[论文笔记]C^3F,MCNN:图片人群计数模型
(万能代码)CommissarMa/Crowd_counting_from_scratch
代码:https://github.com/CommissarMa/Crowd_counting_from_scratch
(万能代码)C^3 Framework开源人群计数框架
科普中文博文:https://zhuanlan.zhihu.com/p/65650998
框架网址:https://github.com/gjy3035/C-3-Framework
web端人群计数标注工具:https://github.com/Elin24/cclabeler
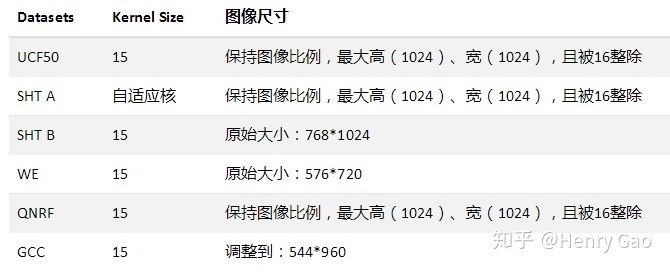
(S1)数据处理:训练集融合了六个主流数据集,并进行数据预处理,UCF_CC_50,Shanghai Tech Part A,WorldExpo'10,UCF-QNRF以及GCC。测试集:Shanghai Tech Part B数据集(选择这个,是因为:图像尺寸相同,便于多batch-size的训练和测试,能够最大化利用显卡,节省显卡资源和训练时间。)。将数据整理成PyTorch下的data loader格式。
(S2)根据原图生成密度图density map
-
因为,在人群计数领域中,常见encoder中一般输出为1/8原图尺寸。所以 ,在预处理时对图像的高和宽进行了限制,使其能够被16整除。从而,确保网络中一些含有下采样down sampling操作的层(conv with stride2 或者池化)能够正确输出。
-
为节约显存,对QNRF和GCC的图像进行了保持长宽比的降采样操作。
(S3)数据预处理
(3.1)多Batch-size训练
由于UCF50、SHT A、QNRF所包含的图像尺寸不一,随机从这三个数据集中取出图片,他们的大小是不一样的,因此需要以尺寸最小的那个为标准,将其他大的图片裁小。我们重写了collate_fn函数。该函数在随机拿到N张图像和GT后,选择最小的高h_min和最小的宽w_min对所有图像进行crop,拼成下面这个size的Tensor送进网络中训练
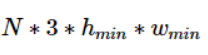
根据经验,(1)如果是from scratch training,对于这几个数据集建议采用多batch size训练或者(2)采用GCC-SFCN中加padding的方案,(3)对于有预训练参数的模型(AlexNet,VGG,ResNet等),建议采用单一batch size进行训练。
(3.2) Label Transform-对密度图进行transform的操作
[1]参考了CSRNet源码[6]中对密度图进行降采样的操作(GTScaleDown)[2]对密度图点乘一个放大因子(LabelNormalize)
(3.3)GTScaleDown
我们的目的是使得密度图之和等于总人数。但是,网络回归密度图为原图的8/1。因此我们选择采用增加上采样层来实现与原图大小的密度图。
其实除了上面这个还有其他方法。比如CSRNet中,作者对密度图进行了降采样,并点乘64以保证密度图之和依然约等于总人数。该操作会带来一个问题:会影响PSNR和SSIM的值。因此我们不建议使用该操作。
(3.4) LabelNormalize
对于密度图乘以一个较大的放大因子,可以使网络更快的收敛,甚至取得更低的估计误差
(S4)我们将常见的分类模型改造成人群计数网络(arwin老师介绍了和多图片分类的特别前沿的模型,可以拿过来试试,说不定会更好?)
-
AlexNet网络:(1)小幅修改了conv1和conv2层的padding,以保证其对于feature map的大小能够正常整除。(2)截取conv5之前的网络,作为人群计数的encoder,其大小为原始输入的1/16。(3)decoder的设计依然遵循简约的原则,用“两层卷积+上采样”直接回归到1-channel的密度图。
-
VGG系列:VGG和VGG+decoder:(1)VGG网络的两个变体都完全采用了VGG-16模型的前10个卷积层(2)VGG采用了最为简单的decoder(3)VGG+decoder则是简单设计了一个含有三个反卷积的模块——结果(1)两者的模型性能(MAE,MSE)差不多,二者的性能非常接近CSRNet(2)VGG+decoder有着更为精细的密度图
-
ResNet系列:Res50和Res101:(1)Encoder部分:为了保证密度图的大小不至于过小(不小于原图尺寸的1/8),将res.layer3中第一层stride的大小,从将原本的2改为1,以此当做encoder。(2)decoder部分:本着简单的原则,decoder由两层卷积构成——结果:在SHT B上 performance score是最高的,直接达到了现有SOTA的水平,和目前性能最好的PACNN+模型一样,体现了ResNet强大的特征提取能力
-
其他主流算法的复现:MCNN,CMTL,CSRNet以及SANet
-
MCNN:与原网络结构的不同:处理的是RGB图像
-
CMTL:在训练前,通过在线裁剪的方式进行了数据增强,扩充了训练集。在线裁剪的方法可以使训练覆盖更多的裁剪区域。
-
(S5)训练技巧:
-
LabelNormalize的调参:用一个合适的放大因子,对密度图density map进行放大会加速模型训练,使其更快地收敛,避免陷入局部最优解local minimum。
-
