Linux perf_event_open 简介
文章目录
- 前言
- 一、简介
- 二、struct perf_event_attr
- 2.1 type
- 2.2 size
- 2.3 config
- 2.3.1 PERF_TYPE_HARDWARE
- 2.3.2 PERF_TYPE_SOFTWARE
- 2.3.3 PERF_TYPE_TRACEPOINT
- 2.3.4 PERF_TYPE_HW_CACHE
- 2.3.5 其他类型
- 三、sample相关参数
- 3.1 sample_period
- 3.2 sample_freq
- 3.3 sample_type
- 四、其他重要参数
- 4.1 read_format
- 4.2 disabled
- 4.3 exclude类型
- 4.4 freq
- 4.5 enable_on_exec
- 五、MMAP layout
- 六、Overflow handling
- 七、perf_event ioctl calls
- 八、demo
- 参考资料
前言
perf 工具 通过系统调用 perf_event_open 与内核交互,接下来我们主要来了解 perf_event_open 系统调用:
NAMEperf_event_open - set up performance monitoring
perf_event_open系统调用从该函数名就可以看出 perf 与 event 联系在一起的。
perf_event_open 对系统中打开的event分配一个对应的perf_event结构,所有对event的操作都是围绕perf_event来展开的。
一、简介
#include <linux/perf_event.h>
#include <linux/hw_breakpoint.h>int perf_event_open(struct perf_event_attr *attr,pid_t pid, int cpu, int group_fd,unsigned long flags);
Glibc没有为这个系统调用提供包装器;使用syscall调用它:
static long perf_event_open(struct perf_event_attr *hw_event, pid_t pid,int cpu, int group_fd, unsigned long flags)
{int ret = syscall(__NR_perf_event_open, hw_event, pid, cpu,group_fd, flags);return ret;
}
给定一个参数列表,perf_event_open()返回一个文件描述符fd,用于随后的系统调用(read、mmap、ioctl、prctl、fcntl等),通常用的是对 fd 进行 mmap、ioctl、read操作。
经过perf_event_open()调用以后返回perf_event对应的fd,后续的文件操作对应perf_fops:
static const struct file_operations perf_fops = {.llseek = no_llseek,.release = perf_release,.read = perf_read,.poll = perf_poll,.unlocked_ioctl = perf_ioctl,.compat_ioctl = perf_ioctl,.mmap = perf_mmap,.fasync = perf_fasync,
};
对perf_event_open()的调用将创建一个文件描述符,用于测量性能信息。每个文件描述符对应于一个被测量的事件;这些可以组合在一起以同时测量多个事件。
perf_ioctl:事件可以通过两种方式启用和禁用:通过ioctl和prctl。禁用事件时,它不会计数或生成溢出,但会继续存在并保持其计数值。
static long perf_ioctl(struct file *file, unsigned int cmd, unsigned long arg)
{struct perf_event *event = file->private_data;void (*func)(struct perf_event *);u32 flags = arg;switch (cmd) {case PERF_EVENT_IOC_ENABLE:func = perf_event_enable;break;case PERF_EVENT_IOC_DISABLE:func = perf_event_disable;break;......
}
事件有两种类型:计数和采样。
perf_read:
计数事件是用于对发生的事件总数进行计数的事件。通常,计数事件结果是通过 read() 系统调用读取收集的。
perf stat 命令工作在计数模式。
perf_mmap:采样事件定期将测量值写入缓冲区,然后可以通过mmap访问该缓冲区。
perf record 命令工作在采样模式。
计数只是记录了event的发生次数,采样记录了大量信息(比如:IP、ADDR、TID、TIME、CPU、BT)。
Arguments:
struct perf_event_attr *attr是该系统调用最重要的参数,先介绍其他的参数。
pid和cpu参数允许指定要监视的进程和cpu:
pid==0,cpu==-1
它测量任何CPU上的调用进程/线程。pid==0,cpu>=0
这仅在指定CPU上运行时测量调用进程/线程。pid>0,cpu==-1
它测量任何CPU上指定的进程/线程。pid>0和cpu>=0
仅当在指定的CPU上运行时,才会测量指定的进程/线程。pid==-1,cpu>=0
这将测量指定CPU上的所有进程/线程。这需要CAP_SYS_ADMIN功能或/proc/sys/kernel/perf_event_paranoid值小于1。pid==-1和cpu==-1
此设置无效,将返回错误。
group_fd参数允许创建事件组。一个事件组有一个事件,即组长。首先创建组长,group_fd=-1。其余的组成员是通过随后的perf_event_open()调用创建的,group_fd被设置为组长的文件描述符(group_fd=-1表示单独创建一个事件,并且被认为是只有1个成员的组)。事件组作为一个单元调度到CPU上:只有当组中的所有事件都可以放到CPU上时,它才会放到CPU上。这意味着可以对成员事件的值进行有意义的比较—相加、除法(以获得比率)等等,因为它们已经对同一组执行指令的事件进行了计数。
flags参数是通过对以下零个或多个值进行“或”运算形成的:
#define PERF_FLAG_FD_NO_GROUP (1UL << 0)
#define PERF_FLAG_FD_OUTPUT (1UL << 1)
#define PERF_FLAG_PID_CGROUP (1UL << 2) /* pid=cgroup id, per-cpu mode only */
#define PERF_FLAG_FD_CLOEXEC (1UL << 3) /* O_CLOEXEC */
该参数通常为零个值,即flags=0。
二、struct perf_event_attr
perf_event_attr结构为正在创建的事件提供详细的配置信息,如下所示:
struct perf_event_attr {__u32 type; /* Type of event */__u32 size; /* Size of attribute structure */__u64 config; /* Type-specific configuration */union {__u64 sample_period; /* Period of sampling */__u64 sample_freq; /* Frequency of sampling */};__u64 sample_type; /* Specifies values included in sample */__u64 read_format; /* Specifies values returned in read */__u64 disabled : 1, /* off by default */inherit : 1, /* children inherit it */pinned : 1, /* must always be on PMU */exclusive : 1, /* only group on PMU */exclude_user : 1, /* don't count user */exclude_kernel : 1, /* don't count kernel */exclude_hv : 1, /* don't count hypervisor */exclude_idle : 1, /* don't count when idle */mmap : 1, /* include mmap data */comm : 1, /* include comm data */freq : 1, /* use freq, not period */inherit_stat : 1, /* per task counts */enable_on_exec : 1, /* next exec enables */task : 1, /* trace fork/exit */watermark : 1, /* wakeup_watermark */precise_ip : 2, /* skid constraint */mmap_data : 1, /* non-exec mmap data */sample_id_all : 1, /* sample_type all events */exclude_host : 1, /* don't count in host */exclude_guest : 1, /* don't count in guest */exclude_callchain_kernel : 1,/* exclude kernel callchains */exclude_callchain_user : 1,/* exclude user callchains */mmap2 : 1, /* include mmap with inode data */comm_exec : 1, /* flag comm events that aredue to exec */use_clockid : 1, /* use clockid for time fields */context_switch : 1, /* context switch data */write_backward : 1, /* Write ring buffer from endto beginning */namespaces : 1, /* include namespaces data */ksymbol : 1, /* include ksymbol events */bpf_event : 1, /* include bpf events */aux_output : 1, /* generate AUX recordsinstead of events */cgroup : 1, /* include cgroup events */text_poke : 1, /* include text poke events */__reserved_1 : 30;union {__u32 wakeup_events; /* wakeup every n events */__u32 wakeup_watermark; /* bytes before wakeup */};__u32 bp_type; /* breakpoint type */union {__u64 bp_addr; /* breakpoint address */__u64 kprobe_func; /* for perf_kprobe */__u64 uprobe_path; /* for perf_uprobe */__u64 config1; /* extension of config */};union {__u64 bp_len; /* breakpoint length */__u64 kprobe_addr; /* with kprobe_func == NULL */__u64 probe_offset; /* for perf_[k,u]probe */__u64 config2; /* extension of config1 */};__u64 branch_sample_type; /* enum perf_branch_sample_type */__u64 sample_regs_user; /* user regs to dump on samples */__u32 sample_stack_user; /* size of stack to dump onsamples */__s32 clockid; /* clock to use for time fields */__u64 sample_regs_intr; /* regs to dump on samples */__u32 aux_watermark; /* aux bytes before wakeup */__u16 sample_max_stack; /* max frames in callchain */__u16 __reserved_2; /* align to u64 */};
perf_event_attr结构的字段如下所述:
2.1 type
此字段指定整个事件类型。它具有以下值之一:
PERF_TYPE_HARDWARE这表示内核提供的“通用”硬件事件之一。有关详细信息,请参阅 config 字段定义。PERF_TYPE_SOFTWARE这表示内核提供的软件定义事件之一(即使没有可用的硬件支持)。PERF_TYPE_TRACEPOINTThis indicates a tracepoint provided by the kernel tracepoint infrastructure.PERF_TYPE_HW_CACHE这表示内核跟踪点基础结构提供的跟踪点。PERF_TYPE_RAW这表示 config 字段中的“raw”实现特定事件。PERF_TYPE_BREAKPOINT (since Linux 2.6.33)这表示CPU提供的硬件断点。断点可以是对地址的读/写访问以及指令地址的执行。dynamic PMU从Linux 2.6.38开始,perf_event_open()可以支持多个PMU。要启用此功能,可以在 type 字段中使用内核导出的值来指示要使用的PMU。要使用的值可以在sysfs文件系统中找到:/sys/bus/event_source/devices下的每个PMU实例都有一个子目录。在每个子目录中都有一个类型文件,其内容是可以在 type 字段中使用的整数。例如,/sys/bus/event_source/devices/cpu/type包含核心cpu PMU的值,通常为4kprobe and uprobe (since Linux 4.17)这两个动态PMU创建一个kprobe/uprobe,并将其附加到perf_event_open生成的文件描述符。kprobe/uprobe将在销毁文件描述符时销毁。有关详细信息,请参见字段kprobe_func、uprobe_path、kprobe_addr和probe_offset。
