Word2vec原理+实战学习笔记(二)
来源:投稿 作者:阿克西
编辑:学姐
前篇:Word2vec原理+实战学习笔记(一)
视频链接:https://ai.deepshare.net/detail/p_5ee62f90022ee_zFpnlHXA/6
5 对比模型(论文Model Architectures部分)
在word2vec提出之前,NNLM与RNNLM通过训练语言模型的方法的训练词向量,使用统计的方法。
本节主要对以下三种模型进行对比:
-
Feedforward Neural Net Language Model
-
Recurrent Neural Net Language Model
-
Parallel Training of Neural networks
5.1 前馈神经网络语言模型(NNLM)
5.1.1 Feedforward Neural Net Language Model
前馈神经网络语言模型全称:Feedforward Neural Net Language Model,简称NNLM,也叫深度神经网络,全连接神经网络。
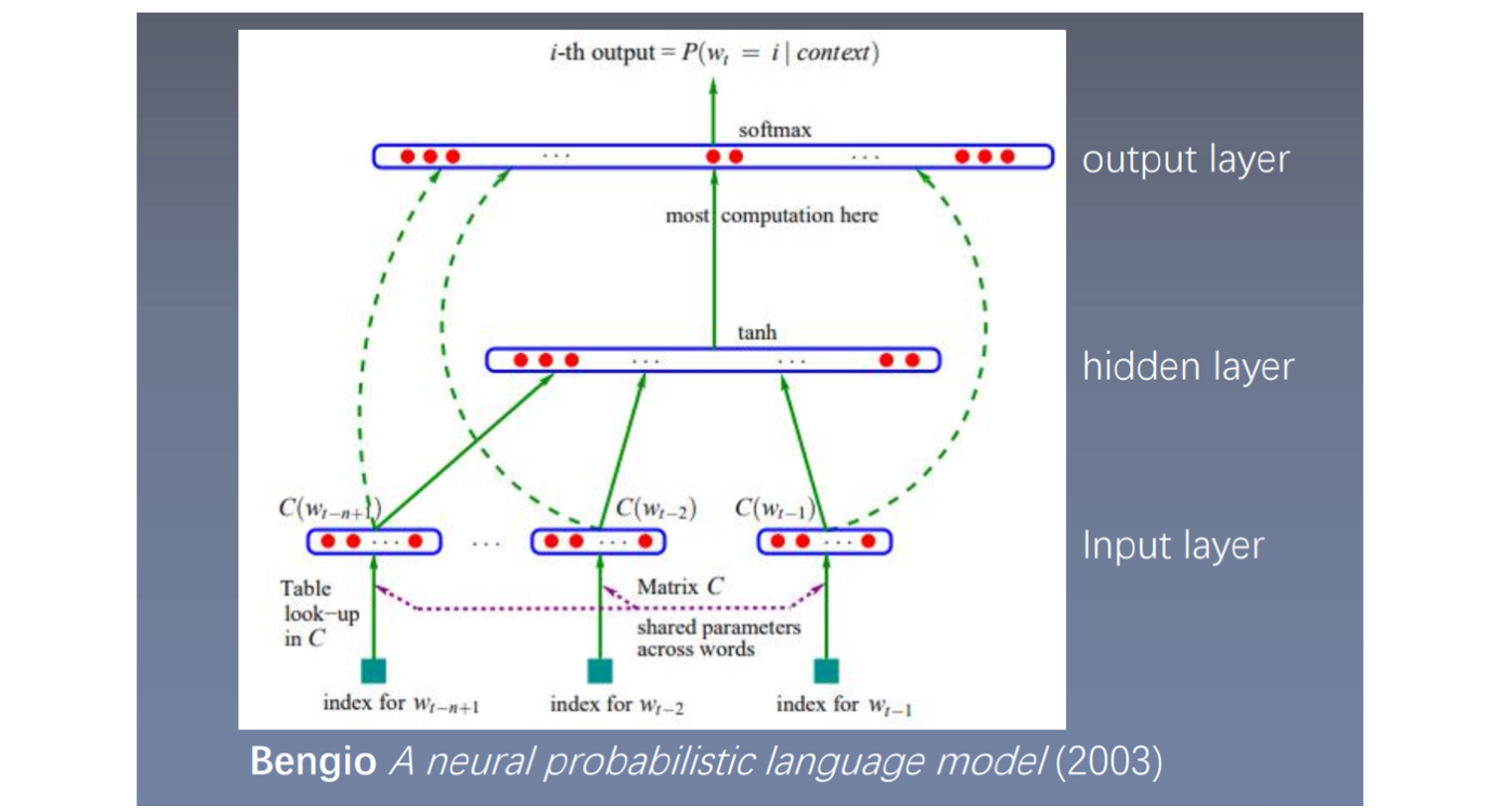
参考文献:Bengio A neural probabilistic language model (2003)
在nlp任务中,首先都会构建word2id以及id2word,它们都是字典类型,word2id的key是word,value是id,id2word相反,表示每个词对应一个id。
-
input layer:输入层,输入的是index,index表示词的编号,把所有词放在一起组成一个词典,这样每个词都有一个编号,用编号表示位置。将每个index映射成一个向量,将这些向量进行拼接(concat),如图中输入的是n-1个词,每个词都是100维,因此拼接完成后变成100×(n-1)维;
-
hidden layer:隐藏层,将上一步得到的100×(n-1)维向量输入到全连接层中,使用tanh激活函数;
-
output layer:输出层,上一步得到的结果再接一个全连接层,然后使用softmax。
根据前n-1个单词,预测第n个位置单词的概率,即n-gram模型。将输入到网络输入层,映射向量,进行拼接,经过两个全连接层使用softmax预测第t个词的概率,这样可以得到句子中每个词的概率,从而得到句子的概率。
语言模型的优点在于它是无监督模型,不需要任何标注语料,爬取网站上相关句子即可。通过前n-1个单词预测第n个单词,使用无监督的方式进行监督学习。
构建模型,首先在一个句子之前pad(填充)用来预测第一个词,生成语料,前n-1个词作为特征,下一个词作为标签,依次类推,可以构造除前馈神经网络的训练所需数据集。然后通过梯度下降优化模型,使得输出的正确的单词概率最大化。
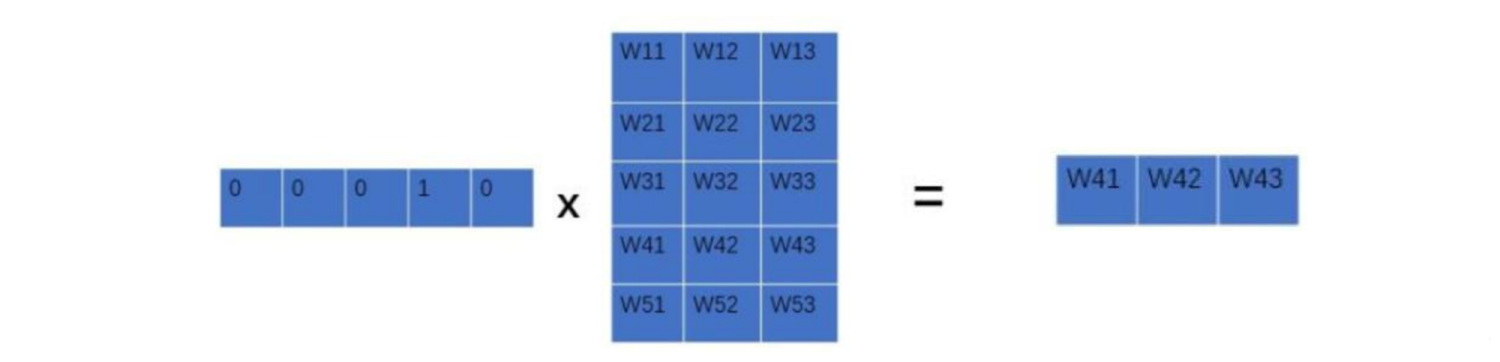
输入层:将词(index)映射成向量,相当于个1×V的one-hot向量乘以V×D的向量得到一个1×D的向量,其中V×D的向量每一行表示一个词向量。
并行计算:
隐藏层:一个以tanh为激活函数的全连接层。
其中d为偏置,U是参数, d和U相当于b和W参数。
输出层:一个全连接层,后面接个 softmax 函数来生成概率分布。
其中y是一个1×V的向量:
5.1.2 语言模型困惑度和Loss的关系
如何求困惑度?
需要将每个句子中每个词的概率给预测出来,然后将他们相乘吗?这样做也是可以的,但在实际中有更加方便巧妙的方法。
先写出Loss,使得预测出得到的每个正确单词得到的概率越大越好,使用了交叉熵损失函数,这个Loss是一句话的Loss:
其中, T表示句子中词的个数。困惑度是句子的概率开负T分之一。
这样在得出loss的情况下,可以很方便的求出困惑度是多少,看看困惑度的情况。现在都是批次进行训练和预测的,每计算batchsize大小的个数进行一次loss的计算。
NLP中,每个句子长度不一致,为了每个batchsize中的句子长度相同,需要补pad,对pad位置求loss是与其他词一起计算,得到的loss求指数得到的不是真实的困惑度,可能偏小,所以需要将pad抵消掉。
5.1.3 回顾网络模型
-
仅对一部分输出进行梯度传播:比如单词the、a、and等他们所包含的信息比较少,但是在语料中又频繁出现,因此这些词能不能或者少进行不进行梯度传播。
-
引入先验知识,如词性等:比如形容词后接名词概率较大,加动词概率较小。加词性之前,先考虑这个模型本身是否会学到词性信息,如果模型本身就可以学习到词性信息,那么就不需要再加了。之后查看网络学习到的词性是否够多,可以先加上词性信息看看效果是否更好。
-
解决一词多义问题:一个词就一个向量,那么一个向量怎么能表示多个意思呢?比如机器翻译中,可以通过上下文信息,详细可见elmo论文。
-
加速softmax层:softmax层的神经元个数是字典V的个数,因为每个词都要输出一下概率,这样就很慢。
5.2 循环神经网络语言模型(RNNLM)
全称:Recurrent Neural Net Language Model
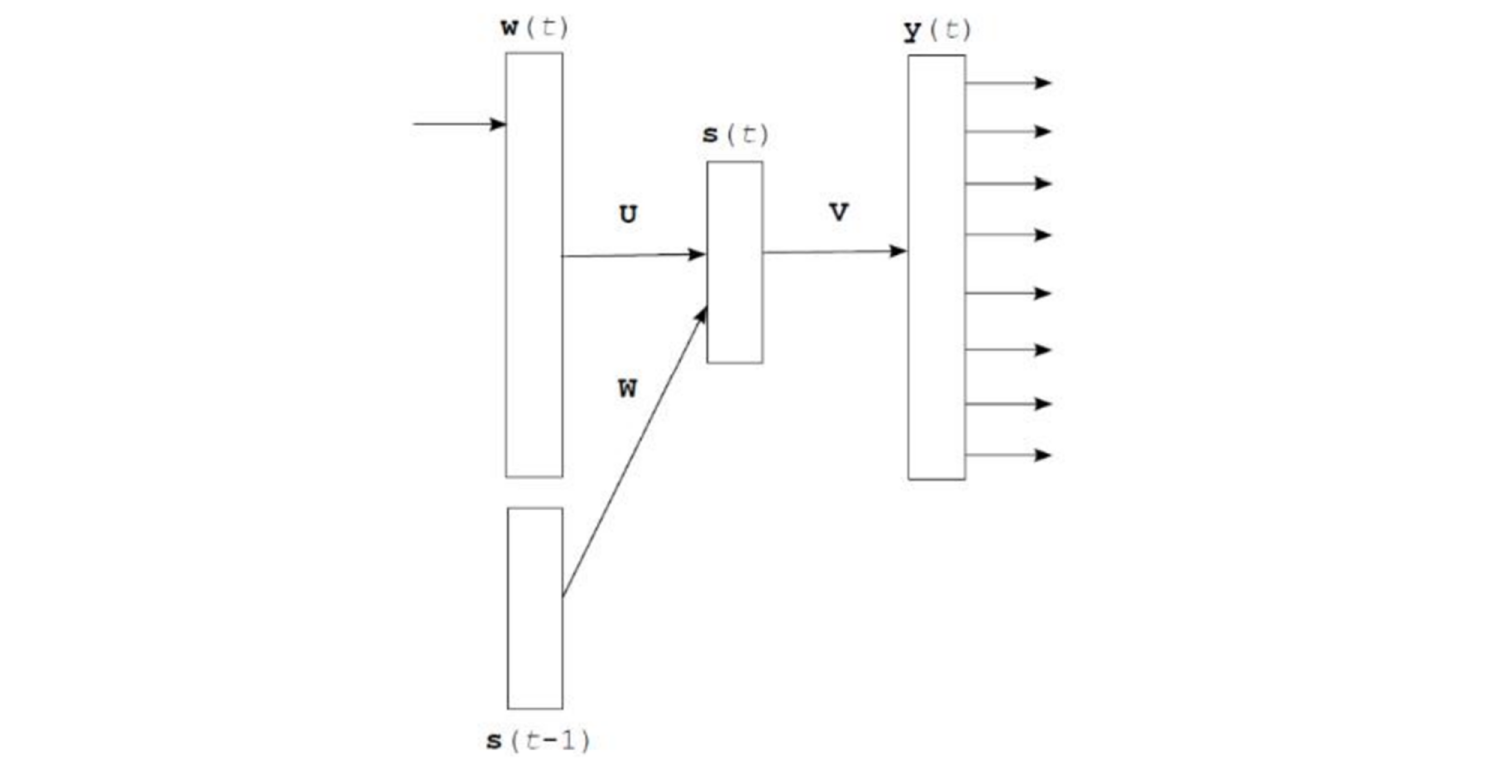
是上一个时间步的输出,
是当前词向量(也是通过one-hot方式转换的)的输入。
输入层:和NNLM一样,需要将当前时间步的转化为词向量。
隐藏层:对输入和上一个时间步的隐藏输出进行全连接层操作。
-
对应维度:
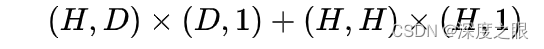
输出层:一个全连接层,后面接一 个 函数来生成概率分布。
-
其中 y是一个
的向量:
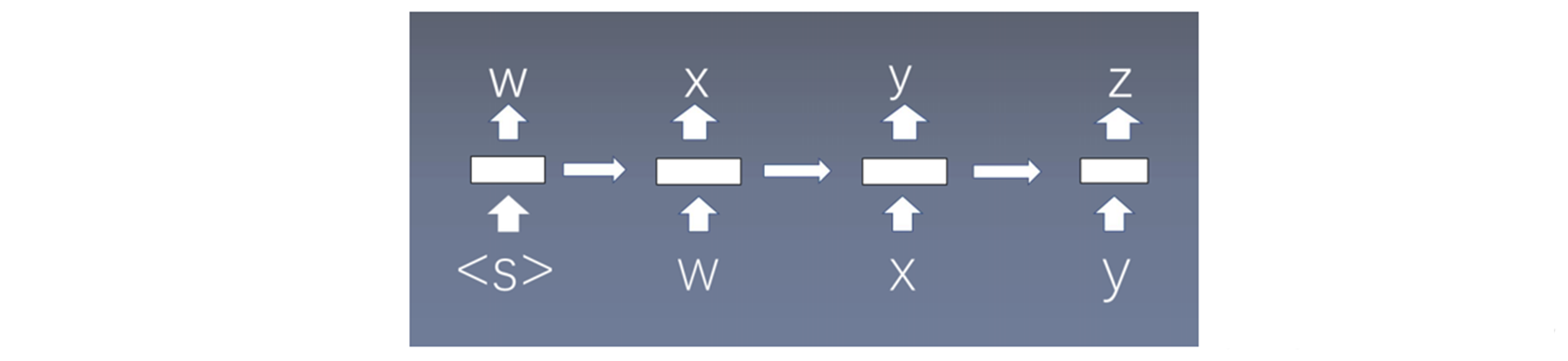
每个时间步预测一个词 ,在预测第n个词时使用了前n - 1个词的信息,没有使用马尔科夫假设了,基于统计的思想。<S>表示开始,第一个词。
5.3 word2vec模型
Log Linear Models定义:将语言模型的建立看成一个多分类问题,相当于线性分类器加上softmax。因为只有softmax求指数部分是非线性,但是加上log就变成了线性,所以称为log线性模型。逻辑斯蒂回归模型就是Log Linear Models。
本节讲述的skip-gram与CBOW也是Log Linear Models。
5.3.1 word2vec原理
跳字模型:
-
语言模型基本思想:句子中下一个词的出现和前面的词是有关系的,所以可以使用前面的词预测下一个词。马尔可夫假设,比如NNLM,以及统计思想,前面所有词预测下一个,如RNNLM。
-
Word2vec基本思想:句子中相近的词之间是有联系的,比如今天后面经常出现上午、下午和晚上。所以Word2vec的基本思想就是用词来预测词,skip-gram使用中心词预测周围词,cbow使用周围词预测中心词。word2vec的基本思想上就对语言模型进行了简化。
5.3.2 Skip-gram
计算过程:
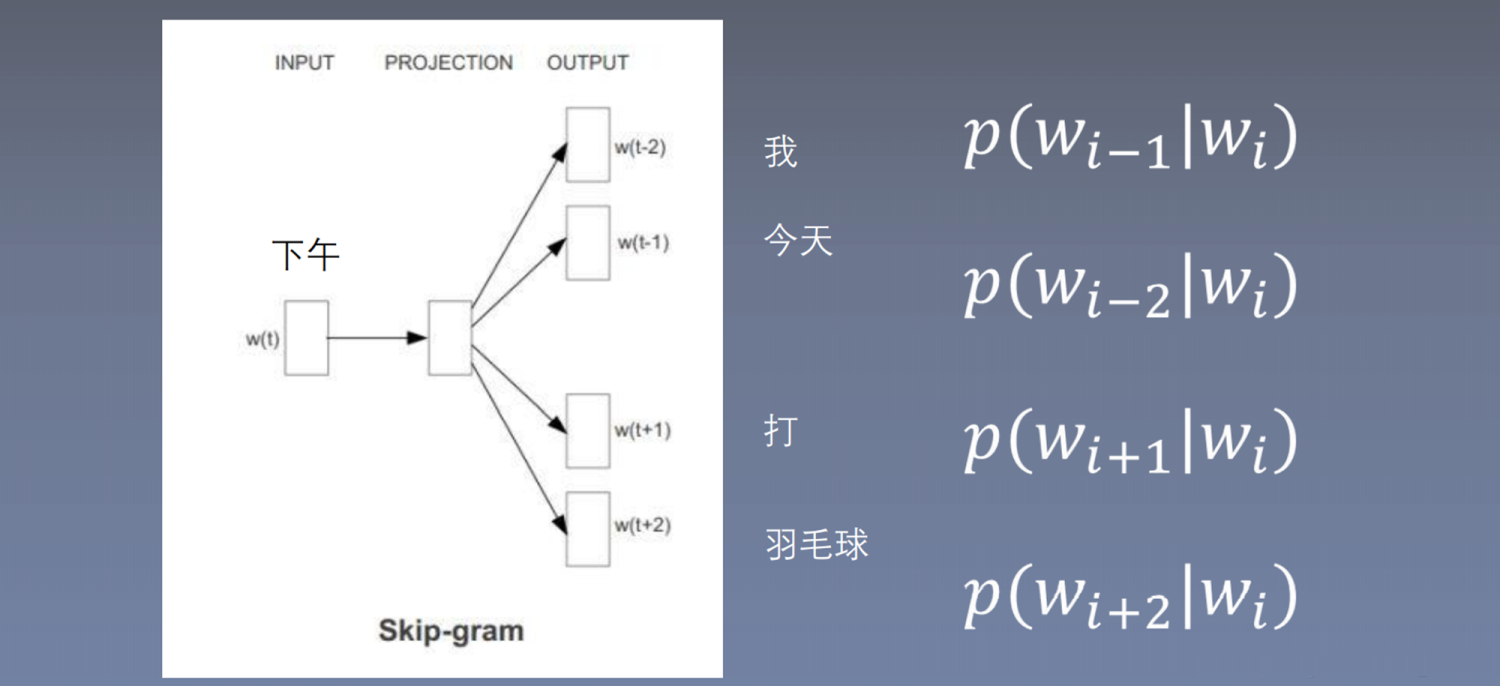
skip-gram使用中心词预测周围词,什么范围内是中心词和周围词?这里选择“下午”作为中心词,窗口为2,因此表示用“下午”预测“我”,
表示用“下午”预测“今天”,
表示用“下午”预测“打”,
表示用“下午”预测“羽毛球”。根据窗口的训练大小,这里产生四个训练样本。
如何求上图中的概率?其实语言模型中概率问题都是一个多分类问题,输入就是,而标签就是
相当于一个词表大小的多分类问题,怎么求概率以及学习词向量?
:用中心词
预测周围词
。

