Java线程池及其实现原理
线程池概述
线程池(Thread Pool)是一种基于池化思想管理线程的工具,经常出现在多线程服务器中,如MySQL。
线程过多会带来额外的开销,其中包括创建销毁线程的开销、调度线程的开销等等,同时也降低了计算机的整体性能。线程池维护多个线程,等待监督管理者分配可并发执行的任务。这种做法,一方面避免了处理任务时创建销毁线程开销的代价,另一方面避免了线程数量膨胀导致的过分调度问题,保证了对内核的充分利用。
使用线程池可以带来的一系列好处:
- 降低资源消耗:通过池化技术重复利用已创建的线程,降低线程创建和销毁造成的损耗。
- 提高响应速度:任务到达时,无需等待线程创建即可立即执行。
- 提高线程的可管理性:线程是稀缺资源,如果无限制创建,不仅会消耗系统资源,还会因为线程的不合理分布导致资源调度失衡,降低系统的稳定性。使用线程池可以进行统一的分配、调优和监控。
- 提供更多更强大的功能:线程池具备可拓展性,允许开发人员向其中增加更多的功能。比如延时定时线程池ScheduledThreadPoolExecutor,就允许任务延期执行或定期执行。
线程池解决的问题
线程池解决的核心问题就是资源管理问题。在并发环境下,系统不能够确定在任意时刻中,有多少任务需要执行,有多少资源需要投入。这种不确定性将带来以下若干问题:
- 频繁申请/销毁资源和调度资源,将带来额外的消耗,可能会非常巨大。
- 对资源无限申请缺少抑制手段,易引发系统资源耗尽的风险。
- 系统无法合理管理内部的资源分布,会降低系统的稳定性。
为解决资源分配这个问题,线程池采用了“池化”(Pooling)思想。为了最大化收益并最小化风险,而将资源统一在一起管理的一种思想。
“池化”思想不仅仅能应用在计算机领域,在金融、设备、人员管理、工作管理等领域也有相关的应用。
在计算机领域中的表现为:统一管理IT资源,包括服务器、存储、和网络资源等等。通过共享资源,使用户在低投入中获益。除去线程池,还有其他比较典型的几种使用策略包括:
- 内存池(Memory Pooling):预先申请内存,提升申请内存速度,减少内存碎片。
- 连接池(Connection Pooling):预先申请数据库连接,提升申请连接的速度,降低系统的开销。
- 对象实例池(Object Pooling):循环使用对象,减少资源在初始化和释放时的昂贵损耗。
线程池核心设计与实现

