谢希仁版《计算机网络》期末总复习【完结】
文章目录
- 说明
- 第一章 计算机网络概述
- 计算机网络和互联网
- 网络边缘
- 网络核心
- 分组交换网的性能
- 网络体系结构
- 控制平面和数据平面
- 第二章 IP地址
- 分类编址
- 子网划分
- 无分类编址
- 特殊用途的IP地址
- IP地址规划和分配
- 第三章 应用层
- 应用层协议原理
- 万维网【URL / HTML / HTTP】
- 域名系统DNS
- 动态主机配置协议DHCP
- 电子邮件【SMTP / POP3 / IMAP】
- 第四章 运输层
- 运输层概述
- 用户数据报协议UDP
- 可靠传输原理
- 传输控制协议TCP
- TCP的连接管理
- TCP的可靠传输
- TCP的流量控制
- TCP的拥塞控制
- 第五章 网络层
- 网络层概述
- 网际协议IP
- IP分组转发
- 网际控制报文协议ICMP
- 路由选择协议
- 专用网相关概念
- 多协议标记交换MPLS
- 第六章 数据链路层
- 数据链路层概述
- 以太网
- 地址解析协议ARP
- 无线局域网
- 点对点协议PPP
- 思维导图总结
- 第一章
- 第二章
- 第三章
- 第四章
- 第五章
- 第六章
- 术语词典
说明
本博客仅供个人复习参考,知识点比较混杂,可作为查阅知识点的参考。
搜索 : Ctrl+F
参考书:
《计算机网络(第7版)》 谢希仁著
链接:https://pan.baidu.com/s/1WLF5CVDIlqRycrAjORxoKQ
提取码:kuoe
《计算机网络——自顶向下方法》 机械工业出版社
文字出现的参考链接是补充信息,用来代替部分知识点的介绍,请自行浏览参考博客。、
末尾的思维导图来源于老师的PPT,非常有用!!!!
最后一章是术语缩写词典,正在更新中。
文章中发现问题烦请指出。
第一章 计算机网络概述
计算机网络和互联网
计算机网络:是由一些通用的、可编程的硬件互连而成。
互联网:是全球最大的、由众多异构网络相互连接而成的计算机网络,是网络的网络。
特点:
连通性:将用户终端彼此相连。
资源共享:信息共享、软件共享、硬件共享等
TCP/IP协议逐渐成为了网络互联的事实标准
制定互联网的正式标准需要经过两个阶段:建议标准和互联网标准
网络边缘
网络边缘部分由所有连接在互联网上的主机以及接入网构成。
主机包括:个人计算机、服务器、超级计算机、智能手机、智能家电、智能可穿戴装备、网络摄像头、汽车以及各种网络传感器等。
接入网指将主机连接到其边缘路由器的网络,边缘路由器指进入互联网核心部分后的第一台路由器。
接入网包括:ADSL接入、光纤同轴混合网、FTTH接入、以太网接入、WiFi接入以及蜂窝移动接入等。
不同的接入网中使用了不同的传输媒体。
传输媒体包括:双绞线、同轴电缆、光纤以及自由空间等。
接入网
ADSL接入
ADSL指非对称数字用户线:
采用频分复用技术把用户线分成了电话、上行数据和下行数据三个相对独立的信道。用户可以边打电话边上网。
光纤同轴混合网HFC是利用有线电视网现有的基础设施,提供的一种宽带接入网。
光纤到户FTTH是FTT技术的一种。最常用的FTTH实现方案是无源光网络PON。
PON分为:窄带PON、APON(ATM PON)、EERON (EthernetPON)GPON (Gigabit PON)等。
通过以太网将主机连接到边缘路由器的方法,称为以太网接入。通过无线局域网的接入,称为WiFi接入。
通过蜂窝移动网络,将主机连接到互联网的方法称为蜂窝移动接入。
蜂窝移动技术的发展已经经历了4代,俗称:1G、2G、3G和4G,第5代(5G)标准正在制定中。
传输媒体

网络核心
网络核心部分由各种网络以及连接这些网络的路由器组成。
网络核心部分为网络边缘部分的主机提供通信服务。
计算机网络采用分组交换方式,路由器是网络核心部分最重要的设备,是实现分组交换的关键构件,其作用是将收到的分组转发到另一个网络。
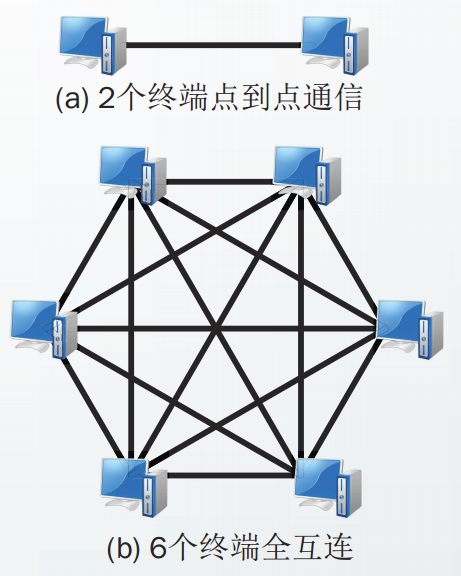
在端系统数量很少时,可以采用全互连方法实现点对点通信。但全互连方式中,需要
N(N-1)/2条互连线。当增加第N+1个端系统时,必须增设N条线路。
因此,引入交换设备称为交换机或交换结点。
所有端系统通过用户线连接到交换结点上,由交换结点控制端系统间的连接。
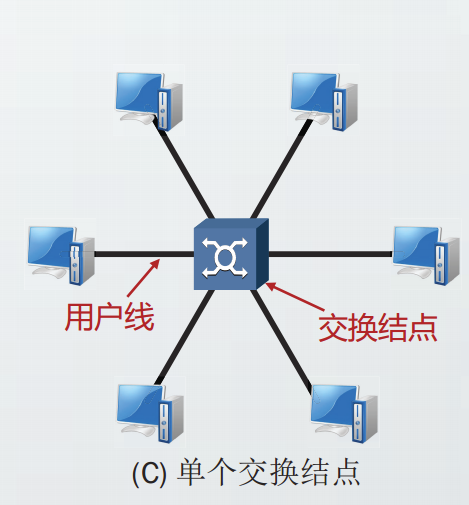
当端系统分布的区域较广时,需设置多个交换结点,交换结点之间用中继线相连。
当交换的范围更大时,需要再次引交换结点,由此形成交换网。
实现通信必须要有3个要素,即端系统、传输和交换。
在通信网络中有多种交换方式,电路交换、分组交换和报文交换是其中最典型的三种。
· 传统的电话网络采用电路交换方式;
· 计算机网络采用分组交换方式;
· 早期的电报网络采用报文交换方式。
从通信资源分配的角度来看,交换就是按照某种方式分配传输线路的资源。
电路交换
电路交换属于通信资源的预分配系统。
电路交换方式是面向连接的交换方式。必须经过
建立连接:例如打电话拨号;
数据传输:例如通话:
释放连接:例如挂断电话。
中继线中多路电话信号可以通过频分复用、时分复用等信道复用技术共享通信线路资源。
特点:
固定分配资源:通信资源在建立连接阶段已经预先分配给通话的双方了,在通话的全部时间内,通话的两个终端始终占用端到端的通信资源。
分组交换
计算机网络数据具有突发特性,如果使用电路交换方式,通信资源的利用率将极低。
因此,计算机网络采用分组交换方式。分组交换技术的出现奠定了互联网发展的基础。
分组交换属于通信资源的动态分配系统。
特点:
分组;
存储转发;
逐段占用通信链路资源;虚电路或数据报。
分组是互联网中传输的数据单元。
待发送的完整数据块称为报文(message)。
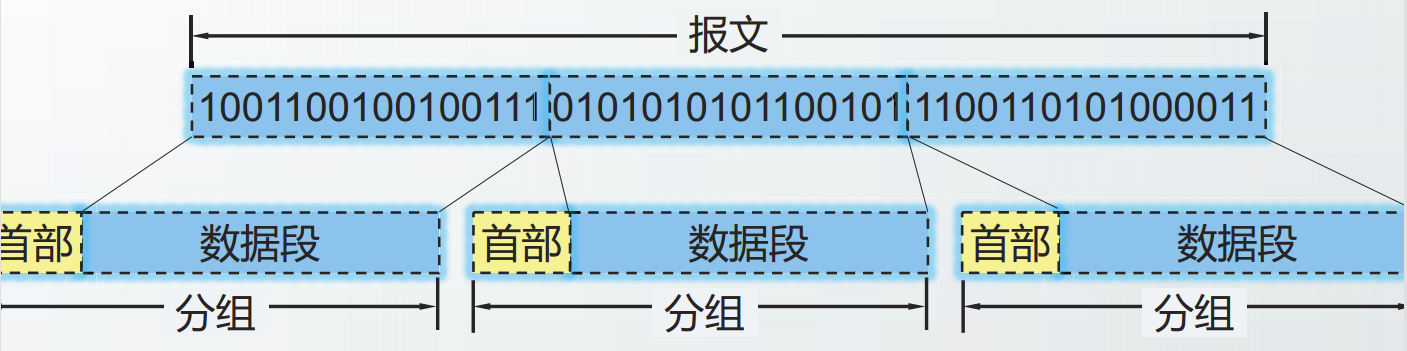
将报文分成较小的数据段,在每个数据段前面增加控制信息,构成分组(packet)。分组也称为包。
增加的控制信息称为首部(header),也称为包头。
存储转发
在互联网中,分组交换结点也称为路由器。路由器收到一个分组后,
- 先暂时存储起来;
- 然后根据首部中的控制信息,找到合适的接口将分组转发出去。
这种工作方式称为存储转发。
每台路由器都以存储转发的方式,逐跳(hop)处理,最终将分组交付目的主机。
目的主机将分组重新还原成报文。

在分组从H1向H4转发的过程中当分组在链路A-F上传输时,其它通信链路资源并不被当前通信的双方所占用,即分组交换是逐段占用通信资源的。
假定在主机H1向主机H4发送分组的同时,主机H7也在向主机H5发送分组,两次通信所发送的分组都会通过链路F-C。链路F-C上的带宽资源并不会预先分配给某次通信,而是可以为多次通信所共享,其通信资源的利用率较高.
虚电路方式
分组交换包括两种方式:虚电路(Virtual Circuit,VC)方式和数据报(datagram)方式。
虚电路方式是面向连接的,虚电路中连接,不是物理连接,只是一条逻辑连接。
建立虚电路后,在数据通信阶段,路由器根据虚电路标识转发分组,属于相同虚电路的数据分组将沿着相同的路径、按序通过网络,到达目的结点。
数据报方式
数据报方式是无连接的,即发送数据之前不需要先建立连接。
数据报方式中,路由器为每个分组独立选择转发接口,从相同源结点发往相同目的结点的数据分组,有可能沿着不同的路径,也有可能失序通过网络,到达目的结点。
目前,互联网采用的交换方式就是数据报方式的分组交换。
分组交换的问题
分组交换虽然提高了资源利用率,但也带来如下问题:
增大了时延:分组在各路由器中存储转发时,需要在队列中排队,这会增加些时延。
增大了开销:每一个分组的首部中都包含一些控制信息,这会增加一定的开销。
报文交换
报文交换方式也采用存储转发方式。
报文交换与分组交换的区别在于:
报文交换传输的数据单元是一个完整的报文,而分组交换传输的数据单元是较小的分组。
三种交换方式的比较

当跨越的结点数较多时,报文交换的时延会显著增大。而分组交换是报文交换的流水线方式,显著减小了时延。
分组交换网的性能
可以用如下指标衡量分组交换的性能:
带宽;
吞吐量;
时延:处理时延、排队时延、传输时延(发送时延)、传播时延;
丢包率;
利用率:信道利用率、网络利用率。
带宽
带宽是频带宽度的简称,单位是赫兹(Hz)。
·信号的带宽指该信号所包含的各种不同频率成分所占据的频率范围;
·信道的带宽指该信道允许通过的信号的频带范围。
如:传统的电话信号的标准带宽是3.1kHz(从300Hz到3.4kHz),传统的电话信道的标准带宽是4kHz(从0Hz到4kHz)。
在计算机网络中,带宽是指在单位时间内能传输的最大数据量,也称为最高数据率,用来表示网络中某信道的数据传送能力,单位是比特每秒(bt/s)。
·如:传统以太网的带宽是10Mbit/s。
在带宽的两种表述中,其本质是相同的,前者是其频域称谓,后者是其时域称谓。
吞吐量
吞吐量表示在单位时间内通过某个网络或接口的实际数据量,单位是比特每秒(bit/s)
以文件传输应用为例,主机在任何瞬间接收到该文件的速率称为瞬时吞吐量,主机收到完整文件后计算的平均速率称为平均吞吐量。
端到端吞吐量是衡量计算机网络性能的一个重要指标。
端到端吞吐量受到网络带宽的限制。
端到端吞吐量也会受到网络中其它通信量的影响。
时延
分组从源主机出发,经过一系列路由器,最终到达目的主机,在这个过程中所花费的时间称为端到端时延。端到端时延由处理时延(processingdelay)、排队时延(queuing delay)、传输时延(transmission delay)和传播时延(propagation delay)等几个部分组成。
处理时延:结点在收到分组后,结点处理分组所花费的时间,称为处理时延
排队时诞:分组进入路由器后,在输入队列或输出队列中排队所产生的时延称为排队时延。
传输时延:结点将分组传输到链路上所需要的时间,也称为发送时延。
发送时延=分组长度(bit) / 发送速率(bit/s)
传播时延:电磁波在信道中传播一定的距离所花费的时间称为传播时延。
传播时延=信道长度(m) / 电磁波在信道上的传播速率(m/s)
端到端时延=处理时延+排队时延+发送时延+传播时延
往返的端到端时延通常称为往返时间(Round-Trip Time,RTT)
丢包率
当分组到达路由器的速率超过路由器发送分组的速率时,路由器有可能丢弃到达的分组,这种现象称为丢包。
丢包代表网络出现了拥塞。丢包率在很大程度上反映网络的阻塞程度,常被用于评价和衡量网络性能。
丢包率=(Ns-Nr) / Ns
其中N代表发送的分组总数,Nr代表收到的分组总数,Ns - Nr 代表丢失的分组总数。
利用率
利用率包括信道利用率和网络利用率两种。
信道利用率指出某信道有百分之几的时间是被利用的(有数据通过)。网络利用率侧是全网络的信道利用率的加权平均值。
信道利用率并非越高越好。当某信道的利用率增大时,该信道引起的时延也就迅速增加。
在适当的假定条件下,时延和网络利用率之间的关系如下式:
D = D0 / (1-U)
其中,D表示网络当前的时延,D0表示网络空闲时的时延,U是网络的利用率
信道或网络的利用率过高会产生非常大的时延。
网络体系结构
分层、协议和服务
为了降低网络设计的复杂性,绝大多数网络都按照分层的方法进行设计。在分层设计思想中,每一层都建立在下一层的基础之上,下层向上一层提供特定的服务。
对等层的双方之间的约定称为协议。
每层协议都完全独立于其它层的协议,完成本层的功能。
分层的设计方式具有灵活性好、耦合性低等优点,并且易于开发和维护,方便进行标准化工作。
在互联网中,为进行网络中的数据交换而建立的规则、标准和约定称为网络协议,简称为协议。
网络协议主要由以下三个要素组成:
①语法:即数据与控制信息的格式:
②语义:即控制信息的含义;
③同步:即事件顺序的详细说明。
各层所有协议的集合被称为协议栈或协议族。
任何发送或接收消息的硬件或软件进程称为实体。在不同主机上,相对应层次上的实体称为对等实体。
每层协议的实现都保证了向上层实体提供服务。

协议是水平方向的,控制着对等实体之间的信息交换;
服务是垂直方向的,控制着相邻层次实体之间的信息交换;
对等实体之间交换的数据单位通常称为协议数据单元PDU;
相邻层次实体之间交换的数据单位通常称为服务数据单元SDU。
层和协议的集合成为网络体系结构。
TCP/IP协议是互联网上事实的国际标准,定义了四层协议栈。
OSI参考模型定义了七层协议栈。
互联网体系结构实际采用了五层协议栈。

对于互联网的五层协议
应用层:
主要任务:通过进程间的通信解决某一类应用问题。
常见协议:
域名系统DNS;超文本传送协HTTP;动态主机配置协议DHCP;简单邮件传送协议SMTP等。
协议数据单元:报文。
运输层:
主要任务:向应用进程提供端到端的通信服务。
常见协议:
传输控制协议TCP:面向连接、可靠;
用户数据报协UDP:无连接、不可靠。
协议数据单元:TCP:报文段;UDP:用户数据报。
网络层:
主要任务:向上层提供主机到主机的通信服务,包括路由选择和分组转发。
常见协议:
网际协议IP;;网际控制报文协议ICMP;网际组管理协议IGMP;地址解析协议ARP等。
协议数据单元:
IP协议:IP分组或P数据报。
数据链路层:
主要任务:
向上层提供相邻结点间的通信服务,包括封装成帧、寻址、差错控制和媒体访问控制等。
常见协议:
以太网Ethernet协议、点对点PPP协议、无线局域网WLAN协议等。
协议数据单元:帧。
物理层:
主要任务:透明的传输比特流。
常见协议:与实际的传输媒体相关,在不同的传输媒体上定义了不同的物理层协议。
协议数据单元:
码元 : 一个码元可以理解为一个脉冲信号,一个码元可以携带一比特信息,也可以携带多比特信息,也允许多个码元一起携带一比特信息。
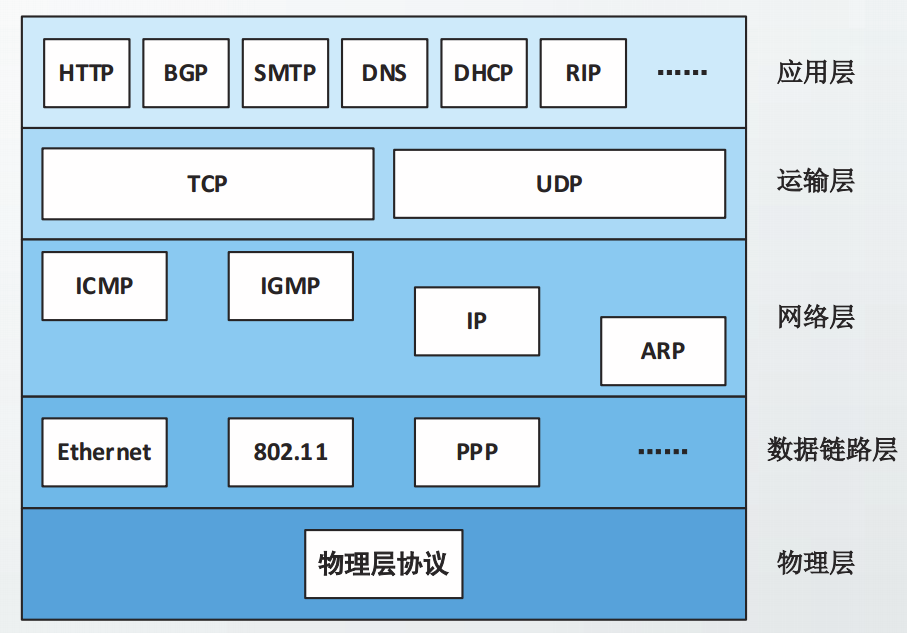
封装和解封
逐层封装的过程发生在发送数据时,逐层解封的过程发生在接收数据时。
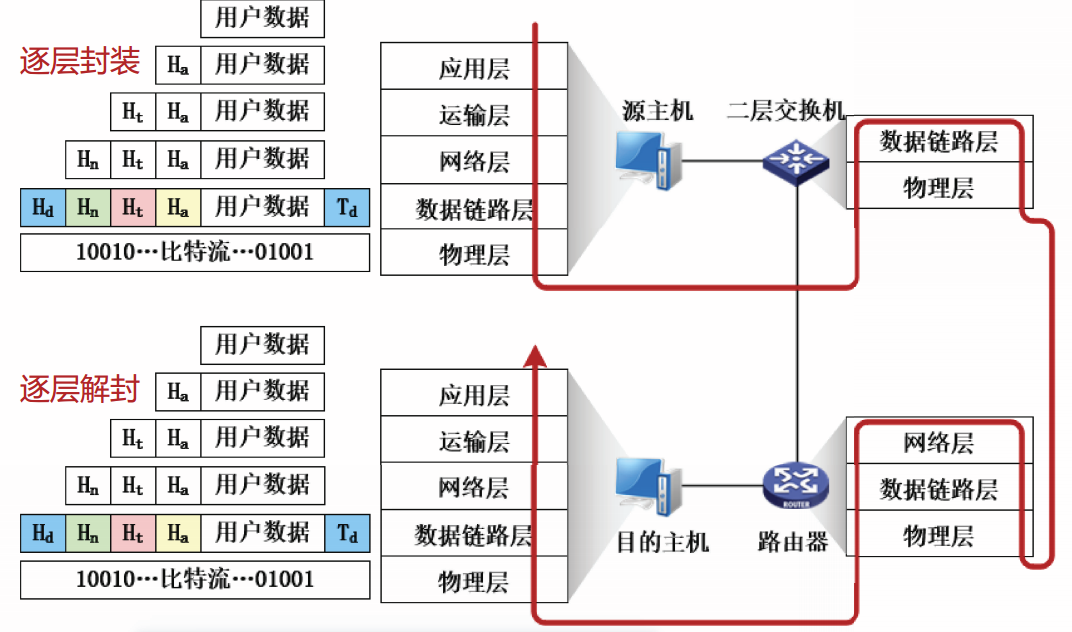 复用和分用
复用和分用
复用可以发生在多个层次,在每层都有不同类型的标识符,用于指明封装的信息属于上层哪一个协议。复用的过程发生在封装时。分用的过程发生在解封时。
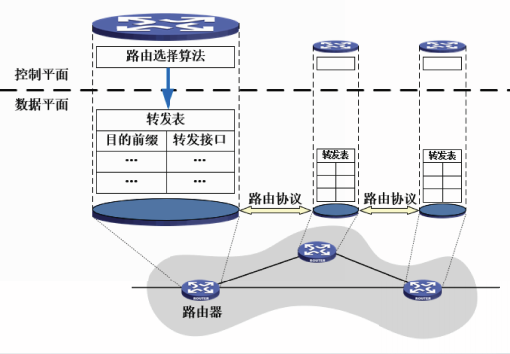
控制平面和数据平面
分组交换网络的操作涉及两种分组的处理:控制分组和数据分组。
控制分组携带的信息用来指导结点如何转发数据,而数据分组则包括用户程序要发送的数据。
控制平面最重要的功能是路由选择。此外还包括差错报告、系统配置和管理以及资源的分配等。
数据平面最重要的功能是分组转发。
传统的计算机网络中,每台分组交换设备都包括一个数据平面和一个控制平面。因此,其控制平面是分布式的。
软件定义网络SDN中的控制平面与数据平面是分离的。即分组交换设备上仅具有数据平面,而控制平面位于一个逻辑上的集中式控制器中。因此,其控制平面是集中式的。
第二章 IP地址
在TCP/IP体系结构中,IP地址是一个最基本的概念。连接到互联网的每台设备至少具有一个IP地址。
IP地址是互联网中使用的网络层地址,用来标识一台主机。严格来说,IP地址用来标识主机上的网络接口。
IP地址现在由互联网名字和数字分配机构ICANN负责分配和管理
IP地址是一个32位的二进制数,为了便于书写和记忆,IP地址采用点分十进制记法表示。
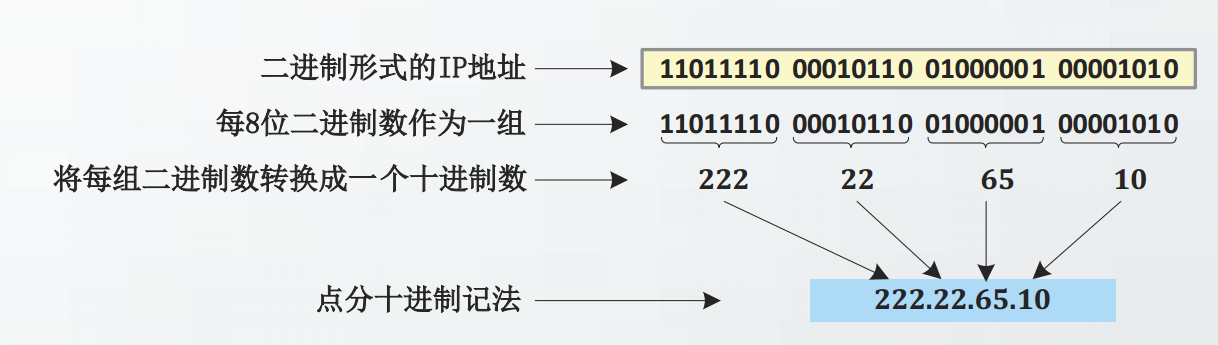
把32位的IP地址分为4组,每组8位,然后将每组数字用十进制表示,并且在这些数字之间加上一个点,就称为IP地址的点分十进制记法。
分层结构
IP地址采用了分层(hierarchical)结构,即IP地址由对应互联网某种层次结构的几个部分构成。
IP地址包括两部分:网络部分和主机部分。
IP地址的网络部分指明主机连接到哪个网络,所有连到同一网络上的主机,其IP地址的网络部分相同。
IP地址的主机部分唯一标识了特定网络中的一台主机。
采用分层结构的IP地址后,路由器可以仅根据IP地址的网络部分来转发分组,而无需考虑IP地址的主机部分。
编址方案的演变
IP地址的编址方案经历了三个历史阶段:
①分类编址。将IP地址分为A、B、C、D、E五类,是最基本的编址方案,在1981年通过的RFC790中就包含了A、B、C类地址的相关规定。
②子网划分。是在分类编址的基础上所作的改进,1985年通过的RFC950中包含了相关的规定。
③无分类编址。基于无类域间路由(Classless Inter-Domain Routing,(CDR)的编址方案,是目前正在使用的编址方案。在1993年通过的RFC1519中提出后,很快就得到推广应用。2006年,RFC1519被RFC4632替换。
分类编址
在分类编址方案中,采用两级编址方案,每个单播IP地址都由两个字段组成。
IP地址 ::= {<网络号>,<主机号>}
其中,网络部分是网络号;主机部分是主机号。
由于不同网络中可能包含不同数量的主机,一种简单的划分方法是依据预计的主机数量,分类编址方案中将不同大小的IP地址空间分配给不同的网络。
路由器根据IP地址的网络部分来转发分组。
五类IP地址
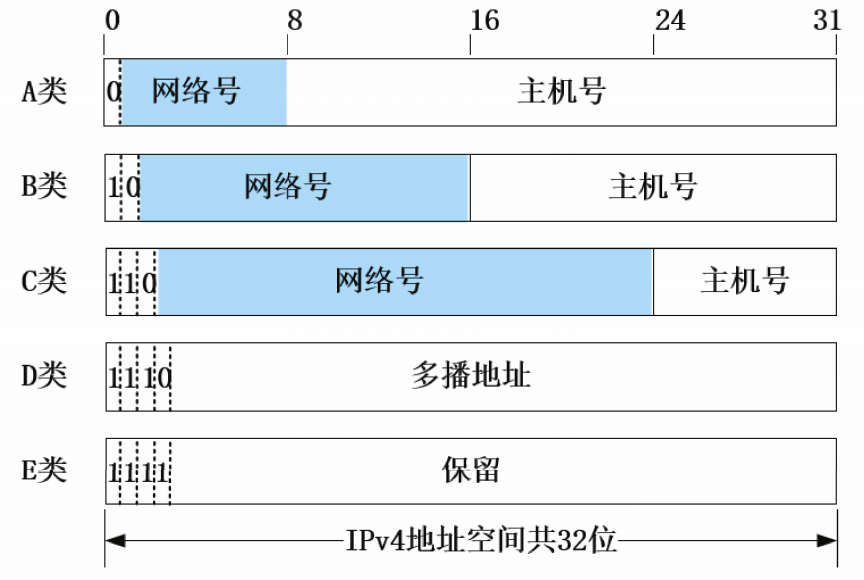
IP地址空间被划分为五类,命名为A、B、C、D和E。
A、B、C类地址空间用于单播地址;
D类地址用于多播地址;
E类地址为保留地址。
A、B、C类IP地址
A类、B类和C类地址属于单播地址,由网络号和主机号两部分组成。在单播地址空间中,有部分地址被用作特殊用途,不作为单播地址使用。
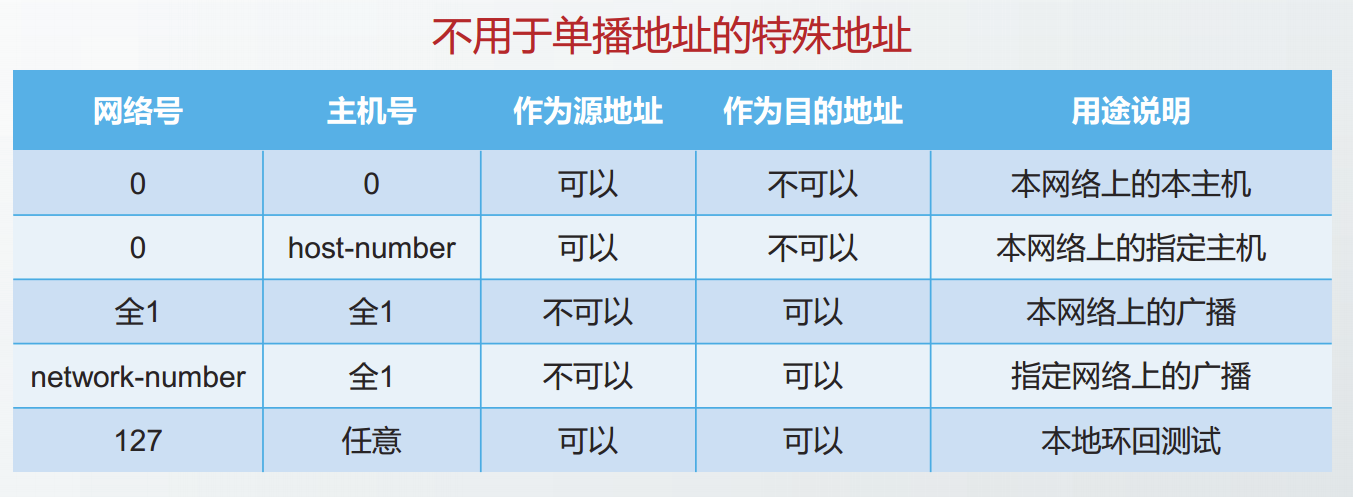
特殊地址中,主机号部分全为1的地址都称为广播地址。
网络号和主机号全1的地址用于本网络上的广播,也称为受限广播,其传播范围仅限发送方所属网络,路由器不转发受限广播。
网络号为指定网络,主机号全1的地址用于向指定网络发送广播数据报,这种广播也称为定向广播。
最初互联网建议支持路由器转发定向广播,而且默认启用。但RFC2644变更了该策略,要求路由器默认禁止转发定向广播。
本地环回测试地址用于本主机的进程间通信使用,通常仅使用127.0.0.1。
排除以上特殊地址后,剩余的地址属于A、B、C类网络的可指派地址
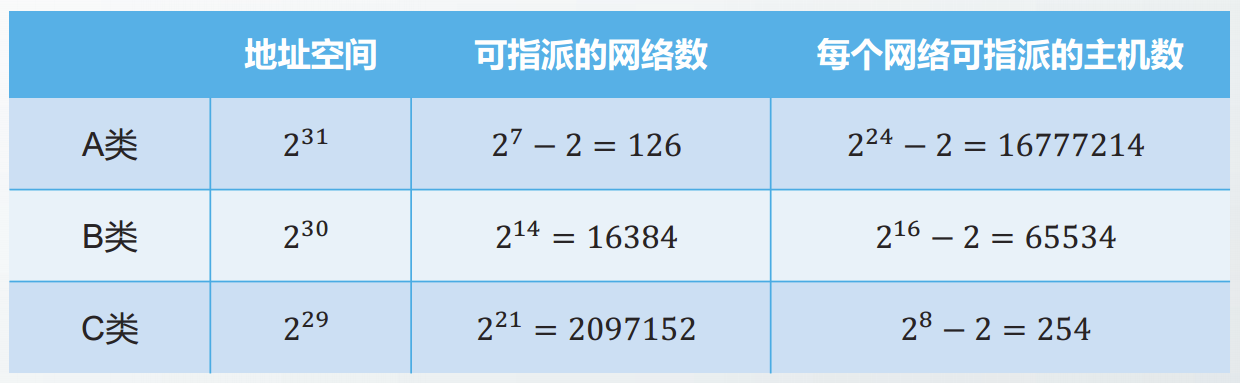 每个网络中主机号全1和主机号全0的不能指派
每个网络中主机号全1和主机号全0的不能指派
A类网络中,网络号0和127不能指派
路由器和主机的IP地址
同一个网络上的主机其IP地址中的网络号都相同;
不同网络上的主机其IP地址中的网络号不同。
路由器总是具有多个IP地址,路由器的每一个接口,其IP地址的网络号都不同。
子网划分
当一些较大的单位或组织内部组建了多个局域网,在IP地址的两级编址方案下,为这些局域网分配IP地址有困难。
RFC950提出了子网划分,来解决这样的问题
子网划分将IP地址从两级编址方案扩展为三级编址方案,包括两种方式:
- 定长子网划分
- 变长子网划分
定长子网划分
子网划分的方法是从IP地址的主机号部分借用若干位作为子网号,这样,两级IP地址在本单位内部就变为三级IP地址。
IP地址:={<网络号>,<子网号>,<主机号>}
互联网上的路由器仍然将网络号看作IP地址的网络部分;
单位的边界路由器和内部路由器将网络号+子网号记作网络地址,将网络地址看作IP地址的网络部分。
路由器根据IP地址的网络部分来转发分组。
例子:
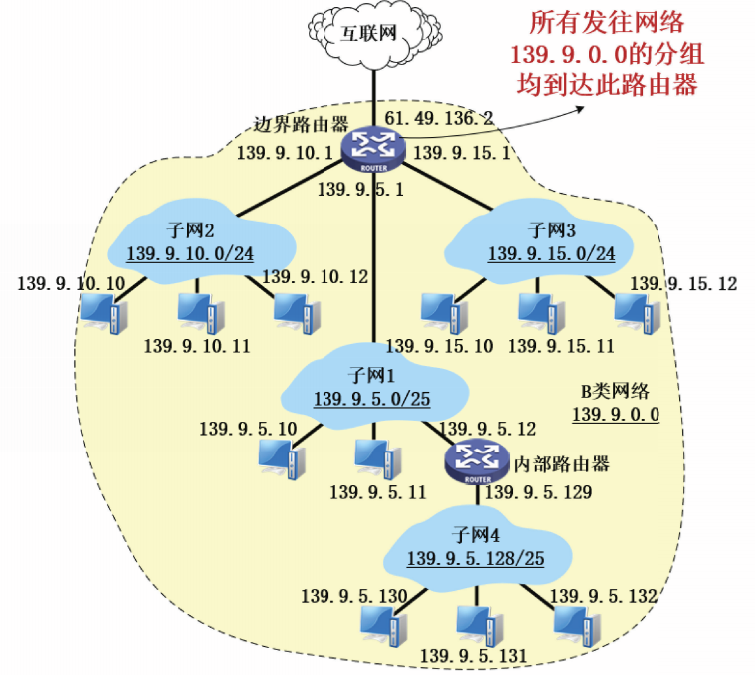
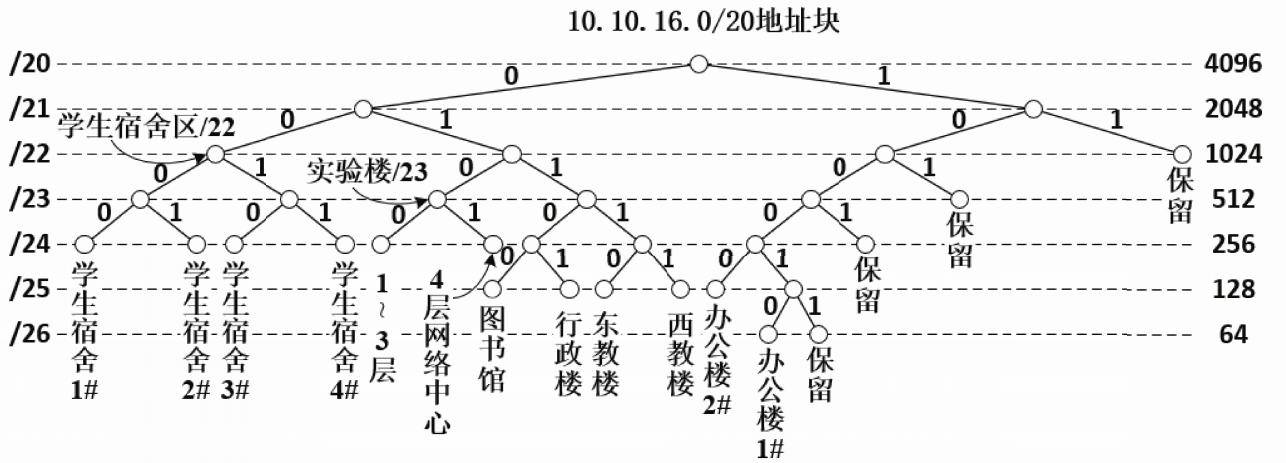
以一个B类网络139.9.0.0为例讨论子网划分。假设申请到该B类地址的单位,从主机号部分借用8位作为子网号,则划分子网后的P地址结构如图所示。
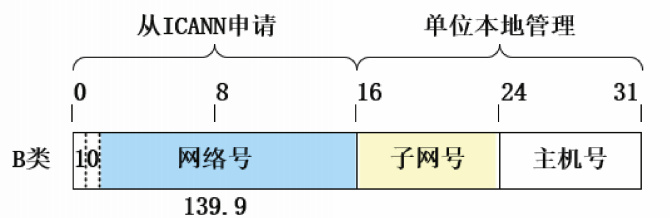
本例中,支持最多配置28=256个子网,每个子网最多可包含28-2=254台主机。
划分子网后,主机号为全0和全1的P地址仍然不能指派给主机。
本例中所有子网的子网号长度相等,这种子网划分方式称为定长子网划分。
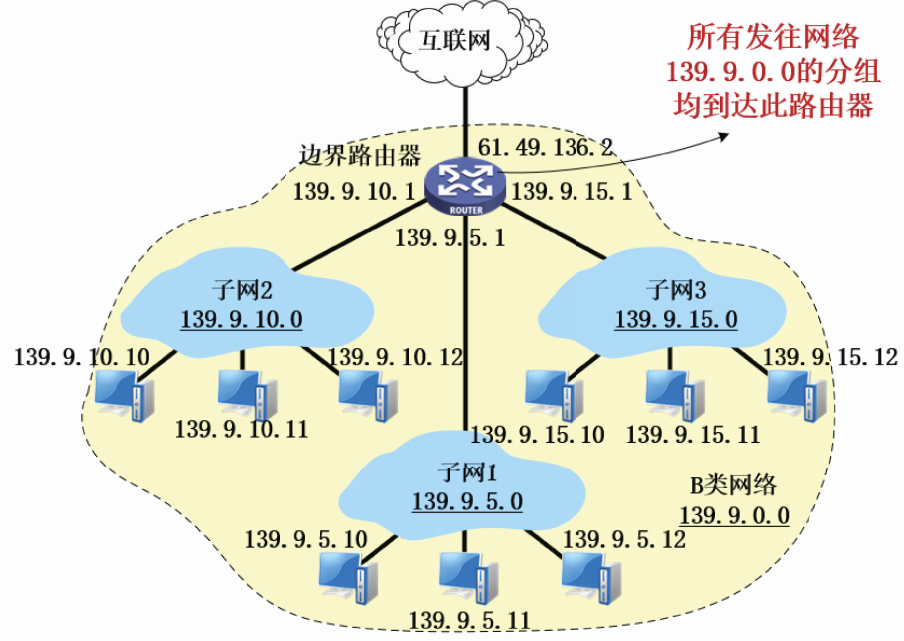
假设该单位已经组建了3个局域网,网络管理员为它们分配了子网号5、10和15,其余的子网号暂时保留。
划分子网后,B类网络139.9.0.0对外部仍表现为一个网络,当边界路由器和内部路由器收到P数据报后按照网络地址转发分组。
子网掩码
划分子网后,网络内部的路由器必须能够区分发往不同子网的分组。
RFC950中定义了子网掩码,用以从IP地址中获取网络地址。
子网掩码中的1对应于引P地址中的网络号和子网号,而子网掩码中的0对应于
子网划分后的P地址中的主机号。
子网掩码可以采用点分十进制记法表示,也可以用掩码中1的位数表示,称为前缀长度。
上例中,三个子网的子网掩码均为255.255.255.0,前缀长度为24。
常见的子网掩码:
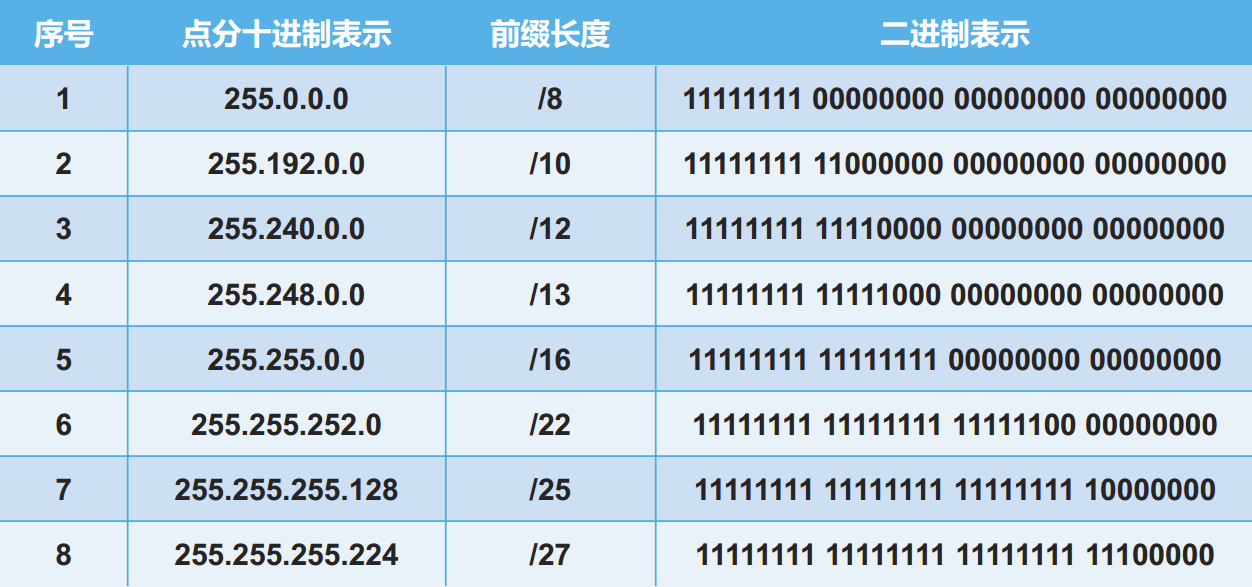
默认子网掩码:
A类地址的默认子网掩码为255.0.0.0;
B类地址的默认子网掩码为255.255.0.0;
C类地址的默认子网掩码为255.255.255.0
子网掩码的按位与操作
将IP地址与其子网掩码做按位与操作(AND),即可得到相应的网络地址。
如上例中,边界路由器收到目的IP地址为139.9.10.11的IP数据报,将该IP地址与子网掩码255.255.255.0做按位与操作的过程如下。
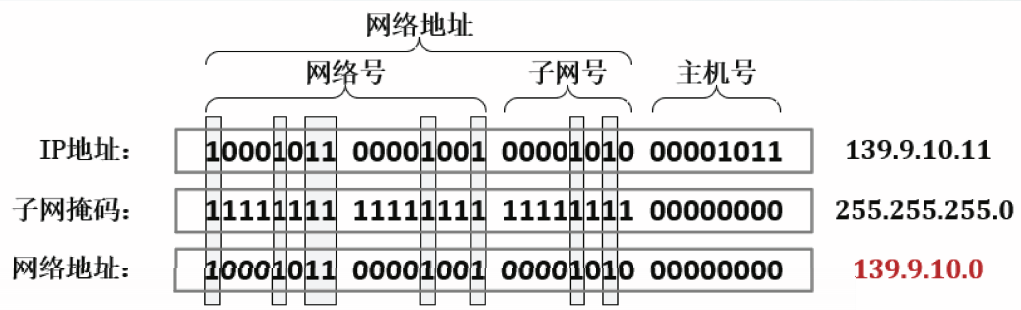 计算得出网络地址为139.9.10.0
计算得出网络地址为139.9.10.0
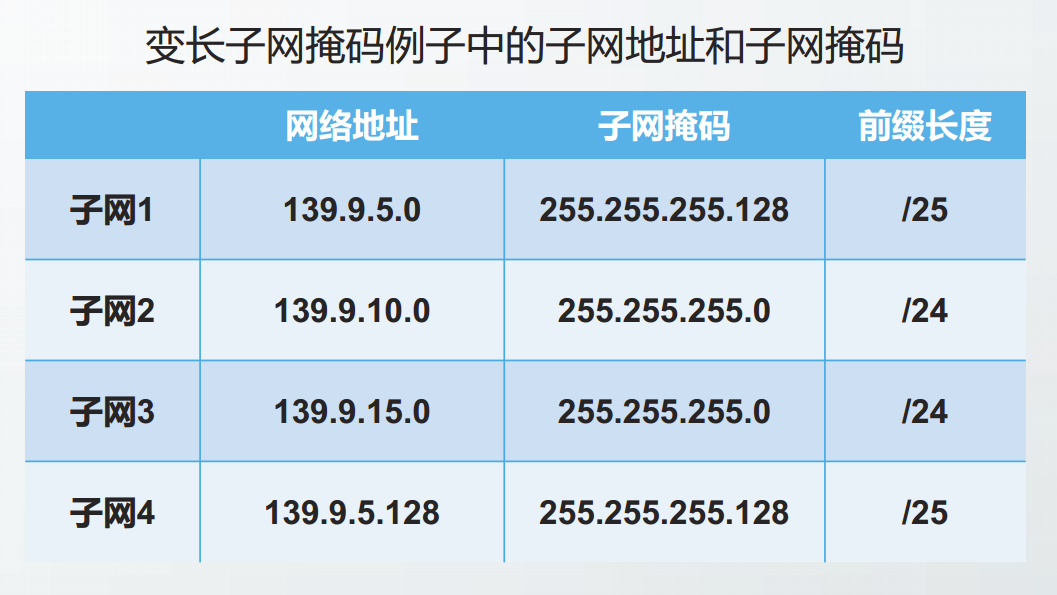
变长子网划分
如果将一个网络划分为多个大小不同的子网,以适应多个子网具有不同数量主机的需求。这种子网划分方式称为变长子网划分。
在变长子网划分中,各子网的子网号部分长度不同,因此其子网掩码的前缀长度不同,这种子网掩码称为变长子网掩码VLSM。
在上小节定长子网划分的例子中,如果将子网1进一步划分为两个子网,将它们的子网掩码配置为255.255.255.128即子网掩码前缀长度为25,就得到一个变长子网划分的实例。
进行了变长子网划分后,整个网络对外部仍表现为一个网络。
无分类编址
无分类编址方案是为了缓解IPV4的分配压力。
ETF在VLSM的基础上,研究出了无分类编址方案,它的正式名字是无分类域间路由选择(Classless Inter-Domain Routing,ClDR)
CIDR消除了传统的A类、B类和C类地址以及划分子网的概念,可以更加有效地分配IPv4地址空间。
CIDR将P地址从三级编址改回两级编址,但这已经是无分类的两级编址。
IP地址:={<网络前缀>,<主机号>}
其中,网络部分是网络前缀;主机部分是主机号。
路由器根据P地址的网络部分来转发分组。
CIDR采用斜线记法,也称为CIDR记法,即在IP地址后面加上斜线 /,然后写上网络前缀所占的位数。
如IP地址:
222.22.65.10/20的网络前缀为20位。
网络前缀消除了一个IP地址中网络和主机号的预定义分隔,使更细粒度的IP地址分配成为可能。
网络前缀都相同的连续的IP地址组成一个CIDR地址块。
已知CIDR地址块中的任何一个地址,就可以求出这个地址块的起始地址(即最小地址)和最大地址,以及地址块中的地址数,

