C/C++基础知识
专栏:C/C++
个人主页:
C/C++基础知识
- 前言
- C++关键字(C++98)
- 命名空间
- 命名空间的定义
- 正常的命名空间的定义
- 如何使用命名空间
- 命名空间可以嵌套
- 同一个工程中允许存在多个相同名称的命名空间,编译器最后会合成同一个命名空间中(一个工程中的.h文件和test.cpp中的同名也会合并成一个)
- C++的输入和输出
- std
- 缺省参数
- 缺省参数定义格式
- 缺省参数分类
- 函数重载
- 函数参数个数不同
- 参数类型顺序不同
- 引用
- 引用的特性
- 常引用
- 做参数
- 做返回值
- 引用和指针的区别
- auto关键字(C++11)
- 基于范围的for循环(C++11)
- 内联函数
- NULL和nullptr
- 语法糖简介
前言
C++是在C语言的基础上,添加了面向对象编程,使程序更加模块化,利于维护和扩展,还增加了很多标准库,库中包含了许多实用的数据结构,算法,容器,输入,输出等。
C++关键字(C++98)
C++总计63个关键字,C语言32个关键字
命名空间
在用C语言编写程序时,要注意命名冲突这一个问题,比如全局变量和局部变量名字相同或者函数名字冲突等。

C语言并没有给出这种问题的解决方法,那么C++呢?
在C++中,给出了namespace关键字,来解决这一问题。
命名空间的定义
命名空间是一种机制,可以将全局作用域划分为更小的独立作用域,从而利于解决命名冲突的问题。
那么命名空间是如何创建的呢?
namespace namespace_name {// 变量、函数、类等定义
}
正常的命名空间的定义
#include <iostream>
#include <stdlib.h>using namespace std;namespace test
{int rand = 100;
}int main()
{return 0;
}
这样,就不会在出现由于命名冲突造成的警告了。
但是怎么去访问test这块空间呢?
using namespace
这两个单词是什么意思呢?—使用命名空间
如何使用命名空间
在C++中使用命名空间,有两种常见的方式,一种是使用using关键字,另一种是直接使用命名空间限定符。
第一种方式是使用using关键字将命名空间引入当前作用域中,这样就可以在当前作用域中直接使用命名空间中的函数、变量等定义。
也可以这样理解,就是将std中的东西暴漏在全局变量中供使用。
#include <iostream>
using namespace std; // 引入 std 命名空间int main() {cout << "Hello, world!" << endl; // 可以直接使用 cout,而不必使用 std::coutreturn 0;
}
需要注意的是,使用using关键字引入命名空间可能会带来命名冲突的问题,因此最好只在函数内部或局部范围内使用,而不要在全局范围内使用。
第二种方式是使用命名空间限定符来访问命名空间中的元素。在访问命名空间中的元素时,需要使用名称前面加上命名空间限定符来表示要访问的元素属于哪个命名空间。例如:
#include <iostream>
#include <stdlib.h>using namespace std;namespace test
{int rand = 100;
}int main()
{cout << test::rand << endl;return 0;
}
使用命名空间限定符的方式可以避免命名冲突问题,但是在代码中会显得比较繁琐。因此,建议在代码中使用合适的方式来使用命名空间。
命名空间可以嵌套
在C++中可以使用命名空间嵌套的方式来实现更加复杂的命名空间划分。
#include <iostream>
#include <stdlib.h>using namespace std;namespace test_1
{int rand_1 = 100;namespace test_2{int rand_2 = 200;}
}int main()
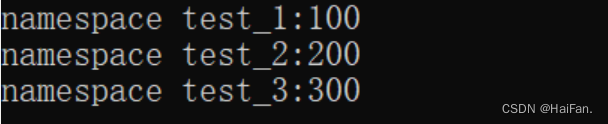
{cout << "namespace test_1:" << test_1::rand_1 << endl;cout << "namespace test_2:" << test_1::test_2::rand_2 << endl;return 0;
}
需要注意的是,命名空间的嵌套使用并不是局限于两层,可以根据现实需求来设计层数。
同一个工程中允许存在多个相同名称的命名空间,编译器最后会合成同一个命名空间中(一个工程中的.h文件和test.cpp中的同名也会合并成一个)
同一个工程中可以存在多个相同名称的命名空间。当编译器编译完这些命名空间中的代码后,编译器会将它们合并为同一个命名空间,不同于相同名称的类。这个过程发生在编译期间,因此当程序运行时,只有一个命名空间被使用。
//.h文件
#include <iostream>using namespace std;namespace test_1
{int rand_3 = 300;
}//.cpp文件#include "test_2.h"namespace test_1
{int rand_1 = 100;namespace test_2{int rand_2 = 200;}
}int main()
{cout << "namespace test_1:" << test_1::rand_1 << endl;cout << "namespace test_2:" << test_1::test_2::rand_2 << endl;cout << "namespace test_3:" << test_1::rand_3 << endl;return 0;
}
C++的输入和输出
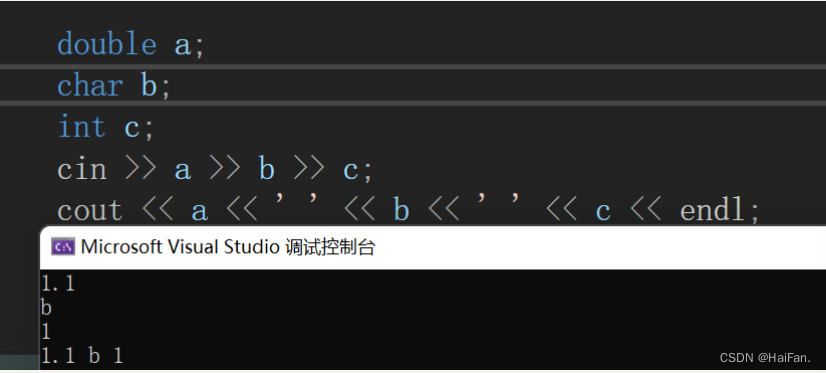
C++的输入和输出与C语言不太一样,C++的输入和输出可以自动识别数据类型,double,char,int等类型的数据都可以直接进行输入和输出。
输入操作为:std::cin
输出操作为:std::cout
在这里要先介绍一下C++的std
std
在C++中,命名空间std是标准库的命名空间,C++标准库包含一组头文件,类型定义,变量和函数,主要主要用于提供常用的基本功能,如文件输入输出、字符串处理、数学计算、容器、算法等等。这些功能和对象被封装在std命名空间中,以防止名称冲突和命名混乱。
具体而言,命名空间std中包含了大量的常用C++库的定义和声明,它的完整的名称是std::。例如std::cout、std::cin、std::endl等等,这些都是C++标准库中定义的常用对象和函数。
需要注意的是,在使用C++标准库中的功能之前,需要包含对应的头文件。例如,为了使用标准输出流cout,需要在程序中包含头文件iostream。
缺省参数
在C++中,缺省参数是指函数或方法在定义时可以给某些参数指定默认值,当调用该函数或者方法的时候,如果没有为这些参数提供实参时,系统会默认使用默认值。
缺省参数定义格式
return_type function_name(type1 param1 = default_value1, type2 param2 = default_value2, ...);
缺省参数必须位于参数列表的末尾,且每个参数只能有一个缺省值。
下面是一个使用缺省参数的函数定义
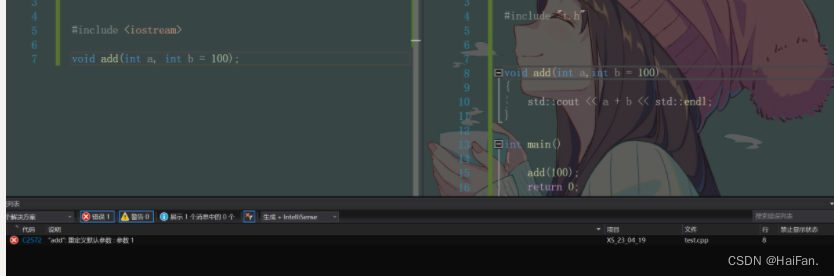
#include <iostream>void add(int a = -1)
{std::cout << "add->a:" << a << std::endl;return;
}int main()
{add();add(10);return 0;
}
这个代码中,函数add中的参数a有一个默认值-1,所以在调用add这个函数的时候,如果没有给实参,则a的值默认为-1,如果给了实参,则a的值就是实参的值。
缺省参数分类
全缺省参数
#include <iostream>void add(int a = -1,int b = 1,int c = 2)
{std::cout << a + b + c << std::endl;return;
}int main()
{add();return 0;
}

