知识图谱 方法、实践与应用 王昊奋 读书笔记(下)
最近读了这本书,在思路上很有启发,对知识图谱有了初步的认识,以下是原书后半部分的内容,可以购买实体书获取更多内容。
知识图谱推理
结合已有规则,推出新的事实,例如持有股份就能控制一家公司,孙宏斌持有融创的股份,那么可以推导出孙宏斌控制融创
基于演绎的推理工具
逻辑编程RDFFox:
java实现,基于DataLog,依靠逻辑编程进行推理,根据自定义的和已有的规则,从已知事实推新事实
例如,根据孙宏斌控制融创,并且只有自然人能控制公司,可以推导出孙宏斌是自然人
产生式推理Drools、Jena、GraphDB等:
由事实集合、产生式集合和推理引擎构成
事实集合:例如(student name:zhangsan age:23)表示有一个叫张三的人23岁
产生式集合:例如IF(student name:) then add(person name)表示如果有一个学生名为x,那么就添加一个名为x的人到person中推理引擎中包含推理规则,将推理规则应用到事实集合和产生式集合中,能产生新的知识例如规则为(type x y),(subClassOf y z)=>add(type x z),事实集合和产生式集合分别为(type zhangsan student) (subClass student person)那么可以推理出(type zhangsan person)当执行规则有很多条时,可以随机选择其中一条、选择最近没有被用的一条、最复杂的一条进行之星,知道没有新规则可以被执行
基于归纳的推理工具
1.基于图结构的推理:
从图中高频出现的一些结构,可以推断出一些隐形的知识,
例如a--妻子--b--孩子--c,并且存在a--孩子--c,那么就可以推断出这两个关系是等价的。
使用以下两种算法,能够发现一些概率很高的关系路径,通过分析,可以确定出这些关系路径的共同模式,并将其总结为新知识
例如已知运动员h位于北京市t,并且其他很多实体中都存在类似于下面路规则的路径,就可以推出一条新的规则:(运动员h)==效力于==》(国安队)==位于==》(北京市t)当对新运动员进行分析时,如果仅知道运动员效力于申花队和申花队位于上海两个知识,
那么就可以应用上面的规则,推断出该运动员位于上海市
PRA(path ranking algorithm)算法:
可以用来预测给定头实体h和关系r,预测尾实体t的概率分别是多少(或者反过来给定t和r,预测头实体h)可以使用前向算法计算k跳之内到达每一个节点的概率(),然后再logistics平滑处理
CoR-PRA算法:
是一种改进,从h和t出发,分别计算特定步数内到达各个节点的概率。当发现h-》x且t-》x时,就可以认为h和t之间存在关系
可以用h和t之间的覆盖度和精确度,来衡量h和t的关系。SFE是进一步的算法,考虑了二元路径,剪枝(假设h对应到关系r连接着很多不同的节点,就忽略r),以及两个节点是否有共同的属性等
参考论文:
Learning relations features with backword random wallks,ni lao,acl 2015Efficient and expressive knowledge base cmpletion using subgraph feature extraction,matt gardner,emnlp 2015
工具库:
github.com/noon99jaki/pra
2.基于规则学习的推理
类似于离散数学的推导 rule:head<–body,例如:
ifFatherOf(X,Z)-<hasWife(X,Y) and hasChild(Y,Z) and notDivocied(X) and notDivocied(y)
评价标准:
support(rule)表示同时满足head(rule)和body(rule)的实例个数置信度=support(rule)/body(rule)头覆盖度=support(rule)/head(rule)pca置信度(部分完全假设)=support(rule)/ (body(rule) and r(x,y^)),分母中过滤了从X类出发但是没有到达Y类节点的情况
常用工具AMIE:
效率高,能挖掘出大量规则,改进版AMIE+
3.基于表示学习的推理
transE:最基础的方法
transH:能够表示1:n,n:n等关系,可以将不同向量投影到同一个平面,并使其投影相同
transR:区分实体向量和关系向量,每个关系都多了一个d * d的矩阵
transD:在transR的基础上,用两个向量代替上面提到的矩阵
DistMult:不需要向量加法,更简单
其他方法:NTN、ConvE等
4.基于图的表示学习
随着信息在节点间的传播,来捕捉节点间的依赖关系,并进行推理,例如节点分类、边分类等
知识库补全:利用已存在的三元组和包含新实体的三元组,对新实体进行表示学习,
连接预测和实体发现:获取缺失节点embedding,预测两个节点之间是否存在一些边
工具库:
networkx可以参考:https://networkx.org/
