Python 之 NumPy 统计函数、数据类型和文件操作
文章目录
- 一、统计函数
- 1. 求平均值 mean()
- 2. 中位数 np.median
- 3. 标准差 ndarray.std
- 4. 方差 ndarray.var()
- 5. 最大值 ndarray.max()
- 6. 最小值 ndarray.min()
- 7. 求和 ndarray.sum()
- 8. 加权平均值 numpy.average()
- 二、数据类型
- 1. 数据存储
- 2. 定义结构化数据
- 3. 结构化数据操作
- 三、操作文件 loadtxt
- 1. 读取文件内数据
- 2. 不同列标识不同信息,数据读取
- 3. 读取指定的列
- 4. 数据中存在空值进行处理
一、统计函数
- NumPy 能方便地求出统计学常见的描述性统计量。
- 最开始呢,我们还是先导入 numpy。
import numpy as np
1. 求平均值 mean()
- mean() 是默认求出数组内所有元素的平均值。
- 我们使用 np.arange(20).reshape((4,5)) 生成一个初始值默认为 0,终止值(不包含)设置为 20,步长默认为 1 的 4 行 5 列的数组。
m1 = np.arange(20).reshape((4,5))
print(m1)
m1.mean()
#[[ 0 1 2 3 4]
# [ 5 6 7 8 9]
# [10 11 12 13 14]
# [15 16 17 18 19]]
#9.5
- 如果我们想求某一维度的平均值,就设置 axis 参数,多维数组的元素指定。

