[NLP]如何训练自己的大型语言模型
简介
大型语言模型,如OpenAI的GPT-4或Google的PaLM,已经席卷了人工智能领域。然而,大多数公司目前没有能力训练这些模型,并且完全依赖于只有少数几家大型科技公司提供技术支持。
在Replit,我们投入了大量资源来建立从头开始训练自己的大型语言模型所需的基础设施。在本文中,我们将概述我们如何训练LLM(Large Language Models),从原始数据到部署到用户面向生产环境。我们将讨论沿途遇到的工程挑战以及如何利用我们认为构成现代LLM堆栈的供应商:Databricks、HuggingFace和MosaicML。
虽然我们的模型主要是针对代码生成用例设计的,但所讨论的技术和教训适用于所有类型的LLMs,包括通用语言模型。在未来几周和月份中,我们计划深入探索过程中繁琐细节并发布一系列博客文章。
为什么要训练你自己的LLMs?
Replit的AI团队经常被问到“为什么要训练自己的模型?”有很多原因可以解释公司决定训练自己的LLM,包括数据隐私和安全性、对更新和改进具有更大的控制力等。
在Replit,我们主要关注定制化、减少依赖以及成本效益。
- 定制化。训练一个定制化模型使我们能够根据特定需求和要求进行调整,包括平台特定功能、术语和上下文,在通用模型(如GPT-4)或甚至代码专用模型(如Codex)中可能无法涵盖。例如,我们的模型经过了针对Replit上流行的某些基于Web的编程语言(包括Javascript React(JSX) 和Typescript React(TSX))进行了优化。
- 减少依赖。虽然我们会根据任务选择正确的模型,但是我们认为减少对只有一小部分AI提供商依赖是有好处的。这不仅适用于Replit还适用于更广泛开发者社区。这就是为什么我们计划开源一些自己训练出来的模型,并且如果没有训练它们将无法实现。
- 成本效率。尽管成本将持续下降,但LLMs对于全球开发者社区来说仍然是难以承受的。在Replit,我们的使命是将下一个十亿软件创作者带到线上。我们相信,在印度用手机编码的学生应该能够访问与硅谷专业开发人员相同的AI。为了实现这一目标,我们训练定制化模型,这些模型更小、更高效,并且可以大幅降低成本进行托管。
数据管道
LLMs需要大量的数据进行训练。为了训练它们,需要构建强大的数据管道,这些管道高度优化,同时又足够灵活,可以轻松地包含新的公共和专有数据来源。
堆栈
我们从Hugging Face上可用的 The Stack 作为我们的主要数据源开始。Hugging Face 是数据集和预训练模型的重要资源。它们还提供各种有用的工具作为 Transformers 库的一部分,包括用于标记化、模型推理和代码评估的工具。
Stack 由BigCode项目提供。关于数据集构建的详细信息可参见Kocetkov等人 (2022) 。经过去重处理后,版本1.2的数据集包含大约2.7 TB以开放授权方式发布的源代码,涵盖超过350种编程语言。
Transformers库在抽象化许多与模型训练相关挑战方面做得非常出色,包括处理大规模数据。然而,在我们的流程中发现这不足够,因为我们需要对数据进行额外控制,并能够以分布式方式处理它。
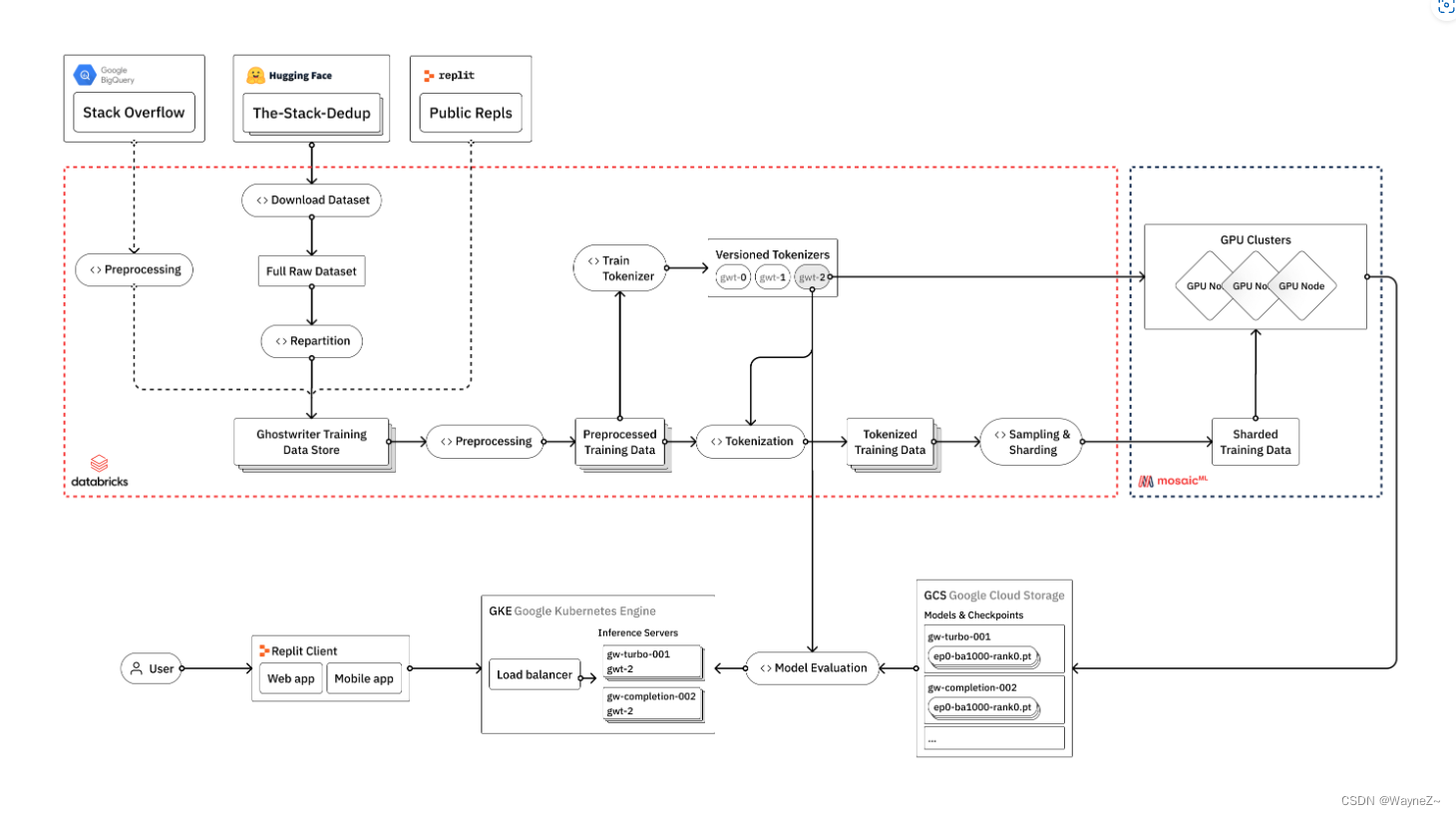
数据处理
当需要进行更高级的数据处理时,我们使用Databricks来构建我们的管道。这种方法还使我们可以轻松地将其他数据源(例如 Replit 或 Stack Overflow)引入到我们的流程中,我们计划在未来的迭代中这样做。
第一步是下载来自Hugging Face的原始数据。我们使用Apache Spark将数据集构建过程在每种编程语言之间并行化。然后,我们重新划分数据,并以优化设置的parquet格式重写出来,供下游处理。
