深入理解Python中的进程与线程
前言
今天我们使用的计算机早已进入多CPU或多核时代,而我们使用的操作系统都是支持“多任务”的操作系统,这使得我们可以同时运行多个程序,也可以将一个程序分解为若干个相对独立的子任务,让多个子任务并发的执行,从而缩短程序的执行时间,同时也让用户获得更好的体验。因此在当下不管是用什么编程语言进行开发,实现让程序同时执行多个任务也就是常说的“并发编程”,应该是程序员必备技能之一。为此,我们需要先讨论两个概念,一个叫进程,一个叫线程。
目录
- 一、Python中的多进程
- 二、Python中的多线程
- 三、多进程还是多线程
- 四、单线程+异步I/O
- 五、案例
- 1. 将耗时间的任务放到线程中以获得更好的用户体验。
- 2. 使用多进程对复杂任务进行“分而治之”
一、Python中的多进程
Unix和Linux操作系统上提供了fork()系统调用来创建进程,调用fork()函数的是父进程,创建出的是子进程,子进程是父进程的一个拷贝,但是子进程拥有自己的PID。fork()函数非常特殊它会返回两次,父进程中可以通过fork()函数的返回值得到子进程的PID,而子进程中的返回值永远都是0。Python的os模块提供了fork()函数。由于Windows系统没有fork()调用,因此要实现跨平台的多进程编程,可以使用multiprocessing模块的Process类来创建子进程,而且该模块还提供了更高级的封装,例如批量启动进程的进程池(Pool)、用于进程间通信的队列(Queue)和管道(Pipe)等。
下面用一个下载文件的例子来说明使用多进程和不使用多进程到底有什么差别,先看看下面的代码:
from random import randint
from time import time, sleepdef download_task(filename):print('开始下载%s...' % filename)time_to_download = randint(5, 10)sleep(time_to_download)print('%s下载完成! 耗费了%d秒' % (filename, time_to_download))def main():start = time()download_task('Python从入门到大神.pdf')download_task('Peking Hot.avi')end = time()print('总共耗费了%.2f秒.' % (end - start))if __name__ == '__main__':main()下面是运行程序得到的一次运行结果。
开始下载Python从入门到大神.pdf...
Python从入门到大神.pdf下载完成! 耗费了6秒
开始下载Peking Hot.avi...
Peking Hot.avi下载完成! 耗费了7秒
总共耗费了13.01秒.从上面的例子可以看出,如果程序中的代码只能按顺序一点点的往下执行,那么即使执行两个毫不相关的下载任务,也需要先等待一个文件下载完成后才能开始下一个下载任务,很显然这并不合理也没有效率。接下来我们使用多进程的方式将两个下载任务放到不同的进程中,代码如下所示。
from multiprocessing import Process
from os import getpid
from random import randint
from time import time, sleepdef download_task(filename):print('启动下载进程,进程号[%d].' % getpid())print('开始下载%s...' % filename)time_to_download = randint(5, 10)sleep(time_to_download)print('%s下载完成! 耗费了%d秒' % (filename, time_to_download))def main():start = time()p1 = Process(target=download_task, args=('Python从入门到住院.pdf', ))p1.start()p2 = Process(target=download_task, args=('Peking Hot.avi', ))p2.start()p1.join()p2.join()end = time()print('总共耗费了%.2f秒.' % (end - start))if __name__ == '__main__':main()在上面的代码中,我们通过Process类创建了进程对象,通过target参数我们传入一个函数来表示进程启动后要执行的代码,后面的args是一个元组,它代表了传递给函数的参数。Process对象的start方法用来启动进程,而join方法表示等待进程执行结束。运行上面的代码可以明显发现两个下载任务“同时”启动了,而且程序的执行时间将大大缩短,不再是两个任务的时间总和。下面是程序的一次执行结果。
启动下载进程,进程号[1530].
开始下载Python从入门到大神.pdf...
启动下载进程,进程号[1531].
开始下载Peking Hot.avi...
Peking Hot.avi下载完成! 耗费了7秒
Python从入门到住院.pdf下载完成! 耗费了10秒
总共耗费了10.01秒.我们也可以使用subprocess模块中的类和函数来创建和启动子进程,然后通过管道来和子进程通信,这些内容我们不在此进行讲解,有兴趣的读者可以自己了解这些知识。接下来我们将重点放在如何实现两个进程间的通信。我们启动两个进程,一个输出Ping,一个输出Pong,两个进程输出的Ping和Pong加起来一共10个。听起来很简单吧,但是如果这样写可是错的哦。
from multiprocessing import Process
from time import sleepcounter = 0def sub_task(string):global counterwhile counter < 10:print(string, end='', flush=True)counter += 1sleep(0.01)def main():Process(target=sub_task, args=('Ping', )).start()Process(target=sub_task, args=('Pong', )).start()if __name__ == '__main__':main()看起来没毛病,但是最后的结果是Ping和Pong各输出了10个,Why?当我们在程序中创建进程的时候,子进程复制了父进程及其所有的数据结构,每个子进程有自己独立的内存空间,这也就意味着两个子进程中各有一个counter变量,所以结果也就可想而知了。要解决这个问题比较简单的办法是使用multiprocessing模块中的Queue类,它是可以被多个进程共享的队列,底层是通过管道和信号量(semaphore)机制来实现的,有兴趣的读者可以自己尝试一下。
二、Python中的多线程
在Python早期的版本中就引入了thread模块(现在名为_thread)来实现多线程编程,然而该模块过于底层,而且很多功能都没有提供,因此目前的多线程开发我们推荐使用threading模块,该模块对多线程编程提供了更好的面向对象的封装。我们把刚才下载文件的例子用多线程的方式来实现一遍。
from random import randint
from threading import Thread
from time import time, sleepdef download(filename):print('开始下载%s...' % filename)time_to_download = randint(5, 10)sleep(time_to_download)print('%s下载完成! 耗费了%d秒' % (filename, time_to_download))def main():start = time()t1 = Thread(target=download, args=('Python从入门到住院.pdf',))t1.start()t2 = Thread(target=download, args=('Peking Hot.avi',))t2.start()t1.join()t2.join()end = time()print('总共耗费了%.3f秒' % (end - start))if __name__ == '__main__':main()我们可以直接使用threading模块的Thread类来创建线程,但是我们之前讲过一个非常重要的概念叫“继承”,我们可以从已有的类创建新类,因此也可以通过继承Thread类的方式来创建自定义的线程类,然后再创建线程对象并启动线程。代码如下所示。