- 顶层接口Executor提供了一种思想:将任务提交和任务执行进行解耦。用户无需关注如何创建线程,如何调度线程来执行任务,用户只需提供Runnable对象,将任务的运行逻辑提交到执行器(Executor)中,由Executor框架完成线程的调配和任务的执行部分。
- ExecutorService接口增加了一些能力:
- 扩充执行任务的能力,补充可以为一个或一批异步任务生成Future的方法;
- 提供了管控线程池的方法,比如停止线程池的运行。
- AbstractExecutorService则是上层的抽象类,将执行任务的流程串联了起来,保证下层的实现只需关注一个执行任务的方法即可。
- 最下层的实现类ThreadPoolExecutor实现了顶层接口Executor。ThreadPoolExecutor实现最复杂的运行部分,ThreadPoolExecutor将会一方面维护自身的生命周期,另一方面同时管理线程和任务,使两者良好的结合从而执行并行任务。
ThreadPoolExecutor运行机制
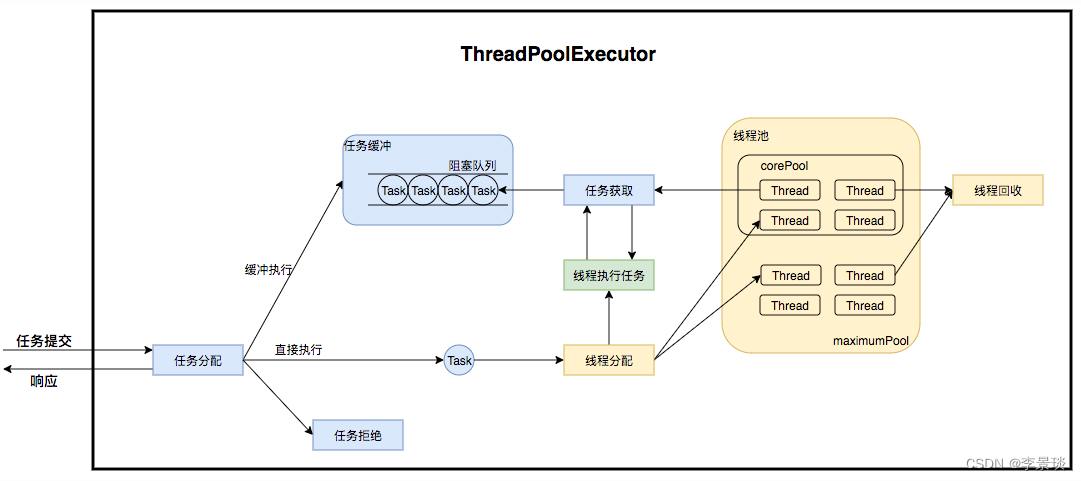
线程池在内部实际上构建了一个生产者消费者模型,将线程和任务两者解耦,并不直接关联,从而良好的缓冲任务,复用线程。
线程池的运行主要分成两部分:任务管理、线程管理。
任务管理部分充当生产者的角色,当任务提交后,线程池会判断该任务后续的流转:
- 直接申请线程执行该任务;
- 缓冲到队列中等待线程执行;
- 拒绝该任务。
线程管理部分是消费者,它们被统一维护在线程池内,根据任务请求进行线程的分配,当线程执行完任务后则会继续获取新的任务去执行,最终当线程获取不到任务的时候,线程就会被回收。
生命周期管理
线程池运行的状态,并不是用户显式设置的,而是伴随着线程池的运行,由内部来维护。线程池内部使用一个变量维护两个值:运行状态(runState)和线程数量 (workerCount)。在具体实现中,线程池将运行状态(runState)、线程数量 (workerCount)两个关键参数的维护放在了一起,如下代码所示:
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
private static final int COUNT_BITS = Integer.SIZE - 3;
private static final int CAPACITY = (1 << COUNT_BITS) - 1;
ctl这个AtomicInteger类型变量,是对线程池的运行状态和线程池中有效线程的数量进行控制的一个字段, 它同时包含两部分的信息:线程池的运行状态 (runState) 和线程池内有效线程的数量 (workerCount),高3位保存runState,低29位保存workerCount,两个变量之间互不干扰。用一个变量去存储两个值,可避免在做相关决策时,出现不一致的情况,不必为了维护两者的一致,而占用锁资源。通过阅读线程池源代码也可以发现,经常出现要同时判断线程池运行状态和线程数量的情况。线程池也提供了若干方法去供用户获得线程池当前的运行状态、线程个数。这里都使用的是位运算的方式,相比于基本运算,速度也会快很多。
关于内部封装的获取生命周期状态、获取线程池线程数量的计算方法如以下代码所示:
private static int runStateOf(int c) { return c & ~CAPACITY; } //计算当前运行状态
private static int workerCountOf(int c) { return c & CAPACITY; } //计算当前线程数量
private static int ctlOf(int rs, int wc) { return rs | wc; } //通过状态和线程数生成ctl
五种运行状态
ThreadPoolExecutor的运行状态有5种,分别为:
private static final int RUNNING = -1 << COUNT_BITS;
private static final int SHUTDOWN = 0 << COUNT_BITS;
private static final int STOP = 1 << COUNT_BITS;
private static final int TIDYING = 2 << COUNT_BITS;
private static final int TERMINATED = 3 << COUNT_BITS;| 运行状态 | 状态描述 |
| RUNNING | 能接受新提交的任务,并且也能处理阻塞队列中的任务。 |
| SHUTDOWN | 关闭状态。不再接受新提交的任务,但却可以继续处理阻塞队列中已保存的任务。 |
| STOP | 不能接受新任务,也不处理队列中的惹怒我,会中断正在处理的线程。 |
| TIDYING | 所有的任务都已终止,workerCount(有效线程数)为0 |
| TERMINATED | 在terminated()方法执行完后进入该状态 |
原子锁
private final ReentrantLock mainLock = new ReentrantLock();
private final Condition termination = mainLock.newCondition();生命周期转换

