【大数据面试题大全】大数据真实面试题(持续更新)
【大数据面试题大全】大数据真实面试题(持续更新)
- 1)Java
- 1.1.Java 中的集合
- 1.2.Java 中的多线程如何实现
- 1.3.Java 中的 JavaBean 怎么进行去重
- 1.4.Java 中 == 和 equals 有什么区别
- 1.5.Java 中的任务定时调度器
- 2)SQL
- 2.1.SQL 中的聚合函数
- 2.2.SQL 中的各种 join 与区别
- 2.3.简单说一下 MySQL 中的数据结构
- 2.4.关系型数据库和大数据组件中的 nosql 数据库有什么区别
- 3)Linux
- 4)Hadoop
- 4.1.Yarn
- 4.1.1.Yarn 提交作业流程
- 4.1.2.Yarn 的资源调度
- 4.1.3.Yarn 成员
- 4.2.HDFS
- 4.2.1.HDFS 读写流程
- 4.2.2.HDFS 中小文件过多会有什么影响
- 4.2.3.HDFS 中小文件过多怎么处理
- 4.2.4.HDFS 成员
- 4.2.5.NameNode 和 SecondaryNameNode 的区别与联系
- 4.2.6.HDFS 中 Fsimage 与 Edits 详解
- 4.3.MapReduce
- 4.3.1.map 阶段的工作机制
- 4.3.2.reduce 阶段的工作机制
- 4.3.3.MR 的优劣
- 4.3.4.MR 的相关配置
- 5)Hive
- 5.1.Hive 相关数据的存储位置
- 5.2.Hive 内外表的区别
- 5.3.Hive 如何实现分区
- 5.4.Hive 装载数据
- 5.5.Hive 修复分区数据
- 5.6.Hive 中的排序方式及对比
- 5.7.row_number()、rank()、dense_rank() 的区别:
- 5.8.Hive 如何实现数据的导入和导出
- 5.9.Hive 中 over() 的使用
- 6)Sqoop
- 6.1.Sqoop 常用命令
- 6.2.Sqoop 如何进行空值处理
- 6.3.Sqoop 如何处理特殊字符
- 6.4.Sqoop 任务有 reduce 阶段吗
- 7)Oozie
- 8)Azkaban
- 9)Flume
- 9.1.Flume 的架构组件
- 9.2.Flume 的多种架构
- 9.3.Flume 的相关配置
- 10)Kafka
- 10.1.Kafka为什么这么快
- 10.2.Kafka 怎么避免重复消费
- 10.3.Kafka 怎么保证顺序消费
- 10.4.Kafka 分区有什么作用
- 10.5.Kafka 如何保证数据不丢失
- 10.6.消费者与消费者组之间的关系
- 10.7.Kafka 架构及基本原理
- 11)HBase
- 11.1.HBase 的架构组成
- 11.2.HBase 的读写流程
- 11.3.HBase 中 rowkey 的设计
- 11.4.Region 的分区和预分区
- 11.5.HBase 优缺点
1)Java
作为目前最火爆的开发语言,使用Java已经是大数据开发者的基本技能,很多大数据组件也适用于Java开发,如:Flink
1.1.Java 中的集合
【Java-Java集合】Java集合详解与区别
1.2.Java 中的多线程如何实现
1、继承Thread类。
2、实现Runnable接口。
3、实现Callable接口。
4、线程池:提供了一个线程队列,队列中保存着所有等待状态的线程。避免了创建与销毁额外开销,提高了响应的速度。
详细:https://www.cnblogs.com/big-keyboard/p/16813151.html
1.3.Java 中的 JavaBean 怎么进行去重
1、利用 HashSet,泛型指定我们创建好的 JavaBean,通过 hashSet 中的 add() 方法,进行去重。
public static void main(String[] args) {Date date=new Date();//获取创建好的javaBean对象并进行赋值JavaBean t1 = new JavaBean();t1.setLat("121");t1.setLon("30");t1.setMmsi("11");t1.setUpdateTime(date);//再创建一个javaBean对象,赋同样的值 JavaBean t2=new JavaBean();t2.setLat("121");t2.setLon("30");t2.setMmsi("11");t2.setUpdateTime(date);//用HashSetHashSet<JavaBean> hashSet = new HashSet<JavaBean>(); hashSet.add(t1); hashSet.add(t2); System.out.println(hashSet); System.out.println();for(JavaBean t:hashSet){ //只会出现一个值System.out.println(t);
}
2、利用 ArrayList,泛型指定我们创建好的 javaBean,通过 ArrayList 中的 contain() 方法进行判断后去重。
//用List
List<TestMain18> lists = new ArrayList<TestMain18>();if(!lists.contains(t1)){lists.add(0, t1);}if(!lists.contains(t2)){//重写equalslists.add(0, t2);}
System.out.println("长度:"+lists.size());
1.4.Java 中 == 和 equals 有什么区别
==用来判断对象在内存中的地址是否相等,equals用来判断对象中的内容是否相等。
1.5.Java 中的任务定时调度器
1、Timer timer = new Timer() timer.schedule(重写 new TimerTask 方法)
//方式1:
Timer timer = new Timer();
//TimerTask task, 要定时执行的任务
//long delay,延迟多久开始执行
//long period,每隔多久执行延迟
timer.schedule(new TimerTask() {@Overridepublic void run() {System.out.println("每隔1s执行一次");}
}, 5000,1000 );*/
2、Executors.newScheduleThreadPool(线程池数量)返回的对象 scheduleAtFixeRate,重写 run 方法。
//方式2:
ScheduledExecutorService executorService = Executors.newScheduledThreadPool(3);
executorService.scheduleAtFixedRate(new Runnable() {@Overridepublic void run() {System.out.println("每隔1s执行一次");}
},5,1, TimeUnit.SECONDS);
3、SprintBoot 中提供了定时任务的相关注解,使用起来特别方便,利用corn定义触发的规则。
