bubbleSort(int arr[], int n) {for (int i 0; i < n - 1; i) { // 外层循环控制排序轮数for (int j 0; j < n - i - 1; j) { // 内层循环控制每轮比…...
简易C语言矩阵运算库
参考网址: 异想家纯C语言矩阵运算库 - Sandeepin - 博客园 这次比opencv快⑥倍!!! 参考上述网址,整理了一下代码: //main.c#include <stdio.h> #include <stdlib.h> #include <string.h…...

通过C/C++编程语言实现“数据结构”课程中的链表
引言 链表(Linked List)是数据结构中最基础且最重要的线性存储结构之一。与数组的连续内存分配不同,链表通过指针将分散的内存块串联起来,具有动态扩展和高效插入/删除的特性。本文将以C/C++语言为例,从底层原理到代码实现,手把手教你构建完整的链表结构,并深入探讨其应…...

java_网络服务相关_gateway_nacos_feign区别联系
1. spring-cloud-starter-gateway 作用:作为微服务架构的网关,统一入口,处理所有外部请求。 核心能力: 路由转发(基于路径、服务名等)过滤器(鉴权、限流、日志、Header 处理)支持负…...

生成 Git SSH 证书
🔑 1. 生成 SSH 密钥对 在终端(Windows 使用 Git Bash,Mac/Linux 使用 Terminal)执行命令: ssh-keygen -t rsa -b 4096 -C "your_emailexample.com" 参数说明: -t rsa&#x…...

鸿蒙中用HarmonyOS SDK应用服务 HarmonyOS5开发一个医院查看报告小程序
一、开发环境准备 工具安装: 下载安装DevEco Studio 4.0(支持HarmonyOS 5)配置HarmonyOS SDK 5.0确保Node.js版本≥14 项目初始化: ohpm init harmony/hospital-report-app 二、核心功能模块实现 1. 报告列表…...

安全突围:重塑内生安全体系:齐向东在2025年BCS大会的演讲
文章目录 前言第一部分:体系力量是突围之钥第一重困境是体系思想落地不畅。第二重困境是大小体系融合瓶颈。第三重困境是“小体系”运营梗阻。 第二部分:体系矛盾是突围之障一是数据孤岛的障碍。二是投入不足的障碍。三是新旧兼容难的障碍。 第三部分&am…...
2025-05-08-deepseek本地化部署
title: 2025-05-08-deepseek 本地化部署 tags: 深度学习 程序开发 2025-05-08-deepseek 本地化部署 参考博客 本地部署 DeepSeek:小白也能轻松搞定! 如何给本地部署的 DeepSeek 投喂数据,让他更懂你 [实验目的]:理解系统架构与原…...

RushDB开源程序 是现代应用程序和 AI 的即时数据库。建立在 Neo4j 之上
一、软件介绍 文末提供程序和源码下载 RushDB 改变了您处理图形数据的方式 — 不需要 Schema,不需要复杂的查询,只需推送数据即可。 二、Key Features ✨ 主要特点 Instant Setup: Be productive in seconds, not days 即时设置 :在几秒钟…...
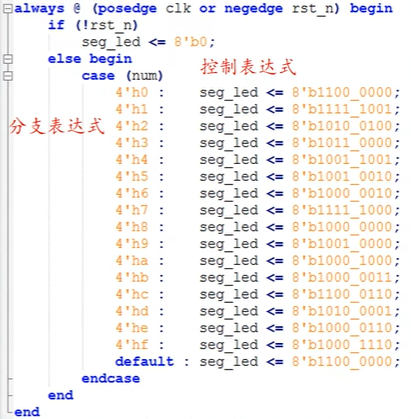
ZYNQ学习记录FPGA(二)Verilog语言
一、Verilog简介 1.1 HDL(Hardware Description language) 在解释HDL之前,先来了解一下数字系统设计的流程:逻辑设计 -> 电路实现 -> 系统验证。 逻辑设计又称前端,在这个过程中就需要用到HDL,正文…...
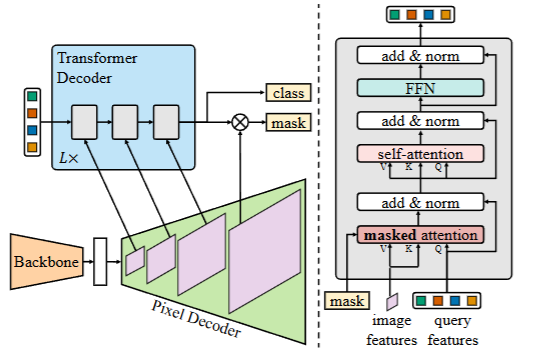
2025-06-08-深度学习网络介绍(语义分割,实例分割,目标检测)
深度学习网络介绍(语义分割,实例分割,目标检测) 前言 在开始这篇文章之前,我们得首先弄明白,什么是图像分割? 我们知道一个图像只不过是许多像素的集合。图像分割分类是对图像中属于特定类别的像素进行分类的过程,即像素级别的…...

CSS(2)
文章目录 Emmet语法快速生成HTML结构语法 Snipaste快速生成CSS样式语法快速格式化代码 快捷键(VScode)CSS 的复合选择器什么是复合选择器交集选择器后代选择器(重要)子选择器(重要)并集选择器(重要)**链接伪类选择器**focus伪类选…...

【NLP】 38. Agent
什么是 Agent? 一个 Agent 就是能够 理解、思考,并且进行世界交互 的模型系统,并不是纯粹的 prompt 返回器。 它可以: 读取外部数据(文件/API)使用记忆进行上下文维持用类Chain-of-Thought (CoT)方式进行…...