输入是index,代表这个词在词表中的位置,映射成1×V的one-hot向量;W是中心词的词向量矩阵,维度为V×D,每一行表示一个词的词向量;将one-hot向量与中心词的词向量矩阵相乘得到一个词的向量;得到1×D的词向量与周围词的词向量矩阵进行相乘,得到1×V的向量,这个向量在经过softmax之后,得到每个词的概率,然后使得正确词的位置上的概率越大越好。
图中W和就是想训练得到的词向量,一般用W就可以,或者用
。1×D的词向量代表的是中心词
的词向量,
是周围词的词向量矩阵,它们相乘后再做softmax,把
这个位置的单词取出来。
分母:中心词向量与所有周围词向量做内积,求和。 分子:的周围词向量的转置与中心词向量内积。
损失函数:
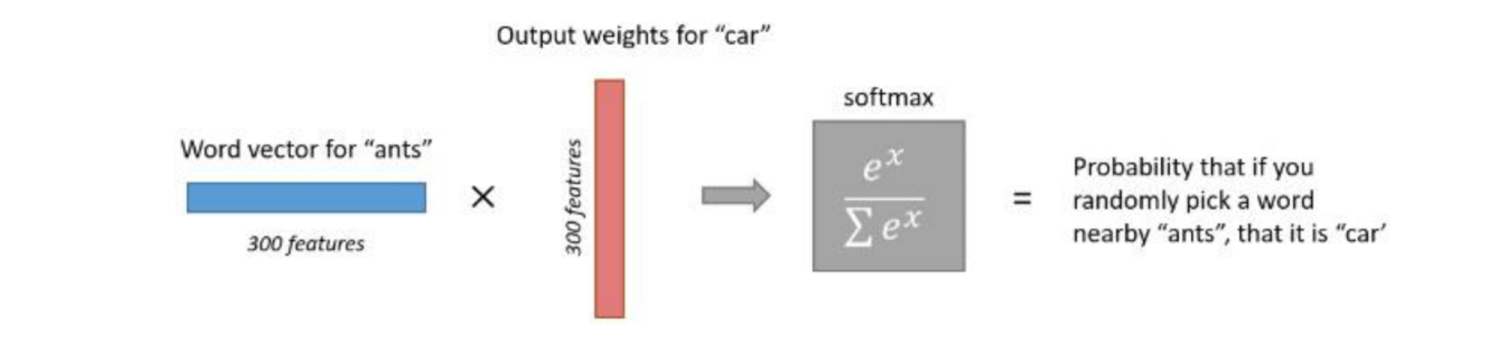
简单直观不准确解释:在词表中将中心词ants所有周围词取出,放在一个袋子里,在袋子里用手随意抓一个,这个词是car的概率。类似于共现矩阵的次数。如果要是car与ant都与同一个词有关系,二者可能存在一定的依赖关系,准确度可能会较高,所以这种解释并不准确。
求最小值:
-
是中心词向量
-
是窗口内上下文某个周围词的词向量
-
是窗口内上下文所有周围词的词向量
-
m是窗口大小
5.3.3 CBOW
全称:Continuous Bag-of-Words Model,词袋模型,忽略了词的顺序。
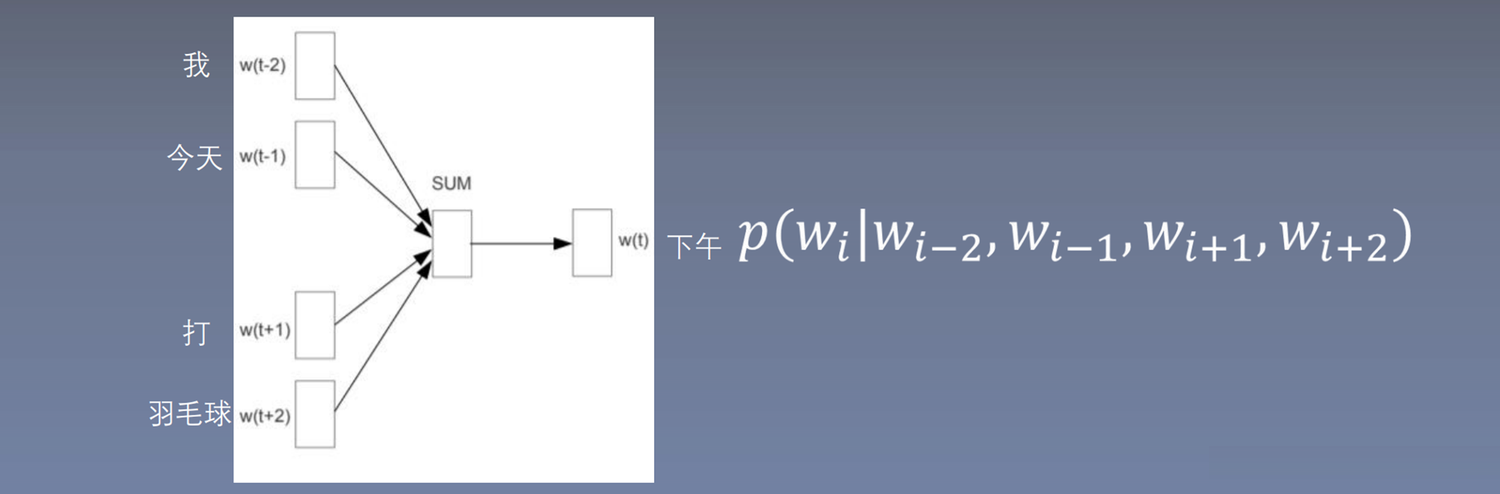
cbow使用周围词预测中心词,NNLM中将输入所有此concat连接在一起,输入较大,求和或者求平均输入与单个词向量维度相同,输入越小,模型复杂度越低。这里采用的求和。
对于中心词来说这里只有一个训练的样本。:
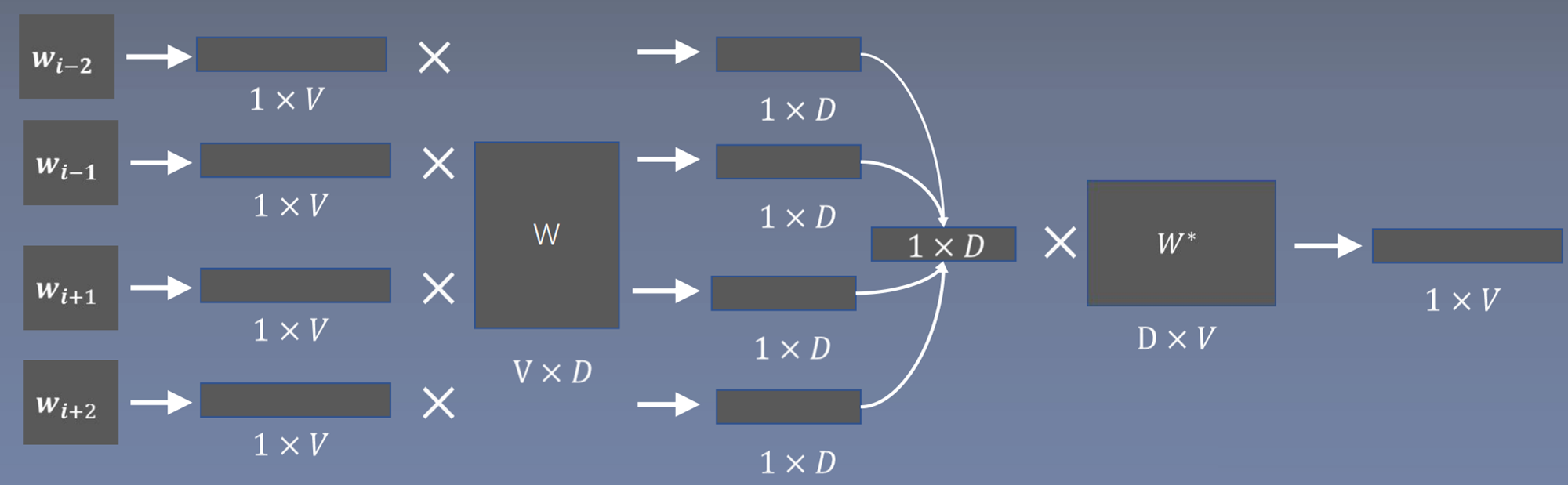
输入的index,转换为1×V大小的one-hot向量。
输入是index,代表这个词在词表中的位置,映射成1×V的one-hot向量;与Skip-gram相反,这里W是周围词的词向量矩阵,维度为V×D,每一行表示一个周围词的词向量;将二者相乘得到每个周围词的词向量;在经过平均或者求和方式得到1×D的向量与与中心词的词向量矩阵进行相乘,得到1×V的向量,这个向量在经过softmax之后,得到每个词的概率,然后使得正确词的位置上的概率越大越好。
-
上下文词
-
-
是中心词向量
6 关键技术
6.1 复杂度讨论
如何降低复杂度?
Softmax 对于要输出V个概率:
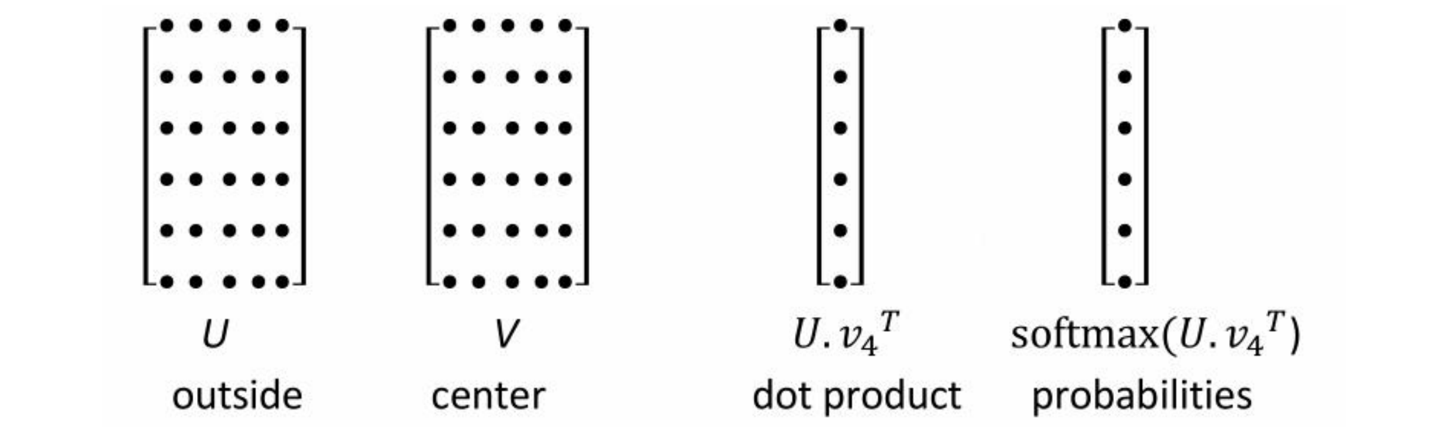
U是周围词的矩阵,V是中心词的矩阵,第三个矩阵相乘相当于是一个没有激活函数也没有偏置的全连接层,全连接层额神经元个数是词表大小,因为softmax层要输出V个概率,V是特别大的,因此这个全连接层也是特别大的,那么如何降低复杂度呢?能不能将softmax的复杂度降低呢?论文中也提到了两种方法,层次softmax和负采样。
6.2 Hierarchical Softmax
将softmax转变为多个sigmoid,可以写成一个二叉树的形式。softmax需要做次指数操作,sigmoid只需要一次指数运算即可。只要转换为少于V次指数操作的sigmoid操作,就相当于进行了加速运算。
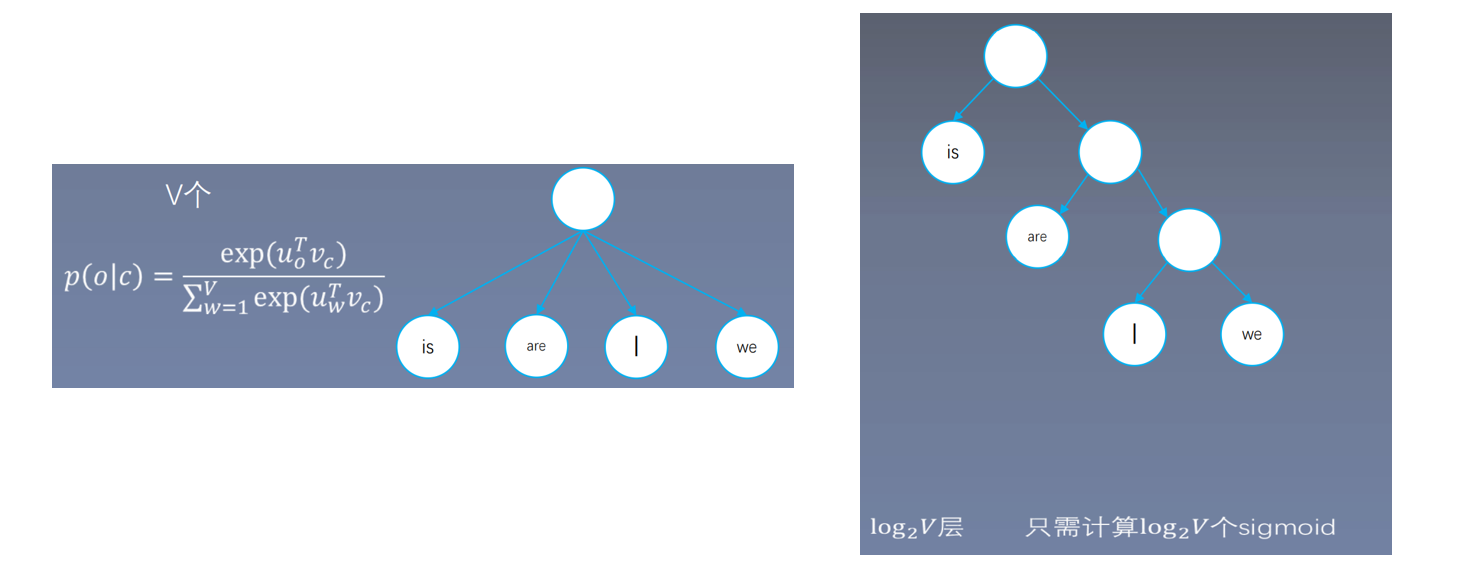
层,只需计算
个
运算。
6.2.1 Skip-gram目标函数
满二叉树: 为什么层次softmax只需计算个sigmoid?
只需要3次就能找到。
假设词表大小是8,softmax需要做8次指数操作,如果计算sigmoid,通过8个节点的满二叉树,判断为a,需要进行3次二分类,判断为b,也需要进行3次二分类,因此,分类次数=树的深度-1。
构建Huffman树:带权重路径最短二叉树