Executor 框架的使用

- 主线程首先创建实现 Runnable或Callable 接口的任务对象。
- 把创建完成的事项 Runnable/Callable 接口的对象直接交给ExecutorService执行。ExecutorService.execute(Runnable command) 或者把 Runnable对象或Callable对象提交给ExecutorService执行
ExecutorService cachedThreadPool = Executors.newCachedThreadPool(); cachedThreadPool.execute(Runnable command); cachedThreadPool.submit(Runnable task); cachedThreadPool.submit(Callable<T> task); - 如果执行ExecutorService execute(...),ExecutorService 将返回一个事项Future接口的对象。由于FutureTask实现了Runnable,也可以在使用时创建FutureTask。然后交给ExecutorService执行。
- 最后,主线程可以执行FutureTask.get()方法来等待任务执行完成。主线程也可以执行FutureTask.cancel(boolean mayInterruptIfRunning)来取消此任务的执行。
核心数据结构
public class ThreadPoolExecutor extends AbstractExecutorService {//...private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));// 存放任务的阻塞队列private final BlockingQueue<Runnable> workQueue;// 对线程池内部各种变量进行互斥访问控制private final ReentrantLock mainLock = new ReentrantLock();// 线程集合private final HashSet<Worker> workers = new HashSet<Worker>();//...
}每一个线程是一个Worker对象。Worker是ThreadPoolExector的内部类,核心数据结构如下:
private final class Worker extends AbstractQueuedSynchronizer implements Runnable {// ...// Worker封装的线程final Thread thread;// Worker接收到的第1个任务Runnable firstTask;// Worker执行完毕的任务个数volatile long completedTasks;// ...
}Worker继承于AQS,也就是说Worker本身就是一把锁。 这把锁用于线程池的关闭、线程执行任务的过程中。
七大核心参数
| 参数 | 说明 |
|---|---|
| corePoolSize | 核心线程数量,线程池维护线程的最少数量 |
| maximumPoolSize | 线程池维护线程的最大数量 |
| keepAliveTime | 线程池除核心线程外的其他线程的最长空闲时间,超过该时间的空闲线程会被销毁 |
| unit | keepAliveTime的单位,TimeUnit中的几个静态属性:NANOSECONDS、MICROSECONDS、MILLISECONDS、SECONDS |
| workQueue | 线程池所使用的任务缓冲队列 |
| threadFactory | 线程工厂,用于创建线程,一般用默认的即可 |
| handler | 线程池对拒绝任务的处理策略 |
public ThreadPoolExecutor(int corePoolSize, // 核心线程数int maximumPoolSize, // 最大线程数long keepAliveTime, // 当线程数大于核心线程数时,多余的空闲线程存活最长时间TimeUnit unit, // 空闲线程存活时间的时间单位BlockingQueue<Runnable> workQueue, // 任务队列ThreadFactory threadFactory, // 线程工厂,用来创建线程RejectedExecutionHandler handler) { // 拒绝策略this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,Executors.defaultThreadFactory(), defaultHandler);
}线程池的处理流程

