只依赖Tensorrt和opencv的yolov5源代码
simple_yolo.hpp
#ifndef SIMPLE_YOLO_HPP
#define SIMPLE_YOLO_HPP/*简单的yolo接口,容易集成但是高性能
*/#include <vector>
#include <memory>
#include <string>
#include <future>
#include <opencv2/opencv.hpp>namespace SimpleYolo{using namespace std;enum class Type : int{V5 = 0,X = 1};enum class Mode : int {FP32,FP16,INT8};struct Box{float left, top, right, bottom, confidence;int class_label;Box() = default;Box(float left, float top, float right, float bottom, float confidence, int class_label):left(left), top(top), right(right), bottom(bottom), confidence(confidence), class_label(class_label){}};typedef std::vector<Box> BoxArray;class Infer{public:virtual shared_future<BoxArray> commit(const cv::Mat& image) = 0;virtual vector<shared_future<BoxArray>> commits(const vector<cv::Mat>& images) = 0;};const char* trt_version();const char* type_name(Type type);const char* mode_string(Mode type);void set_device(int device_id);/* 模型编译max batch size:为最大可以允许的batch数量source_onnx:仅仅只支持onnx格式输入saveto:储存的tensorRT模型,用于后续的加载max workspace size:最大工作空间大小,一般给1GB,在嵌入式可以改为256MB,单位是byteint8 images folder:对于Mode为INT8时,需要提供图像数据进行标定,请提供文件夹,会自动检索下面的jpg/jpeg/tiff/png/bmpint8_entropy_calibrator_cache_file:对于int8模式下,熵文件可以缓存,避免二次加载数据,可以跨平台使用,是一个txt文件*/// 1GB = 1<<30bool compile(Mode mode, Type type,unsigned int max_batch_size,const string& source_onnx,const string& saveto,size_t max_workspace_size = 1<<30,const std::string& int8_images_folder = "",const std::string& int8_entropy_calibrator_cache_file = "");shared_ptr<Infer> create_infer(const string& engine_file, Type type, int gpuid, float confidence_threshold=0.25f, float nms_threshold=0.5f);}; // namespace SimpleYolo#endif // SIMPLE_YOLO_HPP
这是一个简单的yolo接口的头文件,提供了一些用于创建和使用yolo模型的函数和结构体。
Type和Mode是用于指定yolo模型类型和推理模式的枚举类型。
Box结构体表示检测到的物体的边界框、置信度和类别标签。
Infer类是一个抽象类,它提供了一个commit函数,用于执行单个图像的推理,以及一个commits函数,用于执行多个图像的推理。
trt_version、type_name、mode_string和set_device是一些辅助函数,用于获取TensorRT版本、yolo模型类型和推理模式的名称,并设置使用的GPU设备。
compile函数用于将yolo模型从ONNX格式编译为TensorRT格式,并将结果保存到文件中。
create_infer函数用于创建一个推理器,它从文件中加载TensorRT引擎,并使用指定的GPU设备执行推理。
这个头文件提供了一个简单的yolo接口,用于创建和使用yolo模型。
Type和Mode是用于指定yolo模型类型和推理模式的枚举类型。Type包括V5和X两种类型,Mode包括FP32、FP16和INT8三种模式。
Box结构体表示检测到的物体的边界框、置信度和类别标签。它包括一个默认构造函数和一个带有参数的构造函数,用于初始化边界框的位置、置信度和类别标签。
Infer类是一个抽象类,它提供了一个commit函数和一个commits函数。commit函数用于执行单个图像的推理,并返回包含检测到的物体信息的future对象。commits函数用于执行多个图像的推理,并返回包含检测到的物体信息的多个future对象。
trt_version、type_name、mode_string和set_device是一些辅助函数。trt_version返回TensorRT版本号。type_name返回指定yolo模型类型的名称。mode_string返回指定推理模式的名称。set_device用于设置使用的GPU设备。
compile函数用于将yolo模型从ONNX格式编译为TensorRT格式,并将结果保存到文件中。它包括许多参数,如模型类型、推理模式、最大批处理大小和最大工作空间大小等。如果模式为INT8,则需要提供用于标定的图像文件夹路径以及熵缓存文件路径。
create_infer函数用于创建一个推理器,它从文件中加载TensorRT引擎,并使用指定的GPU设备执行推理。它还包括一些参数,如置信度阈值和NMS阈值等。
总的来说,这个头文件提供了一个简单易用的接口,用于创建和使用yolo模型进行对象检测。
simple_yolo.cu
#include "simple_yolo.hpp"
#include <NvInfer.h>
#include <NvOnnxParser.h>
#include <cuda_runtime.h>#include <algorithm>
#include <fstream>
#include <memory>
#include <string>
#include <future>
#include <condition_variable>
#include <mutex>
#include <thread>
#include <queue>
#include <functional>#if defined(_WIN32)
# include <Windows.h>
# include <wingdi.h>
# include <Shlwapi.h>
# pragma comment(lib, "shlwapi.lib")
# undef min
# undef max
#else
# include <dirent.h>
# include <sys/types.h>
# include <sys/stat.h>
# include <unistd.h>
# include <stdarg.h>
#endifnamespace SimpleYolo{using namespace nvinfer1;using namespace std;using namespace cv;#define CURRENT_DEVICE_ID -1#define GPU_BLOCK_THREADS 512#define KernelPositionBlock \int position = (blockDim.x * blockIdx.x + threadIdx.x); \if (position >= (edge)) return;#define checkCudaRuntime(call) check_runtime(call, #call, __LINE__, __FILE__)static bool check_runtime(cudaError_t e, const char* call, int line, const char *file);#define checkCudaKernel(...) \__VA_ARGS__; \do{cudaError_t cudaStatus = cudaPeekAtLastError(); \if (cudaStatus != cudaSuccess){ \INFOE("launch failed: %s", cudaGetErrorString(cudaStatus)); \}} while(0);#define Assert(op) \do{ \bool cond = !(!(op)); \if(!cond){ \INFOF("Assert failed, " #op); \} \}while(false)/* 修改这个level来实现修改日志输出级别 */#define CURRENT_LOG_LEVEL LogLevel::Info#define INFOD(...) __log_func(__FILE__, __LINE__, LogLevel::Debug, __VA_ARGS__)#define INFOV(...) __log_func(__FILE__, __LINE__, LogLevel::Verbose, __VA_ARGS__)#define INFO(...) __log_func(__FILE__, __LINE__, LogLevel::Info, __VA_ARGS__)#define INFOW(...) __log_func(__FILE__, __LINE__, LogLevel::Warning, __VA_ARGS__)#define INFOE(...) __log_func(__FILE__, __LINE__, LogLevel::Error, __VA_ARGS__)#define INFOF(...) __log_func(__FILE__, __LINE__, LogLevel::Fatal, __VA_ARGS__)enum class NormType : int{None = 0,MeanStd = 1,AlphaBeta = 2};enum class ChannelType : int{None = 0,SwapRB = 1};/* 归一化操作,可以支持均值标准差,alpha beta,和swap RB */struct Norm{float mean[3];float std[3];float alpha, beta;NormType type = NormType::None;ChannelType channel_type = ChannelType::None;// out = (x * alpha - mean) / stdstatic Norm mean_std(const float mean[3], const float std[3], float alpha = 1/255.0f, ChannelType channel_type=ChannelType::None);// out = x * alpha + betastatic Norm alpha_beta(float alpha, float beta = 0, ChannelType channel_type=ChannelType::None);// Nonestatic Norm None();};Norm Norm::mean_std(const float mean[3], const float std[3], float alpha, ChannelType channel_type){Norm out;out.type = NormType::MeanStd;out.alpha = alpha;out.channel_type = channel_type;memcpy(out.mean, mean, sizeof(out.mean));memcpy(out.std, std, sizeof(out.std));return out;}Norm Norm::alpha_beta(float alpha, float beta, ChannelType channel_type){Norm out;out.type = NormType::AlphaBeta;out.alpha = alpha;out.beta = beta;out.channel_type = channel_type;return out;}Norm Norm::None(){return Norm();}/* 构造时设置当前gpuid,析构时修改为原来的gpuid */class AutoDevice{public:AutoDevice(int device_id = 0){cudaGetDevice(&old_);checkCudaRuntime(cudaSetDevice(device_id));}virtual ~AutoDevice(){checkCudaRuntime(cudaSetDevice(old_));}private:int old_ = -1;};enum class LogLevel : int{Debug = 5,Verbose = 4,Info = 3,Warning = 2,Error = 1,Fatal = 0};static void __log_func(const char* file, int line, LogLevel level, const char* fmt, ...);inline int upbound(int n, int align = 32){return (n + align - 1) / align * align;}static bool check_runtime(cudaError_t e, const char* call, int line, const char *file){if (e != cudaSuccess) {INFOE("CUDA Runtime error %s # %s, code = %s [ %d ] in file %s:%d", call, cudaGetErrorString(e), cudaGetErrorName(e), e, file, line);return false;}return true;}#define TRT_STR(v) #v#define TRT_VERSION_STRING(major, minor, patch, build) TRT_STR(major) "." TRT_STR(minor) "." TRT_STR(patch) "." TRT_STR(build)const char* trt_version(){return TRT_VERSION_STRING(NV_TENSORRT_MAJOR, NV_TENSORRT_MINOR, NV_TENSORRT_PATCH, NV_TENSORRT_BUILD);}static bool check_device_id(int device_id){int device_count = -1;checkCudaRuntime(cudaGetDeviceCount(&device_count));if(device_id < 0 || device_id >= device_count){INFOE("Invalid device id: %d, count = %d", device_id, device_count);return false;}return true;}static bool exists(const string& path){#ifdef _WIN32return ::PathFileExistsA(path.c_str());#elsereturn access(path.c_str(), R_OK) == 0;#endif}static const char* level_string(LogLevel level){switch (level){case LogLevel::Debug: return "debug";case LogLevel::Verbose: return "verbo";case LogLevel::Info: return "info";case LogLevel::Warning: return "warn";case LogLevel::Error: return "error";case LogLevel::Fatal: return "fatal";default: return "unknow";}}template<typename _T>static string join_dims(const vector<_T>& dims){stringstream output;char buf[64];const char* fmts[] = {"%d", " x %d"};for(int i = 0; i < dims.size(); ++i){snprintf(buf, sizeof(buf), fmts[i != 0], dims[i]);output << buf;}return output.str();}static bool save_file(const string& file, const void* data, size_t length){FILE* f = fopen(file.c_str(), "wb");if (!f) return false;if (data && length > 0){if (fwrite(data, 1, length, f) != length){fclose(f);return false;}}fclose(f);return true;}static bool save_file(const string& file, const vector<uint8_t>& data){return save_file(file, data.data(), data.size());}static string file_name(const string& path, bool include_suffix){if (path.empty()) return "";int p = path.rfind('/');#ifdef U_OS_WINDOWSint e = path.rfind('\\');p = std::max(p, e);
#endifp += 1;//include suffixif (include_suffix)return path.substr(p);int u = path.rfind('.');if (u == -1)return path.substr(p);if (u <= p) u = path.size();return path.substr(p, u - p);}vector<string> glob_image_files(const string& directory){/* 检索目录下的所有图像:"*.jpg;*.png;*.bmp;*.jpeg;*.tiff" */vector<string> files, output;set<string> pattern_set{"jpg", "png", "bmp", "jpeg", "tiff"};if(directory.empty()){INFOE("Glob images from folder failed, folder is empty");return output;}try{vector<cv::String> files_;files_.reserve(10000);cv::glob(directory + "/*", files_, true);files.insert(files.end(), files_.begin(), files_.end());}catch(...){INFOE("Glob %s failed", directory.c_str());return output;}for(int i = 0; i < files.size(); ++i){auto& file = files[i];int p = file.rfind(".");if(p == -1) continue;auto suffix = file.substr(p+1);std::transform(suffix.begin(), suffix.end(), suffix.begin(), [](char c){if(c >= 'A' && c <= 'Z')c -= 'A' + 'a';return c;});if(pattern_set.find(suffix) != pattern_set.end())output.push_back(file);}return output;}static void __log_func(const char* file, int line, LogLevel level, const char* fmt, ...){if(level > CURRENT_LOG_LEVEL)return;va_list vl;va_start(vl, fmt);char buffer[2048];string filename = file_name(file, true);int n = snprintf(buffer, sizeof(buffer), "[%s][%s:%d]:", level_string(level), filename.c_str(), line);vsnprintf(buffer + n, sizeof(buffer) - n, fmt, vl);fprintf(stdout, "%s\n", buffer);if (level == LogLevel::Fatal) {fflush(stdout);abort();}static dim3 grid_dims(int numJobs) {int numBlockThreads = numJobs < GPU_BLOCK_THREADS ? numJobs : GPU_BLOCK_THREADS;return dim3(((numJobs + numBlockThreads - 1) / (float)numBlockThreads));static dim3 block_dims(int numJobs) {return numJobs < GPU_BLOCK_THREADS ? numJobs : GPU_BLOCK_THREADS;}static int get_device(int device_id){if(device_id != CURRENT_DEVICE_ID){check_device_id(device_id);return device_id;}checkCudaRuntime(cudaGetDevice(&device_id));return device_id;}void set_device(int device_id) {if (device_id == -1)return;checkCudaRuntime(cudaSetDevice(device_id));}/CUDA kernelsconst int NUM_BOX_ELEMENT = 7; // left, top, right, bottom, confidence, class, keepflagstatic __device__ void affine_project(float* matrix, float x, float y, float* ox, float* oy){*ox = matrix[0] * x + matrix[1] * y + matrix[2];*oy = matrix[3] * x + matrix[4] * y + matrix[5];}static __global__ void decode_kernel(float* predict, int num_bboxes, int num_classes, float confidence_threshold, float* invert_affine_matrix, float* parray, int max_objects){ int position = blockDim.x * blockIdx.x + threadIdx.x;if (position >= num_bboxes) return;float* pitem = predict + (5 + num_classes) * position;float objectness = pitem[4];if(objectness < confidence_threshold)return;float* class_confidence = pitem + 5;float confidence = *class_confidence++;int label = 0;for(int i = 1; i < num_classes; ++i, ++class_confidence){if(*class_confidence > confidence){confidence = *class_confidence;label = i;}}confidence *= objectness;if(confidence < confidence_threshold)return;int index = atomicAdd(parray, 1);if(index >= max_objects)return;float cx = *pitem++;float cy = *pitem++;float width = *pitem++;float height = *pitem++;float left = cx - width * 0.5f;float top = cy - height * 0.5f;float right = cx + width * 0.5f;float bottom = cy + height * 0.5f;affine_project(invert_affine_matrix, left, top, &left, &top);affine_project(invert_affine_matrix, right, bottom, &right, &bottom);float* pout_item = parray + 1 + index * NUM_BOX_ELEMENT;*pout_item++ = left;*pout_item++ = top;*pout_item++ = right;*pout_item++ = bottom;*pout_item++ = confidence;*pout_item++ = label;*pout_item++ = 1; // 1 = keep, 0 = ignore}static __device__ float box_iou(float aleft, float atop, float aright, float abottom, float bleft, float btop, float bright, float bbottom){float cleft = max(aleft, bleft);float ctop = max(atop, btop);float cright = min(aright, bright);float cbottom = min(abottom, bbottom);float c_area = max(cright - cleft, 0.0f) * max(cbottom - ctop, 0.0f);if(c_area == 0.0f)return 0.0f;float a_area = max(0.0f, aright - aleft) * max(0.0f, abottom - atop);float b_area = max(0.0f, bright - bleft) * max(0.0f, bbottom - btop);return c_area / (a_area + b_area - c_area);}static __global__ void fast_nms_kernel(float* bboxes, int max_objects, float threshold){int position = (blockDim.x * blockIdx.x + threadIdx.x);int count = min((int)*bboxes, max_objects);if (position >= count) return;// left, top, right, bottom, confidence, class, keepflagfloat* pcurrent = bboxes + 1 + position * NUM_BOX_ELEMENT;for(int i = 0; i < count; ++i){float* pitem = bboxes + 1 + i * NUM_BOX_ELEMENT;if(i == position || pcurrent[5] != pitem[5]) continue;if(pitem[4] >= pcurrent[4]){if(pitem[4] == pcurrent[4] && i < position)continue;float iou = box_iou(pcurrent[0], pcurrent[1], pcurrent[2], pcurrent[3],pitem[0], pitem[1], pitem[2], pitem[3]);if(iou > threshold){pcurrent[6] = 0; // 1=keep, 0=ignorereturn;}}}} static void decode_kernel_invoker(float* predict, int num_bboxes, int num_classes, float confidence_threshold, float nms_threshold, float* invert_affine_matrix, float* parray, int max_objects, cudaStream_t stream){auto grid = grid_dims(num_bboxes);auto block = block_dims(num_bboxes);/* 如果核函数有波浪线,没关系,他是正常的,你只是看不顺眼罢了 */checkCudaKernel(decode_kernel<<<grid, block, 0, stream>>>(predict, num_bboxes, num_classes, confidence_threshold, invert_affine_matrix, parray, max_objects));grid = grid_dims(max_objects);block = block_dims(max_objects);checkCudaKernel(fast_nms_kernel<<<grid, block, 0, stream>>>(parray, max_objects, nms_threshold));}static __global__ void warp_affine_bilinear_and_normalize_plane_kernel(uint8_t* src, int src_line_size, int src_width, int src_height, float* dst, int dst_width, int dst_height, uint8_t const_value_st, float* warp_affine_matrix_2_3, Norm