接下来,我们转向清理和预处理我们的数据。通常情况下,重要的是重复数据和修复各种编码问题,但The Stack已经使用Kocetkov等人(2022)中概述的近乎重复的技术为我们做了这些。然而,一旦我们开始将Replit数据引入我们的管道,我们将不得不重新运行重复数据删除过程。这就是拥有Databricks这样的工具的好处,我们可以将The Stack、Stackoverflow和Replit数据视为更大的数据湖中的三个来源,并在下游流程中根据需要利用它们。
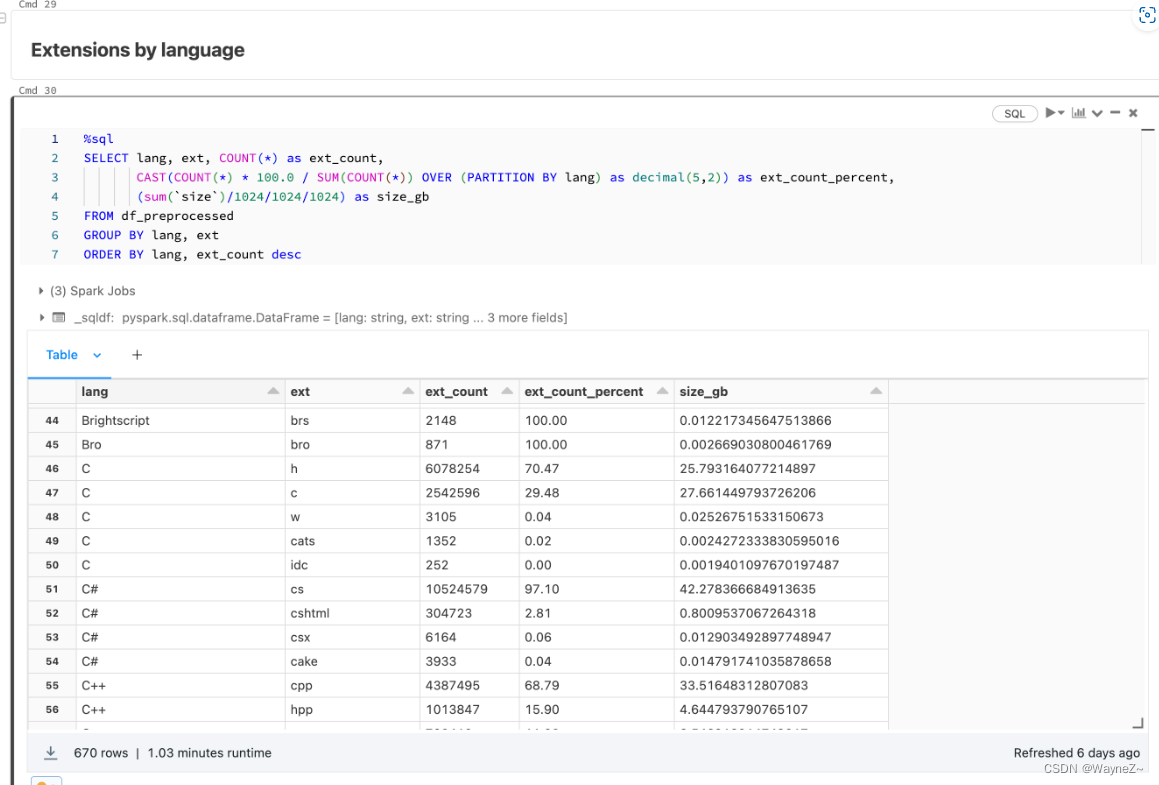
使用Databricks的另一个好处是,我们可以在底层数据上运行可扩展和可操作的分析。我们在数据源上运行所有类型的汇总统计,检查长尾分布,并诊断过程中的任何问题或不一致之处。所有这些都是在Databricks笔记本中完成的,它也可以与MLFlow集成,以跟踪和复制我们所有的分析结果。这一步,相当于对我们的数据进行定期的X光检查,也有助于为我们采取的各种预处理步骤提供信息。
对于预处理,我们采取以下步骤:
- 我们通过删除任何个人身份信息 (PII) 来匿名化数据,包括电子邮件、IP 地址和密钥。
- 我们使用多种启发式方法来检测和删除自动生成的代码。
- 对于一部分语言,我们删除了无法编译或无法使用标准语法解析器解析的代码。
- 我们根据平均行长、最大行长和字母数字字符的百分比过滤掉文件。
标记化和词汇训练
在标记化之前,我们使用我们用于模型训练的相同数据的随机子样本来训练我们自己的自定义词汇表。自定义词汇表使我们的模型能够更好地理解和生成代码内容。这会提高模型性能,并加快模型训练和推理。
此步骤是该过程中最重要的步骤之一,因为它用于我们过程的所有三个阶段(数据管道、模型训练、推理)。它强调了为模型训练过程提供强大且完全集成的基础架构的重要性。
我们计划在未来的博文中更深入地探讨代币化。在高层次上,我们必须考虑的一些重要事项是词汇量、特殊标记和标记标记的保留空间。
一旦我们训练了我们的自定义词汇表,我们就会标记我们的数据。最后,我们构建了我们的训练数据集并将其写成一种分片格式,该格式经过优化以用于模型训练过程。
模型训练
我们使用MosaicML训练我们的模型。在之前部署了我们自己的训练集群后,我们发现 MosaicML 平台为我们提供了一些关键优势。
- 多个云提供商。Mosaic 使我们能够利用来自不同云提供商的 GPU,而无需设置帐户和所有必需的集成的开销。
- LLM 训练配置。Composer 库有许多调整良好的配置,用于训练各种模型和不同类型的训练目标。
- 托管基础设施。他们的托管基础架构为我们提供了编排、效率优化和容错(即从节点故障中恢复)。
在确定我们模型的参数时,我们考虑了模型大小、上下文窗口、推理时间、内存占用等之间的各种权衡。较大的模型通常提供更好的性能并且更能够进行迁移学习。然而,这些模型对训练和推理都有更高的计算要求。后者对我们尤为重要。Replit 是一种云原生 IDE,其性能感觉就像桌面原生应用程序,因此我们的代码完成模型需要快如闪电。出于这个原因,我们通常会选择具有较小内存占用和低延迟推理的较小模型。
除了模型参数外,我们还从各种训练目标中进行选择,每个训练目标都有其独特的优点和缺点。最常见的训练目标是下一个标记预测。这通常适用于代码完成,但未能考虑到文档下游的上下文。这可以通过使用“中间填充”目标来缓解,其中文档中的一系列标记被屏蔽,并且模型必须使用周围的上下文来预测它们。另一种方法是 UL2(无监督潜在语言学习),它将训练语言模型的不同目标函数构建为去噪任务,其中模型必须恢复给定输入的缺失子序列。

