C++之编程规范
目录
谷歌C++风格指南:https://zh-google-styleguide.readthedocs.io/en/latest/google-cpp-styleguide/contents/
编码规则:
• 开闭原则:软件对扩展是开放的,对修改是关闭的
• 防御式编程:简单的说就是程序不能崩溃
• 里氏代换原则:子类型必须能够替代他们的基类型
头文件:
• self-contained头文件: 用来插入文本的文件,说到底它们并不是头文件,所以应以 .inc 结尾——?
• define保护:所有头文件都应该使用 #define 来防止头文件被多重包含, 命名格式当是:
#ifndef FOO_BAR_BAZ_H_
#define FOO_BAR_BAZ_H_
…
#endif // FOO_BAR_BAZ_H_
• 前置声明: 尽可能地避免使用前置声明。使用 #include 包含需要的头文件即可。
○ 优点:
§ 前置声明能够节省编译时间,多余的 #include 会迫使编译器展开更多的文件,处理更多的输入。
§ 前置声明能够节省不必要的重新编译的时间。 #include 使代码因为头文件中无关的改动而被重新编译多次。——有利有弊,如下面的缺点
○ 缺点:
§ 前置声明隐藏了依赖关系,头文件改动时,用户的代码会跳过必要的重新编译过程。
§ 前置声明可能会被库的后续更改所破坏。前置声明函数或模板有时会妨碍头文件开发者变动其 API. 例如扩大形参类型,加个自带默认参数的模板形参等等。
§ 很难判断什么时候该用前置声明,什么时候该用 #include
§ 前置声明了不少来自头文件的 symbol 时,就会比单单一行的 include 冗长。
• 内联函数:
○ 不要内联超过 10 行的函数. 谨慎对待析构函数, 析构函数往往比其表面看起来要更长, 因为有隐含的成员和基类析构函数被调用
○ 内联那些包含循环或 switch 语句的函数常常是得不偿失——?
○ 有些函数即使声明为内联的也不一定会被编译器内联, 这点很重要; 比如虚函数和递归函数就不会被正常内联. 通常, 递归函数不应该声明成内联函数
• #include路径次序如下:
1. dir2/foo2.h (优先位置, 详情如下)
2. C 系统文件
3. C++ 系统文件
4. 其他库的 .h 文件
5. 本项目内 .h 文件
作用域:
• 局部变量: 在尽可能小的作用域中声明变量, 离第一次使用越近越好; 应使用初始化的方式替代声明再赋值, 有一个例外, 在循环作用域中,如果变量是一个对象, 每次进入作用域都要调用其构造函数, 每次退出作用域都要调用其析构函数. 这会导致效率降低.
• 匿名命名空间和静态变量: 所有置于匿名命名空间的声明都具有内部链接性,函数和变量可以经由声明为 static 拥有内部链接性,这意味着你在这个文件中声明的这些标识符都不能在另一个文件中被访问。即使两个文件声明了完全一样名字的标识符,它们所指向的实体实际上是完全不同的。结论是: 推荐、鼓励在 .cc 中对于不需要在其他地方引用的标识符使用内部链接性声明,但是不要在 .h 中使用。
• 非成员函数,静态成员函数和全局函数:
○ 使用静态成员函数或命名空间内的非成员函数, 尽量不要用裸的全局函数.
○ 将一系列函数直接置于命名空间中,不要用类的静态方法模拟出命名空间的效果(?),类的静态方法应当和类的实例或静态数据紧密相关.
○ 所以如果必须定义非成员函数, 又只是在 .cc 文件中使用它, 可使用匿名 命名空间 或 static 链接关键字 (如 static int Foo() {…}) 限定其作用域.
// 应为:
namespace myproject {
namespace foo_bar {
void Function1();
void Function2();
} // namespace foo_bar
} // namespace myproject
// 而非:
namespace myproject {
class FooBar {
public:
static void Function1();
static void Function2();};
} // namespace myproject
• 静态和全局变量:
○ 静态生存 周期的对象,即包括了全局变量,静态变量,静态类成员变量和函数静态变量,都必须是原生数据类型 (POD : Plain Old Data): 即 int, char 和 float, 以及 POD 类型的指针、数组和结构体
○ 静态变量的构造函数、析构函数和初始化的顺序在 C++ 中是只有部分明确的,甚至随着构建变化而变化,导致难以发现的 bug. 所以除了禁用类类型的全局变量,我们也不允许用函数返回值来初始化 POD 变量,除非该函数(如 getenv() 或 getpid() )不涉及任何全局变量。函数作用域里的静态变量除外,毕竟它的初始化顺序是有明确定义的,而且只会在指令执行到它的声明那里才会发生。( 同一个编译单元内是明确的,静态初始化优先于动态初始化,初始化顺序按照声明顺序进行,销毁则逆序。不同的编译单元之间初始化和销毁顺序属于未明确行为) 同理,全局和静态变量在程序中断时会被析构,无论所谓中断是从 main() 返回还是对 exit() 的调用。析构顺序正好与构造函数调用的顺序相反。但既然构造顺序未定义,那么析构顺序当然也就不定了。 综上所述,我们只允许 POD 类型的静态变量,即完全禁用 vector (使用 C 数组替代) 和 string (使用 const char [])。 如果您确实需要一个 class 类型的静态或全局变量,可以考虑在 main() 函数或 pthread_once() 内初始化一个指针且永不回收。注意只能用 raw 指针,别用智能指针,毕竟后者的析构函数涉及到上文指出的不定顺序问题。
函数:
• 参数顺序:输入参数在先,后跟输出参数。 在加入新参数时不要因为它们是新参数就置于参数列表最后, 而是仍然要按照前述的规则
• 编写简短, 凝练的函数, 如果函数超过 40 行, 可以思索一下能不能在不影响程序结构的前提下对其进行分割
• 所有按引用传递的参数必须加上 const。事实上这在 Google Code 是一个硬性约定: 输入参数是值参或 const 引用, 输出参数为指针. 输入参数可以是 const 指针, 但决不能是非 const 的引用参数, 除非特殊要求, 比如 swap().——这是为什么?
• 缺省参数: 只允许在非虚函数中使用缺省参数, 且必须保证缺省参数的值始终一致。 对于虚函数, 不允许使用缺省参数, 因为在虚函数中缺省参数不一定能正常工作.
类:
• 构造函数的职责:不要在构造函数中调用虚函数, 也不要在无法报出错误时进行可能失败的初始化.
1. 缺点:
1. 在没有使程序崩溃 (因为并不是一个始终合适的方法) 或者使用异常 (因为已经被 禁用 了) 等方法的条件下, 构造函数很难上报错误
2. 如果执行失败, 会得到一个初始化失败的对象, 这个对象有可能进入不正常的状态, 必须使用 bool IsValid() 或类似这样的机制才能检查出来, 然而这是一个十分容易被疏忽的方法.
3. 构造函数的地址是无法被取得的, 因此, 举例来说, 由构造函数完成的工作是无法以简单的方式交给其他线程的.
2. 结论: 构造函数不允许调用虚函数. 如果代码允许, 直接终止程序是一个合适的处理错误的方式. 否则, 考虑用 Init() 方法或工厂函数.
• 隐式类型转换: 不要定义隐式类型转换. 对于转换运算符和单参数构造函数, 请使用 explicit 关键字.
○ 用法: explicit 关键字可以用于构造函数或 (在 C++11 引入) 类型转换运算符, 以保证只有当目的类型在调用点被显式写明时才能进行类型转换
