C++入门:初识类和对象
C++入门:类和对象1

本节目录
- C++入门:类和对象1
- 1.auto关键字(C++11)
- 1.1类型别名思考
- 1.2auto简介
- typeid运算符:获取类型信息
- 1.3 auto的使用细则
- 1.4auto不能推到的场景
- 2.基于范围的for循环(C++11)
- 2.1范围for的语法
- 2.2范围for的使用条件
- 3.指针控制nullptr(C++11)
- 3.1C++98中的指针空值
- 4.面向过程和面向对象初步认识
- 5.类的引入
- 6.类的定义
- 7.类的访问限定符及封装
- 7.1访问限定符
- 7.2封装
- 8.类的作用域
- 9.类的实例化
- 10.this指针
- 10.1this指针的定义
- 10.2this指针的特性
- 11. C语言和C++实现Stack的对比
- 11.1 C语言的实现
- 11.2 C++实现
- 12 总结两者区别
1.auto关键字(C++11)
auto关键字是C++11中定义的,所以一些版本较低的编译器可能无法识别auto关键字,比如DevC++,我们来看一下这个关键字的用处。
1.1类型别名思考
我们作为后面接触的程序会越来越复杂,类型也会越来越多,这样也导致很容易就会出现错误,会出现以下问题:
1.类型难以拼写,容易拼写错误
2.含义不明确导致出错
我们先来看看下面的代码(有点超纲,里面的知识点没有讲到)
#include <string>
#include <map>
int main()
{std::map<std::string, std::string> m{ { "apple", "苹果" }, { "orange",
"橙子" }, {"pear","梨"} };std::map<std::string, std::string>::iterator it = m.begin();while (it != m.end()){//....}return 0;
}
std::map<std::string, std::string>::iterator 是一个类型,但是该类型太长了,特别容易写错。聪明的同学可能已经想到:可以通过typedef给类型取别名,比如:
#include <string>
#include <map>
typedef std::map<std::string, std::string> Map;
int main()
{Map m{ { "apple", "苹果" },{ "orange", "橙子" }, {"pear","梨"} };Map::iterator it = m.begin();while (it != m.end()){//....}return 0;
}
使用typedef给类型取别名确实可以简化代码,但是typedef有会遇到新的难题:
typedef char* pstring;
int main()
{const pstring p1; // 编译失败const pstring* p2; // 编译成功return 0;
}
但是为什么p1失败了,p2成功了?

