由浅入深了解HashMap源码
由经典面试题引入,讲解一下HashMap的底层数据结构?这个面试题你当然可以只答,HashMap底层的数据结构是由(数组+链表+红黑树)实现的,但是显然面试官不太满意这个答案,毕竟这里有一个坑需要你去填,那就是在回答HashMap的底层数据结构时需要考虑JDK的版本,因为在JDK8中相较于之前的版本做了一些改进,不仅仅是增加了红黑树的数据结构、还包括了链表结点的插入由头插法改成了尾插法,这些都是底层数据结构的优化问题。
JDK8中HashMap的数据结构

从上面数据结构原理图中我们能看出数组和链表是如何组合使用的,数组不是实际保存数据的结构,数组保存的是Node<K,V>的对象引用地址,实际保存数据的是Node<K,V>结点类。数组中的每个位置只能保存一个Node<K,V>对象,通过链表可以在同一位置保存多个数据,还有链表会在一定条件下转化为红黑树。
- table数组
// 用于保存 Node<K,V> 类型的数组
transient Node<K,V>[] table;- HashMap的默认初始化容量,指的是table数组大小
// HashMap的默认初始化容量为16,1位运算左移4位static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; - HashMap的默认负载因子,用于计算阈值
// HashMap的负载因子用于计算阈值,超过阈值即负载过大需要数组扩容
static final float DEFAULT_LOAD_FACTOR = 0.75f;- HashMap的阈值,当HashMap中的元素个数超过阈值时,数组会扩容为原大小的2倍
// 扩容的阈值(默认阈值 = 默认数组容量 * 负载因子),默认为12 = 16 * 0.75int threshold;- HashMap的链表转换为红黑树的阈值
// 树化的阈值,不是唯一条件,而是必须条件
static final int TREEIFY_THRESHOLD = 8;- Node<K,V>结点类
// HashMap源码的静态内部类
static class Node<K,V> implements Map.Entry<K,V> {final int hash; // 保存key计算出的hash码final K key; // 保存key的值V value; // 保存value的值Node<K,V> next; // 保存下一个结点的引用地址Node(int hash, K key, V value, Node<K,V> next) {this.hash = hash;this.key = key;this.value = value;this.next = next;}HashMap的构造方法
- HashMap的无参构造
// 此时只设置了默认的负载因子,即数组未初始化
public HashMap() {this.loadFactor = DEFAULT_LOAD_FACTOR; }- HashMap的带负载因子和数组容量的构造方法
// 可设置自定义负载因子和数组容量
public HashMap(int initialCapacity, float loadFactor) {// 数组容量不能小于0if (initialCapacity < 0)throw new IllegalArgumentException("Illegal initial capacity: " +initialCapacity);// 数组容量不能大于MAXIMUM_CAPACITYif (initialCapacity > MAXIMUM_CAPACITY)initialCapacity = MAXIMUM_CAPACITY;// 负载因子不能小于等于0if (loadFactor <= 0 || Float.isNaN(loadFactor))throw new IllegalArgumentException("Illegal load factor: " + loadFactor);this.loadFactor = loadFactor;// 用于计算table数组的最终大小,因为数组大小必需为2的n次方数this.threshold = tableSizeFor(initialCapacity);
}- HashMap的可传入Map集合数据的构造方法
public HashMap(Map<? extends K, ? extends V> m) {this.loadFactor = DEFAULT_LOAD_FACTOR;// 遍历Map取出集合的数据依次放入HashMap中putMapEntries(m, false);
}HashMap的put方法
- HashMap的put方法,实际调用了putVal方法
public V put(K key, V value) {// 计算key的哈希值,创建Node<K,V>结点放入数组中return putVal(hash(key), key, value, false, true);
}- HashMap的hash方法返回的哈希值,并不是直接调用Object对象的hashCode()方法返回的那个哈希值,而是经过了异或运算后的哈希值。
// 计算key的哈希值的方法
static final int hash(Object key) {int h;return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}- 异或运算就是两个二进制数值按位比较,同位的值相同则为0,同位的值不同则为1。我们分析一下,先计算出key的哈希值用作第一个数,再把key的哈希值右移16位作为第二个数,然后再把两个数值进行异或运算(^)。这样计算出的哈希值会变得更随机,因为增加了高16位参与,能降低哈希冲突的概率。
// 425918570 对应的32位的二进制哈希值 // 高16位 低16位
0001 1001 0110 0011 --- 0000 0000 0110 1010 // 原始哈希值
0000 0000 0000 0000 --- 0001 1001 0110 0011 // 原始哈希值右移16位的值
