Java序列化引发的血案
1、引言
阿里巴巴Java开发手册在第一章节,编程规约中OOP规约的第15条提到:
**【强制】**序列化类新增属性时,请不要修改serialVersionUID字段,避免反序列失败;如果完全不兼容升级,避免反序列化混乱,那么请修改serialVersionUID值。
说明:注意serialVersionUID不一致会抛出序列化运行时异常
如果没接触过序列化的人,应该会有以下疑问:
- 序列化和反序列化到底是什么?
- 它的主要使用场景有哪些?
- Java 序列化常见的方案有哪些?
- 各种常见序列化方案的区别有哪些?
- 实际的业务开发中有哪些坑点?
2、什么是序列化和反序列化
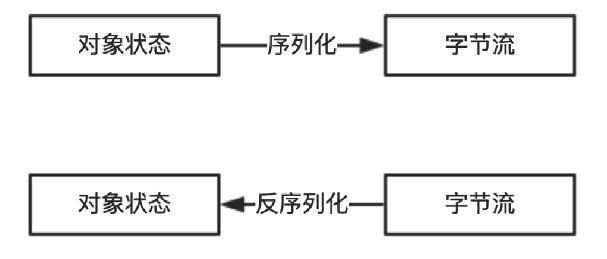
序列化是将内存中的对象信息转化成可以存储或者传输的数据到临时或永久存储的过程。在Java中其实就是把Java对象转换为二进制内容,其本质就是一个byte[]数组
反序列化是从临时或永久存储中读取序列化的数据并转化成内存对象的过程。在Java中就是将一个byte[]转换为Java对象的过程
3、为什么需要序列化和反序列化呢?
大家可以回忆一下,平时都是如果将文字文件、图片文件、视频文件、软件安装包等传给小伙伴时,这些资源在计算机中存储的方式是怎样的。
进而再思考,Java 中的对象如果需要存储或者传输应该通过什么形式呢?
我们都知道,一个文件通常是一个 m 个字节的序列:B0, B1, …, Bk, …, Bm-1。所有的 I/O 设备(例如网络、磁盘和终端)都被模型化为文件,而所有的输入和输出都被当作对应文件的读和写来执行。
因此本质上讲,文本文件,图片、视频和安装包等文件底层都被转化为二进制字节流来传输的,对方得文件就需要对文件进行解析,因此就需要有能够根据不同的文件类型来解码出文件的内容的程序。
大家试想一个典型的场景:如果要实现 Java 远程方法调用,就需要将调用结果通过网路传输给调用方,如果调用方和服务提供方不在一台机器上就很难共享内存,就需要将 Java 对象进行传输。而想要将 Java 中的对象进行网络传输或存储到文件中,就需要将对象转化为二进制字节流,这就是所谓的序列化。存储或传输之后必然就需要将二进制流读取并解析成 Java 对象,这就是所谓的反序列化。
序列化的主要目的是:方便存储到文件系统、数据库系统或网络传输等。
4、序列化和反序列化的使用场景
- 远程方法调用(RPC)的框架里会用到序列化
- 将对象存储到文件中时,需要用到序列化
- 将对象存储到缓存数据库(如 Redis)时需要用到序列化
- 通过序列化和反序列化的方式实现对象的深拷贝
5、常见的序列化方式
常见的序列化方式包括 Java 原生序列化、Hessian 序列化、Kryo 序列化、JSON 序列化等。
1、Java原生序列化
学习的最好方式就是查看源码,我们接下来查看一下Serializable的源码
public interface Serializable {
}
源码非常简单,什么方法都没有,但是注释很长,其核心就是:
- Java 原生序列化需要实现 Serializable 接口。序列化接口不包含任何方法和属性等,它只起到序列化标识作用。
- 一个类实现序列化接口则其子类型也会继承序列化能力,但是实现序列化接口的类中有其他对象的引用,则其他对象也要实现序列化接口。序列化时如果抛出 NotSerializableException 异常,说明该对象没有实现 Serializable 接口。
- 每个序列化类都有一个叫 serialVersionUID 的版本号,反序列化时会校验待反射的类的序列化版本号和加载的序列化字节流中的版本号是否一致,如果序列化号不一致则会抛出 InvalidClassException 异常。
- 强烈推荐每个序列化类都手动指定其 serialVersionUID ,如果不手动指定,那么编译器会动态生成默认的序列化号,因为这个默认的序列化号和类的特征以及编译器的实现都有关系,很容易在反序列化时抛出 InvalidClassException 异常。建议将这个序列化版本号声明为私有,以避免运行时被修改。
- 实现序列化接口的类可以提供自定义的函数修改默认的序列化和反序列化行为。
上面注释也说明,建议序列化版本号声明为私有,以避免运行时被修改。
如果一个类文件序列化到文件后,类的结构发生了改变,是否能被正确的反序列化?
这个答案是不确定的。
通常我们是通过加密算法对文件进行前面,根据签名判断文件是否被修改;但Java序列化的场景并不适用于上述的方案,如果在类文件的某个地方加个空格,执行等符号类的结构,没有发生变化,这个时候签名就不应该发生变;还有一个类新增一个属性,之前的属性都是有值的,之前都被序列化到对象文件中,有些场景下还希望反序列化时可以正常解析,怎么办呢?
序列化测试代码:
public class SerializationTest { public static void main(String[] args) throws IOException { ByteArrayOutputStream buffer = new ByteArrayOutputStream(); try (ObjectOutputStream output = new ObjectOutputStream(buffer)) { // 写入byte: output.writeBytes("小熊学Java"); // 写入String: output.writeUTF("Hello"); // 写入Object: output.writeObject("javaxiaobear"); } System.out.println(Arrays.toString(buffer.toByteArray())); }
}
2、Hessian 序列化
Hessian 是一个动态类型,二进制序列化,也是一个基于对象传输的网络协议。Hessian 是一种跨语言的序列化方案,序列化后的字节数更少,效率更高。Hessian 序列化会把复杂对象的属性映射到 Map 中再进行序列化。
官方介绍👉Hessian 2.0 Serialization Protocol
和JDK自带的序列化方式类似,Hessian采用的也是二进制协议,只不过Hessian序列化之后,字节数更小,性能更优。目前Hessian已经出到2.0版本,相较于1.0的Hessian性能更优。相较于JDK自带的序列化,Hessian的设计目标更明确👇
Hessian 是动态类型的、紧凑的,并且可以跨语言移植。Hessian 协议有以下设计目标:
- 它必须是单次可读或可写的。
- 它必须尽可能紧凑。
- 它必须简单,以便可以有效地测试和实施。
- 它必须尽可能快。
- 它必须支持 Unicode 字符串。
- 它必须支持 8 位二进制数据而不转义或使用附件。
- 它必须支持加密、压缩、签名和事务上下文信封。
Hessian的序列化速度相较于JDK序列化才更快。只不过Java序列化会把要序列化的对象类的元数据和业务数据全部序列化从字节流,并且会保留完整的继承关系,因此相较于Hessian序列化更加可靠。
不过相较于JDK的序列化,Hessian另一个优势在于,这是一个跨语言的序列化方式,这意味着序列化后的数据可以被其他语言使用,兼容性更好。
基础使用
引入pom依赖
<!-- https://mvnrepository.com/artifact/com.caucho/hessian -->
<dependency> <groupId>com.caucho</groupId> <artifactId>hessian</artifactId> <version>4.0.65</version>
</dependency>
不服,咱跑个分
public class SerializationTest { public static void main(String[] args) throws IOException { String javaxiaobear = "小熊学Java"; System.out.println("JDK序列化长度:" + jdkSerialize(javaxiaobear).length); System.out.println("hessian序列化长度:" + hessianSerialize(javaxiaobear).length); } /** * jdk序列化测试 * @param str * @return * @param <T> */ public static <T> byte[] jdkSerialize(T str){ byte[] data = null; try{ ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream(); ObjectOutputStream output = new ObjectOutputStream(byteArrayOutputStream); output.writeObject(str); output.flush(); output.close(); data = byteArrayOutputStream.toByteArray(); }catch (Exception e){ e.printStackTrace(); } return data; } /** * hessian序列化测试 * @param str * @return * @param <T> */ public static <T> byte[] hessianSerialize(T str){ byte[] data = null; try{ ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream(); Hessian2Output output = new Hessian2Output(byteArrayOutputStream); output.writeObject(str); output.flush(); output.close(); data = byteArrayOutputStream.toByteArray(); }catch (Exception e){ e.printStackTrace(); } return data; }