- 如果此时线程池中的数量小于corePoolSize,即使线程池中的线程都处于空闲状态,也要创建新的线程来处理被添加的任务。
- 如果此时线程池中的数量等于corePoolSize,但是缓冲队列workQueue未满,那么任务被放入缓冲队列。
- 如果此时线程池中的数量大于等于corePoolSize,缓冲队列workQueue满,并且线程池中的数量小于maximumPoolSize,建新的线程来处理被添加的任务。
- 如果此时线程池中的数量大于corePoolSize,缓冲队列workQueue满,并且线程池中的数量等于maximumPoolSize,那么通过 handler所指定的策略来处理此任务。
- 当线程池中的线程数量大于 corePoolSize时,如果某线程空闲时间超过keepAliveTime,线程将被终止。这样,线程池可以动态的调整池中的线程数。
总结:处理任务判断的优先级为 核心线程corePoolSize、任务队列workQueue、最大线程maximumPoolSize,如果三者都满了,使用handler处理被拒绝的任务。
注意:
- 当workQueue使用的是无界限队列时,maximumPoolSize参数就变的无意义了,比如new LinkedBlockingQueue(),或者new ArrayBlockingQueue(Integer.MAX_VALUE)。
- 使用SynchronousQueue队列时由于该队列没有容量的特性,所以不会对任务进行排队,如果线程池中没有空闲线程,会立即创建一个新线程来接收这个任务。maximumPoolSize要设置大一点。
- 核心线程和最大线程数量相等时keepAliveTime无作用。
线程池关闭
- shutdown() 不接收新任务,会处理已添加任务
- shutdownNow() 不接受新任务,不处理已添加任务,中断正在处理的任务
常用线程池
| Executors .newCachedThreadPool(); | 创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程。 TimeUnit.SECONDS,new SynchronousQueue()); |
| Executors .newFixedThreadPool(int); | 创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待。 内部实现:new ThreadPoolExecutor(nThreads, nThreads,0L,TimeUnit.MILLISECONDS,new LinkedBlockingQueue()); |
| Executors .newSingleThreadExecutor(); | 创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照顺序执行。 内部实现:new ThreadPoolExecutor(1,1,0L,TimeUnit.MILLISECONDS,new LinkedBlockingQueue()) |
| Executors .newScheduledThreadPool(int) | 创建一个定长线程池,支持定时及周期性任务执行。 内部实现:new ScheduledThreadPoolExecutor(corePoolSize) |
Executors .newSingleThreadScheduledExecutor() | 创建一个单线程的任务调度池(定时任务/延时任务) |
队列

| 名称 | 描述 |
| ArrayBlockingQueue | 一个用数组实现的有界阻塞队列,此队列按照先进先出(FIFO)的原则对元素进行排序。支持公平锁和非公平锁。 |
| LinkedBlockingQueue | 一个由链表结构组成的有界队列,此队列按照先进先出FIFO)的原则对元素进行排序。此队列的默认长度为Integer.MAXVALUE,所以默认创建的该队列有容量危险。 |
| PriorityBlockingQueue | 一个支持线程优先级排序的无界队列,默认自然序进行排序,也可以自定义实现compareTo(方法来指定元素排字规则,不能保证同优先级元素的顺序。 |
| DelayQueue | 一个实现PriorityBlockingQueue实现延迟获取的无界队列,在创建元素时,可以指定多久才能从队列中获取当前元素。只有延时期满后才能从队列中获取元素。 |
| SynchronousQueue | 一个不存储元素的阻塞队列,每一个put操作必须等待take操作,否则不能添加元素。支持公平锁和非公平锁SynchronousQueue的-个使用场景是在线程池里。Executors.newCachedThreadPool0就使用了SynchronousQueue,这个线程池根据需要(新任务到来时)创建新的线程,如果有空闲线程则会重复使用线程空闲了60秒后会被回收。 |
| LinkedTransferQueue | 一个由链表结构组成的无界阳塞队列,相当于其它队列,LinkedTransferQueue队列多了transfer和trvTransfer方法。 |
| LinkedBlockingDeque | 一个由链表结构组成的双向阻塞队列。队列头部和尾部都可以添加和移除元素,多线程并发时,可以将锁的竞争最多降到一半。 |