5表示预测这个词需要做5次sigmoid,7表示预测这个词需要做7次sigmoid,边的个数表示权重,哈夫曼树将频率高的放在树的上层,少于次。
层次softmax构建:
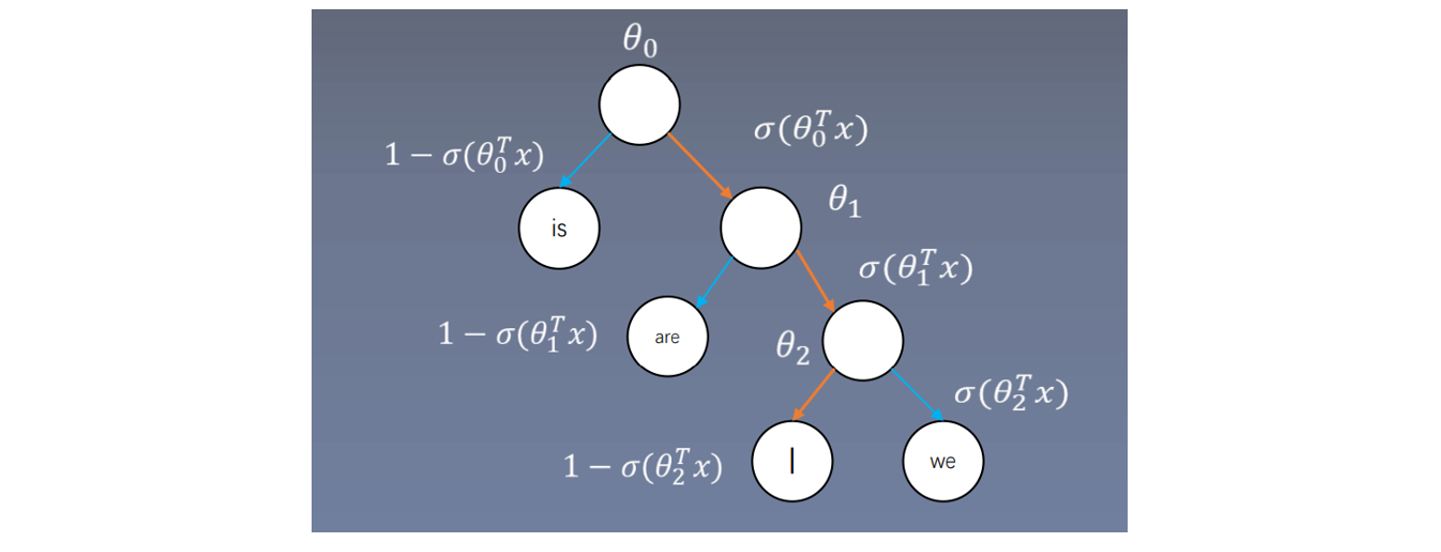
每个分支节点都是一个向量,例如在skip-gram中用中心词向量与相乘,之后进行sigmoid,如果小于零,表示往左进行查找,如果大于零,表示向右进行查找,再与
相乘,同理如果小于零,表示往左进行查找,如果大于零,表示向右进行查找,再与
相乘。之前的词向量为V个,这里的词向量个数少于V个。求I的概率:
-
-
参数相当于上下文词(周围词)向量,约有
个
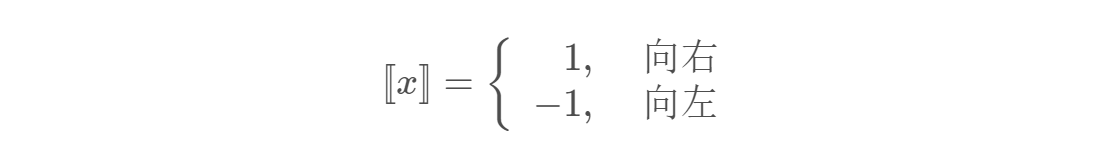
树高度
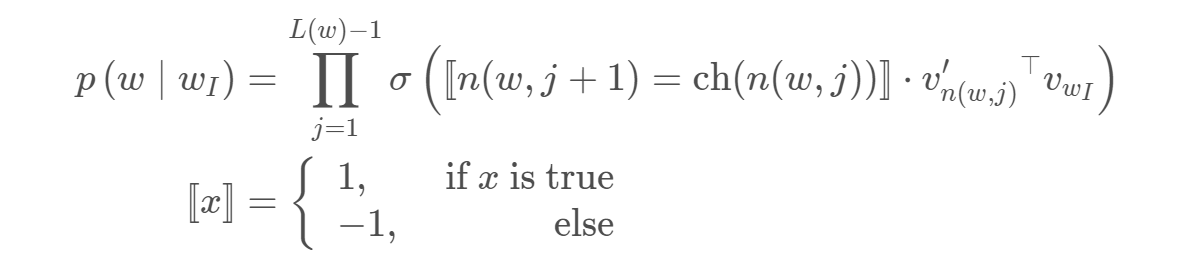

