【面试长文】HashMap的数据结构和底层原理以及在JDK1.6、1.7和JDK8中的演变差异
文章目录
- HashMap的数据结构和底层原理以及在JDK1.6、1.7和JDK8中的演变差异
- HashMap的数据结构和原理
- JDK1.6、1.7和1.8中的HashMap源码演变
- JDK1.6
- JDK1.7
- JDK1.8
- 总结
- 自己实现一个简单的HashMap
- HashMap的时间复杂度分析
- HashMap的空间复杂度分析
- HashMap的应用场景
- HashMap的弊端及解决方案
- HashMap与HashSet的关系
- HashMap与 Hashtable的区别
- HashMap的长度为什么是2的幂次方
- JDK1.8对HashMap的优化
- HashMap的遍历方式
- HashMap的常见面试题
HashMap的数据结构和底层原理以及在JDK1.6、1.7和JDK8中的演变差异
这里是一篇关于HashMap的数据结构、底层原理和代码演变的技术博客:
HashMap的数据结构和原理
HashMap的数据结构采用“链表散列”结构,即一个链表和一个数组,数组称为hash table,链表成为链表数组。HashMap通过key的hashCode来计算index,然后将key-value对存放在hash table的对应位置。如果出现hash冲突,就将数据存放在链表中。HashMap主要由Node[] table、size和loadFactor三个字段组成。
- Node[] table:数组,默认大小为16,扩容时大小一般为原来的2倍。
- size:HashMap中键值对的数量。
- loadFactor:负载因子,默认为0.75。扩容条件是size大于loadFactor和table的长度的乘积。
获取数据的步骤:
-
计算key的hashCode,然后通过hashCode映射到table数组的index。
-
如果table的index位置没有数据,直接添加。
-
如果table的index位置有数据,查看key是equals()。如果equals,则覆盖旧值;如果不equals,进行加链表或树化操作。如果链表长度超过8,则转换为红黑树。
-
添加后,检查是否需要扩容。如果size超过loadFactor*table.length,进行扩容操作。扩容操作是创建一个新的table,新table的大小为旧table的2倍。
JDK1.6、1.7和1.8中的HashMap源码演变
JDK1.6
JDK1.6中的HashMap是非线程安全的,扩容使用synchronized来锁定整个table。
public V put(K key, V value) {// 扩容if (table == EMPTY_TABLE) {inflateTable(threshold);} else if (size >= threshold) {resize(2 * table.length);}// 如果key为null,存储在table[0]中if (key == null) {return putForNullKey(value); } // 计算key的hash值int hash = hash(key);int i = indexFor(hash, table.length);// 进行拉链操作for (Entry<K,V> e = table[i]; e != null; e = e.next) { Object k;// 如果key存在,则覆盖旧值 if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { V oldValue = e.value;e.value = value; return oldValue; }}// 添加新EntrymodCount++;addEntry(hash, key, value, i); return null;
}
JDK1.7
JDK1.7中的HashMap是非线程安全的,采用“链表+红黑树”的结构。当链表长度超过8时会将链表转换为红黑树。扩容时使用synchronized锁定table[0]和table[table.length-1]。
public V put(K key, V value) {// 扩容if (table == EMPTY_TABLE)inflateTable(threshold);// 如果key为null,存储在table[0]中 if (key == null) return putForNullKey(value);int hash = hash(key);// 找到对应的桶int i = indexFor(hash, table.length); // 先找出是否已经存在该key,如果存在则更新值并返回 for (Entry<K,V> e = table[i]; e != null; e = e.next) { if (e.hash == hash && eq(key, e.key)) { V oldValue = e.value; e.value = value; return oldValue; }} // 如果不存在,添加到链表尾部或树中 modCount++;addEntry(hash, key, value, i); // 确定是否需要扩容if (size >= threshold)resize(2 * table.length); return null;
}
JDK1.8
JDK1.8中HashMap是非线程安全的,默认采用"链表+红黑树"的结构,当链表长度超过8时会将链表转换为红黑树。
JDK1.8对扩容做了优化,不再锁定整个table,而是采用"synchronized+CAS"的方式来控制并发度。同时引入了红黑树,减少了链表过长的情况。
final V putVal(K key, V value, boolean onlyIfAbsent) { // 或获取 key 的 hash 值 int hash = spread(key.hashCode()); // 找到对应桶的索引 int i = indexFor(hash, table.length); // 链表或红黑树的节点 Node<K,V> p; boolean newEntry = true;// 如果桶中第一个节点为 TreeNode,则为红黑树结构 if ((p = tab[i]) == null) // CAS 控制并发,初始化首节点 tab[i] = newNode(hash, key, value, null); else { K k; // 如果键 hash 值和节点 hash 值相等,并且键 equals 节点键,则更新节点键值对 if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) // 更新节点值 p.val = value; else { // 判断是否是红黑树 if (p instanceof TreeNode) // 调用红黑树插入方法插入新节点 ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); else { // 若为链表,则插入链表尾部 for (int binCount = 0; ; ++binCount) { // 插入新节点到链表尾部 if (newEntry && binCount >= TREEIFY_THRESHOLD - 1) // 链表长度达 TREEIFY_THRESHOLD 则转化为红黑树treeifyBin(tab, hash); // 遍历至链表尾部,插入新节点 if (p.next == null) { p.next = newNode(hash, key, value, null); break; } p = p.next; } } } } // 判断是否需要扩容 if (++size > threshold) // 将容量扩大两倍 resize(); return onlyIfAbsent ? oldValue : null;
}
总结
通过HashMap的代码演变,我们可以看出:
- JDK1.8引入了红黑树,降低了链表过长的可能性,提高了效率。
- JDK1.8使用synchronized+CAS控制并发扩容,避免锁定整个table,提高了并发度。
- JDK1.8对null key做了优化,null键值对存储在table[0]位置。
- 三个版本的HashMap都采用链表散列结构,通过key的hashCode映射到table,如果hash冲突就采用链表存储。
- 扩容的阈值loadFactor在三个版本都是0.75,阈值size和table大小的乘积超过loadFactor时触发扩容。
自己实现一个简单的HashMap
- 定义Node节点,存储键值对和下一个节点的引用。
static class Node {int key;int value;Node next;public Node(int key, int value) {this.key = key;this.value = value;}
}
- 初始化HashMap,定义数组table的初始大小和加载因子loadFactor。
private static int CAPACITY = 16;
private static float LOAD_FACTOR = 0.75f;
private Node[] table;
private int size = 0;
- 计算key的hash值,然后通过hash值&(table.length - 1)确定其在数组中的位置。
private int hash(int key) {return key & (table.length - 1);
}
- 添加元素,先确定索引位置,如果不存在 hash 冲突则直接插入。如果存在 hash 冲突,则采用拉链法解决冲突。
public void put(int key, int value) {if (size >= LOAD_FACTOR * table.length) {// 进行扩容}int hash = hash(key);Node node = table[hash];if (node == null) {// 插入新节点,无hash冲突table[hash] = new Node(key, value);size++;} else {// 有hash冲突,采用拉链法解决Node pre = null; while (node != null) {if (node.key == key) {node.value = value;return;} pre = node;node = node.next;}// 插入新节点到链表尾部pre.next = new Node(key, value);size++;}
}
- 扩容机制,新table的大小为原来的2倍,并重新计算每个键值对的位置,迁移数据。
private void resize() {Node[] newTable = new Node[table.length * 2];for (Node node : table) {if (node != null) {Node next = null;while (node != null) { next = node.next; int hash = hash(node.key);if (newTable[hash] == null) { newTable[hash] = node; } else { Node n = newTable[hash]; while (n.next != null) n = n.next; n.next = node; } node = next; } } }table = newTable;
}
这就是一个简单的HashMap的实现,通过数组+链表实现“拉链法”解决哈希冲突。当链表长度过长时进行扩容,采用重新计算位置的方式迁移节点。
HashMap的时间复杂度分析
我们来分析一下HashMap的时间复杂度:
- 查找:
- 平均情况下,查找的时间复杂度为O(1)。因为我们可以通过hash值直接定位到数据所在的bucket,然后再通过key的equals方法判断是否命中。
- 最坏情况下,如果HashMap中所有键值对所hash得到的index都是同一个,此时查找的时间复杂度为O(n),需要遍历整个链表。但这种情况的概率很小,可以忽略。
- 添加:
- 平均情况下,添加的时间复杂度也为O(1)。和查找一样,可以通过hash值直接定位到数据所在的bucket,然后再插入。
- 最坏情况下,如果HashMap中所有键值对所hash得到的index都是同一个,此时添加的时间复杂度为O(n),需要遍历整个链表。但这种情况的概率很小,可以忽略。
- 删除:
- 平均情况下,删除的时间复杂度为O(1)。可以通过hash值直接定位到数据所在的bucket,然后再进行删除。
- 最坏情况下,如果要删除的键值对在链表的尾部,需要遍历整个链表,时间复杂度为O(n)。但这种情况概率也很小,可以忽略。
- 扩容:
- 扩容的时间复杂度为O(n),需要重新计算每个键值对的位置,然后迁移数据。但扩容操作很少发生,一般来说可以忽略扩容对时间复杂度的影响。
所以,总体来说,HashMap的时间复杂度可以看作O(1)。除非数据分布极不均匀,导致链表过长或频繁扩容,但这在实际使用中很少出现。HashMap之所以能达到O(1)的时间复杂度,主要得益于它采用的“拉链法”来解决哈希冲突。相比直接在数组中查找,拉链法大大减少了查找的时间复杂度。
HashMap的空间复杂度分析
空间复杂度主要取决于 HashMap 的容量(table的大小)和键值对的数量。
- 容量:HashMap的默认容量为16,之后每次扩容的时候容量都会翻倍。所以如果一共扩容了n次,HashMap的容量大小为16*(2^n)。
- 键值对数量:HashMap最大可以存储2^32个键值对。
所以:
- 如果键值对数量远远小于2^32,则空间复杂度可以看作O(n),n为扩容次数。
- 如果键值对数量接近上限232,则空间复杂度可以看作O(232)。
但由于扩容操作消耗性能,也会浪费一定的空间(相当于目前使用了容量的1/2),所以我们应该在初始化HashMap的时候就指定一个合适的容量,避免过多的扩容操作。
如果我们指定HashMap的初始容量,那么空间复杂度可以简单的分析如下:
- 指定初始容量为n,键值对数量为m,如果m<<n,则空间复杂度为O(n)。
- 如果m>n,又进行了k次扩容,则空间复杂度为O(n + 2^k)。
- 如果一共扩容了32次,达到上限,则空间复杂度为O(2^32)。
所以我们可以得出结论:
- 当键值对数量远小于初始容量时,空间复杂度可看作O(初始容量)。
- 当键值对数量接近HashMap的上限时,空间复杂度为O(2^32)。
- 其余情况下,空间复杂度介于O(初始容量)和O(2^32)之间。
因此,我们在初始化HashMap的时候,应该设置一个合适的初始容量,既不会造成过多扩容,也不会有太大的空间浪费,这需要根据实际场景来判断。
HashMap的应用场景
HashMap是Java中最常用的Map之一,它有以下主要应用场景:
- 缓存:HashMap是实现缓存机制的理想选择,因为它的时间复杂度为O(1),可以快速存取缓存数据。
- 大数据量的键值存储:HashMap是基于哈希表实现的,可以快速地完成大量键值对的存储和查找。
- 数据去重:我们可以把所有数据放入HashMap,然后判断put操作的返回值是否为null来判断该键值对是否已经存在,实现数据去重的功能。
- 数据搜索:我们可以把所有数据categorize到不同的HashMap中,这样可以通过键值快速搜索到所需的数据。例如,在leetcode第一次出现的问题可以存在一个HashMap,出现频率最高的10道题可以存在一个HashMap。这样我们就可以快速搜索到这两个信息。
- 保存在数据库中查重:在示例入库之前,可以先将数据放入HashMap,然后判断HashMap中是否已经存在该数据,如果存在则不入库,这样可以避免数据库中出现重复数据。
- 实现LRU缓存机制:我们可以使用HashMap与双向链表相结合的方式来实现LRU缓存机制。HashMap用来快速存取键值对,双向链表保证最近使用的节点靠近头部,这样我们就可以快速找到最近最少使用的节点进行删除。
class LRUCache {class Node {int key;int value;Node prev;Node next;}private HashMap<Integer, Node> map;private Node head;private Node tail;private int capacity;public LRUCache(int capacity) {this.capacity = capacity;map = new HashMap<>();}public int get(int key) {if (map.containsKey(key)) {// 如果key存在,先从链表中删除该节点Node node = map.get(key);removeFromList(node);// 然后重新插到头部addToHead(node);return node.value;} else {return -1;}}public void put(int key, int value) {if (map.containsKey(key)) {// 如果key已存在,先从链表中删除该节点Node node = map.get(key);removeFromList(node);} // 将新节点添加到头部Node node = new Node(key, value);addToHead(node);map.put(key, node);// 如果容量已满,删除链表尾部节点if (map.size() > capacity) {Node tail = removeTail();map.remove(tail.key);}}
