【深度学习】计算机视觉(13)——模型评价及结果记录
1 Tensorboard怎么解读?
因为意识到tensorboard的使用远不止画个图放个图片那么简单,所以这里总结一些关键知识的笔记。由于时间问题,我先学习目前使用最多的功能,大部分源码都包含summary的具体使用,基本不需要自己修改,因此tensorboard的解读作为目前学习的核心,所以本文的知识结构可能不是很完整,以后的学习中再慢慢调整。
ps:便于更直观的理解,文中给出的代码大多是我学习时直接从项目源码那里复制过来的,如果没有特殊说明,文中出现的路径、字符串等都是项目特定内容,不影响学习也不必深究其含义。
1.1 histogram直方图
1.1.1 概念
通过tf.summary.histogram生成某一张量tensor的直方图,在TensorBoard直方图仪表板上显示。直方图是显示张量在不同时间点的,通过直方图显示某些值的分布随时间变化的情况。
如何理解“随时间”变化?按照初学时的理解,在训练网络的过程中,数据肯定是随着迭代次数的增加慢慢保存更新的,比如loss曲线的生成,横坐标一定与迭代次数正相关。通过阅读代码我了解到,我们设置了每隔一定的时间,保存一次summary,也就是说实际上迭代的次数体现在时间的变化。
The time interval for saving tensorflow summaries
1.1.2 数据解读
先抛开时间不谈,从分布情况的角度看,tf.summary.histogram()将输入的一个任意大小和形状的张量压缩成一个由宽度和数量组成的直方图数据结构。
举个例子便于理解,假设输入的数据为 [0.5, 1.1, 1.3, 2.2, 2.9, 2.5],直方图将横坐标分成三个区间,分别为0-1、1-2、2-3,而纵坐标表示在每个区间内的元素的数量。实际上tensor读取的图片像素是有维度要求的,而且划分区间也有一定的规则,那么模拟一下真实情况,还是用上面的数据构造一个RGB图片:
import tensorflow as tf
from torchvision import transforms
from torch.utils.tensorboard import SummaryWriter
import numpy as npwriter = SummaryWriter("logs")# width = 6 and height = 2
img_row = [0.5, 1.1, 1.3, 2.2, 2.9, 2.5]
img_r = [img_row, img_row]
img_g = [img_row, img_row]
img_b = [img_row, img_row]
img = [img_r, img_g, img_b]ans = np.array(img, dtype='float')to_tensor = transforms.ToTensor()
ans = to_tensor(ans)writer.add_histogram("test histogram sample of img", ans)writer.close()
得到的直方图如下:

其中x和y的对应关系为:
| x = ? | y = ? |
|---|---|
| 0.54 | 6.00 |
| 0.62 | 0.00 |
| 0.94 | 0.00 |
| 1.02 | 3.03 |
| 1.1 | 2.97 |
| 1.18 | 0.00 |
| 1.26 | 3.89 |
| 1.34 | 2.11 |
| 1.42 | 0.00 |
| 2.06 | 0.00 |
| 2.14 | 0.477 |
| 2.22 | 2.22 |
| 2.3 | 2.22 |
| 2.38 | 2.12 |
| 2.46 | 2.02 |
| 2.54 | 2.02 |
| 2.62 | 0.933 |
| 2.7 | 0.00 |
| 2.78 | 0.00 |
| 2.86 | 0.00 |
说明:虽然直方图看起来是连续的,但是鼠标移动时只显示这这几对数据,每组数据之间直线连接。
1.1.3 数据计算
显示在tensorboard时,默认将数据分为30个区间,每个区间的长度为(max-min)/30,即(2.9-05)/30=0.08。而每组xi取区间的中点,比如第一组区间为[0.5, 0.58],则x1=0.54,同理第二组x2=0.62。
但是显示和实际数值是有区别的,实际上,区间并不是等分的,而是从0开始,区间长度是首项为0.1×10-12、公比为1.1的等比数列,且最后一个区间的长度需要进行截取,满足右端点经截取后保证不超过max。它使用指数分布来产生区间,越接近零区间分得越密,越大的数区间的长度越宽。我们将这些区间称为bin。
区间划分的规则清楚后学习实际的数据(x’i, y’i)与显示数据(xj, yj)之间的对应关系。公式为:

比如显示区间[2.50, 2.58]对应的中点x=2.54。
计算实际区间,根据等比数列可知,第300个区间为[2.3791, 2.617](经四舍五入后),"交集长度"为2.58-2.50=0.08,"区间大小"为2.617-2.3791=0.2379。因为在数列[0.5, 1.1, 1.3, 2.2, 2.9, 2.5]中只有2.5在[2.3791, 2.617]范围内,而且我构造的图片是6个这样的数列组成的张量,所以"区间所含元素个数"为1×6=6。
则当x=2.54时,y=0.08÷0.2379×6=2.0176,对照上表,2.0176≈2.02。
附:求实际区间按照等比数列求和公式Sn,已知首项和公比,第n个区间的端点为[Sn-1, Sn]。
验证1:显示数据为(1.02, 3.03),对应实际区间第291个区间[1.009, 1.1099],数据正确。
验证2:显示数据为(2.14, 0.477),对应实际区间第298个区间[1.9662, 2.1628]或第299个区间[2.1628, 2.3791],因为第298个区间里没有数据,所以对照第299个区间,数据正确。
1.1.4 OVERLAY和OFFSET
上一小节没有引入时间的概念,数据范围和数量已经构成了二维图像,那么随时间的变化如何表示呢?直方图有两种模式:OVERLAY和OFFSET。
OVERLAY
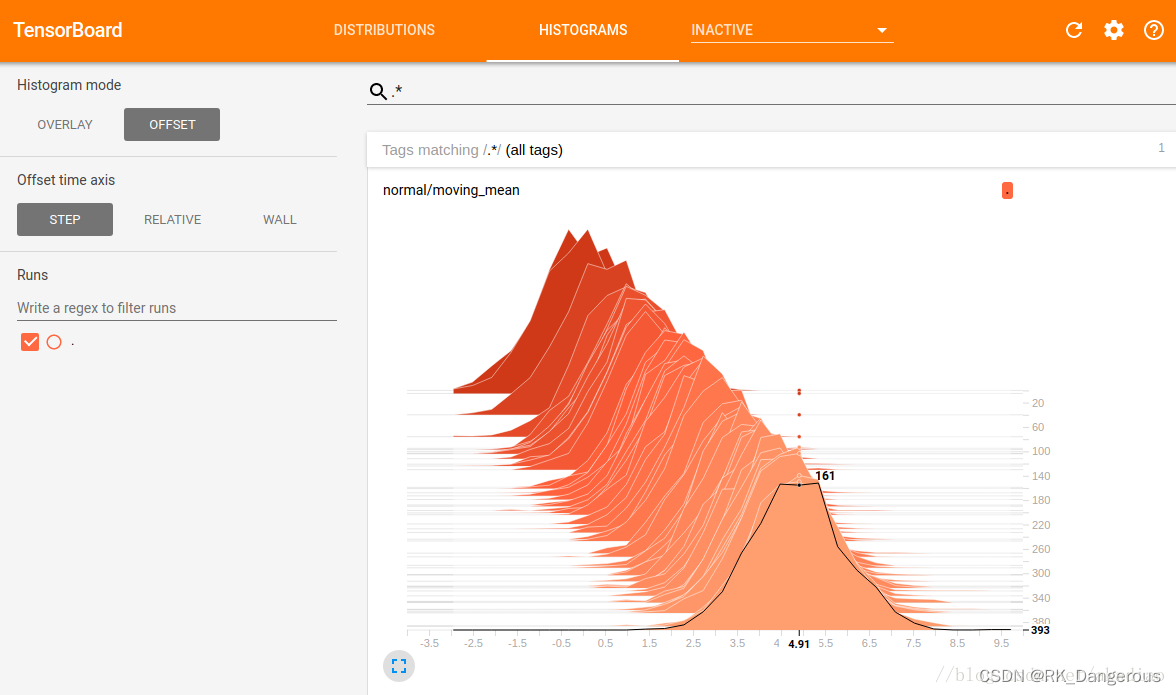
横轴表示bin值,纵轴表示数量,每个切片显示一个直方图,切片按步骤(步数或时间)排列。旧的切片较暗,新的切片颜色较浅。如图,可以看到在第393步时,以4.91为中心的bin中有161个元素。
另外,直方图切片并不总是按步数或时间均匀分布,而是通过水塘抽样/reservoir sampling来抽取所有直方图的一个子集,以节省内存.
OVERLAY
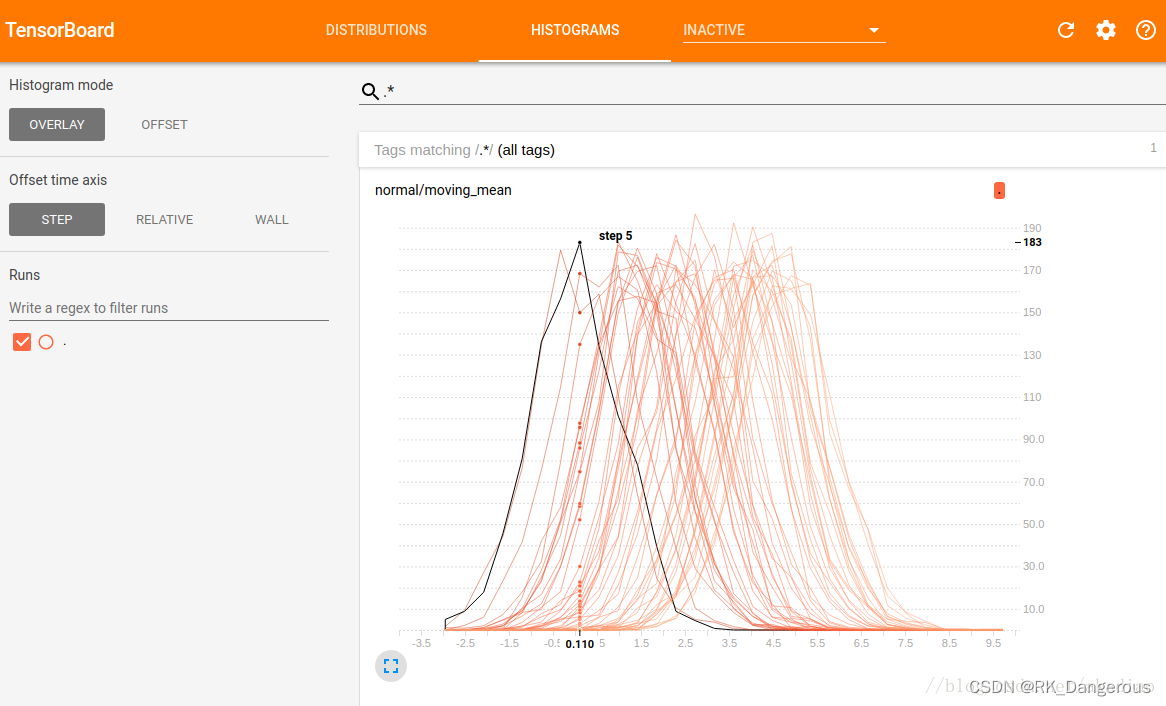
同样,横轴表示bin值,纵轴表示数量。但是OVERLAY模式下各个直方图切片不再展开,而是全部绘制在相同的y轴上,不同的线表示不同的步骤(步数或时间)。如图,可以看到在第5步时,以0.11为中心的bin中有183个元素。
OVERLAY模式用于直接比较不同直方图的计数.
1.1.5 应用
利用tf.summary.histogram可视化梯度、权重或特定层的输出分布,可传入的张量包括但不限于:网络输出特征(act_summary)、训练结果(score_summary)、需要训练的变量(train_summary)。根据代码为不同直方图设置标签,可生成多个直方图。

