码出高效:Java开发手册笔记(线程池及其源码)
码出高效:Java开发手册笔记(线程池及其源码)
码出高效:Java开发手册笔记(线程池及其源码)
- 码出高效:Java开发手册笔记(线程池及其源码)
- 前言
- 一、线程池的作用
- 线程的生命周期
- 二、线程池7大参数
- execute() 与 submit()
- Executors 静态工厂方法创建线程池
- 自定义实现线程工厂 ThreadFactory
- 自定义线程池拒绝策略 实现*RejectedExecutionHandler*
- 线程池拒绝策略
- 三、线程池源码详解
- 总结
前言
线程池
一、线程池的作用
线程使应用能够更加充分合理地协调利用 CPU、内存、网络、 I/O 等系统资源。线程的创建需要开辟虚拟机栈、本地方法栈、程序计数器等线程私有的内存空间。在线程销毁时需要回收这些系统资源。频繁地创建和销毁线程会浪费大量的系统资源,增加并发编程风险。另外,在服务器负载过大的时候,如何让新的线程等待或者友好地拒绝服务?这些都是线程自身无法解决的。所以需要通过线程池协调多个线程 , 并实现类似主次线程隔离、定时执行、周期执行等任务。线程池的作用包括:
- 利用线程池管理并复用线程、控制最大并发数等。
- 实现任务线程队列缓存策略和拒绝机制。
- 实现某些与时间相关的功能,如定时执行、周期执行等。
- 隔离线程环境。比如,交易服务和搜索服务在同一台服务器上,分别开启两个线程池,交易线程的资源消耗明显要大;因此,通过配置独立的线程池 ,将较慢的交易服务与搜索服务隔离开,避免各服务线程相互影响。
线程的生命周期