○ 结论: 在类型定义中, 类型转换运算符和单参数构造函数都应当用 explicit 进行标记. 一个例外是, 拷贝和移动构造函数不应当被标记为 explicit, 因为它们并不执行类型转换。 不能以一个参数进行调用的构造函数不应当加上 explicit. 接受一个 std::initializer_list 作为参数的构造函数也应当省略 explicit, 以便支持拷贝初始化 (例如 MyType m = {1, 2}😉 .
• 可拷贝类型和可移动类型:
○ 如果类型需要, 就让它们支持拷贝 / 移动. 否则, 就把隐式产生的拷贝和移动函数禁用.
• struct vs class: 仅当只有数据成员时使用 struct, 其它一概使用 class. struct 用来定义包含数据的被动式对象, 也可以包含相关的常量
• 继承: 使用组合常常比使用继承更合理. 如果使用继承的话, 定义为 public 继承.
• 多重继承:真正用到多重继承的情况少之又少;只有在以下情况下才允许使用多重继承:最多只有一个基类是非抽象类;其他基类都是以 Interface 为后缀的纯接口类;
○ 结论:只有当所有父类除第一个外都是 纯接口类 时, 才允许使用多重继承. 为确保它们是纯接口, 这些类必须以 Interface 为后缀.
• 接口:
• 运算符重载: 除少数特定环境外, 不要重载运算符. 也不要创建用户定义字面量。 不要重载 &&, ||, , 或一元运算符 &. 不要重载 operator"", 也就是说, 不要引入用户定义字面量.
• 存取控制: 将 所有 数据成员声明为 private, 除非是 static const 类型成员
• 声明顺序: 将相似的声明放在一起, 将 public 部分放在最前。说明:
○ 类定义一般应以 public: 开始, 后跟 protected:, 最后是 private:. 省略空部分.
○ 在各个部分中, 建议将类似的声明放在一起, 并且建议以如下的顺序: 类型 (包括 typedef, using 和嵌套的结构体与类), 常量, 工厂函数, 构造函数, 赋值运算符, 析构函数, 其它函数, 数据成员.
其他C++特性:
• 右值引用:只在定义移动构造函数与移动赋值操作时使用右值引用. 不要使用 std::forward.
○ 缺点: 右值引用是一个相对比较新的特性 (由 C++11 引入), 它尚未被广泛理解. 类似引用崩溃, 移动构造函数的自动推导这样的规则都是很复杂的.
• 尽量不使用函数重载
• 异常:不使用异常;对于到底需不需要使用异常,参考: https://www.zhihu.com/question/22889420
○ 优点:
§ 异常是处理构造函数失败的唯一途径
§ 有些第三方库依赖异常,禁用异常就不好用了
§ 在测试框架很有用
○ 缺点(还需整理)
§ 在现有函数中添加 throw 语句时,必须检查所有调用点。要么让所有调用点统统具备最低限度的异常安全保证,要么眼睁睁地看异常一路欢快地往上跑,最终中断掉整个程序。举例,f() 调用 g(), g() 又调用 h(), 且 h 抛出的异常被 f 捕获。当心 g, 否则会没妥善清理好。
§ 还有更常见的,异常会彻底扰乱程序的执行流程并难以判断,函数也许会在您意料不到的地方返回。您或许会加一大堆何时何处处理异常的规定来降低风险,然而开发者的记忆负担更重了。
§ 异常安全需要RAII和不同的编码实践. 要轻松编写出正确的异常安全代码需要大量的支持机制. 更进一步地说, 为了避免读者理解整个调用表, 异常安全必须隔绝从持续状态写到 “提交” 状态的逻辑. 这一点有利有弊 (因为你也许不得不为了隔离提交而混淆代码). 如果允许使用异常, 我们就不得不时刻关注这样的弊端, 即使有时它们并不值得.
§ 启用异常会增加二进制文件数据,延长编译时间(或许影响小),还可能加大地址空间的压力。
§ 滥用异常会变相鼓励开发者去捕捉不合时宜,或本来就已经没法恢复的「伪异常」。比如,用户的输入不符合格式要求时,也用不着抛异常。如此之类的伪异常列都列不完。
• 运行时类型识别: RTTI 允许程序员在运行时识别 C++ 类对象的类型. 它通过使用 typeid 或者 dynamic_cast 完成.
○ 优点: RTTI 在某些单元测试中非常有用. 比如进行工厂类测试时, 用来验证一个新建对象是否为期望的动态类型. RTTI 对于管理对象和派生对象的关系也很有用.
○ 缺点:
§ 在运行时判断类型通常意味着设计问题. 如果你需要在运行期间确定一个对象的类型, 这通常说明你需要考虑重新设计你的类.
§ 随意地使用 RTTI 会使你的代码难以维护. 它使得基于类型的判断树或者 switch 语句散布在代码各处. 如果以后要进行修改, 你就必须检查它们.
○ 结论:RTTI 有合理的用途但是容易被滥用, 因此在使用时请务必注意. 在单元测试中可以使用 RTTI, 但是在其他代码中请尽量避免. 尤其是在新代码中, 使用 RTTI 前务必三思. 如果你的代码需要根据不同的对象类型执行不同的行为的话, 请考虑用以下的两种替代方案之一查询类型:
§ *虚函数可以根据子类类型的不同而执行不同代码. 这是把工作交给了对象本身去处理.
§ 如果这一工作需要在对象之外完成, 可以考虑使用双重分发的方案, 例如使用访问者设计模式. 这就能够在对象之外进行类型判断.
§ 如果程序能够保证给定的基类实例实际上都是某个派生类的实例, 那么就可以自由使用 dynamic_cast. 在这种情况下, 使用 dynamic_cast 也是一种替代方案.
§ 注意:基于类型的判断树是一个很强的暗示, 它说明你的代码已经偏离正轨了. 不要像下面这样:
if (typeid(*data) == typeid(D1)) {
…} else if (typeid(*data) == typeid(D2)) {
…} else if (typeid(*data) == typeid(D3)) {…
○ 一旦在类层级中加入新的子类, 像这样的代码往往会崩溃. 而且, 一旦某个子类的属性改变了, 你很难找到并修改所有受影响的代码块。不要去手工实现一个类似 RTTI 的方案. 反对 RTTI 的理由同样适用于这些方案, 比如带类型标签的类继承体系. 而且, 这些方案会掩盖你的真实意图.
• 类型转换: 使用 C++ 的类型转换, 如 static_cast<>(). 不要使用 int y = (int)x 或 int y = int(x) 等转换方式
○ 优点: C 语言的类型转换问题在于模棱两可的操作; 有时是在做强制转换 (如 (int)3.5), 有时是在做类型转(如 (int)“hello”). 另外, C++ 的类型转换在查找时更醒目——?难道第一个不是强制类型转换
○ 结论:
§ 用 static_cast 替代 C 风格的值转换, 或某个类指针需要明确的向上转换为父类指针时.
§ 用 const_cast 去掉 const 限定符.
§ 用 reinterpret_cast 指针类型和整型或其它指针之间进行不安全的相互转换. 仅在你对所做一切了然于心时使用.
• 流: 只在记录日志时使用流. 流用来替代 printf() 和 scanf().——?不只是这两个吧,文件流,string流…
○ 优点: 有了流, 在打印时不需要关心对象的类型. 不用担心格式化字符串与参数列表不匹配 (虽然在 gcc 中使用 printf 也不存在这个问题). 流的构造和析构函数会自动打开和关闭对应的文件.
○ 缺点:流使得 pread() 等功能函数很难执行. 如果不使用 printf 风格的格式化字符串, 某些格式化操作 (尤其是常用的格式字符串 %.*s) 用流处理性能是很低的. 流不支持字符串操作符重新排序 (%1s), 而这一点对于软件国际化很有用.——?
○ 结论: 不要使用流, 除非是日志接口需要. 使用 printf + read/write之类的代替.——主要还是从可读性,易出错性等方面来说的