}
输出结果:
//JDK序列化长度:20
//hessian序列化长度:14
3、Kryo 序列化
Kryo 是一个快速高效的 Java 序列化和克隆工具。Kryo 的目标是快速、字节少和易用。Kryo 还可以自动进行深拷贝或者浅拷贝。Kryo 的拷贝是对象到对象的拷贝而不是对象到字节,再从字节到对象的恢复。Kryo 为了保证序列化的高效率,会提前加载需要的类,这会带一些消耗,但是这是序列化后文件较小且反序列化非常快的重要原因。
官方地址:kryo
基础使用
这里只作为基础使用,不作为重点讲解,需要了解的可以去查看官方文档哈
- 引入pom依赖,这里需要JDK11编译哦
<dependency><groupId>com.esotericsoftware</groupId><artifactId>kryo</artifactId><version>5.4.0</version>
</dependency>
测试demo
public static void main(String[] args) throws IOException { String javaxiaobear = "小熊学Java"; System.out.println("JDK序列化长度:" + jdkSerialize(javaxiaobear).length); System.out.println("hessian序列化长度:" + hessianSerialize(javaxiaobear).length); User user = new User("小熊学Java"); byte[] bytes = kryoSerialize(user); System.out.println("kryo序列化的长度:" + bytes.length); }
/** * kryo序列化 * @param user * @return */
public static byte[] kryoSerialize(User user) { Kryo kryo = new Kryo(); kryo.register(user.getClass()); ByteArrayOutputStream bos = new ByteArrayOutputStream(); Output output = new Output(bos); //写入null时会报错 kryo.writeObject(output,user); output.close(); return bos.toByteArray();
}
结果:kryo序列化的长度:14
4、JSON 序列化
JSON (JavaScript Object Notation) 是一种轻量级的数据交换方式。JSON 序列化是基于 JSON 这种结构来实现的。JSON 序列化将对象转化成 JSON 字符串,JSON 反序列化则是将 JSON 字符串转回对象的过程。常用的JSON 序列化和反序列化的库有 Jackson、GSON、Fastjson 等。
1、GSON
Gson提供了fromJson() 和toJson() 两个直接用于解析和生成的方法,前者实现反序列化,后者实现了序列化;同时每个方法都提供了重载方法。
跑个demo
/*** Gson 序列化 与反序列化* @param user*/
public static void gsonSerialize(User user){//gson序列化String userJson = new Gson().toJson(user);System.out.println("gson序列化后的值:" + userJson);//gson反序列化User user1 = new Gson().fromJson(userJson, User.class);System.out.println("gson反序列化后:" + user1.toString());
}
6、Java 常见的序列化方案对比
实验的版本:kryo-shaded 使用 5.4.0版本,gson 使用 2.8.5 版本,hessian 用
4.0.65版本。
实验的数据:构造 50 万 User 对象运行多次。
