01- NumPy 数据库 (机器学习)
numpy 数据库重点:
-
numpy的主要数据格式: ndarray
-
列表转化为ndarray格式: np.array()
-
np.save('x_arr', x) # 使用save可以存一个 ndarray
-
np.savetxt('arr.csv', arr, delimiter = ',') # 存储为 txt 文件
-
np.array([1, 2, 5, 8, 19], dtype = 'float32') # 转换为ndarray格式
- 完全不拷贝: 赋值操作: a = b
- 浅拷贝: b = a.view()
- 深拷贝: b = a.copy()
- 调整数组形状: arr2 = arr1.reshape(12,5) # 形状改变,返回新数组
- np.transpose(arr2,axes=(2,0,1)) # transpose改变数组维度 shape(4,3,6), 原shape: (3, 6, 4)
- np.hstack((arr1,arr2)) # array([[1, 2, 3, 4, 5, 6]]) 水平方向堆叠
- a = np.random.randint(0, 100, size = (3, 4, 5)) # 返回(3, 4, 5)形状的数组
第一部分 基本操作
NumPy(Numerical Python)是Python的一种开源的数值计算扩展。提供多维数组对象,各种派生对象(如掩码数组和矩阵),这种工具可用来存储和处理大型矩阵,比Python自身的嵌套列表(nested list structure)结构要高效的多(该结构也可以用来表示矩阵(matrix)),支持大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库,包括数学、逻辑、形状操作、排序、选择、输入输出、离散傅立叶变换、基本线性代数,基本统计运算和随机模拟等等。
第一节 数组的创建
1.1.1 使用np.array()
创建数组最简单的方法是使用array函数,将list格式 转换为 ndarray.
import numpy as np
l = [1, 2, 3, 4, 5]
arr = np.array(l) # array([1, 2, 3, 4, 5]) # 将列表转换为numpy 数组1.1.2 使用特定内置函数
我们可以利用np中的一些内置函数来创建数组,比如我们创建全0的数组,也可以创建全1数组,全是其他数字的数组,或者等差数列数组,正态分布数组,随机数。
import numpy as np
''' 生成全为1的数组 '''
arr1 = np.ones(6) # array([1., 1., 1., 1., 1., 1.])
''' 全为0的数组 '''
arr2 = np.zeros(6) # array([0., 0., 0., 0., 0., 0.])
''' 生成指定形状的数组 '''
arr3 = np.full(shape = [2, 3], fill_value = 5) # array([[5, 5, 5], [5, 5, 5]])
''' 等差数列, 左闭右开 '''
arr4 = np.arange(start = 0, stop = 12, step = 2) # array([ 0, 2, 4, 6, 8, 10])
''' linspace 线性等分向量 '''
arr5 = np.linspace(start = 0, stop = 6, num = 4) # array([0., 2., 4., 6.])
''' 生成指定形状的随机数 '''
arr6 = np.random.randint(0, 100, size = 5) # array([75, 20, 49, 95, 24])
''' 生成指定数量的正太分布数列 '''
arr7 = np.random.randn(5) # array([-2.2140, -0.3328, -0.3128, 0.4067, -0.0219])
''' 生成float随机数 '''
arr8 = np.random.random(size = 4) # array([0.93003, 0.12817, 0.93971, 0.86931])第二节 查看操作
1.2.1 数组的状态查询
import numpy as np
arr = np.random.randint(0, 100, size = (3, 4, 5))
arr.ndim # 数组的维度 输出 3
''' 数组的形状 '''
arr.shape # 输出(3, 4, 5)
arr.size # 数组的元素总量 输出 60 ( = 3*4*5)
''' 数组的元素类型'''
arr.dtype # 输出 dtype('int64')
''' ndarray对象中每个元素的大小,以字节为单位 '''
arr.itemsize # 输出 4 # 数据类型为int64, int为4个字节第三节文件的 IO操作
1.3.1 保存操作
save方法保存 ndarray 到 .npy 文件,也可以使用 savez 将多个 array 保存到一个.npz 文件中
x = np.random.randn(4) # array([-0.12666, -0.7143 , -0.10106, -0.35565])
y = np.arange(0, 6, 1) # array([0, 1, 2, 3, 4, 5])
''' 使用save可以存一个 ndarray '''
np.save('x_arr', x)
# 使用savez 可以同时保存多个数组,保存时以key = value形式保存,读取时用key 进行读取
np.savez('some_array.npz',xarr = x, yarr = y)1.3.2 读取操作
一般的用load方法来读取存储的数据,如果是 .npz 文件的话,读取之后相当于形成一个key-value类型的变量,通过保存时定义的 key 来获取对应的array.
np.load('x_arr.npy') # 直接加载
np.load('some_array.npz')['yarr']1.3.3 读写csv、txt文件
arr = np.random.randint(0, 10, size = (3, 4))
''' 存储数组到txt文件,文件后缀是txt也是一样的 '''
np.savetxt('arr.csv', arr, delimiter = ',')
# 读取txt文件, delimiter为分隔符,dtype是数据类型
np.loadtxt('arr.csv', delimiter = ',', dtype = np.int32) 第二部分 数据类型
ndarray的数据类型:
- int: int8、uint8、int16、int32、int64 # int8范围: (-127, 127), uint8范围:(0, 256)
- float:float16、float32、float64
- str # 字符串
import numpy as np
np.array([1, 2, 5, 8, 19], dtype = 'float32')
# 输出:array([1., 2., ......19.], dtype = float32)
''' asrray 转换时指定, 可以指定数据类型 '''
arr = [1, 3, 5, 7, 2, 9, 0]
np.asarray(arr, dtype = 'float32') # 输出:array([1., 3., 5., .... 0.])
# 数据类型转换
arr = np.random.randint(0, 10, size = 5, dtype = 'int16')
# 输出:array([6, 9, 6, 2, 3], dtype = int16)
arr.astype('float') # 输出:array([6., 9., 6., 2., 3.])第三部分 数组运算
3.1.1 加减乘除幂运算
import numpy as np
arr1 = np.array([1, 2, 3, 4, 5])
arr2 = np.array([2, 3, 1, 5, 9])
arr1 - arr2 # 减法 array([-1, -1, 2, -1, -4])
arr1 * arr2 # 乘法 array([ 2, 6, 3, 20, 45])
arr1 / arr2 # 除法 array([0.5, 0.66666667, 3., 0.8, 0.55555556])
arr1 ** arr2 # 幂运算 array([1, 8, 3, 1024, 1953125])3.1.2 逻辑运算
import numpy as np
arr1 = np.array([1,2,3,4,5])
arr2 = np.array([1, 0, 2, 3, 5])
arr1 < 5 # array([ True, True, True, True, False]), 输出boolean(布尔) 值
arr1 == 5 # array([False, False, False, False, True])
arr1 == arr2 # array([ True, False, False, False, True])
arr1 > arr2 # array([False, True, True, True, False])3.1.3 数组和标量运算
import numpy as np
arr = np.arange(1, 6)
arr # array([1, 2, 3, 4, 5])
1 / arr # array([1. , 0.5 , 0.33333333, 0.25 , 0.2])
arr + 5 # array([ 6, 7, 8, 9, 10])
arr * 5 # array([ 5, 10, 15, 20, 25])3.1.4 *=、+=、-=操作
import numpy as np
arr1 = np.arange(5) # array([0, 1, 2, 3, 4])
arr1 += 5 # array([5, 6, 7, 8, 9])
arr1 -= 5 # array([-5, -4, -3, -2, -1])
arr1 *= 5 # array([ 0, 5, 10, 15, 20])第四部分 复制和视图
4.1.1 完全没复制
import numpy as np
a = np.random.randint(0, 100, size = (2, 3)) # array([[31 30 68],[59 20 35]])
b = a
a is b # 返回True, a和b是两个不同名字对应同一个内存对象
b[0, 0] = 1024 # 命运共同体 array([[31 30 68], [59 20 35]])
display(a, b) # array([[1024 30 68], [59 20 35]])4.1.2 查看或浅拷贝
