C++入门(C++)
目录
命名空间
1、命名空间的定义
2、命名空间的使用
1、加名空间名称和作用域限定符
2、使用using namespace 命名空间引入
3、使用using将命名空间中某个成员引入
C++的输入与输出
缺省参数
1、缺省参数的概念
2、缺省参数分类
1、全缺省参数
2、半缺省参数
函数重载
1、函数重载的概念
2、c++支持函数重载的原理
引用
1、引用概念
2、引用的特性
3、常引用
4、引用的使用场景
1、做参数
2、做返回值
5、传值,传引用效率比较
1、传参比较
2、做为返回值比较
6、引用和指针的区别
1、语法概念:
2、底层实现:
3、汇编层面对比:
4、引用和指针的不同点
内联函数
1、概念
2、特性
auto关键字
1、auto简介
2、auto的使用细则
3、auto不能推导的场景
基于范围的for循环(C++11)
1、范围for的语法
2、范围for的使用条件
指针空值nullptr(C++11)
1、C++98中的指针空值
2、C++11中的nullptr
命名空间
在C/C++中,变量,函数,以及类都是大量存在的。存在的这些类、变量、函数的名称,都将存在全局作用域中。倘若函数、变量、类的名称相同的时候,会产生命名冲突!
例如:
#include <stdio.h> #include <string.h>int strstr = 20;int main() {int strstr = 10;return 0; }//error(错误):strstr重定义 //因为:在string.h文件中包含一个同名的strstr函数, // 而头文件被包含之后strstr函数也就存在与全局域了 //所以我们再定义一个rand变量的时候会产生一个命名冲突的问题
为了规避命名冲突的问题,C++中提出了namespase也就是定义命名空间域来解决!
1、命名空间的定义
定义:
定义命名空间,需要用到namespace关键字,namespace后面跟命名空间的名字(该名字是我们自己取的),随后下面对接一个{}大括号,{}大括号中的就是命名空间中的成员(命名空间的成员可以是变量、常量、函数、结构、也可以另一个命名空间)!
代码:
//C++库里面的文件(C++的头文件,STL库……等都是存放在std命名空间域中的) #include <iostream>//用namespase 关键字定义命名空间 //NanShe 是命名空间名,是我们自己起的 namespace NanShe {//命名空间的成员//可以是常量、变量、函数、也可以是命名空间//常量 #define N 10//变量int a = 19;//函数int add(int a, int b){return a + b;}//也可以另一个命名空间(嵌套命名空间)namespace N1{int a = 29;//变量const float b = 3.14;//常变量//函数int sum(double a, double b){return a + b;}}}int main() {return 0; }
注意1:
同一个工程中允许存在多个同名的命名空间。而编译器最后在处理的时候会将多个同名的命名空间最后会合并成一个命名空间!切记同名的命名空间中不可再出现相同的变量或函数名……等,若出现相同则合并之后会发生命名冲突问题!
代码:
//在同一个工程中 //若多个命名空间域的相域名相同 //编译器在处理的时候会进行合并! //合并后若两个命名空间的成员有名称相同的 //会出现命名冲突报错!(重定义) namespace NanShe {int b = 20;//变量const int d = 23;//常变量//交换函数int Swap(int* left, int* right){int tmp = *left;*left = *right;*right = tmp;} }namespace NanShe {int c = 30;//加法函数int add(int a, int b){int z = a + b;return z;} }int main() {return 0; }
总结(注意):
定义一个命名空间,就定义了一个新的作用域,命名空间中所有的内容都局限与该命名空间中!
2、命名空间的使用
命名空间定义之后,该如何使用命名空间的成员呢?
错误的使用:
namespace NanShe {int c = 30;//加法函数int add(int a, int b){int z = a + b;return z;} }int main() {//错误的使用方式,不能直接进行访问使用printf("%d", c);return 0; }//error(报错):c未声明的标识符! //不可直接使用C,因为编译器在搜索的时候,默认先搜索main函数的局部区域 //再去搜索全局区域搜索完全局区域之后就结束搜获,不会主动去命名空间中去搜索 //搜获顺序:局部域->全局域->结束(不会主动去命名空间域搜索)
命名空间的使用有三种方式:(如下解释)
1、加名空间名称和作用域限定符
命名空间名+作用域限定符(::)
使用方法:在我们要使用的成员前面加上:命名空间名和作用域限定符!通过指定命名空间名称,以及作用域限定符号进行访问!当指定命名空间后,编译器会自动去我们所指定的命名空间里面寻找我们所使用的成员,若成员存在则正常访问,不存在则报错!
代码:
#include <iostream>namespace NanShe {int c = 30;//加法函数int add(int a, int b){int z = a + b;return z;} }int main() {//通过指定命名空间进行访问!(命名空间名+作用域限定符)printf("c = %d\n", NanShe::c);//指定访问NanShe命名空间中的成员 cint ret = NanShe::add(10, 25);//指定访问命名空减间中的add函数printf("Add(10,25) = %d\n", ret);//printf("%d\n", NanShe::b);//访问空间中不存在的成员 error(报错):未声明的标识符return 0; }
注意:
::作用域限定符前面不指定任何命名空间名的时候,默认访问的是全局域!若不加作用域限定符默认访问的是局部域!
代码:
#include <iostream>//全局 int a = 20;int main() {int a = 10;printf("%d\n", a);//不加作用域限定符,默认去局部域搜索printf("%d\n", ::a);//加作用域限定符,前面不指定命名空间,默认搜索全局域return 0; }
2、使用using namespace 命名空间引入
using namespace +命名空间名;
展开命名空间域,就是将该命名空间的内容都进行展开,暴露在全局域中,当命名空间全部展开之后我们就可以对该命名空间的成员进行访问!
代码:
#include <iostream>namespace NanShe {int c = 30;//加法函数int add(int a, int b){int z = a + b;return z;} }//展开整个命名空间域,将该空间暴露在全局域中 using namespace NanShe;int main() {//命名空间全部展开之后可直接进行访问成员printf("%d\n", c);printf("%d\n", add(10, 30));return 0; }
注意:
整个命名空间展开,暴露在全局之后,有很大的风险。一旦全局域中存在与该命名空间中的成员,命名相同的成员时。直接使用的时候会发生一个错误,错误内容时不明确该使用那个!(此时必须指定命名空间访问才能进行正常访问)!
代码:
#include <iostream>namespace NanShe {int c = 30;//加法函数int add(int a, int b){int z = a + b;return z;} }//展开整个命名空间域,将该空间暴露在全局域中 using namespace NanShe;int c = 222;int main() {//展开之后,是由风险的,若全局域中存在同名的,使用不明确!printf("%d\n", c);return 0; } //error(报错):C的使用不明确(不知道要使用那个域的内容)
解决方案:
展开全局之后,我们依然可以通过指定命名空间来进行访问!
#include <iostream>namespace NanShe {int c = 30;//加法函数int add(int a, int b){int z = a + b;return z;} }//展开整个命名空间域,将该空间暴露在全局域中 using namespace NanShe;int c = 222;int main() {int c = 20;//展开之后全局域中存在与其成员同名的时候,我们进行指定命名空间访问printf("NanShe c = :%d\n", NanShe::c);//指定访问NanShe命名空间域中的Cprintf("全局 c = :%d\n", ::c);//指定访问全局域中的Cprintf("局部 c = :%d\n", c);//默认访问局部域中的C//进行访问NanShe空间域的C 并且修改它的值NanShe::c = 100;printf("修改后的NanShe c = :%d\n", NanShe::c);//修改NanShe命名空间域中的C 是不影响局部域和全局域中的c的printf("\n修改NanShe命名空间域中的 C 不影响局部域和全局域的C\n");printf("全局 c = %d\n", ::c);printf("局部 c = %d\n", c);return 0; }
总结:
展开命名空间域,在全局命名相同的请况下展开,是非常不建议的!需要择情况而定!谨慎展开操作!
有一个问题:
那我们展开之后又进行指定访问,展开整个命名空间域有啥作用呢?是不是多次一举了。那么我们此时可以考虑使用下面一种方法进行展开,也就是选择性展开命名空间里面的成员,我们需要那个展开那个,大大方便了我们的操作!
3、使用using将命名空间中某个成员引入
用using展开命名空间中的指定成员:
用using 命名空间名::成员; 进行指定展开成员操作。有些情况下,为了防止命名空间中的其它成员和全局域中的成员同名发生不确定错误。我们进行指定展开,我们所需要访问的成员即可!
代码:
#include <iostream>namespace NanShe {int c = 30;//加法函数int add(int a, int b){int z = a + b;return z;} }//进行指定展开NanShe命名空间域中的add成员 using NanShe::add;int main() {//直接进行访问addprintf("%d\n", add(12,45));return 0; }
注意:
指定展开的成员,也要注意是否和全局域中的命名相同,若有相同的定然不能指定展开。也不可进行指定访问。然会出现重定义错误!
代码:
#include <iostream>namespace NanShe {int c = 30;//加法函数int add(int a, int b){int z = a + b;return z;} }//进行指定展开NanShe命名空间域中的c成员 using NanShe::c;//全局 int c = 22;int main() {//直接进行访问c,出现重定义错误printf("%d\n", c);//指定命名空间NanShe访问,也出现重定义错误printf("%d\n", NanShe::c);//指定全局域访问,也出现重定义错误printf("%d\n",::c);return 0; } //error(错误):c重定义,多次初始化