act_summary
tf.summary.histogram('ACT/' + tensor.op.name + '/activations', tensor)
传入的张量tensor = [net, rpn],其中net.shape = [1, w/16, h/16, 512],rpn.shape = [1, w/16, h/16, 512],显示神经网络两次特征的输出net、rpn的特征值分布。
score_summary
tf.summary.histogram('SCORE/' + tensor.op.name + '/' + key + '/scores', tensor)
传入的张量生成多个不同功能的分布直方图,例如网络输出、预测分数、预测概率、预测偏移、预测框坐标等。
train_summary
tf.summary.histogram('TRAIN/' + var.op.name, var)
传入的张量包括需要训练的变量的值。
var.op.name是指每个变量在创立时的操作的名字,也即为变量申请内存时的那个操作的名字。而var.name是Tensor名字,Tensor是操作的输出,也就是在创立变量的这个操作的输出就是所创立的变量。
我是这样理解的,python在使用变量的时候像指针一样指来指去的,最外面的那个是var.name,最里面的那个是var.op.name。
参考来源
TensorBoardX histogram查看说明
等比数列的前n项和公式是什么
TensorFlow学习Program1——4.TensorBoard可视化数据流图
TensorFlow学习--tf.summary.histogram与直方图仪表板/tensorboard_histograms
【Tensorflow_DL_Note17】TensorFlow可视化学习4_tf.summary模块的详解
Tensorfow基础知识点&操作
Tensorflow-tf.nn.zero_fraction()详解
相关文章:
【深度学习】计算机视觉(13)——模型评价及结果记录
1 Tensorboard怎么解读? 因为意识到tensorboard的使用远不止画个图放个图片那么简单,所以这里总结一些关键知识的笔记。由于时间问题,我先学习目前使用最多的功能,大部分源码都包含summary的具体使用,基本不需要自己修…...