线程池重要的参数,ctl,是一个包含两个属性的原子整型;一个属性是 workerCount,指的是有效线程数;另一个是 runState,指的是线程的状态(线程的生命周期)
/*** The workerCount is the number of workers that have been* permitted to start and not permitted to stop. The value may be* transiently different from the actual number of live threads,* for example when a ThreadFactory fails to create a thread when* asked, and when exiting threads are still performing* bookkeeping before terminating. The user-visible pool size is* reported as the current size of the workers set.*//*** The runState provides the main lifecycle control, taking on values:** RUNNING: Accept new tasks and process queued tasks* SHUTDOWN: Don't accept new tasks, but process queued tasks* STOP: Don't accept new tasks, don't process queued tasks,* and interrupt in-progress tasks* TIDYING: All tasks have terminated, workerCount is zero,* the thread transitioning to state TIDYING* will run the terminated() hook method* TERMINATED: terminated() has completed*/// runState is stored in the high-order bitsprivate static final int RUNNING = -1 << COUNT_BITS;private static final int SHUTDOWN = 0 << COUNT_BITS;private static final int STOP = 1 << COUNT_BITS;private static final int TIDYING = 2 << COUNT_BITS;private static final int TERMINATED = 3 << COUNT_BITS;
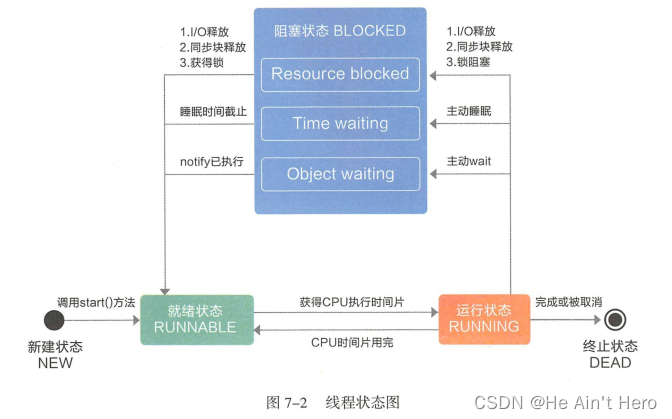
Thread类中的线程生命周期
public enum State {/*** Thread state for a thread which has not yet started.*/NEW,/*** Thread state for a runnable thread. A thread in the runnable* state is executing in the Java virtual machine but it may* be waiting for other resources from the operating system* such as processor.*/RUNNABLE,/*** Thread state for a thread blocked waiting for a monitor lock.* A thread in the blocked state is waiting for a monitor lock* to enter a synchronized block/method or* reenter a synchronized block/method after calling* {@link Object#wait() Object.wait}.*/BLOCKED,/*** Thread state for a waiting thread.* A thread is in the waiting state due to calling one of the* following methods:* <ul>* <li>{@link Object#wait() Object.wait} with no timeout</li>* <li>{@link #join() Thread.join} with no timeout</li>* <li>{@link LockSupport#park() LockSupport.park}</li>* </ul>** <p>A thread in the waiting state is waiting for another thread to* perform a particular action.** For example, a thread that has called <tt>Object.wait()</tt>* on an object is waiting for another thread to call* <tt>Object.notify()</tt> or <tt>Object.notifyAll()</tt> on* that object. A thread that has called <tt>Thread.join()</tt>* is waiting for a specified thread to terminate.*/WAITING,/*** Thread state for a waiting thread with a specified waiting time.* A thread is in the timed waiting state due to calling one of* the following methods with a specified positive waiting time:* <ul>* <li>{@link #sleep Thread.sleep}</li>* <li>{@link Object#wait(long) Object.wait} with timeout</li>* <li>{@link #join(long) Thread.join} with timeout</li>* <li>{@link LockSupport#parkNanos LockSupport.parkNanos}</li>* <li>{@link LockSupport#parkUntil LockSupport.parkUntil}</li>* </ul>*/TIMED_WAITING,/*** Thread state for a terminated thread.* The thread has completed execution.*/TERMINATED;
}
在了解线程池的基本作用后,我们学习一下线程池是如何创建线程的。首先从 ThreadPoolExecutor 构造方法讲起 , 学习如何自定义 ThreadFactory 和RejectedExecutionHandler , 并编写一个最简单的线程池示例。然后,通过分析ThreadPoolExecutor 的 execute 和 addWorker 两个核心方法,学习如何把任务线程加入到线程池中运行。 ThreadPoolExecutor 的构造方法如下:
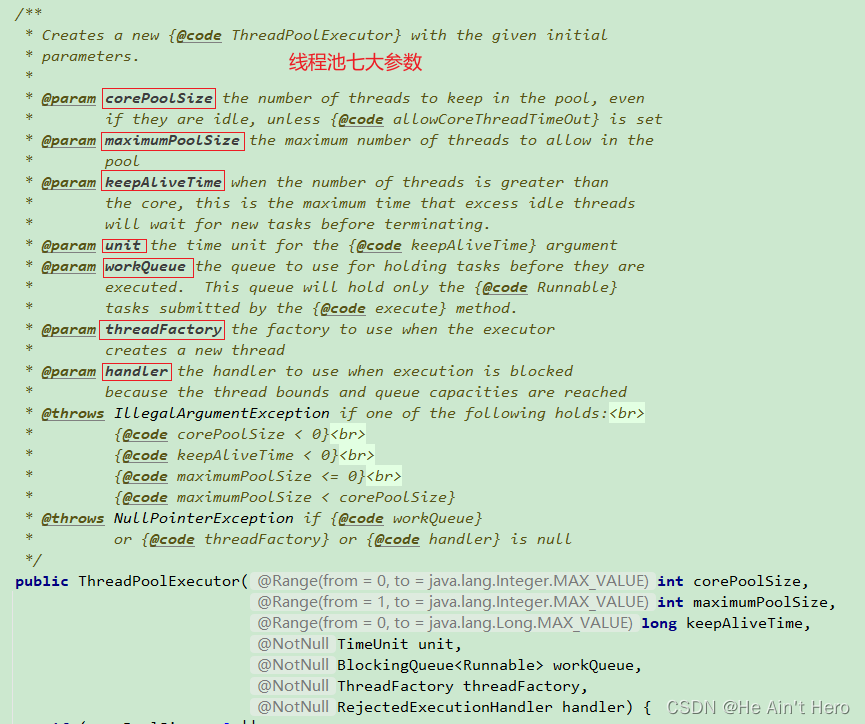
二、线程池7大参数
public ThreadPoolExecutor(int corePoolSize, //(第一个参数)int maximumPoolSize, //(第二个参数)long keepAliveTime, //(第三个参数)TimeUnit unit, //(第四个参数)BlockingQueue<Runnable> workQueue, //(第五个参数)ThreadFactory threadFactory, //(第六个参数)RejectedExecutionHandler handler) { //(第七个参数)if (corePoolSize < 0 ||// maximumPoolSize必须大于或等于1也要大于或等于corePoolSize (第1处)maximumPoolSize <= 0 ||maximumPoolSize < corePoolSize ||keepAliveTime < 0)throw new IllegalArgumentException();// (第2处)if (workQueue == null || threadFactory == null || handler == null)throw new NullPointerException();this.corePoolSize = corePoolSize;this.maximumPoolSize = maximumPoolSize;this.workQueue = workQueue;this.keepAliveTime = unit.toNanos(keepAliveTime);this.threadFactory = threadFactory;this.handler = handler;
}
第 1 个参数:corePoolSize 表示常驻核心线程数。如果等于 0 ,则任务执行完之后 ,没有任何请求进入时销毁线程池的线程;如果大于 0 ,即使本地任务执行完毕,核心线程也不会被销毁。这个值的设置非常关键,设置过大会浪费资源,设置过小会导致线程频繁地创建或销毁。
第 2 个参数: maximumPoolSize 表示线程池能够容纳同时执行的最大线程数。从上方示例代码中的第 1 处来看,必须大于或等于 1。如果待执行的线程数大于此值,需要借助第 5 个参数的帮助,缓存在队列中。如果 maximumPoolSize 与 corePoolSize相等,即是固定大小线程池。
第 3 个参数: keepAliveTime 表示线程池中的线程空闲时间,当空闲时间达到 keepAliveTime 值时,线程会被销毁,直到只剩下 corePoolSize 个线程为止,避免浪费内存和句柄资源。在默认情况下,当线程池的线程数大于 corePoolSize 时,keepAliveTime 才会起作用。但是当 ThreadPoolExecutor 的 allowCoreThreadTimeOut变量设置为 true 时 , 核心线程超时后也会被回收。
第 4 个参数:TimeUnit 表示时间单位。 keepAliveTime 的时间单位通常是TimeUnit.SECONDS 。