半缺省参数
#include <iostream>void add(int a = -1,int b = 1,int c = 2)
{std::cout << a + b + c << std::endl;return;
}int main()
{add(100);return 0;
}

缺省参数不能在函数声明和定义中同时出现。
函数重载
函数重载指的是在同一作用域中定义多个同名函数的行为,这些同名函数具有不同的参数列表,他们的参数类型,参数个数或者参数类型顺序不同。在调用这些同名函数时,编译器会根据实参的类型和个数匹配最合适的函数。
//函数参数类型不同
#include <iostream>float max(float a, float b)
{return a > b ? a : b;
}int max(int a, int b)
{return a > b ? a : b;
}int main()
{std::cout << "float max " << max(1.2, 1.3) << std::endl;std::cout << "int max " << max(1, 2) << std::endl;return 0;
}
这里定义了两个同名函数max,一个接受两个int类型的参数,另一个接受两个float类型的参数。这两个函数实现的功能是计算传入的两个数的最大值。在调用这两个函数时,编译器会根据传入的参数类型的不同来匹配最合适的函数。

需要注意的是,函数的返回值类型并不影响函数重载,也就是说,返回值类型相同的函数也可以重载。但是,如果只有函数的返回值类型不同,则会发生编译错误。
函数重载的底层原理是利用了名字修饰特性,名字修饰指的是将函数名和参数列表的信息编码为一定格式的字符串的过程。
当函数被调用时,编译器会根据函数名和参数列表的类型、数量、顺序等信息生成一个唯一的名字(也就是名字修饰后的字符串)。这个名字被用来表示函数在符号表中的位置,以便于链接器在连接时正确地找到函数的地址。
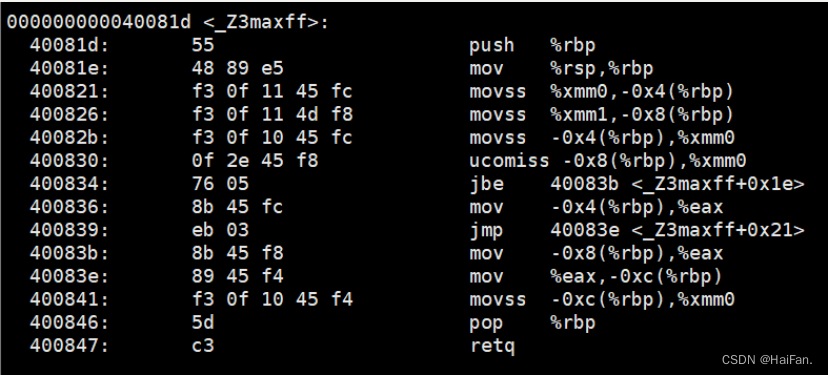
在Linux下,采用g++编译完成后,函数名字的修饰发生改变,float max(float a, float b)的名字就变成了 <_Z3maxff>
函数参数个数不同
void func()
{std::cout << "func()" << std::endl;
}void func(int a)
{std::cout << "func(int a)" << std::endl;
}int main()
{func();func(100);return 0;
}