norm, int edge){int position = blockDim.x * blockIdx.x + threadIdx.x;if (position >= edge) return;float m_x1 = warp_affine_matrix_2_3[0];float m_y1 = warp_affine_matrix_2_3[1];float m_z1 = warp_affine_matrix_2_3[2];float m_x2 = warp_affine_matrix_2_3[3];float m_y2 = warp_affine_matrix_2_3[4];float m_z2 = warp_affine_matrix_2_3[5];int dx = position % dst_width;int dy = position / dst_width;float src_x = m_x1 * dx + m_y1 * dy + m_z1;float src_y = m_x2 * dx + m_y2 * dy + m_z2;float c0, c1, c2;if(src_x <= -1 || src_x >= src_width || src_y <= -1 || src_y >= src_height){// out of rangec0 = const_value_st;c1 = const_value_st;c2 = const_value_st;}else{int y_low = floorf(src_y);int x_low = floorf(src_x);int y_high = y_low + 1;int x_high = x_low + 1;uint8_t const_value[] = {const_value_st, const_value_st, const_value_st};float ly = src_y - y_low;float lx = src_x - x_low;float hy = 1 - ly;float hx = 1 - lx;float w1 = hy * hx, w2 = hy * lx, w3 = ly * hx, w4 = ly * lx;uint8_t* v1 = const_value;uint8_t* v2 = const_value;uint8_t* v3 = const_value;uint8_t* v4 = const_value;if(y_low >= 0){if (x_low >= 0)v1 = src + y_low * src_line_size + x_low * 3;if (x_high < src_width)v2 = src + y_low * src_line_size + x_high * 3;}if(y_high < src_height){if (x_low >= 0)v3 = src + y_high * src_line_size + x_low * 3;if (x_high < src_width)v4 = src + y_high * src_line_size + x_high * 3;}// same to opencvc0 = floorf(w1 * v1[0] + w2 * v2[0] + w3 * v3[0] + w4 * v4[0] + 0.5f);c1 = floorf(w1 * v1[1] + w2 * v2[1] + w3 * v3[1] + w4 * v4[1] + 0.5f);c2 = floorf(w1 * v1[2] + w2 * v2[2] + w3 * v3[2] + w4 * v4[2] + 0.5f);}if(norm.channel_type == ChannelType::SwapRB){float t = c2;c2 = c0; c0 = t;}if(norm.type == NormType::MeanStd){c0 = (c0 * norm.alpha - norm.mean[0]) / norm.std[0];c1 = (c1 * norm.alpha - norm.mean[1]) / norm.std[1];c2 = (c2 * norm.alpha - norm.mean[2]) / norm.std[2];}else if(norm.type == NormType::AlphaBeta){c0 = c0 * norm.alpha + norm.beta;c1 = c1 * norm.alpha + norm.beta;c2 = c2 * norm.alpha + norm.beta;}int area = dst_width * dst_height;float* pdst_c0 = dst + dy * dst_width + dx;float* pdst_c1 = pdst_c0 + area;float* pdst_c2 = pdst_c1 + area;*pdst_c0 = c0;*pdst_c1 = c1;*pdst_c2 = c2;}static void warp_affine_bilinear_and_normalize_plane(uint8_t* src, int src_line_size, int src_width, int src_height, float* dst, int dst_width, int dst_height,float* matrix_2_3, uint8_t const_value, const Norm& norm,cudaStream_t stream) {int jobs = dst_width * dst_height;auto grid = grid_dims(jobs);auto block = block_dims(jobs);checkCudaKernel(warp_affine_bilinear_and_normalize_plane_kernel << <grid, block, 0, stream >> > (src, src_line_size,src_width, src_height, dst,dst_width, dst_height, const_value, matrix_2_3, norm, jobs));}//class MixMemory//* gpu/cpu内存管理自动对gpu和cpu内存进行分配和释放这里的cpu使用的是pinned memory,当对gpu做内存复制时,性能比较好因为是cudaMallocHost分配的,因此他与cuda context有关联*/class MixMemory {public:MixMemory(int device_id = CURRENT_DEVICE_ID);MixMemory(void* cpu, size_t cpu_size, void* gpu, size_t gpu_size);virtual ~MixMemory();void* gpu(size_t size);void* cpu(size_t size);void release_gpu();void release_cpu();void release_all();inline bool owner_gpu() const{return owner_gpu_;}inline bool owner_cpu() const{return owner_cpu_;}inline size_t cpu_size() const{return cpu_size_;}inline size_t gpu_size() const{return gpu_size_;}inline int device_id() const{return device_id_;}inline void* gpu() const { return gpu_; }// Pinned Memoryinline void* cpu() const { return cpu_; }void reference_data(void* cpu, size_t cpu_size, void* gpu, size_t gpu_size);private:void* cpu_ = nullptr;size_t cpu_size_ = 0;bool owner_cpu_ = true;int device_id_ = 0;void* gpu_ = nullptr;size_t gpu_size_ = 0;bool owner_gpu_ = true;};MixMemory::MixMemory(int device_id){device_id_ = get_device(device_id);}MixMemory::MixMemory(void* cpu, size_t cpu_size, void* gpu, size_t gpu_size){reference_data(cpu, cpu_size, gpu, gpu_size); }void MixMemory::reference_data(void* cpu, size_t cpu_size, void* gpu, size_t gpu_size){release_all();if(cpu == nullptr || cpu_size == 0){cpu = nullptr;cpu_size = 0;}if(gpu == nullptr || gpu_size == 0){gpu = nullptr;gpu_size = 0;}this->cpu_ = cpu;this->cpu_size_ = cpu_size;this->gpu_ = gpu;this->gpu_size_ = gpu_size;this->owner_cpu_ = !(cpu && cpu_size > 0);this->owner_gpu_ = !(gpu && gpu_size > 0);checkCudaRuntime(cudaGetDevice(&device_id_));}MixMemory::~MixMemory() {release_all();}void* MixMemory::gpu(size_t size) {if (gpu_size_ < size) {release_gpu();gpu_size_ = size;AutoDevice auto_device_exchange(device_id_);checkCudaRuntime(cudaMalloc(&gpu_, size));checkCudaRuntime(cudaMemset(gpu_, 0, size));}return gpu_;}void* MixMemory::cpu(size_t size) {if (cpu_size_ < size) {release_cpu();cpu_size_ = size;AutoDevice auto_device_exchange(device_id_);checkCudaRuntime(cudaMallocHost(&cpu_, size));Assert(cpu_ != nullptr);memset(cpu_, 0, size);}return cpu_;}void MixMemory::release_cpu() {if (cpu_) {if(owner_cpu_){AutoDevice auto_device_exchange(device_id_);checkCudaRuntime(cudaFreeHost(cpu_));}cpu_ = nullptr;}cpu_size_ = 0;}void MixMemory::release_gpu() {if (gpu_) {if(owner_gpu_){AutoDevice auto_device_exchange(device_id_);checkCudaRuntime(cudaFree(gpu_));}gpu_ = nullptr;}gpu_size_ = 0;}void MixMemory::release_all() {release_cpu();release_gpu();}/class Tensor/* Tensor类,实现张量的管理由于NN多用张量,必须有个类进行管理才方便,实现内存自动分配,计算索引等等如果要调试,可以执行save_to_file,储存为文件后,在python中加载并查看*/enum class DataHead : int{Init = 0,Device = 1,Host = 2};class Tensor {public:Tensor(const Tensor& other) = delete;Tensor& operator = (const Tensor& other) = delete;explicit Tensor(std::shared_ptr<MixMemory> data = nullptr, int device_id = CURRENT_DEVICE_ID);explicit Tensor(int n, int c, int h, int w, std::shared_ptr<MixMemory> data = nullptr, int device_id = CURRENT_DEVICE_ID);explicit Tensor(int ndims, const int* dims, std::shared_ptr<MixMemory> data = nullptr, int device_id = CURRENT_DEVICE_ID);explicit Tensor(const std::vector<int>& dims, std::shared_ptr<MixMemory> data = nullptr, int device_id = CURRENT_DEVICE_ID);virtual ~Tensor();int numel() const;inline int ndims() const{return shape_.size();}inline int size(int index) const{return shape_[index];}inline int shape(int index) const{return shape_[index];}inline int batch() const{return shape_[0];}inline int channel() const{return shape_[1];}inline int height() const{return shape_[2];}inline int width() const{return shape_[3];}inline const std::vector<int>& dims() const { return shape_; }inline int bytes() const { return bytes_; }inline int bytes(int start_axis) const { return count(start_axis) * element_size(); }inline int element_size() const { return sizeof(float); }inline DataHead head() const { return head_; }std::shared_ptr<Tensor> clone() const;Tensor& release();Tensor& set_to(float value);bool empty() const;template<typename ... _Args>int offset(int index, _Args ... index_args) const{const int index_array[] = {index, index_args...};return offset_array(sizeof...(index_args) + 1, index_array);}int offset_array(const std::vector<int>& index) const;int offset_array(size_t size, const int* index_array) const;template<typename ... _Args>Tensor& resize(int dim_size, _Args ... dim_size_args){const int dim_size_array[] = {dim_size, dim_size_args...};return resize(sizeof...(dim_size_args) + 1, dim_size_array);}Tensor& resize(int ndims, const int* dims);Tensor& resize(const std::vector<int>& dims);Tensor& resize_single_dim(int idim, int size);int count(int start_axis = 0) const;int device() const{return device_id_;}Tensor& to_gpu(bool copy=true);Tensor& to_cpu(bool copy=true);inline void* cpu() const { ((Tensor*)this)->to_cpu(); return data_->cpu(); }inline void* gpu() const { ((Tensor*)this)->to_gpu(); return data_->gpu(); }template<typename DType> inline const DType* cpu() const { return (DType*)cpu(); }template<typename DType> inline DType* cpu() { return (DType*)cpu(); }template<typename DType, typename ... _Args> inline DType* cpu(int i, _Args&& ... args) { return cpu<DType>() + offset(i, args...); }template<typename DType> inline const DType* gpu() const { return (DType*)gpu(); }template<typename DType> inline DType* gpu() { return (DType*)gpu(); }template<typename DType, typename ... _Args> inline DType* gpu(int i, _Args&& ... args) { return gpu<DType>() + offset(i, args...); }template<typename DType, typename ... _Args> inline DType& at(int i, _Args&& ... args) { return *(cpu<DType>() + offset(i, args...)); }std::shared_ptr<MixMemory> get_data() const {return data_;}std::shared_ptr<MixMemory> get_workspace() const {return workspace_;}Tensor& set_workspace(std::shared_ptr<MixMemory> workspace) {workspace_ = workspace; return *this;}cudaStream_t get_stream() const{return stream_;}Tensor& set_stream(cudaStream_t stream){stream_ = stream; return *this;}Tensor& set_mat (int n, const cv::Mat& image);Tensor& set_norm_mat(int n, const cv::Mat& image, float mean[3], float std[3]);cv::Mat at_mat(int n = 0, int c = 0) { return cv::Mat(height(), width(), CV_32F, cpu<float>(n, c)); }Tensor& synchronize();const char* shape_string() const{return shape_string_;}const char* descriptor() const;Tensor& copy_from_gpu(size_t offset, const void* src, size_t num_element, int device_id = CURRENT_DEVICE_ID);/**# 以下代码是python中加载Tensorimport numpy as npdef load_tensor(file):with open(file, "rb") as f:binary_data = f.read()magic_number, ndims, dtype = np.frombuffer(binary_data, np.uint32, count=3, offset=0)assert magic_number == 0xFCCFE2E2, f"{file} not a tensor file."dims = np.frombuffer(binary_data, np.uint32, count=ndims, offset=3 * 4)if dtype == 0:np_dtype = np.float32elif dtype == 1:np_dtype = np.float16else:assert False, f"Unsupport dtype = {dtype}, can not convert to numpy dtype"return np.frombuffer(binary_data, np_dtype, offset=(ndims + 3) * 4).reshape(*dims)**/bool save_to_file(const std::string& file) const;private:Tensor& compute_shape_string();Tensor& adajust_memory_by_update_dims_or_type();void setup_data(std::shared_ptr<MixMemory> data);private:std::vector<int> shape_;size_t bytes_ = 0;DataHead head_ = DataHead::Init;cudaStream_t stream_ = nullptr;int device_id_ = 0;char shape_string_[100];char descriptor_string_[100];std::shared_ptr<MixMemory> data_;std::shared_ptr<MixMemory> workspace_;};Tensor::Tensor(int n, int c, int h, int w, shared_ptr<MixMemory> data, int device_id) {this->device_id_ = get_device(device_id);descriptor_string_[0] = 0;setup_data(data);resize(n, c, h, w);}Tensor::Tensor(const std::vector<int>& dims, shared_ptr<MixMemory> data, int device_id){this->device_id_ = get_device(device_id);descriptor_string_[0] = 0;setup_data(data);resize(dims);}Tensor::Tensor(int ndims, const int* dims, shared_ptr<MixMemory> data, int device_id) {this->device_id_ = get_device(device_id);descriptor_string_[0] = 0;setup_data(data);resize(ndims, dims);}Tensor::Tensor(shared_ptr<MixMemory> data, int device_id){shape_string_[0] = 0;descriptor_string_[0] = 0;this->device_id_ = get_device(device_id);setup_data(data);}Tensor::~Tensor() {release();}const char* Tensor::descriptor() const{char* descriptor_ptr = (char*)descriptor_string_;int device_id = device();snprintf(descriptor_ptr, sizeof(descriptor_string_), "Tensor:%p, %s, CUDA:%d", data_.get(),shape_string_, device_id);return descriptor_ptr;}Tensor& Tensor::compute_shape_string(){// clean stringshape_string_[0] = 0;char* buffer = shape_string_;size_t buffer_size = sizeof(shape_string_);for(int i = 0; i < shape_.size(); ++i){int size = 0;if(i < shape_.size() - 1)size = snprintf(buffer, buffer_size, "%d x ", shape_[i]);elsesize = snprintf(buffer, buffer_size, "%d", shape_[i]);buffer += size;buffer_size -= size;}return *this;}void Tensor::setup_data(shared_ptr<MixMemory> data){data_ = data;if(data_ == nullptr){data_ = make_shared<MixMemory>(device_id_);}else{device_id_ = data_->device_id();}head_ = DataHead::Init;if(data_->cpu()){head_ = DataHead::Host;}if(data_->gpu()){head_ = DataHead::Device;}}Tensor& Tensor::copy_from_gpu(size_t offset, const void* src, size_t num_element, int device_id){if(head_ == DataHead::Init)to_gpu(false);size_t offset_location = offset * element_size();if(offset_location >= bytes_){INFOE("Offset location[%lld] >= bytes_[%lld], out of range", offset_location, bytes_);return *this;}size_t copyed_bytes = num_element * element_size();size_t remain_bytes = bytes_ - offset_location;if(copyed_bytes > remain_bytes){INFOE("Copyed bytes[%lld] > remain bytes[%lld], out of range", copyed_bytes, remain_bytes);return *this;}if(head_ == DataHead::Device){int current_device_id = get_device(device_id);int gpu_device_id = device();if(current_device_id != gpu_device_id){checkCudaRuntime(cudaMemcpyPeerAsync(gpu<unsigned char>() + offset_location, gpu_device_id, src, current_device_id, copyed_bytes, stream_));//checkCudaRuntime(cudaMemcpyAsync(gpu<unsigned char>() + offset_location, src, copyed_bytes, cudaMemcpyDeviceToDevice, stream_));}else{checkCudaRuntime(cudaMemcpyAsync(gpu<unsigned char>() + offset_location, src, copyed_bytes, cudaMemcpyDeviceToDevice, stream_));}}else if(head_ == DataHead::Host){AutoDevice auto_device_exchange(this->device());checkCudaRuntime(cudaMemcpyAsync(cpu<unsigned char>() + offset_location, src, copyed_bytes, cudaMemcpyDeviceToHost, stream_));}else{INFOE("Unsupport head type %d", head_);}return *this;}Tensor& Tensor::release() {data_->release_all();shape_.clear();bytes_ = 0;head_ = DataHead::Init;return *this;}bool Tensor::empty() const{return data_->cpu() == nullptr && data_->gpu() == nullptr;}int Tensor::count(int start_axis) const {if(start_axis >= 0 && start_axis < shape_.size()){int size = 1;for (int i = start_axis; i < shape_.size(); ++i) size *= shape_[i];return size;}else{return 0;}}Tensor& Tensor::resize(const std::vector<int>& dims) {return resize(dims.size(), dims.data());}int Tensor::numel() const{int value = shape_.empty() ? 