@Component//表示该类是Spring的组件,会由Spring创建并管理
@EnableScheduling//表示开启定时任务扫描
public class TestTimedTask2 {//https://cron.qqe2.com/@Scheduled(cron = "0/3 * * * * ? ")public void task(){System.out.println("每隔3s执行一次");}
}
2)SQL
SQL 作为计算机行业最基本的语言之一,也是必须要了解的。
2.1.SQL 中的聚合函数
avg(),max(),min(),sum(),count() 等
注意:
聚合函数不会自己使用,也不会和 where 一起使用,一般使用的时候都是和 group by 一起使用(分组必聚合),还有就是在 having 语句后面进行使用。
2.2.SQL 中的各种 join 与区别
inner join(内连接):就是找到两个表中的交集。
left join(左外连接):以左边的表为主,如果没有与右边的表相对应的用 null 补充在表中。
right join(右外连接):以右边的表为主,同上。
full join(满外连接):Hive 中特有的,MySQL 中没有,保留两边的表的所有内容,没有对应的互相都用 null 补充在表中。
2.3.简单说一下 MySQL 中的数据结构
MySQL的数据结构为 B + 树
【计算机基本原理-数据结构】八大数据结构分类
【计算机基本原理-数据结构】数据结构中树的详解
2.4.关系型数据库和大数据组件中的 nosql 数据库有什么区别
1、关系型数据库的特点:
-
结构化的存储
-
采用结构化的查询语言sql
-
操作数据要具有一致性,比如事务操作
-
可以进行join等复杂查询
-
无法进行大量数据的高并发读写
2、nosql数据库的特点:
-
非结构化的数据库
-
高并发大数据下读写能力强
-
事务性差
-
join 的复杂操作能力弱
3)Linux
在大数据环境安装部署、提交 jar 包的时候,都会应用到 Linux 操作系统,所以了解需要了解 Linux 常用命令。
【Linux-Linux常用命令】Linux常用命令总结
4)Hadoop
4.1.Yarn
4.1.1.Yarn 提交作业流程
1、由客户端向 RM 提交任务(MR,Spark…)
2、RM 接收任务,并根据任务随机找一台NM,启动 AppMaster,通知以 container 方式。
container:资源信息容器(节点信息,内存信息,CPU信息),运行:AppMaster
3、指定 NM 启动 AppMaster,启动后和 RM 保持心跳机制,用于报告当前已经启动了,并且通过心跳来传递相关信息。
4、根据 RM 给定任务信息,根据任务信息,对任务进行分配,主要会分配出要启动多少个 map 和多少个 reduce,以及每个 map 和每个 reduce 需要使用多大资源空间,然后将资源申请相关信息发送给 RM(心跳发送)
5、RM 接收到资源申请信息后,将申请信息交给内部资源调度器,由资源调度器,根据相关的资源调度方案,进行资源分配即可,如果当下没有资源,在此处等待。
注意:
资源并不是一次性全部给到 AppMaster,一般会采用极可能满足方案,如果满足不了,会先给与一定资源进行运行,如果空闲资源连一个 container 都不足,就会将这些资源挂起,等待资源充足。
6、AppMaster 基于心跳机制,不断询问RM是否已经准备好了资源了,如果发现已经准备好了,然后直接将资源信息获取。
7、根据资源信息说明,到指定的 NM 上启动 container 资源容器,开始运行相关任务。
8、NM 接收启动的信息后,开始启动执行,此时会和 AppMaster 以及 RM 保持心跳连接。
RM 将任务的相关信息根据心跳通知 AppMaster
AppMaster 将资源的使用信息根据心跳通知 RM
9、当 NM 运行完成后,会通知 AppMaster 并将资源使用完成情况通知给 RM。
10、AppMaster 告知给 RM 任务已经运行完成了, RM 回收资源,通知AppMaster进行自毁即可。
注意:
当 NM 在运行过程中,如果发生错误了,此时 RM 会立即将资源回收,此时 AppMaster 就需要重新和 RM 申请资源。
详情:【Hadoop-Yarn】Yarn 的运行流程
4.1.2.Yarn 的资源调度
1、FIFO scheduler :先进先出调度方案
当一个调度任务进入到调度器之后,那么调度器会优先满足第一个MR任务全部资源,此时就有可能将资源全部都获取到了,导致后续的任务本身的运行时间很短,但是由于第一个MR将资源全部抢走了, 导致后续任务全部等待。
此种调度器在生产中 一般不会使用,因为生产中yarn平台不是你自己的。
2、Fair scheduler:公平调度器
可以预先分配出多个队列, 相当于对资源进行预先的划分。
3、capacity scheduler:容量调度器
此种调度器是有 Yahoo 提供一种调度方案,同时也是当下Apache版本的hadoop默认调度方案。每个队列,可以指定占用多少的百分比的资源,从而保证,大的任务可以有单独的队列来运行,并且小的任务,也可以正常的运行。
4.1.3.Yarn 成员
clustermanager、nodemanager、applicationmaster。
4.2.HDFS
4.2.1.HDFS 读写流程
【Hadoop-HDFS】HDFS的读写流程 & SNN的数据写入流程
4.2.2.HDFS 中小文件过多会有什么影响
HDFS 擅长存储大文件,我们知道,HDFS 中每个文件都有各自的元数据信息,如果 HDFS 中有大量的小文件,就会导致元数据爆炸,集群管理的元数据的内存压力会非常大(namenode 节点)
4.2.3.HDFS 中小文件过多怎么处理
1、使用官方工具 parquet-tools 合并指定的 parquet 文件。
# 合并 HDFS 上的 parquet 文件
hadoop jar parquet-tools-1.9.0.jar merge /tmp/a.parquet /tmp/b.parquet
# 合并本地的 parquet 文件
java -jar parquet-tools-1.9.0.jar merge /tmp/a.parquet /tmp/b.parquet
2、合并本地的小文件,上传到 HDFS(通过 HDFS 客户端的 appendToFile 命令对小文件进行合并上传)
hdfs dfs -appendToFile user1.txt user2.txt /test/upload/merged_user.txt
3、合并 HDFS 的小文件,下载到本地,可以通过 HDFS 客户端的 getmerge 命令,将很多小文件合并成一个大文件,然后下载到本地,最后重新上传至 HDFS。
hdfs dfs -getmerge /test/upload/user*.txt ./merged_user.txt
4、Hadoop Archives (HAR files)是在 0.18.0 版本中引入到 HDFS 中的,它的出现就是为了缓解大量小文件消耗 NameNode 内存的问题。
HAR 文件是通过在 HDFS 上构建一个分层文件系统来工作。HAR 文件通过 hadoop archive 命令来创建,而这个命令实际上是运行 MapReduce 作业来将小文件打包成少量的 HDFS 文件(将小文件进行合并成几个大文件)