• 前置自增/自减: 对简单数值 (非对象), 两种都无所谓. 对迭代器和模板类型, 使用前置自增 (自减).
• const:
○ 缺点: const 是入侵性的: 如果你向一个函数传入 const 变量, 函数原型声明中也必须对应 const 参数 (否则变量需要 const_cast 类型转换), 在调用库函数时显得尤其麻烦.
○ 结论: const 变量, 数据成员, 函数和参数为编译时类型检测增加了一层保障; 便于尽早发现错误. 因此强烈建议在任何可能的情况下使用 const,此外有时改用 C++11 推出的 constexpr 更好; mutable 可以使用, 但是在多线程中是不安全的, 使用时首先要考虑线程安全.
• constexpr: 在 C++11 里,用 constexpr 来定义真正的常量,或实现常量初始化。 变量可以被声明成 constexpr 以表示它是真正意义上的常量,即在编译时和运行时都不变。函数或构造函数也可以被声明成 constexpr, 以用来定义 constexpr 变量。
○ 结论: 靠 constexpr 特性,方才实现了 C++ 在接口上打造真正常量机制的可能。好好用 constexpr 来定义真常量以及支持常量的函数。避免复杂的函数定义,以使其能够与constexpr一起使用。 千万别痴心妄想地想靠 constexpr 来强制代码「内联」。
• 整型: <stdint.h> 定义了 int16_t, uint32_t, int64_t 等整型, 在需要确保整型大小时可以使用它们代替 short, unsigned long long 等. 在 C 整型中, 只使用 int. 在合适的情况下, 推荐使用标准类型如 size_t 和 ptrdiff_t.对于大整数, 使用 int64_t.不要使用 uint32_t 等无符号整型, 除非你是在表示一个位组而不是一个数值, 或是你需要定义二进制补码溢出. 尤其是不要为了指出数值永不会为负, 而使用无符号类型. 相反, 你应该使用断言来保护数据.
• 64位下的可移植性
• 预处理宏: 使用宏时要非常谨慎, 尽量以内联函数, 枚举和常量代替之.如果你要宏, 尽可能遵守:
○ 不要在 .h 文件中定义宏.
○ 在马上要使用时才进行 #define, 使用后要立即 #undef.
○ 不要只是对已经存在的宏使用#undef,选择一个不会冲突的名称;
○ 不要试图使用展开后会导致 C++ 构造不稳定的宏, 不然也至少要附上文档说明其行为.
○ 不要用 ## 处理函数,类和变量的名字。
• nullptr和NULL: 整数用 0, 实数用 0.0, 指针用 nullptr 或 NULL, 字符 (串) 用 ‘\0’.
• sizeof: 尽可能用 sizeof(varname) 代替 sizeof(type). 使用 sizeof(varname) 是因为当代码中变量类型改变时会自动更新——?这个解释怎么理解?
• auto: 可以用 auto 来复制初始化或绑定引用——? auto 在涉及迭代器的循环语句里挺常用
○ 只在局部变量里用,别用在文件作用域变量,命名空间作用域变量和类数据成员里。永远别列表初始化 auto 变量。
○ auto 还可以和 C++11 特性「尾置返回类型(trailing return type)」一起用,不过后者只能用在 lambda 表达式里。
auto x(3); // 圆括号。 它们不是同一回事——x 是 int
auto y{3}; // 大括号。 y 则是 std::initializer_list.
• lambda表达式:
○ 优点:
§ 传函数对象给 STL 算法,Lambdas 最简易,可读性也好。
§ Lambdas, std::functions 和 std::bind 可以搭配成通用回调机制(general purpose callback mechanism);写接收有界函数为参数的函数也很容易了。——?
○ 缺点:
§ Lambdas 的变量捕获略旁门左道,可能会造成悬空指针。
§ Lambdas 可能会失控;层层嵌套的匿名函数难以阅读。
○ 结论:
§ 按 format 小用 lambda 表达式怡情。
§ 禁用默认捕获,捕获都要显式写出来。比起 = {return x + n;}, 应写成 n {return x + n;} 才对,这样读者也好一眼看出 n 是被捕获的值。
§ 匿名函数始终要简短,如果函数体超过了五行,那么还不如起名(即把 lambda 表达式赋值给对象),或改用函数。
§ 如果可读性更好,就显式写出 lambd 的尾置返回类型,就像auto.
• 模板编程: 除了优点外,大量的使用模板编程接口会让重构工具(Visual Assist X, Refactor for C++等等)更难发挥用途. 首先模板的代码会在很多上下文里面扩展开来, 所以很难确认重构对所有的这些展开的代码有用, 其次有些重构工具只对已经做过模板类型替换的代码的AST 有用. 因此重构工具对这些模板实现的原始代码并不有效, 很难找出哪些需要重构.
○ 结论:模板编程最好只用在少量的基础组件, 基础数据结构上, 因为模板带来的额外的维护成本会被大量的使用给分担掉
• boost库: 只使用 Boost 中被认可的库:
命名约定:
• 文件命名:
○ 全部小写, 可以包含下划线 () 或连字符 (-), 依照项目的约定. 如果没有约定, 那么 “” 更好.
○ C++ 文件要以 .cc 结尾, 头文件以 .h 结尾. 专门插入文本的文件则以 .inc 结尾, 参见 头文件自足
○ 定义类时文件名一般成对出现, 如 foo_bar.h 和 foo_bar.cc, 对应于类 FooBar.
○ 内联函数必须放在 .h 文件中. 如果内联函数比较短, 就直接放在 .h 中.——为什么是必须?
• 类型命名: 所有类型命名类, 结构体, 类型定义 (typedef), 枚举, 类型模板参数 —— 均使用相同约定, 即以大写字母开始, 每个单词首字母均大写, 不包含下划线
• 变量命名:
○ 普通变量: 变量 (包括函数参数) 和数据成员名一律小写, 单词之间用下划线连接
○ 类数据成员: 不管是静态的还是非静态的, 类数据成员都可以和普通变量一样, 但要接下划线.
○ 结构体变量:不管是静态的还是非静态的, 结构体数据成员都可以和普通变量一样, 不用像类接下划线
• 常量命名: 声明为 constexpr 或 const 的变量, 或在程序运行期间其值始终保持不变的, 命名时以 “k” 开头, 大小写混合,如const int kDaysInAWeek = 7; 所有具有静态存储类型的变量 (例如静态变量或全局变量) 都应当以此方式命名
• 函数命名:
○ 常规函数使用大小写混合(即 “驼峰变量名” 或 “帕斯卡变量名”), 没有下划线. 对于首字母缩写的单词, 更倾向于将它们视作一个单词进行首字母大写 (例如, 写作 StartRpc() 而非 StartRPC()).
○ 取值和设值函数则要求与变量名匹配, 一般来说它们的名称与实际的成员变量对应 , 但并不强制要求
• 命名空间命名: 命名空间以小写字母命名. 最高级命名空间的名字取决于项目名称。命名空间中的代码, 应当存放于和命名空间的名字匹配的文件夹或其子文件夹中. 注意 不使用缩写作为名称 的规则同样适用于命名空间
• 枚举命名: 枚举的命名应当和 常量 或 宏 一致: kEnumName 或是 ENUM_NAME. 单独的枚举值应该优先采用 常量 的命名方式
格式:
• 行长度: 每一行代码字符数不超过 80.
• 非ASCII字符: 尽量不使用非 ASCII 字符, 使用时必须使用 UTF-8 编码.——这个怎么区分?
• 空格缩进
• 函数声明与定义
cpplint使用总结:
相关文章:

C++之编程规范
目录 谷歌C风格指南:https://zh-google-styleguide.readthedocs.io/en/latest/google-cpp-styleguide/contents/ 编码规则: • 开闭原则:软件对扩展是开放的,对修改是关闭的 • 防御式编程:简单的说就是程序不能崩溃 •…...
ChatGPT做PPT方案,10组提示词方案!
今天我们要搞定的PPT内容是: 活动类型:节日活动、会员活动、新品活动分析类型:用户分析、新品立项、项目汇报内容类型:内容规划、品牌策划 用到的工具: mindshow 邀请码 6509097ChatGPT传送门(免费使用…...
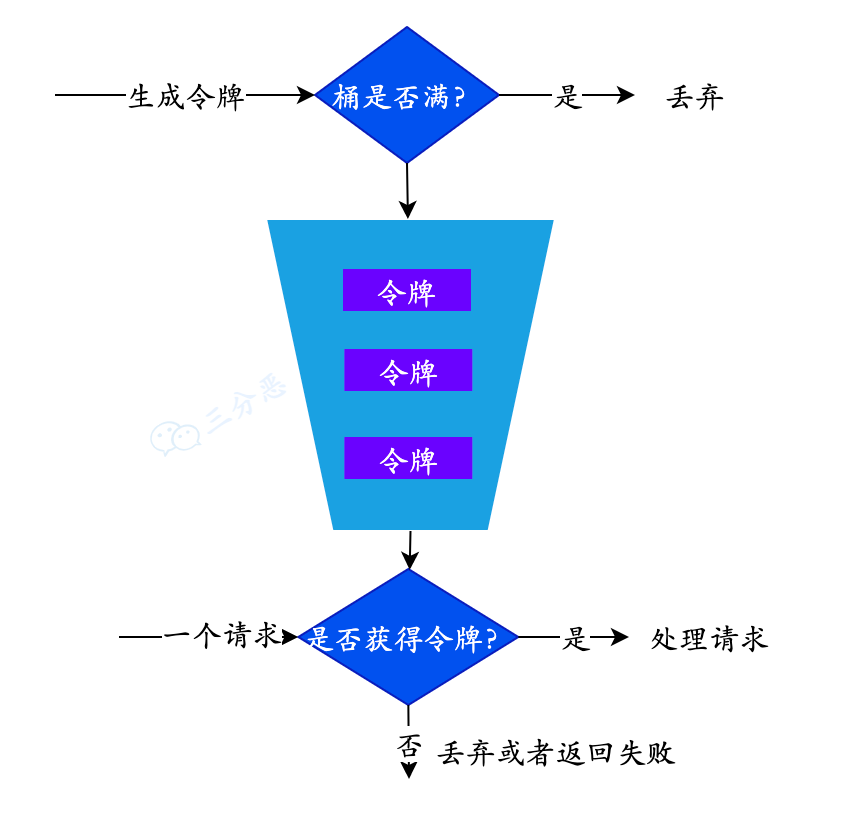
分布式夺命12连问
分布式理论 1. 说说CAP原则? CAP原则又称CAP定理,指的是在一个分布式系统中,Consistency(一致性)、 Availability(可用性)、Partition tolerance(分区容错性)这3个基本…...
sourceTree离线环境部署
目录 1、下载sourceTree安装包,打开之后弹出注册界面(需要去国外网站注册)2、使用技术手段跳过注册步骤3、打开安装包进行安装 注:建议提前安装好git 1、下载sourceTree安装包,打开之后弹出注册界面(需要去…...

