Hudi-集成Flink
文章目录
- 集成Flink
- 环境准备
- sql-client方式
- 启动sql-client
- 插入数据
- 查询数据
- 更新数据
- 流式插入
- code 方式
- 环境准备
- 代码
- 类型映射
- 核心参数设置
- 去重参数
- 并发参数
- 压缩参数
- 文件大小
- Hadoop参数
- 内存优化
- 读取方式
- 流读(Streaming Query)
- 增量读取(Incremental Query)
- 限流
- 写入方式
- CDC 数据同步
- 离线批量导入
- 全量接增量
- 写入模式
- Changelog 模式
- Append 模式
- Bucket 索引
- Hudi Catalog
- 离线 Compaction
- 离线 Clustering
- 常见基础问题
- 核心原理分析
- 数据去重原理
- 表写入原理
- 表读取原理
集成Flink
| Hudi | Supported Flink version |
|---|---|
| 0.12.x | 1.15.x、1.14.x、1.13.x |
| 0.11.x | 1.14.x、1.13.x |
| 0.10.x | 1.13.x |
| 0.9.0 | 1.12.2 |
0.11.x不建议使用,如果要用请使用补丁分支:https://github.com/apache/hudi/pull/6182
环境准备
(1)拷贝编译好的jar包到Flink的lib目录下
cp /opt/software/hudi-0.12.0/packaging/hudi-flink-bundle/target/hudi-flink1.13-bundle_2.12-0.12.0.jar /opt/module/flink-1.13.6/lib/
(2)拷贝guava包,解决依赖冲突
cp /opt/module/hadoop-3.1.3/share/hadoop/common/lib/guava-27.0-jre.jar /opt/module/flink-1.13.6/lib/
(3)配置Hadoop环境变量
sudo vim /etc/profile.d/my_env.shexport HADOOP_CLASSPATH=`hadoop classpath`
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoopsource /etc/profile.d/my_env.sh
(4)启动Hadoop(略)
sql-client方式
启动sql-client
(1)修改flink-conf.yaml配置
vim /opt/module/flink-1.13.6/conf/flink-conf.yamlclassloader.check-leaked-classloader: false
taskmanager.numberOfTaskSlots: 4state.backend: rocksdb
execution.checkpointing.interval: 30000
state.checkpoints.dir: hdfs://hadoop1:8020/ckps
state.backend.incremental: true
(2)local模式
-
修改workers
vim /opt/module/flink-1.13.6/conf/workers #表示:会在本地启动3个TaskManager的 local集群 localhost localhost localhost -
启动Flink
/opt/module/flink-1.13.6/bin/start-cluster.sh查看webui:http://hadoop1:8081
-
启动Flink的sql-client
/opt/module/flink-1.13.6/bin/sql-client.sh embedded
(3)yarn-session模式
-
解决依赖问题
cp /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-client-core-3.1.3.jar /opt/module/flink-1.13.6/lib/ -
启动yarn-session
/opt/module/flink-1.13.6/bin/yarn-session.sh -d -
启动sql-client
/opt/module/flink-1.13.6/bin/sql-client.sh embedded -s yarn-session
插入数据
set sql-client.execution.result-mode=tableau;-- 创建hudi表
CREATE TABLE t1(uuid VARCHAR(20) PRIMARY KEY NOT ENFORCED,name VARCHAR(10),age INT,ts TIMESTAMP(3),`partition` VARCHAR(20)
)
PARTITIONED BY (`partition`)
WITH ('connector' = 'hudi','path' = 'hdfs://hadoop1:8020/tmp/hudi_flink/t1','table.type' = 'MERGE_ON_READ' –- 默认是COW
);
或如下写法
CREATE TABLE t1(uuid VARCHAR(20),name VARCHAR(10),age INT,ts TIMESTAMP(3),`partition` VARCHAR(20),PRIMARY KEY(uuid) NOT ENFORCED
)
PARTITIONED BY (`partition`)
WITH ('connector' = 'hudi','path' = 'hdfs://hadoop1:8020/tmp/hudi_flink/t1','table.type' = 'MERGE_ON_READ'
);-- 插入数据
INSERT INTO t1 VALUES('id1','Danny',23,TIMESTAMP '1970-01-01 00:00:01','par1'),('id2','Stephen',33,TIMESTAMP '1970-01-01 00:00:02','par1'),('id3','Julian',53,TIMESTAMP '1970-01-01 00:00:03','par2'),('id4','Fabian',31,TIMESTAMP '1970-01-01 00:00:04','par2'),('id5','Sophia',18,TIMESTAMP '1970-01-01 00:00:05','par3'),('id6','Emma',20,TIMESTAMP '1970-01-01 00:00:06','par3'),('id7','Bob',44,TIMESTAMP '1970-01-01 00:00:07','par4'),('id8','Han',56,TIMESTAMP '1970-01-01 00:00:08','par4');
查询数据
select * from t1;
更新数据
insert into t1 values('id1','Danny',27,TIMESTAMP '1970-01-01 00:00:01','par1');
注意,保存模式现在是Append。通常,除非是第一次创建表,否则请始终使用追加模式。现在再次查询数据将显示更新的记录。每个写操作都会生成一个用时间戳表示的新提交。查找前一次提交中相同的_hoodie_record_keys在_hoodie_commit_time、age字段中的变化。
流式插入
(1)创建测试表
CREATE TABLE sourceT (uuid varchar(20),name varchar(10),age int,ts timestamp(3),`partition` varchar(20)
) WITH ('connector' = 'datagen','rows-per-second' = '1'
);create table t2(uuid varchar(20),name varchar(10),age int,ts timestamp(3),`partition` varchar(20)
)
with ('connector' = 'hudi','path' = '/tmp/hudi_flink/t2','table.type' = 'MERGE_ON_READ'
);
(2)执行插入
insert into t2 select * from sourceT;
(3)查看job
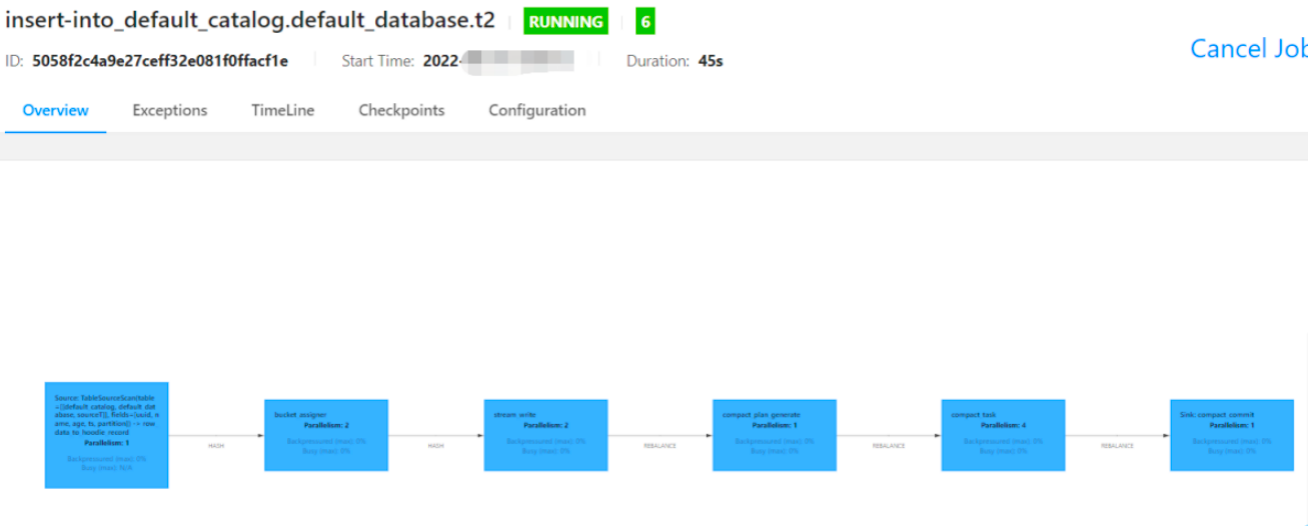
查看HDFS目录:

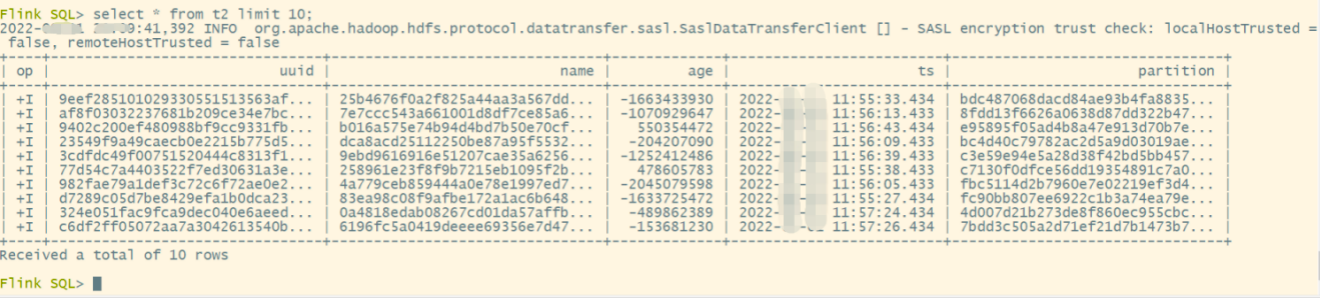
(4)查询结果
set sql-client.execution.result-mode=tableau;
select * from t2 limit 10;
code 方式
除了用sql-client,还可以自己编写FlinkSQL程序,打包提交Flink作业。
环境准备
(1)手动install依赖
mvn install:install-file -DgroupId=org.apache.hudi -DartifactId=hudi-flink_2.12 -Dversion=0.12.0 -Dpackaging=jar -Dfile=./hudi-flink1.13-bundle-0.12.0.jar
(2)创建Maven工程
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.atguigu.hudi</groupId><artifactId>flink-hudi-demo</artifactId><version>1.0-SNAPSHOT</version><properties><maven.compiler.source>8</maven.compiler.source><maven.compiler.target>8</maven.compiler.target><flink.version>1.13.6</flink.version><hudi.version>0.12.0</hudi.version><java.version>1.8</java.version><scala.binary.version>2.12</scala.binary.version><slf4j.version>1.7.30</slf4j.version></properties><dependencies><dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>${flink.version}</version><scope>provided</scope> <!--不会打包到依赖中,只参与编译,不参与运行 --></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java_${scala.binary.version}</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients_${scala.binary.version}</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-planner-blink_${scala.binary.version}</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><!--idea运行时也有webui--><dependency><groupId>org.apache.flink</groupId><artifactId>flink-runtime-web_${scala.binary.version}</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-api</artifactId><version>${slf4j.version}</version><scope>provided</scope></dependency><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-log4j12</artifactId><version>${slf4j.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-to-slf4j</artifactId><version>2.14.0</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-statebackend-rocksdb_${scala.binary.version}</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>3.1.3</version><scope>provided</scope></dependency><!--手动install到本地maven仓库--><dependency><groupId>org.apache.hudi</groupId><artifactId>hudi-flink_2.12</artifactId><version>${hudi.version}</version><scope>provided</scope></dependency></dependencies><build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-shade-plugin</artifactId><version>3.2.4</version><executions><execution><phase>package</phase><goals><goal>shade</goal></goals><configuration><artifactSet><excludes><exclude>com.google.code.findbugs:jsr305</exclude><exclude>org.slf4j:*</exclude><exclude>log4j:*</exclude><exclude>org.apache.hadoop:*</exclude></excludes></artifactSet><filters><filter><!-- Do not copy the signatures in the META-INF folder.Otherwise, this might cause SecurityExceptions when using the JAR. --><artifact>*:*</artifact><excludes><exclude>META-INF/*.SF</exclude><exclude>META-INF/*.DSA</exclude><exclude>META-INF/*.RSA</exclude></excludes></filter></filters><transformers combine.children="append"><transformer implementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer"></transformer></transformers></configuration></execution></executions></plugin></plugins></build></project>
代码
package com.atguigu.hudi.flink;import org.apache.flink.contrib.streaming.state.EmbeddedRocksDBStateBackend;
import org.apache.flink.contrib.streaming.state.PredefinedOptions;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import java.util.concurrent.TimeUnit;public class HudiDemo {public static void main(String[] args) {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 设置状态后端RocksDBEmbeddedRocksDBStateBackend embeddedRocksDBStateBackend = new EmbeddedRocksDBStateBackend(true);embeddedRocksDBStateBackend.setPredefinedOptions(PredefinedOptions.SPINNING_DISK_OPTIMIZED_HIGH_MEM);env.setStateBackend(embeddedRocksDBStateBackend);// checkpoint配置env.enableCheckpointing(TimeUnit.SECONDS.toMillis(30), CheckpointingMode.EXACTLY_ONCE);CheckpointConfig checkpointConfig = env.getCheckpointConfig();checkpointConfig.setCheckpointStorage("hdfs://hadoop1:8020/ckps");checkpointConfig.setMinPauseBetweenCheckpoints(TimeUnit.SECONDS.toMillis(20));checkpointConfig.setTolerableCheckpointFailureNumber(5);checkpointConfig.setCheckpointTimeout(TimeUnit.MINUTES.toMillis(1));checkpointConfig.enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);StreamTableEnvironment sTableEnv = StreamTableEnvironment.create(env);sTableEnv.executeSql("CREATE TABLE sourceT (\n" +" uuid varchar(20),\n" +" name varchar(10),\n" +" age int,\n" +" ts timestamp(3),\n" +" `partition` varchar(20)\n" +") WITH (\n" +" 'connector' = 'datagen',\n" +" 'rows-per-second' = '1'\n" +")");sTableEnv.executeSql("create table t2(\n" +" uuid varchar(20),\n" +" name varchar(10),\n" +" age int,\n" +" ts timestamp(3),\n" +" `partition` varchar(20)\n" +")\n" +"with (\n" +" 'connector' = 'hudi',\n" +" 'path' = '/tmp/hudi_flink/t2',\n" +" 'table.type' = 'MERGE_ON_READ'\n" +")");sTableEnv.executeSql("insert into t2 select * from sourceT");}
}
提交运行:
将代码打成jar包,上传到目录myjars,执行提交命令:
bin/flink run -t yarn-per-job \
-c com.atguigu.hudi.flink.HudiDemo \
./myjars/flink-hudi-demo-1.0-SNAPSHOT.jar
类型映射
| Flink SQL Type | Hudi Type | Avro logical type |
|---|---|---|
| CHAR/VARCHAR/STRING | string | |
| BOOLEAN | boolean | |
| BINARY / VARBINARY | bytes | |
| DECIMAL | fixed | decimal |
| TINYINT | int | |
| SMALLINT | int | |
| INT | int | |
| BIGINT | long | |
| FLOAT | float | |
| DOUBLE | double | |
| DATE | int | date |
| TIME | int | time-millis |
| TIMESTAMP | long | timestamp-millis |
| ARRAY | array | |
| MAP(key must be string/char/varchar type) | map | |
| MULTISET(element must be string/char/varchar type) | map | |
| ROW | record |
核心参数设置
Flink可配参数:https://hudi.apache.org/docs/configurations#FLINK_SQL
去重参数
通过如下语法设置主键:
-- 设置单个主键
create table hoodie_table (f0 int primary key not enforced,f1 varchar(20),...
) with ('connector' = 'hudi',...
)-- 设置联合主键
create table hoodie_table (f0 int,f1 varchar(20),...primary key(f0, f1) not enforced
) with ('connector' = 'hudi',...
)
| 名称 | 说明 | 默认值 | 备注 |
|---|---|---|---|
| hoodie.datasource.write.recordkey.field | 主键字段 | – | 支持主键语法 PRIMARY KEY 设置,支持逗号分隔的多个字段 |
| precombine.field(0.13.0 之前版本为 write.precombine.field) | 去重时间字段 | – | record 合并的时候会按照该字段排序,选值较大的 record 为合并结果;不指定则为处理序:选择后到的 record |
并发参数
参数说明:
| 名称 | 说明 | 默认值 | 备注 |
|---|---|---|---|
| write.tasks | writer 的并发,每个 writer 顺序写 1~N 个 buckets | 4 | 增加并发对小文件个数没影响 |
| write.bucket_assign.tasks | bucket assigner 的并发 | Flink的并行度 | 增加并发同时增加了并发写的 bucekt 数,也就变相增加了小文件(小 bucket) 数 |
| write.index_bootstrap.tasks | Index bootstrap 算子的并发,增加并发可以加快 bootstrap 阶段的效率,bootstrap 阶段会阻塞 checkpoint,因此需要设置多一些的 checkpoint 失败容忍次数 | Flink的并行度 | 只在 index.bootstrap.enabled 为 true 时生效 |
| read.tasks | 读算子的并发(batch 和 stream) | 4 | |
| compaction.tasks | online compaction 算子的并发 | writer 的并发 | online compaction 比较耗费资源,建议走 offline compaction |
案例演示:
可以flink建表时在with中指定,或Hints临时指定参数的方式:在需要调整的表名后面加上 /*+ OPTIONS() */
insert into t2 /*+ OPTIONS('write.tasks'='2','write.bucket_assign.tasks'='3','compaction.tasks'='4') */
select * from sourceT;
压缩参数
参数说明:
在线压缩的参数,通过设置 compaction.async.enabled =false关闭在线压缩执行,但是调度compaction.schedule.enabled 仍然建议开启,之后通过离线压缩直接执行 在线压缩任务 阶段性调度的压缩 plan。
| 名称 | 说明 | 默认值 | 备注 |
|---|---|---|---|
| compaction.schedule.enabled | 是否阶段性生成压缩 plan | true | 建议开启,即使compaction.async.enabled 关闭的情况下 |
| compaction.async.enabled | 是否开启异步压缩 | true | 通过关闭此参数关闭在线压缩 |
| compaction.tasks | 压缩 task 并发 | 4 | |
| compaction.trigger.strategy | 压缩策略 | num_commits | 支持四种策略:num_commits、time_elapsed、num_and_time、num_or_time |
| compaction.delta_commits | 默认策略,5 个 commits 压缩一次 | 5 | |
| compaction.delta_seconds | 3600 | ||
| compaction.max_memory | 压缩去重的 hash map 可用内存 | 100(MB) | 资源够用的话建议调整到 1GB |
| compaction.target_io | 每个压缩 plan 的 IO 上限,默认 5GB | 500(GB) |
案例演示:
CREATE TABLE t3(uuid VARCHAR(20) PRIMARY KEY NOT ENFORCED,name VARCHAR(10),age INT,ts TIMESTAMP(3),`partition` VARCHAR(20)
)
WITH ('connector' = 'hudi','path' = 'hdfs://hadoop1:8020/tmp/hudi_flink/t3','compaction.async.enabled' = 'true','compaction.tasks' = '1','compaction.schedule.enabled' = 'true','compaction.trigger.strategy' = 'num_commits','compaction.delta_commits' = '2','table.type' = 'MERGE_ON_READ'
);set table.dynamic-table-options.enabled=true;
insert into t3
select * from sourceT/*+ OPTIONS('rows-per-second' = '5')*/;
注意:如果没有按照5.2.1中yarn-session模式解决hadoop依赖冲突问题,那么无法compaction生成parquet文件,报错很隐晦,在Exception中看不到,要搜索TaskManager中关于compaction才能看到报错。