dgl可以参考https://docs.dgl.ai/tutorials/blitz/4_link_predict.html#sphx-glr-tutorials-blitz-4-link-predict-py
语义搜索
结构化查询
互联网中大量数据,大量数据以rdf的形式存在,因此可以使用sparql语言进行查询,类似于sql和数据库之间的关系
查询时,可以查询是否存在某个节点,或者按照一定条件查询,或者描述一个节点的全部关系信息,或者为节点增加信息
有删除和插入某些关系功能,没有更新功能
语义搜索
可以借助索引来加速搜索,但是要合理利用缓存,并考虑索引的增量
1.关键词:
可以直接用关键词来定位实体
也可以利用关键词所暗示的起点和终点来构造索引(例如1999-2003年的电影)
也可以利用包含结构化查询实体和关系类别的索引,例如比战狼票房高的电影进行结构化查询时,例如吴京的配偶是谁,配偶一词对应的图谱的关系是“夫妻”,
因此需要构造关键词-》图谱中的实体和边的映射关系
有了映射关系后,能生成局部的子图,将其中的实体或边取出,就能完成排序了。排序分为两部分,同一个关键词可能会生成多个子图,例如吴京真实的妻子、吴京在电视剧中的妻子,
需要对这些进行一次排序,再对每一个子图中的内容进行排序,例如吴京电视剧中有5个妻子,但是最热门的是刘涛等。
2.表示学习
将实体投影到连续的向量空间中,一是方便计算两个不同实体之间的相似度,二是向量的语义更丰富who play in Chicago and won an Oscar?在传统语义搜索中,有以下三步:1.首先将搜索词与知识图谱中的关系做对齐,who是所需检索实体1,Chicago是实体2,play in 是关系
然后用关键字检索的方式找出候选实体和边,可能有很多相关的2.然后对这些边和实体进行消歧(play in Chicago and won Oscar,play有多种解释,但是在上下文中“出演”最合适,
Chicago也有很多解释,但这里“电影Chicago”更合适),3.将消歧后的实体和边做组合(即,出演,电影),通过电影chicago和出演关系找到候选演员集合,
再去看谁拿了Ocasr奖,就能从对应的图谱中筛选出可能的演员。而在表示学习中,可以直接利用向量省略消歧的过程,并进行近似查询。
3.基于es的搜索引擎
首先判断搜索类型,是根据实体搜属性 还是根据属性搜实体
接下来识别知识库中是否包含所需实体,并通过映射,将搜索内容中的属性进行映射(例如用户问多大啦,几岁了,都是是在问年龄)
然后进行细化,例如用户问大于三十岁的篮球运动员,那么就去构造》30的条件,并用es去查询,
也就是说,可以给予每类问题的模板,填充解析时识别出的实体名和属性名,以及属性条件,最终进行es查询
知识问答
背景知识
事实问题:
实体的属性(西红柿原产地)、实体的基本定义(什么是西红柿)、复杂图谱查询(北京2022年gdp、王菲和章子怡的关系)
主观问题:
“如何做蛋糕”、“如何治疗近视”等
知识库:
纯文本知识库、半结构化知识库(excel等)、图片视频;
分布式表示的知识库问答:
例如询问姚明老婆的出生地,首先将这个问句转化为向量a,然后看与姚明相关的实体向量中,哪个与a最相似。
基于符号的传统问答:
先确定逻辑表达式,例如问姚明老婆的出生地,需要先转化为sparql语言,然后再去知识库中查询,需要将老婆映射到"配偶"这一关系中。
早期问答系统:
主要基于模式匹配或语法解析,前者类似识别关键词并填充,后者利用语法解析发现实体并按照一定规则转化为数据库查询
基于信息检索的问答
例如问“中国哪个城市人口最多”,需要经历
1.问题处理,识别出过滤条件和答案所需类型,这里的条件是人口最多,答案需要是一个城市
2.段落检索与排序,基于关键词召回文档,切分段落
3.从段落中选出合适的答案
基于kqba的问答
步骤有四个:
1.问题分析,利用词典、词性分析、分词、实体识别、语法树分析、句法依存分析等提取问题信息,基于机器学习或规则提取,来判断问句的类型和所需答案的类型,2.连接到知识库中,包括关系属性、描述属性、实体分类,例如将“姚明老婆是”映射到“配偶”这一图谱中存在的关系上3.消歧,例如建国路可能指道路本身,也可能指建国路这个社区;可以先生成关于社区和道路的两种查询,然后通过统计方法和机器学习进行筛选4.构建查询,基于前面的问题解析结果,转化为sql或sparql查询。
社区问答 FAQ-QA
也称CommunityQA,类似于百度知道,核心是计算语义相似性
面临的挑战有两点,一是词汇歧),二是语言表达的多样性(相同的语义有很多表达方式)
quora QA数据集和测试,主要就是评价问题的相似度
KQBA技术
挑战:
知识库不完整、泛化语义理解(还活着吗,需要对应“死亡日期”这一属性)、
多样化映射机制(例如外孙应该映射成女儿的儿子这个条件,以及其他过滤、排序条件,例如产量最多的年份、1990年之前等)
计算语义相似度:语言模型、句子主题分析模型、句子结构相似度分析模型
基于模板的方法:
可以参考cui的论文【1】,能够自动化生成问题模板,
例如有人问“请问江苏的人口是多少”,则可以把江苏换为“{省份}”,把人口换为“{地区属性}”,
即得到模板“{省份}{地区属性}”
并去知识图谱中找相关属性,这样就能识别“广东的面积有多大”,处理简单的属性问题、比较问题或组合问题(把组合问题拆成简单问题),