- axis = 0,将从上往下(按列)计算。
m1 = np.arange(20).reshape((4,5))
print(m1)
m1.mean(axis=0)
#[[ 0 1 2 3 4]
# [ 5 6 7 8 9]
# [10 11 12 13 14]
# [15 16 17 18 19]]
#array([ 7.5, 8.5, 9.5, 10.5, 11.5])
- axis = 1,将从左往右(按行)计算。
m1.mean(axis=1)
#array([ 2., 7., 12., 17.])
2. 中位数 np.median
- 中位数又称中点数,中值。
- 它是按顺序排列的一组数据中居于中间位置的数,代表一个样本、种群或概率分布中的一个数值。
- 平均数:是一个"虚拟"的数,是通过计算得到的,它不是数据中的原始数据;中位数:是一个不完全"虚拟"的数。
- 平均数:反映了一组数据的平均大小,常用来一代表数据的总体 “平均水平”;中位数:像一条分界线,将数据分成前半部分和后半部分,因此用来代表一组数据的"中等水平"。
- 接下来看两个例子,第一个中位数是数组中的元素,是一个不虚拟的数。
ar1 = np.array([1,3,5,6,8])
np.median(ar1)
#5.0
- 第二个中位数是一个虚拟的数。
ar1 = np.array([1,3,5,6,8,9])
np.median(ar1)
#5.5
3. 标准差 ndarray.std
- 在概率统计中最常使用作为统计分布程度上的测量,是反映一组数据离散程度最常用的一种量化形式,是表示精确度的重要指标
- 标准差定义是总体各单位标准值与其平均数离差平方的算术平均数的平方根。
- 简单来说,标准差是一组数据平均值分散程度的一种度量。
- 一个较大的标准差,代表大部分数值和其平均值之间差异较大;
- 一个较小的标准差,代表这些数值较接近平均值。
- 例如,A、B 两组各有 6 位学生参加同一次语文测验,A 组的分数为 95、85、75、65、55、45,B 组的分数为 73、72、71、69、68、67,我们分析哪组学生之间的差距大(标准差大的差距大)?
a = np.array([95,85,75,65,55,45])
b = np.array([73,72,71,69,68,67])
print(np.std(a))
print(np.std(b))
#17.07825127659933
#2.160246899469287
- 我们也可以使用数学函数进行标准差的计算(使用标准差的数学公式即可)。
import math
(a - np.mean(a))**2)
math.sqrt(np.sum(((a - np.mean(a))**2)/a.size))
#17.07825127659933
- 标准差应用于投资上,可作为量度回报稳定性的指标。标准差数值越大,代表回报远离过去平均数值,回报较不稳定故风险越高。相反,标准差数值越小,代表回报较为稳定,风险亦较小。
4. 方差 ndarray.var()
- 方差是衡量随机变量或一组数据时离散程度的度量。
a = np.array([95,85,75,65,55,45])
b = np.array([73,72,71,69,68,67])
print('A组的方差为:',a.var())
print('B组的方准差为:',b.var())
#A组的方差为: 291.6666666666667
#B组的方准差为: 4.666666666666667
- 标准差有计量单位,而方差无计量单位,但两者的作用一样,虽然能很好的描述数据与均值的偏离程度,但是处理结果是不符合我们的直观思维的。
5. 最大值 ndarray.max()
- 最大值比较好理解,默认求出数组内所有元素的最大值。
- axis = 0,将从上往下(按列)计算。
- axis = 1,将从左往右(按行)计算。
print(m1)
print(m1.max())
print('axis=0,从上往下查找:',m1.max(axis=0))
print('axis=1,从左往右查找',m1.max(axis=1))
#[[ 0 1 2 3 4]
# [ 5 6 7 8 9]
# [10 11 12 13 14]
# [15 16 17 18 19]]
#19
#axis=0,从上往下查找: [15 16 17 18 19]
#axis=1,从左往右查找 [ 4 9 14 19]
6. 最小值 ndarray.min()
- 最小值比较好理解,默认求出数组内所有元素的最小值。
- axis = 0,将从上往下(按列)计算。
- axis = 1,将从左往右(按行)计算。
print(m1)
print(m1.min())
print('axis=0,从上往下查找:',m1.min(axis=0))
print('axis=1,从左往右查找',m1.min(axis=1))
#[[ 0 1 2 3 4]
# [ 5 6 7 8 9]
# [10 11 12 13 14]
# [15 16 17 18 19]]
#0
#axis=0,从上往下查找: [0 1 2 3 4]
#axis=1,从左往右查找 [ 0 5 10 15]
7. 求和 ndarray.sum()
- 求和比较好理解,默认求出数组内所有元素的总和。
- axis = 0,将从上往下(按列)计算。
- axis = 1,将从左往右(按行)计算。
print(m1)
print(m1.sum())
print('axis=0,从上往下查找:',m1.sum(axis=0))
print('axis=1,从左往右查找',m1.sum(axis=1))
#[[ 0 1 2 3 4]
# [ 5 6 7 8 9]
# [10 11 12 13 14]
# [15 16 17 18 19]]
#190
#axis=0,从上往下查找: [30 34 38 42 46]
#axis=1,从左往右查找 [10 35 60 85]
8. 加权平均值 numpy.average()
- 加权平均值就是将各数值乘以相应的权数,然后加总求和得到总体值,再除以总的单位数。
numpy.average(a, axis=None, weights=None, returned=False)
- 其中,weights 表示数组,是一个可选参数,与 a 中的值关联的权重数组。
- a 中的每个值都根据其关联的权重对平均值做出贡献。权重数组可以是一维的(在这种情况下,它的长度必须是沿给定轴的 a 的大小)或与 a 具有相同的形状。
- 如果 weights=None,则假定 a 中的所有数据的权重等于 1。一维计算是:
avg = sum(a * weights) / sum(weights)
- 对权重的唯一限制是 sum(weights) 不能为 0。`
average_a1 = [20,30,50]
print(np.average(average_a1))
print(np.mean(average_a1))
#33.333333333333336
#33.333333333333336
二、数据类型
| 名称 | 描述 |
|---|---|
| bool_ | 布尔型数据类型(True 或者 False) |
| int_ | 默认的整数类型(类似于 C 语言中的 long,int32 或 int64) |
| intc | 与 C 的 int 类型一样,一般是 int32 或 int 64 |