文件大小
参数说明:
Hudi会自管理文件大小,避免向查询引擎暴露小文件,其中自动处理文件大小起很大作用。在进行insert/upsert操作时,Hudi可以将文件大小维护在一个指定文件大小。
目前只有 log 文件的写入大小可以做到精确控制,parquet 文件大小按照估算值。
| 名称 | 说明 | 默认值 | 备注 |
|---|---|---|---|
| hoodie.parquet.max.file.size | 最大可写入的 parquet 文件大小 | 120 * 1024 * 1024默认 120MB(单位 byte) | 超过该大小切新的 file group |
| hoodie.logfile.to.parquet.compression.ratio | log文件大小转 parquet 的比率 | 0.35 | hoodie 统一依据 parquet 大小来评估小文件策略 |
| hoodie.parquet.small.file.limit | 在写入时,hudi 会尝试先追加写已存小文件,该参数设置了小文件的大小阈值,小于该参数的文件被认为是小文件 | 104857600默认 100MB(单位 byte) | 大于 100MB,小于 120MB 的文件会被忽略,避免写过度放大 |
| hoodie.copyonwrite.record.size.estimate | 预估的 record 大小,hoodie 会依据历史的 commits 动态估算 record 的大小,但是前提是之前有单次写入超过 hoodie.parquet.small.file.limit 大小,在未达到这个大小时会使用这个参数 | 1024默认 1KB(单位 byte) | 如果作业流量比较小,可以设置下这个参数 |
| hoodie.logfile.max.size | LogFile最大大小。这是在将Log滚转到下一个版本之前允许的最大大小。 | 1073741824默认1GB(单位 byte) |
案例演示:
CREATE TABLE t4(uuid VARCHAR(20) PRIMARY KEY NOT ENFORCED,name VARCHAR(10),age INT,ts TIMESTAMP(3),`partition` VARCHAR(20)
)
WITH ('connector' = 'hudi','path' = 'hdfs://hadoop1:8020/tmp/hudi_flink/t4','compaction.tasks' = '1','hoodie.parquet.max.file.size'= '10000','hoodie.parquet.small.file.limit'='5000','table.type' = 'MERGE_ON_READ'
);set table.dynamic-table-options.enabled=true;
insert into t4
select * from sourceT /*+ OPTIONS('rows-per-second' = '5')*/;
Hadoop参数
从 0.12.0 开始支持,如果有跨集群提交执行的需求,可以通过 sql 的 ddl 指定 per-job级别的 hadoop 配置
| 名称 | 说明 | 默认值 | 备注 |
|---|---|---|---|
| hadoop.${you option key} | 通过 hadoop.前缀指定 hadoop 配置项 | – | 支持同时指定多个 hadoop 配置项 |
内存优化
内存参数:
| 名称 | 说明 | 默认值 | 备注 |
|---|---|---|---|
| write.task.max.size | 一个 write task 的最大可用内存 | 1024 | 当前预留给 write buffer 的内存为write.task.max.size -compaction.max_memory当 write task 的内存 buffer达到阈值后会将内存里最大的 buffer flush 出去 |
| write.batch.size | Flink 的写 task 为了提高写数据效率,会按照写 bucket 提前 buffer 数据,每个 bucket 的数据在内存达到阈值之前会一直 cache 在内存中,当阈值达到会把数据 buffer 传递给 hoodie 的 writer 执行写操作 | 256 | 一般不用设置,保持默认值就好 |
| write.log_block.size | hoodie 的 log writer 在收到 write task 的数据后不会马上 flush 数据,writer 是以 LogBlock 为单位往磁盘刷数据的,在 LogBlock 攒够之前 records 会以序列化字节的形式 buffer 在 writer 内部 | 128 | 一般不用设置,保持默认值就好 |
| write.merge.max_memory | hoodie 在 COW 写操作的时候,会有增量数据和 base file 数据 merge 的过程,增量的数据会缓存在内存的 map 结构里,这个 map 是可 spill 的,这个参数控制了 map 可以使用的堆内存大小 | 100 | 一般不用设置,保持默认值就好 |
| compaction.max_memory | 同 write.merge.max_memory: 100MB 类似,只是发生在压缩时。 | 100 | 如果是 online compaction,资源充足时可以开大些,比如 1GB |
MOR:
(1)state backend 换成 rocksdb (默认的 in-memory state-backend 非常吃内存)
(2)内存够的话,compaction.max_memory 调大些 (默认是 100MB 可以调到 1GB)
(3)关注 TM 分配给每个 write task 的内存,保证每个 write task 能够分配到 write.task.max.size 所配置的大小,比如 TM 的内存是 4GB 跑了 2 个 StreamWriteFunction 那每个 write function 能分到 2GB,尽量预留一些 buffer,因为网络 buffer,TM 上其他类型 task (比如 BucketAssignFunction 也会吃些内存)
(4)需要关注 compaction 的内存变化,compaction.max_memory 控制了每个 compaction task 读 log 时可以利用的内存大小,compaction.tasks 控制了 compaction task 的并发
注意: write.task.max.size - compaction.max_memory 是预留给每个 write task 的内存 buffer
COW:
(1)state backend 换成 rocksdb(默认的 in-memory state-backend 非常吃内存)。
(2)write.task.max.size 和 write.merge.max_memory 同时调大(默认是 1GB 和 100MB 可以调到 2GB 和 1GB)。
(3)关注 TM 分配给每个 write task 的内存,保证每个 write task 能够分配到 write.task.max.size 所配置的大小,比如 TM 的内存是 4GB 跑了 2 个 StreamWriteFunction 那每个 write function 能分到 2GB,尽量预留一些 buffer,因为网络 buffer,TM 上其他类型 task(比如 BucketAssignFunction 也会吃些内存)。
注意:write.task.max.size - write.merge.max_memory 是预留给每个 write task 的内存 buffer。
读取方式
流读(Streaming Query)
当前表默认是快照读取,即读取最新的全量快照数据并一次性返回。通过参数 read.streaming.enabled 参数开启流读模式,通过 read.start-commit 参数指定起始消费位置,支持指定 earliest 从最早消费。
WITH参数:
| 名称 | Required | 默认值 | 说明 |
|---|---|---|---|
| read.streaming.enabled | false | false | 设置 true 开启流读模式 |
| read.start-commit | false | 最新 commit | 指定 ‘yyyyMMddHHmmss’ 格式的起始 commit(闭区间) |
| read.streaming.skip_compaction | false | false | 流读时是否跳过 compaction 的 commits,跳过 compaction 有两个用途:1)避免 upsert 语义下重复消费 (compaction 的 instant 为重复数据,如果不跳过,有小概率会重复消费)2) changelog 模式下保证语义正确性****0.11 开始,以上两个问题已经通过保留 compaction 的 instant time 修复**** |
| clean.retain_commits | false | 10 | cleaner 最多保留的历史 commits 数,大于此数量的历史 commits 会被清理掉,changelog 模式下,这个参数可以控制 changelog 的保留时间,例如 checkpoint 周期为 5 分钟一次,默认最少保留 50 分钟的时间。 |
注意:当参数 read.streaming.skip_compaction 打开并且 streaming reader 消费落后于clean.retain_commits 数时,流读可能会丢失数据。从 0.11 开始,compaction 不会再变更 record 的 instant time,因此理论上数据不会再重复消费,但是还是会重复读取并丢弃,因此额外的开销还是无法避免,对性能有要求的话还是可以开启此参数。
CREATE TABLE t5(uuid VARCHAR(20) PRIMARY KEY NOT ENFORCED,name VARCHAR(10),age INT,ts TIMESTAMP(3),`partition` VARCHAR(20)
) WITH ('connector' = 'hudi','path' = 'hdfs://hadoop1:8020/tmp/hudi_flink/t5','table.type' = 'MERGE_ON_READ','read.streaming.enabled' = 'true','read.streaming.check-interval' = '4' -- 默认60s
);insert into t5 select * from sourceT;
select * from t5;
增量读取(Incremental Query)
从 0.10.0 开始支持。
如果有增量读取 batch 数据的需求,增量读取包含三种场景。
(1)Stream 增量消费,通过参数 read.start-commit 指定起始消费位置;
(2)Batch 增量消费,通过参数 read.start-commit 指定起始消费位置,通过参数 read.end-commit 指定结束消费位置,区间为闭区间,即包含起始、结束的 commit
(3)TimeTravel:Batch 消费某个时间点的数据:通过参数 read.end-commit 指定结束消费位置即可(由于起始位置默认从最新,所以无需重复声明)
WITH 参数:
| 名称 | Required | 默认值 | 说明 |
|---|---|---|---|
| read.start-commit | false | 默认从最新 commit | 支持 earliest 从最早消费 |
| read.end-commit | false | 默认到最新 commit |
限流
如果将全量数据(百亿数量级) 和增量先同步到 kafka,再通过 flink 流式消费的方式将库表数据直接导成 hoodie 表,因为直接消费全量部分数据:量大(吞吐高)、乱序严重(写入的 partition 随机),会导致写入性能退化,出现吞吐毛刺,这时候可以开启限速参数,保证流量平稳写入。
WITH 参数:
| 名称 | Required | 默认值 | 说明 |
|---|---|---|---|
| write.rate.limit | false | 0 | 默认关闭限速 |
写入方式
CDC 数据同步
CDC 数据保存了完整的数据库变更,当前可通过两种途径将数据导入 hudi:
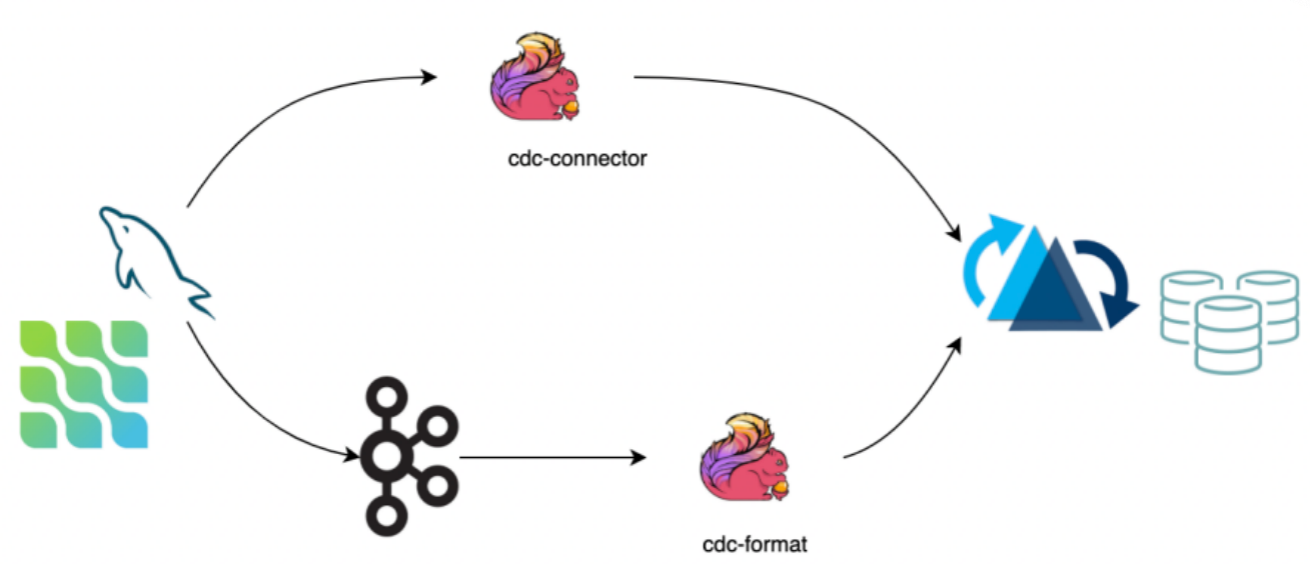
- 第一种:通过 cdc-connector 直接对接 DB 的 binlog 将数据导入 hudi,优点是不依赖消息队列,缺点是对 db server 造成压力。
- 第二种:对接 cdc format 消费 kafka 数据导入 hudi,优点是可扩展性强,缺点是依赖 kafka。
注意:如果上游数据无法保证顺序,需要指定 write.precombine.field 字段。
(1)准备MySQL表
MySQL开启binlog,并建表:
create database test;
use test;
create table stu3 (id int unsigned auto_increment primary key COMMENT '自增id',name varchar(20) not null comment '学生名字',school varchar(20) not null comment '学校名字',nickname varchar(20) not null comment '学生小名',age int not null comment '学生年龄',class_num int not null comment '班级人数',phone bigint not null comment '电话号码',email varchar(64) comment '家庭网络邮箱',ip varchar(32) comment 'IP地址'
) engine=InnoDB default charset=utf8;
(2)flink读取mysql binlog并写入kafka
-
创建MySQL表
create table stu3_binlog(id bigint not null,name string,school string,nickname string,age int not null,class_num int not null,phone bigint not null,email string,ip string,primary key (id) not enforced ) with ('connector' = 'mysql-cdc','hostname' = 'hadoop1','port' = '3306','username' = 'root','password' = 'aaaaaa','database-name' = 'test','table-name' = 'stu3' ); -
创建Kafka表
create table stu3_binlog_sink_kafka(id bigint not null,name string,school string,nickname string,age int not null,class_num int not null,phone bigint not null,email string,ip string,primary key (id) not enforced ) with ('connector' = 'upsert-kafka','topic' = 'cdc_mysql_stu3_sink','properties.zookeeper.connect' = 'hadoop1:2181','properties.bootstrap.servers' = 'hadoop1:9092','key.format' = 'json','value.format' = 'json' ); -
将mysql binlog日志写入kafka
insert into stu3_binlog_sink_kafka select * from stu3_binlog;
(3)flink读取kafka数据并写入hudi数据湖
-
创建kafka源表
create table stu3_binlog_source_kafka(id bigint not null,name string,school string,nickname string,age int not null,class_num int not null,phone bigint not null,email string,ip string ) with ('connector' = 'kafka','topic' = 'cdc_mysql_stu3_sink','properties.bootstrap.servers' = 'hadoop1:9092','format' = 'json','scan.startup.mode' = 'earliest-offset','properties.group.id' = 'testGroup' ); -
创建hudi目标表
create table stu3_binlog_sink_hudi(id bigint not null,name string,`school` string,nickname string,age int not null,class_num int not null,phone bigint not null,email string,ip string,primary key (id) not enforced )partitioned by (`school`)with ('connector' = 'hudi','path' = 'hdfs://hadoop1:8020/tmp/hudi_flink/stu3_binlog_sink_hudi','table.type' = 'MERGE_ON_READ','write.option' = 'insert','write.precombine.field' = 'school'); -
将kafka数据写入到hudi中
insert into stu3_binlog_sink_hudi select * from stu3_binlog_source_kafka;
(4)使用datafaker插入数据
datafaker安装及说明:https://developer.aliyun.com/article/852227
-
新建meta.txt文件,文件内容为:
id||int||自增id[:inc(id,1)] name||varchar(20)||学生名字 school||varchar(20)||学校名字[:enum(qinghua,beida,shanghaijiaoda,fudan,xidian,zhongda)] nickname||varchar(20)||学生小名[:enum(tom,tony,mick,rich,jasper)] age||int||学生年龄[:age] class_num||int||班级人数[:int(10, 100)] phone||bigint||电话号码[:phone_number] email||varchar(64)||家庭网络邮箱[:email] ip||varchar(32)||IP地址[:ipv4] -
生成10000条数据并写入到mysql中的test.stu3表
datafaker rdb mysql+mysqldb://root:aaaaaa@hadoop1:3306/test?charset=utf8 stu3 10000 --meta meta.txt注意:如果要再次生成测试数据,则需要修改meta.txt将自增id中的1改为比10000大的数,不然会出现主键冲突情况。
(5)统计数据入Hudi情况
create table stu3_binlog_hudi_view(id bigint not null,name string,school string,nickname string,age int not null,class_num int not null,phone bigint not null,email string,ip string,primary key (id) not enforced
)partitioned by (`school`)with ('connector' = 'hudi','path' = 'hdfs://hadoop1:8020/tmp/stu3_binlog_sink_hudi','table.type' = 'MERGE_ON_READ','write.precombine.field' = 'school');select count(*) from stu3_binlog_hudi_view;
(6)实时查看数据入湖情况
create table stu3_binlog_hudi_streaming_view(id bigint not null,name string,school string,nickname string,age int not null,class_num int not null,phone bigint not null,email string,ip string,primary key (id) not enforced
)partitioned by (`school`)with ('connector' = 'hudi','path' = 'hdfs://hadoop1:8020/tmp/stu3_binlog_sink_hudi','table.type' = 'MERGE_ON_READ','write.precombine.field' = 'school','read.streaming.enabled' = 'true');select * from stu3_binlog_hudi_streaming_view;