第 5 个参数: workQueue 表示缓存队列。当请求的线程数大于 maximumPoolSize时 , 线程进入 BlockingQueue 阻塞队列。后续示例代码中使用的 LinkedBlockingQueue是单向链表,使用锁来控制入队和出队的原子性,两个锁分别控制元素的添加和获取,是一个生产消费模型队列。
第 6 个参数: threadFactory 表示线程工厂。它用来生产一组相同任务的线程。线程池的命名是通过给这个 factory 增加组名前缀来实现的。在虚拟机栈分析时,就可以知道线程任务是由哪个线程工厂产生的。
第 7 个参数: handler 表示执行拒绝策略的对象。当超过第 5 个参数 workQueue的任务缓存区上限的时候,就可以通过该策略处理请求,这是 种简单的限流保护。像某年双十一没有处理好访问流量过载时的拒绝策略,导致内部测试页面被展示出来,使用户手足无措。友好的拒绝策略可以是如下三种:
( 1 )保存到数据库进行削峰填谷。在空间时再提取出来执行。
( 2 )转向某个提示页由。
( 3 )打印日志。
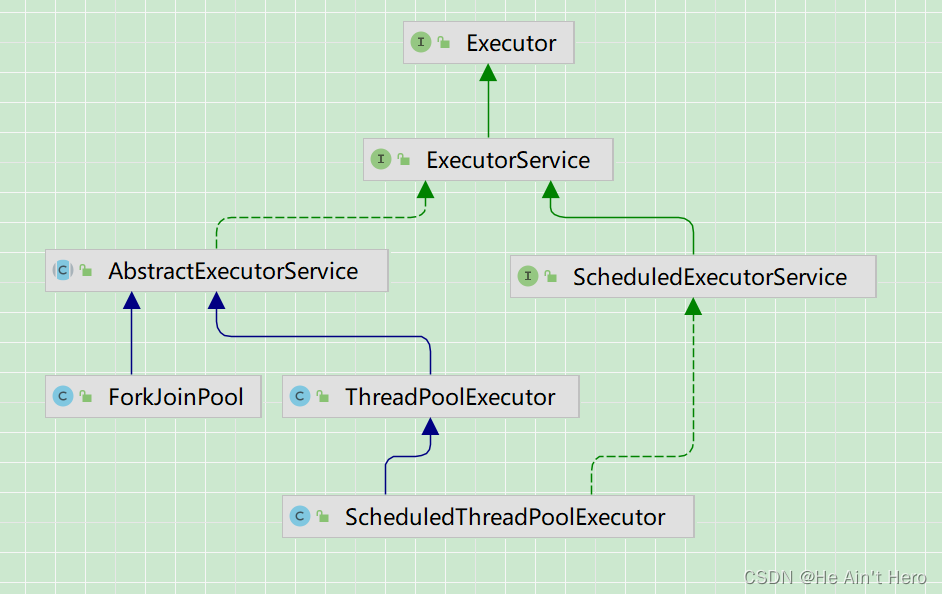
从代码第 2 处来看 , 队列、线程工厂、拒绝处理服务都必须有实例对象 , 但在实际编程中,很少有程序员对这三者进行实例化,而通过 Executors 这个线程池静态工厂提供默认实现 , 那么 Exceutors 与 ThreadPoolExecutor 是什么关系呢?线程池相关类图如下图所示。
execute() 与 submit()
execute为ThreadPoolExecutor里的方法,没有返回值
/*** @param 线程任务* @throws RejectedExecutionException 如果无法创建任何状态的线程任务* /
void execute (Runnable command );
submit为AbstractExecutorService里的方法,有返回值
public Future<?> submit(Runnable task) {if (task == null) throw new NullPointerException();RunnableFuture<Void> ftask = newTaskFor(task, null);execute(ftask);return ftask;
}
Executors 静态工厂方法创建线程池
ExecutorService 接口继承了 Executor 接口,定义了管理线程任务的方法。ExecutorService 的抽象类 AbstractExecutorService 提供了 submit() 、 invokeAll() 等部分方法的实现 , 但是核心方法Executor.execute() 并没有在这里实现。因为所有的任务都在这个方法里执行 , 不同实现会带来不同的执行策略,这点在后续的 ThreadPoolExecutor 解析时 ,会一步步地分析。通过Executors 的静态工厂方法可以创建三个线城池的包装对象。 ForkJoinPool 、 ThreadPooIExecutor、ScheduledThreadPoolExecutor 。 Executors 核心的方法有五个:
- Executors.newWorkStealingPool: JDK8 引人,创建持有足够线程的线程池支持给定的并行度 , 并通过使用多个队列减少竞争 , 此构造方法中把 CPU 数量设置为默认的并行度:
/*** Creates a work-stealing thread pool using all* {@link Runtime#availableProcessors available processors}* as its target parallelism level.* @return the newly created thread pool* @see #newWorkStealingPool(int)* @since 1.8*/public static ExecutorService newWorkStealingPool() {// 返回 ForkJoinPool(JDK7引入)对象,它也是 AbstractExecutorService 的子类return new ForkJoinPool(Runtime.getRuntime().availableProcessors(),ForkJoinPool.defaultForkJoinWorkerThreadFactory,null, true);}
- Executors.newCachedThreadPool: maximumPoolSize 最大可以至 Integer.MAX_VALUE, 是高度可伸缩的线程池 ,如果达到这个上限 , 相信没有任何服务器能够继续工作,肯定会抛出 OOM 异常。 keepAliveTime 默认为 60 秒,工作线程处于空闲状态 , 则回收工作线程。如果任务数增加 ,再次创建出新线程处理任务。
- Executors.newScheduledThreadPool:线程数最大至 Integer.MAX_VALUE,与上述相同,存在 OOM 风险。它是ScheduledExecutorService 接口家族的实现类,支持定时及周期性任务执行。相 比 Timer , ScheduledExecutorService 更安全,功能更强大,与 newCachedThreadPool 的区别是不回收工作线程。
- Executors.newSingleThreadExecutor : 创建一个单线程的线程池,相当于单线程串行执行所有任务,保证按任务的提交顺序依次执行。
- Executors.newFixedThreadPool : 输入的参数即是固定线程数,既是核心线程数也是最大线程数 , 不存在空闲线程,所以keepAliveTime 等于 0:
/*** Creates a thread pool that reuses a fixed number of threads* operating off a shared unbounded queue. At any point, at most* {@code nThreads} threads will be active processing tasks.* If additional tasks are submitted when all threads are active,* they will wait in the queue until a thread is available.* If any thread terminates due to a failure during execution* prior to shutdown, a new one will take its place if needed to* execute subsequent tasks. The threads in the pool will exist* until it is explicitly {@link ExecutorService#shutdown shutdown}.** @param nThreads the number of threads in the pool* @return the newly created thread pool* @throws IllegalArgumentException if {@code nThreads <= 0}*/public static ExecutorService newFixedThreadPool(int nThreads) {return new ThreadPoolExecutor(nThreads, nThreads,0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>());}
这里 , 输入的队列没有指明长度,下面介绍 LinkedBlockingQueue 的构造方法:
/*** Creates a {@code LinkedBlockingQueue} with a capacity of* {@link Integer#MAX_VALUE}.*/public LinkedBlockingQueue() {this(Integer.MAX_VALUE);}
使用这样的无界队列, 如果瞬间请求非常大 , 会有 OOM 的风险。除newWorkStealingPool 外 ,其他四个创建方式都存在资源耗尽的风险。
自定义实现线程工厂 ThreadFactory
Executors 中默认的线程工厂和拒绝策略过于简单,通常对用户不够友好。线程工厂需要做创建前的准备工作,对线程池创建的线程必须明确标识,就像药品的生产批号一样,为线程本身指定有意义的名称和相应的序列号。拒绝策略应该考虑到业务场景,返回相应的提示或者友好地跳转。以下为简单的 ThreadFactory 示例:
package com.example.demo.test1;import java.util.concurrent.ThreadFactory;
import java.util.concurrent.atomic.AtomicInteger;/*** @Author: Ron* @Create: 2023-04-24 15:07*/
public class UserThreadFactory implements ThreadFactory {private final String namePrefix;private final AtomicInteger nextId = new AtomicInteger(1);// 定义线程组名称,在使用jstack来排查线程问题时,可以通过线程组名称来快速定位问题UserThreadFactory(String whatFeatureOfGroup) {namePrefix = "From UserThreadFactory's " + whatFeatureOfGroup + "-Worker-";}@Overridepublic Thread newThread(Runnable task) {String name = namePrefix + nextId.getAndIncrement();Thread thread = new Thread(null, task, name, 0);
// System.out.println(thread.getName());return thread;}
}
上述示例包括线程工厂和任务执体的定义 , 通过 newThread 方法快速、统一地创建线程任务,强调线程一定要有特定意义的名称,方便出错时回溯。
如图 7-5 所示为排查底层公共缓存调用出错时的截图,绿色框采用自定义的线程工厂,明显比蓝色框默认的线程工厂创建的线程名称拥有更多的额外信息 。 如调用来源、线程的业务含义,有助于快速定位到死锁、 StackOverflowError 等问题。