不同的数组对象可以共享相同的数据,该view方法创建一个查看相同数据的新数组对象
import numpy as np
a = np.random.randint(0, 100, size = (2, 3))
b = a.view() # 使用a中的数据创建一个新的数据对象
a is b # 返回false, a和b是两个不同名字对应的同一个内存对象
b.base is a # 返回true, b视图的根数据和a一样
b.flags.owndata # 返回false,b中的数据不是自己的
a.flags.owndata # 返回true, a中的数据是自己的
b[0, 0] = 1024 # a,b数据都发生改变
display(a, b) # array([[1024, 54, 82], [62, 76, 40]])4.1.3 深拷贝
import numpy as np
a = np.random.randint(0, 100, size = (2, 3))
b = a.copy()
b is a # 返回false
b.base is a # 返回false
b.flags.owndata # 返回true
a.flags.owndata # 返回true
b[0, 0] = 1024 # b改变,a不变,分道扬镳
display(a, b) # a: array([[22, 43, 64], [98, 48, 4]])
# b: array([[1024, 43, 64], [98, 48, 4]])copy 应该在不在需要原来的数组情况下,切片后调用,例如,假设a是一个巨大的中间结果,而所求结果只是其中一小部分,则在b使用切片进行构造时应制作一个深拷贝:
import numpy as np
a = np.arange(1e8) # array([0.0000000e+00, 1.0000000e+00,..., 9.9999999e+07])
# 每100万个数据中取一个数据
b = a[::10000000].copy() # array([0., 10000000., 20000000.,..., 90000000.])
del a # 不再需要a ,删除占大内存的a
b.shape # (10, )第五部分 索引、切片和迭代
5.1.1 基本索引和切片
arr = np.array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
# array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
arr[5] # 索引 输出5
arr[5:8] # array([5, 6, 7]) # 切片输出
arr[2::2] # array([2, 4, 6, 8]) # 从索引2开始每两个中取一个,
arr[::3] # array([0, 3, 6, 9]) # 不写索引默认从0开始, 每3个中取一个
arr[1:7:2] # array([1, 3, 5]) # 从1开始到索引7,左闭右开,每两个数取一个
arr[::-1] # array([9, 8......1, 0]) # 倒序
arr[::-2] # array([9, 7, 5, 3, 1]) # 倒序, 倒序每两个取一个值
arr[5: 8] # array([5, 6, 7]) # 切片赋值到每个元素
temp = arr[5: 8] # 赋值属于改了索引, 但没有复制
temp[1] = 1024
arr # arr([0, 1, 2, 3, 4, 12, 1024, 12, 8, 9]) 5.1.2 对于二维或高维数组
arr2d = np.array([[1, 3, 5], [2, 4, 6], [-2, -7, -9], [6, 6, 6]])
# 二维数组,shape(3, 4)
arr2d[0, -1] # 输出5 # 索引 等于arr2d[0][-1]
arr2d[0, 2] # 输出5
arr2d[:2, -2:] # array([[3, 5], [4, 6]]) # 切片,同时对一维、二维切片,为二维数组
arr2d[:2, 1:] # array([[3, 5], [4, 6]]) # 切片 正序和倒序形式,结果其实一致5.2 花式索引和索引技巧
整数数组进行索引即花式索引, 其和切片不一样,它总是将数据复制到新数组中.
import numpy as np
#一维
arr1 = np.array([1,2,3,4,5,6,7,8,9,10]) # array([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
arr2 = arr1[[1,3,3,5,7,7,7]] # 输出: array([2, 4, 4, 6, 8, 8, 8])
arr2[-1] = 1024 # array([2, 4, 4, 6, 8, 8, 1024]) 修改值,不影响arr1#二维
arr2d = np.array([[1,3,5,7,9],[2,4,6,8,10],[12,18,22,23,37],[123,55,17,88,103]])
# shape(4,5)
arr2d[[1,3]] # 获取第二行和第四行,索引从0开始的所以1对应第二行
# 输出: array([[ 2, 4, 6, 8, 10],
# [123, 55, 17, 88, 103]])arr2d[([1,3],[2,4])] # array([ 6, 103])
# 相当于arr2d[1,2]获取一个元素,arr2d[3,4] 获取另一个元素
arr2d[[1,3],[2]] # array([ 6, 17])
# 选择一个区域
arr2d[np.ix_([1,3,3,3],[2,4,4])]
''' 第一个列表存的是待提取元素的行标,第二个列表存的是待提取元素的列标
输出: array([[ 6, 10, 10],[ 17, 103, 103],[ 17, 103, 103],[ 17, 103, 103]])
np.ix_函数就是输入两个数组,产生笛卡尔积的映射关系,得到(1,2),(1,4),(1,4),(3,2)的坐标'''
arr2d[[1,3,3,3]][:,[2,4,4]] # 相当于 arr2d[np.ix_([1,3,3,3],[2,4,4])]
arr2d[([1,3,3,3],[2,4,4,2])] # array([ 6, 103, 103, 17])5.3 boolean 值索引
names = np.array(['softpo','Brandon','Will','Michael','softpo','Will','Brandon'])
cond1 = names == 'Will' # array([False, False, True,... , False]) # cond1取值
names[cond1] # array(['Will', 'Will'], dtype='<U7')
arr = np.random.randint(0,100,size = (10,8)) # 0~100随机数,形状为: 10, 8
cond2 = arr > 90 # 找到所有大于90的索引,返回数组shape(10,8),大于返回True,否则False
arr[cond2] # array([91, 95, 91, 97, 98, 93]) 返回数据全部是大于90的第六部分 形状操作
6.1.1 数组变形
import numpy as np
arr1 = np.random.randint(0,10,size = (3,4,5)) # 返回(3, 4, 5)形状的数组
arr2 = arr1.reshape(12,5) # 形状改变,返回新数组, 需保证数据数量一致
arr3 = arr1.reshape(-1,5) # -1 列的数组, 自动“整形”,自动计算6.1.2 数组转置
import numpy as np
arr1 = np.random.randint(0,10,size = (3,5)) # shape(3,5)
arr1.T # shape(5,3) 转置
arr2 = np.random.randint(0,10,size = (3,6,4)) # shape(3,6,4)
np.transpose(arr2,axes=(2,0,1)) # transpose改变数组维度 shape(4,3,6)6.1.3 数组堆叠
import numpy as np
arr1 = np.array([[1,2,3]])
arr2 = np.array([[4,5,6]])
# 串联合并shape(2,3) axis = 0表示第一维串联 输出为
np.concatenate([arr1,arr2],axis = 0) # array([[1, 2, 3], [4, 5, 6]]) np.concatenate([arr1,arr2],axis = 1) # array([[1, 2, 3, 4, 5, 6]]) shape(1,6)
np.hstack((arr1,arr2)) # array([[1, 2, 3, 4, 5, 6]]) 水平方向堆叠
np.vstack((arr1,arr2)) # array([[1, 2, 3], [4, 5, 6]]) 竖直方向堆叠6.1.4 split 数组拆分
import numpy as np
arr = np.random.randint(0,10,size = (6,5)) # shape(6,5)
np.split(arr,indices_or_sections=2,axis = 0) # 平均分成两份:shape(3, 5)+shape(3, 5)
np.split(arr,indices_or_sections=[2,3],axis = 0)
''' 在第一维(5)以索引2,3为断点分割成3份,列结果为(2, 1, 3)
[array([[1, 0, 5, 9, 6],[7, 1, 0, 1, 0]]),array([[6, 0, 8, 2, 2]]),array([[9, 5, 9, 0, 9],[2, 0, 5, 9, 4],[8, 9, 7, 8, 5]])]'''
np.vsplit(arr,indices_or_sections=3)
# 在竖直方向平均分割成3份,不能整除时报错, 类似上面的拆分结果
np.hsplit(arr,indices_or_sections=[1,4])
''' 在水平方向,以索引1,4为断点分割成3份, 以列为单元
[array([[5],[5],[8],[7],[9],[0]]),array([[7, 5, 6],[9, 8, 0],[7, 8, 7],[7, 7, 0],[2, 4, 2],[1, 6, 3]]),array([[6],[6],[6],[1],[9],[3]])]'''第七部分 广播机制
当两个数组的形状并不相同的时候,我们可以通过扩展数组的方法来实现相加、相减、相乘等操作,这种机制叫做广播(broadcasting).
7.1.1 一维数组广播
