【C++】18.哈希
1.unordered_set和unordered_map
使用与set和map的用法一样
#include <iostream>
#include <unordered_map>
#include <unordered_set>
#include <map>
#include <set>
#include <string>
#include <vector>
#include <time.h>
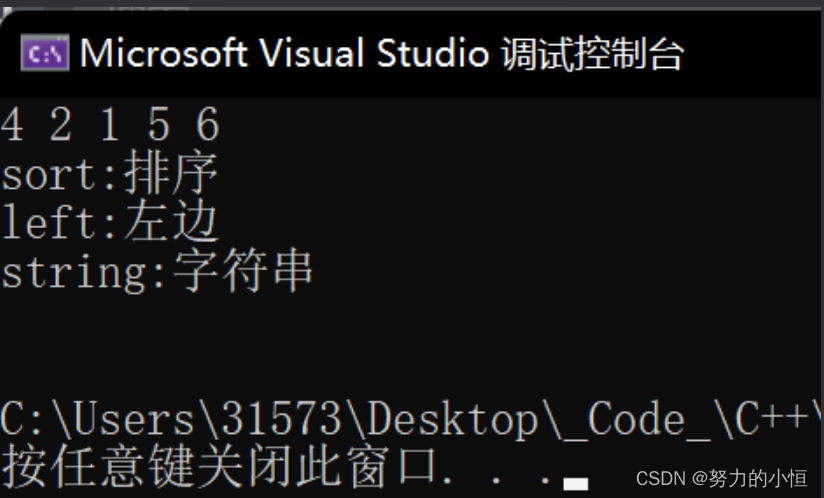
using namespace std;void test_unordered_map_set()
{unordered_set<int> us;// Java HashSet//插入us.insert(4);us.insert(2);us.insert(1);us.insert(5);us.insert(6);us.insert(2);us.insert(2);//去重 不能排序 set可去重+排序 //Java TreeSetunordered_set<int>::iterator it = us.begin();while (it != us.end()){//不可改cout << *it << " ";++it;}cout << endl;//使用与map set一样//unordered_map按插入顺序 不排序 map会排序unordered_map<string, string> dict;//没有仿函数 但可以用 系统给了dict.insert(make_pair("sort", "排序"));dict["string"] = "字符串";dict.insert(make_pair("left", "左边"));//迭代器unordered_map<string, string>::iterator dit = dict.begin();while (dit != dict.end()){cout << dit->first << ":" << dit->second << endl;++dit;}cout << endl;//使用与map和set相同 主要在于底层实现
}
int main()
{test_unordered_map_set();return 0;
}
性能测试
//release下多次测试
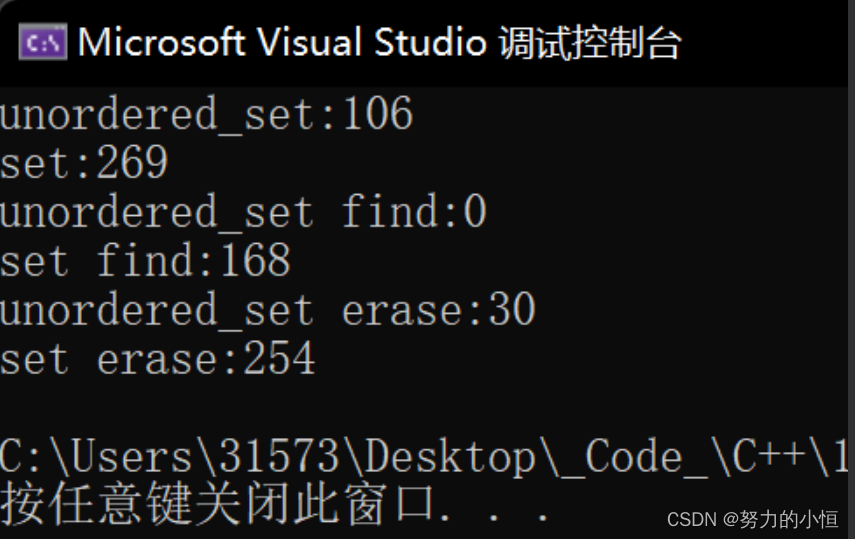
void test_op()
{unordered_set<int> us;set<int> s;const int n = 10000000;vector<int > v;v.reserve(n);srand(time(0));//unorder_set insertsize_t begin1 = clock();for (size_t i = 0; i < n; ++i){us.insert(v[i]);}size_t end1 = clock();cout << "unordered_set:" << end1 - begin1 << endl;//set insertsize_t begin2 = clock();for (size_t i = 0; i < n; ++i){v.push_back(rand());}size_t end2 = clock();cout << "set:" << end2 - begin2 << endl;//unorder_set findsize_t begin3 = clock();for (size_t i = 0; i < n; ++i){us.find(v[i]);}size_t end3 = clock();cout << "unordered_set find:" << end3 - begin3 << endl;//set findsize_t begin4 = clock();for (size_t i = 0; i < n; ++i){s.find(rand());}size_t end4 = clock();cout << "set find:" << end4 - begin4 << endl;//unorder_set erasesize_t begin5 = clock();for (size_t i = 0; i < n; ++i){us.erase(v[i]);}size_t end5= clock();cout << "unordered_set erase:" << end5- begin5 << endl;//set findsize_t begin6 = clock();for (size_t i = 0; i < n; ++i){s.erase(rand());}size_t end6 = clock();cout << "set erase:" << end6 - begin6 << endl;
}
int main()
{test_op();return 0;
}
map/set 和 unordered_map/unordered_set 有什么区别和联系?
1.都可以实现key和key/value的搜索场景 并且功能和使用基本一样
2.map/set的底层是使用红黑树实现的 增删查改的时间复杂度是O(logN) 遍历出序有序的
3.unordered_map/unordered_set的底层是使用哈希表实现的 增删查改的时间复杂度是O(1) 遍历出来时是无序的
4.map和set是双向迭代器 unordered_map和unordered_set是单向迭代器
对比的性能测试可以看到:实际中 如果我们使用的环境支持C++11 那么unordered_xxx效率还是高一些
2.哈希(底层)
1°哈希概念
理想的搜索方法:可以不经过任何比较,一次直接从表中得到要搜索的元素。 如果构造一
种存储结构,通过某种函数(hashFunc)使元素的存储位置与它的关键码之间能够建立一一
映射的关系,那么在查找时通过该函数可以很快找到该元素。
面试题:查找字符串中只出现一次的字符 "abcdabcdef" 第一次只出现一次的是"e"
-
哈希是一种映射关系(一一对应)
int a[256] 统计次数
其次我们之前讲的计数排序 也要统计次数 也是用这种类似的映射
1 2 5 9 1000000 888888 23存起来 方便查找 怎么存?(不使用搜索树)
如果每个值直接进行映射 那么我们存上面的数 得开一个100w大小数组 问题是空间浪
费太多
引入两种方法
-
直接定址法** 映射只跟关键字直接或者间接相关**
-
除留余数法
不再是给每一个值映射一个位置
在限定大小的空间中将我们的值映射进去
index = key % 空间大小
带来的问题:不同的值可能会映射到相同位置上去
导致哈希冲突 哈希冲突越多整体而言效率越低
1 7 6 4 5 9 9998
key%10余数是多少就放哪个位置
查找时也一样 模出来余数是多少就去哪个位置去找
 问题来了 现在我们要存一个11到表中 就会发现冲突了 也就是哈希冲突
问题来了 现在我们要存一个11到表中 就会发现冲突了 也就是哈希冲突
2°哈希冲突
不同关键字通过相同哈希哈数计算出相同的哈希地址,该种现象称为哈希冲突或哈希碰
撞。
那么如何解决哈希冲突呢?
这里引入两种方法:
-
闭散列--开放定址法(冲突了 那么按规则再给你找个位置)
a.线性探测(挨着往后找 直到找到空位置)
b.二次探测(按i^2 跳跃着往后找 直到找到空位置)
闭散列中线性探测有什么问题?
线性思路:key%表大小+i(i=0,1,2,3,4...)
二次探测:key%表大小+i^2(i=0,1,2,3,4...)
线性探测思路就是我的位置被占了 我就挨着往后去占别人的位置 可能会导致一片一片
的冲突 洪水效应
二次探测让冲突的一片数据相对更分散了 不会聚集到一起 形成连片冲突
-
开散列--拉链法(哈希桶)(重点)
闭散列哈希表不能满了再增容 因为如果哈希表快满时插入数据 冲突的概率很大 效率
会很低
如何解决:快接近满的时候就增容
提出一个概念:
负载因子=表中的数据个数/表的大小 一般情况 闭散列的哈希表中 负载因子到0.7就可
以开始增容
一般情况下 负载因子越小 冲突概率越低 效率越高
相反 负载因子越大 冲突概率越高 效率越低
但是负载因子也不敢控制得太小 会导致大量的空间浪费
其实控制负载因子就是一种以空间换时间的思路
闭散列--开放定址法不是一种好的解决方式 因为他是一种我的位置被占了 我就去抢别
人的位置思路
也就是说他的哈希冲突会互相影响 我冲突占你的 你冲突了占他的
他冲突了..... 没完没了 整体效率都偏低
开散列的哈希桶 可以解决上面的问题
我冲突了 我自力更生解决 不占用你的位置 我自己挂起来
当大量的数据冲突 这些哈希冲突的数据就会挂在同一个链式桶中 查找时效率就会降低
所以开散列-哈希桶也是要控制哈希冲突的 如何控制呢? 通过控制负载因子
这里就把空间利用率提高一些 负载因子也可以高一些
一般开散列把负载因子控制到1 会比较好一些
3°总结
哈希(散列):将存储的数据根存储的位置使用哈希函数建立出映射关系 方便我们进行高效查
找
哈希冲突:不同的值映射到了相同的位置
解决哈希冲突:
1.闭散列-开放定制法(我的位置被占了 我就去占别的位置--不推荐)
2.开散列-拉链法(冲突的数据链式结构挂起来--推荐)
查找的时间复杂度O(1)
假设总是有一些桶挂的数据很多 冲突很厉害如何解决?
1°一个链的长度超过一定值 就将挂链表改成挂红黑树(Java HashMap就是这样解决的 当
桶长度超过8就改成挂红黑树)
2°控制负载因子
3.哈希表的实现
用vector放数据 _num记录数据个数 方便扩容
同时把每个位置的状态表示出来
空 存在 删除过的
#pragma once
#include <vector>
#include <iostream>
using namespace std;enum State
{EMPTY,EXIST,DELETE,
};class HashTable
{typedef HashData<T> HashData;public:private:vector<HashData> _tables;size_t _num = 0; //存了几个有效数据
};
1°闭散列
(1)插入
整体思路:
容量为0的时候或者负载因子>=0.7的时候进行扩容
扩容思路:
方法1:
- 开一个2倍的空间出来
- 将旧表中的数据重新映射到新表
- 释放旧表的空间
方法2:
- 新开一个哈希表
- 复用Insert 递归
- 与原来的哈希表交换
#pragma once
#include <vector>
#include <iostream>
using namespace std;template<class K>
struct SetKeyOfT
{const K& operator()(const K& key){return key;}
};namespace CLOSE_HASH
{//unordered_set<K>->HashTable<K,K>//unordered_map<K,V>->HashTable<K,pair<K,V>>enum State{EMPTY,EXIST,DELETE,};template<class T>struct HashData{T _data;State _state;//标记状态 没有状态的话 连续冲突的时候 删除后可能找不到后面的};template<class K, class T, class KeyOfT>//KeyofT 取出value来比class HashTable{typedef HashData<T> HashData;public:bool Insert(const T& d){//KeyOfT koft;//线性探测//负载因子=表中数据/表的大小 衡量哈希表满的程度//表接近满 插入数据越容易冲突 冲突越多 效率越低//哈希表并不是满了才增容 开放定制法中 一般负载因子到0.7左右就开始增容if (_tables.size() == 0 || _num * 10 / _tables.size() >= 7)//两个整型 0.7不好办 搞成*10 >= 7 一开始除0错误 讨论一下{//增容//思路://1.开一个2倍的空间出来//2.将旧表中的数据重新映射到新表//3.释放旧表的空间//--------------------------//写法1//vector<HashData> newtables;//size_t newsize = _tables.size() == 0 ? 10 : _tables.size() * 2;//分类讨论//newtables.resize(newsize);//for (size_t i = 0; i < _tables.size(); ++i)//{// if (_tables[i]._state == EXIST)// {// //计算在新表中的位置并处理冲突// size_t index = koft(_tables[i]._data % newtables.size());// while (newtables[index]._state == EXIST)// {// ++index;// if (index == _tables.size())// {// index = 0;// }// }// newtables[index] = _tables[i];// }//}现代写法//_tables.swap(newtables);//------------------------//写法2HashTable<K, T, KeyOfT> newht;//新开一个哈希表 可复用Insertsize_t newsize = _tables.size() == 0 ? 10 : _tables.size() * 2;//分类讨论newht._tables.resize(newsize);//访问成员tables tables是vector 然后调resizefor (size_t i = 0; i < _tables.size(); ++i){if (_tables[i]._state == EXIST){newht.Insert(_tables[i]._data);//递归 复用插入}}_tables.swap(newht._tables);}//二次探测//计算d中的key在表中映射的位置//size_t start = koft(d) % _tables.size();//size_t index = start;//int i = 1;//while (_tables[index]._state == EXIST)//存在就往后接着探测//{// if (koft(_tables[index]._data) == koft(d))//数据已经存在 去重 直接false// {// return false;// }// index = start + i * i;// ++i;// index %= _tables.size()//可能超过了表的长度 取模//}//_tables[index]._data = d;//_tables[index]._state = EXIST;//_num++;return true;}private:vector<HashData> _tables;size_t _num = 0; //存了几个有效数据};
}
(2)查找
思路:
先找到映射位置
但是映射位置不一定是头部 所以往下走会错过一部分
走完后要将index=0 从头开始走没走的部分
HashData* Find(const K& key)
{KeyOfT koft;//计算d中的key在表中映射的位置size_t index = key % _tables.size();while (_tables[index]._state != EMPTY)//存在或者删除都继续往后找{if (koft(_tables[index]._data) == key)//找到了Key 但是data可能被删了 还要进一步检查{if (_tables[index]._state == EXIST){return &_tables[index];}else if (_tables[index]._state == DELETE){return nullptr;}}++index;if (index == _tables.size())//绕回来{index = 0;}}//遇到EMPTY就跳出循环return nullptr;
}
(3)删除
思路:
先查找要删除的 然后把状态改为删除状态
bool Erase(const K& key)
{HashData* ret = Find(key);if (ret)//找到了 状态变为删除{ret->_state = DELETE;--_num;return true;}else//没有找到{return false;}
}
(4)完整代码
#include <vector>
#include <iostream>
using namespace std;template<class K>
struct SetKeyOfT
{const K& operator()(const K& key){return key;}
};namespace CLOSE_HASH
{//unordered_set<K>->HashTable<K,K>//unordered_map<K,V>->HashTable<K,pair<K,V>>enum State{EMPTY,EXIST,DELETE,};template<class T>struct HashData{T _data;State _state;//标记状态 没有状态的话 连续冲突的时候 删除后可能找不到后面的};template<class K, class T, class KeyOfT>//KeyofT 取出value来比class HashTable{typedef HashData<T> HashData;public:bool Insert(const T& d){//KeyOfT koft;//线性探测//负载因子=表中数据/表的大小 衡量哈希表满的程度//表接近满 插入数据越容易冲突 冲突越多 效率越低//哈希表并不是满了才增容 开放定制法中 一般负载因子到0.7左右就开始增容if (_tables.size() == 0 || _num * 10 / _tables.size() >= 7)//两个整型 0.7不好办 搞成*10 >= 7 一开始除0错误 讨论一下{//增容//思路://1.开一个2倍的空间出来//2.将旧表中的数据重新映射到新表//3.释放旧表的空间//--------------------------//写法1//vector<HashData> newtables;//size_t newsize = _tables.size() == 0 ? 10 : _tables.size() * 2;//分类讨论//newtables.resize(newsize);//for (size_t i = 0; i < _tables.size(); ++i)//{// if (_tables[i]._state == EXIST)// {// //计算在新表中的位置并处理冲突// size_t index = koft(_tables[i]._data % newtables.size());// while (newtables[index]._state == EXIST)// {// ++index;// if (index == _tables.size())// {// index = 0;// }// }// newtables[index] = _tables[i];// }//}现代写法//_tables.swap(newtables);//------------------------//写法2HashTable<K, T, KeyOfT> newht;//新开一个哈希表 可复用Insertsize_t newsize = _tables.size() == 0 ? 10 : _tables.size() * 2;//分类讨论newht._tables.resize(newsize);//访问成员tables tables是vector 然后调resizefor (size_t i = 0; i < _tables.size(); ++i){if (_tables[i]._state == EXIST){newht.Insert(_tables[i]._data);//递归 复用插入}}_tables.swap(newht._tables);}//二次探测//计算d中的key在表中映射的位置//size_t start = koft(d) % _tables.size();//size_t index = start;//int i = 1;//while (_tables[index]._state == EXIST)//存在就往后接着探测//{// if (koft(_tables[index]._data) == koft(d))//数据已经存在 去重 直接false// {// return false;// }// index = start + i * i;// ++i;// index %= _tables.size()//可能超过了表的长度 取模//}//_tables[index]._data = d;//_tables[index]._state = EXIST;//_num++;return true;}HashData* Find(const K& key){KeyOfT koft;//计算d中的key在表中映射的位置size_t index = key % _tables.size();while (_tables[index]._state != EMPTY)//存在或者删除都继续往后找{if (koft(_tables[index]._data) == key)//找到了Key 但是data可能被删了 还要进一步检查{if (_tables[index]._state == EXIST){return &_tables[index];}else if (_tables[index]._state == DELETE){return nullptr;}}++index;if (index == _tables.size())//绕回来{index = 0;}}//遇到EMPTY就跳出循环return nullptr;}bool Erase(const K& key){HashData* ret = Find(key);if (ret)//找到了 状态变为删除{ret->_state = DELETE;--_num;return true;}else//没有找到{return false;}}private:vector<HashData> _tables;size_t _num = 0; //存了几个有效数据};void TestHashTable(){HashTable<int, int, SetKeyOfT<int>> ht;ht.Insert(4);ht.Insert(14);ht.Insert(24);ht.Insert(5);ht.Insert(15);ht.Insert(25);ht.Insert(6);ht.Insert(16);}
}
#include "HashTable.h"int main()
{CLOSE_HASH::TestHashTable();return 0;
}