例如“广东和江苏哪个面积大”,可以拆分为“{省份1}{省份2}{地区属性1}{比较符号}”,
这样就能识别“甘肃和河南哪个人口多”了
同样,例如“广东省会的经济总量是多少”,则可以拆分成“广东省会是哪里”和“省会经济总量是多少”,
其中第一个问题可以套用模板“{省份}{地区属性}”得到广东省会广州,然后可以套用其他末班。可以把问题中的实体提取出来,并映射到不同的分类中,
然后再去找与每个分类中的实体相关模板的相似度,(例如槽位数量,槽位中词汇的类型以及非槽位词的文本相似度)
选择合适的模板并判断所需查询的具体属性。
例如问题“东风有限公司的法人是谁”,可以匹配模板“{公司}{公司属性}”,
但是东风公司对应东风汽车厂和东风导弹厂,因此需要分别查询他们的属性
参考文献:
【1】KBQA;Learning Question Answering over QA Corpora and knowledge Bases,CUI W,VLDB 2017
【2】Auto Template Generation for Question Answering over Knowledge Graphs,Abujabal A,WWW 2017
基于语义解析的方法
进行语法分析,将查询转化为逻辑表达式,然后利用知识库的语义信息将逻辑表达式转为知识查询。
资源映射【1】:
例如文本中可以找出大量的“r1={老婆是}{男性,女性}”、“r2={妻子是}{男性,女性}”,
并且通过统计发现,关系r1所对应的{男性,女性}实例对,与关系r2对应的{男性,女性}实例对高度重合
则可以判断r1和r2是等价的,可以进行资源映射(可以用jaccard距离来判断)
桥接操作【1】:
例如问句“which college did Obama go to”和“which college did obama graduate”,
在后一个句子中,可以直接根据obama和grduate两个词,从知识图谱中查询奥巴马的毕业院校(假设有相关数据)
但是前一个句子,只能识别出奥巴马,无法理解“go to”所代表的属性因此可以利用其他信息,例如obama是人名,college是地名,并且“graduate”这一关系的首尾两端分别是人名和地名,
因此可以将go to理解为“毕业于”。
当知识库中还存在着“奥巴马访问了哈佛大学”的知识时,由于“访问”这一关系的首尾两端的属性是人名和地名,
因此可以将 go to 理解为“访问”。
参考文献:
【1】Semantic Parsing on Freebase from question-answer pairs,berant j,emnlp 2013
基于深度学习的方法
端到端:
文献【1】将问题,以及与问题中关键词相关的实体属性分别映射到低维向量,并做相似度运算,
例如问阿凡达在因果的上映时间,则直接把与阿凡达相关的属性分别送入一个双塔网络。文献【2】同时训练语言词向量和知识库三元组,将问题与知识库映射到同一个空间,
分别得到主题词向量、上下文向量和答案向量,将这三种向量分别点积,将点积结果求和,得到每一个候选属性的分数。
例如询问阿凡达在英国的上映时间,则对应的主题词为阿凡达,上下文为英国,答案向量为一个日期
辅助选择:
可以应用于实体识别模块(bert或lstm+crf)、关系分类意图识别模块(文本分类模型)、
实体消歧(基于深度学习的排序,判断一组概念的语义融洽度)语义解析方面,文献【3】可以将一个问句(例如“谁在武林外传中为佟湘玉配音”)Q1,
和一个图谱中的多跳关系进行融合和扩展的结果R1(例如武林外传=》配音演员=》王伟,和王伟=》饰演佟湘玉,两个关系路径进行融合)
,将Q1和R1分别映射到300维向量,并计算相似度
参考文献:
【1】 Question Answering with subgraph embedding,bordes A,2014
【2】Question Answer over freebase with multi-column convolutional neural network,Dong L,acl 2015
【3】Semantic parsing via staged query graph generation:question answering with knowledge base[J] 2015
实际操作技巧:
S表示主语,P表示谓语,O表示宾语,OP表示运算符
则属性检索可表达为S:P(例如姚明的身高),
多跳查询表达为S:P1:P2(例如姚明妻子的籍贯),
多属性查询表达为P1 OP O1 and P2 OP (O2 or O3),例如身高大于180,并且国籍是中国或美国
分词词典:
可以先将知识库中的实体名和属性名作为分词词典,之后再分词;
属性值的匹配:
在汉语中,也可以尝试在分词后使用n-gram或elasticsearch,或模糊搜索
例如搜索中包含“国展”,那么“中国展览馆”(n-gram)或者“中国艺术展”(模糊搜索)都能完成映射有一些属性值没有明确提到属性名,例如“(国籍)中国的运动员”,
没有提到属性名为中国,那么可以尝试使用该值(中国)出现最频繁的属性名(国籍)作为补全