0 : 1;for(int i = 0; i < shape_.size(); ++i){value *= shape_[i];}return value;}Tensor& Tensor::resize_single_dim(int idim, int size){Assert(idim >= 0 && idim < shape_.size());auto new_shape = shape_;new_shape[idim] = size;return resize(new_shape);}Tensor& Tensor::resize(int ndims, const int* dims) {vector<int> setup_dims(ndims);for(int i = 0; i < ndims; ++i){int dim = dims[i];if(dim == -1){Assert(ndims == shape_.size());dim = shape_[i];}setup_dims[i] = dim;}this->shape_ = setup_dims;this->adajust_memory_by_update_dims_or_type();this->compute_shape_string();return *this;}Tensor& Tensor::adajust_memory_by_update_dims_or_type(){int needed_size = this->numel() * element_size();if(needed_size > this->bytes_){head_ = DataHead::Init;}this->bytes_ = needed_size;return *this;}Tensor& Tensor::synchronize(){ AutoDevice auto_device_exchange(this->device());checkCudaRuntime(cudaStreamSynchronize(stream_));return *this;}Tensor& Tensor::to_gpu(bool copy) {if (head_ == DataHead::Device)return *this;head_ = DataHead::Device;data_->gpu(bytes_);if (copy && data_->cpu() != nullptr) {AutoDevice auto_device_exchange(this->device());checkCudaRuntime(cudaMemcpyAsync(data_->gpu(), data_->cpu(), bytes_, cudaMemcpyHostToDevice, stream_));}return *this;}Tensor& Tensor::to_cpu(bool copy) {if (head_ == DataHead::Host)return *this;head_ = DataHead::Host;data_->cpu(bytes_);if (copy && data_->gpu() != nullptr) {AutoDevice auto_device_exchange(this->device());checkCudaRuntime(cudaMemcpyAsync(data_->cpu(), data_->gpu(), bytes_, cudaMemcpyDeviceToHost, stream_));checkCudaRuntime(cudaStreamSynchronize(stream_));}return *this;}int Tensor::offset_array(size_t size, const int* index_array) const{Assert(size <= shape_.size());int value = 0;for(int i = 0; i < shape_.size(); ++i){if(i < size)value += index_array[i];if(i + 1 < shape_.size())value *= shape_[i+1];}return value;}int Tensor::offset_array(const std::vector<int>& index_array) const{return offset_array(index_array.size(), index_array.data());}bool Tensor::save_to_file(const std::string& file) const{if(empty()) return false;FILE* f = fopen(file.c_str(), "wb");if(f == nullptr) return false;int ndims = this->ndims();int dtype_ = 0;unsigned int head[3] = {0xFCCFE2E2, ndims, static_cast<unsigned int>(dtype_)};fwrite(head, 1, sizeof(head), f);fwrite(shape_.data(), 1, sizeof(shape_[0]) * shape_.size(), f);fwrite(cpu(), 1, bytes_, f);fclose(f);return true;}/class TRTInferImplclass Logger : public ILogger {public:virtual void log(Severity severity, const char* msg) noexcept override {if (severity == Severity::kINTERNAL_ERROR) {INFOE("NVInfer INTERNAL_ERROR: %s", msg);abort();}else if (severity == Severity::kERROR) {INFOE("NVInfer: %s", msg);}else if (severity == Severity::kWARNING) {INFOW("NVInfer: %s", msg);}else if (severity == Severity::kINFO) {INFOD("NVInfer: %s", msg);}else {INFOD("%s", msg);}}};static Logger gLogger;template<typename _T>static void destroy_nvidia_pointer(_T* ptr) {if (ptr) ptr->destroy();}class EngineContext {public:virtual ~EngineContext() { destroy(); }void set_stream(cudaStream_t stream){if(owner_stream_){if (stream_) {cudaStreamDestroy(stream_);}owner_stream_ = false;}stream_ = stream;}bool build_model(const void* pdata, size_t size) {destroy();if(pdata == nullptr || size == 0)return false;owner_stream_ = true;checkCudaRuntime(cudaStreamCreate(&stream_));if(stream_ == nullptr)return false;runtime_ = shared_ptr<IRuntime>(createInferRuntime(gLogger), destroy_nvidia_pointer<IRuntime>);if (runtime_ == nullptr)return false;engine_ = shared_ptr<ICudaEngine>(runtime_->deserializeCudaEngine(pdata, size, nullptr), destroy_nvidia_pointer<ICudaEngine>);if (engine_ == nullptr)return false;//runtime_->setDLACore(0);context_ = shared_ptr<IExecutionContext>(engine_->createExecutionContext(), destroy_nvidia_pointer<IExecutionContext>);return context_ != nullptr;}private:void destroy() {context_.reset();engine_.reset();runtime_.reset();if(owner_stream_){if (stream_) {cudaStreamDestroy(stream_);}}stream_ = nullptr;}public:cudaStream_t stream_ = nullptr;bool owner_stream_ = false;shared_ptr<IExecutionContext> context_;shared_ptr<ICudaEngine> engine_;shared_ptr<IRuntime> runtime_ = nullptr;};class TRTInferImpl{public:virtual ~TRTInferImpl();bool load(const std::string& file);bool load_from_memory(const void* pdata, size_t size);void destroy();void forward(bool sync);int get_max_batch_size();cudaStream_t get_stream();void set_stream(cudaStream_t stream);void synchronize();size_t get_device_memory_size();std::shared_ptr<MixMemory> get_workspace();std::shared_ptr<Tensor> input(int index = 0);std::string get_input_name(int index = 0);std::shared_ptr<Tensor> output(int index = 0);std::string get_output_name(int index = 0);std::shared_ptr<Tensor> tensor(const std::string& name);bool is_output_name(const std::string& name);bool is_input_name(const std::string& name);void set_input (int index, std::shared_ptr<Tensor> tensor);void set_output(int index, std::shared_ptr<Tensor> tensor);std::shared_ptr<std::vector<uint8_t>> serial_engine();void print();int num_output();int num_input();int device();private:void build_engine_input_and_outputs_mapper();private:std::vector<std::shared_ptr<Tensor>> inputs_;std::vector<std::shared_ptr<Tensor>> outputs_;std::vector<int> inputs_map_to_ordered_index_;std::vector<int> outputs_map_to_ordered_index_;std::vector<std::string> inputs_name_;std::vector<std::string> outputs_name_;std::vector<std::shared_ptr<Tensor>> orderdBlobs_;std::map<std::string, int> blobsNameMapper_;std::shared_ptr<EngineContext> context_;std::vector<void*> bindingsPtr_;std::shared_ptr<MixMemory> workspace_;int device_ = 0;};TRTInferImpl::~TRTInferImpl(){destroy();}void TRTInferImpl::destroy() {int old_device = 0;checkCudaRuntime(cudaGetDevice(&old_device));checkCudaRuntime(cudaSetDevice(device_));this->context_.reset();this->blobsNameMapper_.clear();this->outputs_.clear();this->inputs_.clear();this->inputs_name_.clear();this->outputs_name_.clear();checkCudaRuntime(cudaSetDevice(old_device));}void TRTInferImpl::print(){if(!context_){INFOW("Infer print, nullptr.");return;}INFO("Infer %p detail", this);INFO("\tMax Batch Size: %d", this->get_max_batch_size());INFO("\tInputs: %d", inputs_.size());for(int i = 0; i < inputs_.size(); ++i){auto& tensor = inputs_[i];auto& name = inputs_name_[i];INFO("\t\t%d.%s : shape {%s}", i, name.c_str(), tensor->shape_string());}INFO("\tOutputs: %d", outputs_.size());for(int i = 0; i < outputs_.size(); ++i){auto& tensor = outputs_[i];auto& name = outputs_name_[i];INFO("\t\t%d.%s : shape {%s}", i, name.c_str(), tensor->shape_string());}}std::shared_ptr<std::vector<uint8_t>> TRTInferImpl::serial_engine() {auto memory = this->context_->engine_->serialize();auto output = make_shared<std::vector<uint8_t>>((uint8_t*)memory->data(), (uint8_t*)memory->data()+memory->size());memory->destroy();return output;}bool TRTInferImpl::load_from_memory(const void* pdata, size_t size) {if (pdata == nullptr || size == 0)return false;context_.reset(new EngineContext());//build modelif (!context_->build_model(pdata, size)) {context_.reset();return false;}workspace_.reset(new MixMemory());cudaGetDevice(&device_);build_engine_input_and_outputs_mapper();return true;}static std::vector<uint8_t> load_file(const string& file){ifstream in(file, ios::in | ios::binary);if (!in.is_open())return {};in.seekg(0, ios::end);size_t length = in.tellg();std::vector<uint8_t> data;if (length > 0){in.seekg(0, ios::beg);data.resize(length);in.read((char*)&data[0], length);}in.close();return data;}bool TRTInferImpl::load(const std::string& file) {auto data = load_file(file);if (data.empty())return false;context_.reset(new EngineContext());//build modelif (!context_->build_model(data.data(), data.size())) {context_.reset();return false;}workspace_.reset(new MixMemory());cudaGetDevice(&device_);build_engine_input_and_outputs_mapper();return true;}size_t TRTInferImpl::get_device_memory_size() {EngineContext* context = (EngineContext*)this->context_.get();return context->context_->getEngine().getDeviceMemorySize();}void TRTInferImpl::build_engine_input_and_outputs_mapper() {EngineContext* context = (EngineContext*)this->context_.get();int nbBindings = context->engine_->getNbBindings();int max_batchsize = context->engine_->getMaxBatchSize();inputs_.clear();inputs_name_.clear();outputs_.clear();outputs_name_.clear();orderdBlobs_.clear();bindingsPtr_.clear();blobsNameMapper_.clear();for (int i = 0; i < nbBindings; ++i) {auto dims = context->engine_->getBindingDimensions(i);auto type = context->engine_->getBindingDataType(i);const char* bindingName = context->engine_->getBindingName(i);dims.d[0] = max_batchsize;auto newTensor = make_shared<Tensor>(dims.nbDims, dims.d);newTensor->set_stream(this->context_->stream_);newTensor->set_workspace(this->workspace_);if (context->engine_->bindingIsInput(i)) {//if is inputinputs_.push_back(newTensor);inputs_name_.push_back(bindingName);inputs_map_to_ordered_index_.push_back(orderdBlobs_.size());}else {//if is outputoutputs_.push_back(newTensor);outputs_name_.push_back(bindingName);outputs_map_to_ordered_index_.push_back(orderdBlobs_.size());}blobsNameMapper_[bindingName] = i;orderdBlobs_.push_back(newTensor);}bindingsPtr_.resize(orderdBlobs_.size());}void TRTInferImpl::set_stream(cudaStream_t stream){this->context_->set_stream(stream);for(auto& t : orderdBlobs_)t->set_stream(stream);}cudaStream_t TRTInferImpl::get_stream() {return this->context_->stream_;}int TRTInferImpl::device() {return device_;}void TRTInferImpl::synchronize() {checkCudaRuntime(cudaStreamSynchronize(context_->stream_));}bool TRTInferImpl::is_output_name(const std::string& name){return std::find(outputs_name_.begin(), outputs_name_.end(), name) != outputs_name_.end();}bool TRTInferImpl::is_input_name(const std::string& name){return std::find(inputs_name_.begin(), inputs_name_.end(), name) != inputs_name_.end();}void TRTInferImpl::forward(bool sync) {EngineContext* context = (EngineContext*)context_.get();int inputBatchSize = inputs_[0]->size(0);for(int i = 0; i < context->engine_->getNbBindings(); ++i){auto dims = context->engine_->getBindingDimensions(i);auto type = context->engine_->getBindingDataType(i);dims.d[0] = inputBatchSize;if(context->engine_->bindingIsInput(i)){context->context_->setBindingDimensions(i, dims);}}for (int i = 0; i < outputs_.size(); ++i) {outputs_[i]->resize_single_dim(0, inputBatchSize);outputs_[i]->to_gpu(false);}for (int i = 0; i < orderdBlobs_.size(); ++i)bindingsPtr_[i] = orderdBlobs_[i]->gpu();void** bindingsptr = bindingsPtr_.data();//bool execute_result = context->context_->enqueue(inputBatchSize, bindingsptr, context->stream_, nullptr);bool execute_result = context->context_->enqueueV2(bindingsptr, context->stream_, nullptr);if(!execute_result){auto code = cudaGetLastError();INFOF("execute fail, code %d[%s], message %s", code, cudaGetErrorName(code), cudaGetErrorString(code));}if (sync) {synchronize();}}std::shared_ptr<MixMemory> TRTInferImpl::get_workspace() {return workspace_;}int TRTInferImpl::num_input() {return this->inputs_.size();}int TRTInferImpl::num_output() {return this->outputs_.size();}void TRTInferImpl::set_input (int index, std::shared_ptr<Tensor> tensor){Assert(index >= 0 && index < inputs_.size());this->inputs_[index] = tensor;int order_index = inputs_map_to_ordered_index_[index];this->orderdBlobs_[order_index] = tensor;}void TRTInferImpl::set_output(int index, std::shared_ptr<Tensor> tensor){Assert(index >= 0 && index < outputs_.size());this->outputs_[index] = tensor;int order_index = outputs_map_to_ordered_index_[index];this->orderdBlobs_[order_index] = tensor;}std::shared_ptr<Tensor> TRTInferImpl::input(int index) {Assert(index >= 0 && index < inputs_name_.size());return this->inputs_[index];}std::string TRTInferImpl::get_input_name(int index){Assert(index >= 0 && index < inputs_name_.size());return inputs_name_[index];}std::shared_ptr<Tensor> TRTInferImpl::output(int index) {Assert(index >= 0 && index < outputs_.size());return outputs_[index];}std::string TRTInferImpl::get_output_name(int index){Assert(index >= 0 && index < outputs_name_.size());return outputs_name_[index];}int TRTInferImpl::get_max_batch_size() {Assert(this->context_ != nullptr);return this->context_->engine_->getMaxBatchSize();}std::shared_ptr<Tensor> TRTInferImpl::tensor(const std::string& name) {Assert(this->blobsNameMapper_.find(name) != this->blobsNameMapper_.end());return orderdBlobs_[blobsNameMapper_[name]];}std::shared_ptr<TRTInferImpl> load_infer(const string& file) {std::shared_ptr<TRTInferImpl> infer(new TRTInferImpl());if (!infer->load(file))infer.reset();return infer;}//class MonopolyAllocator///* 独占分配器通过对tensor做独占管理,具有max_batch * 2个tensor,通过query获取一个当推理结束后,该tensor释放使用权,即可交给下一个图像使用,内存实现复用*/template<class _ItemType>class MonopolyAllocator{public:class MonopolyData{public:std::shared_ptr<_ItemType>& data(){ return data_; }void release(){manager_->release_one(this);}private:MonopolyData(MonopolyAllocator* pmanager){manager_ = pmanager;}private:friend class MonopolyAllocator;MonopolyAllocator* manager_ = nullptr;std::shared_ptr<_ItemType> data_;bool available_ = true;};typedef std::shared_ptr<MonopolyData> MonopolyDataPointer;MonopolyAllocator(int size){capacity_ = size;num_available_ = size;datas_.resize(size);for(int i = 0; i < size; ++i)datas_[i] = std::shared_ptr<MonopolyData>(new MonopolyData(this));}virtual ~MonopolyAllocator(){run_ = false;cv_.notify_all();std::unique_lock<std::mutex> l(lock_);cv_exit_.wait(l, [&](){return num_wait_thread_ == 0;});}MonopolyDataPointer query(int timeout = 10000){std::unique_lock<std::mutex> l(lock_);if(!run_) return nullptr;if(num_available_ == 0){num_wait_thread_++;auto state = cv_.wait_for(l, std::chrono::milliseconds(timeout), [&](){return num_available_ > 0 || !run_;});num_wait_thread_--;cv_exit_.notify_one();// timeout, no available, exit programif(!state || num_available_ == 0 || !run_)return nullptr;}auto item = std::find_if(datas_.begin(), datas_.end(), [](MonopolyDataPointer& item){return item->available_;});if(item == datas_.end())return nullptr;(*item)->available_ = false;num_available_--;return *item;}int num_available(){return num_available_;}int capacity(){return capacity_;}private:void release_one(MonopolyData* prq){std::unique_lock<std::mutex> l(lock_);if(!prq->available_){prq->available_ = true;num_available_++;cv_.notify_one();}}private:std::mutex lock_;std::condition_variable