自定义线程池拒绝策略 实现RejectedExecutionHandler
下面再简单地实现一下 RejectedExecutionHandler,实现了接口的 rejectedExecution方法,打印出当前线程池状态,源码如下:
package com.example.demo.test1;import java.util.concurrent.RejectedExecutionHandler;
import java.util.concurrent.ThreadPoolExecutor;/*** @Author: Ron* @Create: 2023-04-24 15:48*/
public class UserRejectHandler implements RejectedExecutionHandler {@Overridepublic void rejectedExecution(Runnable task, ThreadPoolExecutor executor) {System.out.println("Task rejected from " + executor.toString());// 可以将task存入队列,等空闲时再去执行}
}
线程池拒绝策略
在ThreadPoolExecutor 中提供了四个公开的内部静态类:
- AbortPolicy (默认):丢弃任务并抛出 RejectedExecutionException 异常。
- DiscardPolicy : 丢弃任务,但是不抛出异常 , 这是不推荐的做法。
- DiscardOldestPolicy : 抛弃队列中等待最久的任务 , 然后把当前任务加入队列中。
- CallerRunsPolicy :调用任务的 run() 方法绕过线程池直接执行,使用调用线程执行任务。
new ThreadPoolExecutor.AbortPolicy(); // 默认,队列满了丢弃任务并抛出异常new ThreadPoolExecutor.CallerRunsPolicy(); // 如果添加线城池失败,使用调用线程执行任务new ThreadPoolExecutor.DiscardOldestPolicy(); // 将最早进入队列的任务删除,之后尝试加入队列new ThreadPoolExecutor.DiscardPolicy(); // 队列满了,丢弃任务不抛出异常
根据之前实现的线程工厂和拒绝策略,线程池的相关代码实现如下:
package com.example.demo.test1;import java.util.concurrent.BlockingQueue;
import java.util.concurrent.LinkedBlockingQueue;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;/*** @Author: Ron* @Create: 2023-04-24 15:59*/
public class UserThreadPool {public static void main(String[] args) {// 缓存队列设置固定长度为2,为了快速触发 rejectHandlerBlockingQueue queue = new LinkedBlockingQueue(2);// 假设外部任务线程的来源由机房1和机房2的混合调用UserThreadFactory f1 = new UserThreadFactory("第1机房");UserThreadFactory f2 = new UserThreadFactory("第2机房");// 自定义拒绝策略UserRejectHandler handler = new UserRejectHandler();// 核心线程为1,最大线程为2,为了保证触发rejectHandlerThreadPoolExecutor threadPoolFirst= new ThreadPoolExecutor(1, 2, 60,TimeUnit.SECONDS, queue, f1, handler);// 利用第二个线程工厂实力创建第二个线程池ThreadPoolExecutor threadPoolSecond= new ThreadPoolExecutor(1, 2, 60,TimeUnit.SECONDS, queue, f2, handler);// 创建400个任务线程Runnable task = new Task();for (int i = 0; i < 200; i++) {threadPoolFirst.execute(task);threadPoolSecond.execute(task);threadPoolSecond.submit(task);}}}执行结果如下:
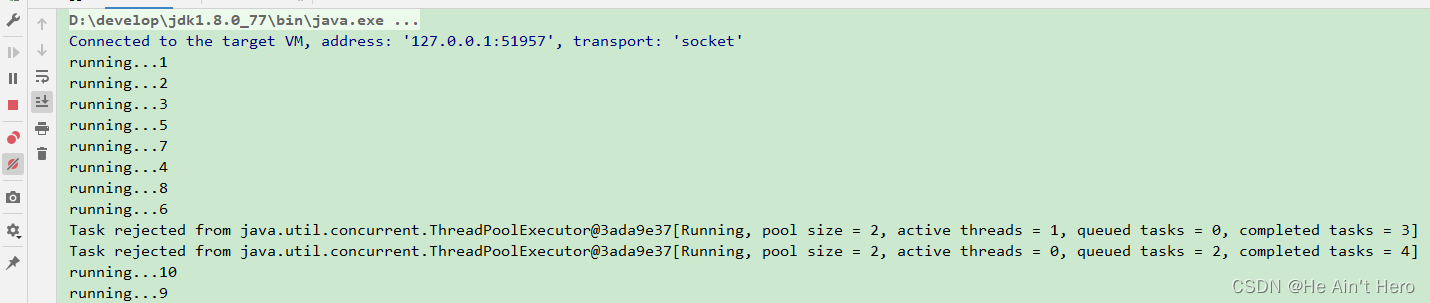
当任务被拒绝的时候,拒绝策略会打印出当前线程池的大小已经达到了maximumPoolSize=2 ,且队列已满,完成的任务数提示已经有 4 个(最后一行)。
三、线程池源码详解
在 ThreadPoolExecutor 的属性定义中频繁地用位移运算来表示线程池状态, 位移运算是改变当前值的一种高效手段 , 包括左移与右移。下面从属性定义开始阅读ThreadPoolExecutor 的源码。
// Integer共有32位,最右边29位表示工作线程数,最左边3位表示线程池状态// 注:简单地说,3个二进制可以表示从0到7共8个不同的数值(第1处)private static final int COUNT_BITS = Integer.SIZE - 3;// 000-11111...1111(29个1),类似于子网掩码,用于位的与运算// 得到左边3位,还是右边29位private static final int CAPACITY = (1 << COUNT_BITS) - 1;// runState is stored in the high-order bits// 用左边3位,实现5种线程池状态。(在左3位之后加入中画线有助于理解)// 111-00000...0000(29个0),十进制值,-536,870,912// 此状态表示线程池能接受新任务private static final int RUNNING = -1 << COUNT_BITS;// 000-00000...0000(29个0),十进制值:0// 此状态不再接受新任务,但可以继续执行队列中的任务private static final int SHUTDOWN = 0 << COUNT_BITS;// 001-00000...0000(29个0),十进制值:536,870,912// 此状态全面拒绝,并中断正在处理的任务private static final int STOP = 1 << COUNT_BITS;// 010-00000...0000(29个0),十进制值:1,073,741,824// 此状态表示所有任务已经被终止private static final int TIDYING = 2 << COUNT_BITS;// 011-00000...0000(29个0),十进制值:1,610,612,736// 此状态表示已清理完现场private static final int TERMINATED = 3 << COUNT_BITS;// Packing and unpacking ctl// 与运算,比如 001-00000...0000(29个0),表示67个工作线程// 掩码取反: 111-00000...0000(29个0),即得到左边3位001// 表示线程池当前出于STOP状态private static int runStateOf(int c) { return c & ~CAPACITY; }// 同理掩码 000-11111...1111(29个1),得到右边29位,即工作线程数private static int workerCountOf(int c) { return c & CAPACITY; }// 把左边3位与右边29位按或运算,合并成一个值private static int ctlOf(int rs, int wc) { return rs | wc; }第 l :处说明 , 线程池的状态用高 3 位表示,其中包括了符号位。五种状态的
十进制值按从小到大依次排序为 RUNNING < SHUTDOWN < STOP < TIDYING <
TERMINATED , 这样设计的好处是可以通过比较值的大小来确定线程池的状态。例
如程序中经常会出现 isRunning 的判断
private static boolean isRunning(int c) {return c < SHUTDOWN;
}
我们都知道 Executor 接口有且只有一个方法 execute , 通过参数传入待执行线程的对象。下面分析 ThreadPoolExecutor 关于 execute 方法的实现,
/*** Executes the given task sometime in the future. The task* may execute in a new thread or in an existing pooled thread.** If the task cannot be submitted for execution, either because this* executor has been shutdown or because its capacity has been reached,* the task is handled by the current {@code RejectedExecutionHandler}.** @param command the task to execute* @throws RejectedExecutionException at discretion of* {@code RejectedExecutionHandler}, if the task* cannot be accepted for execution* @throws NullPointerException if {@code command} is null*/public void execute(Runnable command) {if (command == null)throw new NullPointerException();/** Proceed in 3 steps:** 1. If fewer than corePoolSize threads are running, try to* start a new thread with the given command as its first* task. The call to addWorker atomically checks runState and* workerCount, and so prevents false alarms that would add* threads when it shouldn't, by returning false.** 2. If a task can be successfully queued, then we still need* to double-check whether we should have added a thread* (because existing ones died since last checking) or that* the pool shut down since entry into this method. So we* recheck state and if necessary roll back the enqueuing if* stopped, or start a new thread if there are none.