查询类型确定:
在识别出问题中的实体名、属性名、属性值之后,依据他们的数量和位置,
就可以去匹配不同的模板并执行查询了(每一个模板对应着特定的查询)如果有实体名和多个属性名,那就是多跳检索
如果有一个属性名和一个实体名,并且实体名在前,那么就是查询属性值(张译的身高是多少),
反之则是根据属性值查实体(儿子是金正日的人是谁)如果没有实体名,则是利用属性查实体,
如果有属性值但是没有属性名,则要补全属性名;
如果只有属性名但没有属性值,则需要用正则去匹配属性值,例如“身高大于180cm”,则需要匹配出“>180”
gAnswer
实用系统
在构造数据时,可以参考gAnswer的数据格式,定义出原始的知识表示,
进而识别出所有的实体(主语和宾语)、谓语、以及每一个主语的类型,并将其处理为编号(方便存储)针对一词多义,可以构建倒排索引,针对每一个实体,计算其属于每一个类型的置信度(或在该类型中常出现的上下文词汇)
例如“倒数”一词,可能属于邓紫棋的歌曲,也可能是一个动词,
当其上下文出现“专辑、音乐、演唱”等词汇时,更有可能属于邓紫棋的歌曲
构建知识图谱的流程
知识建模
自顶向下:从顶层概念出发,逐步细化自底向上:先对实体进行归纳,然后逐步抽象,需要考入如何描述复杂知识(匿名节点还是边节点)、是否支持扩展、变更以及调整,
知识存储
单一式存储:利用三元组、属性表或垂直分割等方式
混合式:综合利用多种单一式存储原生数据库:neo4j、allegroGraph,针对复杂节点不灵活
结构数据库:mysql、mongo等,较为灵活,可以构建索引、an数据特点进行划分
知识抽取
结构化数据:mysql数据库等,或者yago、freebase半结构化数据:百科网页、垂类网站等,可以使用包装器进行抽取,包装器是针对数据源的抽取规则需要考虑数据更新、网页变动等包装器有STALKER\Wargo等非结构化数据:文本,文档,数据视频等,分为OpenIE和CloseIE两种,工具分别有Reverb/TextRunner、DeepDive等
知识融合
数据模式层:概念合并(例如在图谱A中有坦克这个概念,在图谱B中有tank这个概念,二者等价)、概念上下位(例如主战坦克是坦克的下级概念)、概念的属性合并(例如发动机马力、发动机功率是一个概念)数据层:实体合并、实体属性融合、属性融合中的冲突检测等
知识计算
知识推理:发现新的知识规则,分为基于本体的推理和基于规则的推理。知识图谱挖掘:图遍历、最短路径、权威节点分析(图排序算法)、族群发现最大流、社区发现、相似节点、路径分析、关联分析、节点聚类等
知识应用
语义搜索:解决传统搜索中关键字多义歧义,通过实体链接实现知识与文档的混合检索,智能问答:准确的语义解析的,获得意图,并确定答案的优先级排序。可视化:提供决策支撑,辅助发现业务模式
相关文章:
)
知识图谱 方法、实践与应用 王昊奋 读书笔记(下)
最近读了这本书,在思路上很有启发,对知识图谱有了初步的认识,以下是原书后半部分的内容,可以购买实体书获取更多内容。 知识图谱推理 结合已有规则,推出新的事实,例如持有股份就能控制一家公司࿰…...
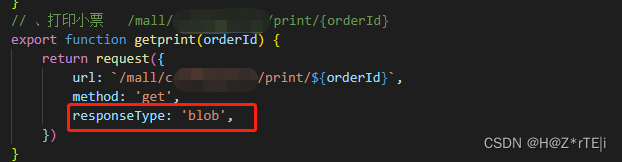
vue实现打印浏览器页面功能(两种方法)
推荐使用方法二 方法一:通过npm 安装插件 1,安装 npm install vue-print-nb --save 2,引入 安装好以后在main.js文件中引入 import Print from vue-print-nbVue.use(Print); //注册 3,现在就可以使用了 div id"printTest…...
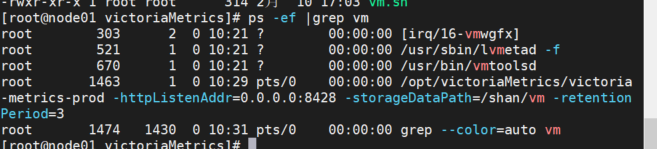
【VictoriaMetrics】VictoriaMetrics单机版批量和单条数据写入(Prometheus格式)
VictoriaMetrics单机版支持以Prometheus格式的数据写入,写入支持单条数据写入以及多条数据写入,下面操作演示下如何使用 1、首先需要启动VictoriaMetrics单机版服务 2、使用postman插入单机版VictoriaMetrics,以当前时间插入数据 地址为 http://victoriaMetricsIP:8428/api…...
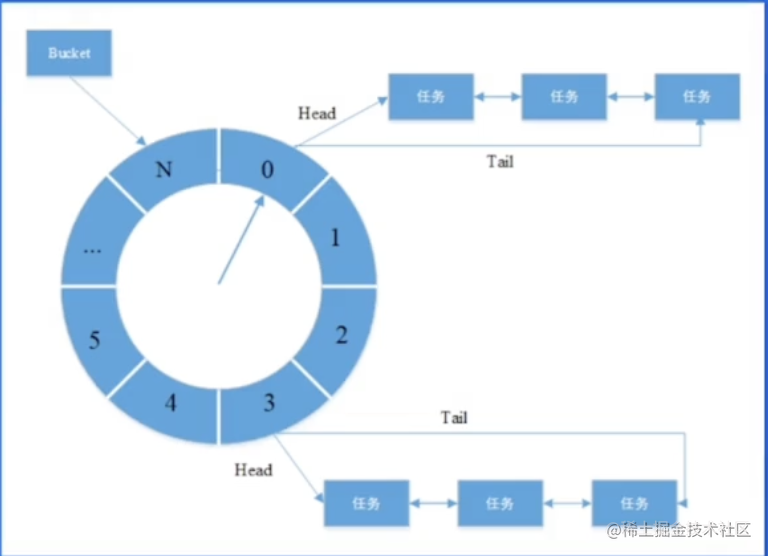
【青训营】分布式定时任务简述
这是我参与「第五届青训营 」伴学笔记创作活动的第 13 天 分布式定时任务简述 定义 定时任务是指系统为了自动完成特定任务,实时、延时、周期性完成任务调度的过程。分布式定时任务是把分散的、可靠性差的定时任务纳入统一平台,并且实现集群管理调度和…...
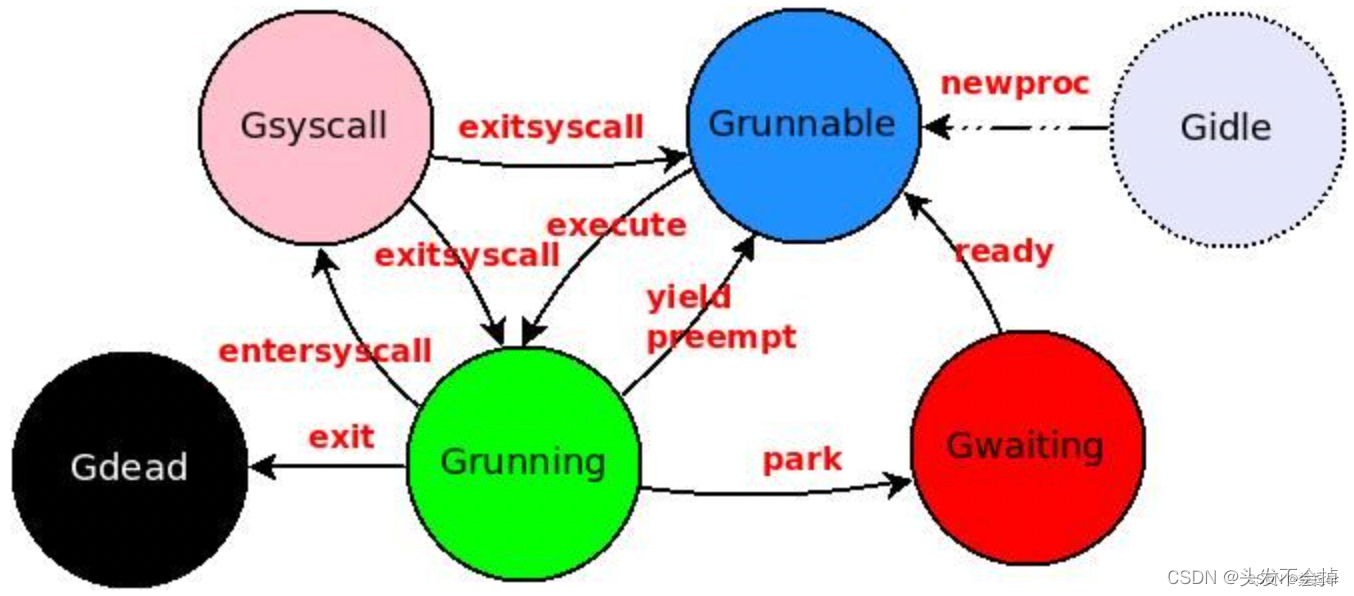
golang语言本身设计点总结
本文参考 1.golang的内存管理分配 golang的内存分配仿造Google公司的内存分配方法TCmalloc算法;她会把将内存请求分为两类,大对象请求和小对象请求,大对象为>32K的对象。 在了解golang的内存分配之前要知道什么事虚拟内存,虚拟内存是把磁盘作为全局…...