2°开散列
(1)插入
扩容思路与闭散列相同
插入的时候 头插到挂的链表中(尾插也可以)
根据研究 容量如果为素数 哈希冲突率会降低 所以引入素数表
除留余数的时候 有些类型无法取模 此时引入仿函数 强制类型转换来进行取模
template<class K>
struct _Hash
{//重载operator()const K& operator()(const K& key){return key;}
};template<class T>
struct HashNode
{T _data;HashNode<T>* _next;直接在桶中进行连接 插入的时候就连接双向是为了删除好删//HashNode<T>* _linknext;//HashNode<T>* _linkprev;HashNode(const T& data):_data(data),_next(nullptr){}
};//模板特化
template<>
struct _Hash<string>
{size_t operator()(const string& key){//BKDR Hashsize_t hash = 0;for (size_t i = 0; i < key.size(); ++i){hash *= 131;//BKDR Hashhash += key[i];}return hash;}
};size_t HashFunc(const K& key)
{Hash hash;//仿函数return hash(key);
}//素数表
size_t GetNextPrime(size_t num)
{const int PRIMECOUNT = 28;const size_t primeList[PRIMECOUNT] ={53ul, 97ul, 193ul, 389ul, 769ul,1543ul, 3079ul, 6151ul, 12289ul, 24593ul,49157ul, 98317ul, 196613ul, 393241ul, 786433ul,1572869ul, 3145739ul, 6291469ul, 12582917ul, 25165843ul,50331653ul, 100663319ul, 201326611ul, 402653189ul, 805306457ul,1610612741ul, 3221225473ul, 4294967291ul};//ul默认是无符号长整型for (size_t i = 0; i < PRIMECOUNT; ++i){if (primeList[i] > num){return primeList[i];}}return primeList[PRIMECOUNT - 1];
}pair<iterator, bool> Insert(const T& data)
{KeyOfT koft;//如果负载因子等于1 则增容 避免大量的哈希冲突if (_tables.size() == _num){//1.开2倍大小的新表(不一定是2倍)//2.遍历旧表的数据 重新计算在新表中位置//3.释放旧表vector<Node*> newtables;//表中如果是素数 冲突率会降低//size_t newsize = _tables.size() == 0 ? 10 : _tables.size() * 2;size_t newsize = GetNextPrime(_tables.size());newtables.resize(newsize);for (size_t i = 0; i < _tables.size(); ++i){//将旧表中的节点取下来重新计算在新表中的位置 并插入进去Node* cur = _tables[i];while (cur){//算新表中的位置Node* next = cur->_next;size_t index = HashFunc(koft(cur->_data)) % newtables.size();cur->_next = newtables[index];newtables[index] = cur;cur = next;}//找不到制空_tables[i] = nullptr;}//交换_tables.swap(newtables);}//计算数据在表中映射的位置size_t index = HashFunc(koft(data)) % _tables.size();Node* cur = _tables[index];//1.先查找这个值在不在表中while (cur){if (koft(cur->_data) == koft(data)){return make_pair(iterator(cur, this), false);}else{cur = cur->_next;}}//2.头插到挂的链表中(尾插也可以)Node* newnode = new Node(data);newnode->_next = _tables[index];_tables[index] = newnode;++_num;return make_pair(iterator(newnode, this), true);
}
(2)查找
先除留余数
然后与单链表的查找相同
Node* Find(const K& key)
{KeyOfT koft;size_t index = HashFunc(key) % _tables.size();Node* cur = _tables[index];while (cur){if (koft(cur->_data) == key){return cur;}else{cur = cur->_next;}}return nullptr;
}
(3)删除
先除留余数
然后与单链表的删除相同
bool Erase(const K& key)
{KeyOfT koft;size_t index = HashFunc(key) % _tables.size();Node* prev = nullptr;//单链表的删除 记录前一个Node* cur = _tables[index];while (cur){if (koft(cur->_data) == key){if (prev == nullptr){//表示要删第一个_tables[index] = cur->_next;}else{prev->_next = cur->_next;}delete cur;return true;}else{prev = cur;cur = cur->_next;}}return false;
}
(4)迭代器
最难的点在于operator++
如何知道一个桶走完了 然后找到下一个桶?
走完后 拿到下一个桶的头部的下标
//迭代器
//前置声明
template<class K, class T, class KeyOfT, class Hash>
class HashTable;template<class K, class T, class KeyOfT, class Hash>
struct __HashTableIterator//++it 这里当一个桶走完了 迭代器如何寻找下一个桶???
{typedef __HashTableIterator<K, T, KeyOfT,Hash> Self;typedef HashTable<K, T, KeyOfT, Hash> HT;//HashTable找不到 加一个前置typedef HashNode<T> Node;Node* _node; HT* _pht;//给一个HashTable的指针 可以拿到每个桶的首地址__HashTableIterator(Node* node, HT* pht):_node(node),_pht(pht){}T& operator*(){return _node->_data;}T* operator->(){return &_node->_data;}Self operator++(){if (_node->_next){_node = _node->_next;}else{//如果一个桶走完了 如何找到下一个桶KeyOfT koft;size_t i = _pht->HashFunc(koft(_node->_data)) % _pht->_tables.size();//_tables是HashTable类里的私有 迭代器类想要访问 友元++i;for (; i < _pht->_tables.size(); ++i){Node* cur = _pht->_tables[i];if (cur){_node = cur;return *this;}}_node = nullptr;}return *this;}bool operator!=(const Self& s){return _node != s._node;}};template<class K, class T, class KeyOfT, class Hash = _Hash<K>>//给默认的 没有封装前
//template<class K, class T, class KeyOfT>typedef HashNode<T> Node;friend struct __HashTableIterator<K, T, KeyOfT, Hash>;//友元typedef __HashTableIterator<K, T, KeyOfT, Hash> iterator;iterator begin(){for (size_t i = 0; i < _tables.size(); ++i){if (_tables[i]){return iterator(_tables[i], this);}}return end();}iterator end(){return iterator(nullptr, this);}~HashTable(){//清理桶就可以Clear();}void Clear(){for (size_t i = 0; i < _tables.size(); ++i){Node* cur = _tables[i];while (cur){Node* next = cur->_next;delete cur;cur = next;}//删完后制空_tables[i] = nullptr;}}
(5)完整代码
#pragma once
#include <vector>
#include <iostream>
using namespace std;template<class K>
struct SetKeyOfT
{const K& operator()(const K& key){return key;}
};//哈希桶
namespace OPEN_HASH
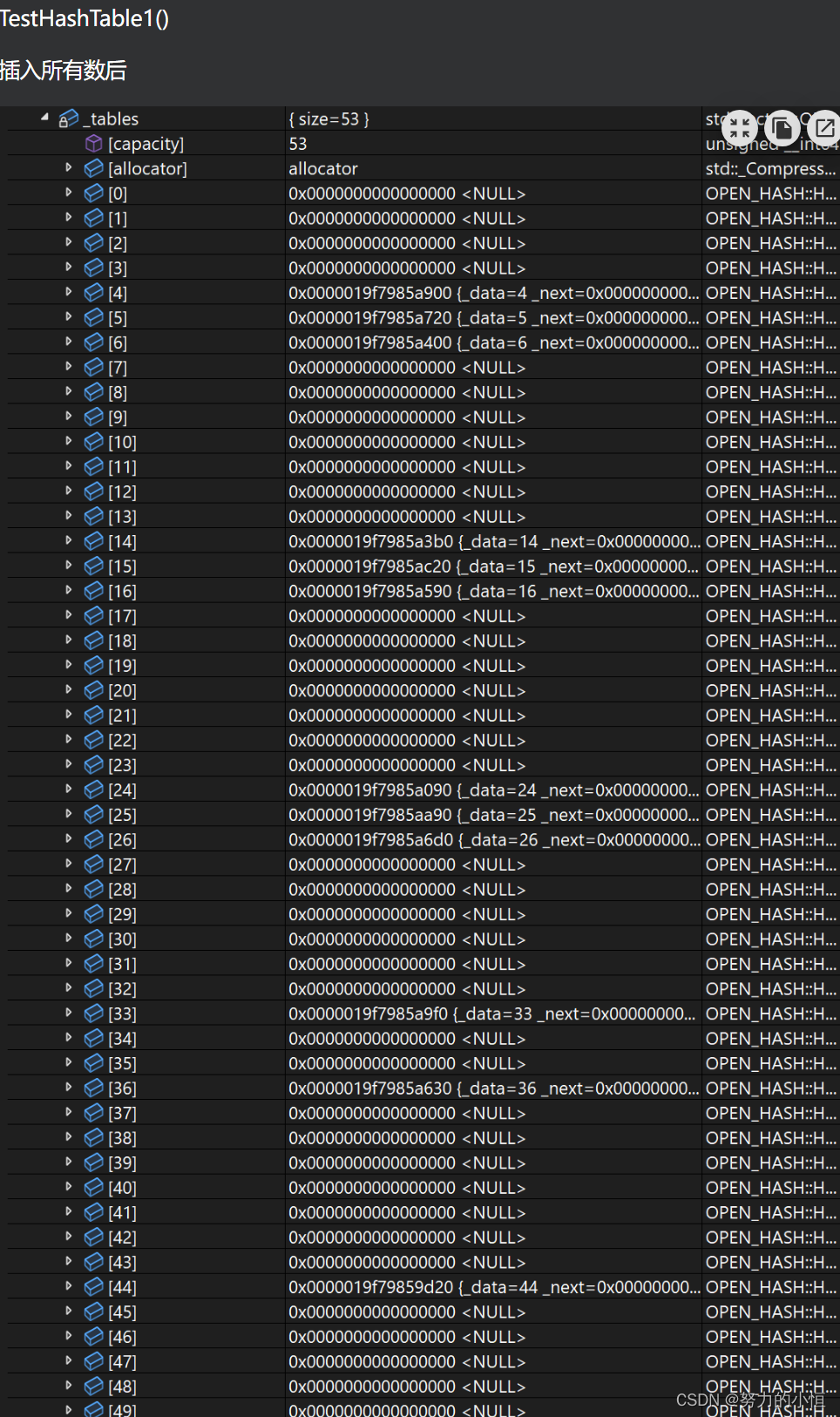
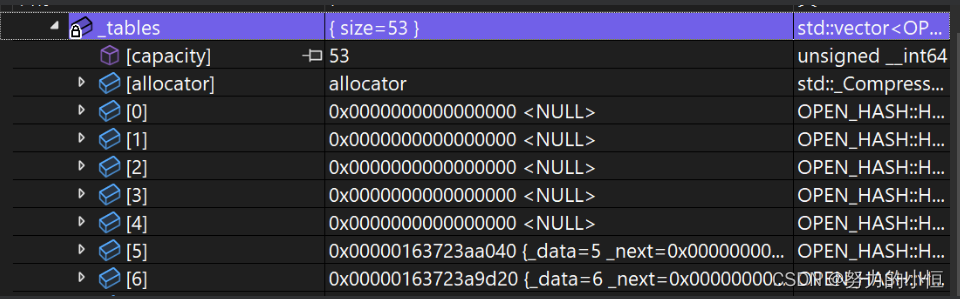