拒绝策略
任务拒绝模块是线程池的保护部分,线程池有一个最大的容量,当线程池的任务缓存队列已满,并且线程池中的线程数目达到maximumPoolSize时,就需要拒绝掉该任务,采取任务拒绝策略,保护线程池。
拒绝策略是一个接口,其设计如下:
public interface RejectedExecutionHandler {void rejectedExecution(Runnable r, ThreadPoolExecutor executor);
}四种拒绝策略
| 名称 | 描述 |
| ThreadPoolExecutor.AbortPolicy | 丢弃任务并抛出RejectedExecutionException异常。 这是线程池默认的拒绝策略,在任务不能再提交的时候,抛出异常,及时反馈程序运行状态。如果是比较关键的业务推荐使用此拒绝策略,这样子在系统不能承载更大的并发量的时候,能够及时的通过异常发现。 |
| ThreadPoolExecutor.DiscardPolicy | 丢弃任务,但是不抛出异常。 使用此策略,可能会使我们无法发现系统的异常状态。建议是一些无关紧要的业务采用此策略。 |
| ThreadPoolExecutor.DiscardOldestPolicy | 丢弃队列最前面的任务,然后重新提交被拒绝的任务。是否要采用此种拒绝策略,还得根据实际业务是否允许丢弃老任务来认真衡量。 |
| ThreadPoolExecutor.CallerRunsPolicy | 由调用线程(提交任务的线程)处理该任务。这种情况是需要让所有任务都执行完毕那么就适合大量计算的任务类型去执行,多线程仅仅是增大吞吐量的手段,最终必须要让每个任务都执行完毕。 |
Worker线程管理
Worker线程
线程池为了掌握线程的状态并维护线程的生命周期,设计了线程池内的工作线程Worker。
private final class Worker extends AbstractQueuedSynchronizer implements Runnable{final Thread thread;//Worker持有的线程Runnable firstTask;//初始化的任务,可以为null
}Worker执行任务的模型

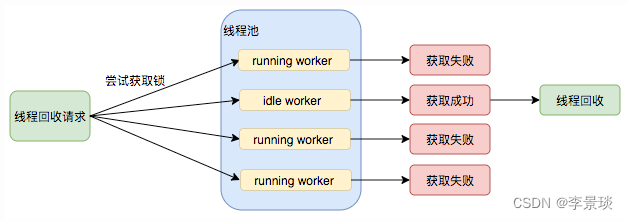
线程池需要管理线程的生命周期,需要在线程长时间不运行的时候进行回收。线程池使用一张Hash表去持有线程的引用,这样可以通过添加引用、移除引用这样的操作来控制线程的生命周期。这个时候重要的就是如何判断线程是否在运行。
Worker是通过继承AQS,使用AQS来实现独占锁这个功能。没有使用可重入锁ReentrantLock,而是使用AQS,为的就是实现不可重入的特性去反应线程现在的执行状态。
- lock方法一旦获取了独占锁,表示当前线程正在执行任务中。
- 如果正在执行任务,则不应该中断线程。
- 如果该线程现在不是独占锁的状态,也就是空闲的状态,说明它没有在处理任务,这时可以对该线程进行中断。
- 线程池在执行shutdown方法或tryTerminate方法时会调用interruptIdleWorkers方法来中断空闲的线程,interruptIdleWorkers方法会使用tryLock方法来判断线程池中的线程是否是空闲状态;如果线程是空闲状态则可以安全回收。
在线程回收过程中就使用到了这种特性,回收过程如下图所示:
线程池使用场景
场景1:快速响应用户请求
场景2:快速处理批量任务
【附】阿里巴巴Java开发手册中对线程池的使用规范
- 【强制】创建线程或线程池时请指定有意义的线程名称,方便出错时回溯
- 【强制】线程资源必须通过线程池提供,不允许在应用中自行显式创建线程。
说明: 使用线程池的好处是减少在创建和销毁线程上所花的时间以及系统资源的开销,解决资源不足的问题。如果不使用线程池,有可能造成系统创建大量同类线程而导致消耗完内存或者“过度切换”的问题。 - 【强制】线程池不允许使用 Executors 去创建,而是通过 ThreadPoolExecutor 的方式创建,这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险。
说明: Executors 返回的线程池对象的弊端如下:
1) FixedThreadPool 和 SingleThreadPool:
允许的请求队列长度为 Integer.MAX_VALUE,可能会堆积大量的请求,从而导致 OOM。
2) CachedThreadPool 和 ScheduledThreadPool:
允许的创建线程数量为 Integer.MAX_VALUE, 可能会创建大量的线程,从而导致 OOM。
相关文章:
Java线程池及其实现原理
线程池概述 线程池(Thread Pool)是一种基于池化思想管理线程的工具,经常出现在多线程服务器中,如MySQL。 线程过多会带来额外的开销,其中包括创建销毁线程的开销、调度线程的开销等等,同时也降低了计算机…...
进程替换函数组介绍exec*
目录 前述 execl execlp execle execv execvp execvpe 前述 介绍后缀的意义: l (list):表示参数采用列表。 v(vector):参数同数组表示。 p(path):自…...
欧科云链OKLink:2023年4月安全事件盘点
一、基本信息 2023年4月安全事件共造约6000万美金的损失,与上个月相比,损失金额有所降落,但安全事件数量依旧不减。其中,Yearn Finance因参数配置错误,导致了1000多万美金的损失。同时,有一些已经出现过的…...