from random import randint
from threading import Thread
from time import time, sleepclass DownloadTask(Thread):def __init__(self, filename):super().__init__()self._filename = filenamedef run(self):print('开始下载%s...' % self._filename)time_to_download = randint(5, 10)sleep(time_to_download)print('%s下载完成! 耗费了%d秒' % (self._filename, time_to_download))def main():start = time()t1 = DownloadTask('Python从入门到住院.pdf')t1.start()t2 = DownloadTask('Peking Hot.avi')t2.start()t1.join()t2.join()end = time()print('总共耗费了%.2f秒.' % (end - start))if __name__ == '__main__':main()因为多个线程可以共享进程的内存空间,因此要实现多个线程间的通信相对简单,大家能想到的最直接的办法就是设置一个全局变量,多个线程共享这个全局变量即可。但是当多个线程共享同一个变量(我们通常称之为“资源”)的时候,很有可能产生不可控的结果从而导致程序失效甚至崩溃。如果一个资源被多个线程竞争使用,那么我们通常称之为“临界资源”,对“临界资源”的访问需要加上保护,否则资源会处于“混乱”的状态。下面的例子演示了100个线程向同一个银行账户转账(转入1元钱)的场景,在这个例子中,银行账户就是一个临界资源,在没有保护的情况下我们很有可能会得到错误的结果。
from time import sleep
from threading import Threadclass Account(object):def __init__(self):self._balance = 0def deposit(self, money):# 计算存款后的余额new_balance = self._balance + money# 模拟受理存款业务需要0.01秒的时间sleep(0.01)# 修改账户余额self._balance = new_balance@propertydef balance(self):return self._balanceclass AddMoneyThread(Thread):def __init__(self, account, money):super().__init__()self._account = accountself._money = moneydef run(self):self._account.deposit(self._money)def main():account = Account()threads = []# 创建100个存款的线程向同一个账户中存钱for _ in range(100):t = AddMoneyThread(account, 1)threads.append(t)t.start()# 等所有存款的线程都执行完毕for t in threads:t.join()print('账户余额为: ¥%d元' % account.balance)if __name__ == '__main__':main()运行上面的程序,结果让人大跌眼镜,100个线程分别向账户中转入1元钱,结果居然远远小于100元。之所以出现这种情况是因为我们没有对银行账户这个“临界资源”加以保护,多个线程同时向账户中存钱时,会一起执行到new_balance = self._balance + money这行代码,多个线程得到的账户余额都是初始状态下的0,所以都是0上面做了+1的操作,因此得到了错误的结果。在这种情况下,“锁”就可以派上用场了。我们可以通过“锁”来保护“临界资源”,只有获得“锁”的线程才能访问“临界资源”,而其他没有得到“锁”的线程只能被阻塞起来,直到获得“锁”的线程释放了“锁”,其他线程才有机会获得“锁”,进而访问被保护的“临界资源”。下面的代码演示了如何使用“锁”来保护对银行账户的操作,从而获得正确的结果。
from time import sleep
from threading import Thread, Lockclass Account(object):def __init__(self):self._balance = 0self._lock = Lock()def deposit(self, money):# 先获取锁才能执行后续的代码self._lock.acquire()try:new_balance = self._balance + moneysleep(0.01)self._balance = new_balancefinally:# 在finally中执行释放锁的操作保证正常异常锁都能释放self._lock.release()@propertydef balance(self):return self._balanceclass AddMoneyThread(Thread):def __init__(self, account, money):super().__init__()self._account = accountself._money = moneydef run(self):self._account.deposit(self._money)def main():account = Account()threads = []for _ in range(100):t = AddMoneyThread(account, 1)threads.append(t)t.start()for t in threads:t.join()print('账户余额为: ¥%d元' % account.balance)if __name__ == '__main__':main()比较遗憾的一件事情是Python的多线程并不能发挥CPU的多核特性,这一点只要启动几个执行死循环的线程就可以得到证实了。之所以如此,是因为Python的解释器有一个“全局解释器锁”(GIL)的东西,任何线程执行前必须先获得GIL锁,然后每执行100条字节码,解释器就自动释放GIL锁,让别的线程有机会执行,这是一个历史遗留问题,但是即便如此,就如我们之前举的例子,使用多线程在提升执行效率和改善用户体验方面仍然是有积极意义的。
三、多进程还是多线程
无论是多进程还是多线程,只要数量一多,效率肯定上不去,为什么呢?我们打个比方,假设你不幸正在准备中考,每天晚上需要做语文、数学、英语、物理、化学这5科的作业,每项作业耗时1小时。如果你先花1小时做语文作业,做完了,再花1小时做数学作业,这样,依次全部做完,一共花5小时,这种方式称为单任务模型。如果你打算切换到多任务模型,可以先做1分钟语文,再切换到数学作业,做1分钟,再切换到英语,以此类推,只要切换速度足够快,这种方式就和单核CPU执行多任务是一样的了,以旁观者的角度来看,你就正在同时写5科作业。
但是,切换作业是有代价的,比如从语文切到数学,要先收拾桌子上的语文书本、钢笔(这叫保存现场),然后,打开数学课本、找出圆规直尺(这叫准备新环境),才能开始做数学作业。操作系统在切换进程或者线程时也是一样的,它需要先保存当前执行的现场环境(CPU寄存器状态、内存页等),然后,把新任务的执行环境准备好(恢复上次的寄存器状态,切换内存页等),才能开始执行。这个切换过程虽然很快,但是也需要耗费时间。如果有几千个任务同时进行,操作系统可能就主要忙着切换任务,根本没有多少时间去执行任务了,这种情况最常见的就是硬盘狂响,点窗口无反应,系统处于假死状态。所以,多任务一旦多到一个限度,反而会使得系统性能急剧下降,最终导致所有任务都做不好。
是否采用多任务的第二个考虑是任务的类型,可以把任务分为计算密集型和I/O密集型。计算密集型任务的特点是要进行大量的计算,消耗CPU资源,比如对视频进行编码解码或者格式转换等等,这种任务全靠CPU的运算能力,虽然也可以用多任务完成,但是任务越多,花在任务切换的时间就越多,CPU执行任务的效率就越低。计算密集型任务由于主要消耗CPU资源,这类任务用Python这样的脚本语言去执行效率通常很低,最能胜任这类任务的是C语言,我们之前提到过Python中有嵌入C/C++代码的机制。