总结:
在部分展开的时候,一定要明确全局中是否有同名的,若有不展开,进行指定访问操作。若没有可进行展开,访问操作!
C++的输入与输出
在C++中有两个流分别代表输入和输出:
1、cout:标准输出对象(控制台),cin标准输入对象(键盘)、在使用两者的前提下都必须包含<iostream>头文件!C++的头文件是包含在std命名空间域中的,要使用输入和输出,得按照命名空间的使用方式使用std。输入:cin 输出:cout!
2、cout和cin是全局流对象,endl是特殊的C++符号表示换行输出,它们都包含在<iostream>头文件中
3、<< 是流插入运算符、>>是流提取运算符
4、C++的输入输出会自动识别类型以及格式。比起C语言更加方便,不需要像printf/scanf输入输出时那样需要控制格式!
代码:
//包含头文件 #include <iostream>//展开std命名空间域 using namespace std;int main() {int a = 0;int b = 0;int c = 0;//cin标准输入对象,输入a的值,会自动识别类型cin >> a;//cout标准输出对象,输出a,自动识别类型输出,endl表示换行cout << a << endl;//输入b和c的值cin >> b >> c;//输出b和ccout << b <<' '<< c;return 0; }
注意:
C++中为了和C的头文件区分,也为了正确的使用命名空间域,C++规定头文件不带.h,旧编译器(VC6.0)中还支持<iostream.h>的写法,后续编译器已经不在使用该.h的写法了!后续C++我们也推荐写<ioseam>+std这样的写法!
缺省参数
1、缺省参数的概念
概念:
缺省参数是声明或定义函数时为函数的参数指定一个缺省值。在调用的时候如果没有指定实参,则采用该形参的缺省值,否则使用指定的实参
代码:
#include <iostream>//指定展开 using std::cout; using std::cin; using std::endl;//定义函数,给参数,缺省值 int add(int a = 20 , int b = 10) {return a + b; }int main() {//若不指定参数,会使用缺省值来计算int ret = add();//输出cout << ret << endl;//若指定参数会将实参当成值ret = add(1, 2);cout << ret << endl;return 0; }
注意:
函数的参数给缺省值的时候,如果有函数的声明,建议在声明处给缺省值。若没有声明情况下才在函数定义上给缺省值。如果声明和定义同时都在,缺省值要么给声明要么给定义!不能同时给缺省值!(建议有声明的情况下,缺省值给声明,没有声明的情况下给定义。若两者同时存在,给声明和定义都行,但建议给声明,不可同时给缺省值)!
代码:
#include <iostream>//全部展开 using namespace std;//只有定义的请情况下,缺省值给定义 // 即有有定义又有声明的情况下要么给声明缺省值,要么给定义缺省值,不能同时给 // 建议给声明缺省值! ////函数声明,声明处给参数 void add(int a = 10, int b = 20);//函数定义 void add(int a , int b) {cout << a + b << endl; }int main() {//调用函数,不传参add();//调用函数传参add(2, 1);return 0; }
2、缺省参数分类
1、全缺省参数
全缺省参数:
顾名思义就是给函数的所有参数都给一个缺省值!
代码:
#include <iostream>using namespace std;//全缺省参数,给所有参数都给一个参数值 void Sub(double a = 3.12, double b = 4.15, int c = 10) {cout << c - a - b << endl; }int main() {//若不传参数,则默认用缺省值计算Sub();//传参数用实参的参数计算Sub(1.1, 2.2, 12);return 0; }
2、半缺省参数
半缺省参数:
就是只给部分参数缺省值,剩余的参数不给缺省值!,但是有一点要注意,在给部分参数缺省值的时候,必须从右往左,依次来给参数,不能间隔给!
代码:
#include <iostream>//全部展开 using namespace std;//使用半缺省参数的函数,从右往左依次给参数,不能间隔着给缺省值 void Add(int a, int b, int c = 20) {cout << a + b + c << endl; } int main() {//没有给缺省值的参数必须传实参//有缺省值的参数不传参数默认使用它的缺省值!Add(10,30);return 0; }
注意:
1、半缺省值,必须从右往左依次来给,不能间隔的给
2、缺省参数不能在函数声明和定义同时出现
3、缺省值必须是常量或全局变量
代码:
#include <iostream>//指定展开 using std::cin; using std::cout; using std::endl;//声明和定义不能同时出现参数!//函数声明 void Sub(int a, int b, int c, int d);//缺省参数必须是常量或全局变量 #define N 100 int s = 22; //参数的缺省值必须从右往左给,不能间隔给 void Sub(int a, int b = N, int c = 10,int d= s) {cout << b - c -d - a << endl; }int main() {Sub(15);return 0; }
函数重载
1、函数重载的概念
在自然语言中一个词可以有多种含义,人们可以根据情景,以及上下文来判断该词具体表示的含义。即该词被重载了!
概念:
函数重载:是函数的一种特殊情况,C++允许在同名作用域中声明几个功能类似的同名函数,而这些同名函数的形参(参数个数,或类型,或类型的顺序)不同。常用来处理不同数据类型实现同一功能的问题!
通俗点讲,就是在同一作用域中,可出现同一名称的函数,但要求是同名函数的类型,或者参数个数,或类型顺序,不相同,至少要满足其中一种才能实现重载的概念!
1、参数类型不同
#include <iostream>using namespace std;//1、参数类型不同 void Add(int a, int b) {int c = a + b;cout << c << endl; }void Add(double a, double b) {double c = a + b;cout << c << endl; }int main() {Add(1, 3);Add(1.2, 3.14);return 0; }
2、参数个数不同
#include <iostream>using namespace std;//2、参数个数不同 void fun(int a) {cout << a << endl; }void fun(int a, int b) {cout << a << ' ' << b << endl; }int main() {fun(10);fun(10, 20);return 0; }
3、参数类型顺序不同
#include <iostream>using namespace std;//3、参数类型顺序不同 //注意同类型的参数,顺序不同是不能构成重载的! void Sub(int a, float b) {cout << (b - a) << endl; }void Sub(float b, int a) {cout << (b - a) << endl; }int main() {Sub(10, 12.3f);Sub(3.14f, 1);return 0; }
注意:
1、参数类型顺序不同,是不同类型的参数的顺序不同才能构成重载,同类型参数顺序不同,是不能构成重载的!
2、函数的返回值不同是不构成函数重载的!
3、构成函数重载的函数也是可以给缺省值的!
2、c++支持函数重载的原理
我们知道C语言是不支持函数重载的!而C++是支持函数重载的!为什么?
我们知道在C/C++中,一个程序要运行起来,需要经历几个阶段:预处理、编译、汇编、链接。源文件先进行编译生成目标文件,再将所有目标文件和链接库进行链接,最后生成一个可执行程序!(详解参考主页:程序环境和预处理(C语言)文章)
我们知道在链接街阶段,当一个源文件中调用另一个源文件中的函数的时候,链接器会找函数的地址,找到之后链接到一起!在C中我们知道链接过程中链接器是通过函数的名称去寻找其所对应的函数。而每个编译器都有自己的函数名修饰规则!
由于Windows下的vs对链接时产生的函数名修饰规则比较复杂,而Linux的g++修饰规则简单易懂、所以我们使用Linux来查看函数名的修饰!
使用C语言编译器编译后的结果:
结论:
在Linux下 ,采用和gcc编译完成后,函数名的修饰没有发生改变!
采用C++编译器编译后的结果:
注意:
用g++编译的时候,函数名的修饰是发生改变的,由图add函数为例(_z3Addii),我们可推断:_z是一个前缀,3表示函数名的长度,紧接着是Add表示函数名,第一个i表示int类型,第二个i也表示int类型。由此可知在C++中函数名修饰的时候是添加了参数类型以及函数名长度等信息,进行修饰!
由此修饰规则我们可知:
当函数名相同的时候,参数类型不同,以及参数个数不同,和参数类型的顺序不同,编译器在底层对函数名进行修饰的时候最终结果也是不同的!因为结果不同,在链接阶段找到的函数也是不同的,会根据不同的函数名修饰结果,找到不同的函数!
总结:
综上所述,C语言是没办法支持函数重载的,因为同名函数没办法区分。而在C++中可出现:参数类型不同、或者参数个数不同、或者参数类型顺序不同,的同名函数,也就是构成函数重载!而返回值不同是不构成函数重载的,因为返回值是不参与函数名修饰规则的!
总代码:
#include <iostream>using namespace std;//1.参数类型不同,构成函数重载 void Add(int a, int b) {cout << a + b << endl; } void Add(float a, float b) {cout << a + b << endl; }//2、参数个数不同,构成函数重载 void Sub(int a, int b) {cout << a - b << endl; } void Sub(int a, int b, int c) {cout << a - b - c << endl; }//3、参数类型顺序不同,构成函数重载 void Mult(int a, float b) {cout << a * b << endl; } void Mult(float a, int b) {cout << a * b << endl; }//4、返回值不同是不构成函数重载的 //error(报错):无法重载仅按返回类型区分的函数 void Div(int a, int b) {cout << a / b << endl; }int Div(int a, int b) {return a / b; }int main() {//1、参数类型不同Add(1, 2);Add(1.1f, 2.2f);//2、参数个数不同Sub(9, 3);Sub(10, 1, 2);//3、参数类型顺序不同Mult(2, 2.5);Mult(1.25, 5);//4、返回值不同是不构成重载的!Div(3, 5);int ret = Div(3, 5);//error:无法重载仅按返回类型区分的函数return 0; }