离线批量导入
如果存量数据来源于其他数据源,可以使用批量导入功能,快速将存量数据导成 Hoodie 表格式。
(1)原理
-
批量导入省去了 avro 的序列化以及数据的 merge 过程,后续不会再有去重操作,数据的唯一性需要自己来保证。
-
bulk_insert 需要在 Batch Execuiton Mode 下执行更高效,Batch 模式默认会按照 partition path 排序输入消息再写入 Hoodie,避免 file handle 频繁切换导致性能下降。
SET execution.runtime-mode = batch; SET execution.checkpointing.interval = 0; -
bulk_insert write task 的并发通过参数 write.tasks 指定,并发的数量会影响到小文件的数量,理论上,bulk_insert write task 的并发数就是划分的 bucket 数,当然每个 bucket 在写到文件大小上限(parquet 120 MB)的时候会 roll over 到新的文件句柄,所以最后:写文件数量 >= bulk_insert write task 数。
(2)WITH参数
| 名称 | Required | 默认值 | 说明 |
|---|---|---|---|
| write.operation | true | upsert | 配置 bulk_insert 开启该功能 |
| write.tasks | false | 4 | bulk_insert 写 task 的并发,最后的文件数 >= write.tasks |
| write.bulk_insert.shuffle_by_partitionwrite.bulk_insert.shuffle_input(从 0.11 开始) | false | true | 是否将数据按照 partition 字段 shuffle 再通过 write task 写入,开启该参数将减少小文件的数量 但是可能有数据倾斜风险 |
| write.bulk_insert.sort_by_partitionwrite.bulk_insert.sort_input(从 0.11 开始) | false | true | 是否将数据线按照 partition 字段排序再写入,当一个 write task 写多个 partition,开启可以减少小文件数量 |
| write.sort.memory | 128 | sort 算子的可用 managed memory(单位 MB) |
(3)案例
-
Mysql建表
create database test; use test; create table stu4 (id int unsigned auto_increment primary key COMMENT '自增id',name varchar(20) not null comment '学生名字',school varchar(20) not null comment '学校名字',nickname varchar(20) not null comment '学生小名',age int not null comment '学生年龄',score decimal(4,2) not null comment '成绩',class_num int not null comment '班级人数',phone bigint not null comment '电话号码',email varchar(64) comment '家庭网络邮箱',ip varchar(32) comment 'IP地址' ) engine=InnoDB default charset=utf8; -
新建meta.txt文件,文件内容为:
id||int||自增id[:inc(id,1)] name||varchar(20)||学生名字 school||varchar(20)||学校名字[:enum(qinghua,beida,shanghaijiaoda,fudan,xidian,zhongda)] nickname||varchar(20)||学生小名[:enum(tom,tony,mick,rich,jasper)] age||int||学生年龄[:age] score||decimal(4,2)||成绩[:decimal(4,2,1)] class_num||int||班级人数[:int(10, 100)] phone||bigint||电话号码[:phone_number] email||varchar(64)||家庭网络邮箱[:email] ip||varchar(32)||IP地址[:ipv4] -
使用datafaker生成10万条数据并写入到mysql中的test.stu4表
datafaker rdb mysql+mysqldb://root:aaaaaa@hadoop1:3306/test?charset=utf8 stu4 100000 --meta meta.txt备注:如果要再次生成测试数据,则需要将meta.txt中的自增id改为比100000大的数,不然会出现主键冲突情况。
-
Flink SQL client 创建myql数据源
create table stu4(id bigint not null,name string,school string,nickname string,age int not null,score decimal(4,2) not null,class_num int not null,phone bigint not null,email string,ip string,PRIMARY KEY (id) NOT ENFORCED ) with ('connector' = 'jdbc','url' = 'jdbc:mysql://hadoop1:3306/test?serverTimezone=GMT%2B8','username' = 'root','password' = 'aaaaaa','table-name' = 'stu4' ); -
Flink SQL client创建hudi表
create table stu4_sink_hudi(id bigint not null,name string,`school` string,nickname string,age int not null,score decimal(4,2) not null,class_num int not null,phone bigint not null,email string,ip string,primary key (id) not enforced )partitioned by (`school`)with ('connector' = 'hudi','path' = 'hdfs://hadoop1:8020/tmp/hudi_flink/stu4_sink_hudi','table.type' = 'MERGE_ON_READ','write.option' = 'bulk_insert','write.precombine.field' = 'school'); -
Flink SQL client执行mysql数据插入到hudi中
insert into stu4_sink_hudi select * from stu4;
全量接增量
如果已经有全量的离线 Hoodie 表,需要接上实时写入,并且保证数据不重复,可以开启 index bootstrap 功能。
如果觉得流程冗长,可以在写入全量数据的时候资源调大直接走流模式写,全量走完接新数据再将资源调小(或者开启限流功能)。
WITH 参数:
| 名称 | Required | 默认值 | 说明 |
|---|---|---|---|
| index.bootstrap.enabled | true | false | 开启索引加载,会将已存表的最新数据一次性加载到 state 中 |
| index.partition.regex | false | * | 设置正则表达式进行分区筛选,默认为加载全部分区 |
使用流程:
(1) CREATE TABLE 创建和 Hoodie 表对应的语句,注意 table type 要正确
(2)设置 index.bootstrap.enabled = true开启索引加载功能
(3)flink conf 中设置 checkpoint 失败容忍 execution.checkpointing.tolerable-failed-checkpoints = n(取决于checkpoint 调度次数)
(4)等待第一次 checkpoint 成功,表示索引加载完成
(5)索引加载完成后可以退出并保存 savepoint (也可以直接用 externalized checkpoint)
(6)重启任务将 index.bootstrap.enabled 关闭,参数配置到合适的大小,如果RowDataToHoodieFunction 和 BootstrapFunction 并发不同,可以重启避免 shuffle
说明:
(1)索引加载是阻塞式,所以在索引加载过程中 checkpoint 无法完成
(2)索引加载由数据流触发,需要确保每个 partition 都至少有1条数据,即上游 source 有数据进来
(3)索引加载为并发加载,根据数据量大小加载时间不同,可以在log中搜索
finish loading the index under partition 和 Load records from file 日志来观察索引加载的进度
(4)第一次checkpoint成功就表示索引已经加载完成,后续从 checkpoint 恢复时无需再次加载索引
注意:在当前的0.12版本,以上划横线的部分已经不再需要了。(0.9 cherry pick 分支之后)
写入模式
Changelog 模式
如果希望 Hoodie 保留消息的所有变更(I/-U/U/D),之后接上 Flink 引擎的有状态计算实现全链路近实时数仓生产(增量计算),Hoodie 的 MOR 表通过行存原生支持保留消息的所有变更(format 层面的集成),通过流读 MOR 表可以消费到所有的变更记录。
(1)WITH 参数
| 名称 | Required | 默认值 | 说明 |
|---|---|---|---|
| changelog.enabled | false | false | 默认是关闭状态,即 UPSERT 语义,所有的消息仅保证最后一条合并消息,中间的变更可能会被 merge 掉;改成 true 支持消费所有变更。 |
批(快照)读仍然会合并所有的中间结果,不管 format 是否已存储中间状态。
开启 changelog.enabled 参数后,中间的变更也只是 Best Effort: 异步的压缩任务会将中间变更合并成 1 条,所以如果流读消费不够及时,被压缩后只能读到最后一条记录。当然,通过调整压缩的 buffer 时间可以预留一定的时间 buffer 给 reader,比如调整压缩的两个参数:
- compaction.delta_commits:5
- compaction.delta_seconds: 3600。
说明:
Changelog 模式开启流读的话,要在 sql-client 里面设置参数:
set sql-client.execution.result-mode=tableau;
或者
set sql-client.execution.result-mode=changelog;
否则中间结果在读的时候会被直接合并。(参考:https://nightlies.apache.org/flink/flink-docs-release-1.13/docs/dev/table/sqlclient/#running-sql-queries)
(2)流读 changelog
仅在 0.10.0 支持,本 feature 为实验性。
开启 changelog 模式后,hudi 会保留一段时间的 changelog 供下游 consumer 消费,我们可以通过流读 ODS 层 changelog 接上 ETL 逻辑写入到 DWD 层,如下图的 pipeline:
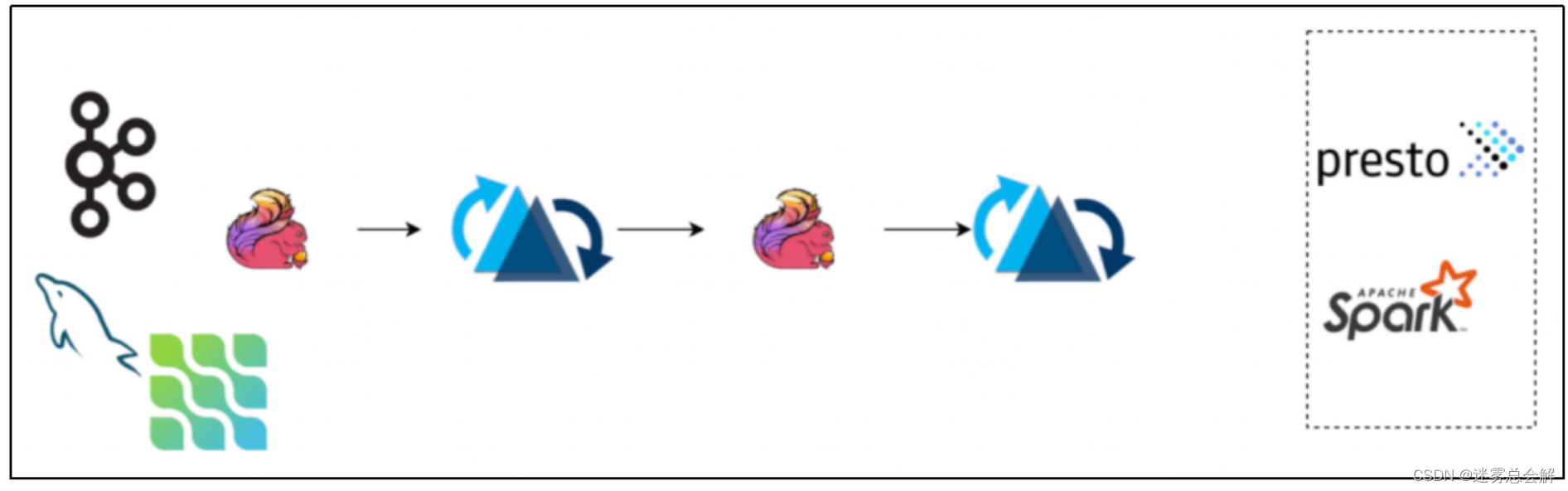
流读的时候我们要注意 changelog 有可能会被 compaction 合并掉,中间记录会消除,可能会影响计算结果,需要关注sql-client的属性(result-mode)同上。
(3)演示案例
-
使用changelog
set sql-client.execution.result-mode=tableau; CREATE TABLE t6(id int,ts int,primary key (id) not enforced ) WITH ('connector' = 'hudi','path' = 'hdfs://hadoop1:8020/tmp/hudi_flink/t6','table.type' = 'MERGE_ON_READ','read.streaming.enabled' = 'true','read.streaming.check-interval' = '4','changelog.enabled' = 'true' );insert into t6 values (1,1); insert into t6 values (1,2);set table.dynamic-table-options.enabled=true; select * from t6/*+ OPTIONS('read.start-commit'='earliest')*/; select count(*) from t6/*+ OPTIONS('read.start-commit'='earliest')*/; -
不使用changelog
CREATE TABLE t6_v(id int,ts int,primary key (id) not enforced ) WITH ('connector' = 'hudi','path' = 'hdfs://hadoop1:8020/tmp/hudi_flink/t6','table.type' = 'MERGE_ON_READ','read.streaming.enabled' = 'true','read.streaming.check-interval' = '4' );select * from t6_v/*+ OPTIONS('read.start-commit'='earliest')*/; select count(*) from t6_v/*+ OPTIONS('read.start-commit'='earliest')*/;
Append 模式
从 0.10 开始支持
对于 INSERT 模式:
- MOR 默认会 apply 小文件策略: 会追加写 avro log 文件
- COW 每次直接写新的 parquet 文件,没有小文件策略
Hudi 支持丰富的 Clustering 策略,优化 INSERT 模式下的小文件问题:
(1)Inline Clustering
只有 Copy On Write 表支持该模式:
| 名称 | Required | 默认值 | 说明 |
|---|---|---|---|
| write.insert.cluster | false | false | 是否在写入时合并小文件,COW 表默认 insert 写不合并小文件,开启该参数后,每次写入会优先合并之前的小文件(不会去重),吞吐会受影响 |
(2)Async Clustering
从 0.12 开始支持
-
WITH参数
名称 Required 默认值 说明 clustering.schedule.enabled false false 是否在写入时定时异步调度 clustering plan,默认关闭 clustering.delta_commits false 4 调度 clsutering plan 的间隔 commits,clustering.schedule.enabled 为 true 时生效 clustering.async.enabled false false 是否异步执行 clustering plan,默认关闭 clustering.tasks false 4 Clustering task 执行并发 clustering.plan.strategy.target.file.max.bytes false 1024 * 1024 * 1024 Clustering 单文件目标大小,默认 1GB clustering.plan.strategy.small.file.limit false 600 小于该大小的文件才会参与 clustering,默认600MB clustering.plan.strategy.sort.columns false N/A 支持指定特殊的排序字段 clustering.plan.partition.filter.mode false NONE 支持NONE:不做限制RECENT_DAYS:按时间(天)回溯SELECTED_PARTITIONS:指定固定的 partition clustering.plan.strategy.daybased.lookback.partitions false 2 RECENT_DAYS 生效,默认 2 天 -
Clustering Plan Strategy
支持定制化的 clustering 策略。
名称 Required 默认值 说明 clustering.plan.partition.filter.mode false NONE 支持· NONE:不做限制· RECENT_DAYS:按时间(天)回溯· SELECTED_PARTITIONS:指定固定的 partition clustering.plan.strategy.daybased.lookback.partitions false 2 RECENT_DAYS 生效,默认 2 天 clustering.plan.strategy.cluster.begin.partition false N/A SELECTED_PARTITIONS 生效,指定开始 partition(inclusive) clustering.plan.strategy.cluster.end.partition false N/A SELECTED_PARTITIONS 生效,指定结束 partition(incluseve) clustering.plan.strategy.partition.regex.pattern false N/A 正则表达式过滤 partitions clustering.plan.strategy.partition.selected false N/A 显示指定目标 partitions,支持逗号 , 分割多个 partition
Bucket 索引
从 0.11 开始支持
默认的 flink 流式写入使用 state 存储索引信息:primary key 到 fileId 的映射关系。当数据量比较大的时候,state的存储开销可能成为瓶颈,bucket 索引通过固定的 hash 策略,将相同 key 的数据分配到同一个 fileGroup 中,避免了索引的存储和查询开销。
(1)WITH参数
| 名称 | Required | 默认值 | 说明 |
|---|---|---|---|
| index.type | false | FLINK_STATE | 设置 BUCKET 开启 Bucket 索引功能 |
| hoodie.bucket.index.hash.field | false | 主键 | 可以设置成主键的子集 |
| hoodie.bucket.index.num.buckets | false | 4 | 默认每个 partition 的 bucket 数,当前设置后则不可再变更。 |
(2)和 state 索引的对比:
- bucket index 没有 state 的存储计算开销,性能较好
- bucket index 无法扩 buckets,state index 则可以依据文件的大小动态扩容
- bucket index 不支持跨 partition 的变更(如果输入是 cdc 流则没有这个限制),state index 没有限制
Hudi Catalog
从 0.12.0 开始支持,通过 catalog 可以管理 flink 创建的表,避免重复建表操作,另外 hms 模式的 catalog 支持自动补全 hive 同步参数。
DFS 模式 Catalog SQL样例:
CREATE CATALOG hoodie_catalogWITH ('type'='hudi','catalog.path' = '${catalog 的默认路径}','mode'='dfs' );
Hms 模式 Catalog SQL 样例:
CREATE CATALOG hoodie_catalogWITH ('type'='hudi','catalog.path' = '${catalog 的默认路径}','hive.conf.dir' = '${hive-site.xml 所在的目录}','mode'='hms' -- 支持 'dfs' 模式通过文件系统管理表属性);
(1)WITH 参数
| 名称 | Required | 默认值 | 说明 |
|---|---|---|---|
| catalog.path | true | – | 默认的 catalog 根路径,用作表路径的自动推导,默认的表路径:${catalog.path}/${db_name}/${table_name} |
| default-database | false | default | 默认的 database 名 |
| hive.conf.dir | false | – | hive-site.xml 所在的目录,只在 hms 模式下生效 |
| mode | false | dfs | 支持 hms模式通过 hive 管理元数据 |