}
这就是使用HashMap和双向链表实现的LRU缓存机制。我们利用HashMap的O(1)时间复杂度快速存取键值对,利用双向链表保证最近使用的数据靠近头部,这样在容量满的时候可以快速删除最近最少使用的节点。
HashMap的弊端及解决方案
HashMap也有一些弊端,主要包括:
- 线程不安全:HashMap是非线程安全的,在多线程环境下使用时需要外部同步机制来保证线程安全,这会影响性能。解决方案:可以使用ConcurrentHashMap,它是HashMap的线程安全版本,内部采用了锁分段技术来实现高度并发下的线程安全。
- 键值对顺序不保证:HashMap的键值对顺序是由hash值决定的,所以遍历HashMap时的顺序是不确定的。如果需要保证顺序,HashMap不太适用。解决方案:可以使用TreeMap,它是基于红黑树实现的,可以保证键值对的顺序。也可以使用LinkedHashMap,它是HashMap的子类,可以保证键值对的插入顺序。
- hash冲突:由于hash函数的局限性,不同的键可能会哈希到同一个位置,这种情况称为hash冲突。HashMap采用拉链法解决hash冲突,如果超出一定长度就会转化为红黑树,这样会消耗一定的时间和空间。解决方案:可以选择一个良好的hash函数来降低hash冲突的概率。也可以初始化HashMap的时候指定一个合理的容量,避免在容量过小的情况下就产生过多hash冲突。
- 空间占用可能很高:如果HashMap中的键值对数量远小于初始容量,就会造成空间的浪费。如果键值对数量不断增加,HashMap的空间占用会急剧上升(每次扩容为原来的2倍)。解决方案:初始化HashMap的时候指定一个合理的容量,既不会造成空间的浪费,也不会由于频繁扩容导致空间占用急剧上升。也可以使用ConcurrentHashMap,它的扩容机制可以避免空间的浪费。
- 键为null的问题:如果KeyValue中键为null,那么它会被存储在table[0]的bucket中,这会影响get和put的性能。解决方案:可以选择不允许null作为键,或者使用ConcurrentHashMap,它对null键进行了优化,不会影响性能。
综上,ConcurrentHashMap可以很好的解决HashMap的上述弊端,所以在高并发环境下,ConcurrentHashMap通常被用来替代HashMap。但当键值对数量较小,并发度不高的场景下,HashMap也是一种非常高效的数据结构。
HashMap与HashSet的关系
HashSet底层实际上是基于HashMap实现的。它使用HashMap的key来存储元素,value使用默认对象PRESENT。HashSet的主要方法底层实际上是调用的HashMap的方法。例如:
-
add(E e) -> put(e, PRESENT)
-
remove(E e) -> remove(e)
-
contains(E e) -> containsKey(e)
-
size() -> size()
-
isEmpty() -> isEmpty()
-
iterator() -> keySet().iterator()
所以我们可以总结:
-
HashSet底层使用HashMap来实现。
-
HashSet中的元素实际上被当作HashMap的键。
-
HashSet不允许存储重复元素,是由于HashMap的键也不允许重复导致的。
-
HashSet的迭代顺序取决于HashMap的键迭代顺序,这是不确定的。
-
HashSet不保证元素的顺序,这也是由HashMap决定的。
下面通过一个示例体现他们的关系:
HashSet<String> set = new HashSet<>();
set.add("a");
set.add("b");
set.add("c");HashMap<String, Object> map = (HashMap<String, Object>) set;
// map是 {a=PRESENT, b=PRESENT, c=PRESENT} // set和map的方法调用是相同的
set.remove("a");
map.remove("a");set.contains("b");
map.containsKey("b");set.size();
map.size();
从此示例可以很清楚的看出,HashSet仅仅是在HashMap上做了一层包装,它使用HashMap的键来存储元素,value使用默认的PRESENT对象。
所以每当我们调用HashSet的方法时,实际上都是在调用HashMap对应的方法,二者之间的关系十分密切。理解了HashSet和HashMap的关系,也就很容易理解HashSet的实现原理和工作机制了。所以这是一个比较重要的知识点,值得我们深入学习和理解。
HashMap与 Hashtable的区别
HashMap和Hashtable都是基于哈希表实现的Map,但是在实现上有一定的区别。主要区别如下:
- 线程安全性:HashMap是非线程安全的,Hashtable是线程安全的。Hashtable内部的方法基本都经过synchronized修饰,达到了线程安全。
- Null键和值:HashMap允许null键和null值,Hashtable不允许任何null键和null值。
- 容量和扩容:HashMap的默认初始容量是16,扩容时容量翻倍。Hashtable的默认初始容量是11,之后每次扩容时容量翻倍加1。
- 扩容方式:HashMap的扩容方式是在旧表中取值,Hashtable的扩容方式是创建一个新表,将旧表的值拷贝到新表中。HashMap的扩容方式更加高效。
- 迭代器:HashMap的迭代器是fail-fast的,而Hashtable的迭代器是fail-safe的。所以在遍历的时候,Hashtable更加适合高并发的场景。
- 底层数据结构:JDK1.8以前,HashMap和Hashtable的底层都采用数组+链表实现。JDK1.8后,HashMap采用了数组+链表+红黑树实现,Hashtable依然保持数组+链表。所以HashMap的性能优于Hashtable。
除了以上区别外,HashMap和Hashtable的方法使用方式基本相同,功能也基本相同。所以除非对线程安全有较高要求,否则更推荐使用HashMap来代替Hashtable。
下面通过一个示例来体现他们的一些区别:
// HashMap
HashMap<String, String> map = new HashMap<>();
map.put(null, null);
map.put("a", "a");
map.put(null, "b");// Hashtable
Hashtable<String, String> table = new Hashtable<>();
table.put("a", "a"); // OK
table.put(null, null); // java.lang.NullPointerException
table.put(null, "b"); // java.lang.NullPointerException
从示例可以看出HashMap允许null键null值,而Hashtable则抛出异常。这就是二者在这一点的重要区别。
所以总体来说,除非对线程安全有较高要求,HashMap在大多数情况下都优于Hashtable。Hashtable相比来说耗时耗空间,体现不出现代计算机异构计算能力。
HashMap的长度为什么是2的幂次方
HashMap的长度为什么要取2的幂(一般初始化为2的4次方16),这是因为:
- hash算法的最后一步通常是对表长length取模运算(hash%length),如果length是2的幂,那么length-1的二进制码全部为1,这种情况下取模运算等价于与运算(hash&(length-1)),与运算的效率高于取模运算。所以将长度定为2的幂可以提高hash寻址的效率。
- 如果存在大量hash冲突,链表会变得较长。如果表长为2的幂,容易通过二进制码与运算定位到冲突的链表,否则需要取模运算,效率较低。
- 扩容时,如果新表长仍然是2的幂,原来的hash值仍然有效。只需要将原来的hash值对新表长取与运算,就可以直接定位到数据位置。否则所有的hash值都需要重新hash,效率较低。
举个例子,假设当前HashMap的容量为16(10000),扩容后容量变为32(100000)。
如果是2的幂,只需要将原本的hash值(如11011)与新的表长-1(11111)做与运算(11011)。得到新的位置(11011)。如果不是2的幂,需要重新hash。
比如原来位置是hash%16=11,新位置应该是hash%32=19。这需要重新计算hash值,效率较低。
所以总结来说,HashMap的长度取2的幂主要出于3个方面的考虑:
- hash寻址的效率。
- 2的幂的length-1全部为1,适合用与运算代替取模运算。解决hash冲突时,容易通过与运算定位到冲突链表。
- 扩容时,可以通过与运算重新定位,无需全表rehash。
这也就是HashMap容量为什么要选用2的幂的原因了。这在一定程度上也提高了HashMap的性能,值得我们学习和理解。
JDK1.8对HashMap的优化
在JDK1.8之前,HashMap采用数组+链表实现,数组是HashMap的主体,链表则是解决哈希冲突的手段。
但是当链表长度过长时,HashMap的性能会受到比较大的影响。JDK1.8对这一点进行了优化,引入了红黑树。
当链表长度太长(默认超过8)时,链表就转化为红黑树,利用红黑树快速增删改查的特点提高HashMap的性能。
所以JDK1.8的HashMap底层采用数组+链表+红黑树实现,当链表长度不足8时仍然采用链表解决冲突,当链表长度超过8时转化为红黑树,这样既发挥了链表在冲突少的情况下性能高的优点,又利用了红黑树在冲突多的情况下性能高的优点。
tips: 其中红黑树的插入、删除、查找时间复杂度均为O(logN),效率很高。
除此之外,JDK1.8的HashMap还有其他优化:
- 引入红黑树之前,HashMap扩容是一个比较消耗性能的操作(rehash),JDK1.8在扩容时做了优化,不再像之前那样全部rehash,而是采用相对高效的方式进行rehash。
- JDK1.8的HashMap中,链表转红黑树会选择比较高的阈值(8),这样可以尽量减少红黑树结点过少导致性能不如链表的情况出现。
- JDK1.8的HashMap中,链表转红黑树和红黑树转链表都采取了较为高效的方式,而不是全部重新构建,这也提高了性能。
- JDK1.8的HashMap废除了原来的Entry对象,取而代之的是Node对象。其中,Node是一个泛型类。这也带来了一定的性能提高。
- …
通过以上几点优化,JDK1.8的HashMap在时间和空间两方面都取得较大提高。它既解决了之前版本在大容量和高冲突率下性能下降的问题,也不失在一般场景下的高性能,这也是它成为如今最主流的Map实现的原因。
所以如果你的程序需要支持JDK1.8以上的环境,强烈建议使用JDK1.8及之后的HashMap,这会让你的程序既高效又具有很好的拓展性。理解JDK1.8对HashMap的优化,也有助于我们更深入地理解HashMap这个数据结构。
HashMap的遍历方式
HashMap提供了几种方式遍历所有键值对:
- entrySet()遍历:通过HashMap.entrySet()获得key-value的Set集合,然后进行遍历。这是最常用的遍历方式。
HashMap<String, Integer> map = new HashMap<>();
for (Map.Entry<String, Integer> entry : map.entrySet()) {String key = entry.getKey();Integer value = entry.getValue();// do something
}
- keySet()遍历:通过HashMap.keySet()获得所有的key,然后通过get(key)获得对应的value。
HashMap<String, Integer> map = new HashMap<>();
for (String key : map.keySet()) {Integer value = map.get(key);// do something
}
- values()遍历:通过HashMap.values()获得所有的value,这种方式我们无法获取到key,只能遍历value。
HashMap<String, Integer> map = new HashMap<>();
for (Integer value : map.values()) {// do something
}
- 迭代器遍历:通过HashMap.entrySet().iterator()获取迭代器进行遍历。
HashMap<String, Integer> map = new HashMap<>();
Iterator<Map.Entry<String, Integer>> iter = map.entrySet().iterator();
while (iter.hasNext()) {Map.Entry<String, Integer> entry = iter.next();String key = entry.getKey();Integer value = entry.getValue();// do something
}
- Lambda表达式遍历(JDK1.8+):JDK1.8提供了Lambda表达式,使我们可以更简洁地遍历HashMap。
HashMap<String, Integer> map = new HashMap<>();
map.forEach((k, v) -> {// do something
});
以上就是HashMap提供的几种遍历方式,entrySet()方法是最常用的方式,我们在学习和使用HashMap时可以灵活运用这几种遍历方式。
需要注意的是,无论使用哪种遍历方式,遍历过程中如果对HashMap进行修改(增加、删除键值对),都有可能会产生 ConcurrentModificationException,这是因为遍历时使用的迭代器或是HashMap的快照,并不反映在遍历过程中对原HashMap的修改。
所以在遍历HashMap的过程中,如果对其进行修改,应该使用Iterator.remove()等保证迭代器稳定的方法,或者捕获ConcurrentModificationException并在catch块中进行相应处理。
HashMap的常见面试题
- HashMap的工作原理?HashMap底层采用哈希表实现,它包含数组+链表/红黑树的结构。HashMap会根据键的hashCode计算出对应的数组下标,如果发生哈希冲突,就将键值对存储在链表或者红黑树中。JDK1.8之前,HashMap采用数组+链表结构,1.8之后引入了红黑树来优化链表过长的情况。
- HashMap的底层实现?JDK1.8之前,HashMap底层采用数组+链表实现,数组是HashMap的主体,链表用来解决哈希冲突。JDK1.8引入了红黑树,当链表长度过长时会转化为红黑树,以提高性能。
- HashMap的扩容机制是什么?当HashMap中存储的键值对个数超过数组大小*加载因子时,HashMap会进行扩容操作。扩容时,容量会翻倍,并进行rehash操作。JDK1.8在扩容时做了优化,只对哈希值和扩容后的索引不等的键值对进行rehash。
- HashMap的线程安全性?HashMap是非线程安全的,在多线程环境下使用时需要外部同步机制来保证线程安全。 HashTable是线程安全的,内部的方法基本都加了synchronized关键字进行同步。如果需要考虑线程安全,建议使用ConcurrentHashMap。
- HashMap判断两个键值对相等的标准?HashMap判断两个键值对相等的标准是两个键的hashCode相等,并且两个键通过equals方法比较也返回true。hashCode相等表明两个键可能相等,但需要进一步通过equals方法确定。
- HashMap允许存放null键null值吗?HashMap允许存放null键和null值。当键为null时,会存储在数组的第0个位置。
- HashMap的初始容量大小是多少?加载因子是多少?HashMap的默认初始容量是16,加载因子是0.75。加载因子用来控制HashMap的空间利用率,过小会导致HashMap大小增加过快,而过大会导致链表过长。
以上是HashMap常见的一些面试题,我们在学习和使用HashMap的时候需要理解这些概念和机制,这也有助于我们在面试时回答问题。如果有不理解的地方可以再回过头来复习。
相关文章:

【面试长文】HashMap的数据结构和底层原理以及在JDK1.6、1.7和JDK8中的演变差异
文章目录 HashMap的数据结构和底层原理以及在JDK1.6、1.7和JDK8中的演变差异HashMap的数据结构和原理JDK1.6、1.7和1.8中的HashMap源码演变JDK1.6JDK1.7JDK1.8 总结自己实现一个简单的HashMapHashMap的时间复杂度分析HashMap的空间复杂度分析HashMap的应用场景HashMap的弊端及解…...
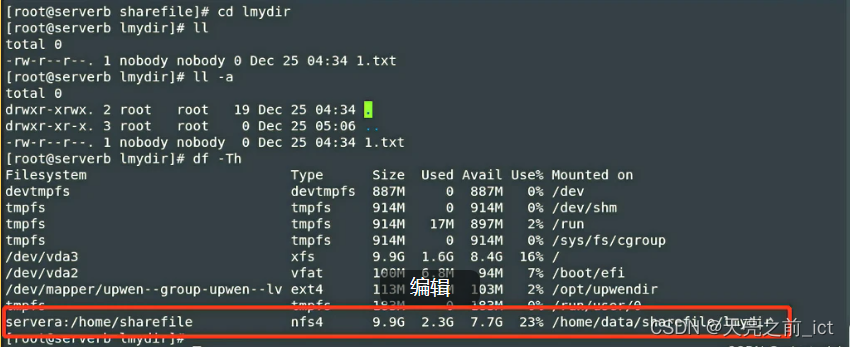
【25】linux进阶——网络文件系统NFS
大家好,这里是天亮之前ict,本人网络工程大三在读小学生,拥有锐捷的ie和红帽的ce认证。每天更新一个linux进阶的小知识,希望能提高自己的技术的同时,也可以帮助到大家 另外其它专栏请关注: 锐捷数通实验&…...