引用
1、引用概念
概念:
引用不是新定义了一个变量,而是对已存在的变量取了一个别名,编译器不会对单独给引用开辟空间,它和它引用的变量共用一块内存空间。
例如:
一个人可以有很多个名字,比如博主名字叫楠舍,有人叫博主小楠,也有人叫博主小舍,也有人叫博主舍舍……等,很多名字,而除了楠舍本名之外,其它的都是博主的别名!归根结底,这些名字都是在指一个人,只是叫法不同而已!而在编程中,起别名就被叫做引用!
语法:
类型& 引用变量名(引用对象名)= 引用实体;
代码:
#include <iostream> using namespace std;int main() {//定义变量a并赋值int a = 10;//给a起别名b(b是a的引用)b和a是表示同一块空间int& b = a;cout << &a << endl;cout << &b << endl;return 0; }
2、引用的特性
特性:
1、引用在定义时必须初始化
2、一个变量可以有多个引用
3、引用一旦引用一个实体,再不能引用其它实体
4、引用与实体的类型必须相同
1、引用在定义时必须初始化
#include <iostream>using namespace std;int main() {int a = 20;//定义a的引用b,引用在定义的时候必须初始化int& b = a;//不初始化会报错int& c;//error(报错):引用变量C需要初始值设定项!return 0; }
2、一个变量可以有多个引用
#include <iostream>using std::cout; using std::endl;int main() {int a = 20;//一个变量可以有多个引用int& b = a;int& c = a;//也可以通过引用再取引用int& d = b;cout << &a << endl;cout << &b << endl;cout << &c << endl;cout << &d << endl;return 0; }
3、引用一旦引用一个实体,就不能引用其它实体
#include <iostream>using std::cout; using std::endl;int main() {int a = 30;int c = 40;//b引用实体aint& b = a;//一旦引用一个实体,不能再引用其它实体b = c;//此操作不是引用,而是赋值操作,是将c空间的值赋值给b引用的空间acout << "a 的地址:" << &a << endl;cout << "b 的地址:" << &b << endl;cout << "c 的地址:" << &c << endl << endl;cout << "a 的值:" << a << endl;cout << "b 的值:" << b << endl;cout << "c 的值:" << c << endl;return 0; }
4、引用与实体的类型必须相同
#include <iostream>using namespace std;int main() {int a = 10;//引用与实体的类型必须相同int& b = a;//引用与实体类型不同会进行报错double& c = a;//error(报错):E0434 无法用"int"类型的值初始化"double &"类型的引用(非常量限定)return 0; }
3、常引用
概念:
引用在引用一个实体的时候,权限可以平移,可以缩小,但权限不能放大!
例如:
用const修饰的变量的值是不能被改变的,而如果用一个不用const修饰的引用,去引用该变量是不允许的,因为不用const修饰的引用的权限是可以改变其值,而该变量本身的权限是不能改变值。即权限进行了放大,是不被允许的!
#include <iostream>using namespace std;int main() {//引用的时候权限可以平移,可以缩小,但是不可以放大//引用中,权限可以平移const int a = 20;const int& c = a;//引用中权限可以缩小double fd = 3125;const double& fg = fd;//const修饰的常变量const int s = 10;//对赋予常变量的属性,进行引用是不可行的!int& b = s;//因为b引用将a的权限放大了,本身a是由const修饰的,是不可改变的,// 而a的引用b不是由const修饰的,所以b引用的权限是可以改变的,// 引用b对a本身的权限进行了放大,所以是不允许的!return 0; }
4、引用的使用场景
1、做参数
引用做参数:
用引用做参数,可以直接通过形参访问实参,不再使用繁琐的指针来传地址解引用访问,更加方便了我们的使用!
代码:
#include <iostream>using namespace std;//交换函数,指针写法 void Swap(int* a, int* b) {int tmp = *a;*a = *b;*b = tmp; }//交换函数,引用写法 void Swap(int& a, int& b) {int tmp = a;a = b;b = tmp; }int main() {int a = 10;int b = 20;Swap(&a, &b);cout << a << " " << b << endl;Swap(a, b);cout << a << " " << b << endl;return 0; }//引用更加方便我们操作,我们可以直接操作 //指针法中如果是n级指针,就很吃力了 //而如果是引用我们直接引用就能直接访问到它了
总结:
引用大大方便了我们的操作,如果是n级指针,我们再进行解引用访问就很繁琐而且还容易出错。而使用引用我们就可以直接访问到要访问的内容了!使用起来更加方便
2、做返回值
引用做返回值:
引用是可以做函数返回值的,函数在返回值的时候,会开辟一个临时变量将返回的值存储起来,随后销毁函数栈帧,再将临时变量里的值返回到调用地方去!而引用做返回值是不开辟临时空间的,是直接返回!
代码:
#include <iostream>using namespace std;//用引用做返回值 int& Sub() {static int a = 10;return a; }//用引用做返回值 int& Add(int a, int b) {int c = a + b;return c;//返回c空间的引用,在返回的时候不开辟临时变量 }int main() {int& sun = Sub();//用sun接收a的引用,sun就是a的引用// 而a变量是存储在静态区的,Sub栈帧销毁a不会销毁// 自始至终都可以通过sun访问到acout << sun << endl;int& ret = Add(1, 3);//用ret接收c的引用//ret就是c空间的引用//有风险,如果Add函数的栈帧被操作系统清理了,或者被其它函数使用了//ret会产生随机值的风险cout << ret << endl;//调用以下Sub函数Sub();//此时的ret会成为一个不可预测的结果//因为Sub函数调用的时候会复用Add函数使用的栈帧cout << ret << endl;return 0; }
注意:
如果函数返回时,出了函数作用域,如果返回对象的空间没有销毁(没有还给操作系统),则可以使用引用返回。若空间销毁(还给了操作系统),则必须使用传值返回,继续使用引用会出现不可预测的结果!
5、传值,传引用效率比较
1、传参比较
传值,传引用,效率:
以值作为参数或者返回类型,在传参和返回期间,函数不会直接传递实参或者将变量直接返回,而是传递实参或者返回变量的一份临时拷贝。因此用值作为参数或者返回值类型,效率是非常底下的,尤其是当参数或者返回类型非常大时,效率就更底!然而引用的效率就比较高了,引用只是取别名!不需要将类型全都传过来,也不需要进行临时拷贝!
例如:
传入或者返回一个非常大的结构体时:
传值调用的时候形参是实参的临时拷贝,会拷贝一份非常大的结构体,返回的时候也是一样会产生零时变量来保存这个非常大的结构体,此时耗费的空间就很大,效率也很底下!
传引用,只是对其空间起了个别名,可以直接通过别名访问该空间,一般理解下引用是不占用空间的,(实际上引用的底层和指针一样的,哪怕占用空间也占用几个字节)相对于传值调用引用的效率就非常之高了!
代码:
#include <iostream>using namespace std;//定义学生结构体 struct student {char name[10];char id[12];int age;double hight;double wight; };//传值调用,形参是实参的一份临时拷贝,改变形参不影响实参 void Print(struct student s) {cout << s.id << endl;cout << s.name << endl;cout << s.age << endl;cout << s.hight << endl;cout << s.wight << endl; }//引用是给sd空间起了个别名s通过别名访问空间,效率高! void Print(struct student& s,int a) //a只是为了实现函数重载而传的,不必太在乎 {cout << s.id << endl;cout << s.name << endl;cout << s.age << endl;cout << s.hight << endl;cout << s.wight << endl;cout << a << endl; } int main() {struct student sd = { 0 };//传值调用Print(sd);//引用Print(sd,10);return 0; }
效率比较代码:
#include <iostream> using namespace std;#include <time.h> struct A { int a[10000]; };void TestFunc1(A a) {}void TestFunc2(A& a) {}void TestRefAndValue() {A a;// 以值作为函数参数size_t begin1 = clock();for (size_t i = 0; i < 10000; ++i)TestFunc1(a);size_t end1 = clock();// 以引用作为函数参数size_t begin2 = clock();for (size_t i = 0; i < 10000; ++i)TestFunc2(a);size_t end2 = clock();// 分别计算两个函数运行结束后的时间cout << "TestFunc1(A)-time:" << end1 - begin1 << endl;cout << "TestFunc2(A&)-time:" << end2 - begin2 << endl; }int main() {//效率测试TestRefAndValue();return 0; }//引用的效率明显比传值的效率高,数据越大效率越明显
总结:
传引用的效率,比传值的效率高的多,数据越大越明显!
2、做为返回值比较
值和引用作为返回值性能比较:
值作为返回值,返回时,会产生一个临时变量,拷贝一份该值,放入到临时变量中,再通过零时变量进行返回。当数据量过大的时候,相应的临时变量的空间也会开很大,性能就比较底下!而使用引用返回时,是不需要开辟临时空间的,引用是直接返回别名,不需要用临时空间,效率相对就快一点!
性能比较代码:
#include <iostream> using namespace std; #include <time.h> struct A { int a[10000]; }; A a;// 值返回 A TestFunc1() { return a; }// 引用返回 A& TestFunc2() { return a; }void TestReturnByRefOrValue() {// 以值作为函数的返回值类型size_t begin1 = clock();for (size_t i = 0; i < 100000; ++i)TestFunc1();size_t end1 = clock();// 以引用作为函数的返回值类型size_t begin2 = clock();for (size_t i = 0; i < 100000; ++i)TestFunc2();size_t end2 = clock();// 计算两个函数运算完成之后的时间cout << "TestFunc1 time:" << end1 - begin1 << endl;cout << "TestFunc2 time:" << end2 - begin2 << endl; }int main() {TestReturnByRefOrValue();return 0; }//引用的性能,比传值的性能明显高的多的多
总结:
传值和传引用在作为返回类型上,性能有很大的差距,引用比传值更优!
6、引用和指针的区别
1、语法概念:
语法概念:
在语法概念上,引用就是一个别名,没有独立的空间,和其引用的实体共用同一片空间。
代码:
#include <iostream>using namespace std;int main() {//语法概念上,引用是不开空间,和实体共用一块空间int a = 10;//b是a的引用int& b = a;//引用和实体共用同一块空间cout << &a << endl;cout << &b << endl;return 0; }
2、底层实现:
底层实现:
引用在底层实现上实际上是开辟空间的,因为引用时按照指针的方式来实现的!
代码:
#include <iostream>using namespace std;int main() {//底层实现中引用是开空间的//底层指针和引用的实现方式是一样的int a = 10;int& b = a;b = 20;int* pa = &a;*pa = 20;cout << a << endl;return 0; }
3、汇编层面对比:
汇编层面对比:
汇编底层,引用和指针实现是一样的!