一旦我们决定了我们的模型配置和训练目标,我们就会在 GPU 的多节点集群上启动我们的训练运行。我们能够根据我们正在训练的模型的大小以及我们希望多快完成训练过程来调整为每次运行分配的节点数。运行大型 GPU 集群的成本很高,因此以尽可能最有效的方式利用它们非常重要。我们密切监控 GPU 利用率和内存,以确保我们从计算资源中获得最大可能的使用率。
我们使用 Weights & Biases 来监控训练过程,包括资源利用率和训练进度。我们监控我们的损失曲线,以确保模型在训练过程的每个步骤中都能有效地学习。我们还关注损失峰值。这些是损失值的突然增加,通常表明底层训练数据或模型架构存在问题。因为这些事件通常需要进一步调查和潜在的调整,我们在我们的流程中强制执行数据确定性,因此我们可以更轻松地重现、诊断和解决任何此类损失峰值的潜在来源。
评估
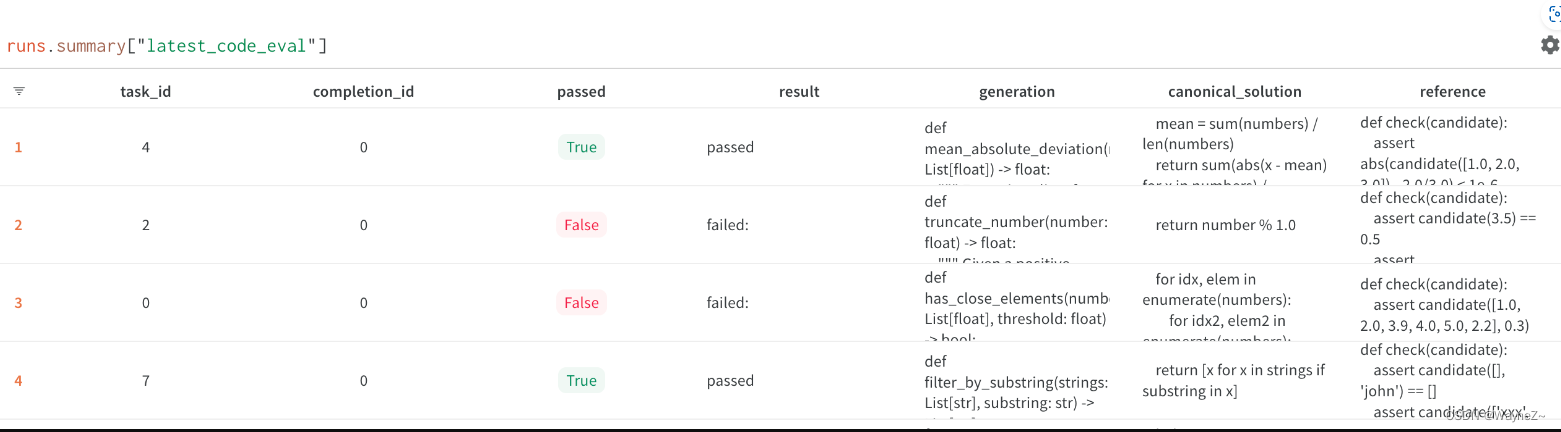
为了测试我们的模型,我们使用 Chen 等人中描述的 HumanEval 框架的变体。(2021)。给定函数签名和文档字符串,我们使用该模型生成一段 Python 代码。然后,我们对生成的函数运行测试用例,以确定生成的代码块是否按预期工作。我们运行多个样本并分析相应的Pass@K数字。
这种方法对Python来说效果最好,因为它有现成的评估器和测试案例。但由于Replit支持许多编程语言,我们需要对各种额外语言的模型性能进行评估。我们发现这很难做到,而且没有广泛采用的工具或框架来提供全面的解决方案。两个具体的挑战包括在任何编程语言中建立一个可重复的运行环境,以及对没有广泛使用的测试案例标准的编程语言(如HTML、CSS等)的模糊性。幸运的是,"任何编程语言的可重现的运行环境 "是我们在Replit的工作!我们目前正在建立一个评估框架,允许任何研究人员插入并测试他们的多语言基准。我们将在未来的一篇博文中讨论这个问题。
部署到生产