0001 1001 0110 0011 --- 0001 1001 0000 1001 // 异或运算得到的哈希值- putVal方法是添加数据的核心方法,table数组会在第一次添加元素时进行初始化,默认初始化容量为16,在添加数据时需要通过哈希值计算出数据放入的table数组所在的索引下标位置。添加完元素后需要判断数组是否需要扩容,扩容大小是原数组的两倍。
// HashMap添加数据的核心方法,// onlyIfAbsent = false表示key相等时会覆盖旧valuefinal V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {Node<K,V>[] tab; Node<K,V> p; int n, i;// table数组是第一次使用时才进行初始化,懒惰使用if ((tab = table) == null || (n = tab.length) == 0)// resize()包括了数组的初始化和扩容n = (tab = resize()).length;// table数组当前计算出的下标位置还未保存过元素if ((p = tab[i = (n - 1) & hash]) == null)// 创建新结点,直接放入计算出的数组下标位置中tab[i] = newNode(hash, key, value, null);else {Node<K,V> e; K k;// 出现哈希冲突,需要判断是否是相同key,因为不同key也可能有相同的哈希值if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))e = p;// 当前计算的数组下标保存的是树结点,即红黑树结构else if (p instanceof TreeNode)// 采用红黑树的插入方法e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);else {// 从数组下标所在的头结点开始遍历链表for (int binCount = 0; ; ++binCount) {// 找到尾结点,在尾结点后插入新结点,即尾插法if ((e = p.next) == null) {// 先插入结点,再判断阈值,故链表长度大于8时才是树化必须条件p.next = newNode(hash, key, value, null);// 链表的长度大于8时,走树化方法if (binCount >= TREEIFY_THRESHOLD - 1) treeifyBin(tab, hash);break;}// 如果当前遍历到的链表结点和需要添加的数据key相同,则无需插入,直接退出if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))break;p = e;}}// 添加结点数据时发现key已经存在,此时不是插入而是更新if (e != null) { V oldValue = e.value;// put相同key的数据时会覆盖旧值if (!onlyIfAbsent || oldValue == null)e.value = value;afterNodeAccess(e);// 返回当前key的旧值return oldValue;}}++modCount;// HashMap中元素个数大于阈值,进行扩容if (++size > threshold)resize();afterNodeInsertion(evict); return null;
}- putVal方法中添加Node<K,V>的结点元素时,如何计算元素所在的table数组下标位置呢?这里就需要用到我们的哈希值了,我们可以利用哈希值对数组的最大索引下标值进行取模运算,这样就可以把取模运算的结果当做数组的下标位置。但是实际源码中并不是这样做的,而是采用了与运算(&),利用哈希值和数组的最大索引下标进行按位与运算。
// 32位的二进制哈希值// 高16位 低16位
0001 1001 0110 0011 --- 0001 1001 0000 1001 // 最终计算出的哈希值
0000 0000 0000 0000 --- 0000 0000 0000 1111 // table数组的最大索引下标,使用默认大小就是15
0000 0000 0000 0000 --- 0000 0000 0000 1001 // 与运算(&)的结果 9,即下标位置HashMap的数组长度为2的n次方数的原因
- 面试经常会问HashMap的数组长度为什么强制使用2的幂次方数?要回答这个问题,那么我们就需要知道数组长度在哪个地方用到了,通过源码我们发现数组的长度被用于添加元素时计算数组的下标位置。数组下标是通过与运算(&)计算出来的,与运算的特点是(全1为1,有0为0),而2的幂次方数减一正好保证后面全为1,这样就可以使与运算计算的结果降低相同值的概率,本质就是减少哈希冲突的概率。
// 数组下标计算公式
int i = (n - 1) & hash// 当hash值为10,数组长度n为9时
// 高16位 低16位
0000 0000 0000 0000 --- 0000 0000 0000 1010 // 影响&运算的有效位为1位,容易产生哈希冲突
0000 0000 0000 0000 --- 0000 0000 0000 1000 // (n - 1)的值为8
0000 0000 0000 0000 --- 0000 0000 0000 1000 // 计算出的数组下标为8// 当hash值为10,数组长度n为16时
// 高16位 低16位
0000 0000 0000 0000 --- 0000 0000 0000 1010 // 影响&运算结果的有效位为4位,不易产生哈希冲突
0000 0000 0000 0000 --- 0000 0000 0000 1111 // (n - 1)的值为15
0000 0000 0000 0000 --- 0000 0000 0000 1010 // 计算出的数组下标为10- 数组扩容后Node<K,V>元素的存放的数组下标位置变化不大,只有两种可能,不是在新数组的原索引值位置,就是在原索引值+原数组长度的位置。我们知道数组扩容是在原数组容量的基础上乘以2,根据原理可推断,在重新计算元素保存的数组下标位置时,(n - 1)带来的影响很小,只会增加一个有效位的计算。即扩容前(n - 1) = 15是4个1,扩容后(n - 1) = 31是5个1。