JAVA入坑之JAVADOC(Java API 文档生成器)与快速生成
目录 一、JAVADOC(Java API 文档生成器) 1.1概述 1.2Javadoc标签 1.3Javadoc命令 1.4用idea自带工具生成API帮助文档 二、IDEA如何生成get和set方法 三、常见快捷方式 3.1快速生成main函数 3.2快速生成println()语句 3.3快速生成for循环 3.4“…...
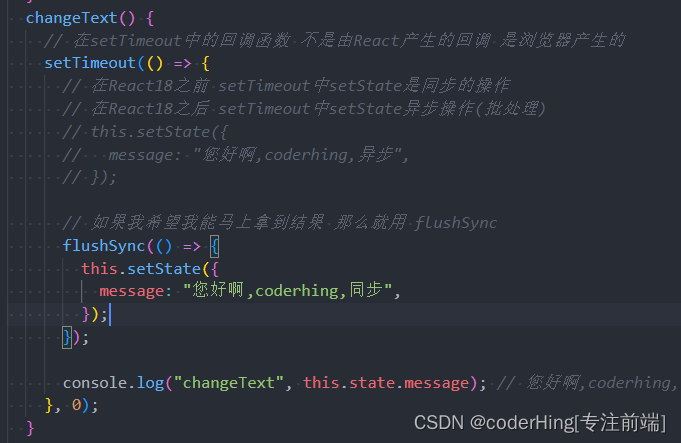
React | React组件化开发
✨ 个人主页:CoderHing 🖥️ React .js专栏:React .js React组件化开发 🙋♂️ 个人简介:一个不甘平庸的平凡人🍬 💫 系列专栏:吊打面试官系列 16天学会Vue 11天学会React Node…...