一旦我们训练和评估了我们的模型,就可以将其部署到生产环境中了。正如我们之前提到的,我们的代码完成模型应该感觉很快,请求之间的延迟非常低。我们使用 NVIDIA 的 FasterTransformer 和 Triton Server 加速我们的推理过程。FasterTransformer 是一个为基于 transformer 的神经网络的推理实现加速引擎的库,而 Triton 是一个稳定且快速的推理服务器,易于配置。这种组合为我们在转换器模型和底层 GPU 硬件之间提供了一个高度优化的层,并允许对大型模型进行超快速分布式推理。
在将我们的模型部署到生产环境中后,我们能够使用我们的 Kubernetes 基础设施对其进行自动缩放以满足需求。尽管我们在之前的博文中讨论过自动缩放,但值得一提的是,托管推理服务器会带来一系列独特的挑战。这些包括大型工件(即模型权重)和特殊硬件要求(即不同的 GPU 大小/数量)。我们设计了我们的部署和集群配置,以便我们能够快速可靠地交付。例如,我们的集群旨在解决个别区域的 GPU 短缺问题,并寻找最便宜的可用节点。
在我们将模型放在实际用户面前之前,我们喜欢自己测试它并了解模型的“氛围”。我们之前计算的 HumanEval 测试结果很有用,但没有什么比使用模型来感受它更好的了,包括它的延迟、建议的一致性和一般帮助。将模型放在 Replit 工作人员面前就像拨动开关一样简单。一旦我们对它感到满意,我们就会翻转另一个开关并将其推广给我们的其他用户。
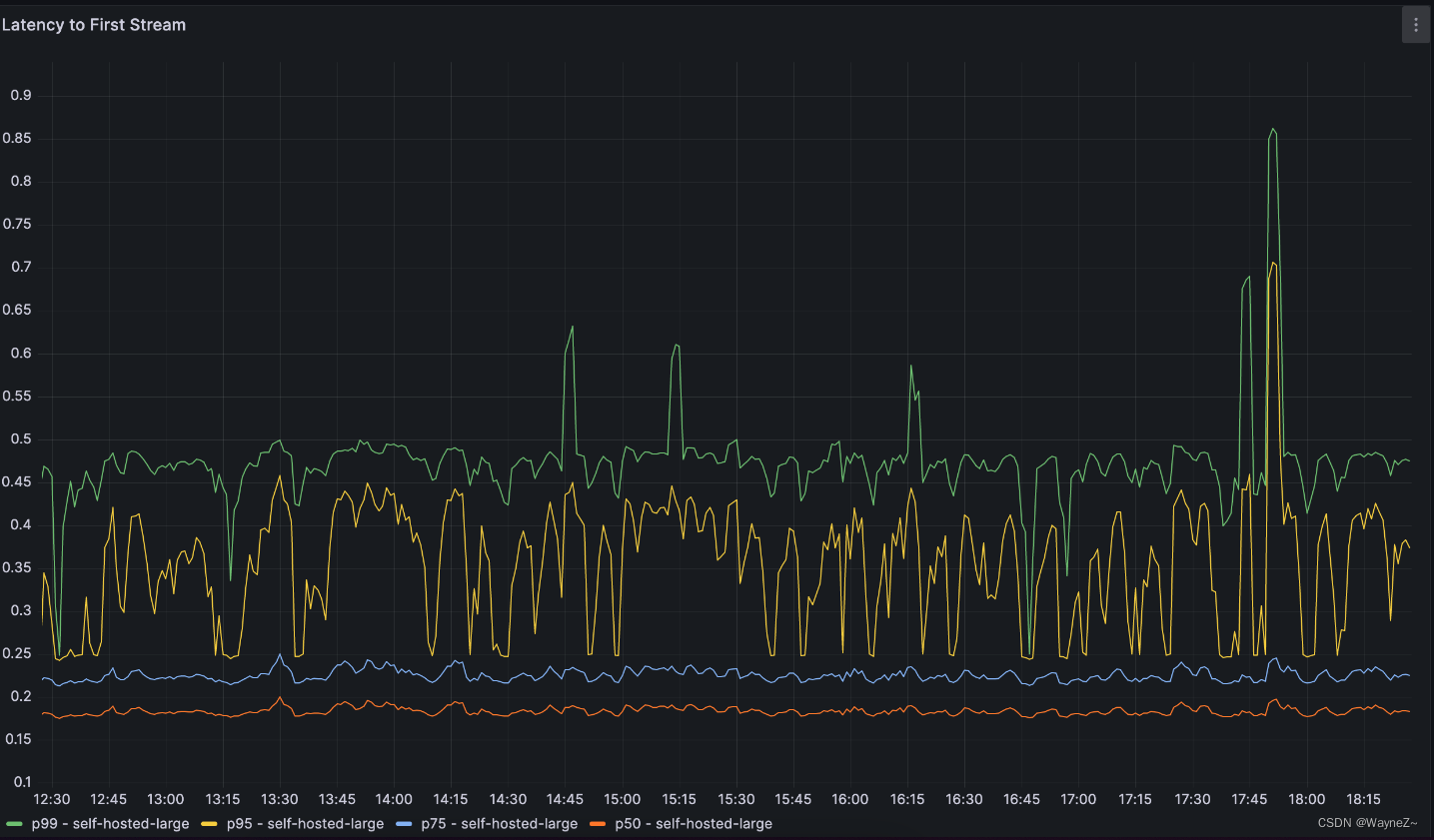
我们将继续监控模型性能和使用指标。对于模型性能,我们监控请求延迟和 GPU 利用率等指标。对于使用情况,我们跟踪代码建议的接受率,并将其分解到包括编程语言在内的多个维度。这也允许我们对不同的模型进行 A/B 测试,并获得一个模型与另一个模型比较的定量度量。
反馈与迭代
