Scala之集合(2)

目录
集合基本函数:
(1)获取集合长度
(2)获取集合大小
(3)循环遍历
(4)迭代器
(5)生成字符串
(6)是否包含
衍生集合:
(1)获取集合的头
(2)获取集合的尾
(3)集合最后一个数据
(4)集合初始数据
(5)反转
(6)取前(后)n 个元素
(7)去掉前(后)n 个元素
(8)并集(不去重)
(9)交集
(10)差集
(11)拉链
(12)滑窗
集合的低级函数:
求和:
乘积:
最大值:
最小值:
排序:
简单排序:
从大到小:
从小到大:
排序二元组:
自定义排序:
sortWith排序:
集合计算高级函数:
过滤:
map转化(映射):
转化1:
转化2:
转化3:
扁平化:
flatMap函数:
分组:
Reduce:
1.归约:
2.折叠(fold):
foldLeft():
两个Map的归约(合并):
方法1:
方法二:
集合基本函数:
(1)获取集合长度
val length: Int = list.length
(2)获取集合大小
val size: Int = list.size
(3)循环遍历
list.foreach(println)
(4)迭代器
val iterator: Iterator[Int] = list.iteratorwhile (iterator.hasNext){println(iterator.next())}(5)生成字符串
val str: String = list.mkString("\t")println(str)(6)是否包含
val bool: Boolean = list.contains(2)println(bool)衍生集合:
调用一个方法 原集合保持不变 生成一个新的集合
(1)获取集合的头
val head: Int = list.headprintln(head)(2)获取集合的尾
val tail: List[Int] = list.tailprintln(tail)(3)集合最后一个数据
val last: Int = list.lastprintln(last)(4)集合初始数据
val init: List[Int] = list.initprintln(init)(5)反转
val reverse: List[Int] = list.reverseprintln(reverse)(6)取前(后)n 个元素
取前两个
val ints: List[Int] = list.take(2)取后两个
val ints1: List[Int] = list.takeRight(2)
(7)去掉前(后)n 个元素
去掉前俩 返回值为剩下的元素
val ints2: List[Int] = list.drop(2)
去掉后俩
val ints3: List[Int] = list.dropRight(2)
(8)并集(不去重)
val ints4: List[Int] = list.union(list1)(9)交集
val ints5: List[Int] = list.intersect(list1)
(10)差集
val ints6: List[Int] = list.diff(list1)
(11)拉链
---就是把两个集合进行拼接成二元组 当两个集合元素数量正好相等的时候 恰好组成元组 两恶搞集合元素数量不等的时候 会把多余的给舍弃
val tuples: List[(Int, Int)] = list.zip(list1)
(12)滑窗
场景:
给一个数组 (-200,50,-10,0,0,-80) 求任意相邻的三个数 成绩最大的是那三个
val list2 = List(-200, 50, -100, 0, -80)
val iterator: Iterator[List[Int]] = list2.sliding(3, 1)var result=0for (elem <- iterator) {if (result<elem.product) {result=elem.product}}参数 窗口大小 步长(一次几个格子) 如果在最后元素少于窗口大小 则依然输出剩下的 product product()方法属于类Abstract Iterator的具体值成员。它用于乘以指定集合的所有元素。
集合的低级函数:
求和:
val sum: Int = ints.sum乘积:
val product: Int = ints.product
最大值:
val max: Int = ints.max
最小值:
val min: Int = ints.min
上述函数都没有()但是他是有参数的 他是一种隐式参数
排序:
简单排序:
排序计算机是采用的快排,默认是从小到大排序,如果需要从大到小需要重写他的参数
从大到小:
val sorted: List[Int] = ints.sorted
从小到大:
val ints1: List[Int] = ints.sorted(Ordering.Int.reverse)
排序结果的输出可以迭代器也可以for循环
val iterator: Iterator[Int] = sorted.iteratorwhile(iterator.hasNext){print(iterator.next()+" ")}排序二元组:
val tuples = List(("hello", 10), ("world", 20), ("tuple", 32), ("spark", 58))
默认按照第一个元素进行排序
val tuples1: List[(String, Int)] = tuples.sorted(Ordering[(String, Int)])
反转排序:它是按照字母的倒叙进行排序
val reverse: List[(String, Int)] = tuples.sorted(Ordering[(String, Int)]).reverse
两种排序的运行结果对比:

自定义排序:
按照单词出现的次数排序:
这样是需要自定义的 调用sortBy()函数(By---什么方式)
设置返回类型就是按照什么排序(匿名函数)
val tuples2: List[(String, Int)] = tuples.sortBy((tuples: (String, Int)) => tuples._2)
按照单词出现的次数反转排序:
通过sortBy()源码可知他是采用了柯里化写法(闭包---把上层变量定义成常量传给下一层)
val reverse1: List[(String, Int)] = tuples.sortBy((tuples: (String, Int)) => tuples._2)(Ordering[Int]).reverse
上述代码在第一次传入参数返回的是以Int类型的集合 在对他进行封装成常量传递给下层 所以 在柯里化的第二个()的时候在设置类型的时候要设置Int类型
sortWith排序:
sortWith参数形式: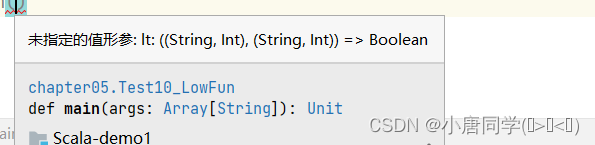
这个就是类似于冒泡排序左边于靠近的右边的进行比较,当不满足某条件的时候进行调换
val tuples3: List[(String, Int)] = tuples.sortWith((lift: (String, Int), right: (String, Int)) => lift._2 > right._2)
集合计算高级函数:
下边所写高阶函数都有一个默认的foreach()逻辑,在进行下边操作的时候都会一个一个的传入(遍历)
过滤:
val ints1: List[Int] = ints.filter(i=> i %2 == 0)
map转化(映射):
map转化是使用集合的map方法进行结构转化
map方法的参数形式:

转化1:
val ints2: List[Int] = ints.map(i => i * 2)
转化2:
val tuples: List[(String, Int)] = ints.map((i:Int) => ("我是", i))
转化3:
在Hadoop的hdfs中我们存储的是半结构化数据(一条条的数据字符串)
val list = List("zhangsan,18,男,180", "tangxiaocong,19,男,185")list.map((line:String)=>{val strings: Array[String] = line.split(",")//构造元组(strings(0),strings(1),strings(2),strings(3))})扁平化:
扁平化的使用场景为List集合嵌套List集合,对于这种情况需要使用炸裂
val list1 = List(List(1, 2, 3, 4), List(4, 5, 6, 7), List(7, 8, 9, 10))val flatten: List[Int] = list1.flatten执行结果:(不去重)

元素必须是可拆分的集合才能调用扁平化
特例:
如果在List中是String则可以使用flatten函数(String是char的集合)
上述情况会把String转换成char的形式
所以在扁平化的时候需要将集合中的字符串转化成List形式(map转化)
val list2 = List("hello world", "hello scala", "hello spark")val list3: List[List[String]] = list2.map((line: String) => {val strings: Array[String] = line.split(",")strings.toList})让后在进行扁平化(直接调用flatten)
val flatten1: List[String] = list3.flatten

在框架中使用的是flatMap(实际是map+flatten)
flatMap函数:
传入的参数还是map转化的逻辑,让后默认调用flatten函数
val strings1: List[String] = list2.flatMap((line: String) => {line.split(",")})flattenMap函数需要的参数是集合的形式,是不需要转化成List集合的
分组:
分组之后多组数据转换成了一行数据 生成数据有相同的key value值变成了一个List集合
val tuples1 = List(("A", 10), ("B", 20), ("C", 11), ("D", 15),("A", 16), ("B", 26), ("C", 41), ("D", 35))val map: Map[String, List[(String, Int)]] = tuples1.groupBy(tuple => tuple._1)
分组条件不止可以为元组的某个值,也可以是自己特定的(通过匿名函数设定)
val ints3 = List(1, 2, 3, 5, 4, 6, 7, 8, 9)val map1: Map[Int, List[Int]] = ints3.groupBy((i: Int) => i % 2)返回值的结果是什么就按照什么进行排序
Reduce:
1.归约:
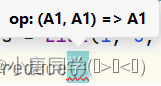
参数表示:输入输出的数据类型是一致的
第一个A1:表示每次调用的结果值
第二个A1:表示当前元素值
第三个A3:本次调用的返回结果, 作为下次的结果值
reduce将第一个初始值作为结果值进行传递 让后直接进行下次reduce(跳过第一个元素从第二个元素开始运行逻辑)
val ints = List(1, 5, 6, 7, 8)val i1: Int = ints.reduce((res: Int, i: Int) => res +i*2)正确结果该是54 输出结果为53 因为运算逻辑为(1+5*2+6*2+7*2+8*2=53)
而我们正确的逻辑应该为1*2+5*2+6*2+7*2+8*2=54

