手把手教你 ,带你彻底掌握八大排序算法【数据结构】
文章目录
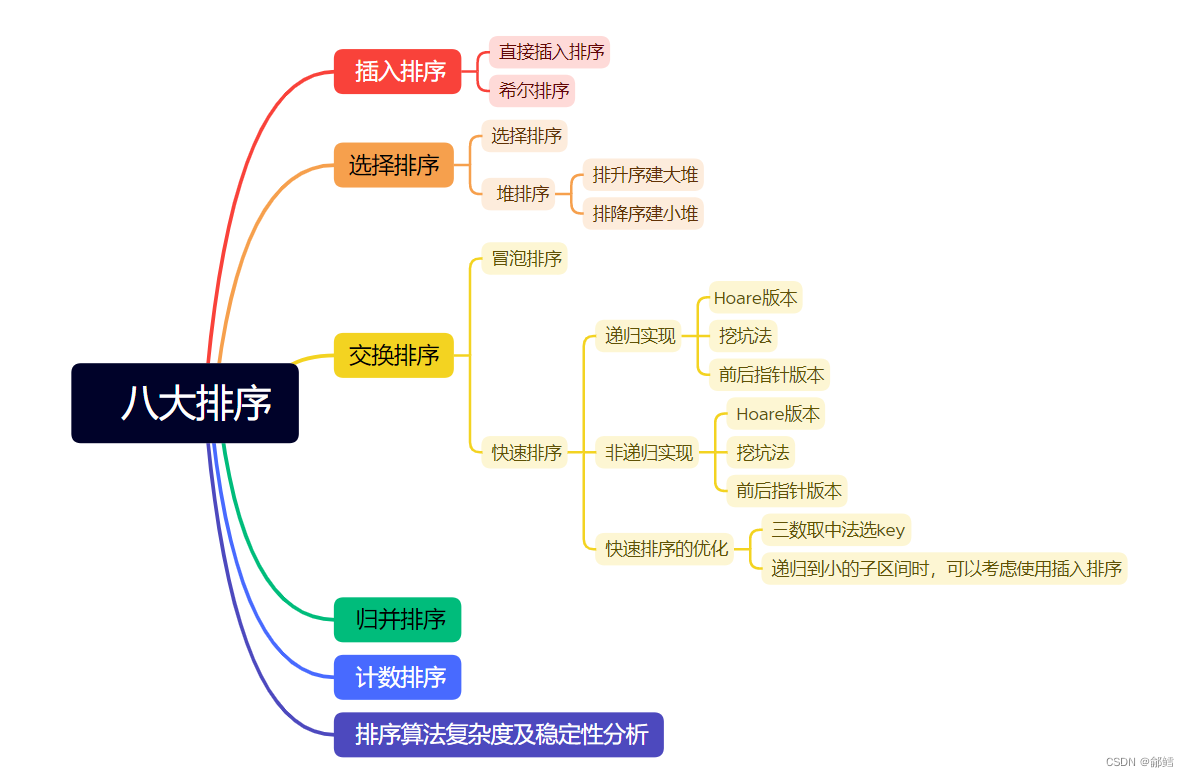
- 插入排序
- 直接插入排序
- 希尔排序
- 选择排序
- 选择排序
- 堆排序
- 升序
- 交换排序
- 冒泡排序
- 快速排序
- 递归
- hoare版本
- 挖坑法
- 前后指针版本
- 非递归
- Hoare
- 挖坑法
- 前后指针
- 快排的优化
- 三数取中法选key
- 递归到小的子区间时,可以考虑使用插入排序
- 归并排序
- 递归实现
- 非递归实现
- 排序算法复杂度以及稳定性
插入排序
直接插入排序
直接插入排序是一种简单的插入排序法,其基本思想:是把待排序的记录按其关键码值的大小逐个插入到一个已经排好序的有序序列中,直到所有的记录插入完为止,得到一个新的有序序列
可以理解为一遍摸扑克牌,一边进行排序
在待排序的元素中,假设前面n-1(其中n>=2)个数已经是排好顺序的,现将第n个数插到前面已经排好的序列中,然后找到合适自己的位置,使得插入第n个数的这个序列也是排好顺序的。
按照此法对所有元素进行插入,直到整个序列排为有序的过程,称为插入排序
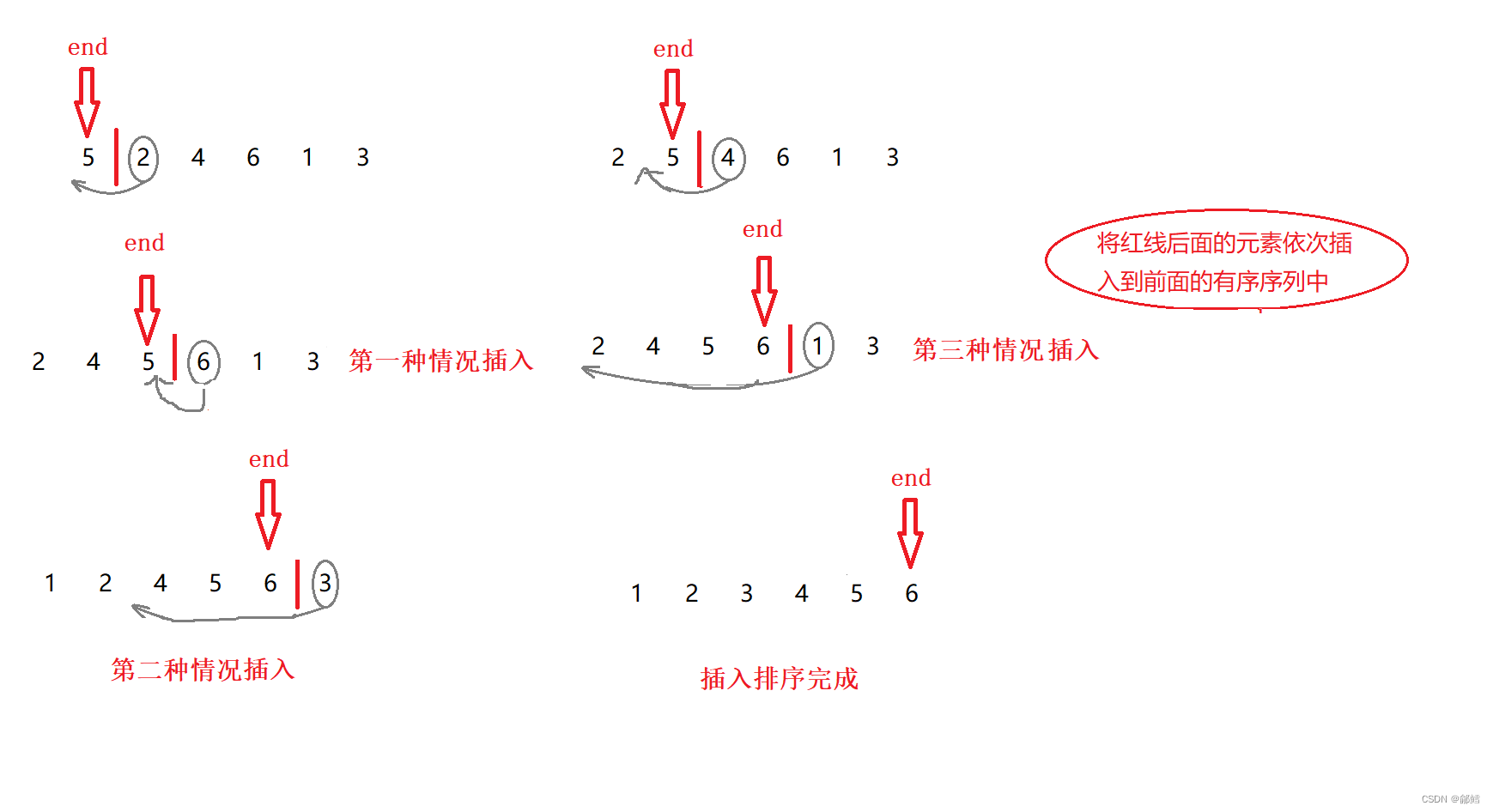
- 当插入第n个元素时,前面的n-1个数已经有序
- 用第n个数与前面的n-1个数比较,我们将第n个数假设为tmp ,也就是说将tmp插入到[0 ,end] 的区间中
第一种情况:如果tmp比end大就放在end后面
第二种情况:如果tmp比end小但是比数组前面的几个数据大,插入之后,tmp之后的数据就往后挪动
第三种情况:如果tmp比数组所有元素都小,所有数据都需要挪动,end就得挪动到数组下标为-1的位置才结束