6.2.2 CBOW Hierarchical Softmax
层次softmax分类
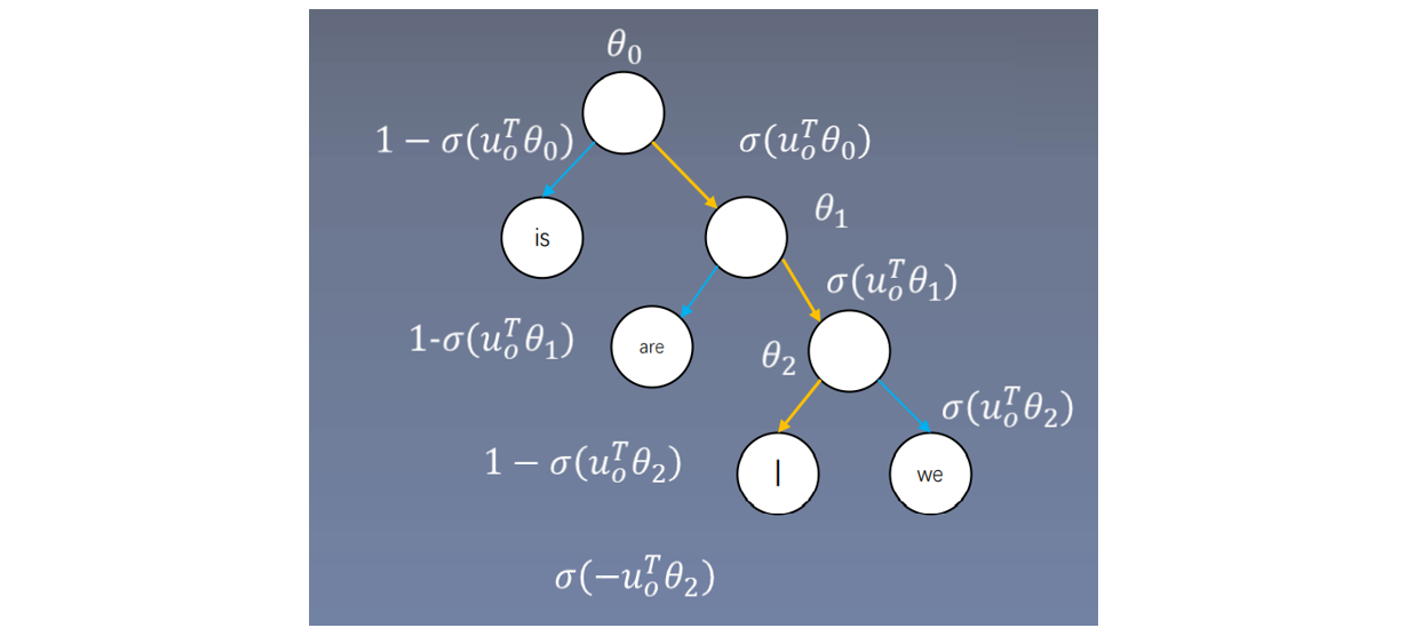
-
之前的skip-gram与CBOW都是最终词向量可以是中心词向量与周围词向量的相加或者平均,但是在层次softmax中只有一组词向量,因为个数少于V个,其具体含义并不明确,比如
可能表示一簇词类别的意义。
6.3 Negative Sample(应用较多)
在效果与效率上,负采样(Negative Sample)均好于层次softmax。
舍弃多分类,提升速度,将多分类变为二分类。二分类需要正样本与负样本,一个中心词与周围词在一起是正样本,例如图中的jump over,在skip-gram里,中心词+词表任意一词作为负样本,例如图中的jumps again,负样本可能正好选择了中心词与其周围词,但词表非常大,可能性非常小,可忽略不计。

基本思想:增大正样本概率,减小负样本概率。
对于每个词,一次要输出1个正样本的概率,注意不能只选择一个负样本,否则会有偏差,因为正样本是真实的,负样本是采样出来的,一般选择3-10个之间负样本。假如选择K个负样本,则输出K个负样本概率,总共K+1个概率,K<<V并且效果比多分类要好。这里还是需要每个词的上下文词向量,矩阵维度为,总的参数比HS(层次softmax)多(每次计算量不多,层次softmax需要
个概率,这里仅需要K+1个)。
损失函数:
-
-
-
是负采样上下文词向量
6.3.1 如何采样?
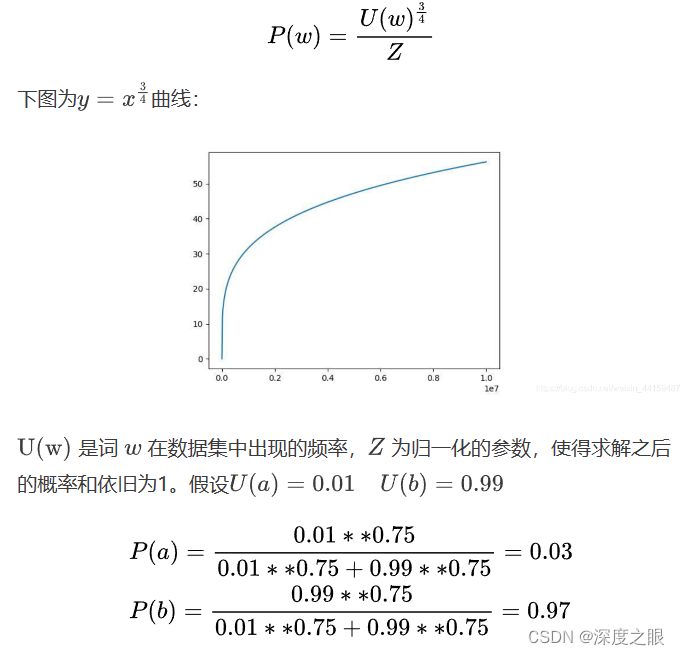
减少频率大的词的抽样概率,增加频率小的词的抽样概率。因为一些不重要的词出现的概率较大,比如the,a等,重要的词出现的概率较大。可以加速训练,得到更好的效果。
6.3.2 CBOW Negative Sampling
同理,二分类需要正样本与负样本,所有周围词的词向量的平均与真正的中心词在一起是正样本,所有周围词的词向量的平均与随机采样的词组合在一起是负样本。

损失函数与上述相同:
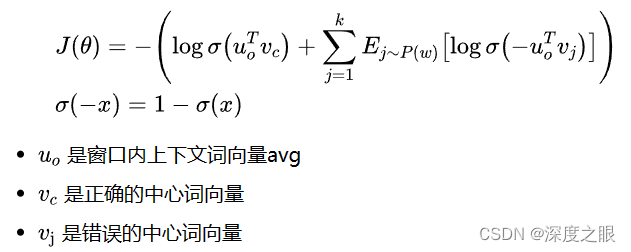
6.4 高频词重采样(Subsampling of Frequent Words)
自然语言处理共识:文档或者数据集中出现频率高的词往往携带信息较少,比如the,is,a,and,而出现频率低的词往往携带信息多。
什么是青蛙?
-
什么是深度学习,什么是CNN,什么是RNN,这篇告诉你。
-
青蛙(Frog)属于脊索动物门、两栖纲、无尾目、蛙科的两栖类动物,成体无尾,卵产于水中。
重采样的原因:
-
想更多地训练重要的词对,比如训练“France”和“Paris”之间的关系比训练“France”和“the”之间的关系要有用。
-
高频词很快就训练好了,而低频次需要更多的轮次。
重采样方法:

优点:加速训练,能够得到更好的词向量。
7 模型复杂度
7.1 模型复杂度的概念
模型的复杂度也就是时间上的复杂度:

7.2 基于前馈网络的语言模型的时间复杂度
NNLM通过前面N个词,预测第N+1个词:
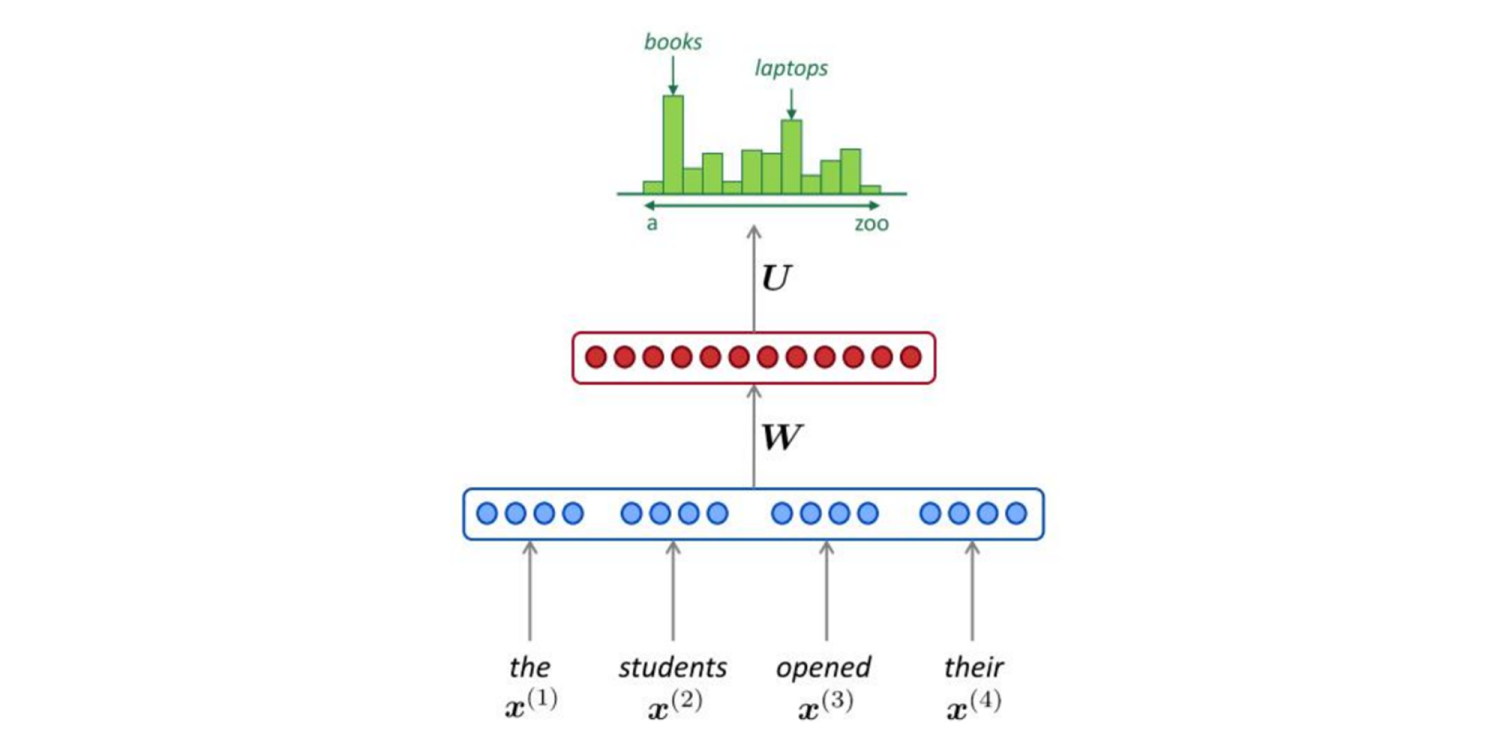
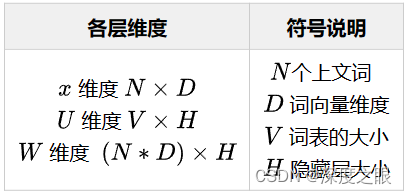
模型复杂度:

Bengio A neural probabilistic language mode/(2003)
7.3 基于循环神经网络的语言模型的时间复杂度
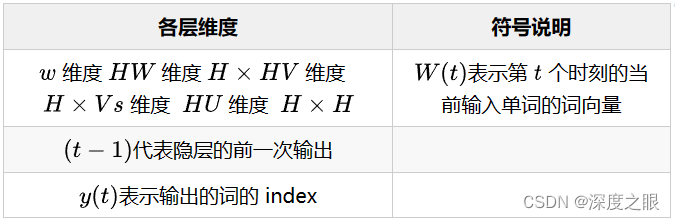
RNNLM模型复杂度:
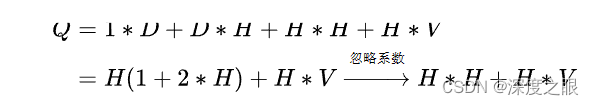
7.4 Skip-gram复杂度
7.4.1 Hierarchical Softmax 复杂度

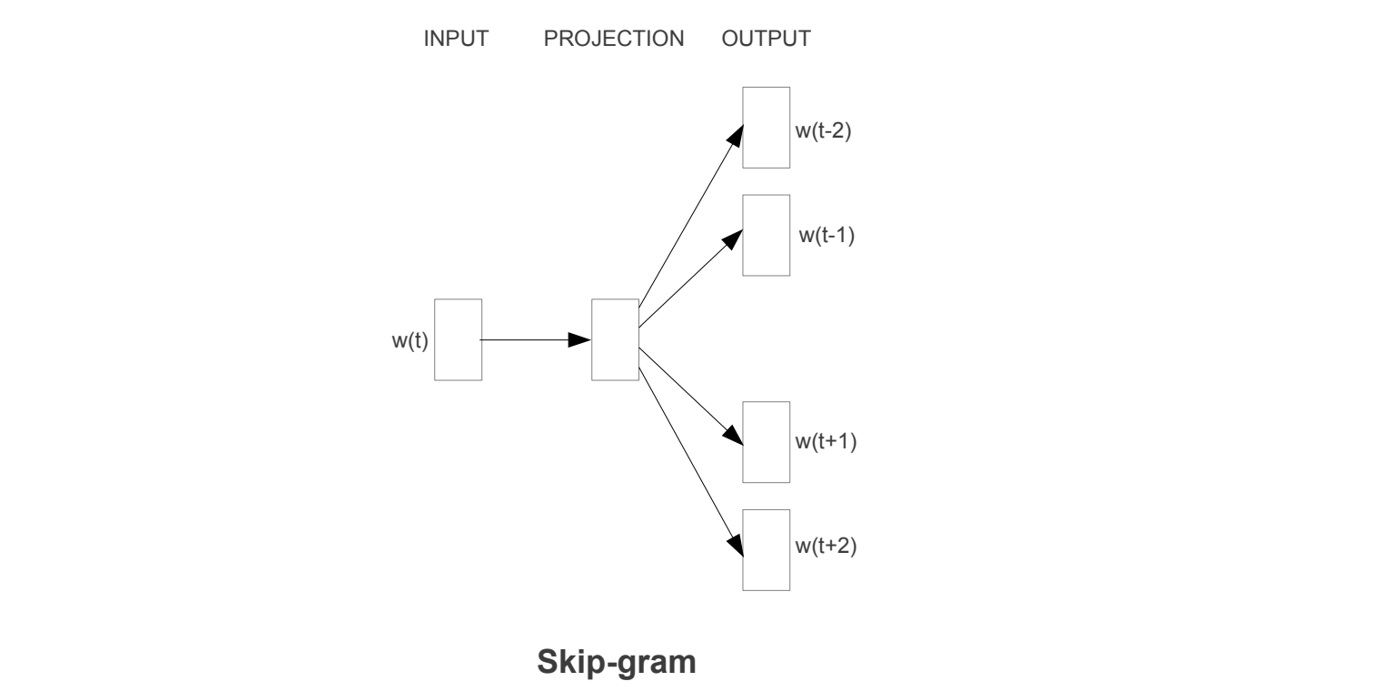
7.4.2 Negative Sampling 复杂度
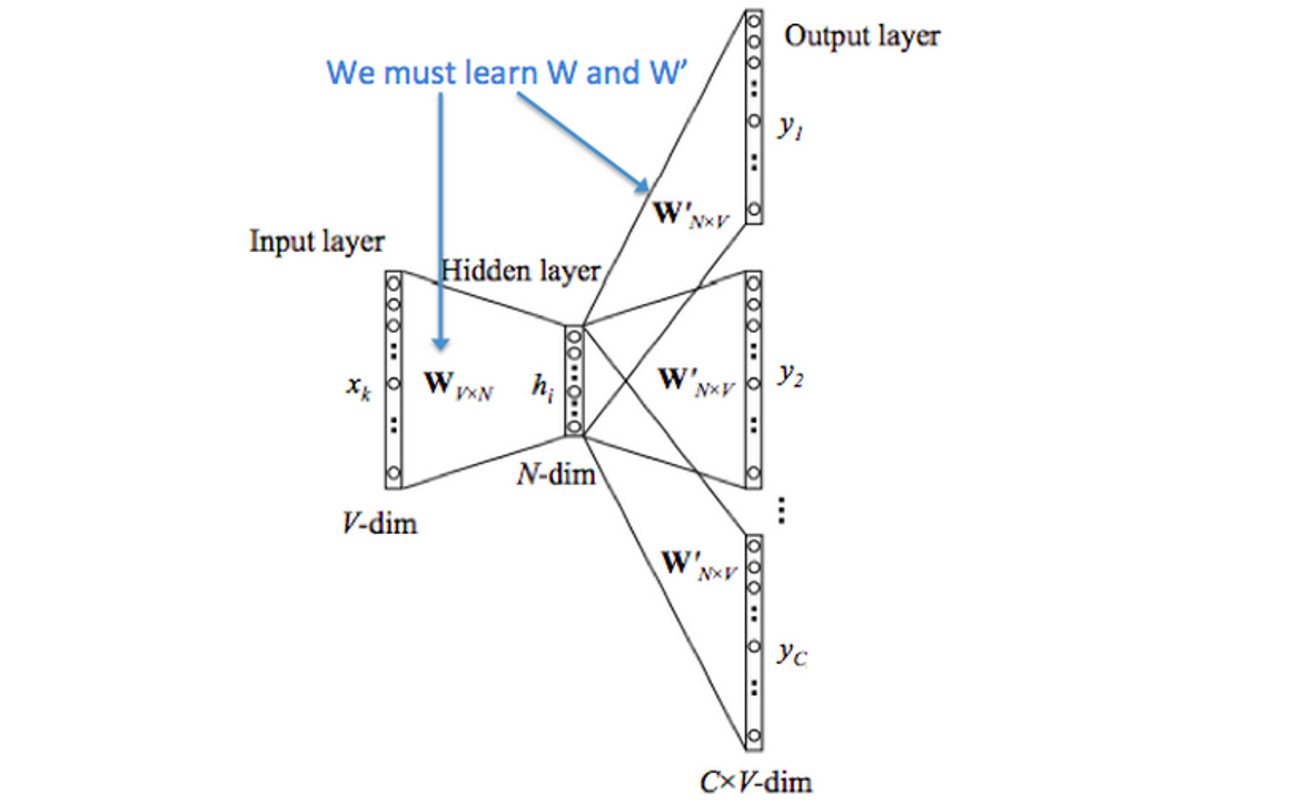
对于每一个中心词来说,有一个正样本和K个负样本,每个都会变成一个D维的词向量,便得到上图中第二个公式。
7.5 CBOW 复杂度
CBOW 复杂度:
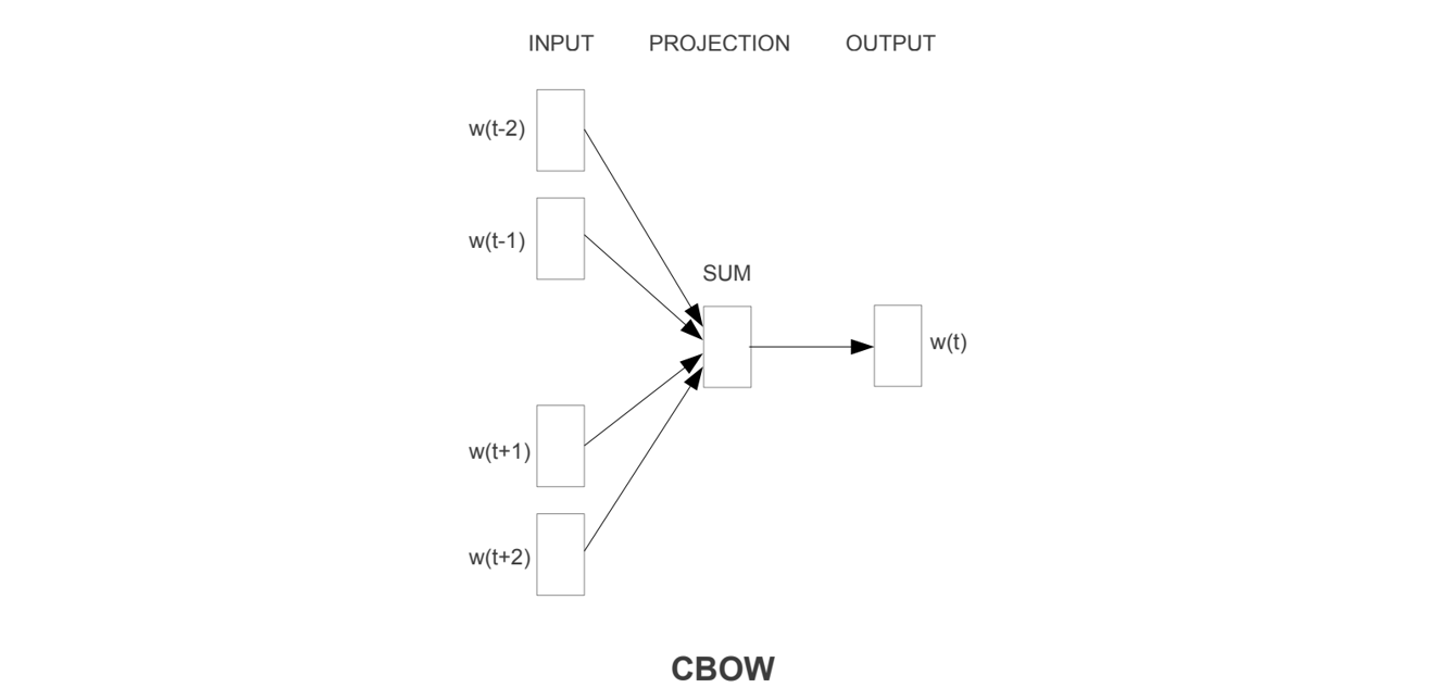