2.折叠(fold):
归约的一种方法

这个函数是采用的柯里化写法第一个()传入初始值(也是结果值),第二个()传入运算逻辑
fold方法就很好的设置了初始值,解决了Reduce方法的缺点
val i2: Int = ints.fold(0)((res: Int, i: Int) => res + i * 2)
运行结果:
![]()
foldLeft():
初始值可以为不同类型(常用于Map,tuple)

val tuple: (String, Int) = ints.foldLeft(("sum : elem*2", 0))((res: (String, Int), elem: Int) => {//创建一个新的二元组(res._1, res._2 + elem * 2)})两个Map的归约(合并):
两个Map集合 一个作为结果存储 一个作为集合遍历
方法1:
val map = mutable.Map(("String", 14), ("Scala", 35))val map1 = Map(("String", 14), ("Scala", 35), ("Spark", 33))for (elem <- map1) {val key: String = elem._1val value: Int = elem._2if (map.contains(key)){map.update(key, value + map.getOrElse(key,0))}else{map.put(key,value)}}上述方法的两个Map(一个是不可变 一个是可变)---不可以重复执行(不稳定,会不断的累加)
方法二:
下边两个Map都是不可变的:
不可变集合 做出改变后要重新返回一个对象
val map2 = Map(("String", 14), ("Scala", 35))val map3 = Map(("String", 14), ("Scala", 35), ("Spark", 33))val map4: Map[String, Int] = map2.foldLeft(map3)((mape, elem) => {mape.updated(elem._1, mape.getOrElse(elem._1, 0) + elem._2)})println(map4)相关文章:
Scala之集合(2)
目录 集合基本函数: (1)获取集合长度 (2)获取集合大小 (3)循环遍历 (4)迭代器 (5)生成字符串 (6)是否包含 衍生集合…...

【图像分割】视觉大模型SEEM(Segment Everything Everywhere All at Once)原理解读
文章目录 摘要(效果)二、前言三、相关工作四、method4.1 多用途4.2 组合性4.3 交互式。4.4 语义感知 五、实验 论文地址:https://arxiv.org/abs/2304.06718 测试代码:https://github.com/UX-Decoder/Segment-Everything-Everywher…...

Linux: command: ibstat; infiniband
文章目录 如何在Linux上安装infiniband相关的软件。ibstat相关资料 如何在Linux上安装infiniband相关的软件。 https://access.redhat.com/solutions/301643 https://docs.oracle.com/cd/E19436-01/820-3522-10/ch3-linux.html yum groupinstall “Infiniband Support” Pack…...
UML简介与类图详解
1 UML简介 1.1 UML是什么 UML,全称为Unified Model Language,即统一建模语言,是由一整套图表组成的,为面向对象系统的产品进行说明、可视化和编制文档的一种标准语言。UML 代表了一组最佳工程实践,这些实践已被证明在…...

【每日一题】1994.好子集的数目
1994.好子集的数目 题目描述解决方案:状态压缩动态规划代码:Python 题目来源:LeetCode 原文链接:https://mp.weixin.qq.com/s/myI7_ZwJM7kizrwUtWgAZQ 难度级别:困难 题目描述 给你一个整数数组 nums。如果 nums 的一…...

坚持伙伴优先,共创数据存储新生态
4 月 26 日,2023 阿里云合作伙伴大会上,阿里巴巴集团董事会主席兼 CEO、阿里云智能集团 CEO 张勇表示,阿里云的核心定位是一家云计算产品公司,生态是阿里云的根基。让被集成说到做到的核心,是要坚定走向“产品被集成”…...
树形结构的三级分类如何实现?
概述: 本三级联动分类服务端使用的是: Springboot MyBatis-plus,前端使用的是:VueElementUI,树形控件使用的是el-tree。本三级联动分类可以把任一子项拖拽到其它目录,可以添加、编辑、删除分类。 效果图:…...

SSM整合完整流程
🏠个人主页:shark-Gao 🧑个人简介:大家好,我是shark-Gao,一个想要与大家共同进步的男人😉😉 🎉目前状况:23届毕业生,目前在某公司实习…...