6.1.1 图:基本概念
一,基本概念 1.基本定义 (1)图的定义 顶点集不可以是空集,但边集可以是空集。 (2) 有向图的表示: 圆括号 无向图的表示: 尖括号 简单图、多重图: 简单图:…...
SlickEdit for Windows and Linux crack
SlickEdit for Windows and Linux crack 现在可以在“新建注释”对话框中对颜色进行排序,使调色板中的颜色阵列看起来更符合逻辑。 在拆分或扩展行注释时添加了撤消步骤,这样您只需点击“撤消”一次即可撤消行注释扩展。 已更新VHDL颜色编码,…...
ChatGPT实现stackoverflow 解释
stackoverflow 解释 ChatGPT 公开服务以来,程序员们无疑是最早深入体验和"测试"的一批人。出色的效果也引发了一系列知识产权上的争议。著名的 stackoverflow 网站,就宣布禁止用户使用 ChatGPT 生成的内容来回答问题,一经发现&…...
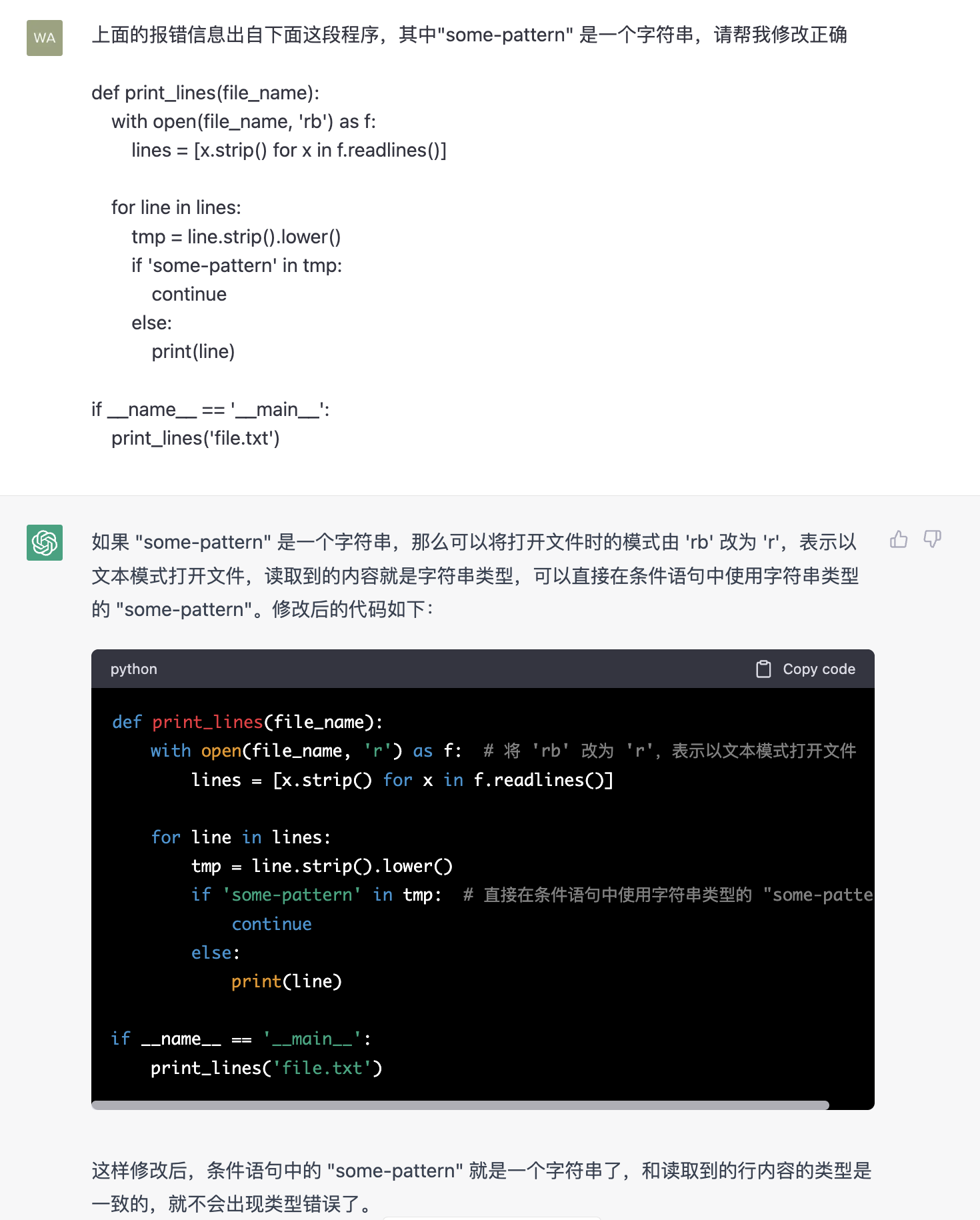
第五章 作业(123)【编译原理】
第五章 作业【编译原理】 前言推荐第五章 作业123 随堂练习课前热身04-17随堂练习04-17课前热身04-24 最后 前言 2023-5-3 22:12:46 以下内容源自《【编译原理】》 仅供学习交流使用 推荐 第四章 作业(123)【编译原理】 第五章 作业 1 1.令文法G为…...