cv_;std::condition_variable cv_exit_;std::vector<MonopolyDataPointer> datas_;int capacity_ = 0;volatile int num_available_ = 0;volatile int num_wait_thread_ = 0;volatile bool run_ = true;};/class ThreadSafedAsyncInfer//* 异步线程安全的推理器通过异步线程启动,使得调用方允许任意线程调用把图像做输入,并通过future来获取异步结果*/template<class Input, class Output, class StartParam=std::tuple<std::string, int>, class JobAdditional=int>class ThreadSafedAsyncInfer{public:struct Job{Input input;Output output;JobAdditional additional;MonopolyAllocator<Tensor>::MonopolyDataPointer mono_tensor;std::shared_ptr<std::promise<Output>> pro;};virtual ~ThreadSafedAsyncInfer(){stop();}void stop(){run_ = false;cond_.notify_all();// cleanup jobs{std::unique_lock<std::mutex> l(jobs_lock_);while(!jobs_.empty()){auto& item = jobs_.front();if(item.pro)item.pro->set_value(Output());jobs_.pop();}};if(worker_){worker_->join();worker_.reset();}}bool startup(const StartParam& param){run_ = true;std::promise<bool> pro;start_param_ = param;worker_ = std::make_shared<std::thread>(&ThreadSafedAsyncInfer::worker, this, std::ref(pro));return pro.get_future().get();}virtual std::shared_future<Output> commit(const Input& input){Job job;job.pro = std::make_shared<std::promise<Output>>();if(!preprocess(job, input)){job.pro->set_value(Output());return job.pro->get_future();}///{std::unique_lock<std::mutex> l(jobs_lock_);jobs_.push(job);};cond_.notify_one();return job.pro->get_future();}virtual std::vector<std::shared_future<Output>> commits(const std::vector<Input>& inputs){int batch_size = std::min((int)inputs.size(), this->tensor_allocator_->capacity());std::vector<Job> jobs(inputs.size());std::vector<std::shared_future<Output>> results(inputs.size());int nepoch = (inputs.size() + batch_size - 1) / batch_size;for(int epoch = 0; epoch < nepoch; ++epoch){int begin = epoch * batch_size;int end = std::min((int)inputs.size(), begin + batch_size);for(int i = begin; i < end; ++i){Job& job = jobs[i];job.pro = std::make_shared<std::promise<Output>>();if(!preprocess(job, inputs[i])){job.pro->set_value(Output());}results[i] = job.pro->get_future();}///{std::unique_lock<std::mutex> l(jobs_lock_);for(int i = begin; i < end; ++i){jobs_.emplace(std::move(jobs[i]));};}cond_.notify_one();}return results;}protected:virtual void worker(std::promise<bool>& result) = 0;virtual bool preprocess(Job& job, const Input& input) = 0;virtual bool get_jobs_and_wait(std::vector<Job>& fetch_jobs, int max_size){std::unique_lock<std::mutex> l(jobs_lock_);cond_.wait(l, [&](){return !run_ || !jobs_.empty();});if(!run_) return false;fetch_jobs.clear();for(int i = 0; i < max_size && !jobs_.empty(); ++i){fetch_jobs.emplace_back(std::move(jobs_.front()));jobs_.pop();}return true;}virtual bool get_job_and_wait(Job& fetch_job){std::unique_lock<std::mutex> l(jobs_lock_);cond_.wait(l, [&](){return !run_ || !jobs_.empty();});if(!run_) return false;fetch_job = std::move(jobs_.front());jobs_.pop();return true;}protected:StartParam start_param_;std::atomic<bool> run_;std::mutex jobs_lock_;std::queue<Job> jobs_;std::shared_ptr<std::thread> worker_;std::condition_variable cond_;std::shared_ptr<MonopolyAllocator<Tensor>> tensor_allocator_;};///class YoloTRTInferImpl///* Yolo的具体实现通过上述类的特性,实现预处理的计算重叠、异步垮线程调用,最终拼接为多个图为一个batch进行推理。最大化的利用显卡性能,实现高性能高可用好用的yolo推理*/const char* type_name(Type type){switch(type){case Type::V5: return "YoloV5";case Type::X: return "YoloX";default: return "Unknow";}}struct AffineMatrix{float i2d[6]; // image to dst(network), 2x3 matrixfloat d2i[6]; // dst to image, 2x3 matrixvoid compute(const cv::Size& from, const cv::Size& to){float scale_x = to.width / (float)from.width;float scale_y = to.height / (float)from.height;float scale = std::min(scale_x, scale_y);i2d[0] = scale; i2d[1] = 0; i2d[2] = -scale * from.width * 0.5 + to.width * 0.5 + scale * 0.5 - 0.5;i2d[3] = 0; i2d[4] = scale; i2d[5] = -scale * from.height * 0.5 + to.height * 0.5 + scale * 0.5 - 0.5;cv::Mat m2x3_i2d(2, 3, CV_32F, i2d);cv::Mat m2x3_d2i(2, 3, CV_32F, d2i);cv::invertAffineTransform(m2x3_i2d, m2x3_d2i);}cv::Mat i2d_mat(){return cv::Mat(2, 3, CV_32F, i2d);}};using ThreadSafedAsyncInferImpl = ThreadSafedAsyncInfer<cv::Mat, // inputBoxArray, // outputtuple<string, int>, // start paramAffineMatrix // additional>;class YoloTRTInferImpl : public Infer, public ThreadSafedAsyncInferImpl{public:/** 要求在TRTInferImpl里面执行stop,而不是在基类执行stop **/virtual ~YoloTRTInferImpl(){stop();}virtual bool startup(const string& file, Type type, int gpuid, float confidence_threshold, float nms_threshold){if(type == Type::V5){normalize_ = Norm::alpha_beta(1 / 255.0f, 0.0f, ChannelType::SwapRB);}else if(type == Type::X){//float mean[] = {0.485, 0.456, 0.406};//float std[] = {0.229, 0.224, 0.225};//normalize_ = Norm::mean_std(mean, std, 1/255.0f, ChannelType::Invert);normalize_ = Norm::None();}else{INFOE("Unsupport type %d", type);}confidence_threshold_ = confidence_threshold;nms_threshold_ = nms_threshold;return ThreadSafedAsyncInferImpl::startup(make_tuple(file, gpuid));}virtual void worker(promise<bool>& result) override{string file = get<0>(start_param_);int gpuid = get<1>(start_param_);set_device(gpuid);auto engine = load_infer(file);if(engine == nullptr){INFOE("Engine %s load failed", file.c_str());result.set_value(false);return;}engine->print();const int MAX_IMAGE_BBOX = 1024;const int NUM_BOX_ELEMENT = 7; // left, top, right, bottom, confidence, class, keepflagTensor affin_matrix_device;Tensor output_array_device;int max_batch_size = engine->get_max_batch_size();auto input = engine->tensor("images");auto output = engine->tensor("output");int num_classes = output->size(2) - 5;input_width_ = input->size(3);input_height_ = input->size(2);tensor_allocator_ = make_shared<MonopolyAllocator<Tensor>>(max_batch_size * 2);stream_ = engine->get_stream();gpu_ = gpuid;result.set_value(true);input->resize_single_dim(0, max_batch_size).to_gpu();affin_matrix_device.set_stream(stream_);// 这里8个值的目的是保证 8 * sizeof(float) % 32 == 0affin_matrix_device.resize(max_batch_size, 8).to_gpu();// 这里的 1 + MAX_IMAGE_BBOX结构是,counter + bboxes ...output_array_device.resize(max_batch_size, 1 + MAX_IMAGE_BBOX * NUM_BOX_ELEMENT).to_gpu();vector<Job> fetch_jobs;while(get_jobs_and_wait(fetch_jobs, max_batch_size)){int infer_batch_size = fetch_jobs.size();input->resize_single_dim(0, infer_batch_size);for(int ibatch = 0; ibatch < infer_batch_size; ++ibatch){auto& job = fetch_jobs[ibatch];auto& mono = job.mono_tensor->data();affin_matrix_device.copy_from_gpu(affin_matrix_device.offset(ibatch), mono->get_workspace()->gpu(), 6);input->copy_from_gpu(input->offset(ibatch), mono->gpu(), mono->count());job.mono_tensor->release();}engine->forward(false);output_array_device.to_gpu(false);for(int ibatch = 0; ibatch < infer_batch_size; ++ibatch){auto& job = fetch_jobs[ibatch];float* image_based_output = output->gpu<float>(ibatch);float* output_array_ptr = output_array_device.gpu<float>(ibatch);auto affine_matrix = affin_matrix_device.gpu<float>(ibatch);checkCudaRuntime(cudaMemsetAsync(output_array_ptr, 0, sizeof(int), stream_));decode_kernel_invoker(image_based_output, output->size(1), num_classes, confidence_threshold_, nms_threshold_, affine_matrix, output_array_ptr, MAX_IMAGE_BBOX, stream_);}output_array_device.to_cpu();for(int ibatch = 0; ibatch < infer_batch_size; ++ibatch){float* parray = output_array_device.cpu<float>(ibatch);int count = min(MAX_IMAGE_BBOX, (int)*parray);auto& job = fetch_jobs[ibatch];auto& image_based_boxes = job.output;for(int i = 0; i < count; ++i){float* pbox = parray + 1 + i * NUM_BOX_ELEMENT;int label = pbox[5];int keepflag = pbox[6];if(keepflag == 1){image_based_boxes.emplace_back(pbox[0], pbox[1], pbox[2], pbox[3], pbox[4], label);}}job.pro->set_value(image_based_boxes);}fetch_jobs.clear();}stream_ = nullptr;tensor_allocator_.reset();INFO("Engine destroy.");}virtual bool preprocess(Job& job, const Mat& image) override{if(tensor_allocator_ == nullptr){INFOE("tensor_allocator_ is nullptr");return false;}job.mono_tensor = tensor_allocator_->query();if(job.mono_tensor == nullptr){INFOE("Tensor allocator query failed.");return false;}AutoDevice auto_device(gpu_);auto& tensor = job.mono_tensor->data();if(tensor == nullptr){// not inittensor = make_shared<Tensor>();tensor->set_workspace(make_shared<MixMemory>());}Size input_size(input_width_, input_height_);job.additional.compute(image.size(), input_size);tensor->set_stream(stream_);tensor->resize(1, 3, input_height_, input_width_);size_t size_image = image.cols * image.rows * 3;size_t size_matrix = upbound(sizeof(job.additional.d2i), 32);auto workspace = tensor->get_workspace();uint8_t* gpu_workspace = (uint8_t*)workspace->gpu(size_matrix + size_image);float* affine_matrix_device = (float*)gpu_workspace;uint8_t* image_device = size_matrix + gpu_workspace;uint8_t* cpu_workspace = (uint8_t*)workspace->cpu(size_matrix + size_image);float* affine_matrix_host = (float*)cpu_workspace;uint8_t* image_host = size_matrix + cpu_workspace;//checkCudaRuntime(cudaMemcpyAsync(image_host, image.data, size_image, cudaMemcpyHostToHost, stream_));// speed upmemcpy(image_host, image.data, size_image);memcpy(affine_matrix_host, job.additional.d2i, sizeof(job.additional.d2i));checkCudaRuntime(cudaMemcpyAsync(image_device, image_host, size_image, cudaMemcpyHostToDevice, stream_));checkCudaRuntime(cudaMemcpyAsync(affine_matrix_device, affine_matrix_host, sizeof(job.additional.d2i), cudaMemcpyHostToDevice, stream_));warp_affine_bilinear_and_normalize_plane(image_device, image.cols * 3, image.cols, image.rows, tensor->gpu<float>(), input_width_, input_height_, affine_matrix_device, 114, normalize_, stream_);return true;}virtual vector<shared_future<BoxArray>> commits(const vector<Mat>& images) override{return ThreadSafedAsyncInferImpl::commits(images);}virtual std::shared_future<BoxArray> commit(const Mat& image) override{return ThreadSafedAsyncInferImpl::commit(image);}private:int input_width_ = 0;int input_height_ = 0;int gpu_ = 0;float confidence_threshold_ = 0;float nms_threshold_ = 0;cudaStream_t stream_ = nullptr;Norm normalize_;};void image_to_tensor(const cv::Mat& image, shared_ptr<Tensor>& tensor, Type type, int ibatch){Norm normalize;if(type == Type::V5){normalize = Norm::alpha_beta(1 / 255.0f, 0.0f, ChannelType::SwapRB);}else if(type == Type::X){//float mean[] = {0.485, 0.456, 0.406};//float std[] = {0.229, 0.224, 0.225};//normalize_ = CUDAKernel::Norm::mean_std(mean, std, 1/255.0f, CUDAKernel::ChannelType::Invert);normalize = Norm::None();}else{INFOE("Unsupport type %d", type);}Size input_size(tensor->size(3), tensor->size(2));AffineMatrix affine;affine.compute(image.size(), input_size);size_t size_image = image.cols * image.rows * 3;size_t size_matrix = upbound(sizeof(affine.d2i), 32);auto workspace = tensor->get_workspace();uint8_t* gpu_workspace = (uint8_t*)workspace->gpu(size_matrix + size_image);float* affine_matrix_device = (float*)gpu_workspace;uint8_t* image_device = size_matrix + gpu_workspace;uint8_t* cpu_workspace = (uint8_t*)workspace->cpu(size_matrix + size_image);float* affine_matrix_host = (float*)cpu_workspace;uint8_t* image_host = size_matrix + cpu_workspace;auto stream = tensor->get_stream();memcpy(image_host, image.data, size_image);memcpy(affine_matrix_host, affine.d2i, sizeof(affine.d2i));checkCudaRuntime(cudaMemcpyAsync(image_device, image_host, size_image, cudaMemcpyHostToDevice, stream));checkCudaRuntime(cudaMemcpyAsync(affine_matrix_device, affine_matrix_host, sizeof(affine.d2i), cudaMemcpyHostToDevice, stream));warp_affine_bilinear_and_normalize_plane(image_device, image.cols * 3, image.cols, image.rows, tensor->gpu<float>(ibatch), input_size.width, input_size.height, affine_matrix_device, 114, normalize, stream);}shared_ptr<Infer> create_infer(const string& engine_file, Type type, int gpuid, float confidence_threshold, float nms_threshold){shared_ptr<YoloTRTInferImpl> instance(new YoloTRTInferImpl());if(!instance->startup(engine_file, type, gpuid, confidence_threshold, nms_threshold)){instance.reset();}return instance;}//Compile Model/const char* mode_string(Mode type) {switch (type) {case Mode::FP32:return "FP32";case Mode::FP16:return "FP16";case Mode::INT8:return "INT8";default:return "UnknowCompileMode";}}typedef std::function<void(int current, int count, const std::vector<std::string>& files, std::shared_ptr<Tensor>& tensor)> Int8Process;class Int8EntropyCalibrator : public IInt8EntropyCalibrator2{public:Int8EntropyCalibrator(const vector<string>& imagefiles, nvinfer1::Dims dims, const Int8Process& preprocess) {Assert(preprocess != nullptr);this->dims_ = dims;this->allimgs_ = imagefiles;this->preprocess_ = preprocess;this->fromCalibratorData_ = false;files_.resize(dims.d[0]);checkCudaRuntime(cudaStreamCreate(&stream_));}Int8EntropyCalibrator(const vector<uint8_t>& entropyCalibratorData, nvinfer1::Dims dims, const Int8Process& preprocess) {Assert(preprocess != nullptr);this->dims_ = dims;this->entropyCalibratorData_ = entropyCalibratorData;this->preprocess_ = preprocess;this->fromCalibratorData_ = true;files_.resize(dims.d[0]);checkCudaRuntime(cudaStreamCreate(&stream_));}virtual ~Int8EntropyCalibrator(){checkCudaRuntime(cudaStreamDestroy(stream_));}int getBatchSize() const noexcept {return dims_.d[0];}bool next() {int batch_size = dims_.d[0];if (cursor_ + batch_size > allimgs_.size())return false;int old_cursor = cursor_;for(int i = 0; i < batch_size; ++i)files_[i] = allimgs_[cursor_++];if (!tensor_){tensor_.reset(new Tensor(dims_.nbDims, dims_.d));tensor_->set_stream(stream_);tensor_->set_workspace(make_shared<MixMemory>());}preprocess_(old_cursor, allimgs_.size(), files_, tensor_);return true;}bool getBatch(void* bindings[], const char* names[], int nbBindings) noexcept {if (!next()) return false;bindings[0] = tensor_->gpu();return true;}const vector<uint8_t>& getEntropyCalibratorData() {return entropyCalibratorData_;}const void* readCalibrationCache(size_t& length) noexcept {if (fromCalibratorData_) {length = this->entropyCalibratorData_.size();return this->entropyCalibratorData_.data();}length = 0;return nullptr;}virtual void writeCalibrationCache(const void* cache, size_t