// 数组下标计算公式
int i = (n - 1) & hash// 当hash值为10,扩容前,数组长度n为16
// 高16位 低16位
0000 0000 0000 0000 --- 0000 0000 0000 1010 // &运算结果的有效位为4位
0000 0000 0000 0000 --- 0000 0000 0000 1111 // (n - 1)的值为15
0000 0000 0000 0000 --- 0000 0000 0000 1010 // 计算出的数组下标为10// 当hash值为10,扩容后,数组长度n为32
// 高16位 低16位
0000 0000 0000 0000 --- 0000 0000 0000 1010 // &运算结果的有效位为5位,增加一位有效位计算
0000 0000 0000 0000 --- 0000 0000 0001 1111 // (n - 1)的值为31
0000 0000 0000 0000 --- 0000 0000 0000 1010 // 计算出的数组下标还是10HashMap的链表树化的条件
- 链表什么时候树化,我们可以查看在添加结点时判断是否需要树化的源码逻辑。
// 树化的阈值,不是唯一条件,而是必须条件
static final int TREEIFY_THRESHOLD = 8;// 当遍历的结点数大于等于8时
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st// 进入是否需要树化的方法treeifyBin(tab, hash);- 从源码中我们可以了解到链表转换为红黑树需要满足两个条件:一是数组的容量需要大于64,二是链表的长度要大于阈值8。当必要条件链表的长度要大于8时,才会选择优化缩短链表长度,此时不一定就需要直接转换为红黑树,还可以通过扩容数组的方式来使链表长度变短,所以当数组的容量小于64时,是采取数组扩容来优化链表的。
// 将链表结点转换为红黑树,如果数组容量太小则先扩容数组
final void treeifyBin(Node<K,V>[] tab, int hash) {int n, index; Node<K,V> e;// 数组为空或容量小于64,扩容数组if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)resize();// 找到当前链表的头结点else if ((e = tab[index = (n - 1) & hash]) != null) {TreeNode<K,V> hd = null, tl = null;// 遍历普通结点链表转换为树结点的双向链表do {// 链表结点替换成树结点返回TreeNode<K,V> p = replacementTreeNode(e, null);// 第一次保存树的头结点if (tl == null)hd = p;else {// 树结点间建立双向链表关系p.prev = tl;tl.next = p;}tl = p;} while ((e = e.next) != null);// 将数组中的普通结点链表替换成树结点的双向链表if ((tab[index] = hd) != null)// 构造生成红黑树hd.treeify(tab);}}JDK8的HashMap为什么在链表中使用尾插法代替了头插法
- 链表结点的头插法,就是在链表的头部插入数据,就是每次插入的新结点数据都会成为链表的头结点。JDK7的HashMap中是否真的使用了头插法,我们可以从源码中求证。
// 用于添加Entry<K,V>结点的方法,jdk1.7叫Entry
void createEntry(int hash, K key, V value, int bucketIndex) {// table数组保存的头结点Entry保存到e变量Entry<K,V> e = table[bucketIndex];// 1. 把e元素作为新结点的next结点,即原头结点作为新结点的下一个结点// 2. 新结点作为头结点保存到table[bucketIndex],即头插法table[bucketIndex] = new Entry<>(hash, key, value, e);// HashMap中保存的元素总数+1size++;}- 链表结点的尾插法,就是在链表的尾部插入数据,这样就需要遍历链表找到尾结点,使尾结点的Node<K,V> next结点指向新结点。JDK8的HashMap添加结点使用尾插法的源码实现就是如此,前面在源码中已经看到过。
// 从数组下标所在的头结点开始遍历链表
for (int binCount = 0; ; ++binCount) {// 找到尾结点,在尾结点后插入新结点,即尾插法if ((e = p.next) == null) {// 新结点作为尾结点的next结点,并成为新尾结点p.next = newNode(hash, key, value, null);// 链表的长度大于8时,走树化方法if (binCount >= TREEIFY_THRESHOLD - 1) treeifyBin(tab, hash);break;}// 如果当前遍历到的链表结点和需要添加的数据key相同,则无需插入,直接退出if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))break;p = e;
}- 了解了头插法和尾插法的区别,那么JDK8中的HashMap为什么抛弃了头插法而使用尾插法呢?这是因为头插法在数组扩容时,链表重新在新数组中生成时会导致链表元素倒序,这里比较难理解。因为链表的遍历是从头结点开始的,而链表插入是头插法,会一直更新头结点;所以就是最早插入的结点成为尾结点,最后插入的结点成为头结点,这是头插法的特点。这里的链表元素倒序表面上看起来问题不大,但是在多线程同时操作一个HashMap的情况下容易产生死链问题,这才是根本的。