参数类型顺序不同
#include <iostream>void f(int a, char b)
{std::cout << "f int a char b" << std::endl;
}void f(char a, int b)
{std::cout << "f char a int b" << std::endl;
}int main()
{f(1, 'b');f('b', 1);return 0;
}

引用
引用并不是定义一个新的变量,而是对一个已经存在的变量,取一个外号(别名),(比如:张三的外号叫大牛,那么我问大牛吃过饭没是不是等价于问张三吃过饭没?),编译器不会为引用变量新开一个空间,他和他引用的变量共用一块空间。
int x = 10;
int &ref = x;
//这里的int 和变量名字都是自己定义的,可以修改
注:引用类型必须和引用实体是同种类型,
引用的特性
- 引用必须在定义时初始化,因为引用是已存在的变量的别名,如果没有初始化,就没有引用的对象
#include <iostream>int main()
{int a = 1;int& ra;return 0;
}

- 引用一旦初始化后,就不能在改变他锁引用的对象(引用一旦绑定,就不能解绑了)
- 引用使用时可以像变量一样自然的直接调用
- 引用同样需要遵循作用域的规则。在引用的作用域内,它所引用的对象必须处于有效状态
- 一个变量可以有多个引用
常引用
void TestConstRef()
{
const int a = 10;
//int& ra = a; // 该语句编译时会出错,a为常量,a只有读的权限,不能提升为不加const的引用之后,权限提升---读和写
const int& ra = a;
// int& b = 10; // 该语句编译时会出错,b为常量
const int& b = 10;
double d = 12.34;
//int& rd = d; // 该语句编译时会出错,类型不同
const int& rd = d;//,临时空间具有常性
}
做参数
#include <iostream>void func(int& a)
{a--;
}int main()
{int a = 10;func(a);std::cout << a << std::endl;return 0;
}

当我们想要在函数内部修改某个变量的值,并使这个变化保持在函数外部,可以考虑使用引用作为参数。使用引用作为函数参数的好处在于可以避免函数传递过程中对变量的拷贝,提高程序的效率,同时也可以方便地在函数内部修改变量的值。
做返回值
在用引用做返回值:使用引用作为函数的返回值,使得函数的返回值是某个已经存在的变量,而不是函数内部新创建的一个变量。
#include <iostream>int& func()
{static int n = 0;n++;return n;
}int main()
{std::cout << func() << std::endl;return 0;
}

n被static修饰了,所以这个代码没什么问题。
#include <iostream>
#include <cstdlib>
int& func()
{int n = 0;n++;return n;
}int main()
{int &ret = func();std::cout << ret << std::endl;rand();std::cout << ret << std::endl;return 0;
}