| intp | 用于索引的整数类型(类似于 C 的 ssize_t,一般情况下仍然是 int32 或 int64) |
| int8 | 字节(-128 to 127) |
| int16 | 整数(-32768 to 32767) |
| int32 | 整数(-2147483648 to 2147483647) |
| int64 | 整数(-9223372036854775808 to 9223372036854775807) |
| uint8 | 无符号整数(0 to 255) |
| uint16 | 无符号整数(0 to 65535) |
| uint32 | 无符号整数(0 to 4294967295) |
| uint64 | 无符号整数(0 to 18446744073709551615) |
| float_ | float64 类型的简写 |
| float16 | 半精度浮点数,包括:1 个符号位,5 个指数位,10 个尾数位 |
| float32 | 单精度浮点数,包括:1 个符号位,8 个指数位,23 个尾数位 |
| float64 | 双精度浮点数,包括:1 个符号位,11 个指数位,52 个尾数位 |
| complex_ | complex128 类型的简写,即 128 位复数 |
| complex64 | 复数,表示双 32 位浮点数(实数部分和虚数部分) |
| complex128 | 复数,表示双 64 位浮点数(实数部分和虚数部分) |
1. 数据存储
- 我们可以将数组中的类型存储为浮点型。
a = np.array([1,2,3,4],dtype=np.float64)
a
#array([1., 2., 3., 4.])
- 我们可以将数组中的类型存储为布尔类型。
a = np.array([0,1,2,3,4],dtype=np.bool_)
print(a)
a = np.array([0,1,2,3,4],dtype=np.float_)
print(a)
#[False True True True True]
#[0. 1. 2. 3. 4.]
- 其中 str_ 和 string_ 区别如下:
str1 = np.array([1,2,3,4,5,6],dtype=np.str_)
string1 = np.array([1,2,3,4,5,6],dtype=np.string_)
str2 = np.array(['我们',2,3,4,5,6],dtype=np.str_)
print(str1,str1.dtype)
print(string1,string1.dtype)
print(str2,str2.dtype)
#['1' '2' '3' '4' '5' '6'] <U1
#[b'1' b'2' b'3' b'4' b'5' b'6'] |S1
#['我们' '2' '3' '4' '5' '6'] <U2
- 在内存里统一使用 unicode, 记录到硬盘或者编辑文本的时候都转换成了utf8 UTF-8 将 Unicode 编码后的字符串保存到硬盘的一种压缩编码方式
2. 定义结构化数据
- 在上述数据存储的过程种,我们对于 U1、S1、U2 并不能直接理解,这里使用其实是数据类型标识码。
| 字符 | 对应类型 | 字符 | 对应类型 | 字符 | 对应类型 | 字符 | 对应类型 |
|---|---|---|---|---|---|---|---|
| b | 代表布尔型 | i | 带符号整型 | u | 无符号整型 | f | 浮点型 |
| c | 复数浮点型 | m | 时间间隔(timedelta) | M | datatime(日期时间) | O | Python对象 |
| S,a | 字节串(S)与字符串(a) | U | Unicode | V | 原始数据(void) |
- 还可以将两个字符作为参数传给数据类型的构造函数。
- 此时,第一个字符表示数据类型, 第二个字符表示该类型在内存中占用的字节数(2、4、8分别代表精度为16、32、64位的 浮点数)。
- 首先,我们创建结构化数据类型,然后,将数据类型应用于 ndarray 对象。
dt = np.dtype([('age','U1')])
print(dt)
students = np.array([("我们"),(128)],dtype=dt)
print(students,students.dtype,students.ndim)
print(students['age'])
#[('age', '<U1')]
#[('我',) ('1',)] [('age', '<U1')] 1
#['我' '1']
- 以下示例描述了一位老师的姓名、年龄、工资的特征,该结构化数据其包含以下字段:
- str 字段:name。
- int 字段:age。
- float 字段:salary。
import numpy as np
teacher = np.dtype([('name',np.str_,2), ('age', 'i1'), ('salary', 'f4')])
b = np.array([('wl', 32, 8357.50),('lh', 28, 7856.80)], dtype = teacher)
print(b)
b['name']
b['age']
#[('wl', 32, 8357.5) ('lh', 28, 7856.8)]
#array([32, 28], dtype=int8)
3. 结构化数据操作
- 我们可以使用数组名 [结构化名],取出数组中的所有名称,取出数据中的所有年龄。
print(b)
print(b['name'])
print(b['age'])
#[('wl', 32, 8357.5) ('lh', 28, 7856.8)]
#['wl' 'lh']
#[32 28]
三、操作文件 loadtxt
- loadtxt 可以读取 txt 文本和 csv 文件。
loadtxt(fname, dtype=<type 'float'>, comments='#', delimiter=None, converters=None, skiprows=0, usecols=None, unpack=False, ndmin=0,encoding='bytes')
- 其中参数具有如下含义:
- (1) fname:指定文件名称或字符串。支持压缩文件,包括 gz、bz 格式。
- (2) dtype:数据类型。默认 float。
- (3) comments:字符串或字符串组成的列表。表示注释字符集开始的标志,默认为 #。
- (4) delimiter:字符串。分隔符。
- (5) converters:字典。将特定列的数据转换为字典中对应的函数的浮点型数据。例如将空值转换为 0,默认为空。
- (6) skiprows:跳过特定行数据。例如跳过前 1 行(可能是标题或注释),默认为 0。
- (7) usecols:元组。用来指定要读取数据的列,第一列为 0。例如(1, 3, 5),默认为空。
- (8) unpack:布尔型。指定是否转置数组,如果为真则转置,默认为 False。
- (9) ndmin:整数型。指定返回的数组至少包含特定维度的数组。值域为 0、1、2,默认为 0。
- (10) encoding:编码, 确认文件是 gbk 还是 utf-8 格式
- 返回:从文件中读取的数组。
1. 读取文件内数据
- 例如 data1.txt 存在数据:
- 0 1 2 3 4 5 6 7 8 9
- …
- 20 21 22 23 24 25 26 27 28 29
- 我们在读取普通文件时,可以不用设置分隔符(空格 制表符)。
data = np.loadtxt(r'D:\桌面\数据分析-班级\1-2班\data1.txt',dtype=np.int32)
print(data,data.shape)
#[[ 0 1 3 3 4 5 6 7 8 9]
# [20 21 22 23 24 25 26 27 28 29]] (2, 10)
- 我们在读取 csv 文件时,与普通文件不同,需要设置分隔符,csv 默认为 , 号。
data = np.loadtxt('csv_test.csv',dtype=np.int32,delimiter=',')
print(data,data.shape)
#[[ 0 1 2 3 4 5 6 7 8 9]
# [10 11 12 13 14 15 16 17 18 19]
# [20 21 22 23 24 25 26 27 28 29]] (3, 10)
2. 不同列标识不同信息,数据读取
- 我们有如下数据:
| 姓名 | 年龄 | 性别 | 身高 |
|---|---|---|---|
| 小王 | 21 | 男 | 170 |
| … | … | … | … |
| 老王 | 50 | 男 | 180 |
文件:has_title.txt。- (1) 以上数据由于不同列数据标识的含义和类型不同,因此我们需要自定义数据类型。
user_info = np.dtype([('name','U10'),('age','i1'),('gender','U1'),('height','i2')])
- (2) 使用我们自定义的数据类型,进行读取数据操作。
data = np.loadtxt('has_title.txt',dtype=user_info,skiprows=1, encoding='utf-8')
- 这里需要注意的是,以上参数中,(1) 设置类型;(2) 跳过第一行;(3) 编码。
print(data['age'])
#[21 25 19 40 24 21 19 26 21 21 19 20]
- 在读取到文件数据后,我们可以对其数据进行一定的操作。
- 首先,我们可以获取年龄的数组,计算年龄的中位数。
ages = data['age']
ages.mean()
# 23.0
- 我们也可以计算女生的平均身高(设置一个读取条件即可)。
isgirl = data['gender'] == '女'
print(isgirl)
print(data['height'])
data['height'][isgirl]
girl_mean = np.mean(data['height'][isgirl])
'{:.2f}'.format(girl_mean)
#[False True True False False True True False False True True True]
#[170 165 167 180 168 167 159 170 168 175 160 167]
#'165.71'
3. 读取指定的列
- 读取指定的列 usecols=(1,3) 标识只读取第 2 列和第 4 列(索引从 0 开始)。
user_info = np.dtype([('age','i1'),('height','i2')])
print(user_info)
#[('age', 'i1'), ('height', '<i2')]
- 然后,使用自定义的数据类型,读取数据。
data = np.loadtxt('has_title.csv',dtype=user_info,delimiter=',',skiprows=1,usecols=(1,3))
- 这里需要注意的是,在以上参数中:(1) 设置类型;(2) 跳过第一行;(3) 分隔符。
print(data)
#[(22, 170) (25, 165) (19, 167) (20, 169) (21, 161) (19, 159) (27, 177)]
4. 数据中存在空值进行处理
- 需要借助用于 converters 参数,传递一个字典,key 为列索引,value 为对列中值的处理。
- 比如,我们具体如下数据,csv 中学生信息中存在空的年龄信息:
| 姓名 | 年龄 | 性别 | 身高 |
|---|---|---|---|
| 小王 | 21 | 男 | 170 |
| … | … | … | … |
| 小谭 | 男 | 169 | |
| … | … | … | … |
| 小陈 | 27 | 男 | 177 |
- 文件:
has_empty_data.csv。 - 如果我们直接读取指定的列 usecols=(1,3) ,会出现错误。
- 因此,在需要处理空数据的时候,我们需要创建一个函数接收列的参数,并加以处理。
def parse_age(age):try:return int(age)except:return 0
- 和之前一样的步骤,使用自定义的数据类型,读取数据。
print(user_info)
data = np.loadtxt('has_empty_data.csv',dtype=user_info,delimiter=',',skiprows=1,usecols=(1,3),converters={1:parse_age,3:parse_age})
print(data)
#[('age', 'i1'), ('height', '<i2')]
#[(21, 170) (25, 165) (19, 167) ( 0, 169) (21, 161) (19, 0) (27, 177)]age_arr = data['age']
age_arr
#array([21, 25, 19, 0, 21, 19, 27], dtype=int8)age_arr[age_arr == 0] = np.median(age_arr[age_arr != 0])
age_arr.mean()
#21.857142857142858
- 计算班级年龄的平均值,由于存在 0 的数据,因此一般做法是将中位数填充。
- 首先,我们填充中位数,然后,我们计算平均值。
ages = data['age']
ages[ages==0] = np.median(ages)
print(ages)
np.round(np.mean(ages),2)
#[22 25 19 20 21 19 27]
#21.86
相关文章:
Python 之 NumPy 统计函数、数据类型和文件操作
文章目录一、统计函数1. 求平均值 mean()2. 中位数 np.median3. 标准差 ndarray.std4. 方差 ndarray.var()5. 最大值 ndarray.max()6. 最小值 ndarray.min()7. 求和 ndarray.sum()8. 加权平均值 numpy.average()二、数据类型1. 数据存储2. 定义结构化数据3. 结构化数据操作三、…...
互联网新时代要到来了(一)什么是Web3.0?
什么是Web3.0? tips:内容来自百度百科、知乎、搜狐新闻、李留白公众号、CSDN「Meta.Qing」博客等网页 什么是Web3.0?1.什么是Web3.0(概念介绍)?2.Web3.0简单理解3.Web3.0的技术特点4.Web3.0项目1.什么是Web3.0(概念…...