除了计算密集型任务,其他的涉及到网络、存储介质I/O的任务都可以视为I/O密集型任务,这类任务的特点是CPU消耗很少,任务的大部分时间都在等待I/O操作完成(因为I/O的速度远远低于CPU和内存的速度)。对于I/O密集型任务,如果启动多任务,就可以减少I/O等待时间从而让CPU高效率的运转。有一大类的任务都属于I/O密集型任务,这其中包括了我们很快会涉及到的网络应用和Web应用。
四、单线程+异步I/O
现代操作系统对I/O操作的改进中最为重要的就是支持异步I/O。如果充分利用操作系统提供的异步I/O支持,就可以用单进程单线程模型来执行多任务,这种全新的模型称为事件驱动模型。Nginx就是支持异步I/O的Web服务器,它在单核CPU上采用单进程模型就可以高效地支持多任务。在多核CPU上,可以运行多个进程(数量与CPU核心数相同),充分利用多核CPU。用Node.js开发的服务器端程序也使用了这种工作模式,这也是当下并发编程的一种流行方案。
在Python语言中,单线程+异步I/O的编程模型称为协程,有了协程的支持,就可以基于事件驱动编写高效的多任务程序。协程最大的优势就是极高的执行效率,因为子程序切换不是线程切换,而是由程序自身控制,因此,没有线程切换的开销。协程的第二个优势就是不需要多线程的锁机制,因为只有一个线程,也不存在同时写变量冲突,在协程中控制共享资源不用加锁,只需要判断状态就好了,所以执行效率比多线程高很多。如果想要充分利用CPU的多核特性,最简单的方法是多进程+协程,既充分利用多核,又充分发挥协程的高效率,可获得极高的性能。关于这方面的内容,在后续的课程中会进行讲解。
五、案例
1. 将耗时间的任务放到线程中以获得更好的用户体验。
如下所示的界面中,有“下载”和“关于”两个按钮,用休眠的方式模拟点击“下载”按钮会联网下载文件需要耗费10秒的时间,如果不使用“多线程”,我们会发现,当点击“下载”按钮后整个程序的其他部分都被这个耗时间的任务阻塞而无法执行了,这显然是非常糟糕的用户体验,代码如下所示。
import time
import tkinter
import tkinter.messageboxdef download():# 模拟下载任务需要花费10秒钟时间time.sleep(10)tkinter.messagebox.showinfo('提示', '下载完成!')def show_about():tkinter.messagebox.showinfo('关于', '作者: 霸哥')def main():top = tkinter.Tk()top.title('单线程')top.geometry('200x150')top.wm_attributes('-topmost', True)panel = tkinter.Frame(top)button1 = tkinter.Button(panel, text='下载', command=download)button1.pack(side='left')button2 = tkinter.Button(panel, text='关于', command=show_about)button2.pack(side='right')panel.pack(side='bottom')tkinter.mainloop()if __name__ == '__main__':main()如果使用多线程将耗时间的任务放到一个独立的线程中执行,这样就不会因为执行耗时间的任务而阻塞了主线程,修改后的代码如下所示。
import time
import tkinter
import tkinter.messagebox
from threading import Threaddef main():class DownloadTaskHandler(Thread):def run(self):time.sleep(10)tkinter.messagebox.showinfo('提示', '下载完成!')# 启用下载按钮button1.config(state=tkinter.NORMAL)def download():# 禁用下载按钮button1.config(state=tkinter.DISABLED)# 通过daemon参数将线程设置为守护线程(主程序退出就不再保留执行)# 在线程中处理耗时间的下载任务DownloadTaskHandler(daemon=True).start()def show_about():tkinter.messagebox.showinfo('关于', '作者: 霸哥')top = tkinter.Tk()top.title('单线程')top.geometry('200x150')top.wm_attributes('-topmost', 1)panel = tkinter.Frame(top)button1 = tkinter.Button(panel, text='下载', command=download)button1.pack(side='left')button2 = tkinter.Button(panel, text='关于', command=show_about)button2.pack(side='right')panel.pack(side='bottom')tkinter.mainloop()if __name__ == '__main__':main()2. 使用多进程对复杂任务进行“分而治之”
我们来完成1~100000000求和的计算密集型任务,这个问题本身非常简单,有点循环的知识就能解决,代码如下所示。
from time import timedef main():total = 0number_list = [x for x in range(1, 100000001)]start = time()for number in number_list:total += numberprint(total)end = time()print('Execution time: %.3fs' % (end - start))if __name__ == '__main__':main()在上面的代码中,我故意先去创建了一个列表容器然后填入了100000000个数,这一步其实是比较耗时间的,所以为了公平起见,当我们将这个任务分解到8个进程中去执行的时候,我们暂时也不考虑列表切片操作花费的时间,只是把做运算和合并运算结果的时间统计出来,代码如下所示。
from multiprocessing import Process, Queue
from random import randint
from time import timedef task_handler(curr_list, result_queue):total = 0for number in curr_list:total += numberresult_queue.put(total)def main():processes = []number_list = [x for x in range(1, 100000001)]result_queue = Queue()index = 0# 启动8个进程将数据切片后进行运算for _ in range(8):p = Process(target=task_handler,args=(number_list[index:index + 12500000], result_queue))index += 12500000processes.append(p)p.start()# 开始记录所有进程执行完成花费的时间start = time()for p in processes:p.join()# 合并执行结果total = 0while not result_queue.empty():total += result_queue.get()print(total)end = time()print('Execution time: ', (end - start), 's', sep='')if __name__ == '__main__':main()比较两段代码的执行结果(在我目前使用的MacBook上,上面的代码需要大概6秒左右的时间,而下面的代码只需要不到1秒的时间,再强调一次我们只是比较了运算的时间,不考虑列表创建及切片操作花费的时间),使用多进程后由于获得了更多的CPU执行时间以及更好的利用了CPU的多核特性,明显的减少了程序的执行时间,而且计算量越大效果越明显。当然,如果愿意还可以将多个进程部署在不同的计算机上,做成分布式进程,具体的做法就是通过multiprocessing.managers模块中提供的管理器将Queue对象通过网络共享出来(注册到网络上让其他计算机可以访问),这部分内容也留到爬虫的专题再进行讲解。
相关文章:

深入理解Python中的进程与线程
前言 今天我们使用的计算机早已进入多CPU或多核时代,而我们使用的操作系统都是支持“多任务”的操作系统,这使得我们可以同时运行多个程序,也可以将一个程序分解为若干个相对独立的子任务,让多个子任务并发的执行,从而…...

Data retry场景介绍
本文介绍PDN激活失败或者IP Address缺失时的处理机制。 终端是否会retry? 如何设置data retry timer? Modem retry还是上层应用发起retry? IPV4V6 Fallback 3GPP TS 24.008 6.1.3.1定义了UE使用IPV4V6 pdp type建PDN失败后,如果网络以#Cause50、#Cause51或者#Cause52 …...
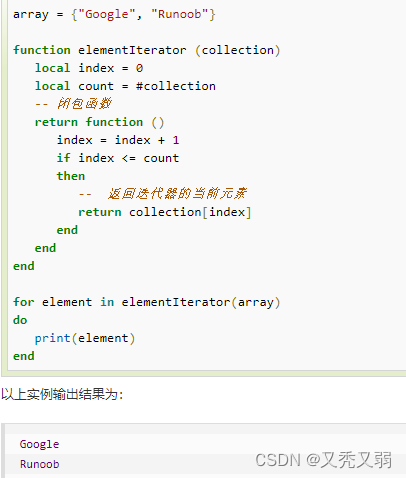
lua | 数组与迭代器的使用
目录 一、数组 一维数组 多维数组 二、迭代器 泛型for迭代器 无状态的迭代器 多状态的迭代器 本文章为笔者学习分享 学习网站:Lua 基本语法 | 菜鸟教程 一、数组 数组:相同数据类型的元素按一定顺序排列的集合,可以是一维数组和多维数…...
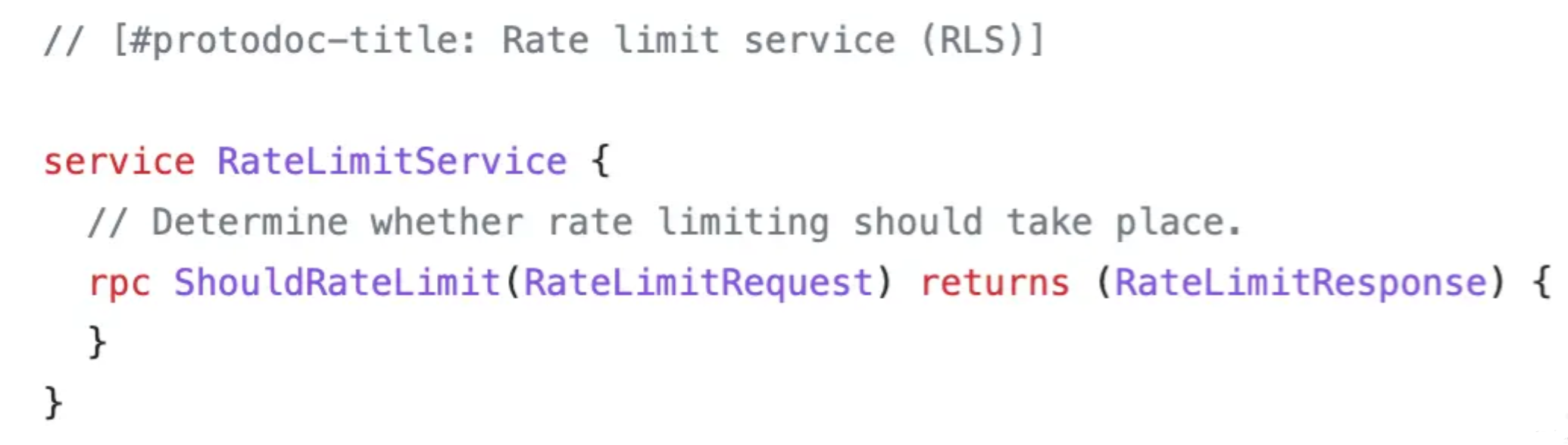
【云原生】云原生服务网格流量控制思考
文章目录 前言一、什么是流量控制?二、存在三种场景三、场景分析 前言 随着云原生技术的不断发展及应用,很多服务都已部署上云。 保障云上环境的稳定是重要的一环。 一个重要的影响稳定的场景就是突发大流量冲击。 面对该场景,较好的应对…...