/** attr.type*/
enum perf_type_id {PERF_TYPE_HARDWARE = 0,PERF_TYPE_SOFTWARE = 1,PERF_TYPE_TRACEPOINT = 2,PERF_TYPE_HW_CACHE = 3,PERF_TYPE_RAW = 4,PERF_TYPE_BREAKPOINT = 5,PERF_TYPE_MAX, /* non-ABI */
};
2.2 size
向前/向后兼容性的perf_event_attr结构的大小。使用sizeof(struct perf_event_attr)设置此值,以允许内核在编译时查看结构大小。
即perf_event_attr.size = sizeof(struct perf_event_attr)。
2.3 config
这将与 type 字段一起指定所需的事件。设置 config 字段的方法多种多样,取决于前面描述的 type 字段的值。以下是按 type 区分的 config 的各种可能设置。
2.3.1 PERF_TYPE_HARDWARE
如果类型为PERF_TYPE_HARDWARE,将测量一个通用硬件CPU事件。并非所有平台都有这些功能。将config设置为以下值之一:
PERF_COUNT_HW_CPU_CYCLESTotal cycles. Be wary of what happens duringCPU frequency scaling.PERF_COUNT_HW_INSTRUCTIONSRetired instructions. Be careful, these canbe affected by various issues, most notablyhardware interrupt counts.PERF_COUNT_HW_CACHE_REFERENCESCache accesses. Usually this indicates LastLevel Cache accesses but this may varydepending on your CPU. This may includeprefetches and coherency messages; again thisdepends on the design of your CPU.PERF_COUNT_HW_CACHE_MISSESCache misses. Usually this indicates LastLevel Cache misses; this is intended to beused in conjunction with thePERF_COUNT_HW_CACHE_REFERENCES event tocalculate cache miss rates.PERF_COUNT_HW_BRANCH_INSTRUCTIONSRetired branch instructions. Prior to Linux2.6.35, this used the wrong event on AMDprocessors.PERF_COUNT_HW_BRANCH_MISSESMispredicted branch instructions.PERF_COUNT_HW_BUS_CYCLESBus cycles, which can be different from totalcycles.PERF_COUNT_HW_STALLED_CYCLES_FRONTEND (since Linux
3.0)Stalled cycles during issue.PERF_COUNT_HW_STALLED_CYCLES_BACKEND (since Linux
3.0)Stalled cycles during retirement.PERF_COUNT_HW_REF_CPU_CYCLES (since Linux 3.3)Total cycles; not affected by CPU frequencyscaling.
/** Generalized performance event event_id types, used by the* attr.event_id parameter of the sys_perf_event_open()* syscall:*/
enum perf_hw_id {/** Common hardware events, generalized by the kernel:*/PERF_COUNT_HW_CPU_CYCLES = 0,PERF_COUNT_HW_INSTRUCTIONS = 1,PERF_COUNT_HW_CACHE_REFERENCES = 2,PERF_COUNT_HW_CACHE_MISSES = 3,PERF_COUNT_HW_BRANCH_INSTRUCTIONS = 4,PERF_COUNT_HW_BRANCH_MISSES = 5,PERF_COUNT_HW_BUS_CYCLES = 6,PERF_COUNT_HW_STALLED_CYCLES_FRONTEND = 7,PERF_COUNT_HW_STALLED_CYCLES_BACKEND = 8,PERF_COUNT_HW_REF_CPU_CYCLES = 9,PERF_COUNT_HW_MAX, /* non-ABI */
};
2.3.2 PERF_TYPE_SOFTWARE
如果类型是PERF_TYPE_SOFTWARE,将测量内核提供的软件事件。将config设置为以下值之一:
PERF_COUNT_SW_CPU_CLOCKThis reports the CPU clock, a high-resolution per-CPU timer.PERF_COUNT_SW_TASK_CLOCKThis reports a clock count specific to the task that is running.PERF_COUNT_SW_PAGE_FAULTSThis reports the number of page faults.PERF_COUNT_SW_CONTEXT_SWITCHESThis counts context switches. Until Linux 2.6.34, these were all reported as user-space events, after that they are reported as happening in the kernel.PERF_COUNT_SW_CPU_MIGRATIONSThis reports the number of times the process has migrated to a new CPU.PERF_COUNT_SW_PAGE_FAULTS_MINThis counts the number of minor page faults. These did not require disk I/O to handle.PERF_COUNT_SW_PAGE_FAULTS_MAJThis counts the number of major page faults. These required disk I/O to handle.PERF_COUNT_SW_ALIGNMENT_FAULTS (since Linux 2.6.33)This counts the number of alignment faults. These happen when unaligned memory accesses happen; the kernel can handle these but it reduces performance. Thishappens only on some architectures (never on x86).PERF_COUNT_SW_EMULATION_FAULTS (since Linux 2.6.33)This counts the number of emulation faults. The kernel sometimes traps on unimplemented instructions and emulates them for user space. This can negativelyimpact performance.PERF_COUNT_SW_DUMMY (since Linux 3.12)This is a placeholder event that counts nothing. Informational sample record types such as mmap or comm must be associated with an active event. This dummyevent allows gathering such records without requiring a counting event.
/** Special "software" events provided by the kernel, even if the hardware* does not support performance events. These events measure various* physical and sw events of the kernel (and allow the profiling of them as* well):*/
enum perf_sw_ids {PERF_COUNT_SW_CPU_CLOCK = 0,PERF_COUNT_SW_TASK_CLOCK = 1,PERF_COUNT_SW_PAGE_FAULTS = 2,PERF_COUNT_SW_CONTEXT_SWITCHES = 3,PERF_COUNT_SW_CPU_MIGRATIONS = 4,PERF_COUNT_SW_PAGE_FAULTS_MIN = 5,PERF_COUNT_SW_PAGE_FAULTS_MAJ = 6,PERF_COUNT_SW_ALIGNMENT_FAULTS = 7,PERF_COUNT_SW_EMULATION_FAULTS = 8,PERF_COUNT_SW_DUMMY = 9,PERF_COUNT_SW_BPF_OUTPUT = 10,PERF_COUNT_SW_MAX, /* non-ABI */
};
2.3.3 PERF_TYPE_TRACEPOINT
如果类型是PERF_type_TRACEPOINT,那么正在测量内核跟踪点。如果内核中启用了ftrace,则可以从debugfs文件系统的以下目录中获取配置中使用的值:
tracing/events/*/*/id
2.3.4 PERF_TYPE_HW_CACHE
如果类型为PERF_TYPE_HW_CACHE,则正在测量硬件CPU缓存事件。要计算适当的配置值,请使用以下公式:
(perf_hw_cache_id) | (perf_hw_cache_op_id << 8) |(perf_hw_cache_op_result_id << 16)
where perf_hw_cache_id is one of:PERF_COUNT_HW_CACHE_L1Dfor measuring Level 1 Data CachePERF_COUNT_HW_CACHE_L1Ifor measuring Level 1 Instruction CachePERF_COUNT_HW_CACHE_LLfor measuring Last-Level CachePERF_COUNT_HW_CACHE_DTLBfor measuring the Data TLBPERF_COUNT_HW_CACHE_ITLBfor measuring the Instruction TLBPERF_COUNT_HW_CACHE_BPUfor measuring the branch prediction unitPERF_COUNT_HW_CACHE_NODE (since Linux 3.1)for measuring local memory accessesand perf_hw_cache_op_id is one of:PERF_COUNT_HW_CACHE_OP_READfor read accessesPERF_COUNT_HW_CACHE_OP_WRITEfor write accessesPERF_COUNT_HW_CACHE_OP_PREFETCHfor prefetch accessesand perf_hw_cache_op_result_id is one of:PERF_COUNT_HW_CACHE_RESULT_ACCESSto measure accessesPERF_COUNT_HW_CACHE_RESULT_MISSto measure misses
/** Generalized hardware cache events:** { L1-D, L1-I, LLC, ITLB, DTLB, BPU, NODE } x* { read, write, prefetch } x* { accesses, misses }*/
enum perf_hw_cache_id {PERF_COUNT_HW_CACHE_L1D = 0,PERF_COUNT_HW_CACHE_L1I = 1,PERF_COUNT_HW_CACHE_LL = 2,PERF_COUNT_HW_CACHE_DTLB = 3,PERF_COUNT_HW_CACHE_ITLB = 4,PERF_COUNT_HW_CACHE_BPU = 5,PERF_COUNT_HW_CACHE_NODE = 6,PERF_COUNT_HW_CACHE_MAX, /* non-ABI */