云计算的优势与未来发展趋势
一、前言二、云计算的基础概念2.1 云计算的定义2.2 云计算的发展历程2.3 云计算的基本架构2.4 云计算的主要服务模式 三、企业采用云计算的优势3.1 降低成本3.2 提高效率和灵活性3.3 提升信息系统的安全性和可靠性3.4 拥有更加丰富的应用和服务 四、行业应用案例4.1 金融行业4.…...

shell编程lesson01
命令行和脚本关系 命令行:单一shell命令,命令行中编写与执行; 脚本:众多shell命令组合成一个完成特定功能的程序,在脚本文件中进行编写维护。 脚本是一个文件,一个包含有一组命令的文件。 编写一个shel…...
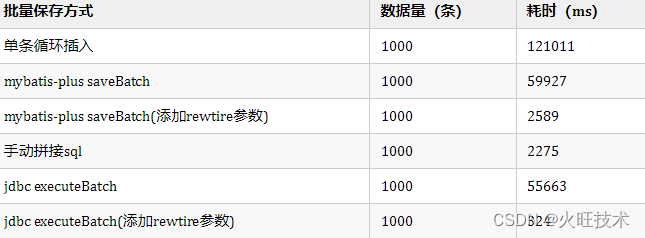
看看人家的MyBatis批量插入数据优化,从120s到2.5s,那叫一个优雅!
粗略的实验 最后 最近在压测一批接口的时候,我发现接口处理速度比我们预期的要慢。这让我感到有点奇怪,因为我们之前已经对这些接口进行了优化。但是,当我们进行排查时,发现问题出在数据库批量保存这块。 我们的项目使用了 myb…...