项目经理在项目中是什么角色?
有人说,项目经理就是一个求人的差事,你是在求人帮你做事。 有人说,项目经理就是一个与人扯皮的差事,你要不断的与开发、产品、测试等之间沟通、协调。 确实,在做项目的时候,有的人是为了完成功能&#x…...

【技术分享】防止根据IP查域名,防止源站IP泄露
有的人设置了禁止 IP 访问网站,但是别人用 https://ip 的形式,会跳到你服务器所绑定的一个域名网站上 直接通过 https://IP, 访问网站,会出现“您的连接不是私密连接”,然后点高级,会出现“继续前往 IP”,…...

Baumer工业相机堡盟相机如何使用偏振功能(偏振相机优点和行业应用)(C#)
项目场景: Baumer工业相机堡盟相机是一种高性能、高质量的工业相机,可用于各种应用场景,如物体检测、计数和识别、运动分析和图像处理。 Baumer的万兆网相机拥有出色的图像处理性能,可以实时传输高分辨率图像。此外࿰…...
无损以太网与网络拥塞管理(PFC、ECN)
无损以太网 无损以太网(Lossless Ethernet)是一种专门用于数据中心网络的网络技术,旨在提供低延迟、高吞吐量和可靠性的传输服务。它是在传统以太网的基础上进行了扩展,引入了新的拥塞管理机制,以避免数据包丢失和网络…...

爬虫大全:从零开始学习爬虫的基础知识
爬虫是一种自动获取网站信息的技术,它可以帮助我们快速地抓取海量网站数据,进行统计分析、挖掘和展示。本文旨在为初学者详细介绍爬虫的基础知识,包括:爬虫原理、爬虫分类、网页结构分析、爬虫工具和技能、爬虫实践示范࿰…...

【Python】【进阶篇】21、Django Admin数据表可视化
目录 21、Django Admin数据表可视化1. 创建超级用户2. 将Model注册到管理后台1)在admin.py文件中声明 3. django_admin_log数据表 21、Django Admin数据表可视化 在《Django Admin后台管理系统》介绍过 Django 的后台管理系统是为了方便站点管理人员对数据表进行操作。Django …...