在编程时,常常需要把表达式的值赋值给变量,这就要求在声明变量的时候清楚地知道表达式的类型。然而有时候要做到这点并非那么容易,因此C++11给auto赋予了新的含义。
1.2auto简介
在早期C/C++中auto的含义是:使用auto修饰的变量,是具有自动存储器的局部变量,但遗憾的是一直没有人去使用它,大家可思考下为什么?
C++11中,标准委员会赋予了auto全新的含义即:auto不再是一个存储类型指示符,而是作为一个新的类型指示符来指示编译器,auto声明的变量必须由编译器在编译时期推导而得。
int main()
{int a = 0;//int b = a;auto b = a;auto c = &a;cout << typeid(b).name() << endl;cout << typeid(c).name() << endl
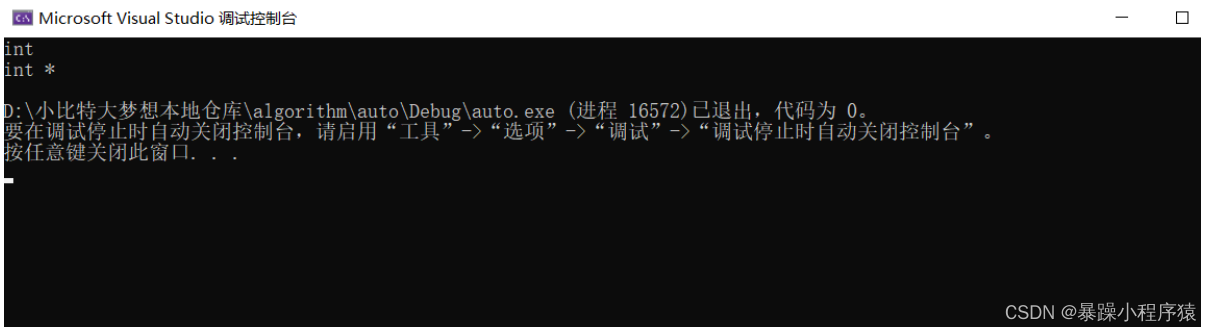
我们来看一下上面的代码,我们自己可以定义b变量的类型是int型,然后将int a赋给int b,但是我们也可以不自己写类型,就让编译器自己来推导,我们要做的就是写一个auto,是不是很方便,这里我们介绍一下typeid运算符
typeid运算符:获取类型信息
typeid 运算符用来获取一个表达式的类型信息。类型信息对于编程语言非常重要,它描述了数据的各种属性:
- 对于基本类型(int、float 等C++内置类型)的数据,类型信息所包含的内容比较简单,主要是指数据的类型。
- 对于类类型的数据(也就是对象),类型信息是指对象所属的类、所包含的成员、所在的继承关系等。
类型信息是创建数据的模板,数据占用多大内存、能进行什么样的操作、该如何操作等,这些都由它的类型信息决定
typeid 的操作对象既可以是表达式,也可以是数据类型,下面是它的两种使用方法:
typeid( dataType )
typeid( expression )
dataType 是数据类型,expression 是表达式,这和 sizeof 运算符非常类似,只不过 sizeof 有时候可以省略括号( ),而 typeid 必须带上括号。
typeid 会把获取到的类型信息保存到一个 type_info 类型的对象里面,并返回该对象的常引用;当需要具体的类型信息时,可以通过成员函数来提取。typeid 的使用非常灵活,请看下面的例子(只能在 VC/VS 下运行):
#include <iostream>
#include <typeinfo>
using namespace std;
class Base{ };
struct STU{ };
int main(){//获取一个普通变量的类型信息int n = 100;const type_info &nInfo = typeid(n);cout<<nInfo.name()<<" | "<<nInfo.raw_name()<<" | "<<nInfo.hash_code()<<endl;//获取一个字面量的类型信息const type_info &dInfo = typeid(25.65);cout<<dInfo.name()<<" | "<<dInfo.raw_name()<<" | "<<dInfo.hash_code()<<endl;//获取一个对象的类型信息Base obj;const type_info &objInfo = typeid(obj);cout<<objInfo.name()<<" | "<<objInfo.raw_name()<<" | "<<objInfo.hash_code()<<endl;//获取一个类的类型信息const type_info &baseInfo = typeid(Base);cout<<baseInfo.name()<<" | "<<baseInfo.raw_name()<<" | "<<baseInfo.hash_code()<<endl;//获取一个结构体的类型信息const type_info &stuInfo = typeid(struct STU);cout<<stuInfo.name()<<" | "<<stuInfo.raw_name()<<" | "<<stuInfo.hash_code()<<endl;//获取一个普通类型的类型信息const type_info &charInfo = typeid(char);cout<<charInfo.name()<<" | "<<charInfo.raw_name()<<" | "<<charInfo.hash_code()<<endl;//获取一个表达式的类型信息const type_info &expInfo = typeid(20 * 45 / 4.5);cout<<expInfo.name()<<" | "<<expInfo.raw_name()<<" | "<<expInfo.hash_code()<<endl;return 0;
}
auto 实际价值 简化代码,类型很长时,可以考虑自动推导
【注意】
使用auto定义变量时必须对其进行初始化,在编译阶段编译器需要根据初始化表达式来推导auto的实际类型。因此auto并非是一种类型”的声明,而是一个类型声明时的占位符,编译器在编译期会将auto替换为变量实际的类型。
1.3 auto的使用细则
1.auto与指针和引用结合起来使用
用auto声明指针类型时,用auto和auto*是没有任何区别的,但用auto声明引用类型时则必须加&
int main()
{int x = 10;auto a = &x;auto* b = &x;auto& c = x;cout << typeid(a).name() << endl;cout << typeid(b).name() << endl;cout << typeid(c).name() << endl;*a = 20;*b = 30;c = 40;return 0;
}
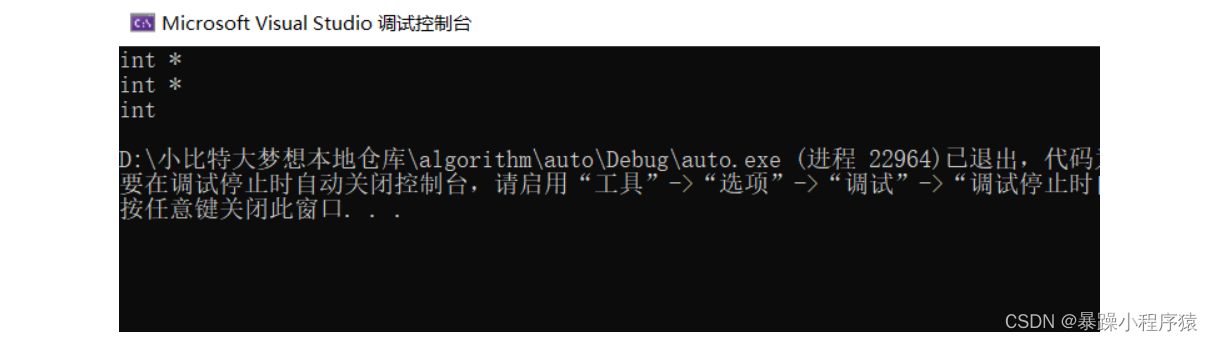
2.在同一行定义多个变量
在同一行声明多个变量时,这些变量必须是相同的类型,否则编译器将会报错,因为编译器实际只对第一个类型进行推导,然后用推导出来的类型定义其他变量。
void TestAuto()
{auto a = 1, b = 2; auto c = 3, d = 4.0; // 该行代码会编译失败,因为c和d的初始化表达式类型不同
}
1.4auto不能推到的场景
1.auto不能作为函数的参数
// 此处代码编译失败,auto不能作为形参类型,因为编译器无法对a的实际类型进行推导
void TestAuto(auto a)
{}
2.auto不能直接用来声明数组
void TestAuto()
{int a[] = {1,2,3};auto b[] = {4,5,6};
}
-
为了避免与C++98中的auto发生混淆,C++11只保留了auto作为类型指示符的用法
-
auto在实际中最常见的优势用法就是跟以后会讲到的C++11提供的新式for循环,还有lambda表达式等进行配合使用。
2.基于范围的for循环(C++11)
2.1范围for的语法
我们在C++98中如果要遍历一个数组,可以按照以下方式进行:
void TestFor()
{
int array[] = { 1, 2, 3, 4, 5 };
for (int i = 0; i < sizeof(array) / sizeof(array[0]); ++i)array[i] *= 2;
for (int* p = array; p < array + sizeof(array)/ sizeof(array[0]); ++p)cout << *p << endl;
}
对于这种有给定范围的循环,让我们来自己写出循环的范围明显是多余的,有时还会因为人为原因出错,因此C++11中引入了基于范围的for循环,for循环后的括号由冒号 :分为两部分:第一部分是范围内用于迭代的变量,第二部分则表示被迭代的范围。
//自动依次取数组中数据赋值给e对象,自动判断结束for (auto& e : array){e *= 2;cout << e << " ";}cout << endl;//for (int x : array)for (auto x : array){cout << x << " ";}cout << endl;return 0;
}
如果我们想在循环的时候改变数组中的元素的大小,那么我们就可以利用C++的引用,auto& e,然后就可以直接对e进行操作,同时改变数组中的元素大小。当然我们如果知道数组的元素类型的话我们也可以自己写出迭代变量的类型,但是还是建议写出auto的形式,不容易出错
注意:与普通的循环类似,可以使用continue来结束本次循环,也可以用break来跳出整个循环。
2.2范围for的使用条件
1.for循环迭代的范围必须是确定的
对于数组而言,就是数组中第一个元素和最后一个元素的范围;对于类而言,应该提供begin和end的方法,begin和end就是for循环迭代的范围。
注意:以下代码就有问题,因为for的范围不确定
void TestFor(int array[])
{for(auto& e : array)cout<< e <<endl;
}
2.迭代的对象要实现+=和==操作。
3.指针控制nullptr(C++11)
3.1C++98中的指针空值
在良好的C/C++编程习惯中,声明一个变量时最好给该变量一个合适的初始值,否则可能会出现不可预料的错误,比如未初始化的指针(野指针)。如果一个指针没有合法的指向,我们基本都是按照如下
方式对其进行初始化:
void TestPtr()
{
int* p1 = NULL;
int* p2 = 0;
// ……
}
那么问题就来了,NULL到底是什么呢?又是怎么定义的呢?
NULL实际是一个宏,在传统的C头文件(stddef.h)中,可以看到如下代码:
#ifndef NULL
#ifdef __cplusplus
#define NULL 0
#else
#define NULL ((void *)0)
#endif
#endif
可以看到,NULL可能被定义为字面常量0,或者被定义为无类型指针(void*)的常量。不论采取何种定义,在使用空值的指针时,都不可避免的会遇到一些麻烦,比如:
void f(int)
{cout<<"f(int)"<<endl;
}
void f(int*)
{cout<<"f(int*)"<<endl;
}
int main()
{f(0);f(NULL);f((int*)NULL);return 0;
}
程序本意是想通过f(NULL)调用指针版本的f(int*)函数,但是由于NULL被定义成0,因此与程序的初衷相悖。
在C++98中,字面常量0既可以是一个整形数字,也可以是无类型的指针(void*)常量,但是编译器默认情况下将其看成是一个整形常量,如果要将其按照指针方式来使用,必须对其进行强转(void *)0