** 3. If we cannot queue task, then we try to add a new* thread. If it fails, we know we are shut down or saturated* and so reject the task.*/// 返回包含线程数及线程池状态的Integer类型数值int c = ctl.get();// 如果工作线程数小于核心线程数,则创建线程任务并执行if (workerCountOf(c) < corePoolSize) {// addWorker是另一个极为重要的方法,见下一段源码解析(第1处)if (addWorker(command, true))return;// 如果创建失败,防止外部已经在线程池中加入新任务,重新获取一下c = ctl.get();}// 只有线程池处于RUNNING状态,才执行后半句:置入队列if (isRunning(c) && workQueue.offer(command)) {int recheck = ctl.get();// 如果线程池不是RUNNING状态,则将刚加入队列的任务移除if (! isRunning(recheck) && remove(command))reject(command);// 如果之前的线程已被消费完,新建一个线程else if (workerCountOf(recheck) == 0)addWorker(null, false);}// 核心池和队列都已满,尝试创建一个新线程else if (!addWorker(command, false))// 如果addWorker返回是false,即创建失败,则唤醒拒绝策略(第2处)reject(command);}
第 1 处: execute 方法在不同的阶段有三次 addWorker 的尝试动作。
第 2 处: 发生拒绝的理由有两个
( 1 )线程池状态为非 RUNNING状态
( 2 )等待队列己满。
下面继续分析 addWorker 方法的源码:
/*** 根据当前线程池状态,检查是否可以添加新的任务线程,如果则创建并启动任务* 如果一切正常则返回true。返回false的可能性如下:* 1.线程池没有处于RUNNING状态* 2.线程工厂创建新的任务线程失败* @param firstTask 外部启动线程池是需要构造的第一个线程,他是线程的母体* @param core 新增工作线程时的判断指标,解释如下* true 表示新增工作线程时,需要判断当前RUNNING状态的线程是否少于corePoolSize* false 表示新增工作线程时,需要判断当前RUNNING状态的线程是否少于maximumPoolSize* @return*/private boolean addWorker(Runnable firstTask, boolean core) {// 不需要任务预定义的语法标签,响应下文的continue retry,快速退出多层嵌套循环(第1处)retry:for (;;) {// 参考之前的状态分析:如果RUNNING状态,则条件为假,不执行后面的判断// 如果是STOP及之上的状态,或者firstTask初始线程不为空,或者工作队列不为空,// 都会直接返回创建失败(第2处)int c = ctl.get();int rs = runStateOf(c);// Check if queue empty only if necessary.if (rs >= SHUTDOWN && ! (rs == SHUTDOWN && firstTask == null && ! workQueue.isEmpty()))return false;for (;;) {// 如果超过最大允许线程数则不能再添加新的线程// 最大线程数不能超过2^29,否则影响左边3位的线程池状态值int wc = workerCountOf(c);if (wc >= CAPACITY ||wc >= (core ? corePoolSize : maximumPoolSize))return false;// 将当前活动线程数+1 (第3处)if (compareAndIncrementWorkerCount(c))break retry;// 线程池状态和工作线程数是可变化的,需要经常提取这个最新值c = ctl.get(); // Re-read ctl// 如果已经关闭,则再次从retry标签处进入,在第2处再做判断 (第4处)if (runStateOf(c) != rs)continue retry;// else CAS failed due to workerCount change; retry inner loop// 如果线程还是处于RUNNING状态,那就在说明仅仅是第3处失败// 继续循环执行 (第5处)}}// 开始创建工作线程boolean workerStarted = false;boolean workerAdded = false;ThreadPoolExecutor.Worker w = null;try {// 利用Worker构造方法中的线程池工厂创建线程,并封装成工作线程Worker对象w = new ThreadPoolExecutor.Worker(firstTask);// 注意这是Worker中的属性对象thread (第6处)final Thread t = w.thread;if (t != null) {// 在进行ThreadPoolExecutor的敏感操作时// 都需要持有主锁,避免在添加和启动线程时被干扰final ReentrantLock mainLock = this.mainLock;mainLock.lock();try {// Recheck while holding lock.// Back out on ThreadFactory failure or if// shut down before lock acquired.int rs = runStateOf(ctl.get());// 当线程池状态为RUNNING或SHUTDOWN// 且firstTask初始线程为空时if (rs < SHUTDOWN ||(rs == SHUTDOWN && firstTask == null)) {if (t.isAlive()) // precheck that t is startablethrow new IllegalThreadStateException();workers.add(w);int s = workers.size();// 整个线程池在运行期间的最大并发任务个数if (s > largestPoolSize)largestPoolSize = s;workerAdded = true;}} finally {mainLock.unlock();}if (workerAdded) {// 终于看到亲切的start方法// 注意,并非线程池的execute的command参数指向的线程t.start();workerStarted = true;}}} finally {if (! workerStarted)// 线程启动失败,把刚才第3处加上的工作线程计数再减回去addWorkerFailed(w);}return workerStarted;}
这段代码晦涩难懂,部分地方甚至违反了代码规约,但其中蕴含的丰富的编码知识点值得我们去学习,下面接序号来依次讲解。
第 1 处, 配合循环语旬出现的 label ,类似于 goto 作用。 label 定义时,必须把标签和冒号的组合语旬紧紧相邻定义在循环体之前,否则会编译出错。目的是在实现多重循环时能够快速退出到任何一层。这种做法的出发点似乎非常贴心,但是在大型软件项目中 ,滥用标签行跳转的后果将是灾难性的。示例代码中,在 retry 下方有两个无限循环,在 workerCount 加 1 成功后,直接退出两层循环。
第 2 处,这样的表达式不利于代码阅读,应该改成:
Boolean isNotAllowedToCreateTask= runStateLeast(c, SHUTDOWN) && (runStateAtLeast(c, STOP)|| firstTask != null || workQueue.isEmpty());
if (isNotAllowedToCreateTask) {// ...
}
第 3 处, 与第 1 处的标签呼应 , Atomiclnteger 对象的加1操作是原子性的。break retry 表示直接跳出与 retry 相邻的这个循环体。
第 4 处,此 continue 跳转至标签处,继续执行循环。如果条件为假,则说明线程池还处于运行状态,即继续在 for( ;;)循环内执行。
第 5 处, compareAndlncrementWorkerCount 方法执行失败的概率非常低。即使失败 , 再次执行时成功的概率也是极高的,类似于自旋锁原理。这里的处理逻辑是先加 1,创建失败再减1,这是轻量处理并发创建线程的方式。如果先创建线程,成功再加1,当发现超出限制后再销毁线程,那么这样的处理方式明显比前者代价要大。
第 6 处 , Worker 对象是工作线程的核心类实现,部分源码如下:
/*** 它实现Runnable接口,并把本对象作为参数输入给run()方法中的runWorker(this),* 所以内部属性线程thread在start的时候,即会调用runWorker方法*/private final class Worker extends AbstractQueuedSynchronizer implements Runnable {/*** Creates with given first task and thread from ThreadFactory.* @param firstTask the first task (null if none)*/Worker(Runnable firstTask) {// 它是AbstractQueuedSynchronizer的方法// 在runWorker方法执行之前禁止线程被中断setState(-1); // inhibit interrupts until runWorkerthis.firstTask = firstTask;this.thread = getThreadFactory().newThread(this);}// 当thread被start()之后,执行runWorker的方法/** Delegates main run loop to outer runWorker */public void run() {runWorker(this);}}
总结
线程池的相关源码比较精炼,还包括线程池的销毁、任务提取和消费等,与线程状态图一样,线程池也有自己独立的状态转化流程,本节不再展开。总结一下,使用线程池要注意如下几点:
( 1 )合理设置各类参数,应根据实际业务场景来设置合理的工作线程数。
( 2 )线程资源必须通过线城池提供,不允许在应用中自行显式创建线程。
( 3 )创建线程或线城池时请指定有意义的线程名称,方便出错时回溯。
线程池不允许使用 Executors ,而是通过 ThreadPoolExecutor 的方式创建 ,这样的处理方式能更加明确线程池的运行规则,规避资源耗尽的风险。
相关文章:
码出高效:Java开发手册笔记(线程池及其源码)
码出高效:Java开发手册笔记(线程池及其源码) 码出高效:Java开发手册笔记(线程池及其源码) 码出高效:Java开发手册笔记(线程池及其源码)前言一、线程池的作用线程的生命周…...
【MySQL】交叉连接、自然连接和内连接查询
一、引入 实际开发中往往需要针对两张甚至更多张数据表进行操作,而这多张表之间需要使用主键和外键关联在一起,然后使用连接查询来查询多张表中满足要求的数据记录。一条SQL语句查询多个表,得到一个结果,包含多个表的数据。效率高…...