基于Vue的个性化网络学习笔记系统
1.系统登录:系统登录是用户访问系统的路口,设计了系统登录界面,包括用户名、密码和验证码,然后对登录进来的用户判断身份信息,判断是管理员用户还是普通用户。 2.系统用户管理:不管是…...

如何搭建一个HTTP实验环境
这一讲是“破冰篇”的最后一讲,我会先简单地回顾一下之前的内容,然后在 Windows 系统上实际操作,用几个应用软件搭建出一个“最小化”的 HTTP 实验环境,方便后续的“基础篇”“进阶篇”“安全篇”的学习。 “破冰篇”回顾 HTTP …...

Electron 环境搭建
https://start.spring.io/ 在线数据分析网站 https://tj.aldwx.com/ https://www.spsspro.com/ win10如何分屏 拖到边缘 Electron 环境搭建 https://www.electronjs.org/zh/docs/latest/tutorial/%E6%89%93%E5%8C%85%E6%95%99%E7%A8%8B electron 隐藏菜单 electron 标题栏 设…...

农机电招平台~java
摘要 随着农机电招行业的不断发展,农机电招在现实生活中的使用和普及,农机电招行业成为近年内出现的一个新行业,并且能够成为大群众广为认可和接受的行为和选择。设计农机电招平台的目的就是借助计算机让复杂的销售操作变简单,变…...

springboot+vue体质测试数据分析及可视化设计(源码+文档)
风定落花生,歌声逐流水,大家好我是风歌,混迹在java圈的辛苦码农。今天要和大家聊的是一款基于springboot的体质测试数据分析及可视化设计。项目源码以及部署相关请联系风歌,文末附上联系信息 。 💕💕作者&a…...
thinkphp+vue+html高校固定资产管理系统维修 租借4h80u
本高校资产管理系统采用的数据库是Mysql,使用thinkphp框架开发。在设计过程中,充分保证了系统代码的良好可读性、实用性、易扩展性、通用性、便于后期维护、操作方便以及页面简洁等特点。运行环境:phpstudy/wamp/xammp等 开发语言:php 后端框…...