在这里补充分析一下函数调用在反汇编的情况:

我们函数的调用在底层就是一个call命令,然后操作的数据就是一个地址,然后我们找到这个地址发现原来这个地址执行的是一个jmp跳转指令,我们的jmp指令也有它操作的地址,但是我们看到跳转过去之后是一系列的指令,jmp的地址是第一个指针的地址,最终经过一系列的指令就可以完成函数的调用。
接下来就要正式进入类和对象了:
4.面向过程和面向对象初步认识
C语言是面向过程的,关注的是过程,分析出求解问题的步骤,通过函数调用逐步解决问题
比如洗衣服,我们看看下面的过程:
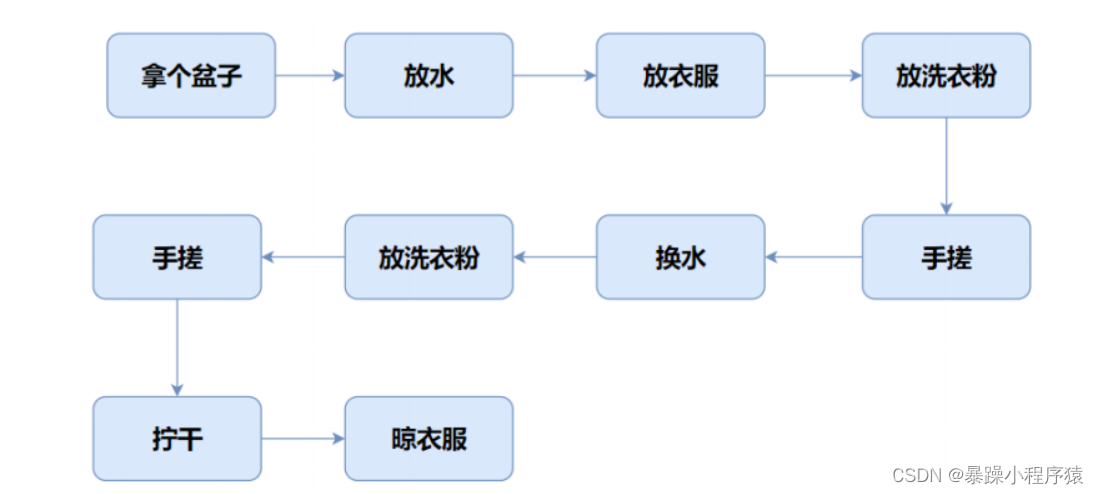
C++是基于面向对象的,关注的是对象,将一件事情拆分成不同的对象,靠对象之间的交互完成。
我们看看下面的图:
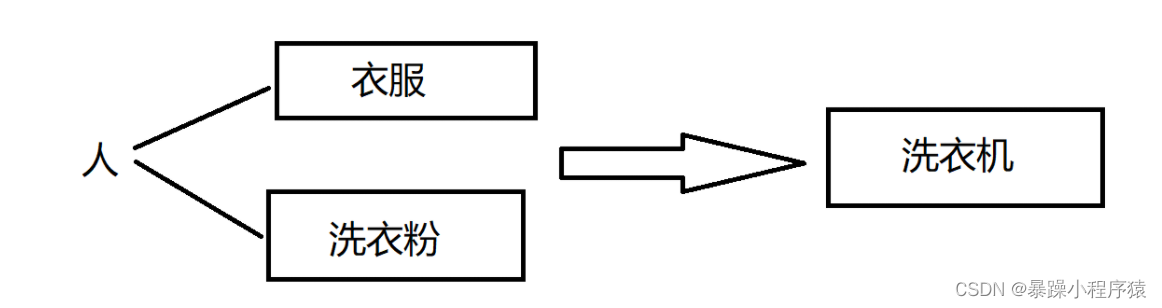
整个过程主要是:人,衣服,洗衣粉,洗衣机四个对象之间交互完成的,我们不用关注洗衣机具体是怎么洗衣服的。
5.类的引入
C语言结构体中只能定义变量,在C++中,结构体内不仅可以定义变量,也可以定义函数。比如:之前在数据结构初阶中,用C语言方式实现的栈,结构体中只能定义变量;现在以C++方式实现,会发现struct中也可以定义函数
首先我们要了解到C++兼容C结构体的语法,我们来看一下C语言的结构体是怎么样的:
typedef struct ListNode // C struct ListNode是类型
{int val;struct ListNode* next;//切记这里必须是struct ListNode*,缺少什么都不行,//LTN要在结构体后面才可以用,在这个结构体内暂时用不了
}LTN;
C++将结构体升级成了类
struct ListNode
{int val;ListNode* next;
};
这就是结构体和类在变量上的变化,同时升级成了类还有一个很重要的作用,就是可以将函数写在类里面,在C语言中我们结构体只可以定义变量,如果要写函数就要写到结构体的外面去,但是C++优化后的类就解决了这个问题:
// 成员函数直接定义到类里面
struct Stack
{// 成员函数void Init(int n = 4){a = (int*)malloc(sizeof(int)* n);if (nullptr == a){perror("malloc申请空间失败");return;}capacity = n;size = 0;}
}
typedef int DataType;
struct Stack
{void Init(size_t capacity){_array = (DataType*)malloc(sizeof(DataType) * capacity);if (nullptr == _array){perror("malloc申请空间失败");return;}_capacity = capacity;_size = 0;}void Push(const DataType& data){// 扩容_array[_size] = data;++_size;}DataType Top(){return _array[_size - 1];}void Destroy(){if (_array){free(_array);_array = nullptr;_capacity = 0;_size = 0;}}DataType* _array;size_t _capacity;size_t _size;
};
int main()
{Stack s;s.Init(10);s.Push(1);s.Push(2);s.Push(3);cout << s.Top() << endl;s.Destroy();return 0;
}
但是在C++里面我们的更喜欢用class来替换struct。
6.类的定义
class className
{
// 类体:由成员函数和成员变量组成
}; // 一定要注意后面的分号

类的两种定义方式:
- 声明和定义全部放在类体中,需注意:成员函数如果在类中定义,编译器可能会将其当成内联函数处理。

- 类声明放在.h文件中,成员函数定义放在.cpp文件中,注意:成员函数名前需要加类名::