动图演示:
void InsertSort(int* a , int n )
{for (int i = 1; i <n ; i++){//一趟插入排序 int tmp = a[i];int end = i-1; //end是数组下标while (end >= 0){//如果tmp比end小但是比数组前面的几个数据大,插入之后,tmp之后的数据就往后挪动if (tmp < a[end]){a[end + 1] = a[end];//往后挪动end--;}else{break;}}//如果tmp比数组所有元素都小,所有数据都需要挪动,end就得挪动到数组下标为-1的位置才结束//如果tmp比end大就放在end后面a[end + 1] = tmp;//包含上述两种情况}
}
时间复杂度:O(N^2)
空间复杂度:O(1)
希尔排序
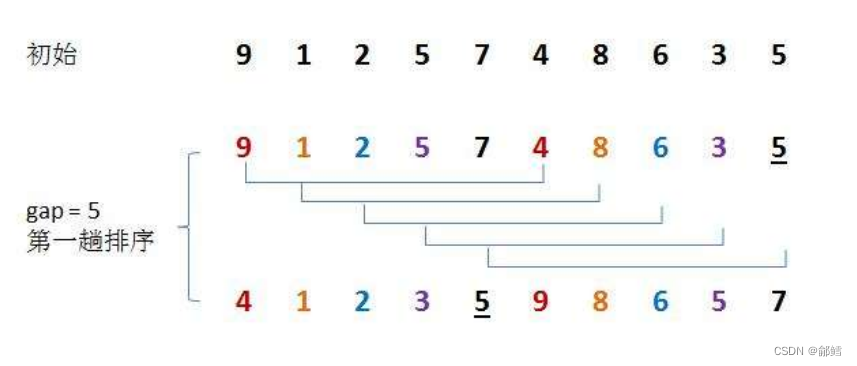
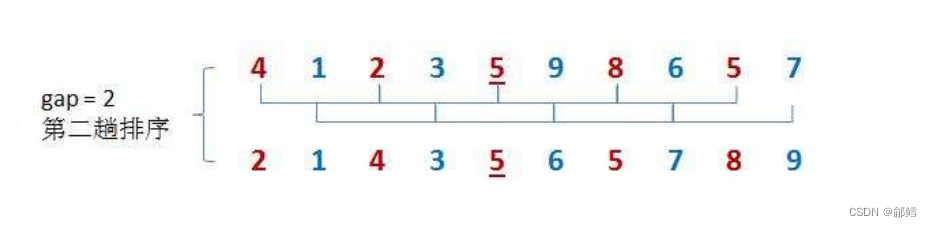
第一步先选定个小于n的数字作为gap,将所有距离为gap的数分为一组进行预排序,预排序的目的就是使数组接近有序,与直接插入排序相同,直接插入排序的间隔为1,预排序的间隔变为gap了
再选一个小于gap的数作为新的gap,重复第一步的操作
当gap的大小减到1时,就相当于整个序列被分到一组,进行一次直接插入排序,排序完成
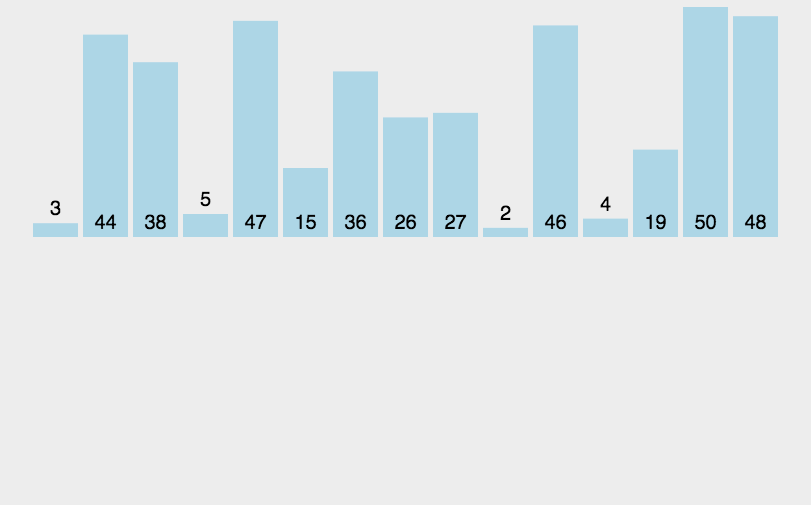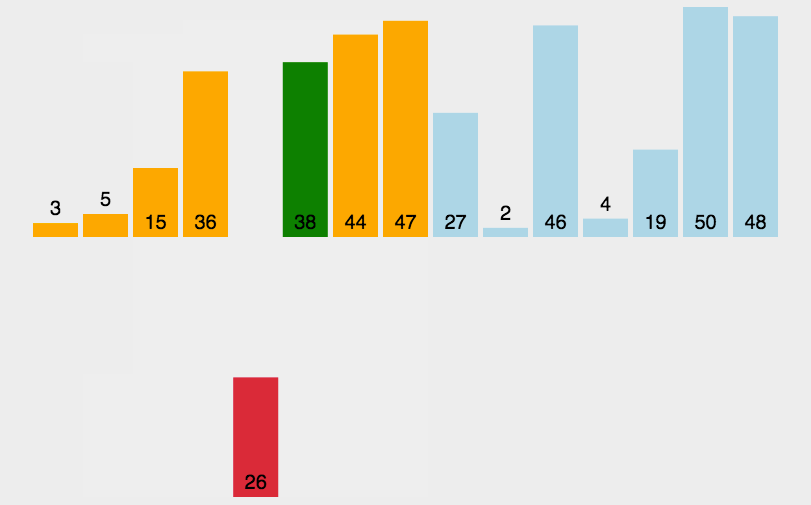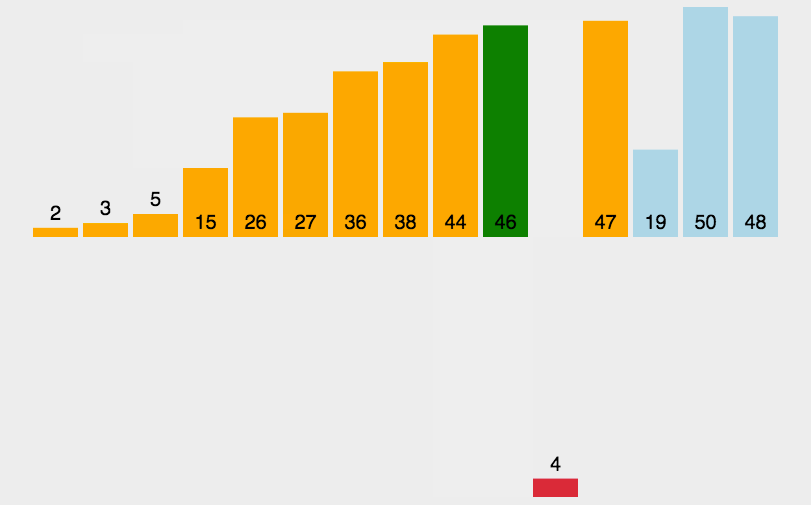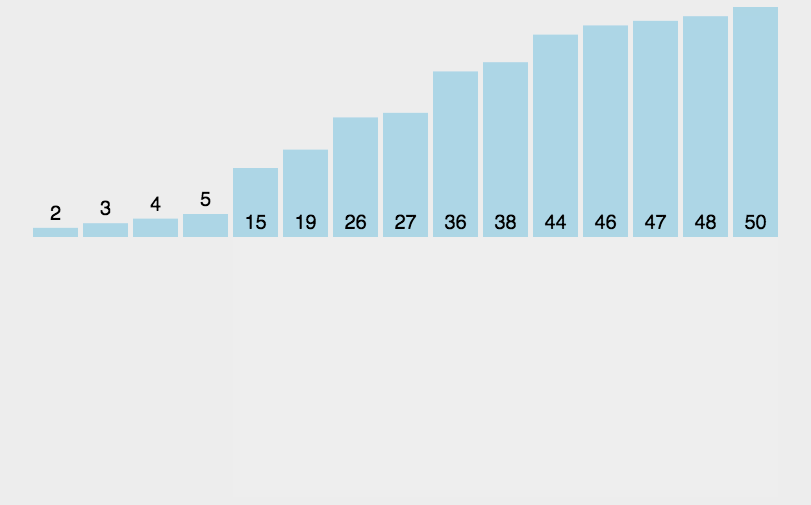
举例分析一下:
我们用序列长度的一半作为第一次排序时gap的值,此时相隔距离为5的元素被分为一组(共分了5组,每组有2个元素),然后分别对每一组进行直接插入排序
gap的值折半,此时相隔距离为2的元素被分为一组(共分了2组,每组有5个元素),然后再分别对每一组进行直接插入排序
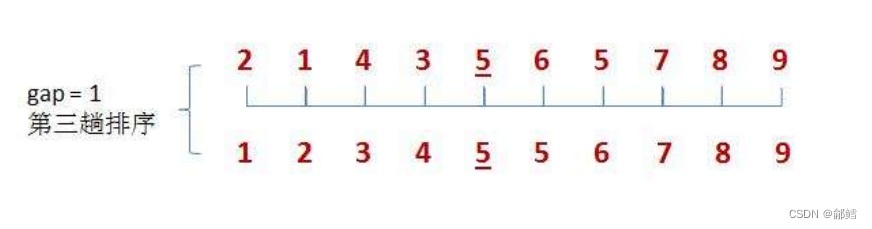
gap的值再次减半,此时gap减为1,即整个序列被分为一组,进行一次直接插入排序。
为什么是选一个小于gap的数作为新的gap,也就是要gap由大变小?
gap越大,数据跳跃的幅度越大,数据挪动得越快;gap越小,数据跳跃的幅度越小,数据挪动得越慢。前期让gap较大,可以让数据更快得移动到自己对应的位置附近,减少挪动次数,提高算法效率
void ShellSort(int* a, int n) // 希尔排序
{int gap = n;while (gap > 1){//一趟排序gap /= 2;for (int i = gap; i < n; i += gap){int end = i - gap; //有序序列最后一个元素的下标int tmp = a[end + gap];while (end >= 0){//如果tmp比end小但是比数组前面的几个数据大,插入之后,tmp之后的数据就往后挪动if (tmp < a[end]){a[end + gap] = a[end]; //往后挪动 end -= gap;}else{break;}}//tmp比数组中所有数据都小 ,一直往后挪动 ,end挪到了-1//tmp >a[end] a[end + gap] = tmp;}}
}
选择排序
选择排序
基本思想 : 每一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置;直到全部待排序的数据元素排完
在元素集合array[i]到array[n-1]中选择关键码最大(小)的数据元素;
若它不是这组元素中的最后一个(第一个)元素,则将它与这组元素中的最后一个(第一个)元素交换;
在剩余的array[i] 到 array[n-2](array[i+1]–array[n-1])集合中,重复上述步骤,直到集合剩余1个元素
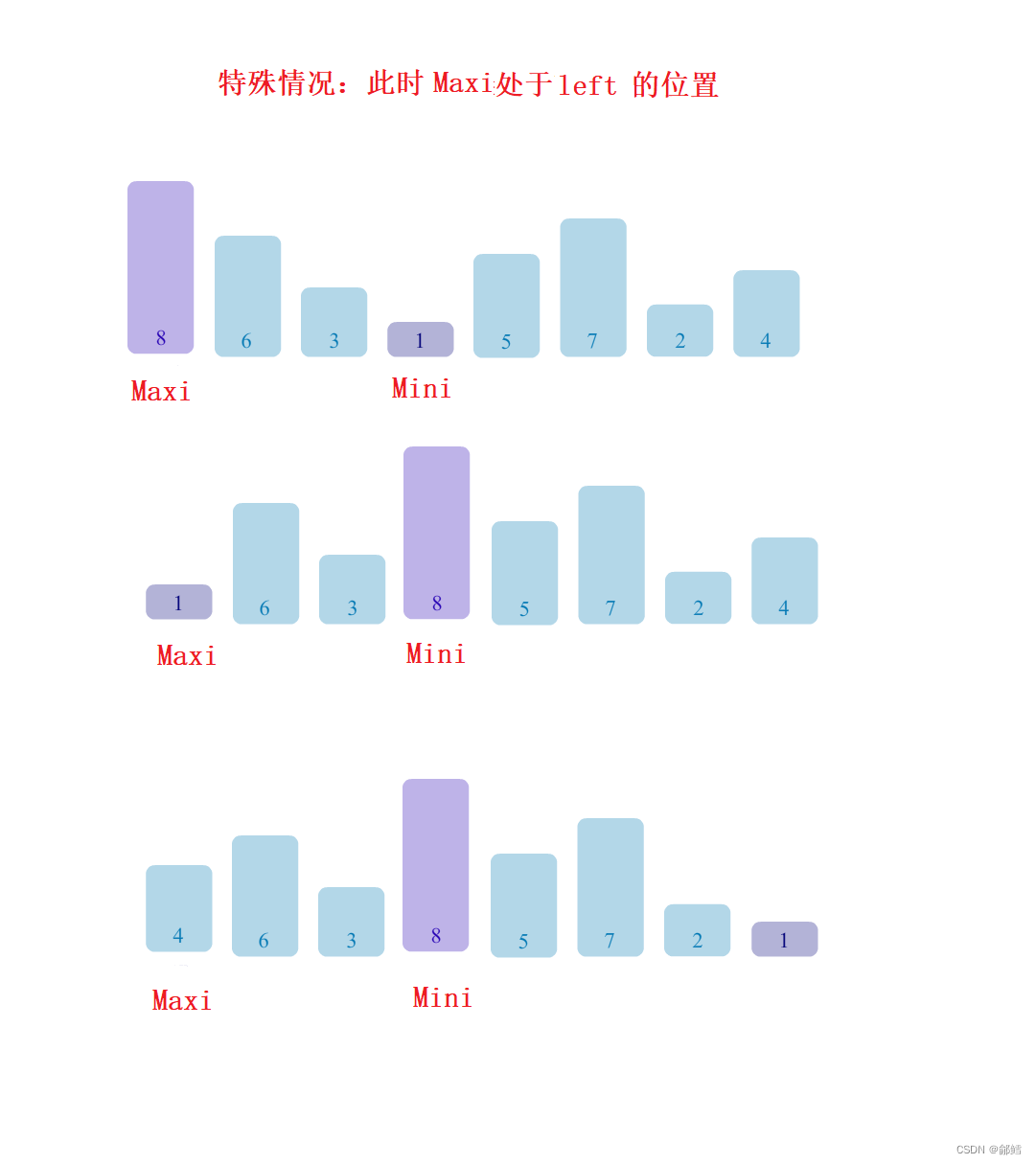
注意特殊情况 :如果Maxi在left位置,当a [ Mini ] 和 a [ left ] 互换时,此时Maxi的位置就变成了Mini, 我们添加一个判断条件 ,判断left == Maxi , 修正Maxi ,防止Maxi更改
以升序为例做分析:
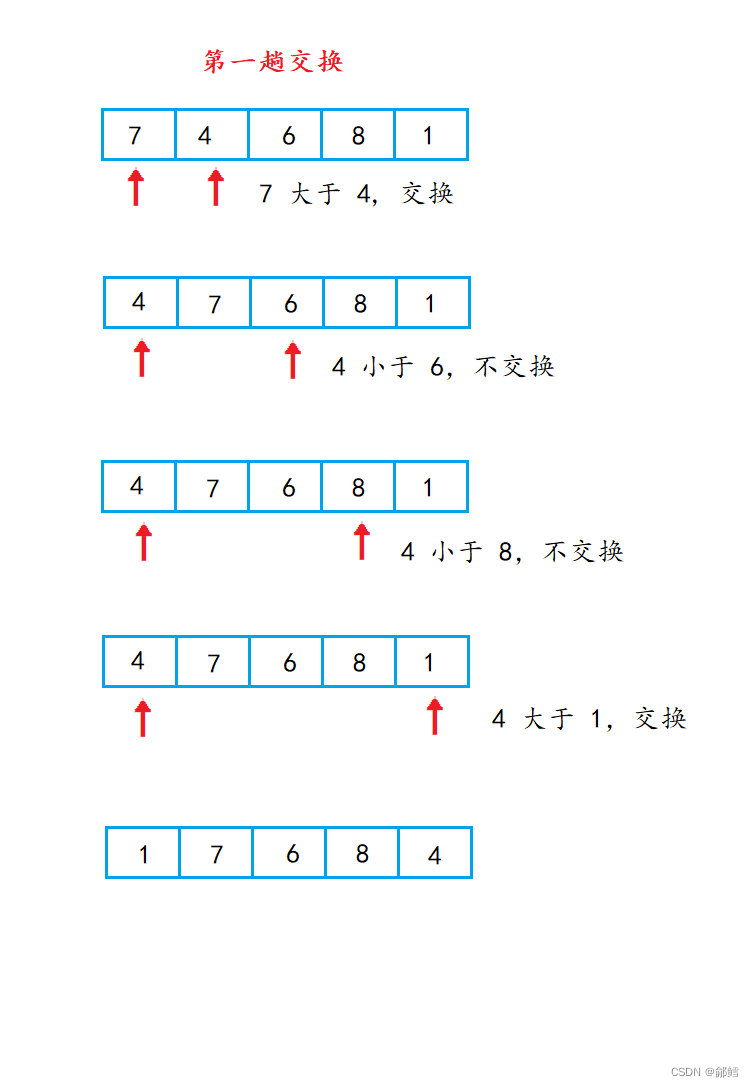
经过第一躺交换,最小的元素排在了数组的第一个位置
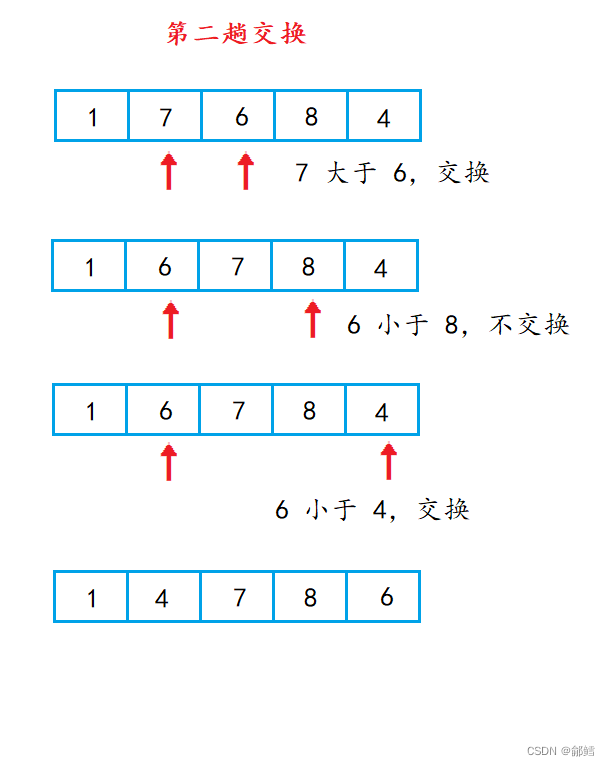
经过第二趟交换 ,第二小的元素已经到了数组第二个元素位置
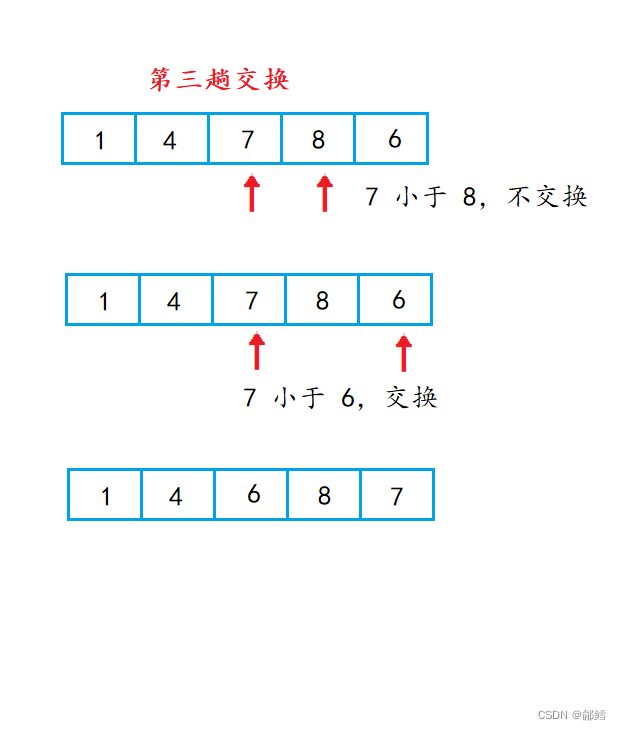
经过第三趟排序 ,第三小的元素已经排在了第三个位置
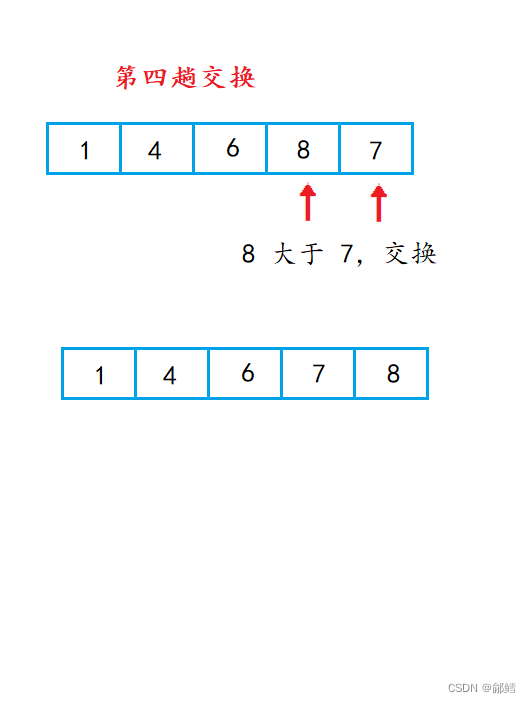
最后一趟排序 ,数组已经有序了
动图演示 :
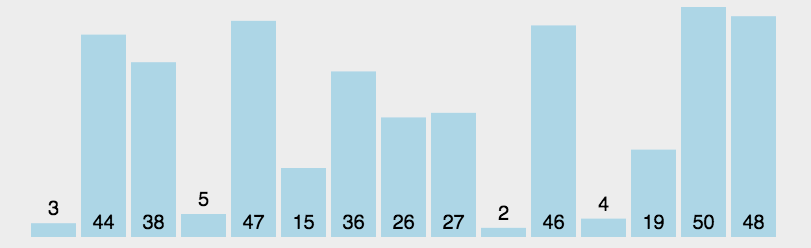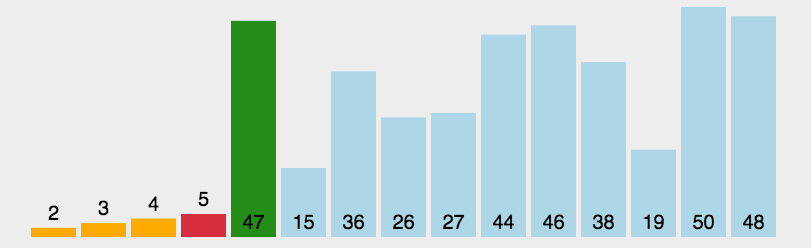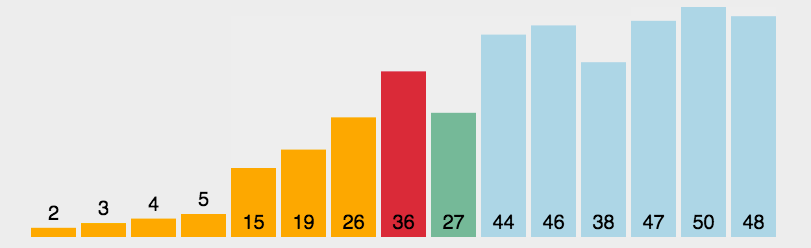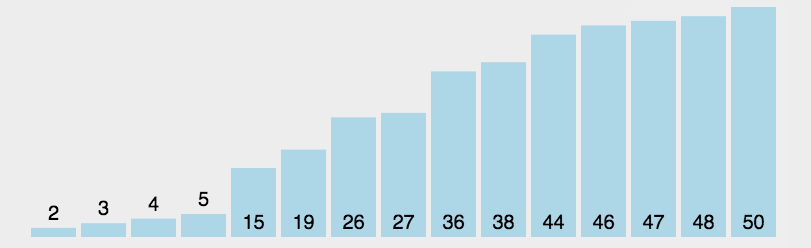
代码实现:
void SelectSort(int* a, int n)//选择排序
{//升序 int left = 0, right = n - 1;while (left < right){//选出最大最小数的下标 int Mini = left;int Maxi = left;//一趟 for (int i = left+1 ; i <= right; i++){if (a[i] < a[Mini]){Mini = i; // 更新Mini}if (a[i] > a[Maxi]){Maxi = i; //更新Maxi }}// Mini和左边交换Swap(&a[left], &a[Mini]);// Maxi 在左边 ,Maxi 被换成Mini, 修正Maxiif (left == Maxi){Maxi = Mini; }//Maxi与右边交换Swap(&a[right], &a[Maxi]);left++;right--;}
}
选择排序效率较低,实际中很少使用
时间复杂度:O(N^2)
空间复杂度:O(1)
稳定性:不稳定
堆排序
排降序 建立小堆
排升序 建立大堆
升序
向上调整建堆,时间复杂度为O(N* longN)
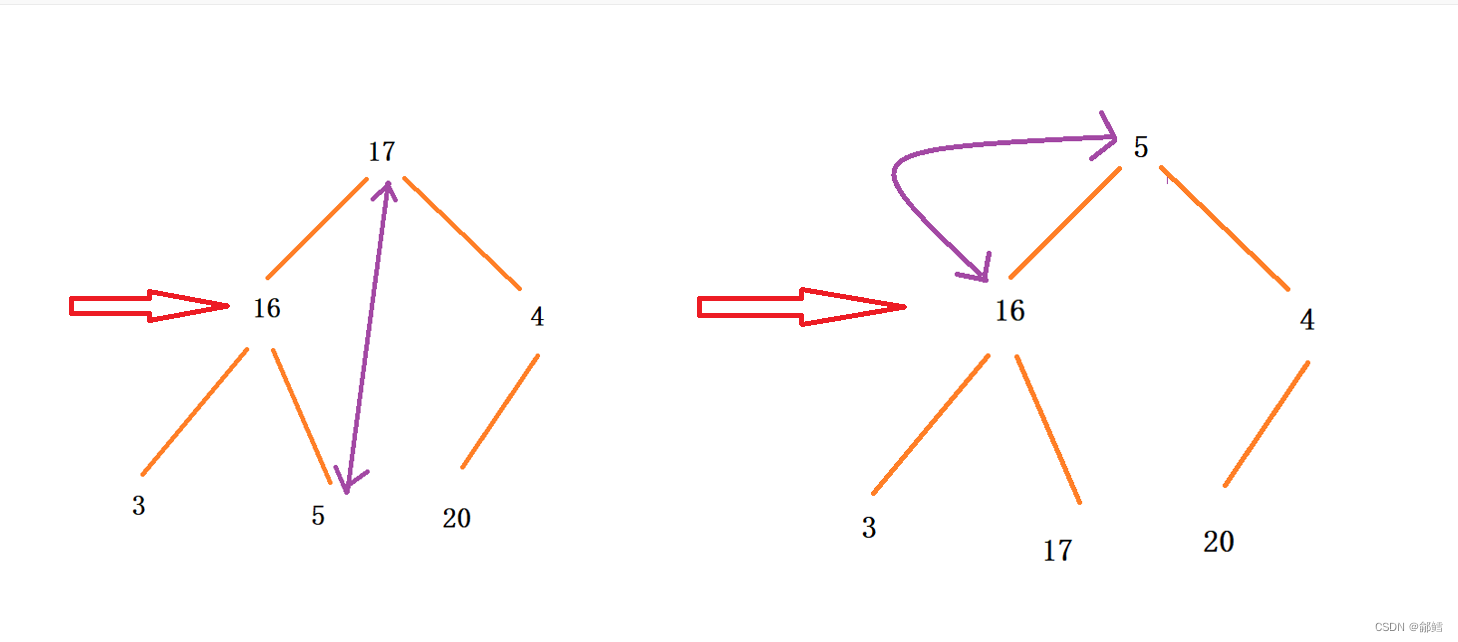
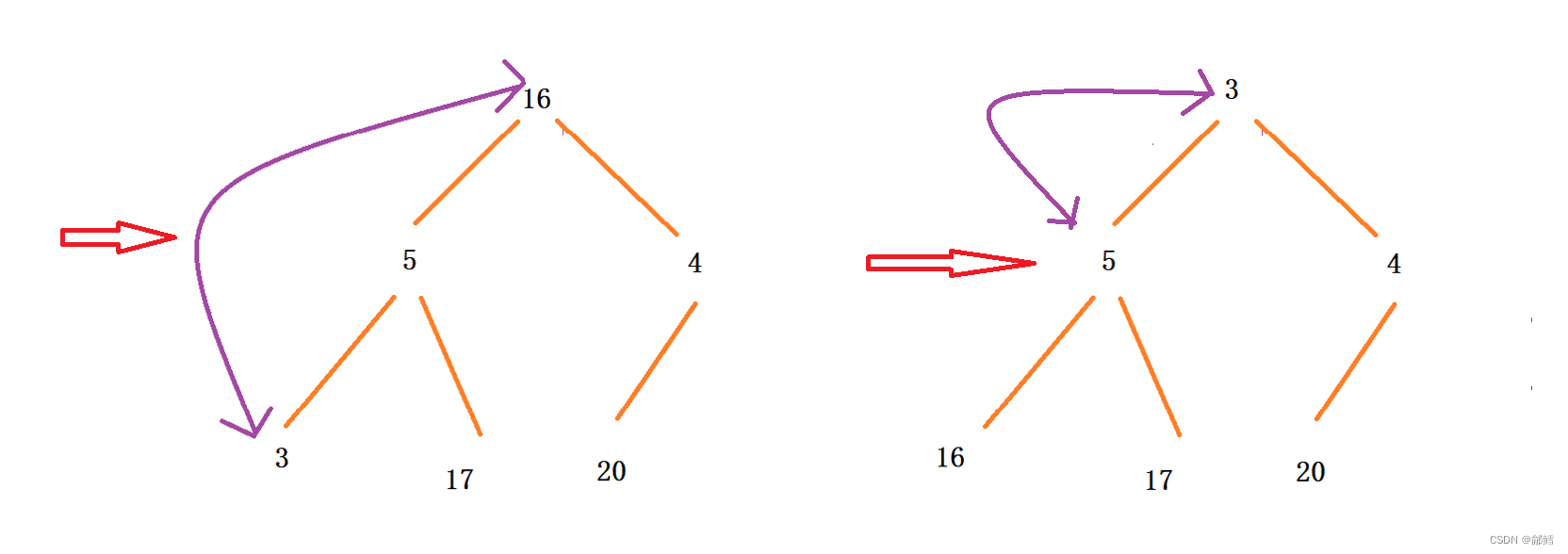
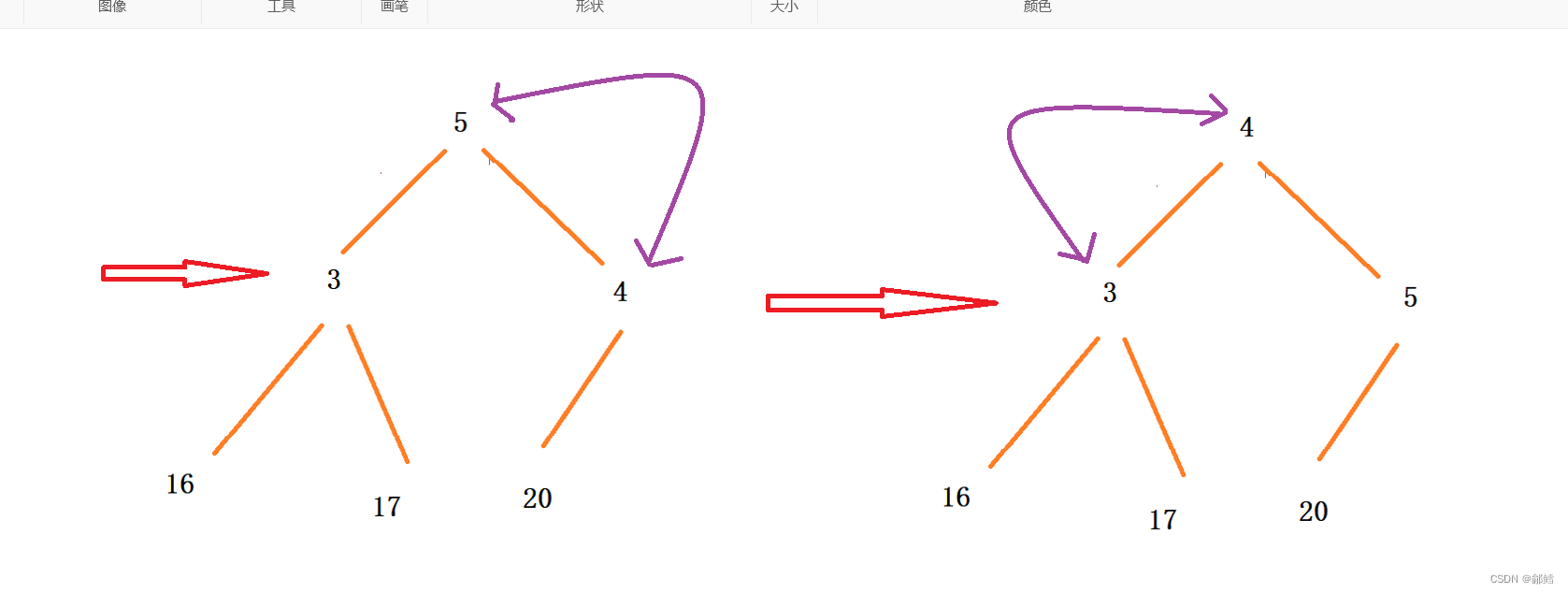
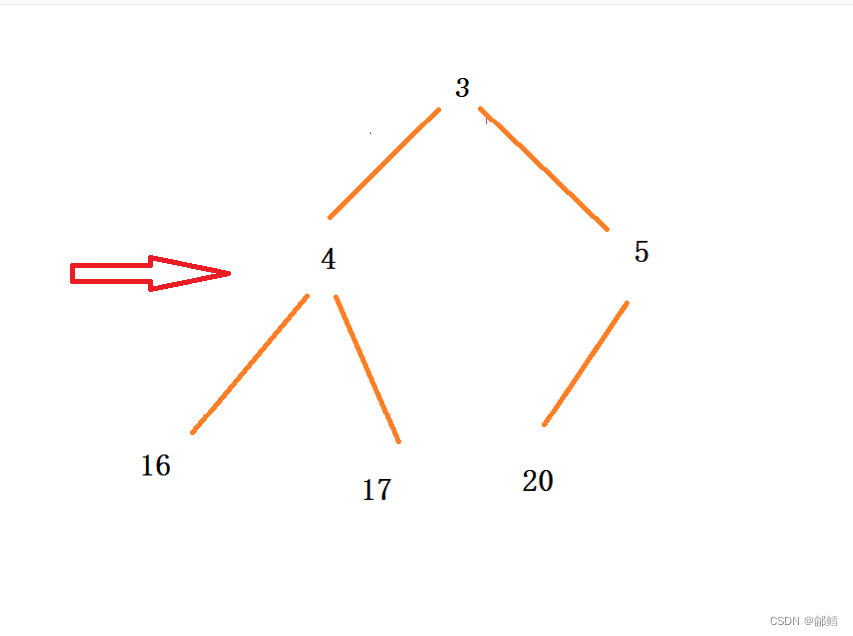
使用向上调整算法建大堆,将数组建成大堆后,此时堆顶元素是最大的 ,将堆顶元素和最后一个元素进行交换,这样最大的元素就到了数组最后一个元素,对剩下的元素使用向下调整 , 当下一次向下调整时,我们不管这个处在数组最后一个位置的最大元素(有点类似堆的删除 ),此时第二大的元素来到的堆顶 ,堆顶元素继续与最后一个元素进行交换,(注意第一个交换过去的最大的元素已经不在范围内了) ,依次类推 ,升序就完成了
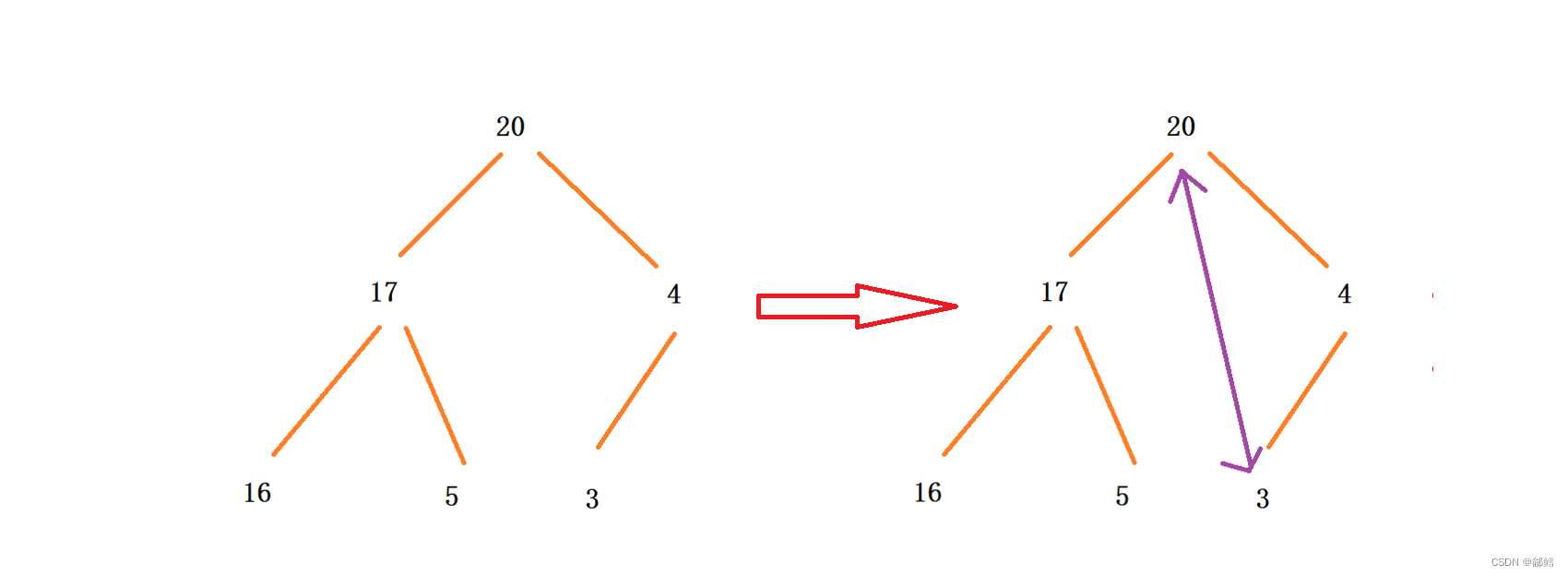
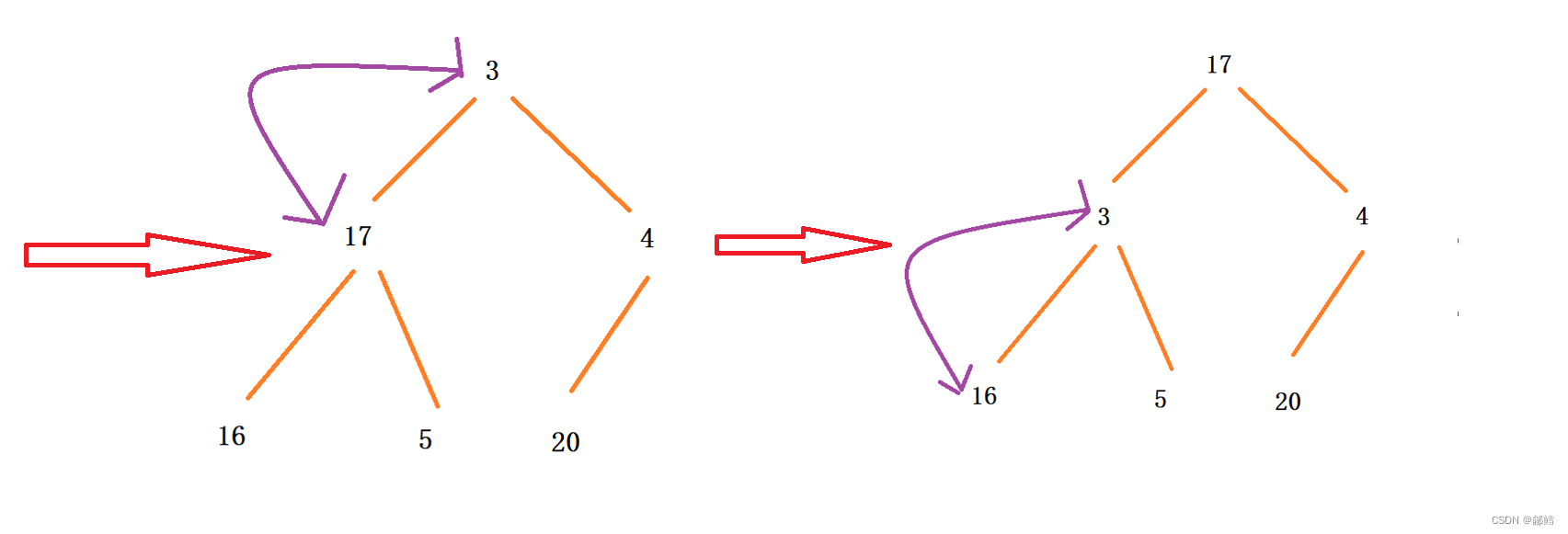
void HeapSort(int* a, int n){//向上调整建堆for (int i = 0; i < n; i++){AdjustUp(a, i);}//向下调整排序int end = n - 1;// end 是最后一个元素的下标while (end > 0){Swap(&a[0], &a[end]);AdjustDown(a, end, 0);end--;}}int main(){int a[10] = { 2, 1, 5, 7, 6, 8, 0, 9, 4, 3 };HeapSort(a, 10);return 0; }
向下调整建堆的前提是左右子树都是堆 ,从倒数第一个非叶子节点开始倒着调整,如何找到倒数第一个非叶子节点?通过最后一个节点的父节点来找到 , 那为什么要找倒数第一个非叶子节点? 因为倒数第一个非叶子节点的左右子树都满足大堆或小堆的条件