该地址块共有212=4096个地址,最大允许指派的主机数为212一2=4094个。
通常用地址块中的最小地址和网络前缀的位数标识地址块,上述地址块可记为222.22.64.0/20。
CIDR掩码
在CIDR中,使用地址掩码从IP地址中获取网络前缀。地址掩码由一串1和一串0组成,而1的个数就是网络前缀的长度。地址掩码也称为CIDR掩码,或简称为掩码。
IP地址与CIDR掩码做按位与操作,可以获得网络前缀。
虽然CIDR不再使用子网的概念和子网号,但申请到一个CIDR地址块的单位仍然可以在本单位内根据需要划分出一些子网。这些子网的网络前缀比整个单位的网络前缀要长些。
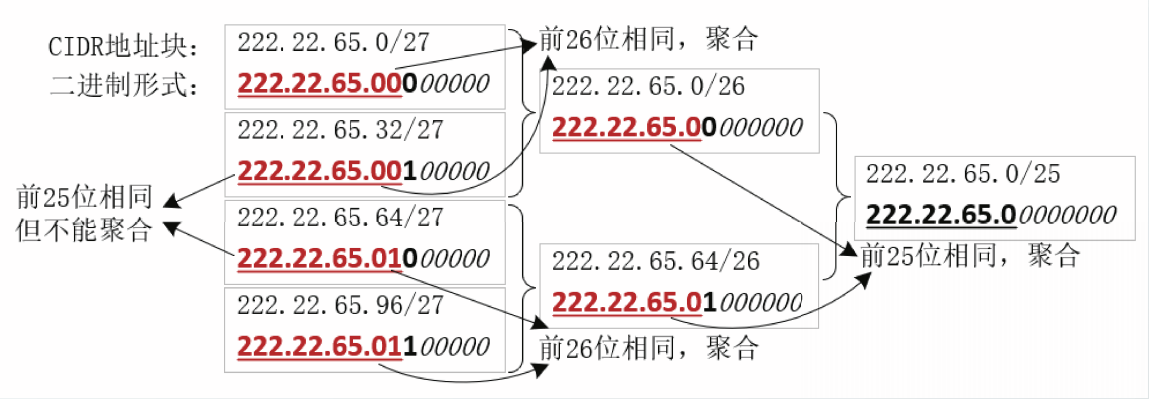
路由聚合
CIDR不仅可以提高IPv4地址空间的分配效率,也可以用来减少路由器中路由表的项目数,改善路由器的性能,这个功能可以通过路由聚合来实现。
路由聚合是指将相邻CIDR地址块的网络前缀合并成一个较短的网络前缀,聚合后的一条路由信息可以覆盖更多地址空间。
由于有些聚合后的CIDR地址块包含了多个C类地址,路由聚合也被称为构成超网。
两个CIDR地址块能够聚合需要满足以下条件:
①两个地址块相邻且大小一致;
②两个地址块的前n位相同:
③聚合前后,CIDR地址块包含的IP地址相同。
在CIDR的应用中,有一种特殊的情况,主机号全0和全1的P地址可以使用。
当路由器之间被一条点到点链路连接,则每个端点都需要分配一个IP地址,且两台路由器之间的网络仅包含两个IP地址,为了节省IP地址,RFC3021建议将/31地址块中包含的两个地址分配给两台路由器。
相应的,在IPv6中,对于这种特殊情况,RFC6164中也建议使用/127地址块。
特殊用途的IP地址
常见的特殊用途地址包括:
专用网络地址
"链路本地”地址
运营商级NAT共享地址
用于文档的测试网络地址
环回测试地址
受限广播地址
专用网络地址
专用网是指企业或机构内部专用的网络,也称为私有网络。
专用网络内的IP地址不需要向ICANN申请,RFC1918和RFC6890规定了三块IP地址空间作为专用网络地址,它们也称为专有地址,仅用于专用网络内部的主机和路由器之间的通信。
①10.0.0.0-10.255.255.255(10.0.0.0/8);
②172.16.0.0~172.31.255.255(172.16.0.0/12);
③192.168.0.0~192.168.255.255(192.168.0.0/16)。
在专用网络内分配P地址,只需要保证在专用网络内唯一即可。
当专用网络内的主机需要和互联网上的主机通信时,需要利用网络地址转换NAT。
链路本地地址
为主机配置IP地址,可以采用手动方式或自动方式。
手动配置的方式称为静态IP地址配置,自动配置方式利用动态主机配置协议DHCP进行配置。
在选择自动配置P地址后,如果主机获取P地址失败,则操作系统会自动分配一个链路本地地址(Link-Local address)给主机。
链路本地地址由RFC3927规定,包含一个/16地址块:169.254.0.0/16。
链路本地地址仅用于同一个物理网络上的、都配置了链路本地地址的主机之间的通信。
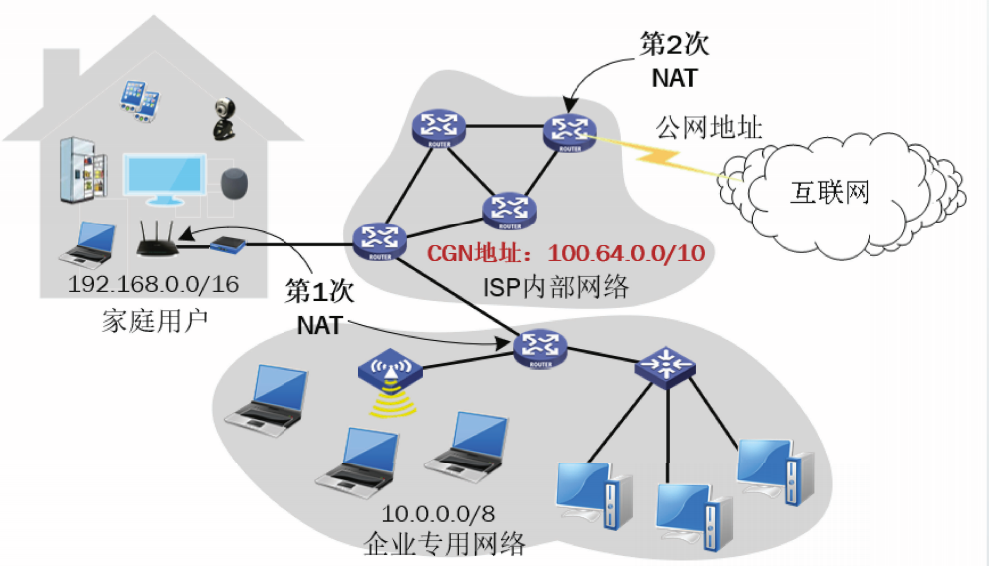
运营商级NAT共享地址
ISP也被称为运营商。由于能用于互联网通信的公网地址非常紧缺,运营商也不能够再获得新的公网IP地址。
为了满足新用户接入互联网的需求,RFC6598规定了一个/10地址块:100.64.0.0/10,用作运营商级NAT(Carrier-Grade NAT,CGN)共享地址,记作CGN地址。
CGN地址只能用于ISP的内部网络,每个ISP都可以使用CGN地址。
用户通过ISP访问互联网需要经过两次NAT。
用于文档的测试网络地址
在各种技术规范或者技术文档中,经常需要使用某些网络示例。为了避免使用已分配给他人的地址而引起冲突的可能,RFC5737保留了3个地址块,专用于在文档中做测试网络地址。
①TEST-NET-1:192.0.2.0~192.0.2.255(192.0.2.0/24);
②TEST-NET-2:198.51.100.0-198.51.100.255(198.51.100.0/24);
③TEST-NET-3:203.0.113.0~203.0.113.255(203.0.113.0/24)。
用于文档的测试网络地址也不会出现在公共互联网中
IP地址规划和分配
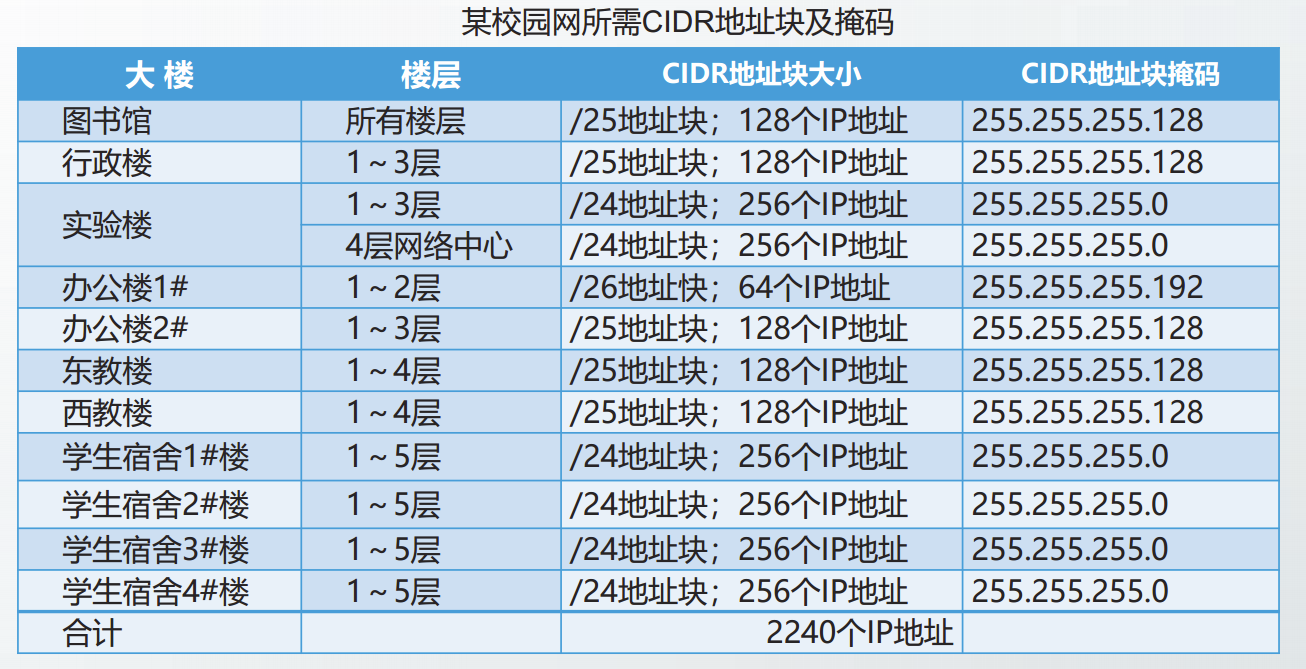
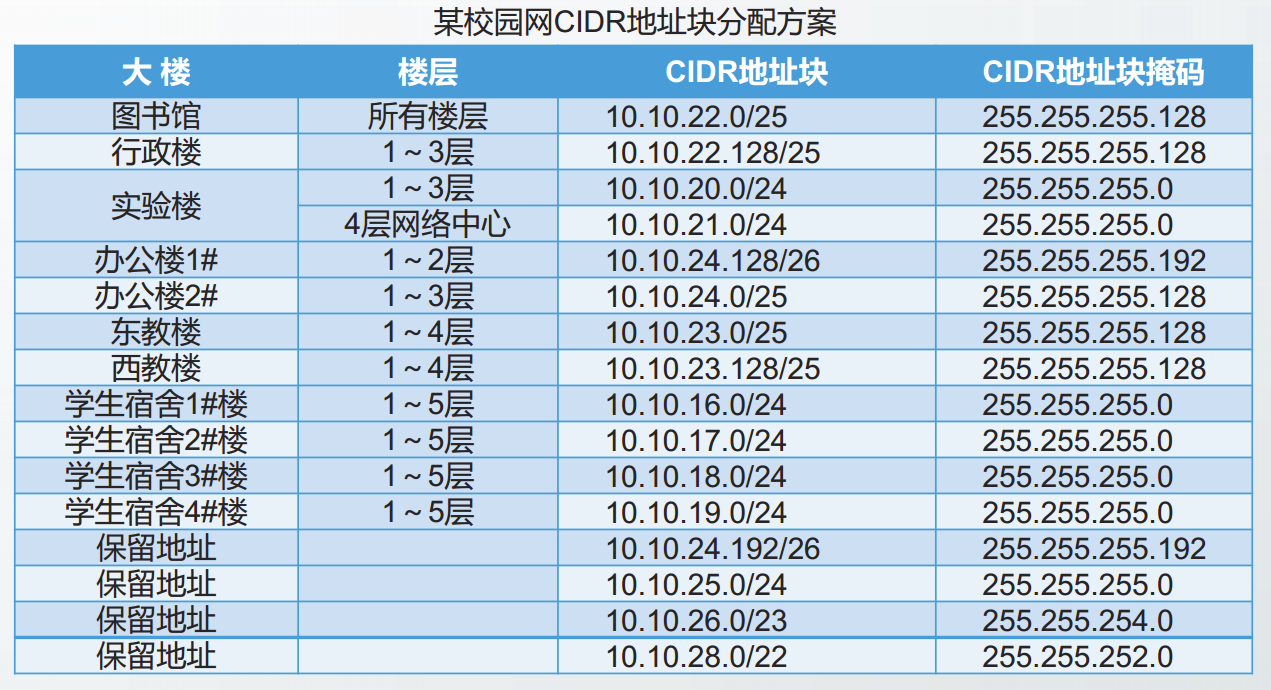
利用CIDR进行IP地址规划与分配主要考虑以下三个步骤:
(1)确定需要的CIDR地址块的数量和大小。
综合考虑建筑物的分布位置以及部门的数量,确定需要的CIDR地址块的数量
根据建筑物内或部门中的信息点数量,确定每个CIDR地址块包括的IP地址数目
每个CIDR地址块包括的IP地址数目是2的整数次幂,且其中的最小地址和最大地址不能分配给主机。
(2)确定掩码。
根据CIDR地址块的大小,计算并确定掩码。
(3)CIDR地址块分配。
进行CIDR地址块的分配,需要遵循以下规则:
①应先为较大的地址块分配网络前缀;
②在相同路径上的地址块应具有相同的前缀,便于进行路由聚合;
③应保留部分地址块,以备将来扩展使用。
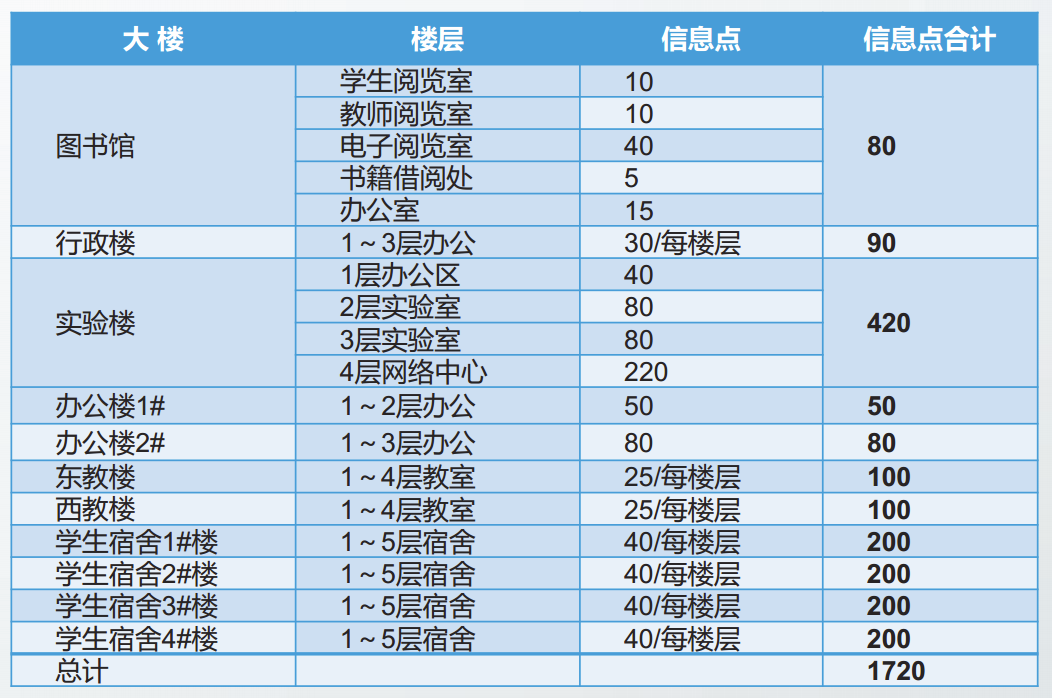
举例
某校园网信息点分布情况
第三章 应用层
应用层协议原理

网络应用程序的核心是能够运行在不同的端系统并通过网络相互通信的程序。
“主机A和主机B进行网络通信”,实际上是指:运行在主机A上的某个网络应用程序和运行在主机B上的某个网络应用程序进行通信
在计算机网络中,我们并不特别关注同一台主机上的进程间的通信,而关注运行在不同端系统(可能具有不同的操作系统)上的应用进程之间如何通过计算机网络进行通信。
在互联网的应用层,应用进程之间的通信方式分为两种:
- 客户-服务器(Client-Server,C/S)方式
- 对等连接(Peer-to-Peer,P2P)方式
客户-服务器方式
客户和服务器都是指通信中所涉及的应用进程。
客户-服务器方式所描述的是进程之间服务和被服务的关系。
客户是服务的请求方。
服务器是服务的提供方。
特点
客户进程:
①被用户调用后开始运行,需要通信时主动向服务器发起通信,请求对方提供服务。因此,客户进程必须知道服务器进程的地址。这里的地址由主机的IP地址和进程绑定的端口组成。
②不需要特殊的硬件和很复杂的操作系统的支持。
服务器进程:
①专门用来提供某种服务的进程,可以同时处理一个或多个远程或本地客户的请求。
②当服务器进程被启动后即自动调用并一直不断地运行着,被动地等待并接受来自多个客户进程的通信请求,因此,服务器进程不需要知道客户进程的地址。
③一般需要性能好的硬件和功能强大的操作系统支持。
对等连接方式
对等连接方式的思想是整个网络中共享的内容不再被保存在中心服务器上,各个终端结点不明确区分哪一个是服务请求方哪一个是服务提供方。
对等连接中的每个结点既作为客户访问其它结点的资源,也作为服务器提供资源给其它结点访问。从本质上看,对等连接方式仍然是客户-服务器方式。
进程通信
在一对进程之间的通信会话场景中,发起通信的进程叫做客户进程,在会话开始时等待通信请求的进程叫做服务器进程。
应用进程通过称为套接字(socket)的软件接口向网络发送报文和从网络接收报文。
套接字就是应用程序进程和运输层协议之间的接口。
套接字也是应用进程为了获得网络通信服务而与操作系统进行交互时使用的一种机制。
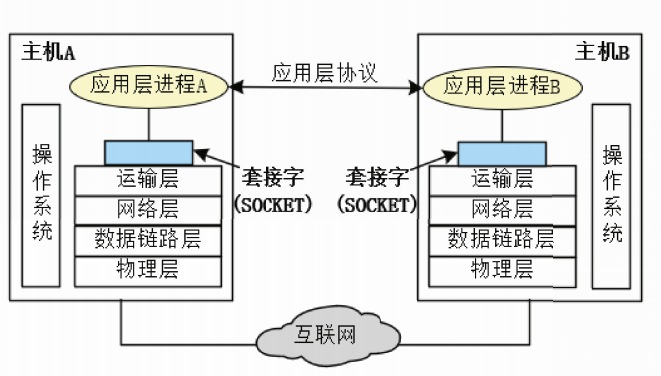
套接字的另外一种含义就是"IP地址+端口”,它也可以理解为进程地址。
万维网【URL / HTML / HTTP】
万维网(Vorld Wide Web,WWW)简称为Web,是一个大规模的、联机式的信息储藏所。
万维网是一个分布式的超媒体系统,它是超文本系统的扩展。
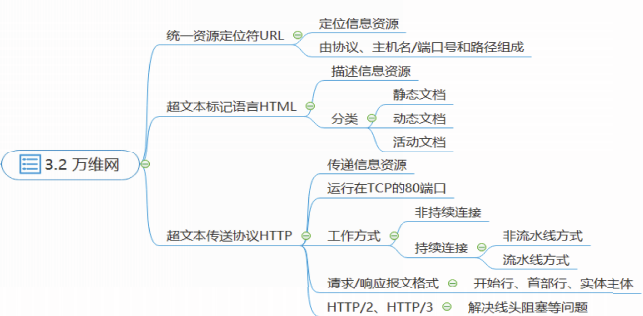
万维网应用通过统一资源定位符URL定位信息资源,通过超文本标记语言HTML描述信息资源,通过超文本传输协议HTTP传递信息资源。
URL、HTML和HTTP三个规范构成了万维网的核心构建技术,是支撑着万维网运行的基石。
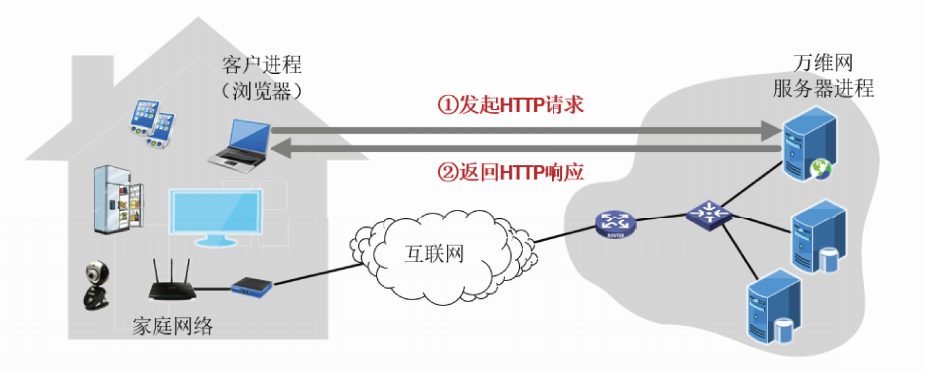
HTTP的请求和响应过程
浏览器将URL封装入HTTP请求,发给万维网服务器;
万维网服务器收到请求后,利用URL找到资源,将该资源封装入HTTP响应发回给浏览器;
浏览器解析HTML文件,渲染后展示给用户。
URL HTML HTTP
URL、HTML和HTTP三个规范解决了万维网应用面对的三个关键问题:
-
用URL解决了如何标识分布在整个互联网上的资源的问题。
-
用HTML解决了万维网文档以及超链接的标准化问题,使不同人员创作的不同风格的万维网文档,都能以统一的形式在各种主机上显示出来,同时使跨越站点的资源访问更加方便。
-
用HTTP协议解决了万维网上的信息资源的传递问题。
URL
统一资源定位符URL用来表示互联网上资源的位置和访问这些资源的方法。
URL的一般形式由以下三个部分组成:
<协议>://<主机><端口号/<路径>
“<协议>://”:指出访问该资源所使用的协议,或称为服务方式。
“<主机>:<端口>”:指出保存该资源的主机和处理该URL的服务器进程。
如果服务器上采用的端口是该协议注册过的熟知端口,则“:<端口>”可以省略。“<路径>”:指出资源在该主机中的具体位置。
如果在服务器上设置了某目录下的默认资源,则“<路径>”中可以省略文件名;如果服务器上设置了根目录下的默认资源,则“”/<路径>”部分都可以省略。
HTML文档
超文本标记语言HTML是制作万维网页面的标准语言。目前版本HTML5.0。
HTML使用标签来描述网页文档,HTML标签是由尖括号包围的关键词,通常是成对出现的,例如<body>和</body>。其中第一个标签是开始标签,第二个标签是结束标签。HTML标签的组成如下:
<tag-name[[attribute-name[=attribute-value]]……]>(文本内容)<tag-name>
从开始标签到结束标签的所有代码称为HTML元素。
HTML文档由一组嵌套的元素组成。
HTML定义了几十种元素,用来定义不同的对象,如<img>元素用来定义图像,<p>元素用来定义段落,<a>元素用来定义超链接等。
HTML的目标是指定文档的结构,而不是文档的外观。
为了控制文档的呈现方式,通常会使用层叠样式表CSS。
HTML文档分为静态文档、动态文档和活动文档三种:
- 静态HTML文档:静态HTML文档在创作完毕后就存放在万维网服务器中,它的内容不会根据浏览器发来的数据而改变。
- 动态HTML文档:动态HTML文档在浏览器访问服务器时才得以创建。当浏览器的请求到达时,服务器将URL映射到一个应用程序,由应用程序根据请求中的数据创建一个HTML文档。
- 活动HTML文档:活动HTML文档把创建文档的工作移到浏览器进行。服务器发回给浏览器的文档中包含脚本程序,浏览器执行脚本后,得到完整的活动HTML文档。
超文本传送协议HTTP
超文本传送协议HTTP是万维网的核心。
目前,HTTP/1.1和HTTP/2是互联网建议标准。
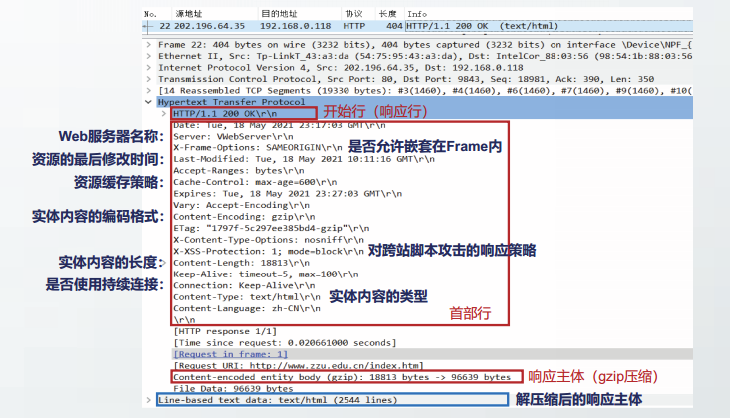
HTTP客户程序通常是浏览器,HTTP服务器程序通常是万维网服务器。浏览器和万维网服务器,通过交换HTTP报文进行会话。
HTTP定义了这些报文的结构以及客户和服务器进行报文交换的方式。
HTTP协议的目的是实现浏览器从万维网服务器获取资源。资源包括文本、声音、图像等各种多媒体文件。
HTTP协议工作过程
- 客户浏览器进程分析URL;
- 浏览器向DNS服务器请求将URL中的主机域名解析为IP地址:
- DNS服务器解析出IP地址;
- 浏览器用IP地址和端口与万维网服务器建立TCP连接;
- 浏览器发出HTTP请求报文;
- 服务器进程返回HTTP响应报文,
- 由浏览器进行解释显示;
- 释放TCP连接。
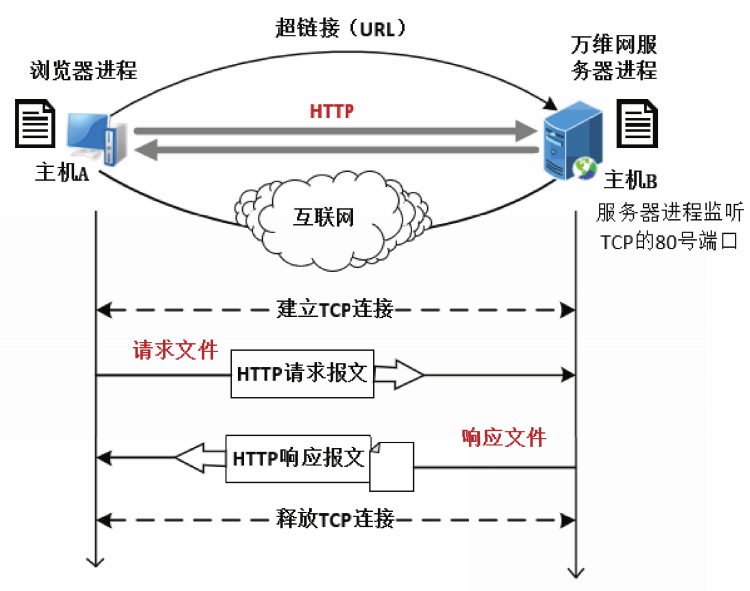
注意:HTTP协议是无状态协议
持续连接和非持续连接
运输层的TCP协议是面向连接的。如果客户-服务器应用选用TCP作为运输层协议,则应用程序的设计有两种方式
- 每个请求/响应对都需要经过一个单独的TCP连接发送,这种设计方法称为非持续连接
- 一系列的请求及其响应都经过相同的TCP连接发送,这种设计方法被称为持续连接。
HTTP/1.0仅支持非持续连接;
HTTP/1.1既支持非持续连接,也支持持续连接。
非持续连接工作方式下,每获取一个文件就要有两倍RTT的开销,
效率很低。
持续连接的两种工作方式
HTTP/1.1在默认情况下使用持续连接,其持续连接支持两种工作方式:
- 非流水线方式:客户在收到前一个HTTP响应报文后才能发出下一个HTTP请求报文。
- 流水线方式:客户在收到服务器发回的HTTP的响应报文之前就能够接着发送新的HTTP请求报文。一个接一个的请求报文到达服务器后,服务器就可连续发回响应报文。
HTTP/1.1的流水线方式依然要求服务器按顺序发回响应报文,如果某一个请求需要的处理时间很长,即使服务器采用多线程的方式已经完成了后续请求的处理,也必须等待这个请求处理完成,在其响应报文发出后,才能够发送后续的响应报文。
HTTP/2针对该问题做了改进,允许在相同连接中交错发送多个HTTP请求报文和HTTP应答报文。
HTTP报文格式
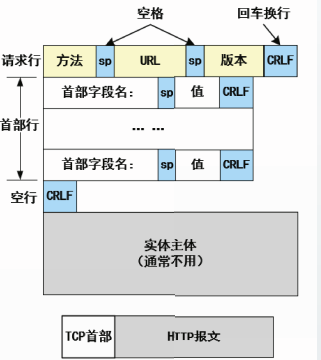
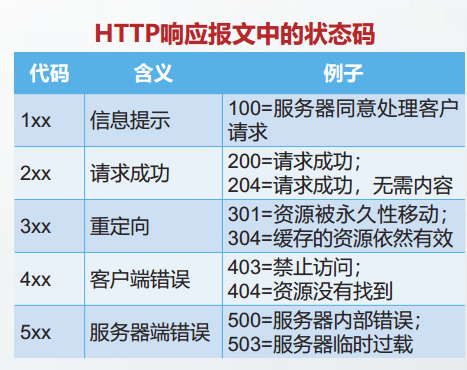
HTTP有两类报文:请求报文和响应报文。
HTTP是面向文本的,在报文中的每一个字段都是一些ASCII码串。
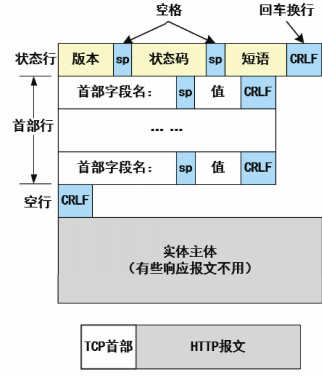
HTTP请求报文和响应报文都是由三个部分组成的。
- 开始行:在请求报文中的开始行叫做请求行,而在响应报文中的开始行叫做状态行。
- 首部行:用来说明浏览器、服务器或报文主体的一些信息。首部可以包含多行,也可以不使用。每一个首部行中都包含首部字段名和它的值。
- 实体主体:在请求报文中称为
请求主体,HTTP请求中一般不使用这个字段。在响应报文中称为响应主体。
HTTP请求报文

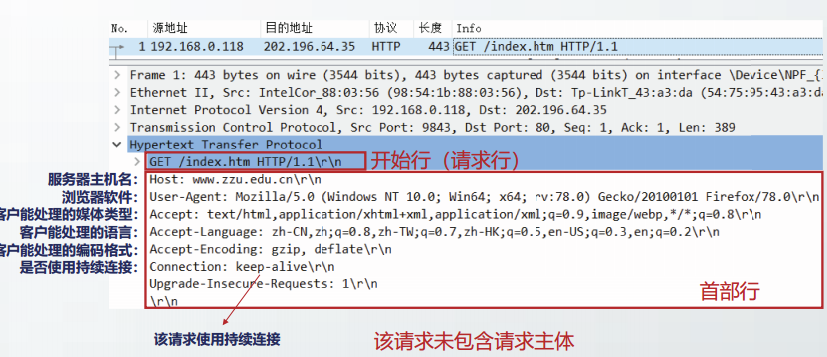
HTTP响应报文
 Cookie
Cookie
HTTP协议是无状态协议,每次请求之间是相互独立的。
当业务逻辑需要了解多次请求之间的关联时,可以使用Cookie,用来弥补HTTP协议无状态的不足。
Cookie包含有四个组件:
①在HTTP响应报文中的一个Set-Cookie首部行;
②在HTTP请求报文中的一个Cookie首部行;
③在用户系统中保存的Cookie,Cookie可以保存在内存中或磁盘上,由用户浏览器进行管理;
④位于万维网服务器的一个后端数据库。
代理服务器
代理服务器也称为万维网缓存。
代理服务器把最近请求过的资源的副本保存在自己的存储空间,当收到新请求时,如果代理服务器发现新请求的资源与缓存的资源相同,就返回缓存的资源,而不需要按URL再次访问该资源。
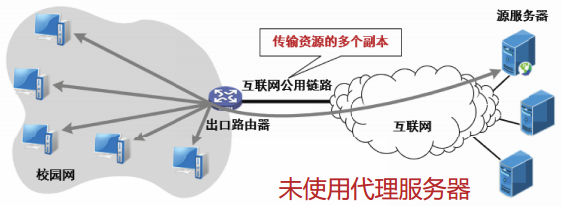
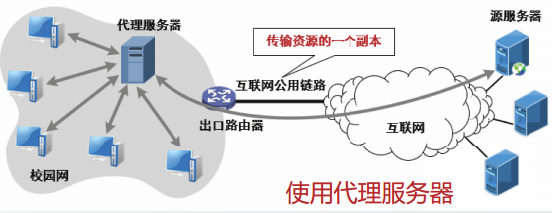
部署并使用代理服务器具有以下两个优势:
- 代理服务器从整体上降低了万维网上的通信流量,从而改善网络性能。
- 代理服务器可以降低浏览器请求的响应时间。
内容分发网络
内容分发网络CDN是也是一种Web缓存。
提供内容分发服务的公司简称为CDN公司,他们在互联网上部署了许多代理服务器,因而使大量流量实现了本地化。
CDN公司部署的代理服务器也称为CDN集群。
一旦CDN集群部署完成,CDN公司就可以动态地将客户的HTTP请求定向到CDN中的某个代理服务器上。
CDN不依赖客户在浏览器中配置代理服务器,而是依赖DNS将不同的客户定向到不同的代理服务器上。
举例
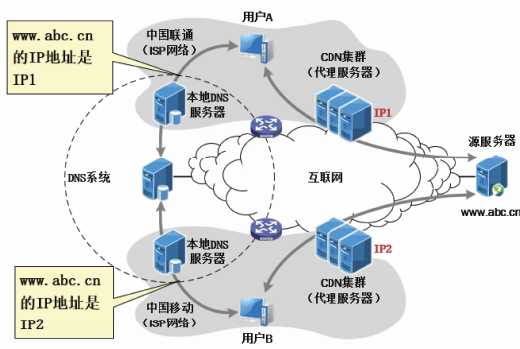
- 客户浏览器向DNS系统发起查询,查找www.abc.cn的P地址。
- DNS系统依据发起查询的客户端不同,返回不同的结果。
例如对于中国联通的用户A,DNS系统返回部署在中国联通的CDN集群的IP地址P1。 - 客户端浏览器依据DNS查询结果,向CDN集群发起HTTP请求。
- CDN集群根据代理服务器的工作流程,直接返回资源给客户浏览器,或者向源服务器请求资源
HTTP/1.X存在的问题
随着互联网的发展,HTTP/1.x已经无法满足现代万维网的需求了,这主要体现在:
- 线头阻塞问题:服务器按序处理请求和返回响应报文,需要缓存多个请求,从而占用更多资源;
- TCP并发连接数限制:利用多个TCP连接,并发访问万维网服务器,会大量消耗服务器的资源;因此,浏览器与服务器之间通常最多建立5~10个TCP并发连接;
- 没有报文首部压缩方案:HTTP报文首部内容很多,但每次请求首部的变化并不大;
- 明文传输不安全:HTTP依赖运输层安全TLS协议,才能实现加密传输。
HTTP/2的新特性
二进制格式的帧:HTTP/1.1的报文格式是基于文本的,而HTTP/2采用了新的二进制格式;
基于流的多路复用:HTTP/2中引入了流的概念,每一对HTTP请求报文和响应报文被视为同一个流,在同一个TCP连接上实现了基于流的多路复用,不同流中的帧可以交错地发送给对方;
服务端推送:HTTP2允许服务器为客户的单个请求发送多个响应,也就是说,服务器可以向客户推送额外的资源;
首部压缩:HTTP/2采用了HPACK压缩格式来压缩请求和响应中的首部信息;
增强的安全性:主流浏览器Chrome、.Firefox等都公开宣布只支持加密的HTTP/2,并且HTTP/2对TLS的安全性做了进一步加强。
详细介绍:HTTP/2的新特性
HTTP/2解决了很多旧版本HTTP的问题,但是它还是存在以下两个待解决问题:
- TCP建立连接的时延问题:HTTP基于TCP协议实现,发送HTTP请求报文前需要先建立TCP连接,TCP连接建立时的三报文握手机制有较大时延;
- 线头阻塞问题未完全解决:HTTP2改进了由应用层“先进先出”引起的线头阻塞问题,但是由TCP“丢失重传“机制引起的线头阻塞问题,HTTP2不能解决。
上述两个问题,都是运输层协议TCP引起的,如果要从根本上解决,需要替换TCP协议。
HTTP/3的改进
与HTTP/2相比,HTTP3有以下几点改进:
- HTTP/3不再基于TCP协议进行数据传输,而是基于UDP上的QUIC协议
实现的。没有建立TCP连接时的时延。 - QUIC在UDP的基础之上增加了功能,实现了类似TCP的流量控制、可靠
传输等功能。 - QUIC集成了TLS的加密功能,进行密钥协商时也可以降低时延。
- QUIC实现了在一条连接上传输多个独立的逻辑数据流,解决了TCP中线头阻塞的问题。
- TCP是在内核空间实现的拥塞控制,而HTTP3通过用户空间来实现拥塞
控制。 - HTTP/3将采用兼容HPACKI的QPACK压缩方案。

域名系统DNS

32位IP地址很难记忆,为了方便记忆和使用,人们引入了主机名hostname。
在ARPANET时代,计算机网络规模比较小,主机名和IP地址的对应关系保存在一个名为hosts的文件中。
自1983年起,互联网开始采用层次树型结构的命名方法,任何一个连接在互联网上的主机或由器,都可以拥有一个唯一的层次结构的名字,称为域名(domain name)
分布式的域名系统DNS能够进行域名到IP地址的解析。
域名系统是互联网中的核心服务,为互联网上的各种网络应用提供域名解析服务。
域名服务器运行在UDP的53号端口上。
域名空间
DNS中使用的名字集合构成了域名空间。早期的互联网使用了非等级的域名空间;目前,互联网采用层次树状结构的域名空间。
域(domain)是域名空间中一个可被管理的划分。域可以划分为子域,而子域还可继续划分为子域的子域,这样就形成了顶级域、二级域、三级域等。
从语法上讲,每一个域名都由标号序列组成,各标号之间用点隔开。
能够唯一地标识互联网上某台主机的域名称为完全限定域名FQDN,其格式如下:
[hostname].[domain].[tld]
其中
hostname是主机名,domain可以是任意的子域,tld是顶级域
例如域名www.zzu.edu.cn是郑州大学Web服务器的完全域名
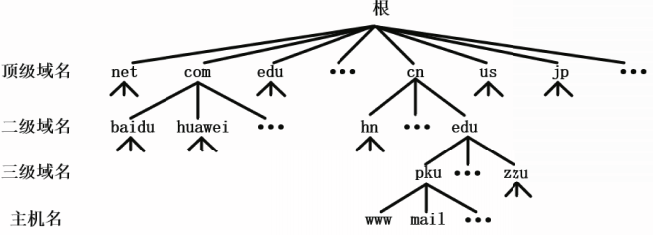
用域名树来表示域名空间的结构是比较直观的。
顶级域名由ICANN进行管理,其它各级域名由其上一级的域名管理机构管理。
域名服务器
DNS系统使用了大量的域名服务器,它们以层次方式组织,每一个域名服务器都只对域名体系中的一部分进行管辖。
根据域名服务器所起的作用,可以把域名服务器划分为四种类型:
·根域名服务器
·顶级域名服务器
·授权域名服务器
·本地域名服务器
根域名服务器
最高层次的域名服务器
根域名服务器都知道所有的顶级域名服务器的域名和对应的P地址。
目前,根域名服务器使用了13个不同P地址的域名,即(a~m).rootservers.net。由12个独立的机构负责运营。
所有根域名服务器都是采用任播部署的。使用任播后,DNS解析器不再需要知道DNS服务器的真正IP地址,只需要知道任播地址就可以在世界各地与当地的最优实例通信了。
每个根服务器的运营者独立负责管理自己的任播实例,不同根服务器的任播实例数量有很大差异,例如B根域名服务器只有4个任播实例,而E根却有308个实例。
到2021年6月,全世界已经安装了1380个根域名服务器的实例,在我国有37个根域名服务器实例。
顶级域名服务器:负责管理在该顶级域注册的所有二级域名
·收到DNS查询请求时,顶级域名服务器会给出相应的回答。
·回答可能是最终的IP地址,也可能是下一步应当找的域名服务器的IP地址。
授权域名服务器:负责管理某个区域的域名服务器
·授权域名服务器有权限管理的范围称为区域(Zone),区域的边界划分由各单位负责。
·区域可能等于域或者小于域。
·在授权域名服务器中保存了该区域中的所有主机的域名到P地址的映射。
本地域名服务器:直接为用户提供域名解析服务的域名服务器
·当一台主机发出DNS查询请求时,这个查询请求报文被发送给本地域名服务器
·每一个互联网服务提供者ISP,都可以拥有一个本地域名服务器,这种域名服务器有时也称为默认域名服务器
资源记录
域名服务器中保存的每一个条目称作为一个资源记录,保存资源记录的文件被称为区域文件。
所有域名服务器中的保存的资源记录共同构成了分布式的DNS数据库。
DNS的资源记录分为很多种类型,常见的资源记录类型如下:
- A记录:指
地址(Address)记录,也称为主机记录,作用是将域名映射到主机的IPv4地址。 - AAAA记录:与A记录的作用类似,它将域名映射到主机的IPv6地址。
- SOA记录:指
起始授权(Start Of Authority,SOA)记录。SOA记录是所有区域文件中
的强制性记录,它必须是一个区域文件中的第一条记录。SO记录描述区域文件所属区
域、该区域的主域名服务器的完全域名FQDN等必要参数。 - NS记录:指
域名服务器记录,用来指明该域名由哪一个DNS服务器来进行解析。NS记
录的作用是将域名映射为管理该域名的DNS服务器的完全域名FQDN。 - MX记录:指
邮件交换记录,用来指明该域的邮件服务器。MX记录的作用是将域名映射
为该域的邮件服务器的完全域名FQDN。 - CNAME记录:指
别名记录,用于将多个域名映射到同一台主机 - PTR记录:PTR记录指
指针记录,也成为反向记录。PTR记录的作用是将P地址反向映
射为域名。
当解析器把一个域名发送给DNS服务器请求解析时,它能获得的DNS服务器的应答就是与该域名相关联的资源记录,每个DNS应答报文都包含了一条或多条资源记录。
例如:
域edu.cn的授权域名服务器收到了一条解析域名www.zzu.edu.cn的请求,由于该域名服务器不是主机www.zzu.edu.cn的授权域名服务器,因此,它返回的应答中包含一条NS记录和包含一条A记录,
其中,NS记录指明管理www.zzu.edu.cn的授权域名服务器为dns.zzu.edu.cn。
A记录指明dns.zzu.edu.cn的IP地址。
因此,这条DNS应答指引DNS解析器向dns.zzu.edu.cn发起下一步的查询。
DNS域名解析可以采用递归查询和迭代查询两种方法。
递归查询
如果DNS客户所询问的域名服务器不知道被查询域名的IP地址,那么该域名服务器就代替该DNS客户,继续向其他域名服务器发出查询请求报文,直至得到结果。
通常主机向本地域名服务器发起的查询是递归查询
迭代查询
当域名服务器收到迭代查询请求报文时,要么给出所要查询的主机的IP地址,要么告知DNS客户下一步应当向哪一个域名服务器进行查询而不会代替DNS客户进行下一步查询。
本地域名服务器向其它域名服务器发起的查询是迭代查询
DNS高速缓存
为了提高DNS查询效率,并减轻根域名服务器的负荷和减少互联网上的DNS查询报文数量,在域名服务器中广泛地使用了高速缓存。
高速缓存用来存放最近查询过的域名以及从何处获得域名映射信息的记录。为保持高速缓存中的内容正确,域名服务器为每项内容设置计时器并删除超过合理时间的项。
本地DNS服务器不仅缓存最终的查询结果,也能够缓存顶级域名服务器的IP地址,因而本地DNS服务器可以绕过查询链中的根DNS服务器。
动态主机配置协议DHCP
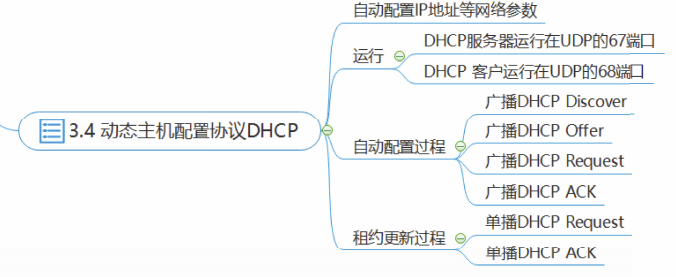
互联网上广泛使用动态主机配置协议(Dynamic Host Configuration Protocol,DHCP)自动配置网络参数。
配置信息一般包括0IP地址、子网掩码、默认路由器的IP地址和本地域名服务器的IP地址。
DHCP服务器分配给DHCP客户的IP地址等网络参数是临时的,只能在一段有限的时间内使用,这段时间称为租用期。
DHCP客户使用UDP的68号端口,DHCP服务器使用UDP的67号端口。
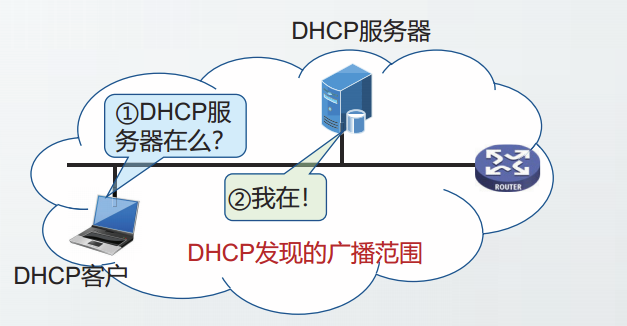
DHCP客户启动时,需要利用广播报文寻找DHCP服务器,该广播报文属于本地网络广播,不能被路由器转发。
因此,要求每个网络上都有一台DHCP服务器。
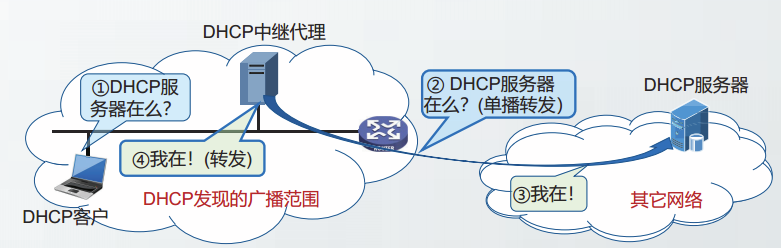
为了避免DHCP服务器过多,DHCP利用DHCP中继代理解决该问题
- DHCP中继代理配置了DHCP服务器的P地址信息。
- DHCP中继代理收到DHCP客户以广播形式发送的发现报文后,就以单播方式向DHCP服务器转发此报文,并等待其回答。
- 收到DHCP服务器的回答报文后,DHCP中继代理再把此回答报文发回给DHCP客户。
例子
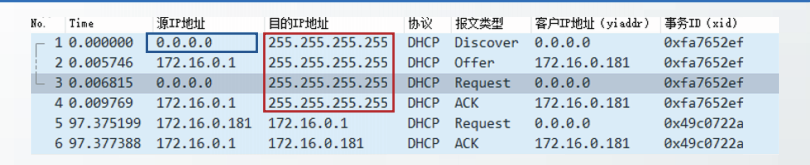
-
DHCP客户从UDP端口68以广播方式发送
DHCP Discover报文。目的IP地址:255.255.255.255 源IP地址:0.0.0.0 -
DHCP服务器广播发送DHCP,Offer报文给予响应

3. DHCP客户从收到的Offer报文中中选择一个服务器,向所选择的DHCP服务器广播发送DHCP
Request报文
4. DHCP服务器收到Request报文后,向DHCP客户广播发送DHCP ACK报文
收到DHCP ACK报文时,DHCP客户真正获得、并能够使用分配的IP地址
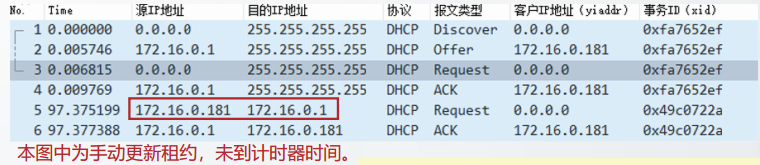
5. 将租期记为T,当到达0.5T时DHCP客户单播发送DHCP Request报文请求续租,如果没有收到DHCP ACK报文,则在到达0.875T时,会再次单播发送DHCP Request报文请求续租。

DHCP服务器收到单播DHCP Request报文,向DHCP客户单播发送DHCP ACK报文或DHCP
NAK报文。
如果DHCP客户收到DHCP ACK报文,则更新租用期,重新设置计时器
如果DHCP客户收到DHCP NAK报文,则停止使用原来的IP地址,发送DHCP Discover报文重新请求

DHCP报文详细格式请参考博客:DHCP报文格式
电子邮件【SMTP / POP3 / IMAP】
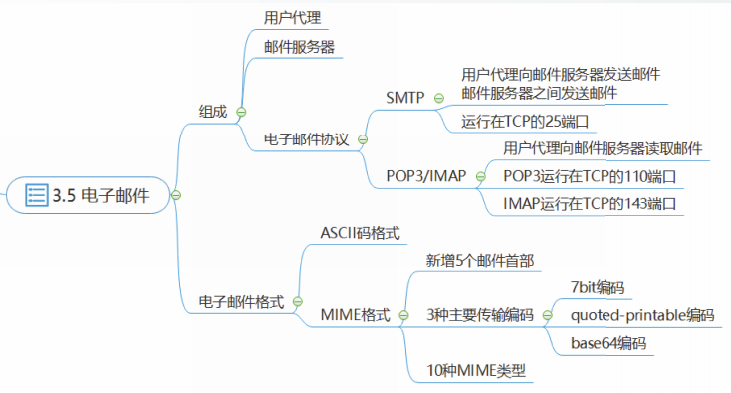
①发送方使用用户代理撰写好一封邮件,通过SMTP发送到发送方的邮件服务器,暂存在发送方邮件服务器的缓存中。
②发送方邮件服务器定期扫描邮件缓存,发现邮件后,通过SMTP将邮件发送到接收方邮件服务器,接收方邮件服务器将邮件存储在用户B的邮箱中。
若投递失败,则发送方邮件服务器将邮件保存在一个队列中,稍后尝试再次发送。
若在规定期限内投递不成功,则删除邮件,并通知发送方投递失败。
③当接收方访问他的邮件时,邮件服务器对接收方的身份进行验证。接收方访问邮件可以使用POP3协议或者IMAP协议。
简单邮件传送协议SMTP
SMTP最初由RFC821规定,目前由RFC5321规定。
SMTP使用客户-服务器方式工作,它工作在TCP的25端口上。
每个邮件服务器都既能充当SMTP客户,也能充当SMTP服务器。
负责发送邮件的SMTP进程就是SMTP客户,而负责接收邮件的SMTP进程就是SMTP服务器。
SMTP规定了14条命令和21种应答信息。
每条命令用几个字母组成,而每一种应答信息一般只有一行信息,由一个3位数字的代码开始,后面附上(也可不附上)很简单的文字说明。
早期版本的SMTP存在着一些缺点:
- 发送电子邮件不需要经过鉴别,造成互联网上垃圾邮件非常多。
·解决:
1、利用POP协议的账号进行身份鉴别
2、RFC5321定义了扩展的SMTP(ESMTP),增加了客户端身
份鉴别功能。
- SMTP仅支持传送ASCII码,而不支持传送二进制数据。
·解决:
定义了多用途互联网邮件扩展MME,支持传送二进制数据
邮局协议POP3
由RFC1939规定的版本3,记为POP3
POP3使用客户-服务器的工作方式,它的服务器工作在TCP的110端口上
邮局协议POP是一个非常简单、但功能有限的邮件读取协议
POP有两种工作模式:“下载并保留”和“下载并删除”
互联网报文存取协议IMAP
由RFC3501规定的MAP协议的第4版
IMAP使用客户-服务器的工作方式,它的服务器工作在TCP的143端口上
IMAP也是一个邮件读取协议,它是一个联机协议
在用户未发出删除邮件的命令之前,MAP服务器邮箱中的邮件一直保存着
IMAP允许用户代理仅读取邮件中某些部分,如只读取一个邮件的首部
IMAP为用户提供了创建文件夹,以及将邮件从一个文件夹移动到另一个文件夹的命令
电子邮件格式部分略。
第四章 运输层
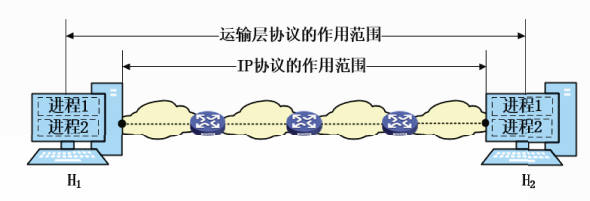
运输层概述