| table.external | false | false | 是否创建外部表,只在 hms 模式下生效 |
(2)使用dfs方式
-
创建sql-client初始化sql文件
vim /opt/module/flink-1.13.6/conf/sql-client-init.sqlCREATE CATALOG hoodie_catalogWITH ('type'='hudi','catalog.path' = '/tmp/hudi_catalog','mode'='dfs' );USE CATALOG hoodie_catalog; -
指定sql-client启动时加载sql文件
hadoop fs -mkdir /tmp/hudi_catalogbin/sql-client.sh embedded -i conf/sql-client-init.sql -s yarn-session -
建库建表插入
create database test; use test;create table t2(uuid varchar(20),name varchar(10),age int,ts timestamp(3),`partition` varchar(20),primary key (uuid) not enforced ) with ('connector' = 'hudi','path' = '/tmp/hudi_catalog/default/t2','table.type' = 'MERGE_ON_READ' );insert into t2 values('1','zs',18,TIMESTAMP '1970-01-01 00:00:01','a'); -
退出sql-client,重新进入,表信息还在
use test; show tables; select * from t2;
离线 Compaction
MOR 表的 compaction 默认是自动打开的,策略是 5 个 commits 执行一次压缩。 因为压缩操作比较耗费内存,和写流程放在同一个 pipeline,在数据量比较大的时候(10w+/s qps),容易干扰写流程,此时采用离线定时任务的方式执行 compaction 任务更稳定。
(1)设置参数
- compaction.async.enabled 为 false,关闭在线 compaction。
- compaction.schedule.enabled 仍然保持开启,由写任务阶段性触发压缩 plan。
(2)原理
一个 compaction 的任务的执行包括两部分:
-
schedule 压缩 plan
该过程推荐由写任务定时触发,写参数 compaction.schedule.enabled 默认开启
-
执行对应的压缩 plan
(3)使用方式
-
执行命令
离线 compaction 需要手动执行 Java 程序,程序入口:
hudi-flink1.13-bundle-0.12.0.jar
org.apache.hudi.sink.compact.HoodieFlinkCompactor
// 命令行的方式 ./bin/flink run -c org.apache.hudi.sink.compact.HoodieFlinkCompactor lib/hudi-flink1.13-bundle-0.12.0.jar --path hdfs://xxx:8020/table -
参数配置
参数名 required 默认值 备注 –path true – 目标表的路径 –compaction-tasks false -1 压缩 task 的并发,默认是待压缩 file group 的数量 –compaction-max-memory false 100 (单位 MB) 压缩时 log 数据的索引 map,默认 100MB,内存足够可以开大些 –schedule false false 是否要执行 schedule compaction 的操作,当写流程还在持续写入表数据的时候,开启这个参数有丢失查询数据的风险,所以开启该参数一定要保证当前没有任务往表里写数据, 写任务的 compaction plan 默认是一直 schedule 的,除非手动关闭(默认 5 个 commits 一次压缩) –seq false LIFO 执行压缩任务的顺序,默认是从最新的压缩 plan 开始执行,可选值:LIFO: 从最新的 plan 开始执行;FIFO: 从最老的 plan 开始执行 –service false false 是否开启 service 模式,service 模式会打开常驻进程,一直监听压缩任务并提交到集群执行(从 0.11 开始执行) –min-compaction-interval-seconds false 600 (单位 秒) service 模式下的执行间隔,默认 10 分钟 -
案例演示
创建表,关闭在线压缩
create table t7(id int,ts int,primary key (id) not enforced ) with ('connector' = 'hudi','path' = '/tmp/hudi_catalog/default/t7','compaction.async.enabled' = 'false','compaction.schedule.enabled' = 'true','table.type' = 'MERGE_ON_READ' );insert into t7 values(1,1); insert into t7 values(2,2); insert into t7 values(3,3); insert into t7 values(4,4); insert into t7 values(5,5);// 命令行的方式 ./bin/flink run -c org.apache.hudi.sink.compact.HoodieFlinkCompactor lib/hudi-flink1.13-bundle-0.12.0.jar --path hdfs://hadoop1:8020/tmp/hudi_catalog/default/t7
离线 Clustering
异步的 clustering 相对于 online 的 async clustering 资源隔离,从而更加稳定。
(1)设置参数
- clustering.async.enabled 为 false,关闭在线 clustering。
- clustering.schedule.enabled 仍然保持开启,由写任务阶段性触发 clustering plan。
(2)原理
一个 clustering 的任务的执行包括两部分:
- schedule plan 推荐由写任务定时触发,写参数 clustering.schedule.enabled 默认开启。
- 执行对应的 plan
(3)使用方式
-
执行命令
离线 clustering 需要手动执行 Java 程序,程序入口:
- hudi-flink1.13-bundle-0.12.0.jar
- org.apache.hudi.sink.clustering.HoodieFlinkClusteringJob
注意:必须是分区表,否则报错空指针异常。
// 命令行的方式 ./bin/flink run -c org.apache.hudi.sink.clustering.HoodieFlinkClusteringJob lib/hudi-flink1.13-bundle-0.12.0.jar --path hdfs://xxx:8020/table -
参数配置
参数名 required 默认值 备注 –path true – 目标表的路径。 –clustering-tasks false -1 Clustering task 的并发,默认是待压缩 file group 的数量。 –schedule false false 是否要执行 schedule clustering plan 的操作,当写流程还在持续写入表数据的时候,开启这个参数有丢失查询数据的风险,所以开启该参数一定要保证当前没有任务往表里写数据, 写任务的 clustering plan 默认是一直 schedule 的,除非手动关闭(默认 4 个 commits 一次 clustering)。 –seq false FIFO 执行压缩任务的顺序,默认是从最老的 clustering plan 开始执行,可选值:LIFO: 从最新的 plan 开始执行;FIFO: 从最老的 plan 开始执行 –target-file-max-bytes false 1024 1024 1024 最大目标文件,默认 1GB。 –small-file-limit false 600 小于该大小的文件会参与 clustering,默认 600MB。 –sort-columns false N/A Clustering 可选排序列。 –service false false 是否开启 service 模式,service 模式会打开常驻进程,一直监听压缩任务并提交到集群执行(从 0.11 开始执行)。 –min-compaction-interval-seconds false 600 (单位 秒) service 模式下的执行间隔,默认 10 分钟。 -
案例演示
创建表,关闭在线压缩:
create table t8(id int,age int,ts int,primary key (id) not enforced ) partitioned by (age) with ('connector' = 'hudi','path' = '/tmp/hudi_catalog/default/t8','clustering.async.enabled' = 'false','clustering.schedule.enabled' = 'true','table.type' = 'COPY_ON_WRITE' );insert into t8 values(1,18,1); insert into t8 values(2,18,2); insert into t8 values(3,18,3); insert into t8 values(4,18,4); insert into t8 values(5,18,5);// 命令行的方式 ./bin/flink run -c org.apache.hudi.sink.clustering.HoodieFlinkClusteringJob lib/hudi-flink1.13-bundle-0.12.0.jar --path hdfs://hadoop1:8020/tmp/hudi_catalog/default/t8
常见基础问题
(1)存储一直看不到数据
如果是 streaming 写,请确保开启 checkpoint,Flink 的 writer 有 3 种刷数据到磁盘的策略:
- 当某个 bucket 在内存积攒到一定大小 (可配,默认 64MB)
- 当总的 buffer 大小积攒到一定大小(可配,默认 1GB)
- 当 checkpoint 触发,将内存里的数据全部 flush 出去
(2)数据有重复
如果是 COW 写,需要开启参数 write.insert.drop.duplicates,COW 写每个 bucket 的第一个文件默认是不去重的,只有增量的数据会去重,全局去重需要开启该参数;MOR 写不需要开启任何参数,定义好 primary key 后默认全局去重。(注意:从 0.10 版本开始,该属性改名 write.precombine 并且默认为 true。)
如果需要多 partition 去重,需要开启参数: index.global.enabled 为 true。(注意:从 0.10 版本开始,该属性默认为 true)
索引 index 是判断数据重复的核心数据结构,index.state.ttl 设置了索引保存的时间,默认为 1.5 天,对于长时间周期的更新,比如更新一个月前的数据,需要将 index.state.ttl 调大(单位天),设置小于 0 代表永久保存。(注意:从 0.10 版本开始,该属性默认为 0。)
(3)Merge On Read 写只有 log 文件
Merge On Read 默认开启了异步的 compaction,策略是 5 个 commits 压缩一次,当条件满足参会触发压缩任务,另外,压缩本身因为耗费资源,所以不一定能跟上写入效率,可能会有滞后。
可以先观察 log,搜索 compaction 关键词,看是否有 compact 任务调度:
After filtering, Nothing to compact for 关键词说明本次 compaction strategy 是不做压缩。
核心原理分析
数据去重原理
Hoodie 的数据去重分两步:
- 写入前攒 buffer 阶段去重,核心接口HoodieRecordPayload#preCombine
- 写入过程中去重,核心接口HoodieRecordPayload#combineAndGetUpdateValue
(1)消息版本新旧
相同 record key (主键)的数据通过write.precombine.field 指定的字段来判断哪个更新,即 precombine 字段更大的 record 更新,如果是相等的 precombine 字段,则后来的数据更新。
从 0.10 版本开始,write.precombine.field 字段为可选,如果没有指定,会看 schema 中是否有 ts 字段,如果有,ts 字段被选为 precombine 字段;如果没有指定,schema 中也没有 ts 字段,则为处理顺序:后来的消息默认较新。
(2)攒消息阶段的去重
Hoodie 将 buffer 消息发给 write handle 之前可以执行一次去重操作,通过HoodieRecordPayload#preCombine 接口,保留 precombine 字段较大的消息,此操作为纯内存的计算,在同一个 write task 中为单并发执行。
注意:write.precombine 选项控制了攒消息的去重。
(3)写 parquet 增量消息的去重
在Hoodie 写入流程中,Hoodie 每写一个 parquet 都会有 base + 增量 merge 的过程,增量的消息会先放到一个 spillable map 的数据结构构建内存 index,这里的增量数据如果没有提前去重,那么同 key 的后来消息会直接覆盖先来的消息。
Writer 接着扫 base 文件,过程中会不断查看内存 index 是否有同 key 的新消息,如果有,会走 HoodieRecordPayload#combineAndGetUpdateValue 接口判断保留哪个消息。
注意: MOR 表的 compaction 阶段和 COW 表的写入流程都会有 parquet 增量消息去重的逻辑。
(4)跨 partition 的消息去重
默认情况下,不同的 partition 的消息是不去重的,即相同的 key 消息,如果新消息换了 partition,那么老的 partiiton 消息仍然保留。
开启 index.global.enabled 选项开启跨 partition 去重,原理是先往老的 partiton 发一条删除消息,再写新 partition。
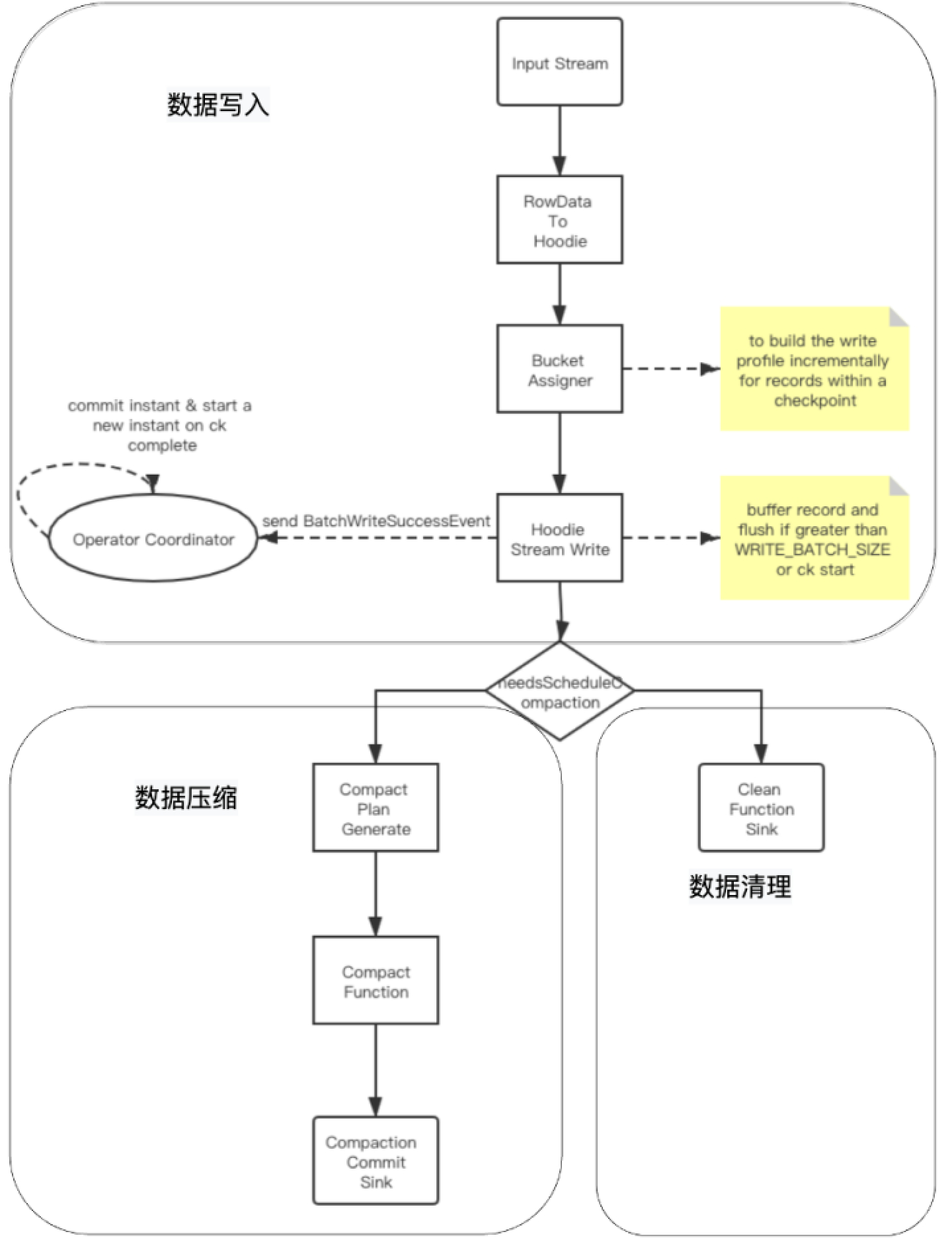
表写入原理
分为三个模块:数据写入、数据压缩与数据清理。
(1)数据写入分析
- 基础数据封装:将数据流中flink的RowData封装成Hoodie实体;
- BucketAssigner:桶分配器,主要是给数据分配写入的文件地址:若为插入操作,则取大小最小的FileGroup对应的FileId文件内进行插入;在此文件的后续写入中文件 ID 保持不变,并且提交时间会更新以显示最新版本。这也意味着记录的任何特定版本,给定其分区路径,都可以使用文件 ID 和 instantTime进行唯一定位;若为更新操作,则直接在当前location进行数据更新;
- Hoodie Stream Writer:数据写入,将数据缓存起来,在超过设置的最大flushSize或是做checkpoint时进行刷新到文件中;
- Oprator Coordinator:主要与Hoodie Stream Writer进行交互,处理checkpoint等事件,在做checkpoint时,提交instant到timeLine上,并生成下一个instant的时间,算法为取当前最新的commi时间,比对当前时间与commit时间,若当前时间大于commit时间,则返回,否则一直循环等待生成。
(2)数据压缩
压缩(compaction)用于在 MergeOnRead存储类型时将基于行的log日志文件转化为parquet列式数据文件,用于加快记录的查找。compaction首先会遍历各分区下最新的parquet数据文件和其对应的log日志文件进行合并,并生成新的FileSlice,在TimeLine 上提交新的Instance:
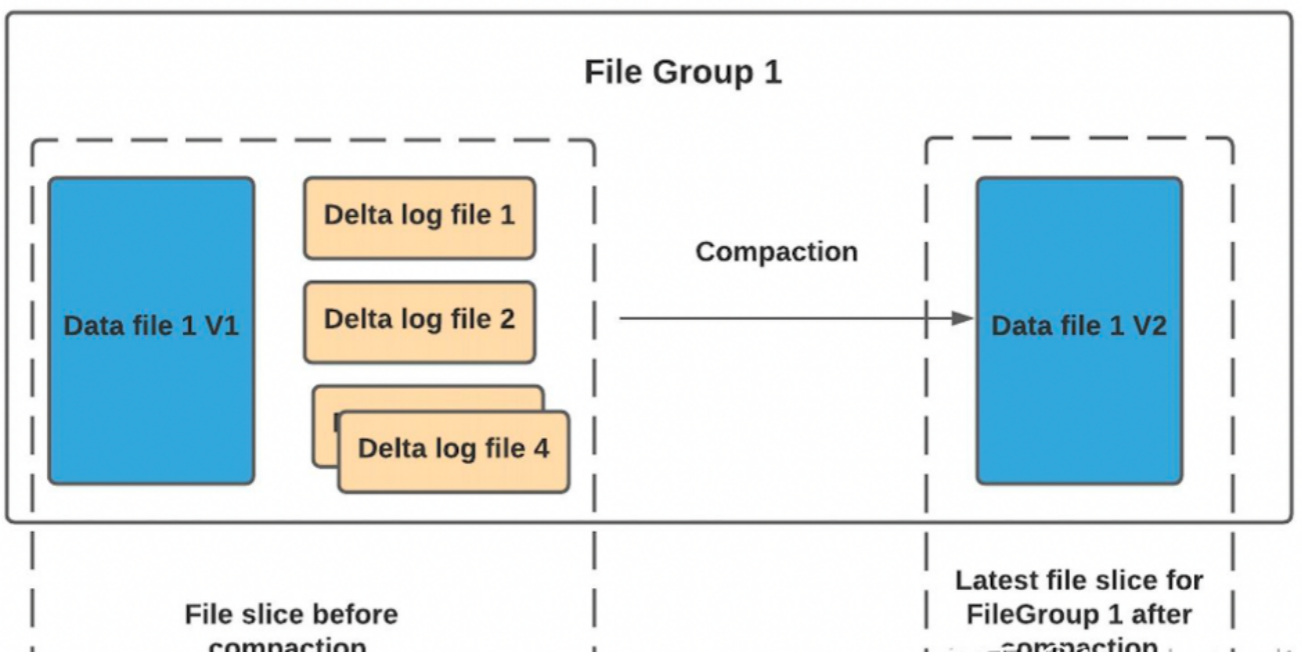
具体策略分为4种,具体见官网说明:
compaction.trigger.strategy:
Strategy to trigger compaction, options are
1.'num_commits': trigger compaction when reach N delta commits;
2.'time_elapsed': trigger compaction when time elapsed > N seconds since last compaction;
3.'num_and_time': trigger compaction when both NUM_COMMITS and TIME_ELAPSED are satisfied;
4.'num_or_time': trigger compaction when NUM_COMMITS or TIME_ELAPSED is satisfied. Default is 'num_commits'
Default Value: num_commits (Optional)
在项目实践中需要注意参数’read.streaming.skip_compaction’ 参数的配置,其表示在流式读取该表是否跳过压缩后的数据,若该表用于后续聚合操作表的输入表,则需要配置值为true,表示聚合操作表不再消费读取压缩数据。若不配置或配置为false,则该表中的数据在未被压缩之前被聚合操作表读取了一次,在压缩后数据又被读取一次,会导致聚合表的sum、count等算子结果出现双倍情况。
(3)数据清理
随着用户向表中写入更多数据,对于每次更新,Hudi会生成一个新版本的数据文件用于保存更新后的记录(COPY_ON_WRITE)或将这些增量更新写入日志文件以避免重写更新版本的数据文件(MERGE_ON_READ)。在这种情况下,根据更新频率,文件版本数可能会无限增长,但如果不需要保留无限的历史记录,则必须有一个流程(服务)来回收旧版本的数据,这就是 Hudi 的清理服务。
具体清理策略可参考官网,一般使用的清理策略为:KEEP_LATEST_FILE_VERSIONS:此策略具有保持 N 个文件版本而不受时间限制的效果。会删除N之外的FileSlice。
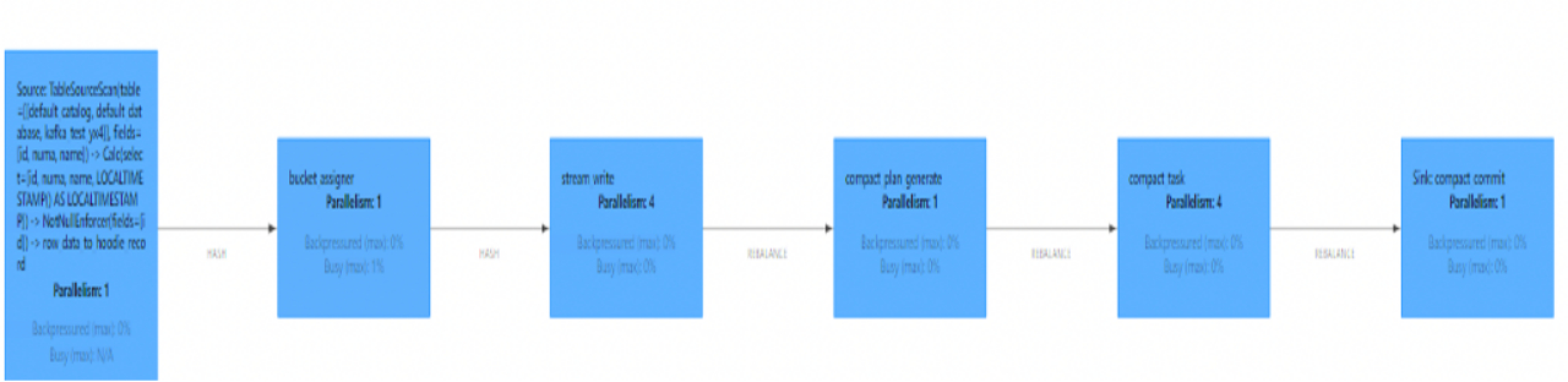
(4)Job图
如下为生产环境中flink Job图,可以看到各task和上述分析过程对应,需要注意的是可以调整并行度来提升写入速度。
表读取原理
如下为Hudi数据流式读取Job图。
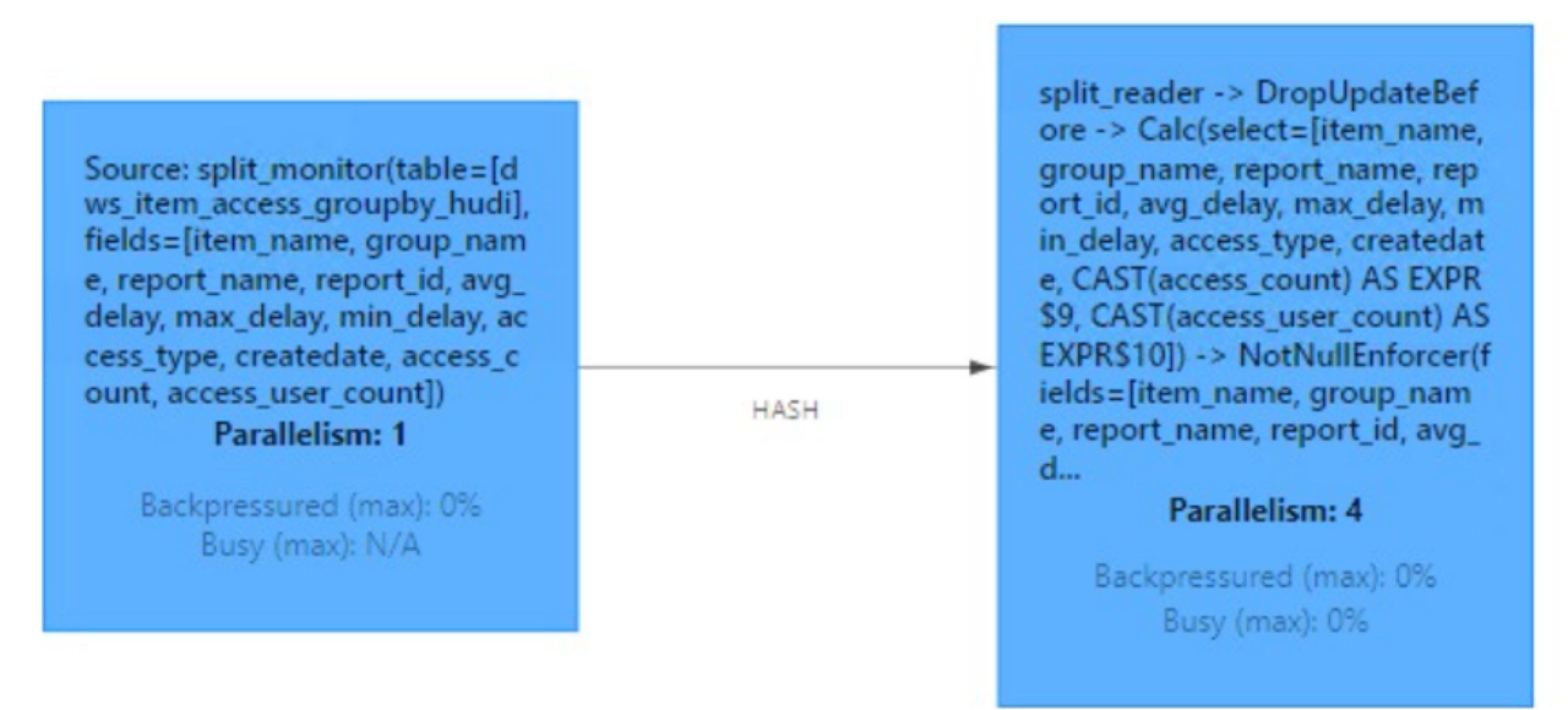
其过程为:
- 开启split_monitor算子,每隔N秒(可配置)监听TimeLine上变化,并将变更的Instance封装为FileSlice。
- 分发log文件时候,按照fileId值进行keyBy,保证同一file group下数据文件都给一个Task进行处理,从而保证数据处理的有序性。
- split_reader根据FileSlice信息进行数据读取。
相关文章:
Hudi-集成Flink
文章目录集成Flink环境准备sql-client方式启动sql-client插入数据查询数据更新数据流式插入code 方式环境准备代码类型映射核心参数设置去重参数并发参数压缩参数文件大小Hadoop参数内存优化读取方式流读(Streaming Query)增量读取(Increment…...
重新认识 React Hooks useContext
通常来说,React 数据的传递方式都是一层一层把资料 props 传到子层的 就算第二层(Function Component)、第三层(Button Group Compontn) 根本没有用到这个资料,但是为了传到最底层(button) ,每一层还是必须要传props // App.js const App = () => {const [dark, setDark…...
数据库(2)--加深对统计查询的理解,熟练使用聚合函数
一、内容要求 利用sql建立学生信息数据库,并定义以下基本表: 学生(学号,年龄,性别,系号) 课程(课号,课名,学分,学时) 选课࿰…...
stm32f407探索者开发板(十五)——NVIC中断优先级管理
文章目录零、前言一、NVIC中断优先级分组1.1 中断的管理方法1.2 抢占优先级&相应优先级的区别1.3 举例1.4 特别说明1.5 中断优先级分组函数二、NVIC中断优先级设置2.1 中断设置相关寄存器2.2 中断设置优先级2.2.1 中断优先级控制的寄存器组 IP[240]2.2.2 中断使能寄存器组 …...
【Azure 架构师学习笔记】-Azure Logic Apps(6)- Logic Apps调用ADF
本文属于【Azure 架构师学习笔记】系列。 本文属于【Azure Logic Apps】系列。 接上文【Azure 架构师学习笔记】-Azure Logic Apps(5)- 标准和使用量类型的区别 前言 Logic Apps 和 ADF 的搭配使用是常见的组合,它们可以互相弥补各自的不足和…...