- JDK7中的HashMap在数组扩容时为什么会死链,当然这是并发问题,是可能出现,不是说一定就会死链。我们要结合扩容的源码进行分析,不一定要非常深入理解,能找到问题所在就行。
// jdk1.7的扩容过程
void transfer(Entry[] newTable, boolean rehash) {// 获取新数组的容量int newCapacity = newTable.length;// 遍历旧数组,获取头结点,单节点也是链表for (Entry<K,V> e : table) {// 遍历链表while(null != e) {// 取出当前结点的next结点Entry<K,V> next = e.next;// 判断是否需要重新计算hash值if (rehash) {e.hash = null == e.key ? 0 : hash(e.key);}// 因为数组扩容了,重新计算元素存放的数组位置int i = indexFor(e.hash, newCapacity);// 当前添加的结点e作为头结点,所以它的e.next指向旧的头结点e.next = newTable[i];// 最新添加的结点成为新数组保存的头结点,每次更新头结点,即头插法newTable[i] = e;// 遍历的写法,取下一个节点,e = next; }}
}- 分析Entry[ ] newTable作为外部传入的引用变量存在线程安全问题,Entry[ ] table不是方法的局部变量也存在线程安全问题。我们通过分析知道,头插法会导致链表结点元素倒序,即从A > B > C变为C > B > A,这就出现了大问题。在多线程环境下,如果一个线程完成了扩容,Entry[ ] table会引用新数组Entry[ ] newTable,由于链表结点引用指向发生了倒序,那么另一个线程就会产生死链,在遍历中产生死链会陷入死循环。
// 假设扩容前当前遍历的链表为: A > B > C
// 分析t1线程发生死链的情况,有两个线程 t1 和 t2,都在执行扩容操作while(null != e) {// t2线程未扩容成功时,t1线程执行,当 e = B,e.next一定为 CEntry<K,V> next = e.next;// t1线程发生上下文切换,此时t2线程先完成了扩容// 由于链表倒序为:C > B > A,当 e = B时,e.next的引用变为了 A, next还是引用 Cif (rehash) {e.hash = null == e.key ? 0 : hash(e.key);}int i = indexFor(e.hash, newCapacity);// B结点指向头结点C,即 B > c > B,发生死链e.next = newTable[i];// B结点变为头结点newTable[i] = e;// 继续遍历,下一个节点变为C,由于死链会变为死循环e = next;
}JDK8的HashMap为什么引入了红黑树的数据结构
- 红黑树是一种自平衡二叉搜索树,并不是完全平衡的二叉树。完全平衡二叉树需要自旋多次才能达到平衡,而红黑树不需要多次自旋,同样有很好的查询性能,缺点是引入了结点颜色维护,变得更加复杂。
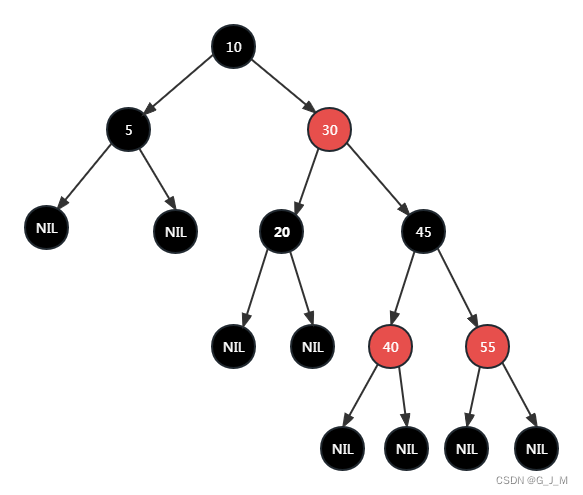
- 《算法导论》中对于红黑树的定义:①每个结点不是红结点就是黑结点 ;②根结点是黑色的; ③每个叶子节点(NIL)都是黑的;④如果一个节点是红的,那么它的两个儿子都是黑的;⑤对于任意一个结点,其到叶子节点(NIL)的所有路径上的黑结点数都是相等的。HashMap中使用红黑树的目的是为了提升查询效率,因为链表过长,会导致查询效率变低。HashMap中的链表会在数组容量大于64和链表长度大于8时转换为红黑树,同时红黑树也会在结点数小于等于6时退化为链表。
相关文章:
由浅入深了解HashMap源码
由经典面试题引入,讲解一下HashMap的底层数据结构?这个面试题你当然可以只答,HashMap底层的数据结构是由(数组链表红黑树)实现的,但是显然面试官不太满意这个答案,毕竟这里有一个坑需要你去填&a…...
P5318 【深基18.例3】查找文献
题目描述 小K 喜欢翻看洛谷博客获取知识。每篇文章可能会有若干个(也有可能没有)参考文献的链接指向别的博客文章。小K 求知欲旺盛,如果他看了某篇文章,那么他一定会去看这篇文章的参考文献(如果他之前已经看过这篇参考…...