大致得出一个结论:
从二进制流大小来讲:JSON 序列化 > Java 序列化 > Hessian2 序列化 > Kryo 序列化 > Kryo 序列化注册模式;
从序列化耗时而言来讲:GSON 序列化 > Java 序列化 > Kryo 序列化 > Hessian2 序列化 > Kryo 序列化注册模式;
从反序列化耗时而言来讲:GSON 序列化 > Java 序列化 > Hessian2 序列化 > Kryo 序列化注册模式 > Kryo序列化;
从总耗时而言:Kryo 序列化注册模式耗时最短。
7、序列化引发的一个血案
我们看下面的一个案例
前端调用服务 A,服务 A 调用服务 B,服务 B 首次接到请求会查 DB,然后缓存到 Redis(缓存 1 个小时)。服务 A 根据服务 B 返回的数据后执行一些处理逻辑,处理后形成新的对象存到 Redis(缓存 2 个小时)。服务 A 通过 Dubbo 来调用服务 B,A 和 B 之间数据通过 Map<String,Object> 类型传输,服务 B 使用Fastjson 来实现 JSON 的序列化和反序列化。
服务 B 的接口返回的 Map 值中存在一个 Long 类型的 id 字段,服务 A 获取到 Map ,取出 id 字段并强转为 Long 类型使用。
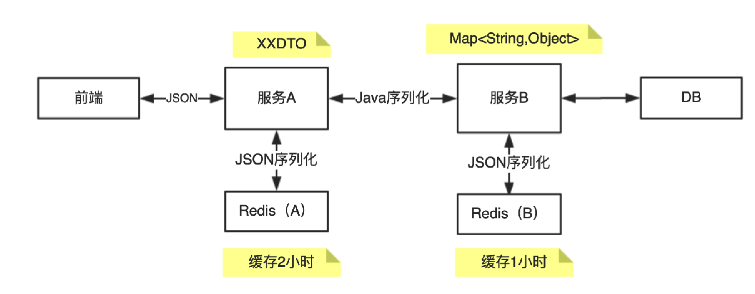
通过分析我们发现,服务 A 和服务 B 的 RPC 调用使用 Java 序列化,因此类型信息不会丢失。
但是由于服务 B 采用 JSON 序列化进行缓存,第一次访问没啥问题,其执行流程如下:
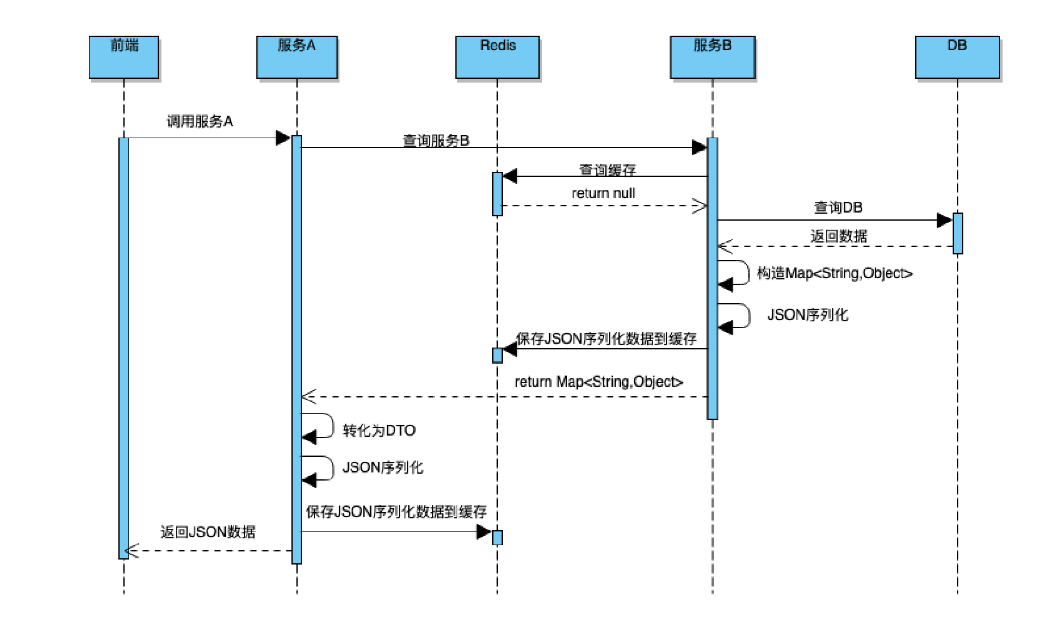
如果服务 A开启了缓存 ,服务 A 在第一次请求服务 B 后,缓存了运算结果,且服务 A 缓存时间比服务 B 长,因此不会出现错误。
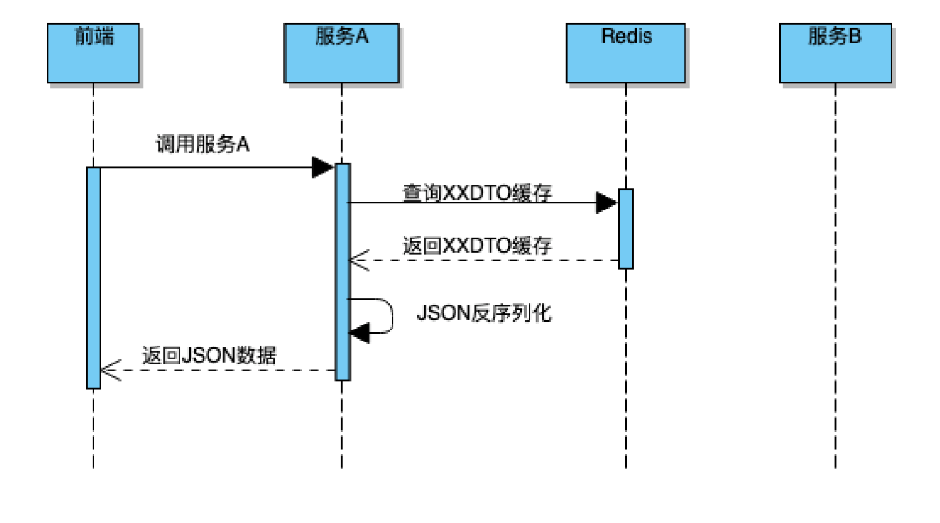
如果服务 A 不开启缓存 ,服务 A 会请求服务 B ,由于首次请求时,服务 B 已经缓存了数据,服务 B 从Redis(B)中反序列化得到 Map 。流程如下图所示:
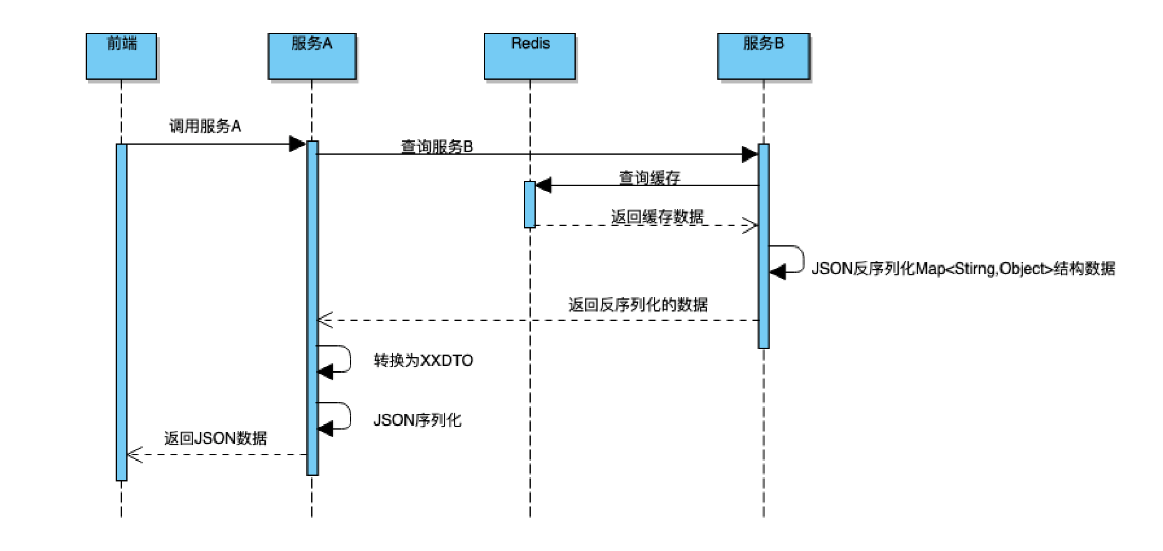
然而问题来了: 服务 A 从 Map 取出此 Id 字段,强转为 Long 时会出现类型转换异常。
最后定位到原因是 Json 反序列化 Map 时如果原始值小于 Int 最大值,反序列化后原本为 Long 类型的字段,变为了 Integer 类型,服务 B 的同学紧急修复。
服务 A 开启缓存时, 虽然采用了 JSON 序列化存入缓存,但是采用 DTO 对象而不是 Map 来存放属性,所以JSON 反序列化没有问题。
因此大家使用二方或者三方服务时,当对方返回的是 Map<String,Object> 类型的数据时要特别注意这个问题。
作为服务提供方,可以采用 JDK 或者 Hessian 等序列化方式;
作为服务的使用方,我们不要从 Map 中一个字段一个字段获取和转换,可以使用 JSON 库直接将 Map 映射成所需的对象,这样做不仅代码更简洁还可以避免强转失败。
来个demo
@Test
public void testFastJsonObject() {Map<String, Object> map = new HashMap<>();final String name = "name";final String id = "id";map.put(name, "张三");map.put(id, 20L);String fastJsonString = FastJsonUtil.getJsonString(map);// 模拟拿到服务B的数据Map<String, Object> mapFastJson = FastJsonUtil.parseJson(fastJsonString,map.getClass());// 转成强类型属性的对象而不是使用map 单个取值User user = new JSONObject(mapFastJson).toJavaObject(User.class);// 正确Assert.assertEquals(map.get(name), user.getName());// 正确Assert.assertEquals(map.get(id), user.getId());
}
8、总结
主要描述了Java序列化的场景和使用,以及案例分析,在开发中我们还是要注意细节,避开趟坑!
相关文章:
Java序列化引发的血案
1、引言 阿里巴巴Java开发手册在第一章节,编程规约中OOP规约的第15条提到: **【强制】**序列化类新增属性时,请不要修改serialVersionUID字段,避免反序列失败;如果完全不兼容升级,避免反序列化混乱&#x…...