};enum perf_hw_cache_op_id {PERF_COUNT_HW_CACHE_OP_READ = 0,PERF_COUNT_HW_CACHE_OP_WRITE = 1,PERF_COUNT_HW_CACHE_OP_PREFETCH = 2,PERF_COUNT_HW_CACHE_OP_MAX, /* non-ABI */
};enum perf_hw_cache_op_result_id {PERF_COUNT_HW_CACHE_RESULT_ACCESS = 0,PERF_COUNT_HW_CACHE_RESULT_MISS = 1,PERF_COUNT_HW_CACHE_RESULT_MAX, /* non-ABI */
};
2.3.5 其他类型
PERF_TYPE_RAW
PERF_TYPE_BREAKPOINT
kprobe or uprobe
三、sample相关参数
3.1 sample_period
“采样”事件是每N个事件生成一个溢出通知的事件,其中N由sample_period给出。采样事件的sample_period>0。发生溢出时,请求的数据将记录在mmap缓冲区中。sample_type字段控制每次溢出时记录的数据。
3.2 sample_freq
如果希望使用频率而不是周期,可以使用sample_freq。在本例中,您设置了freq标志。内核将调整采样周期以尝试实现所需的速率。调整率为计时器刻度。
3.3 sample_type
此字段中的各个位指定要包含在样本中的值。它们将被记录在一个环形缓冲区中,该缓冲区可用于使用mmap的用户空间。值保存在样本中的顺序记录在下面的 MMAP Layout 小节中;它不是enum perf_event_sample_format顺序。
/** Bits that can be set in attr.sample_type to request information* in the overflow packets.*/
enum perf_event_sample_format {PERF_SAMPLE_IP = 1U << 0,PERF_SAMPLE_TID = 1U << 1,PERF_SAMPLE_TIME = 1U << 2,PERF_SAMPLE_ADDR = 1U << 3,PERF_SAMPLE_READ = 1U << 4,PERF_SAMPLE_CALLCHAIN = 1U << 5,PERF_SAMPLE_ID = 1U << 6,PERF_SAMPLE_CPU = 1U << 7,PERF_SAMPLE_PERIOD = 1U << 8,PERF_SAMPLE_STREAM_ID = 1U << 9,PERF_SAMPLE_RAW = 1U << 10,PERF_SAMPLE_BRANCH_STACK = 1U << 11,PERF_SAMPLE_REGS_USER = 1U << 12,PERF_SAMPLE_STACK_USER = 1U << 13,PERF_SAMPLE_WEIGHT = 1U << 14,PERF_SAMPLE_DATA_SRC = 1U << 15,PERF_SAMPLE_IDENTIFIER = 1U << 16,PERF_SAMPLE_TRANSACTION = 1U << 17,PERF_SAMPLE_REGS_INTR = 1U << 18,PERF_SAMPLE_PHYS_ADDR = 1U << 19,PERF_SAMPLE_MAX = 1U << 20, /* non-ABI */
};
四、其他重要参数
4.1 read_format
此字段指定系统待用 read 读取perf_event_open()文件描述符返回的数据的格式。
4.2 disabled
该位指定计数器开始时是禁用还是启用。如果disabled = 1,则可以稍后通过ioctl、prctl或enable_on_exec启用该事件。
创建事件组时,通常将组组长初始化为禁用设置为1,将所有子事件初始化为禁用设为0。尽管禁用为0,但子事件在组长 enable 之前不会启动。
4.3 exclude类型
exclude_userIf this bit is set, the count excludes events that happen in user space.exclude_kernelIf this bit is set, the count excludes events that happen in kernel space.exclude_hvIf this bit is set, the count excludes events that happen in the hypervisor. This is mainly for PMUs that have built-in support for handling this (such as POWER). Extrasupport is needed for handling hypervisor measurements on most machines.exclude_host (since Linux 3.2)When conducting measurements that include processes running VM instances (i.e., have executed a KVM_RUN ioctl(2)), only measure events happening inside a guest instance.This is only meaningful outside the guests; this setting does not change counts gathered inside of a guest. Currently, this functionality is x86 only.exclude_guest (since Linux 3.2)When conducting measurements that include processes running VM instances (i.e., have executed a KVM_RUN ioctl(2)), do not measure events happening inside guest instances.This is only meaningful outside the guests; this setting does not change counts gathered inside of a guest. Currently, this functionality is x86 only.
4.4 freq
如果设置了该位,则在设置采样间隔时使用sample_frequency而不是sample_period。
4.5 enable_on_exec
如果设置了此位,则在调用exec系统调用后会自动启用计数器。
五、MMAP layout
在采样模式下使用perf_event_open()时,异步事件(如计数器溢出或PROT_EXEC mmap跟踪)会记录到环形缓冲区中。这个环形缓冲区是通过mmap创建和访问的。
mmap大小应为1+2^n页,其中第一页是元数据页(struct perf_event_mmap_page),其中包含各种信息位,例如环形缓冲区头的位置。
第一个元数据mmap页面的结构如下:
struct perf_event_mmap_page {__u32 version; /* version number of this structure */__u32 compat_version; /* lowest version this is compat with */__u32 lock; /* seqlock for synchronization */__u32 index; /* hardware counter identifier */__s64 offset; /* add to hardware counter value */__u64 time_enabled; /* time event active */__u64 time_running; /* time event on CPU */union {__u64 capabilities;struct {__u64 cap_usr_time / cap_usr_rdpmc / cap_bit0 : 1,cap_bit0_is_deprecated : 1,cap_user_rdpmc : 1,cap_user_time : 1,cap_user_time_zero : 1,};};__u16 pmc_width;__u16 time_shift;__u32 time_mult;__u64 time_offset;__u64 __reserved[120]; /* Pad to 1 k */__u64 data_head; /* head in the data section */__u64 data_tail; /* user-space written tail */__u64 data_offset; /* where the buffer starts */__u64 data_size; /* data buffer size */__u64 aux_head;__u64 aux_tail;__u64 aux_offset;__u64 aux_size;
}
以下描述了perf_event_mmap_page结构中的几个字段:
data_head:这指向数据段的开头。该值持续增加,但不会换行。在访问样本之前,需要根据mmap缓冲区的大小手动包装该值。
data_tail:当映射为PROT_WRITE时,data_tail值应按用户空间写入,以反映上次读取的数据。在这种情况下,内核不会覆盖未读数据。
data_offset (since Linux 4.1):包含mmap缓冲区中性能样本数据开始位置的偏移量。
data_size (since Linux 4.1):包含mmap缓冲区中perf样本区域的大小。
aux_head, aux_tail, aux_offset, aux_size (since Linux 4.1):
AUX区域允许为 high-bandwidth 数据流合成单独的采样缓冲区(与主性能采样缓冲区分开)。high-bandwidth 流的一个例子是指令跟踪支持,这在较新的英特尔处理器中可以找到。
要设置AUX区域,需要将第一个aux_offset设置为大于data_offset+data_size的偏移,并且需要将aux_size设置为所需的缓冲区大小。所需的偏移量和大小必须与页面对齐,并且大小必须是2的幂。然后将这些值传递给mmap,以映射AUX缓冲区。AUX缓冲区中的页面作为RLIMIT_MEMLOCK资源限制的一部分(请参见setrlimit),也作为perf_event_mlock_kb许可的一部分。
默认情况下,如果AUX缓冲区无法容纳环形缓冲区中的可用空间,则会将其截断。如果AUX缓冲区被映射为只读缓冲区,那么它将以环形缓冲区模式运行,其中旧数据将被新数据覆盖。在覆盖模式下,可能无法推断新数据的开始位置,用户的工作是在读取时禁用测量,以避免可能的数据竞争。
aux_head和aux_tail环形缓冲区指针具有与前面描述的data_head和data_tail相同的行为和排序规则。
PERF_RECORD_AUX (since Linux 4.1)This record reports that new data is available in the separate AUX buffer region.struct {struct perf_event_header header;u64 aux_offset;u64 aux_size;u64 flags;struct sample_id sample_id;};aux_offsetoffset in the AUX mmap region where the new data begins.aux_sizesize of the data made available.flags describes the AUX update.PERF_AUX_FLAG_TRUNCATEDif set, then the data returned was truncated to fit the available buffer size.PERF_AUX_FLAG_OVERWRITEif set, then the data returned has overwritten previous data.
六、Overflow handling
事件可以设置为在超过阈值时发出通知,表示溢出。可以通过使用poll、select或epoll监视事件文件描述符来捕获溢出条件。或者,通过在文件描述符上启用I/O信令,可以通过sa信号处理器捕获溢出事件;请参见fcntl中F_SETOWN和F_SETSIG操作的讨论。
溢出仅由采样事件生成(sample_period必须具有非零值)。
有两种方法可以生成溢出通知。
第一种方法是设置一个wakeup_events或wakeup_watermark值,如果向mmap环形缓冲区写入了一定数量的样本或字节,则会触发该值。在这种情况下,指示POLL_IN。
另一种方法是使用PERF_EVENT_IOC_REFRESH ioctl。此ioctl添加到一个计数器,该计数器在每次事件溢出时递减。当非零时,指示POLL_IN,但一旦计数器达到0,则指示POLL_HUP,并禁用基础事件。
刷新事件 group leader 将刷新所有 siblings。
从Linux 3.18开始,如果正在监视的事件附加到另一个进程并且该进程退出,则指示POLL_HUP。
七、perf_event ioctl calls
各种ioctl作用于perf_event_open()文件描述符:
PERF_EVENT_IOC_ENABLEThis enables the individual event or event group specifiedby the file descriptor argument.If the PERF_IOC_FLAG_GROUP bit is set in the ioctlargument, then all events in a group are enabled, even ifthe event specified is not the group leader (but seeBUGS).PERF_EVENT_IOC_DISABLEThis disables the individual counter or event groupspecified by the file descriptor argument.Enabling or disabling the leader of a group enables ordisables the entire group; that is, while the group leaderis disabled, none of the counters in the group will count.Enabling or disabling a member of a group other than theleader affects only that counter; disabling a non-leaderstops that counter from counting but doesn't affect anyother counter.If the PERF_IOC_FLAG_GROUP bit is set in the ioctlargument, then all events in a group are disabled, even ifthe event specified is not the group leader (but seeBUGS).PERF_EVENT_IOC_REFRESHNon-inherited overflow counters can use this to enable acounter for a number of overflows specified by theargument, after which it is disabled. Subsequent calls ofthis ioctl add the argument value to the current count.An overflow notification with POLL_IN set will happen oneach overflow until the count reaches 0; when that happensa notification with POLL_HUP set is sent and the event isdisabled. Using an argument of 0 is considered undefinedbehavior.PERF_EVENT_IOC_RESETReset the event count specified by the file descriptorargument to zero. This resets only the counts; there isno way to reset the multiplexing time_enabled ortime_running values.If the PERF_IOC_FLAG_GROUP bit is set in the ioctlargument, then all events in a group are reset, even ifthe event specified is not the group leader (but seeBUGS).PERF_EVENT_IOC_PERIODThis updates the overflow period for the event.Since Linux 3.7 (on ARM) and Linux 3.14 (all otherarchitectures), the new period takes effect immediately.On older kernels, the new period did not take effect untilafter the next overflow.The argument is a pointer to a 64-bit value containing thedesired new period.Prior to Linux 2.6.36, this ioctl always failed due to abug in the kernel.PERF_EVENT_IOC_SET_OUTPUTThis tells the kernel to report event notifications to thespecified file descriptor rather than the default one.The file descriptors must all be on the same CPU.The argument specifies the desired file descriptor, or -1if output should be ignored.PERF_EVENT_IOC_SET_FILTER (since Linux 2.6.33)This adds an ftrace filter to this event.The argument is a pointer to the desired ftrace filter.PERF_EVENT_IOC_ID (since Linux 3.12)This returns the event ID value for the given event filedescriptor.The argument is a pointer to a 64-bit unsigned integer tohold the result.PERF_EVENT_IOC_SET_BPF (since Linux 4.1)This allows attaching a Berkeley Packet Filter (BPF)program to an existing kprobe tracepoint event. You needCAP_PERFMON (since Linux 5.8) or CAP_SYS_ADMIN privilegesto use this ioctl.The argument is a BPF program file descriptor that wascreated by a previous bpf(2) system call.PERF_EVENT_IOC_PAUSE_OUTPUT (since Linux 4.7)This allows pausing and resuming the event's ring-buffer.A paused ring-buffer does not prevent generation ofsamples, but simply discards them. The discarded samplesare considered lost, and cause a PERF_RECORD_LOST sampleto be generated when possible. An overflow signal maystill be triggered by the discarded sample even though thering-buffer remains empty.The argument is an unsigned 32-bit integer. A nonzerovalue pauses the ring-buffer, while a zero value resumesthe ring-buffer.PERF_EVENT_MODIFY_ATTRIBUTES (since Linux 4.17)This allows modifying an existing event without theoverhead of closing and reopening a new event. Currentlythis is supported only for breakpoint events.The argument is a pointer to a perf_event_attr structurecontaining the updated event settings.PERF_EVENT_IOC_QUERY_BPF (since Linux 4.16)This allows querying which Berkeley Packet Filter (BPF)programs are attached to an existing kprobe tracepoint.You can only attach one BPF program per event, but you canhave multiple events attached to a tracepoint. Queryingthis value on one tracepoint event returns the ID of allBPF programs in all events attached to the tracepoint.You need CAP_PERFMON (since Linux 5.8) or CAP_SYS_ADMINprivileges to use this ioctl.The argument is a pointer to a structurestruct perf_event_query_bpf {__u32 ids_len;__u32 prog_cnt;__u32 ids[0];};The ids_len field indicates the number of ids that can fitin the provided ids array. The prog_cnt value is filledin by the kernel with the number of attached BPF programs.The ids array is filled with the ID of each attached BPFprogram. If there are more programs than will fit in thearray, then the kernel will return ENOSPC and ids_len willindicate the number of program IDs that were successfullycopied.
/** Ioctls that can be done on a perf event fd:*/
#define PERF_EVENT_IOC_ENABLE _IO ('$', 0)
#define PERF_EVENT_IOC_DISABLE _IO ('$', 1)
#define PERF_EVENT_IOC_REFRESH _IO ('$', 2)
#define PERF_EVENT_IOC_RESET _IO ('$', 3)
#define PERF_EVENT_IOC_PERIOD _IOW('$', 4, __u64)
#define PERF_EVENT_IOC_SET_OUTPUT _IO ('$', 5)
#define PERF_EVENT_IOC_SET_FILTER _IOW('$', 6, char *)
#define PERF_EVENT_IOC_ID _IOR('$', 7, __u64 *)
#define PERF_EVENT_IOC_SET_BPF _IOW('$', 8, __u32)
#define PERF_EVENT_IOC_PAUSE_OUTPUT _IOW('$', 9, __u32)
#define PERF_EVENT_IOC_QUERY_BPF _IOWR('$', 10, struct perf_event_query_bpf *)
八、demo
下面是硬件类型计数(count)的一个demo:
#include <stdlib.h>
#include <stdio.h>
#include <unistd.h>
#include <string.h>
#include <sys/ioctl.h>
#include <linux/perf_event.h>
#include <asm/unistd.h>static long perf_event_open(struct perf_event_attr *hw_event, pid_t pid,int cpu, int group_fd, unsigned long flags)
{int ret = syscall(__NR_perf_event_open, hw_event, pid, cpu,group_fd, flags);return ret;
}int main(int argc, char **argv)
{struct perf_event_attr pe;long long count;int fd;memset(&pe, 0, sizeof(struct perf_event_attr));pe.type = PERF_TYPE_HARDWARE;pe.size = sizeof(struct perf_event_attr);pe.config = PERF_COUNT_HW_INSTRUCTIONS;pe.disabled = 1;pe.exclude_kernel = 1;pe.exclude_hv = 1;fd = perf_event_open(&pe, 0, -1, -1, 0);if (fd == -1) {fprintf(stderr, "Error opening leader %llx\n", pe.config);exit(EXIT_FAILURE);}ioctl(fd, PERF_EVENT_IOC_RESET, 0);ioctl(fd, PERF_EVENT_IOC_ENABLE, 0);printf("Measuring instruction count for this printf\n");ioctl(fd, PERF_EVENT_IOC_DISABLE, 0);read(fd, &count, sizeof(long long));printf("Used %lld instructions\n", count);close(fd);
}
结果:
Measuring instruction count for this printf
Used 3489 instructions
参考资料
man perf_event_open
https://pwl999.blog.csdn.net/article/details/81200439
相关文章:

Linux perf_event_open 简介
文章目录前言一、简介二、struct perf_event_attr2.1 type2.2 size2.3 config2.3.1 PERF_TYPE_HARDWARE2.3.2 PERF_TYPE_SOFTWARE2.3.3 PERF_TYPE_TRACEPOINT2.3.4 PERF_TYPE_HW_CACHE2.3.5 其他类型三、sample相关参数3.1 sample_period3.2 sample_freq3.3 sample_type四、其他…...

Java给定两组起止日期,求交集
/*** 判断2个时间段是否有重叠(交集)* param startDate1 时间段1开始时间戳* param endDate1 时间段1结束时间戳* param startDate2 时间段2开始时间戳* param endDate2 时间段2结束时间戳* param isStrict 是否严格重叠,true 严格࿰…...
数组的复制与二维数组的用法
今天学习的主要内容有 数组的复制 数组的复制 利用循环进行数组的复制 import java.util.Arrays; public class Main3 {public static void main(String[] args) {int []arr new int[]{1,2,3,4,5,6};int []arr1 new int[arr.length];for (int i 0; i < arr.length; i…...
)
JS判断两个table数据是否完全相等(判断两个数组对象是否完全相等)
需求 现有的table为tableA,有多个要做对比的table为一个数组 CompareArray 涉及到的问题 外层是数组,但是内部数据都是对象,对象属性名的排序不一样外层数组也涉及到 顺序不一样的问题 思路 对compareArray做长度筛选 filter 得到 同长度…...