import numpy as np
np.sort(np.array([0,1,2,3]*3)) # array([0, 0, 0, 1, 1, 1, 2, 2, 2, 3, 3, 3])
arr1 = np.sort(np.array([0,1,2,3]*3)).reshape(4,3) # shape(4,3)
''' array([[0, 0, 0],[1, 1, 1],[2, 2, 2],[3, 3, 3]]) '''
arr2 = np.array([1,2,3]) # array([1, 2, 3]) shape(3,)
arr3 = arr1 + arr2
''' arr2进行广播复制4份 shape(4,3)
array([[1, 2, 3],[2, 3, 4],[3, 4, 5],[4, 5, 6]])'''7.1.2 二维数组广播
import numpy as np
# np.sort() 对数组进行排序, 默认axis = 1, (按行排序), axis = 0 时, 按列排序
arr1 = np.sort(np.array([0,1,2,3]*3)).reshape(4,3) # shape(4,3)
arr2 = np.array([[1],[2],[3],[4]]) # array([[1],[2],[3],[4]]) shape(4,1)
arr3 = arr1 + arr2 # arr2 进行广播复制3份 shape(4,3)
'''array([[1, 1, 1],[3, 3, 3],[5, 5, 5],[7, 7, 7]])'''7.1.3 三维数组广播
import numpy as np
arr1 = np.array([0,1,2,3,4,5,6,7]*3).reshape(3,4,2) # shape(3,4,2)
arr2 = np.array([0,1,2,3,4,5,6,7]).reshape(4,2)
# array([[0, 1],[2, 3],[4, 5],[6, 7]]) shape(4,2)
arr3 = arr1 + arr2 # arr2数组在0维上复制3份 shape(3,4,2)
'''array([[[ 0, 2],[ 4, 6],[ 8, 10],[12, 14]],[[ 0, 2],[ 4, 6],[ 8, 10],[12, 14]],[[ 0, 2],[ 4, 6],[ 8, 10],[12, 14]]])'''第八部分 通用函数
8.1.1 通用函数:元素级数字函数
import numpy as np
arr1 = np.array([1,4,8,9,16,25]) # array([ 1, 4, 8, 9, 16, 25])
np.sqrt(arr1) # array([1. , 2., 2.82842712, 3., 4. ,5.]) 开平方
np.square(arr1) # array([ 1, 16, 64, 81, 256, 625]) 平方
np.clip(arr1,2,16) # array([ 2, 4, 8, 9, 16, 16]) # np.clip :限定最大值及最小值x = np.array([1,5,2,9,3,6,8])
y = np.array([2,4,3,7,1,9,0])
np.maximum(x,y) # array([2, 5, 3, 9, 3, 9, 8]) # 返回两个数组中的比较大的值
arr2 = np.random.randint(0,10,size = (5,5)) # 0-9的随机数
'''array([[2 1 5 1 3][1 4 9 4 7][9 0 9 4 5][5 1 0 9 9][0 5 0 3 2]])'''
np.inner(arr2[0],arr2) # array([40, 76, 82, 47, 14]) 返回一维数组向量内积8.1.2 where函数
import numpy as np
arr1 = np.array([1,3,5,7,9])
arr2 = np.array([2,4,6,8,10])
cond = np.array([True,False,True,True,False])
np.where(cond,arr1,arr2) # array([1, 4, 5, 7,10]) # True选择arr1,False选择arr2的值arr3 = np.random.randint(0,30,size = 10)
np.where(arr3 < 15, arr3, -15) # array([6, 10, -15, 1, 14, 6, -15, 9, 7, 11])
# 小于15还是自身的值,大于15设置成-158.1.3 排序方法
import numpy as np
arr = np.array([9,3,11,6,17,5,4,15,1])
arr.sort() # array([ 1, 3, 4, 5, 6, 9, 11, 15, 17]) # 直接改变原数组
np.sort(arr) # array([ 1, 3, 4, 5, 6, 9, 11, 15, 17]) # 返回深拷贝结果, 原数组不变
arr = np.array([9,3,11,6,17,5,4,15,1])
k_lst = arr.argsort() # 返回从小到大排序索引 array([8, 1, 6, 5, 3, 0, 2, 7, 4])
[arr[i] for i in k_lst] # [1, 3, 4, 5, 6, 9, 11, 15, 17]8.1.4 集合运算函数
A = np.array([2,4,6,8])
B = np.array([3,4,5,6])
np.intersect1d(A,B) # array([4, 6]) # 交集
np.union1d(A,B) # array([2, 3, 4, 5, 6, 8]) # 并集
np.setdiff1d(A,B) # array([2, 8]) # 差集,A中有,B中没有 8.1.5 数学和统计函数
import numpy as np
arr1 = np.array([1,7,2,19,23,5,88,11,6,11])
arr1.min() # 返回:1 # 计算最小值
arr1.argmax() # 返回:6 # 计算最大值的索引
np.argwhere(arr1 > 20) # array([[4], [6]], dtype=int64) # 返回大于20的元素索引
np.cumsum(arr1) # array([1,8,10,29,52,57,145,156,162,173]) # 计算累加和
arr2 = np.random.randint(0,10,size = (4,5))
''' 生成shape(4, 5)的数组:
array([[0, 5, 0, 9, 3],[6, 7, 8, 0, 5],[6, 4, 3, 2, 4],[5, 2, 1, 4, 1]])'''
arr2.mean(axis = 0) # array([4.25, 4.5, 3., 3.75, 3.25]) # 计算列的平均值
arr2.mean(axis = 1) # array([3.4, 5.2, 3.8, 2.6]) # 计算行的平均值
np.cov(arr2, rowvar=True) '''协方差矩阵'''
'''array([[14.3 , -9.6 , -3.65, 1.2 ],[-9.6 , 9.7 , 2.3 , -2.65],[-3.65, 2.3 , 2.2 , 0.9 ],[ 1.2 , -2.65, 0.9 , 3.3 ]])'''
np.corrcoef(arr2,rowvar=True) '''相关性系数'''
'''array([[ 1. , -0.81511211, -0.65074899, 0.17468526],[-0.81511211, 1. , 0.49788682, -0.46838506],[-0.65074899, 0.49788682, 1. , 0.33402133],[ 0.17468526, -0.46838506, 0.33402133, 1. ]])'''8.1.6 常用函数:
# 常用的函数
import numpy as np # 导入类库 numpy
data = np.loadtxt('./iris.csv',delimiter = ',') # 读取数据文件,data是二维的数组
data.sort(axis = -1) # 简单排序
print('简单排序后:', data)
print('数据去重后:', np.unique(data)) # 去除重复数据
print('数据求和:', np.sum(data)) # 数组求和
print('元素求累加和', np.cumsum(data)) # 元素求累加和
print('数据的均值:', np.mean(data)) # 均值
print('数据的标准差:', np.std(data)) # 标准差
print('数据的方差:', np.var(data)) # 方差
print('数据的最小值:', np.min(data)) # 最小值
print('数据的最大值:', np.max(data)) # 最大值第九部分 线性代数
9.1.1 矩阵乘积
#矩阵的乘积
A = np.array([[4,2,3],[1,3,1]]) # shape(2,3)
B = np.array([[2,7],[-5,-7],[9,3]]) # shape(3,2)
np.dot(A,B) # array([[ 25, 23], [ -4, -11]]) 矩阵运算: A的列数和B的行数一致
A @ B # 结果与上式一致, 符号 @ 表示矩阵乘积运算 9.1.2 矩阵其他计算
#计算矩阵的逆
from numpy.linalg import inv,det,eig,qr,svd
A = np.array([[1,2,3],[2,3,4],[4,5,8]]) # shape(3,3)
inv(A) # 逆矩阵
'''array([[-2.00000000e+00, 5.00000000e-01, 5.00000000e-01],[ 5.92118946e-16, 2.00000000e+00, -1.00000000e+00],[ 1.00000000e+00, -1.50000000e+00, 5.00000000e-01]])'''
det(A) # -2.0000000000000004 # 计算矩阵行列式相关文章:
)
01- NumPy 数据库 (机器学习)
numpy 数据库重点: numpy的主要数据格式: ndarray 列表转化为ndarray格式: np.array() np.save(x_arr, x) # 使用save可以存一个 ndarray np.savetxt(arr.csv, arr, delimiter ,) # 存储为 txt 文件 np.array([1, 2, 5, 8, 19], dtype float32) # 转换…...