# Usage: hadoop archive -archiveName name -p <parent> <src> <dest>
# har命令说明
# 参数 “-p” 为 src path 的前缀,src 可以写多个 path
# 归档文件:
hadoop archive -archiveName m3_monitor.har -p /tmp/test/archive_test/m3_monitor/20220809 /tmp/test/archive# 删除数据源目录:
hdfs dfs -rm -r /tmp/test/archive_test/m3_monitor/20220809
# 查看归档文件:
hdfs dfs -ls -R har:///tmp/test/archive/m3_monitor.har
# 解归档:将归档文件内容拷贝到另一个目录
hdfs dfs -cp har:///tmp/test/archive/m3_monitor.har/part-1-7.gz /tmp/test/
4.2.4.HDFS 成员
namenode、datanode、secondarynamenode;namenode 有 active 和 standby。
4.2.5.NameNode 和 SecondaryNameNode 的区别与联系
SecondaryNameNode 并不是 NameNode 的备份节点,主要是将内存中的 Fsimage 和磁盘上的 Fsimage 文件进行合并。
4.2.6.HDFS 中 Fsimage 与 Edits 详解
【Hadoop-HDFS】HDFS中Fsimage与Edits详解
4.3.MapReduce
4.3.1.map 阶段的工作机制
【Hadoop-MapReduce】MapReduce编程步骤及工作原理(详见标题4:map 阶段的工作机制)
4.3.2.reduce 阶段的工作机制
【Hadoop-MapReduce】MapReduce编程步骤及工作原理(详见标题5:reduce 阶段的工作机制)
4.3.3.MR 的优劣
不管是 map 阶段还是 reduce 阶段,大量进行磁盘到内存,内存到磁盘相关的 IO 操作,主要目的能够解决处理海量数据计算问题。
-
带来好处:能够处理海量的数据。
-
带来的弊端:造成大量的磁盘 IO 工作导致效率比较低。
4.3.4.MR 的相关配置
| 配置 | 默认值 | 释义 |
|---|---|---|
| mapreduce.task.io.sort.mb | 100 | 设置环型缓冲区的内存值大小 |
| mapreduce.map.sort.spill.percent | 0.8 | 设置溢写的比例 |
| mapreduce.cluster.local.dir | ${hadoop.tmp.dir}/mapred/local | 溢写数据目录 |
| mapreduce.task.io.sort.factor | 10 | 设置一次合并多少个溢写文件 |
5)Hive
5.1.Hive 相关数据的存储位置
Hive 的元数据存储在mysql中(默认derby,不支持多客户端访问),数据存储在 HDFS,执行引擎为 MR。
5.2.Hive 内外表的区别
1、建表时用 external 区分。
2、删除外表时删除元数据,删除内表是删除的是元数据和存储数据。
3、外表存储位置自己定,内表存储位置在 /uer/hive/warehouse 中。
5.3.Hive 如何实现分区
1、创建表时指定字段进行分区。
2、使用 alter table 对已经创建完成的表进行分区的增加和删除操作。
# 建表:
create table tablename(col1 string) partitioned by(col2 string);
# 添加分区:
alter table tablename add partition(col2=’202101’);
# 删除分区:
alter table tablename drop partition(col2=’202101’);
3、修改分区。
alter table db.tablename
set location '/warehouse/tablespace/external/hive/test.db/tablename'
5.4.Hive 装载数据
alter table db.tablename add if not exists partition (sample_date='20220102',partition_name='r') location '/tmp/db/tablename/sample_date=20220102/partition_name=r';
5.5.Hive 修复分区数据
msck repair table test;
5.6.Hive 中的排序方式及对比
1、Hive 中的排序方式有:order by,sort by,distribute by,cluster by
2、四种排序方式的区别:
-
order by: 对数据进行全局排序,只有一个 reduce 工作 -
sort by: 一般和 distribute by 一起使用,当 task 为 1 时效果和 order by 一样 -
distribute by: 对 key 进行分区,和 sort by 一起实现对分区内数据的排序工作 -
cluster by: 当 order by 和 distribute by 的字段相同时可以用 cluster by 代替,但是只能升序
注意:
生产环境中使用 sort by 比较少,容易造成 oom,使用 sort by 和 distribute by 较多。
5.7.row_number()、rank()、dense_rank() 的区别:
三者都是对数据进行标号排序
-
row_number():不会出现序号的增加或减少,当数值相同时也会有排名先后之分 -
rank():当排序相同时序号重复,总序不会变化 -
dense_rank():当排序相同时序号重复,总序会减少
5.8.Hive 如何实现数据的导入和导出
-
导入数据:
① load data 的方式可以对本地或HDFS上的数据进行导入
② Location方式
create external if not exists stu2 like student location '/user/hive/warehouse/student/student.txt';③ sqoop方式
-
导出数据:一般用sqoop方式
5.9.Hive 中 over() 的使用
6)Sqoop
6.1.Sqoop 常用命令
【Sqoop-命令】Sqoop相关了解及命令
6.2.Sqoop 如何进行空值处理
导出数据时采用 --input-null-string 和 --input-null-non-string 两个参数。
导入数据时采用 --null-string 和 --null-non-string。
6.3.Sqoop 如何处理特殊字符
Sqoop 中遇到特殊字符可以使用 hive-drop-import-delims 丢弃,也可以使用 --hive-delims-replacement,它会将特殊字符替换为我们设定的字符。