《数据库的嵌套查询和统计查询》
选择Study数据库,用SQL语句进行以下查询操作。 1.嵌套查询 ①求选修了数据结构的学生学号和成绩。 SELECT Sno, grade FROM sc WHERE Cno 007;②求007课程的成绩高于于文轩的学生学号和成绩。 SELECT Sno, grade FROM sc WHERE Cno 007 AND grade …...
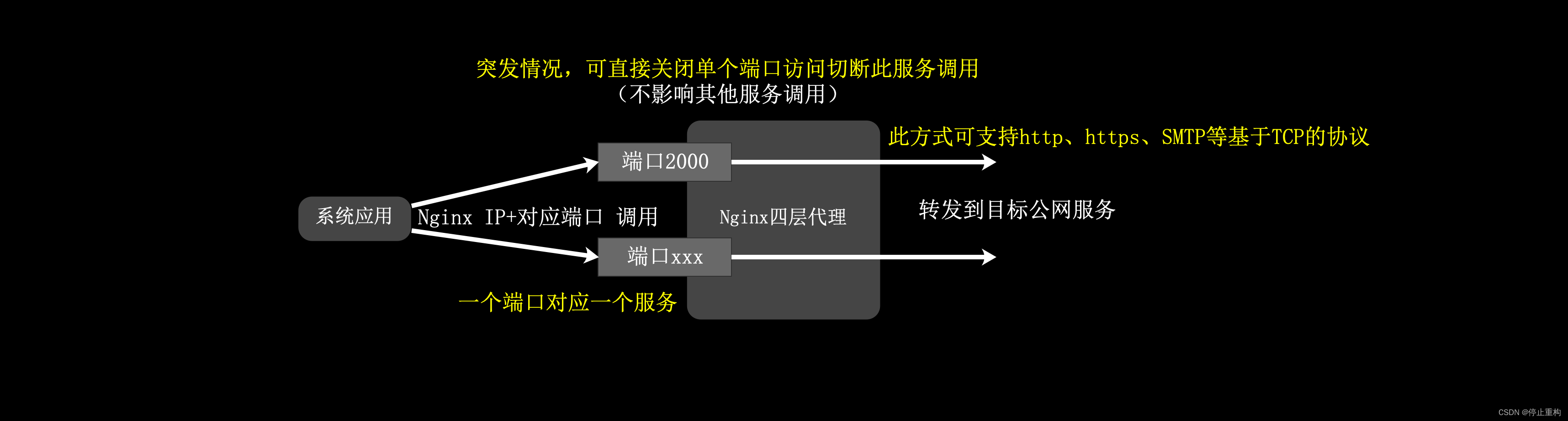
【网站架构】Nginx 4层、7层代理配置,正向代理、反向代理详解
大家好,欢迎来到停止重构的频道。 本期我们讨论网络代理。 在往期《大型网站 安全性》介绍过,出于网络安全的考虑,一般大型网站都需要做网络区域隔离,以防止攻击者直接操控服务器。 网站系统的应用及数据库都会放在这个网络安全…...