length) noexcept {entropyCalibratorData_.assign((uint8_t*)cache, (uint8_t*)cache + length);}private:Int8Process preprocess_;vector<string> allimgs_;size_t batchCudaSize_ = 0;int cursor_ = 0;nvinfer1::Dims dims_;vector<string> files_;shared_ptr<Tensor> tensor_;vector<uint8_t> entropyCalibratorData_;bool fromCalibratorData_ = false;cudaStream_t stream_ = nullptr;};bool compile(Mode mode, Type type,unsigned int max_batch_size,const string& source_onnx,const string& saveto,size_t max_workspace_size,const std::string& int8_images_folder,const std::string& int8_entropy_calibrator_cache_file) {bool hasEntropyCalibrator = false;vector<uint8_t> entropyCalibratorData;vector<string> entropyCalibratorFiles;auto int8process = [=](int current, int count, const vector<string>& files, shared_ptr<Tensor>& tensor){for(int i = 0; i < files.size(); ++i){auto& file = files[i];INFO("Int8 load %d / %d, %s", current + i + 1, count, file.c_str());auto image = cv::imread(file);if(image.empty()){INFOE("Load image failed, %s", file.c_str());continue;}image_to_tensor(image, tensor, type, i);}tensor->synchronize();};if (mode == Mode::INT8) {if (!int8_entropy_calibrator_cache_file.empty()) {if (exists(int8_entropy_calibrator_cache_file)) {entropyCalibratorData = load_file(int8_entropy_calibrator_cache_file);if (entropyCalibratorData.empty()) {INFOE("entropyCalibratorFile is set as: %s, but we read is empty.", int8_entropy_calibrator_cache_file.c_str());return false;}hasEntropyCalibrator = true;}}if (hasEntropyCalibrator) {if (!int8_images_folder.empty()) {INFOW("int8_images_folder is ignore, when int8_entropy_calibrator_cache_file is set");}}else {entropyCalibratorFiles = glob_image_files(int8_images_folder);if (entropyCalibratorFiles.empty()) {INFOE("Can not find any images(jpg/png/bmp/jpeg/tiff) from directory: %s", int8_images_folder.c_str());return false;}if(entropyCalibratorFiles.size() < max_batch_size){INFOW("Too few images provided, %d[provided] < %d[max batch size], image copy will be performed", entropyCalibratorFiles.size(), max_batch_size);int old_size = entropyCalibratorFiles.size();for(int i = old_size; i < max_batch_size; ++i)entropyCalibratorFiles.push_back(entropyCalibratorFiles[i % old_size]);}}}else {if (hasEntropyCalibrator) {INFOW("int8_entropy_calibrator_cache_file is ignore, when Mode is '%s'", mode_string(mode));}}INFO("Compile %s %s.", mode_string(mode), source_onnx.c_str());shared_ptr<IBuilder> builder(createInferBuilder(gLogger), destroy_nvidia_pointer<IBuilder>);if (builder == nullptr) {INFOE("Can not create builder.");return false;}shared_ptr<IBuilderConfig> config(builder->createBuilderConfig(), destroy_nvidia_pointer<IBuilderConfig>);if (mode == Mode::FP16) {if (!builder->platformHasFastFp16()) {INFOW("Platform not have fast fp16 support");}config->setFlag(BuilderFlag::kFP16);}else if (mode == Mode::INT8) {if (!builder->platformHasFastInt8()) {INFOW("Platform not have fast int8 support");}config->setFlag(BuilderFlag::kINT8);}shared_ptr<INetworkDefinition> network;shared_ptr<nvonnxparser::IParser> onnxParser;const auto explicitBatch = 1U << static_cast<uint32_t>(nvinfer1::NetworkDefinitionCreationFlag::kEXPLICIT_BATCH);network = shared_ptr<INetworkDefinition>(builder->createNetworkV2(explicitBatch), destroy_nvidia_pointer<INetworkDefinition>);//from onnx is not markOutputonnxParser.reset(nvonnxparser::createParser(*network, gLogger), destroy_nvidia_pointer<nvonnxparser::IParser>);if (onnxParser == nullptr) {INFOE("Can not create parser.");return false;}if (!onnxParser->parseFromFile(source_onnx.c_str(), 1)) {INFOE("Can not parse OnnX file: %s", source_onnx.c_str());return false;}auto inputTensor = network->getInput(0);auto inputDims = inputTensor->getDimensions();shared_ptr<Int8EntropyCalibrator> int8Calibrator;if (mode == Mode::INT8) {auto calibratorDims = inputDims;calibratorDims.d[0] = max_batch_size;if (hasEntropyCalibrator) {INFO("Using exist entropy calibrator data[%d bytes]: %s", entropyCalibratorData.size(), int8_entropy_calibrator_cache_file.c_str());int8Calibrator.reset(new Int8EntropyCalibrator(entropyCalibratorData, calibratorDims, int8process));}else {INFO("Using image list[%d files]: %s", entropyCalibratorFiles.size(), int8_images_folder.c_str());int8Calibrator.reset(new Int8EntropyCalibrator(entropyCalibratorFiles, calibratorDims, int8process));}config->setInt8Calibrator(int8Calibrator.get());}INFO("Input shape is %s", join_dims(vector<int>(inputDims.d, inputDims.d + inputDims.nbDims)).c_str());INFO("Set max batch size = %d", max_batch_size);INFO("Set max workspace size = %.2f MB", max_workspace_size / 1024.0f / 1024.0f);int net_num_input = network->getNbInputs();INFO("Network has %d inputs:", net_num_input);vector<string> input_names(net_num_input);for(int i = 0; i < net_num_input; ++i){auto tensor = network->getInput(i);auto dims = tensor->getDimensions();auto dims_str = join_dims(vector<int>(dims.d, dims.d+dims.nbDims));INFO(" %d.[%s] shape is %s", i, tensor->getName(), dims_str.c_str());input_names[i] = tensor->getName();}int net_num_output = network->getNbOutputs();INFO("Network has %d outputs:", net_num_output);for(int i = 0; i < net_num_output; ++i){auto tensor = network->getOutput(i);auto dims = tensor->getDimensions();auto dims_str = join_dims(vector<int>(dims.d, dims.d+dims.nbDims));INFO(" %d.[%s] shape is %s", i, tensor->getName(), dims_str.c_str());}int net_num_layers = network->getNbLayers();INFO("Network has %d layers", net_num_layers); builder->setMaxBatchSize(max_batch_size);config->setMaxWorkspaceSize(max_workspace_size);auto profile = builder->createOptimizationProfile();for(int i = 0; i < net_num_input; ++i){auto input = network->getInput(i);auto input_dims = input->getDimensions();input_dims.d[0] = 1;profile->setDimensions(input->getName(), nvinfer1::OptProfileSelector::kMIN, input_dims);profile->setDimensions(input->getName(), nvinfer1::OptProfileSelector::kOPT, input_dims);input_dims.d[0] = max_batch_size;profile->setDimensions(input->getName(), nvinfer1::OptProfileSelector::kMAX, input_dims);}config->addOptimizationProfile(profile);INFO("Building engine...");auto time_start = chrono::duration_cast<chrono::milliseconds>(chrono::system_clock::now().time_since_epoch()).count();shared_ptr<ICudaEngine> engine(builder->buildEngineWithConfig(*network, *config), destroy_nvidia_pointer<ICudaEngine>);if (engine == nullptr) {INFOE("engine is nullptr");return false;}if (mode == Mode::INT8) {if (!hasEntropyCalibrator) {if (!int8_entropy_calibrator_cache_file.empty()) {INFO("Save calibrator to: %s", int8_entropy_calibrator_cache_file.c_str());save_file(int8_entropy_calibrator_cache_file, int8Calibrator->getEntropyCalibratorData());}else {INFO("No set entropyCalibratorFile, and entropyCalibrator will not save.");}}}auto time_end = chrono::duration_cast<chrono::milliseconds>(chrono::system_clock::now().time_since_epoch()).count();INFO("Build done %lld ms !", time_end - time_start);// serialize the engine, then close everything downshared_ptr<IHostMemory> seridata(engine->serialize(), destroy_nvidia_pointer<IHostMemory>);return save_file(saveto, seridata->data(), seridata->size());}
};
这段代码是 simple_yolo.hpp 头文件的实现部分,它包含了一些必要的库和头文件,以及一些辅助函数的实现。
其中,包含了 NvInfer.h、NvOnnxParser.h 和 cuda_runtime.h 头文件,它们是使用 NVIDIA TensorRT 进行推理所必需的库和头文件。
还包含了一些标准库和头文件,如 、、、 等,用于处理文件、内存等。
此外,还包含一些多线程相关的头文件,如 、<condition_variable>、、 等,用于实现多线程并发执行推理。
最后,还包含了一些条件编译指令,用于在不同的操作系统和编译器环境下进行编译和链接,以确保代码的可移植性和兼容性。
main.cpp
#include "simple_yolo.hpp"#if defined(_WIN32)
# include <Windows.h>
# include <wingdi.h>
# include <Shlwapi.h>
# pragma comment(lib, "shlwapi.lib")
# pragma comment(lib, "ole32.lib")
# pragma comment(lib, "gdi32.lib")
# undef min
# undef max
#else
# include <dirent.h>
# include <sys/types.h>
# include <sys/stat.h>
# include <unistd.h>
# include <stdarg.h>
#endifusing namespace std;static const char* cocolabels[] = {"person", "bicycle", "car", "motorcycle", "airplane","bus", "train", "truck", "boat", "traffic light", "fire hydrant","stop sign", "parking meter", "bench", "bird", "cat", "dog", "horse","sheep", "cow", "elephant", "bear", "zebra", "giraffe", "backpack","umbrella", "handbag", "tie", "suitcase", "frisbee", "skis","snowboard", "sports ball", "kite", "baseball bat", "baseball glove","skateboard", "surfboard", "tennis racket", "bottle", "wine glass","cup", "fork", "knife", "spoon", "bowl", "banana", "apple", "sandwich","orange", "broccoli", "carrot", "hot dog", "pizza", "donut", "cake","chair", "couch", "potted plant", "bed", "dining table", "toilet", "tv","laptop", "mouse", "remote", "keyboard", "cell phone", "microwave","oven", "toaster", "sink", "refrigerator", "book", "clock", "vase","scissors", "teddy bear", "hair drier", "toothbrush"
};static std::tuple<uint8_t, uint8_t, uint8_t> hsv2bgr(float h, float s, float v){const int h_i = static_cast<int>(h * 6);const float f = h * 6 - h_i;const float p = v * (1 - s);const float q = v * (1 - f*s);const float t = v * (1 - (1 - f) * s);float r, g, b;switch (h_i) {case 0:r = v; g = t; b = p;break;case 1:r = q; g = v; b = p;break;case 2:r = p; g = v; b = t;break;case 3:r = p; g = q; b = v;break;case 4:r = t; g = p; b = v;break;case 5:r = v; g = p; b = q;break;default:r = 1; g = 1; b = 1;break;}return make_tuple(static_cast<uint8_t>(b * 255), static_cast<uint8_t>(g * 255), static_cast<uint8_t>(r * 255));
}static std::tuple<uint8_t, uint8_t, uint8_t> random_color(int id){float h_plane = ((((unsigned int)id << 2) ^ 0x937151) % 100) / 100.0f;;float s_plane = ((((unsigned int)id << 3) ^ 0x315793) % 100) / 100.0f;return hsv2bgr(h_plane, s_plane, 1);
}static bool exists(const string& path){#ifdef _WIN32return ::PathFileExistsA(path.c_str());
#elsereturn access(path.c_str(), R_OK) == 0;
#endif
}static string get_file_name(const string& path, bool include_suffix){if (path.empty()) return "";int p = path.rfind('/');int e = path.rfind('\\');p = std::max(p, e);p += 1;//include suffixif (include_suffix)return path.substr(p);int u = path.rfind('.');if (u == -1)return path.substr(p);if (u <= p) u = path.size();return path.substr(p, u - p);
}static double timestamp_now_float() {return chrono::duration_cast<chrono::microseconds>(chrono::system_clock::now().time_since_epoch()).count() / 1000.0;
}bool requires_model(const string& name) {auto onnx_file = cv::format("%s_dynamic.onnx", name.c_str());if (!exists(onnx_file)) {printf("Auto download %s\n", onnx_file.c_str());system(cv::format("wget http://zifuture.com:1556/fs/25.shared/%s", onnx_file.c_str()).c_str());}bool isexists = exists(onnx_file);if (!isexists) {printf("Download %s failed\n", onnx_file.c_str());}return isexists;
}static void inference_and_performance(int deviceid, const string& engine_file, SimpleYolo::Mode mode, SimpleYolo::Type type, const string& model_name){auto engine = SimpleYolo::create_infer(engine_file, type, deviceid, 0.4f, 0.5f);if(engine == nullptr){printf("Engine is nullptr\n");return;}vector<cv::String> files_;files_.reserve(10000);cv::glob("inference/*.jpg", files_, true);vector<string> files(files_.begin(), files_.end());vector<cv::Mat> images;for(int i = 0; i < files.size(); ++i){auto image = cv::imread(files[i]);images.emplace_back(image);}// warmupvector<shared_future<SimpleYolo::BoxArray>> boxes_array;for(int i = 0; i < 10; ++i)boxes_array = engine->commits(images);boxes_array.back().get();boxes_array.clear();/const int ntest = 100;auto begin_timer = timestamp_now_float();for(int i = 0; i < ntest; ++i)boxes_array = engine->commits(images);// wait all resultboxes_array.back().get();float inference_average_time = (timestamp_now_float() - begin_timer) / ntest / images.size();auto type_name = SimpleYolo::type_name(type);auto mode_name = SimpleYolo::mode_string(mode);printf("%s[%s] average: %.2f ms / image, FPS: %.2f\n", engine_file.c_str(), type_name, inference_average_time, 1000 / inference_average_time);string root = "simple_yolo_result";for(int i = 0; i < boxes_array.size(); ++i){auto& image = images[i];auto boxes = boxes_array[i].get();for(auto& obj : boxes){uint8_t b, g, r;tie(b, g, r) = random_color(obj.class_label);cv::rectangle(image, cv::Point(obj.left, obj.top), cv::Point(obj.right, obj.bottom), cv::Scalar(b, g, r), 5);auto name = cocolabels[obj.class_label];auto caption = cv::format("%s %.2f", name, obj.confidence);int width = cv::getTextSize(caption, 0, 1, 2, nullptr).width + 10;cv::rectangle(image, cv::Point(obj.left-3, obj.top-33), cv::Point(obj.left + width, obj.top), cv::Scalar(b, g, r), -1);cv::putText(image, caption, cv::Point(obj.left, obj.top-5), 0, 1, cv::Scalar::all(0), 2, 16);}string file_name = get_file_name(files[i], false);string save_path = cv::format("%s/%s.jpg", root.c_str(), file_name.c_str());printf("Save to %s, %d object, average time %.2f ms\n", save_path.c_str(), boxes.size(), inference_average_time);cv::imwrite(save_path, image);}engine.reset();
}static void test(SimpleYolo::Type type, SimpleYolo::Mode mode, const string& model){int deviceid = 0;auto mode_name = SimpleYolo::mode_string(mode);SimpleYolo::set_device(deviceid);const char* name = model.c_str();printf("===================== test %s %s %s ==================================\n", SimpleYolo::type_name(type), mode_name, name);if(!requires_model(name))return;string onnx_file = cv::format("%s_dynamic.onnx", name);string model_file = cv::format("%s_dynamic.%s.trtmodel", name, mode_name);int test_batch_size = 16;if(!exists(model_file)){SimpleYolo::compile(mode, type, // FP32、FP16、INT8test_batch_size, // max batch sizeonnx_file, // source model_file, // save to1 << 30,"inference");}inference_and_performance(deviceid, model_file, mode, type, name);
}int main(){test(SimpleYolo::Type::V5, SimpleYolo::Mode::FP32, "yolov5s");return 0;
}
这是使用TensorRT引擎实现的YOLO目标检测算法的C++实现。该实现基于SimpleYolo库,该库提供了一个简单易用的接口来使用YOLO算法。
代码首先定义了一组实用函数,用于颜色转换、文件处理和性能测量。然后定义了一个名为requires_model()的函数,如果本地目录中不存在YOLO模型,则该函数下载模型。主函数main()调用这个函数下载模型,然后调用测试test()函数进行推理并测量性能。
测试函数test()设置设备ID和模式,然后调用SimpleYolo::compile()将ONNX模型编译为TensorRT引擎,如果引擎文件不存在于本地目录中。然后调用inference_and_performance()函数执行推理并测量模型的性能。结果以带有边界框和标签的图像形式保存在本地目录中。
总体来说,这个实现提供了一个简单而高效的方式,在C++中使用YOLO算法进行目标检测任务。
相关文章:

只依赖Tensorrt和opencv的yolov5源代码
simple_yolo.hpp #ifndef SIMPLE_YOLO_HPP #define SIMPLE_YOLO_HPP/*简单的yolo接口,容易集成但是高性能 */#include <vector> #include <memory> #include <string> #include <future> #include <opencv2/opencv.hpp>namespace Si…...
多路I/O转接 poll(了解)
poll() 的机制与 select() 类似,与 select() 在本质上没有多大差别,管理多个描述符也是进行轮询,根据描述符的状态进行处理,但是 poll() 没有最大文件描述符数量的限制(但是数量过大后性能也是会下降)。 p…...

听说你也在为配置tomcat server而烦恼,看我这一篇,让你醍醐灌顶!
一.通过maven创建项目 二.下载tomcat服务器 我们一般在tomcat官网中进行tomcat的下载 Apache Tomcat - Welcome! 三.添加配置:我们点击下图中的文件配置 四.测试配置的tomcat 我们在文件的body中输入 测试内容: 在控制台中显式tomcat运行的信息&#…...
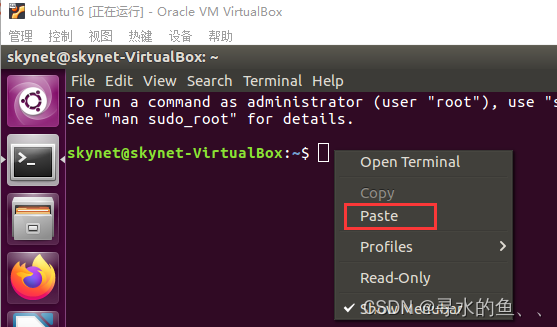
【从零开始学Skynet】工具篇(二):虚拟机文件的复制粘贴
大家在Linux系统下开发的时候肯定会遇到虚拟机与主机间无法复制粘贴的问题,现在我们就来解决这样的问题,方便我们的开发。 1、打开设置 我们可以系统界面的菜单栏点击“控制”,然后打开“设置”; 也可以在VirtualBox界面打开“设…...
全球自动驾驶竞争力最新排行榜,4家中国企业上榜
发展至今,自动驾驶技术不仅是汽车行业的一个主战场,更是全球科技领域中备受关注和充满竞争的一个重要领域。近年来,各大汽车制造商和科技公司都在投入大量财力物力人力进行自动驾驶技术的研发,并进一步争夺市场份额。 当然&#…...