【MySQL约束】数据管理实用指南
1、数据库约束的认识 数据库约束的概念:数据库的约束是关系型数据库的一个重要的功能,它提供了一种“校验数据”合法性的机制,能够保证数据的“完整性”、“准确性”和“正确性” 数据库的约束: not null:不能存储 nul…...
2023年第二十届五一数学建模竞赛C题:“双碳”目标下低碳建筑研究-思路详解与代码答案
该题对于模型的考察难度较低,难度在于数据的搜集以及选取与处理。 这里推荐数据查询的网站:中国碳核算数据库(CEADs) https://www.ceads.net.cn/ 国家数据 国家数据data.stats.gov.cn/easyquery.htm?cnC01 以及各省市《统…...

Vue父组件生命周期和子组件生命周期触发顺序
加载渲染过程 父 beforeCreate -> 父 created -> 父 beforeMount -> 子 beforeCreate -> 子 created -> 子 beforeMount -> 子 mounted -> 父 mounted子组件更新过程 父 beforeUpdate -> 子 beforeUpdate -> 子 updated -> 父 updated父组件更新…...

DevOps工程师 - 面试手册
DevOps工程师 - 面试手册 岗位概述 DevOps工程师是一种专注于提高软件开发和运维团队协作、提高软件产品交付速度和质量的职位。这种角色要求具备跨领域的知识,以便在开发和运维过程中建立起稳定、可靠的基础设施和自动化流程。 常见的职位招聘描述 负责设计、实…...

Netty内存管理--内存池空间规格化SizeClasses
一、规格化 内存池类似于一个内存零售商, 从操作系统中申请一整块内存, 然后对其进行合理分割, 将分割后的小内存返回给程序。这里存在3个尺寸: 分割尺寸: 底层内存管理的基本单位, 比如常见的以页为单位分配, 但是页的大小是灵活的;申请尺寸: 内存使用者希望申请到的内存大小…...

数据结构刷题(三十):96不同的二叉搜索树、01背包问题理论、416分割等和子集
一、96. 不同的二叉搜索树 1.这个题比较难想递推公式, dp[3],就是元素1为头结点搜索树的数量 元素2为头结点BFS的数量 元素3为头结点BFS的数量 元素1为头结点搜索树的数量 右子树有2个元素的搜索树数量 * 左子树有0个元素的搜索树数量 元素2为头结…...

bash的进程与欢迎讯息自定义
在bash shell中,可以通过多种方式自定义欢迎讯息和提示符。主要有: 修改/etc/profile文件: 该文件在用户登录后执行,定义了PROMPT_COMMAND和PS1提示符。可以修改其内容实现自定义欢迎讯息和提示符。 例如,修改为: bash PROMPT_COMMANDecho -e "\nWelcome to My Bash She…...

本周大新闻|苹果首款MR没有主打卖点;Meta认为AI是AR OS的基础
本周XR大新闻,AR方面,苹果首款MR或没有主打卖点,反而尽可能支持更多App和服务;扎克伯格表示基于AI的AR眼镜操作系统是下一代计算平台的基础;微软芯片工程VP Jean Boufarhat加入Meta芯片团队;Humane展示了…...

Java中工具类Arrays、Collections、Objects
Arrays Arrays是Java中提供的一个针对数组操作的工具类,所有的方法都是静态的。 大致有这些常用的方法 sort()针对常用的基本数据类型,都能进行排序,byte、char、int、long、float、doubleparallelSort()并行排序,多线程排序&am…...

Docker安装Nginx/Python/Golang/Vscode【亲测可用】
一、docker安装nginx docker安装nginx,安装的是最新版本的:docker pull nginx:latest 创建一个容器:docker run --name my-nginx -p 80:80 -d nginx:latest 开启一个交互模式终端:docker exec -it my-nginx bash 创建django项…...