运输层的主要任务是向应用进程提供端到端的逻辑通信服务。
运输层协议是在网络边缘部分的主机中实现的,只有主机的协议栈才有运输层。
路由器在转发分组时只用到协议栈的下三层。
 运输层协议的作用范围是发送方进程到接收方进程。
运输层协议的作用范围是发送方进程到接收方进程。
- 在发送方,运输层协议实体从发送方应用进程接收数据,并依据运输层协议约定的方法,将数据封装到运输层数据单元内,交给下层实体处理;
- 在接收方,运输层实体从下层实体收到运输层数据单元,解封后将数据取出交给接收方应用进程。
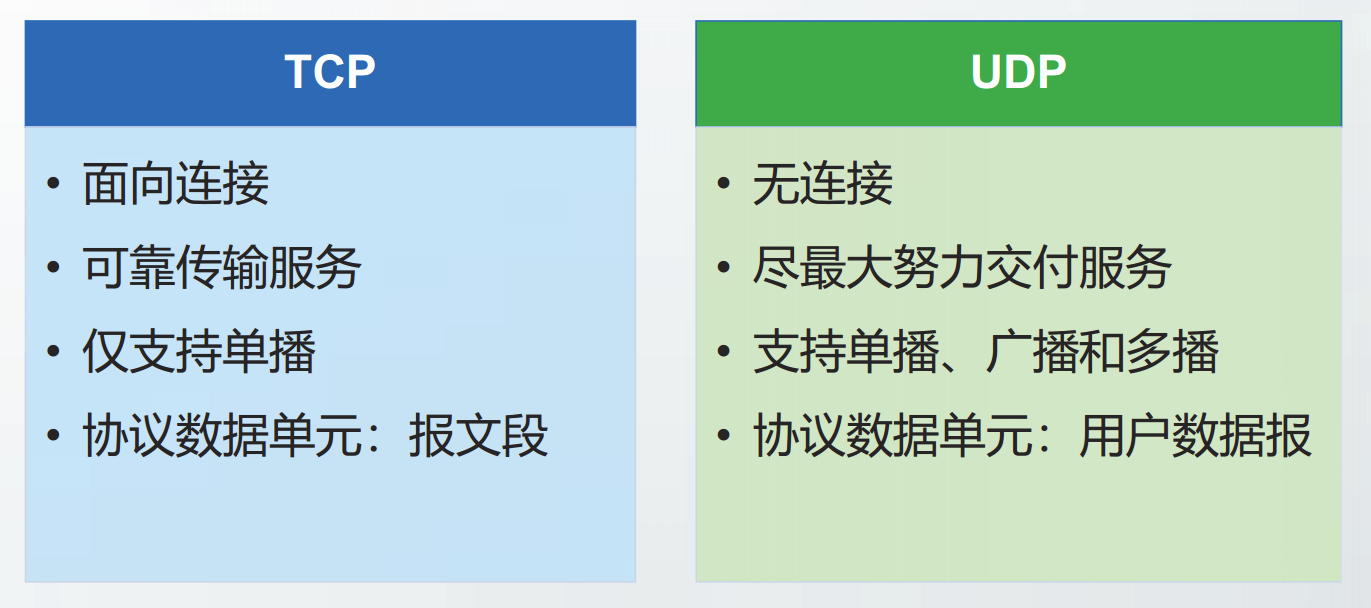
运输层的两个重要协议
运输层中最重要的协议是传输控制协议TCP和用户数据报协议UDP。

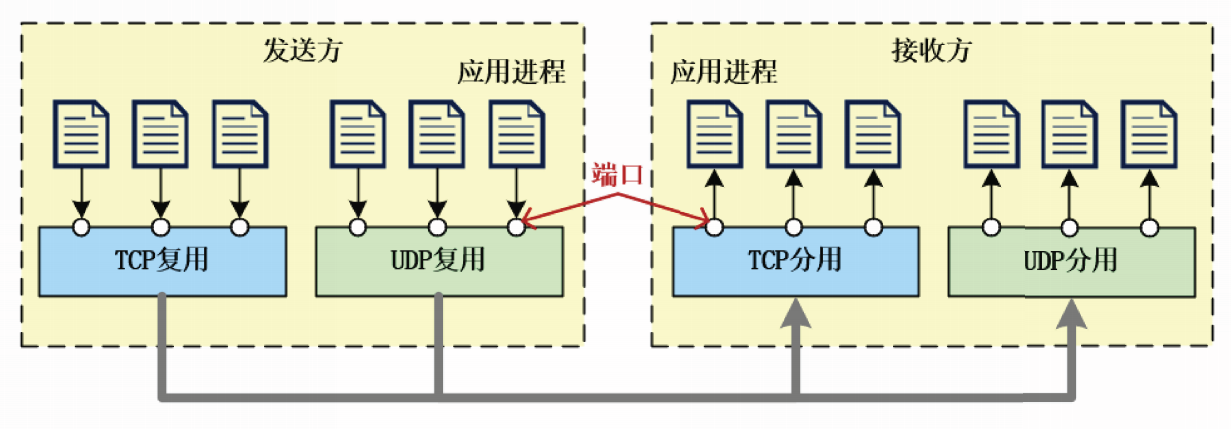
运输层复用和端口
运输层复用是指将多种应用数据封装在同一种运输层协议数据单元中。
运输层分用是指将封装在同一种运输层协议数据单元中的数据分发给不同的应用进程。
实现运输层的复用和分用,需要一个标识符来标识不同的应用进程。
在计算机的操作系统中,一般采用进程标识符来标识进程。但不同的操作系统,其进程标识符格式不同。
为了使不同操作系统上的进程能够互相通信,就必须选择与操作系统无关的、统一的标识符来标识通信中的进程。
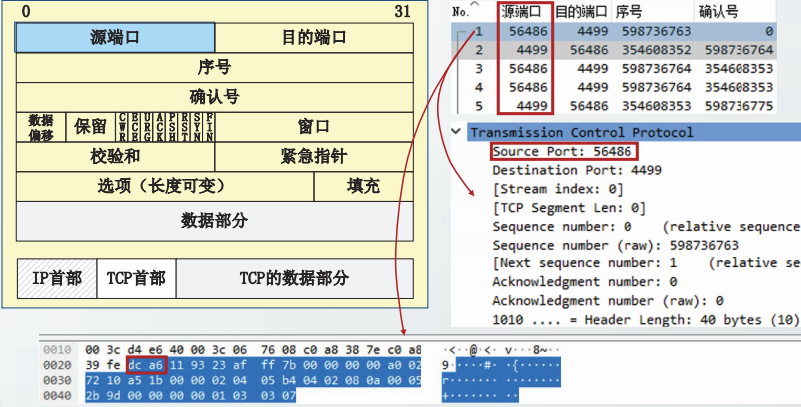
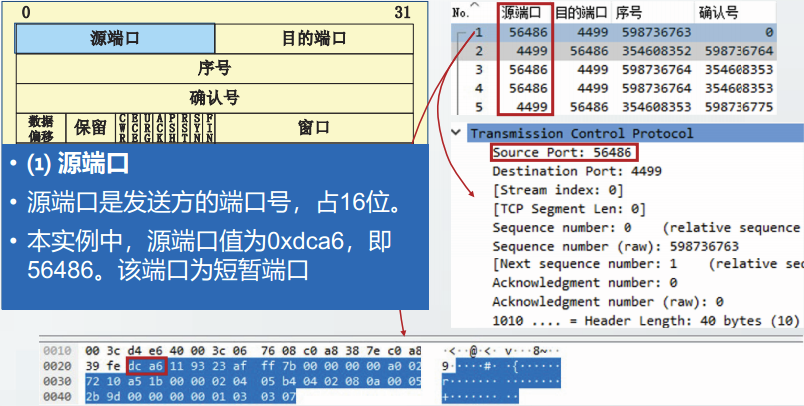
运输层协议使用端口号来标识应用进程,端口号也简称为端口
TCP和UDP的首部中均包含源端口字段和目的端口字段
源端口字段用来标识发送方进程目的端口字段用来标识接收方进程
在接收方进行处理时,源端口通常用作“返回地址”的一部分。
端口字段长度为16比特,其取值范围在0~65535之间
运输层的端口仅具有本地意义,即它所标识的是本计算机中的应用进程。
端口种类
IANA将端口分为三类:系统端口、用户端口、动态端口。

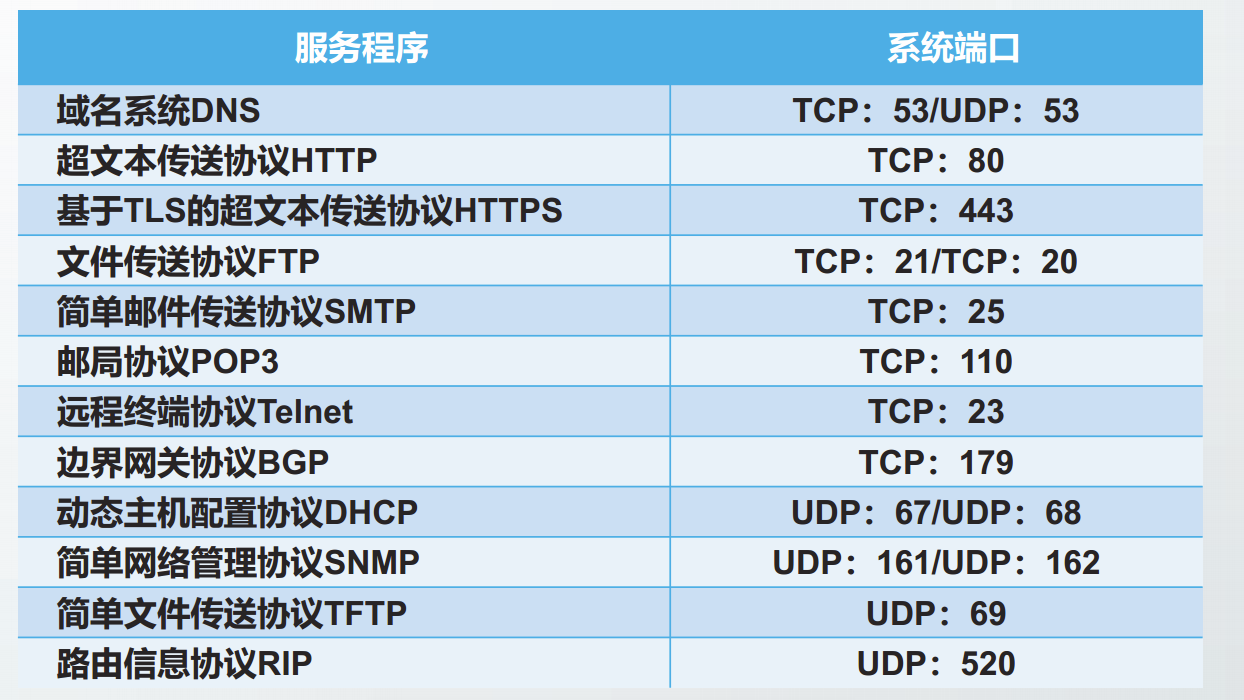
常见的服务程序及系统端口
用户数据报协议UDP
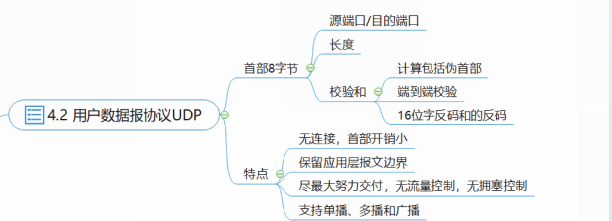
UDP提供运输层最小服务,包括复用分用功能和差错检测功能。
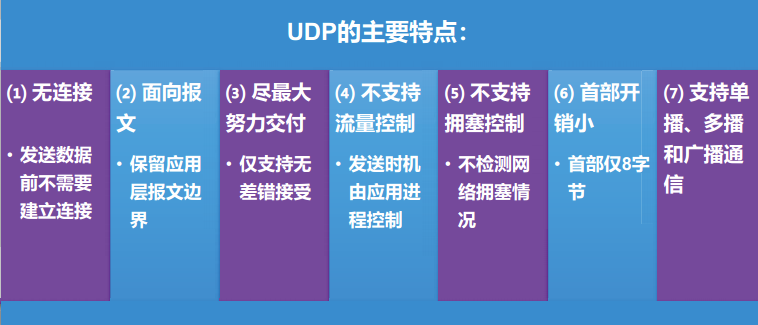
无连接:
发送前不需要建立连接
面向报文:
- UDP保留应用层报文边界。
·将应用进程传递来的报文作为UDP的数据部分直接封装进UDP用户数据报。 - UDP对应用层报文,既不拆分,也不合并,一次发送一个报文。
UDP报文长度
UDP报文的长度是由应用进程决定的
过长和过短的UDP报文都会影响通信效率
报文过长,则下层的IP协议在传送时有可能需要分片,这会造成传输效率的下降
报文过短,则逐层封装所增加的各层首部所占比例会较大,也会造成效率的下降
典型的UDP应用进程,将报文长度控制在512字节以内。如DNS、DHCP。
尽最大努力交付
尽最大努力交付的实质是不可靠交付。
但UDP不会随意的丢弃用户数据报;
UDP提供从发送方到接收方的、端到端的差错检测功能,提供无差错接受服务。
对于可能出现的用户数据报的丢失、重复或者失序,UDP都不进行处理,因此UDP不提供可靠交付服务。
使用UDP的应用进程,如果需要可靠交付,需要自己实现。
UDP不提供流量控制功能
UDP也不提供拥塞控制功能
也就是说:UDP发送用户数据报时,既不考虑接收方当前的状态和处理能力;也不考虑网络当前的拥塞情况和承载能力。
一旦应用进程将数据传递给UDP,UDP立即将用户数据封装并发送出去。
因此,UDP发送用户数据报的时机是由应用进程控制的。
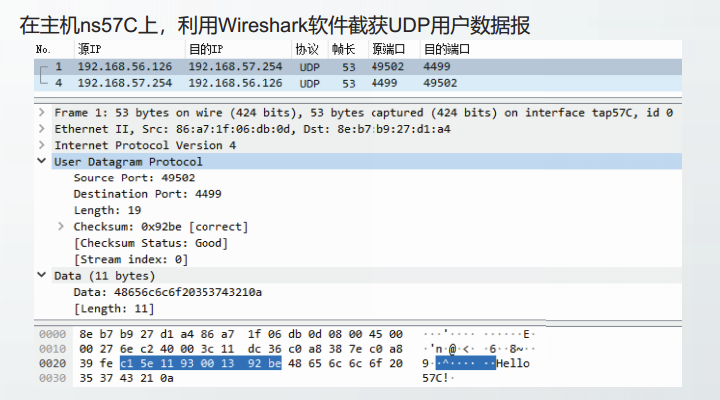
UDP用户数据报格式
在Linux虚拟网络环境中,构建UDP通信实例网络拓扑。
利用Linux的nc指令,进行UDP通信

截获的UDP报文
 ·
·
源端口
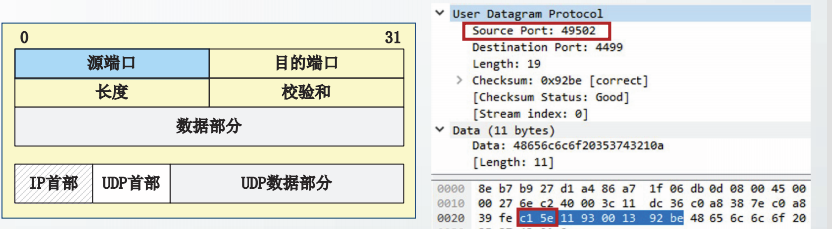
源端口是发送方的端口号,占16位。
源端口号是可选的,如果UDP的发送方不需要对方回复,该字段允许置为全0。
UDP通信实例截获的用户数据报中,源端口值为0xc15e,即49502。该端口为短暂端口
目的端口
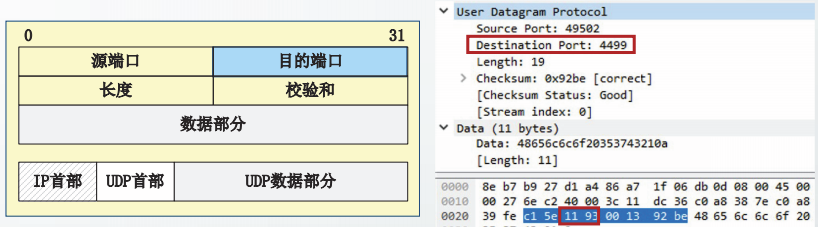
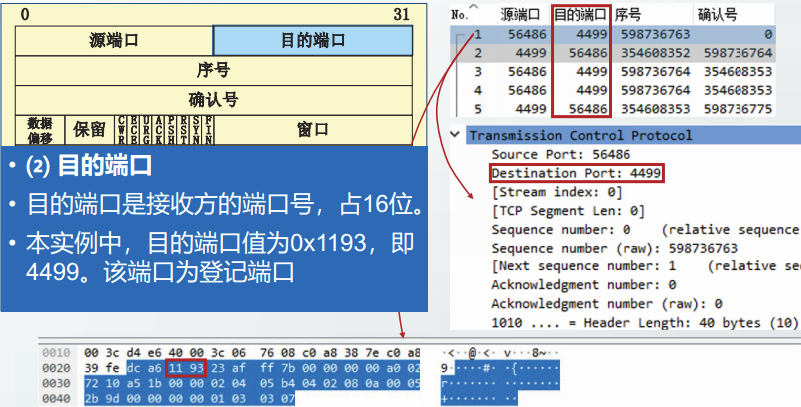
目的端口是接收方的端口号,占16位。
接收方UDP向应用层交付报文时需要使用该字段。
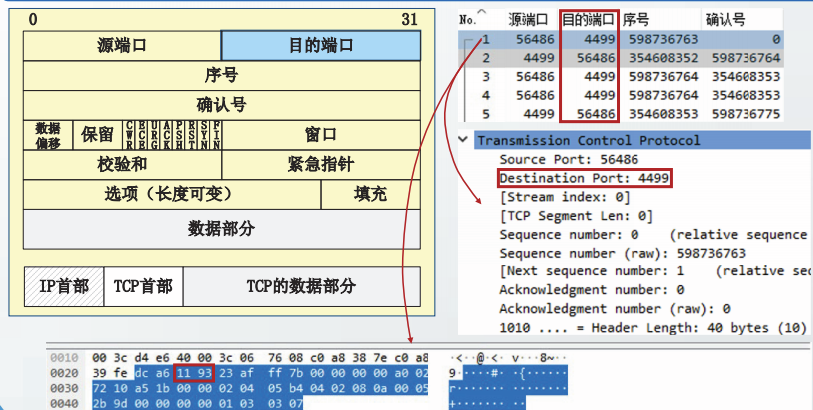
UDP通信实例截获的用户数据报中,目的端口值为0x1193,即4499。该端口为登记端口
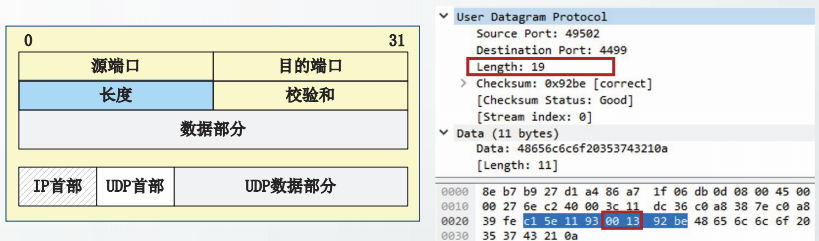
长度
长度指UDP首部和UDP数据部分的总长度,占16位。
长度的最小取值是8字节。
UDP通信实例截获的用户数据报中,长度字段的值为0x0013,即19。本例中,UDP数据部分长度11字节、UDP首部长度8字节。
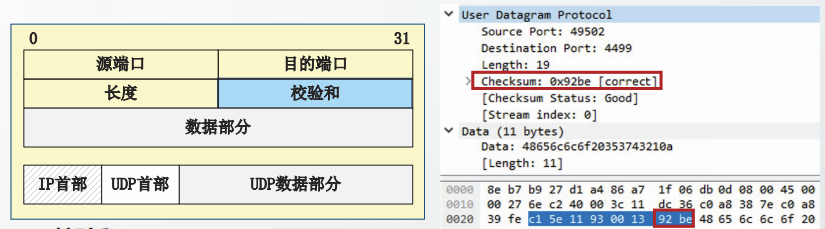
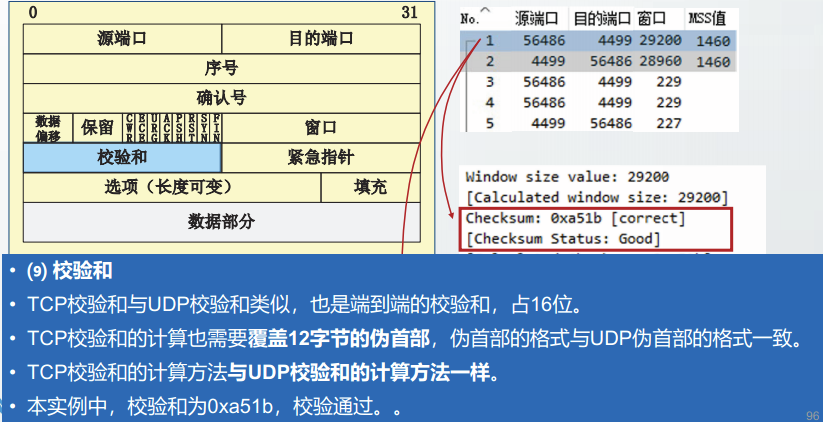
校验和
UDP校验和是一个端到端的校验和,占16位。
UDP校验和由初始发送方计算得到,由最终接收方进行校验,用于校验端到端的传输过程中,是杏出现了比特差错。
对于不能通过校验的用户数据报,UDP仅做丢弃处理
UDP通信实例截获的用户数据报中,校验和字段的值为0x92be,校验通过。
UDP校验和的计算范围覆盖UDP首部、UDP数据部分和一个伪首部。
伪首部衍生自IP首部和UDP首部中的某些字段,共12字节长。
伪首部并不是用户数据报真正的首部,只是在计算机校验和时,临时添加到UDP用户数据报前面,参加UDP校验和的计算。
伪首部既不向下层传送,也不向上层提交,更不会被封装传输。
在运输层的TCP协议中,TCP校验和的计算也采用了相似的伪首部。
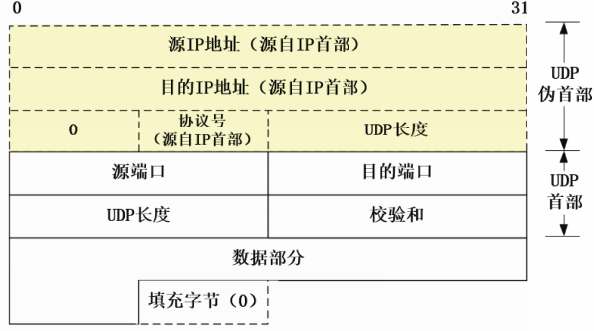 伪首部
伪首部
源IP地址和目的IP地址均来源于IP首部。
协议号字段也来源于IP首部,对于IP-UDP数据报来说,该字段值为17
UDP长度字段来源于UDP首部.
UDP校验和的计算方法是求16位字的反码和的反码,
这种校验和计算方法在P协议、TCP协议中都有应用。
UDP校验和的计算方法要求16位对齐,即必须是偶数个字节,但UDP用户数据报的长度允许是奇数个字节。
因此,对于奇数长度的用户数据报,UDP在尾部追加一个全0的填充字节。
这个填充字节也仅仅是为了校验和的计算和验证,实际上不会被传送出去

可靠传输原理
所谓可靠传输服务是指为上层实体提供一条可靠的逻辑信道,通过该信道传输的数据,不会发生比特差错或者丢失,并且所有数据都按照其发送顺序进行交付。
提供可靠传输服务的协议称为可靠传输协议。理想的可靠信道,满足以下两个假定:
(1)传输的数据不会产生比特差错、丢包或延迟;
(2)接收方的接收速率能够与发送方的发送速率一样快。
本节从理想的可靠信道开始,逐步去除假定条件,讨论在不可靠信道上如何实现可靠传输。
本节讨论的可靠传输原理协议,仅考虑单向数据通信的情况,对于全双工数据通信的情况,在可靠传输的实现方法上,与本节所述原理一致
为方便描述,我们将发送方称为A(Alice),将接收方称为B(Bob)。
本节讨论的可靠传输原理适用于一般的计算机网络协议,因此本节采用术语协议数据单元PDU进行后续的讨论
停止等待协议
在理想的可靠信道上传输数据,显然不需要任何协议就可以实现可靠传输。
我们去除理想信道的第(2)个假定,保留第(1)个假定,即信道是无比特差错、丢包或延迟的。
为了保证接收方B能够正确的接收和处理收到的数据,我们增加流量控制机制:
当B收到一个PDU,处理完毕,做好接收下一个PDU的准备时,B发送给A一个确认PDU,记为
ACK(Acknowledgment)。
A每次发送完一个PDU就必须停止发送,等待B发来的ACK。在收到ACK后,A才能够发送下一个PDU。
这种具有流量控制的,每发一个PDU就停下来等待的协议称为停止等待协议,简称为停等协议,SW协议。
仅具有流量控制功能的停等协议记为SW1.0协议。
我们去除理想信道的第(1)个假定,那么信道中传输的数据有可能出现比特差错、丢包或延迟。
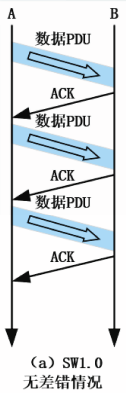
分别考虑三个情况:
数据PDU出错或丢失
在SW1.0基础上,增加如下措施,得到SW2.0协议:
- B在接收PDU时,可以通过
校验和计算等措施检测到差错。对于出错的PDU,B直接丢弃,不发送ACK。 - 为发送方增加超时重传机制:A每发送一个PDU后,设定一个超时计时器,如果超时计时器到期仍然没有收到B发送的ACK,A就重传前面发过的PDU。
- 如果超时计时器到期之前收到了B发送的ACK,则撤销超时计时器。
- 显然,如果A发送的数据PDU在传输过程中丢失,B将收不到PDU,也就不会发送ACK,超时计时器到期后,A也会重发丢失的PDU。
具有超时重传机制,不需要接收方的请求就能自动重传出错或丢失的PDU,这种协议称为自动重传请求ARQ协议
ACK出错或丢失
如果B发送给A的确认ACK在传输过程中出现差错或丢失,由于A收不到正确的ACK,当超时计时器到期后,A将重发前面发过的PDU。
但是B曾经正确接收到该PDU,为了避免B将重复的PDU交给上层议实体,在SW2.0基础上,为数据PDU增加序号,得到SW3.0协议。
- A每发送一个PDU,将序号加1,写入新PDU的序号字段。
- 超时重传的PDU与出错或丢失的PDU具有相同的序号。
- B可以根据序号判断收到的PDU是否是重复的,如果是重复的PDU,说明B发给A的ACK没有正确送达,于是B丢弃重复的PDU,并重传ACK。
ACK延迟
B发给A的ACK在信道中传输时,有可能会延迟到达A。
如果A曾经重传过某个PDU,当迟到的ACK到达时,A不能判断该ACK是对哪一个数据PDU的确认,SW3.0将失效。
在SW3.0基础上,为ACK增加序号,得到SW4.0协议。
- B每收到一个数据PDU,取出该PDU的序号,在发送ACK时,将序号写入ACK的确认号字段,以此说明该ACK确认哪个数据PDU。
- A可以根据确认号判断收到的ACK是否是重复的,如果是重复的ACK,则A丢弃该重复的ACK,不做任何其它处理。
停止等待协议的控制措施
停等协议增加如下几条控制措施,在不可靠信道上实现了可靠传输。
1. 基于确认反馈的流量控制机制;
2. 基于超时计时器的自动重传机制;
3. 基于序号和确认号的重复PDU识别机制。
停止等待协议的信道利用率
例题:
考虑相距约3000公里的两台主机A和B用停等协议进行通信。假定主机A和B通过一条发送速率为1Gbit/s(10bit/s)的信道,相连数据PDU的长度为1500字节,忽略从A到B途中经过的所有结点的处理时延和排队时延,也忽略B主机处理数据PDU的时延和发送ACK的时延。
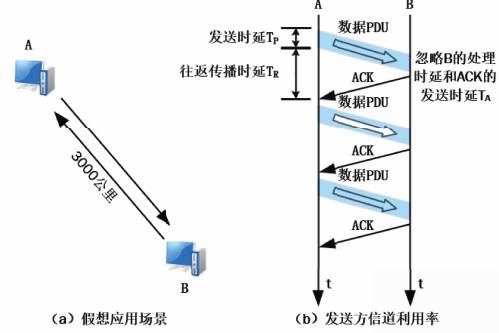
计算发送方A的信道利用率

停等协议信道利用率低,造成了通信资源的极大浪费。
连续ARQ协议
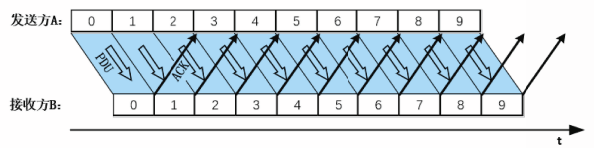
为了提高传输效率,可以采用流水线传输的方式。
流水线传输方式使信道上不断有数据在传送,可以获得较高的信道利用率。
采用流水线传输方式的可靠传输协议称为连续ARQ协议,也称为滑动窗口协议
根据差错恢复方式的不同,连续ARQ协议分为两种:回退N步(GBN)的连续ARQ协议和选择重传(SR)的连续ARQ协议。
滑动窗口
执行滑动窗口协议的通信双方根据自己的缓存空间,各自维护一个窗口。
发送方维持发送窗口swnd,接收方维持接收窗口rwnd。

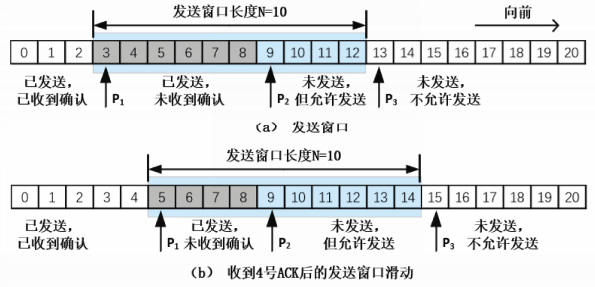
对于发送窗口:
指针P1指向最早未确认的PDU,
指针P2指向下一个待发送的PDU,
指针P3指向发送窗口外的第一个PDU。
[0,P-1]区间内对应已经发送并收到确认的PDU,
[P1,P2-1]区间内对应已经发送但尚未收到确认的PDU,
[P2,P3-1]区间内对应允许发送但尚未发送的PDU,
大于等于P3区间内对应不允许发送的PDU
[P1,P3-1]区间称为发送窗口
发送窗口长度N=P3-P1
本例中,发送窗口长度为固定值10
当发送方收到对3号和4号PDU的确认ACK后,发送窗口将向前滑动,如图(b)所示。P1指针
滑动后指向5号PDU,由于本例中窗口长度是固定值,所以P3指针也随之向前滑动,保持发送窗口长度值10不变。
习惯上,“向前”指向时间增大的方向,“向后”指向时间减少的方向。
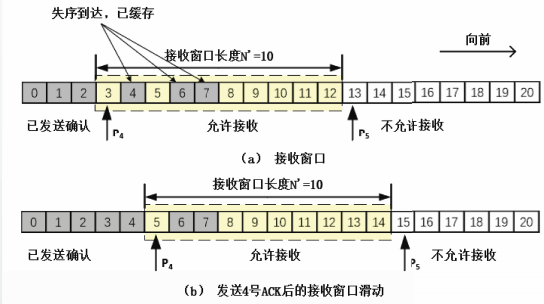
对于接收窗口:
指针P4指向下一个待接收的PDU
指针P5指向接收窗口外的第一个PDU
[0,P4-1]区间内对应已经收到,并且已经发送确认的PDU,
[P4,P5-1]区间内对应允许接收的PDU
大于等于P5区间内对应不允许接收的PDU。
[P4,P5-1]区间为接收窗口,接收窗口长度N’=P5-P4
在本例中,接收窗口长度为固定值10。
当接收方收到3号PDU后,由于之前接收方已经缓存了4号PDU,接收方可以连续发送对3号和4号PDU的确认ACK。
发送4号ACK后,接收窗口将向前滑动,如图(b)所示。P指针滑动后指向5号PDU,
由于本例中窗口长度是固定值,所以P指针也随之向前滑动,保持接收窗口长度值10不变
累积确认
接收方允许采用累积确认的方式发送确认ACK。
累积确认指接收方不必对收到的分组逐个发送ACK,而是在收到几个分组后,对按序到达的最后一个PDU发送ACK,该ACK表示到这个分组为止的所有分组都已经正确收到了。
回退N步GBN协议
对比停等协议和滑动窗口协议的基本概念,不难发现,停等协议实质上是发送窗口长度为1,接收窗口长度也为1的滑动窗口协议。
GBN协议是发送窗口长度大于1,接收窗口长度等于1的滑动窗口协议。
我们观察一个发送窗口长度为4,接收窗口长度为1的GBN协议运行的例子
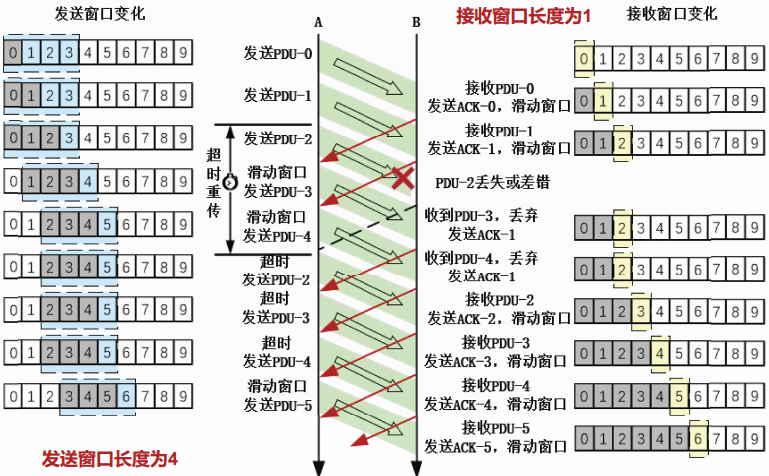
GBN协议中的发送方行为
- 若发送窗口未满,则用发送缓存中的数据组装一个PDU,发送出去,登记超时计时器;若发送窗口已满,则等待发送窗口滑动。
- 若收到确认ACK,则取消该ACK确认的PDU以及之前的PDU的超时计时器。然后根据ACK的确认序号和发送窗口长度,计算并滑动当前发送窗口。
- 若检测到超时事件,则重传超时的PDU。
GBN协议中的接收方行为
- 若收到的PDU落在接收窗口内,则接收该PDU,发送对该PDU的确认ACK,并滑动接收窗口。
- 若收到的PDU未落在接收窗口内,则丢弃该PDU,发送对最后一个正确PDU的确认ACK。
GBN的信道利用率
观察GBN协议的运行过程,可以发现流水线方式的传输使信道中不断有数据在传送,确实可以提高信道利用率。
但由于接收窗口仅为1,造成丢失或差错的PDU之后到达的所有PDU均被发送方重传,即使这些失序到达的PDU都是正确的。这种处理方式造成了信道资源的浪费。
从发送方角度来看,一旦发生超时重传事件,则需要回退N步,从超时的PDU开始重新发送所有后续PDU。
选择重传SR协议
停等协议是发送窗口长度为1,接收窗口长度也为1的滑动窗口协议。
GBN协议是发送窗口长度大于1,接收窗口长度等于1的滑动窗口协议。
SR协议是发送窗口长度大于1,接收窗口长度也大于1的滑动窗口协议。
SR协议中,接收方使用按序到达的最后一个PDU序号对所有按序到达的PDU进行累积确认,同时使用选择确认(Selective Acknowledgement,SACK)对失序到达的PDU进行单独确认。
此处的SACK是选择重传SR协议的选择确认,与本书后面章节介绍的TCP的选择确认选项不同。
我们观察一个发送窗口长度为4,接收窗口长度也为4的SR协议运行的例子
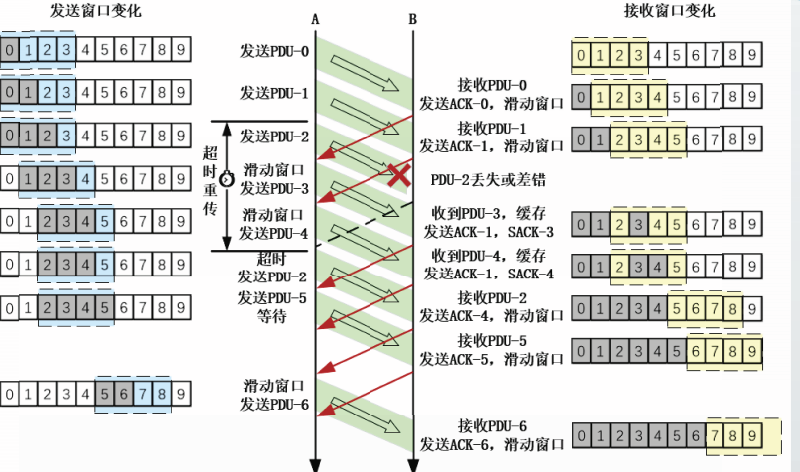
SR协议中的发送方行为
- 若发送窗口未满,则用发送缓存中的数据组装一个PDU,发送出去,登记超时计时器;若发送窗口已满,则等待发送窗口滑动。
- 若收到确认ACK,则取消该ACK确认的PDU以及之前的PDU的超时计时器。然后根据ACK的确认序号和发送窗口长度,计算并滑动当前发送窗口。
- 若收到选择确认SACK,则取消该SACK确认的PDU的超时计时器。
- 若检测到超时事件,则重传超时的PDU。
SR协议中的接收方行为
- 若收到的PDU落在接收窗口内,且该PDU是按序到达的PDU,则接收该PDU,对所有按序到达的正确PDU发送累积确认ACK,并滑动接收窗口。
- 若收到的PDU落在接收窗口内,但该PDU是失序到达的PDU,则缓存该PDU,发送对该PDU的选择确认SACK,并重新发送对最后一个正确PDU的确认ACK。
否定确认NAK的概念
选择重传$R协议可以跟否定策略结合在一起使用,即当接收方检测到错误的PDU时,它就发送一个否定确认(Negative Acknowledgement,NAK)
在发送方,收到NAK可以触发该PDU的重传操作,而不需要等到对应的超时计时器超时,因此可以提高协议性能。
传输控制协议TCP
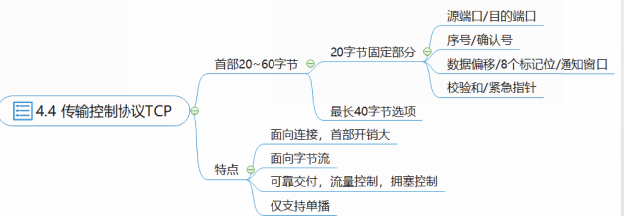
TCP协议是面向连接的可靠传输协议,提供连接管理、可靠传输、流量控制和拥塞控制等功能。

TCP连接是逻辑连接,TCP把连接作为最基本的抽象。
TCP连接的端点称为套接字(socket)
RFC793中定义套接字由端口号拼接到P地址构成:
套接字=(IP地址:端口号)
每一条TCP连接有且仅有两个端点,每一条TCP连接唯一地被通信两端的两个套接字确定。
TCP连接两端的主机需要维护TCP连接状态
一旦建立连接,主机中的TCP进程将设置并维护发送缓存和接收缓存
面向连接
通信之前需要建立连接
面向字节流
TCP不保留应用层报文边界
应用进程和TCP进程的交互是每次一个数据块,但TCP进程把这些数据块看成一串无结构的字节流
TCP在合适的时候从发送缓存中取出字节流封装成报文段发送出去
TCP报文长度
TCP报文段长度由TCP进程决定
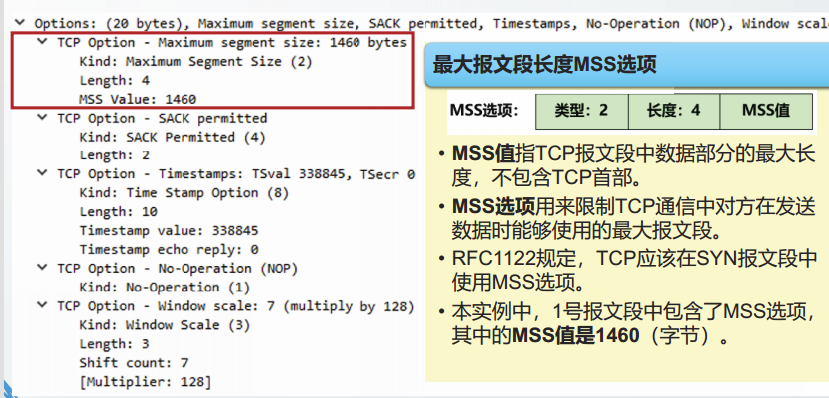
TCP进程 从 发送缓存中取出并放入报文段的字节流长度 受 最大报文段长度(Maximum Segment Size,MSS)限制,与应用层报文笾界无关。
MSS指TCP报文段中数据部分的最大长度,不包含TCP首部
TCP在建立连接时,通过协商确定MSS值。
其他特点
TCP采用以字节为单位的滑动窗口协议实现可靠交付服务。
通过TCP连接传送的数据,可以保证无差错、不丢失、不重复,按序到达。
TCP采用基于窗口的流量控制机制,接收方将接收窗口值发给发送方,发送方根据该值调整发送窗口长度,并以此控制发送速率。
TCP可以根据超时重传事件和快速重传事件检测网络的拥塞情况,减缓发送速度,进行拥塞控制。
TCP也支持用**显式拥塞通知(Explicit Congestion Notification,ECN)**的方式进行拥塞控制。
TCP发送报文段的发送时机是由TCP进程控制的。
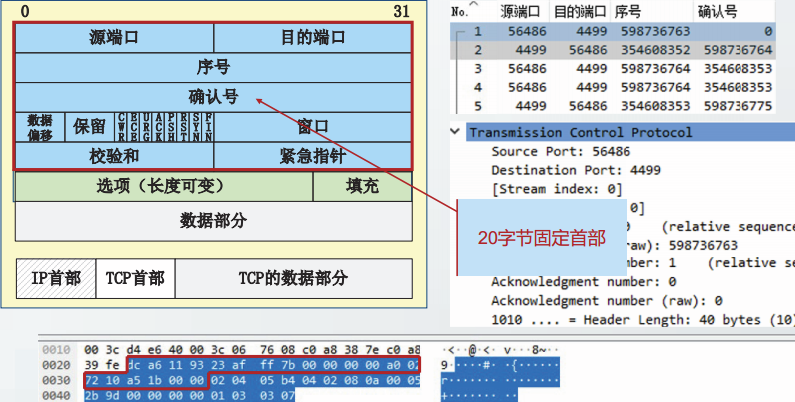
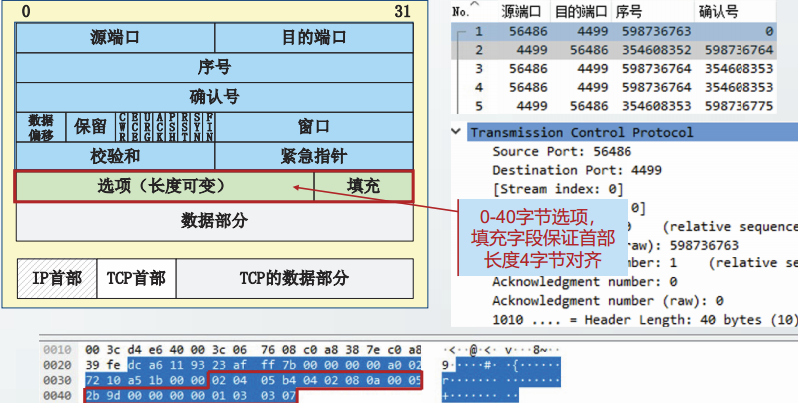
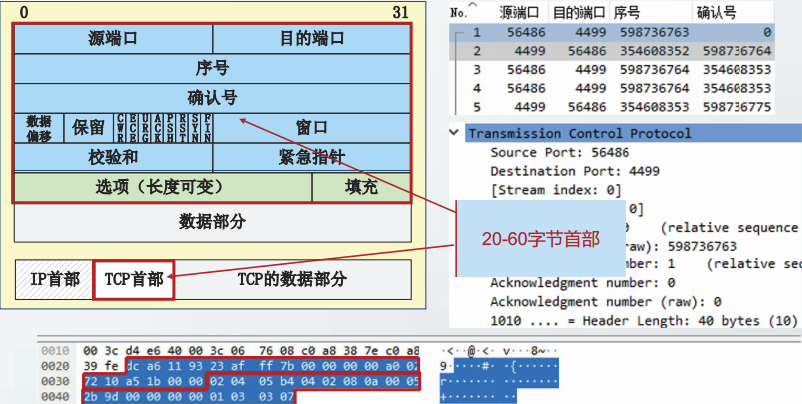
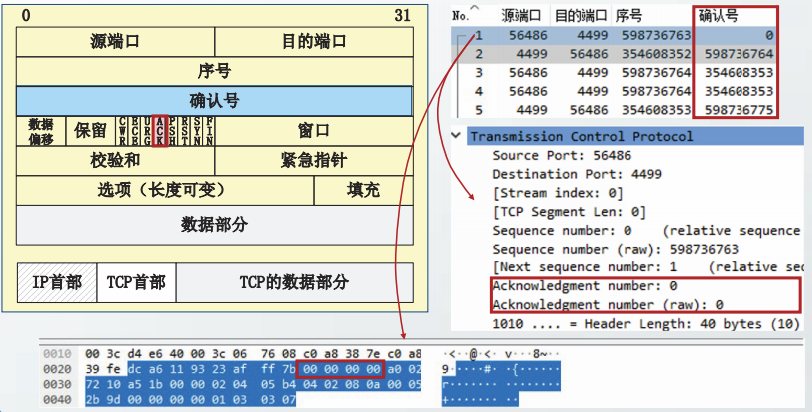
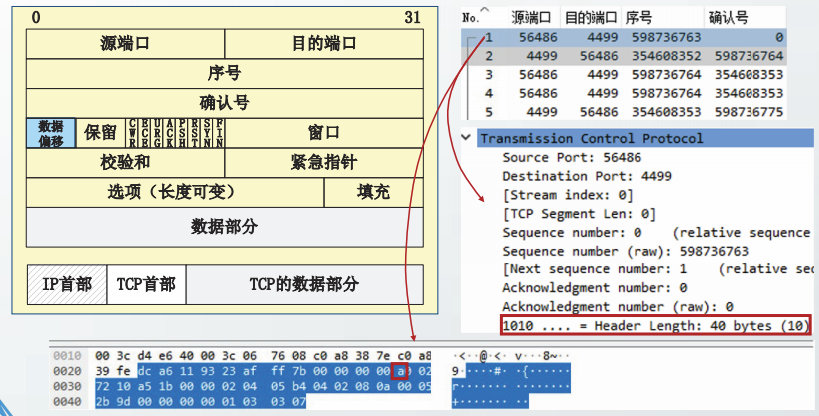
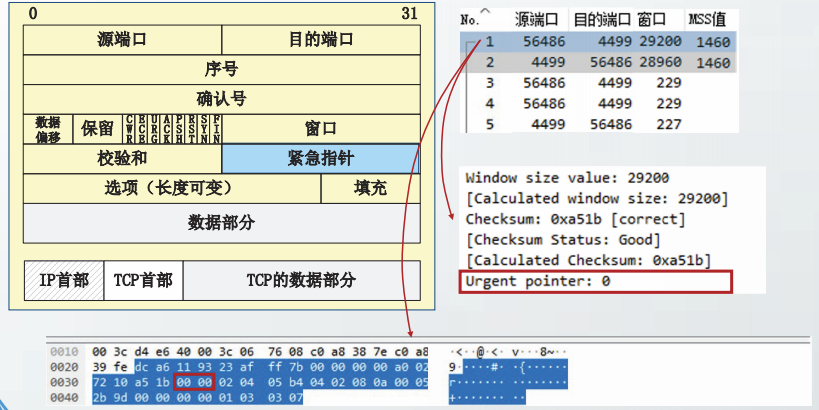
TCP报文格式
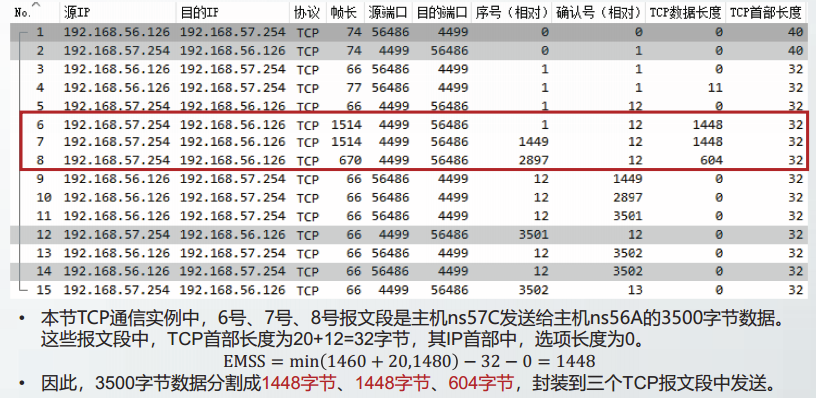
在主机ns57C上,制作一个3500字节的文本文件,命名为3500.0。
从主机ns56A向主机ns57C发起TCP通信,并读取3500.0文件。在ns57C上截获TCP报文段。

以下部分较多图片,文字可参考博客:
http://c.biancheng.net/view/6441.html
https://blog.csdn.net/a19881029/article/details/29557837



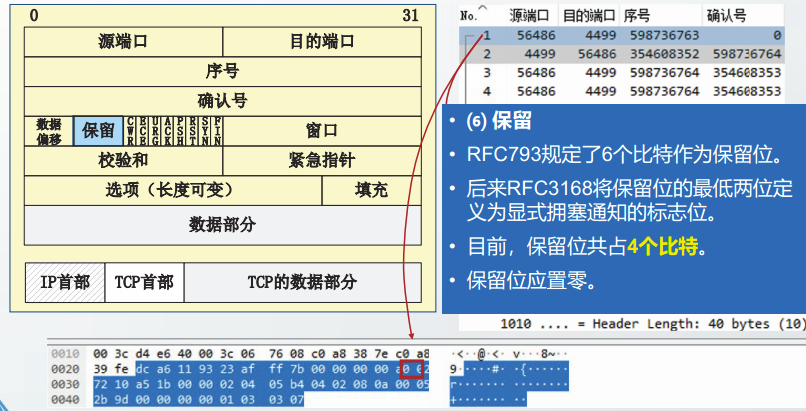
 保留位
保留位
CWR:拥塞窗口缩减。
当CWR=1时,表明根据ECN回显,发送方已经降低发送速率。
ECE: ECN回显。
ECE=1的报文段是一个来自接收方的显示拥塞通知,表明发送方之前发送的报文段曾经遇到了网络拥塞。
CWR和ECE用于TCP的显式拥塞控制,将在后续中介绍。
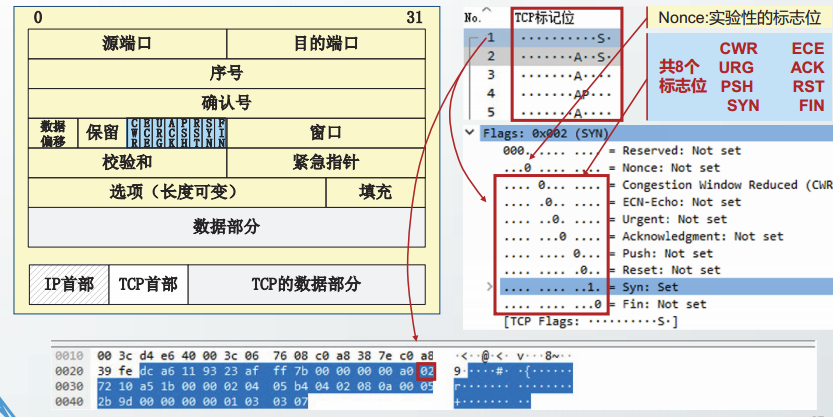
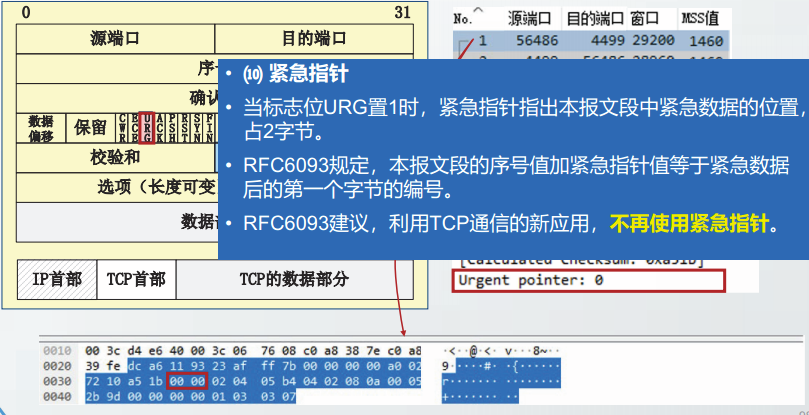
URG:紧急数据标志。
当URG=1时,紧急指针字段生效表明报文段中包含紧急数据,紧急数据的位置由紧急指针字段指明。
2011年RFC6093建议不再使用紧急数据。
ACK:确认标志。
当ACK=1时,确认号字段生效,表明报文段中包含确认信息。
TCP规定,连接建立后的所有报文段都必须把ACK置1。
PSH:推送标志。
当PSH=1时,表明发送方要求接收方尽快将报文段中的数据交付给上层。在包括Berkeley Socket在内的多数TCP/IP实现中PSH标志置1代表发送方缓存中已经没有待发送数据。在处理telnet等交互模式的连接时,该标志总是置1的。
RST:重置连接。
当RST=1时,表明TCP连接中出现了错误,需要取消连接。
RST=1的报文段通常称为RST报文段。
SYN:同步连接
当SYN=1时,表明报文段是一个TCP建立连接请求。
SYN=1的报文段通常称为SYN报文段。
FIN:终止连接。
当FN=1时,表明发送方的数据已经发送完毕,并请求释放TCP连接。
FN=1的报文段通常称为FN报文段。