软件和信息服务业专题讲座
软件和信息服务业专题讲座 单选题(共 10 题,每题 3 分) 1、根据本讲,我国要加强物联网应用领域()开发和应用。 A、大数据 2、根据本讲,要充分发挥软件对城市管理和惠民服务的(&am…...
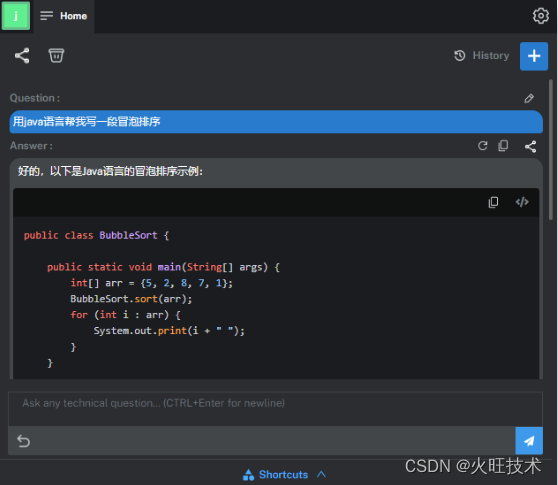
由 ChatGPT 团队开发,堪称辅助神器!IntelliJ IDEA 神级插件
什么是Bito? 为什么要使用Bito? 如何安装Bito插件 如何使用Bito插件 什么是Bito? Bito是一款由ChatGPT团队开发的IntelliJ IDEA编辑器插件,旨在提高开发人员的工作效率。此插件强大之处在于它不仅可以帮助开发人员更快地提交…...
spass modeler
课时1:SPSS Modeler 简介 本课时一共分为五个模块,分别是Modeler概述、工具安装、窗口说明以及功能介绍和应用案例。相信通过本课时内容的学习,大家将会对SPSS Modeler有个基础的了解. 在学习本节课内容之前,先来看看本节课我们究…...