在后面工作中优先第二种。
我们对于类中的成员变量的命名也有一定的规则:
// 我们看看这个函数,是不是很僵硬?
class Date
{
public:void Init(int year){// 这里的year到底是成员变量,还是函数形参?year = year;}
private:int year;
};
// 所以一般都建议这样
class Date
{
public:void Init(int year){_year = year;}
private:int _year;
};
// 或者这样
class Date
{
public:void Init(int year){mYear = year;}
private:int mYear;
};
我们这个没有特殊的规定,合理即可,最后根据要求改变自己的风格即可。
7.类的访问限定符及封装
7.1访问限定符
C++实现封装的方式:用类将对象的属性与方法结合在一块,让对象更加完善,通过访问权限选择性的将其接口提供给外部的用户使用
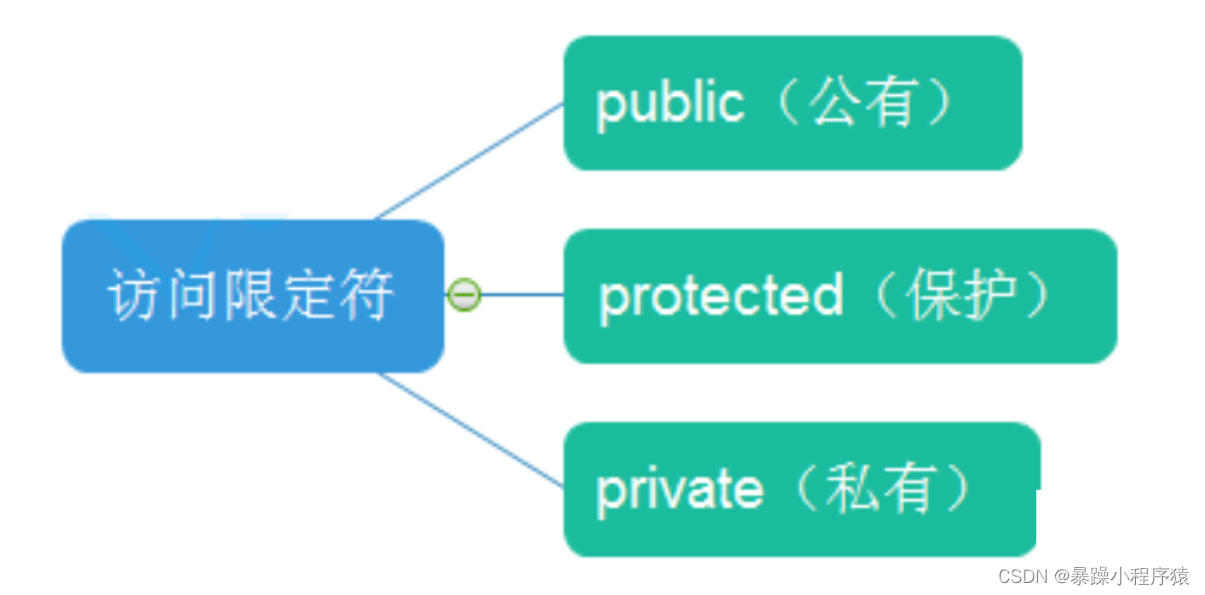
【访问限定符说明】
-
public修饰的成员在类外可以直接被访问
-
protected和private修饰的成员在类外不能直接被访问(此处protected和private是类似的)
-
访问权限作用域从该访问限定符出现的位置开始直到下一个访问限定符出现时为止
-
如果后面没有访问限定符,作用域就到 } 即类结束。
-
class的默认访问权限为private,struct为public(因为struct要兼容C)
注意:访问限定符只在编译时有用,当数据映射到内存后,没有任何访问限定符上的区别
7.2封装
封装:将数据和操作数据的方法进行有机结合,隐藏对象的属性和实现细节,仅对外公开接口来
和对象进行交互。
封装本质上是一种管理,让用户更方便使用类。比如:对于电脑这样一个复杂的设备,提供给用
户的就只有开关机键、通过键盘输入,显示器,USB插孔等,让用户和计算机进行交互,完成日
常事务。但实际上电脑真正工作的却是CPU、显卡、内存等一些硬件元件。
在C++语言中实现封装,可以通过类将数据以及操作数据的方法进行有机结合,通过访问权限来
隐藏对象内部实现细节,控制哪些方法可以在类外部直接被使用
8.类的作用域
类定义了一个新的作用域,类的所有成员都在类的作用域中**。**在类体外定义成员时,需要使用 ::
作用域操作符指明成员属于哪个类域
class Person
{
public:void PrintPersonInfo();
private:char _name[20];char _gender[3];int _age;
};
// 这里需要指定PrintPersonInfo是属于Person这个类域
void Person::PrintPersonInfo()
{cout << _name << " "<< _gender << " " << _age << endl;}
9.类的实例化
用类类型创建对象的过程,称为类的实例化
- 类是对对象进行描述的,是一个模型一样的东西,限定了类有哪些成员,定义出一个类并没有分配实际的内存空间来存储它;比如:入学时填写的学生信息表,表格就可以看成是一个类,来描述具体学生信息。
类就像谜语一样,对谜底来进行描述,谜底就是谜语的一个实例。
- 一个类可以实例化出多个对象,实例化出的对象 占用实际的物理空间,存储类成员变量
- 做个比方。类实例化出对象就像现实中使用建筑设计图建造出房子,类就像是设计图,只设计出需要什么东西,但是并没有实体的建筑存在,同样类也只是一个设计,实例化出的对象才能实际存储数据,占用物理空间
类的实例化就是开辟空间,而类就像一个图纸
那么问题又来了?
为什么成员变量在对象中,成员函数不在对象中呢?
每个对象成员变量时不一样的,需要独立存储,每个对象调用成员函数是一样的,放到共享公共区域(代码段)。
class Date
{
public:// 定义void Init(int year, int month, int day){_year = year;_month = month;_day = day;}//private:int _year; // 声明int _month;int _day;
};class A2 {
public:void f2() {}
};// 类中什么都没有---空类
class A3
{};int main()
{// 类对象实例化 -- 开空间// 实例化 -- 用设计图建造一栋栋别墅Date d1;Date d2;d1.Init(2023, 2, 2);d1._year++;d2.Init(2022, 2, 2);d2._year++;cout << sizeof(d1) << endl;A2 aa1;A2 aa2;cout << &aa1 << endl;cout << &aa2 << endl;cout << sizeof(aa1) << endl;// 大小是1,这1byte不存储有效数据// 占位,标识对象被实例化定义出来了return 0;
}
也就是说即便我们对类进行实例化,只是给类的成员变量开辟空间,成员函数存储在公共区据(代码段)