{template<class K>struct _Hash{//重载operator()const K& operator()(const K& key){return key;}};//模板特化template<>struct _Hash<string>{size_t operator()(const string& key){//BKDR Hashsize_t hash = 0;for (size_t i = 0; i < key.size(); ++i){hash *= 131;//BKDR Hashhash += key[i];}return hash;}};//可以显示调用 可以特化//struct _HashString//{// size_t operator()(const string& key)// {// //BKDR Hash// size_t hash = 0;// for (size_t i = 0; i < key.size(); ++i)// {// hash *= 131;//BKDR Hash// hash += key[i];// }// return hash;// }//};template<class T>struct HashNode{T _data;HashNode<T>* _next;直接在桶中进行连接 插入的时候就连接双向是为了删除好删//HashNode<T>* _linknext;//HashNode<T>* _linkprev;HashNode(const T& data):_data(data),_next(nullptr){}};//迭代器//前置声明template<class K, class T, class KeyOfT, class Hash>class HashTable;template<class K, class T, class KeyOfT, class Hash>struct __HashTableIterator//++it 这里当一个桶走完了 迭代器如何寻找下一个桶???{typedef __HashTableIterator<K, T, KeyOfT,Hash> Self;typedef HashTable<K, T, KeyOfT, Hash> HT;//HashTable找不到 加一个前置typedef HashNode<T> Node;Node* _node; HT* _pht;//给一个HashTable的指针 可以拿到每个桶的首地址__HashTableIterator(Node* node, HT* pht):_node(node),_pht(pht){}T& operator*(){return _node->_data;}T* operator->(){return &_node->_data;}Self operator++(){if (_node->_next){_node = _node->_next;}else{//如果一个桶走完了 如何找到下一个桶KeyOfT koft;size_t i = _pht->HashFunc(koft(_node->_data)) % _pht->_tables.size();//_tables是HashTable类里的私有 迭代器类想要访问 友元++i;for (; i < _pht->_tables.size(); ++i){Node* cur = _pht->_tables[i];if (cur){_node = cur;return *this;}}_node = nullptr;}return *this;}bool operator!=(const Self& s){return _node != s._node;}};template<class K, class T, class KeyOfT, class Hash = _Hash<K>>//给默认的 没有封装前//template<class K, class T, class KeyOfT>class HashTable{typedef HashNode<T> Node;public:friend struct __HashTableIterator<K, T, KeyOfT, Hash>;//友元typedef __HashTableIterator<K, T, KeyOfT, Hash> iterator;iterator begin(){for (size_t i = 0; i < _tables.size(); ++i){if (_tables[i]){return iterator(_tables[i], this);}}return end();}iterator end(){return iterator(nullptr, this);}~HashTable(){//清理桶就可以Clear();}void Clear(){for (size_t i = 0; i < _tables.size(); ++i){Node* cur = _tables[i];while (cur){Node* next = cur->_next;delete cur;cur = next;}//删完后制空_tables[i] = nullptr;}}//有些类型不能取模 利用仿函数强制转换类型进行取模size_t HashFunc(const K& key){Hash hash;//仿函数return hash(key);}//bool Insert(const T& data)//{// KeyOfT koft;// //如果负载因子等于1 则增容 避免大量的哈希冲突// if (_tables.size() == _num)// {// //1.开2倍大小的新表(不一定是2倍)// //2.遍历旧表的数据 重新计算在新表中位置// //3.释放旧表// vector<Node*> newtables;// size_t newsize = _tables.size() == 0 ? 10 : _tables.size() * 2;// newtables.resize(newsize);// for (size_t i = 0; i < _tables.size(); ++i)// {// //将旧表中的节点取下来重新计算在新表中的位置 并插入进去// Node* cur = _tables[i];// while (cur)// {// //算新表中的位置// Node* next = cur->_next;// size_t index = HashFunc(koft(cur->_data)) % newtables.size();// cur->_next = newtables[index];// newtables[index] = cur;// // cur = next;// }// //找不到制空// _tables[i] = nullptr;// }// //交换// _tables.swap(newtables);// }// //计算数据在表中映射的位置// size_t index = HashFunc(koft(data)) % _tables.size();// Node* cur = _tables[index];// //1.先查找这个值在不在表中// while (cur)// {// if (koft(cur->_data) == koft(data))// {// return false;// }// else// {// cur = cur->_next;// }// }// //2.头插到挂的链表中(尾插也可以)// Node* newnode = new Node(data);// newnode->_next = _tables[index];// _tables[index] = newnode;// ++_num;// return true;//}//素数表size_t GetNextPrime(size_t num){const int PRIMECOUNT = 28;const size_t primeList[PRIMECOUNT] ={53ul, 97ul, 193ul, 389ul, 769ul,1543ul, 3079ul, 6151ul, 12289ul, 24593ul,49157ul, 98317ul, 196613ul, 393241ul, 786433ul,1572869ul, 3145739ul, 6291469ul, 12582917ul, 25165843ul,50331653ul, 100663319ul, 201326611ul, 402653189ul, 805306457ul,1610612741ul, 3221225473ul, 4294967291ul};//ul默认是无符号长整型for (size_t i = 0; i < PRIMECOUNT; ++i){if (primeList[i] > num){return primeList[i];}}return primeList[PRIMECOUNT - 1];}//完整的pair<iterator, bool> Insert(const T& data){KeyOfT koft;//如果负载因子等于1 则增容 避免大量的哈希冲突if (_tables.size() == _num){//1.开2倍大小的新表(不一定是2倍)//2.遍历旧表的数据 重新计算在新表中位置//3.释放旧表vector<Node*> newtables;//表中如果是素数 冲突率会降低//size_t newsize = _tables.size() == 0 ? 10 : _tables.size() * 2;size_t newsize = GetNextPrime(_tables.size());newtables.resize(newsize);for (size_t i = 0; i < _tables.size(); ++i){//将旧表中的节点取下来重新计算在新表中的位置 并插入进去Node* cur = _tables[i];while (cur){//算新表中的位置Node* next = cur->_next;size_t index = HashFunc(koft(cur->_data)) % newtables.size();cur->_next = newtables[index];newtables[index] = cur;cur = next;}//找不到制空_tables[i] = nullptr;}//交换_tables.swap(newtables);}//计算数据在表中映射的位置size_t index = HashFunc(koft(data)) % _tables.size();Node* cur = _tables[index];//1.先查找这个值在不在表中while (cur){if (koft(cur->_data) == koft(data)){return make_pair(iterator(cur, this), false);}else{cur = cur->_next;}}//2.头插到挂的链表中(尾插也可以)Node* newnode = new Node(data);newnode->_next = _tables[index];_tables[index] = newnode;++_num;return make_pair(iterator(newnode, this), true);}Node* Find(const K& key){KeyOfT koft;size_t index = HashFunc(key) % _tables.size();Node* cur = _tables[index];while (cur){if (koft(cur->_data) == key){return cur;}else{cur = cur->_next;}}return nullptr;}bool Erase(const K& key){KeyOfT koft;size_t index = HashFunc(key) % _tables.size();Node* prev = nullptr;//单链表的删除 记录前一个Node* cur = _tables[index];while (cur){if (koft(cur->_data) == key){if (prev == nullptr){//表示要删第一个_tables[index] = cur->_next;}else{prev->_next = cur->_next;}delete cur;return true;}else{prev = cur;cur = cur->_next;}}return false;}private:vector<Node*> _tables;size_t _num = 0; //记录表中存储的数据个数};void TestHashTable1(){//HashTable<int, int, SetKeyOfT<int>, _Hash<int>> ht;//传仿函数HashTable<int, int, SetKeyOfT<int>> ht;//不传ht.Insert(4);ht.Insert(14);ht.Insert(24);ht.Insert(5);ht.Insert(15);ht.Insert(25);ht.Insert(6);ht.Insert(16);ht.Insert(26);ht.Insert(36);ht.Insert(33);ht.Insert(44);ht.Erase(4);ht.Erase(44);}void TestHashTable2(){//字符串类型不支持取模 不用默认的 显示传//HashTable<string, string, SetKeyOfT<string>, _HashString> ht;//传仿函数//HashTable<string, string, SetKeyOfT<string>> ht;//不传仿函数 用模板特化HashTable<string, string, SetKeyOfT<string>, _Hash<string>> ht;ht.Insert("sort");ht.Insert("string");ht.Insert("left");//冲突了 ASCII码值相同//BKDR哈希解决 *131cout << ht.HashFunc("abcd") << endl;cout << ht.HashFunc("aadd") << endl;}
}
TestHashTable1()
插入所有数后
删除4
删除44
TestHashTable2()