RapperBot僵尸网络最新进化:删除恶意软件后仍能访问主机
自 2022 年 6 月中旬以来,研究人员一直在跟踪一个快速发展的 IoT 僵尸网络 RapperBot。该僵尸网络大量借鉴了 Mirai 的源代码,新的样本增加了持久化的功能,保证即使在设备重新启动或者删除恶意软件后,攻击者仍然可以通过 SSH 继续…...
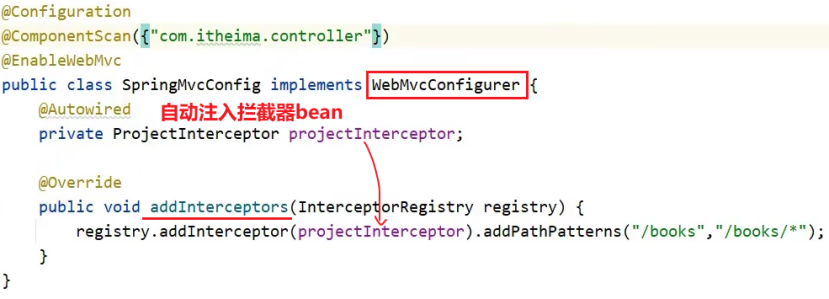
拦截器interceptor总结
拦截器一. 概念拦截器和AOP的区别:拦截器和过滤器的区别:二. 入门案例2.1 定义拦截器bean2.2 定义配置类2.3 执行流程2.4 简化配置类到SpringMvcConfig中一. 概念 引入: 消息从浏览器发送到后端,请求会先到达Tocmat服务器&#x…...
轻松实现微信小程序上传多文件/图片到腾讯云对象存储COS(免费额度)
概述 对象存储(Cloud Object Storage,COS)是腾讯云提供的一种存储海量文件的分布式存储服务,用户可通过网络随时存储和查看数据。个人账户首次开通COS可以免费领取50GB 标准存储容量包6个月(180天)的额度。…...
)
Golang中defer和return的执行顺序 + 相关测试题(面试常考)
参考文章: 【Golang】defer陷阱和执行原理 GO语言defer和return 的执行顺序 深入理解Golang defer机制,直通面试 面试富途的时候,遇到了1.2的这个进阶问题,没回答出来。这种题简直是 噩梦\color{purple}{噩梦}噩梦,…...