4、引用和指针的不同点
不同点:
1、引用概念上定义一个变量的别名,指针存储一个变量的地址
2、引用在定义时必须初始化,指针没有要求
3、引用在初始化时引用一个实体后,就不能再引用其它实体。指针可以改变指向
4、没有NULL引用。但有NULL指针
5、sizeof中结果不同,引用的结果是引用类型的大小。指针始终是4/8个字节(32位下4字节,64位下8字节)
6、引用进行自增或自减,即引用实体自增或自减。指针自增或自减,指针向前或向后偏移一个类型大小!
7、有多级指针,没有多级引用
8、访问实体不同,指针需要解引用。引用编译器自己处理
9、引用比指针使用起来相对更加安全!(指针可能有NULL指针,野指针,不安全)
内联函数
1、概念
概念:
以inline修饰的函数叫做内联函数,在编译的时候,C++编译器会在调用内联函数的地方进行展开。展开之后没有函数调用时建立栈帧的开销,内联函数提升程序的运行效率!
理解:
未用lnline修饰的函数,在汇编层面会出现栈帧调用指令,(Call指令)
若在上述函数前增加inline关键字,将其改成内联函数,在编译期间编译器会用函数体替换函数调用!
Vs下查看:
1、在release模式下,直接查看汇编代码中是否有call Add 函数调用指令
2、在Debug模式下,需要对编译器进行设置才能查看,否则内联函数是不会展开的,因为展开了不便于我们调试(因为在Debug模式下,编译器默认对代码不进行优化)
用inline修饰后:
适用:
代码短小,而调用次数少的函数,适合用inline修饰,成为内联函数。内联函数的特性是在调用位置展开,减少函数栈帧的开销,若是代码太庞大,展开之后也会占用部分空间。再倘若调用次数过多,每次都在调用的地方展开,也是一种空间的消耗,倒不如开辟栈帧的效率了!实际上编译器也会对上面的情况自动进行处理,编译器允许短小的函数用inline 修饰。不允许将庞大的用inline修饰,若你执意用inline修饰了,编译器底层是不会把该函数当成内联函数的,会按照正常的函数开辟栈帧空间处理!当然每个编译器规定允许成为内联函数的代码行数是不一样的(在VS2019下是10行以内允许,以外不允许)!