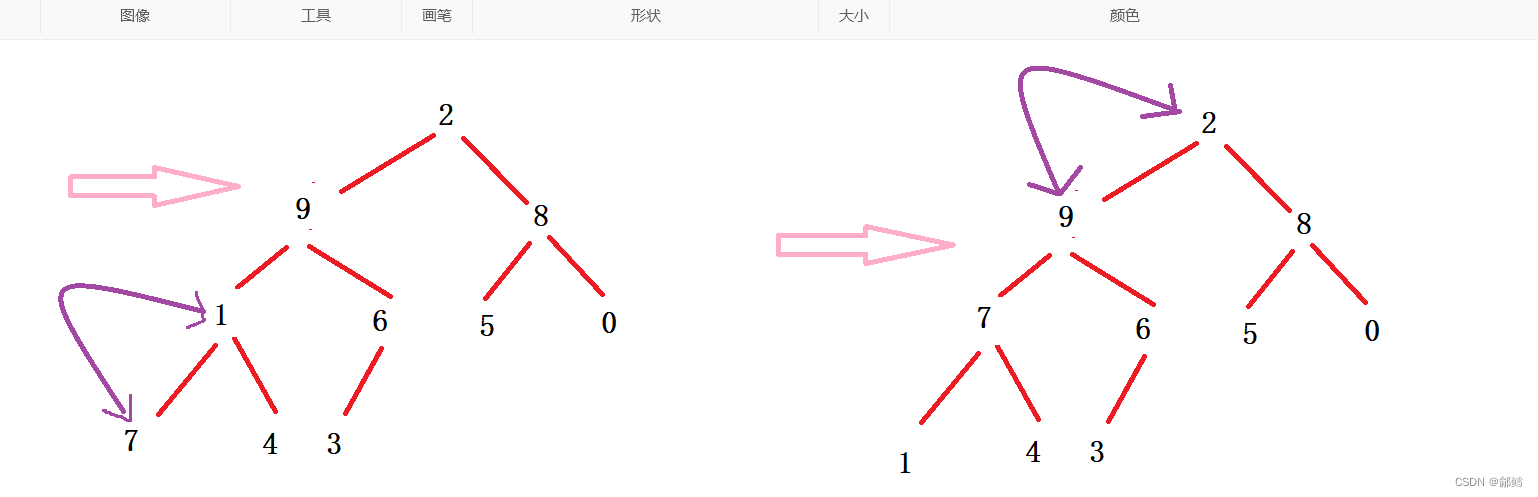
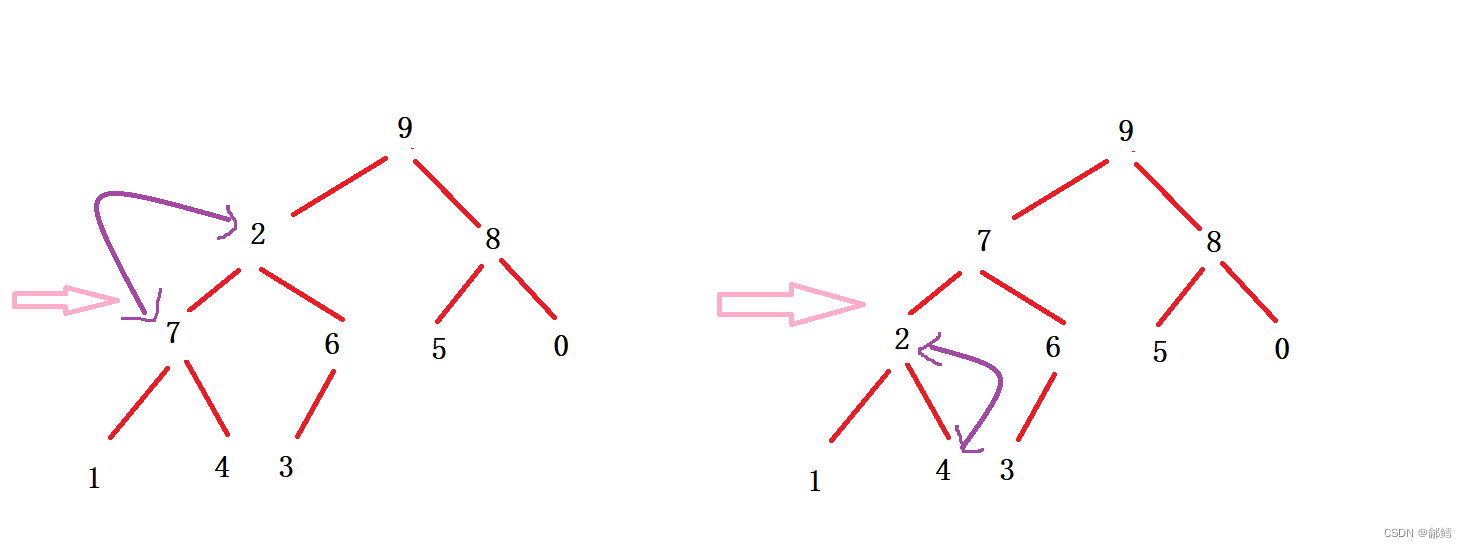
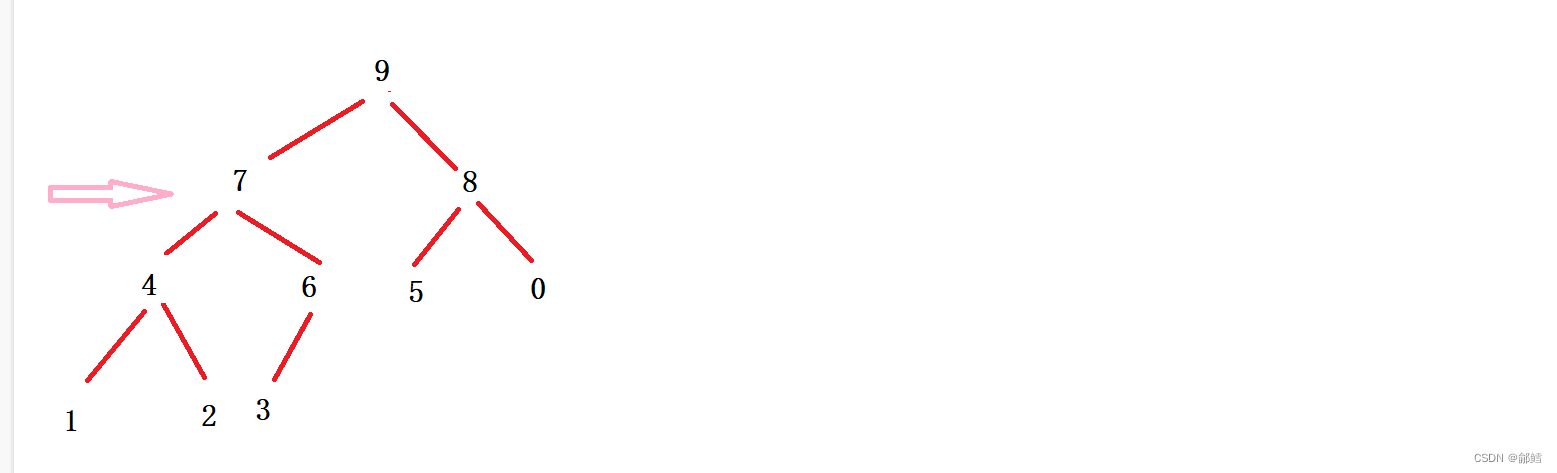
void HeapSort(int* a, int n){//向下调整建堆for (int i = (n-1-1)/ 2; i >= 0; i--) // n-1是最后一个节点的下标,(n-1-1)/2 通过下标找到最后一个节点的父节点{AdjustDown(a,n , i);}//向下调整排序int end = n - 1; //end 是最后一个元素的下标 while (end >=0){Swap(&a[0], &a[end]);AdjustDown(a, end, 0);end--;}}int main(){int a[10] = { 2, 1, 5, 7, 6, 8, 0, 9, 4, 3 };HeapSort(a, 10);return 0; }
交换排序
冒泡排序
以升序为例
冒泡排序,该排序的命名非常形象,即一个个将气泡冒出。冒泡排序一趟冒出一个最大(或最小)值
如果前一位的数字大于后一位的,那么这两个数字交换位置,因此,最大的数字在第一轮循环中不断像一个气泡一样向上冒