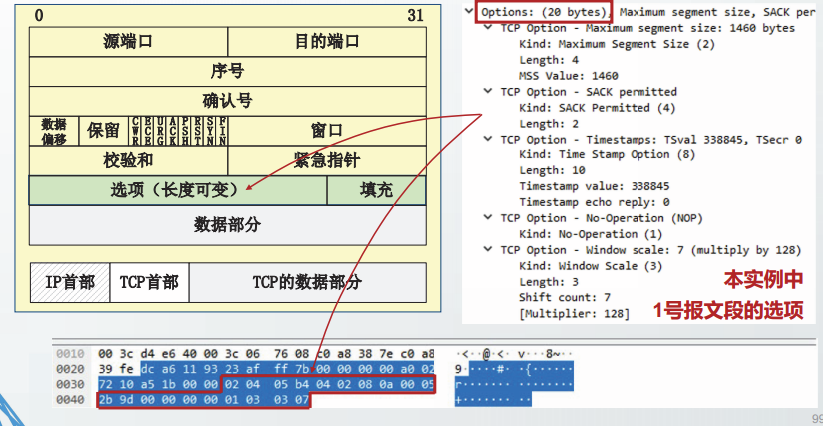
选项



 发送方有效最大报文段长度的计算
发送方有效最大报文段长度的计算
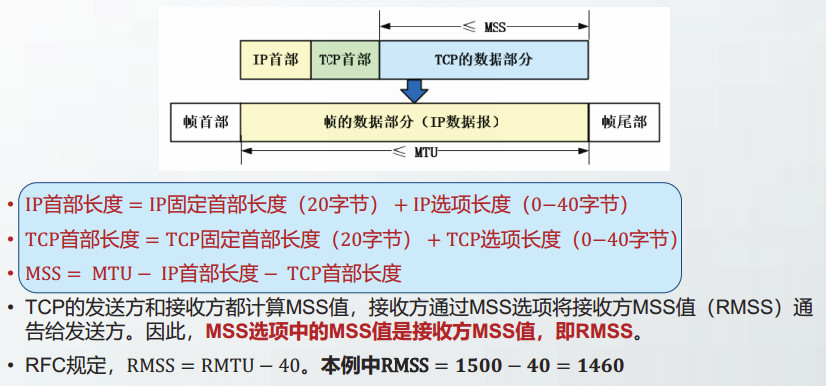
TCP发送方在封装报文段时,需要计算有效最大报文段长度EMSS。
EMSS受到对方发来的RMSS的限制,也受到发送方自己的MTU值、TCP选项长度以及P选项长度的限制。
RFC1122规定EMSS的计算公式如下:
EMSS = min(RMSS + 20,MSS_S) - TCPhdrsize - IPoptionsize
其中:
RMSS为对方发来的MSS选项中的MSS值;
MSS_S为发送方能够发送的包含TCP首部的报文段的最大值,计算公式为:
MSS.S = 发送方的MTU-20;
TCPhdrsize为包含选项的TCP首部长度;
IPoptionsize为lP选项长度。
将RFC1122规定的EMSS的计算公式,做一个简单的变换,可以得到:
EMSS=min(RMTU,SMTU)-TCPhdrsize-IPhdrsize
即EMSS值为:发送方和接收方MTU中的较小值减去TCP首部长度和IP首部长度
在TCP的具体实现中,有效最大报文段长度EMSS的计算还需要考虑路径MTU(PMTU)的限制。PMTU指整个网络路径上的所有链路中最小的MTU。
TCP发送方发送数据时,为提高传输效率,会尽可能按照EMSS值封装TCP报文段,
按照EMSS值封装的报文段称为全长报文段(Full-sized Segment)。
 RMSS
RMSS
RFC1122中规定,RMSS的默认值为536字节。
如果在SYN报文段中未包含MSS选项,则TCP将RMSS设置为536字节。
在早期的计算机网络中,X.25协议应用广泛,它的MTU值是576字节。该MTU值减去20字节的P固定首部长度和20字节的TCP固定首部长度,刚好得到536字节。
当前的网络环境中,最典型的RMSS值是1460字节。
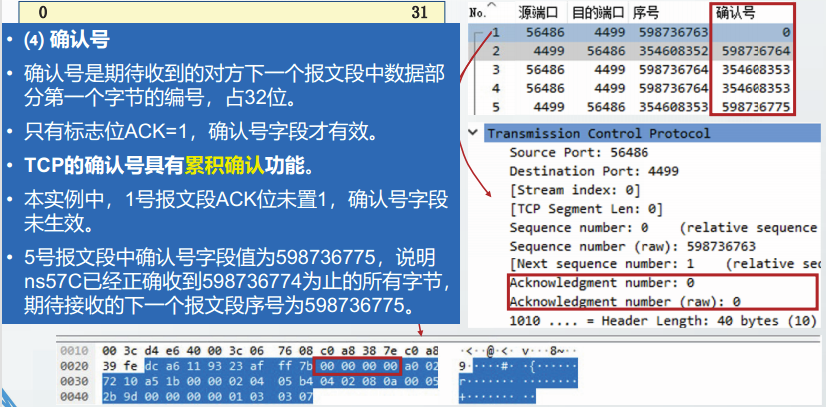
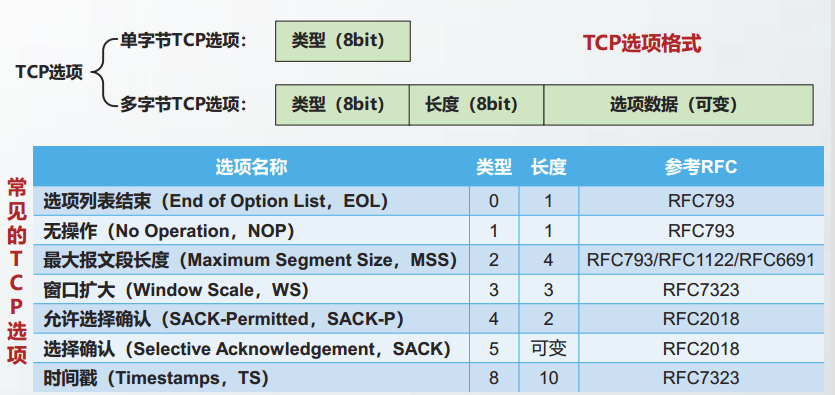
WS


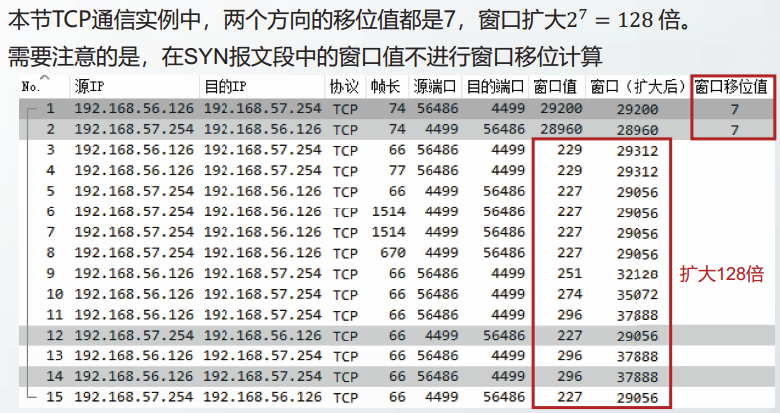
SACK-P和SACK
TCP的确认号具有累积确认功能。因此,对于失序到达的报文段,TCP接收方不能用确认号字段进行确认。
RFC2018定义的选择确认SACK选项,用以确认失序到达的报文段。
如果TCP通信方希望使用SACK选项,需要在初始的SYN报文段中增加允许选择确认(SACK Permitted,SACK-P)选项。

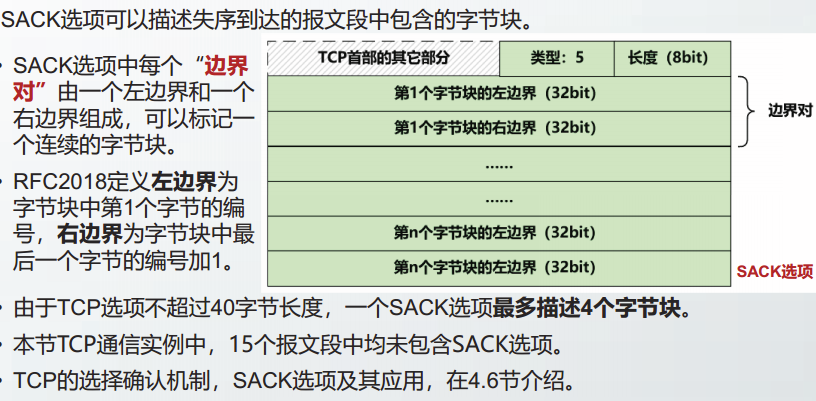
TS


TCP的连接管理
可参考视频:
TCP的三次握手和四次挥手
主动建立连接的一端称为客户
被动等待连接建立的一端称为服务器。
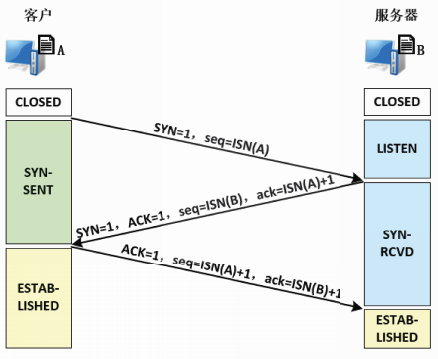
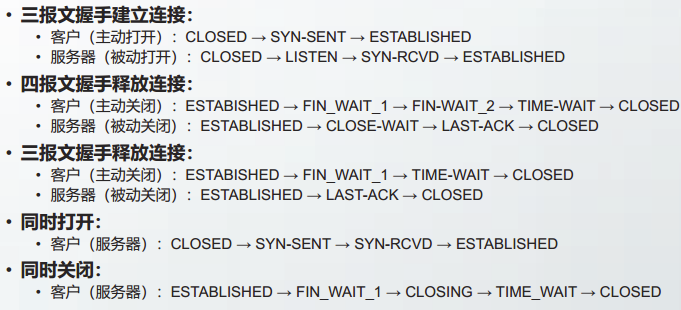
TCP建立连接的过程中需要在客户和服务器之间进行三次报文段交换,称为三次握手或三报文握手。
首先,服务器进程B被动打开连接,从CLOSED状态进入LISTEN状态,等待来自客户的建立连接请求。
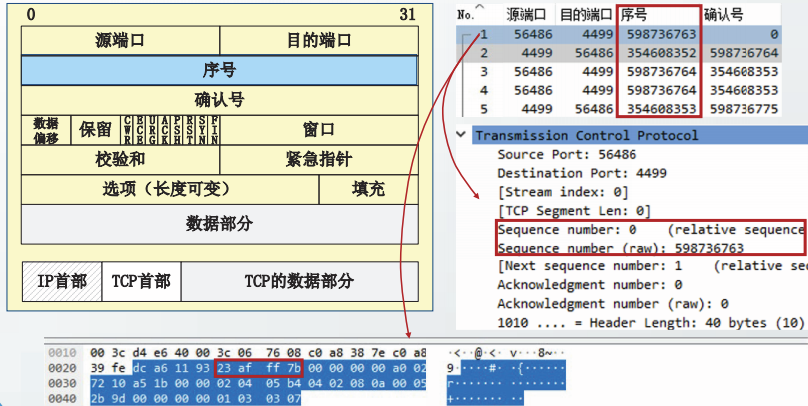
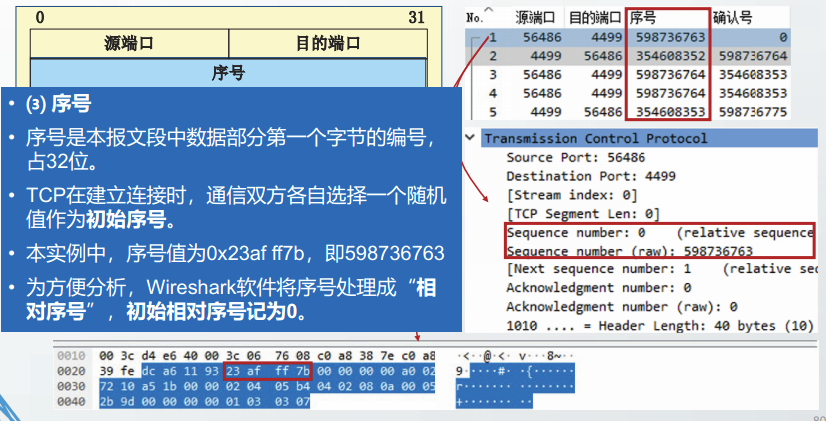
第1次握手
客户进程A将SYN标志置1,选择初始序号ISN(A),以服务器B的IP地址和端口号作为参数,构造TCP报文段,发送给B。
该报文段称为SYN报文段。
虽然SYN报文段的数据部分长度为0,但是占用1字节编号,以方便服务器对SYN请求进行确认。
客户从CLOSED的状态进入SYN-SENT状态。
第2次握手
收到客户A的SYN报文段后,服务器进程B发送自己的SYN报文段作为响应。
报文段中,将SYN标志置1,选择初始序号ISN(B);并将ACK标志置1,将ISN(A)+1作为确认号。
该报文段称为SYN-ACK报文段。
SYN-ACK报文段也占用1字节编号。以方便客户对该SYN请求进行确认。
服务器从LISTEN状态进入SYN-RCVD状态。
第3次握手
收到服务器B的SYN-ACK报文段后,客户进程A发送确认报文段。
报文段中,将ACK标志置1,将ISN(B)+1作为确认号。序号字段为ISN(A)+1。
该报文段称为ACK报文段。
ACK报文段可以携带数据,也可以不携带数据。如果不携带数据,则不占用序号,客户A随后发送的数据报文段中序号字段任然是ISN(A)+1。
连接建立
发完ACK后,客户A从SYN-SENT状态进入ESTABLISHED状态。
此时,对于客户进程A,TCP连接已经建立,可以开始进行数据传输了。
服务器B收到客户A的ACK报文段后,从SYN-RCVD状态进入ESTABLISHED状态。
此时,服务器进程B也可以开始进行数据传输了。
发完ACK后,客户A从SYN-SENT状态进入ESTABLISHED状态。
此时,对于客户进程A,TCP连接已经建立,可以开始进行数据传输了。
服务器B收到客户A的ACK报文段后,从SYN-RCVD状态进入ESTABLISHED状态。
此时,服务器进程B也可以开始进行数据传输了。
RST重置连接
如果客户进程向某Socket发送SYN报文段请求建立TCP连接,
但该Socket指向的端口并没有绑定服务器应用进程,即该端口上没有服务进程处于LISTEN状态,
则服务器上的TCP进程会设置RST标志,发送RST报文段给客户进程,拒绝建立连接。
TCP的 连接 释放
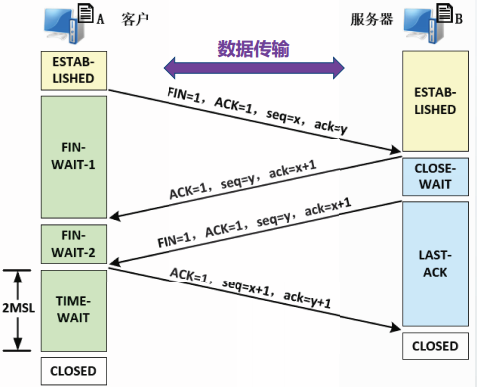
数据传输结束后,通信双方都可以主动释放TCP连接。
主动释放连接的一端称为客户,被动释放连接的一端称为服务器。
TCP释放连接的过程中需要在客户和服务器之间进行四次报文段交换,称为四次握手或四报文握手。
假定进程A主动释放连接。将数据传输过程中,进程A发送给进程B的最后一字节编号记为x-1,
进程B发送给进程A的最后一字节编号记为y-1。
第1次握手
·A向B发送释放连接请求报文段。
在该报文段内,将FIN标志置1,填写序号为×。
由于TCP建议连接建立后的所有报文段中ACK标志都置1,所以A也将ACK标志置1,并填写确认号为y,用以确认收到的最后一字节数据。
该报文段一般称为FIN报文段。
FIN报文段数据部分长度为0,但是占用1字节编号,以方便通信中对方对FIN请求进行确认。
客户从ESTABLISHED状态进入FIN-WAIN-1状态。
第2次握手
收到A的释放连接请求后,服务器进程B应立即确认。
在确认报文段中,B将ACK标志置1,填写确认号为x+1,填写序号为y。
如果该ACK不含数据,则不占用字节编号。
服务器从ESTABLISHED状态进入CLOSE-WAIN状态。
客户收到确认报文段后,从FIN-WAIT-1状态进入FIN-WAIT-2状态
这时的TCP连接处于半关闭状态,
A不能再发送数据。B如果有数据,还可以继续发送,A仍然要接收。
第3次握手
左图示例中,半关闭状态下,B没有发送数据。
当进程B需要释放连接时,也需要发送一个FIN请求。
该报文段中,FIN标志置1,序号仍然为y。B也将ACK标志置1,确认号仍然为x 1。
FIN报文段虽然不包含数据,但占用1字节编号,
服务器从CLOSE-WAIT状态进入LAST-ACK状态
第4次握手
收到B的FIN请求后,客户进程A应立即确认。
在确认报文段中,A将ACK标志置1,填写确认号为y+1,填写序号为x+1。
客户A发送了确认报文段后,从FIN-WAIT-2状态进入TIME-WAIT状态。
连接释放
服务器进程B收到最后一个ACK报文后,从LAST-ACK状态进入COLOSED状态。此时,对于B来说TCP连接已关闭。
客户进程A需要在TIME-WAIT状态等待2MSL时间之后,才能进入COLOSED状态。
MSL代表最长报文段生存期,RFC793建议MSL取值2分钟。
当2MSL计时器超时后,A从TIME-WAIT状态进入CLOSED状态。对于A来说,TCP连接才关闭。
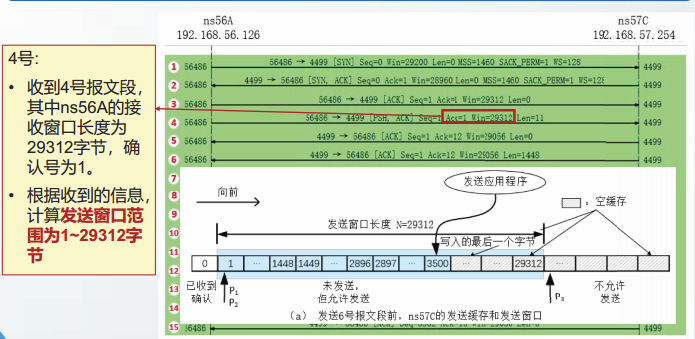
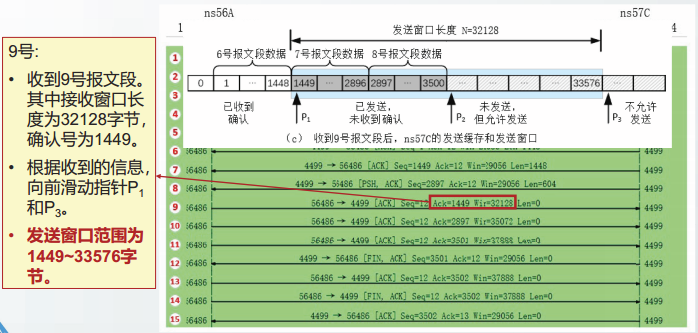
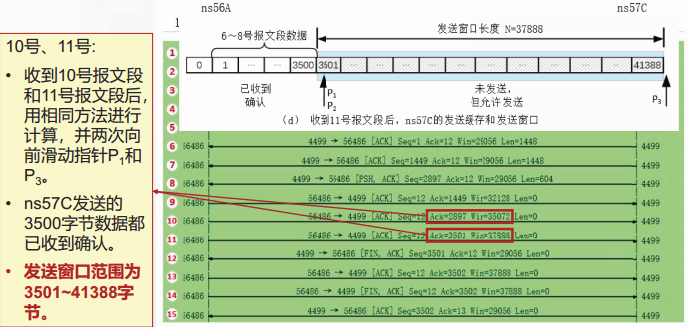
TCP的可靠传输

TCP的可靠传输协议是以字节为单位的滑动窗口协议。
TCP可靠传输的特点:
1.TCP窗口内的序号不是以PDU为单位编号,而是以字节为单位编号。
2.TCP的发送窗口和接收窗口均大于1。
3.TCP的发送窗口和接收窗口长度不是固定的,而是动态变化的。
4.TCP支持多种重传机制:超时重传、快重传和SACK重传。
以字节为单位的滑动窗口
TCP的滑动窗口运行原理与连续ARQ协议的原理一致。
实例分析:



接收缓存和接收窗口
由于时延的影响,从主机ns56A上观察上述TCP通信实例,得到的报文段顺序不同。
假定ns56A收到报文段后,都立即发送确认信息,则在ns56A上观察本节TCP通信实例,得到的TCP报文段顺序应该是:
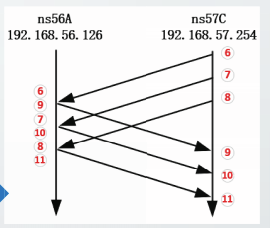

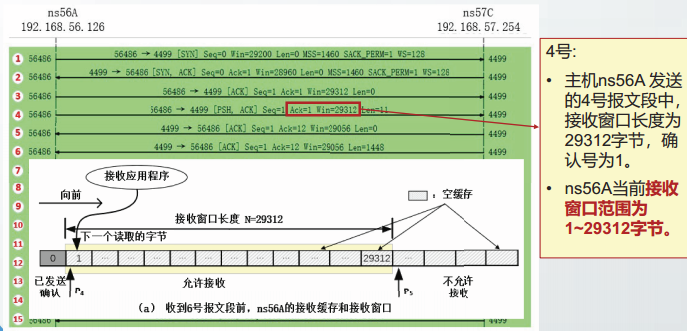
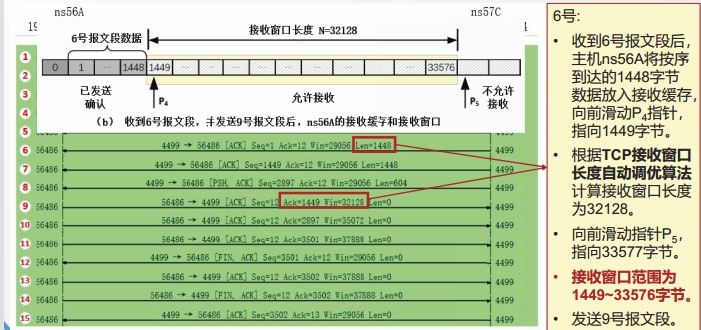
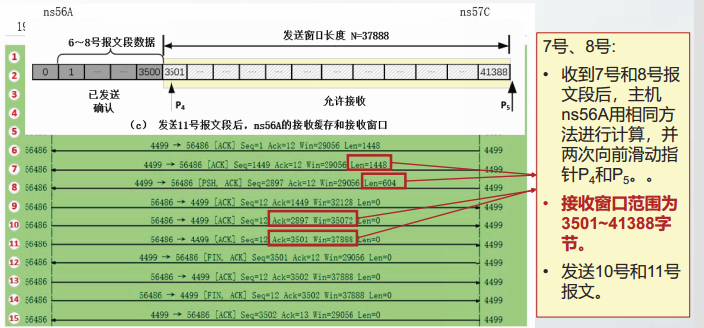
超时重传
如果出现了报文段丢失或差错,TCP将会采用先前介绍的超时重传机制,对超时且未收到确认的报文段进行自动重传。
TCP的超时重传类似于GBN协议,采用累积确认,不能单独对失序到达的报文段进行确认。
TCP的超时重传概念很简单,但实践中超时重传时间RTO的选择却比较复杂。
TCP测量往返时延RTT,计算平滑往返时间,并计算超时重传时间RTO。
往返时间RTT的估算
TCP记录一个报文段的发出时间,以及收到对应确认信息的时间,二者之差作为一个RTT测量值,也称为RTT样本,记作RTTsam
TCP维护一个RTT的加权平均值,称为平滑往返时间,记作SRTT。
每进行一次测量,TCP按照如下公式计算新的平滑往返时间SRTT:
SRTT = ( 1-α ) x SRTT + α x RTTsam
RFC6298中,建议α取值 0.125 。
SRTT的初值应设置为第一个有效的RTT样本。
类似SRTT这种加权平均值称为指数移动加权平均值,时间越靠近当前时刻的数据权重越大。
超时重传时间RTO的估算
RFC6298定义了RTT偏差,记作RTTV,用以估算RTT样本偏离SRTT的程度。
RTT偏差也是一个指数移动加权平均值,每取得一次RTTsam,TCP按照如下公式计算RTTV:
RTTV = ( 1 - β ) x RTTV + β x | SRTT - RTTsam |
RFC6298中,建议 β 取值0.25。
RTTV的初值设置为第一个RTT样本值的一半。
超时重传时间RTO应略大于平滑往返时间SRTT。
每取得一次RTTsam,TCP计算SRTT和RTTV,然后按照如下公式计算RTO:
RTO = SRTT + max(G,4 x RTTV)
上式中G代表系统的时钟粒度(clock granularity),即使计算得到的RTTV趋近零,RTO也应该比SRTT大1个时钟粒度。
在Liux系统中,TCP时钟粒度为1ms,因此RTO至少比SRTT大1ms。
RFC6298建议给RTO设定上界和下界,上界的建议值是60秒,下界的建议值是1秒。
在尚未取得有效RTT样本之前,RFC6298建议将RTO初值设置为1秒。
RTT样本测量
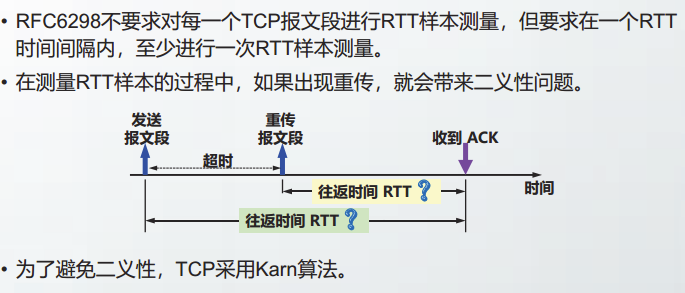 Karn算法
Karn算法
Karn算法包括两部分:
- 当报文段重传后,不采用该报文段作为RTT样本。
- 报文段每重传一次,将RTO增大为原来的2倍,直至不再发生重传。
Karn算法使TCP可以区分有效和无效样本,保证RTO计算结果更加合理
基于时间戳选项的RTT样本测量
在前文中,我们介绍了TCP的时间戳选项可以用于往返时间测量。
当发送方收到确认信息时,用当前时间减去回显时间戳的时间,即可得到往返时间。
利用时间戳选项计算往返时间,显然可以避免上述二义性,因此不必采用Karn算法的第①部分。

快重传
超时重传机制可以实现可靠传输,但有如下缺点:
- TCP的超时重传机制类似于GBN协议。
- TCP的超时重传机制会带来更大的网络负载。
- 根据Karn算法的第②部分,超时重传事件还会引起RTO快速增长,因而会引起网络利用率下降
RFC5681和RFC6582中定义了更为高效的快重传机制。
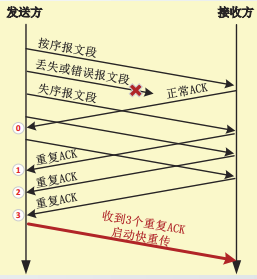
快重传机制不依赖重传计时器超时,而是基于接收方的反馈信息来引发重传。快重传机制通过检测重复ACK(duplicate ACK)事件发现丢包,触发重传。
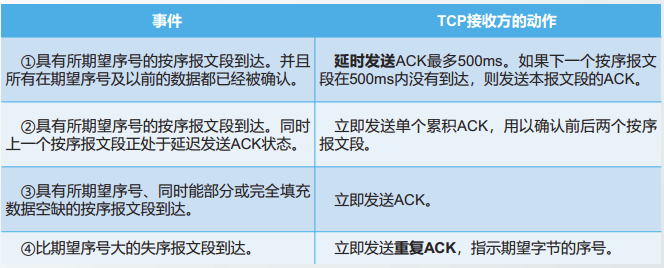
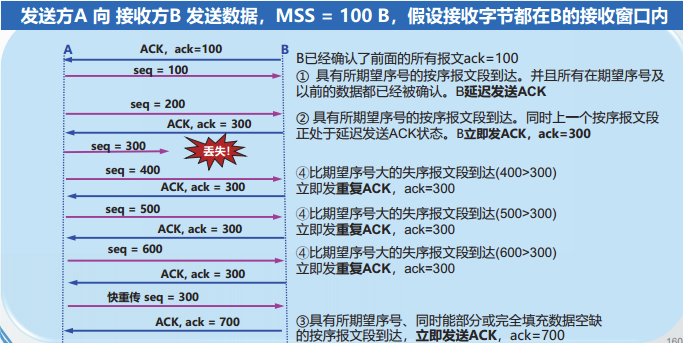
由于TCP的确认号具有累积确认功能,因此,当接收方TCP收到失序的报文段时,发送的ACK中的确认号,与确认最后一个按序到达的报文段的确认号一样。这种再次确认某个报文段的ACK称为重复ACK。
我们首先介绍接收方发送ACK的策略
TCP接收方发送ACK的 策略
 重复ACK的阈值
重复ACK的阈值
由于网络层不保证按序提交数据报,因此TCP发送方仅收到一个重复ACK,并不能确认是发生了
丢包还是发生了失序传输。
RFC5681规定重复ACK的阈值(DupThresh)默认为3。注意:重复ACK的阈值是允许调整的。
当收到3个重复的ACK,才认为这个已经被确认4次(1次正常的确认 3次重复的确认)的报文段之后的报文段已经丢失。
当TCP发送方收到3个重复ACK时,TCP就启动快重传,立即重传丢失的报文段而不必等待重传计时器超时。
有效ACK
快重传机制属于选择重传协议,启动快重传后,在收到有效ACK前,TCP只能重传一个报文段。
有效ACK是指确认了新到达数据的ACK。有效ACK包括两种:完全ACK和部分ACK,这两种有效ACK的区分依赖恢复点的定义。
当发送方启动快重传算法时,已经发送了多个失序报文段,RFC6582将此时发送方已经发送的最大序号称为恢复点。

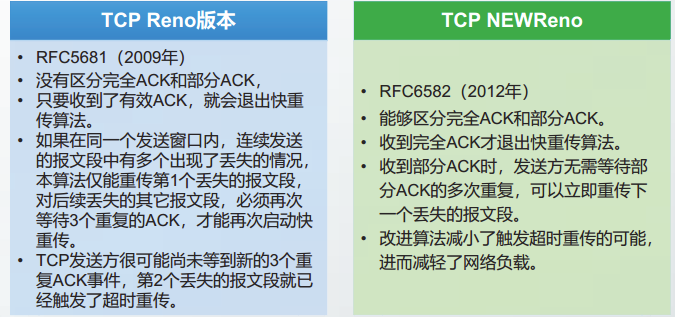
快重传算法的要点
TCP NEWReno版本的快重传算法的要点可以总结如下:
收到3个重复ACK:记录恢复点,启动快重传算法,重传丢失的报文段;收到部分ACK:立即重传下一个丢失的报文段:收到完全ACK:退出快重传。
TCP的快重传机制,实际上以重复ACK的形式实现了隐式的否定确认(NAK)
优势:与超时重传相比,快重传能更加及时有效地修复丢包情况,提高重传效率。
不足:虽然可以对一个窗口内的多个丢失报文段进行快速重传,但是第2次重传是在收到第次重传的确认信息之后,两次重传之间的时间间隔大于一个RTT,因此效率不高,并且仍然容易触发超时重传。
SACK重传
快重传机制收到部分ACK后才能得到下一个丢失的报文段的信息,因此在一个RTT内仅能够重传一个报文段。
TCP的SACK选项用来描述失序到达的报文段信息。
在重复ACK中携带的SACK选项信息可以反映接收方存在的多个数据空缺,因而发送方可以根据SACK的信息,在一个RTT内重传多个报文段。
基于SACK的重传机制也属于选择重传协议。但TCP的SACK重传机制,与先前介绍的选择重传的原理协议有很多不同。
TCP是在复杂的网络环境中运行的协议,其SACK重传机制考虑了更多因素,其通信双方的行为更复杂。
为方便描述,这里将采用SACK选项的数据接收方简称为SACK接收方,将采用SACK选项的数据发送方简称为SACK发送方。
SACK接收方行为
SACK接收方收到失序报文段后,将报文段内的失序数据暂存在接收缓存中,然后就生成并发回发送方一个包含SACK选项的报文段。
对于SACK发送方来说,根据该报文段中的确认号判定,这个包含SACK选项的报文段属于一个重复ACK。
一个SACK选项中可以包含多个字节块,SACK选项中的字节块简称为SACK块。
RFC2018规定接收方生成SACK选项的规则如下:
①在生成SACK选项时,接收方应该填写尽可能多的SACK块。
②第一个SACK块必须指明触发该SACK选项的失序数据序号
③其它的SACK块指明最近接收到的失序数据序号。这些SACK块曾经填写在之
前发送过的SACK选项中。
SACK发送方行为
SACK发送方除了需要记录收到的累积确认信息,还需记录收到的SACK信息。
根据累积确认信息和SACK信息,SACK发送方维护一个数据结构,用来记录已被正确接收的失序数据块的序号范围和数据空缺的序号范围。
在RFC6675中,该数据结构被称为记分板(scoreboard)

发送方在收到SACK选项后,如果判定报文段丢失,则启动SACK重传。
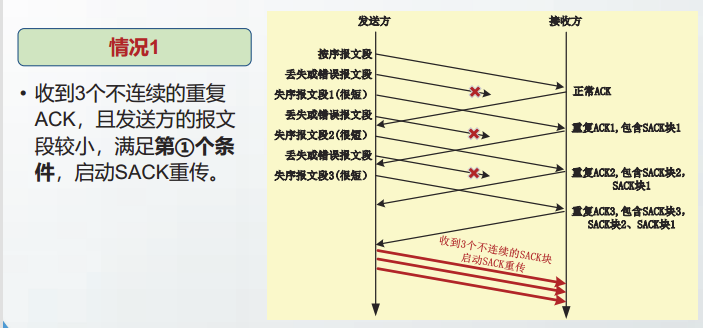
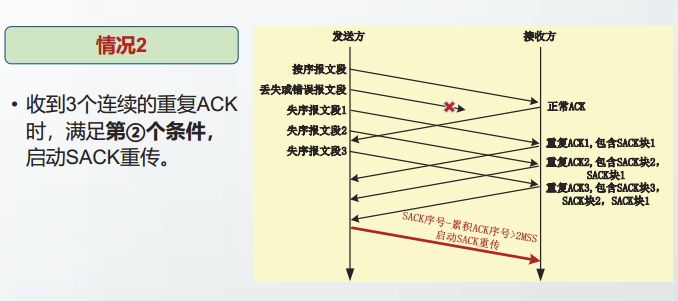
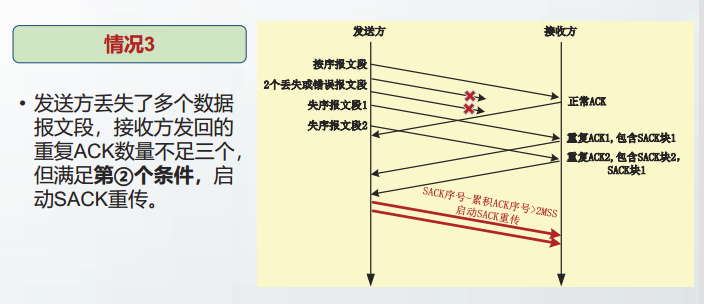
依据重复ACK阈值(DupThresh),RFC6675规定满足以下两个条件之一时,启动SACK重传:
- 收到
DupThresh个不连续的SACK块 SACK块的最高数据序号 - 累积ACK号 > (DupThresh - 1) × MSS。
上述两个条件在以下多种情况下,可以触发SACK重传。
- 收到3个不连续的重复ACK,且发送方的报文段较小,满足第①个条件,启动SACK重传。
- 收到3个连续的重复ACK时,满足第②个条件,启动SACK重传。
- 发送方丢失了多个数据报文段,接收方发回的重复ACK数量不足三个,但满足第②个条件,启动SACK重传。
- 在TCP协议的设计中,对于不包含数据的”纯ACK”,没有确认和重传的机制。如果接收方发出的重复ACK丢失,但后续到达的重复ACK满足第②个条件,也就是说只要收到的SACK块的序号足够大,也能够触发SACK重传。
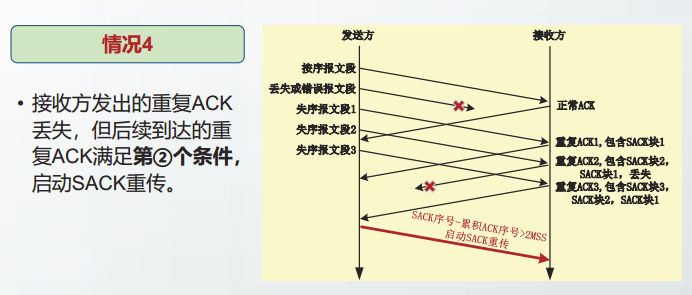
SACK重传时,TCP根据“记分板”中的信息,从低序号向高序号依次重传空缺报文段。没有空缺报文段后,TCP才会发送新数据。
优点:基于SACK的重传算法,其判断报文段丢失的方法比快重传算法更灵活,且可以在一个RTT内重传多个空缺报文段,在丢包严重的情况下,比快重传算法更高效,也更不易触发超时重传。
注意1:SACK发送方在收到一个SACK后,不能清除其重传缓存中对应的数据,只有收到累积ACK后,才能清除其重传缓存中对应的数据。
注意2:RFC2018规定,当TCP启动超时重传时,应该忽略SACK中的信息。即使已经收到过SACK确认,也需要重传超时的报文段之后的所有报文段。
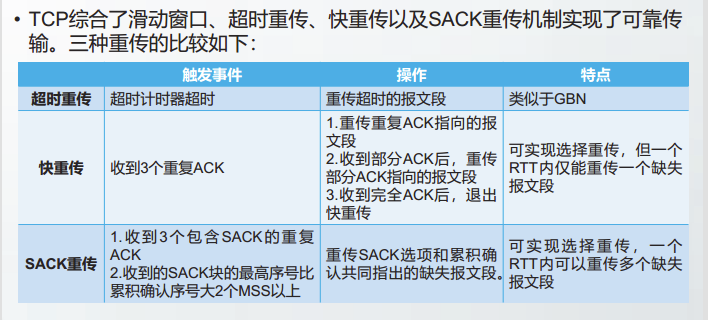
TCP三种重传的比较
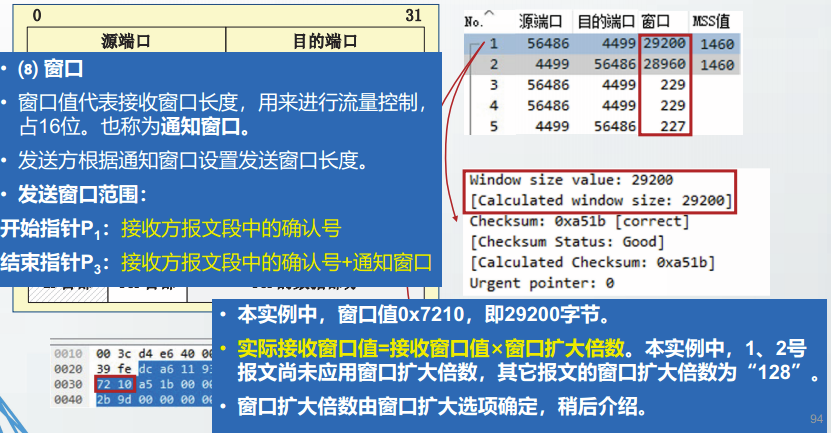
TCP的流量控制

如果接收方应用进程读取数据的速度相对缓慢,而发送方发送数据太多、太快,发送的数据就可能会造成接收缓存溢出。
TCP的流量控制机制完成了对发送速度的调节,它是基于ACK报文段中的通知窗口长度来实现的。这种方式提供了明确的来自接收方的状态信息,可以避免接收方缓存溢出。
停等协议和连续ARQ协议,两者都采用了固定长度的发送窗口,不能根据接收方的情况进行调节。
TCP协议采用了可变长度的发送窗口,其发送窗口根据接收方的通知窗口设定。
TCP流量控制的过程
接收方每收到一个报文段,都重新计算自己的接收窗口长度。
·较早的TCP实现中,TCP接收方被分配一个固定大小的接收缓存,用以下公式计算接收窗口长度:
接收窗口长度 = 接收缓存字节数 - 已缓存但未被读取的按序到达字节数
较新版本的TCP实现中,增加了TCP接收窗口长度自动调优算法,该算法综合考虑当前可用缓存容量以及本连接的带宽时延积等因素,调整分配给TCP连接的接收缓存,然后计算接收窗口长度。
接收方在发送确认信息给发送方时,将计算得到的接收窗口长度填入TCP首部中的窗口字段通知给发送方
发送方要求自己的发送窗口必须小于等于通知窗口,在不考虑拥塞控制的影响时,发送方设置发送窗口等于通知窗口。
发送方根据自己的发送窗口发送报文段。
零窗口通知 / 窗口更新报文 / 窗口探测报文
在流量控制过程中,如果接收缓存耗尽,接收方会将通知窗口长度设置为0。发送零窗口通知给发送方,不允许发送方继续发送新数据。
在接收方重新获得可用缓存空间后,主动传送给发送方窗口更新报文。窗口更新报文通常不包含数据。属于纯ACK
在TCP协议的设计中,对于不包含数据的纯ACK,没有确认和重传的机制。如果窗口更新报文丢失,发送方将一直等待窗口更新报文,而接收方则一直等待新的数据,协议将陷入死锁状态。
为避免这种死锁状态的出现,TCP发送方会维持一个持续计时器。
一旦收到零窗口通知,发送方就设定持续计时器,持续计时器超时则发送一个窗口探测报文,查询接收方通知窗口变化。
糊涂窗口综合征
如果应用进程读取数据后,接收方获得的可用缓存空间很小,这时发送窗口更新报文,会造成传输效率的下降。
在极端情况下,会造成发送方和接收方交互的都是仅包含1字节数据的报文段,这种现象在RFC813中称为糊涂窗口综合征。
为避免糊涂窗口综合征,RFC1122建议:在满足以下两种情况之一时,TCP才发送窗口更新报文。
- 可用缓存可以容纳一个全长报文段
- 可用缓存达到接收缓存空间的一半。
Nagle算法
TCP发送方发送数据时,会尽可能按照EMSS值封装全长报文段。
对交互式应用来说,TCP的这种发送机制时效性较差。
如果对交互式应用的每字节数据单独封装发送,则传输效率很低。在交互式应用中,TCP广泛采用Naglet算法,兼顾传输效率和时效性。
- 若发送应用进程把待发送的数据逐个字节地送到TCP的发送缓存,则发送方就把第一个数据字节先发送出去,把后面到达的数据字节都缓存起来。
- 当发送方收到对第一个数据字节的确认后,再把发送缓存中的所有数据封装成一个报文段发送出去,同时继续对随后到达的数据进行缓存。
- 只有在收到对前一个报文段的确认后才继续发送下一个报文段。
- 此外,当缓存的数据已达到发送窗口大小的一半或已达到报文段的最大长度时,就立即发送一个报文段。
TCP的拥塞控制

路由器无法处理高速率到达的流量而被迫丢弃分组的现象称为拥塞。
处于拥塞状态的路由器称为拥塞结点。
拥塞产生的原因很多:
结点的缓存空间较少
输出链路的容量较低
结点处理机的运算能力较弱
等等
拥塞是一个复杂的综合问题,依靠增加资源等简单措施不能解决。
网络拥塞会带来很多负面影响:

 拥塞控制
拥塞控制
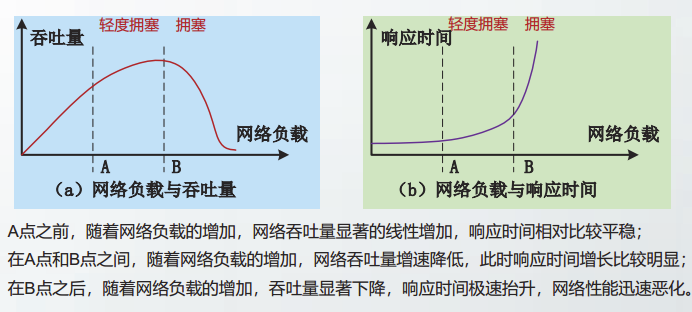
进行拥塞控制的目标就是避免网络进入拥塞状态,即让网络负载处于B点之前。
所谓拥塞控制就是由相关算法控制TCP发送方行为,防止过多的分组进入网络,避免网络中的路由器或者链路过载。
拥塞控制需要通过限制发送方的发送速率来实现。
拥塞控制与流量控制:

TCP的拥塞控制方法
1988年Van Jacobson提出了最初的TCP拥塞控制算法,其算法基于数据包守恒准侧:
A new packet isn't put into the network until an old packet leaves.
Jacobsoni提出的拥塞控制算法,包括慢开始和拥塞避免,奠定了TCP协议的拥塞控制算法的基石。
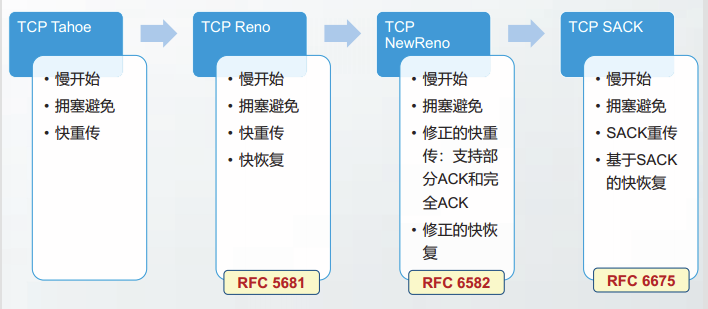
TCP采用的拥塞控制方法是基于窗口的。
TCP增加了一个状态变量,叫拥塞窗口(congestion windows,cwnd)
拥塞窗口长度取决于网络的拥塞程度,并能根据网络拥塞情况动态变化。发送方要求自己的发送窗口必须小于等于拥塞窗口,以此控制发送速率TCP进行拥塞控制的原则是:
如果网络中没有出现拥塞,就增大拥塞窗口,以此提高发送速率,提高吞吐量;
如果网络中出现了拥塞,就减小拥塞窗口,以此降低发送速率,降低网络负载。。
注意:
最终的发送窗口长度 = Min(通知窗口长度,拥塞窗口长度)
本节讨论中,暂时忽略通知窗口的影响。
TCP发送方如何监测网络的拥塞程度呢?
监测先前介绍的三种重传事件:
超时重传:超时计时器超时事件
快重传:3个重复ACK事件
SACK重传:RFC6675规定的两个条件之一
出现了以上三种重传事件,TCP认为出现了不同程度的网络拥塞,应用不同的拥塞控制算法进行处理。
慢开始
在TCP连接建立之初或者发生超时重传事件后,都需要执行慢开始算法。
TCP连接建立之后,需要设定初始拥塞窗口,记为初始窗口IW。
RFC5681规定IW值为2~4个发送方最大报文段长度SMSS,具体规定如下:

每收到一个有效ACK,把拥塞窗口增加不超过1个SMSS的数值。
RFC5681规定的计算公式如下:
cwnd += min(N,SMSS)
其中N代表原先未被确认的,现在被刚到达的ACK确认的字节数。
显然,当N<SMSS时,每收到一个ACK,cwnd的增加量要小于SMSS。
大多数情况下,TCP发送的报文段是全长报文段,此时,每收到一个ACK,cwnd增加1个SMSS。
从TCP发送一轮报文段到TCP收到这些报文段的确认为止,经历的时间大约等于一个RTT,我们将之称为一个传输轮次。使用传输轮次这个术语,更便于我们描述TCP的拥塞控制算法。
在慢开始阶段,拥塞窗口cwnd随轮次呈指数增长,每经过一个传输轮次,cwnd加倍。
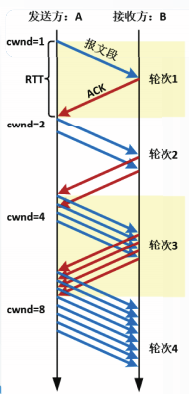
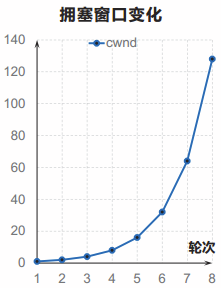
关于延迟确认:
在快重传中已经介绍,RFC5681中规定:如果TCP接收方收到的两个报文段间隔时间小于500ms,则每两个报文段发送一个ACK,这称为延迟确认。
如果采用延迟确认,那么慢开始阶段cwnd的增长速度将放缓。
在某些操作系统的 TCP/IP 实现中,在慢开始阶段采用了快速确认模式,即慢开始阶段不使用延迟确认。
慢开始–ssthresh
什么时候结束这种指数增长呢?慢开始算法提供了以下几种策略:
- 拥塞窗口增长超出慢开始阈值ssthresh
- 监测到重传事件时
TCP维持一个状态变量叫慢开始阈值ssthresh,也译作慢开始门限。
当cwnd<ssthresh时,TCP采用慢开始算法;
当cwnd>ssthresh时,TCP停用慢开始算法,改用拥塞避免算法:
当cwnd=ssthresh时,TCP选用慢开始算法或者拥塞避免算法。
ssthresh的初值应设置得尽可能高,然后ssthresh值随拥塞控制而调整。
慢开始–超时事件
当监测到超时事件时,TCP停止cwnd的增长,按照以下公式计算ssthresh:
ssthresh = max(FlightSize/2 , 2 x SMSS)
其中,FlightSize为在途数据量,代表已经发出但尚未被累积确认的字节数。
在不考虑通知窗口的限制时,可以近似认为FlightSize ≈ cwnd , 此时ssthresh的计算公式变换为:
ssthresh = max(cwnd/2 , 2 X SMSS)
然后,将cwnd设为1,重新执行慢开始算法。

慢开始算法要点小结:
- IW的初值2~4个SMSS,ssthresh的初值尽可能高
- 每收到一个有效ACK,cwnd+1 smss;即每经过一个轮次,cwnd加倍
- 若cwnd > ssthresh,停止慢开始,执行拥塞避免算法
- 出现超时事件,设置ssthresh = cwnd/2,然后设置cwnd=1,重新执行慢开始
- 出现快重传或SACK重传事件,执行快恢复算法
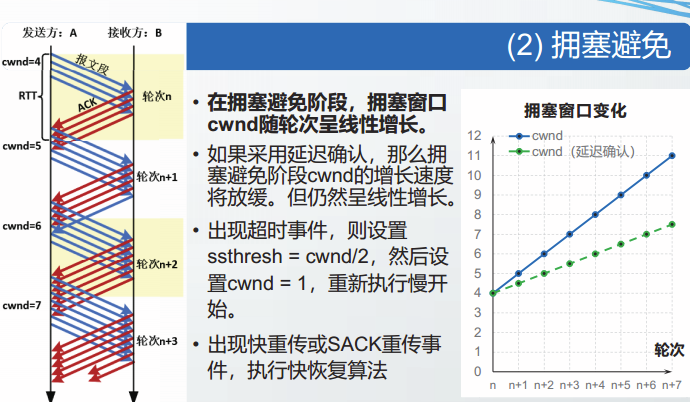
拥塞避免