蓝桥杯2022年第十三届决赛真题-最大数字
蓝桥杯2022年第十三届决赛真题-最大数字 时间限制: 3s 内存限制: 320MB 题目描述 给定一个正整数 N。你可以对 N 的任意一位数字执行任意次以下 2 种操作: 将该位数字加 1。如果该位数字已经是 9,加 1 之后变成 0。 将该位数字减 1。如果该位数字已经…...
smbms项目搭建
目录 1.搭建一个maven web项目 2.配置Tomcat 3.测试项目是否能够跑起来 4.导入项目中会遇到的Jar包 5.项目结构搭建 6.项目实体类搭建 7.编写基础公共类 1.数据库配置文件 2.编写数据库的公共类 3.编写字符编码过滤器 3.1web配置注册 4.导入静态资源 1.搭建一个maven web项目 …...
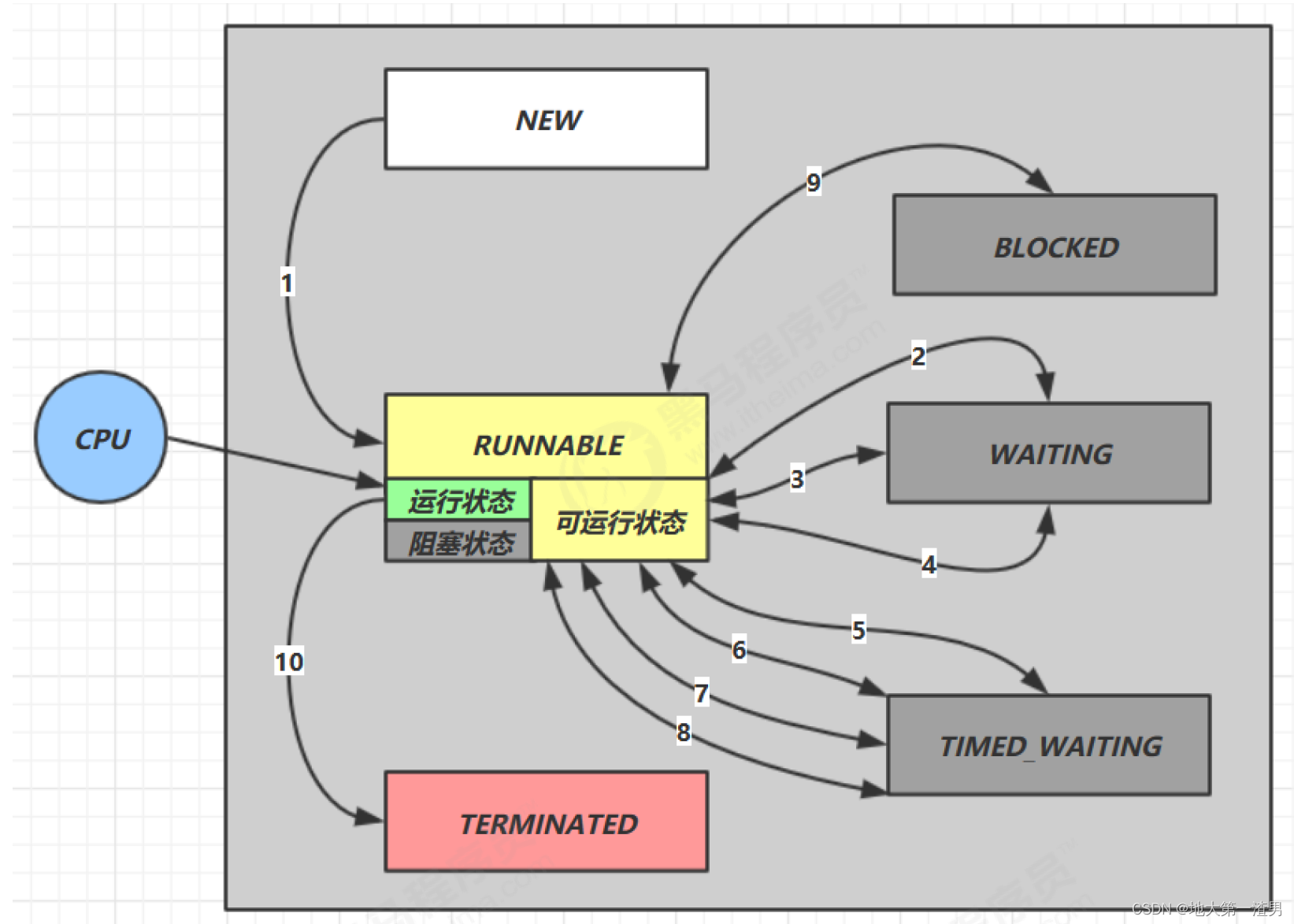
进程/线程 状态模型详解
前言:最近操作系统复习到线程的状态模型(也可以说进程的状态模型,本文直接用线程来说)时候,网上查阅资料,发现很多文章都说的很不一样,有五状态模型、六状态模型、七状态模型.......虽然都是对的…...