2、特性
特性:
1、inline是一种以空间换时间的做法,如果编译器将函数当成内联函数,在编译阶段编译器会用函数体替换函数调用,也就是展开。缺陷:可能使目标文件变大。优点:少了栈帧开销,提高程序运行效率!
2、inline对于编译器来说只是一种建议,不同编译器对inline的处理是不一样的。建议:将函数规模较小的、且不是递归、不频繁调用的函数,用inline修饰)而inline对编译器只是建议,具体是否采纳你的建议就要看编译器本身的处理了!很多编译器都不支持内联递归函数,而且代码太长太多的函数,编译器也不会采用inline的建议!总的来说:inline只是一种建议,也就是对编译器发出的请求,而编译器可以忽略这个请求!
3、inline不建议,函数声明和定义分离,分离之后会导致链接错误。因为在编译的时候inline函数就被在调用地方展开了,而在链接阶段就找不到地址了,无法链接,就会报错!
代码:
// Fun.h 代码 #pragma once #include <iostream> using namespace std;//声明 inline int Add(int left, int right);//Fun.cpp 代码 #include "Fun.h"//定义 inline int Add(int left, int right) {return left + right; }//Test.cpp 代码 #include "Fun.h"int main() {int ret = Add(1, 2);cout << ret << endl;return 0; }//error(报错):链接错误,无法解析的外部符号
auto关键字
1、auto简介
简介:
在早期C/C++中,auto的含义是:使用auto修饰的变量,是具有自动存储器的局部变量,但很少有人去用它!
在C++11中,标准委员会赋予了auto全新的含义:auto不再是一个存储类型指示符,而是一个新的类型指示符来指示编译器,auto声明的变量必须由编译器在编译时期推导而得!
通俗点说:auto关键字,就是用来自动识别类型的关键字!
代码:
#include <iostream> using namespace std;int main() {int a = 10;auto b = a;auto c = 'c';auto d = "abcd";//打印类型cout << typeid(a).name() << endl;cout << typeid(b).name() << endl;cout << typeid(c).name() << endl;cout << typeid(d).name() << endl;auto e;//无法编译通过,auto定义的变量必须给它初始化//auto使用来识别类型的,而不初始化压根就不知道是什么类型return 0; }
注意:
auto修饰的变量必须进行初始化,在编译阶段,编译器是根据初始化的表达式来推导auto的类型。auto并非是一种类型的声明,而是一种类型的占位符,编译器在编译时会将auto替换成变量实际的类型!
2、auto的使用细则
1、auto与指针和引用结合起来使用
用auto声明指针类型时用auto和auto* 没有任何区别,但在声明引用类型时必须加上&
代码:
#include <iostream> using namespace std;int main() {int a = 10;//声明指针类型auto b = &a;auto* c = &a;//声明引用类型auto& d = a;//打印类型cout << typeid(a).name() << endl;cout << typeid(b).name() << endl;cout << typeid(c).name() << endl;cout << typeid(d).name() << endl;*b = 20;cout << a << endl;*c = 30;cout << a << endl;d = 40;cout << a << endl;return 0; }
2、在同一行定义多个变量
用auto 在用一行声明多个变量时,这些变量必须是相同类型的变量,因为编译器在编译阶段实际只对第一个变量类型进行推导,然后用推导出来的类型来定义后面的其它变量!
代码:
#include <iostream>using namespace std;int main() {//推导定义多个变量时,这些变量必须时同类型的//因为编译器只推导第一个变量的类型,后面的由推导出来的类型来定义auto a = 10, b = 20, c = 30;cout << a << endl;cout << b << endl;cout << c << endl;auto d = 12, e = 3.14;//这种情况会报错//error(报错):在声明符列表中,“auto”必须始终推导为同一类型return 0; }
3、auto不能推导的场景
1、auto不能作为函数的参数
auto作为形参类型的时候,会报错,因为编译器无法进行对形参实际类型进行推导!
代码:
#include <iostream>using namespace std;//auto不能作为函数参数, //因为编译器无法对实际的参数类型进行推导 void Add(auto a) {a++;cout << a << endl; }int main() {Add(10);return 0; }//error(报错):参数不能为包含“auto”的类型
2、auto不能直接用来声明数组
C++11规定 auto不能用来推导数组的类型!
代码:
#include <iostream>using namespace std;int main() {//auto不能推导数组的类型auto a[] = { 1,2,3,4,5 };auto b[] = { 1.2,1.3,1.4 };return 0; }//error(报错):“auto[]”: 数组不能具有其中包含“auto”的元素类型 //“auto”类型不能出现在顶级数组类型中
总结:
为了避免与C++98混淆,C++11只保留了auto作为类型指示符的用法!
auto在实际中的用法,主要是范围for,以及lambada表达式等进行配合使用!
基于范围的for循环(C++11)
1、范围for的语法
语法:
若用c++98遍历一个数组,需要先计算个数,再用for循环遍历!
代码:
#include <iostream>using namespace std;int main() {int arr[] = { 1,2,3,4,5,6,7,8,9 };//改变数组元素的值for (int i = 0; i < sizeof(arr) / sizeof(arr[0]); i++){arr[i] *= 10;}//遍历数组for (int i = 0; i < sizeof(arr) / sizeof(arr[0]); i++){cout << arr[i] << ' ';} }
然而对于一个有范围的数组集合而言,对于我们来说,再去写循环的范围是多余的!有时候还会犯错误。因此C++11中引入了基于范围的for循环。for循环的括号里面分为两部分:第一部分是范围内用于迭代的变量,第二部分则表示被迭代的范围,两者之间用冒号:分割开!
代码:
#include <iostream>using namespace std;int main() {//遍历数组int arr[] = { 1,2,3,4,5,6,7,8,9 };//范围for遍历数组,用auto关键字来识别类型,且通过引用改变它的值//第一部分是auto& e 表示迭代的变量,是对数组每个元素的引用//第二部分:arr 表示迭代的范围,是arr数组内!for (auto& e : arr){e *= 10;}//范围for遍历数组,用auto关键字来识别类型\//第一部分是auto e 表示迭代的变量//第二部分:arr 表示迭代的范围,是arr数组内!for (auto e : arr){cout << e << ' ';} }
注意:
范围for与普通循环类似,可用continue 结束本次循环,也可用break跳出循环!
2、范围for的使用条件
1、for循环迭代的范围必须是确定的!
对于数组而言就是数组元素的第一个元素和最后一个元素的范围。对于类而言应该提供begin和end的方法!begin和end就是for循环迭代的范围!
代码:
#include <iostream> using namespace std;//这种情况下 for的范围就不确定了,不能使用 //因为arr是一个指针,没法确定去确定数组的范围会报错 void Print(int arr[]) {for (auto e : arr){cout << e << ' ';} }int main() {int arr[] = { 1,2,3,4,5,6,7,8,9 };Print(arr);return 0; }//error(报错):此基于范围的“for”语句需要适合的 "begin" 函数,但未找到
2、迭代的对象要实现++或==操作。
关于该使用,我们后续迭代器文章再进行详解!
指针空值nullptr(C++11)
1、C++98中的指针空值
在C++98中指针的空值为:NULL,而NULL的底层是一个宏,在传统的C头文件<stddef.h>中可以看到:
由以上可知,NULL可能被定义为字面常量0,或者被定义为无类型指针(void*)的常量。不论采取哪种定义,使用NULL空值的指针时,会出现一些问题!
例如:以下函数调用问题
#include <iostream> using namespace std;void f(int) {cout << "f(int)" << endl; } void f(int*) {cout << "f(int*)" << endl; } int main() {//程序本意是第一个调用int参数的函数ff(0);//第二个NULL调用int*参数的函数,实际上NULL也是调用第一个int参数的函数f(NULL);//只有通过强制类型转换之后才可调用int*的函数f((int*)NULL);return 0; }以上代码,程序本意是想通过0调用int类型参数的函数f,通过NULL 调用int*类型参数的函数f。然而在实际上我们在调用的时候是两者都调用了int类型参数的函数f。因为NULL在底层宏定义的时候可能会被定义成0,在C++98 中,字面常量0 既可以是一个整型数字,也可以是无类型的指针(void*)常量,但编译器默认情况下会将其看成是一个整数常量来处理。所以才会出现该问题!则必须进行强制转换之后才可达到效果!
2、C++11中的nullptr
nullptr:
为了解决以上C++98中的问题,C++11中以关键字的形式引入了nullptr关键字。nullptr更加明确的表示是空指针!后续我们在给指针初始值的时候建议采用nullptr。nullptr是指针特有的!使用nullptr就很好的解决和规避使用NULL导致出现的问题!在C++11中sizeof(nullptr)和sizeof((void*)0) 所占字节数相同!
代码:
#include <iostream> using namespace std;void f(int) {cout << "f(int)" << endl; } void f(int*) {cout << "f(int*)" << endl; } int main() {//对于这种情况我们使用nullptr 就很好的解决问题了f(0);//调用int参数类型的函数ff(nullptr);//调用 int* 参数类型的函数 f//sizeof(nullptr)和sizeof((void*)0)占用字节数相同//三者所占大小相同cout << sizeof(nullptr) << endl;cout << sizeof((void*)0) << endl;cout << sizeof(NULL) << endl;return 0; }
注意:
1、在使用nullptr表示指针空值时,不需要包含头文件,因为nullptr是C++11作为新关键字引入的。
2、在C++11中sizoef(nullptr) 和sizeof((void*)0)所占字节数相同
3、为了提高代码效率,建议使用nullptr
相关文章:

C++入门(C++)
目录 命名空间 1、命名空间的定义 2、命名空间的使用 1、加名空间名称和作用域限定符 2、使用using namespace 命名空间引入 3、使用using将命名空间中某个成员引入 C的输入与输出 缺省参数 1、缺省参数的概念 2、缺省参数分类 1、全缺省参数 2、半缺省参数 函数重载 1、函数重…...

Linux 利用网络同步时间
yum -y install ntp ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime ntpdate ntp1.aliyun.com 创建加入crontab echo "*/20 * * * * /usr/sbin/ntpdate -u ntp.api.bz >/dev/null &" >> /var/spool/cron/rootntp常用服务器 中国国家授…...

炫技亮点 SpringBoot下消灭If Else,让你的代码更亮眼
文章目录 背景案例第一阶段 萌芽第二阶段 屎上雕花第三阶段 策略工厂模式重构第四阶段 优化 总结 背景 大家好,我是大表哥laker。今天,我要和大家分享一篇关于如何使用策略模式和工厂模式消除If Else耦合问题的文章。这个方法能够让你的代码更加优美、简…...
免费ChatGPT接入网站-网站加入CHATGPT自动生成关键词文章排名
网站怎么接入chatGPT 要将ChatGPT集成到您的网站中,需要进行以下步骤: 注册一个OpenAI账户:访问OpenAI网站并创建一个账户。这将提供访问API密钥所需的身份验证凭据。 获取API密钥:在您的OpenAI控制台中,您可以找到您…...

PostgreSQL的数据类型有哪些?
数据类型分类 分类名称说明与其他数据库的对比布尔类型PG支持SQL标准的boolean数据类型与MySQL中的bool、boolean类型相同,占用1字节存储空间数值类型整数类型有2字节的smallint、4字节的int、8字节的bigint;精确类型的小数有numeric;非精确…...

Android 9.0 系统开机自启动第三方app
1.前言 在9.0的系统rom定制化开发中,在framework定制话的功能开发中,在内置的app中,有时候在系统开机以后会要求启动第三方app的功能,所以这就需要在监听开机完成的广播,然后在启动第三方app就可以了,接下来就需要在系统类中监听开机完成的广播流程来实现功能 2.系统开…...

一些想法:关于学习一门新的编程语言
很多人可能长期使用一种编程语言,并感到很有成就感和舒适感,发现学习一种新的编程语言的想法令人生畏而痛苦。或者可能知道并使用多种编程语言,但有一段时间没有学习新的语言。更或者可能只是好奇别人是如何潜心学习新的编程语言并迅速取得成…...