快恢复
当监测到3个重复ACK或收到的SACK满足RFC6675的两个条件之一时,
TCP启动快重传或SACK重传,同时启动快恢复。
RFC规定:快恢复算法与快重传算法一起实现。
·RFC5681规定了TCP Reno版本的快重传和快恢复算法。
·RFC6582规定了TCP NewReno版本的快重传和快恢复算法。
·RFC6675规定了启用SACK支持后的快重传和快恢复算法。
三个版本的快恢复算法在经过快恢复阶段的调整之后,当退出快恢复算法时,cwnd值和ssthresh值均为启动快恢复算法时的cwnd值的一半。
退出快恢复算法后,TCP启动拥塞避免算法。
**注意:**在TCP快恢复算法执行过程中,如果监测到超时重传事件,TCP将退出快恢复算法,将cwnd设为1个SMSS,重新执行慢开始算法。
拥塞控制状态变迁
根据执行算法不同,TCP经典拥塞控制包括三个阶段:慢开始、拥塞避免、快恢复。
三个阶段的作用如下:
- 慢开始阶段是TCP探测当前网络传输能力的阶段。
- 拥塞避免阶段是TCP的稳定运行阶段,在该阶段TCP继续探测可能利用的网络资源。
- 快恢复阶段是TCP发现网络拥塞后,调整和恢复稳定运行的阶段。
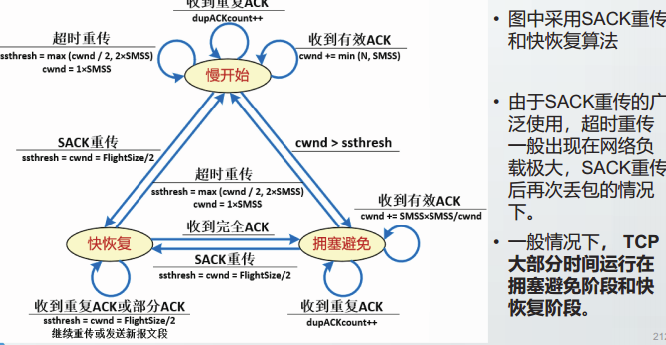
AIMD算法
TCP拥塞控制算法被称为AIMD算法:
在拥塞避免阶段,TCP线性增加拥塞窗口cwd,缓慢探测网络传输能力,该特点被称为加法增大。
在快恢复阶段,经过快速的调整和恢复,TCP将慢开始阈值ssthresh和拥塞窗口cwnd设置为触发快恢复时的cwnd的一半,该特点被称为乘法减小。
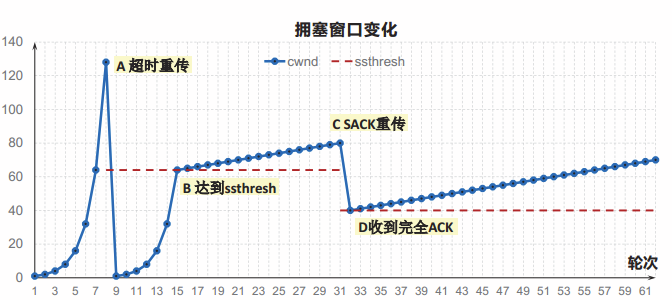 AIMD算法公平性讨论
AIMD算法公平性讨论
什么样的拥塞控制算法是公平的?
经过某个结点的多条TCP连接,在拥塞控制算法的控制下,平均占用带宽资源,则算法是公平的。
·例如:n条TCP连接,都经过一个最大处理能力为Xbit/s的路由器。如果没有拥塞控制机制,每个连接的发送方都以最大速率发送数据,则网络拥塞。在拥塞控制算法的调节下,如果最终每条连接的发送速率都收敛至Xbit/s,则该拥塞控制算法是公平的。
AIMD算法是公平的
影响发送窗口值的两个因素
影响发送窗口swnd的两个因素为:
- 通知窗口awnd:TCP的流量控制要求TCP的发送窗口小于等于通知窗口
- 拥塞窗口cwnd:TCP的拥塞控制要求发送方的发送窗口小于等于拥塞窗口
swnd = min(awnd,cwnd)
上式说明:
当awnd较小时,决定发送方发送速率的是TCP的流量控制
当cwnd较小时,决定发送方发送速率的是TCP的拥塞控制
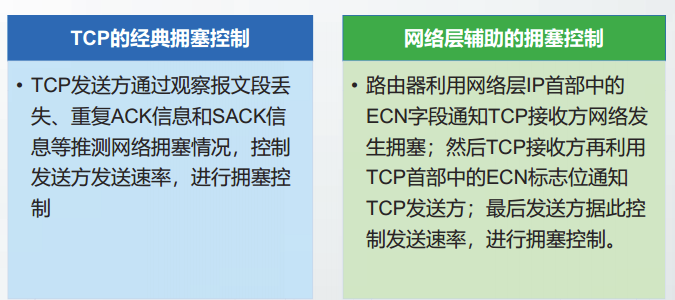
网络层辅助的拥塞控制
网络层辅助的拥塞控制方法包括:主动队列管理AQM和显式拥塞通知ECN

主动队列管理:
尾部丢弃策略:当队列已满时,以后到达的所有分组将都被丢弃。
路由器的尾部丢弃会导致一批分组的丢失,TCP发送方根据拥塞控制算法将降低拥塞窗口值。
当网络中有多条TCP连接通过瓶颈路由器时,路由器的尾部丢弃策略会造成多条TCP连接同时降低拥塞窗口值。这种现象称为TCP全局同步。
为了避免发生全局同步现象,ETF提出主动队列管理AQM。
AQM不等到路由器的队列满时才丢弃分组,而是在队列长度达到某个数值时或当网络有了某些拥塞征兆时,就主动丢弃部分到达的分组。
AQM仅引起部分TCP连接降低拥塞窗口值,避免了全局同步。
典型的AQM方法是随机早期检测RED
随机早期检测AQM:
实现RED算法需要路由器预先设定三个参数:队列长度最小阈值minth、最大阈值maxth和最大丢包概率maxp

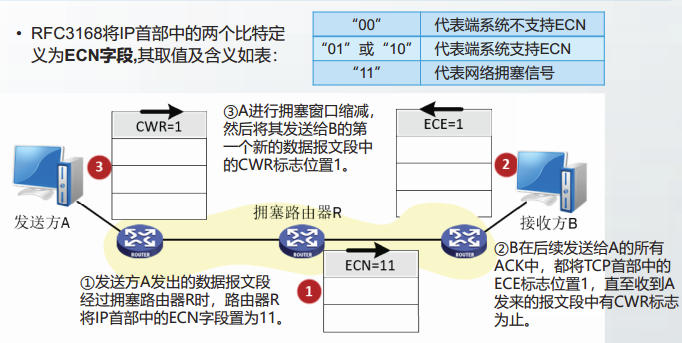
显式拥塞通知
第五章 网络层
网络层概述
网络层是互联网体系结构中最重要的一层,其主要任务是向上层提供主机到主机的通信服务。
互联网采用的交换方式是分组交换,实现分组交换的关键设备是网络核心部分的路由器。
路由器中的网络层是本章介绍的重点。
传统网络的控制平面和数据平面
路由器是一种具有多个接口的专用计算机,每个接口连接了不同的网络。路由器能够连接异构的网络。
路由器的主要功能包括分组转发和路由选择,其中分组转发功能属于数据平面,路由选择功能属于控制平面。
传统网络中,每台路由器都由实现路由选择功能的控制平面和实现分组转发功能的数据平面构成。
路由器的结构
控制平面的核心构件是路由选择处理机。
数据平面由一组输入接口、一组输出接口和交换结构组成。
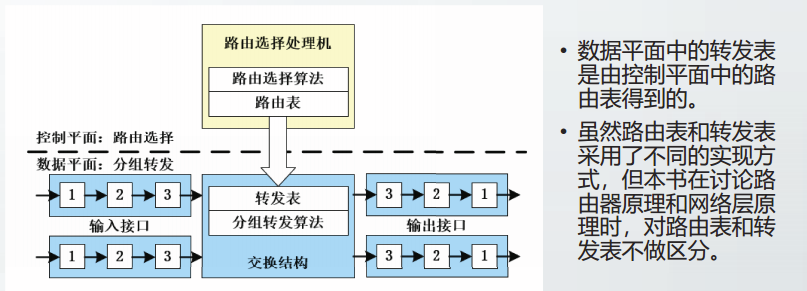
传统网络的控制平面是分布式实现的。每台路由器中都包含控制平面。
每台路由器通过路由协议与其它路由器交换网络拓扑信息,独立维护路由表(转发表)
传统网络的数据平面采用基于目的地址的转发策略
路由器根据收到分组的目的IP地址,查找转发表,转发分组。
软件定义网络的控制平面与数据平面
软件定义网络SDN通过将控制平面和数据平面分离,构建可编程控制的网络体系结构。
SDN的网络交换设备仅需实现数据平面的功能,控制平面的功能集中在远程控制器上实现。
为区别于传统路由器,SDN将受控网络交换设备称为SDN网元或SDN交换机。
SDN的控制平面是集中式实现的。
SDN的控制逻辑全部在SDN控制器中实现,SDN控制器通过控制数据平面接口CDPI对SDN交换机进行控制和管理。
SDN控制器维护流表,并通过OpenFlow协议将流表下发给SDN交换机。
SDN控制器通过北向接口向网络控制应用程序开放编程能力。
SDN的数据平面采用通用转发策略,即基于流表的转发策略。流表的匹配域是首部字段的集合。SDN的转发策略能够匹配协议栈中的多个首部字段。
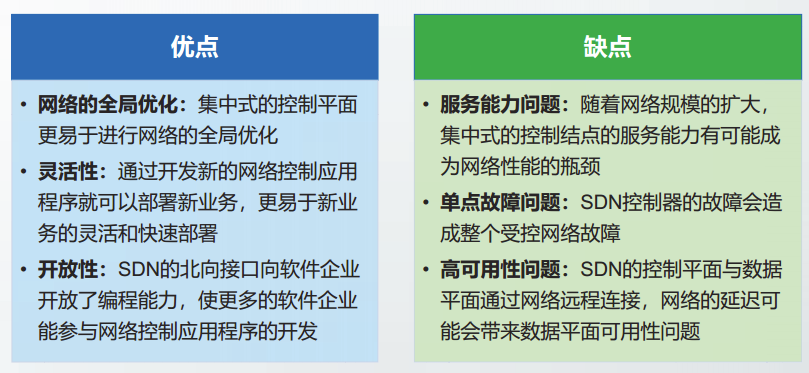
数据平面与控制平面分离的优缺点:
 目前的网络仍然以传统网络为主
目前的网络仍然以传统网络为主
虽然SDN已经提出并发展多年,但由于以下几点原因,软件定义网络SDN仍不可能完全取代传统网络
①SDN仍然没有统一的国际标准;
②互联网上已经部署了大量的传统网络设备;
③互联网中自治系统之间的路由协议一边界网关协议的功能和作用仍不可替代;
在目前的互联网中,传统网络仍然占据较大市场。本书的讨论依然以传统网络为主
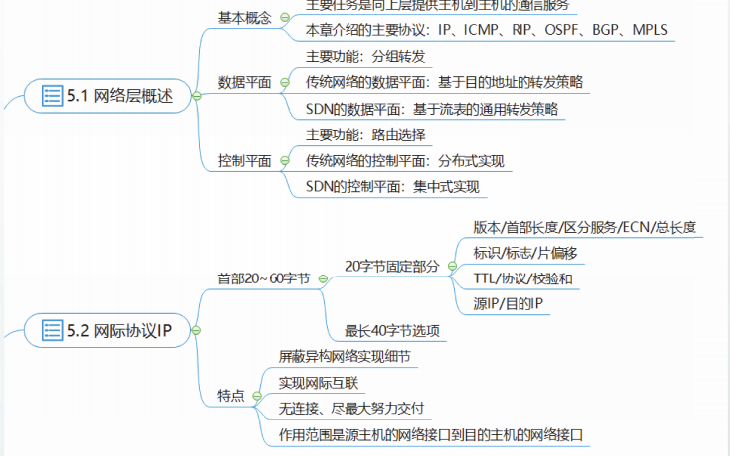
本章主要协议:
网际协议IP:网络层核心协议,运输层TCP、UDP等协议的数据都通过P数据报传
输。
网际控制报文协议ICMP:提供与网络配置信息和IP数据报处置相关的诊断和控制信息。
路由协议:路由器之间用来交换路由信息、链路状态信息或网络拓扑信息的协议,主要包括路由信息协议RIP、开放最短路径优先OSPF协议和边界网关协议BGP
多协议标记交换MPLS:为P等网络层协议提供面向连接的服务质量,支持流量工程、负载均衡,支持MPLS VPN等,在运营商和ISP中得到广泛应用。
相关协议地址解析协议ARP
网际协议IP
IP协议是为了实现网际互联才设计的协议。
IP的协议数据单元通常称为 IP分组或IP数据报。
IP协议屏蔽了底层网络的实现细节,采用IP协议后,网络层之上的协议实体都无需再考虑具体网络的实现细节。
统一采用了IP协议的网络,也称为IP网络或简称IP网。
IP网络中,具有相同网络前缀的IP地址属于相同网络;具有不同网络前缀的IP地址属于不同网络。
目前有两个版本的IP协议正在使用,分别是IPV4和IPv6。
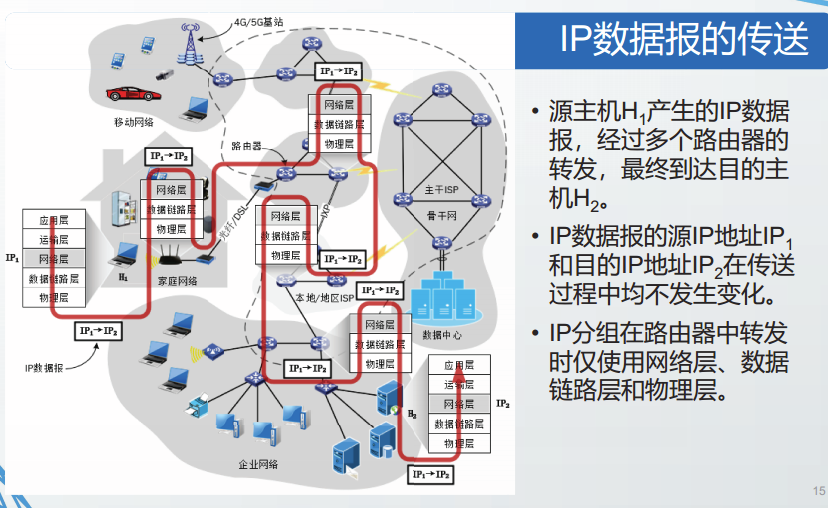
IP协议的作用范围
IP协议的作用范围是源主机的网络接口到目的主机的网络接口。
IP协议向上层仅提供简单灵活的、无连接的、尽最大努力交付的数据报服务。
每一个IP数据报独立发送,与其前后的IP数据报无关。
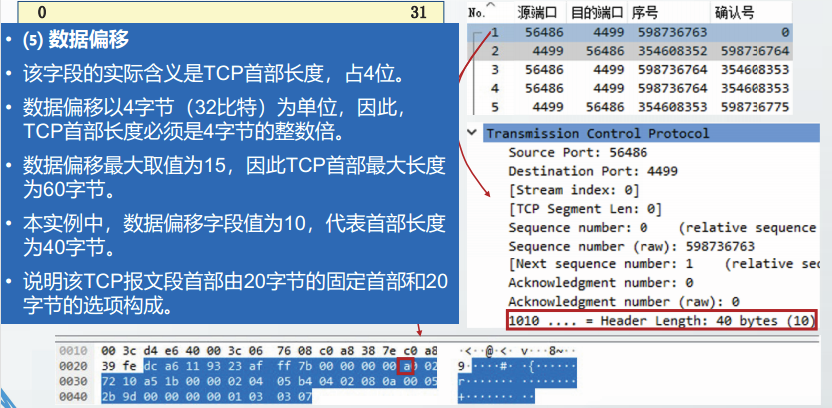
IP数据报格式
IP 数据报文由首部(称为报头)和数据两部分组成。首部的前一部分是固定长度,共 20 字节,是所有 IP 数据报必须具有的。在首部的固定部分的后面是一些可选字段,其长度是可变的。
每个 IP 数据报都以一个 IP 报头开始。源计算机构造这个 IP 报头,而目的计算机利用 IP 报头中封装的信息处理数据。IP 报头中包含大量的信息,如源 IP 地址、目的 IP 地址、数据报长度、IP 版本号等。每个信息都被称为一个字段。
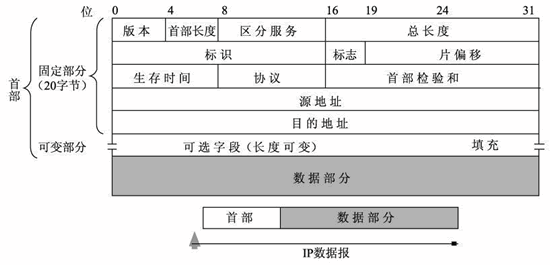
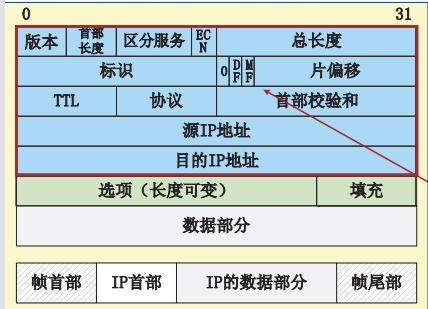
IP 报头的最小长度为 20 字节,上图中每个字段的含义如下:
1) 版本(version)
占 4 位,表示 IP 协议的版本。通信双方使用的 IP 协议版本必须一致。目前广泛使用的IP协议版本号为 4,即 IPv4。
2) 首部长度(网际报头长度IHL)
占 4 位,可表示的最大十进制数值是 15。这个字段所表示数的单位是 32 位字长(1 个 32 位字长是 4 字节)。因此,当 IP 的首部长度为 1111 时(即十进制的 15),首部长度就达到 60 字节。当 IP 分组的首部长度不是 4 字节的整数倍时,必须利用最后的填充字段加以填充。
数据部分永远在 4 字节的整数倍开始,这样在实现 IP 协议时较为方便。首部长度限制为 60 字节的缺点是,长度有时可能不够用,之所以限制长度为 60 字节,是希望用户尽量减少开销。最常用的首部长度就是 20 字节(即首部长度为 0101),这时不使用任何选项。
3) 区分服务(tos)
也被称为服务类型,占 8 位,用来获得更好的服务。这个字段在旧标准中叫做服务类型,但实际上一直没有被使用过。1998 年 IETF 把这个字段改名为区分服务(Differentiated Services,DS)。只有在使用区分服务时,这个字段才起作用。
4) 总长度(totlen)
首部和数据之和,单位为字节。总长度字段为 16 位,因此数据报的最大长度为 2^16-1=65535 字节。
5) 标识(identification)
用来标识数据报,占 16 位。IP 协议在存储器中维持一个计数器。每产生一个数据报,计数器就加 1,并将此值赋给标识字段。当数据报的长度超过网络的 MTU,而必须分片时,这个标识字段的值就被复制到所有的数据报的标识字段中。具有相同的标识字段值的分片报文会被重组成原来的数据报。
6) 标志(flag)
占 3 位。第一位未使用,其值为 0。第二位称为 DF(不分片),表示是否允许分片。取值为 0 时,表示允许分片;取值为 1 时,表示不允许分片。第三位称为 MF(更多分片),表示是否还有分片正在传输,设置为 0 时,表示没有更多分片需要发送,或数据报没有分片。
7) 片偏移(offsetfrag)
占 13 位。当报文被分片后,该字段标记该分片在原报文中的相对位置。片偏移以 8 个字节为偏移单位。所以,除了最后一个分片,其他分片的偏移值都是 8 字节(64 位)的整数倍。
8) 生存时间(TTL)
表示数据报在网络中的寿命,占 8 位。该字段由发出数据报的源主机设置。其目的是防止无法交付的数据报无限制地在网络中传输,从而消耗网络资源。
路由器在转发数据报之前,先把 TTL 值减 1。若 TTL 值减少到 0,则丢弃这个数据报,不再转发。因此,TTL 指明数据报在网络中最多可经过多少个路由器。TTL 的最大数值为 255。若把 TTL 的初始值设为 1,则表示这个数据报只能在本局域网中传送。
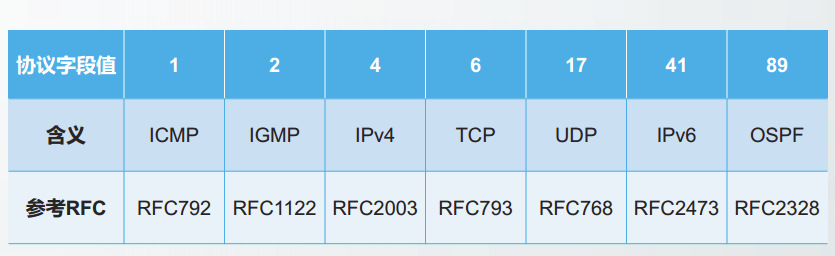
9) 协议
表示该数据报文所携带的数据所使用的协议类型,占 8 位。该字段可以方便目的主机的 IP 层知道按照什么协议来处理数据部分。不同的协议有专门不同的协议号。
例如,TCP 的协议号为 6,UDP 的协议号为 17,ICMP 的协议号为 1。
10) 首部检验和(checksum)
用于校验数据报的首部,占 16 位。数据报每经过一个路由器,首部的字段都可能发生变化(如TTL),所以需要重新校验。而数据部分不发生变化,所以不用重新生成校验值。
11) 源地址
表示数据报的源 IP 地址,占 32 位。
12) 目的地址
表示数据报的目的 IP 地址,占 32 位。该字段用于校验发送是否正确。
13) 可选字段
该字段用于一些可选的报头设置,主要用于测试、调试和安全的目的。这些选项包括严格源路由(数据报必须经过指定的路由)、网际时间戳(经过每个路由器时的时间戳记录)和安全限制。
14) 填充
由于可选字段中的长度不是固定的,使用若干个 0 填充该字段,可以保证整个报头的长度是 32 位的整数倍。
15) 数据部分
表示传输层的数据,如保存 TCP、UDP、ICMP 或 IGMP 的数据。数据部分的长度不固定。
补充
区分服务:
支持区分服务DS功能的结点称为DS结点。
跳过区分服务的细节个绍
IP协议中,对lP数据报采取的转发处理行为称为每跳行为(Per-Hop Behavior,PHB)。
不同的PHB种类代表了不同种类的服务质量。
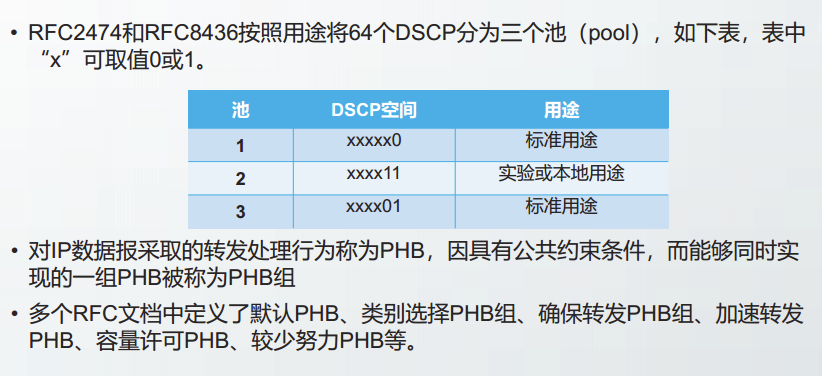
6位DS字段可以定义64个区分服务码点DSCP。
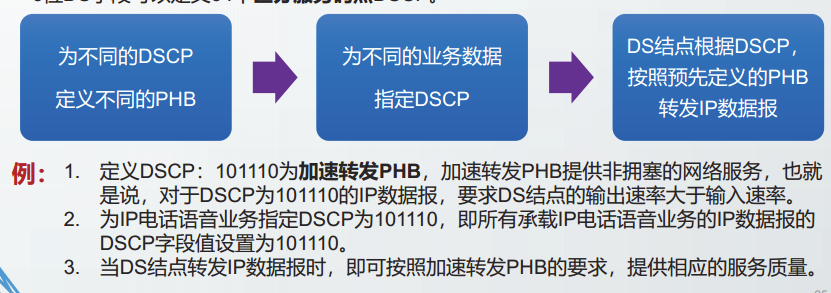
默认PHB(Default PHB,DF PHB)
DSCP的默认值为全0,代表采用常规的尽最大努力交付的IP数据报转发策略。
类别选择PHB组(Class Selector PHB,CS PHB)
RFC2474规定:按照从高位到低位的顺序,DS字段的第0-2位与早期服务类型字段中的优先级定义保持兼容,DS字段中的第3-5位均为0的DSCP值对应的PHB称为CSPHB。
确保转发PHB组(Assured Forwarding PHB,AF PHB)
RFC2597定义了AF组。按照从高位到低位的顺序,AF组用DSCP的第0-2位把通信量划分为四个AF类,分别为001,010,011和100。对于每个AF类,再用DSCP的第3-5位划分出三个“丢弃优先级”,从最低丢弃优先级到最高丢弃优先级分别为010,100和110。
AF类为i,丢弃优先级为j的IP数据报标记为Af,如DSCP值为010110的IP数据报标记为AF23。
对于不同的AF类,RFC2597要求DS结点分配不同的转发资源,如缓存或带宽等。
丢弃优先级仅用来配合路由器的主动队列管理AQM策略使用。相同AF类中,“丢弃优先级”较高的分组适用较高的丢包概率。
加速转发PHB(expedited forwarding PHB,EF PHB)
RFC3246定义了加速转发PHB,DSCP值为101110.
加速转发EF提供了非拥塞的网络服务,对于EF流量,要求DS结点的输出速率大于输入速率。在一台路由器的队列中,EF流量仅排在其他EF流量之后。
容量许可流量(Capacity-Admitted Traffic)
由RFC5865定义,DSCP值为101100。该DSCP命名为VOICE-ADMIT,主要用于VolP业务。
较少努力PHB(Lower-Effort PHB,LE PHB)
·由RFC8622定义,DSCP值为000001,主要用于低优先级流量,如搜索引擎的爬虫。
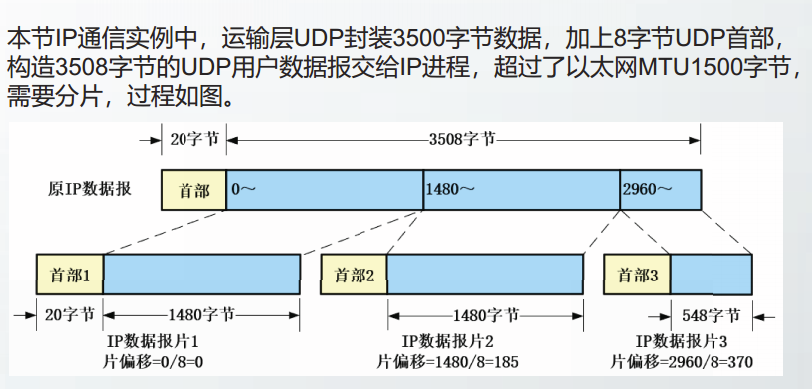
IP分片和重组
IP数据报总长度超过MTU则需要分片
IPV4中的分片操作可以在发送方主机和任何中间路由器上进行。
注意:IPv6的分片操作仅允许在发送方主机上进行。
IP的重组操作只能在最终目的主机上进行。
总长度字段、标识字段、标志字段和片偏移字段用来完成IP的分片和重组。
IP分片操作时,将原IP数据报的首部复制到各IP数据报片中,并根据需要修改总长度、标志、片偏移等字段的值,重新计算首部校验和。
IP数据报片的数据部分长度需要满足以下3个条件:
①数据部分长度 首部长度 ≤ MTU:
②数据部分长度是8字节整数倍,最后一个分片可以不满足该条件:
③数据部分长度取满足以上两个条件的数值中的最大值。
常见的协议字段值
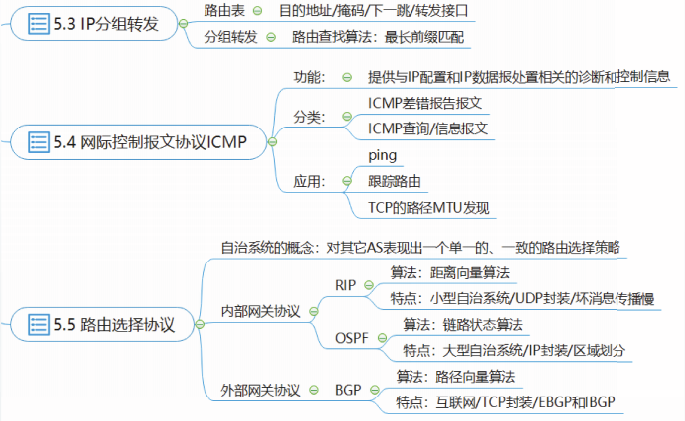
IP分组转发
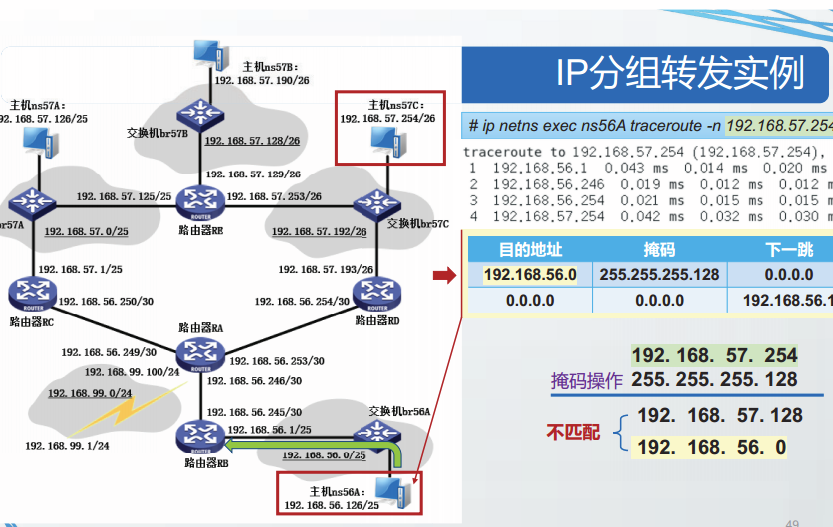
互联网中的主机和路由器都维护了至少一张路由表,用来实现分组转发功能。
主机或路由器查找路由表,将IP数据报从某个网络接口转发出去的过程称为IP分组转发。
当互联网中的结点要把一个IP数据报发送给目的主机时,需要判断目的主机是否与自己直接相连。
- 转发结点与目的结点位于相同网络,则直接相连。
- 如果直接相连,则不需要经过任何路由器,IP数据报就直接发送到目的主机,这个过程称为直接交付。
- 如果不是直接相连,则必须把IP数据报发送给某个路由器,由该路由器将IP数据报交付到目的主机,这个过程称为间接交付。
路由表
P协议没有规定路由表或转发表的精确格式,为了支持CDR,路由表中每个项目至少应包含以下字段:目的地址、掩码、下一跳和转发接口。
目的地址:
目的地址是一个32位值,用于与掩码操作结果做匹配。可以代表以下三种含义:
①目的主机地址:当掩码是32位,即掩码为255.255.255.255时,目的地址仅能匹配某一个主机的IP地址,这样的路由表项目称为特定主机路由;
②所有主机:当掩码长度是0位,即掩码为0.0.0.0,且目的地址字段值为0.0.0.0时,该目的地址可以匹配所有的P地址,这样的路由表项目称为默认路由:
③目的网络前缀:当掩码长度是1~31位,目的地址能匹配某个CIDR网络前缀,这样的路由表项目称为目的网络路由。
掩码:
掩码指CIDR掩码,长度32位,可以用来和IP数据报中的目的IP地址做掩码操作
下一跳:
下一跳是一个P地址,指向一个直接相连的路由器,IP数据报将被转发到该地址。
转发接口:
转发接口是一个网络层使用的标识符,用以指明将P数据报发送到下一跳的网络接口。
路由表的维护可以由系统管理员手动进行,也可以由一个或多个路由选择协议维护。
结点进行分组转发的过程如下:
- 获取目的IP地址ID:
解析待发送P数据报的首部,读取目的P地址ID: - 按照最长前缀匹配算法搜索路由表:
在路由表中搜索所有与ID“匹配”的路由项目。
所谓“匹配”是指:将ID与路由项目的掩码字段做按位与操作,得到的结果与该项目的目的地址字段值相同。在所有与ID匹配的路由项目中,选出掩码中1的位数最多的路由项目,即最长前缀匹配。 - 按照最长前缀匹配的路由项目进行
转发:
读取最长前缀匹配的路由项目的接口字段和下一跳字段,将IP数据报从指定接口发送出去。
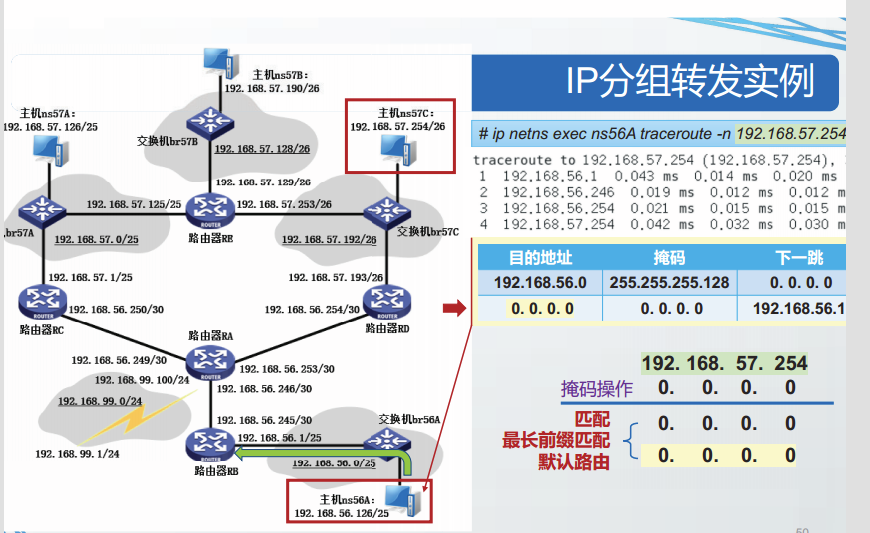
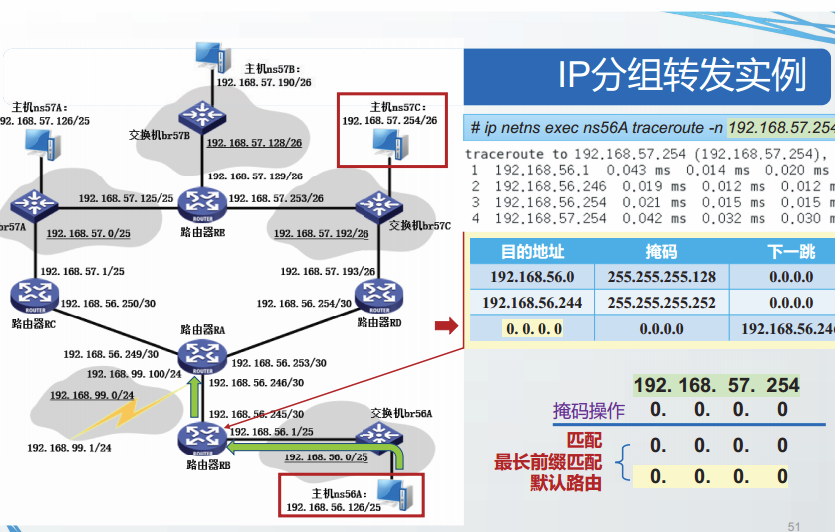
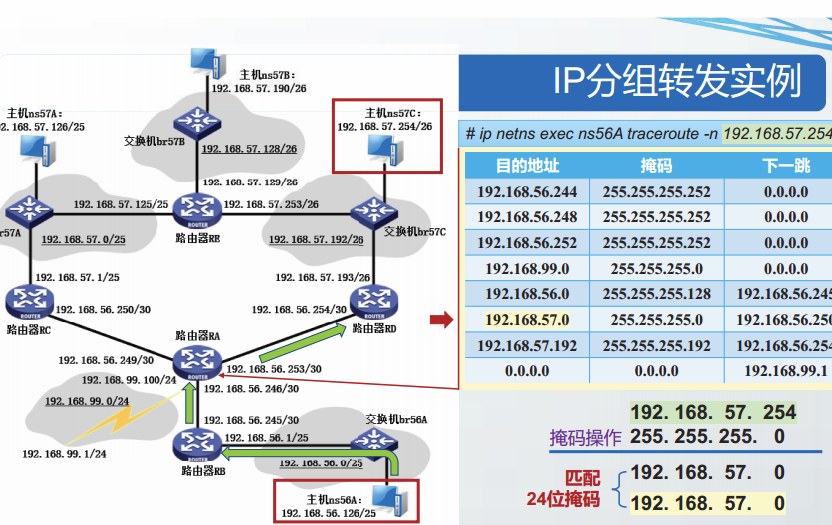
路由表的快速查找
经过精心设计的路由查找算法不需要遍历路由表,即可高效、快速地找到最长前缀匹配项目。
最容易想到的方法是按照掩码长度的顺序,存储路由表,掩码越长的表项存储位置越靠前,这样按序查找后,最先找到的匹配就是最长前缀匹配。各种路由表的实现中,有更多更高效的算法,如Linux中实现的Hash查找算法和Tire树查找算法。
网际控制报文协议ICMP
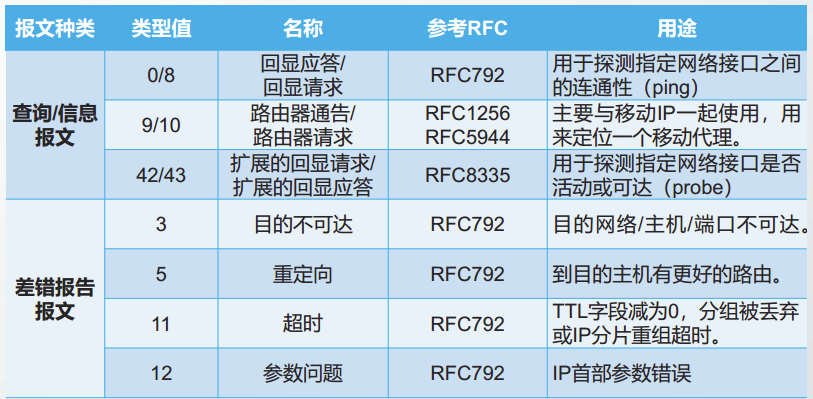
网际控制报文协议ICMP负责传送差错报文以及其它控制信息,它必须与IP协议一起实现,通常被认为是网络层的一部分。
ICMP报文可分为两大类:ICMP差错报告报文和ICMP查询/信息报文。

ICMP报文格式
 常见类型值
常见类型值
常见代码值
ICMP差错报告报文
所有的ICMP差错报告报文中的数据字段都具有同样的格式。
包含一个完整的原始IP数据报(导致差错的IP数据报)的首部副本,以及原始IP数据报的数据部分的前n字节。
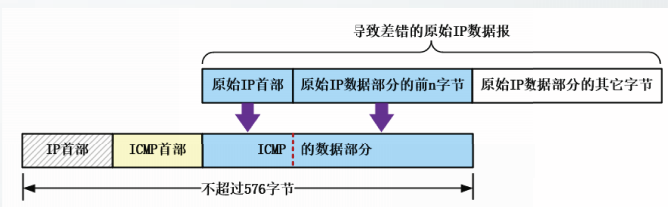
ICMP差错报告报文中应包含原始IP数据报中的尽可能多的数据,但要确保新生成的IP数据报长度不超过576字节。
拓展的ICMP报文格式

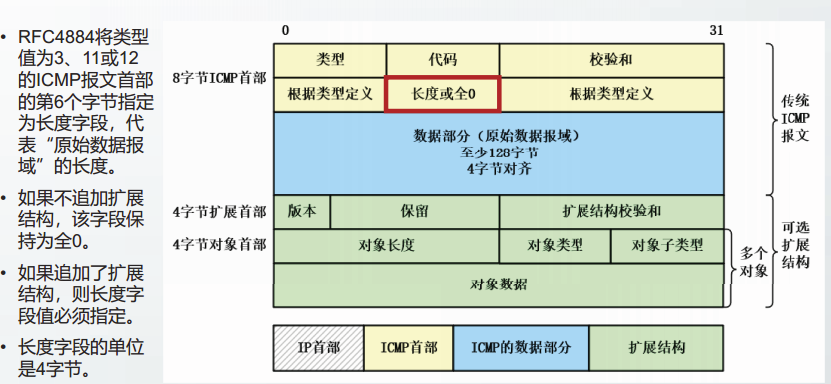
RFC4884规定了ICMP扩展结构的格式,但是扩展结构中的对象由其它RFC文档具体规定。
如:RFC4950为多协议标记交换MPLS规定了标记堆栈对象,标记堆栈对象可以应用在目的不可达报文和超时报文中,当使用traceroute程序时,可以用来记录转发路径中的标记。
再如:RFC8335将扩展结构应用在ICMP查询/信息类报文中,利用扩展结构对回显请求和回显应答报文进行扩展,提出了一种新型的网络可达性探测工具Probe。
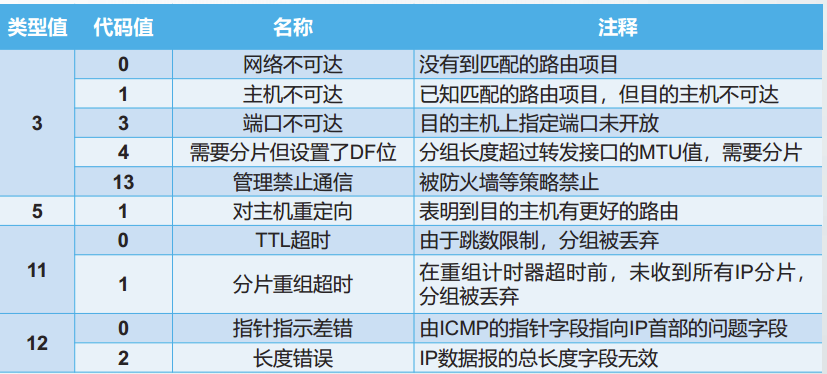
目的不可达差错报告报文
目的不可达差错报告报文用来表示IP数据报无法送达目的地,可能的原因很多。
ICMPv4为此报文定义了16个不同的代码,其中有5个是较常用的,分别是:
网络不可达
主机不可达
端口不可达
需要分片
管理禁止通信
重定向差错报告报文
如果路由器收到一个IP数据报,查找路由表后发现自己并不是将该IP数据报投递到目的地址的最佳路由,则该路由器发送一个重定向差错报告报文给源主机,同时仍然将该IP数据报转发到正确的下一跳路由器。
路由器比较IP数据报的输入接口是否与其下一跳转发接口相同,如果输入接口等于输出接口,则需要产生重定向差错报告报文。
超时差错报告报文
每台路由器在转发数据报时都将IP数据报中的TTL值减1。
当TTL值减为0时,路由器丢弃该IP数据报,并发送一个超时差错报告报文给源主机。

不产生ICMP差错报告报文的情况
根据RFC1812的规定,以下几种情况不应产生和发送CMP差错报告报文:
ICMP差错报告报文;
第一个IP分片以外的其它IP数据报片;
IP首部校验和验证失败的IP数据报;
目的地址是IPv4广播地址或IPv4多播地址的IP数据报;
作为链路层广播的IP数据报;
源IP地址不是单播地址的IP数据报,或者源地址无效(全零地址、环回地址等)的IP数据报。
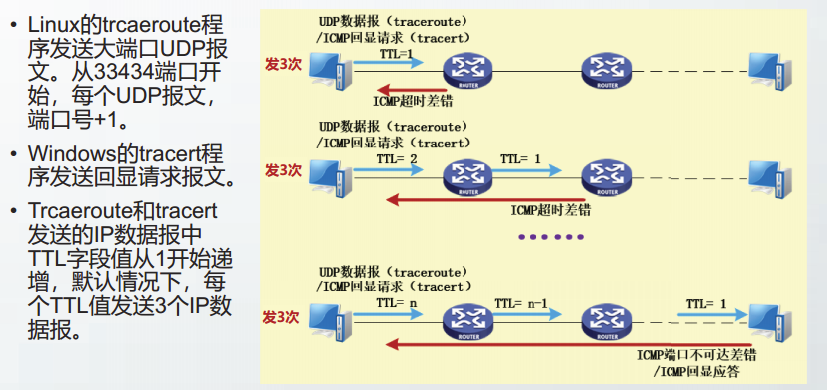
ICMP应用实例
ping / traceroute / tracert / TCP路径MTU发现
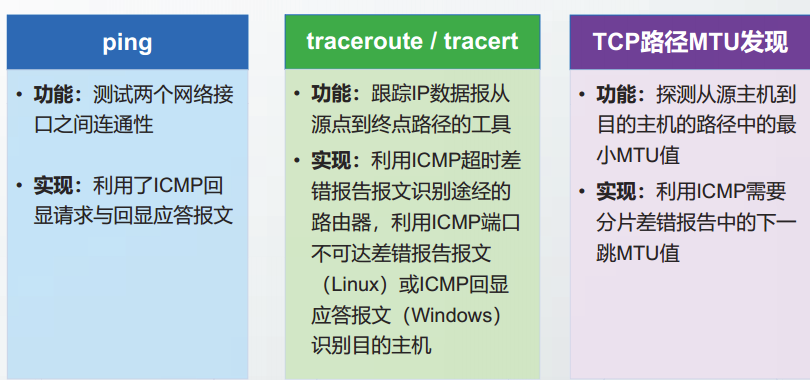
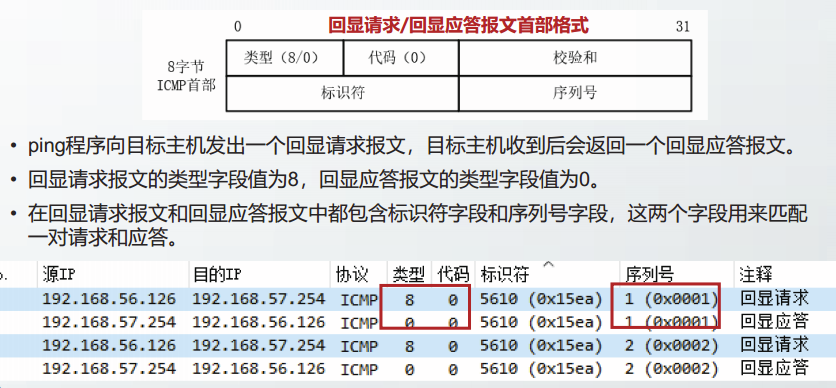
ping
traceroute / tracert
TCP的路径MTU发现


路由选择协议
实现路由选择功能的算法称为路由选择算法。
为路由选择算法传递必要信息的网络协议称为路由选择协议。
路由选择算法是路由选择协议的核心,其目的是找到从发送方到接收方的最佳路由。
互联网中的路由选择算法根据特定的指标定义并度量“最佳”路由。这些度量可以统称为开销,通常最佳路由指具有最低开销的路由。
路由选择算法的目标就是找出从源到目的之间的最低开销路径,即最佳路径。

可以用图来形式化描述路由选择算法。
图G=(N,E)是一个具有N个顶点和E条边的集合。
图中的一个顶点代表一台路由器或者一个其它结点,这是做出分组转发决定的点。
两个顶点之间的边代表两台相邻路由器之间的链路。每条边用一个值代表它的开销。
E中的任一条边(x,y),我们用c(x,y)代表边(x,y)的开销。
一旦图中的每条边都给定了开销,路由选择算法找出从源到目的之间的最低开销路径,即最佳路径。
路由选择协议为路由选择算法传递和提供边的“开销”。
不同的路由选择协议,采用不同的度量指标,对边的开销的定义也不同。
即使网络拓扑相同,不同的路由协议也有可能得出不同的最佳路由。
常用的路由选择算法包括:
- 距离向量算法(DV)
- 链路状态算法(LS)
- 路径向量算法(PV)
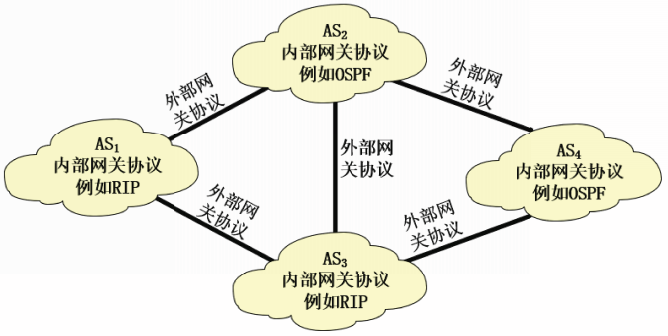
自治系统AS
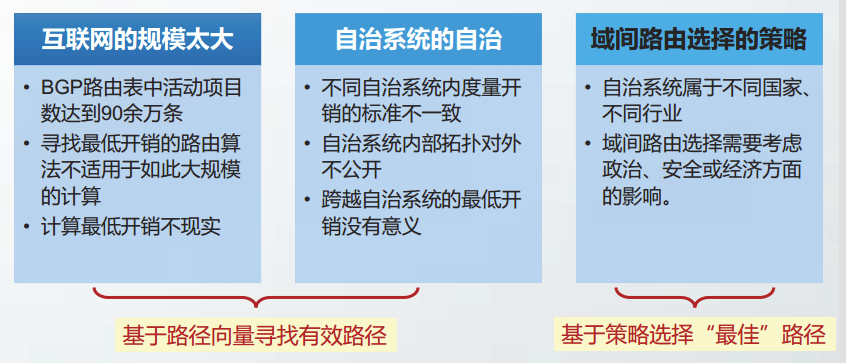
互联网的规模为路由选择协议带来了巨大的困难。解决路由选择扩展能力的方法是引入层次结构。
为了实现分层次的路由选择,互联网被划分为许多自治系统(Autonomous System,AS)
自治系统AS是指在单一技术管理下的一组路由器,这些路由器使用一种自治系统内部的路由选择协议和共同的度量。
RFC4271强调,自治系统AS的关键在于:对其它AS表现出一个单一的、一致的路由选择策略。
每个自治系统拥有一个全球唯一的自治系统号ASN,ASN由IANA管理和分配,最初规定为一个16位数值,RFC6793将其扩展到了32位。
引入自治系统后,互联网的路由选择协议就被划分为两大类:
内部网关协议IGP
外部网关协议EGP

自治系统、内部网关协议和外部网关协议之间的关系
路由信息协议RIP
RIP是互联网的正式标准,由RFC2453规定,目前版本2,记为RIPv2.
RIPv2支持CIDR,其最大优点是简单。
RIPv2支持简单认证,RFC4822为RIPv2补充规定了加密认证机制。
RIP采用距离向量算法(DV)。
距离向量算法(DV)
DV算法不需要知道网络的全局信息,它是一种迭代的、异步的和分布式的算法。
DV算法的基础是Bellman-Ford方程
d(x,y)=minv{c(x,v), d(v,y)},v∈{x的邻居顶点}
Bellman-Ford方程给出了一种求顶点x到顶点y的最低开销的方法。DV算法利用Bellman-Ford方程求解最短路径。
思路:我到目的地的最小距离,等于 我到邻居距离与邻居到目的地最小距离之和(存在一个或多个邻居) 的最小值。
参考博客:
距离向量DV算法
RIP协议概述
RIP规定所有路由器到与其直接连接的网络的开销为1。
RIP将两台路由器之间的最低开销称为“距离”,也称为“跳数”。每经过一台路由器,跳数加1。
RIP允许一条路径的“距离”的最大值为15,因此“距离等于16即相当于不可达。
RIP仅适用于小型自治系统。
RIP更新算法
运行RIP的路由器中维护的路由信息数据,由多个路由项目组成
RIP协议的报文中也包括多个路由项目。来自路由器G的RIP报文中的一个路由项目如下所示:


RIP协议其他规定
路由器最初仅知道直连网络的路由信息。
RIP规定每间隔30秒,路由器都需要发送RIP路由更新报文给所有邻居。RIP路由更新报文中的路由项目包括本路由器已知的全部路由信息。每台路由器只和数目有限的相邻路由器交换并更新路由信息。
RIP规定超时计时器,默认为3分钟,若超时计时器到期,仍未收到邻居路由器G的路由更新报文,则将下一跳为G的所有路由都标记为无效,即将距离修改为16。
RP规定垃圾回收计时器,默认为2分钟,若垃圾回收计时器到期,才会删除无效路由项目。
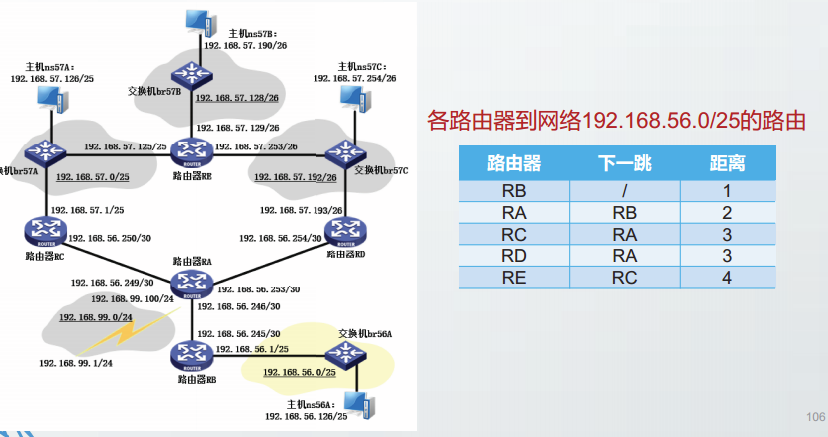
示例
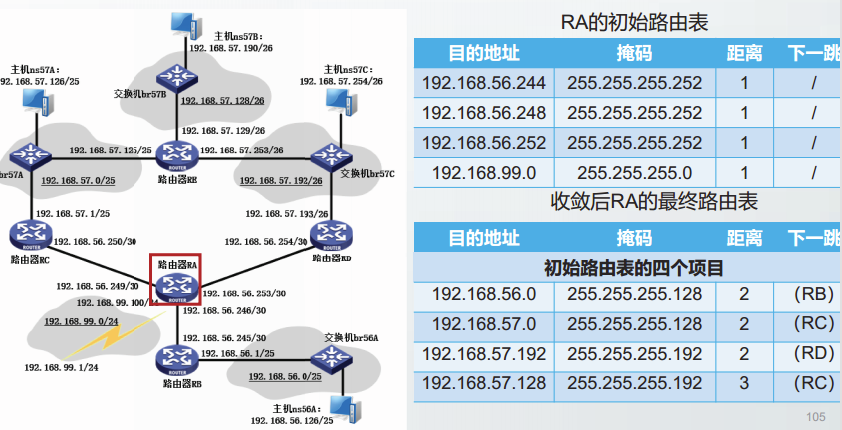
“无穷计数”问题
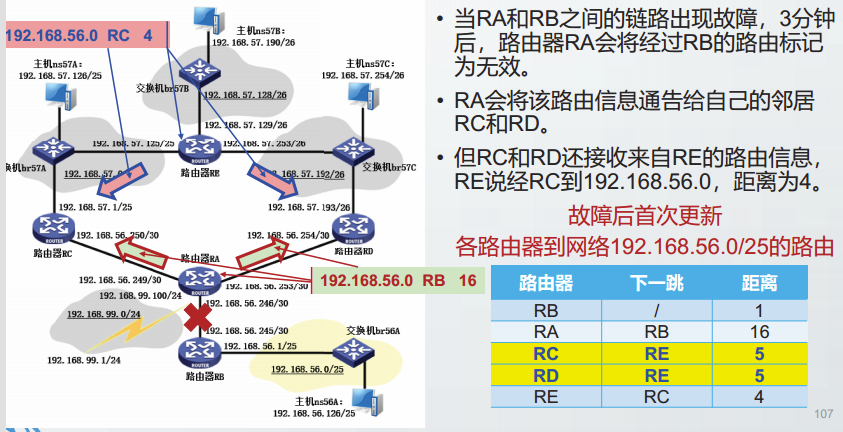

无穷计数问题的解决方法
带毒性逆转的水平分割:
简单水平分割:向邻居发送路由更新时,不包含从该邻居学习到的项目:
带毒性逆转的水平分割:向邻居发送路由更新时包含从该邻居学习到的项目,但将这些项目的距离设置为16。
可以完全避免两台路由器之间的路由环路。但是当三台以上路由器构成环路,并相互学习时,带毒性逆转的水平分割方案就无法避免无穷计算问题了。
触发更新:
当路由器一旦发现路由项目的距离发生变化,就立即发送路由更新信息给邻居路由器。
综合采用上述机制可以使发生无穷计数问题的概率降到极低,但仍然不能完全避免该问题的发生。
RIP报文格式
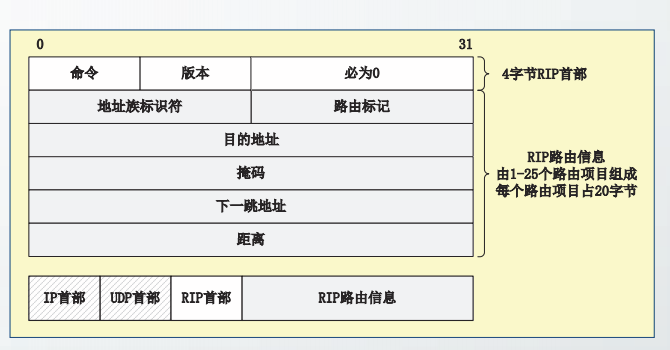
参考连接:
RIP报文格式
开放最短路径优先OSPF
OSPF是互联网的正式标准,IPv4使用的是第2版的OSPF,由RFC2328规定。
OSPF也支持CIDR,其最大特点是支持在自治系统内再次分层。
OSPF支持身份鉴别。
OSPF采用链路状态算法。
链路状态算法(LS算法)
LS算法是一种使用全局信息的算法。
在LS算法中,网络拓扑和所有的链路开销都是已知的,可以用作LS算法的输入,计算最小开销。
在实践中,链路开销通常通过链路状态广播通知给网络中的其它路由器。链路状态广播的结果就是网络中的所有路由器都拥有包含网络拓扑和所有链路开销的一致数据,这些数据称为链路状态数据库。
LS算法利用链路状态数据库进行路由计算。
基于链路状态的路由选择分为两个阶段:链路状态广播阶段和路由计算阶段。OSPF采用的LS算法是Dijkstra算法(前向算法)。
参考链接:
OSPF介绍
LS算法介绍
OSPF协议概述
OSPF协议非常复杂和繁琐,
本节仅从以下几个方面介绍OSPF协议的基本原理:
·OSPF的区域划分
·OSPF的链路状态广播
·OSPF的工作过程
OSPF的区域划分
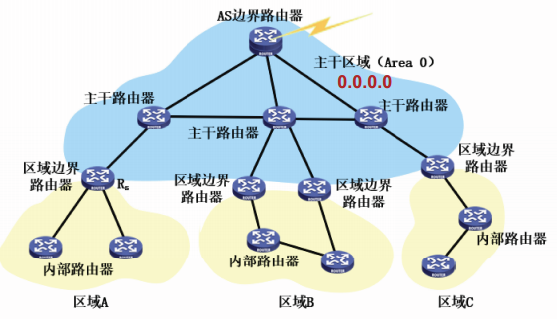
OSPF在自治系统内引入了层次结构,将一个自治系统进分为多个区域
在上层的区域叫做主干区域,用于连通其它区域,
OSPF规定每个区域必须有一32位的标识符。主干区域的标识符为0.0.0.0,一般称为区域0。划分区域后,链路状态广播被限制在区域内部。
OSPF自治系统内包括四种类型的路由器:
- 内部路由器
- 主干路由器
- 区域边界路由器
- AS边界路由器
内部路由器:广播发送自己的链路状态信息,参与区域内的路由计算,并从区域边界路由器那里学习其它区域的路由信息。
主干路由器:主干区域的内部路由器。
区域边界路由器:属于多个区域,执行LS算法的多个拷贝,每个拷贝参与一个区域的路由计算。
区域边界路由器负责将所属区域的路由信息汇总后发往主干区域,也将来自主干区域的路由信息汇总后发往自己所属的区域。
AS边界路由器:运行OSPF获得AS内的路由信息,也运行外部网关协议如BGP,学习AS外的路由信息,并将外部路由信息在整个AS内通告。
桩(stub)区域
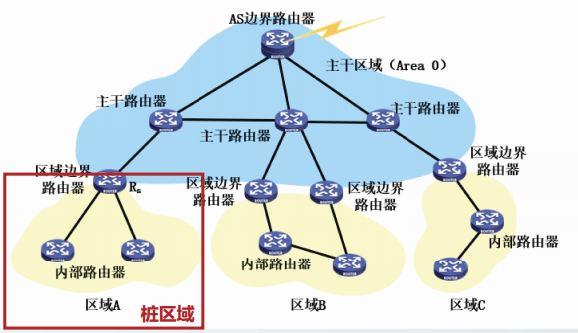
OSPF定义了一类特殊的区域,它们不需要接收本区域外的路由信息,这类特殊区域称为桩区域(stub areas)
当某区域只有唯一的出口时,或者某区域的出口不需要根据网络拓扑进行设定时,可以将该区域配置为桩区域。
OSPF的链路状态广播
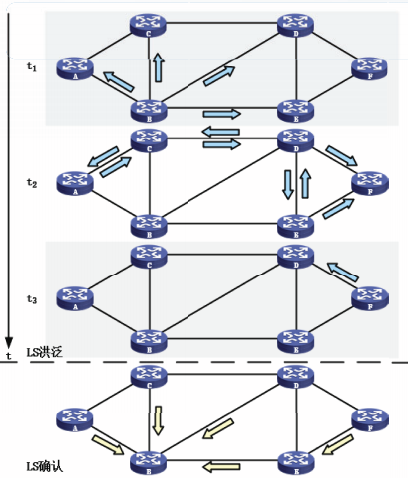
OSPF采用可靠洪泛方法实现行链路状态广播。
可靠洪泛方法的基本步骤包括洪泛和确认。
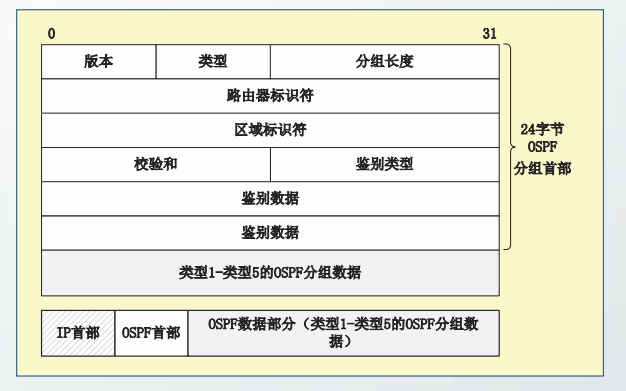
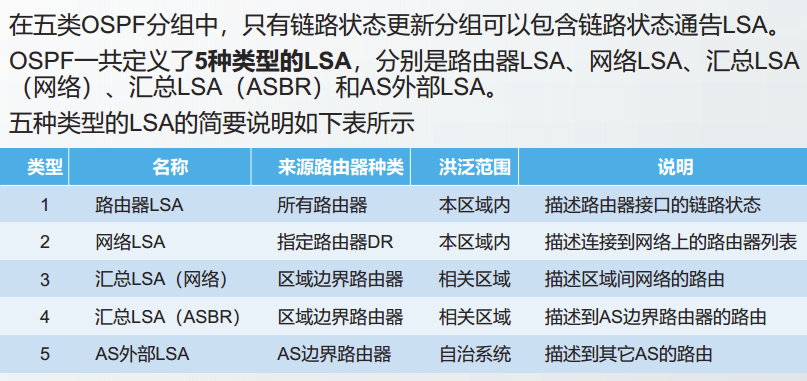
运行OSPF的路由器会创建一个或多个链路状态通告LSA,封装在OSPF的分组中。
OSPF共定义了5种LSA,每种LSA都至少包含如下信息:
- 创建LSA的路由器ID;
- 与路由器
直接相邻的链路信息,包括链路开销: - 链路状态序号(LS sequence number);
- 链路状态老化时间(LS age)
可靠洪泛法
LS洪泛:路由器X收到来自同一个区域的路由器Y的LSA时,X将检查该LSA是否是新的。只有收到新的LSA,路由器X才更新自己的LSDB并将新的LSA从本次接收接口以外的其它所有接口转发出去。
LS确认:收到LS更新的路由器将确认信息通过本次接收接口,发向相邻路由器。LS确认不需要洪泛。

OSPF的工作过程

参考链接:
OSPF详解
OSPF分组格式
参考链接:
OSPF分组格式
五类LSA
OSPF的特点

边界网关协议BGP
边界网关协议BGP是目前域间路由协议的事实标准,其当前版本号为4,记
为BGP-4,由RFC4271规定。
BGP一直被认为是互联网最复杂的部分之一。
BGP支持CIDR,支持鉴别。
BGP采用路径向量算法,寻找有效路径。
BGP基于策略,选择“最佳”路由。
BGP的路径向量算法仅和其邻居路由器交换可达性信息,路由信息包含到达目的网络的完整路径信息,因而称为路径向量算法。
但BGP不追求寻找一条最低开销路径,BGP只力求寻找一条无环的通往目的网络的有效路径。
当存在多条有效路径时,BGP基于策略选择出“最佳”路径。
采用路径向量算法的原因
BGP- 自治系统AS分类
依据允许的流量不同,可以对AS进行分类:
本地流量指起止点都在AS内的通信量,
中转流量指穿过一个AS传送的通信量。


每个AS都有一台或多台AS边界路由器。
AS边界路由器是负责在AS之间完成分组转发的路由器。
每个AS可以拥有多个网络前缀。
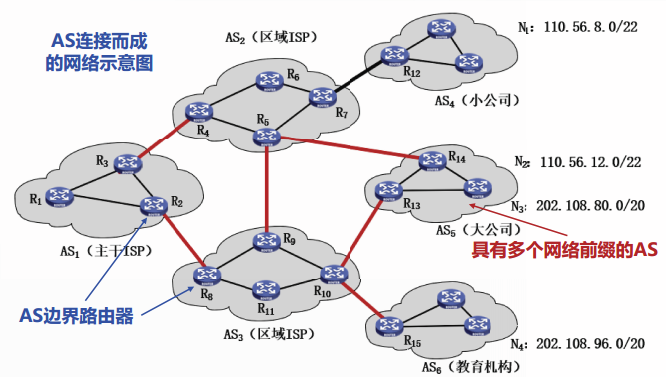
路径向量交换
每一个参与BGP的AS必须至少选择一个BGP发言人
通常选择AS边界路由器作为BGP发言人,但AS边界路由器并不一定必须成为BGP发言人。
BGP发言人之间通过TCP通信,交换路由信息。
建立TCP连接的两个BGP发言人,彼此成为对方的邻站或对等站。
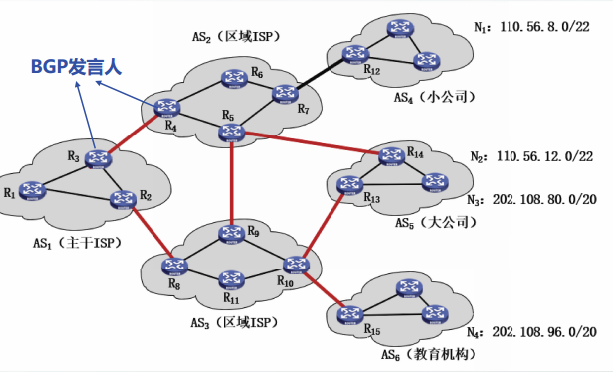
BGP路由信息的构成:
BGP路由=[前缀,BGP属性]
前缀支持CIDR,由[目的P地址,掩码]构成
BGP属性有很多,最重要的是AS-PATH属性,AS-PATH属性包含到目的网络的完整路径信息。
BGP还可以包含很多其它属性。
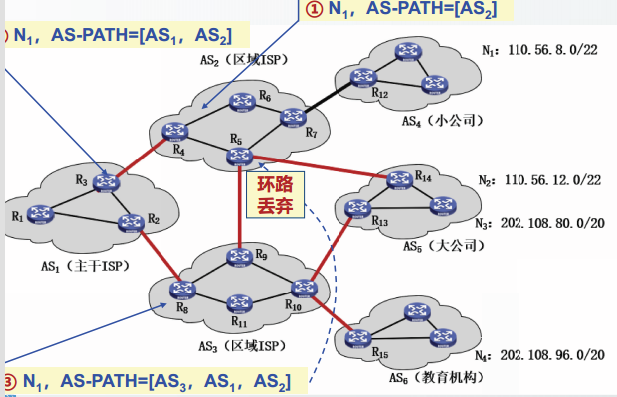 AS-PATH属性可以防止
AS-PATH属性可以防止环路出现。
AS-PATH中,每个AS用唯一编号ASN表示
对于桩AS,可以不分配ASN
当收到的AS-PATH中包含自己的编号时,说明出现环路,丢弃。
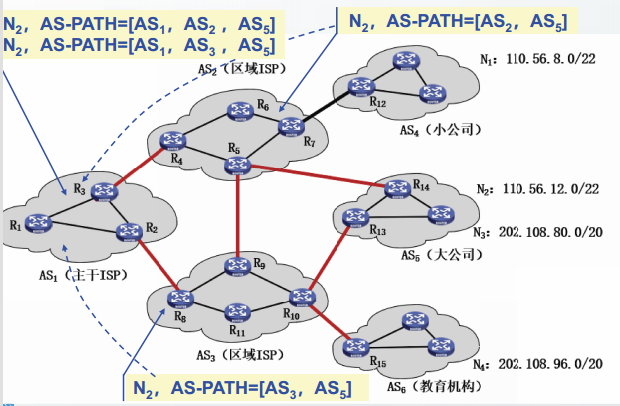
基于策略的最佳路由选择
AS1到N2有两条路径,应该如何选择?
AS1可以根据预先配置的路由选择策略来进行选择。
根据不同的属性可以设定不同的规则。
规则举例:AS跳数较少的路由较好。
所谓策略就是一系列按照顺序执行的规则。
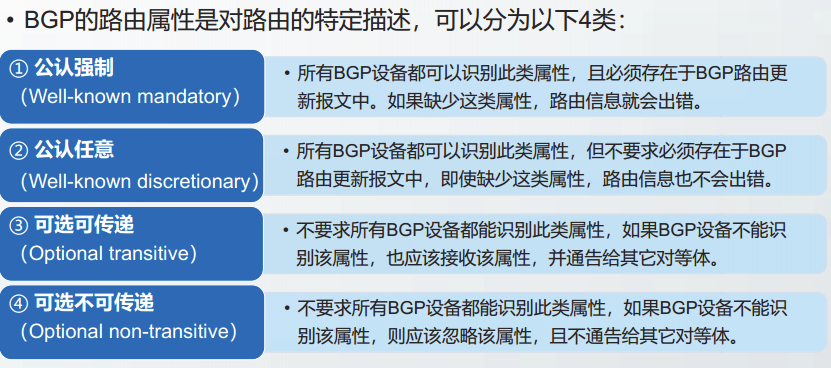


BGP报文种类
当TCP连接建立后,BGP首先发送OPEN报文,如果邻站接受这种关系,就用KEEPALIVE报文响应。这样,两个BGP发言人就建立了对等站关系。
在BGP最初运行时,BGP对等站交换完整的BGP路由表。但以后只在路由发生变化时更新有变化的部分。这样可以节约网络带宽和减少路由器的处理开销。
一旦建立了对等站关系,双方都需要周期性地发送KEEPALIVE报文,以证实自己还在线。
BGP发言人可以用UPDATE报文宣布增加新的路由,也可以通告撤销过时路由。
检测到BGP差错时,BGP发送NOTIFICATION报文,随后将关闭BGP连接
域间路由与域内路由的集成
当BGP发言人收到对等站的路由信息后,如何才能把这些域间路由信息通知给本AS内的其它路由器呢?
1、最简单的情况,只有一台AS边界路由器的桩AS:
·AS边界路由器只需将一个默认路由导入内部网关协议,然后内部网关协议将默认路由扩散到AS内的全部路由器。
2、多连接AS和中转AS的情况
由于有多台AS边界路由器,因而AS内部路由器需要决定将IP数据报从哪台AS边界路由器发送出去。
BGP路由表非常庞大,如果把BGP路由表都导入内部网关协议,依靠内部网关协议将这些域间路由信息扩散到AS内部路由器,会极大增加网络的负载和路由器的计算开销。
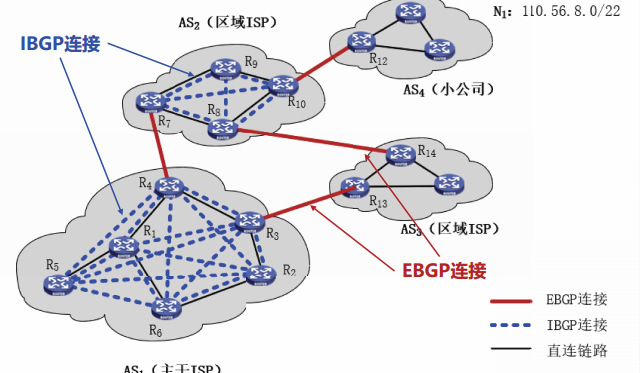
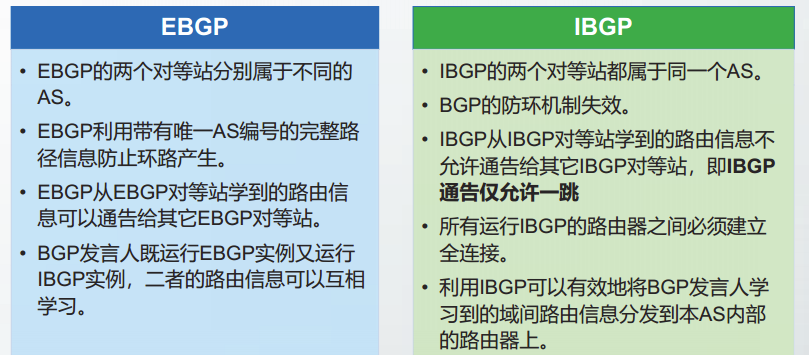
解决方案:BGP将其应用范围扩展到了自治系统AS内部。RFC4271将BGP分为两种形式:外部BGP(External BGP,EBGP)和内部BGP(Internal BGP)
运行于不同AS之间的BGP称为EBGP
运行于同一AS内部的BGP称为IBGP
EBGP与IBGP本质上没有区别,都是为了传递域间路由信息
BGP报文格式

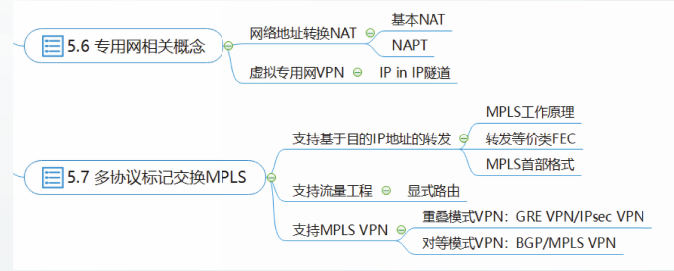
专用网相关概念
网络地址转换NAT
专用网是指企业或机构内部专用的网络。
专用网上的主机与公用的互联网上的主机通信需要利用网络地址转换NAT。
专用网上的地址称为专网地址(Private Address),它们仅需要在一定的范围内唯一。在互联网的不同部分,这些IP地址可以被重复使用。因此,也称为可重用地址。
网络地址转换也被用来延缓IP地址空间耗尽。
需要向IANA申请才能使用的全球唯一的IP地址称为全球地址(Global Address)或公网地址。

使用NAT需要在专用网络连接到互联网的路由器上安装NAT软件。
安装了NAT软件的路由器称为NAT路由器,它至少应具有一个有效的全球地址。
NAT存在两种形左式:
- 基本NAT
- 网络地址与端口转换NAPT
基本NAT
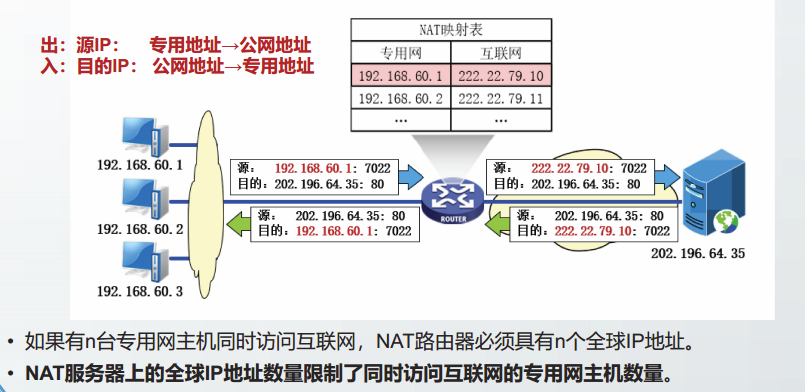
网络地址与端口转换NAPT

NAT(Network Address Translation,网络地址转换):NAT是将IP数据报头中的IP地址转换为另一个IP地址的过程。使用少量的公网IP地址代表较多的私网IP地址的方式,仅支持地址转换,不支持端口映射
NAPT(网络地址端口转换):支持端口的映射并允许多台主机共享一个公用IP地址,这样就可以支持同时多个位于NAT后面的机器和外部进行交互了。支持端口转换的NAT又可以分为两类:源地址转换(SNAT)和目的地址转换NAT(DNAT),下面说的NAT都是指NAPT。
不管采用NAT,还是采用NAPT,NAT路由器的地址映射表都有两种实现方式:
动态映射和静态映射。

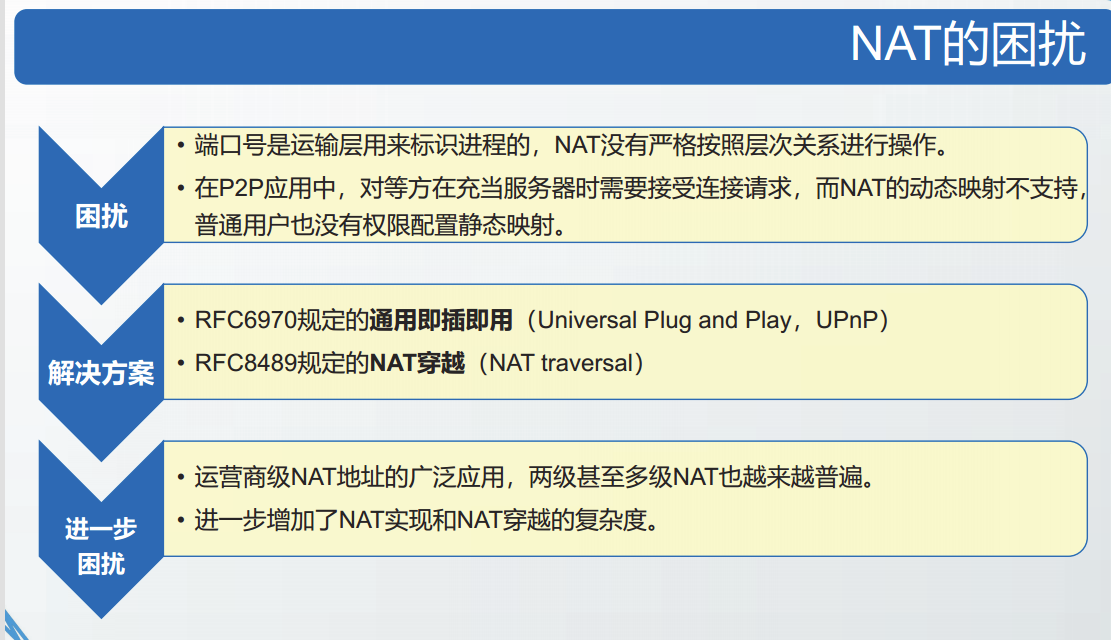
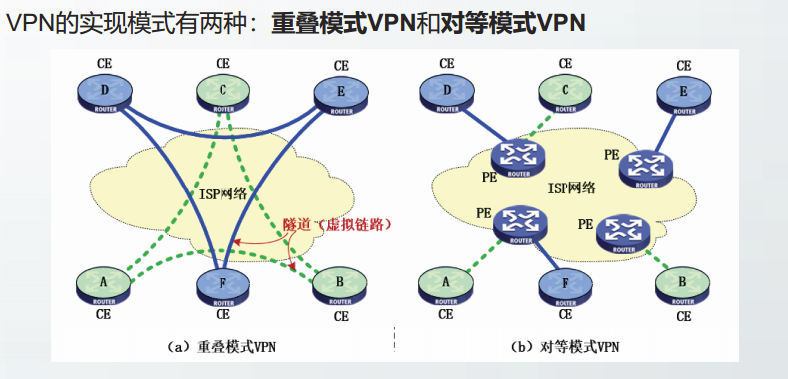
虚拟专用网VPN
机构内部的专用网之间的链路通常是·私有的·。
利用公网的互联网作为本机构各专用网之间通信载体的专用网称为虚拟专用网(VPN)
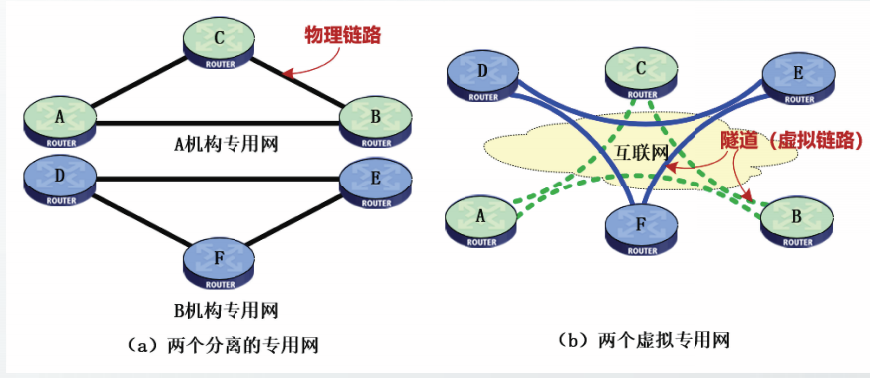
隧道技术
在公用互联网上创建虚拟链路建设VPN的技术称为隧道技术。
可以把隧道想象成一对结点间的一条虚拟链路,这对结点之间事实上可以相隔任意多个网络。
最基础的隧道是IP in IP隧道,即利用IP协议构建隧道。
通过将隧道两端路由器的IP地址提供给虚拟链路,就可以在隧道两端的路由器之间创建虚拟链路。
在隧道两端路由器的路由表中,这条虚链路像一条普通的链路一样。隧道链路具有一个虚接口号。
隧道的实质是再次封装。
经虚接口转发出去的数据报将经过再次封装,来自虚接口的数据报将被再次解封。
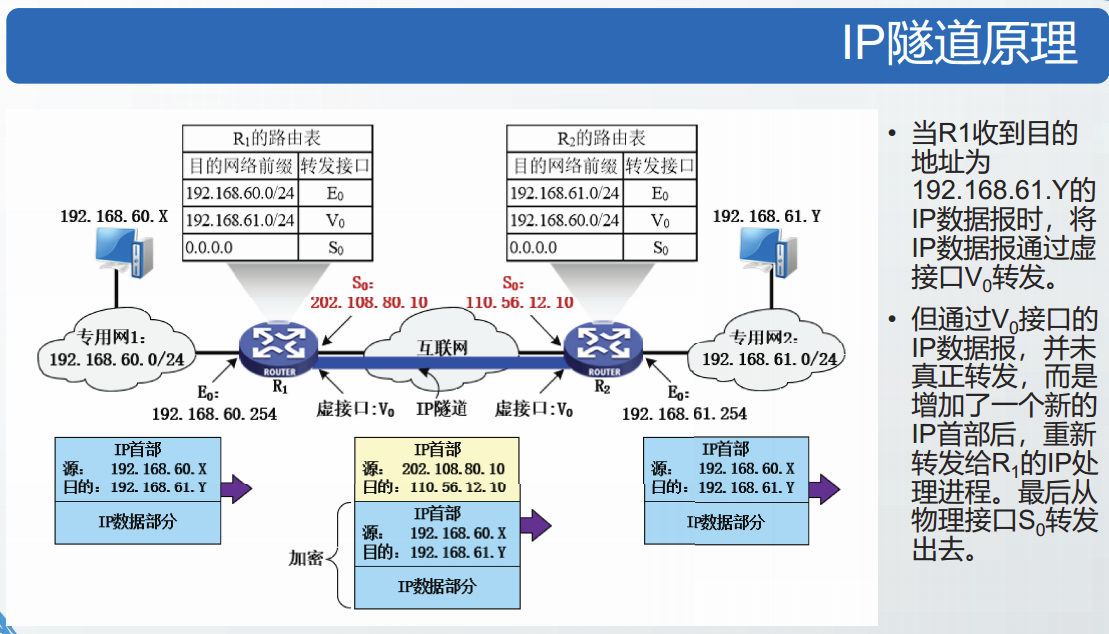 隧道协议
隧道协议
IP in IP隧道由RFC1853规定。
在IP in IP隧道中,隧道中的数据以明文形式在互联网中传送,没有提供数据安全保障。
实际中,用于建立隧道的协议通常将原IP数据报加密后才再次封装。
用于构建VPN的常见协议包括:
通用路由封装(Generic Routing Encapsulation,GRE)
点对点隧道协议(Point-to-Point Tunneling Protocol,PPTP)
第2层隧道协议(Layer Two Tunneling Protocol,.L2TP)
IP层安全((Internet Protocol Security,IPSec)
多协议标记交换MPLS
多协议标记交换(Multi--Protocol Label Switching,IMPLS)是IETF的MPLS工作组开发的一种协议,它试图将虚电路的一些特点与数据报的灵活性结合起来。
2001年成为互联网建议标准。它主要应用于以下三个方面:
①使不知道如何转发P数据报的设备支持基于目的P地址的转发;
②利用显式路由,支持负载均衡和流量工程;
③利用BGP,支持对等模式VPN。
支持MPLS技术的路由器称为标记交换路由器LSR。
许多彼此相邻的LSR组成的集合称为MPLS域。
MPLS的重要特点就是在MPLS域的入口处,给每一个IP数据报打上固定长度的“标记”,然后按照标记转发IP数据报。
MPLS标记是MPLS首部中的一个字段,MPLS首部位于数据链路层首部和网络层IP首部之间。

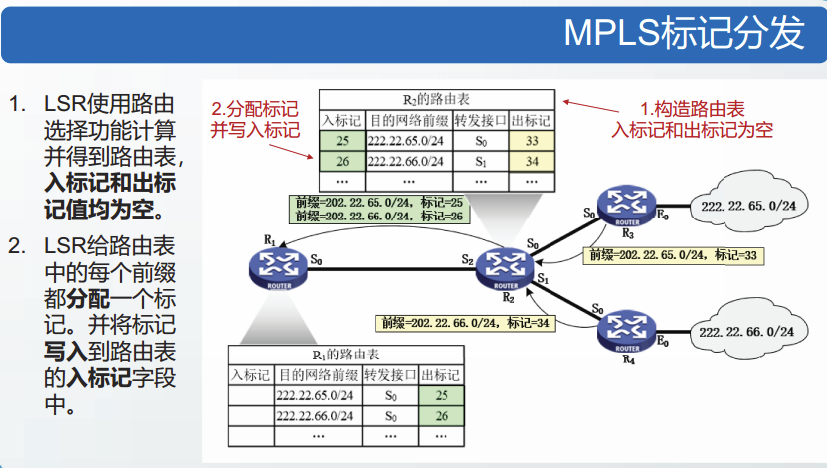
入标点和出标点
LSR同时具有标记交换和路由选择这两种功能。
为了支持和记录MPLS标记,LSR在路由表中增加了两个字段:入标记和出标记。
入标记:代表接收到的分组中携带的MPLS标记,
出标记:代表自己发出的分组中携带的MPLS标记。
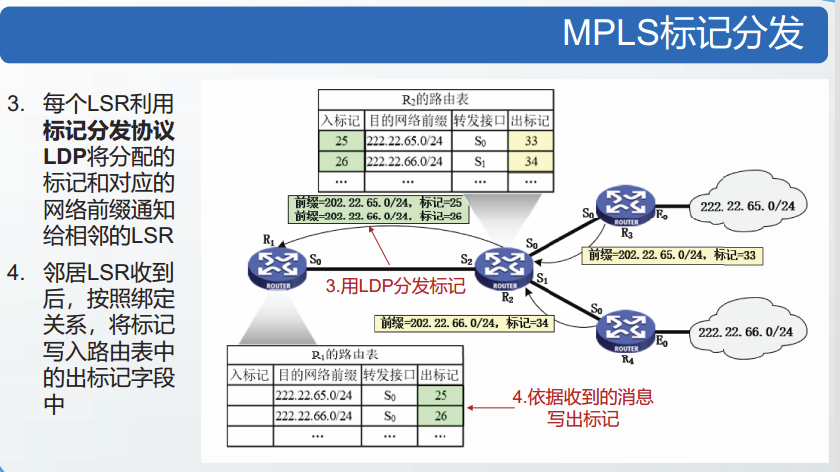
MPLS转发IP分组
MPLS入口结点根据目的IP地址,为分组增加标记。
MPLS域内结点根据标记转发,并完成标记对换。
MPLS出口结点去除标记
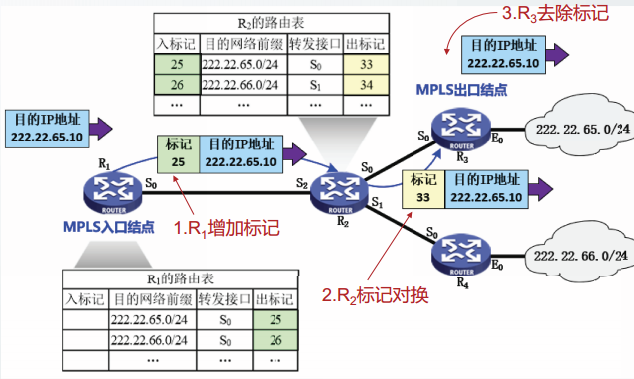
MPLS优点
更快速的转发IP分组
除了MPLS入口结点以外,其它的LSR在转发分组时,只需检索
入标记。
目的IP地址的查找算法是最长前缀匹配算法,而标记查找算法是一种精确匹配算法。
标记查找算法比目的IP地址查找算法效率更高,速度更快
支持基于目的IP地址的转发
虽然我们替换了路由表的查找算法,但路由选择算法可以不做改变。
基于目的地址分配标记后,分组经过的路径与不使用MPLS时经过的路径是相同的
以前不知道如何转发IP数据报的设备,在MPLS域内能够支持P数据报的转发
这种结果可以应用在ATM上,也可以应用在光交换设备上
MPLS中的核心概念就是转发等价类FEC。
转发等价类FEC是指路由器按照同样方式对待的IP数据报的集合。
显然,每个MPLS标记与一个转发等价类FEC一一对应。
上例中,路由表中每个相同的网络前缀是一个FEC,即所有网络前缀相同的分组,都沿着相同的路径进行转发。这种转发等价类等价于基于目的IP地址的转发。
FEC是非常强大和灵活的概念,划分FEC的方法不受什么限制,并不局限在基于目的IP地址划分FEC。
可以将所有源地址与目的地址都相同的IP数据报划分为一个FEC,
也可以将具有某种服务质量需求的IP数据报划分为一个FEC。
MPLS首部格式
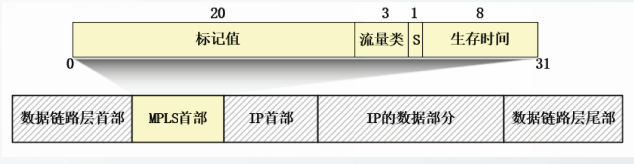
标记值
占20位,理论上允许最多220个标记。RFC3032规定标记0~15保留用于特殊用途。。
流量类(Traffic Class,TC)
占3位,最初这3位保留用于试验。RFC5462将这三位重命名为流量类,包括服务质量信息和显式拥塞通知ECN.
栈底标记S
占1位。当多次插入MPLS首部,构成标记栈时使用。位于栈底的MPLS首部,即最后一个MPLS首部的S位置1.
生存时间TTL
占8位。每经过一个LSR,TTL减1。当TTL为0时,丢弃分组。
支持流量工程
MPLS实现了相同标记的分组都沿着相同的路径转发,在MPLS域内,这样的路径称为标记交换路径。
显然一个转发等价类对应一条标记交换路径LSP。
每条LSP在入口结点为分组指定标记时就已经确定了。这种“**由入口结点确定进入MPLS域以后转发路径”**的方法称为显式路由。
显式路由与我们之前讨论的“"逐跳路由”完全不同。显式路由可以应用于负载均衡和流量工程。
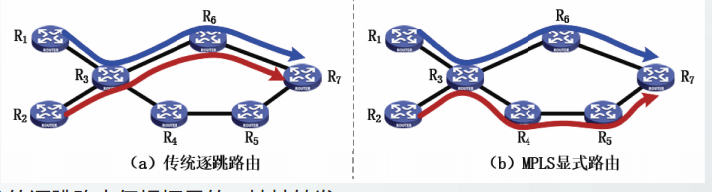
传统的逐跳路由仅根据目的IP地址转发
显式路由可以灵活定义FEC,比如根据分组的不同来源划分FEC,分配标记,完成网络通信量的负载均衡。
由网络管理员采用自定义的FEC来均衡网络负载的做法称为流量工程。
在MPLS流量工程中,显式路由不需要网络管理员手动计算,可以采用约束最短路径优先算法自动计算。
支持MPLS VPN
 重叠模式VPN和对等模式VPN
重叠模式VPN和对等模式VPN
 对等模式VPN
对等模式VPN
在MPLS网络上,构建对等模式VPN,是MPLS最广泛的应用,也是MPLS在互联网工程界被广泛部署的原因之一。
RFC4364规定了利用MPLS和BGP实现对等模式VPN的技术方案。这种VPN被称为MPLS L3VPN,也称为BGP/MPLS VPN.
MPLS的显式路由可以用来构建隧道,BGP被用来传递VPN的路由信息和分发MPLS标记。
RFC4760对BGP-4进行了多协议扩展,使BGP可以为三层VPN等多种协议传递路由信息。扩展后的BGP称为MP-BGP,属于HBGP.
MP-BGP还可以为MPLS分发专网标记,以区别VPN用户数据的归属。
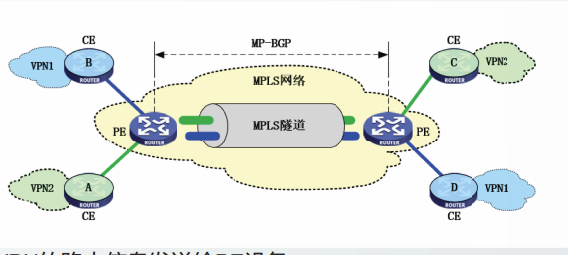
BGP/MPLS VPN
CE设备将VPN的路由信息发送给PE设备。
PE设备之间利用MP-BGP交换路由信息,得到到达其它VPN子网的路由
利用MP-BGP分发MPLS标记,
这些MPLS标记用来在PE设备之间构建MPLS隧道。
第六章 数据链路层
数据链路层概述
在EEE802的系列标准中,将所有运行了数据链路层(二层)协议的网络设备称为站点或站(station)
结点通常是指运行了网络层(三层)协议的网络设备,如主机和路由器。
链路是指从一个站点到相邻站点之间的一段物理线路(有线或无线),中间没有任何其它的站点,也称为物理链路。
数据链路是指在一段物理链路之上增加了控制数据传输的协议软件或硬件,也称为逻辑链路。

数据链路层的协议数据单元PDU称为帧。
每个数据帧中包含的源地址和目的地址称为硬件地址或物理地址。
数据帧的源地址是发送方结点的发送接口的硬件地址;
数据帧的目的地址是下一跳结点的接收接口的硬件地址。
每经过一台路由器,数据帧中的源地址和目的地址都会发生变化
数据链路层协议的作用范围
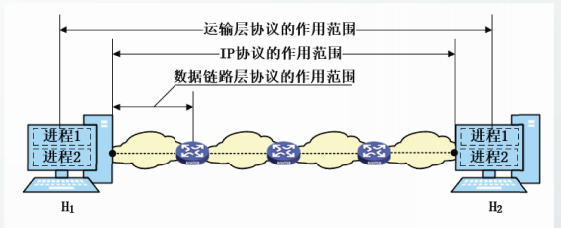
数据链路层的主要任务是提供相邻结点之间的通信服务。大多数数据链路层协议的作用范围是相邻的结点之间。
当无线AP连接了以太网和无线局域网时,以太网协议和无线局域网协议的作用范围较小,不能覆盖到两个相邻的结点之间,仅覆盖到相邻的两个站点之间。
数据链路层的信道
数据链路层使用的信道主要有以下两种类型:广播信道和点对点信道
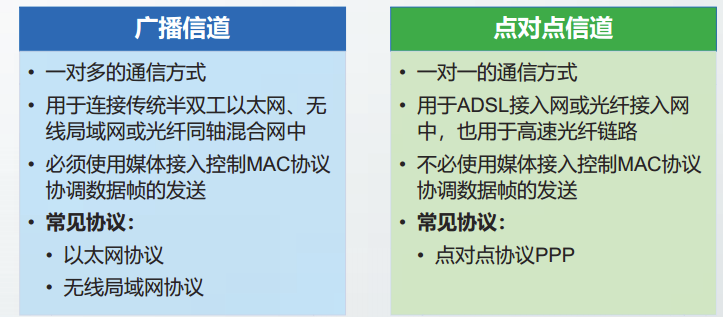
封装成帧
封装成帧是数据链路层最基本的功能。
由于帧在物理层上以比特流的形式传输,所以数据链路层在接收时必须能够确定每一帧的边界。确定帧开始和帧结束的位置,称为帧定界。
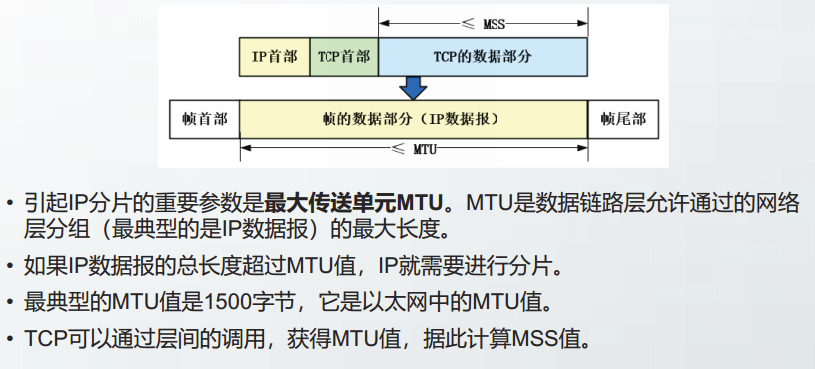
帧长度和MTU
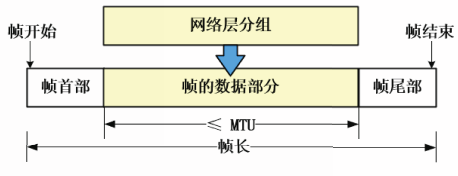
帧长等于帧的数据部分长度加上帧首部以及帧尾部的长度。
数据链路层协议规定的它能传送的数据部分的长度上限,称为最大传送单元MTU。
显然,为了提高帧的传输效率,应该使帧的数据部分长度尽可能地接近MTU。
帧定界方法
典型的帧定界方法包括:
- 标志字符法
- 标志比特法
- 特殊的物理层编码法
网络层协议无需了解数据链路层采用的帧定界方法,即帧定界方法对网络层是透明的,这称为透明传输。
不同的帧定界方法实现透明传输的方式也不一样。
标志字符法
定界方法:对于以字符为基本传送单元的协议,可以指定特殊字符作为帧开始和帧结束的标志字符,称为帧定界符。
透明传输:如果标志字符出现在数据中时,会干扰帧定界功能的实现。采用字符填充法实现透明传输。(转义符)
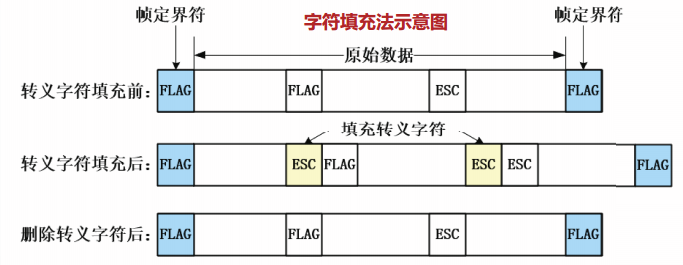
典型协议:PPP协议用于异步传输时,采用标志字符法。

标志比特法
定界方法:对于以比特为基本传送单元的协议,可以指定特殊的比特组合作为帧开始或帧结束的标志。
透明传输:采用比特填充法,避免传送的数据中包含标志比特组合,实现透明传输。

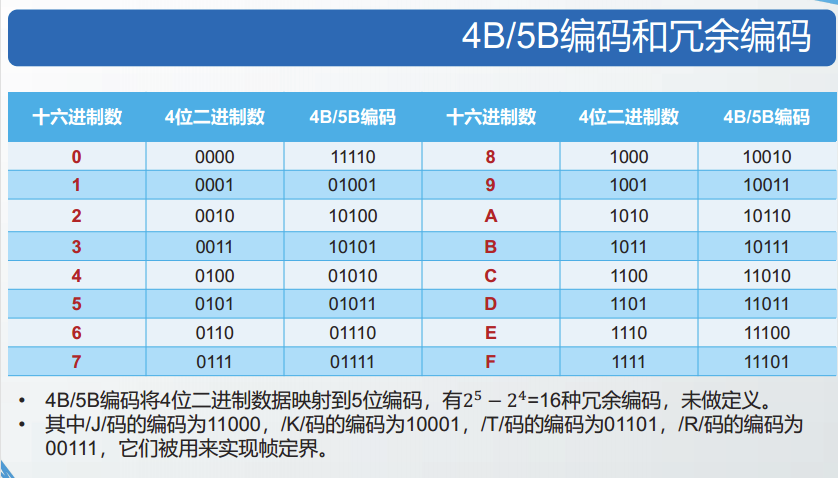
特殊的物理层编码法
定界方法:利用物理层的特殊编码标记帧的边界。要求:物理层编码方案中包含冗余编码。
透明传输:由于冗余编码不会出现在常规数据中,因而不需要额外处理,即可实现透明传输。