APP启动流程分析
1、要分析的问题 1、与正常trace比对,确认过耗时在哪个步骤(am create/pause/stop/start/doframe)? 2、与正常trace比对,确认过耗时在哪个cpu state(Running/Runnable/Sleep/Uninterruptible Sleep)? 2、启动分析 …...

IIR数字滤波器简介与实现
一、简介: IIR是一种数字滤波器,其输出是输入信号和过去输出的某些加权和。IIR滤波器由反馈和前馈组成,可以用于滤除或增强信号的特定频率成分。 IIR滤波器的输出表示为: y[n] b0 * x[n] b1 * x[n-1] b2 * x[n-2] … - a1 * …...

3.5 函数的极值与最大值和最小值
学习目标: 我要学习函数的极值、最大值和最小值,我会采取以下几个步骤: 理解基本概念:首先,我会理解函数的极值、最大值和最小值的概念。例如,我会学习函数在特定区间内的最高点和最低点,并且理…...

第五十八天打卡
第五十八天打卡 739. 每日温度 提示 中等 1.5K company 亚马逊 company Facebook company 字节跳动 给定一个整数数组 temperatures ,表示每天的温度,返回一个数组 answer ,其中 answer[i] 是指对于第 i 天,下一个更高温度出现在…...
双一流大学计算机专业月薪拿2000?网友:我裂开
**“计算机不行了”“求求不要再学计算机”……**这样的言论时不时就会在网上掀起一番热议,知了姐看得不少。尤其最近有则新闻,更是给计算机专业盖上“不值钱”的帽子。 某985、211大学校招会上,有企业招聘计算机相关岗位时,提出…...
ChatGPT的“N宗罪”?|AI百态(上篇)
序: AI诞生伊始,那是人人欣喜若狂的科技曙光,深埋于哲学、想象和虚构中的古老的梦,终于成真,一个个肉眼可见的智能机器人,在复刻、模仿和服务着他们的造物主——人类。 但科技树的点亮,总会遇到…...
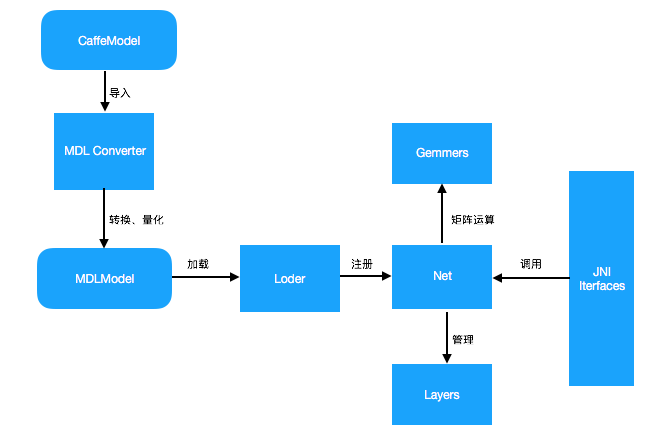
48.现有移动端开源框架及其特点—MDL(mobile-deep-learning)
48.1 功能特点 一键部署,脚本参数就可以切换ios或者android支持iOS gpu运行MobileNet、squeezenet模型已经测试过可以稳定运行MobileNet、GoogLeNet v1、squeezenet、ResNet-50模型体积极小,无任何第三方依赖。纯手工打造。提供量化函数,对32位float转8位uint直接支持,模型…...
---沉淀ing)
4.9--计算机网络之TCP篇之TCP Keepalive 和 HTTP Keep-Alive --(复习+大总结)---沉淀ing
HTTP 的 Keep-Alive,是由应用层(用户态) 实现的,称为 HTTP 长连接; TCP 的 Keepalive,是由 TCP 层(内核态) 实现的,称为 TCP 保活机制 HTTP 的 Keep-Alive HTTP 是基于…...