动图演示:
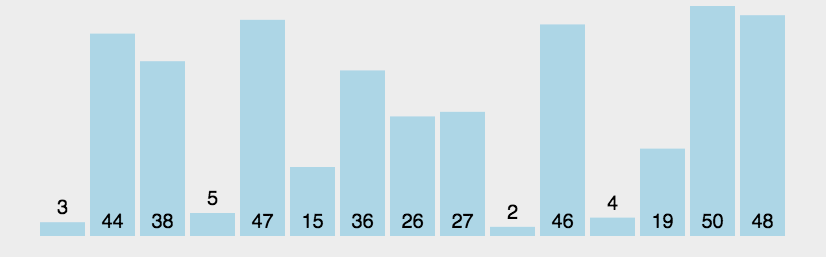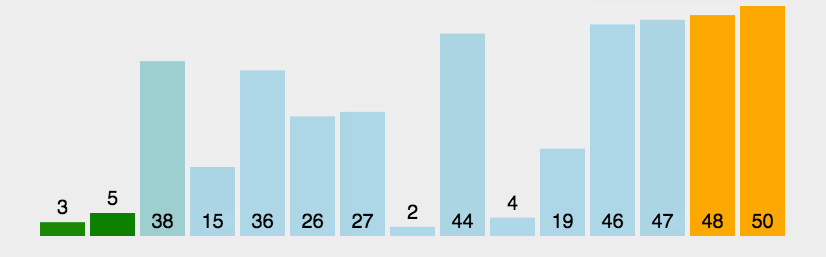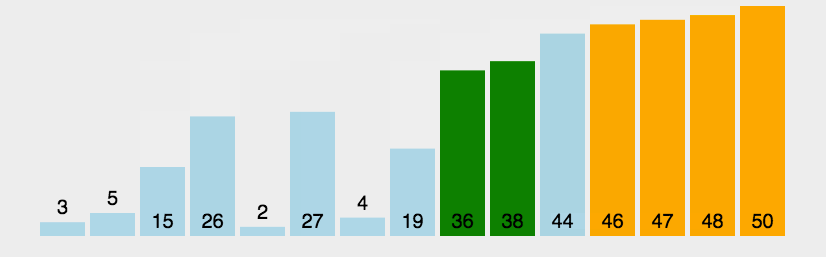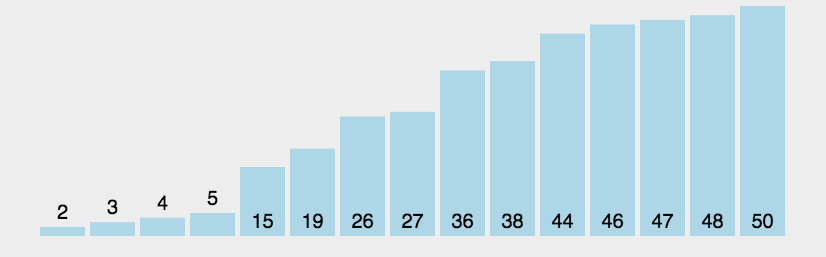
代码实现 :
void BubbleSort(int* a, int n)
{for (int i = 0; i < n-1; i++){//一趟 for (int j = 0; j < n-1 - i; j++){assert(j < n-1);if (a[j] > a[j + 1]){assert(j + 1 < n);Swap(&a[j], &a[j + 1]);}}}
}
冒泡排序:
时间复杂度 :O(N^2)
快速排序
递归
hoare版本
快速排序是Hoare于1962年提出的一种二叉树结构的交换排序方法,其基本思想为:任取待排序元素序列中的某元素作为基准值,按照该排序码将待排序集合分割成两子序列,左子序列中所有元素均小于基准值,右子序列中所有元素均大于基准值,然后最左右子序列重复该过程,直到所有元素都排列在相应位置上为止。
单趟排序 : 一趟下来的结果是让Key左边的数据全部都小于Key,Key右边的数据全部都大于Key, 就相当于Key这个基准值被排好序了,快速排序的单趟排序本质上就是在排一个数的顺序
步骤:
1 选最左边的或者最右边的当作基准值Key
2 定义一个Left和一个Right,Right从右向左走, 若Right遇到小于Keyi的数,则停下,Left从左向右开始走,直到Left遇到一个大于Keyi的数时,将Left和Right的内容交换 ,Right再次开始走,如此进行下去,直到Left和Right最终相遇,此时将相遇点的内容与key交换即可
(需要注意的是:若选择最左边的数据作为基准值Key,则需要Right先走;若选择最右边的基准值数据作为基准值Key,则需要Left先走)
注意:Left 和Right相遇位置一定比Key小
3 然后我们再将Key的左序列和右序列再次进行这种单趟排序,如此反复操作下去 ,其实就是一个递归
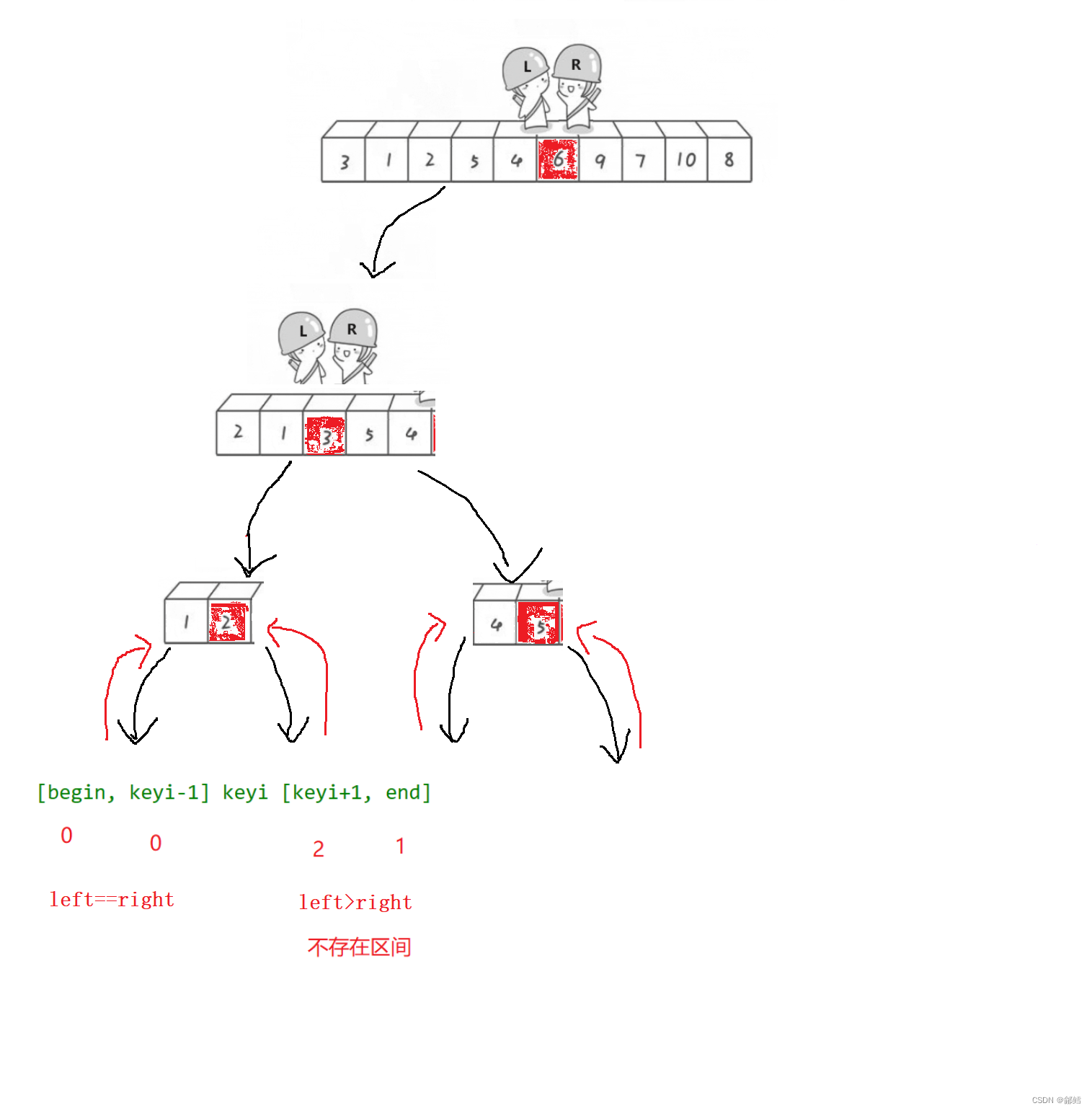
如果选择最左边的数据作为基准值Key ,为什么不能Left先走呢?