虹科方案 | 助力高性能视频存储解决方案-2
上篇文章《虹科方案 | 助力高性能视频存储解决方案-1》我们分享了虹科&ATTO 和 Avid 共同创建协作解决方案,助力高性能视频存储,今天我们再深入介绍一下我们的案例详情。 一、行业挑战 从高端广播设施到小型独立工作室的媒体后期制作环境都需要允许多…...

java版深圳 工程管理系统软件 自主研发,工程行业适用 软件源码
Java版工程项目管理系统 Spring CloudSpring BootMybatisVueElementUI前后端分离 功能清单如下: 首页 工作台:待办工作、消息通知、预警信息,点击可进入相应的列表 项目进度图表:选择(总体或单个)项目显示…...
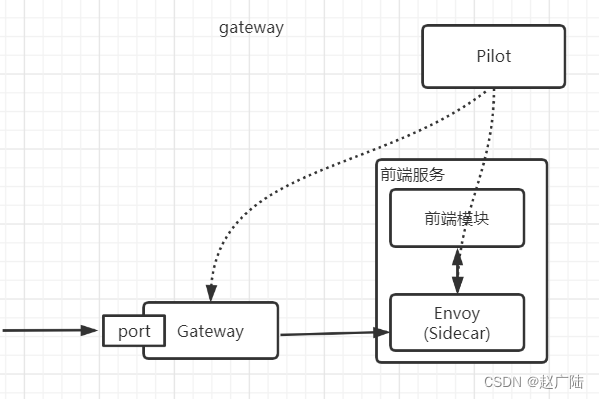
云原生Istio架构和组件介绍
目录 1 Istio 架构2 Istio组件介绍2.1 Pilot2.2 Mixer2.3 Citadel2.4 Galley2.5 Sidecar-injector2.6 Proxy(Envoy)2.7 Ingressgateway2.8 其他组件 1 Istio 架构 Istio的架构,分为控制平面和数据面平两部分。 - 数据平面:由一组智能代理([En…...
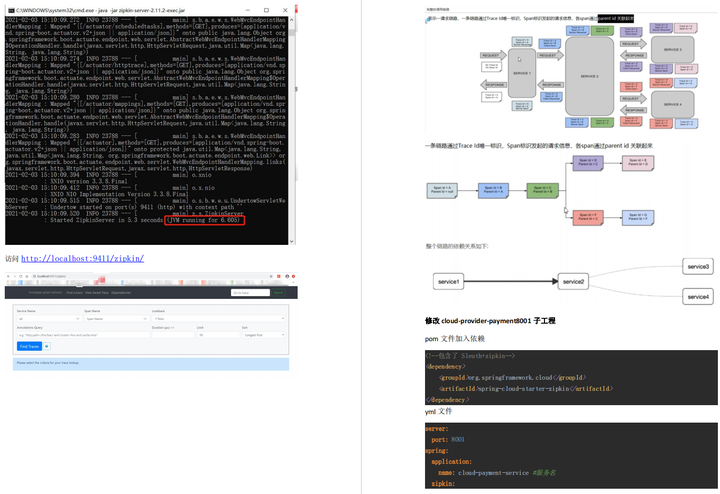
吹爆,全网第一个手把手教你从零开始搭建Spring Cloud Alibaba的笔记
Spring Cloud Alibaba 是阿里巴巴提供的微服务开发一站式解决方案,是阿里巴巴开源中间件与 Spring Cloud 体系的融合。 Springcloud 和 Srpingcloud Alibaba 区别? SpringCloud: 部分组件停止维护和更新,给开发带来不便;SpringCl…...