4.MyUnorderedSet和MyUnorderedMap
接口全是调用哈希表的函数
unordered_set
#pragma once#include "HashTable.h"using namespace OPEN_HASH;namespace szh
{template<class K, class Hash = OPEN_HASH::_Hash<K>>class unordered_set{struct SetKOfT{const K& operator()(const K& k){return k;}};public://typename告诉编译器这里是模板类型typedef typename HashTable<K, K, SetKOfT, Hash>::iterator iterator;iterator begin(){return _ht.begin();}iterator end(){return _ht.end();}pair<iterator, bool> insert(const K& k){return _ht.Insert(k);}private:HashTable<K, K, SetKOfT, Hash> _ht;};void test_unordered_set(){unordered_set<int> s;s.insert(1);s.insert(5);s.insert(4);s.insert(2);unordered_set<int>::iterator it = s.begin();while (it != s.end()){cout << *it << " ";++it;}cout << endl;//了解//遍历出来是1 2 4 5 如果std的话就是1 5 4 2//如何实现1 5 4 2?//再建立一个链表存储数据//尾插 迭代器遍历时 遍历链表//就可以保持遍历有序//这个方法有没有什么缺陷?//删除的时候需要查找 时间复杂度增加//建立链表 直接就是单链表的迭代器}
}
unordered_map
#pragma once#include "HashTable.h"using namespace OPEN_HASH;namespace szh
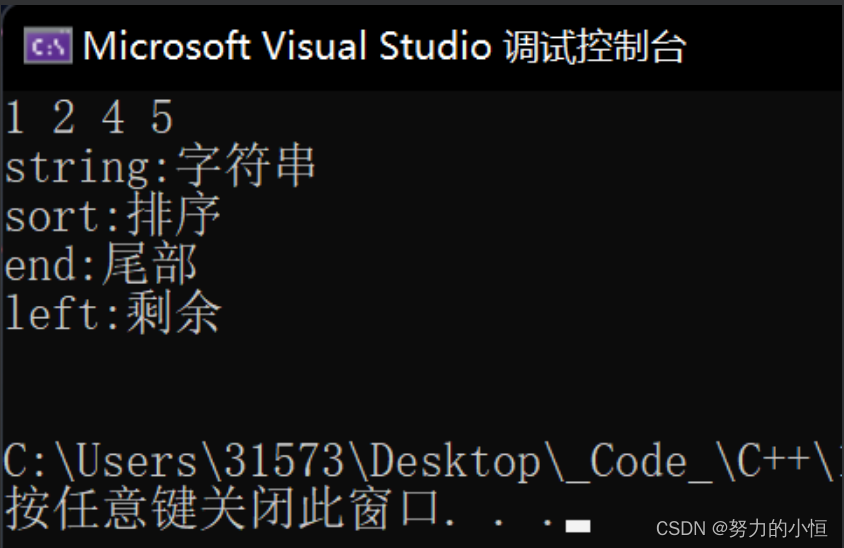
{template<class K, class V,class Hash = OPEN_HASH::_Hash<K>>//这一层加仿函数 传过来之后再看 HashTable中实现仿函数 到map和set再用//因为HashTable默认不传仿函数 利用的模板特化class unordered_map{struct MapKOfT{const K& operator()(const pair<K, V>& kv){return kv.first;}};public:typedef typename HashTable<K, pair<K, V>, MapKOfT, Hash>::iterator iterator;//HashTable在命名空间里 直接展开iterator begin(){return _ht.begin();}iterator end(){return _ht.end();}pair<iterator, bool> insert(const pair<K, V>& kv){return _ht.Insert(kv);}V& operator[](const K& key){pair<iterator, bool> ret = _ht.Insert(make_pair(key, V()));return ret.first->second;//ret->first拿到迭代器 .second拿到value}private:HashTable<K, pair<K, V>, MapKOfT, Hash> _ht;};void test_unordered_map(){unordered_map<string, string> dict;dict.insert(make_pair("sort","排序"));dict.insert(make_pair("left","左边"));dict.insert(make_pair("string", "字符串"));dict["left"] = "剩余";dict["end"] = "尾部";//先插入后修改//unordered_map<string, string>::iterator it = dict.begin();auto it = dict.begin();while (it != dict.end()){cout << it->first << ":" << it->second << endl;++it;}cout << endl;}
}
int main()
{ szh::test_unordered_set();szh::test_unordered_map();return 0;
}
5.位图
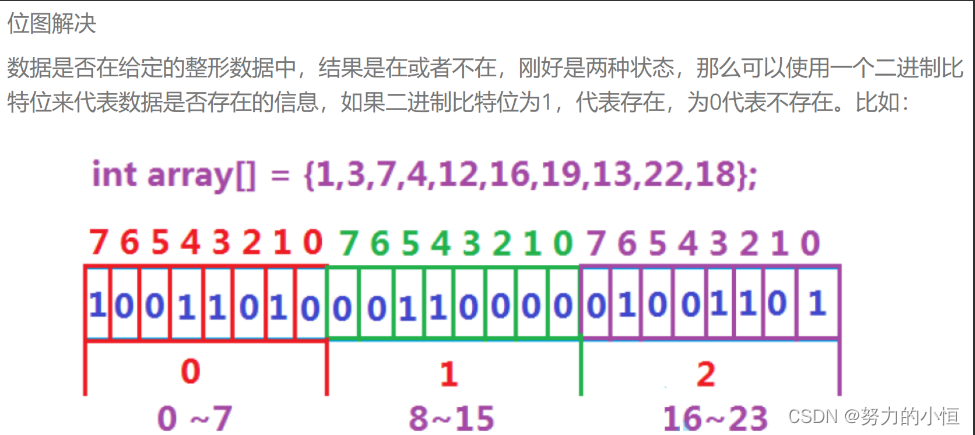
1°位图的概念
所谓位图,就是用每一位来存放某种状态,适用于海量数据,数据无重复的场景。通常是
用来判断某个数据存不存在的。
2°位图的实现
set
功能:把当前位置置成1
先算出x映射在第几个整型 再算出x映射在第几个位置 与1左移pos位进行按位或
reset
功能:把当前位置制成0
先算出x映射在第几个整型 再算出x映射在第几个位置 与取反后的1左移pos位按位与
移动后取反 再& 只有pos位置是1&0=0 其他位置0/1&1=0/1
test
功能:判断x在不在(也就是说x映射的位置是否为1)
先算出x映射在第几个整型 再算出x映射在第几个位置 x映射的位置与1左移pos位按位与
0&(0/1)=0 1&0=0 1&1=1
所以pos那一位如果是0 那么最后结果就是0
pos那一位不是0 那么最后结果就是非0
#pragma once#include <vector>namespace szh
{class bitset{public:bitset(size_t N){//100个整型 3200个位 _bits.resize(N / 32 + 1, 0);//比如说100个位 3个不够 4个才行_num = 0;}void set(size_t x)//置1{size_t index = x / 32;//算出x映射的位在第几个整型size_t pos = x % 32;//算出x在这个整型中第几个位置_bits[index] |= (1 << pos);//<<优先级很低 加括号 第pos个位置成1//左右移不是方向 左移是向高位移动 右移是向低位移动//C语言设计的bug 历史遗留问题 容易让人误导 有大端机 也有小端机++_num;}void reset(size_t x)//置0{size_t index = x / 32;size_t pos = x % 32;_bits[index] &= ~(1 << pos);//移动后取反 再& 只有pos位置是1&0=0 其他位置0/1&1=0/1--_num;}//判断x在不在(也就是说x映射的位知否为1)bool test(size_t x){size_t index = x / 32;size_t pos = x % 32;return _bits[index] & (1 << pos);//0&(0/1)=0 1&0=0 1&1=1//所以pos那一位如果是0 那么最后结果就是0//pos那一位不是0 那么最后结果就是非0}private://int* _bits;std::vector<int> _bits;//vectorsize_t _num;//映射存储的数据个数 存了多少个1};void test_bitset(){bitset bs(100);bs.set(99);bs.set(98);bs.set(97);bs.set(5);bs.reset(98);for (int i = 0; i < 100; ++i)//size_t i{printf("[%d]:%d\n", i, bs.test(i));}//bitset bs(-1);//无符号 整型最大值bitset bs(pow(2, 32));可以bitset bs(0xffffffff);也可以}
}
#include "HashTable.h"
#include "MyUnorderedMap.h"
#include "MyUnorderedSet.h"
#include "bitset.h"
#include "BloomFilter.h"int main()
{ szh::test_bitset();return 0;
}