【学习笔记】「北大集训 2021」经典游戏
我觉得很厉害。要是考场上能把这道题切了的话数据结构的水平肯定是不低的。 考虑简化版问题:如果只询问一个点的答案怎么做。 注意,我这么做是有风险的。我把战线拉长了。不过当然,如果连简化版的问题都做不了,那何谈正解&#…...
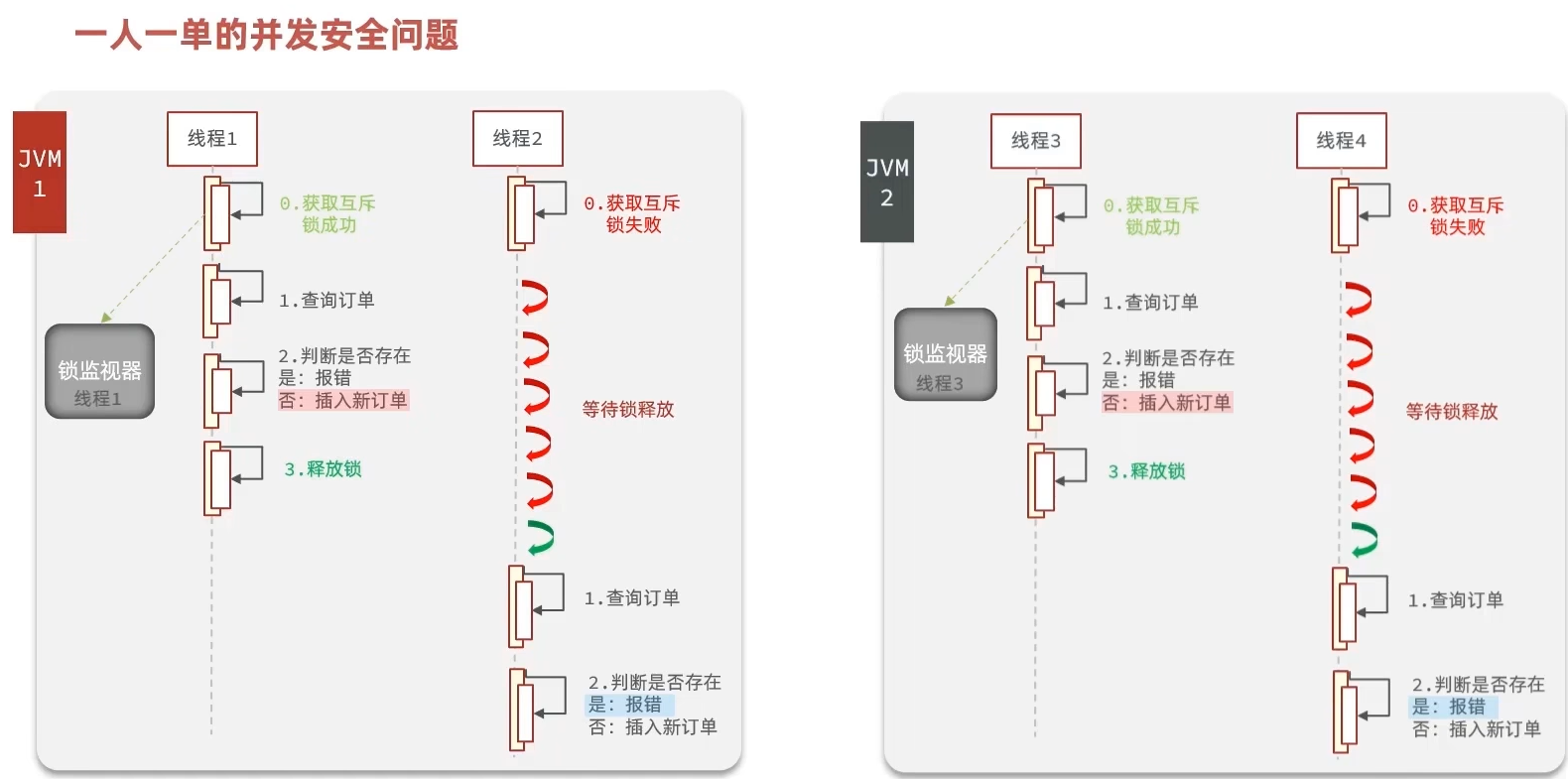
优惠卷秒杀功能、全局唯一ID、乐观锁解决超卖问题、悲观锁实现一人一单、集群下锁失效问题
文章目录 1 全局唯一ID的需求分析2 Redis实现全局唯一Id3 添加优惠卷4 实现秒杀下单5 库存超卖问题分析6 乐观锁解决超卖问题6 悲观锁实现一人一单7 集群环境下的并发问题 1 全局唯一ID的需求分析 每个店铺都可以发布优惠券: 当用户抢购时,就会生成订单…...

Nest的基本概念,以及如何使用Nest CLI来构建一个简单的Web应用程序
Nest是一个用于构建高效、可扩展的Node.js服务器端应用程序的框架。它是基于Express.js构建的,并且提供了多种新特性和抽象层,可以让开发者更加轻松地构建复杂的应用程序。 本文将介绍Nest的基本概念,以及如何使用Nest CLI来构建一个简单的W…...