寻址
广播信道上的数据链路层协议必须有寻址功能,在广播信道上的主机或路由器的网络接口必须具有硬件地址才能够发送和接收数据帧。
点对点信道上的发送方和接收方都只有一个,因此其数据链路层协议的寻址功能不是必须的。
以太网协议和WLAN协议都采用了48位的硬件地址,该硬件地址也称为MAC地址。
在以太网上,主机和路由器的网络接口都必须具有MAC地址,但是二层交换机的接口允许没有MAC地址。
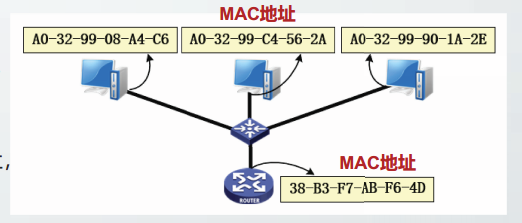
MAC地址
IEEE规定了两种类型的扩展唯一标识符EUI,分别为6字节长度的EUI-48和8字节长度的EUI-64。
EUI-48通常用作IEEE802网络设备的硬件地址,如以太网MAC地址、WLAN的MAC地址。
MAC地址分为两个部分,每部分占3字节。
- 组织唯一标识符OUI:前三个字节(高24位),由IEEE的注册管理机构负载分配;
- 扩展标识符EI:后三个字节(低24位),由获得OUI的厂商自行分配。
最高字节的最低位称为I/G位
最高字节的次低位称为U/L位
48位全为1的地址是广播地址。
差错控制
任何通信链路都不是理想的,在传输过程中都会出现差错,0可能变成1,1也可能变成0,这称为比特差错。
数据链路层,不同的协议提供不同程度的差错控制功能,包括无差错接受或可靠传输。
在光纤、同轴电缆和双绞线等比特差错率很低的链路上的数据链路层协议,如以太网协议、PPP协议等仅提供无差错接受功能,而不提供可靠传输功能。
在无线链路等比特差错率较高的链路上的数据链路层协议,如无线局域网WLAN协议,依靠确认重传机制,提供相邻MAC站(MAC station)之间的可靠传输功能。
无论是无差错接受功能,还是可靠传输功能的实现,都需要差错检测算法来发现比特差错。
差错检测算法CRC
在数据链路层,目前应用广泛的差错检测算法是循环冗余校验(Cyclic Redundancy Check,CRC)
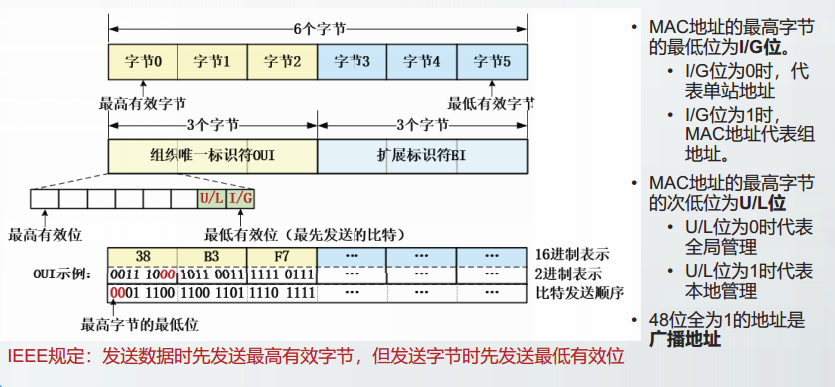
冗余码和帧校验序列FCS
发送方,把数据划分为组,每次发送一组数据。
假定每组数据k个比特,将待发送数据记为M。
发送方利用CRC算法在数据M的后面添加供差错检测用的比特冗余码,一起发送出去。
对于一个帧来说,为了进行检错而添加的冗余码常称为帧检验序列FCS
在数据后面增加 r 比特冗余码,增大了数据传输的开销,但提供了差错检测能力
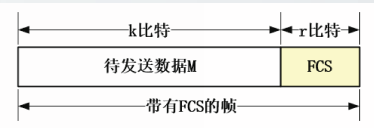

CRC-32
CRC校验也称为多项式编码,其基本思想是将比特串看作系数为0或1的多项式,对比特串的计算被解释为多项式计算。
收发双方商定的P来源于生成多项式P(x),其最高位和最低位系数必须是1.
经过精心挑选的生成多项式P(x)可以确保CRC算法漏判的慨率极低。
CRC-32被EEE应用在包括以太网在内的多种数据链路层协议中:
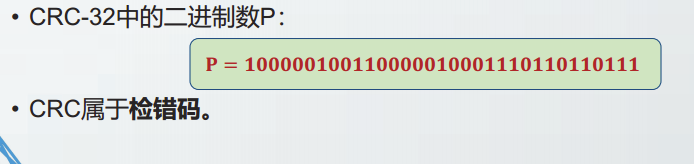
CRC属于检错码
媒体介入控制
媒体接入控制(Medium Access Control,MAC)协议用来规定共享信道的访问方式和访问者。
在点对点信道上,仅有一个发送方和一个接收方,只要信道是全双工的,就无需MAC协议。例如PPP就不需要MAC协议。
在广播信道上的MAC协议也称为多点接入协议,或多路访问协议。
实现媒体接入控制的方法可以分为三类:
- 静态信道分配方法、
- 随机接入方法
- 受控接入方法。
其中,静态信道分配方法属于物理层的方法。
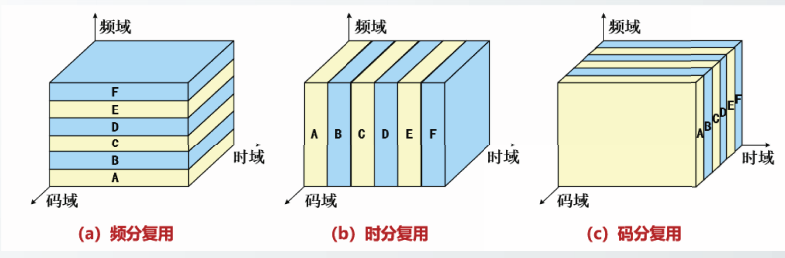
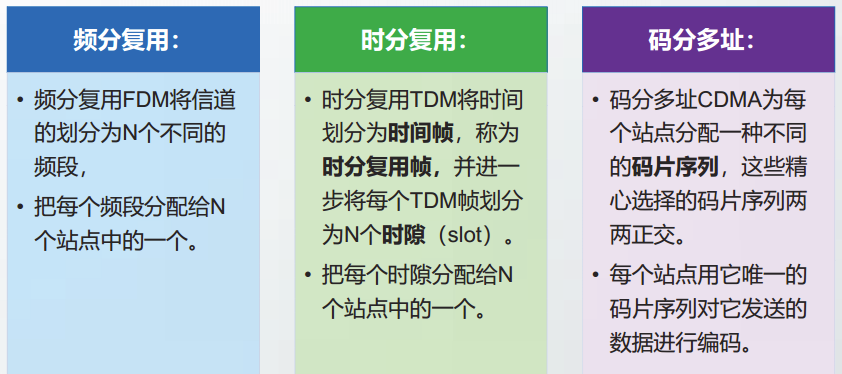
静态信道分配方法
常见的静态信道划分方法包括频分复用、时分复用和码分复用。
码分复用也成为码分多址CDMA。
随机接入方法
随机接入方法是一种基于争用的信道分配方法。
随机接入的特点是所有站点可随机地发送数据。
如果恰巧有两个或更多的站点在同一时刻发送数据,那么在共享信道上就会产生碰撞,也称为发生了冲突。随机接入方法必须有处理冲突的方法。
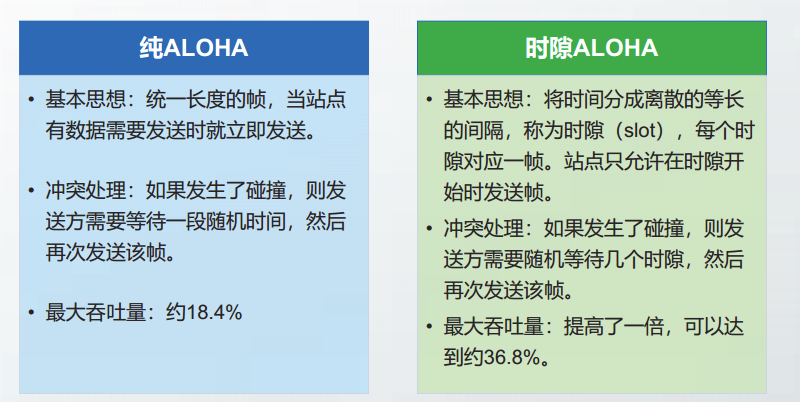
随机接入的MAC协议主要包括:
- 纯ALOHA
- 隙ALOHA
- CSMA/CD:带有碰撞检测的载波监听多点接入
- CSMA/CA:带有碰撞避免的载波监听多点接入
ALLOHA
CSMA/CD
不再采用统一长度的帧,在ALOHA协议的基础之上增加了更多的控制措施。
可以用以下四句话描述:
- 发送前先监听
- 闲则发送,忙则等待
- 边发送边监听
- 碰撞则停发,随机退避重传
CSMA/CD采用二进制指数退避算法进行随机退避。随着重传次数的增加,增大随机退避的时间范围。
CSMA/CD的争用期、传输期和空闲期
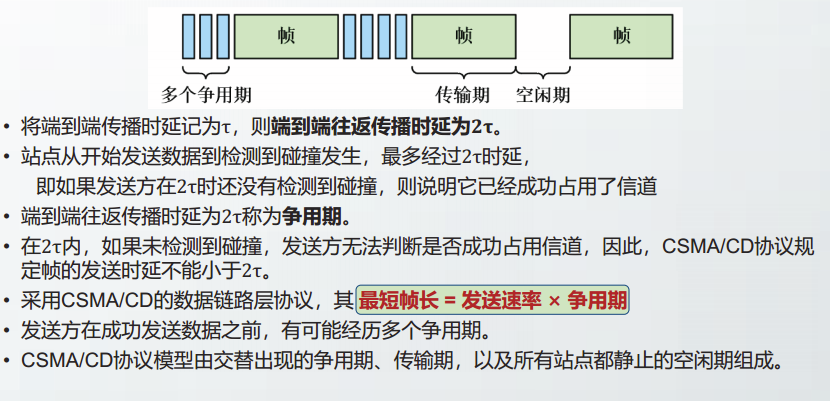
CSMA/CD的应用

无线局域网WLAN中使用分布协调功能DCF时,采用的MAC协议是CSMA/CA协议。
在无线局域网中,由于不能进行碰撞检测,只要开始发送数据,就不会中途停止发送,而一定会把整个帧发送完毕。因此,CSMA/CA用确认重传和碰撞避免机制代替以太网中的碰撞检测机制`。
碰撞避免机制虽然能减少碰撞发生的概率,但并不能完全避免碰撞的发生。
受控接入方法
受控接入方法是一种无争用的信道分配方法。
受控接入的特点是站点发送数据必须服从一定的控制,因而不会产生碰撞。
受控接入协议分别包括轮询和令牌传递。

流量控制
流量控制是数据链路层协议的可选功能。
流量控制用于解决发送方的发送速度超出接收方的处理速度的问题。
在TCPP协议族中,运输层的TCP协议依赖滑动窗口机制实现了端到端的流量控制。因此,很多数据链路层协议并未设计流量控制功能,而将流量控制交给运输层处理。
但是,以太网协议设计了流量控制功能。
在以太网中,流量控制功能也是可选的。它可以由用户激活或通过自动协商激活。以太网中,通常并未使用流量控制。
以太网设计了两种流量控制机制:背压机制和暂停帧。 本章的主要协议
本章的主要协议
以太网协议Ethernet
地址解析协议ARP
无线局域网协议WLAN
点对点协议PPP
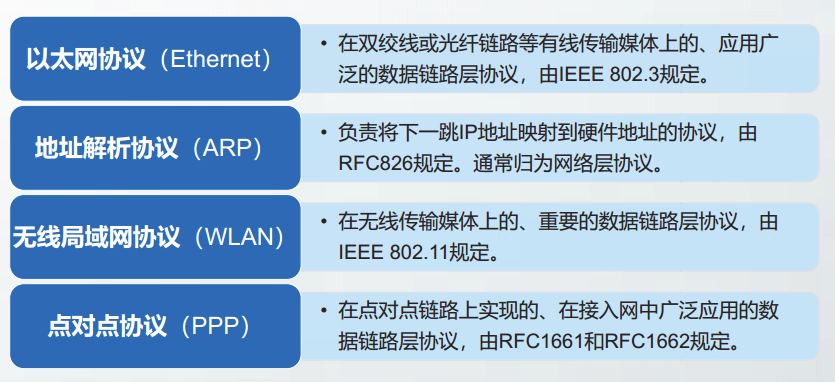
以太网

以太网的发展趋势
经过几十年的发展,以太网的发展趋势包含以下几个方面:
从低速到高速
从共享传输媒体到独享传输媒体
从局域网到城域网再到广域网
从低速到高速
最早用于实验的以太网速率仅3Mbt/S.
第一个标准的以太网速率为10Mbit/s,称为传统以太网。
1995年发布的100Mbit/s的以太网,称为快速以太网(Fast Ethernet)。
超过100Mbit/s速率的以太网,称为高速以太网。
2019年和2020年分别发布了单模光纤、多模光纤上的400Gbit/s以太网标准。

从共享传输媒体到独享传输媒体
传统以太网采用同轴电缆作为共享传输媒体,也被称为共享以太网。
多个站被连接到一根共享总线上,采用CSMA/CD协议协调多个站的数据发送。
随着10BASE-T的开发,各站点通过双绞线连接到集线器上,而不再连接到同轴电缆上。出现了星形共享以太网。
·依然采用CSMA/CD协议。
随着100BASE-T以太网的发展和流行,交换机逐渐取代集线器。
交换机完全取代集线器、并工作在全双工模式下的网络,称为全双工网络。
全双工网络中各站独享传输媒体,不再使用CSMA/CD协议。
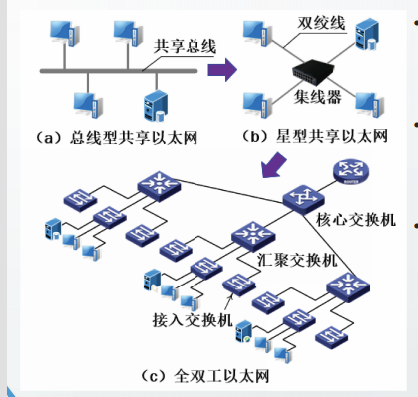
从局域网到城域网再到广域网

以太网的帧格式
最初的以太网标准由DEC、Intel和施乐公司联合推出,称为称为DIX Etherneti标准。该联盟推出Ethernet V2标准后没有继续更新。
IEEE802委员会对Ethernet V:2帧格式稍加修改,推出了802.3标准的以太网帧格式。
IEEE802.3为了支持各种类型的局域网互连,将数据链路层分为两个子层:媒体接
入控制(Media Access Control,.MAC)子层和逻辑链路控制(Logical Link
Control,LLC)子层。
因此,数据链路层首部分为MAC首部和LLC首部。它们的关系如下:

随着其它种类的局域网被以太网淘汰,EEE于2010年撤销了802.2标准,802.3以
太网标准中不再使用LLC首部。本节讨论以太网,不再考虑LLC子层。
目前,LLC首部仍然应用在802.11无线局域网中。
802.3以太网帧格式
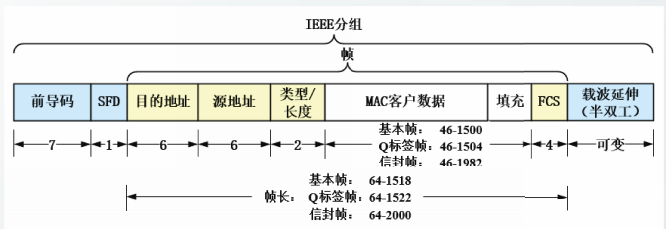

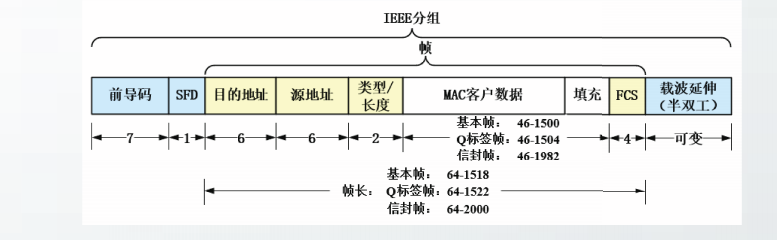
在IEEE分组中,前导码、帧开始符SFD和载波延伸字段属于物理层,其它字段属于数据链路层,数据链路层的各字段共同构成了帧。
前导码
占7个字节,取值为交替的1和0。其作用是使接收端的适配器在接收MAC帧时能够迅速调整其时钟频率,实现位同步
帧开始符SFD
占1个字节,取值“10101011”。SFD的前六位的作用和前导码一样,最后的两个连续的1代表帧即将开始传送。
目的地址:
占6字节,接收方MAC地址。
源地址:
占6字节,发送方MAC地址。
类型长度
占2字节。由于历史原因,该字段包含两种含义。当取值小于等于1500时,该字段理解为长度字段,代表基本帧中MAC客户数据的字节数。
当取值大于等于1536时,该字段理解为类型字段,代表MAC客户协议类型。
MAC客户数据(MAC Client Data)
MAC客户数据包含可选的标签和上层协议数据。
EEE802.3定义了三种类型的以太网帧:基本帧(basic frame)、Q标签帧(Q-tagged frame)和信封帧(envelope frame)
基本帧不包含标签,Q标签帧和信封帧包含标签。

三种类型的以太网帧中封装的上层协议的数据最大长度都是1500字节,也就是说以太网的MTU为1500字节。
填充
以太网最小帧长为64字节。当上层协议交下来的数据小于46字节,将导致封装的以太网帧不足64字节,以太网协议实体必须在填充字段用“0”补足。
帧检验序列FCS
占4字节,利用CRC算法进行帧检验。帧检验计算范围包括目的地址、源地址、类型长度、MAC客户数据和填充字段。
以太网的FCS采用IEEE标准的CRC32进行计算利用CRC算法进行帧检验。
载波延伸
在1Gbit/s的以太网中,当工作在半双工模式时,为了保持CSMA/CD协议的有效性,需要在较短的帧后补充载波延伸字段,该字段值全为0
当工作在全双工模式时,不需要该字段。
帧间间隔
以太网规定,每发送完一帧,必须停下来等待一小段时间,才能发送下一帧。这段时间称为帧间间隔。帧间间隔的作用有两点:
- 在运行CSMA/CD协议时,停止发送可以让信道空闲下来,方便多个站点争用信道;
- 停止发送代表帧结束标记,再次发送新帧时,前导码和SFD可以代表帧开始标记。((10Mbit/s的传统以太网中的规定)
IEEE规定的以太网的帧间间隔为96bit时间。
对于10Mbit/s的传统以太网来说,帧间间隔为9.6μs;对于100Mbit/s的快速以太网来说,帧间间隔为0.96μs
网桥和交换机
我们可以使用中继器或集线器来扩展以太网的地理覆盖范围。
中继器和集线器都属于物理层设备,通过中继器或集线器的接口连接在一起的所有站点都处于同一个碰撞域。
所谓碰撞域是指站点发送的物理层信号可以到达的范围。
处于同一个碰撞域内的站点,在任一时刻只能有一个站点发送数据,否则将会发生碰撞。
随着100BASE-T网络和交换机的普及,集线器最终被交换机所替代。交换机本质上是多接口、高性能的网桥。
交换机工作在数据链路层,也称为二层交换机。
交换机的每个端口下连接的站点处于同一个碰撞域。
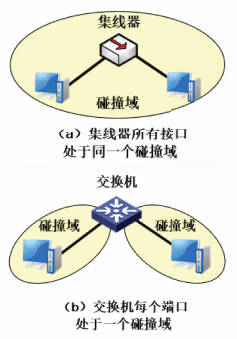
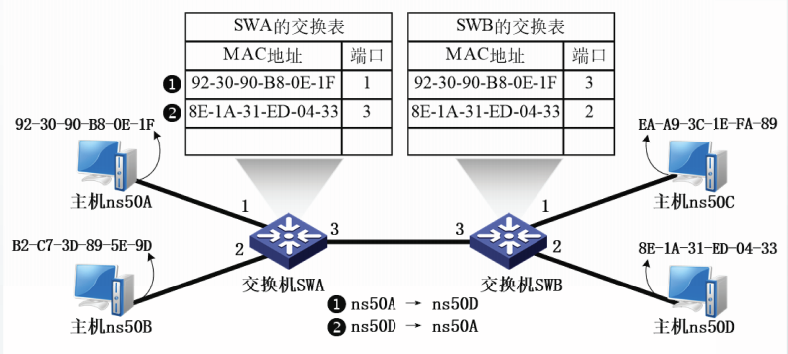
交换机的工作原理

交换机收到一个数据帧后,首先进行自学习填写交换表,然后转发数据帧。
如果交换表中某项目的老化时间到达了“有效期”,则交换机会删除该项目
自学习算法和转发算法

交换机工作原理实例
生成树协议
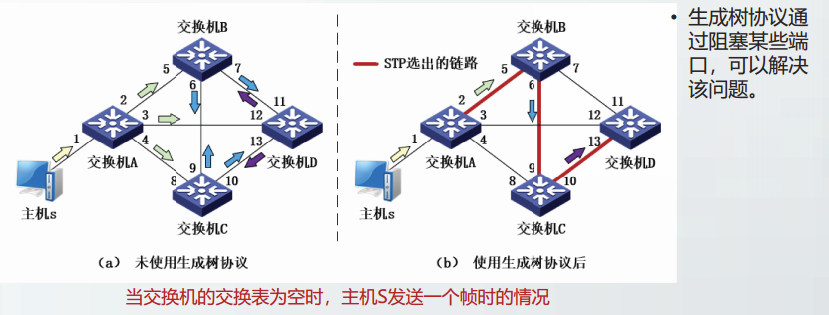
当多个交换机连接在一起共同工作时,由于存在冗余链路的可能性,可能会形成很多循环帧。引起广播风暴和交换表震荡等问题。
虚拟局域网
IEEE规定48位全为1的地址是广播地址,目的地址为广播地址的帧称为广播帧。广播帧能够被分发到同一以太网上的所有主机。
随着交换式以太网的大量应用,位于同一以太网中的主机数量越来越多,为了更有效地利用网络带宽资源,需要限制以太网广播的范围。
站点发送的广播帧能够到达的范围称为广播域。
交换机的所有端口下连接的站点处于同一个广播域。
路由器收到以太网广播时,不进行转发。路由器的每个接口下连接的站点处于同一个广播域。
虚拟局域网
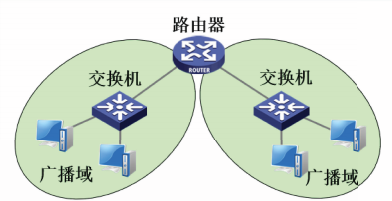
在同一个以太网内部可以利用虚拟局域网隔离广播域。
虚拟局域网VLAN是由一些局域网网段构成的与物理位置无关的逻辑组,如下图所示。
支持VLAN功能的交换机称为VLAN交换机。
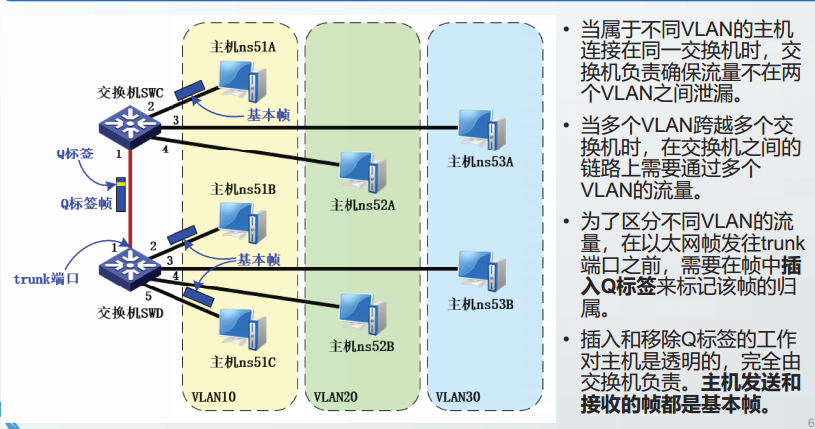
Q标签帧格式
标签协议TPID:
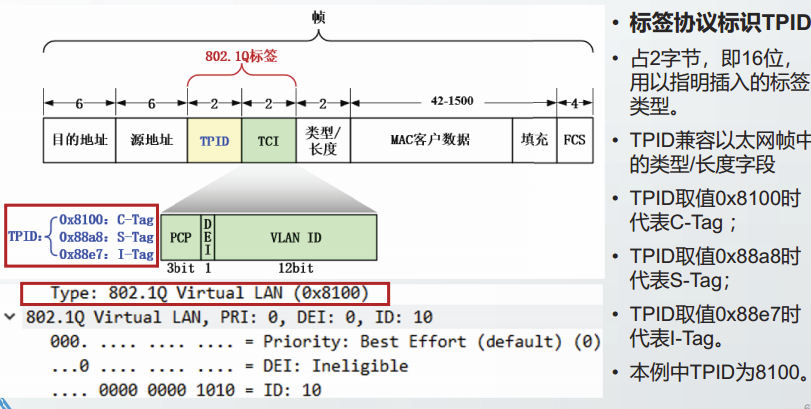
三种Q标签:

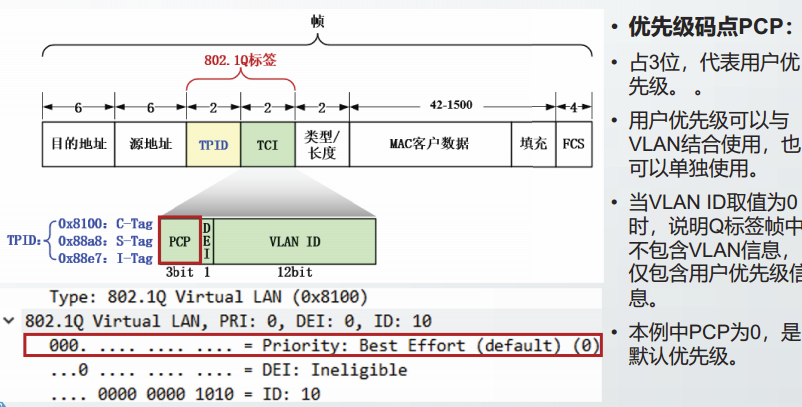
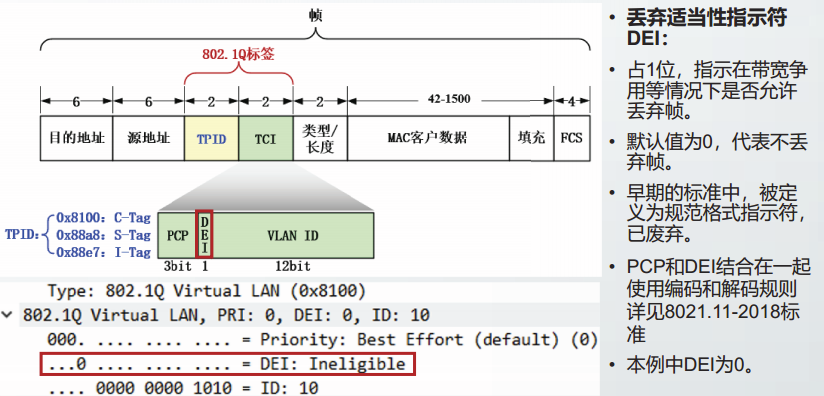
优先级码点PCP:
丢弃适当性指示符DEI:
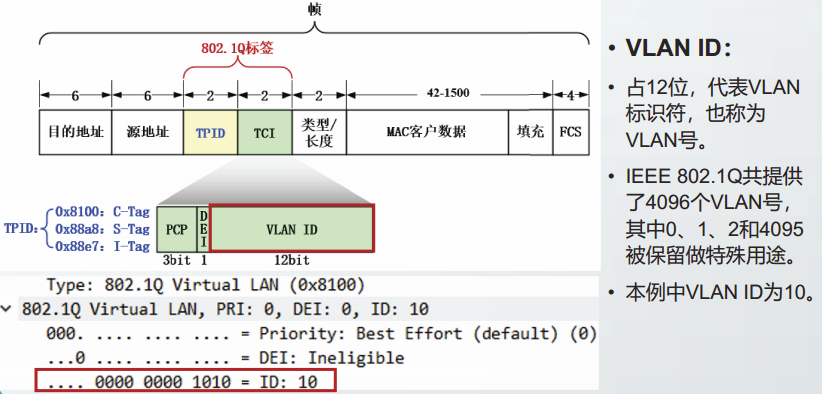
 VLAN ID:
VLAN ID:
地址解析协议ARP
ARP协议提供了一种从网络层的IP地址解析出数据链路层的硬件地址的方法。
ARP协议需要做的是在每一个网络中将下一跳结点的P地址解析为其对应的MAC地址。
以太网协议可以将解析出的MAC地址作为目的MAC地址写入帧首部中,完成发送。
对于间接交付网络,下一跳IP地址可以从路由表中获得;对于直接交付网络,下一跳P地址即目的地址。
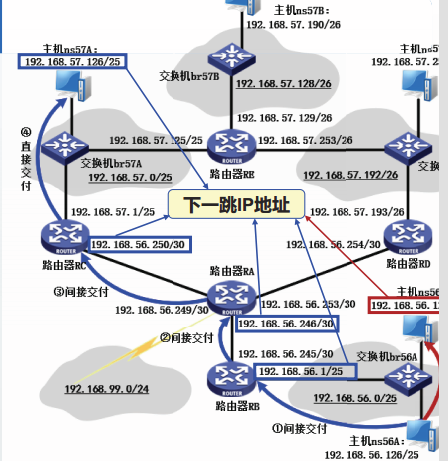
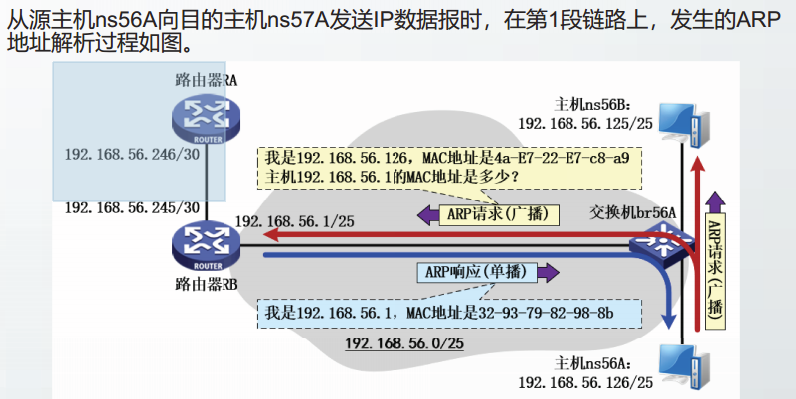
ARP地址解析过程
ARP报文格式:
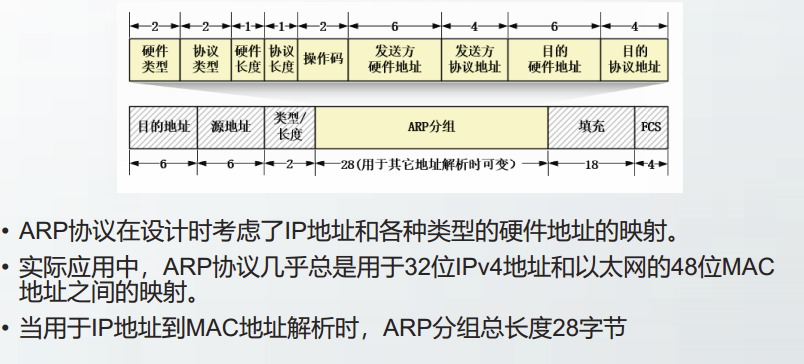 参考链接:
参考链接:
ARP报文格式
ARP缓存
ARP缓存用来存放IP地址和MAC地址之间的最新映射。
主机或路由器的每个网络接口维护一张ARP缓存表。
ARP缓存表包括三个字段:
IP地址
MAC地址
生存时间
当主机需要解析IP地址对应的MAC地址时,首先查询本机的ARP缓存表,只有在查询不到时,才发起广播形式ARP请求。
使用ARP缓存,可以很大程度上减少ARP请求的数量,减少网络中的广播流量。
ARP缓存策略
- 一台主机发送了ARP请求后,当它收到ARP响应时,会将对方的IP地址和MAC地址记录在ARP缓存表中。
- 如果一台主机收到了一个ARP请求,这个ARP请求的目的地址是本机,这台主机会将ARP请求中的发送方IP地址和MAC地址记录在ARP缓存中。
- 如果一台主机收到了一个ARP请求,这个ARP请求中的发送方IP地址已经在本机的ARP缓存表中,这台主机会将发送方IP地址和MAC地址更新在ARP缓存表中。
ARP缓存删除策略
-
当生存时间超过规定的时间后,ARP缓存记录将被删除。
-
在RFC1122中,规定了ARP缓存的验证方法。
主机采用单播轮询方式,周期性地向远程主机发送单播ARP请求。
如果连续两次单播ARP请求都未收到对方的ARP响应,则删除相应ARP缓存记录。
无线局域网
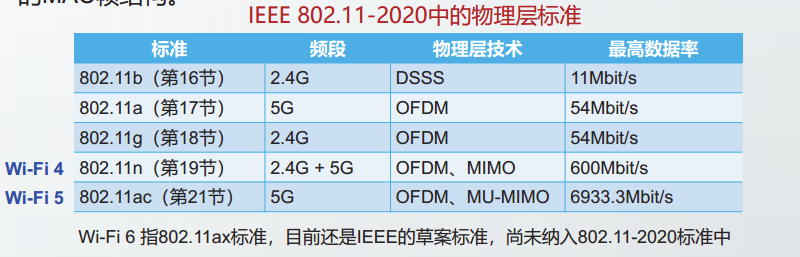
无线局域网WLAN也称为Wi-Fi,它的标准是IEEE802.11,包括无线局域网的MAC层标准和物理层标准,目前最新的版本是802.11-2020.
802.11网络定义了多种物理层标准,但都使用相同的MAC协议,采用相同的MAC帧结构。
无线局域网的组成
802.11无线局域网分为两类,一类是基础设施(infrastructure)网络,另一类是自组织(ad hoc)网。

接入点AP :提供分布系统接入功能的站点,也负责一个BSS内的流量转发,
门户portal:指提供802.11WLAN和非802.11LAN交互服务的逻辑点。
在一台设备内可以同时实现AP和门户功能。
分布系统DS可以连接多个AP.
分布系统中用来连接AP的媒体称为分布系统媒体DSM。最常见的DSM是802.3媒体。
用无线媒体连接的分布系统称为无线分布系统WDS.
Mesh是一种网状网,其中的站点称为mesh站点。
Mesh网关是指提供分布系统接入功能的mesh站点。
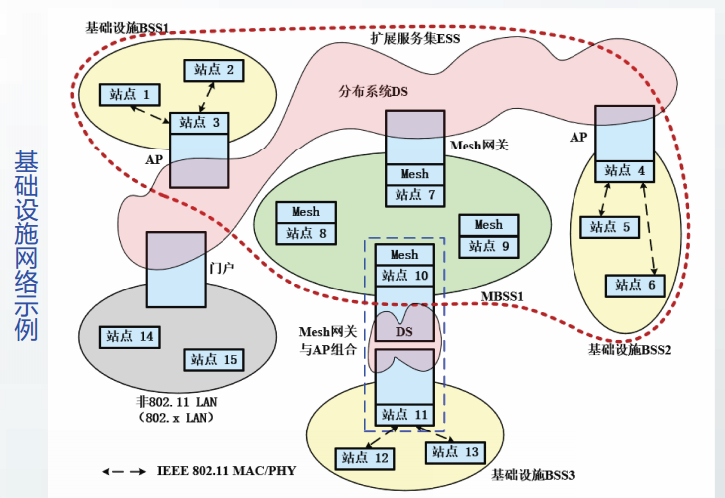
基本服务集BSS
基本服务集BSS是802.11体系结构中的基本构件,它由多个无线站点组成。
根据基本服务集中站点的种类和功能,802.11-2020标准将基本服务集分为:
- 独立基本服务集(Independent BSS,IBSS)
- 个人基本服务集(Personal BSS,PBSS)
- 基础设施基本服务集(infrastructure BSS)
- 网状网基本服务集(Mesh BSS,MBSS)
独立基本服务集
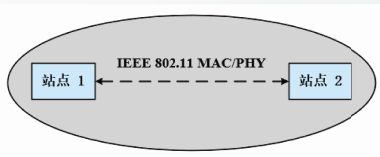
独立基本服务集IBSS是802.11WLAN中最基础、最简单的BSS,由多个站点组成。
BSS中的站点之间是对等关系,站点之间直接相连,可以直接通信。
BSS中的站点不具备转发能力,BSS网络不具有多跳传输功能。
BSS中不包含接入点、门户以及分布系统等基础设施,属于自组织网络。
个人基本服务集PBSS
个人基本服务集PBSS与IBSS类似,它也由多个站点组成,站点之间可以直接通信。
PBSS的各站点之间不是对等关系。在PBSS中,只有一个站点承担PBSS控制点PCP的角色。PCP负责发送信标帧,为PBSS中的站点提供基于竞争的信道访问服务。
PBSS只能由DMG站点建立,DMG工作在60Ghz频段,由IEEE802.11ad规定。
基本设施基本服务集infrastructure BSS
拓展服务集EBS

网状网基本服务集MBSS
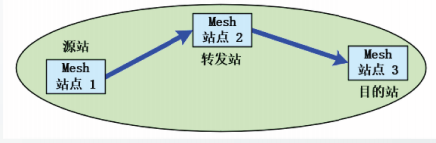
网状网由ad hoc网络发展而来,具有多跳传输功能。
MBSS由Mesh站点组成,Mesh站点可以作为源站、目的站或者转发站。
MBSS允许通过一个或多个Mesh网关接入分布系统DS。
MBSS中的所有站点都可以通过无线媒体互相通信,因此MBSS也可以用来作为分布系统媒体DSM。
Mesh网关与AP可以组合在一起,在一台设备内实现。
无线局域网的MAC帧
IEEE802.11-2020中定义了多种类型的MAC帧格式。
在所有802.11的MAC帧中,前2个比特的定义是一样的,为协议版本号(Protocol Version,PV)字段。
目前,802.11标准共定义了两个版本号,分别为PV0和PV1。
PV0格式的MAC帧是绝大多数802.11WLAN中采用的MAC帧;
PV1格式的MAC帧是802.11ah中定义的MAC帧,该格式为物联网领域做了优化,更适用于低功耗的应用场景。
PV0格式的MAC帧的前8个比特的定义是一样的,分别是
- 协议版本(2bit)
- 类型(2bit)
- 子类型(4bit)
其它部分的格式定义与类型和子类型相关。
在802.11中共定义了3种类型的MAC帧,分别是
数据帧
管理帧
控制帧
子类型很多,可以参考802.11-2020。
数据帧格式
本部分表格例图较多,不再做文字解释,这里贴上学校的PPT作为参考。
(∪.∪ )…zzz
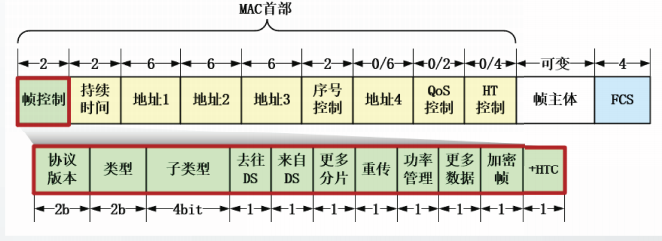
WLAN数据帧由MAC首部、帧主体和帧检验序列FCS三个部分组成。


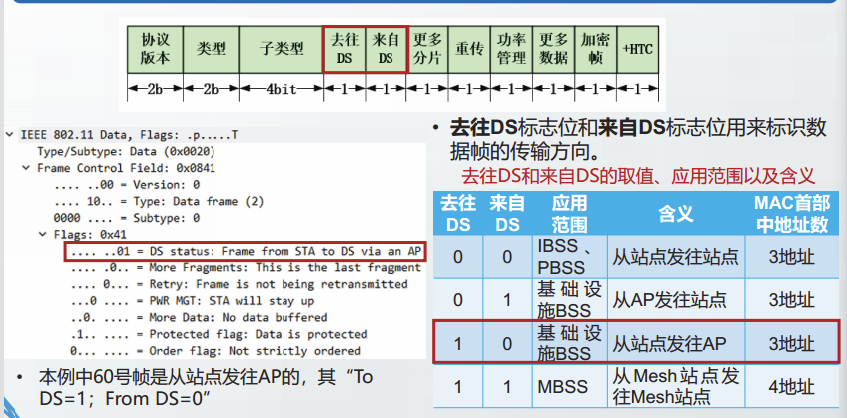







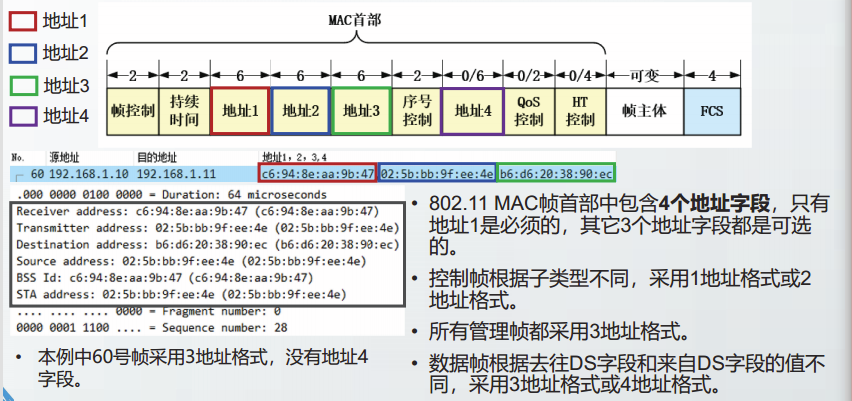


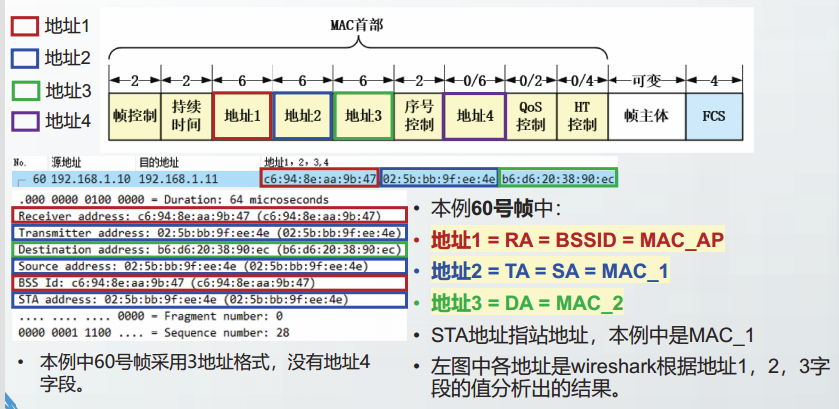


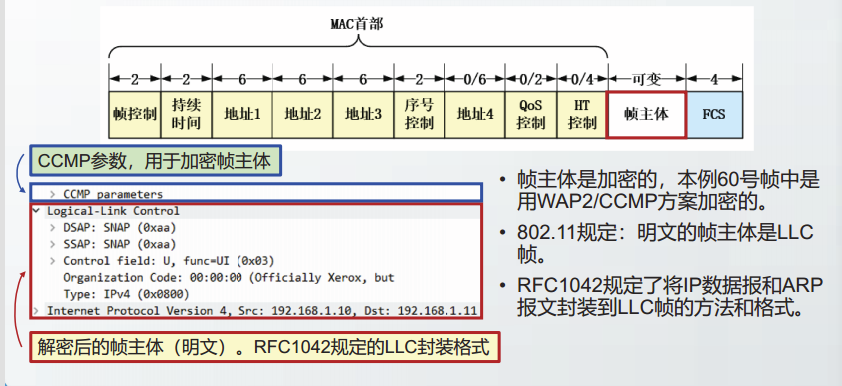

802.11帧到802.3帧的转换
当802.11无线局域网与802.3以太网互连时,AP需要完成802.11帧和802.3帧之间的格式转换。
在下图所示网络拓扑中,考虑主机H3向主机H1发送P数据报的过程。主机H3发出的802.11数据帧中:
地址1为MAC_AP2(RA)
地址2为MAC_3(TA/SA)
地址3为MAC_1(DA)
当AP2收到该数据帧后,需要将其转换成802.3以太网帧格式转发向交换机。
转换后的802.3帧中:目的地址为MAC_1,源地址为MAC_3。
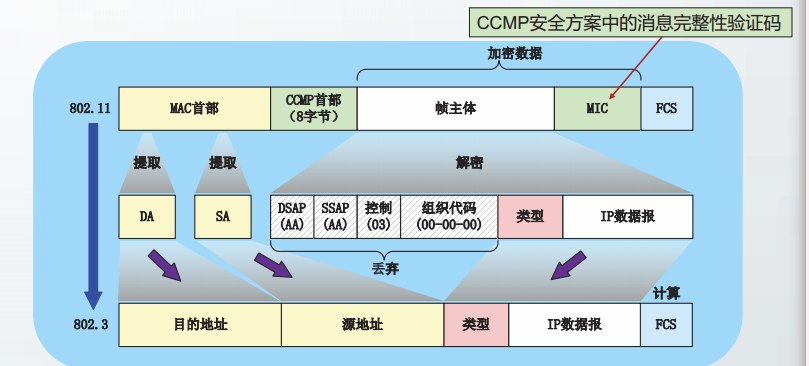 帧校验序列FCS
帧校验序列FCS
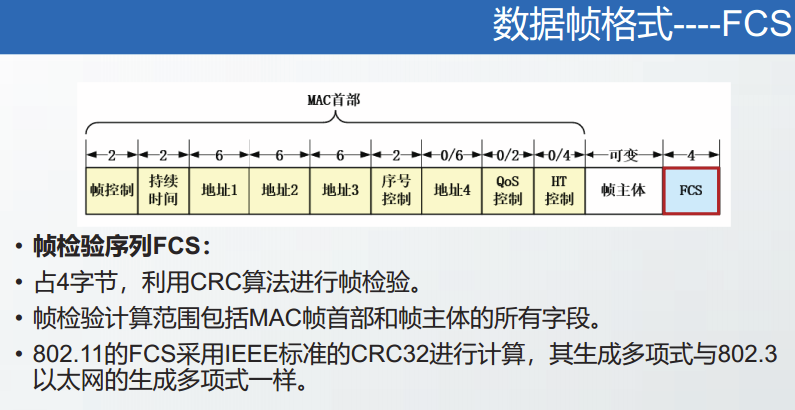
管理帧
管理帧主要用于创建、维持、终止站点和AP之间的关联。
常见的管理帧包括信标帧、关联请求帧、关联响应帧、探测情求帧和探测响应帧等。
关联意味着在无线站点和AP之间创建一个虚拟线路。AP仅向与其关联的无线站点发送数据帧,无线站点也仅通过关联AP向其它站点或因特网发送数据帧。
与AP建立关联的方法有被动扫描和主动扫描。
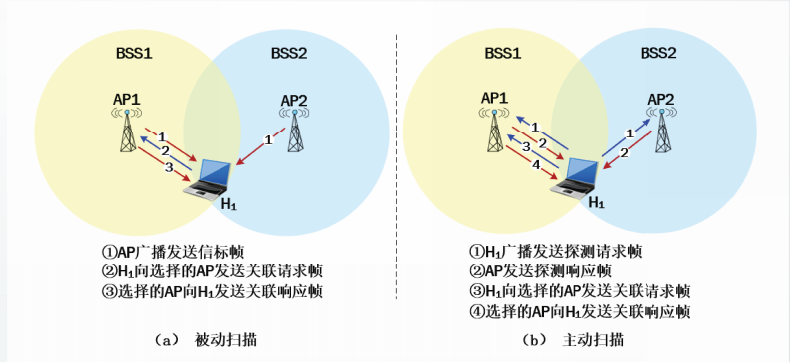
控制帧
控制帧主要用于预约信道和数据帧确认等。
常见的控制帧主要包括确认帧ACK、请求发送帧RTS和允许发送帧CTS等。
802.11无线局域网采用了停止等待协议,在数据链路层实现可靠传输。
当WLAN中某站点正确收到一帧数据时,它等待一个短帧间间隔SIFS,然后发回一个确认帧ACK。
802.11的停止等待协议是在直接发送站和直接接收站之间实现的。
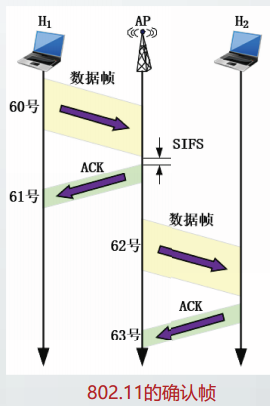
隐蔽站问题
无线站点H1和H2都与AP关联,但互相不在对方的无线信号范围之内。
如果两个站点同时发送数据给AP,显然会产生碰撞,但由于无线信号覆盖范围的问题,双方都不能通过载波监听的方法发现对方正在发送数据,这个问题被称为隐蔽站问题。
802.11允许采用RTS帧和CTS帧进行信道预约,用来避免隐蔽站带来的碰撞可能。
RTS帧和CTS帧
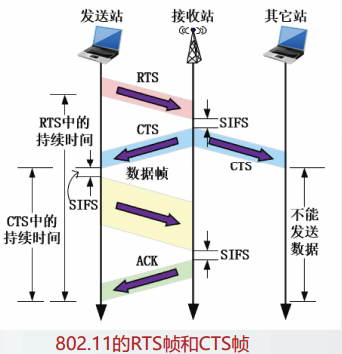
发送站在发送数据帧前,首先向接收站AP发送一个RTS帧,用持续时间字段指示传输数据帧和确认帧需要的总时间。
当接收站AP收到RTS帧后,它发送一个CTS帧作为响应。
CTS帧有两个目的:
给发送站明确的发送许可,
也通知其它站点在持续时间内不要发送数据。
RTS和CTS;数据帧和确认帧之间均采用短帧间间隔SIFS。
一般情况下,802.11协议的实现会提供一个称为RTS阈值的配置选项,超过阈值长度的帧才会触发一个RTS帧,预约信道。
RTS帧、CTS帧和ACK帧
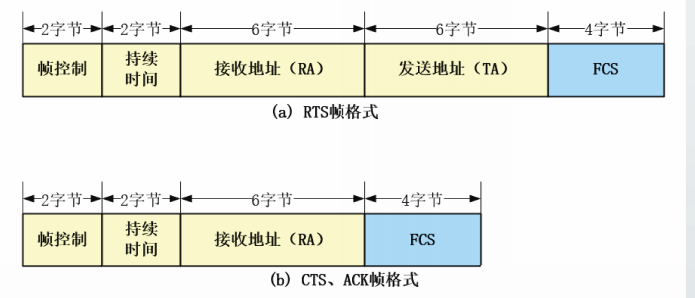
无线局域网的MAC协议
802.11-2020标准采用三种方法解决无线媒体接入控制问题:
- 分布协调功能(Distributed Coordination Function,DCF)
DCF是WLAN中媒体接入控制的基本方法,用于竞净服务,是HCF和MCF的基础,
802.11协议规定所有站都应该实现DCF。
- 混合协调功能(hybrid coordination function,HCF)
HCF用于支持802.11e和802.11n中的QoS,所有支持QoS的设备都应该实现HCF。
HCF包括受控接入和竞净接入两种方法。
HCF受控接入即HCF受控信道接入(HCF Controlled Channel Access,HCCA)
·HCF竞争接入即增强型分布式信道接入(Enhanced Distributed ChannelAccess,EDCA)。
- Mesh协调功能(Mesh coordination function,McF)
MCF仅用于MBSS中。MCF不在本书讨论范围。
在较早期的802.11标准中还定义了点协调功能(Point Coordination Function,PCF),PCF的应用非常少,在802.11-2020中已经废弃了PCF。
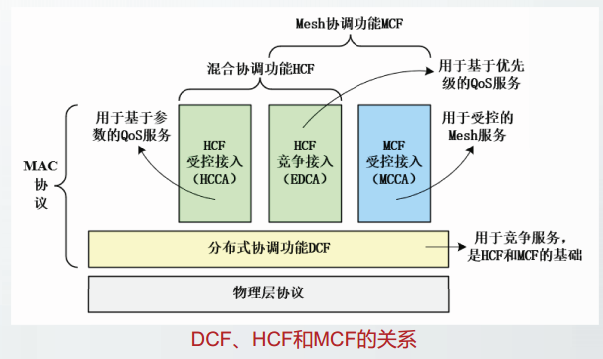
分布协调功能DCF
分布协调功能DCF使用CSMA/CA协议,即带有碰撞避免的载波监听多点接入协议。
- 载波监听用来检测传输媒体是否繁忙,
- 多点接入用来确保每一个无线终端可以公平地访问传输媒介,
- 碰撞避免用以降低碰撞发生的概率,期望在指定时间内只有一个无线终端能够访问传输媒体。
DCF采取的接入控制措施
802.11WLAN中实现了停止等待协议,利用确认帧ACK,代替802.3中的
碰撞检测机制。
802.11的无线站点无法同时发送和接收数据,不能边发送边检测。
802.11中,如果发送站没有收到ACK帧,就认为发送失败,重传该数据帧。
802.11中规定广播帧和多播帧不需要进行确认。
- 802.11采用碰撞避免机制来减少碰撞发生的概率。
当监听到信道空闲时,WLAN的站点先利用二进制指数退避算法随机退避一段时间后,才允许发送数据。
- 802.11的载波监听包括物理载波监听和虚拟载波监听。
802.11还采用RTS帧/CTS帧预约信道,解决隐蔽站问题,进一步减少碰撞发生的概率。
802.11的碰撞避免机制
802.11的碰撞避免机制包含以下几方面内容:
帧间间隔
可以提供接入无线媒体的优先级
载波监听
包括物理载波监听和虚拟载波监听
·随机退避
802.11的二进制指数退避算法
帧间间隔
帧发送完成后,必须等待一段很短的时间才能发送下一帧。这段时间称为帧间间隔IFS。