mysql备份和恢复
mysql备份和恢复 数据丢失的原因: 程序错误 人为操作错误 运算错误 磁盘故障 灾难(火灾,地震)和盗窃 数据库备份分类 物理备份 数据库此操作系统的物理文件(数据文件,日志文件等)的备份 …...

新闻月刊 | GBASE 4月市场动态一览
产品动态 4月,GBASE南大通用大规模分布式并行数据库GBase 8a MPP Cluster中标人保财险“2022年基础软件产品及服务采购”项目。这是自2019年GBASE与人保财险达成合作以来支持建设的第三期项目。项目上线后,将极大满足人保财险大数据中心及研发中心的增量…...
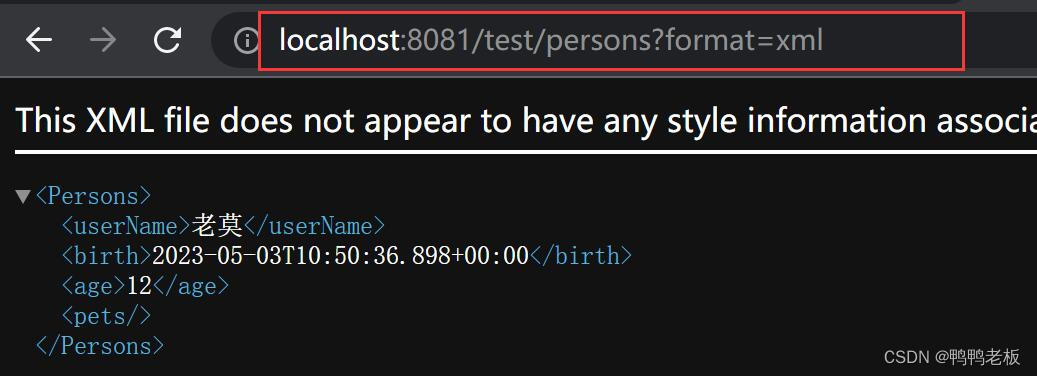
Java --- springboot2数据响应与内容协商
目录 一、数据响应与内容协商 1.1、响应json 1.1.1、返回值解析器 1.1.2、springMVC支持的返回值类型 1.1.3、HttpMessageConverter原理 1.2、内容协商 1.2.1、引入依赖 1.2.2、 postman分别测试返回json和xml 1.2.3、开启浏览器参数方式内容协商功能 1.3、自定义 Message…...

“中特估”乘风破浪!后续机遇在哪?
5月第一个交易日,“中特估”继续乘风破浪,A股银行板块集体大涨。 随着新一轮国企改革正在推进,中特估体系也在积极构建之中。在市场缺乏增量资金背景下,市场选股范式已经转向数字经济AI、央国企价值重估的两条主线,此…...
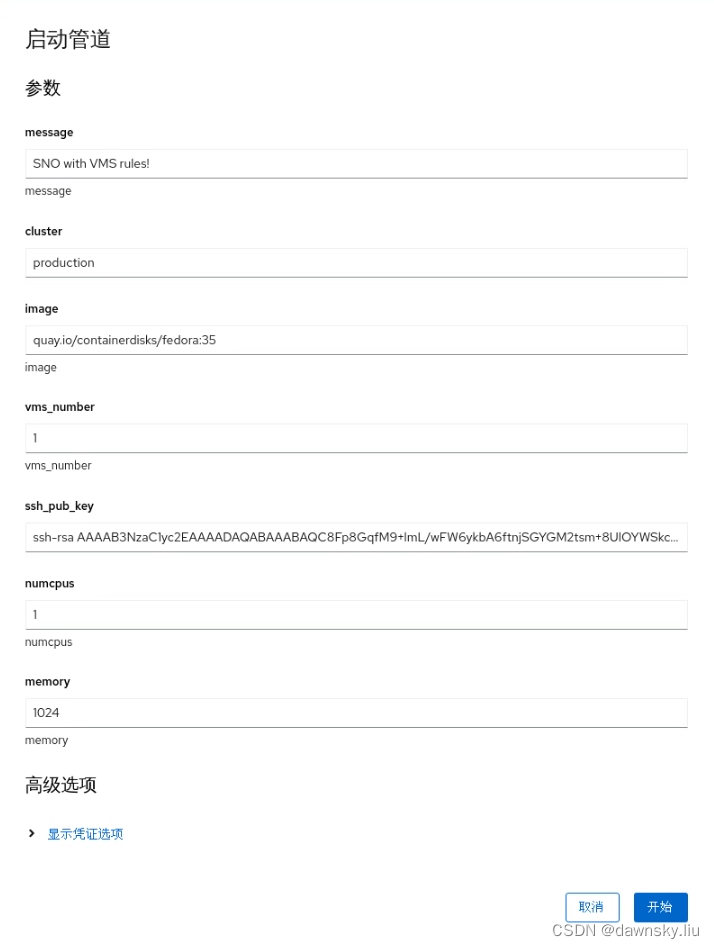
OpenShift 4 - 在 CI/CD Pipeline 中创建 KubeVirt 容器虚拟机 - 方法3
《OpenShift / RHEL / DevSecOps 汇总目录》 说明:本文已经在支持 OpenShift 4.12 的 OpenShift 环境中验证 文章目录 创建并运行 CI/CD Pipeline访问 VMPipeline 的 Task 解读 创建并运行 CI/CD Pipeline 执行命令,生成公钥-私钥对。 $ ssh-keygen$ l…...