这个代码输出随机值的原因是因为,在函数func()中,我们返回的是一个局部变量n的引用。当函数返回时,局部变量n会被销毁,它的内存空间被系统回收,所以返回的引用实际上是指向了一个不存在的内存空间。
因此,当我们在主函数中使用返回的引用变量ret时,由于其指向了一个已经被销毁的内存空间,所以输出的结果是不确定的,可能是随机值,也可能是0,也可能是程序崩溃。
解决这个问题的方法是,我们需要将相关变量的生命周期扩展到函数外部。例如,在这个例子中,我们可以将变量n定义为静态变量,使其生命周期和程序的生命周期相同,或者动态分配一个内存空间,并将其地址作为引用返回。
引用和指针的区别
C++中引用和指针都可以用来间接访问变量,在某些情况下它们可以相互替换使用,但是它们仍然有着不同的实现和应用。
- 内存占用:指针需要额外使用内存来存放指针变量的地址,而引用本质上并不需要占用额外的内存空间。
- 使用限制:指针可以被初始化为空指针或指向任意地址,而引用必须在声明时被初始化,并且不能更改其指向的变量。
- 空值:引用永远不会为空,而指针可以为空。
- 作为函数参数:引用作为函数参数时,可以避免对象的复制,提高效率。而指针作为函数参数时,可以方便地修改指针指向的变量。
- 在sizeof中的含义不同,指针是地址,占用空间为32/64 — 4/8
- 引用自加即引用的实体增加1,指针自加即指针向后偏移一个类型的大小
auto关键字(C++11)
C++11引入了auto关键字,使得程序员可以使用类型推导的方式定义变量,让编译器自动推断变量的类型。它的语法形式为:
auto variable = value;
其中,variable为变量名,value为变量的初始值,编译器会根据value的类型推导出variable的类型。
auto关键字的使用可以使代码更加简洁、易读、易维护,同时也方便定义一些复杂类型的变量,例如迭代器、函数返回值等。以下是auto关键字的一些应用场景:
- 推导迭代器类型
map<string, int> m;
for(auto it = m.begin(); it != m.end(); ++it) {...
}
- 推导函数返回值类型
auto sum(int a, int b) {return a + b;
}
...
auto result = sum(1, 2);
- 推导类成员变量类型
class Example {auto num = 10;
};
需要注意的是,在使用auto关键字时需要确保变量的类型能够被准确地推导出来,否则会导致编译错误。
基于范围的for循环(C++11)
C++11引入了基于范围的for循环语句,它提供了一种便捷的方式遍历容器(如数组、向量和映射等)及其它支持begin()和end()函数的对象。
基于范围的for循环的语法形式如下:
for (declaration : sequence) {statement
}
其中,declaration是用于定义循环的迭代变量的声明(推荐使用auto关键字来进行类型推导),sequence是需要遍历的容器或数据结构,statement是每一次循环要执行的操作。
下面是一个使用基于范围的for循环对数组进行遍历的例子:
int arr[] = {1, 2, 3, 4, 5};
for (auto x : arr) {cout << x << " ";
}
输出结果为:1 2 3 4 5
下面是使用基于范围的for循环对向量进行遍历的例子:
vector<int> vec = {1, 2, 3, 4, 5};
for (auto x : vec) {cout << x << " ";
}
输出结果为:1 2 3 4 5
基于范围的for循环相比于传统的for循环更加简洁、易读,并且能够避免因数组越界而导致的程序崩溃等问题。此外,它也支持使用const关键字限制迭代变量,使得其值在循环体内不能被修改。
除此之外,也可以修改值
int arr[] = {1, 2, 3, 4, 5};
for (auto& x : arr) {x += 1;
}
for (auto x : arr) {cout << x << " ";
}
输出结果为:2 3 4 5 6
内联函数
内联函数指的是使用关键字inline定义的函数,表示该函数是一个内联函数。内联函数与普通函数的区别在于,内联函数的调用不是通过函数栈帧的方式,而是直接在调用位置进行代码展开,从而减少了函数调用的开销,提高了程序的执行效率。
具体来说,当我们使用内联函数时,编译器会将函数体的代码直接展开到调用的位置,从而避免了函数调用时压栈和出栈的操作,减少了开销。但是,内联函数也有一些限制,如函数体不能过于复杂,否则可能会导致代码大小明显增加,进而扰动了缓存、提高了指令访问路径(instruction access path)的长度,降低了CPU Pipeline的效率。
一个内联函数的定义通常是放在头文件中,它的定义一般是在函数体前加上inline关键字。例如下面的图片
注:内联函数只是像编译器发出一个请求,编译器可以选择忽略这个请求
NULL和nullptr
NULL和nullptr都表示空指针。它们的区别在于,NULL实际上是一个宏定义,通常被定义为0,而nullptr是C++11中引入的关键字,它是一个真正意义上的空指针,可以避免一些因为0被隐式转换为指针而导致的错误。
#ifndef NULL
#ifdef __cplusplus
#define NULL 0
#else
#define NULL ((void *)0)
#endif
#endif
C语言中我们通常使用NULL来表示空指针,例如:
int* ptr = NULL;
而在C++11中,我们可以使用nullptr来表示空指针,例如:
int* ptr = nullptr;
关于这两者的使用,在一些情况下,它们可以互换使用。但是,nullptr减少了一些因为0被隐式转换为指针而导致的错误,例如在函数重载时:
void func(int);
void func(char*);func(NULL); // 该调用将会调用 func(int);
func(nullptr); // 该调用将会调用 func(char*);
上述代码中,由于NULL是一个宏定义,实际上被展开为0,因此编译器无法通过调用参数来区分是调用func(int)还是func(char*)。而使用nullptr则可以避免这种情况,因为它是一个真正的指针类型,不会被隐式转换为其他类型。
注意:
- 在使用nullptr表示指针空值时,不需要包含头文件,因为nullptr是C++11作为新关键字引入
- 在C++11中,sizeof(nullptr) 与 sizeof((void*)0)所占的字节数相同。
- 为了提高代码的健壮性,在后续表示指针空值时建议最好使用nullptr。
语法糖简介
在程序设计中,语法糖(Syntactic sugar)指的是一种让代码更加易读、易写的语法修饰特性,它并不会引入新的功能特性,但却可以减少代码的输入量、提高代码的可读性或可维护性。
常见的语法糖包括但不限于:
- 运算符重载:使用运算符进行类对象的操作,使得代码更加简洁易懂,如C++中的operator+等。
- 容器类的简化:通过STL等标准库提供的容器类,简化复杂的数据结构操作,如C++中的vector、list、map等。
- 面向对象的语言特性:如继承、多态、虚函数等,可以使得代码更具有可扩展性和易维护性。
- 内置函数和函数库:如C++提供的sort等算法库可以使得编写代码的效率更高,同时代码也更加简洁。
相关文章:
C/C++基础知识
专栏:C/C 个人主页: C/C基础知识 前言C关键字(C98)命名空间命名空间的定义正常的命名空间的定义如何使用命名空间 命名空间可以嵌套同一个工程中允许存在多个相同名称的命名空间,编译器最后会合成同一个命名空间中(一个工程中的.h文件和test.…...

Java 入门 - 语法基础
hello world public class Hello {public static void main(String[] args) {System.out.println("hello world");} } 复制代码 public: 是关键字;表示公开的class: 是关键字;用来定义类Hello: 是类名;大小写敏感;命名…...