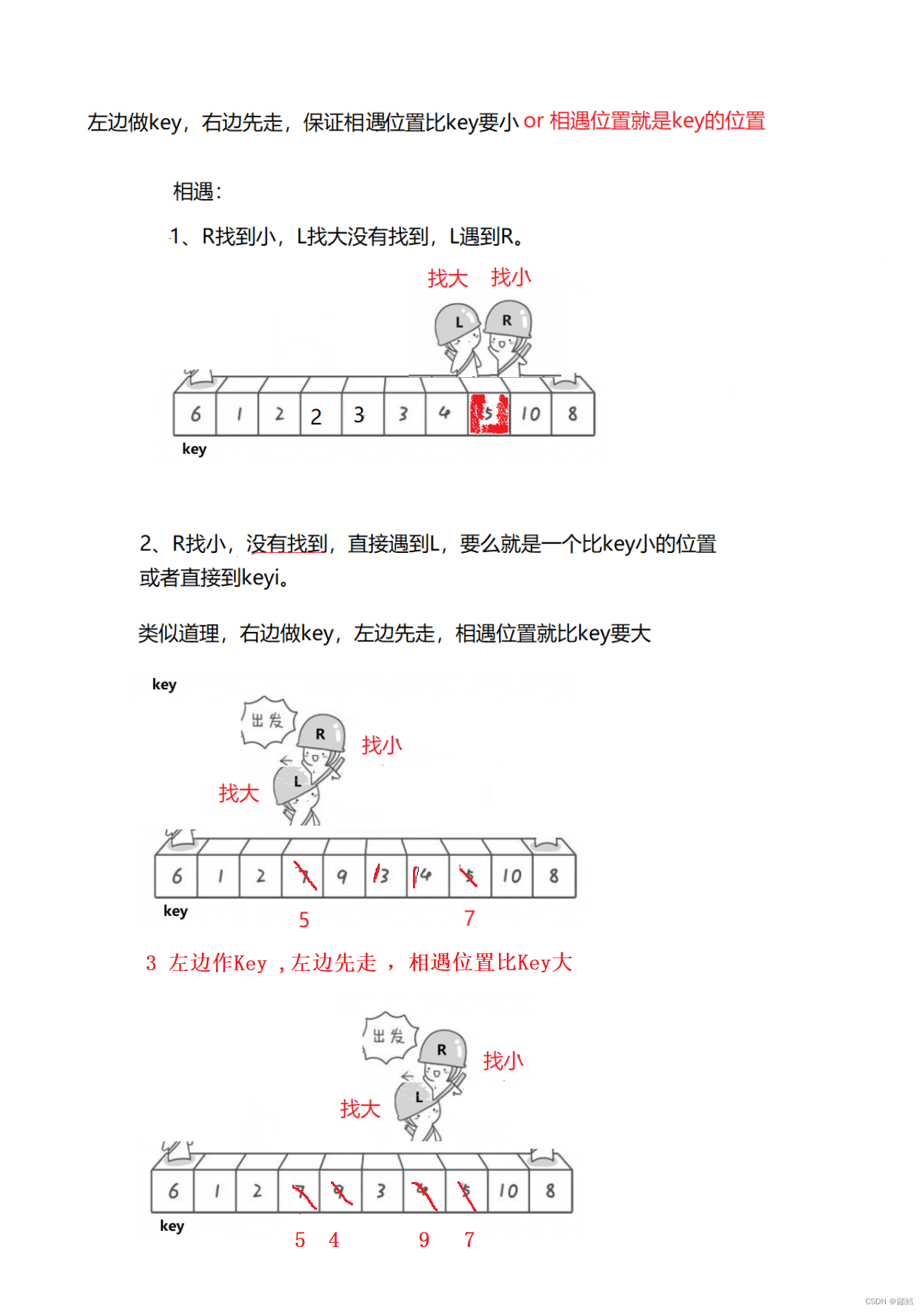
快排hoare版本 单趟动图演示:
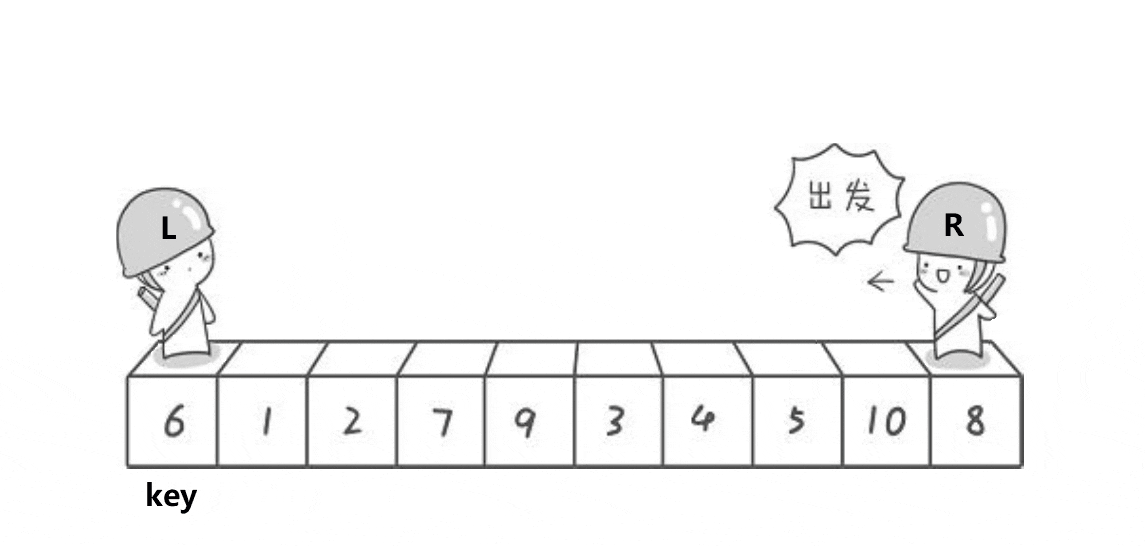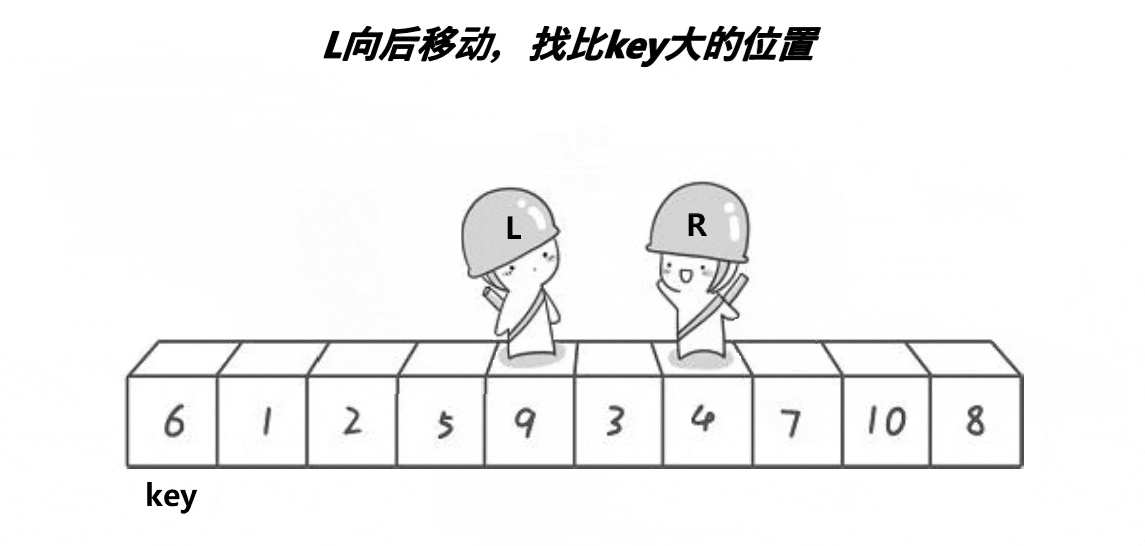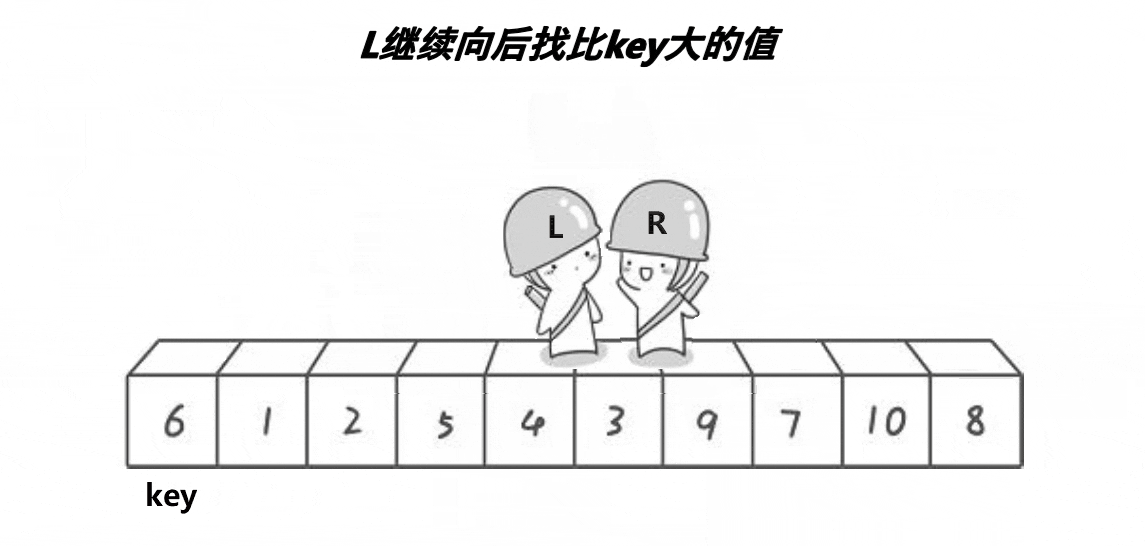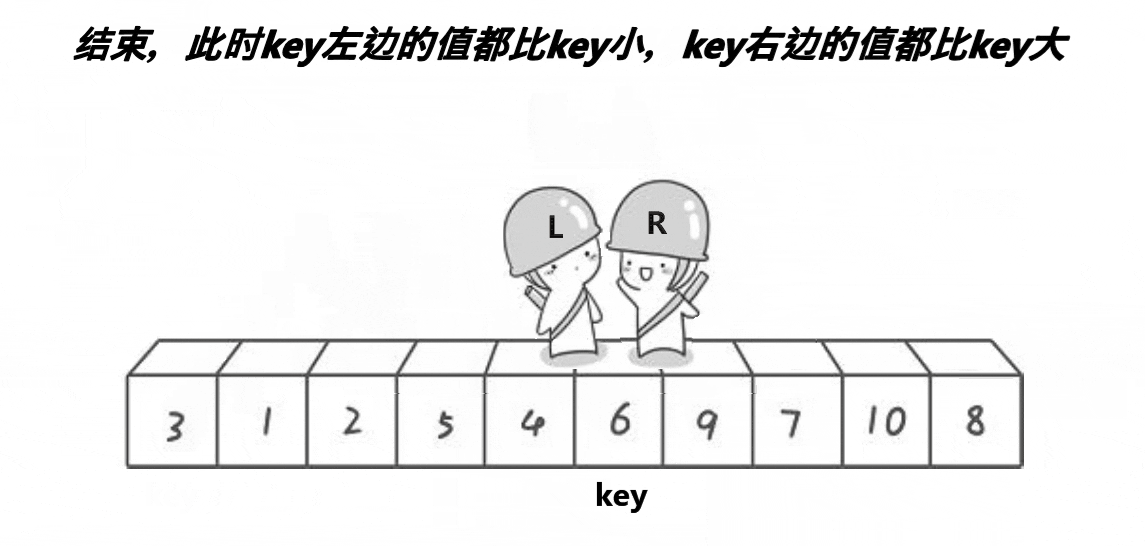
代码实现:
void QuickSort(int* a, int left , int right ) // Hoare 版本
{int begin = left;int end = right;//升序 // 从左向右走 , 从右向左走 int Keyi = left; // 最左边为基准值 if (left >= right)return; while (left <right ){//单趟排序 //右边找小 while (right > left && a[right] >= a[Keyi]){right--;assert(right > 0);}//左边找大while (left < right && a[left] <= a[Keyi]){left++;assert(left <= right);}Swap(&a[left], &a[right]);}Swap(&a[Keyi], &a[left]); //Left和Right最终相遇,此时将相遇点的内容与key交换即可//递归 类似二叉树的前序遍历 // [begin , Keyi-1 ] Keyi [Keyi+1 , end] Keyi = left;assert(Keyi - 1 >= 0);QuickSort( a, begin, Keyi -1);QuickSort(a, Keyi+1, end );}
快排时间复杂度 :
如果每趟排序所选的Key都正好是该序列的中间值,即单趟排序结束后Key位于序列正中间,那么快速排序的时间复杂度就是O(NlogN)
挖坑法
以升序为例
单趟排序:一趟下来的结果是让Key左边的数据全部都小于Key,Key右边的数据全部都大于Key
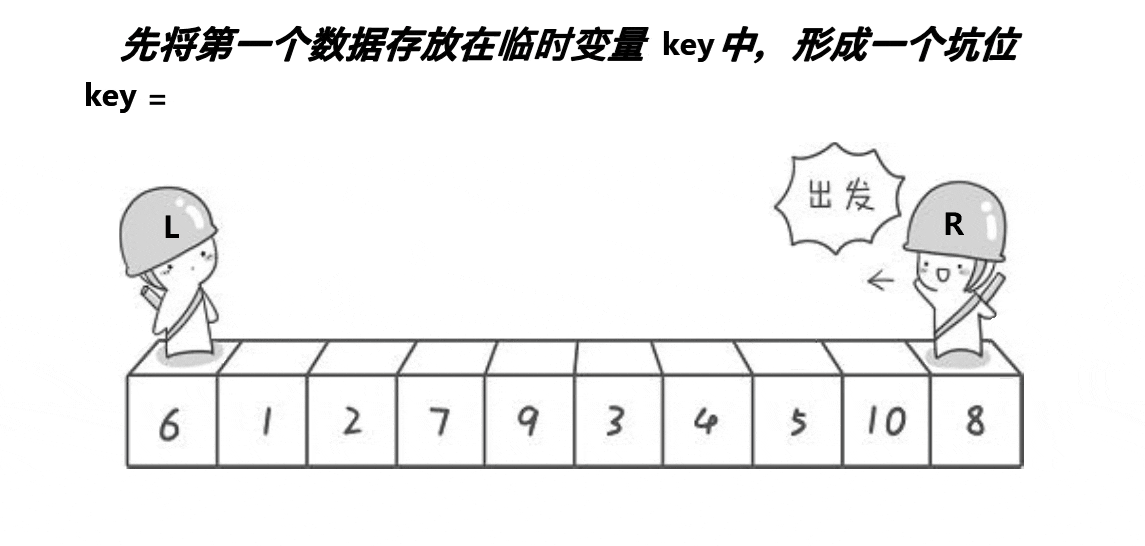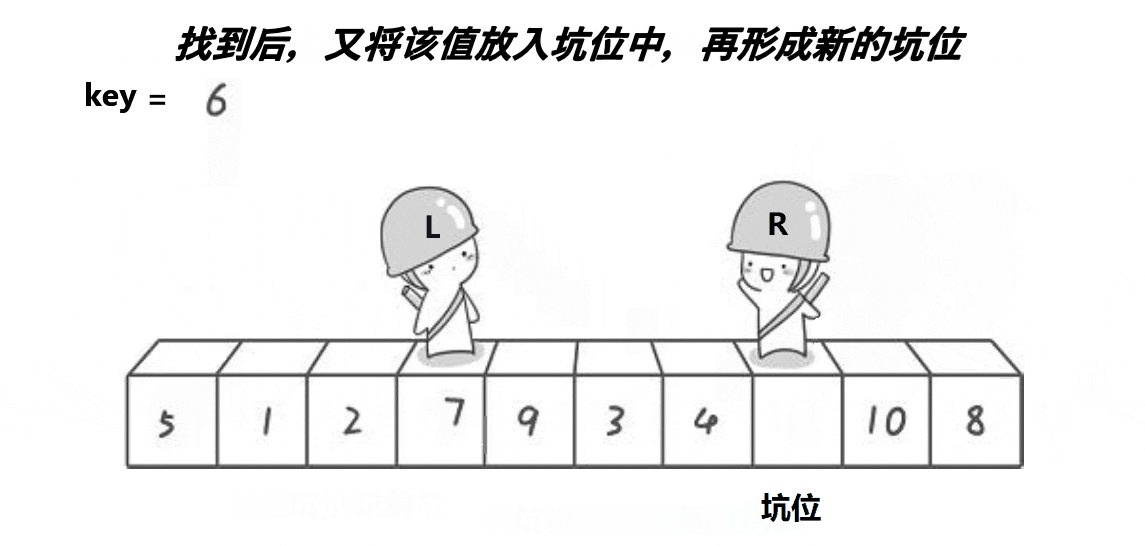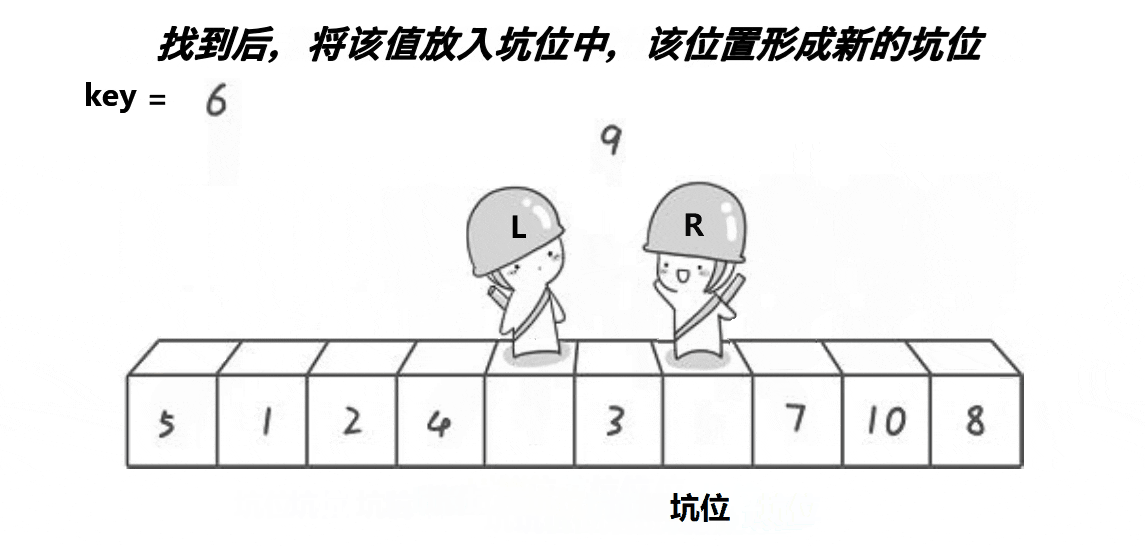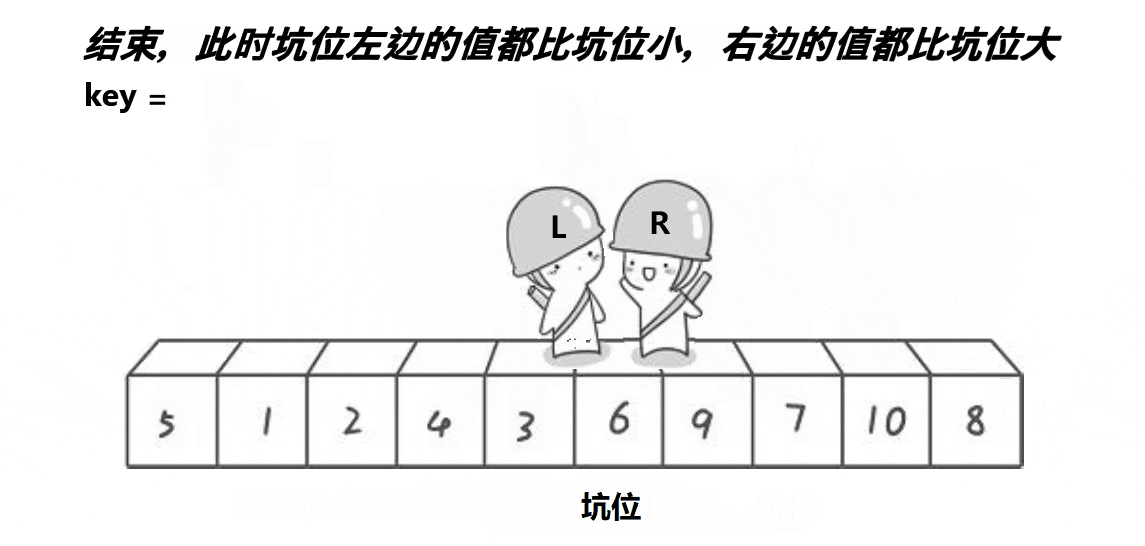
步骤(在最左边挖坑为例) :
1 选出最左边或者最右边的一个数 ,存放在Key变量中,并且在该数据位置形成一个坑
2 定义一个Left和一个Right,Left从左向右走,找比Key大的数 ,Right从右向左走,找比Key小的数。(注意: 如果是在最左边挖坑,则需要Right先走;如果是在最右边挖坑,则需要Left先走)
3 因为是以最左边挖坑为例 ,所以是Right 先走 , 在Left和Right 遍历的过程中,如果Right遇到小于Key的数,则将该数放到最左边的坑位,并在Right当前位置形成新的坑位,这时Left再向右边走,若遇到大于Key的数,则将其抛入到刚才在Right位置形成的一个坑位,然后在Left 当前位置形成一个坑位,如此循环下去,直到最终Left和Right相遇,而且Left和Right相遇一定相遇在坑位处 ,这时将Key填在坑位即可。
Key的左序列和右序列再次进行这种单趟排序,如此反复操作下去,直到左右序列只有一个数据,或是左右序列不存在时,便停止操作
单趟动图演示:
代码实现:
//快排挖坑法
void QuickSort(int* a, int left, int right)
{int begin = left;int end = right;if (left >= right)return; // 升序 ,最左边挖坑 ,右边先走//选最左边为 Key,并形成hole int hole=left;int Key = a[left];while (left < right){//单趟排序 //right 找小 while (left < right && a[right] > Key){right--;}//找到比Key小的数 ,放进最左边的坑位 ,并在right当前位置形成新的坑位a[hole] = a[right];hole = right;assert(hole >= 0);//left 找 大 while (right > left && a[left] < Key){left++;}// 找到比Key大的数 ,放进right当时形成的坑位 ,并在Left当前位置形成新的坑位 a[hole] = a[left];hole = left;assert(hole >= 0);}//直到最终Left和Right相遇,这时将Key填在坑位即可。assert(hole >= 0);a[hole] = Key;//递归 //递归 类似二叉树的前序遍历 // [begin , Key-1 ] Key [Key+1 , end] Key = left;assert(Key - 1 >= 0);QuickSort( a, begin, Key -1);QuickSort(a, Key+1, end );}
前后指针版本
以升序为例
单趟排序:一趟下来的结果是让Key左边的数据全部都小于Key,Key右边的数据全部都大于Key
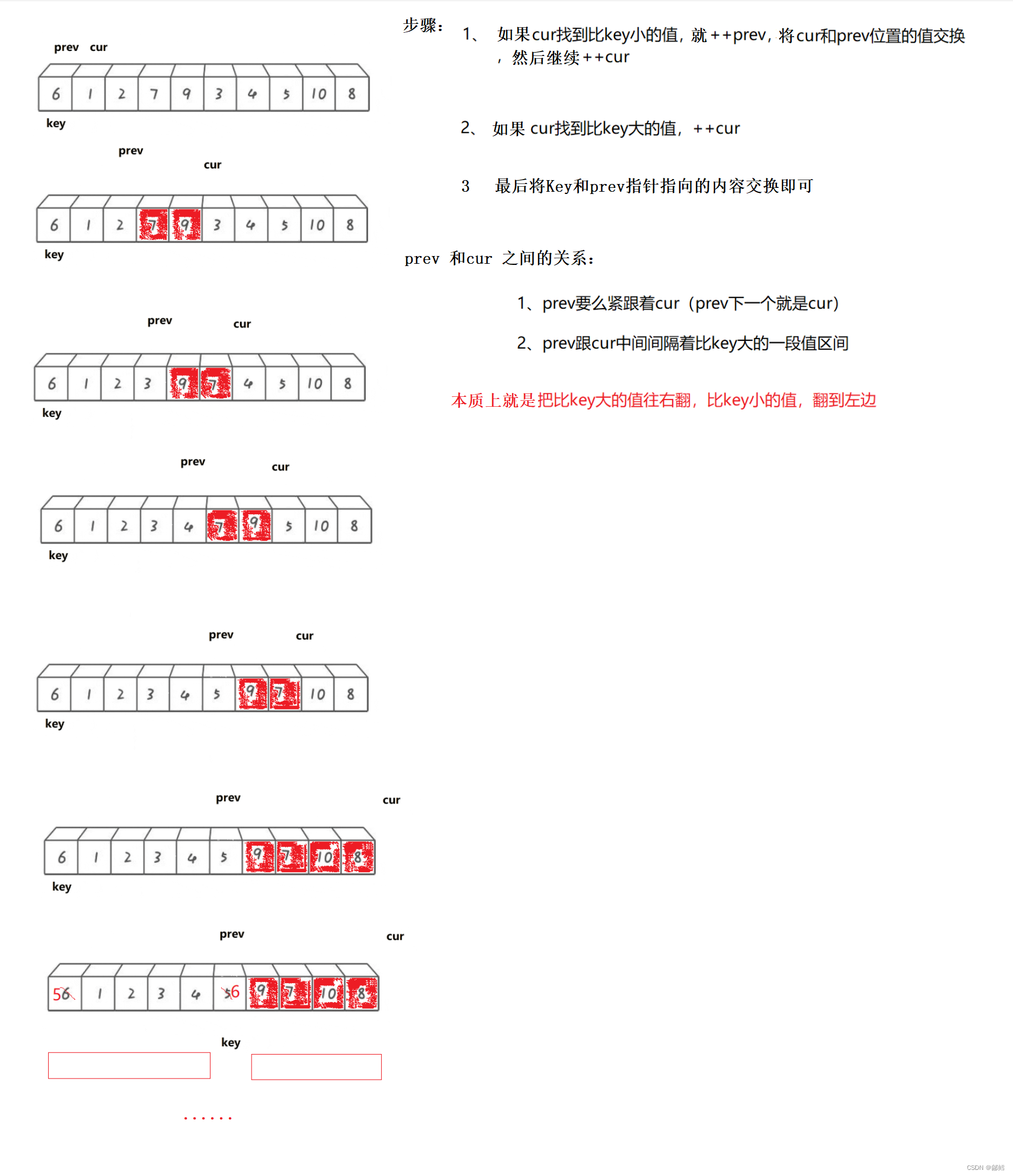
步骤(以最左边为Key 为例) :
1 选最左边的或者最右边的当作基准值Key
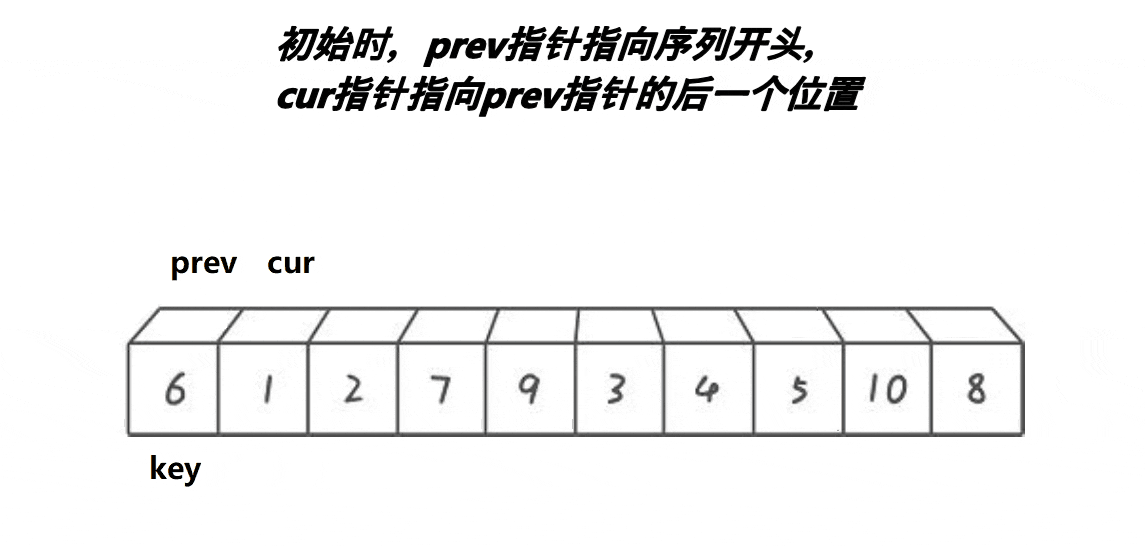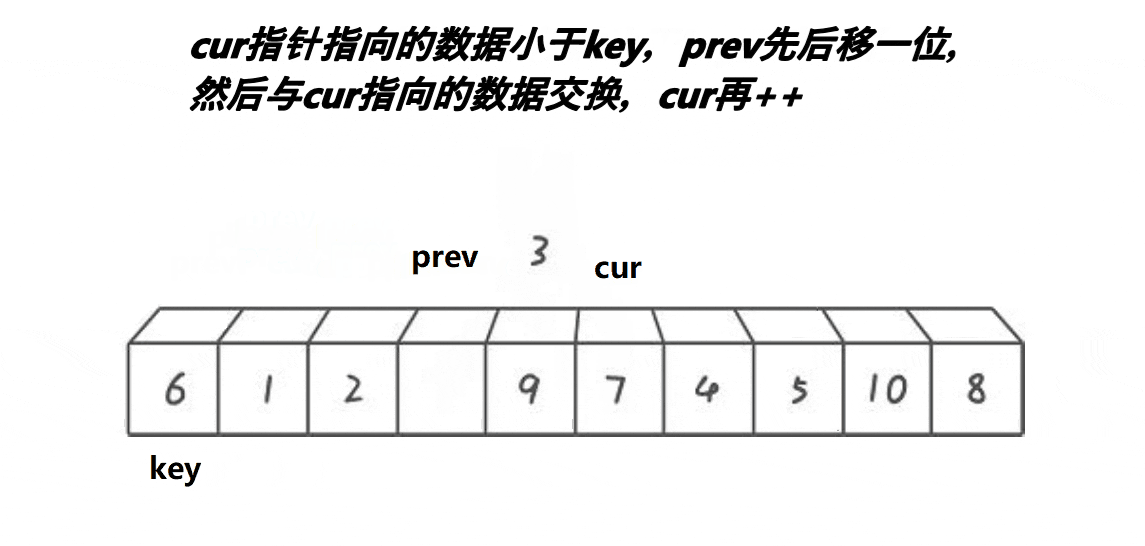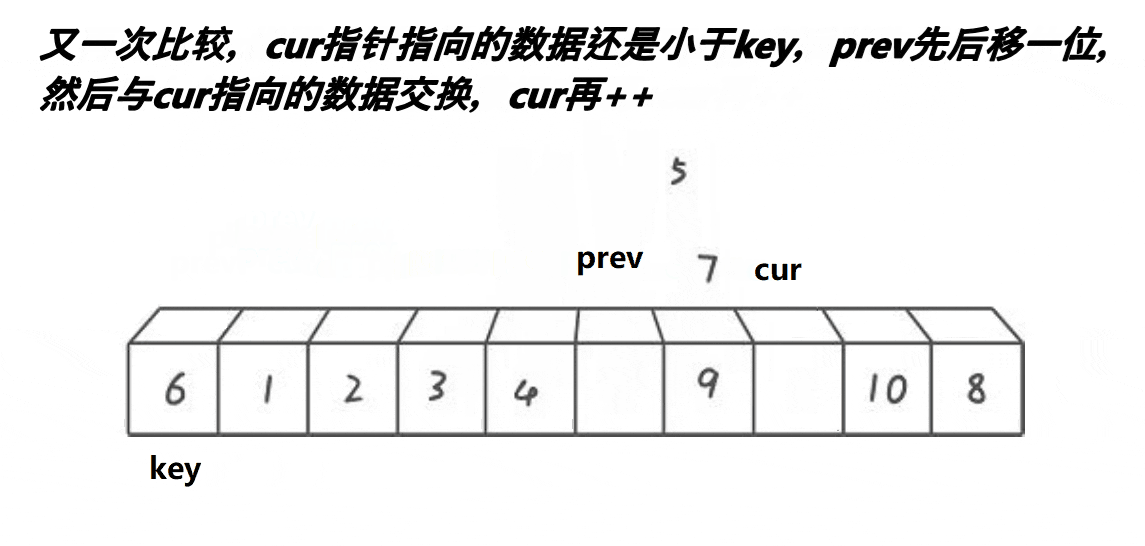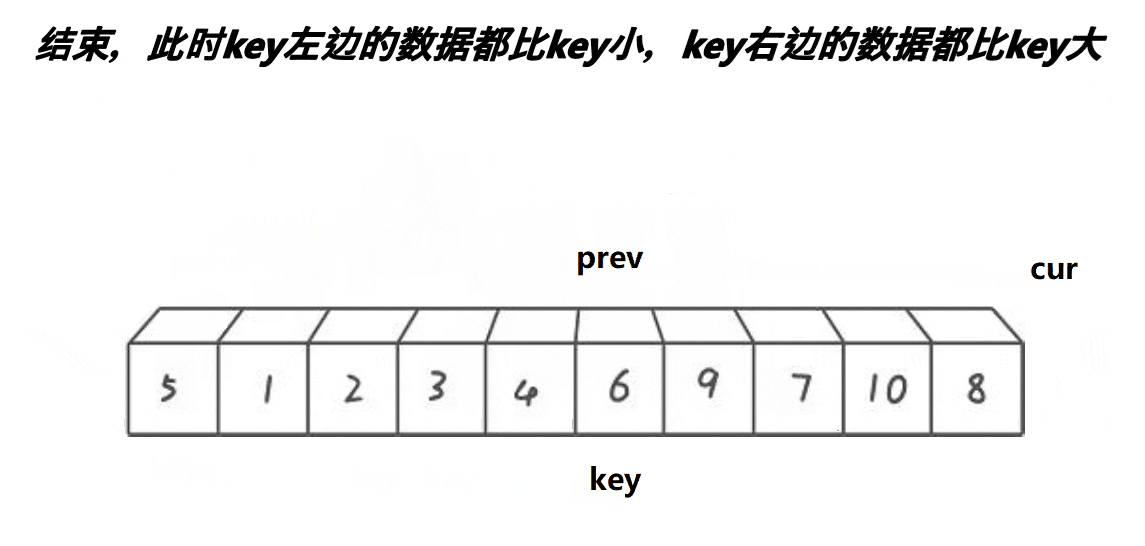
2 定义一个prev 和 cur ,prev指针指向序列开头 ,prev 从左往右遍历 ,cur指针指向prev+1, cur从左往右遍历 。
3、若cur指向的内容小于Key,则prev先++,然后交换prev和cur的值,然后cur++;若cur的值大于key,则cur指针直接++。如此进行下去,直到cur指针越界,此时将Key和prev指针指向的内容交换即可。
然后我们再将Key的左序列和右序列再次进行这种单趟排序,如此反复操作下去 ,其实就是一个递归
单趟动图演示:
代码实现:
int PartSort2(int* a, int left, int right) //前后指针法
{int begin = left;int end = right;//升序 // 单趟排序int prev = left;int cur = prev + 1;int Keyi = left; //选最左边为Key //cur 找比Key小的 while (cur <= right) //cur未越界就继续 {//如果cur找到比Key小 ,往后++if (a[cur] < a[Keyi] && ++prev != cur) //++prev !=cur , 有可能数组前几个元素比Key小,但是没必要交换{Swap(&a[cur], &a[prev]); //交换 }cur++; }assert(cur <= right+1); Swap(&a[prev], &a[Keyi]);/*递归 类似二叉树的前序遍历 [begin , Keyi-1 ] Keyi [Keyi+1 , end] */Keyi = prev;assert(Keyi - 1 >= 0);return prev;
}
void QuickSort(int* a, int left, int right)
{//递归 if (left >= right)return;int keyi = PartSort2(a, left, right);QuickSort(a, left, keyi - 1);QuickSort(a, keyi + 1, right);
}
非递归
将一个用递归实现的算法改为非递归时,一般需要借用一个数据结构,那就是栈。将Hoare版本、挖坑法以及前后指针法的快速排序改为非递归版本
Hoare版本、挖坑法和前后指针法 ,这三种排序都只写单趟 ,后面再写一个非递归的快速排序,在函数内部调用单趟排序的函数
Hoare
单趟排序代码实现:
//Hoare版本(单趟排序)
int PartSort1(int* a, int left, int right)
{int keyi = left;//key的下标while (left < right){//right走,找小while (left < right&&a[right] >= a[keyi]){right--;}//left先走,找大while (left < right&&a[left] <= a[keyi]){left++;}if (left < right){Swap(&a[left], &a[right]);//交换left和right的值}}int meeti = left;//L和R的相遇点Swap(&a[keyi], &a[meeti]);//交换key和相遇点的值return meeti;//返回相遇点,即key的当前位置
}挖坑法
单趟排序代码实现:
//挖坑法(单趟排序)
int PartSort2(int* a, int left, int right)
{int key = a[left];//在最左边形成一个坑位while (left < right){//right向左,找小while (left < right&&a[right] >= key){right--;}//填坑a[left] = a[right];//left向右,找大while (left < right&&a[left] <= key){left++;}//填坑a[right] = a[left];}int meeti = left;//L和R的相遇点a[meeti] = key;//将key抛入坑位return meeti;//返回key的当前位置
}前后指针
单趟排序代码实现:
//前后指针法(单趟排序)
int PartSort3(int* a, int left, int right)
{int prev = left;int cur = left + 1;int keyi = left;while (cur <= right)//当cur未越界时继续{if (a[cur] < a[keyi] && ++prev != cur)//cur指向的内容小于key{Swap(&a[prev], &a[cur]);}cur++;}int meeti = prev;//cur越界时,prev的位置Swap(&a[keyi], &a[meeti]);//交换key和prev指针指向的内容return meeti;//返回key的当前位置
}快排的优化
三数取中法选key
如果这个序列是非常无序,快速排序的效率是非常高的 ,一旦序列有序 ,每次选取最左边或是最右边的数作为基准值Key,时间复杂度就会从O(N*logN)变为O(N^2),这样快排的效率极低
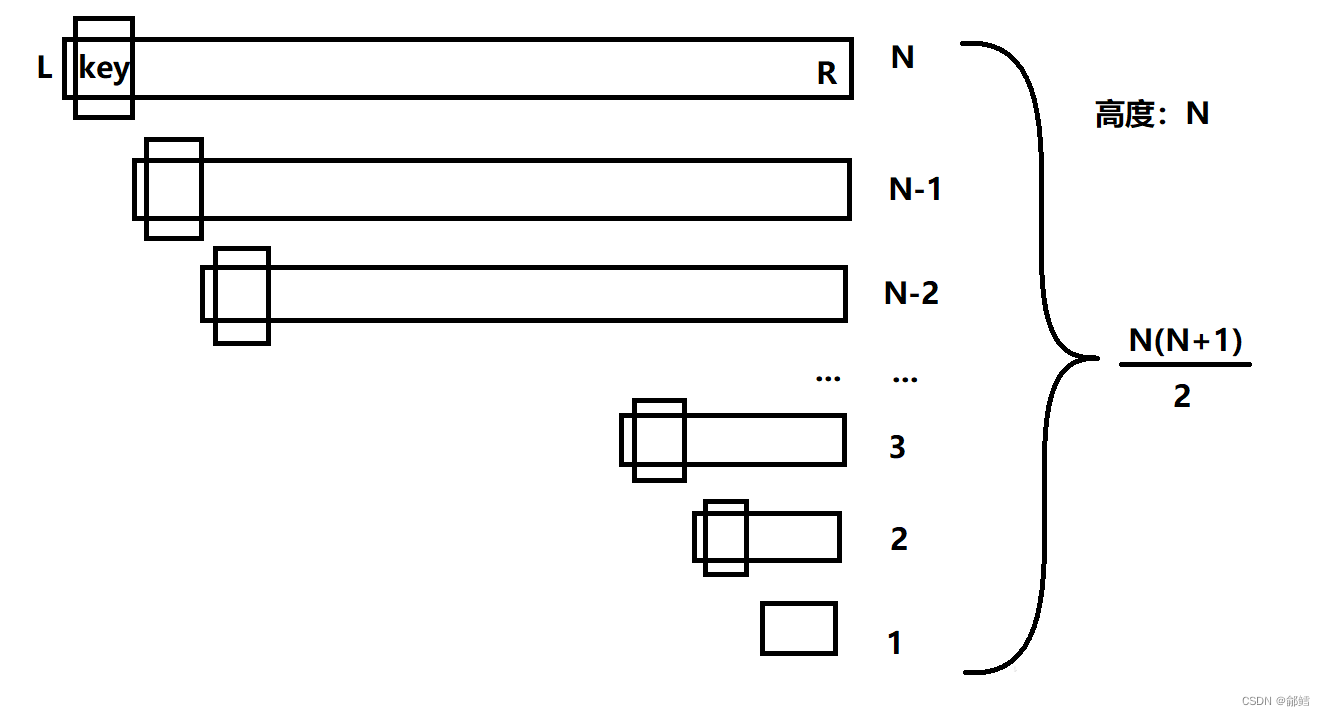
也就是说影响快排时间复杂度就是基准值Key的选取,如果选取的Key离中间位置越近,则效率越高
为了解决这个问题 ,也就出现了三数取中 :
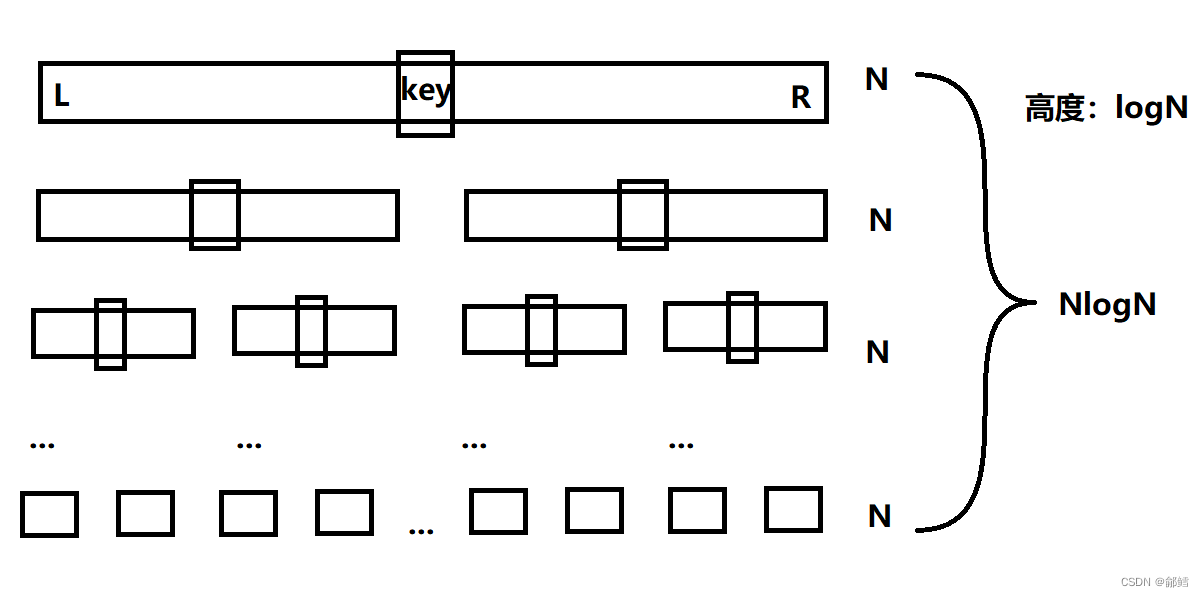
三数取中,当中的三个数指的是:最左边的数、最右边的数以及中间位置的数。
三数取中就是取这三个数当中,值的大小居中的那个数作为该趟排序的Key ,因为它离中间位置最近。这就确保了我们所选取的数不会是序列中的最左边的数、最右边的数
代码实现:
//三数取中 ,得到中间元素的下标
int GetMiddleIndexi(int* a, int left, int right)
{int mid = (left + right) / 2;if (a[left] < a[mid]){if (a[right] > a[mid]){return mid;// a[right] > a[mid] > a[left]}// a[mid]>=a[right] ,此时a[mid]是最大的 ,只需要比较a[left] ,a[right] else if (a[left] > a[right])// a[mid] > a[left] > a[right] {return left;}else //a[left] < a[right]{return right; // a[mid] > a[right] > a[left]}}else //a[left] >= a[mid]{if (a[mid] > a[right]){return mid;}//a[mid] <= a[right] ,此时a[mid]已经是最小的 只需要比较a[left] 和a[right]else if (a[left] > a[right]) // a[left] > a[right] > a[mid] {return right; }else // a[left] <= a[right]{return left; //a[right] > a[left] > a[mid ]}}}
递归到小的子区间时,可以考虑使用插入排序
归并排序
归并排序是采用分治法的一个非常典型的应用。其基本思想是:将已有序的子序合并,从而得到完全有序的序列,即先使每个子序有序,再使子序列段间有序
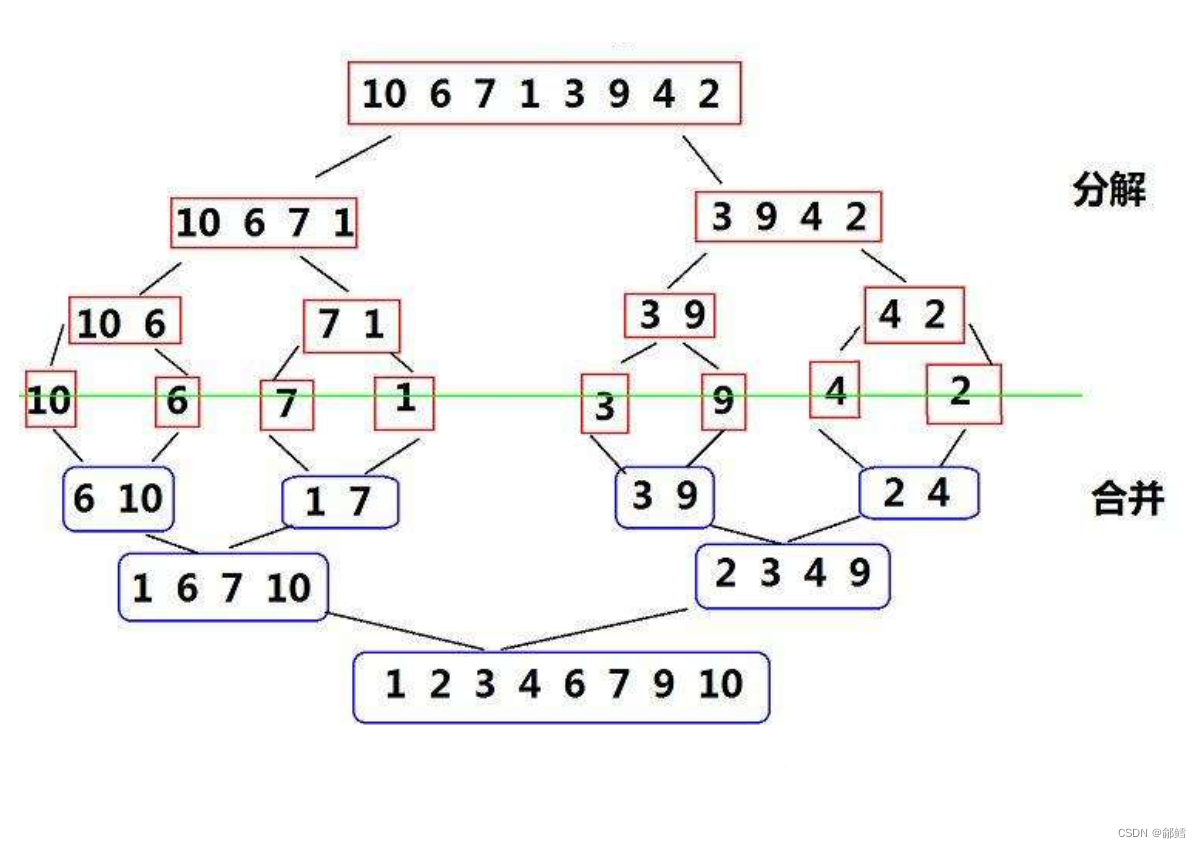
动图演示:
递归实现
核心步骤:
分解得到子序列
如何得到有序的子序列 ? 序列分解到只有一个元素或是没有元素时,就可以认为是有序了
然后合并两个有序的子序列 ,思路与Leetcode. 88合并两个有序数组 相似 ,依次比较 ,较小值尾插到tmp数组中
创建一个与待排序列大小相同的tmp数组 ,合并完毕后再将tmp数组里的数据拷贝回原数组 ,最后将tmp 数组释放 。
代码实现 :
void _MergeSort(int* a, int left, int right, int * tmp)
{int mid = (left + right) / 2;//分割// [begin , mid] [mid+1 , end ]int begin = left;int end = right; if (begin >= end)//序列分解到只有一个元素或是没有元素时,就可以认为是有序了return;_MergeSort(a, begin, mid, tmp); //end-begin+1 是元素个数 _MergeSort(a, mid + 1, end, tmp);//归并 ——类似合并两个有序数组 ,[begin , mid] [mid+1 , end ]int begin1 = begin, end1 = mid;int begin2 = mid + 1, end2 = end;int i = begin; //不能取0 , 两段有序区间不一定是从头开始的区间 while (begin1 <= end1 && begin2 <=end2 ) {if (a[begin1] < a[begin2]){tmp[i++] = a[begin1++];}else{tmp[i++] = a[begin2++];}}//begin1 先走完 ,begin2还没有走完,begin2尾插到tmp数组后面while (begin2 <= end2 ){tmp[i++] = a[begin2++];}//begin2 先走完 ,begin1还没有走完, begin1尾插到tmp数组后面 while (begin1 <= end1){tmp[i++] = a[begin1++];}//将tmp数组拷贝到原数组中 memcpy(a+begin, tmp+begin, sizeof(int*) * ( right- left +1));
}
void MergeSort(int* a , int left , int right , int *tmp )
{//申请一个与原数组大小的tmp数组 tmp = (int*)malloc(sizeof(int) * (right -left +1 ) );//归并_MergeSort( a, left, right , tmp);//释放tmp 数组 free(tmp);}
tmp 和 a的后面为什么都要加begin ?
如图所示:

非递归实现
递归实现的缺点就是会一直调用栈帧,而栈帧内存往往是很小的。所以,我们尝试着用循环的办法去实现,也就是用非递归的方式去实现 ,但是非递归需要处理几个边界条件
和递归的区别就是递归要将区间一直细分,要将左区间一直递归划分完了,再递归划分右区间,而借助数组的非递归是一次性就将数据处理完毕,并且每次都将下标拷贝回原数组
归并排序的非递归基本思路是将待排序序列a[0…n-1]看成是n个长度为1的有序序列,将相邻的有序表成对归并
非递归的核心就是需要控制每次参与合并的元素个数,使序列变为有序:
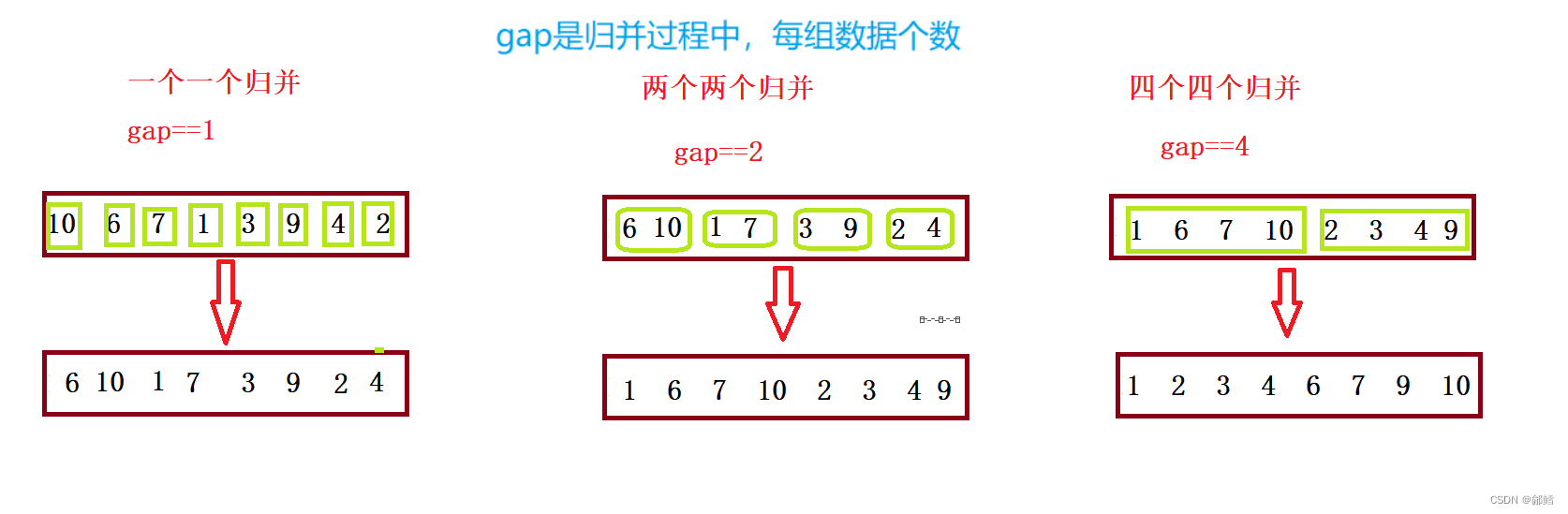
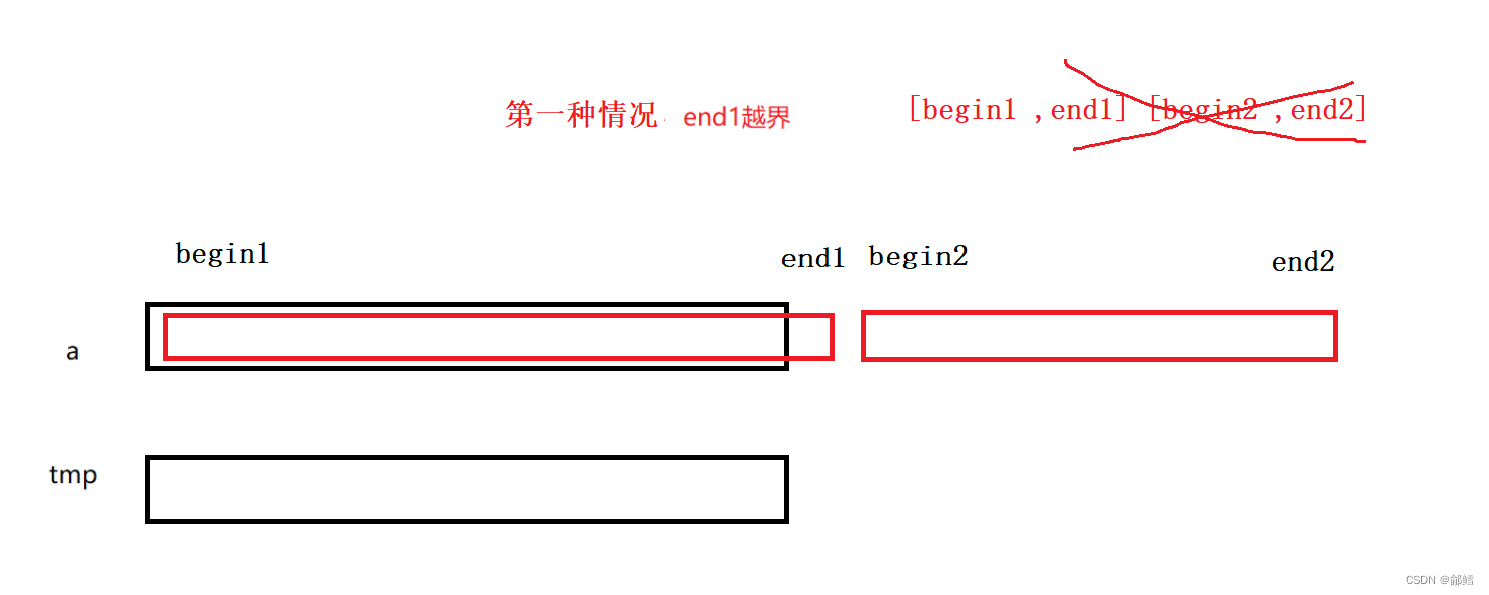
如果排序的数是奇数,就会出现一些越界的情况需要特殊处理
end1越界,begin2 和end2绝对也越界了 ,那就不对end1后面的进行归并
举例