kafka的push、pull分别有什么优缺点
文章目录 kafka的push、pull分别有什么优缺点Push 模式优点缺点 Pull 模式优点缺点 实践操作 kafka的push、pull分别有什么优缺点 Kafka 是由 Apache 软件基金会开发的一个开源流处理平台,广泛应用于各大互联网公司的消息系统中。在 Kafka 中,生产者使用…...

【Canvas入门】从零开始在Canvas上绘制简单的动画
这篇文章是观看HTML5 Canvas Tutorials for Beginners教程做的记录,所以代码和最后的效果比较相似,教程的内容主要关于这四个部分: 创建并设置尺寸添加元素让元素动起来与元素交互 设置Canvas的大小 获取到canvas并设置尺寸为当前窗口的大…...

【技术整合】各技术解决方案与对应解决的问题
文章目录 基本实现性能安全 本文将框架分为三大类: 基本实现:包括某个供能或者提供web、移动端、桌面端、或者上述端上的某种功能性能:提升高可用、高并发的框架安全:包括网络安全、权限与容灾等 基本实现 .NET CORE、.NET web基…...
公网远程访问公司内网象过河ERP系统「内网穿透」
文章目录 概述1.查看象过河服务端端口2.内网穿透3. 异地公网连接4. 固定公网地址4.1 保留一个固定TCP地址4.2 配置固定TCP地址 5. 使用固定地址连接 概述 ERP系统对于企业来说重要性不言而喻,不管是财务、生产、销售还是采购,都需要用到ERP系统来协助。…...

Win11的两个实用技巧系列之修改c盘大小方法、功能快捷键大全
Win11 c盘无法更改大小什么原因?Win11修改c盘大小方法 有不少朋友反应Win11 c盘无法更改大小是怎么回事?本文就为大家带来了详细的更改方法,需要的朋友一起看看吧 Win11 c卷无法更改大小什么原因?有用户电脑的系统盘空间太小了,…...

离散数学下--- 代数系统
代数系统 定义: 代数系统是用代数运算构造数学模型的方法。 • 通过构造手段生成,所以也称代数结构 • 代数运算:在集合上建立满足一定规则的运算系统 (一)二元运算 二元运算的定义 二元运算需要满足的两个条件&a…...

java基础入门-04
Java基础入门-04 11、集合&学生管理系统11.1.ArrayList集合和数组的优势对比:11.1.1 ArrayList类概述11.1.2 ArrayList类常用方法11.1.2.1 构造方法11.1.2.2 成员方法11.1.2.3 示例代码 11.1.3 ArrayList存储字符串并遍历11.1.3.1 案例需求11.1.3.2 代码实现 11…...