企业短信遭疯狂盗用,可能是没配置验证码
手机短信作为一种快捷的通讯方式被广泛应用。不仅在个人日常生活中,企业也习惯使用手机短信来进行验证和提醒,以保证业务的正常进行。随着数字化的发展,手机短信也成为了不法分子滥用的目标之一,给个人和企业带来不同经济损失。 个…...
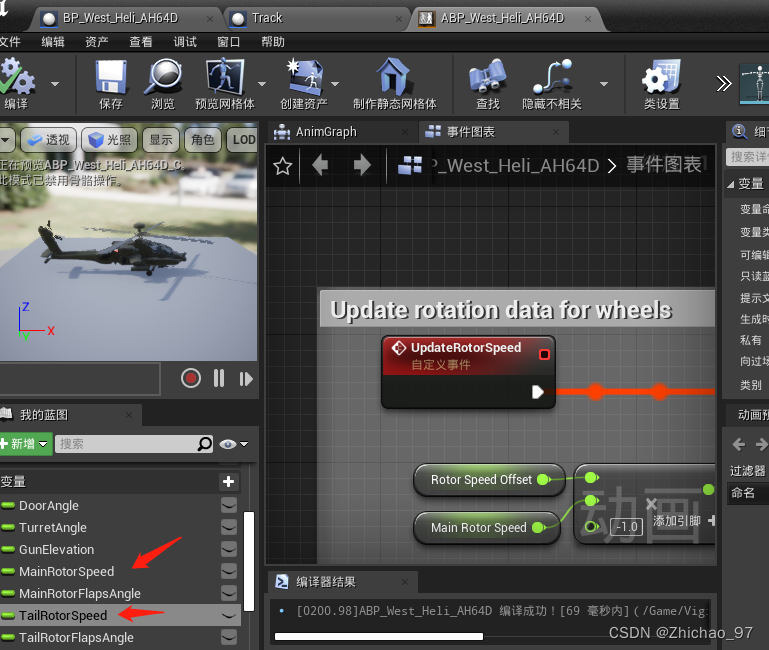
【UE】直升机沿样条线移动
效果 步骤 1. 将虚幻商城中的免费资产导入工程 下载完毕后可以看到如下文件 2. 新建一个Actor蓝图类,命名为“Track”,这个蓝图就是用来画样条线的 打开“Track”,添加样条组件 3. 打开“BP_West_Heli_AH64D” 在事件图表中先新建一个时间轴…...

GaussDB_200_6.5.1部署安装
目录 安装前准备 安装依赖 修改/etc/hosts 上传解压介质 预安装 拷贝安装包 预安装配置 编辑preinstall.ini配置文件 编辑host0配置文件 执行预安装命令 安装FusionInsight_Manager 修改install安装配置文件 执行安装命令 web操作安装数据库 GaussDB200测试 配…...

软件工具 | Python调用运筹优化求解器(一):以CVRPVRPTW为例
目录 1. 引言2. 求解器介绍3. 基础语言3.1 创建模型3.2 添加变量3.3 添加目标函数3.4 添加约束3.5 设置参数3.6 求解 4. 数学模型4.1 [CVRP数学模型](https://mp.weixin.qq.com/s/DYh-5WkrYxk1gCKo8ZjvAw)4.2 [VRPTW数学模型](https://mp.weixin.qq.com/s/tF-ayzjpZfuZvelvItue…...

如何在JAVA中实现网络编程?
在Java中实现网络编程通常需要使用Java提供的网络编程库——Java Networking API。Java Networking API支持常见的TCP和UDP协议,包括Socket、ServerSocket、DatagramSocket等类,通过这些类,我们可以创建、连接、监听和传输数据。 下面是在Ja…...

【redis】redis的缓存过期淘汰策略
【redis】redis的缓存过期淘汰策略 文章目录 【redis】redis的缓存过期淘汰策略前言一、面试题二、redis内存满了怎么办?1、redis默认内存是多少?在哪查看?如何修改?在conf配置文件中可以查看 修改,内存默认是0redis的默认内存有…...
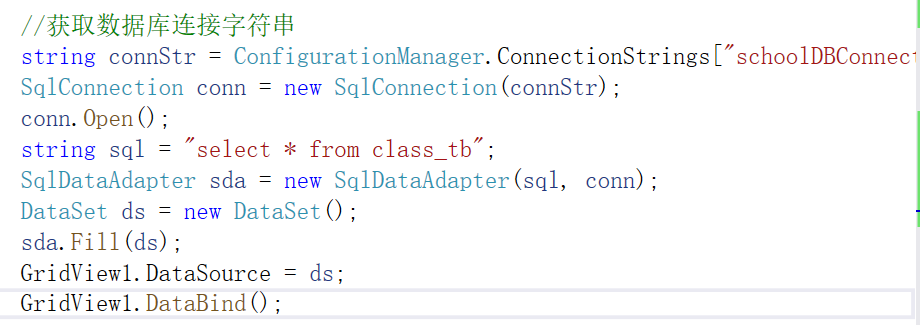
ASP.NET动态Web开发技术第8章
第8章ASP.NET数据访问 一.预习笔记 1.SqlDataSource控件 SqlDataSource数据源控件支持连接SQL关系数据库,它使用SQL命令来检索和修改数据。通常将SqlDataSource数据源控件与数据绑定控件一起使用。 属性1:ID:当前数据源控件的唯一标识符 …...
【旋转编码器如何工作以及如何将其与Arduino一起使用】
在本教程中,我们将学习旋转编码器的工作原理以及如何将其与Arduino一起使用。您可以观看以下视频或阅读下面的书面教程。 1. 概述 旋转编码器是一种位置传感器,用于确定旋转轴的角度位置。它根据旋转运动产生模拟或数字电信号。 有许多不同类型的旋转编码器按输出信号或传感…...