UE5 BaseEditorSettings.ini加载原理与配置生效机制
1. 为什么你改了BaseEditorSettings.ini却没生效?——从UE5编辑器启动流程讲起很多人在UE5项目里折腾半天,把BaseEditorSettings.ini文件翻来覆去改了十几遍,重启编辑器后发现:缩放比例还是不对、网格间距没变、甚至“启用实时预览…...

告别道路预测老套路:用ParkPredict+模型思路,解决停车场里的‘鬼探头’难题
破解泊车场景预测困局:ParkPredict模型的技术革新与实践停车场里的每一次转向、倒车和避让,都是对自动驾驶系统预测能力的极限挑战。与开放道路的规则明确不同,这里没有清晰的车道线指引,没有统一的行驶方向,只有随时可…...

阿波罗登月,不可能:读心术与影子叙事 ——不是向全世界展示登月,而是向全世界注射登月
阿波罗登月,不可能:读心术与影子叙事 ——不是向全世界展示登月,而是向全世界注射登月 Jianbing Zhu 1^{1}1 1^{1}1 ECT-OS-JiuHuaShan 文明实验室 ORCID: 0009-0006-8591-1891 DOI: 10.5281/zenodo.20373157 Email: ect-os-jiuhuashanzoho…...
)
别再手动编译了!Matlab一键调用CEC2017测试函数的完整配置指南(附30个函数调用示例)
别再手动编译了!Matlab一键调用CEC2017测试函数的完整配置指南(附30个函数调用示例) 算法研究者们常常需要借助标准测试函数来验证优化算法的性能,而CEC2017测试函数集因其复杂性和多维度的挑战性,成为评估算法鲁棒性的…...

基于ESP8266与MQTT的家庭水压自动控制系统设计与实现
1. 项目概述与核心需求解析家里水压不稳、供水时断时续,这大概是很多朋友都遇到过的烦心事。我所在的城市供水情况就很不理想,为了解决这个问题,我不得不自己动手,搭建了一套基于ESP8266微控制器的家庭水压增压与储水自动控制系统…...

危急时刻的六条基本安全提示
人机协作,AI模型:Deepseek 仅供参考 危急时刻的六条基本安全提示 以下内容仅为通用性安全建议,供在紧急情况下保持冷静、保护自身安全时参考。所有建议均基于常理和公共安全常识,不包含任何具体操作细节或可能被不当使用的信息…...

简单学习 --> SSE
我们使用AI时,AI对我们说的话不会一次性把全部内容弹出来,而是会像流水一样,一点点吐出来,那么这种丝滑的交互体验,背后的核心就是 SSE (Server-Sent Events)。 什么是 SSE? SSE(Server-Sent …...

对比自行维护多个 API 源,使用 Taotoken 聚合服务在运维复杂度上的降低
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比自行维护多个 API 源,使用 Taotoken 聚合服务在运维复杂度上的降低 在构建依赖多个大语言模型的应用时,…...

PvZ Toolkit终极指南:三步掌握植物大战僵尸最强修改器
PvZ Toolkit终极指南:三步掌握植物大战僵尸最强修改器 【免费下载链接】pvztoolkit 植物大战僵尸 PC 版综合修改器 项目地址: https://gitcode.com/gh_mirrors/pv/pvztoolkit PvZ Toolkit是一款专为植物大战僵尸PC版设计的综合修改器工具,能够让你…...

XZ6128A工作电压5-100V 输出电流5A 升压型大功率LED灯恒流驱动控制芯片
概述 XZ6128A是一款高效率、高精度的升压型大功率LED灯恒流驱动控制芯片。 XZ6128A内置高精度误差放大器,固定关断时间控制电路,恒流驱动电路等,特别适合大功率、多个高亮度LED灯串的恒流驱动。 XZ6128A采用固定关断时间的控制方式࿰…...