python随机获取列表中某一元素
1、利用Python中的random模块中的choice方法 random.choice()可以从任何序列,比如list列表中,选取一个随机的元素返回,可以用于字符串、列表、元组等。 import random arr[1,2,3,4,5,6] print(random.choice(arr))2、利用Python中的random模…...

Nacos微服务笔记
Nacos安装Nacos 的 Github(Tags alibaba/nacos GitHub)下载我们所需的 Nacos 版本,可以选择 windows 或者 Linux。 进入官网,选择合适版本,tar.gz为linux版本,zip为windows版本。下载并解压 nacos-server…...
MAC文件误删怎么办?mac数据恢复,亲测很好用的方法
电脑文件误删,应该很多人都经历过。之前分享了很多关于Windows电脑文件误删如何恢复的方法,那么MAC电脑文件误删该怎么办?有什么好方法可以使得mac数据恢复回来吗?下面就给大家分享一些亲测好用的方法! 一、MAC电脑的文…...

机械革命z2黑苹果改造计划第二番-MacOS实用软件渗透工具
机械革命z2黑苹果改造计划第二番-实用软件 Mac实用工具 这是旧电脑改造计划的第二篇,就是安装一些常用软件和一些渗透测试工具,武装灵魂成为真正的生产力工具 首先推荐一个网站,www.mactools.app,这个软件里边有大多数常用的软…...
【LeetCode】每日一题(4)
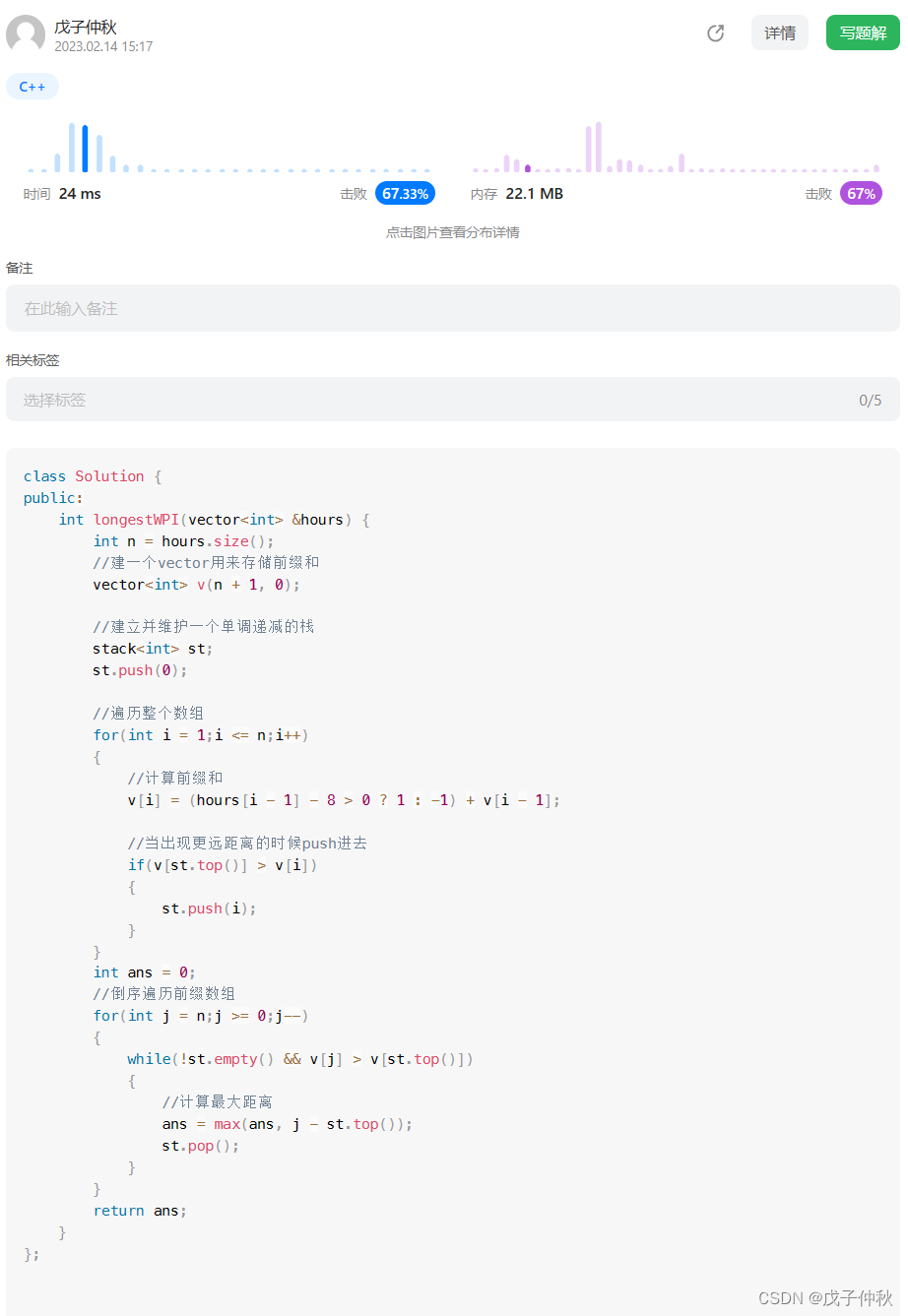
目录 题目:1124. 表现良好的最长时间段 - 力扣(Leetcode) 题目的接口: 解题思路: 代码: 过啦!!! 写在最后: 题目:1124. 表现良好的最长时间…...