关于小程序,你想知道的这些
近年来,各大平台纷纷上架小程序,迎来了小程序的爆发式增长。今天就来跟大家简单分享一下小程序基本的运行机制和安全机制。 小程序的由来 在小程序没有出来之前,最初微信WebView逐渐成为移动web重要入口,微信发布了一整套网页开…...

WuThreat身份安全云-TVD每日漏洞情报-2023-02-13
漏洞名称:THORSTEN PHPMYFAQ 跨站点脚本 漏洞级别:高危 漏洞编号:CVE-2023-0791 相关涉及:THORSTEN PHPMYFAQ 3.1.10 漏洞状态:POC 参考链接:https://tvd.wuthreat.com/#/listDetail?TVD_IDTVD-2023-03506 漏洞名称:TENDA AC23 越界写入 漏洞级别:高危 漏洞编号:CVE-2023-078…...
【Linux】软件安装(三分钟教会你如何在linux下安装软件)
🔥🔥 欢迎来到小林的博客!! 🛰️博客主页:✈️小林爱敲代码 🛰️博客专栏:✈️Linux之路 🛰️社区:✈️进步学堂 目录&…...

Fluent Python 笔记 第 10 章 序列的修改、散列和切片
本章将以第 9 章定义的二维向量 Vector2d 类为基础,向前迈出一大步,定义表示多维向量的 Vector 类。这个类的行为与 Python 中标准的不可变扁平序列一样。 10.3 协议和鸭子类型 在 Python 中创建功能完善的序列类型无需使用继承,只需实现符…...
在中国程序员工作是青春饭吗?
上个月公司告诉我毕业了。 我打开boss直聘,一溜溜的外包公司和我打招呼。 我寻思我说不定啥时候就离开深圳了,外包不外包也无所谓钱到位就行。(大公司学历不够格也进不去) 结果华为、平安的外包告诉我,不好意思呀&a…...