KubeVirt备份与还原方案【翻译】
KubeVirt备份与还原方案【翻译】 ref:https://github.com/kubevirt/kubevirt/blob/main/docs/backup-restore-integration.md 备份 为所有必需的k8s资源构建依赖关系图冻结应用程序pvc数据快照解冻应用程序将所有必需的k8s资源定义拷贝到一个共享的存储位置(可选…...
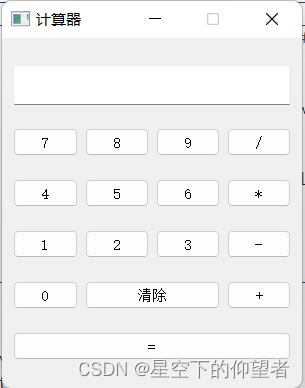
使用PyQt5设计一款简单的计算器
目录 一、环境配置: 二、代码实现 三、主程序 四、总结 本文使用PyQt5设计一款简单的计算器,可以通过界面交互实现加减乘除的功能,希望能够给初学者一些帮助。主要涉及的知识点有类的定义与初始化、类的成员函数、pyqt5的信号与槽函数等。…...

Htop使用说明
目录 引言 什么是htop htop安装 htop界面介绍 htop功能介绍 引言 我们使用服务器的时候常常需要关注下自己的程序资源占用情况,htop就是一种互动式的进程查查看器,整齐用下来感觉比top的逼格高,造作可视化都更方便些,我觉得还…...

PostgreSQL Linux安装
安装依赖: sudo yum -y install readline-devel zlib-devel 安装Postgres: ssh hadoophadoop001 #下载Postgres wget https://ftp.postgresql.org/pub/source/v14.2/postgresql-14.2.tar.gz tar -zxvf postgresql-14.2.tar.gz -C /data #编译前准备 /dat…...

亚商投资顾问 早餐FM/0509车辆电动化
01/亚商投资顾问 早间导读 1.上交所拟于5月11日举办“发现央企投资价值,促进央企估值回归”交流会 2.监管部门十方面举措加强房地产经纪行业管理 3.广东:推动城市公共服务及货运配送车辆电动化替代 4.昆山两楼盘因大幅降价被暂停网签:降幅…...

AI绘画天花板——Midjourney注册使用保姆级教程(5月5日验证有效)
大家好,我是可夫小子,关注AIGC、读书和自媒体。解锁更多ChatGPT、AI绘画玩法。加我,备注:aigc,拉你进群。 现在市面上AI绘图大概有三大阵营:Midjourney、Stable Diffusion,还有一个就是OpenAI实…...
项目结构描述 - manifest.json和pages.json)
学习笔记(2)项目结构描述 - manifest.json和pages.json
目录 1,manifest.json2,pages.json2.1,pages2.2,globalStyle2.3,tabBar 1,manifest.json 官方详情 uni-app 的 appid 由 DCloud 云端分配,主要用于 DCloud 相关的云服务,请勿自行修…...