Error caught was: No module named ‘triton‘
虽然报错但是不影响程序运行: A matching Triton is not available, some optimizations will not be enabled. Error caught was: No module named triton解决: pip install -i https://pypi.tuna.tsinghua.edu.cn/simple triton2.0.0.dev20221120...

Ruby设计-开发日志
Log 1 产品 Product 1.1 创建 Product 创建名为 project 的 rails 应用 rails new project创建 Product 模型 rails generate scaffold Product title:string description:text image_url:string price:decimal这会生成一个 migration ,我们需要进一步修改这个…...

SpringBoot 调用外部接口的三种方式
方式一:使用原始httpClient请求 /** description get方式获取入参,插入数据并发起流程* params documentId* return String*/ RequestMapping("/submit/{documentId}") public String submit1(PathVariable String documentId) throws ParseE…...
C 中的结构体
C 中的结构体 C 数组允许定义可存储相同类型数据项的变量,结构是 C 编程中另一种用户自定义的可用的数据类型,它允许您存储不同类型的数据项。 结构体中的数据成员可以是基本数据类型(如 int、float、char 等),也可以…...

nodejs安装教程
Node.js 是一个基于 Chrome V8 引擎的 JavaScript 运行时,可以用于在服务器端运行 JavaScript 代码。以下是 Node.js 的安装教程: 步骤 1:下载 Node.js 访问 Node.js 的官方网站 https://nodejs.org/,进入官方下载页面。 在下载页…...