15个创新世界119座城:1~10章音频
感恩每一个喜欢我文字的朋友,感恩每一次遇见。 最近后台总有朋友留言,能不能每一章配上音频,这样平时开车或挤地铁时也能听听。 谢谢你们在开车和挤地铁的时候都会产生听这本书的冲动。 五一抽空先把前十章的音频转录出来,希望你们…...

AI面试必刷算法题 附答案和解析 --持续更新中
面试中发现很多同学一股脑优化、润色项目经历,但聊到基本的算法,反而会一脸懵X,得空整理下算法题给大家,希望对你有帮助。 1. tail(head(tail(C))) ( ) 已知广义表: A(a,b), B(A,A), C(a,(b,A),B), 求下列运算的结果:(…...
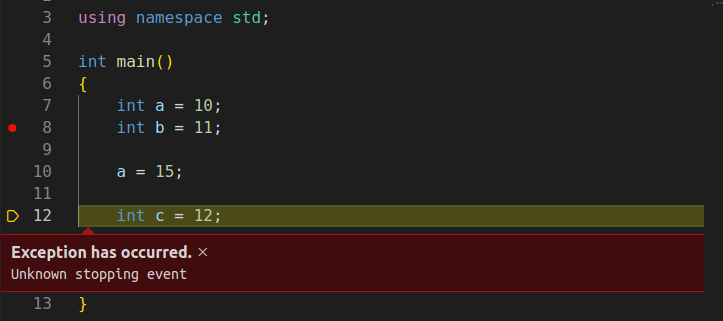
聊一聊 GDB 调试程序时的几个实用命令
一:背景 1. 讲故事 用惯了宇宙第一的 Visual Studio 再用其他的开发工具还是有一点不习惯,不习惯在于想用的命令或者面板找不到,总的来说还是各有千秋吧,今天我们来聊一下几个在调试中比较实用的命令: 查看内存硬件…...

Linux 文件类型,目录与路径,文件与目录管理
文件类型 后面的字符表示文件类型标志 普通文件:-(纯文本文件,二进制文件,数据格式文件) 如文本文件、图片、程序文件等。 目录文件:d(directory) 用来存放其他文件或子目录。 设备…...

C++初阶-list的底层
目录 1.std::list实现的所有代码 2.list的简单介绍 2.1实现list的类 2.2_list_iterator的实现 2.2.1_list_iterator实现的原因和好处 2.2.2_list_iterator实现 2.3_list_node的实现 2.3.1. 避免递归的模板依赖 2.3.2. 内存布局一致性 2.3.3. 类型安全的替代方案 2.3.…...

逻辑回归:给不确定性划界的分类大师
想象你是一名医生。面对患者的检查报告(肿瘤大小、血液指标),你需要做出一个**决定性判断**:恶性还是良性?这种“非黑即白”的抉择,正是**逻辑回归(Logistic Regression)** 的战场&a…...

Day131 | 灵神 | 回溯算法 | 子集型 子集
Day131 | 灵神 | 回溯算法 | 子集型 子集 78.子集 78. 子集 - 力扣(LeetCode) 思路: 笔者写过很多次这道题了,不想写题解了,大家看灵神讲解吧 回溯算法套路①子集型回溯【基础算法精讲 14】_哔哩哔哩_bilibili 完…...

华为云Flexus+DeepSeek征文|DeepSeek-V3/R1 商用服务开通全流程与本地部署搭建
华为云FlexusDeepSeek征文|DeepSeek-V3/R1 商用服务开通全流程与本地部署搭建 前言 如今大模型其性能出色,华为云 ModelArts Studio_MaaS大模型即服务平台华为云内置了大模型,能助力我们轻松驾驭 DeepSeek-V3/R1,本文中将分享如何…...

图表类系列各种样式PPT模版分享
图标图表系列PPT模版,柱状图PPT模版,线状图PPT模版,折线图PPT模版,饼状图PPT模版,雷达图PPT模版,树状图PPT模版 图表类系列各种样式PPT模版分享:图表系列PPT模板https://pan.quark.cn/s/20d40aa…...

如何在网页里填写 PDF 表格?
有时候,你可能希望用户能在你的网站上填写 PDF 表单。然而,这件事并不简单,因为 PDF 并不是一种原生的网页格式。虽然浏览器可以显示 PDF 文件,但原生并不支持编辑或填写它们。更糟的是,如果你想收集表单数据ÿ…...

高效线程安全的单例模式:Python 中的懒加载与自定义初始化参数
高效线程安全的单例模式:Python 中的懒加载与自定义初始化参数 在软件开发中,单例模式(Singleton Pattern)是一种常见的设计模式,确保一个类仅有一个实例,并提供一个全局访问点。在多线程环境下,实现单例模式时需要注意线程安全问题,以防止多个线程同时创建实例,导致…...

【无标题】路径问题的革命性重构:基于二维拓扑收缩色动力学模型的零点隧穿理论
路径问题的革命性重构:基于二维拓扑收缩色动力学模型的零点隧穿理论 一、传统路径模型的根本缺陷 在经典正方形路径问题中(图1): mermaid graph LR A((A)) --- B((B)) B --- C((C)) C --- D((D)) D --- A A -.- C[无直接路径] B -…...

xmind转换为markdown
文章目录 解锁思维导图新姿势:将XMind转为结构化Markdown 一、认识Xmind结构二、核心转换流程详解1.解压XMind文件(ZIP处理)2.解析JSON数据结构3:递归转换树形结构4:Markdown层级生成逻辑 三、完整代码 解锁思维导图新…...