10.this指针
10.1this指针的定义
class Date
{
public:void Init(int year, int month, int day){_year = year;_month = month;_day = day;}void Print(){cout <<_year<< "-" <<_month << "-"<< _day <<endl;}private:int _year; // 年int _month; // 月int _day; // 日
};
int main()
{Date d1, d2;d1.Init(2022,1,11);d2.Init(2022, 1, 12);d1.Print();d2.Print();return 0;
}
对于上述类,有这样的一个问题:
Date类中有 Init 与 Print 两个成员函数,函数体中没有关于不同对象的区分,那当d1调用 Init 函
数时,该函数是如何知道应该设置d1对象,而不是设置d2对象呢?
C++中通过引入this指针解决该问题,即:C++编译器给每个非静态的成员函数增加了一个隐藏的指针参数,让该指针指向当前对象函数运行时调用该函数的对象,在函数体中所有成员变量的操作,都是通过该指针去访问。只不过所有的操作对用户是透明的,即用户不需要来传递,编译器自动完成。

//class Date
{
public:// 定义void Init(int year, int month, int day){/*_year = year;_month = month;_day = day;*/cout << this << endl;this->_year = year;this->_month = month;this->_day = day;}void func(){cout << this << endl;cout << "func()" << endl;}//private:int _year; // 声明int _month;int _day;
};
10.2this指针的特性
-
this指针的类型:类类型 *const,即成员函数中,不能给this指针赋值。
-
只能在“成员函数”的内部使用
-
this指针本质上是成员函数的形参,当对象调用成员函数时,将对象地址作为实参传递给
this形参。所以对象中不存储this指针**。**
- this指针是“成员函数”第一个隐含的指针形参,一般情况由编译器通过ecx寄存器自动传递,不需要用户传递
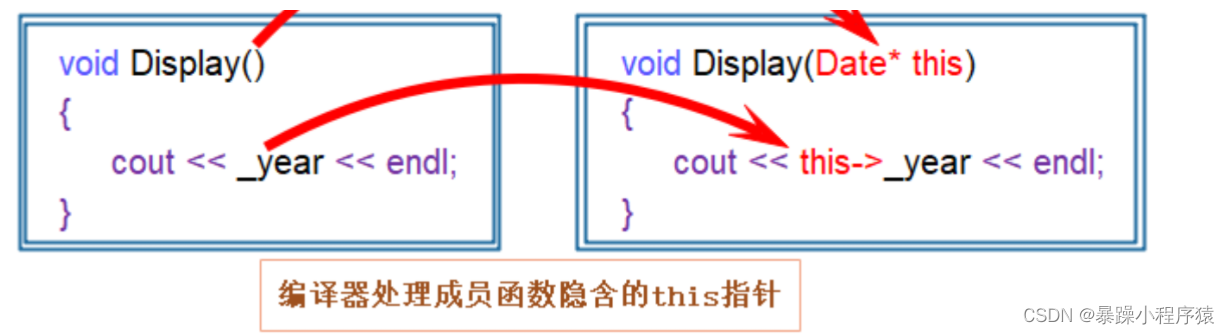
this存在哪里?
栈,因为他是隐含形参 / vs下面是通过ecx寄存器
那么this指针可以为空吗?
// 空指针问题
int main()
{Date d1;Date d2;d1.Init(2022, 2, 2);d2.Init(2023, 2, 2);// 编译报错 运行崩溃 正常运行Date* ptr = nullptr;//ptr->Init(2022, 2, 2); // 运行崩溃 有箭头不一定解引用//this指针为空是否可以运行取决于是否进入了类的内部,上述代码进入了类的内部ptr->func(); // 正常运行//因为func存储在公共空间(*ptr).func(); // 正常运行
//这里看似对ptr进行了解引用,但是我们发现它是调用func()的操作,看似解引用,实则并没有解引用操作return 0;
}
也就是说如果出现空指针,如果我们只是调用公共区域的函数就不会出现错误,也就是说只要不对指针解引用就是正确的,同时,代码看上去是解引用也不一定会解引用。
空指针调用函数不崩溃,但是解引用就会崩溃

判断是否进行了解引用操作的方法是分析这个操作需不需要进入对象中去找数据,不是由->决定的。
11. C语言和C++实现Stack的对比
11.1 C语言的实现
typedef int DataType;
typedef struct Stack
{DataType* array;int capacity;int size;
}Stack;
void StackInit(Stack* ps)
{assert(ps);ps->array = (DataType*)malloc(sizeof(DataType) * 3);if (NULL == ps->array){assert(0);return;}ps->capacity = 3;ps->size = 0;
}
void StackDestroy(Stack* ps)
{assert(ps);if (ps->array){free(ps->array);ps->array = NULL;ps->capacity = 0;ps->size = 0;}
}
void CheckCapacity(Stack* ps)
{if (ps->size == ps->capacity){int newcapacity = ps->capacity * 2;DataType* temp = (DataType*)realloc(ps->array,
newcapacity*sizeof(DataType));if (temp == NULL){perror("realloc申请空间失败!!!");return;}ps->array = temp;ps->capacity = newcapacity;}
}
void StackPush(Stack* ps, DataType data)
{assert(ps);CheckCapacity(ps);ps->array[ps->size] = data;ps->size++;
}
int StackEmpty(Stack* ps)
{assert(ps);return 0 == ps->size;
}
void StackPop(Stack* ps)
{if (StackEmpty(ps))return;ps->size--;
}
DataType StackTop(Stack* ps)
{assert(!StackEmpty(ps));return ps->array[ps->size - 1];
}
可以看到,在用C语言实现时,Stack相关操作函数有以下共性:
每个函数的第一个参数都是Stack*
函数中必须要对第一个参数检测,因为该参数可能会为NULL
函数中都是通过Stack*参数操作栈的
调用时必须传递Stack结构体变量的地址
结构体中只能定义存放数据的结构,操作数据的方法不能放在结构体中,即数据和操作数据的方式是分离开的,而且实现上相当复杂一点,涉及到大量指针操作,稍不注意可能就会出错。
11.2 C++实现
typedef int DataType;
class Stack
{
public:void Init(){_array = (DataType*)malloc(sizeof(DataType) * 3);if (NULL == _array){perror("malloc申请空间失败!!!");return;}_capacity = 3;_size = 0;}void Push(DataType data){CheckCapacity();_array[_size] = data;_size++;}void Pop(){if (Empty())return;_size--;}DataType Top(){ return _array[_size - 1];}int Empty() { return 0 == _size;}int Size(){ return _size;}void Destroy(){if (_array){free(_array);_array = NULL;_capacity = 0;_size = 0;}}
private:void CheckCapacity(){if (_size == _capacity){int newcapacity = _capacity * 2;DataType* temp = (DataType*)realloc(_array, newcapacity *
sizeof(DataType));if (temp == NULL){perror("realloc申请空间失败!!!");return;}_array = temp;_capacity = newcapacity;}}
private:DataType* _array;int _capacity;int _size;
};
int main()
{Stack s;s.Init();s.Push(1);s.Push(2);s.Push(3);s.Push(4);printf("%d\n", s.Top());printf("%d\n", s.Size());s.Pop();s.Pop();printf("%d\n", s.Top());printf("%d\n", s.Size());s.Destroy();return 0;
}
C++中通过类可以将数据 以及 操作数据的方法进行完美结合,通过访问权限可以控制那些方法在类外可以被调用,即封装,在使用时就像使用自己的成员一样,更符合人类对一件事物的认知。
而且每个方法不需要传递Stack*的参数了,编译器编译之后该参数会自动还原,即C++中 Stack 参数是编译器维护的,C语言中需用用户自己维护。
12 总结两者区别
我们现在总结一下:
相关文章:
C++入门:初识类和对象
C入门:类和对象1 本节目录C入门:类和对象11.auto关键字(C11)1.1类型别名思考1.2auto简介typeid运算符:获取类型信息1.3 auto的使用细则1.4auto不能推到的场景2.基于范围的for循环(C11)2.1范围for的语法2.2范围for的使用条件3.指针…...
BERT在CNN上也能用?看看这篇ICLR Spotlight论文丨已开源
如何在卷积神经网络上运行 BERT?你可以直接用 SparK —— 字节跳动技术团队提出的提出的稀疏层次化掩码建模 ( Designing BERT for Convolutional Networks: Sparse and Hierarchical Masked Modeling ),近期已被人工智能顶会 ICLR 2023 收录为 Spotligh…...