PTA L1-046 整除光棍(详解)
前言:内容包括四大模块:题目,代码实现,大致思路,代码解读 题目: 这里所谓的“光棍”,并不是指单身汪啦~ 说的是全部由1组成的数字,比如1、11、111、1111等。传说任何一个光棍都能被…...
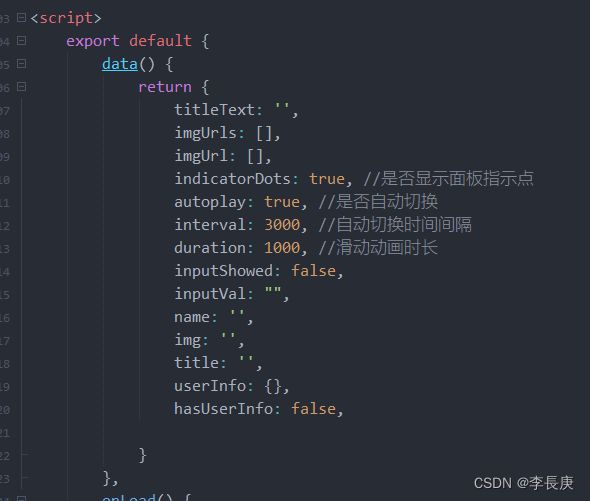
将小程序代码转成uni-app代码
最近因为公司项目原因需要将小程序的项目转换成uni—app的项目,所以总结了以下几点: 首先你可以先到uni-app的官网简单看一下对它的介绍,本次文章的介绍是针对简单的微信小程序来进行的转化。 在这之前我们来看一下目录对比 下面就来介绍一下…...