6.4.Sqoop 任务有 reduce 阶段吗
只有 map 阶段,没有 reduce 阶段的任务。默认是 4 个 MapTask。
7)Oozie
1、Oozie 一般不单独使用,因为需要配置 xml 文件很麻烦。
2、Oozie 一般与 Hue 一起使用,可以调度各种任务比如 Shell,MR,Hive等。
3、无论是单独使用还是与 Hue 集成,Oozie中最重要的点都在于 workflow 的配置。
4、与 Hue 整合时在 Schedule 中配置定时任务的时间,在 workflow 中配置任务的相关位置信息。
8)Azkaban
1、元数据存储在 Mysql 中。
2、有三种部署模式: solo-server(所有服务在一台服务器上), tow-server(web,executor在不同服务器上),multiple-executor-server(一般不常用)。
3、azkaban的任务调度:
-
Hive脚本: test.sql
use default; drop table aztest; create table aztest(id int,name string) row format delimited fields terminated by ','; load data inpath '/aztest/hiveinput' into table aztest;c reate table azres as select * from aztest;insert overwrite directory '/aztest/hiveoutput' select count(1) from aztest; -
hive.job(名称.job)
type=command #固定 dependencies=xx #有依赖的任务的时候添加这个 command=/home/hadoop/apps/hive/bin/hive -f 'test.sql' -
将所有文件打包成 zip 包上传到 Azkaban 上,然后点击 summary,然后选择 schedule 进行时间的配置。
9)Flume
Flume 是一个用来实时采集流数据的分布式数据采集系统,容错性强,可靠性高。
9.1.Flume 的架构组件
(source,channel,sink)
1、Flume 中的 agent:包含 source,channel,sink 的统称。
2、source:是用来采集数据的组件,可以监控一个文件的变化,可以监控一个目录下新文件的变化,可以监控一个目录下所有文件的内容变化,也可以自定义数据源,在配置的时候要配置 source 的名称。
3、channnel:可以配置两种方式进行数据的缓存,一种是内存,另一种是以生成文件的方式。
4、sink:支持 HDFS,Kafka,自定义目标源等,还可以支持下一个 agent。
5、event:Flume 将采集到的数据封装到 event 中进行传输,本质上是一个字节数组。
9.2.Flume 的多种架构
1、Flume 可以以 agent 的方式进行串联。
2、Flume 可以并联,将多个 agent 的 sink 传输到新的 agent 的 source 中。
3、Flume 可以 串联+并联+多sink 等。
9.3.Flume 的相关配置
1、source,channel,sink 的名称。
2、channel 是基于内存还是基于文件。
3、sink 对应的 channel。
4、sink 到 kafka 的话要配置 kafka 的 topic,端口号,ack 等。
10)Kafka
10.1.Kafka为什么这么快
1、查询速度快
-
分区,文件分段。
-
二分查找法定位消息在哪个段(文件)中。
2、写入速度快
-
顺序写入。
-
零拷贝:数据直接从磁盘文件复制到网卡设备中,不需要经过应用程序之手。零拷贝技术通过 DMA 技术,将文件内容复制到内核模式下的 ReadBuffer,直接将数据内核的数据传递到网卡设备中,所以零拷贝是针对于内核,数据再内核模式下实现了零拷贝。
-
批量发送:通过 batch.size 参数来设置批量提交数据的大小,默认是16K,当数据积压到这一值时就会统一发送,数据会发送到一个分区中。
-
数据压缩:Producer 端压缩,Broker 端保持,Consumer 端解压缩。
10.2.Kafka 怎么避免重复消费
可以利用两阶段事务提交(Flink)或者容器去重(HashSet,Redis,布隆过滤器)
10.3.Kafka 怎么保证顺序消费
Kafka 是全局无序但是局部有序,只要我们在推送消息的时候都推送到同一个分区,消费时也指定一个分区消费即可。
10.4.Kafka 分区有什么作用
提升读写效率 + 方便集群扩容 + 消费者负载均衡
10.5.Kafka 如何保证数据不丢失
1、生产者端,设置 ack(0、1、-1 / all)
0:生产者端不会等到 Broker 端返回 ack,继续生产数据。
1:当 Broker 中的 Leader 端收到数据就返回 ack。
-1 / all:当 Broker 中的 Leader 和 所有的Follower 都接收到数据才返回 ack。
2、消费者端,采用先消费后提交的方式,宁愿重复消费也不能让数据丢失。
3、Broker 端:有副本机制保证数据安全性。
10.6.消费者与消费者组之间的关系
同一时间一条消息,只能被同一个消费者组的一个消费者消费,不能被同一个消费者组的其他消费者消费。但是可以被不同消费者的消费者组所消费。
10.7.Kafka 架构及基本原理
【Kafka-架构及基本原理】Kafka生产者、消费者、Broker原理解析 & Kafka原理流程图
11)HBase
11.1.HBase 的架构组成
-
HMaster
-
HRegionServer
-
Region
-
zookeeper
HBase:Client -> Zookeeper -> HRegionServer -> HLog -> Region -> store -> memorystore -> storeFile -> HFile
11.2.HBase 的读写流程
【HBase-读写流程】HBase的读写流程与内部执行机制
11.3.HBase 中 rowkey 的设计
-
Hash
-
时间戳倒转
11.4.Region 的分区和预分区
-
HBase 在创建表的时候可以指定预分区规则。
-
HBase 建表后和可以通过 split 命令进行分区的更改。
-
HBase 也可以再建表的时候通过 split.txt 文件中的信息通过 SPLIT_FILE 命令进行预分区。
11.5.HBase 优缺点
-
优点:
-
支持非结构化数据的存储
-
相对于关系型数据库HBase采用列式存储,写入的效率很快
-
HBase中的null值不会被记录在内,节省空间并提高了读写性能
-
支持高并发的读写
-
支持大量数据的存储工作
-
-
缺点:
-
本身并不支持sql查询
-
不适合大范围的扫描查询
-
相关文章:
)
【大数据面试题大全】大数据真实面试题(持续更新)
【大数据面试题大全】大数据真实面试题(持续更新) 1)Java1.1.Java 中的集合1.2.Java 中的多线程如何实现1.3.Java 中的 JavaBean 怎么进行去重1.4.Java 中 和 equals 有什么区别1.5.Java 中的任务定时调度器 2)SQL2.1.SQL 中的聚…...