功率放大器在Lamb波信号波包模型验证研究中的应用
实验名称:窄带激励条件下的兰姆波时域信号参数估计研究 研究方向:Lamb波 测试目的: 基于Lamb波的二阶频散理论,提出了时域信号的波包模型,为全文奠定理论基础。模型考虑两种情况:初始激励以单模态传播和…...

Apache Hadoop
一、Apache Hadoop入门 1.1、Hadoop介绍 狭义上:hadoop指的是Apache一款java开源软件,是一个大数据分析处理平台。 Hadoop HDFS:分布式文件系统。 解决了海量数据存储问题。 Hadoop Distributed File System (HDFS™)Hadoop MapReduce&…...
PHP+vue大学生心理健康评价和分析系统8w3ff
本整个大学生心理健康管理系统是按照整体需求来实现各个功能的,它可以通过心理健康测评来检测大学生的心理健康,并且给予预警,还可以预约医生来解决问题。并且,管理员可以查看用户信息,发布一些关于心理健康的文章。该…...

【图像分割】【深度学习】SAM官方Pytorch代码-Mask decoder模块MaskDeco网络解析
【图像分割】【深度学习】SAM官方Pytorch代码-Mask decoder模块MaskDeco网络解析 Segment Anything:建立了迄今为止最大的分割数据集,在1100万张图像上有超过1亿个掩码,模型的设计和训练是灵活的,其重要的特点是Zero-shot(零样本迁…...
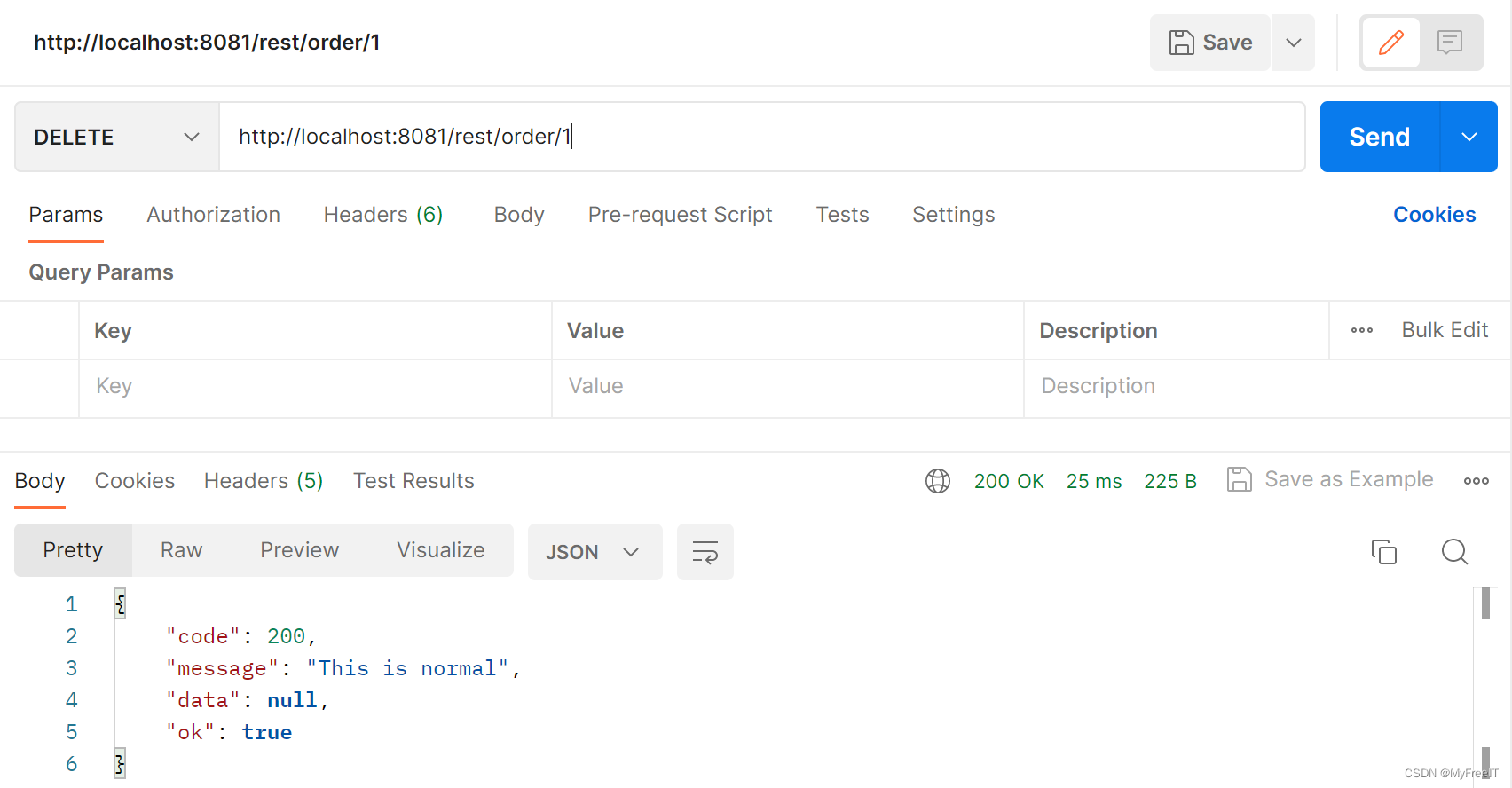
A Restful API
SpringBoot 定义Restful API 定义POJOOrderBuyer 定义RestfulControllerGet API for queryPost API for addPut API for updateDelete API for delete 定义AjaxResponse Patavariable RequestParm RequestBodyRequestHeader 定义POJO Order import java.util.Date; import ja…...