【原因】:个初始化好的计数网络来说,自身参数符合一定的分布,如果目标分布和初始化分布相差过大的话,网络会陷入一个比较差的局部解,难以训练出好的结果。——
-
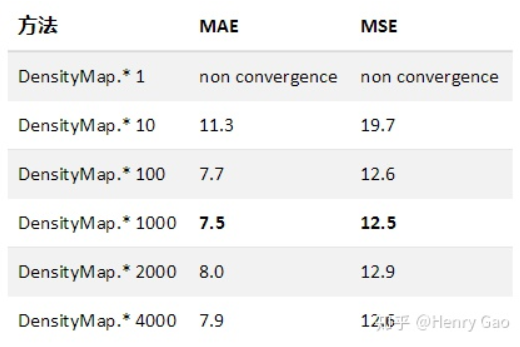
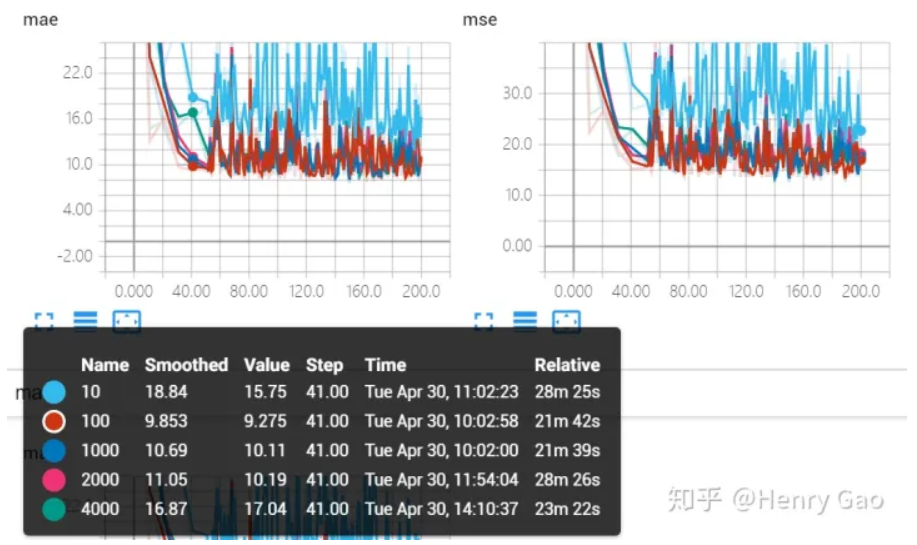
下图展示了,Res50网络下,在SHT B上,分别测试在对密度图分别乘以[1,10,100,1000,2000,4000]不同的放大因子时,网络的计数性能差异。第一行表示,如果采用原始密度图时,网络并不能正确收敛。
-
-
放大因子最小要取10:下图展示了在六组不同的放大因子下,MAE和MSE在验证集上随时间的变化曲线。橙色曲线表示对密度图不进行放大情况下,网络性能的表现。上面第一条线,橙色的线,表示放大因子为1,就是不做放大的时候,mae降低到60左右就不再随着训练的次数增加而下降了,也就是说网络陷入到一个局部解难以跳出。
-
-
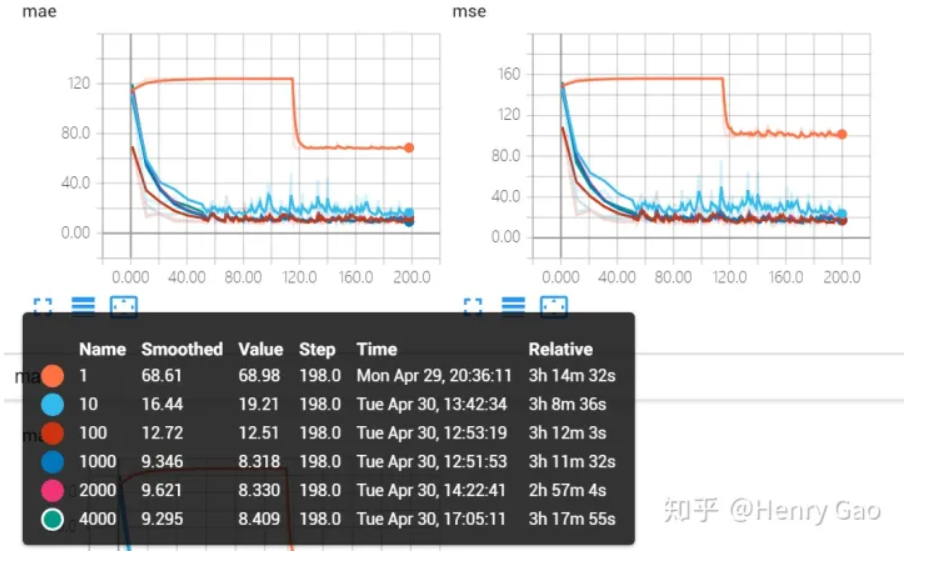
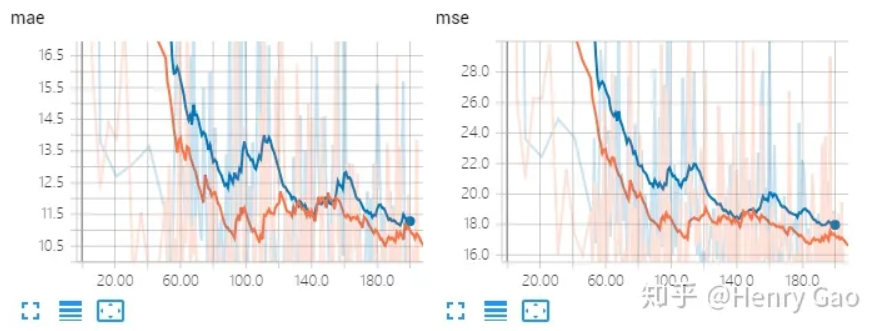
下图表示了移除掉橙色曲线后,即放大因子为[10,100,1000,2000,4000]的曲线对比。从图中可以看出,除了放大因子取10时,效果较差,其他几种曲线重合度非常高。也就是放大因子最小取100以后,再给出更大的放大因子的意义就不大了。
-
-
特征图大小对比:1/8 size v.s 1/16 size
-
过小的特征图尺寸会对计数的性能产生非常大的影响,在这个情况下1/8 sIze比1/16size要好.
-
对比实验:1) ResNet-50中res.layer3以前的层原封不动当做backbone,最终输出密度图作16x的上采样(stride=1);2) C3F最终采用的方案,输出密度图作8x的上采样(stride=2)。——----结果:在将stride改为1后,模型输出了分辨率更高的密度图,同时在计数误差上取得了更好的效果。下图是MAE和MSE的随着训练次数越来越多而变化的曲线。蓝色表示stride=2,橘黄色表示stride=1。我们明显可以看出来,stride=1,stride更小的曲线,特征图更大的曲线,橘黄色曲线,整体显著地低于蓝色曲线。也就是说这里特征图大一点更好。
-
实验结果
最优的算法:得益于ResNet-101强大的学习能力,以其为Backbone的人群计数器在MAE和MSE指标上超越了其他所有算法
有预训练参数的网络,不需要修改网络的结构,直接用,就可以拿一个很高的performance score,比如Dilated Conv、Multi-column Conv、Scale Aggregation
| Method | MAE | MSE |
| vgg-16(conv4_3) | 10.3 | 16.5 |
| VGG(conv4_3)+decoder | 10.5 | 17.4 |
| ResNet-50(layer3) | 7.7 | 12.6 |
| ResNet-101(layer3) | 7.6 | 12.2 |
| MCNN(RGB Image) | 21.5 | 38.1 |
| CMTL | 14 | 22.3 |
| CSRNet | 10.6 | 16 |
| SASNet | 12.1 | 19.2 |
| AlexNet(conv5) | 13.6 | 21.7 |
人群计数与语义分割之间的关系
二者同属于逐像素任务,前者为逐像素分类,后者为逐像素回归。根据我的实验,某些分割网络直接修改最后一层为回归层后,其效果与backbone相比,提升非常有限。甚至性能会有所下降。深层问题
Crowd_counting_from_scratch (大概率能跑,我没跑)
CommissarMa/Crowd_counting_from_scratch : https://github.com/CommissarMa/Crowd_counting_from_scratch
2016(有代码)_MCNN(+11次)
(CVPR 2016),入门最适合看的
MCNN:Single-Image Crowd Counting via Multi-Column Convolutional Neural Network(首次引入CNN到人群计数领域)
https://github.com/svishwa/crowdcount-mcnn
另外两个版本的代码:
(1)https://github.com/CommissarMa/Crowd_counting_from_scratch/blob/master/crowd_model/mcnn_model.py
(2)https://github.com/CommissarMa/MCNN-pytorch
规模感知模型(什么叫规模感知?),基于完整图像
想解决的问题
图片任意尺寸、任意人群密度、任意拍摄角度、任意人头尺度scale、任意分辨率 图像的 密集人群计数面临的难题
每列CNN学习得到的特征可以自适应由于透视或图像分辨率引起的人/头大小的变化
在不需要输入图的透视先验情况下通过几何自适应的核来精确计算人群密度图
创新:
(1)在原图映射到人群密度图crowd density map这个过程中,引入了CNN,这种CNN是“Multi-Column Convolutional Neural Network”;