Linux [常见指令 (1)]
Linux常见指令 ⑴ 1. 操作系统1.1什么事操作系统1.2选择指令的原因 2.使用工具3.Linux的指令操作3.1mkdir指令描述:用法:例子 mkdir 目录名例子 mkdir -p 目录1/ 目录2/ 目录3 3.2 touch指令描述:用法:例子 touch 文件 3.2pwd指令描述:用法:例子 pwd 3.4cd指令描述:用法:例子 c…...
进程控制下篇
进程控制下篇 1.进程创建 1.1认识fork / vfork 在linux中fork函数时非常重要的函数,它从已存在进程中创建一个新进程。新进程为子进程,而原进程为父进程 #include<unistd.h> int main() {pid_t i fork;return 0; }当前进程调用fork,…...

PS学习笔记(零基础PS学习教程)
很多新手学习PS不知从何下手,做设计的第一阶段肯定是打牢基础,把工具用熟练;本期特别为大家整理了PS入门的学习笔记,把每个工具的用法整理了下来,在使用过程中有哪里不清楚的可以翻看来看看~ 一、ps的工作界面的介绍 …...

如何构建数据血缘系统
1、明确需求,确定边界 在进行血缘系统构建之前,需要进行需求调研,明确血缘系统的主要功能,从而确定血缘系统的最细节点粒度,实体边界范围。 例如节点粒度是否需要精确到字段级,或是表级。一般来说&#x…...