6.布隆过滤器
1°概念
- 用哈希表存储用户记录,缺点:浪费空间
- 用位图存储用户记录,缺点:不能处理哈希冲突
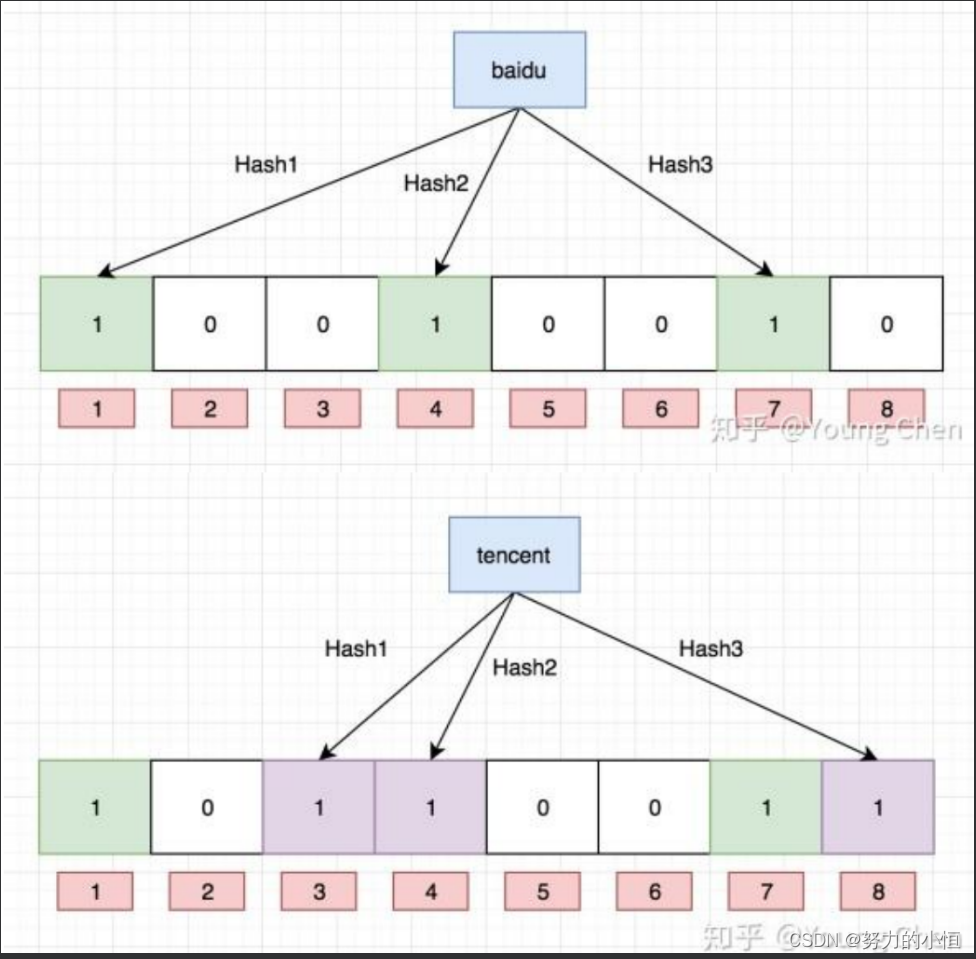
- 将哈希与位图结合,即布隆过滤器
图片来源:Young Chen
2°实现
布隆过滤器的思想是将一个元素用多个哈希函数映射到一个位图中,因此被映射到的位置
的比特位一定为1。所以可以按照以下方式进行查找:分别计算每个哈希值对应的比特位置
存储的是否为零,只要有一个为零,代表该元素一定不在哈希表中,否则可能在哈希表
中。
#pragma once
#include "bitset.h"
#include <string>namespace szh
{struct HashStr1{//BKDRsize_t operator()(const std::string& str){size_t hash = 0;for (size_t i = 0; i < str.size(); ++i){hash *= 131;hash += str[i];}return hash;}};struct HashStr2{//RSHashsize_t operator()(const std::string& str){size_t hash = 0;size_t magic = 63689;//魔数for (size_t i = 0; i < str.size(); ++i){hash *= magic;hash += str[i];magic *= 378551;}return hash;}};struct HashStr3{//SDBMHashsize_t operator()(const std::string& str){size_t hash = 0;for (size_t i = 0; i < str.size(); ++i){hash *= 65599;hash += str[i];}return hash;}};template<class K = std::string, class Hash1 = HashStr1, class Hash2 = HashStr2, class Hash3 = HashStr3>//k=m/n*ln2 k为哈希函数个数 m为布隆过滤器长度 n为插入的元素个数 p为误报率//3 = m/n * 0.69 -> m = 4.3*nclass bloomfilter{public:bloomfilter(size_t num):_bs(5*num),_N(5*num){}void set(const K& key){//仿函数对象调operator()size_t index1 = Hash1()(key) % _N;size_t index2 = Hash2()(key) % _N;size_t index3 = Hash3()(key) % _N;cout << index1 << endl;cout << index2 << endl;cout << index3 << endl;cout << endl << endl;//标记三个位置 检测三个位置_bs.set(index1);_bs.set(index2);_bs.set(index3);}bool test(const K& key){size_t index1 = Hash1()(key) % _N;if (_bs.test(index1) == false)return false;size_t index2 = Hash2()(key) % _N;if (_bs.test(index2) == false)return false;size_t index3 = Hash3()(key) % _N;if (_bs.test(index3) == false)return false;return true;//但是这里也不一定是真的在 还是可能存在误判//判断在 是不准确的//判断不在 是准确的}void reset(const K& key){//将映射的位置给置0就可以?->会影响其他的 误删了//不支持删除 可能会存在误删//一般布隆过滤器不支持删除}private:bitset _bs;//位图 底层size_t _N;};void test_bloomfilter(){bloomfilter<std::string> bf(100);bf.set("abcd");bf.set("aadd");bf.set("bcad");//ASCII码值相同 但映射到了不同位置cout << bf.test("abcd") << endl;cout << bf.test("aadd") << endl;cout << bf.test("bcad") << endl;cout << bf.test("cbad") << endl;}
}
#include "HashTable.h"
#include "MyUnorderedMap.h"
#include "MyUnorderedSet.h"
#include "bitset.h"
#include "BloomFilter.h"int main()
{ szh::test_bloomfilter();return 0;
}
7.题目
1.给40亿个不重复的无符号整数,没排过序。给一个无符号整数,如何快速判断一个
数是否在这40亿个数中?
40亿个不重复的无符号整数占多少空间?
16G
1.排序 二分查找
2.set/unordered_set(红黑树/哈希表)存起来再查找
以上方案的问题:数据量太大 放不到内存中
空间如果够
直接定址法存储数据(要开42亿多)+查找
开空间要开数据的范围 才能满足全部映射进去
开2^32个空间 来对所有数直接定址法建立映射关系
2^32个位->位图
占用500M就可以
位图:既节省了空间 效率又非常高
2.给定100亿个整数,设计算法找到只出现一次的整数?
1G=2^32 byte 10亿byte
100亿个整数=400亿字节=40G左右
如果使用map/unordered_map 存在的问题:可能内存不够
所以这还得靠位图的变形的思路
分析:
判断一个值在不在?只需要两种状态 所以使用一个位就可以了
这里我们要找出只出现一次的整数
出现0次的 出现1次的 出现2次及以上的 这里需要三种状态 也就是说每个值使用2个位表示
出现0次:00
出现1次:01
出现2次及以上:10或者11
3.给两个文件 分别有100亿个整数 我们只有1G内存 如何找到两个文件交集?
方案1:
将其中一个文件的整数放到一个位图中 读取另外一个文件中的整数 判断在不在位图
中 在就是交集 消耗500M内存
方案2:
将文件1的整数映射到位图1 将文件2的整数映射到位图2中 然后将在两个位图中的数按位
与 与之后为1的位就是交集 消耗内存1G
4.给两个文件,分别有100亿个query(查询),我们只有1G内存,如何找到两个文件交
集?分别给出精确算法和近似算法
分析:
(query一般是sql查询语句或者网络请求的url等 一般是一个字符串)
100亿个query占用多少空间呢?假设平均一个query 30-60 byte
100亿个query占用大约300-600G
方案一:
将文件1中的query映射到一个布隆过滤器 读取文件2中的query 判断在不在布隆过
滤器中 在就是交集
方案一缺陷:
交集中有些数不准确 还是有些交集的数据漏掉了?
在是不准确的 不在就是准确的
交集中有些数不准确√
精确解法:
这两个文件都非常大 大概在300-600G之间 也没有合适的数据结构能直接精确的找出交集
文件很大 不能都放到内存中 那么我们可以把文件切分多个小文件 小文件数据加载到内存
中
切分成多少份:
一般切出来一个小文件的大小能放进内存就可以 那么这里一个文件300-600G 切1000份
一个文件300-600M 这里有1G内存 可以搞定
5.如何扩展BloomFilter使得它支持删除元素的操作?
每个位标记成计数器 那么到底用几个位表示计数器呢?
给的位如果少了
如果多个值映射一个位置就会导致计数器溢出
比如用1个byte最多计数256 假设有260个值都映射到一个位置 就出问题
如果使用更多的位映射一个位置 那么空间消耗就大了 不要忘了布隆过滤器的特点就是节省
空间
再分析:
如果是平均切分 那么A0可以放到内存中存储到一个set中
那么B0-B999小文件中的数据都得跟A0比较
以此内推 A1放到内存中后 也得跟B0-B999小文件中的数据比较 可以看到这里的优势就是
比较的过程放到内存中
但是这里要不断的互相比较
可以看到这里解决的优势:
1.部分数据放到内存中
2.不是暴力比较 因为Ax的小文件的数据放在set中 比较效率还是能高一些
还能不能更加优化?
哈希切分:hashstr(query) % 1000 i是多少
query就进入第Ai/Bi的小文件中 文件A/文件B都这样处理
将Ai放小文件的数据放到一个set中 读取对应的Bi小文件中query 看在不在Ai中 在就是交
集
A和B中相同的query一定进入编号相同的Ai和Bi小文件 所以下面只需要编号相同找交集就
可以
6.给一个超过100G大小的log file, log中存着IP地址, 设计算法找到出现次数最多的IP
地址? 与上题条件相同,如何找到top K的IP?如何直接用Linux系统命令实现?
分析:首先这里要做的是统计次数 同次数我们一般用kv模型的map解决 但是这里的问题是
有100G数据 放不到内存中
先创建1000个小文件A0-A999 读取IP计算出i=hashstr(IP)%1000
i是多少 IP就进入对应编号的Ai小文件 这样相同IP一定进入了同一个小文件
map<string,int> countMap 读取Ai中的IP统计出次数 一个读完了clear 再读另一个
使用一个pair<string,int> max记录出现次数最多的IP就可以求出
如果要找topK 那么就是用一个堆来搞定
一般情况下现在一台电脑4-8G 硬盘是500-1024G
假设我们要存储每个人的微信号和他的朋友圈信息
并且要方便快速查找。 <微信号,朋友圈>
我们现在真正需要考虑的是存储数据的问题
因为微信有10亿用户 假设平均一个用户的信息是100M
那么大概需要 (10亿*100M,1亿G->10万T)
也就是说至少需要10万台服务器来存储
多机存储 还需要满足增删查改数据的需求
分析一下:用户laoganma发朋友圈了 插入到哪台机器 浏览和删朋友圈取哪台机器查找?
用户的朋友圈信息存储和机器建立一个映射关系
比如laoganma的信息存几号机器呢?i = hashstr(laoganma)%10W
i是多少 laoganma的信息就存到第i号机器
(注意实际中可以需要用一台额外的机器存储机器编号和IP的映射关系 这样我算出是i号机
器 就可以找到他的IP 就可以找访问服务器了)
上面方案的缺陷:假设随着大家发朋友圈越来越多 或者用户量继续增长 10W台不够了
我们需要增加机器数量到15W台 那么之前10W台机器上的数据映射关系就不对了 就需要
重新计算位置迁移数据
一致性哈希:不再%10W %2^32(42亿)
注意这里的大小也可以是其他值 不过要大一些就可以 比如说50亿 100亿
0-2^32-1中一段范围的值去映射一台服务器
整个段的范围就映射这10W台机器
如果你要增加5W台机器 那么不需要所有数据迁移 只需要迁移部分负载重的机器上数据
比如10000-20000范围映射3号服务器 现在增加机器了
那么10000-15000范围映射新增机器X 迁移3号服务器中映射在10000-15000范围的数据
到新机器
总结:一致性哈希就是给一个特别大的除数 那么增加机器也不需要整个重新计算迁移
他是一段范围值映射一个一台机器<x1-x2,ip> 那么增加机器只需要改变映射范围即可
且迁移极小部分的数据
位图
优点:节省空间 效率高
缺点:只能处理整型
布隆过滤器
优点:节省空间 高效 可以标记存储任意类型
缺点:存在误判 不支持删除
【C++】18.哈希 完
相关文章:
【C++】18.哈希
1.unordered_set和unordered_map 使用与set和map的用法一样 #include <iostream> #include <unordered_map> #include <unordered_set> #include <map> #include <set> #include <string> #include <vector> #include <time.h&…...
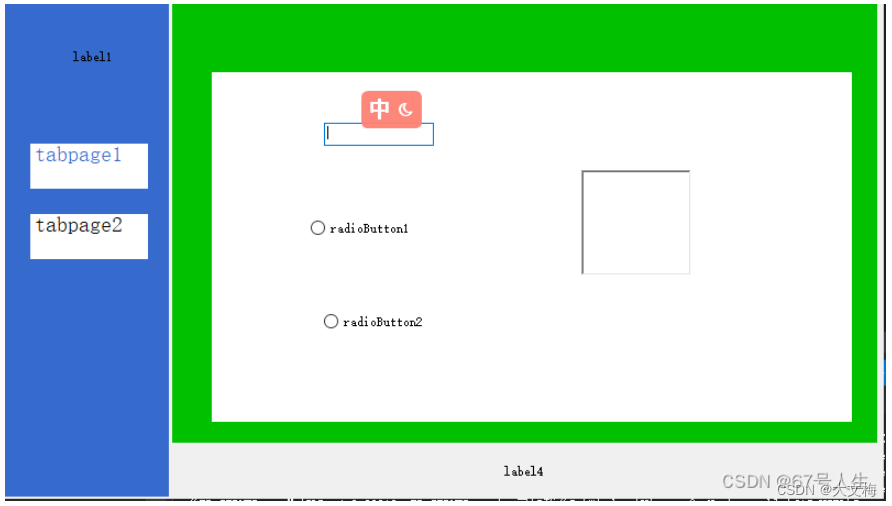
C# 利用TabControl控件制作多窗口切换
TabControl控件切换时触发的事件 选项卡切换触发的是TabControl控件的SelectedIndexChanged事件。 当TabControl控件的任何一个TabPage被点击或选择,即发生SelectedIndexChanged事件事件。 代码如下: private void tabControl1_SelectedIndexChanged(o…...