vector、deque、list相关知识点
vector erase返回迭代器指向删除元素后的元素insert返回迭代器指插入的元素reserve只给容器底层开指定大小内存空间,并不添加新元素 deque 底层数据结构 动态开辟的二维数组,一维数组从2开始,以2倍方式扩容,每次扩容和&#x…...
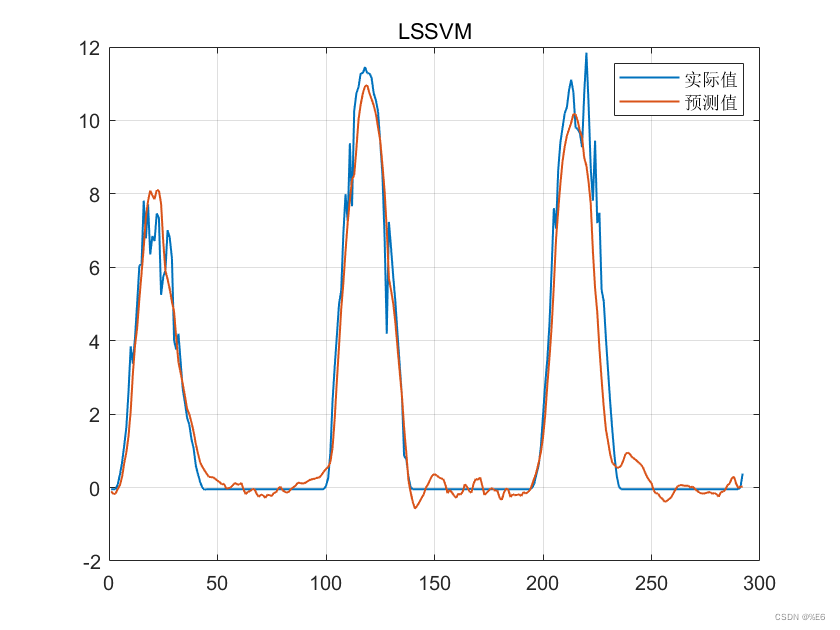
多维时序 | MATLAB实现基于VMD-SSA-LSSVM、SSA-LSSVM、VMD-LSSVM、LSSVM的多变量时间序列预测对比
多维时序 | MATLAB实现基于VMD-SSA-LSSVM、SSA-LSSVM、VMD-LSSVM、LSSVM的多变量时间序列预测对比 目录 多维时序 | MATLAB实现基于VMD-SSA-LSSVM、SSA-LSSVM、VMD-LSSVM、LSSVM的多变量时间序列预测对比预测效果基本介绍程序设计学习总结参考资料 预测效果 基本介绍 多维时序 …...
设计模式——适配器模式(类适配器、对象适配器)
是什么? 我们平时的有线耳机接口分为USB的和Type-C的接口,但是手机的耳机插口却只有一个,像华为的耳机插口现在基本都是Type-c的,那如果我们现在只有USB接口的耳机怎么办呢,这个时候就需要使用到一个转换器,…...

iOS开发多target
场景 背景:设想一下有一个场景,一个业务分为多种身份,他们大部分功能是相同的,但是也有自己的差异性。这种情况,想要构建出不同身份的APP。你会怎么做??? 当然,你可以拷贝一份代码出来,给项目重新命名。这样做的好处是,他们互相不会冲突,不用去关心是否有逻辑的冲…...

100种思维模型之每日评估思维模型-58
曾子曰:吾日三省吾省,为人谋而不忠乎?与朋友交不信乎?传不习乎? 曾国藩,坚持每日写复盘日记,最后他用自己的实践经历向我们证明:一个智商很平庸、出身很普通且有着各种毛病的人&…...

libreoffice api
libreOffice API是用于访问libreOffice的编程接口。可以使用libreOffice API创建、打开、修改和打印libreOffice文档。 LibreOffice API支持Basic、Java、C/C、Javascript、Python语言。 这是通过一种称为通用网络对象 (Universal Network Objects, UNO) 的技术实现的ÿ…...
全网最火,Web自动化测试驱动模型详全,一语点通超实用...
目录:导读 前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜) 前言 自动化测试模型&a…...

如何写软件测试简历项目经验,靠这个面试都要赶场
一、前言:浅谈面试 面试是我们进入一个公司的门槛,通过了面试才能进入公司,你的面试结果和你的薪资是息息相关的。那如何才能顺利的通过面试,得到公司的认可呢?面试软件测试要注意哪些问题呢?下面和笔者一起来看看吧。这里分享一…...
【Linux】Linux下安装Mysql(图文解说详细版)
文章目录 前言第一步,进到opt文件夹下面,为什么?因为opt文件夹相当于Windows下的D://software第二步,用yum安装第三步,设置mysql的相关配置第四步,设置远程连接。第五步,更改mysql的语言第六步&…...

Cookie和Session的API、登录页面
目录 一、Cookie 和 Session 1、HttpServletRequest 类中的相关方法 2、HttpServletResponse 类中的相关方法 3、HttpSession 类中的相关方法 4、Cookie 类中的相关方法 二、网页登录 1、约定前后端交互接口 2、编写一个简单的登录页面 3、编写一个Servlet 来处理这个…...