长/短 链接/轮询 和websocket
短连接和长连接 短连接: http协议底层基于socket的tcp协议,每次通信都会新建一个TCP连接,即每次请求和响应过程都经历”三次握手-四次挥手“优点:方便管理缺点:频繁的建立和销毁连接占用资源 长连接: 客…...

数据库的事务
数据库的事务 1、事务是什么 TRANSACTION(事务)是数据库管理系统执行过程中的一个逻辑单位,由一个有限的数据库操作序列构成。 2、事务可以做什么 数据库事务通常包含了一个序列的对数据库的读/写操作。包含有以下两个目的: …...

专利进阶(二):专利撰写常用技术及算法汇总(持续更新中)
文章目录 一、前言二、常用技术及算法2.1 区跨链技术2.2 聚类算法2.3 边缘算法2.4 蚁群算法2.4.1 路径构建2.4.2 信息素更新 2.5 哈希算法2.5.1 常见算法 2.6 数字摘要2.72.82.92.10 三、拓展阅读 一、前言 专利撰写过程中使用已有技术或算法解决新问题非常常见,本…...
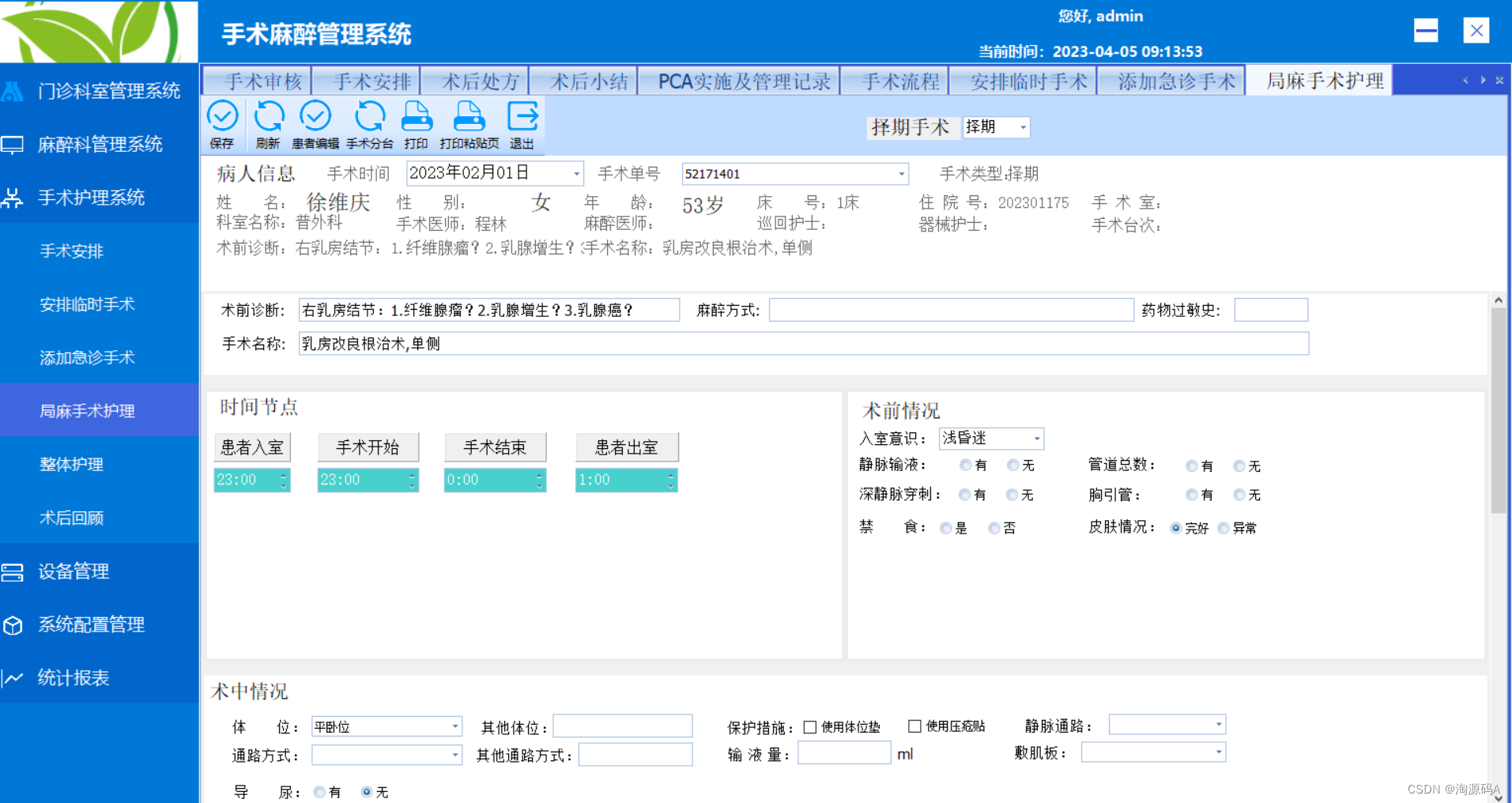
C#手术麻醉临床信息系统源码,实现体征数据自动采集绘制
手麻系统源码,自动生成电子单据 基于C# 前端框架:Winform后端框架:WCF 数据库:sqlserver 开发的手术麻醉临床信息系统源码,应用于医院手术室、麻醉科室的计算机软件系统。该系统针对整个围术期,对病人进…...