从零开始学习JSP,让你全面掌握Web开发技能
JSP(Java Server Pages),是一种动态网页技术,它允许开发者使用Java代码和HTML标签来创建网页。在这篇文章中,我们将详细介绍JSP的基本概念、语法和应用。 一、JSP的基本概念 1.1 JSP的含义 JSP是一种网页技术&#…...

java基于知识库的中医药问询系统
本系统主要包含了等系统用户管理、中医药常识管理、科室信息管理、知识库管理多个功能模块。下面分别简单阐述一下这几个功能模块需求。 管理员的登录模块:管理员登录系统对本系统其他管理模块进行管理。 用户的登录模块:用户登录本系统,对个…...

【新星计划-2023】什么是ARP?详解它的“解析过程”与“ARP表”。
一、什么是ARP ARP(地址解析协议)英文全称“Address Resolution Protocol”,是根据IP地址获取物理地址的一个TCP/IP协议。主机发送信息时将包含目标IP地址的ARP请求广播到局域网络上的所有主机,并接收返回消息,以此确…...

自动驾驶行业观察之2023上海车展-----车企发展趋势(2)
自主品牌发展 比亚迪:展示3款新车,均于2023年年内上市 比亚迪在本次展会上推出了3款新车:宋L概念车(王朝系列)、驱逐舰07(海洋系列)、海鸥(海洋系列)。 • 宋L&#x…...

Day131 | 灵神 | 回溯算法 | 子集型 子集
Day131 | 灵神 | 回溯算法 | 子集型 子集 78.子集 78. 子集 - 力扣(LeetCode) 思路: 笔者写过很多次这道题了,不想写题解了,大家看灵神讲解吧 回溯算法套路①子集型回溯【基础算法精讲 14】_哔哩哔哩_bilibili 完…...

centos 7 部署awstats 网站访问检测
一、基础环境准备(两种安装方式都要做) bash # 安装必要依赖 yum install -y httpd perl mod_perl perl-Time-HiRes perl-DateTime systemctl enable httpd # 设置 Apache 开机自启 systemctl start httpd # 启动 Apache二、安装 AWStats࿰…...

Auto-Coder使用GPT-4o完成:在用TabPFN这个模型构建一个预测未来3天涨跌的分类任务
通过akshare库,获取股票数据,并生成TabPFN这个模型 可以识别、处理的格式,写一个完整的预处理示例,并构建一个预测未来 3 天股价涨跌的分类任务 用TabPFN这个模型构建一个预测未来 3 天股价涨跌的分类任务,进行预测并输…...

大语言模型如何处理长文本?常用文本分割技术详解
为什么需要文本分割? 引言:为什么需要文本分割?一、基础文本分割方法1. 按段落分割(Paragraph Splitting)2. 按句子分割(Sentence Splitting)二、高级文本分割策略3. 重叠分割(Sliding Window)4. 递归分割(Recursive Splitting)三、生产级工具推荐5. 使用LangChain的…...

【CSS position 属性】static、relative、fixed、absolute 、sticky详细介绍,多层嵌套定位示例
文章目录 ★ position 的五种类型及基本用法 ★ 一、position 属性概述 二、position 的五种类型详解(初学者版) 1. static(默认值) 2. relative(相对定位) 3. absolute(绝对定位) 4. fixed(固定定位) 5. sticky(粘性定位) 三、定位元素的层级关系(z-i…...

基于数字孪生的水厂可视化平台建设:架构与实践
分享大纲: 1、数字孪生水厂可视化平台建设背景 2、数字孪生水厂可视化平台建设架构 3、数字孪生水厂可视化平台建设成效 近几年,数字孪生水厂的建设开展的如火如荼。作为提升水厂管理效率、优化资源的调度手段,基于数字孪生的水厂可视化平台的…...

python如何将word的doc另存为docx
将 DOCX 文件另存为 DOCX 格式(Python 实现) 在 Python 中,你可以使用 python-docx 库来操作 Word 文档。不过需要注意的是,.doc 是旧的 Word 格式,而 .docx 是新的基于 XML 的格式。python-docx 只能处理 .docx 格式…...

【决胜公务员考试】求职OMG——见面课测验1
2025最新版!!!6.8截至答题,大家注意呀! 博主码字不易点个关注吧,祝期末顺利~~ 1.单选题(2分) 下列说法错误的是:( B ) A.选调生属于公务员系统 B.公务员属于事业编 C.选调生有基层锻炼的要求 D…...

C# SqlSugar:依赖注入与仓储模式实践
C# SqlSugar:依赖注入与仓储模式实践 在 C# 的应用开发中,数据库操作是必不可少的环节。为了让数据访问层更加简洁、高效且易于维护,许多开发者会选择成熟的 ORM(对象关系映射)框架,SqlSugar 就是其中备受…...

Mac下Android Studio扫描根目录卡死问题记录
环境信息 操作系统: macOS 15.5 (Apple M2芯片)Android Studio版本: Meerkat Feature Drop | 2024.3.2 Patch 1 (Build #AI-243.26053.27.2432.13536105, 2025年5月22日构建) 问题现象 在项目开发过程中,提示一个依赖外部头文件的cpp源文件需要同步,点…...