论文阅读《PIDNet: A Real-time Semantic Segmentation Network Inspired by PID》
论文地址:https://arxiv.org/pdf/2206.02066.pdf 源码地址:https://github.com/XuJiacong/PIDNet 概述 针对双分支模型在语义分割任务上直接融合高分辨率的细节信息与低频的上下文信息过程中细节特征会被上下文信息掩盖的问题,提出了一种新的…...
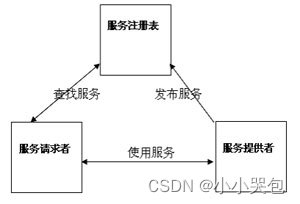
SOA与中间件、基础件的发展
应运而生的SOA 美国著名的IT市场研究和顾问咨询公司Gartner预测:到2006年,采用面向服务的企业级应用将占全球销售出的所有商业应用产品的80 以上到2008年,SOA将成为绝对主流的软件工程实践方法。近几年全球各大IT巨头纷纷推出自己的面向服务的应用平…...
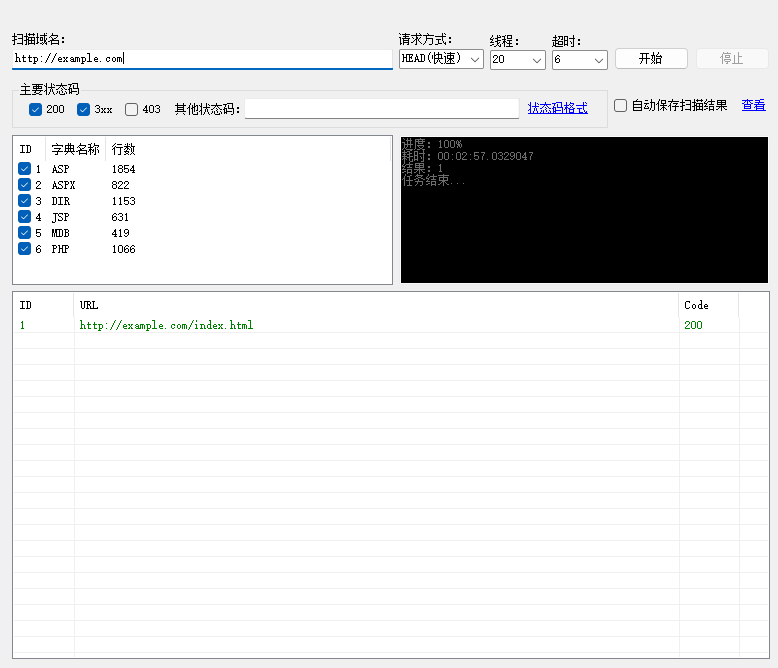
渗透测试 | 目录扫描
0x00 免责声明 本文仅限于学习讨论与技术知识的分享,不得违反当地国家的法律法规。对于传播、利用文章中提供的信息而造成的任何直接或者间接的后果及损失,均由使用者本人负责,本文作者不为此承担任何责任,一旦造成后果请自行承担…...
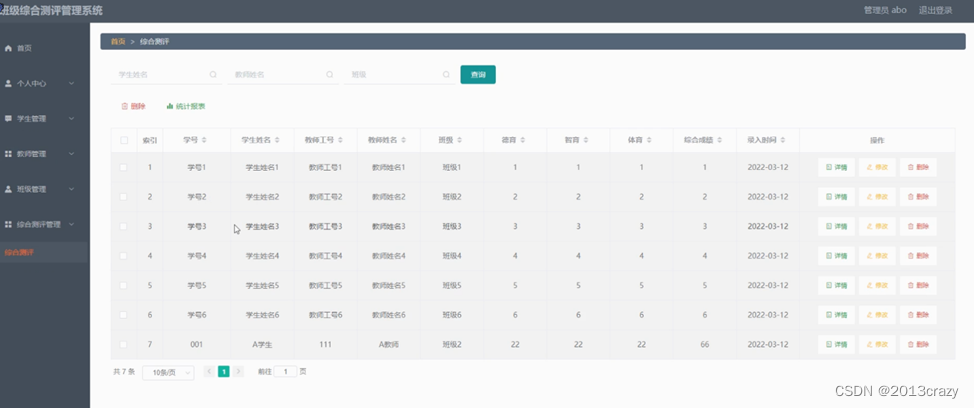
基于Springboot的班级综合测评管理系统的设计与实现
摘要 随着互联网技术的高速发展,人们生活的各方面都受到互联网技术的影响。现在人们可以通过互联网技术就能实现不出家门就可以通过网络进行系统管理,交易等,而且过程简单、快捷。同样的,在人们的工作生活中,也就需要…...