【华为OD机试】1029 - 整数与IP地址间的转换
文章目录一、题目🔸题目描述🔸输入输出🔸样例1二、代码参考作者:KJ.JK🌈 🌈 🌈 🌈 🌈 🌈 🌈 🌈 🌈 🌈 &#x…...
【FPGA实验1】FPGA点灯工程师养成记
对于FPGA几个与LED相关的实验(包括按键点灯、流水灯、呼吸灯等)的记录,方便日后查看。这世界上就又多了一个FPGA点灯工程师了😏 成为一个FPGA点灯工程师分三步:一、按键点灯1、按键点灯程序2、硬件实现二、流水灯1、流…...
操作系统论文导读(三):Stack-based scheduling of realtime processes基于堆栈的实时进程调度
目录 一、论文核心思想: 二、基本的相关条件 作业运行的条件: 作业抢占其他作业的条件: 三、基本的相关定义 四、基本的相关调度 五、基本的相关调度 六、堆栈资源共享 七、与PCP的比较 一、论文核心思想: -引入了一个抢占优…...

音频延时测试方法与实现
音频延时测试方法有以下几种 1、使用专业的测试设备,通过专业的音频测试仪器可以准确测量音频延时,如常见声学分析仪、信号发生器、声卡Smaart(介绍测试延时方法链接:https://blog.csdn.net/weixin_48408892/article/details/1273…...

在 Python 中管理机密的四种方法
我们生活在一个应用程序用于做任何事情的世界,无论是股票交易还是预订沙龙,但在幕后,连接是使用秘密完成的。必须适当管理机密,例如数据库密码、API 密钥、令牌等,以避免任何泄露。 管理机密的需求对任何组织都至关重…...

全国青少年信息素养大赛Python编程挑战赛初赛试题说明
Python 编程挑战赛初赛采用线上考试比赛形式,分为小学组和初中组。不同组别的考核重难点略有不同,考核内容主要是 Python 基础知识,共 30 题,均为单选题,具体考核如下: 小学组考核内容主要是 Python 基础知识,包括输入输出,变量,条件结构,计次循环和无限循环,海龟库…...

无需魔法打开即用的 AI 工具集锦
作者:明明如月学长, CSDN 博客专家,蚂蚁集团高级 Java 工程师,《性能优化方法论》作者、《解锁大厂思维:剖析《阿里巴巴Java开发手册》》、《再学经典:《EffectiveJava》独家解析》专栏作者。 热门文章推荐…...

如何进行SEO站内优化,让你的网站更易被搜索引擎收录
我们了解了 SEO 的流程,知道了哪些元素对 SEO 的效果会产生关键影响,接下来,我们就该正式开始动手,打造一个让搜索引擎“爱不释手”的网站。 为了方便理解与记忆,我们将网站划分为几个模块,告诉你优化网站…...

组件内部watch后切换数据报错Error in callback for watcher “xxxx“
报错信息: 报错代码: 百度了一下是因为这里写了箭头函数,导致this指向为父级作用域上下文,不是vue实例导致 修改为: progressData: {handler: function(newValue, oldValue) {this.setChartData(newValue)},deep: …...

VMware ESXi 7.0 U3l macOS Unlocker OEM BIOS (标准版和厂商定制版)
VMware ESXi 7.0 U3l macOS Unlocker & OEM BIOS (标准版和厂商定制版) 提供标准版和 Dell (戴尔)、HPE (慧与)、Lenovo (联想)、Inspur (浪潮)、Cisco (思科) 定制版镜像 请访问原文链接:https://sysin.org/blog/vmware-esxi-7-u3-oem/,查看最新版…...

华为阿里版ChatGPT横空出世,谁的成效更好呢?
“你训练的大模型涌现了吗?”“还没有。好难受。”一时间成为了最近AI赛道玩家的一个爆热梗。 不管承不承认,相信每个玩家都不愿意输掉这场激烈的竞争。自百度成为国内“第一个吃螃蟹的人”后,又有两大中国科技巨头做好了准备——华为和阿里…...