为Linux系统添加一块新硬盘,并扩展根目录容量
我的原来ubuntu20.04系统装的时候不是LVM格式的分区, 所以先将新硬盘转成LVM,再将原来的系统dd到新硬盘,从新硬盘的分区启动,之后再将原来的分区转成LVM,在融入进来 1:将新硬盘制作成 LVM分区 我的新硬盘…...

树莓派Opencv调用摄像头(Raspberry Pi 11)
前言:本人初玩树莓派opencv,使用的是树莓派Raspberry Pi OS 11,系统若不一致请慎用,本文主要记录在树莓派上通过Opencv打开摄像头的经验。 1、系统版本 进入树莓派,打开终端输入以下代码(查看系统的版本&…...

国产ChatGPT命名图鉴
很久不见这般热闹的春天。 随着ChatGPT的威名席卷全球,大洋对岸的中国厂商也纷纷亮剑,各式本土大模型你方唱罢我登场,声势浩大的发布会排满日程表。 有趣的是,在这些大模型产品初入历史舞台之时,带给世人的第一印象其…...

操作系统——进程管理
0.关注博主有更多知识 操作系统入门知识合集 目录 0.关注博主有更多知识 4.1进程概念 4.1.1进程基本概念 思考题: 4.1.2进程状态 思考题: 4.1.3进程控制块PCB 4.2进程控制 思考题: 4.3线程 思考题: 4.4临界资源与临…...