C语言在游戏中播放音乐
使用 mciSendString 播放音乐 mciSendString 支持 mp3、wma、wav、mid 等多种媒体格式,使用非常简单。这里做一个简单的范例,用 mciSendString 函数播放 MP3 格式的音乐,代码如下: // 编译该范例前,请把 music.mp3 放…...
机器学习算法:随机森林
在经典机器学习中,随机森林一直是一种灵丹妙药类型的模型。 该模型很棒有几个原因: 与许多其他算法相比,需要较少的数据预处理,因此易于设置充当分类或回归模型不太容易过度拟合可以轻松计算特征重要性在本文[1]中,我想…...
如何做好多项目全生命周期的资源调配,提升资源利用效率?【橙子】
随着产品研发中心各团队承接的研发项目数量和规模日趋增加,人均产值和利润目标逐步提升,人均承接的项目数量也逐渐增加,目前缺乏合理的研发资源管理方案,存在多项目研发过程中资源冲突及部分项目研发人员忙闲不均等现象࿰…...

JVM - 内存分配
目录 JVM的简化架构和运行时数据区 JVM的简化架构 运行时数据区 PC寄存器 Java栈 Java堆 方法区 运行时常量池 本地方法栈 栈、堆、方法区交互关系 Java堆内存模型和分配 Java堆内存概述 Java堆的结构 对象的内存布局 对象的访问定位 Trace跟踪和Java堆的参数配…...
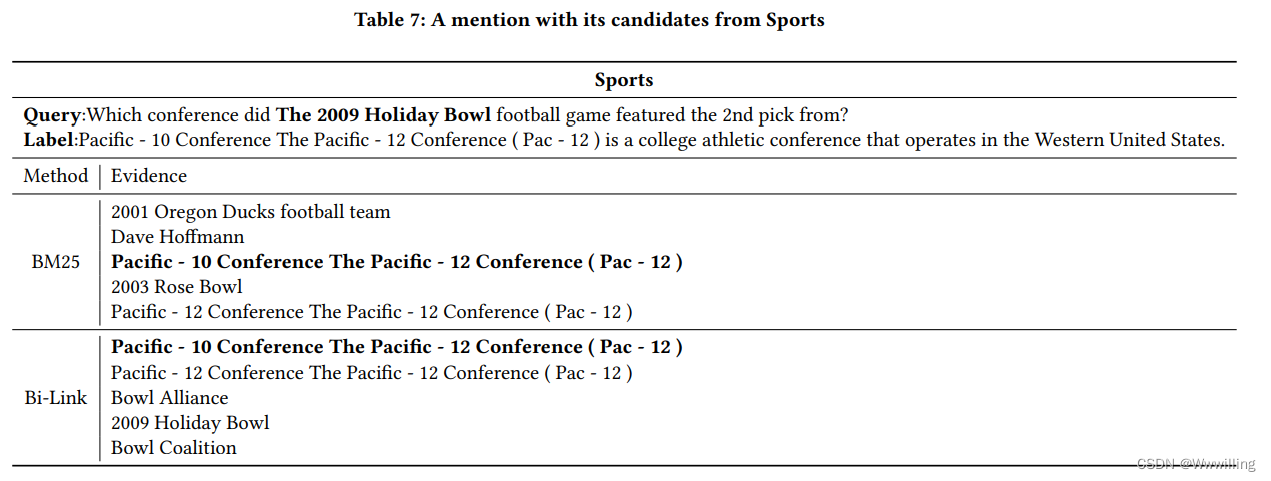
【知识图谱论文】Bi-Link:通过转换器和提示的对比学习桥接来自文本的归纳链接预测
文献题目:Bi-Link: Bridging Inductive Link Predictions from Text via Contrastive Learning of Transformers and Prompts发表期刊:WWW2023代码: https://anonymous.4open.science/r/Bi-Link-2277/. 摘要 归纳知识图的完成需要模型来理解…...
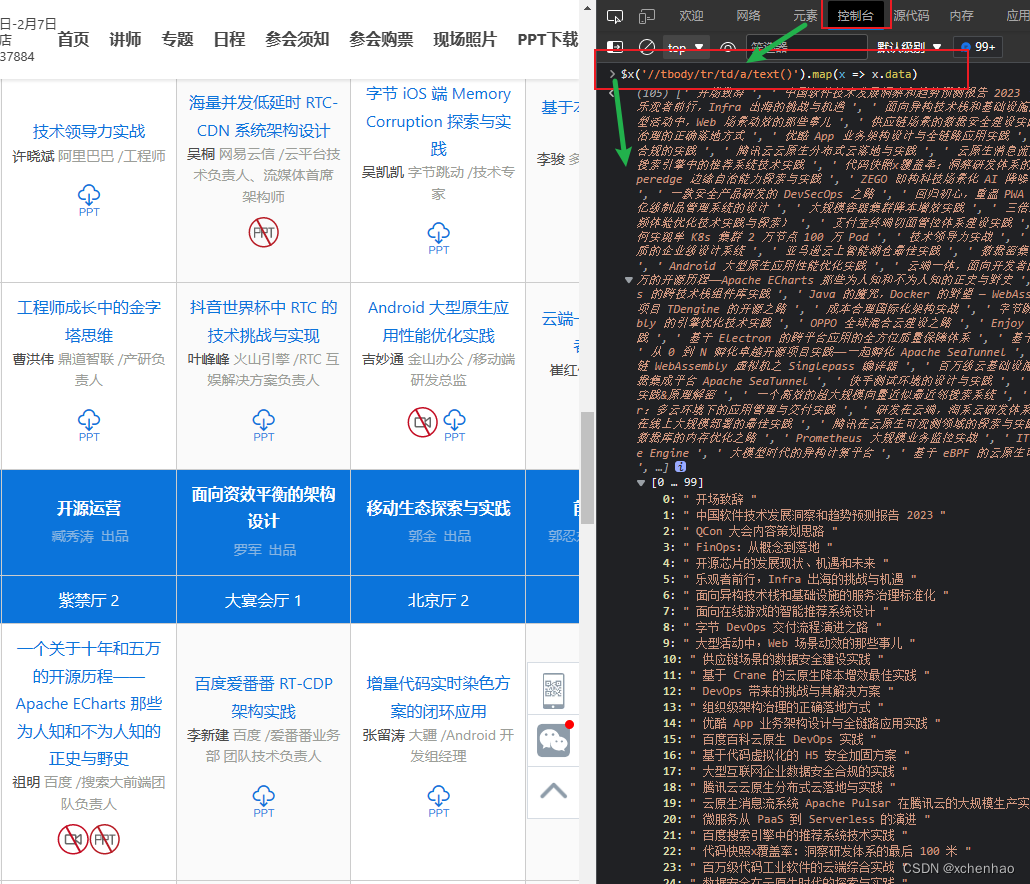
jieba+wordcloud 词云分析 202302 QCon 议题 TOP 关键词