谁说菜鸟不会数据分析,不用Python,不用代码也轻松搞定
作为一个菜鸟,你可能觉得数据分析就是做表格的,或者觉得搞个报表很简单。实际上,当前有规模的公司任何一个岗位如果没有数据分析的思维和能力,都会被淘汰,数据驱动分析是解决日常问题的重点方式。很多时候,…...
php mysql保健品购物商城系统
目 录 1 绪论 1 1.1 开发背景 1 1.2 研究的目的和意义 1 1.3 研究现状 2 2 开发技术介绍 2 2.1 B/S体系结构 2 2.2 PHP技术 3 2.3 MYSQL数据库 4 2.4 Apache 服务器 5 2.5 WAMP 5 2.6 系统对软硬件要求 6 …...
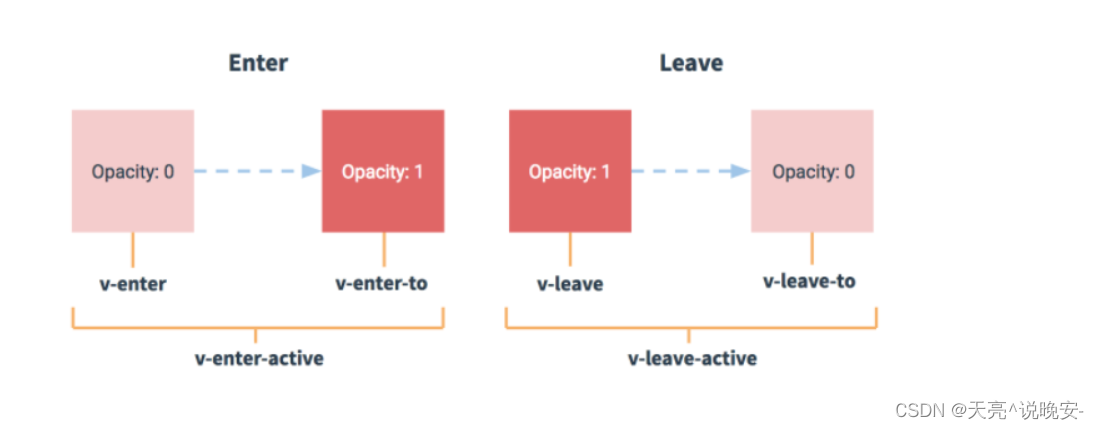
Vue3电商项目实战-首页模块6【22-首页主体-补充-vue动画、23-首页主体-面板骨架效果、4-首页主体-组件数据懒加载、25-首页主体-热门品牌】
文章目录22-首页主体-补充-vue动画23-首页主体-面板骨架效果24-首页主体-组件数据懒加载25-首页主体-热门品牌22-首页主体-补充-vue动画 目标: 知道vue中如何使用动画,知道Transition组件使用。 当vue中,显示隐藏,创建移除&#x…...