【云原生之Docker实战】使用docker部署kooteam在线团队协作工具
【云原生之Docker实战】使用docker部署kooteam在线团队协作工具 一、kooteam介绍1.kooteam介绍2.kooteam的技术选型二、检查本地docker环境1.检查Docker版本2.检查Docker状态三、下载kooteam镜像四、部署kooteam文档管理系统1.创建安装目录2.创建mysql数据库3.新建kooteam数据库…...

ITSS认证是什么认证,itss资质认证
一、ITSS是什么 ITSS根据英文翻译信息技术服务标准(InformationTechnologyServiceStandards,简称ITSS),它既是一套成体系和综合配套的标准库,又是一套选择和提供IT服务的方法学,对企业IT服务而言࿰…...

SkyWalking 10.2.0 SWCK 配置过程
SkyWalking 10.2.0 & SWCK 配置过程 skywalking oap-server & ui 使用Docker安装在K8S集群以外,K8S集群中的微服务使用initContainer按命名空间将skywalking-java-agent注入到业务容器中。 SWCK有整套的解决方案,全安装在K8S群集中。 具体可参…...

Java 8 Stream API 入门到实践详解
一、告别 for 循环! 传统痛点: Java 8 之前,集合操作离不开冗长的 for 循环和匿名类。例如,过滤列表中的偶数: List<Integer> list Arrays.asList(1, 2, 3, 4, 5); List<Integer> evens new ArrayList…...

《从零掌握MIPI CSI-2: 协议精解与FPGA摄像头开发实战》-- CSI-2 协议详细解析 (一)
CSI-2 协议详细解析 (一) 1. CSI-2层定义(CSI-2 Layer Definitions) 分层结构 :CSI-2协议分为6层: 物理层(PHY Layer) : 定义电气特性、时钟机制和传输介质(导线&#…...

Cilium动手实验室: 精通之旅---20.Isovalent Enterprise for Cilium: Zero Trust Visibility
Cilium动手实验室: 精通之旅---20.Isovalent Enterprise for Cilium: Zero Trust Visibility 1. 实验室环境1.1 实验室环境1.2 小测试 2. The Endor System2.1 部署应用2.2 检查现有策略 3. Cilium 策略实体3.1 创建 allow-all 网络策略3.2 在 Hubble CLI 中验证网络策略源3.3 …...

基于Uniapp开发HarmonyOS 5.0旅游应用技术实践
一、技术选型背景 1.跨平台优势 Uniapp采用Vue.js框架,支持"一次开发,多端部署",可同步生成HarmonyOS、iOS、Android等多平台应用。 2.鸿蒙特性融合 HarmonyOS 5.0的分布式能力与原子化服务,为旅游应用带来…...

(二)原型模式
原型的功能是将一个已经存在的对象作为源目标,其余对象都是通过这个源目标创建。发挥复制的作用就是原型模式的核心思想。 一、源型模式的定义 原型模式是指第二次创建对象可以通过复制已经存在的原型对象来实现,忽略对象创建过程中的其它细节。 📌 核心特点: 避免重复初…...

spring:实例工厂方法获取bean
spring处理使用静态工厂方法获取bean实例,也可以通过实例工厂方法获取bean实例。 实例工厂方法步骤如下: 定义实例工厂类(Java代码),定义实例工厂(xml),定义调用实例工厂ÿ…...

vue3 定时器-定义全局方法 vue+ts
1.创建ts文件 路径:src/utils/timer.ts 完整代码: import { onUnmounted } from vuetype TimerCallback (...args: any[]) > voidexport function useGlobalTimer() {const timers: Map<number, NodeJS.Timeout> new Map()// 创建定时器con…...

HTML前端开发:JavaScript 常用事件详解
作为前端开发的核心,JavaScript 事件是用户与网页交互的基础。以下是常见事件的详细说明和用法示例: 1. onclick - 点击事件 当元素被单击时触发(左键点击) button.onclick function() {alert("按钮被点击了!&…...

Java面试专项一-准备篇
一、企业简历筛选规则 一般企业的简历筛选流程:首先由HR先筛选一部分简历后,在将简历给到对应的项目负责人后再进行下一步的操作。 HR如何筛选简历 例如:Boss直聘(招聘方平台) 直接按照条件进行筛选 例如:…...