qt完善登录界面(2023-4-6)
点击登录按钮后,判断账号和密码是否一致,如果匹配失败,则弹出错误对话框,文本内容“账号密码不匹配,是否重新登录”,给定两个按钮ok和cancel,点击ok后,会清除密码框中的内容…...

104.(cesium篇)cesium卫星轨道模拟
听老人家说:多看美女会长寿 地图之家总目录(订阅之前建议先查看该博客) 文章末尾处提供保证可运行完整代码包,运行如有问题,可“私信”博主。 效果如下所示: 下面献上完整代码,代码重要位置会做相应解释 <html lang="en"> <...

Linux shell编程
Shell脚本入门 touch helloWorld.sh 【创建脚本文件】 vim helloWorld.sh 【编辑文件】 以#!/bin/bash开头 echo "helloWorld" 调用脚本 方式一:bash 【绝对路径|相对路径】 方式二:chomd x helloWorld.sh 绝对…...

Rasa 3.x 学习系列-Rasa [3.5.4] -2023-04-05新版本发布
Rasa 3.x 学习系列-Rasa [3.5.4] -2023-04-05新版本发布 Rasa Pro 3.5 中引入的两项新功能将帮助您更好地测试和保护您的 AI 助手:端到端测试和机密管理。 端到端测试 通过全面的验收和集成测试评估 AI 助手的性能。我们易于更新的端到端测试可以设置为运行每个流程和集成,…...

进程和线程
1.实现多线程 进程:是正在运行的程序 是系统进行资源分配和调用的独立单位 每一个进程都有它自己的内存空间和系统资源 线程:是进程中的单个顺序控制流,是一条执行路径 单线程:一个进程如果只有一条执行路径,则称为单线…...

ps 备忘清单_开发速查表分享
ps 命令速查备忘清单 Linux我们提供了一个名为 ps 的实用程序,用于查看与系统上的进程相关的信息,它是 Process Status 的缩写这份 ps 命令备忘清单的快速参考列表,包含常用选项和示例。入门,为开发人员分享快速参考备忘单。 开…...
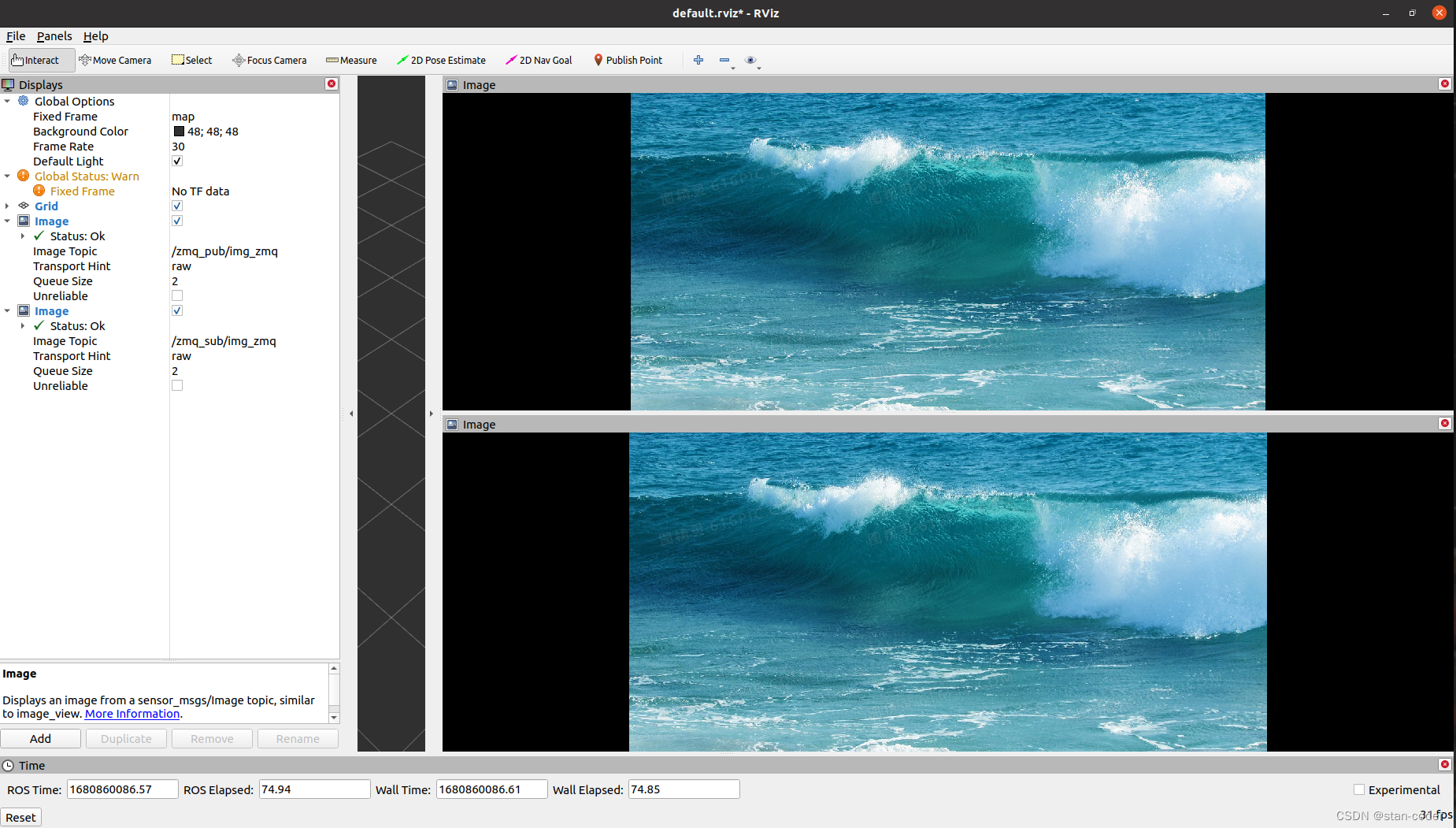
【ROS】基于WIFI网络实现图像消息跨机实时传输
【开发背景】 研究机器人目标检测算法的时候,常常需要把推理图像实时展示出来,以供观摩。而ROS1提供的跨机通信方法,要么是配置单Master,要么是配置多Master;一方面配置麻烦,另一方面传输效率低下…...

C++_核心编程_多态案例二-制作饮品
#include <iostream> #include <string> using namespace std;/*制作饮品的大致流程为:煮水 - 冲泡 - 倒入杯中 - 加入辅料 利用多态技术实现本案例,提供抽象制作饮品基类,提供子类制作咖啡和茶叶*//*基类*/ class AbstractDr…...

云启出海,智联未来|阿里云网络「企业出海」系列客户沙龙上海站圆满落地
借阿里云中企出海大会的东风,以**「云启出海,智联未来|打造安全可靠的出海云网络引擎」为主题的阿里云企业出海客户沙龙云网络&安全专场于5.28日下午在上海顺利举办,现场吸引了来自携程、小红书、米哈游、哔哩哔哩、波克城市、…...

2024年赣州旅游投资集团社会招聘笔试真
2024年赣州旅游投资集团社会招聘笔试真 题 ( 满 分 1 0 0 分 时 间 1 2 0 分 钟 ) 一、单选题(每题只有一个正确答案,答错、不答或多答均不得分) 1.纪要的特点不包括()。 A.概括重点 B.指导传达 C. 客观纪实 D.有言必录 【答案】: D 2.1864年,()预言了电磁波的存在,并指出…...

Spring AI 入门:Java 开发者的生成式 AI 实践之路
一、Spring AI 简介 在人工智能技术快速迭代的今天,Spring AI 作为 Spring 生态系统的新生力量,正在成为 Java 开发者拥抱生成式 AI 的最佳选择。该框架通过模块化设计实现了与主流 AI 服务(如 OpenAI、Anthropic)的无缝对接&…...

使用 Streamlit 构建支持主流大模型与 Ollama 的轻量级统一平台
🎯 使用 Streamlit 构建支持主流大模型与 Ollama 的轻量级统一平台 📌 项目背景 随着大语言模型(LLM)的广泛应用,开发者常面临多个挑战: 各大模型(OpenAI、Claude、Gemini、Ollama)接口风格不统一;缺乏一个统一平台进行模型调用与测试;本地模型 Ollama 的集成与前…...

【Java学习笔记】BigInteger 和 BigDecimal 类
BigInteger 和 BigDecimal 类 二者共有的常见方法 方法功能add加subtract减multiply乘divide除 注意点:传参类型必须是类对象 一、BigInteger 1. 作用:适合保存比较大的整型数 2. 使用说明 创建BigInteger对象 传入字符串 3. 代码示例 import j…...

【VLNs篇】07:NavRL—在动态环境中学习安全飞行
项目内容论文标题NavRL: 在动态环境中学习安全飞行 (NavRL: Learning Safe Flight in Dynamic Environments)核心问题解决无人机在包含静态和动态障碍物的复杂环境中进行安全、高效自主导航的挑战,克服传统方法和现有强化学习方法的局限性。核心算法基于近端策略优化…...

算法:模拟
1.替换所有的问号 1576. 替换所有的问号 - 力扣(LeetCode) 遍历字符串:通过外层循环逐一检查每个字符。遇到 ? 时处理: 内层循环遍历小写字母(a 到 z)。对每个字母检查是否满足: 与…...

WebRTC调研
WebRTC是什么,为什么,如何使用 WebRTC有什么优势 WebRTC Architecture Amazon KVS WebRTC 其它厂商WebRTC 海康门禁WebRTC 海康门禁其他界面整理 威视通WebRTC 局域网 Google浏览器 Microsoft Edge 公网 RTSP RTMP NVR ONVIF SIP SRT WebRTC协…...

flow_controllers
关键点: 流控制器类型: 同步(Sync):发布操作会阻塞,直到数据被确认发送。异步(Async):发布操作非阻塞,数据发送由后台线程处理。纯同步(PureSync…...