如何实现百度网盘下载加速?KinhDown让大文件传输效率倍增
如何实现百度网盘下载加速?KinhDown让大文件传输效率倍增 【免费下载链接】baidupcs-web 项目地址: https://gitcode.com/gh_mirrors/ba/baidupcs-web 还在忍受百度网盘的龟速下载吗?当你急需工作文件却被限制在几十KB/s的速度时,当重…...

从BiomixQA到黄帝内经:聊聊2024年那些‘小而美’的垂直医学问答数据集
2024医学垂直问答数据集全景:从BiomixQA到黄帝内经的实战选型指南 当ChatGPT在通用领域大放异彩时,医学AI的战场正悄然转向那些"小而美"的垂直数据集。不同于通用语料的粗放式训练,专业医学问答需要精确到细胞级的语义理解——一个…...
自动推导DC-DC变换器的小信号模型)
别再死记硬背!用Python(SymPy库)自动推导DC-DC变换器的小信号模型
用Python解放双手:SymPy自动推导DC-DC变换器小信号模型的工程实践 当电源工程师面对Buck、Boost电路的小信号模型推导时,那些繁琐的矩阵运算和拉普拉斯变换是否让你头疼不已?传统手工推导不仅耗时费力,还容易在代数运算中出错。本…...

【第四周】论文精读:Frustratingly Simple Retrieval Improves Challenging, Reasoning-Intensive Benchmarks
极简检索即可大幅刷新高难度推理基准主流观点认为简单RAG无法提升MMLU、MATH、GPQA等高难度推理任务,甚至会损害性能;本文推翻这一共识,证明核心瓶颈并非检索范式,而是缺少高质量、广覆盖、可单机部署的检索库;提出COM…...

毕业季求生指南:用百考通AI重塑你的论文写作全流程
深夜的电脑屏幕前,面对空白的文档和堆积如山的文献,你是否感到无从下手?当查重率居高不下、导师的修改意见密密麻麻时,是否渴望一种更智能的解决方案?本文将为你揭示一个学术写作的新可能。 01 开题之困:从…...

Phi-3-Mini-128K技术文档翻译与润色对比:中英互译质量评估
Phi-3-Mini-128K技术文档翻译与润色对比:中英互译质量评估 最近在折腾一些开源项目,免不了要和英文技术文档打交道。对于咱们中文开发者来说,直接阅读原版文档虽然最准确,但有时候效率确实不高。机器翻译就成了一个绕不开的工具。…...

RexUniNLU开源镜像免配置教程:自动下载权重+端口映射一步到位
RexUniNLU开源镜像免配置教程:自动下载权重端口映射一步到位 1. 这不是另一个NLP工具,而是一站式中文语义理解中枢 你有没有遇到过这样的情况:想快速验证一段中文文本里藏着多少信息——谁说了什么、发生了什么事、情绪是好是坏、背后有哪些…...

Open Interpreter实时流处理:Kafka消费脚本部署案例
Open Interpreter实时流处理:Kafka消费脚本部署案例 1. 项目背景与需求场景 在实际的数据处理项目中,我们经常需要处理实时数据流。想象一下这样的场景:你的电商平台每秒钟产生成千上万的用户行为数据,这些数据通过Kafka消息队列…...

设计师不用写代码了?实测TRAE SOLO Builder如何将Figma稿秒变可交互网页
设计师如何用TRAE SOLO Builder实现零代码网页开发 在数字产品设计领域,设计师与开发者之间的协作断层长期存在。设计精美的Figma稿转化为实际网页时,往往面临还原度不足、交互细节丢失等问题。TRAE SOLO Builder的出现,正在重新定义设计到开…...

Dalsa线阵相机采图实战:从FreeRun到编码器触发的保姆级配置流程
Dalsa线阵相机采图实战:从FreeRun到编码器触发的工业级配置指南 在工业视觉检测领域,线阵相机凭借其高分辨率、高速成像的特性,已成为印刷、纺织、板材检测等连续运动场景的首选方案。作为行业标杆的Dalsa线阵相机,其工作模式切换…...