(2)多个大小不同的卷积核并行训练parallel CNNs,这些卷积感受野receptive fields有大有小with local receptive fields of different sizes., 这样他们可以捕捉到不同大小尺度的特征to capture characteristics of crowd density at different scales.
(3)制作groun truth使用的是基于几何自适应核geometry adaptive kernels, 不需要知道输入图像的透视图(透视图一般很难获取), 就可以准确地计算出真实密度图
(4)抛弃了前景分割这一步骤
(5)收集并开源了Shanghaitech这个人群数据集,这个数据集是已成为业内性能指标必刷榜。
模型细节
(1)三个大小不同的卷积核并行提取特征,以便于适应不同大小的人头,最后三个模型做融合。
-
三个并行模型的网络结构和网络深度完全相同,都是 conv–pooling–conv–pooling。
-
三个模型的卷积核大小不同,分别是 大9*9、中7*7、小5*5,因此三个网络的receptive field感受野不同,能够抓住不同大小人头的特征。——pooling用的Max pooling is applied for each 2×2 region,从模型示意图中可以看到,2×2的max pooling用了两次,对训练样本的feature的 size也缩小到1/4,,激活函数是ReLU,
-
最后融合--把所有的输出特征图堆叠在一起stack the output feature maps of all CNNs,其实就是简单的channel堆在一起,小(channel数=8)、中(channel数=10)、大(channel数=12)三个channel直接堆在一起,得到channel数为8+10+12=30个channel
-
最后将三列子网络的特征图做线性加权(由1x1的卷积完成),将数据从30个channel降低到1个channel的人群密度图。这个权重是通过反向传播不断学习优化和调整的。这个过程就是在做模型融合
-
由于我们的网络最后输出的是二维密度图,没有使用全连接层把输出降到一维,是全卷积网络,[ 1 ] 因此参数很少,训练起来很快。 [ 2 ] 另外一个好处是输入图像可以是任意大小,从而避免了因调整图像大小(Resize)产生的图像扭曲(Image Distortion)对算法性能的影响。
其实你可以不止并行融合3个CNN模型,你可以并行并融合5个、7个、15个不同卷积核大小的模型,但是参数量会因此增大很多,不建议这样。作者通过实验发现用3个是tradeoff最佳的。
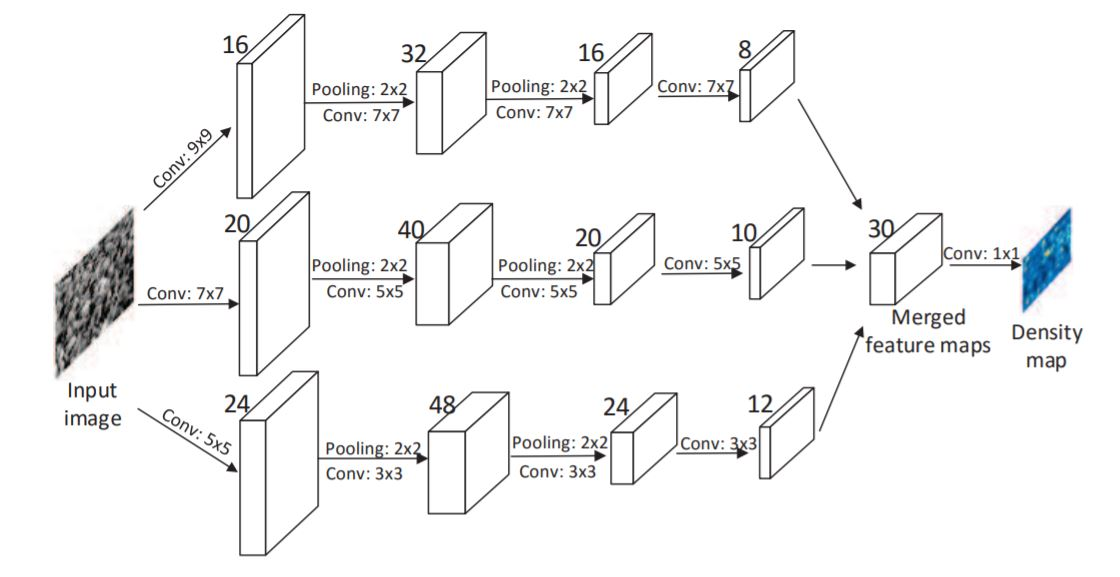
(2)最后一个组件从全连接层替换成了1×1卷积,这样输出的密度图就变成了和输入图片size完全一样了。这样就避免了全连接层输出是一维向量,丢失二维信息的问题。
F是密度图,N是图片数目
这里的ground truth就是上面 density map estimation讲的 那个用高斯核卷积得出的那个
F(X; $$\theta$$)就是上面这个模型融合映射出的图
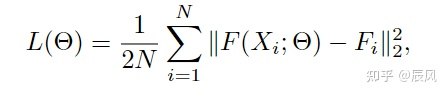
where Θ is a set of learnable parameters in the MCNN. N is the number of the training image. X(i )is the input image and F(i )is the ground truth density map of image X(i). F(X(i); Θ) stands for the estimated density map generated by MCNN which is parameterized with Θ for sample X(i). L is the loss between the estimated density map and the ground truth density map.
这篇文章很明显的模仿了FCN(1)不同卷积核的数据做融合,可以捕捉到不同大小的特征(2)用1×1卷积替代了最后的全连接层,保留二维结构的信息
劣势:(1)三个CNN并行,有较多的参数,计算量大,消耗的计算资源多,难以实际应用,无法进行实时的人群计数预测(2)多列/多网络需要预训练但网络,比端到端训练更复杂(3)多阵列的网络并不能如所描述的那样提取不同的人头特征。有很多低效的分支结构。
相关文章:
[论文笔记]C^3F,MCNN:图片人群计数模型
(万能代码)CommissarMa/Crowd_counting_from_scratch 代码:https://github.com/CommissarMa/Crowd_counting_from_scratch (万能代码)C^3 Framework开源人群计数框架 科普中文博文:https://zhuanlan.zhihu.com/p/65650998 框架网址:https…...
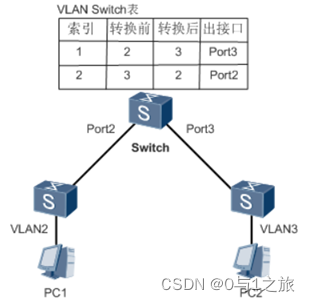
HCIP-7.2VLAN间通信单臂、多臂、三层交换方式学习
VLAN间通信单臂、多臂、三层交换方式学习 1、单臂路由2、多臂路由3、三层交换机的SVI接口实现VLAN间通讯3.1、VLANIF虚拟接口3.2、VLAN间路由3.2.1、单台三层路由VLAN间通信,在一台三层交换机内部VLAN之间直连。3.2.2、两台三层交换机的之间的VLAN通信。3.2.3、将物…...