IPsec中IKE与ISAKMP过程分析(主模式-消息3)
IPsec中IKE与ISAKMP过程分析(主模式-消息1)_搞搞搞高傲的博客-CSDN博客 IPsec中IKE与ISAKMP过程分析(主模式-消息2)_搞搞搞高傲的博客-CSDN博客 阶段目标过程消息IKE第一阶段建立一个ISAKMP SA实现通信双发的身份鉴别和密钥交换&…...
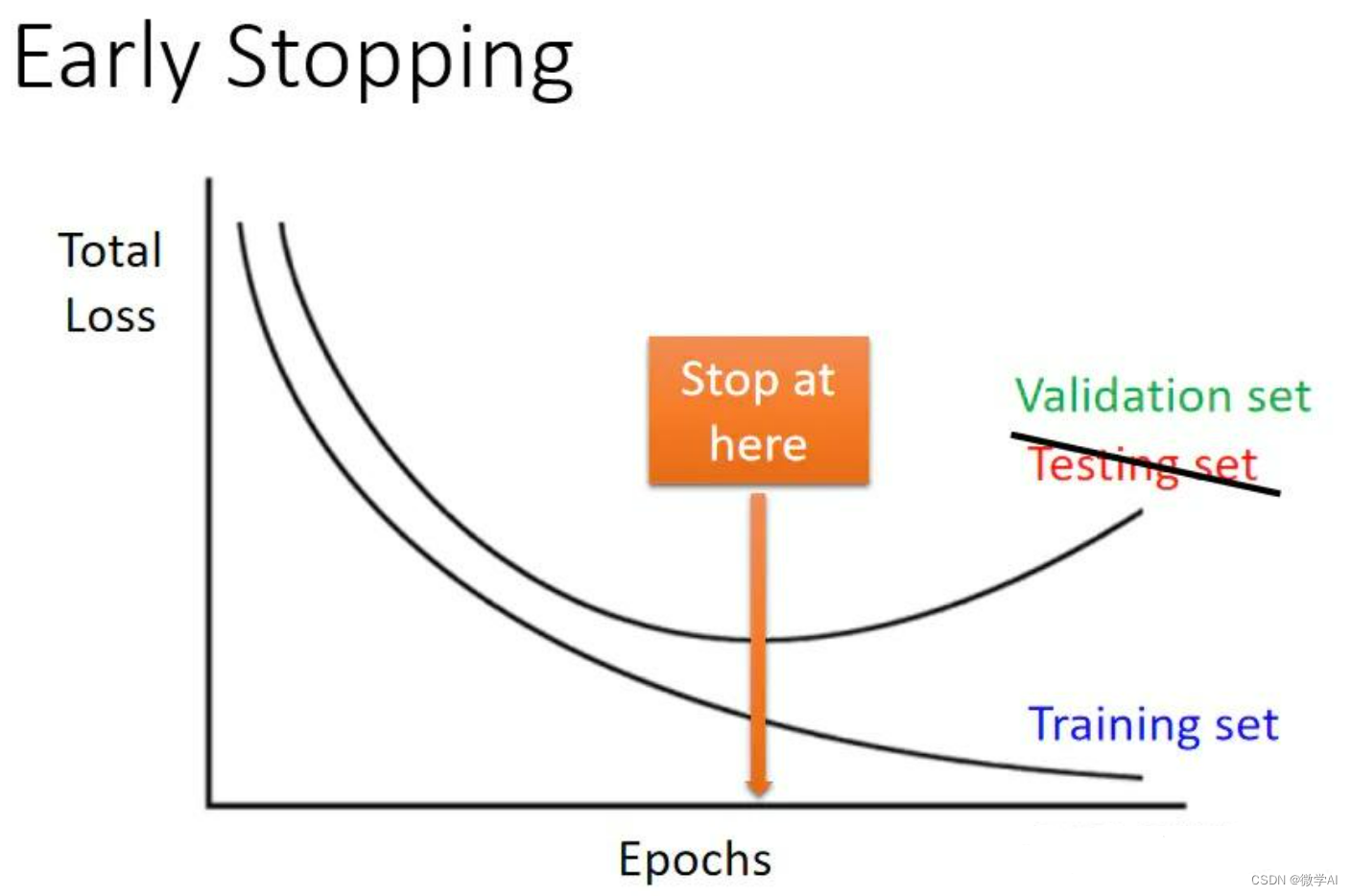
深度学习技巧应用10-PyTorch框架中早停法类的构建与运用
大家好,我是微学AI,今天给大家介绍一下深度学习技巧应用10-PyTorch框架中早停法类的构建与运用,文章将介绍深度学习训练过程中的一个重要技巧—早停法,以及如何在PyTorch框架中实现早停法。文章将从早停法原理和实践出发,结合实际案例剖析早停法的优缺点及在PyTorch中的应…...
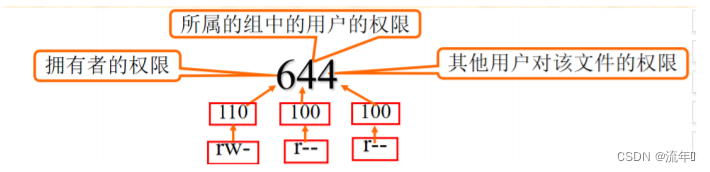
Linux文件系统权限
目录标题 文件权限文件和目录的一般权限文件的权限针对三类对象进行定义文件和目录中,r、w、x的作用 设置文件和目录的一般权限修改文件或目录的权限—chmod(change mode)命令权限值的表示方法—使用3位八进制数表示权限值的表示方法—使用字符串表示修改文件或目录…...