Java线程池及拒绝策略详解
前文提到线程的使用以及线程间通信方式,通常情况下我们通过new Thread或者new Runnable创建线程,这种情况下,需要开发者手动管理线程的创建和回收,线程对象没有复用,大量的线程对象创建与销毁会引起频繁GC,…...
GitLABJenkins
GitLAB & Jenkins 目录 实践:基于Jenkins提交流水线(测试成功)-2023.4.25 目的:掌握通过触发器将GitLab和Jenkins集成,实现提交流水线。 1、触发Jenkins构建 安装Generic Webhook Trigger插件 重启后,进入一个Pipeline项目设…...
)
互联网摸鱼日报(2023-04-26)
互联网摸鱼日报(2023-04-26) InfoQ 热门话题 神州数码:抢抓云原生发展机遇,共建共治共享 OpenNJet 应用引擎开源生态 《产业数字人才研究与发展报告(2023)》 如何写出CPU友好的代码,百倍提升…...
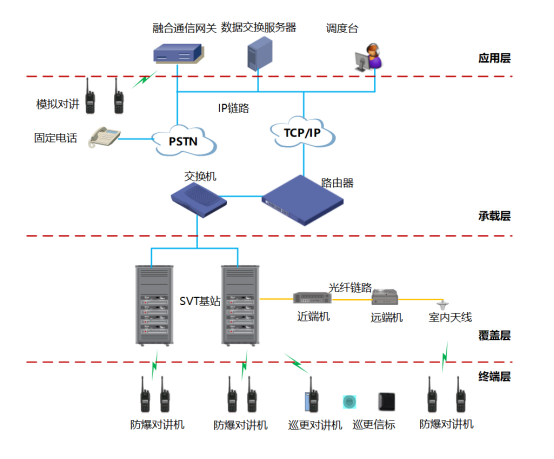
石化企业数字化防爆融合通信解决方案
项目背景 石化工业是我国国民经济和社会发展的基础性、战略性产业,其发展和壮大受到了党和国家的高度重视。随着石化企业厂区规模的不断扩大以及技术的快速发展,现有石化企业专网通信系统建设相对滞后,缺乏结合人员管理、安全生产、安全通信…...
)
NTT学习笔记(快速数论变换)
一些概念 欧拉函数 ϕ ( n ) \phi(n) ϕ(n) 欧拉函数简介 阶 若 g g g和 n n n互质,则令 g x % n 1 g^x\%n1 gx%n1的最小正整数 x x x称为 g g g模 n n n的阶。 原根 对于互质的两个正整数 g g g和 n n n,如果 g g g模 n n n的阶为 ϕ ( n ) \phi…...
Android类似微信首页的页面开发教程(Kotlin)二
前提条件 安装并配置好Android Studio Android Studio Electric Eel | 2022.1.1 Patch 2 Build #AI-221.6008.13.2211.9619390, built on February 17, 2023 Runtime version: 11.0.150-b2043.56-9505619 amd64 VM: OpenJDK 64-Bit Server VM by JetBrains s.r.o. Windows 11 …...

PAt A1015 Reversible Primes
1015 Reversible Primes 分数 20 作者 CHEN, Yue 单位 浙江大学 A reversible prime in any number system is a prime whose "reverse" in that number system is also a prime. For example in the decimal system 73 is a reversible prime because its rever…...