linux 使用
一、操作系统命令 1、版本命令:lsb_release -a 2、内核命令:cat /proc/version 二、debian与CentOS区别 debian德班和CentOS是Linux里两个著名的版本。两者的包管理方式不同。 debian安装软件是用apt(apt-get install),而CentOS是用yum de…...
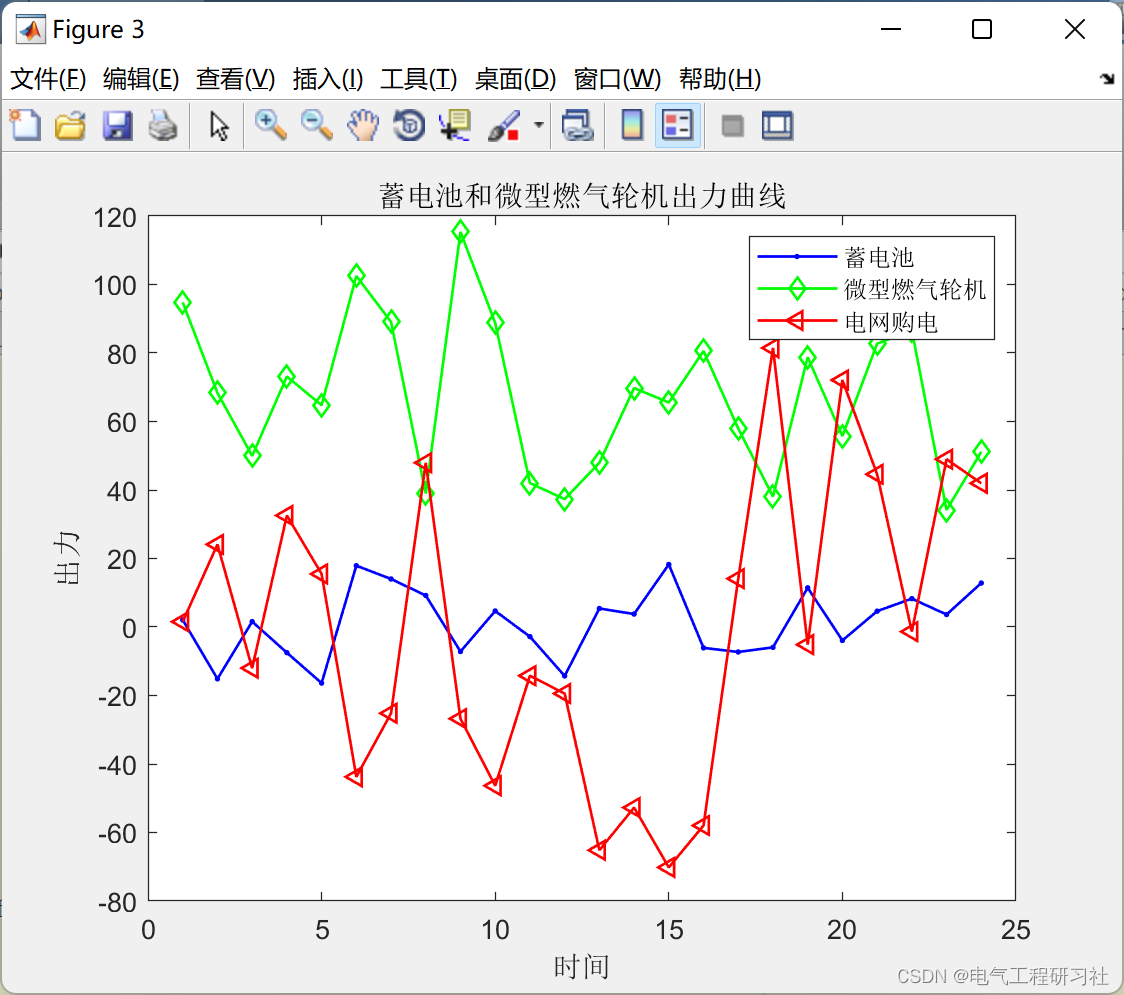
基于遗传算法的微电网调度(风、光、蓄电池、微型燃气轮机)(Matlab代码实现)
💥💥💥💞💞💞欢迎来到本博客❤️❤️❤️💥💥💥🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清…...
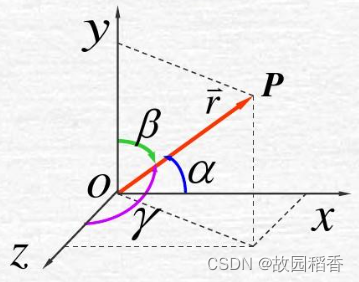
方向导数与梯度下降
文章目录方向角与方向余弦方向角方向余弦方向导数定义性质梯度下降梯度下降法(Gradient descent)是一个一阶最优化算法,通常也称为最速下降法。 要使用梯度下降法找到一个函数的局部极小值,必须向函数上当前点对应梯度(…...