【MFC】模拟采集系统——界面设计(17)
功能介绍 启动界面 开始采集: PS:不涉及 数据保存,重现等功能 界面设计 界面分为三块:顶部黑条带关闭按钮、左边对话框,右边的主界面 资源: 顶部黑条 top.bmp 2* 29 (宽 * 高 像素点&…...

锐捷(十五)mpls vxn跨域optionc场景
一 实验拓扑二 实验需求ce1和ce2为两个分公司,要求两个分公司之间用mpls vxn 进行通信,组网方式是optionc。三 实验分析optionc在转发平面上有点难理解,有一些关键点需要注意,大家点击链接可以参考我上篇发过的一个文章࿱…...
)
2023备战金三银四,Python自动化软件测试面试宝典合集(七)
马上就又到了程序员们躁动不安,蠢蠢欲动的季节~这不,金三银四已然到了家门口,元宵节一过后台就有不少人问我:现在外边大厂面试都问啥想去大厂又怕面试挂面试应该怎么准备测试开发前景如何面试,一个程序员成长之路永恒绕…...
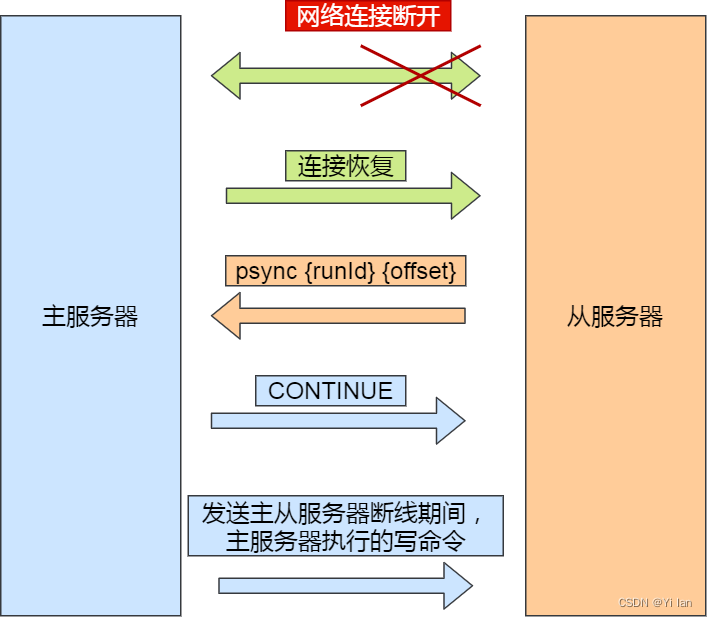
redis 主从复制
在redis的持久化RDB与AOF详解文章中,我们知道如果redis宕机了,我们可以通过AOF 和 RDB 文件的方式恢复数据,从而保证数据的丢失(或少量损失)从而提高稳定性。但是,如果我们数据只存在一台redis服务器中&…...
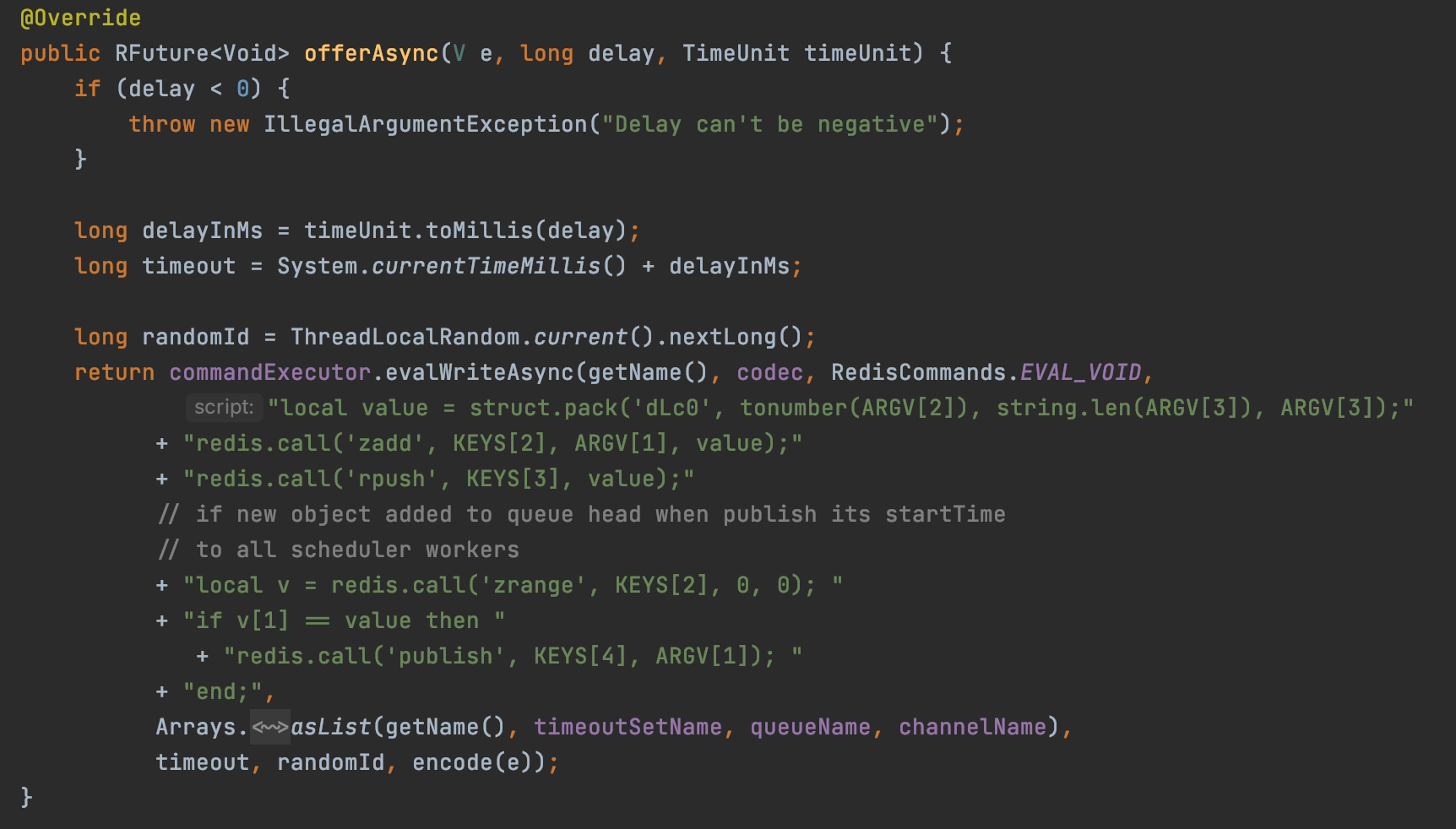
如何用Redis实现延迟队列
背景前段时间有个小项目需要使用延迟任务,谈到延迟任务,我脑子第一时间一闪而过的就是使用消息队列来做,比如RabbitMQ的死信队列又或者RocketMQ的延迟队列,但是奈何这是一个小项目,并没有引入MQ,我也不太想…...