[Yocto] 直接向deploy/images目录部署binary
最近用yocto的时候碰到一个问题,有一些IP的FW binary是从别的地方直接拿来的,没有source code,有一个需求就是需要把它用wks script的方式把它们打包到最后的image里,这篇文章就是来谈谈这个问题。 yocto patch/deploy等做了什么 首先,虽然我们的code,bbfile,或者说pa…...
设备控制开发与实现(二))
HarmonyOS Connect原子化服务功能开发(Wi-Fi/Combo)设备控制开发与实现(二)
规设备控制 在“device”目录下的“DeviceApplication.java”文件中,在onInitialize函数中初始化应用。示例代码如下: Override public void onInitialize() {AiLifeServiceHelper.initApplication(this);DeviceHandlerAbility.register(this, "&qu…...

浅析 Makefile
Makefile逻辑 Makefile就是将一系列的工作流串在一起自动执行,构成Makefile最基本的要素是目标、依赖、命令。也就是为了实现目标需要哪些依赖并执行什么样的命令。 target: dependences1 dependences2 ... command1 command2 ...其中,target表示要生…...

保护品牌线上声誉的5种方法
我们如今生活在一个搜索便捷的世界,对于一个企业和个人来说,品牌的线上声誉也尤为重要。在客户考虑与您的公司开展业务之前,他们理所当然会先使用众多软件和平台搜索相关信息,以帮助他们了解和做决定。 因此,您的品牌…...

Java多重选择结构,超详细整理,适合新手入门
目录 一、什么是多重选择结构? 二、if 语句的语法 1、什么是嵌套if语句? 2、if 语句循环基本用法: 3、案例: 二、if...else多重选择结构语法 1、什么是if-else语句? 2、if...else 循环基本用法 3、案例&#…...

SCI写作,一定要避开这些“雷点”!
SCI论文写作中,除了要符合各部分的写作要求,还有许多细节问题需要我们注意,不然可能一不小心就会“踩雷”。 今天我们就来和大家分享SCI各个部分写作时的注意事项。 下面就进入正题! SCI写作注意事项 01 标题的拟定 1.避免使用无…...
))
3GPP-NR Band14标准定义频点和信道(3GPP V17.7.0 (2022-12))
Reference test frequencies for NR operating band n14 Table 4.3.1.1.1.14-1: Test frequencies for NRoperating band n14 and SCS 15 kHz CBW [MHz]carrierBandwidth...
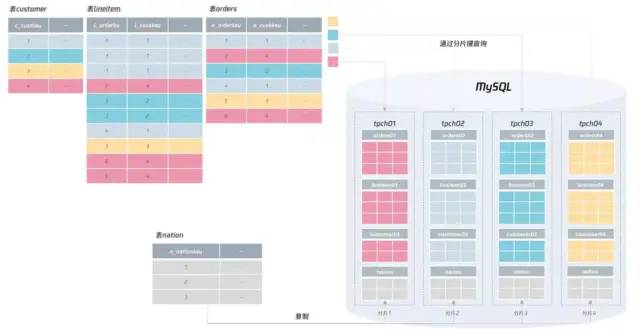
分库分表索引设计:分布式环境下的 主键索引、二级索引、全局索引的最佳设计实践
文章目录主键选择索引设计全局表唯一索引总结结语主键选择 对主键来说,要保证在所有分片中都唯一,它本质上就是一个全局唯一的索引。如果用大部分同学喜欢的自增作为主键,就会发现存在很大的问题。 因为自增并不能在插入前就获得值…...

2023年全国最新保安员精选真题及答案
百分百题库提供保安员考试试题、保安职业资格考试预测题、保安员考试真题、保安职业资格证考试题库等,提供在线做题刷题,在线模拟考试,助你考试轻松过关。 一、单选题(1-480题)以下备选答案中只有一项最符合题目要求&a…...