PHP快速入门17-用spl_autoload_register实现类的自动加载
文章目录 前言实现过程创建两个类创建入口文件 总结 前言 本文已收录于PHP全栈系列专栏:PHP快速入门与实战 PHP类自动载入是指在PHP应用程序中,当需要使用某个类文件时,系统会自动加载该类文件,无需手动引入。 在PHP中…...
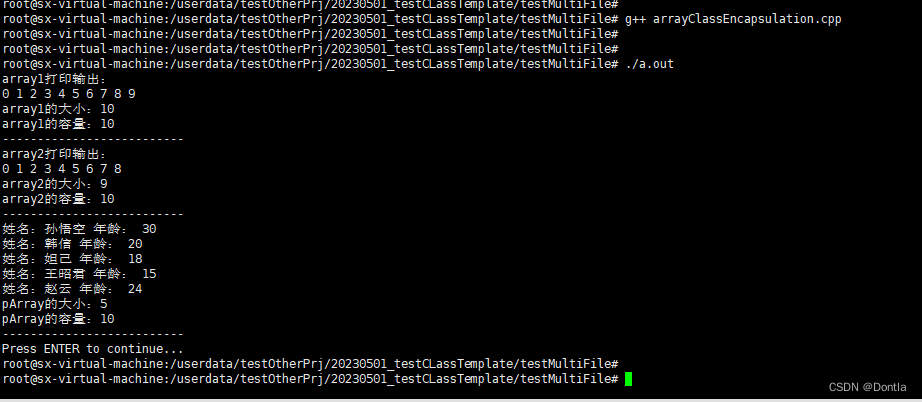
【黑马程序员 C++教程从0到1入门编程】【笔记8】 泛型编程——模板
https://www.bilibili.com/video/BV1et411b73Z?p167 C泛型编程是一种编程范式,它的核心思想是编写通用的代码,使得代码可以适用于多种不同的数据类型。 而模板是C中实现泛型编程的一种机制,它允许我们编写通用的代码模板,然后在需…...
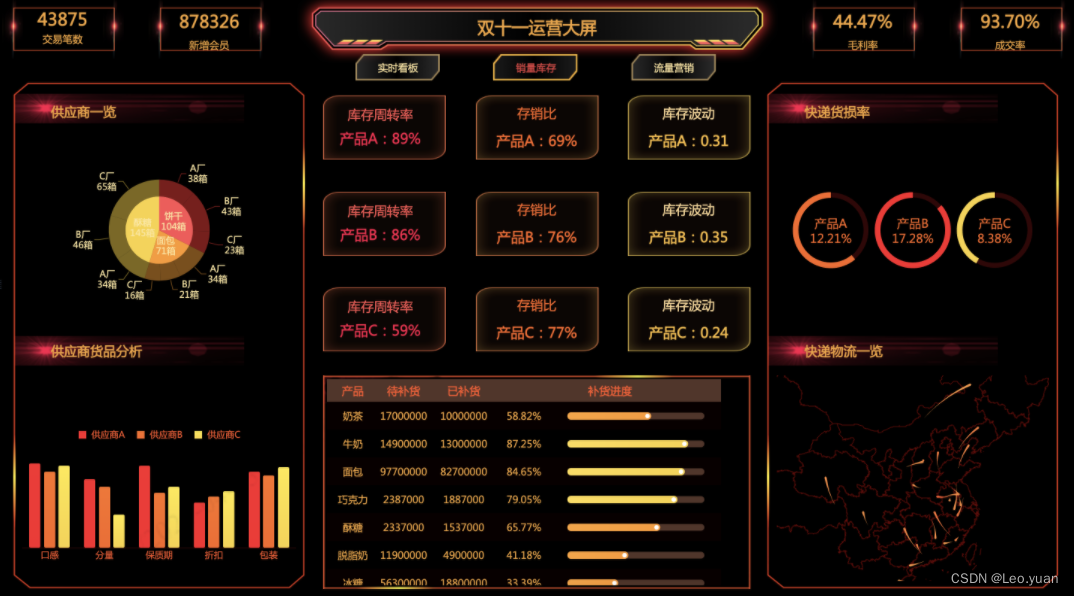
分享10个精美可视化模板,解决95%的大屏需求!
前段时间和朋友一起喝茶,我吐槽着excel表格做报表的繁琐,他惊讶的问我竟然不知道大屏模板这种东西,说是直接套用数据就可以,我震惊的同时吃下了这个安利。 回来之后,我好好研究了一番这个叫可视化大屏的“新鲜玩意儿”…...