项目文件相关总结
风险登记册 风险登记册记录了已识别单个风险的详细信息。其主要内容包括: 已识别的风险清单潜在的风险责任人潜在的风险应对措施清单风险管理计划要求的其他信息供方选择标准 供方选择标准用于确保选出的建议书将提供最佳质量的所需服务,主要内容 包括: 能力和潜力产品成本…...
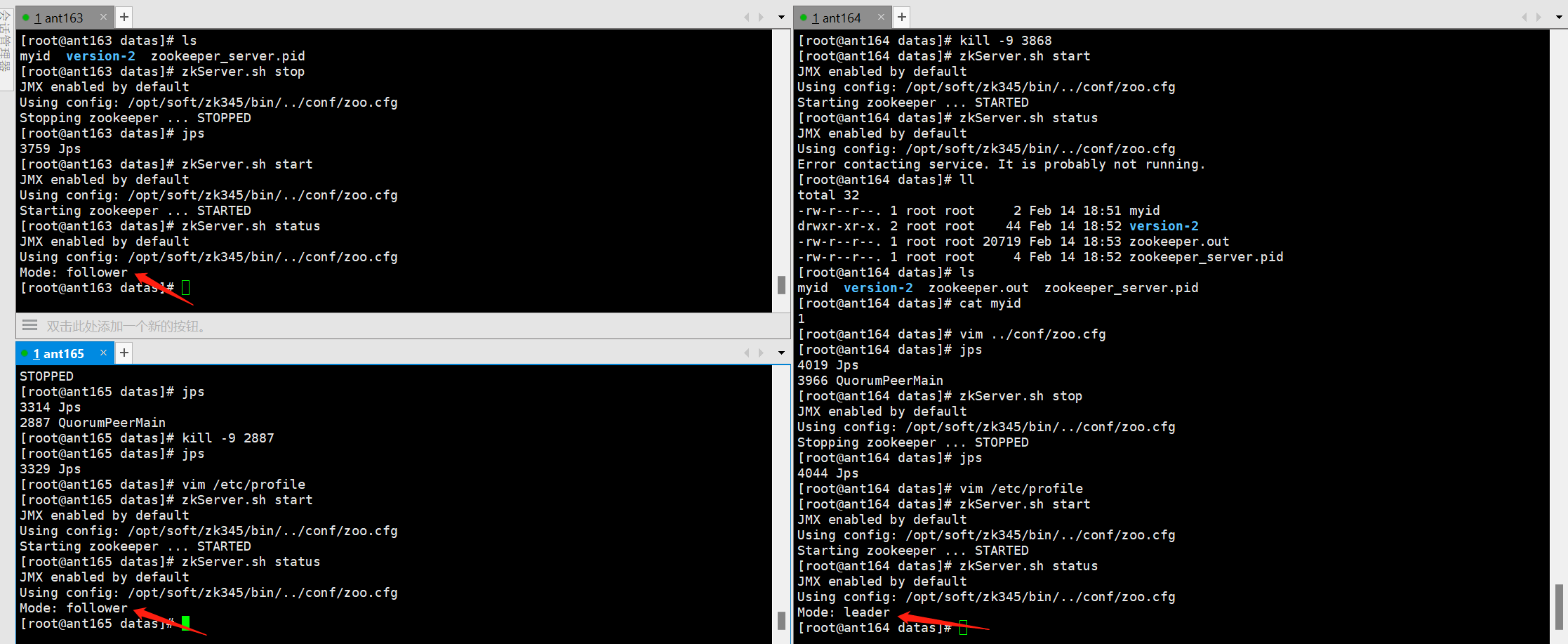
ZooKeeper集群搭建步骤
一、准备虚拟机准备三台虚拟机,对应ip地址和主机名如下:ip地址Hostname192.168.153.150ant163192.168.153.151ant164192.168.153.152ant165修改hostname,并使之生效[rootlocalhost /]# hostnamectl set-hostname zookeeper1 //修改hostname …...

网际协议IP
网际协议IP 文章目录网际协议IP[toc]虚拟互联网IP地址及其表示方法分类IP地址(两级)无分类编址 CIDR网路前缀地址块地址掩码子网划分(三级IP地址)IP地址和MAC地址地址解析协议ARPIP数据报的格式IP数据报首部的固定部分中的各字段IP数据报首部的可变部分分…...

Python 语言参考手册、教程、标准库
官方文档:https://docs.python.org/zh-cn/3.11/ Python 语言参考手册 介绍了 Python 句法与“核心语义”。在力求简明扼要的同时,我们也尽量做到准确、完整。有关内置对象类型、内置函数、模块的语义在 Python 标准库 中介绍。有关本语言的非正式介绍&am…...

数据库连接池 BoneCP、HikariCP 等
文章目录 数据库连接池 BoneCP、HikariCP 等BoneCPDruidTomcat Jdbc PoolHikariCPC3p0DbcpLRUPSCachePS数据库连接池 BoneCP、HikariCP 等 BoneCP 官方说法 BoneCP 是一个高效、免费、开源的 Java 数据库连接池实现库 设计初衷就是为了提高数据库连接池性能,根据某些测试数…...