比较全的颜色RGB值对应表 8位 16位
实色效果英文名称R.G.B16色实色效果英文名称R.G.B16色Snow255 250 250#FFFAFAPaleTurquoise1187 255 255#BBFFFFGhostWhite248 248 255#F8F8FFPaleTurquoise2174 238 238#AEEEEEWhiteSmoke245 245 245#F5F5F5PaleTurquoise3150 205 205#96CDCDGainsboro220 220 220#DCDCDCPaleT…...

freertos使用基础
FreeRtos快速入门 一,基础知识1.工作方式简介(不深入介绍原理)2,移值3,什么是内存管理 二,API的作用跟使用方法1,创建任务 最近跟着韦东山老师学习 FreeRTOS ,记录下来加…...

Spring Boot引用外部JAR包和将自己的JAR包发布到本地Maven库
Spring Boot引用外部JAR包 Spring Boot 项目可以通过在项目中引入外部 JAR 包来增强功能。以下是使用Spring Boot引用外部JAR包的步骤: 将外部JAR包添加到项目中,可以通过直接将JAR包复制到项目目录下的“lib”目录中,或者使用Maven的方式添…...

微信小程序原生开发功能合集十二:编辑界面的实现
本章实现编辑界面的实现处理,包括各编辑组件的使用及添加数据保存数据流程的实现处理。 另外还提供小程序开发基础知识讲解课程,包括小程序开发基础知识、组件封装、常用接口组件使用及常用功能实现等内容,具体如下: 1. CSDN课程: https://edu.csdn.net/course/…...
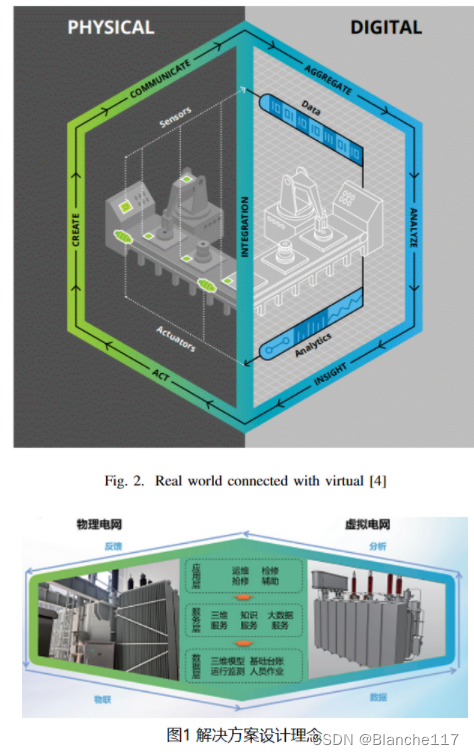
基于3D渲染和基于虚拟/增强现实的IIoT原理的数字孪生平台的方案论文阅读笔记
基于3D渲染和基于虚拟/增强现实的IIoT原理的数字孪生平台的方案论文阅读笔记 论文原文链接:https://ieeexplore.ieee.org/abstract/document/9039804 本笔记对部分要点进行了翻译和批注,原文和翻译可参考链接阅读,此处不进行完整翻译。 论文…...

腾讯云镜YunJing——Agent定时任务脚本分析
缘起 如果你有台腾讯云主机,会发现默认有个叫 YunJing 的进程。 把它kill掉后,发现一段时间又出现了 这是为什么捏? 分析定时任务配置文件 通过crontab定时任务目录, 会发现有个叫yunjing的配置文件。 */30 * * * * root /usr/local/qc…...

如何使用java编写差分进化算法
差分进化算法属于一种进化算法,以全局最优性、收敛速度快等特点,得到很多学者的关注,并将其扩展到参数优化、数值优化、工程优化、路径优化、机器学习等一系列研究中。 而差分进化算法的原理即过程又是什么呢? 一、什么是差分进…...
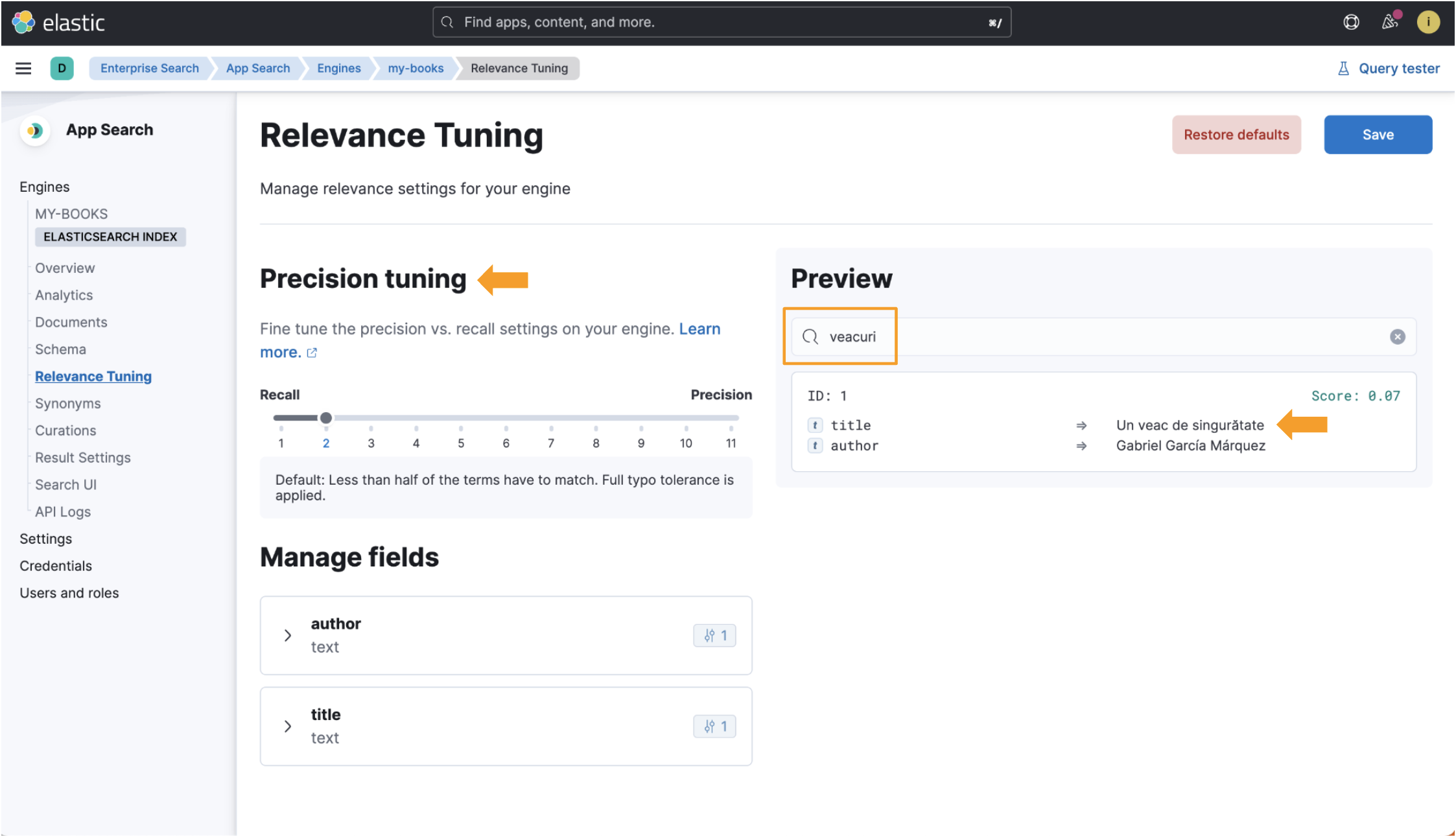
Enterprise:如何在 Elastic 企业搜索引擎中添加对更多语言的支持
作者:Ioana-Alina Tagirta Elastic App Search 中的引擎(engines)使你能够索引文档并提供开箱即用的可调搜索功能。 默认情况下,引擎支持预定义的语言列表。 如果你的语言不在该列表中,此博客将说明如何添加对其他语言…...
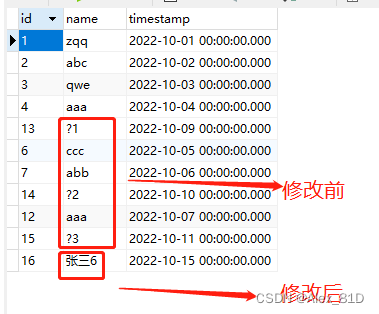
SqlServer数据库中文乱码问题解决方法
这个问题在网上找了很多资料都没找到真正解决问题的办法,最终去了官网,终于找到问题的答案了,整理出来做个记录。 问题描述: 项目中遇到一个问题,sqlserver中的数据是ok的,结果保存到mysql中是乱码&#…...