效果图 步骤 (1)依赖 python 库 pip install jieba wordcloud数据 概览 $ head -n 5 input.txt 中国软件技术发展洞察和趋势预测报告 2023 QCon 大会内容策划思路 FinOps:从概念到落地 开源芯片的发展现状、机遇和未来 乐观者前行࿰…...
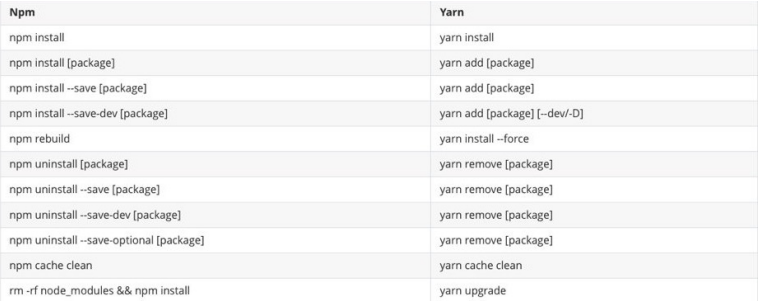
包管理工具-npm-npx-yarn-cnpm
代码共享方案 在我们通过模块化的方式将代码划分成一个个小的结构后,在以后的开发中我们就可以通过模块化的方式来封装自己的代码,并且封装成一个工具,这个工具我们可以让同事通过导入的方式来使用,甚至你可以分享给世界各地的程…...
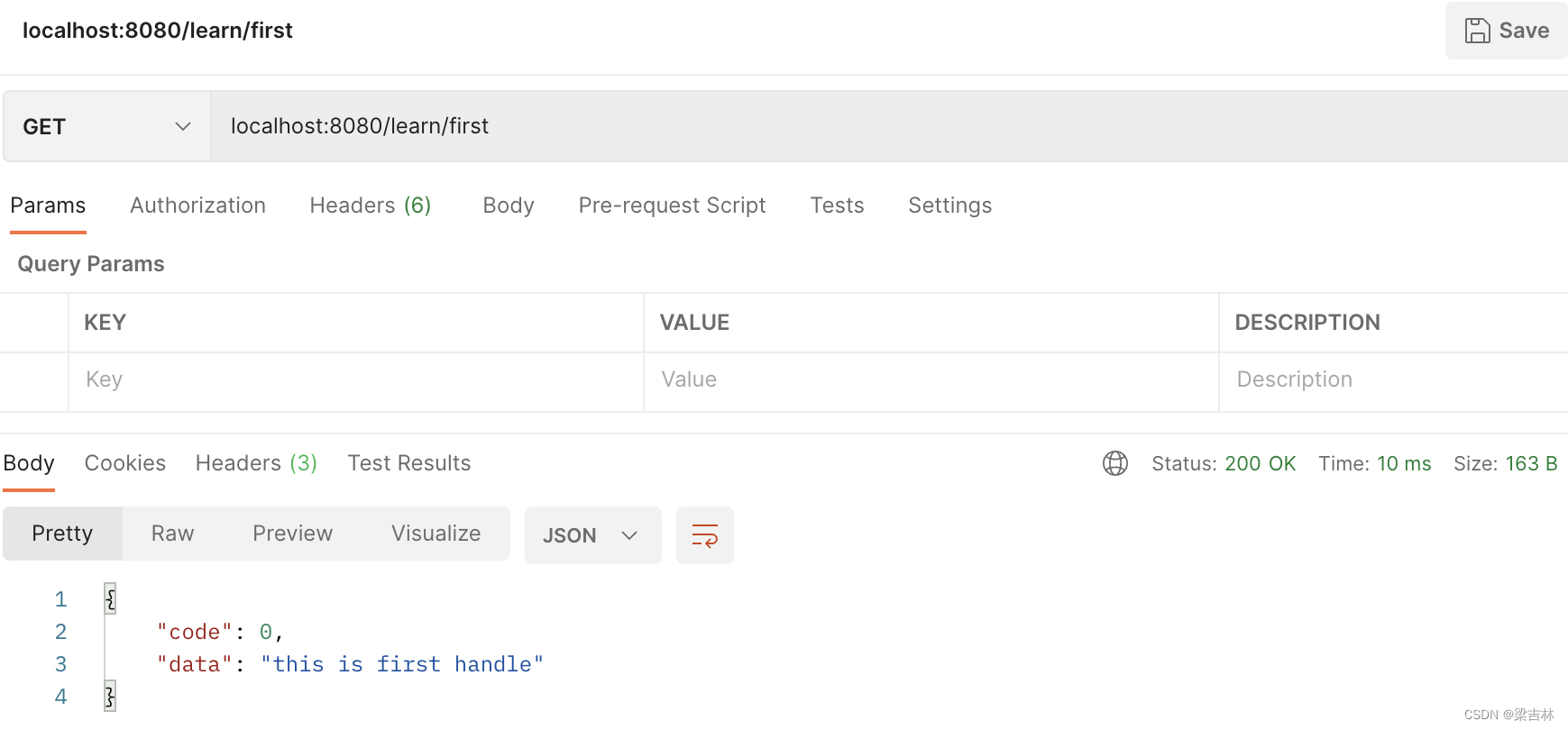
go gin学习记录1
环境: MAC M1,Go 1.17.2,GoLand 默认执行指令的终端,如果没有特别说明,指的都是goland->Terminal 创建项目 Goland中新建项目,在$GOPATH/src/目录下建立t_gin项目。 进入项目,在goland的T…...
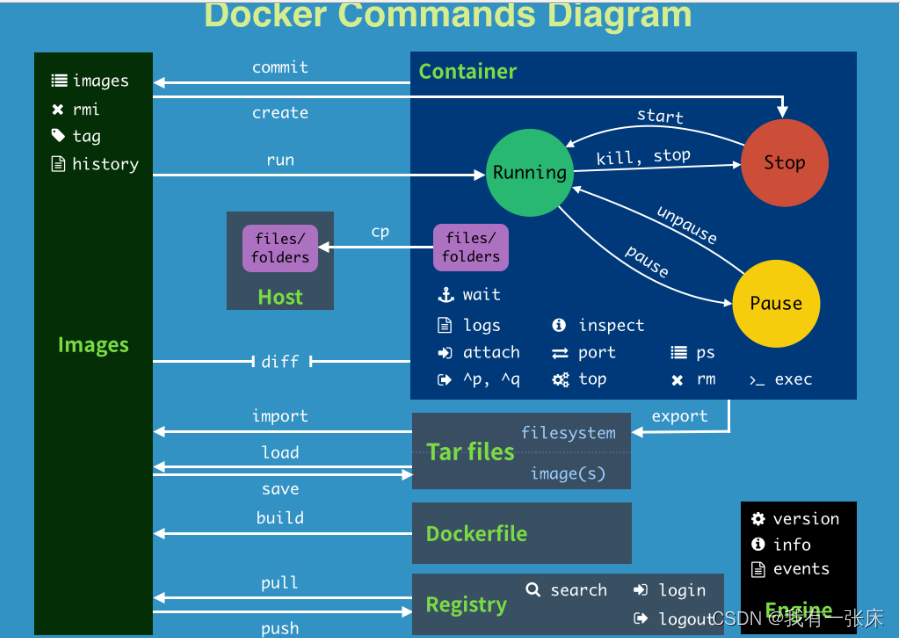
Docker常用命令
1:帮助命令docker versiondocker infodocker --help2:镜像命令docker images(列出本地主机上的镜像)各个选项说明:docker imagesREPOSITORY:表示镜docker images像的仓库源TAG:镜像的标签IMAGE IDÿ…...
论文写作——公式编辑器、latex表格、颜色搭配器
1、公式编辑器(网页版mathtype可用于latex公式编辑): MathType demo - For DevelopersLive demonstration about the features of Mathtype which allows edition equations and formulas (PNG, flash, SVG, PDF, EPS), based on MathML and compatible with LaTeX.https:/…...