博客系统 SSM 超强硬核良心推荐之第一弹 - 预备工作
硬核 ! 从 0 到 1 完美实现 SSM 版本的博客系统 , 学会保准不吃亏!一 . SSM 版本相比于 Servlet 版本的亮点二 . 初始化数据库三 . 前端页面3.1 注册页面3.2 登录功能3.3 文章总列表页3.4 自己的文章列表页3.5 文章详情页3.6 编写博客页面大家好 , 这是新的专栏 , 博客系统 SSM…...

[Web] 简单瀑布流布局实现
目前的纯 CSS 布局, 是没办法实现比较完美的瀑布流布局的. 参考: CSS总结:瀑布流布局 - 黑白程序员 我使用 JS CSS, 并且自动布局实现了较为简单, 观赏性好的瀑布流布局. 代码 HTML: <!DOCTYPE html> <html lang"en"> <head><link rel&quo…...

多线程之死锁,哲学家就餐问题的实现
1.死锁是什么 死锁是这样一种情形:多个线程同时被阻塞,它们中的一个或者全部都在等待某个资源被释放。由于线程被无限期地阻塞,因此程序不可能正常终止。 2.哲学家就餐问题 有五个哲学家,他们的生活方式是交替地进行思考和进餐…...
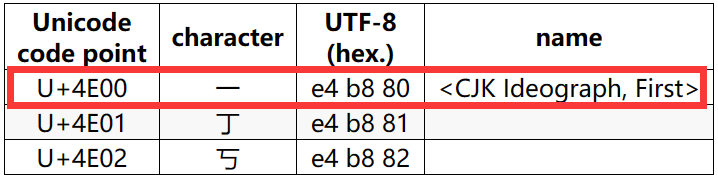
UTF-8编码
介绍 UTF-8 编码 UTF-8 是一种针对 Unicode 的可变长度字符编码。 针对 Unicode:UTF-8 是 Unicode 的实现方式之一。相当于 Unicode 规定了字符对应的代码值,这个代码值需要转换为字节序列的形式,用于数据存储、传输。代码值到字节序列的转…...
likeshop单商户SaaS版V1.8.2说明!
likeshop单商户SaaS版V1.8.2主要更新如下: 新增 前端登录引导用户填写头像昵称 PC端—注册页面显示服务协议和隐私政策 PC端—首次进入商城弹出协议提示 PC端—结算页新增门店自提的配送方式 后台—PC端菜单导航栏的跳转链接支持添加自定义链接 优…...

算法训练营 day46 动态规划 最后一块石头的重量 II 目标和 一和零
算法训练营 day46 动态规划 最后一块石头的重量 II 目标和 一和零 最后一块石头的重量 II 1049. 最后一块石头的重量 II - 力扣(LeetCode) 有一堆石头,用整数数组 stones 表示。其中 stones[i] 表示第 i 块石头的重量。 每一回合…...
nginx-host绕过实例复现
绕过Nginx Host限制第一种处理方法Nginx在处理Host的时候,会将Host用冒号分割成hostname和port,port部分被丢弃。所以,我们可以设置Host的值为2023.mhz.pw:xxx"example.com,这样就能访问到目标Server块:第二种处理…...

Java学习记录day9
类与对象 内部类 成员内部类 在一个类的内部定义的类。 public class Outer {private int a 10;public void outMethod() {System.out.println("这是外部类中的方法");}// 成员内部类public class Inner{private int b 10;public void innerMethod() {// 外部类…...

PPT|230页| 制造集团企业供应链端到端的数字化解决方案:从需求到结算的全链路业务闭环构建
制造业采购供应链管理是企业运营的核心环节,供应链协同管理在供应链上下游企业之间建立紧密的合作关系,通过信息共享、资源整合、业务协同等方式,实现供应链的全面管理和优化,提高供应链的效率和透明度,降低供应链的成…...

vscode(仍待补充)
写于2025 6.9 主包将加入vscode这个更权威的圈子 vscode的基本使用 侧边栏 vscode还能连接ssh? debug时使用的launch文件 1.task.json {"tasks": [{"type": "cppbuild","label": "C/C: gcc.exe 生成活动文件"…...

CocosCreator 之 JavaScript/TypeScript和Java的相互交互
引擎版本: 3.8.1 语言: JavaScript/TypeScript、C、Java 环境:Window 参考:Java原生反射机制 您好,我是鹤九日! 回顾 在上篇文章中:CocosCreator Android项目接入UnityAds 广告SDK。 我们简单讲…...

2025盘古石杯决赛【手机取证】
前言 第三届盘古石杯国际电子数据取证大赛决赛 最后一题没有解出来,实在找不到,希望有大佬教一下我。 还有就会议时间,我感觉不是图片时间,因为在电脑看到是其他时间用老会议系统开的会。 手机取证 1、分析鸿蒙手机检材&#x…...

BCS 2025|百度副总裁陈洋:智能体在安全领域的应用实践
6月5日,2025全球数字经济大会数字安全主论坛暨北京网络安全大会在国家会议中心隆重开幕。百度副总裁陈洋受邀出席,并作《智能体在安全领域的应用实践》主题演讲,分享了在智能体在安全领域的突破性实践。他指出,百度通过将安全能力…...

3-11单元格区域边界定位(End属性)学习笔记
返回一个Range 对象,只读。该对象代表包含源区域的区域上端下端左端右端的最后一个单元格。等同于按键 End 向上键(End(xlUp))、End向下键(End(xlDown))、End向左键(End(xlToLeft)End向右键(End(xlToRight)) 注意:它移动的位置必须是相连的有内容的单元格…...

什么是Ansible Jinja2
理解 Ansible Jinja2 模板 Ansible 是一款功能强大的开源自动化工具,可让您无缝地管理和配置系统。Ansible 的一大亮点是它使用 Jinja2 模板,允许您根据变量数据动态生成文件、配置设置和脚本。本文将向您介绍 Ansible 中的 Jinja2 模板,并通…...

【Java学习笔记】BigInteger 和 BigDecimal 类
BigInteger 和 BigDecimal 类 二者共有的常见方法 方法功能add加subtract减multiply乘divide除 注意点:传参类型必须是类对象 一、BigInteger 1. 作用:适合保存比较大的整型数 2. 使用说明 创建BigInteger对象 传入字符串 3. 代码示例 import j…...

用机器学习破解新能源领域的“弃风”难题
音乐发烧友深有体会,玩音乐的本质就是玩电网。火电声音偏暖,水电偏冷,风电偏空旷。至于太阳能发的电,则略显朦胧和单薄。 不知你是否有感觉,近两年家里的音响声音越来越冷,听起来越来越单薄? —…...

C/C++ 中附加包含目录、附加库目录与附加依赖项详解
在 C/C 编程的编译和链接过程中,附加包含目录、附加库目录和附加依赖项是三个至关重要的设置,它们相互配合,确保程序能够正确引用外部资源并顺利构建。虽然在学习过程中,这些概念容易让人混淆,但深入理解它们的作用和联…...