我们的模型训练平台使我们能够在不到一天的时间内将原始数据转化为部署在生产环境中的模型。但更重要的是,它允许我们训练和部署模型、收集反馈,然后根据该反馈快速迭代。
对于我们的流程来说,保持对底层数据源、模型训练目标或服务器架构的任何变化的鲁棒性也很重要。这使我们能够在快速发展的领域中利用新的进步和功能,在这个领域中,似乎每天都有新的令人兴奋的公告。
接下来,我们将扩展我们的平台,使我们能够使用 Replit 本身来改进我们的模型。这包括基于人类反馈的强化学习 (RLHF) 等技术,以及使用从 Replit Bounties 收集的数据进行指令调整。
下一步
虽然我们取得了很大进步,但我们仍处于训练LLMs的早期阶段。我们有很多改进要做,还有很多难题需要解决。随着语言模型的不断进步,这种趋势只会加速。将会有一系列与数据、算法和模型评估相关的新挑战。
Replit - How to train your own Large Language Models
相关文章:
[NLP]如何训练自己的大型语言模型
简介 大型语言模型,如OpenAI的GPT-4或Google的PaLM,已经席卷了人工智能领域。然而,大多数公司目前没有能力训练这些模型,并且完全依赖于只有少数几家大型科技公司提供技术支持。 在Replit,我们投入了大量资源来建立从…...
LeetCode1047. 删除字符串中的所有相邻重复项
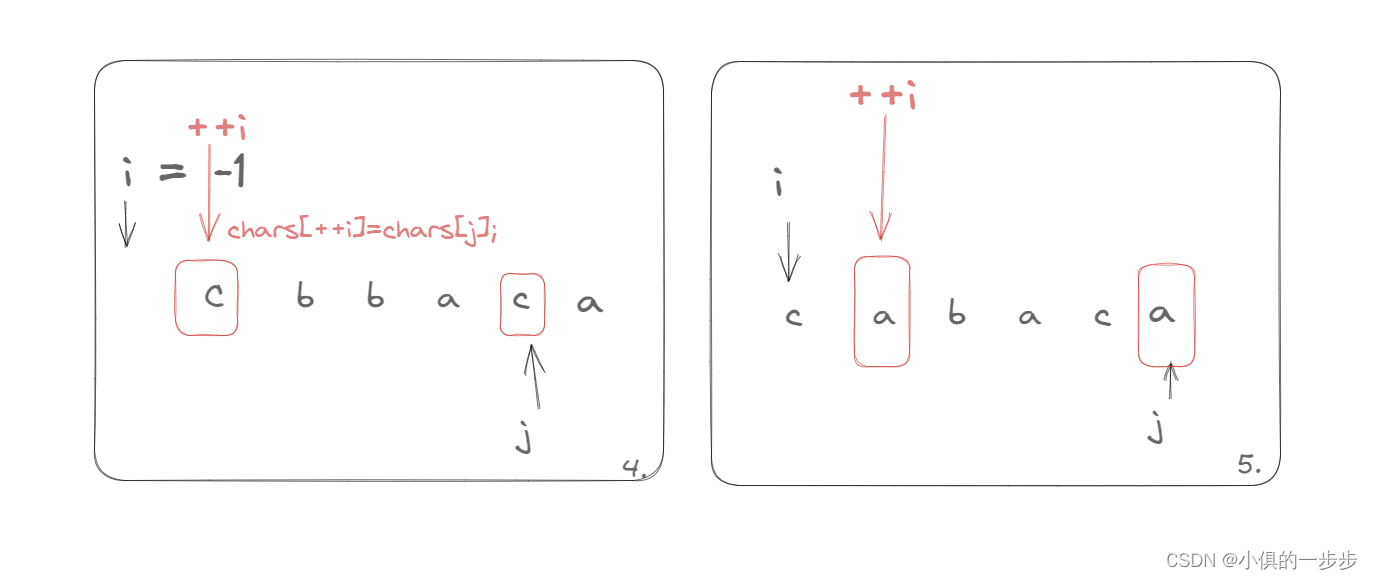
1047. 删除字符串中的所有相邻重复项 给出由小写字母组成的字符串 S,重复项删除操作会选择两个相邻且相同的字母,并删除它们。 在 S 上反复执行重复项删除操作,直到无法继续删除。 在完成所有重复项删除操作后返回最终的字符串。答案保证唯一…...
)
3。数据结构(3)
嵌入式软件开发第三部分,各类常用的数据结构及扩展,良好的数据结构选择是保证程序稳定运行的关键,(1)部分包括数组,链表,栈,队列。(2)部分包括树,…...