现代CMake高级教程 - 第 7 章:变量与缓存
双笙子佯谬老师的【公开课】现代CMake高级教程课程笔记 第 7 章:变量与缓存 重复执行 cmake -B build 会有什么区别? ❯ cmake -B build -- The C compiler identification is GNU 11.3.0 -- The CXX compiler identification is GNU 11.3.0 -- Detec…...

SQL知识汇总
什么时候用存储过程合适 当一个事务涉及到多个SQL语句时或者涉及到对多个表的操作时就要考虑用存储过程;当在一个事务的完成需要很复杂的商业逻辑时(比如,对多个数据的操作,对多个状态的判断更改等)要考虑;…...
区位码-GB2312
01-09区为特殊符号 10-15区为用户自定义符号区(未编码) 16-55区为一级汉字,按拼音排序 56-87区为二级汉字,按部首/笔画排序 88-94区为用户自定义汉字区(未编码) 特殊符号 区号:01 各类符号 0 1 2 3 4 …...
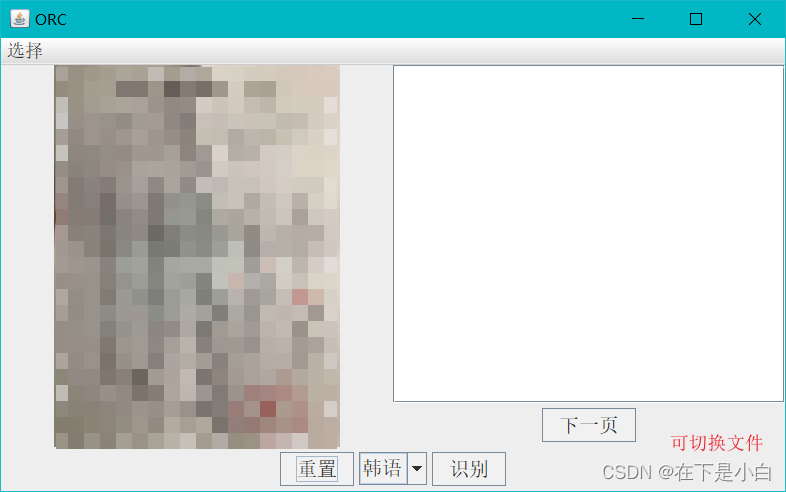
文本识别、截图识别保存和多文件识别
一、源码 github源码 二、介绍 采用Tesseract OCR识别 采用多线程进行图片识别 界面 选择 文件是可以识别本地的多张图片文件夹是识别文件夹里面的所有图片的内容截图 可以复制到剪切板、可以识别也可以直接保存 重置 是清除选择的图片和识别结果语言选择 是选择不同的模型…...
针对近日ChatGPT账号大批量封禁的理性分析
文 / 高扬 这两天不太平。 3月31号,不少技术圈的朋友和我闲聊说,ChatGPT账号不能注册了。 我不以为然,自己有一个号足够了,并不关注账号注册的事情。 后面又有不少朋友和我说ChatGPT账号全部不能注册了,因为老美要封锁…...
)
MATLAB算法实战应用案例精讲-【人工智能】对比学习(概念篇)
目录 前言 几个高频面试题目 推荐领域的对比学习在设计代理任务时与CV和NLP领域有什么不同?...

WeakMap 与 WeakSet
WeakSet WeakSet 结构与 Set 类似,也是不重复的值的集合。 成员都是数组和类似数组的对象,WeakSet 的成员只能是对象,而不能是其他类型的值。 若调用 add() 方法时传入了非数组和类似数组的对象的参数,就会抛出错误。 const b …...
【hello Linux】进程信号
目录 1. 进程信号的引出及整体概况 2. 信号的产生 1. 键盘产生 2. 进程异常 3. 系统调用 4. 软件条件 3. 信号的保存 1. 信号相关的常见概念 2. sigset_t 3. 信号集操作函数 4. sigprocmask:对block位图的操作 5. sigpending:对pending位图的操作 6. 捕捉…...

【SpringBoot】获取HttpServletRequest的三种方式
方法一: Controller中增加request参数 RestController public class DemoController { RequestMapping("/demo")public void demo(HttpServletRequest request) { System.out.println(request.getParameter("hello"));} }线程安全缺点: 每个方法都…...

k8s DCGM GPU采集指标项说明
dcgm-exporter 采集指标项 指标解释dcgm_fan_speed_percentGPU风扇转速占比(%)dcgm_sm_clockGPU sm 时钟(MHz)dcgm_memory_clockGPU 内存时钟(MHz)dcgm_gpu_tempGPU 运行的温度(℃)dcgm_power_usageGPU 的功率(w)dcgm_pcie_tx_throughputGPU PCIeTX 传输的字节总数 (kb)dcgm_pc…...

从线程安全到锁粒度,使用Redis分布式锁的注意事项
关于 Redis 的分布式锁 在分布式的场景下,多个服务器之间的资源竞争和访问频繁性,为了数据的安全和性能的优化,我们需要引入分布式锁的概念,这把锁可以加在上层业务需要的共享数据/资源上,能够同步协调多个服务器的访…...