Linux tcpdump
tcpdump - 转储网络上的数据流 是不是感觉很懵?全方位描述tcpdump: 通俗:tcpdump是一个抓包工具,用于抓取网络中传输的数据包形象:tcpdump如同国家海关,凡是入境和出境的货物,海关都要抽样检查࿰…...
redis知识汇总(部署、高可用、集群)
文章目录一、redis知识汇总什么是redisredis的优缺点:为什么要用redis做缓存redis为什么这么快什么是持久化redis持久化机制是什么?各自优缺点?AOF和RDB怎么选择redis持久化数据和缓存怎么做扩容什么是事务redis事务的概念ACID概念主从复制re…...

【手写 Vuex 源码】第十篇 - Vuex 命名空间的实现
一,前言 上一篇,主要介绍了 Vuex 响应式数据和缓存的实现,主要涉及以下几个点: Vuex 的响应式实现原理;响应式核心方法 resetStoreVM;commit 和 dispatch 的处理; 本篇,继续介绍 …...
面试腾讯测试岗后感想,真的很后悔这5年一直都干的是基础测试....
前两天,我的一个朋友去大厂面试,跟我聊天时说:输的很彻底… 我问她:什么情况?她说:很后悔这5年来一直都干的是功能测试… 相信许多测试人也跟我朋友一样,从事了软件测试很多年,却依…...
)
知识图谱 方法、实践与应用 王昊奋 读书笔记(下)
最近读了这本书,在思路上很有启发,对知识图谱有了初步的认识,以下是原书后半部分的内容,可以购买实体书获取更多内容。 知识图谱推理 结合已有规则,推出新的事实,例如持有股份就能控制一家公司࿰…...
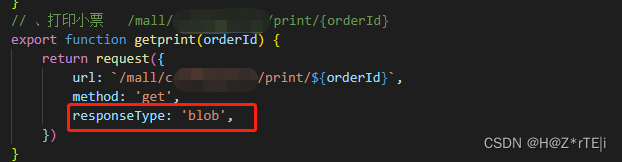
vue实现打印浏览器页面功能(两种方法)
推荐使用方法二 方法一:通过npm 安装插件 1,安装 npm install vue-print-nb --save 2,引入 安装好以后在main.js文件中引入 import Print from vue-print-nbVue.use(Print); //注册 3,现在就可以使用了 div id"printTest…...
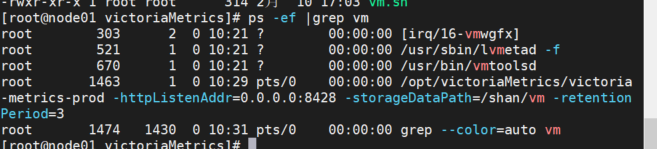
【VictoriaMetrics】VictoriaMetrics单机版批量和单条数据写入(Prometheus格式)
VictoriaMetrics单机版支持以Prometheus格式的数据写入,写入支持单条数据写入以及多条数据写入,下面操作演示下如何使用 1、首先需要启动VictoriaMetrics单机版服务 2、使用postman插入单机版VictoriaMetrics,以当前时间插入数据 地址为 http://victoriaMetricsIP:8428/api…...
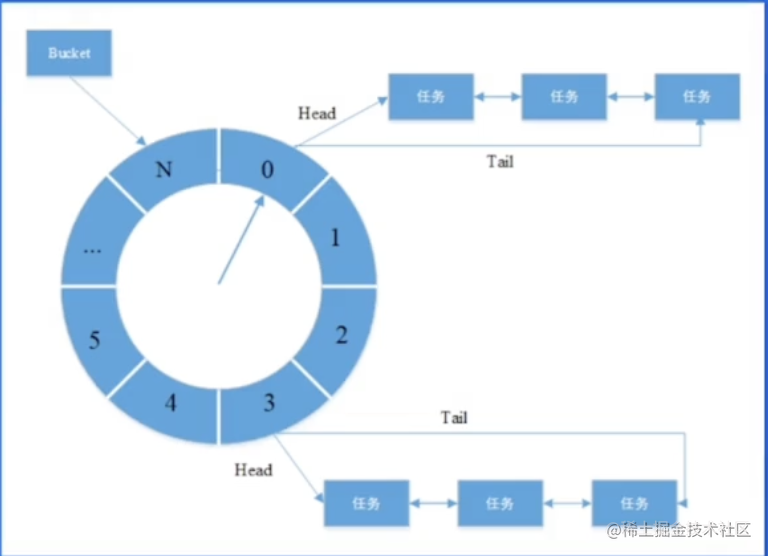
【青训营】分布式定时任务简述
这是我参与「第五届青训营 」伴学笔记创作活动的第 13 天 分布式定时任务简述 定义 定时任务是指系统为了自动完成特定任务,实时、延时、周期性完成任务调度的过程。分布式定时任务是把分散的、可靠性差的定时任务纳入统一平台,并且实现集群管理调度和…...
golang语言本身设计点总结
本文参考 1.golang的内存管理分配 golang的内存分配仿造Google公司的内存分配方法TCmalloc算法;她会把将内存请求分为两类,大对象请求和小对象请求,大对象为>32K的对象。 在了解golang的内存分配之前要知道什么事虚拟内存,虚拟内存是把磁盘作为全局…...