QT停靠窗口QDockWidget类
QT停靠窗口QDockWidget类 QDockWidget类简介函数和方法讲解 QDockWidget类简介 QDockWidget 类提供了一个部件,它可以停靠在 QMainWindow 内或作为桌面上的顶级窗口浮动。 QDockWidget 提供了停靠窗口部件的概念,也称为工具面板或实用程序窗口。 停靠窗…...

【LeetCode】139. 单词拆分
139. 单词拆分(中等) 思路 首先将大问题分解成小问题: 前 i 个字符的子串,能否分解成单词;剩余子串,是否为单个单词; 动态规划的四个步骤: 确定 dp 数组以及下标的含义 dp[i] 表示 s…...

【三维重建】NeRF原理+代码讲解
文章目录 一、技术原理1.概览2.基于神经辐射场(Neural Radiance Field)的体素渲染算法3.体素渲染算法4.位置信息编码(Positional encoding)5.多层级体素采样 二、代码讲解1.数据读入2.创建nerf1.计算焦距focal与其他设置2.get_emb…...
IntelliJ IDEA 社区版2021.3配置SpringBoot项目详细教程及错误解决方法
目录 一、SpringBoot的定义 二、Spring Boot 优点 三、创建一个springboot的项目 四、使用IDEA创建SpringBoot失败案例 一、SpringBoot的定义 Spring 的诞⽣是为了简化 Java 程序的开发的,⽽ Spring Boot 的诞⽣是为了简化 Spring 程序开发的。 Spring Boot 翻…...
Qt中QDebug的使用
QDebug类为调试信息(debugging information)提供输出流。它的声明在<QDebug>中,实现在Core模块中。将调试或跟踪信息(debugging or tracing information)写出到device, file, string or console时都会使用QDebug。 此类的成员函数参考:https://doc…...