begin2 和end2越界,那不需要对begin2和end2之间的数进行归并
举例


end2 越界,还是需要归并,修正end2就可以了
举例:


void MergeSort(int* a,int n )
{int* tmp = (int*)malloc(sizeof(int) * (n ) );if (tmp == NULL){printf("malloc fail");exit(-1);}int gap = 1;while (gap<n){//归并for (int i = 0; i < n; i += 2 * gap){//归并 ——类似合并两个有序数组 ,[begin , end1] [begin2 , end2 ]int begin1 = i, end1 = i + gap - 1;int begin2 = i + gap - 1 + 1, end2 =i+ 2 * gap - 1; //从图中分析可得int index= i;printf("[%d %d] [%d %d] ", begin1, end1, begin2, end2);/*end1 和begin2越界*/if (end1 >=n || begin2 >=n){break;}//end2越界,修正if (end2 >=n){end2 = n - 1;}while (begin1 <= end1 && begin2 <= end2){if (a[begin1] < a[begin2]){tmp[index++] = a[begin1++];}else{tmp[index++] = a[begin2++];}}//begin1 先走完 ,begin2还没有走完,begin2尾插到tmp数组后面while (begin2 <= end2){tmp[index++] = a[begin2++];}//begin2 先走完 ,begin1还没有走完, begin1尾插到tmp数组后面 while (begin1 <= end1){tmp[index++] = a[begin1++];}//将tmp数组拷贝到原数组中 memcpy(a + i, tmp + i, sizeof(int) * (end2 - i + 1));}gap *= 2;}free(tmp);
}
归并排序时间复杂度:
每一层归并排序的消耗是O(N) ,有 log层 , 所以归并排序的时间复杂度 O(N * logN)
排序算法复杂度以及稳定性
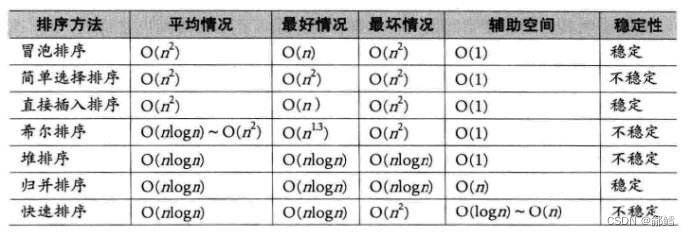
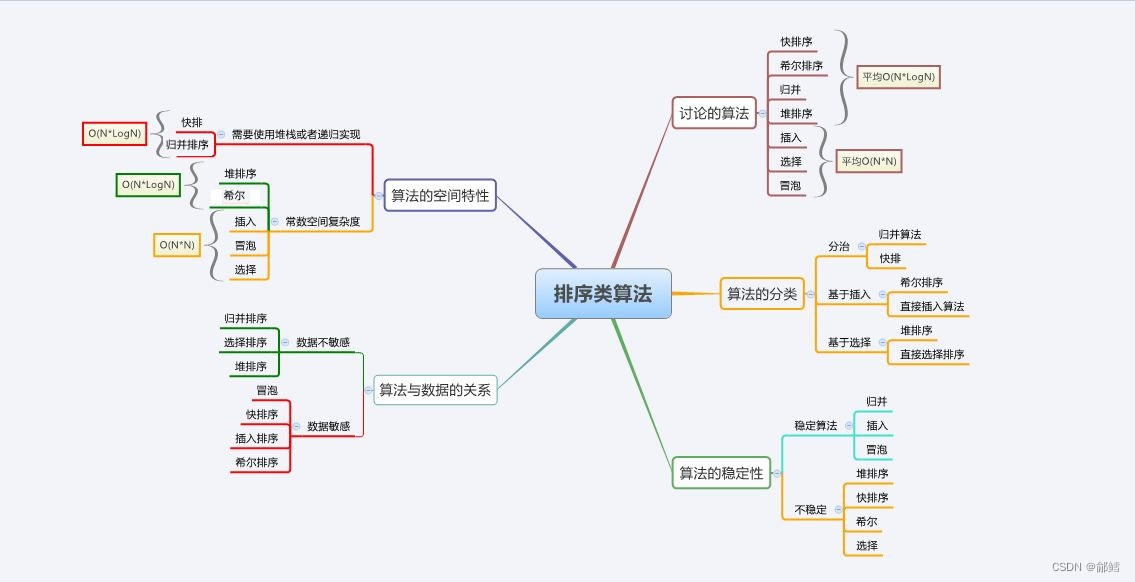
稳定的排序有:直接插入排序、冒泡排序、归并排序
不稳定的排序有:希尔排序、选择排序、堆排序、快速排序、计数排序