《面试1v1》java反射
我是 javapub,一名 Markdown 程序员从👨💻,八股文种子选手。 面试官: 你好,请问你对 Java 反射有了解吗? 候选人: 是的,我了解一些。 面试官: 那你能简单…...
【C语言】struct结构体
文章目录 一. 结构体简述二. 结构体的声明和定义1、简单地声明一个结构体和定义结构体变量2、声明结构体的同时也定义结构体变量3、匿名结构体4、配合typedef,声明结构体的同时为结构体取别名5、在声明匿名结构体时,使用typedef给这个匿名结构体取别名 三…...
Docker代码环境打包
1. 介绍 Docker是一种开源的容器化平台,它可以在操作系统级别运行应用程序。通过将应用程序及其依赖项封装成一个可移植的容器,Docker使得应用程序可以在任何环境中轻松部署、运行和管理。使用Docker,开发人员可以避免在不同环境中出现的配置…...
)
Stata实战:5分钟搞定熵权法计算(附完整代码与避坑指南)
Stata熵权法极简实战:从数据清洗到权重生成的全流程解析 熵权法作为客观赋权的重要工具,在学术研究和商业分析中广泛应用。但许多用户在Stata实现过程中常陷入代码报错、指标处理不当等困境。本文将用最简洁的代码演示完整流程,并分享三个关键…...

Ubuntu双系统安装失败?天选5Pro的Intel RST问题全解析
天选5Pro双系统安装困境:Intel RST技术原理与实战解决方案 当技术爱好者们满怀期待地在新购置的天选5Pro笔记本上尝试安装Ubuntu双系统时,往往会遭遇一个令人困惑的障碍——安装程序无法识别磁盘设备。这个看似简单的硬件兼容性问题背后,实际…...
)
Python 3.9环境下dlib库安装全攻略:从依赖配置到离线安装(附国内镜像源)
Python 3.9环境下dlib库高效安装指南:避坑实践与性能优化 在计算机视觉和机器学习领域,dlib库以其强大的人脸识别和特征检测功能而闻名。然而,许多开发者在Python 3.9环境下安装dlib时,往往会遇到各种棘手的依赖问题和编译错误。…...
)
YOLOv8实战:5种IoU损失函数调参指南(附最新代码适配技巧)
YOLOv8实战:5种IoU损失函数调参指南(附最新代码适配技巧) 目标检测模型的性能优化一直是算法工程师关注的核心问题,而IoU(Intersection over Union)损失函数的选择直接影响模型的收敛速度和检测精度。本文将…...

医学图像分割的“降维打击”:手把手教你用FreMIM的前景掩码策略,告别无效背景干扰
医学图像分割的“降维打击”:手把手教你用FreMIM的前景掩码策略,告别无效背景干扰 在医学影像分析领域,数据标注成本高、模型训练效率低一直是困扰开发者的两大痛点。一张典型的CT或MRI图像中,病灶区域可能只占全图的5%不到&#…...

Pycharm 2023.3 + Pandas 2.0:解决数据预览‘三点’困扰的保姆级配置指南
PyCharm 2023.3 Pandas 2.0:数据科学家的显示优化实战手册 当你面对一个包含50列的数据集时,是否经常遇到这样的困扰——PyCharm的DataFrame预览窗口只显示前10列和后10列,中间30列被无情地替换为那三个令人沮丧的点?更糟糕的是&…...

Socket.IO性能优化全攻略:从负载均衡到监控调试
Socket.IO性能优化全攻略:从负载均衡到监控调试 在当今高度互联的数字世界中,实时通信已成为企业级应用的标配需求。无论是金融交易平台的毫秒级数据更新,还是大型多人在线游戏的即时互动,都对系统的并发处理能力提出了严苛要求。…...
)
5分钟搞定Ollama本地大模型:用LiteLLM实现OpenAI API无缝兼容(附完整代码)
5分钟实现Ollama本地大模型与OpenAI API无缝兼容的终极方案 当开发者需要将现有基于OpenAI API的项目迁移到本地大模型时,往往面临接口不兼容、代码重构成本高等痛点。本文将介绍如何利用LiteLLM这一轻量级代理工具,在5分钟内完成从Ollama本地模型部署到…...

FFmpeg硬件编解码实战:C++跨平台性能调优与疑难解析
1. 为什么需要硬件编解码? 第一次用FFmpeg做视频转码时,我盯着CPU占用率飙到100%的风扇狂转的笔记本,突然理解了为什么需要硬件加速。当时处理一段4K视频,软件编码花了整整40分钟,而换成NVIDIA显卡的NVENC后࿰…...
)
Windows 效率翻倍!PowerToys 这5个隐藏功能90%的人没用过(附详细配置指南)
Windows 效率革命:PowerToys 高阶玩家完全指南 1. 从工具集到生产力中枢的蜕变 当微软在2019年宣布重启PowerToys项目时,很少有人能预料到这个曾经的小工具合集会成长为Windows生态中最强大的效率增强套件。如今,这个开源项目已经整合了超过…...