跨域的五种最常见解决方案
在开发Web应用程序时,一个常见的问题是如何处理跨域请求。跨域请求是指来自不同源的请求,这些请求可能会受到浏览器的限制而不能被正常处理。在这篇文章中,我们将探讨跨域请求的常见解决方案,并了解每种解决方案的优缺点。 一、J…...
作为一个C++新手,我感兴趣的C++开源项目
2023年4月30日,周日晚上。 昨天完成了一个C项目后,想再开始一个C项目,但不知道做什么,于是决定看看有什么好的C开源项目。 今晚在网上逛了一圈后,发现了好多有趣的C开源项目。 参考文章: GitHub Top 10 …...

杭州云降价只是敲锣
1. 陈年旧事 大约是2015年,某友商宣布存储免费,当时我们公司如临大敌,我也被拽过去开会。后来我们才发现……对方的套路是: 文件存储原始收费是一毛钱。文档存储免费的条件是,需要客户当月有一次下载文件的行为才能免费…...
RabbitMQ笔记
一、MQ与RabbitMQ概述 1. MQ简述 MQ(Message Queue)消息队列,是基础数据结构中 “先进先出” 的一种数据结构,也是在消息的传输过程中保存消息的容器(中间件),多用于分布式系统之间进行通信。 …...

【Latex】如何在表格中使用footnote
Latex table cell中是不支持\footnote的。 如果你在table中用\footnote,那么要么这个脚注根本不显示出来,要么就会出现计数出错等问题。总之非常麻烦。 解决策略 笔者在搜集大量资料后,也并没有找到一种“完美的”解决方案。我们只能用一些…...

网络六边形受到攻击
大家读完觉得有帮助记得关注和点赞!!! 抽象 现代智能交通系统 (ITS) 的一个关键要求是能够以安全、可靠和匿名的方式从互联车辆和移动设备收集地理参考数据。Nexagon 协议建立在 IETF 定位器/ID 分离协议 (…...

CMake基础:构建流程详解
目录 1.CMake构建过程的基本流程 2.CMake构建的具体步骤 2.1.创建构建目录 2.2.使用 CMake 生成构建文件 2.3.编译和构建 2.4.清理构建文件 2.5.重新配置和构建 3.跨平台构建示例 4.工具链与交叉编译 5.CMake构建后的项目结构解析 5.1.CMake构建后的目录结构 5.2.构…...

【算法训练营Day07】字符串part1
文章目录 反转字符串反转字符串II替换数字 反转字符串 题目链接:344. 反转字符串 双指针法,两个指针的元素直接调转即可 class Solution {public void reverseString(char[] s) {int head 0;int end s.length - 1;while(head < end) {char temp …...
)
python爬虫:Newspaper3k 的详细使用(好用的新闻网站文章抓取和解析的Python库)
更多内容请见: 爬虫和逆向教程-专栏介绍和目录 文章目录 一、Newspaper3k 概述1.1 Newspaper3k 介绍1.2 主要功能1.3 典型应用场景1.4 安装二、基本用法2.2 提取单篇文章的内容2.2 处理多篇文档三、高级选项3.1 自定义配置3.2 分析文章情感四、实战案例4.1 构建新闻摘要聚合器…...

论文浅尝 | 基于判别指令微调生成式大语言模型的知识图谱补全方法(ISWC2024)
笔记整理:刘治强,浙江大学硕士生,研究方向为知识图谱表示学习,大语言模型 论文链接:http://arxiv.org/abs/2407.16127 发表会议:ISWC 2024 1. 动机 传统的知识图谱补全(KGC)模型通过…...

图表类系列各种样式PPT模版分享
图标图表系列PPT模版,柱状图PPT模版,线状图PPT模版,折线图PPT模版,饼状图PPT模版,雷达图PPT模版,树状图PPT模版 图表类系列各种样式PPT模版分享:图表系列PPT模板https://pan.quark.cn/s/20d40aa…...

SiFli 52把Imagie图片,Font字体资源放在指定位置,编译成指定img.bin和font.bin的问题
分区配置 (ptab.json) img 属性介绍: img 属性指定分区存放的 image 名称,指定的 image 名称必须是当前工程生成的 binary 。 如果 binary 有多个文件,则以 proj_name:binary_name 格式指定文件名, proj_name 为工程 名&…...
【无标题】湖北理元理律师事务所:债务优化中的生活保障与法律平衡之道
文/法律实务观察组 在债务重组领域,专业机构的核心价值不仅在于减轻债务数字,更在于帮助债务人在履行义务的同时维持基本生活尊严。湖北理元理律师事务所的服务实践表明,合法债务优化需同步实现三重平衡: 法律刚性(债…...
Kubernetes 节点自动伸缩(Cluster Autoscaler)原理与实践
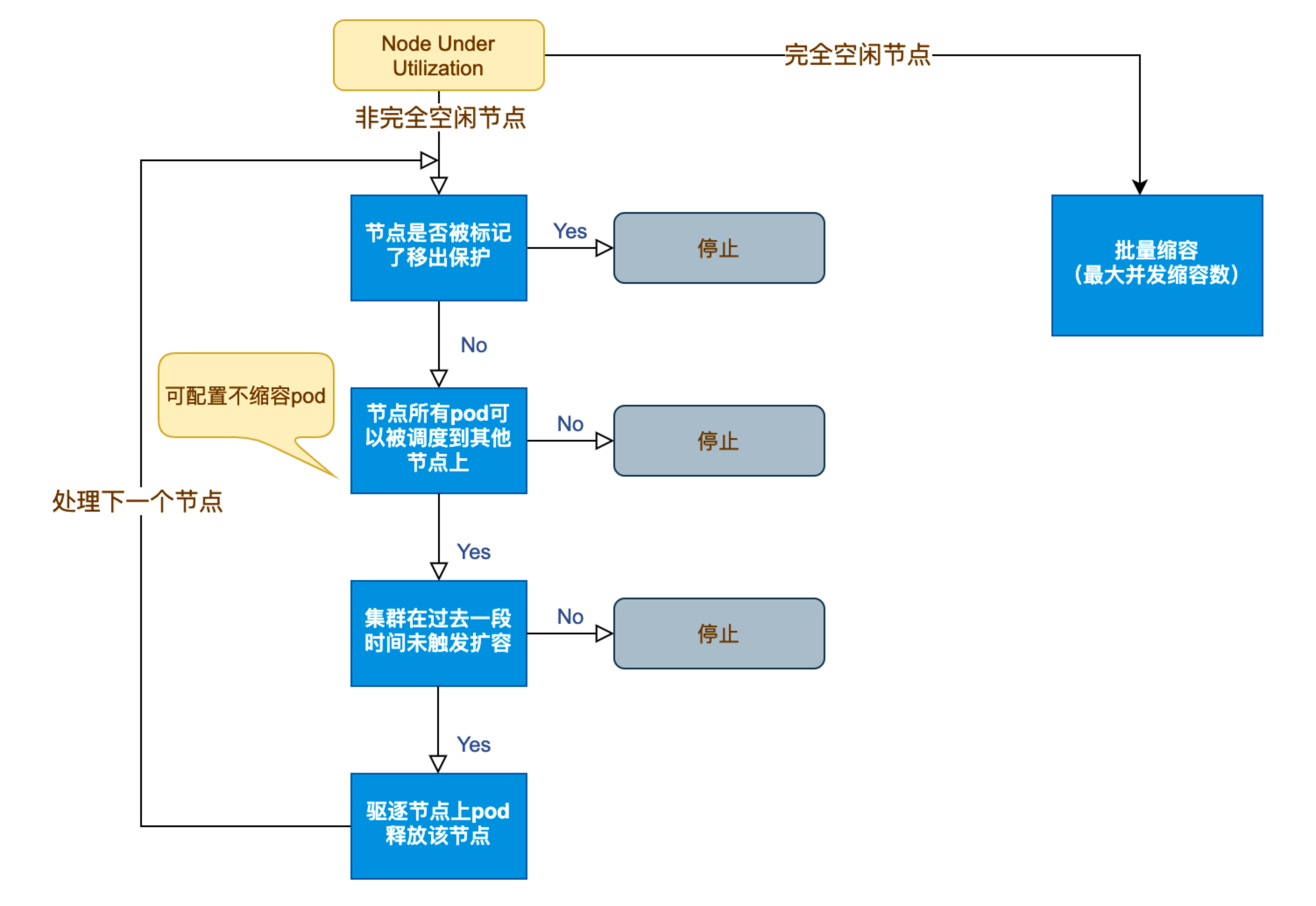
在 Kubernetes 集群中,如何在保障应用高可用的同时有效地管理资源,一直是运维人员和开发者关注的重点。随着微服务架构的普及,集群内各个服务的负载波动日趋明显,传统的手动扩缩容方式已无法满足实时性和弹性需求。 Cluster Auto…...

Matlab实现任意伪彩色图像可视化显示
Matlab实现任意伪彩色图像可视化显示 1、灰度原始图像2、RGB彩色原始图像 在科研研究中,如何展示好看的实验结果图像非常重要!!! 1、灰度原始图像 灰度图像每个像素点只有一个数值,代表该点的亮度(或…...