Java岗面试题--Java基础(日积月累,每日三题)
目录面试题一:Java中有哪些容器(集合类)?追问:Java中的容器,线程安全和线程不安全的分别有哪些?面试题二: HashMap 的实现原理/底层数据结构? JDK1.7 和 JDK1.8追问一&am…...
java基础—Volatile关键字详解
java基础—Volatile关键字详解 文章目录java基础—Volatile关键字详解并发编程的三大特性:volatile的作用是什么volatile如何保证有可见性volatile保证可见性在JMM层面原理volatile保证可见性在CPU层面原理可见性问题的例子volatile如何保证有序性单例模式使用volat…...

内存检测工具Sanitizers
Sanitizers介绍 Sanitizers 是谷歌开源的内存检测工具,包括AddressSanitizer、MemorySanitizer、ThreadSanitizer、LeakSanitizer。 Sanitizers是LLVM的一部分。 gcc4.8:支持Address和Thread Sanitizer。 gcc4.9:支持Leak Sanitizer和UBSani…...

Triton : OpenAI 开发的用于Gpu开发语言
Triton : OpenAI 开发的用于Gpu开发语言https://openai.com/blog/triton/1、介绍 https://openai.com/blog/triton/ 2、git地址 https://github.com/openai/triton 3、论文 http://www.eecs.harvard.edu/~htk/publication/2019-mapl-tillet-kung-cox.pdf SIMD : Single Inst…...
Python文件操作-代码案例
文章目录文件打开文件open写文件上下文管理器第三方库简单应用案例使用python生成二维码使用python操作excel程序员鼓励师学生管理系统文件 变量就在内存中,文件在硬盘中. 内存空间更小,访问速度快,成本贵,数据容易丢失,硬盘空间大,访问慢,偏移,持久化存储. \\在才是 \的含义…...

活动目录(Active Directory)管理,AD自动化
每个IT管理员几乎每天都在Active Directory管理中面临许多挑战,尤其是在管理Active Directory用户帐户方面。手动配置用户属性非常耗时、令人厌烦且容易出错,尤其是在大型、复杂的 Windows 网络中。Active Directory管理员和IT经理大多必须执行重复和世俗…...
Allegro如何使用Vertext命令修改丝印线段的形状操作指导
Allegro如何使用Vertext命令修改丝印线段的形状操作指导 在用Allegro画丝印线段的时候,如果画了一段不是自己需要形状的线段,无需删除重画,可以用Vertext命令直接编辑 如下图 修改前 修改后 具体操作如下 选择Edit...

Leetcode力扣秋招刷题路-0030
从0开始的秋招刷题路,记录下所刷每道题的题解,帮助自己回顾总结 30. 串联所有单词的子串 给定一个字符串 s 和一个字符串数组 words。 words 中所有字符串 长度相同。 s 中的 串联子串 是指一个包含 words 中所有字符串以任意顺序排列连接起来的子串。…...
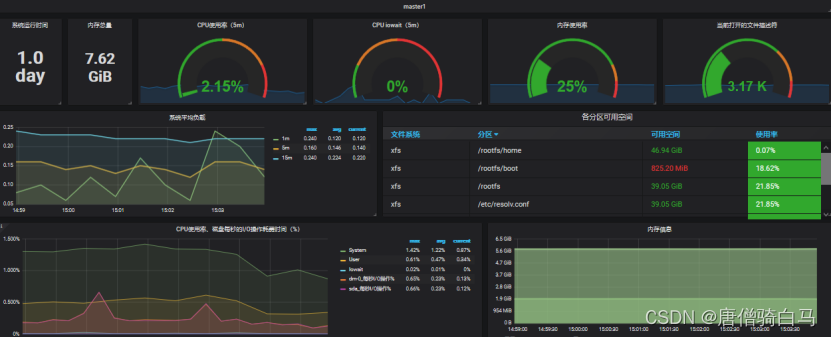
基于Prometheus和k8s搭建监控系统
文章目录1、实验环境2、Prometheus介绍?3、Prometheus特点3.1 样本4、Prometheus组件介绍5、Prometheus和zabbix对比分析6、Prometheus的几种部署模式6.1 基本高可用模式6.2 基本高可用远程存储6.3 基本HA 远程存储 联邦集群方案7、Prometheus的四种数据类型7.1 C…...

Vue记事本应用实现教程
文章目录 1. 项目介绍2. 开发环境准备3. 设计应用界面4. 创建Vue实例和数据模型5. 实现记事本功能5.1 添加新记事项5.2 删除记事项5.3 清空所有记事 6. 添加样式7. 功能扩展:显示创建时间8. 功能扩展:记事项搜索9. 完整代码10. Vue知识点解析10.1 数据绑…...

MongoDB学习和应用(高效的非关系型数据库)
一丶 MongoDB简介 对于社交类软件的功能,我们需要对它的功能特点进行分析: 数据量会随着用户数增大而增大读多写少价值较低非好友看不到其动态信息地理位置的查询… 针对以上特点进行分析各大存储工具: mysql:关系型数据库&am…...

vscode(仍待补充)
写于2025 6.9 主包将加入vscode这个更权威的圈子 vscode的基本使用 侧边栏 vscode还能连接ssh? debug时使用的launch文件 1.task.json {"tasks": [{"type": "cppbuild","label": "C/C: gcc.exe 生成活动文件"…...

测试markdown--肇兴
day1: 1、去程:7:04 --11:32高铁 高铁右转上售票大厅2楼,穿过候车厅下一楼,上大巴车 ¥10/人 **2、到达:**12点多到达寨子,买门票,美团/抖音:¥78人 3、中饭&a…...
)
WEB3全栈开发——面试专业技能点P2智能合约开发(Solidity)
一、Solidity合约开发 下面是 Solidity 合约开发 的概念、代码示例及讲解,适合用作学习或写简历项目背景说明。 🧠 一、概念简介:Solidity 合约开发 Solidity 是一种专门为 以太坊(Ethereum)平台编写智能合约的高级编…...