解决Lemuroid识别不到蓝牙键盘的问题
Android系统基于libretro的全能游戏模拟器,目前有RetroArch,Kodi,Lemuroid。 而且这三个都是开源免费的APP。 Lemuroid相对前面两个功能比较简陋。也不能自己下载核心。但代码也是最少的。 在使用Lemuroid的时候,发现它不能检测…...
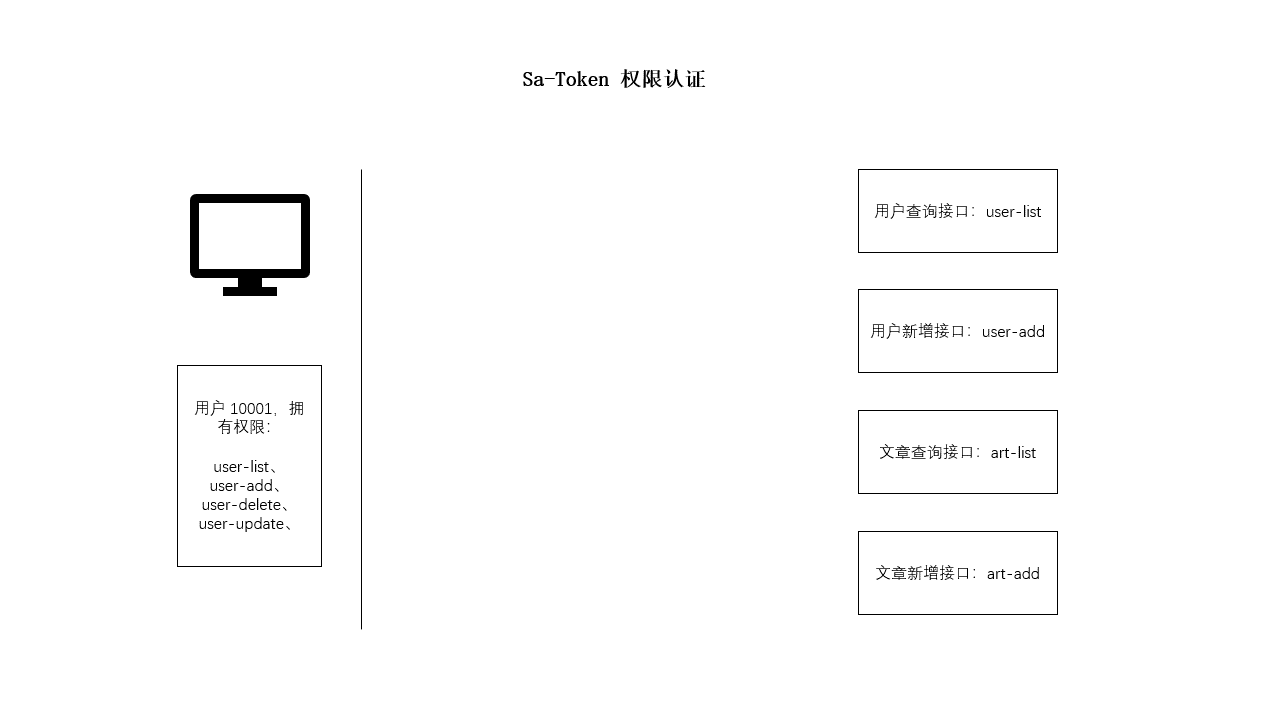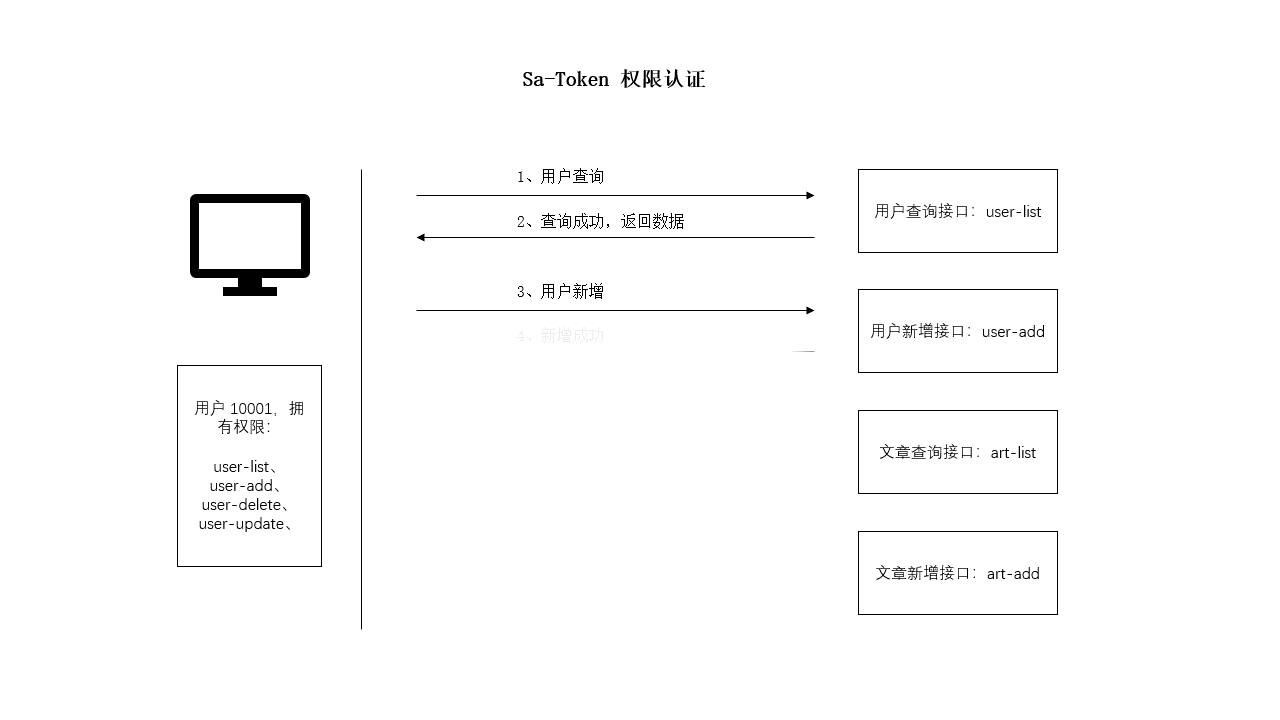