CopyOnWriteArrayList 的底层原理与多线程注意事项
文章目录 CopyOnWriteArrayList 的底层原理与多线程注意事项1. CopyOnWriteArrayList 底层原理1.1 概念说明1.2 实现原理1.3 优点1.4 缺点 2. CopyOnWriteArrayList 多线程注意事项与实例2.1 注意事项2.2 示例2.2.1 示例代码 3. 总结 CopyOnWriteArrayList 的底层原理与多线程注…...
互斥锁深度理解与使用
大家好,我是易安! 我们知道一个或者多个操作在CPU执行的过程中不被中断的特性,称为“原子性”。理解这个特性有助于你分析并发编程Bug出现的原因,例如利用它可以分析出long型变量在32位机器上读写可能出现的诡异Bug,明明已经把变量…...

Elasticsearch --- 数据聚合、自动补全
一、数据聚合 聚合(aggregations)可以让我们极其方便的实现对数据的统计、分析、运算。例如: 什么品牌的手机最受欢迎? 这些手机的平均价格、最高价格、最低价格? 这些手机每月的销售情况如何? 实现这…...

观成科技:隐蔽隧道工具Ligolo-ng加密流量分析
1.工具介绍 Ligolo-ng是一款由go编写的高效隧道工具,该工具基于TUN接口实现其功能,利用反向TCP/TLS连接建立一条隐蔽的通信信道,支持使用Let’s Encrypt自动生成证书。Ligolo-ng的通信隐蔽性体现在其支持多种连接方式,适应复杂网…...

SkyWalking 10.2.0 SWCK 配置过程
SkyWalking 10.2.0 & SWCK 配置过程 skywalking oap-server & ui 使用Docker安装在K8S集群以外,K8S集群中的微服务使用initContainer按命名空间将skywalking-java-agent注入到业务容器中。 SWCK有整套的解决方案,全安装在K8S群集中。 具体可参…...

springboot 百货中心供应链管理系统小程序
一、前言 随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱,百货中心供应链管理系统被用户普遍使用,为方…...

在HarmonyOS ArkTS ArkUI-X 5.0及以上版本中,手势开发全攻略:
在 HarmonyOS 应用开发中,手势交互是连接用户与设备的核心纽带。ArkTS 框架提供了丰富的手势处理能力,既支持点击、长按、拖拽等基础单一手势的精细控制,也能通过多种绑定策略解决父子组件的手势竞争问题。本文将结合官方开发文档,…...

日常一水C
多态 言简意赅:就是一个对象面对同一事件时做出的不同反应 而之前的继承中说过,当子类和父类的函数名相同时,会隐藏父类的同名函数转而调用子类的同名函数,如果要调用父类的同名函数,那么就需要对父类进行引用&#…...

elementUI点击浏览table所选行数据查看文档
项目场景: table按照要求特定的数据变成按钮可以点击 解决方案: <el-table-columnprop"mlname"label"名称"align"center"width"180"><template slot-scope"scope"><el-buttonv-if&qu…...
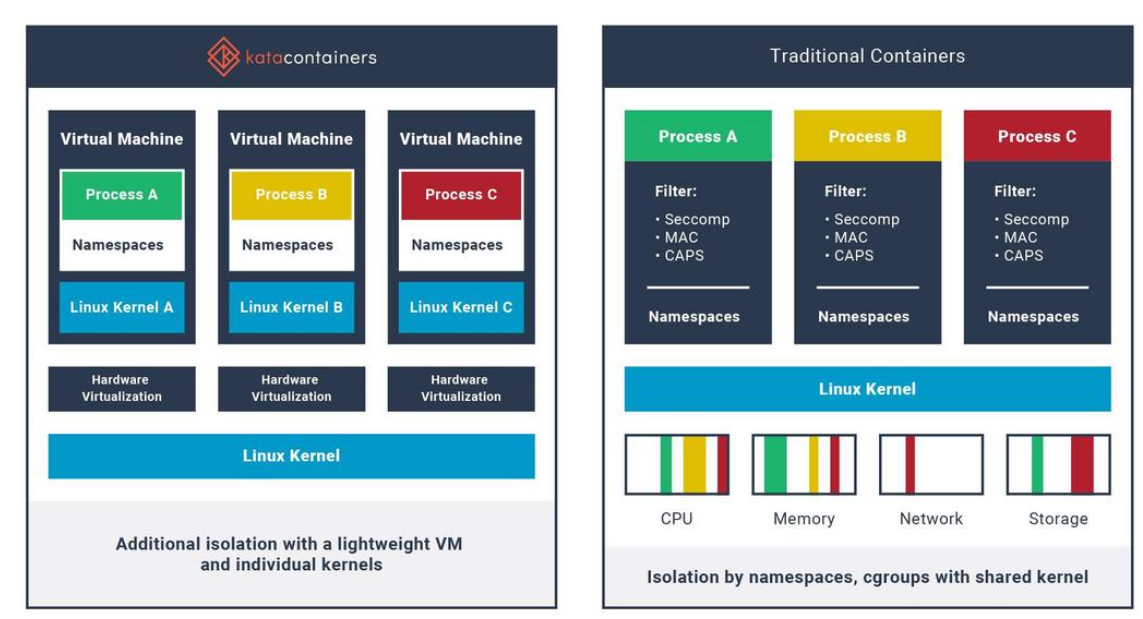
沙箱虚拟化技术虚拟机容器之间的关系详解
问题 沙箱、虚拟化、容器三者分开一一介绍的话我知道他们各自都是什么东西,但是如果把三者放在一起,它们之间到底什么关系?又有什么联系呢?我不是很明白!!! 就比如说: 沙箱&#…...

算术操作符与类型转换:从基础到精通
目录 前言:从基础到实践——探索运算符与类型转换的奥秘 算术操作符超级详解 算术操作符:、-、*、/、% 赋值操作符:和复合赋值 单⽬操作符:、--、、- 前言:从基础到实践——探索运算符与类型转换的奥秘 在先前的文…...

用 Rust 重写 Linux 内核模块实战:迈向安全内核的新篇章
用 Rust 重写 Linux 内核模块实战:迈向安全内核的新篇章 摘要: 操作系统内核的安全性、稳定性至关重要。传统 Linux 内核模块开发长期依赖于 C 语言,受限于 C 语言本身的内存安全和并发安全问题,开发复杂模块极易引入难以…...

云原生时代的系统设计:架构转型的战略支点
📝个人主页🌹:一ge科研小菜鸡-CSDN博客 🌹🌹期待您的关注 🌹🌹 一、云原生的崛起:技术趋势与现实需求的交汇 随着企业业务的互联网化、全球化、智能化持续加深,传统的 I…...