手机平板能效生态设计指令EU 2023/1670标准解读
手机平板能效生态设计指令EU 2023/1670标准解读 以下是针对欧盟《手机和平板电脑生态设计法规》(EU) 2023/1670 的核心解读,综合法规核心要求、最新修正及企业合规要点: 一、法规背景与目标 生效与强制时间 发布于2023年8月31日(OJ公报&…...

pikachu靶场通关笔记19 SQL注入02-字符型注入(GET)
目录 一、SQL注入 二、字符型SQL注入 三、字符型注入与数字型注入 四、源码分析 五、渗透实战 1、渗透准备 2、SQL注入探测 (1)输入单引号 (2)万能注入语句 3、获取回显列orderby 4、获取数据库名database 5、获取表名…...

小木的算法日记-多叉树的递归/层序遍历
🌲 从二叉树到森林:一文彻底搞懂多叉树遍历的艺术 🚀 引言 你好,未来的算法大神! 在数据结构的世界里,“树”无疑是最核心、最迷人的概念之一。我们中的大多数人都是从 二叉树 开始入门的,它…...
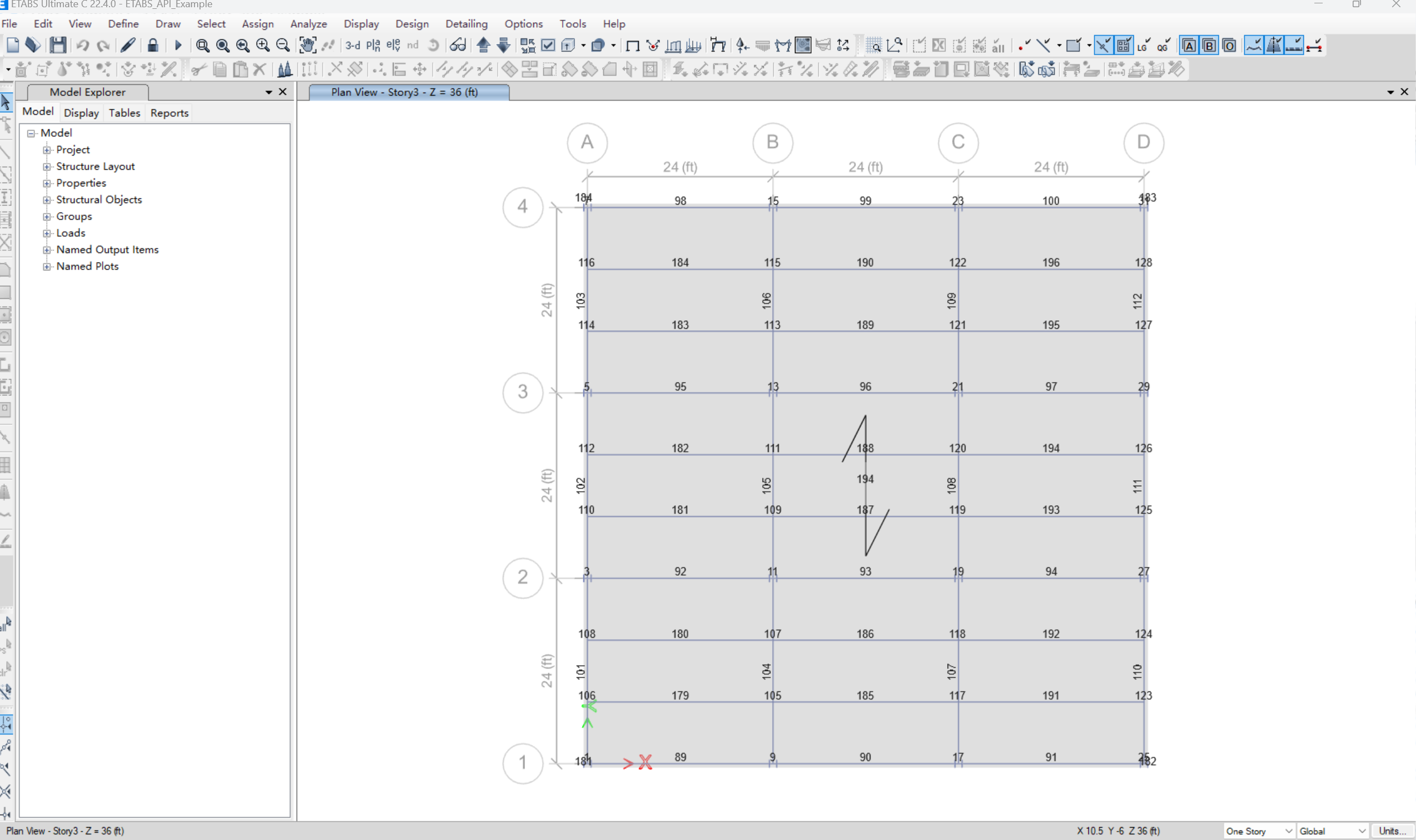
【Post-process】【VBA】ETABS VBA FrameObj.GetNameList and write to EXCEL
ETABS API实战:导出框架元素数据到Excel 在结构工程师的日常工作中,经常需要从ETABS模型中提取框架元素信息进行后续分析。手动复制粘贴不仅耗时,还容易出错。今天我们来用简单的VBA代码实现自动化导出。 🎯 我们要实现什么? 一键点击,就能将ETABS中所有框架元素的基…...

【深度学习新浪潮】什么是credit assignment problem?
Credit Assignment Problem(信用分配问题) 是机器学习,尤其是强化学习(RL)中的核心挑战之一,指的是如何将最终的奖励或惩罚准确地分配给导致该结果的各个中间动作或决策。在序列决策任务中,智能体执行一系列动作后获得一个最终奖励,但每个动作对最终结果的贡献程度往往…...