第四十一章 Unity 输入框 (Input Field) UI
本章节我们学习输入框 (Input Field),它可以帮助我们获取用户的输入。我们点击菜单栏“GameObject”->“UI”->“Input Field”,我们调整一下它的位置,效果如下 我们在层次面板中发现,这个InputField UI元素包含两个子元素&…...

10.集合
1.泛型 1.1泛型概述 泛型的介绍 泛型是JDK5中引入的特性,它提供了编译时类型安全检测机制 泛型的好处 把运行时期的问题提前到了编译期间避免了强制类型转换 泛型的定义格式 <类型>: 指定一种类型的格式.尖括号里面可以任意书写,一般只写一个字母.例如:…...

强化学习p3-策略学习
Policy Network (策略网络) 我们无法知道策略函数 π \pi π所以要做函数近似,求一个近似的策略函数 使用策略网络 π ( a ∣ s ; θ ) \pi(a|s;\theta) π(a∣s;θ) 去近似策略函数 π ( a ∣ s ) \pi(a|s) π(a∣s) ∑ a ∈ A π ( a ∣ s ; θ ) 1 \sum_{a\in …...

初学Verilog语言基础笔记整理(实例点灯代码分析)持续更新~
实例:点灯学习 一、Verilog语法学习 1. 参考文章 刚接触Verilog,作为一个硬件小白,只能尝试着去理解,文章未完…持续更新。 参考博客文章: Verilog语言入门学习(1)Verilog语法【Verilog】一文…...
关于 std::condition_variable
一. std::condition_variable是什么? std::condition_variable 是 C 标准库提供的一个线程同步的工具,用于实现线程间的条件变量等待和通知机制。 条件变量的发生通常与某个共享变量的状态改变相关。 在多线程编程中,条件变量通常和互斥锁…...
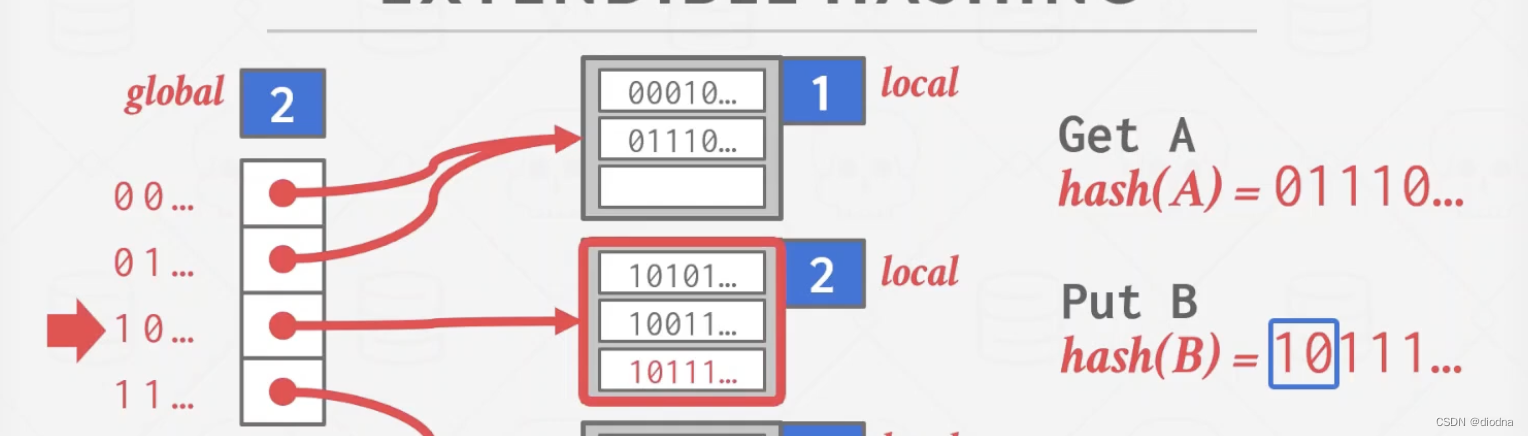
可拓展哈希
可拓展哈希 借CMU 15445的ppt截图来说明问题。 我们传统静态hash的过程是hash函数后直接将值存入对应的bucket,但是在可扩展hash中,得查询Directory(左),存入directory指向的bucket(右)。 下面…...