计算机网络之http07 http2,http3
HTTP1.2 http1.2都做了哪些优化 (1)头部压缩 使用HPACK压缩头部 头部冗长,大量重复字段 (2)二进制帧 将报文头部和内容字符编码改为二进制格式 字符编码未压缩 (3)并发传输 解决h1.1 队头阻塞问题,多车道 …...
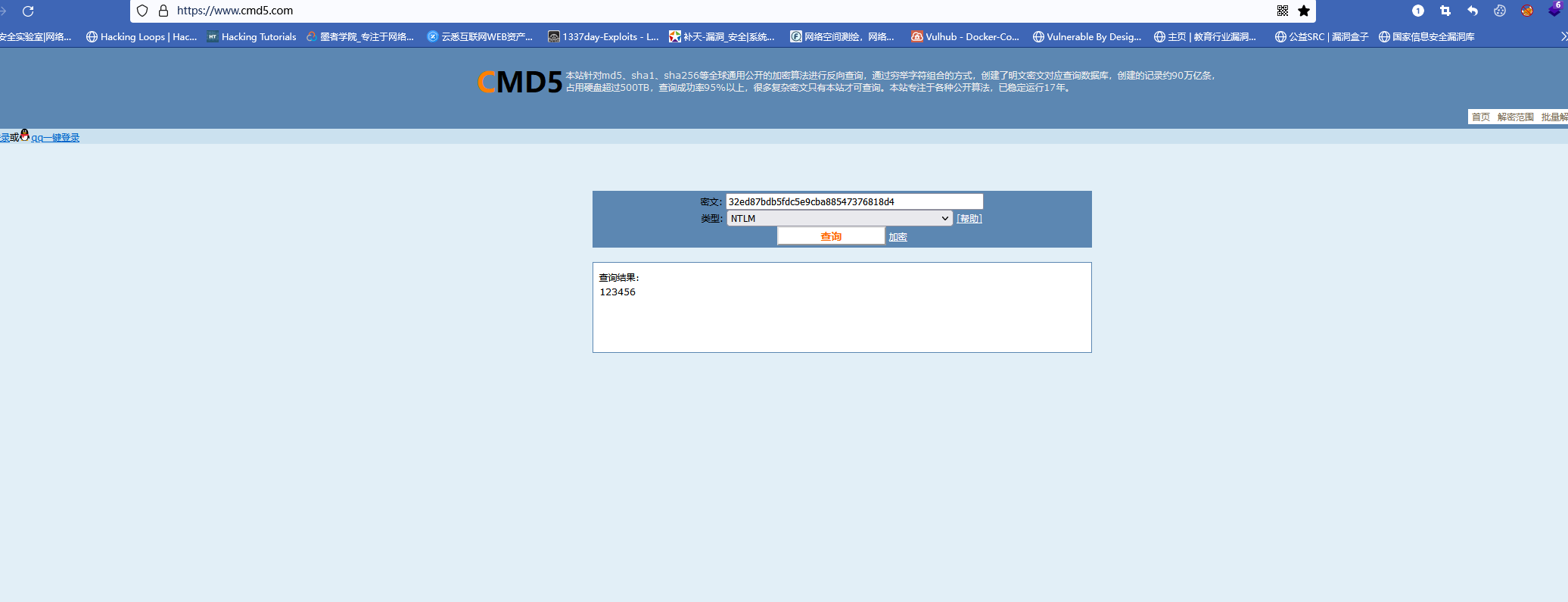
内网渗透(二十五)之Windows协议认证和密码抓取-使用Hashcat和在线工具破解NTLM Hash
系列文章第一章节之基础知识篇 内网渗透(一)之基础知识-内网渗透介绍和概述 内网渗透(二)之基础知识-工作组介绍 内网渗透(三)之基础知识-域环境的介绍和优点 内网渗透(四)之基础知识-搭建域环境 内网渗透(五)之基础知识-Active Directory活动目录介绍和使用 内网渗透(六)之基…...
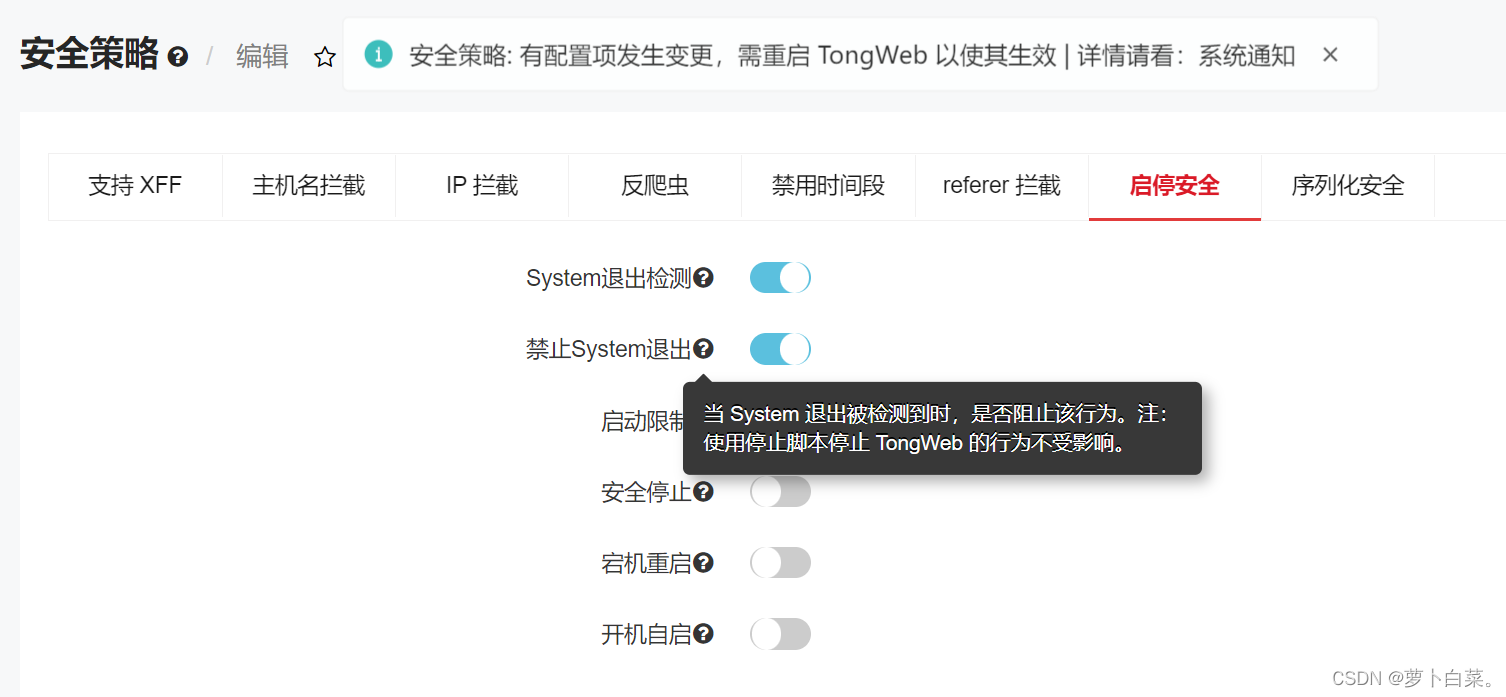
TongWeb8防止System.exit代码导致的进程停止