PTA L1-046 整除光棍(详解)
前言:内容包括四大模块:题目,代码实现,大致思路,代码解读 题目: 这里所谓的“光棍”,并不是指单身汪啦~ 说的是全部由1组成的数字,比如1、11、111、1111等。传说任何一个光棍都能被…...
将小程序代码转成uni-app代码
最近因为公司项目原因需要将小程序的项目转换成uni—app的项目,所以总结了以下几点: 首先你可以先到uni-app的官网简单看一下对它的介绍,本次文章的介绍是针对简单的微信小程序来进行的转化。 在这之前我们来看一下目录对比 下面就来介绍一下…...

ProperTree:为什么这款跨平台GUI编辑器让配置管理变得如此简单?
ProperTree:为什么这款跨平台GUI编辑器让配置管理变得如此简单? 【免费下载链接】ProperTree Cross platform GUI plist editor written in python. 项目地址: https://gitcode.com/gh_mirrors/pr/ProperTree 还在为手动编辑复杂的Plist配置文件而…...
 uniapp中使用vuex)
【uniapp】(6) uniapp中使用vuex
uniapp内置了vuex,不需要通过npm重新安装,直接引用即可1、创建 Vuex Store(1)在uniapp项目根目录下创建 store/index.jsimport Vue from vue import Vuex from vuexVue.use(Vuex)const store new Vuex.Store({//存放状态state: …...

Automerge与区块链技术结合:构建去中心化数据协作的终极指南
Automerge与区块链技术结合:构建去中心化数据协作的终极指南 【免费下载链接】automerge A JSON-like data structure (a CRDT) that can be modified concurrently by different users, and merged again automatically. 项目地址: https://gitcode.com/gh_mirr…...

Swin2SR小白快速上手:无需代码,在线修复低清图片
Swin2SR小白快速上手:无需代码,在线修复低清图片 1. 什么是Swin2SR图像修复技术 Swin2SR是一种基于Swin Transformer架构的AI图像超分辨率技术,它能将低质量图片无损放大4倍。与传统的插值放大方法不同,Swin2SR能够"理解&q…...

5步搞定Anything V5:Stable Diffusion二次元图像生成服务快速搭建
5步搞定Anything V5:Stable Diffusion二次元图像生成服务快速搭建 1. 项目概述 Anything V5是基于Stable Diffusion技术的高质量二次元图像生成模型,特别适合动漫风格内容创作。本教程将带您快速搭建一个完整的图像生成服务,支持Web界面和A…...
)
GD32单片机ADC实战:从传感器到上位机,一步步搞定50kg压力采集(附源码/原理图)
GD32单片机ADC实战:从传感器到上位机的50kg压力采集全流程解析 在嵌入式开发领域,ADC(模数转换器)的应用一直是连接物理世界与数字系统的关键桥梁。想象一下,当你需要精确测量一个50kg范围内的压力变化时,从…...

OFA图像语义蕴含Web应用5分钟部署教程:图文匹配AI一键搭建
OFA图像语义蕴含Web应用5分钟部署教程:图文匹配AI一键搭建 1. 项目简介与核心价值 OFA(One For All)图像语义蕴含模型是阿里巴巴达摩院研发的多模态深度学习系统,能够智能分析图像内容与文本描述之间的逻辑关系。这个Web应用将强…...

FUTURE POLICE模型ComfyUI可视化工作流搭建指南
FUTURE POLICE模型ComfyUI可视化工作流搭建指南 你是不是也对那些能生成未来感、赛博朋克风格图像的AI模型感到好奇?但一看到复杂的代码和命令行,就觉得头大,不知道从何下手。今天,我们就来聊聊一个特别酷的解决方案——用ComfyU…...

【AI实战项目】项目三:序列标注技术深度解析与应用实战
分享一个大牛的人工智能教程。零基础!通俗易懂!风趣幽默!希望你也加入到人工智能的队伍中来!请轻击人工智能教程https://www.captainai.net/troubleshooter 项目背景: 序列标注在AI技术中有⾮常⼴泛的应⽤&am…...

gciWidget:面向车载嵌入式系统的轻量级GUI组件库
1. 项目概述gciWidget是面向大众汽车集团(Volkswagen Group)CARIAD 车载软件平台定制开发的轻量级图形用户界面(GUI)组件库,专为嵌入式车载显示系统设计。其核心定位并非通用型 GUI 框架(如 LVGL 或 TouchG…...