Linux内核移植:内核的启动过程分析、启动配置与rootfs必要文件
Linux内核移植:内核的启动过程、启动配置与rootfs必要文件一、启动过程二、启动配置(一)SysV初始化(二)systemd初始化三、rootfs中的启动配置文件1、inittab2、/etc/init.d/rcS 脚本3、fstab4、profile 文件5、其他文件…...

【代码随想录训练营】【Day14】第六章|二叉树|理论基础|递归遍历|迭代遍历|统一迭代
理论基础 二叉树的定义形式有:节点指针和数组 在数组中,父节点的下标为i,那么其左孩子的下标即i*21,右孩子的下标即为i*22 二叉树的常见遍历形式有:前序遍历、后序遍历、中序遍历和层序遍历 前序遍历:二…...

AXI-Stream 学习笔记
参考 https://wuzhikai.blog.csdn.net/article/details/121326701 https://zhuanlan.zhihu.com/p/152283168 AXI4 介绍 AXI4 是ARM公司提出的一种片内总线,描述了主从设备之间的数据传输方式。主要有AXI4_LITE、AXI4_FULL、AXI4_STREAM三种。 AXI4_LITE࿱…...
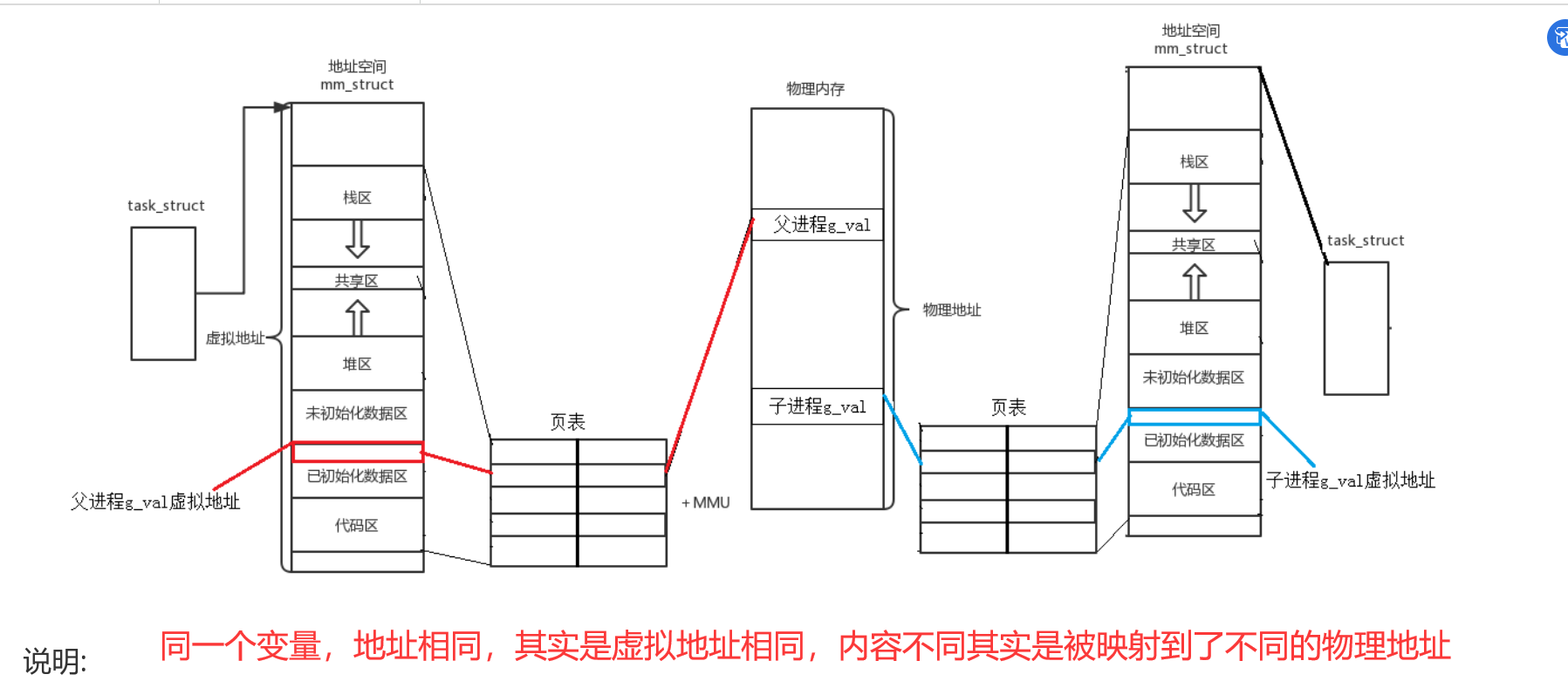
【Linux】程序进程地址空间
文章目录程序地址空间进程地址空间程序地址空间 在Linux下,这种地址叫做 虚拟地址, 我们在用C/C语言所看到的地址,全部都是虚拟地址!物理地址,用户一概看不到,由OS统一管理 问:C/C程序地址空间是内存吗? -> 根本就不是内存! 是进程虚拟地址空间 堆栈…...