现象:当应用中存在System.exit 、Runtime.exit代码执行时,会导致TongWeb进程停止,从而产生如下日志:2023-02-14 09:47:36 [WARN] - The web application [webtest01] is still processing a request that has yet to finish. This…...
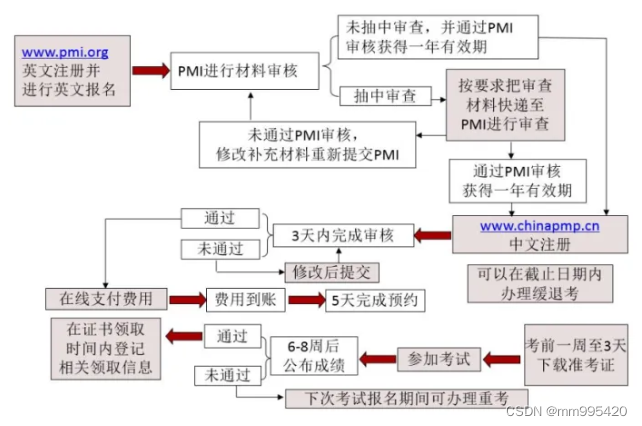
PMP每年考几次,费用如何?
一,PMP每年考几次,怎么准备? PMP项目管理证书是美国PMI发起的在全球200多个国家进行的项目管理专业人士资格认证,它的含金量和给认证者带来的作用已经很明显。 PMP考试是项目管理专业人士资格认证考试,通过PMP考试是…...
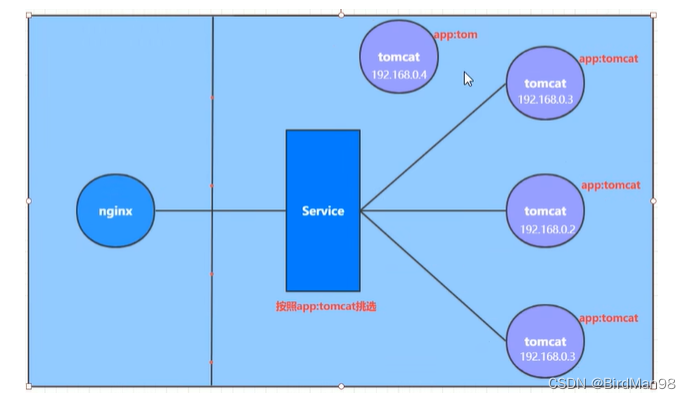
【Kubernetes】【一】Kubernetes介绍
Kubernetes介绍 应用部署方式演变 在部署应用程序的方式上,主要经历了三个时代: 传统部署:互联网早期,会直接将应用程序部署在物理机上 优点:简单,不需要其它技术的参与 缺点:不能为应用程序定…...