如果你觉得这篇文章对你有帮助,不妨动动手指给点赞收藏加转发,给鄃鳕一个大大的关注
你们的每一次支持都将转化为我前进的动力!!!
相关文章:
手把手教你 ,带你彻底掌握八大排序算法【数据结构】
文章目录 插入排序直接插入排序希尔排序 选择排序选择排序堆排序升序 交换排序冒泡排序快速排序递归hoare版本挖坑法前后指针版本 非递归Hoare挖坑法前后指针 快排的优化三数取中法选key递归到小的子区间时,可以考虑使用插入排序 归并排序递归实现非递归实现 排序算…...
第十一章 Transform组件(上)
本章节我们介绍Transform类,它是一个组件,每一个游戏对象有拥有该组件。因此,它值得我们重点介绍一下。Transform代表了游戏对象的世界变换,也就是移动,选择和缩放。 首先,我们先介绍它的属性(…...
aac音频怎么转mp3,这几个方法很简便
对于aac来说,其是一种高级音频编码,也是专门为声音数据设计的文件压缩格式。通常来说,aac与mp3有一些不同。aac使用了全新的算法进行编码的,其整体的效率较mp3更高一些。同时,aac格式的音质较好一些。但是,…...
分屏视图上线,详情数据秒切换
分屏视图 路径 表单 >> 表单设计 功能简介 新增「分屏视图」。分屏视图是一种对数据阅读提供沉浸式体验的视图组织形式,用户可通过分屏视图更快速的查看数据详情。 使用场景: 对于数据类型是「订单」数据的表单,管理人员往往会对…...
怎么释放C盘空间?清理C盘空间的4大方法分享!
案例:怎么释放c盘空间 【朋友们,最近我的c盘空间内存严重不足了,想释放一下c盘的空间,大家有什么好的方法吗?】 在使用电脑的过程中,经常会遇到C盘空间不足的问题,这时候就需要释放C盘的空间。…...
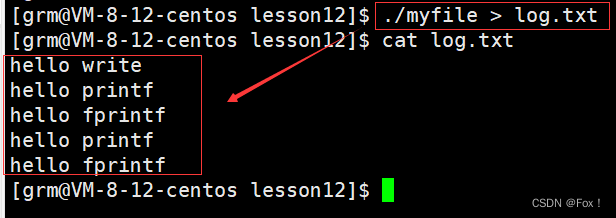
【文件描述符|重定向|缓冲区】
1 C语言文件操作的回顾 这块博主在讲解C语言时就已经做了很详细的讲解,这里就不详细讲了,直接给出代码。 写操作: #include<stdio.h> #include<stdlib.h> #include<errno.h> #define LOG "log.txt" …...
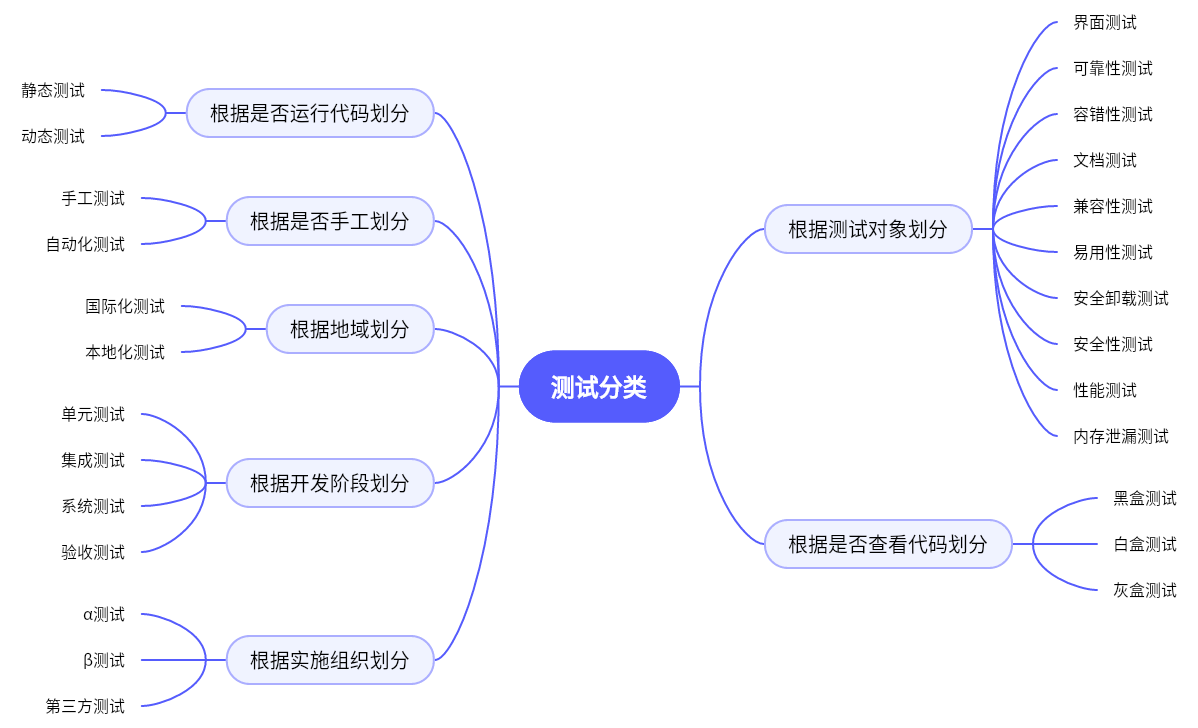
软件测试—进阶篇
软件测试—进阶篇 🔎根据测试对象划分界面测试可靠性测试容错性测试文档测试兼容性测试易用性测试安装卸载测试安全性测试性能测试内存泄漏测试 🔎根据是否查看代码划分黑盒测试白盒测试灰盒测试 🔎根据开发阶段划分单元测试集成测试系统测试…...

设计模式:创建型设计模式、结构型设计模式
目录 前言如何学习设计模式?设计模式基础设计原则 一. 创建型设计模式1. 模板方法2. 观察者模式3. 策略模式 二. 结构型设计模式1. 单例模式2. 工厂模式3. 抽象工厂4. 责任链5. 装饰器6. 组合模式 前言 如何学习设计模式? 明确目的 在现有的设计模式上…...

如何选择多参数水质分析仪?
如何选择适合的多参数水质分析仪? 首先水质检测仪分为实验室(台式)和户外使用的便携式多参数水质检测仪。我们呢就要了解自己的需 求使用在什么领域,根据使用领域选择仪器;其次就是选择需要测定的指标,最好…...

明确自动化测试目的
明确自动化测试目的 1.提高测试人员的工作成就感和幸福感,减少手工测试中重复性的工作 目前,在大部分中小企业中,手工测试在日常测试工作占据的比例很大。测试人员必须跟随开发团队不断地进行选代式开发和测试。一个功能模块可能在整个测试周…...

DevExpress.XtraGrid.GridControl导出excel需要添加表头
string head ""; head "单号 \t" txtcCode.Text ; string foot ""; foot "制单人 \t" "制单日期 \t" "审核人: \t" "审核日期 \t" "修改人 \t&q…...

守护进程Daemon
进程组、对话期和控制终端关系 每个会话有且只有一个前台进程组,但会有0个或者多个后台进程组。产生在控制终端上的输入(Input)和信号(Signal)将发送给会话的前台进程组中的所有进程。对于输出(Output&…...

学生成绩管理系统 002
学生成绩管理系统 *****************学生成绩管理系统***************** 1、成绩添加 2、成绩输出 3、成绩查询 4、成绩统计 5、成绩排名 6、成绩删除 7、成绩修改 8、成绩按学号排序 0、退出系统 ************************************************** 请选择功能:1 **********…...

换个花样玩C++(4)细聊C++的引用精妙之处
引用是C++引入的新语言特性。而且在日常工作开发过程中,经常会使用到引用,对于一些做系统架构的架构师而言,这也是不可或缺的一门基本功,我在工作中发现,很多人并没有搞清楚引用。因此我在本篇中将对引用进行详细讨论,希望对大家更好地理解和使用引用起到抛砖引玉的作用。…...

Linux安装helm
前言 运行环境:CentOS7.9 官方参考文档:官方文档 文章末尾附有一键安装脚本 下载安装包 github下载对应版本的安装包,下载地址 进入对应版本的下载页面,这里以v3.11.3为例 选择对应系统的安装包,这里以linux为例 …...
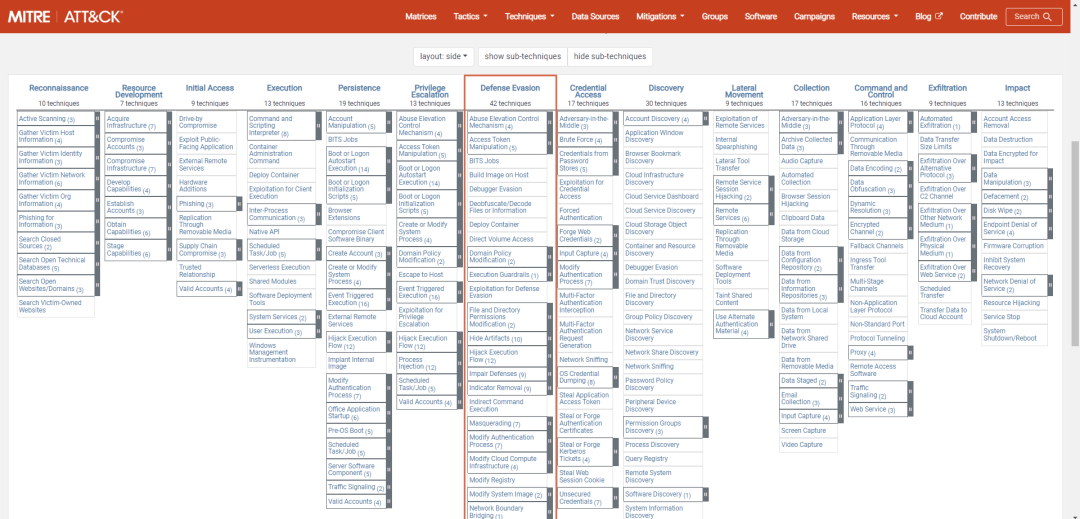
ATTCK v12版本战术介绍——防御规避(四)
一、引言 在前几期文章中我们介绍了ATT&CK中侦察、资源开发、初始访问、执行、持久化、提权战术理论知识及实战研究、部分防御规避战术,本期我们为大家介绍ATT&CK 14项战术中防御规避战术第19-24种子技术,后续会介绍防御规避其他子技术…...
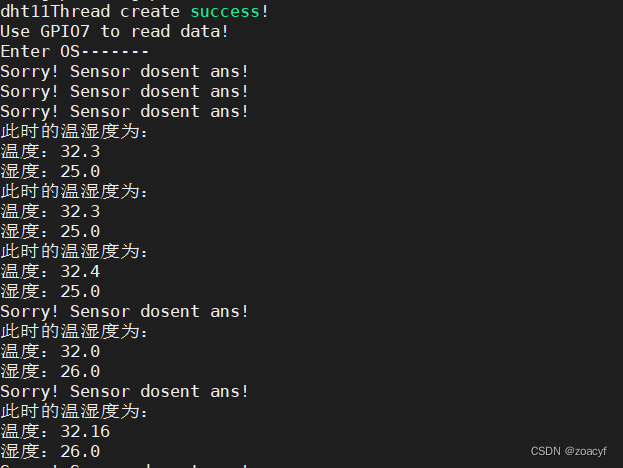
Orangepi Zero2 全志H616(DHT11温湿度检测)
最近在学习Linux应用和安卓开发过程中,打算把Linux实现的温湿度显示安卓app上,于是在此之前先基于Orangepi Zero2 全志H616下的wiringPi库对DHT11进行开发,本文主要记录开发过程的一些问题和细节,主要简单通过开启线程来接收温湿度…...
abbyy是什么软件
ABBYY,一款强大的OCR文字识别软件! 在日常的工作中,我们常常需要提取PDF或图片上的大段文字,如果字数少的话,我们可以直接手打,但如果出现大篇幅的文字,那就有点头疼了。今天,我就向…...

软件测试技术(四)白盒测试
白盒测试 白盒测试(White Box Testing)又称结构测试、透明盒测试、逻辑驱动测试或基于代码的测试。白盒测试只测试软件产品的内部结构和处理过程,而不测试软件产品的功能,用于纠正软件系统在描述、表示和规格上的错误,…...
:try-catch块)
Java基础语法(十二):try-catch块
目录 前言 一、try-catch是什么? 二、其他异常处理机制 总结 前言 Java 异常处理机制是 Java 程序设计中至关重要的一部分。它允许程序员像处理普通数据一样处理异常,并根据异常类型采取合适的措施。其中一个非常基本的异常处理机制是 try-catch 块…...

基于距离变化能量开销动态调整的WSN低功耗拓扑控制开销算法matlab仿真
目录 1.程序功能描述 2.测试软件版本以及运行结果展示 3.核心程序 4.算法仿真参数 5.算法理论概述 6.参考文献 7.完整程序 1.程序功能描述 通过动态调整节点通信的能量开销,平衡网络负载,延长WSN生命周期。具体通过建立基于距离的能量消耗模型&am…...

Appium+python自动化(十六)- ADB命令
简介 Android 调试桥(adb)是多种用途的工具,该工具可以帮助你你管理设备或模拟器 的状态。 adb ( Android Debug Bridge)是一个通用命令行工具,其允许您与模拟器实例或连接的 Android 设备进行通信。它可为各种设备操作提供便利,如安装和调试…...

模型参数、模型存储精度、参数与显存
模型参数量衡量单位 M:百万(Million) B:十亿(Billion) 1 B 1000 M 1B 1000M 1B1000M 参数存储精度 模型参数是固定的,但是一个参数所表示多少字节不一定,需要看这个参数以什么…...

在rocky linux 9.5上在线安装 docker
前面是指南,后面是日志 sudo dnf config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo sudo dnf install docker-ce docker-ce-cli containerd.io -y docker version sudo systemctl start docker sudo systemctl status docker …...

iPhone密码忘记了办?iPhoneUnlocker,iPhone解锁工具Aiseesoft iPhone Unlocker 高级注册版分享
平时用 iPhone 的时候,难免会碰到解锁的麻烦事。比如密码忘了、人脸识别 / 指纹识别突然不灵,或者买了二手 iPhone 却被原来的 iCloud 账号锁住,这时候就需要靠谱的解锁工具来帮忙了。Aiseesoft iPhone Unlocker 就是专门解决这些问题的软件&…...

大数据零基础学习day1之环境准备和大数据初步理解
学习大数据会使用到多台Linux服务器。 一、环境准备 1、VMware 基于VMware构建Linux虚拟机 是大数据从业者或者IT从业者的必备技能之一也是成本低廉的方案 所以VMware虚拟机方案是必须要学习的。 (1)设置网关 打开VMware虚拟机,点击编辑…...

1688商品列表API与其他数据源的对接思路
将1688商品列表API与其他数据源对接时,需结合业务场景设计数据流转链路,重点关注数据格式兼容性、接口调用频率控制及数据一致性维护。以下是具体对接思路及关键技术点: 一、核心对接场景与目标 商品数据同步 场景:将1688商品信息…...

定时器任务——若依源码分析
分析util包下面的工具类schedule utils: ScheduleUtils 是若依中用于与 Quartz 框架交互的工具类,封装了定时任务的 创建、更新、暂停、删除等核心逻辑。 createScheduleJob createScheduleJob 用于将任务注册到 Quartz,先构建任务的 JobD…...

【ROS】Nav2源码之nav2_behavior_tree-行为树节点列表
1、行为树节点分类 在 Nav2(Navigation2)的行为树框架中,行为树节点插件按照功能分为 Action(动作节点)、Condition(条件节点)、Control(控制节点) 和 Decorator(装饰节点) 四类。 1.1 动作节点 Action 执行具体的机器人操作或任务,直接与硬件、传感器或外部系统…...

k8s业务程序联调工具-KtConnect
概述 原理 工具作用是建立了一个从本地到集群的单向VPN,根据VPN原理,打通两个内网必然需要借助一个公共中继节点,ktconnect工具巧妙的利用k8s原生的portforward能力,简化了建立连接的过程,apiserver间接起到了中继节…...