好用的项目管理软件的具体功能有哪些
随着企业规模不断的扩大,项目管理往往会面临更多的挑战与难题,最常见的会出现以下几个问题:资源消耗失控,而项目部门和相关部门之间沟通越来越困难;团队凝聚力下降、项目进度难以把控,项目成本几乎失控&…...

< 每日小技巧: 基于Vue状态的过渡动画 - Transition 和 TransitionGroup>
》基于Vue状态的过渡动画 - Transition 和 TransitionGroup 👉 一、Vue Transition 简介> Transition 和 TransitionGroup 之间的区别 👉 二、<Transition> 组件> 触发 <Transition> 组件的场景:> 基于 CSS 的过渡效果&…...
vmware安装redhat 8
vmware安装redhat 8 1、下载镜像文件1.1 镜像文件 2、安装系统2.1、选择自定义安装2.2、兼容性选择2.3、选择镜像文件导入2.4、设置用户名密码2.5、选择虚拟机在磁盘上的位置2.6、选择处理器数量2.7、选择内存大小2.8、选择桥接或NAT2.9、选择SCSI控制器类型2.10、选择虚拟机磁…...

OpenCV C++案例实战三十一《动态时钟》
OpenCV C案例实战三十一《动态时钟》 前言一、绘制表盘二、绘制刻线三、获取系统时间四、结果展示五、源码总结 前言 本案例将使用OpenCV C实现动态时钟效果。原理也很简单,主要分为绘制表盘、以及获取系统时间两步。 一、绘制表盘 首先为了效果显示美观一点&…...