vue使用路由的query配置项时如何清除地址栏的参数
写vue项目时,如果想通过路由的query配置项把参数从一个组件传到另一个组件,但是又不希望?idxxx显示在地址栏(如:http://localhost:8080/test?idxxx的?idxxx),该怎么做: 举一个案例࿱…...
)
Redis-列表(List)
Redis列表(List) 介绍 单键多值Redis 列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)它的底层实际是个双向链表,对两端的操作性能很高,通过索…...

ripro主题修改教程-首页搜索框美化教程
先看效果图: 我们来看怎么实现: 1、找到wp-content/themes/ripro/assets/css/diy.css并将下面的内容整体复制进去并保存 /*首页搜索框*/ .bgcolor-fff {background-color: #fff; } .row,.navbar .menu-item-mega>.sub-menu{margin-left:-10px;margin-right:-10px;} .home…...

写作业用白光还是暖光?盘点色温4000K的护眼台灯
台灯的白光或者暖光指的是台灯的色温,低色温的光线看起来发黄发红,高色温的光线发白发蓝。 如果灯光的光源是高品质光源,本身没有蓝光问题,那么色温的选择对护眼的影响是比较少的,更多的是对人学习工作状态,…...
-- SimpleDateFormat类)
Java时间类(一)-- SimpleDateFormat类
目录 1. SimpleDateFormat的构造方法: 时间模式字母: 2. SimpleDateFormat的常用方法: “工欲善其事,必先利其器”。学习时间类之前,需要先学习SimpleDateFormat类。 java.text.SimpleDateFormat类是以与语言环境有关的方式来格式...
07 Kubernetes 网络与服务管理
课件 Kubernetes Service是一个抽象层,用于定义一组Pod的访问方式和访问策略,其作用是将一组Pod封装成一个服务,提供一个稳定的虚拟IP地址和端口号,以便于其他应用程序或服务进行访问。 以下是Kubernetes Service YAML配置文件的…...

并发编程之Atomic原子操作类
基本类型:AtomicInteger、AtomicBoolean、AtomicLong 引用类型:AtomicReference、AtomicMarkableReference、AtomicStampedReference 数组类型:AtomicIntegerArray、AtomicLongArray、AtomicReferenceArray 对象属性原子修改器:…...
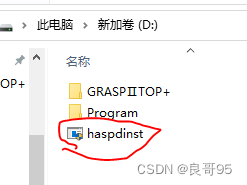
管家婆辉煌Ⅱ 13.32版安装方法
因管家婆辉煌版已经长期不更新,现已经出现蓝屏的问题,故此新开此贴,慢慢更新安装方法。 首先管家婆下载地址:http://www.grasp.com.cn/download.aspx?id116 先安装sql server 2008 下载后,运行安装,请注…...

常见的接口优化技巧思路
一、背景 针对老项目,去年做了许多降本增效的事情,其中发现最多的就是接口耗时过长的问题,就集中搞了一次接口性能优化。本文将给小伙伴们分享一下接口优化的通用方案。 二、接口优化方案总结 1.批处理 批量思想:批量操作数据…...