MySQL数据库12——视图(VIEW)
视图概念 视图是一个虚拟表,称其为虚拟表的原因是:视图内的数据并不属于视图本身,而属于创建视图时用到的基本表。可以认为,视图是一个表中的数据经过某种筛选后的显示方式;或者多个表中的数据经过连接筛选后的显示方…...

第四代英特尔至强重磅发布,芯片进入下半场:软硬加速、绿色可持续
编辑 | 宋慧 出品 | CSDN 云计算 2023 年的第二周,英特尔重磅发布其企业级芯片领域重要的产品——第四代英特尔 至强 可扩展处理器。作为数据中心处理器当之无愧的王牌产品,迄今为止,英特尔已经向全球客户交付了超8500万颗至强可扩展处理器…...

c++-运算符函数与运算符重载
目录概述例子注意问题概述 运算符重载是函数一个特殊情况,重载的运算符视为特殊的函数,称为运算符函数。 编译系统能依据使用运算符的不同环境,即参数(操作数)的数量或类型的差异,区分同一运算符的不同含义…...

国防科技大学计算机基础课程笔记02信息编码
1.机内码和国标码 国标码就是我们非常熟悉的这个GB2312,但是因为都是16进制,因此这个了16进制的数据既可以翻译成为这个机器码,也可以翻译成为这个国标码,所以这个时候很容易会出现这个歧义的情况; 因此,我们的这个国…...

(十)学生端搭建
本次旨在将之前的已完成的部分功能进行拼装到学生端,同时完善学生端的构建。本次工作主要包括: 1.学生端整体界面布局 2.模拟考场与部分个人画像流程的串联 3.整体学生端逻辑 一、学生端 在主界面可以选择自己的用户角色 选择学生则进入学生登录界面…...

智慧工地云平台源码,基于微服务架构+Java+Spring Cloud +UniApp +MySql
智慧工地管理云平台系统,智慧工地全套源码,java版智慧工地源码,支持PC端、大屏端、移动端。 智慧工地聚焦建筑行业的市场需求,提供“平台网络终端”的整体解决方案,提供劳务管理、视频管理、智能监测、绿色施工、安全管…...

无法与IP建立连接,未能下载VSCode服务器
如题,在远程连接服务器的时候突然遇到了这个提示。 查阅了一圈,发现是VSCode版本自动更新惹的祸!!! 在VSCode的帮助->关于这里发现前几天VSCode自动更新了,我的版本号变成了1.100.3 才导致了远程连接出…...

Qwen3-Embedding-0.6B深度解析:多语言语义检索的轻量级利器
第一章 引言:语义表示的新时代挑战与Qwen3的破局之路 1.1 文本嵌入的核心价值与技术演进 在人工智能领域,文本嵌入技术如同连接自然语言与机器理解的“神经突触”——它将人类语言转化为计算机可计算的语义向量,支撑着搜索引擎、推荐系统、…...

HBuilderX安装(uni-app和小程序开发)
下载HBuilderX 访问官方网站:https://www.dcloud.io/hbuilderx.html 根据您的操作系统选择合适版本: Windows版(推荐下载标准版) Windows系统安装步骤 运行安装程序: 双击下载的.exe安装文件 如果出现安全提示&…...

【python异步多线程】异步多线程爬虫代码示例
claude生成的python多线程、异步代码示例,模拟20个网页的爬取,每个网页假设要0.5-2秒完成。 代码 Python多线程爬虫教程 核心概念 多线程:允许程序同时执行多个任务,提高IO密集型任务(如网络请求)的效率…...

uniapp中使用aixos 报错
问题: 在uniapp中使用aixos,运行后报如下错误: AxiosError: There is no suitable adapter to dispatch the request since : - adapter xhr is not supported by the environment - adapter http is not available in the build 解决方案&…...

HashMap中的put方法执行流程(流程图)
1 put操作整体流程 HashMap 的 put 操作是其最核心的功能之一。在 JDK 1.8 及以后版本中,其主要逻辑封装在 putVal 这个内部方法中。整个过程大致如下: 初始判断与哈希计算: 首先,putVal 方法会检查当前的 table(也就…...

AI病理诊断七剑下天山,医疗未来触手可及
一、病理诊断困局:刀尖上的医学艺术 1.1 金标准背后的隐痛 病理诊断被誉为"诊断的诊断",医生需通过显微镜观察组织切片,在细胞迷宫中捕捉癌变信号。某省病理质控报告显示,基层医院误诊率达12%-15%,专家会诊…...