字节后端入门 - Go 语言原理与实践
1.1什么是Go语言 1.2Go语言入门 环境 1.3基础语法 1.3.1变量 var name"value" 自己推断变量类型; 也可以显式类型 var c int 1 name: type(value) 常量: const name "value" g : a"foo" 字符串拼接 1.3.2 if else {}花括号…...

锂电材料浆料匀浆搅拌设备轴承经常故障如何处理?
锂电材料浆料匀浆搅拌设备是锂电池生产中重要的设备之一,用于将活性材料、导电剂、粘结剂和溶剂混合成均匀的浆料,是电极制备过程中不可或缺的步骤。然而,由于高速搅拌和化学腐蚀等因素的影响,轴承经常会出现故障,导致…...
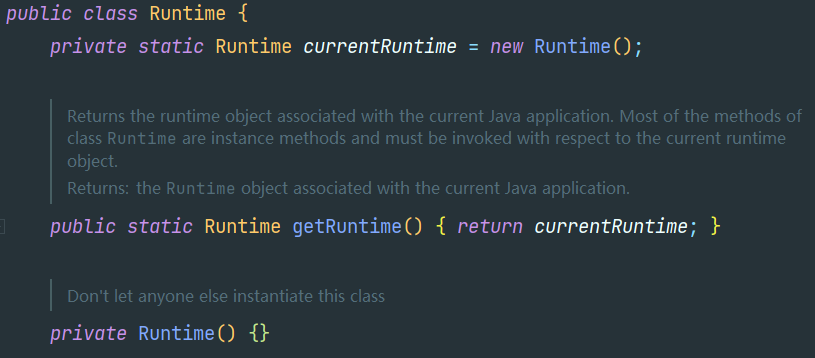
设计模式——设计模式介绍和单例设计模式
导航: 【黑马Java笔记踩坑汇总】JavaSEJavaWebSSMSpringBoot瑞吉外卖SpringCloud黑马旅游谷粒商城学成在线设计模式牛客面试题 目录 一、设计模式概述和分类 1.1 设计模式介绍 1.2 设计模式分类 二、创建型设计模式-单例模式 2.1 介绍 2.2 八种单例模式的创…...
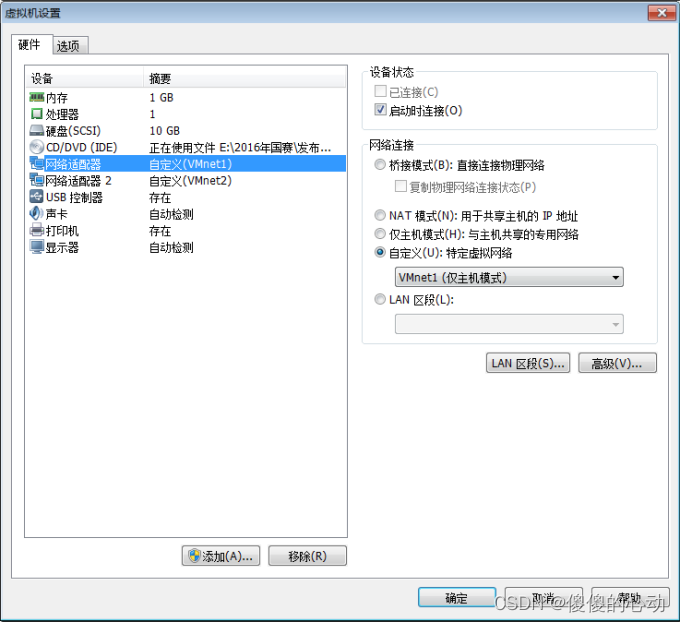
利用Iptables构建虚拟路由器
利用Iptables构建虚拟路由器 (1)修改网络类型 在VMware Workstation软件中选择“编辑→虚拟网络编辑器”菜单命令,在虚拟网络列表中选中VMnet1,将其配置为“仅主机模式(在专用网络内连接虚拟机)”&#x…...