线性代数——矩阵
文章目录 版权声明基础概念矩阵的运算矩阵的加法数与矩阵相乘矩阵的乘法矩阵的转置 矩阵和方程组方阵和行列式伴随矩阵可逆矩阵分块矩阵矩阵的初等变换初等矩阵等价矩阵行阶梯矩阵行最简矩阵初等变换在矩阵求解中的应用 矩阵的秩 版权声明 本文大部分内容皆来自李永乐老师考研…...

taro之小程序持续集成
小程序持续集成 Taro 小程序端构建后支持 CI(持续集成)的插件 tarojs/plugin-mini-ci。 目前已支持(企业)微信、京东、字节、支付宝、钉钉、百度小程序 功能包括: 构建完毕后自动唤起小程序开发者工具并打开项目上传…...
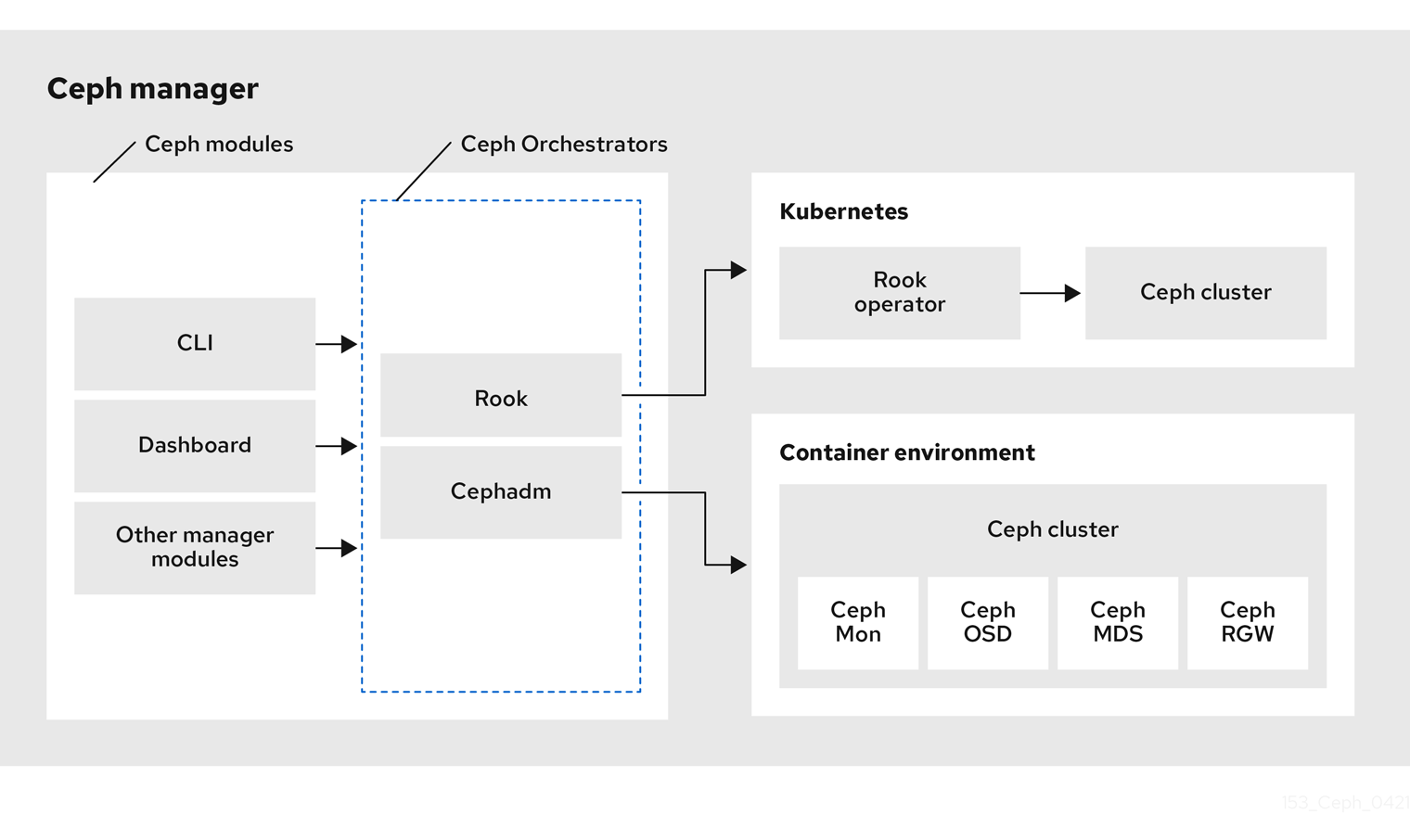
Ceph入门到精通-Ceph 编排器简介
第 1 章 Ceph 编排器简介 作为存储管理员,您可以将 Ceph 编排器与 Cephadm 实用程序搭配使用,能够发现设备并在 Red Hat Ceph Storage 集群中创建服务。 1.1. 使用 Ceph Orchestrator Red Hat Ceph Storage Orchestrators 是经理模块,主要…...

【Feign扩展】OpenFeign日志打印Http请求参数和响应数据
SpringBoot使用log4j2 在Spring Boot中所有的starter 都是基于spring-boot-starter-logging的,默认使用Logback。使用Log4j2的话,你需要排除 spring-boot-starter-logging 的依赖,并添加 spring-boot-starter-log4j2的依赖。 配置依赖 <…...
 安装和简单使用)
MongoDB (零) 安装和简单使用
1.安装(Ubuntu) 1.1.安装gnupg sudo apt-get install gnupg1.2.获取GPG Key curl -fsSL https://pgp.mongodb.com/server-6.0.asc | \sudo gpg -o /usr/share/keyrings/mongodb-server-6.0.gpg \--dearmor1.3.创建本地文件 echo "deb [ archamd64,arm64 signed-by/usr…...