ctfshow之_萌新web1至web7
一、访问在线靶场ctfshow ctf.showhttps://ctf.show/challenges如下图所示,进入_萌新赛的web1问题: 如上图所示,页面代码提示id1000时,可以查询到flag,进行如下尝试: 如下图所示,传入参数id1时…...

HPDA的资料
HPDA,英文全称为High Performance Data Analysis,直译为高性能数据分析。 适用场景 机器学习大数据分析 技术挑战 大量的元数据操作数据的同步随机读写高IOPOS的小IO请求高带宽的文件请求 技术关键字 存算分离移动计算大I/O直通,小I/O聚…...
项目管理软件可以用来做什么?这篇文章说清楚了
项目管理软件是用来干嘛的,就得看对项目的理解。项目是为创造独特的产品、服务或成果而进行的临时性工作。建造一座大楼可以是一个项目,进行一次旅游活动、日常办公活动、期末考试复习等也都可以看成一个项目。 项目管理不善会导致项目超时、超支、返工、…...

ETL工具 - Kettle 转换算子介绍
一、Kettle 转换算子 上篇文章对 Kettle 中的输入输出算子进行了介绍,本篇文章继续对转换算子进行讲解。 下面是上篇文章的地址: ETL工具 - Kettle 输入输出算子介绍 转换是ETL里面的T(Transform),主要做数据转换&am…...

界面设计的读书笔记
所见即所得,属于绝大多数的人。 所想即所想,属于极少数的人。 当复杂度,超出了大脑的负荷,人会觉得很累,直到放弃追求。 地图的显示,必须有足够多的描述性的数据。 点信息 :标签,位…...
C#底层库--自定义进制转换器(可去除特殊字符,非Convert.ToString方式)
系列文章 C#底层库–程序日志记录类 本文链接:https://blog.csdn.net/youcheng_ge/article/details/124187709 C#底层库–MySQLBuilder脚本构建类(select、insert、update、in、带条件的SQL自动生成) 本文链接:https://blog.csd…...

Doris(24):Doris的函数—聚合函数
1 APPROX_COUNT_DISTINCT(expr) 返回类似于 COUNT(DISTINCT col) 结果的近似值聚合函数。 它比 COUNT 和 DISTINCT 组合的速度更快,并使用固定大小的内存,因此对于高基数的列可以使用更少的内存。 select city,approx_count_distinct(user_id) from site_visit group by c…...

干货! ICLR:将语言模型绑定到符号语言中个人信息
点击蓝字 关注我们 AI TIME欢迎每一位AI爱好者的加入! ╱ 作者简介╱ 承洲骏 上海交通大学硕士生,研究方向为代码生成,目前在香港大学余涛老师的实验室担任研究助理。 个人主页:http://blankcheng.github.io 谢天宝 香港大学一年级…...
Windows安装mariadb,配置环境变量(保姆级教学)
软件下载地址:https://mariadb.com/downloads/ 1.双击下载好的软件 2.点击next 3.勾选我同意,点击next 4.这里那你可以设置你要安装的路径,也可以使用默认的,之后点击next 5.如图所示,设置完点击next 6.接下来就默…...
)
华为OD机试 - 积木最远距离(Python)
题目描述 小华和小薇一起通过玩积木游戏学习数学。 他们有很多积木,每个积木块上都有一个数字,积木块上的数字可能相同。 小华随机拿一些积木挨着排成一排,请小薇找到这排积木中数字相同且所处位置最远的2块积木块,计算他们的距离,小薇请你帮忙替她解决这个问题。 输入描…...