C++——类和对象[中]
0.关注博主有更多知识 C知识合集 目录 1.类的默认成员函数 2.构造函数和析构函数基础 3.构造函数进阶 4.析构函数进阶 5.拷贝构造函数 6.运算符重载 7.日期类 7.1输入&输出&友元函数 8.赋值运算符重载 9.const成员函数 9.1日期类完整代码 10.取地址重载 …...

Symbol.iterator和Symbol.asyncIterator
Symbol是什么? symbol是ES6标准中新增的一种基本数据类型,symbol 的值是通过 Symbol()函数返回的,每一个 symbol 的值都是唯一的,即使传入相同的描述值。 注:Symbol 函数不允许通过 new 的方式调用 Symbol的作用是什…...

忆暖行动|“他一个人推着老式自行车在厚雪堆的道路上走,车上带着学生考试要用的司机”
忆暖行动|“他一个人推着老式自行车在厚雪堆的道路上走,车上带着学生考试要用的sj” 一头白发,满山青葱 在那斑驳的物件褶皱中,透过泛黄的相片,掩藏着岁月的冲刷和青葱的时光。曾经的青年早已经不复年轻,但是那份热爱…...
)
Python中True、False、None的判断(避坑)
2.4 Python中True、False、None的判断 在Python中,所有的空值和0在作为条件表达式时,隐式的进行bool转换后都是False,比如:空列表:[]、空字符串:‘’、空字典:{}等等。 from icecream import …...

Spring Bean定义有哪些方式?
概述 对于学习Spring的兄弟姐妹来说,觉得这个问题很熟悉,若是要把它回答得很清楚,却是很为难?平时写代码的时候,不会在意这些概念问题,但面试时这个问题出现的频率却是很高,所以还是必须要掌握…...
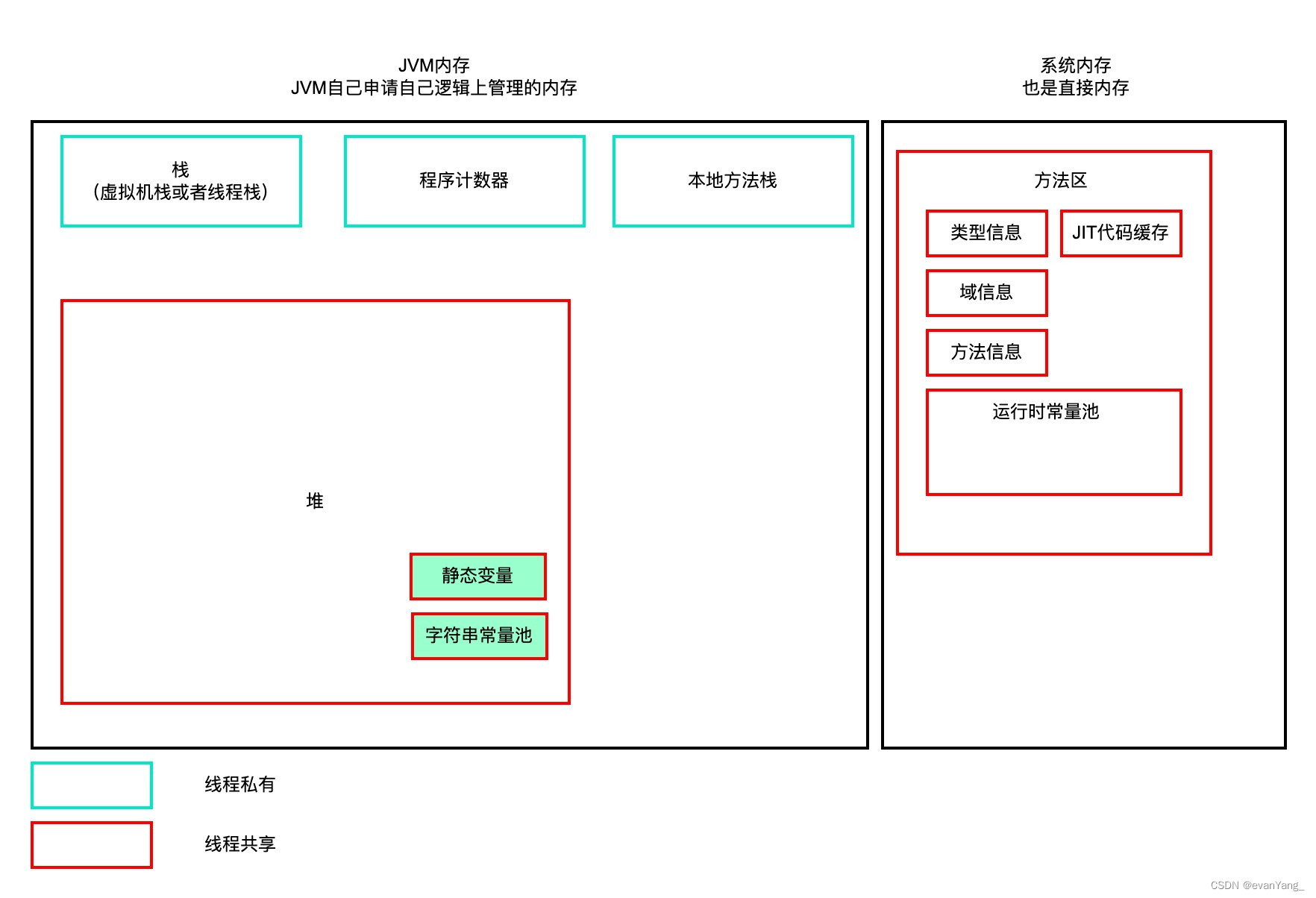
JVM内存模型的演变
1,背景 class文件、类的加载过程。我们的class文件就要进入到JVM内存里,我们沿着经典的JDK1.6,JDK1.7,JDK1.8看看在其中都经历了哪些改变 概念的统一: 方法区: 方法区可以看作是JVM逻辑上管理一片区域的…...
DataX3同步Mysql数据库数据到Mysql数据库和DataX3同步mysql数据库数据到Starrocks数据库
DataX3同步Mysql数据库数据到Mysql数据库和DataX3同步mysql数据库数据到Starrocks 一、认识DataX二、DataX3概览三、DataX3框架设计四、DataX3插件体系五、DataX3核心架构六、DataX 3六大核心优势1.可靠的数据质量监控2.丰富的数据转换功能3.精准的速度控制4.强劲的同步性能5.健…...