C语言:结构体
往期文章 C语言:初识C语言C语言:分支语句和循环语句C语言:函数C语言:数组C语言:操作符详解C语言:指针详解 目录往期文章前言1. 结构体的声明2. 结构体变量的定义和初始化3. 结构体成员的访问3. 结构体传参…...

搭建pclpy环境与读取pandaset数据并转换为pkl格式为pcd格式
1.搭建pclpy环境 问题:需要处理pcd文件,于是开始摸索搭建环境,有python-pcl,但是安装过程频频出现问题,于是转向pclpy。 参考链接:GitHub - davidcaron/pclpy: Python bindings for the Point Cloud Libr…...

别在用scroll去做懒加载了,交叉观察器轻松搞定
Ⅰ、前言 「懒加载」是网页中非常 常见的;为了减少系统的压力,对于一些电商系统出场频率非常高;那么大家一般用什么方式去实现 「懒加载」 呢 ? ① 通过 scroll 的形式: 通过 滚动「scroll」事件,然后去判…...

工欲善其事,必先利其器,分享5款Windows效率软件
工欲善其事,必先利其器。作为全球最多人使用的桌面操作系统,Windows 的使用效率与我们的工作学习息息相关。今天,小编就为大家整理了5款提高效率的利器,让你的 Windows 更具生产力。 1.桌面自定义——Rainmeter Rainmeter是一款…...

AI头像生成器惊艳效果:Qwen3-32B生成‘蒸汽朋克猫娘’Prompt细节拆解
AI头像生成器惊艳效果:Qwen3-32B生成‘蒸汽朋克猫娘’Prompt细节拆解 1. 引言:当AI遇上头像创意设计 你有没有遇到过这样的困扰:想要一个独特的头像,但自己不会画画,又找不到合适的设计师?或者有了创意想…...

CasRel关系抽取模型快速上手:无需训练直接调用预训练中文Base模型
CasRel关系抽取模型快速上手:无需训练直接调用预训练中文Base模型 想从一大段文字里,自动找出“谁在什么时候做了什么”或者“谁和谁是什么关系”吗?比如,从一篇人物传记里,自动提取出“张三的出生地是北京”、“李四…...

Gemma-3-270m实战落地:为制造业MES系统添加自然语言工单查询入口
Gemma-3-270m实战落地:为制造业MES系统添加自然语言工单查询入口 1. 引言:让MES系统听懂人话 想象一下这个场景:车间主任老张站在生产线旁,想快速了解"上个月华为订单P20型号还有多少未完成",传统MES系统需…...

Phi-3-vision-128k-instruct镜像免配置:Docker一键拉起+Chainlit前端自动对接
Phi-3-vision-128k-instruct镜像免配置:Docker一键拉起Chainlit前端自动对接 1. 模型简介 Phi-3-Vision-128K-Instruct是一个轻量级的多模态模型,支持图文对话功能。这个模型基于高质量的训练数据构建,特别擅长处理需要复杂推理的文本和视觉…...

Windows计划任务终极指南:从schtasks命令到taskschd.msc的完整实战手册
Windows计划任务终极指南:从schtasks命令到taskschd.msc的完整实战手册 对于系统管理员和运维工程师而言,计划任务是实现自动化运维的核心工具。无论是日常的日志清理、定期备份,还是复杂的批处理作业调度,Windows计划任务都能提供…...

RimSort:基于拓扑排序的模组依赖管理系统技术解析
RimSort:基于拓扑排序的模组依赖管理系统技术解析 【免费下载链接】RimSort 项目地址: https://gitcode.com/gh_mirrors/ri/RimSort 一、核心价值:模组管理的范式革新 在《边缘世界》模组生态系统中,随着平均模组数量突破27个&#…...

手把手教你修复libgit2报错:从corrupted loose reference到完整恢复Git仓库
手把手教你修复libgit2报错:从corrupted loose reference到完整恢复Git仓库 当你正在专注地开发项目,突然遇到corrupted loose reference file: refs/heads/master这样的Git错误时,那种感觉就像是在高速公路上突然爆胎。这个错误不仅会中断你…...
)
用Kubernetes搭建大数据分析平台:Spark on K8s完整配置指南(附Flink集成方案)
Kubernetes大数据平台实战:Spark与Flink的容器化部署与优化 大数据处理框架的容器化部署已经成为企业级数据平台的标准配置。本文将深入探讨如何在Kubernetes上构建高性能的Spark和Flink集群,从基础配置到高级优化,为大数据工程师提供一站式解…...
:UEFI XBL GraphicsOutput BMP图片显示流程解析)
Android Qcom Display学习(五):UEFI XBL GraphicsOutput BMP图片显示流程解析
1. UEFI XBL阶段图形显示基础 在深入探讨BMP图片显示流程之前,我们需要先理解高通平台UEFI XBL阶段图形显示的基本架构。XBL(eXtensible Boot Loader)作为高通私有代码部分,负责芯片级初始化和核心驱动加载。与PC平台的UEFI实现不…...

宝塔面板多域名SSL配置避坑指南:一个网站绑定a.com和b.com的正确姿势
宝塔面板多域名SSL配置实战:从零搭建到完美避坑 当你的网站需要同时支持a.com和b.com访问时,SSL证书配置往往会成为技术路上的第一个绊脚石。上周我就亲眼目睹了同事因为错误操作导致整个线上服务中断两小时的惨剧——仅仅因为在宝塔面板中多点击了一次&…...