Python F1数据分析终极指南:5个高级技巧掌握赛车性能可视化
Python F1数据分析终极指南:5个高级技巧掌握赛车性能可视化 【免费下载链接】Fast-F1 FastF1 is a python package for accessing and analyzing Formula 1 results, schedules, timing data and telemetry 项目地址: https://gitcode.com/GitHub_Trending/fa/Fas…...

终极指南:如何用Ice打造清爽Mac菜单栏?2025年最强大的macOS菜单栏管理工具
终极指南:如何用Ice打造清爽Mac菜单栏?2025年最强大的macOS菜单栏管理工具 【免费下载链接】Ice Powerful menu bar manager for macOS 项目地址: https://gitcode.com/GitHub_Trending/ice/Ice Ice是一款强大的macOS菜单栏管理工具,它…...

别再让LVGL卡顿了!手把手教你用思澈SDK的menuconfig优化framebuffer配置,帧率翻倍
别再让LVGL卡顿了!手把手教你用思澈SDK的menuconfig优化framebuffer配置,帧率翻倍 嵌入式UI开发中,LVGL的流畅度直接影响用户体验。许多开发者在使用思澈SDK时,常遇到界面卡顿、帧率低的问题。本文将深入分析framebuffer配置对性能…...

Fortran模块编译避坑指南:为什么你的.mod文件总是找不到?
Fortran模块编译避坑指南:为什么你的.mod文件总是找不到? 当你第一次尝试在Fortran项目中使用模块(module)时,很可能会遇到那个令人困惑的错误信息:"Cant open module file xxx.mod for reading"。这个看似简单的问题背…...

CasaOS应用商店太单调?试试这几个社区维护的源,青龙面板、迅雷都能一键装
CasaOS社区应用源全攻略:解锁青龙面板、迅雷等本土化神器 如果你已经厌倦了CasaOS官方应用商店里那些千篇一律的容器镜像,正为找不到迅雷下载、青龙面板这类中国特色应用而发愁,那么这篇文章就是为你准备的。作为一个长期折腾家庭服务器的玩家…...

告别复杂状态机:用C语言结构体数组为STM32设计可维护的多级菜单
用结构体数组重构STM32菜单系统:从状态机到模块化设计的进阶之路 在嵌入式开发中,菜单系统是许多产品不可或缺的交互界面。传统的状态机或switch-case实现方式虽然直接,但随着功能迭代,代码往往会变得臃肿难维护。我曾接手过一个使…...

企业级图片批量处理方案:InstructPix2Pix在电商修图中的落地实践
企业级图片批量处理方案:InstructPix2Pix在电商修图中的落地实践 1. 引言:电商修图的效率困局 想象一下,一家中型电商公司,每天要上新几百个商品。每个商品都需要一组高质量的主图、细节图、场景图。设计师团队忙得焦头烂额&…...

CSS 嵌套语法最佳实践:从入门到精通的完整指南
CSS 嵌套语法最佳实践:从入门到精通的完整指南 CSS 是流动的韵律,JS 是叙事的节奏。而 CSS 嵌套,是让这份韵律更加优雅、结构更加清晰的魔法。 一、CSS 嵌套:现代样式表的革命 CSS 嵌套(Nesting)是 CSS 原…...

实测通义千问3-Reranker-0.6B:轻量模型如何让电商商品搜索更准确
实测通义千问3-Reranker-0.6B:轻量模型如何让电商商品搜索更准确 1. 电商搜索的痛点与解决方案 在电商平台上,用户输入"真丝连衣裙"却看到牛仔裤推荐,这种糟糕的搜索体验每天都在发生。传统搜索技术依赖关键词匹配和简单规则&…...

像素幻梦·创意工坊实操手册:实时HUD状态栏信息读取与调试技巧
像素幻梦创意工坊实操手册:实时HUD状态栏信息读取与调试技巧 1. 认识像素幻梦的HUD状态栏 像素幻梦创意工坊的HUD(Head-Up Display)状态栏位于界面顶部,采用16-bit像素风格设计,为创作者提供实时系统状态反馈。这个看…...