关于对于springcloud中的注册中心和consume消费者和provier服务者之间的关系理解
关于对于springcloud中的注册中心和consume消费者和provier服务者之间的关系理解 pringCloud provider(服务提供方) consumer(服务调用方) server(注册中心) 运行原理 Provider 第一步 provider注册到se…...

【学习笔记】「JOISC 2022 Day1」错误拼写
久违的字符串计数题。 显然只用考虑 [ i : j ] [i:j] [i:j]这一段拼成的串。不难得出结论:设 n x t i nxt_i nxti表示 i i i之后第一个本质不同的字符的位置,那么 n x t i ≤ j nxt_i\le j nxti≤j,并且 s i ? s n x t i s_i?s_{nxt_i…...

iOS 26 携众系统重磅更新,但“苹果智能”仍与国行无缘
美国西海岸的夏天,再次被苹果点燃。一年一度的全球开发者大会 WWDC25 如期而至,这不仅是开发者的盛宴,更是全球数亿苹果用户翘首以盼的科技春晚。今年,苹果依旧为我们带来了全家桶式的系统更新,包括 iOS 26、iPadOS 26…...
)
云计算——弹性云计算器(ECS)
弹性云服务器:ECS 概述 云计算重构了ICT系统,云计算平台厂商推出使得厂家能够主要关注应用管理而非平台管理的云平台,包含如下主要概念。 ECS(Elastic Cloud Server):即弹性云服务器,是云计算…...

《Qt C++ 与 OpenCV:解锁视频播放程序设计的奥秘》
引言:探索视频播放程序设计之旅 在当今数字化时代,多媒体应用已渗透到我们生活的方方面面,从日常的视频娱乐到专业的视频监控、视频会议系统,视频播放程序作为多媒体应用的核心组成部分,扮演着至关重要的角色。无论是在个人电脑、移动设备还是智能电视等平台上,用户都期望…...

Redis相关知识总结(缓存雪崩,缓存穿透,缓存击穿,Redis实现分布式锁,如何保持数据库和缓存一致)
文章目录 1.什么是Redis?2.为什么要使用redis作为mysql的缓存?3.什么是缓存雪崩、缓存穿透、缓存击穿?3.1缓存雪崩3.1.1 大量缓存同时过期3.1.2 Redis宕机 3.2 缓存击穿3.3 缓存穿透3.4 总结 4. 数据库和缓存如何保持一致性5. Redis实现分布式…...

Debian系统简介
目录 Debian系统介绍 Debian版本介绍 Debian软件源介绍 软件包管理工具dpkg dpkg核心指令详解 安装软件包 卸载软件包 查询软件包状态 验证软件包完整性 手动处理依赖关系 dpkg vs apt Debian系统介绍 Debian 和 Ubuntu 都是基于 Debian内核 的 Linux 发行版ÿ…...

Swift 协议扩展精进之路:解决 CoreData 托管实体子类的类型不匹配问题(下)
概述 在 Swift 开发语言中,各位秃头小码农们可以充分利用语法本身所带来的便利去劈荆斩棘。我们还可以恣意利用泛型、协议关联类型和协议扩展来进一步简化和优化我们复杂的代码需求。 不过,在涉及到多个子类派生于基类进行多态模拟的场景下,…...

AtCoder 第409场初级竞赛 A~E题解
A Conflict 【题目链接】 原题链接:A - Conflict 【考点】 枚举 【题目大意】 找到是否有两人都想要的物品。 【解析】 遍历两端字符串,只有在同时为 o 时输出 Yes 并结束程序,否则输出 No。 【难度】 GESP三级 【代码参考】 #i…...

基于当前项目通过npm包形式暴露公共组件
1.package.sjon文件配置 其中xh-flowable就是暴露出去的npm包名 2.创建tpyes文件夹,并新增内容 3.创建package文件夹...

屋顶变身“发电站” ,中天合创屋面分布式光伏发电项目顺利并网!
5月28日,中天合创屋面分布式光伏发电项目顺利并网发电,该项目位于内蒙古自治区鄂尔多斯市乌审旗,项目利用中天合创聚乙烯、聚丙烯仓库屋面作为场地建设光伏电站,总装机容量为9.96MWp。 项目投运后,每年可节约标煤3670…...

P3 QT项目----记事本(3.8)
3.8 记事本项目总结 项目源码 1.main.cpp #include "widget.h" #include <QApplication> int main(int argc, char *argv[]) {QApplication a(argc, argv);Widget w;w.show();return a.exec(); } 2.widget.cpp #include "widget.h" #include &q…...