电压放大器在液滴微流控芯片的功能研究中的应用
实验名称:电压放大器在液滴微流控芯片的功能研究中的应用研究方向:微流控生物芯片测试目的:液滴微流控技术能够在微通道内实现液滴生成,精准控制生成液滴的尺寸以及生成频率。结合芯片结构设计和外部控制条件,可以对液…...
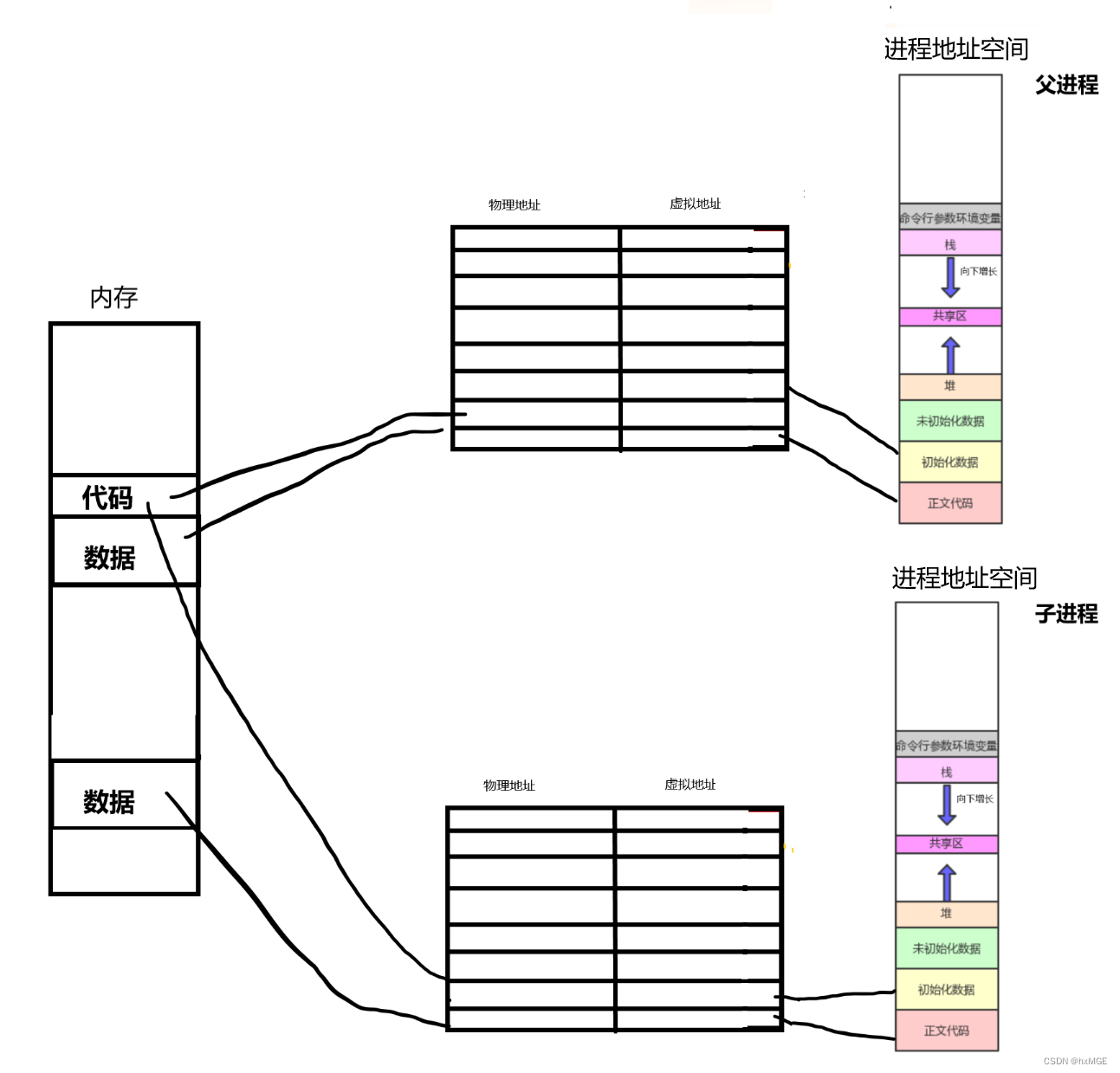
Linux操作系统学习(进程地址空间)
文章目录进程地址空间奇怪的现象什么是进程地址空间???虚拟地址是如何与物理内存联系的?页表是什么呢?为什么要有页表和地址空间,让进程直接访问内存不行吗?现象解释进程地址空间 在我们学习其…...

【排序】快速排序实现
目录 一、快速排序是什么? 二、左右指针法 1.实现原理 2.代码如下: 三、挖坑法 1.实现原理 2.代码如下: 四、前后指针法 1.实现原理 2.代码如下: 五、三数取中 1.实现思想 2.代码如下: 3.使用方法 总结…...

YOLOv5/v7 Flask Web 车牌识别 | YOLOv7 + EasyOCR 实现车牌识别
YOLOv7 Flask Web 车牌识别图片效果展示 本篇博文只包含源码以及使用方式,目前不同提供详细开发教程。 YOLOv7 Flask Web 车牌识别视频效果展示 YOLOv7 + EasyOCR 实现车牌识别 什么是Flask? 简介 Flask是一个轻量级的可定制框架,使用Python语言编写,较其他同类型框架更…...

【Opencv实战】几十年前的Vlog火了:黑白老照片如何上色?这黑科技操作一定要知道,复原度超高,竟美的出奇~(图像修复神级代码)
导语 哈喽大家好呀!我是每天疯狂赶代码的木木子吖~情人节快乐呀! 所有文章完整的素材源码都在👇👇 粉丝白嫖源码福利,请移步至CSDN社区或文末公众hao即可免费。 我们都知道,有很多经典的老照片…...

React源码分析(一)Fiber
前言 本次React源码参考版本为17.0.3。 React架构前世今生 查阅文档了解到, React16.x是个分水岭。 React15及之前 在16之前,React架构大致可以分为两层: Reconciler: 主要职责是对比查找更新前后的变化的组件;R…...

【Python】 -- 趣味代码 - 小恐龙游戏
文章目录 文章目录 00 小恐龙游戏程序设计框架代码结构和功能游戏流程总结01 小恐龙游戏程序设计02 百度网盘地址00 小恐龙游戏程序设计框架 这段代码是一个基于 Pygame 的简易跑酷游戏的完整实现,玩家控制一个角色(龙)躲避障碍物(仙人掌和乌鸦)。以下是代码的详细介绍:…...

Oracle查询表空间大小
1 查询数据库中所有的表空间以及表空间所占空间的大小 SELECTtablespace_name,sum( bytes ) / 1024 / 1024 FROMdba_data_files GROUP BYtablespace_name; 2 Oracle查询表空间大小及每个表所占空间的大小 SELECTtablespace_name,file_id,file_name,round( bytes / ( 1024 …...
)
WEB3全栈开发——面试专业技能点P2智能合约开发(Solidity)
一、Solidity合约开发 下面是 Solidity 合约开发 的概念、代码示例及讲解,适合用作学习或写简历项目背景说明。 🧠 一、概念简介:Solidity 合约开发 Solidity 是一种专门为 以太坊(Ethereum)平台编写智能合约的高级编…...

汇编常见指令
汇编常见指令 一、数据传送指令 指令功能示例说明MOV数据传送MOV EAX, 10将立即数 10 送入 EAXMOV [EBX], EAX将 EAX 值存入 EBX 指向的内存LEA加载有效地址LEA EAX, [EBX4]将 EBX4 的地址存入 EAX(不访问内存)XCHG交换数据XCHG EAX, EBX交换 EAX 和 EB…...

浅谈不同二分算法的查找情况
二分算法原理比较简单,但是实际的算法模板却有很多,这一切都源于二分查找问题中的复杂情况和二分算法的边界处理,以下是博主对一些二分算法查找的情况分析。 需要说明的是,以下二分算法都是基于有序序列为升序有序的情况…...

人机融合智能 | “人智交互”跨学科新领域
本文系统地提出基于“以人为中心AI(HCAI)”理念的人-人工智能交互(人智交互)这一跨学科新领域及框架,定义人智交互领域的理念、基本理论和关键问题、方法、开发流程和参与团队等,阐述提出人智交互新领域的意义。然后,提出人智交互研究的三种新范式取向以及它们的意义。最后,总结…...

MinIO Docker 部署:仅开放一个端口
MinIO Docker 部署:仅开放一个端口 在实际的服务器部署中,出于安全和管理的考虑,我们可能只能开放一个端口。MinIO 是一个高性能的对象存储服务,支持 Docker 部署,但默认情况下它需要两个端口:一个是 API 端口(用于存储和访问数据),另一个是控制台端口(用于管理界面…...
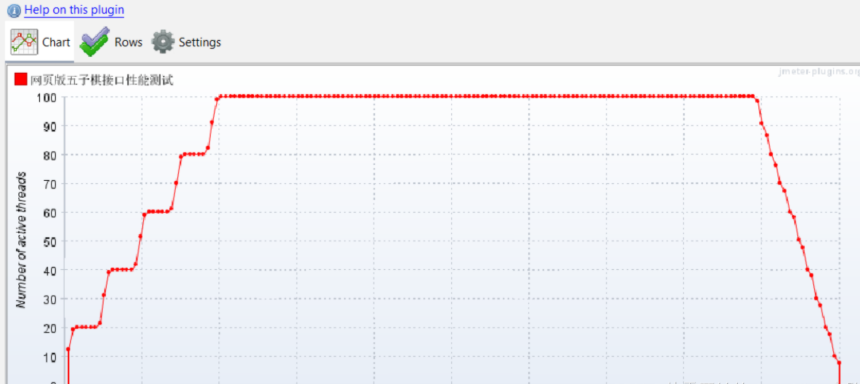
五子棋测试用例
一.项目背景 1.1 项目简介 传统棋类文化的推广 五子棋是一种古老的棋类游戏,有着深厚的文化底蕴。通过将五子棋制作成网页游戏,可以让更多的人了解和接触到这一传统棋类文化。无论是国内还是国外的玩家,都可以通过网页五子棋感受到东方棋类…...

图解JavaScript原型:原型链及其分析 | JavaScript图解
忽略该图的细节(如内存地址值没有用二进制) 以下是对该图进一步的理解和总结 1. JS 对象概念的辨析 对象是什么:保存在堆中一块区域,同时在栈中有一块区域保存其在堆中的地址(也就是我们通常说的该变量指向谁&…...

数据结构第5章:树和二叉树完全指南(自整理详细图文笔记)
名人说:莫道桑榆晚,为霞尚满天。——刘禹锡(刘梦得,诗豪) 原创笔记:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 上一篇:《数据结构第4章 数组和广义表》…...