载波监听
802.11CSMA/CA设备在开始传输前必须进行载波监听,用以检查传输媒体是否被占用。
802.11的载波监听包括两种方式:物理载波监听和虚拟载波监听。
物理载波监听和虚拟载波监听是同时执行判断的,只有两种方式都认为信道空闲时,才判定信道空闲。
物理载波监听(Physical Carrier Sense)
·每个802.11的物理层规范都需要提供一种评估信道是否空闲的功能,它通常基于能量和波形识别。
·这种功能称为空闲信道评估(Clear Channel Assessment,CCA),用于了解媒体当前是否繁忙。
虚拟载波监听(Virtual Carrier Sense)
执行虚拟载波监听的每个站维持一个称为网络分配向量(Network Allocation Vector,NAV)的本地计数器,用来估计信道将处于繁忙状态的时间。
只要NAV变量不为0,信道就会被认为是繁忙的。
发送站发送单播帧时,会设置持续时间字段。
·虚拟载波监听机制将检查每个MAC帧中的持续时间字段,并据此更新NAV变量。
当一个站监听到一个大于本地NAV的持续时间时,它用持续时间值更新本地NAV变量。
·NAV变量基于本地时钟递减,当监听到一个ACK帧时,本地NAV被重置为O。
数据帧、RTS帧和CTS帧的持续时间
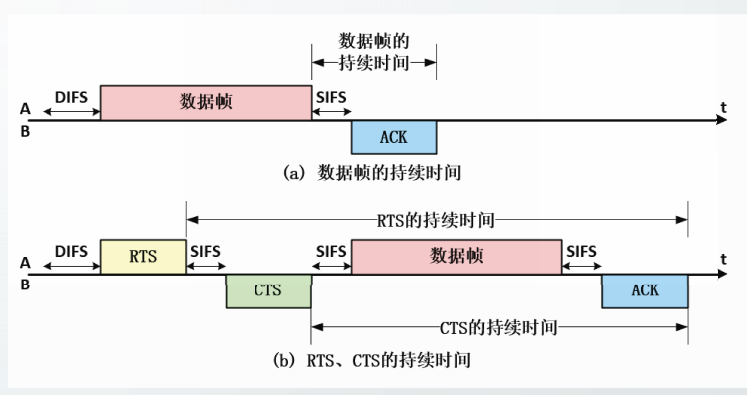
随机退避
在802.11WLAN中,需要发送数据的站需要执行随机退避算法。
例外:发送站需要发送的数据是本站的第1帧数据,且载波监听时信道空闲,而非信道由忙转闲
WLAN的随机退避算法是二进制指数退避算法。
退避时间等于一个随机数与时隙的乘积。
时隙依赖物理层标准不同,通常是几十微秒。
随机数是在区间[O,CW中随机选择的一个整数,其中CW代表竞争窗口,是一个整数,且满足aCWmin< CW < aCWmax。
aCWmin和aCWmax由物理层标准定义。
CW的值从物理层指定的常数aCWmin开始,随着重传次数增加,以2的幂次减1增加,直到aCWmax为止。
竞争窗口CW的变化

随机退避的过程
随机退避计时器是无线站点传输帧之前的最后一个计时器。
当信道从忙转闲,并持续空闲DIFS时间后,随机退避计时器开始计时。
在退避过程中,每经过一个时隙,站点会监听一次信道
若信道空闲侧则随机退避计时器的值减1;
若信道忙则挂起随机退避计时器,直至信道再次从忙转闲,并持续DIFS时间后,计时器恢复计时。
当站点的随机退避计时器倒数至0时,意味着站点竞争获得信道,可以发送数据。
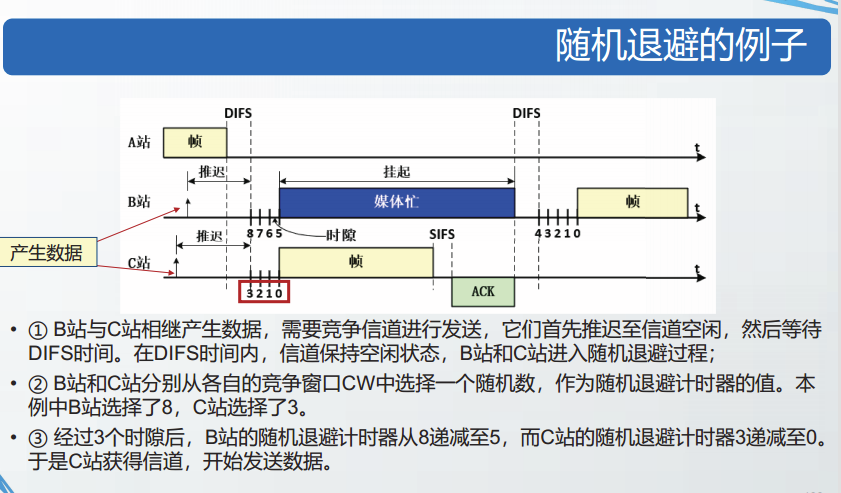
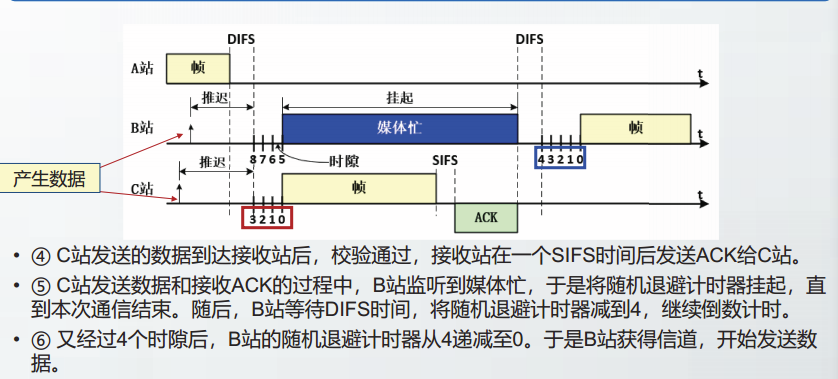
混合协调功能HCF
2004年,802.11e标准为WLAN增加了QoS功能。
后续的802.11标准中的QoS功能基本都来源于802.11e的主要设计。混合协调功能HCF用来支持QoS功能。包括:
HCF受控信道接入HCCA:使用轮询方法控制媒体接入,HCCA的应用很少。
增强型分布式信道接入EDCA:基于DCF改进的媒体接入控制机制。
我们仅讨论EDCA。
EDCA对DCF主要做了两点改进:
·传输机会(Transmission Opportunity,TXOP)
·接入类别(Access Category,AC)。
传输机会TXOP
传统的DCF中,当站点竞争到信道后,可以获得发送一帧的机会,即**“竞争一次,传输一个帧”**。这会带来`速率异常问题:

改进:引入了传输机会TXOP,将竞争方式改进为**“竞争一次,传输一段时间”**
当站点竞争到信道后,可以获得一段传输时间,在这段时间内,站点可以传输多个数据帧,称为帧突发(frame burst)。
在帧突发期间,每个帧之间使用SFS。
TXOP的传输时间可以通过虚拟载波监听保证。
接入类别AC
 4个介入类别:
4个介入类别:

按用户优先级对流量分类

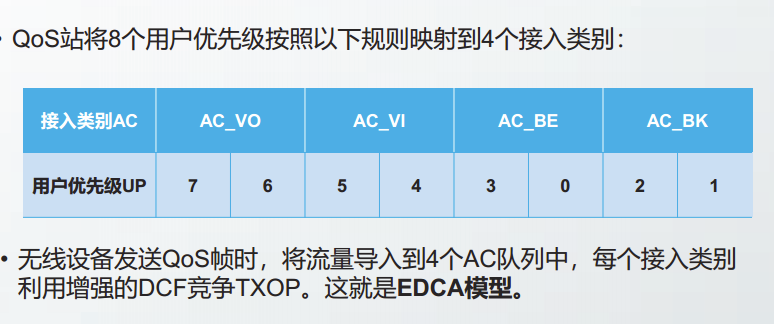 EDCA模型
EDCA模型
在EDCA中,帧间间隔不再采用DCF中的DIFS,而是采用AIFS[AC]。
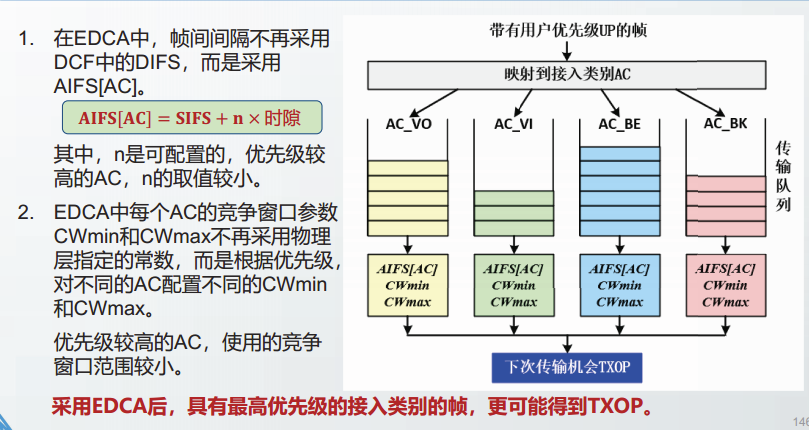
点对点协议PPP
**点对点协议(Point to Point Protocol,PPP)**是一种在传统拨号上网、ADSL接入网、光纤接入网以及SDH网络中广泛使用的协议。
PPP来源于另一种广泛应用的协议:高级数据链路控制HDLC协议。
PPP协议用来在全双工、点对点链路上传输网络层分组,由RFC1661和RFC1662规定,是互联网正式标准。
PPP实际上是一个协议集合,它包括三个主要组成部分:
- 一种将网络层分组封装到串行链路的方法。
- 一个用来处理连接建立、选项协商、测试线路和释放连接的链路控制协议LCP。
- 一组网络控制协议NCP。其中每一个网络控制协议支持不同的网络层协议,如用于HP的网络控制协议IPCP。
PPP的帧格式
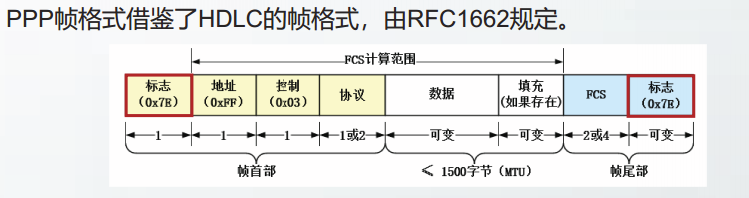
PPP帧格式
以下是对PPP帧格式各部分的介绍:
标志:
帧首部的第一个字段和帧尾部的最后一个字段都是标志字段,各占1字节。
标志字段表示一个帧的开始或结束。。
标志字段规定取值为0x7E,二进制表示为01111110。
当PPP用于异步传输时,采用字符填充法实现透明传输:
PPP规定转义字符为0x7D,按照如下方法进行填充:
- 把数据字段中出现的每一个0x7E字符转换成为2字节序列(0x7D,0x5E)。
- 若数据字段中出现0x7D字符,则将其转换为2字节序列(0x7D,0x5D)。
- 若数据字段中出现ASCII码的控制字符(即数值小于0x20的字符),则在该字符前面插入一个0x7D字符,并将该字符的编码加0x20。例如,字符0x03被转换成(0x7D,0x23),字符0x11被转换成(0x7D,0x31)等。
接收方在收到数据后需要进行相反的变换。
当PPP用于同步传输时,采用比特填充法实现透明传输:
·发送方在数据中发现连续5个1时,就立即在其后方填充1个0。
·接收方如果收到连续5个1时,将其后的0删除。
地址和控制:
PPP的地址字段来源于HDLC,占1字节。HDLC可用于多点链路,地址字段用来指明接收方。
但加粗样式PPP仅用于点对点链路,仅有一个接收方,地址字段总是被设置为0xFF。
PPP的控制字段也来源于HDLC,占1字节。在HDLC中,控制字段用来指明帧类型,
但PPP仅使用了一种帧,控制字段总是被设置为0xO3。
PPP中这两个字段实际上并没有意义。
PPP协议使用LCP进行链路层参数协商时,通常会省略这两个字段。
协议:
协议字段用来指明数据部分封装的是何种协议的数据,占1或2个字节。
在默认情况下,协议字段占2字节,但PPP协议使用LCP进行链路层选项协商时,允许将协议字段配置为1字节的压缩形式。
当协议字段为0x0021时,说明数据字段封装的是IP数据报。
当协议字段为0xC021时,说明数据字段封装的是LCP分组。
当协议字段为0x8021时,说明数据字段封装的是IPCP分组
数据和填充
PPP的最大传送单元MTU默认为1500字节。
PPP协议使用LCP进行链路层选项协商时,可以将MTU配置为其它值。
FCS
FCS字段占2字节或4字节。
PPP的FCS字段采用CRC算法校验除FCS字段本身和标志字段之外的整个帧。
在默认情况下,PPP采用16位的FCS,其生成多项式所对应的二进制数为10001000000100001。
PPP协议使用LCP进行链路层选项协商时,允许将CRC从16位扩展到32位,此时,CRC的生成多项式与以太网相同的CRC-32。
PPP链路的状态
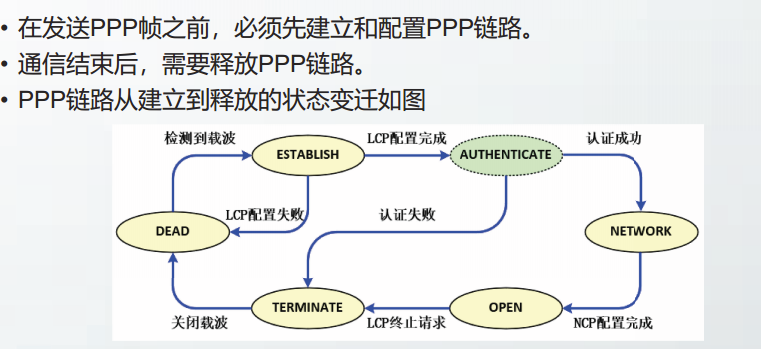
链路状态变迁的细节不再阐释。
PPPoE协议
随着以太网占据市场主导地位,利用以太网接入互联网成为一种宽带接入方案。
ISP需要一种能在以太网上运行的、基于单用户计费的接入控制方案。
RFC2516规定了PPPoE(PPP over Ethernet)协议,它将PPP帧封装在以太网帧内,利用PPP协议,使以太网上的每个用户站点都可以与一个远程的PPPoE服务站点建立一个PPP会话,
该服务站点位于ISP内,称为接入集中器(Access Concentrator,AC)。
当用户通过PPP会话获得一个ISP地址,ISP就可以通过IP地址和特定的用户相关联。以此完成单用户计费。
发现阶段和PPP会话阶段
 PPPoE帧格式
PPPoE帧格式
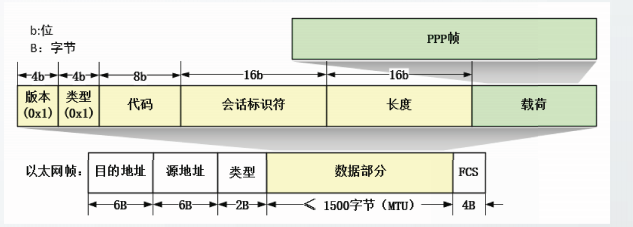
版本和类型字段:
各占4位,目前均取值为0x01。
代码字段:
占8位,用以区分发现阶段和PPP会话阶段中各种类型的PPPoE帧
会话标识符字段:
占16位,每一个PPPoE会话都会具有一个唯一标识符。
长度字段:
占16位,代表PPPOE载荷部分的长度,以字节为单位。
载荷字段:
根据代码不同,载荷部分封装的数据不同。
在发现阶段,载荷字段封装PPPoE用来分配会话标识符的各种帧。
在PPP会话阶段,载荷部分封装PPP帧。
发现阶段
 会话阶段
会话阶段
在PPPOE会话阶段,PPPOE数据封装在以太网帧中,以太网帧的类型字段填写0x8864。
以太网帧以远程接入集中器AC和用户站点的MAC地址为目的地址和源地址交互。
PPPOE帧会话标识符字段填写发现阶段获得的会话标识符。
上层的PPP实体就像进行普通的PPP会话一样运行。
当LCP发出终止请求帧,终止一个PPP会话时,PPPOE会话也会被终止。
PPPOE也定义了一个PPPOE会话终止帧,。AC和用户站点也可以主动发送PPPOE会话终止帧以结束会话。
思维导图总结
第一章
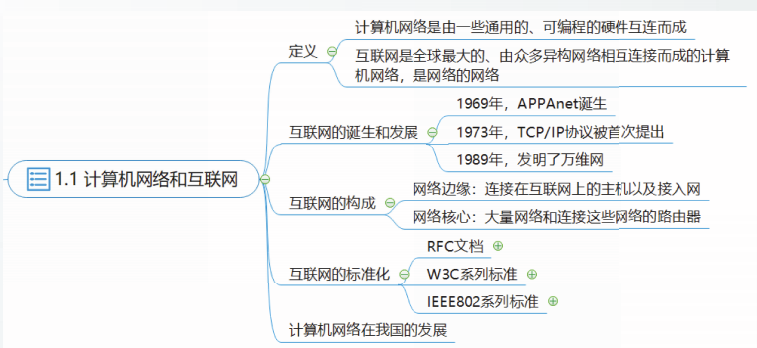
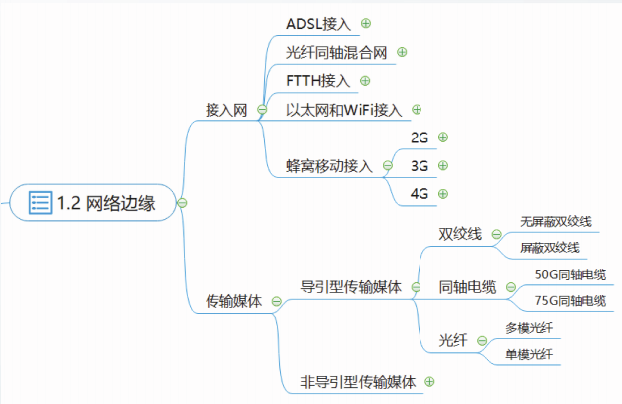
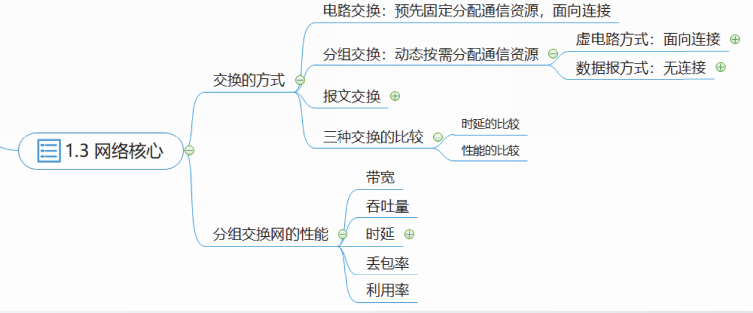
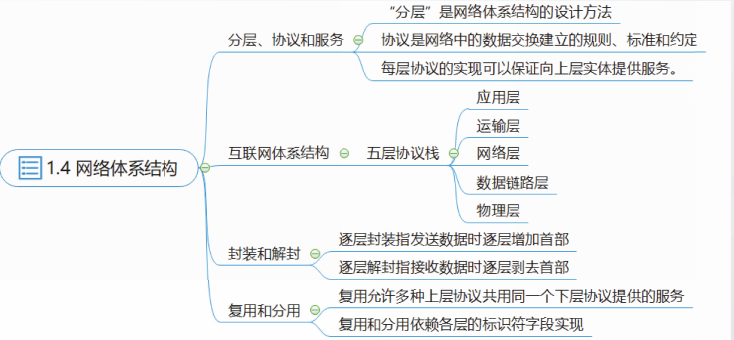

第二章
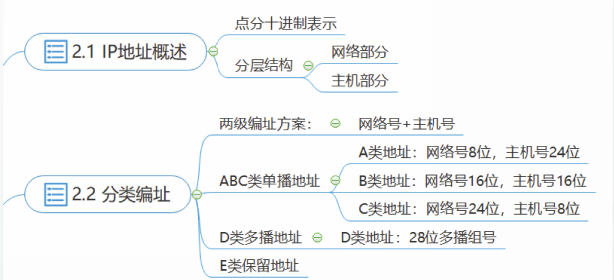
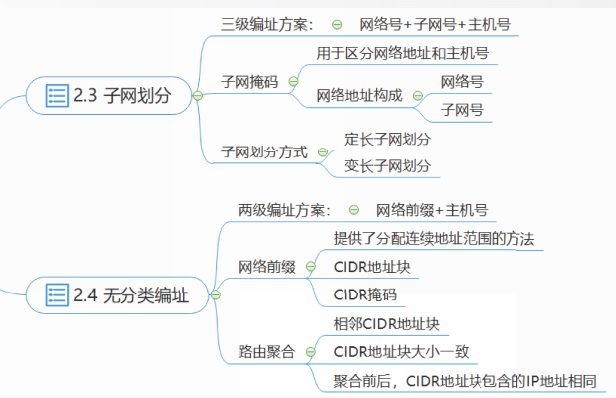
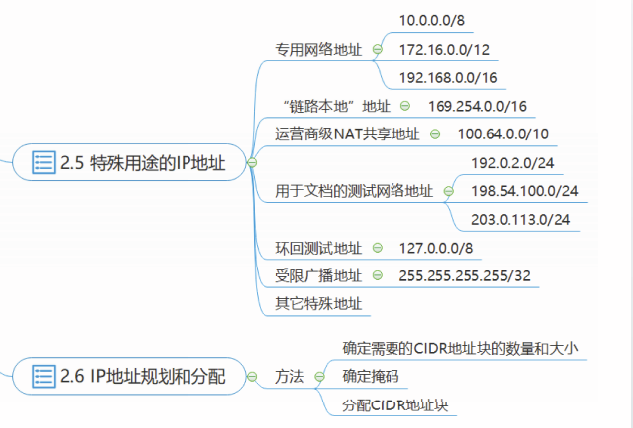
第三章
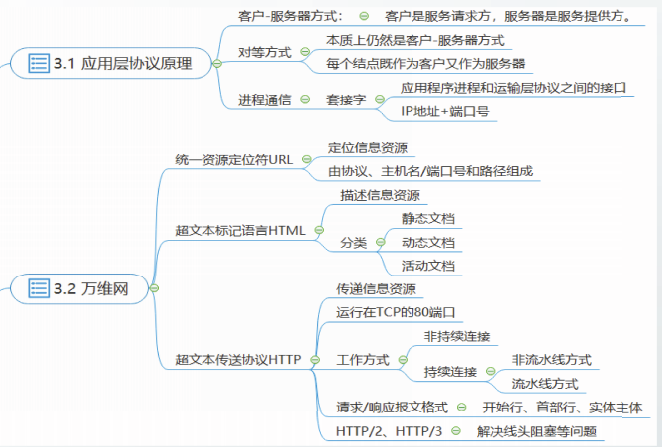
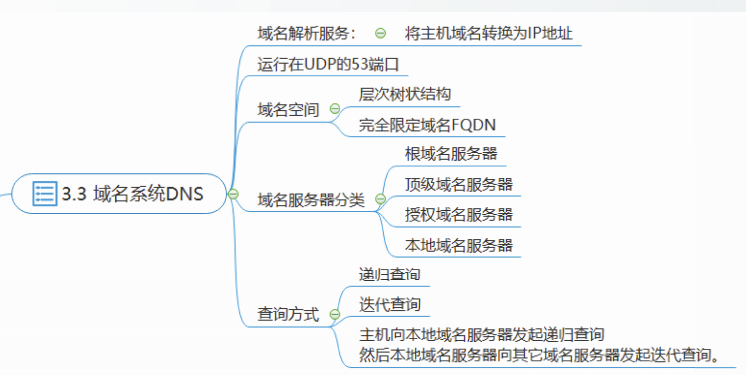
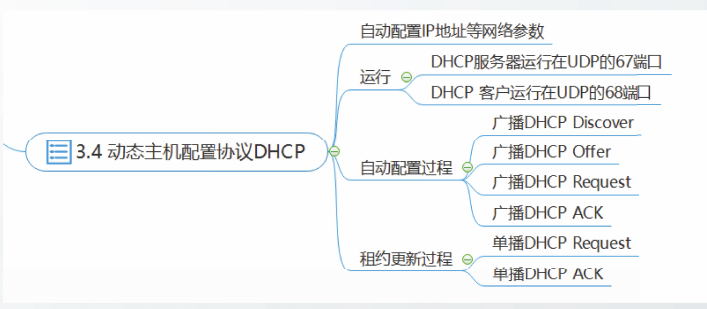
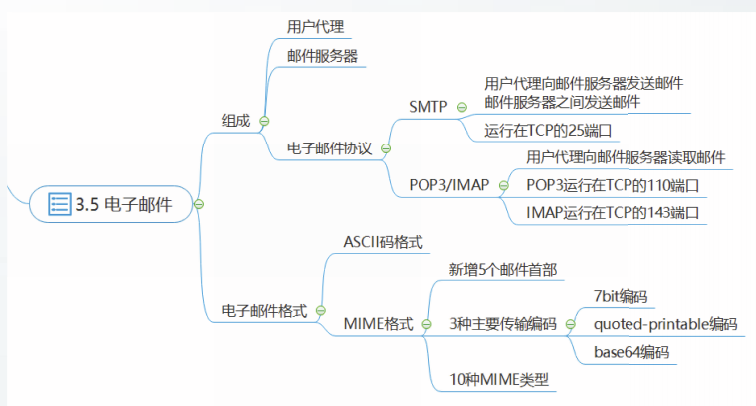
第四章
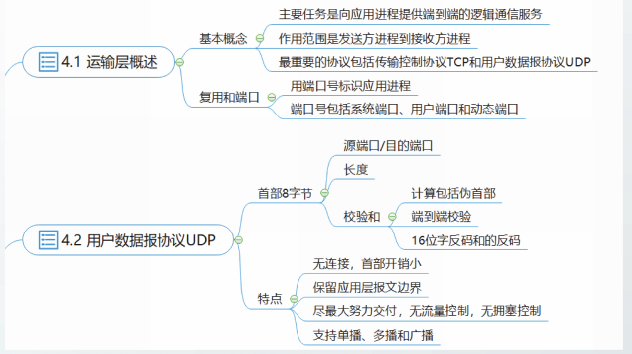
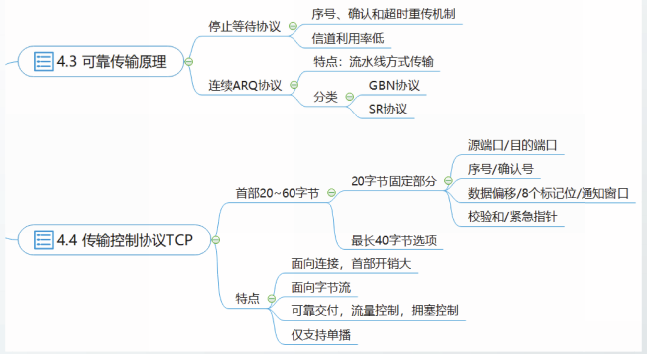


第五章
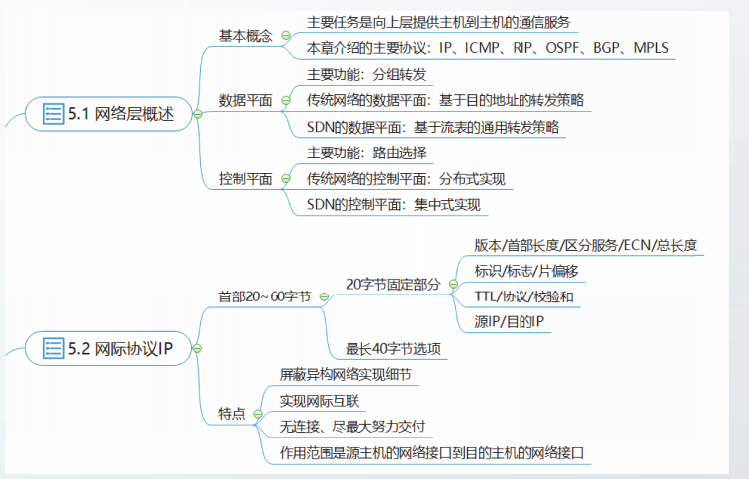
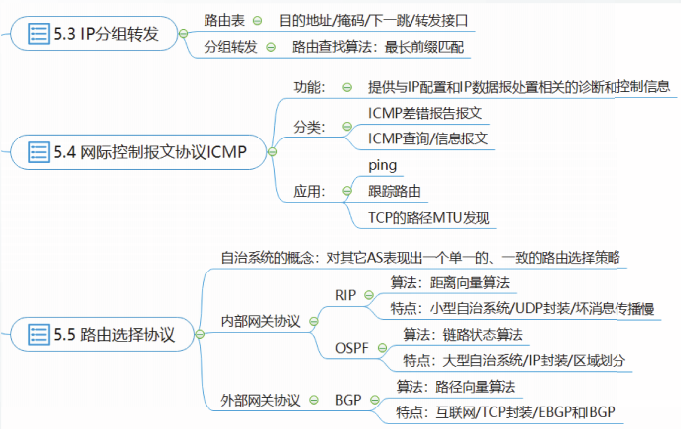
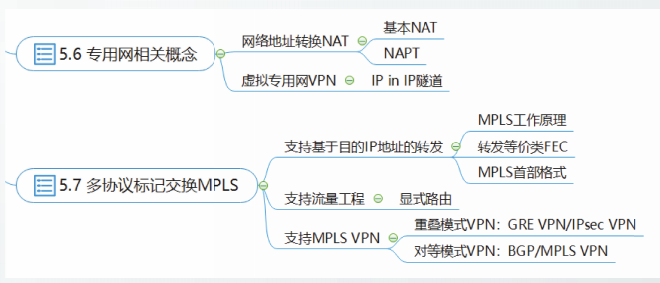
第六章
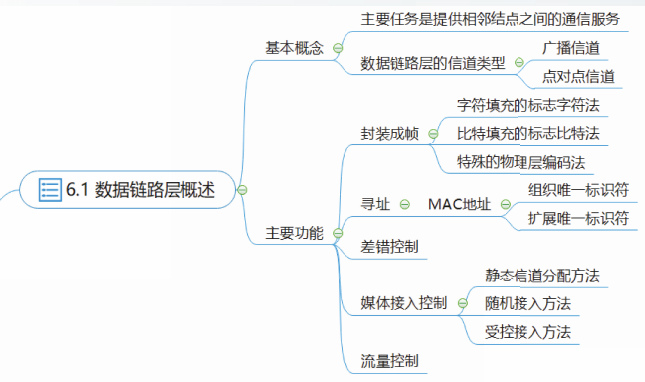
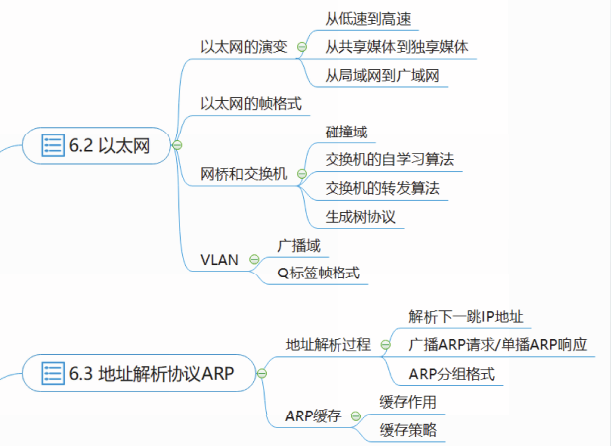
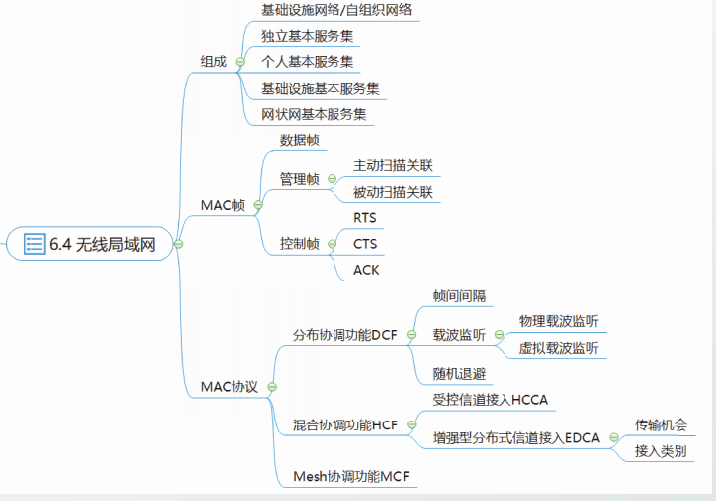
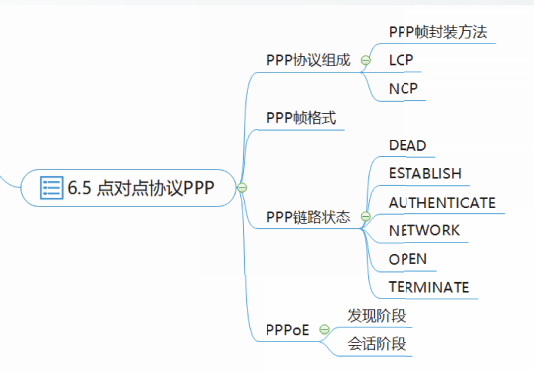
术语词典
待更新
相关文章:
谢希仁版《计算机网络》期末总复习【完结】
文章目录说明第一章 计算机网络概述计算机网络和互联网网络边缘网络核心分组交换网的性能网络体系结构控制平面和数据平面第二章 IP地址分类编址子网划分无分类编址特殊用途的IP地址IP地址规划和分配第三章 应用层应用层协议原理万维网【URL / HTML / HTTP】域名系统DNS动态主机…...

问:React的useState和setState到底是同步还是异步呢?
先来思考一个老生常谈的问题,setState是同步还是异步? 再深入思考一下,useState是同步还是异步呢? 我们来写几个 demo 试验一下。 先看 useState 同步和异步情况下,连续执行两个 useState 示例 function Component() {const…...
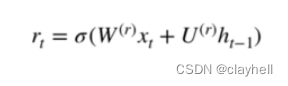
深度理解机器学习16-门控循环单元
评估简单循环神经网络的缺点。 描述门控循环单元(Gated Recurrent Unit,GRU)的架构。 使用GRU进行情绪分析。 将GRU应用于文本生成。 基本RNN通常由输入层、输出层和几个互连的隐藏层组成。最简单的RNN有一个缺点,那就是它们不…...

Python中Generators教程
要想创建一个iterator,必须实现一个有__iter__()和__next__()方法的类,类要能够跟踪内部状态并且在没有元素返回的时候引发StopIteration异常. 这个过程很繁琐而且违反直觉.Generator能够解决这个问题. python generator是一个简单的创建iterator的途径…...

数据结构与算法基础-学习-10-线性表之栈的清理、销毁、压栈、弹栈
一、函数实现1、ClearSqStack(1)用途清理栈的空间。只需要栈顶指针和栈底指针相等,就说明栈已经清空,后续新入栈的数据可以直接覆盖,不用实际清理数据,提升了清理效率。(2)源码Statu…...

Leetcode 每日一题 1234. 替换子串得到平衡字符串
Halo,这里是Ppeua。平时主要更新C语言,C,数据结构算法......感兴趣就关注我吧!你定不会失望。 🌈个人主页:主页链接 🌈算法专栏:专栏链接 我会一直往里填充内容哒! &…...

【MYSQL中级篇】数据库数据查询学习
🍁博主简介 🏅云计算领域优质创作者 🏅华为云开发者社区专家博主 🏅阿里云开发者社区专家博主 💊交流社区:运维交流社区 欢迎大家的加入! 相关文章 文章名文章地址【MYSQL初级篇】入门…...
)
华为OD机试真题JAVA实现【火星文计算】真题+解题思路+代码(20222023)
🔥系列专栏 华为OD机试(JAVA)真题目录汇总华为OD机试(Python)真题目录汇总华为OD机试(C++)真题目录汇总华为OD机试(JavaScript)真题目录汇总文章目录 🔥系列专栏题目输入输出描述示例一输入输出说明解题思路核心知识点Code运行结果版...

Linux基础知识
♥️作者:小刘在C站 ♥️个人主页:小刘主页 ♥️每天分享云计算网络运维课堂笔记,努力不一定有收获,但一定会有收获加油!一起努力,共赴美好人生! ♥️夕阳下,是最美的绽放࿰…...
Linux 游戏性能谁的 更优秀X.Org还是Wayland!
导读X.Org 和 Wayland 是目前 Linux 平台上的两大主流显示服务器,那么两者在 Linux 游戏性能上谁更优秀呢?国外科技媒体 Phoronix 在 Ubuntu 22.10 上对其进行了多款游戏的实测。评测在运行 GNOME 43.1 的 Ubuntu 22.10 上进行测试,在安装英伟…...

【数据结构】算法的复杂度分析:让你拥有未卜先知的能力
👑专栏内容:数据结构⛪个人主页:子夜的星的主页💕座右铭:日拱一卒,功不唐捐 文章目录一、前言二、时间复杂度1、定义2、大O的渐进表示法3、常见的时间复杂度三、空间复杂度1、定义2、常见的空间复杂度一、前…...
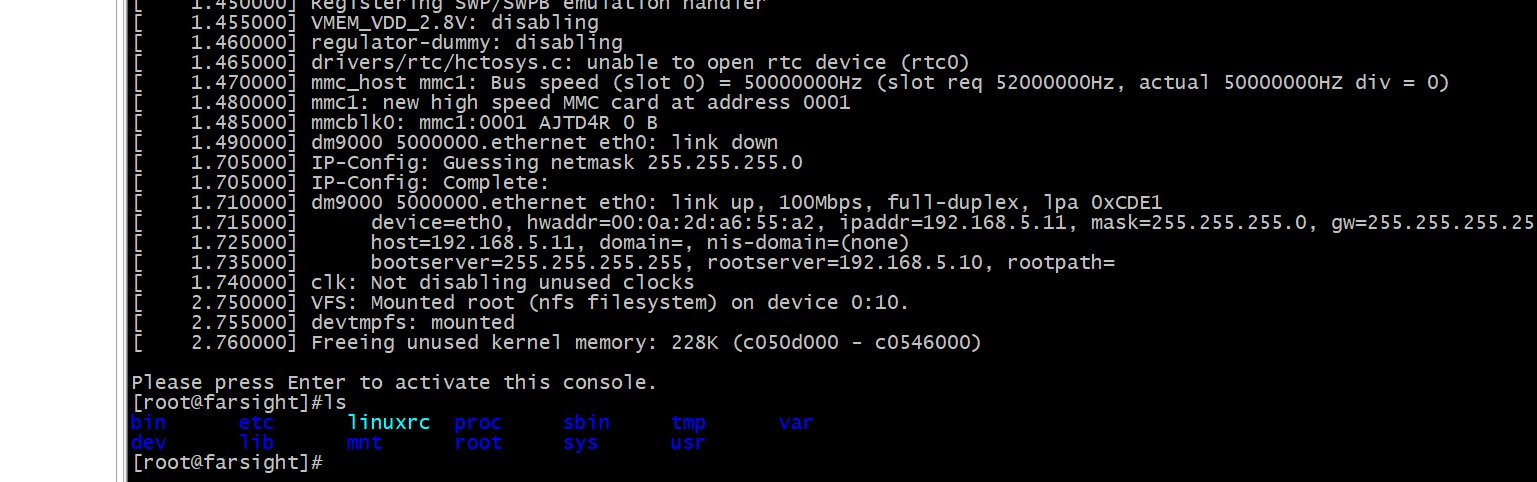
Linux根文件系统移植
目录 一、根文件系统 1.1根文件系统 1.2根文件系统内容 二、根文件系统移植 2.1BusyBox 2.2BusyBox的获取 2.3BusyBox的使用 2.4make menuconfig 2.5编译和安装 2.6修改根文件系统 一、根文件系统 1.1根文件系统 根文件系统是内核启动后挂载的第一个文件系统系统引…...
Three.js 无限平面快速教程【Plane】
Three.js 提供了 Plane 概念来表示在 3d 空间中无限延伸的二维表面。 这对于光标交互很有用,因此你可能需要了解如何设置此平面、将其可视化并根据需要进行调整。 推荐:使用 NSDT场景设计器 快速搭建 3D场景。 Three.js 的 Plane 文档很好而且准确&…...
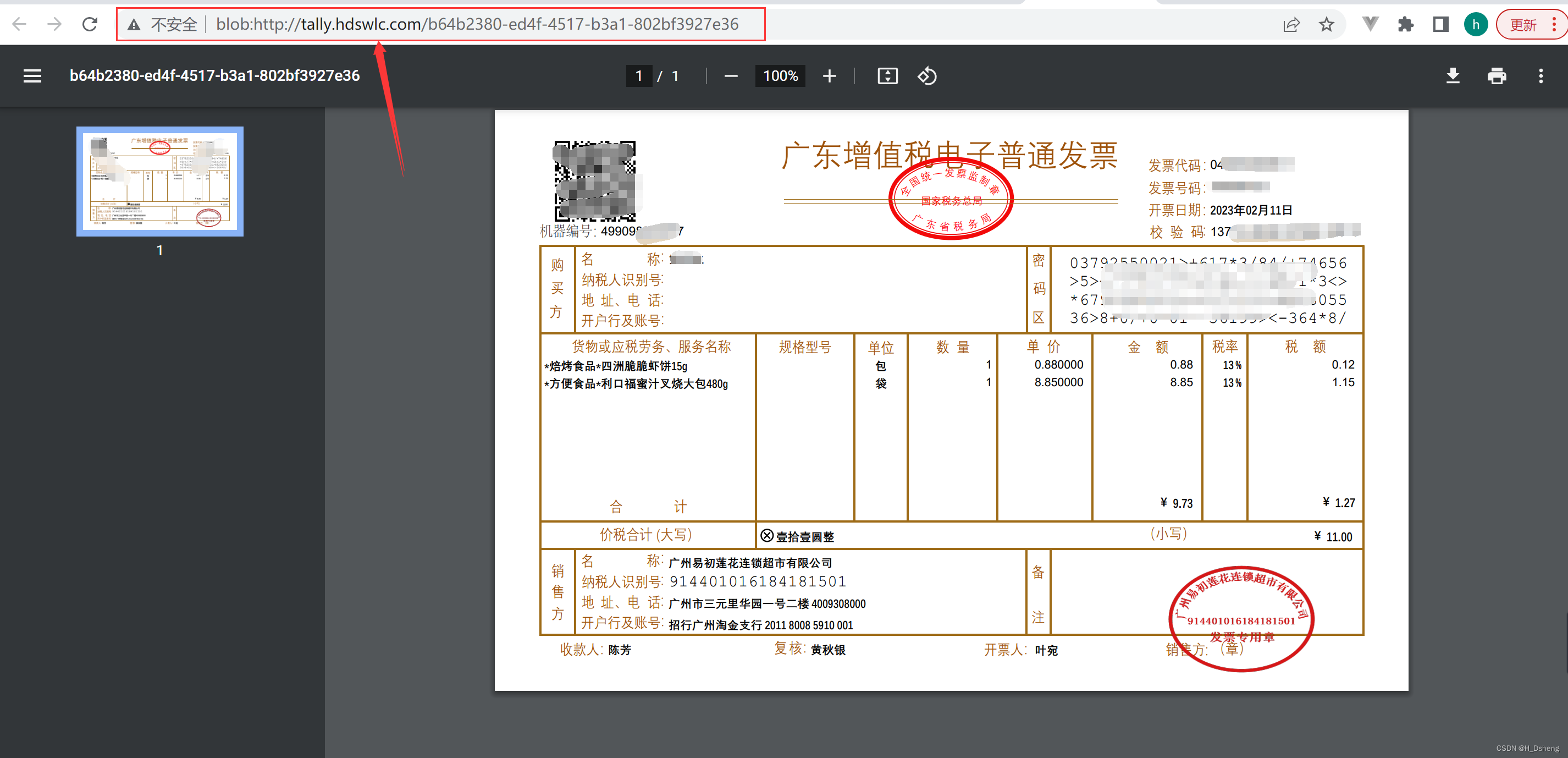
在线预览PDF文件、图片,并且预览地址不显示文件或图片的真实路径。
实现在线预览PDF文件、图片,并且预览地址不显示文件或图片的真实路径。1、vue使用blob流在线预览PDF、图片(包括jpg、png等格式)。1、按钮的方法:2、方法详细:(此方法可以在发起请求时携带token,…...
Allegro如何设置导入Subdrawing可自由选择目录操作指导
Allegro如何设置导入Subdrawing可自由选择目录操作指导 用Allgro做PCB设计的时候,导入Subdrawing是非常常用的功能,在导入Subdrawing的时候,通常需要把Subdrawing文件放在需要导入PCB的相同目录下,不能自由选择,如下图 但是Allegro是支持自由选择目录的,只需按照下方的步…...

SpirngMVC执行原理--自学版
DispatcherServlet表示前置控制器,是整个SpringMVC的控制中心,用户发出请求,DispatcherServlet接收请求并拦截请求HandlerMapper为处理器映射。DispatcherServlet调用。HandlerMapping根据请求url查找HandlerHandlerExecution表示具体的Handl…...

获取savemodel的输入输出节点
saved_model_cli show --dir savemodels --all 结果: MetaGraphDef with tag-set: ‘serve’ contains the following SignatureDefs: signature_def[‘translation_signature’]: The given SavedModel SignatureDef contains the following input(s): inputs[‘i…...
《Learning to Reconstruct Botanical Trees from Single Images》学习从单幅图像重建植物树
读书报告下载https://download.csdn.net/download/weixin_43042683/87448211论文原文https://dl.acm.org/doi/10.1145/3478513.3480525论文视频https://www.bilibili.com/video/BV1cb4y127Vp/?fromseopage&vd_source5212838c127b01db69dcc8b2d27ca5171引言植物存在在室外与…...

vant 4 正式发布,支持暗黑主题,那么是如何实现的呢
2022年10月25日首发于掘金,现在同步到公众号。11. 前言大家好,我是若川。我倾力持续组织了一年多源码共读,感兴趣的可以加我微信 lxchuan12 参与。另外,想学源码,极力推荐关注我写的专栏《学习源码整体架构系列》&…...

MySQL的复制 二
复制是MySQL的一项功能,使服务器能够将更改从一个实例恢复到另一个实例 主服务器(master)将所有数据和结构更改记录到二进制日志中。二进制日志格式是基于语句的、基于行的和混合的。 从属服务器(slave)从主服务器请求…...

大数据零基础学习day1之环境准备和大数据初步理解
学习大数据会使用到多台Linux服务器。 一、环境准备 1、VMware 基于VMware构建Linux虚拟机 是大数据从业者或者IT从业者的必备技能之一也是成本低廉的方案 所以VMware虚拟机方案是必须要学习的。 (1)设置网关 打开VMware虚拟机,点击编辑…...

Go 语言接口详解
Go 语言接口详解 核心概念 接口定义 在 Go 语言中,接口是一种抽象类型,它定义了一组方法的集合: // 定义接口 type Shape interface {Area() float64Perimeter() float64 } 接口实现 Go 接口的实现是隐式的: // 矩形结构体…...
)
Typeerror: cannot read properties of undefined (reading ‘XXX‘)
最近需要在离线机器上运行软件,所以得把软件用docker打包起来,大部分功能都没问题,出了一个奇怪的事情。同样的代码,在本机上用vscode可以运行起来,但是打包之后在docker里出现了问题。使用的是dialog组件,…...
)
Android第十三次面试总结(四大 组件基础)
Activity生命周期和四大启动模式详解 一、Activity 生命周期 Activity 的生命周期由一系列回调方法组成,用于管理其创建、可见性、焦点和销毁过程。以下是核心方法及其调用时机: onCreate() 调用时机:Activity 首次创建时调用。…...

人工智能(大型语言模型 LLMs)对不同学科的影响以及由此产生的新学习方式
今天是关于AI如何在教学中增强学生的学习体验,我把重要信息标红了。人文学科的价值被低估了 ⬇️ 转型与必要性 人工智能正在深刻地改变教育,这并非炒作,而是已经发生的巨大变革。教育机构和教育者不能忽视它,试图简单地禁止学生使…...

解读《网络安全法》最新修订,把握网络安全新趋势
《网络安全法》自2017年施行以来,在维护网络空间安全方面发挥了重要作用。但随着网络环境的日益复杂,网络攻击、数据泄露等事件频发,现行法律已难以完全适应新的风险挑战。 2025年3月28日,国家网信办会同相关部门起草了《网络安全…...

比较数据迁移后MySQL数据库和OceanBase数据仓库中的表
设计一个MySQL数据库和OceanBase数据仓库的表数据比较的详细程序流程,两张表是相同的结构,都有整型主键id字段,需要每次从数据库分批取得2000条数据,用于比较,比较操作的同时可以再取2000条数据,等上一次比较完成之后,开始比较,直到比较完所有的数据。比较操作需要比较…...

【 java 虚拟机知识 第一篇 】
目录 1.内存模型 1.1.JVM内存模型的介绍 1.2.堆和栈的区别 1.3.栈的存储细节 1.4.堆的部分 1.5.程序计数器的作用 1.6.方法区的内容 1.7.字符串池 1.8.引用类型 1.9.内存泄漏与内存溢出 1.10.会出现内存溢出的结构 1.内存模型 1.1.JVM内存模型的介绍 内存模型主要分…...
【无标题】湖北理元理律师事务所:债务优化中的生活保障与法律平衡之道
文/法律实务观察组 在债务重组领域,专业机构的核心价值不仅在于减轻债务数字,更在于帮助债务人在履行义务的同时维持基本生活尊严。湖北理元理律师事务所的服务实践表明,合法债务优化需同步实现三重平衡: 法律刚性(债…...

【深度学习新浪潮】什么是credit assignment problem?
Credit Assignment Problem(信用分配问题) 是机器学习,尤其是强化学习(RL)中的核心挑战之一,指的是如何将最终的奖励或惩罚准确地分配给导致该结果的各个中间动作或决策。在序列决策任务中,智能体执行一系列动作后获得一个最终奖励,但每个动作对最终结果的贡献程度往往…...