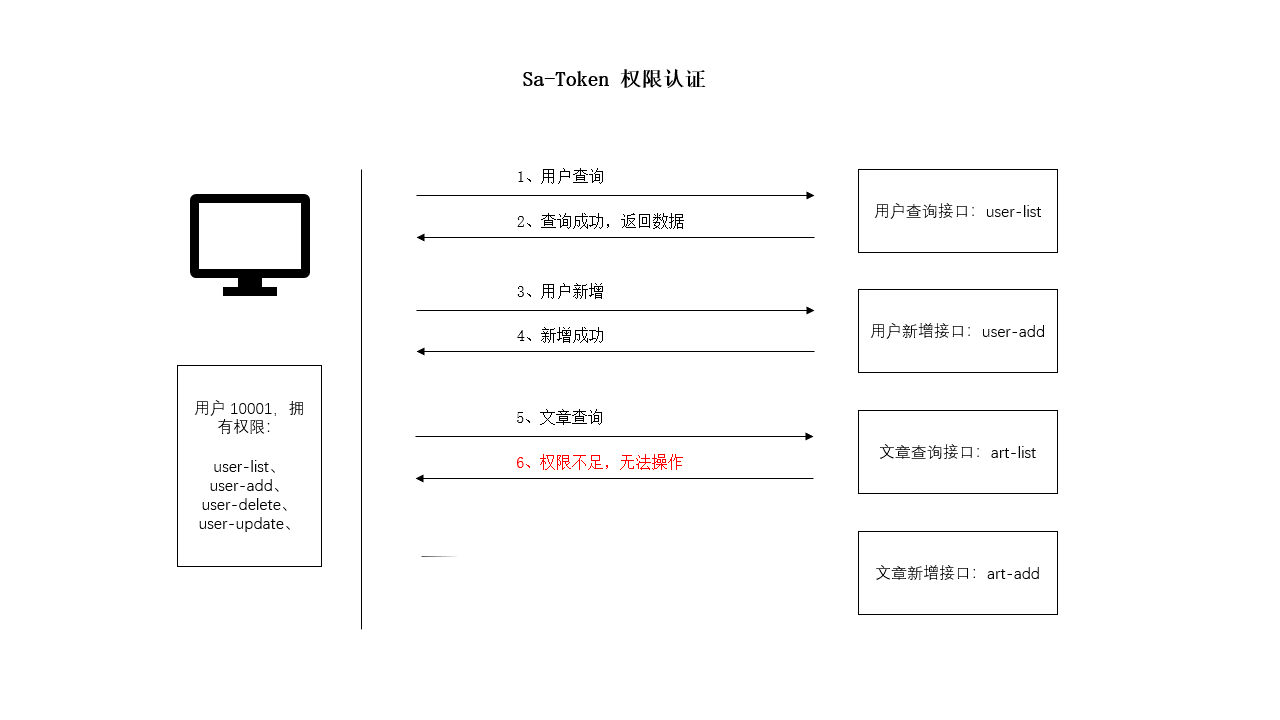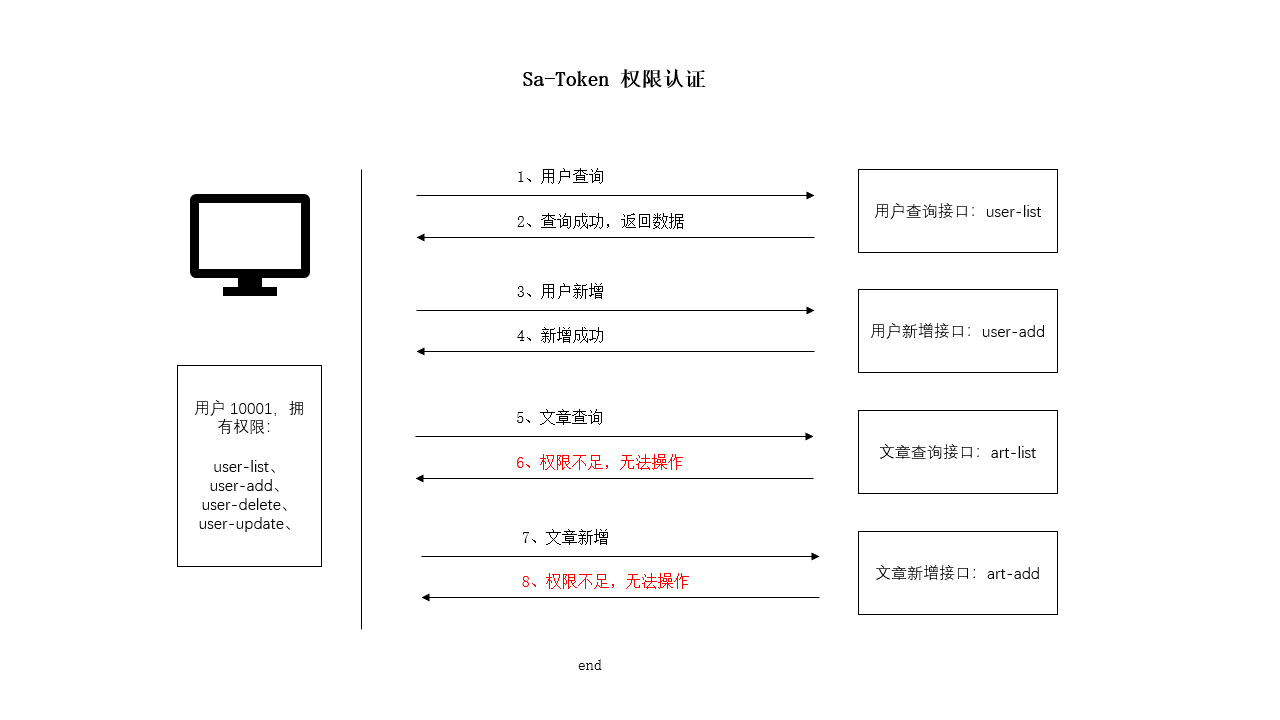
SpringBoot 使用 Sa-Token 完成权限认证
一、设计思路 所谓权限认证,核心逻辑就是判断一个账号是否拥有指定权限: 有,就让你通过。没有?那么禁止访问! 深入到底层数据中,就是每个账号都会拥有一个权限码集合,框架来校验这个集合中是…...