【Java EE】-使用Fiddler抓包以及HTTP的报文格式
作者:学Java的冬瓜 博客主页:☀冬瓜的主页🌙 专栏:【JavaEE】 分享: 在满园弥漫的沉静的光芒之前,一个人更容易看到时间,并看到自己的身影。——史铁生《我与地坛》 主要内容:使用FIddler抓包的…...

Java异步编程
Java异步编程 1、什么是java异步编程2、异步编程有什么作用3、异步编程常用于哪些业务4、异步编程的方式5、Async异步调用Async简介 1、什么是java异步编程 Java异步编程是一种处理并发问题的技术,它可以在执行耗时操作的同时,不阻塞主线程,…...

C++类与对象(二)——构造函数与析构函数
文章目录 一.类的默认6个成员函数二.构造函数1.引例2.构造函数的概念及特性 三.析构函数😋析构函数的特性 前言: 上篇文章初步认识了类以及类的相关知识,本篇将继续深入学习类与对象——类的默认6个成员函数: 一.类的默认6个成员函…...
。】2022-5-15)
【根据当天日期输出明天的日期(需对闰年做判定)。】2022-5-15
缘由根据当天日期输出明天的日期(需对闰年做判定)。日期类型结构体如下: struct data{ int year; int month; int day;};-编程语言-CSDN问答 struct mdata{ int year; int month; int day; }mdata; int 天数(int year, int month) {switch (month){case 1: case 3:…...

Golang 面试经典题:map 的 key 可以是什么类型?哪些不可以?
Golang 面试经典题:map 的 key 可以是什么类型?哪些不可以? 在 Golang 的面试中,map 类型的使用是一个常见的考点,其中对 key 类型的合法性 是一道常被提及的基础却很容易被忽视的问题。本文将带你深入理解 Golang 中…...

大型活动交通拥堵治理的视觉算法应用
大型活动下智慧交通的视觉分析应用 一、背景与挑战 大型活动(如演唱会、马拉松赛事、高考中考等)期间,城市交通面临瞬时人流车流激增、传统摄像头模糊、交通拥堵识别滞后等问题。以演唱会为例,暖城商圈曾因观众集中离场导致周边…...

LeetCode - 394. 字符串解码
题目 394. 字符串解码 - 力扣(LeetCode) 思路 使用两个栈:一个存储重复次数,一个存储字符串 遍历输入字符串: 数字处理:遇到数字时,累积计算重复次数左括号处理:保存当前状态&a…...

STM32F4基本定时器使用和原理详解
STM32F4基本定时器使用和原理详解 前言如何确定定时器挂载在哪条时钟线上配置及使用方法参数配置PrescalerCounter ModeCounter Periodauto-reload preloadTrigger Event Selection 中断配置生成的代码及使用方法初始化代码基本定时器触发DCA或者ADC的代码讲解中断代码定时启动…...

转转集团旗下首家二手多品类循环仓店“超级转转”开业
6月9日,国内领先的循环经济企业转转集团旗下首家二手多品类循环仓店“超级转转”正式开业。 转转集团创始人兼CEO黄炜、转转循环时尚发起人朱珠、转转集团COO兼红布林CEO胡伟琨、王府井集团副总裁祝捷等出席了开业剪彩仪式。 据「TMT星球」了解,“超级…...

跨链模式:多链互操作架构与性能扩展方案
跨链模式:多链互操作架构与性能扩展方案 ——构建下一代区块链互联网的技术基石 一、跨链架构的核心范式演进 1. 分层协议栈:模块化解耦设计 现代跨链系统采用分层协议栈实现灵活扩展(H2Cross架构): 适配层…...

零基础设计模式——行为型模式 - 责任链模式
第四部分:行为型模式 - 责任链模式 (Chain of Responsibility Pattern) 欢迎来到行为型模式的学习!行为型模式关注对象之间的职责分配、算法封装和对象间的交互。我们将学习的第一个行为型模式是责任链模式。 核心思想:使多个对象都有机会处…...

自然语言处理——Transformer
自然语言处理——Transformer 自注意力机制多头注意力机制Transformer 虽然循环神经网络可以对具有序列特性的数据非常有效,它能挖掘数据中的时序信息以及语义信息,但是它有一个很大的缺陷——很难并行化。 我们可以考虑用CNN来替代RNN,但是…...

在Ubuntu24上采用Wine打开SourceInsight
1. 安装wine sudo apt install wine 2. 安装32位库支持,SourceInsight是32位程序 sudo dpkg --add-architecture i386 sudo apt update sudo apt install wine32:i386 3. 验证安装 wine --version 4. 安装必要的字体和库(解决显示问题) sudo apt install fonts-wqy…...