注意:上述是每一次计算所需的参数。
7.6 模型复杂度对比
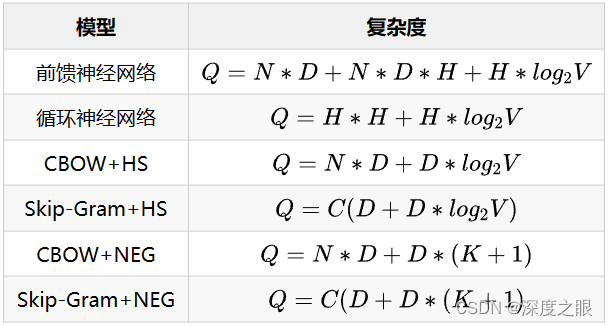
从理论分析:层次softmax与负采样速度均快于前馈神经网络与循环神经网络,CBOW速度快于Skip-Gram,负采样速度快于层次softmax。
8 实验结果分析
8.1 任务描述
任务是一个词对推理的任务,下图中前五个是语义类,后九个是语法类。
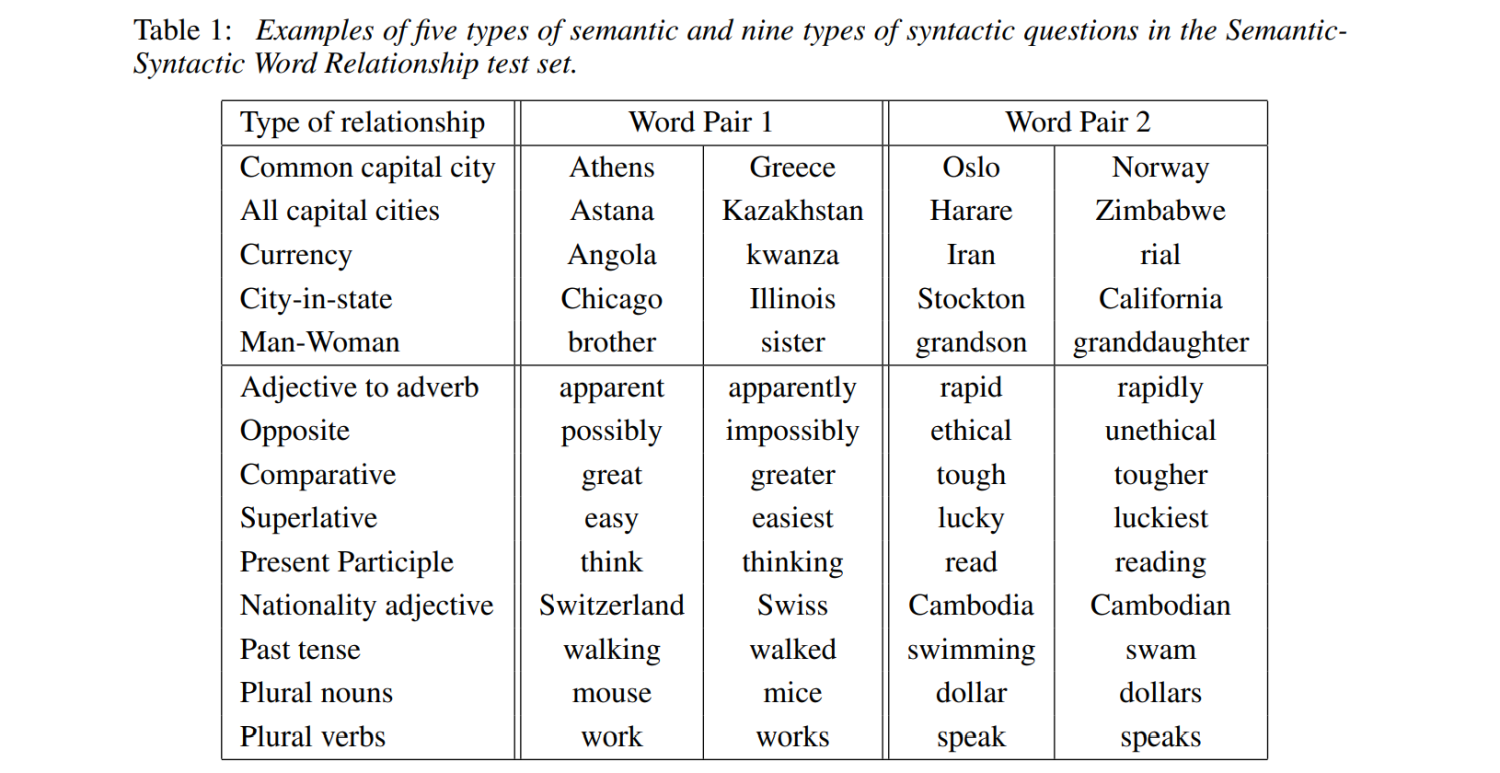
语法类数据易收集,语义类数据难收集。
| 关系类型 | 翻译 |
|---|---|
| capital-common-countries | 常见国家首都 |
| capital-world | 各国首都 |
| currency | 货币 |
| city-in-state | 州-城市 |
| family | 家庭关系 |
| gram1-adjective-to-adverb | 形容词-副词 |
| gram2-opposite | 反义词 |
| gram3-comparative | 比较级 |
| gram4-superlative | 最高级 |
| gram5-present-participle | 现在进行式 |
| gram6-nationality-adjective | 国家的形容词 |
| gram7-past-tense | 过去式 |
| gram8-plural | 复数 |
| gram9-plural-verb | 第三人称单数 |
Word2vec程序中 questions-words.txt:
// Copyright 2013 Google Inc. All Rights Reserved.
: capital-common-countries
Athens Greece Baghdad Iraq
Athens Greece Bangkok Thailand
Athens Greece Beijing China
Athens Greece Berlin Germany
Athens Greece Bern Switzerland
Athens Greece Cairo Egypt
Athens Greece Canberra Australia
Athens Greece Hanoi Vietnam
Athens Greece Havana Cuba
Athens Greece Helsinki Finland
...
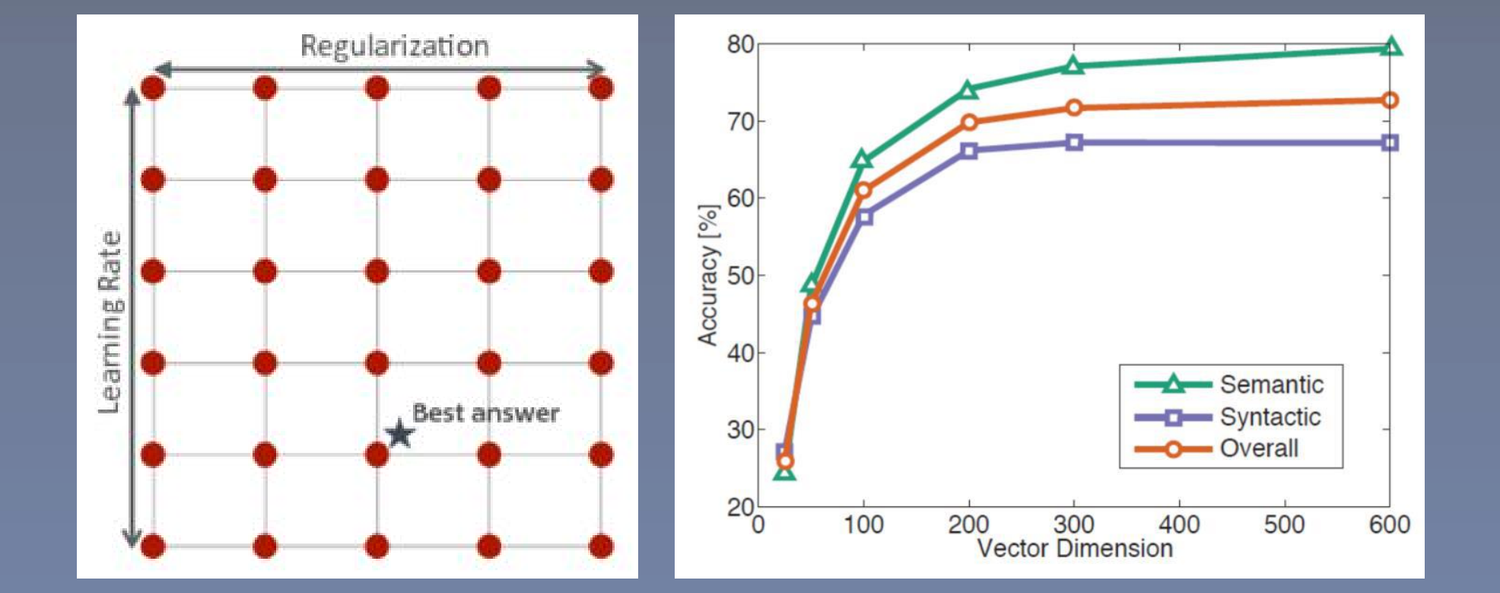
8.2 最大化正确率(优化参数)
用小数据集调参,选择最好的参数,参数包括维度、训练的数据量,是2个需要寻找的参数。
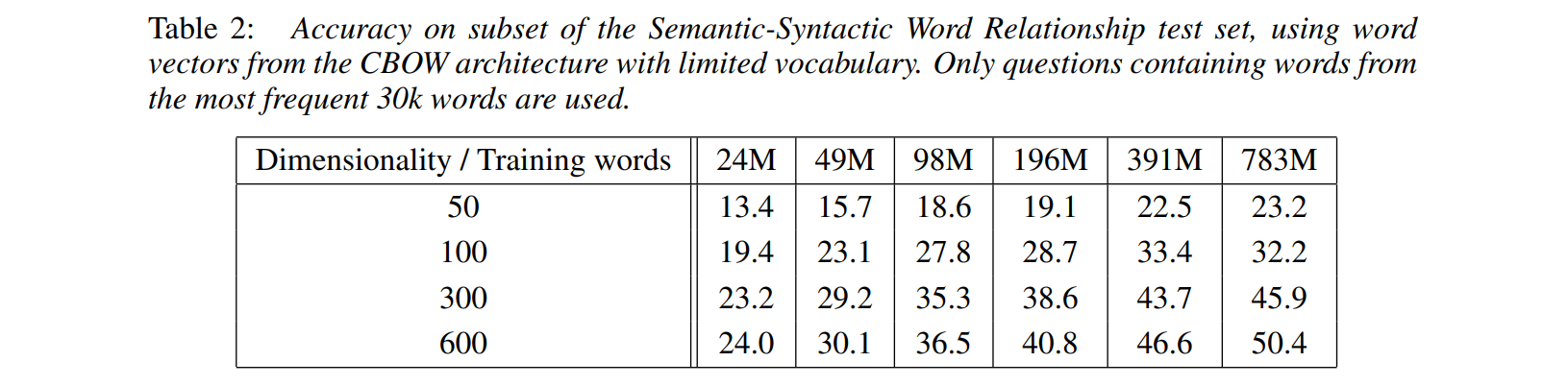
随着维度的增加(纵轴),随着数据集的扩大(横轴),效果基本上是越来越好的。
8.3 模型比较
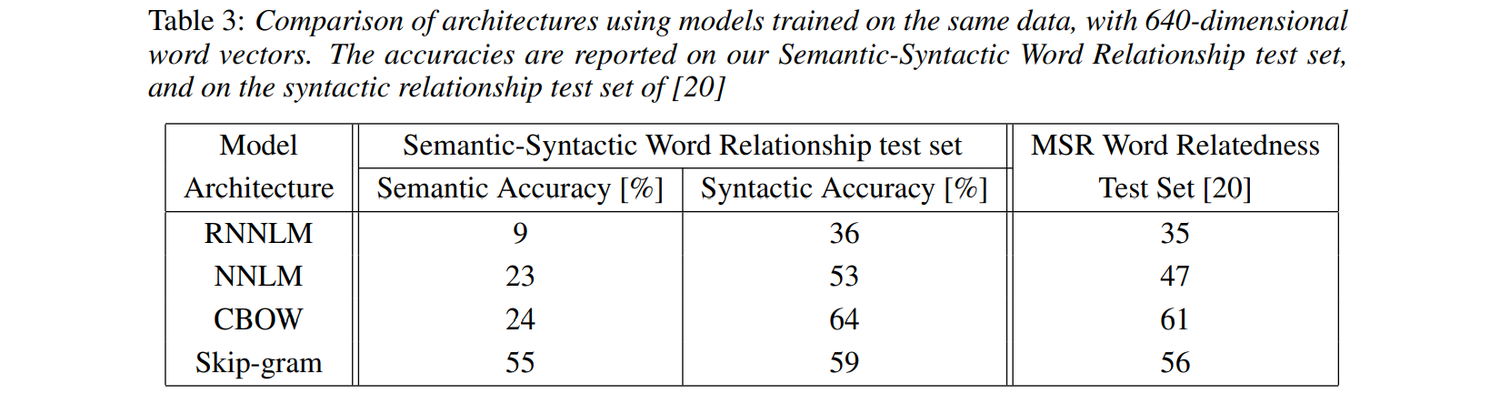
MSR Word Relatedness测试集大部分都是语法数据。RNNLM和NNLM都在语义上(Syntactic Accuracy)表现的比较好,在语法上(Semantic Accuracy)表现的比较差,CBOW也是,而skip-gram在语法和语义上都表现的比较好。
RNNLM单机用了8周,NNLM计算量更大。
RNN相对在语法问题上较好,NNLM效果更好,CBOW更好。
Skip-gram更平衡,在语义问题上效果好。
LDC corpora 320M words,82K
和其他人开源的词向量比较:

Our NNLM使用了层次softmax进行了加速。
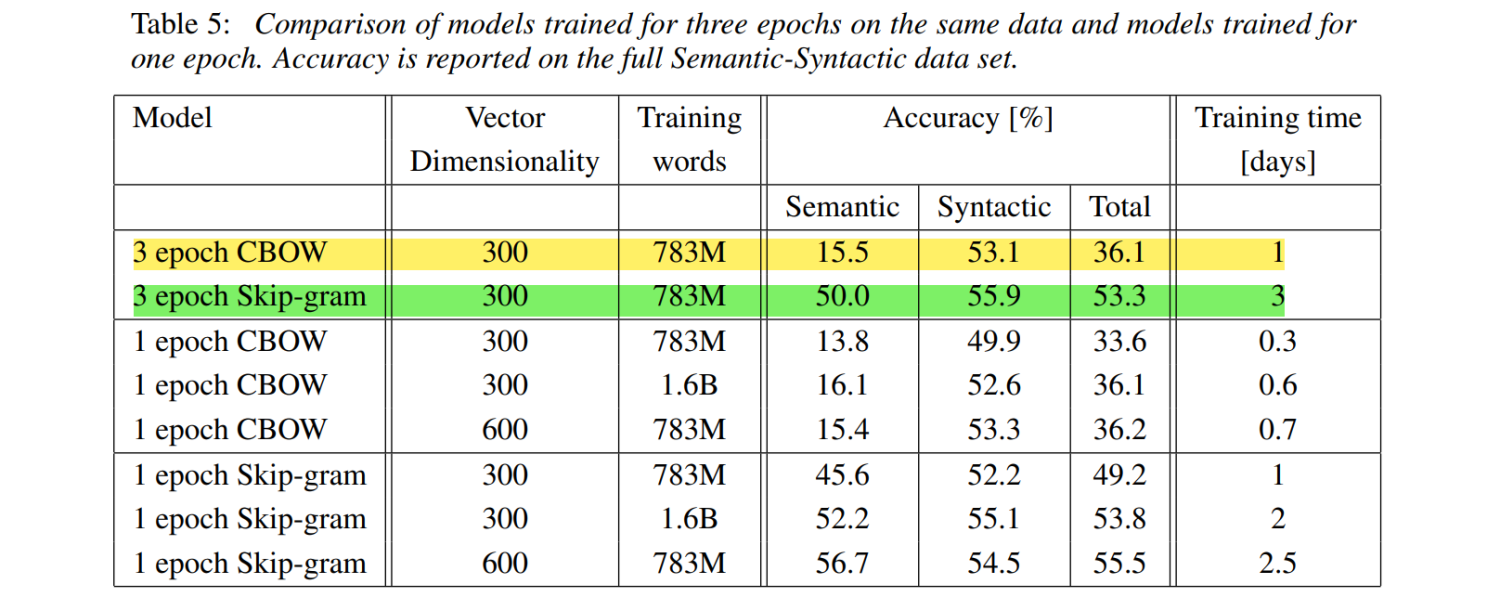
3 epoch CBOW(36.1) < 1 epoch skip-gram(49.2) 3 epoch 300dim < 1 epoch 600d
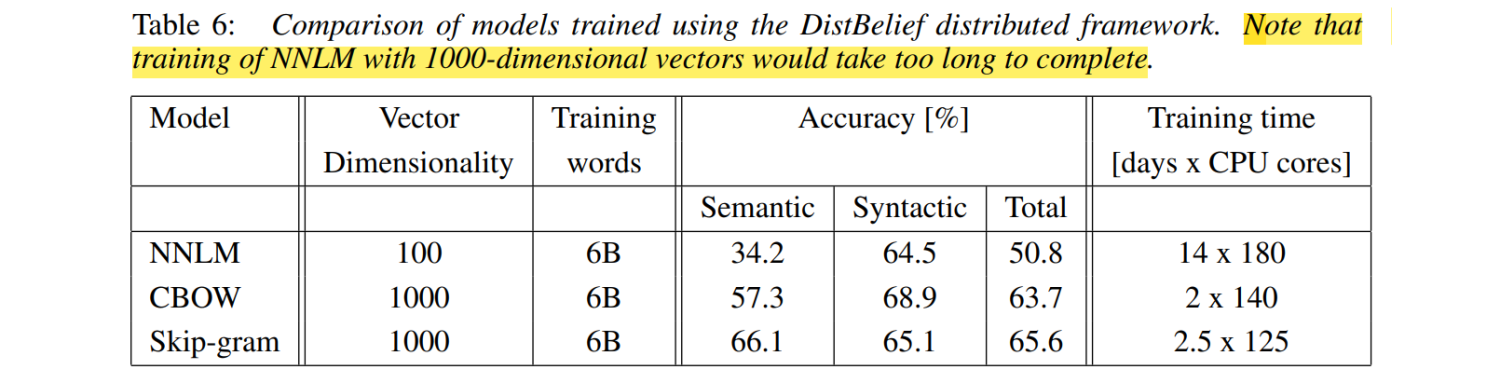
8.4 大规模并行模型训练
Large Scale Parallel Training of Model
8.5 微软研究院句子完成比赛

类似完形填空,一句话盖住一个词,给出5个预测结果。
skip-gram只统计了周围词,没有用到词与词之间的关系,所以可以联合语言模型RNNLM进行训练。
8.6 HS和NEG比较
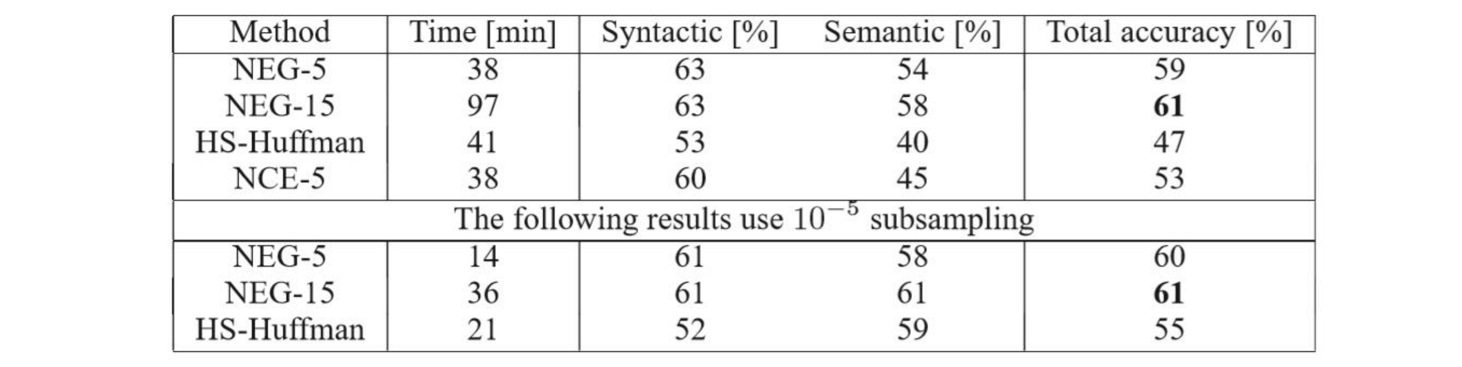
NCE:其他负采样方法。
下方表格为使用了重采样,可以发现速度大大提升了。
例子:学习到的关系


使用十个关系词对做平均可以将偏差抵消掉。
out-of-the-list words:不符合当前分类的词。
9 讨论和总结
讨论论文中存在的问题,总结本阶段所学内容。
9.1 讨论
超参数选择:请问,利用gensim做word2vec的时候,词向量的维度和单词数目有没有一个比较好的对照范围呢?
dim一般在100-500之间选择,初始值词典大小V的1/4次方,例如V=10K,dim=100。min_count一般在2-10之间选择,min_count表示词在语料中出现的最小次数,小于该次数的词进行舍弃,决定了词表大小。
gridsearch
9.2 总结
论文主要创新点: 1、提出一种新的结构:这个结构是使用词预测词,而不是用前面的一系列词来预测词,简化了结构。也提出了层次softmax和负采样,大大减少了计算量,从而可以使用更高的维度,更大的数据集。 2、利用分布式训练框架:在大数据上训练,从而达到更好的效果。 3、提出了新的词相似度任务:Analogy词类别。
关键点:
-
更简单的预测模型 —— word2vec
-
更快的分类方案 —— HS和NEG
创新点:
-
使用词对的预测来替换语言模型的预测
-
使用HS和NEG降低分类复杂度
-
使用subsampling加速训练
-
新的词对推理数据集来客观评估词向量的质量
启发点:
1、大数据集上的简单模型往往强于小数据集上的复杂模型 simple models trained on huge amounts of data outperform complex systems trained on less data.(1 Introduction p1)
2、King的词向量减去Man的词向量加上Woman的词向量和Queen的词向量最接近 vector(”King”) - vector(”Man”) + vector(”Woman”) results in a vector that is closest to the vector representation of the word Queen (1.1 Goals of the Paper p3) 说明了word2vec可以很好的学习词对之间的代数关系,在神经网络中都是数与数之间的计算,如果可以学习到词向量之间的代数关系,则词向量也非常使用于神经网络。
3、我们决定设计简单的模型来训练词向量,虽然简单的模型无法像神经网络那么准确地表示数据,但是可以在更多地数据上更快地训练 we decided to explore simpler models that might not be able to represent the data as precisely as neural networks, but can possibly be trained on much more data efficiently (3 New Log-linear Models p1)
4、我们相信在更大的数据集上使用更大的词向量维度能够训练得到更好的词向量。 We believe that word vectors trained on even larger data sets with larger dimensionality will perform significantly better(5 Examples of the Learned Relationshops p1)
关注下方《学姐带你玩AI》🚀🚀🚀
论文资料+比赛方案+AI干货all in
码字不易,欢迎大家点赞评论收藏!
相关文章:
Word2vec原理+实战学习笔记(二)
来源:投稿 作者:阿克西 编辑:学姐 前篇:Word2vec原理实战学习笔记(一) 视频链接:https://ai.deepshare.net/detail/p_5ee62f90022ee_zFpnlHXA/6 5 对比模型(论文Model Architectur…...

什么是Java的多线程?
Java的多线程是指在同一时间内,一个程序中同时运行多个线程。每个线程都是一个独立的执行路径,可以独立地执行代码。Java中的多线程机制使得程序可以更高效地利用计算机的多核处理器和CPU时间,从而提高程序的性能和响应能力。 创建和使用Jav…...

“use strict“是什么? 使用它有什么优缺点?
严格模式 - JavaScript | MDN Javascript 严格模式详解 - 阮一峰的网络日志 1、"use strict" 是什么? "use strict" :指定代码在严格条件下执行; 2、 使用 "use strict" 有什么优缺点? ① 严格模式通过抛出错…...
【C++】C++11常用特性总结
哥们哥们,把书读烂,困在爱里是笨蛋! 文章目录 一、统一的列表初始化1.统一的{}初始化2.std::initializer_list类型的初始化 二、简化声明的关键字1.decltype2.auto && nullptr 三、STL中的一些变化1.新增容器:array &…...

泛型——List 优于数组
数组与泛型有很大的不同: 1. 数组是协变的(covariant) 意思是:如果Sub是Super的子类型,则数组类型Sub[] 是数组类型Super[] 的子类型。 2. 泛型是不变的(invariant) 对于任何两种不同的类型Ty…...

JavaScript中对象的定义、引用和复制
JavaScript是一种广泛使用的脚本语言,其设计理念是面向对象的范式。在JavaScript中,对象就是一系列属性的集合,每个属性包含一个名称和一个值。属性的值可以是基本数据类型、对象类型或函数类型,这些类型的值相互之间有着不同的特…...

JavaScript通过函数异常处理来输入圆的半径,输出圆的面积的代码
以下为实现通过函数异常处理来输入圆的半径,输出圆的面积的代码和运行截图 目录 前言 一、通过函数异常处理来输入圆的半径,输出圆的面积 1.1 运行流程及思想 1.2 代码段 1.3 JavaScript语句代码 1.4 运行截图 前言 1.若有选择,您可以…...

Ubuntu 安装 Mysql
主要内容 本文主要是实现在虚拟机 Ubuntu 18.04 成功安装 MySQL 5.7,并实现远程访问功能,以 windows 下客户端访问虚拟机上的 mysql 数据库。 1. 切换至 root 用户 ,shell 终端指令均执行在 root 用户下 sudo su 2. 安装并设置 mysql 安…...