Java中的异常是什么?
Java中的异常是指在程序运行时发生的错误或异常情况。这些异常可能会导致程序崩溃或无法正确执行,因此需要在代码中进行处理。Java中的异常机制可以帮助程序员捕获并处理异常,从而保证程序的稳定性和可靠性。 Java中的异常分为两种类型:受检…...
微短剧“小阳春”,“爱优腾芒”抢滩登陆?
降本增效一整年,长视频平台们似乎扭转了市场对于它们“烧钱”的印象。 爱奇艺宣布2022全年盈利,腾讯视频宣布从去年10月起开始盈利,视频平台们结束了一场“无限战争”。 与此同时,随着短视频平台的崛起,视频内容的形…...
C++菱形继承(再剖析)
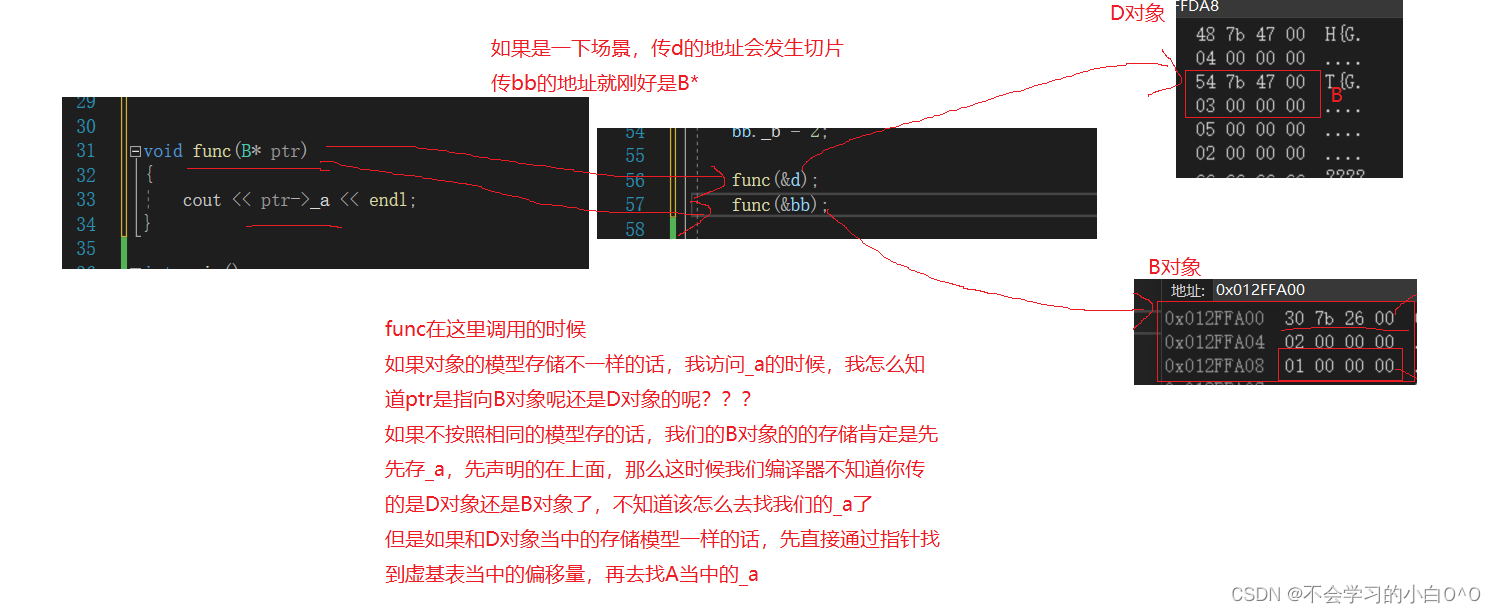
当子类对象给父类对象的时候,怎么找公共的虚基类(A) 就得通过偏移量来算虚基类的位置 ---------------------------------------------------------------------------------------------------------------------------- 我们来分析一下B…...

java获取星期几
如果你要问 java什么时候学习比较好,那么答案肯定是 java的星期几。 在 Java中,你可以使用 public static void main ()方法来获取一个类的所有成员变量,然后在所有类中调用这个方法来获取对象的所有成员变量。它能以对…...

【TypeScript】03-TypeScript基本类型
TypeScript基本类型 在TypeScript中,基本类型是非常重要的一部分,下面我们将详细介绍TypeScript中的基本类型。 基本类型约束 在TypeScript中,可以使用基本类型来约束变量的类型。常见的基本类型有: number:表示数…...

什么是跨域?
什么是跨域 什么是跨域? 什么是同源策略及其限制内容? 同源策略是一种约定,它是浏览器最核心也最基本的安全功能,如果缺少了同源策略,浏览器很容易受到XSS、CSRF等攻击。所谓同源是指"协议域名端口"三者相…...

Gradle理论与实践—Gradle构建脚本基础
Gradle构建脚本基础 Project: 根据业务抽取出来的一个个独立的模块Task:一个操作,一个原子性操作。比如上传一个jar到maven中心库等Setting.gradle文件:初始化及整个工程的配置入口build.gradle文件: 每个Project都会有个build.gradle的文件…...

【Vue 基础】vue-cli初始化项目及相关说明
目录 1. 创建项目 2. 项目文件介绍 3. 项目的其它配置 3.1 项目运行时,让浏览器自动打开 3.2 关闭eslint校验功能 3.3 src文件夹简写方法 1. 创建项目 vue create 项目名 2. 项目文件介绍 创建好的项目中包含如下文件: (1)…...

在软件开发中正确使用MySQL日期时间类型的深度解析
在日常软件开发场景中,时间信息的存储是底层且核心的需求。从金融交易的精确记账时间、用户操作的行为日志,到供应链系统的物流节点时间戳,时间数据的准确性直接决定业务逻辑的可靠性。MySQL作为主流关系型数据库,其日期时间类型的…...

CTF show Web 红包题第六弹
提示 1.不是SQL注入 2.需要找关键源码 思路 进入页面发现是一个登录框,很难让人不联想到SQL注入,但提示都说了不是SQL注入,所以就不往这方面想了 先查看一下网页源码,发现一段JavaScript代码,有一个关键类ctfs…...

利用ngx_stream_return_module构建简易 TCP/UDP 响应网关
一、模块概述 ngx_stream_return_module 提供了一个极简的指令: return <value>;在收到客户端连接后,立即将 <value> 写回并关闭连接。<value> 支持内嵌文本和内置变量(如 $time_iso8601、$remote_addr 等)&a…...

DeepSeek 赋能智慧能源:微电网优化调度的智能革新路径
目录 一、智慧能源微电网优化调度概述1.1 智慧能源微电网概念1.2 优化调度的重要性1.3 目前面临的挑战 二、DeepSeek 技术探秘2.1 DeepSeek 技术原理2.2 DeepSeek 独特优势2.3 DeepSeek 在 AI 领域地位 三、DeepSeek 在微电网优化调度中的应用剖析3.1 数据处理与分析3.2 预测与…...
-----深度优先搜索(DFS)实现)
c++ 面试题(1)-----深度优先搜索(DFS)实现
操作系统:ubuntu22.04 IDE:Visual Studio Code 编程语言:C11 题目描述 地上有一个 m 行 n 列的方格,从坐标 [0,0] 起始。一个机器人可以从某一格移动到上下左右四个格子,但不能进入行坐标和列坐标的数位之和大于 k 的格子。 例…...

2025 后端自学UNIAPP【项目实战:旅游项目】6、我的收藏页面
代码框架视图 1、先添加一个获取收藏景点的列表请求 【在文件my_api.js文件中添加】 // 引入公共的请求封装 import http from ./my_http.js// 登录接口(适配服务端返回 Token) export const login async (code, avatar) > {const res await http…...

【python异步多线程】异步多线程爬虫代码示例
claude生成的python多线程、异步代码示例,模拟20个网页的爬取,每个网页假设要0.5-2秒完成。 代码 Python多线程爬虫教程 核心概念 多线程:允许程序同时执行多个任务,提高IO密集型任务(如网络请求)的效率…...

NFT模式:数字资产确权与链游经济系统构建
NFT模式:数字资产确权与链游经济系统构建 ——从技术架构到可持续生态的范式革命 一、确权技术革新:构建可信数字资产基石 1. 区块链底层架构的进化 跨链互操作协议:基于LayerZero协议实现以太坊、Solana等公链资产互通,通过零知…...

分布式增量爬虫实现方案
之前我们在讨论的是分布式爬虫如何实现增量爬取。增量爬虫的目标是只爬取新产生或发生变化的页面,避免重复抓取,以节省资源和时间。 在分布式环境下,增量爬虫的实现需要考虑多个爬虫节点之间的协调和去重。 另一种思路:将增量判…...

MFC 抛体运动模拟:常见问题解决与界面美化
在 MFC 中开发抛体运动模拟程序时,我们常遇到 轨迹残留、无效刷新、视觉单调、物理逻辑瑕疵 等问题。本文将针对这些痛点,详细解析原因并提供解决方案,同时兼顾界面美化,让模拟效果更专业、更高效。 问题一:历史轨迹与小球残影残留 现象 小球运动后,历史位置的 “残影”…...