Spring核心与设计思想、创建与使用
文章目录 一、Spring是什么二、为什么要学习框架三、IoC和DI(一)IoC1. 认识IoC2. Spring的核心功能 (二)DI 四、Spring项目的创建(一)使用 Maven 方式创建一个 Spring 项目 五、Spring项目的使用࿰…...

mysql 备份 还原
1:备份 执行命令方案1: /usr/local/mysql/bin/mysqldump -uX -pX -h 127.0.0.1 --set-gtid-purgedOFF --skip-extended-insert --add-drop-table --add-locks --create-options --disable-keys --lock-tables --quick --set-charset -e --max_allowed_packet16777216 --net_b…...

每日学术速递4.26
CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理 Subjects: cs.CV 1.AutoNeRF: Training Implicit Scene Representations with Autonomous Agents 标题:AutoNeRF:使用自主代理训练隐式场景表示 作者:Pierre Marz…...

RabbitMQ使用StringRedisTemplate-防止重复消费
造成重复消费的原因: MQ向消费者推送message,消费者向MQ返回ack,告知所推送的消息消费成功。但是由于网络波动等原因,可能造成消费者向MQ返回的ack丢失。MQ长时间(一分钟)收不到ack,于是会向消…...

临沂大学张继群寄语
目录 寄语 1、不能有不良睹好 2、坚毅的个性和勤奋的品质 3、会存钱...

线程学习笔记
1:Thread 线程的生命周期控制 2:Runnable 可执行的任务和程序 3:Callable 执行程序后返回结果 4:Future 收集程序返回结果 5:Executor 线程池 6:ForkJoin 默认线程池 每个线程有工作队列 工作窃取 7:RunnableFuture FutureTask 实现 Runnable 和 Future 执…...

代码随想录算法训练营第四十二天|01背包问题,你该了解这些!、01背包问题,你该了解这些! 滚动数组 、416. 分割等和子集
文章目录 01背包问题,你该了解这些!01背包问题,你该了解这些! 滚动数组416. 分割等和子集 01背包问题,你该了解这些! 题目链接:代码随想录 二维数组解决0-1背包问题 解题思路: 1.dp…...

结构体指针、数组指针和结构体数组指针
结构体指针 首先让我们定义结构体: struct stu { char name[20]; long number; float score[4]; }; 再定义指向结构体类型变量的指针变量: struct stu *student; /*定义结构体类型指针*/ student malloc(sizeof(struct stu)); /*为指针变量分…...

项目架构一些注意点
考虑系统的 稳定性 一、微服务的稳定性 1、如何解决那些不稳定的因素/问题?也是常说的如何容错。 2、一个系统的高可用取决于它本身和其强依赖的组件的高可用 3、消除单点 保活机制 健康检查 注册中心如何保障稳定性 注册中心集群 微服务本身对注册信息的本地持…...

wordpress后台更新后 前端没变化的解决方法
使用siteground主机的wordpress网站,会出现更新了网站内容和修改了php模板文件、js文件、css文件、图片文件后,网站没有变化的情况。 不熟悉siteground主机的新手,遇到这个问题,就很抓狂,明明是哪都没操作错误&#x…...

网络六边形受到攻击
大家读完觉得有帮助记得关注和点赞!!! 抽象 现代智能交通系统 (ITS) 的一个关键要求是能够以安全、可靠和匿名的方式从互联车辆和移动设备收集地理参考数据。Nexagon 协议建立在 IETF 定位器/ID 分离协议 (…...

R语言AI模型部署方案:精准离线运行详解
R语言AI模型部署方案:精准离线运行详解 一、项目概述 本文将构建一个完整的R语言AI部署解决方案,实现鸢尾花分类模型的训练、保存、离线部署和预测功能。核心特点: 100%离线运行能力自包含环境依赖生产级错误处理跨平台兼容性模型版本管理# 文件结构说明 Iris_AI_Deployme…...

NLP学习路线图(二十三):长短期记忆网络(LSTM)
在自然语言处理(NLP)领域,我们时刻面临着处理序列数据的核心挑战。无论是理解句子的结构、分析文本的情感,还是实现语言的翻译,都需要模型能够捕捉词语之间依时序产生的复杂依赖关系。传统的神经网络结构在处理这种序列依赖时显得力不从心,而循环神经网络(RNN) 曾被视为…...

IT供电系统绝缘监测及故障定位解决方案
随着新能源的快速发展,光伏电站、储能系统及充电设备已广泛应用于现代能源网络。在光伏领域,IT供电系统凭借其持续供电性好、安全性高等优势成为光伏首选,但在长期运行中,例如老化、潮湿、隐裂、机械损伤等问题会影响光伏板绝缘层…...

Linux --进程控制
本文从以下五个方面来初步认识进程控制: 目录 进程创建 进程终止 进程等待 进程替换 模拟实现一个微型shell 进程创建 在Linux系统中我们可以在一个进程使用系统调用fork()来创建子进程,创建出来的进程就是子进程,原来的进程为父进程。…...

Xen Server服务器释放磁盘空间
disk.sh #!/bin/bashcd /run/sr-mount/e54f0646-ae11-0457-b64f-eba4673b824c # 全部虚拟机物理磁盘文件存储 a$(ls -l | awk {print $NF} | cut -d. -f1) # 使用中的虚拟机物理磁盘文件 b$(xe vm-disk-list --multiple | grep uuid | awk {print $NF})printf "%s\n"…...

【生成模型】视频生成论文调研
工作清单 上游应用方向:控制、速度、时长、高动态、多主体驱动 类型工作基础模型WAN / WAN-VACE / HunyuanVideo控制条件轨迹控制ATI~镜头控制ReCamMaster~多主体驱动Phantom~音频驱动Let Them Talk: Audio-Driven Multi-Person Conversational Video Generation速…...
与常用工具深度洞察App瓶颈)
iOS性能调优实战:借助克魔(KeyMob)与常用工具深度洞察App瓶颈
在日常iOS开发过程中,性能问题往往是最令人头疼的一类Bug。尤其是在App上线前的压测阶段或是处理用户反馈的高发期,开发者往往需要面对卡顿、崩溃、能耗异常、日志混乱等一系列问题。这些问题表面上看似偶发,但背后往往隐藏着系统资源调度不当…...

mac 安装homebrew (nvm 及git)
mac 安装nvm 及git 万恶之源 mac 安装这些东西离不开Xcode。及homebrew 一、先说安装git步骤 通用: 方法一:使用 Homebrew 安装 Git(推荐) 步骤如下:打开终端(Terminal.app) 1.安装 Homebrew…...