【五一创作】【Midjourney】Midjourney 连续性人物创作 ② ( 获取大图和 Seed 随机种子 | 通过 seed 随机种子生成类似图像 )
文章目录 一、获取大图和 Seed 随机种子二、通过 seed 种子生成类似图像 一、获取大图和 Seed 随机种子 注意 : 一定是使用 U 按钮 , 在生成的大图的基础上 , 添加 信封 表情 , 才能获取该大图的 Seed 种子编码 ; 在上一篇博客生成图像的基础上 , 点击 U3 获取第三张图的大图 ;…...
分布式事务 --- Seata事务模式、高可用
一、事务模式 1.1、XA模式 XA 规范 是 X/Open 组织定义的分布式事务处理(DTP,Distributed Transaction Processing)标准,XA 规范 描述了全局的TM与局部的RM之间的接口,几乎所有主流的数据库都对 XA 规范 提供了支持。…...

SQL(基础)
DDL: 数据定义语言 Definition,用来定义数据库对象(数据库、表、字段)CREATE、DROP、ALTER DML: 数据操作语言 Manipulation,用来对数据库表中的数据进行增删改 INSERT、UPDATE、DELETE 注意: DDL是改变表的结构 DML…...

「OceanBase 4.1 体验」OceanBase 4.1社区版的部署及使用体验
「OceanBase 4.1 体验」OceanBase 4.1社区版的部署及使用体验 一、前言1.1 本次实践介绍1.2 本次实践目的 二、准备环境资源2.1 部署前需准备工作2.2 本地环境规划 三、部署Docker环境3.1 安装Docker3.2 配置Docker镜像加速3.3 开启路由转发3.4 重启Docker服务 四、检查本地Doc…...
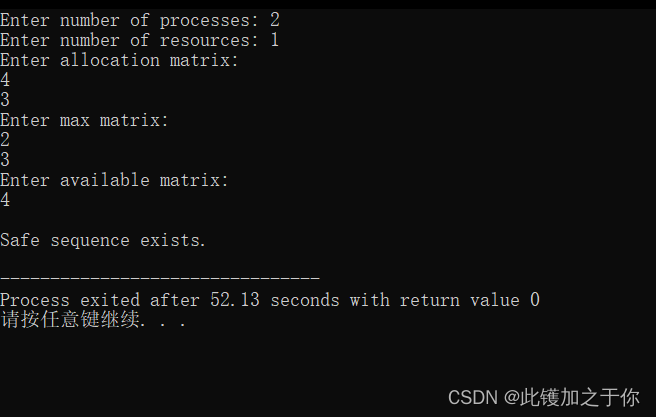
计算机操作系统实验:银行家算法模拟
目录 前言实验目的实验内容实验原理实验过程代码如下代码详解算法过程运行结果 总结 前言 本文是计算机操作系统实验的一部分,主要介绍了银行家算法的原理和实现。银行家算法是一种用于解决多个进程对多种资源的竞争和分配的算法,它可以避免死锁和资源浪…...
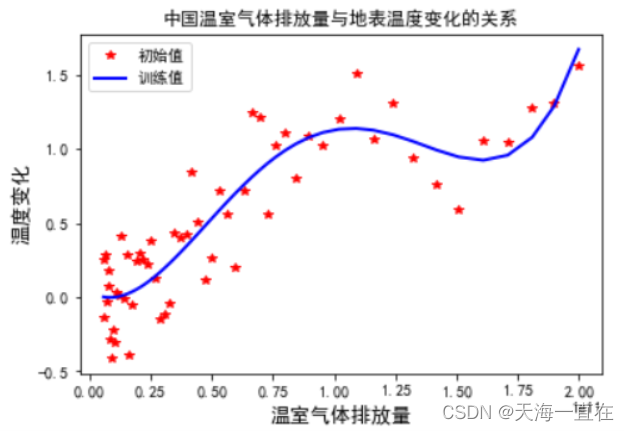
机器学习:多项式拟合分析中国温度变化与温室气体排放量的时序数据
文章目录 1、前言2、定义及公式3、案例代码1、数据解析2、绘制散点图3、多项式回归、拟合4、注意事项 1、前言 当分析数据时,如果我们找的不是直线或者超平面,而是一条曲线,那么就可以用多项式回归来分析和预测。 2、定义及公式 多项…...

一个 24 通道 100Msps 逻辑分析仪
这是一个创建非常便宜的逻辑分析仪的项目,但其功能可与昂贵的商业分析仪相媲美。该分析仪可以以每秒 1 亿个样本的最高速度对多达 24 个通道进行采样,并且可以通过单个通道中的极性变化或多达 16 个通道形成的模式来触发。 该项目不仅包含硬件࿰…...

使用Process Explorer和Dependency Walker排查C++程序中dll库动态加载失败问题
目录 1、exe主程序启动时的库加载流程说明 2、加载dll库两种方式 2.1、dll库的隐式引用...
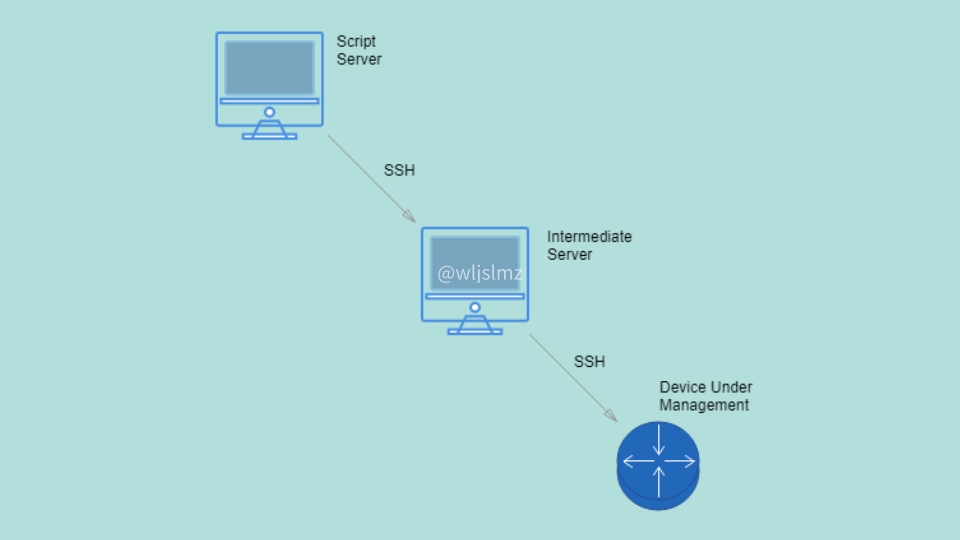
网工Python:如何使用Netmiko的SCP函数进行文件传输?
在网络设备管理中,传输配置文件、镜像文件等是经常需要进行的操作。Netmiko是一个Python库,可用于与各种网络设备进行交互,提供了一些用于传输文件的函数,其中包括SCP(Secure Copy Protocol)函数。本文将介…...
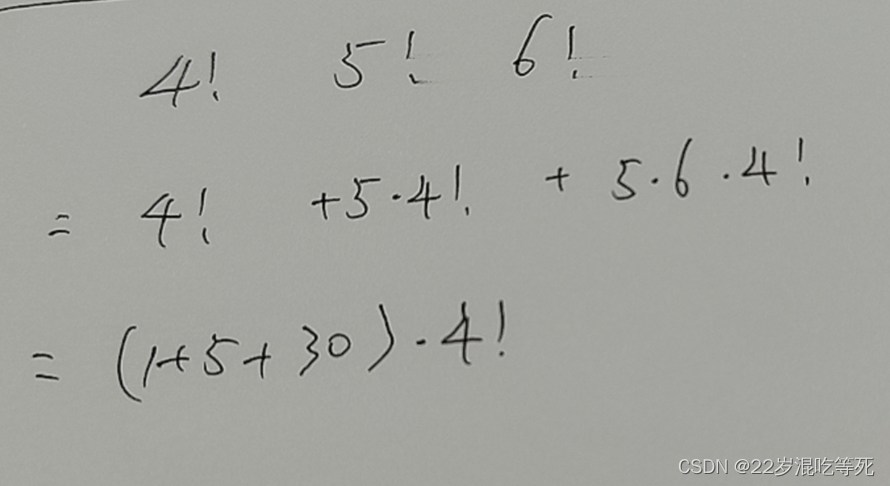
题目 3166: 蓝桥杯2023年第十四届省赛真题-阶乘的和--不能完全通过,最好情况通过67.
原题链接: 题目 3166: 蓝桥杯2023年第十四届省赛真题-阶乘的和 https://www.dotcpp.com/oj/problem3166.html 致歉 害,首先深感抱歉,这道题还是没有找到很好的解决办法。目前最好情况就是67分。 这道题先这样跳过吧,当然以后还…...
 介绍)
ChatGPT- OpenAI 的 模型(Model) 介绍
ChatGPT的火爆程度大家都知道了,该章节我们来了解一下 ChatGPT 一个关键概念 - 模型(Model)。主要是为大家介绍一下在 OpenAI 中,究竟有哪些模型可以使用。 在后续的章节,我们会分单独的小章节逐一的为大家介绍各个不同模型的调用以及接口参…...

X 态及基于 VCS 的 X-Propagation 检测
🔥点击查看精选 IC 技能树系列文章🔥 🔥点击进入【芯片设计验证】社区,查看更多精彩内容🔥 📢 声明: 🥭 作者主页:【MangoPapa的CSDN主页】。⚠️ 本文首发于CSDN&#…...

利用最小二乘法找圆心和半径
#include <iostream> #include <vector> #include <cmath> #include <Eigen/Dense> // 需安装Eigen库用于矩阵运算 // 定义点结构 struct Point { double x, y; Point(double x_, double y_) : x(x_), y(y_) {} }; // 最小二乘法求圆心和半径 …...
)
云计算——弹性云计算器(ECS)
弹性云服务器:ECS 概述 云计算重构了ICT系统,云计算平台厂商推出使得厂家能够主要关注应用管理而非平台管理的云平台,包含如下主要概念。 ECS(Elastic Cloud Server):即弹性云服务器,是云计算…...

css实现圆环展示百分比,根据值动态展示所占比例
代码如下 <view class""><view class"circle-chart"><view v-if"!!num" class"pie-item" :style"{background: conic-gradient(var(--one-color) 0%,#E9E6F1 ${num}%),}"></view><view v-else …...

在HarmonyOS ArkTS ArkUI-X 5.0及以上版本中,手势开发全攻略:
在 HarmonyOS 应用开发中,手势交互是连接用户与设备的核心纽带。ArkTS 框架提供了丰富的手势处理能力,既支持点击、长按、拖拽等基础单一手势的精细控制,也能通过多种绑定策略解决父子组件的手势竞争问题。本文将结合官方开发文档,…...

将对透视变换后的图像使用Otsu进行阈值化,来分离黑色和白色像素。这句话中的Otsu是什么意思?
Otsu 是一种自动阈值化方法,用于将图像分割为前景和背景。它通过最小化图像的类内方差或等价地最大化类间方差来选择最佳阈值。这种方法特别适用于图像的二值化处理,能够自动确定一个阈值,将图像中的像素分为黑色和白色两类。 Otsu 方法的原…...

使用van-uploader 的UI组件,结合vue2如何实现图片上传组件的封装
以下是基于 vant-ui(适配 Vue2 版本 )实现截图中照片上传预览、删除功能,并封装成可复用组件的完整代码,包含样式和逻辑实现,可直接在 Vue2 项目中使用: 1. 封装的图片上传组件 ImageUploader.vue <te…...

TRS收益互换:跨境资本流动的金融创新工具与系统化解决方案
一、TRS收益互换的本质与业务逻辑 (一)概念解析 TRS(Total Return Swap)收益互换是一种金融衍生工具,指交易双方约定在未来一定期限内,基于特定资产或指数的表现进行现金流交换的协议。其核心特征包括&am…...

Spring Boot面试题精选汇总
🤟致敬读者 🟩感谢阅读🟦笑口常开🟪生日快乐⬛早点睡觉 📘博主相关 🟧博主信息🟨博客首页🟫专栏推荐🟥活动信息 文章目录 Spring Boot面试题精选汇总⚙️ **一、核心概…...

IoT/HCIP实验-3/LiteOS操作系统内核实验(任务、内存、信号量、CMSIS..)
文章目录 概述HelloWorld 工程C/C配置编译器主配置Makefile脚本烧录器主配置运行结果程序调用栈 任务管理实验实验结果osal 系统适配层osal_task_create 其他实验实验源码内存管理实验互斥锁实验信号量实验 CMISIS接口实验还是得JlINKCMSIS 简介LiteOS->CMSIS任务间消息交互…...

【数据分析】R版IntelliGenes用于生物标志物发现的可解释机器学习
禁止商业或二改转载,仅供自学使用,侵权必究,如需截取部分内容请后台联系作者! 文章目录 介绍流程步骤1. 输入数据2. 特征选择3. 模型训练4. I-Genes 评分计算5. 输出结果 IntelliGenesR 安装包1. 特征选择2. 模型训练和评估3. I-Genes 评分计…...