黑丝空姐-造相Z-Turbo部署避坑指南:3步解决启动失败问题
黑丝空姐-造相Z-Turbo部署避坑指南:3步解决启动失败问题 1. 部署前的准备工作 1.1 系统环境检查 在部署黑丝空姐-造相Z-Turbo镜像前,请确保您的环境满足以下基本要求: 操作系统:推荐使用Ubuntu 20.04/22.04 LTS或兼容的Linux发…...

fast-DTW算法优化指南:如何提升时间序列匹配效率与准确性
Fast-DTW算法实战优化:从原理到参数调优的全方位指南 时间序列分析在金融预测、工业设备监控、医疗诊断等领域扮演着关键角色。当我们面对两条长度不同的时间序列数据时,如何准确衡量它们的相似度?传统DTW(动态时间规整࿰…...

MusePublic Art StudioUI交互设计解析:按钮动效与状态反馈逻辑
MusePublic Art Studio UI交互设计解析:按钮动效与状态反馈逻辑 1. 设计哲学与用户体验核心 MusePublic Art Studio 的交互设计遵循"工具隐形,创作凸显"的理念。在AI图像生成领域,用户最需要的是流畅无阻的创作体验,而…...

松下A6BE伺服电机增益调整与振动抑制:如何通过自动调整功能提升系统稳定性
松下A6BE伺服电机增益调整与振动抑制实战指南 在工业自动化领域,伺服系统的稳定性直接影响着设备运行效率与产品质量。作为松下MINAS A6系列的核心产品,A6BE伺服电机凭借其实时自动调整和适应滤波器两大创新功能,为工程师提供了解决系统振动问…...

DAMO-YOLO在软件测试中的自动化视觉验证
DAMO-YOLO在软件测试中的自动化视觉验证 1. 引言 在软件测试领域,UI界面的视觉验证一直是个耗时耗力的环节。传统的测试方法需要人工检查每个界面元素的位置、大小、颜色和内容,不仅效率低下,还容易出错。随着软件迭代速度的加快࿰…...

黑丝空姐-造相Z-Turbo快速部署:5分钟搭建专属AI绘画服务
黑丝空姐-造相Z-Turbo快速部署:5分钟搭建专属AI绘画服务 1. 引言 想不想拥有一个能随时为你生成高质量“黑丝空姐”主题图片的AI助手?不用羡慕别人,也不用去排队等待在线服务,今天我就带你用5分钟时间,在自己的服务器…...

海森矩阵可视化教程:用Python画出二阶偏导数的几何意义
海森矩阵可视化教程:用Python画出二阶偏导数的几何意义 当你在优化一个机器学习模型的损失函数时,是否好奇过为什么有些优化路径会"卡住"?或者在训练神经网络时,为什么有些参数更新方向会突然变得不稳定?这些…...

Idea高效开发秘籍:从快捷键到性能优化全解析
1. 快捷键操作:指尖飞舞的代码艺术 第一次用Idea时,我被同事行云流水的操作惊呆了——他几乎不用鼠标,光靠键盘就能在几秒内完成类创建、方法跳转、代码重构。后来才发现,这都归功于精准的快捷键组合。比如用CtrlAltV提取变量时&a…...

Unity粒子系统碰撞检测实战:保持粒子物理属性的技巧
1. 为什么需要粒子碰撞但不受力? 在游戏开发中,粒子系统经常被用来模拟各种视觉效果,比如火焰、烟雾、魔法特效等。有时候我们需要粒子能够检测到碰撞,但又不希望碰撞影响粒子的运动轨迹。这种需求在以下场景特别常见:…...

为什么ESRGAN去掉BN层效果反而更好?深入解析网络设计中的取舍艺术
为什么ESRGAN去掉BN层效果反而更好?深入解析网络设计中的取舍艺术 在超分辨率重建领域,ESRGAN(Enhanced Super-Resolution Generative Adversarial Network)凭借其卓越的图像恢复质量成为业界标杆。但令人意外的是,这个…...