Java 版 spring cloud 工程系统管理 +二次开发 工程项目管理系统源码
工程项目各模块及其功能点清单 一、系统管理 1、数据字典:实现对数据字典标签的增删改查操作 2、编码管理:实现对系统编码的增删改查操作 3、用户管理:管理和查看用户角色 4、菜单管理:实现对系统菜单的增删改查操…...

通过伴随矩阵怎么求逆矩阵
设矩阵A为n阶方阵,其伴随矩阵为Adj(A),则A的逆矩阵为: A⁻ (1/|A|) Adj(A) |A|为A的行列式 Adj(A)为A的伴随矩阵 具体步骤如下: 求出A的行列式|A| 求出A的伴随矩阵 Adj(A) 。伴随矩阵的定义为:对于A的第i行第j列…...

巡检机器人之仪表识别系统
作者主页:爱笑的男孩。 博客简介:分享机器学习、深度学习、python相关内容、日常BUG解决方法及Windows&Linux实践小技巧。 如发现文章有误,麻烦请指出,我会及时去纠正。有其他需要可以私信我或者发我邮箱:zhilong666foxmail.c…...
)
面试官反感的求职者(下)
上期给大家总结了面试中常见的一些问题,今天就接着上次的话题再给大家说说HR反感的求职者,希望同学们可以自省,避免踩雷。小编从如信银行考试中心了解到的有: 第一、缺乏个性者 这种考生在答题中往往表现得千篇一律,从…...
-生存曲线(LM曲线)(补充篇))
可视化绘图技巧100篇分析篇(二)-生存曲线(LM曲线)(补充篇)
目录 前言 知识储备 生存分析中的基本概念 生存分析 (survival analysis) 事件 (event)...

【100%通过率 】【华为OD机试python】钟表重合时刻【 2023 Q1考试题 A卷|100分】
华为OD机试- 题目列表 2023Q1 点这里!! 2023华为OD机试-刷题指南 点这里!! ■ 题目描述 钟表是日常生活中不可缺少的时间度量计, 其时针、分针、秒针三者的转动速度满足特定规律(见备注)。 现在输入时刻 time ,请计算出时刻 time 小时和 time+1 小时之间, 时针和分针…...

Java线程池编码示例
第1步:自定义线程实现类 Java中多线程编码时,定义线程类有两种方式: 继承Thread类实现Runnable接口(由于Java的单继承特性,一般推荐使用此方式) public class BizThread implements Runnable {private int …...

如何优化Android 4.x系统设置字体大小
android4.x系统设置字体大小导致应用布局混乱的解决方案 在前几年,Android系统的设置界面还是相对简单的,用户可以通过设置菜单进行各种系统设置,如字体大小、壁纸、铃声等。但是随着用户对系统功能的需求越来越多,Android系统也在…...
Docker安装、Docker基本操作
一、Dokcer安装 1.安装 # 1、yum 包更新到最新,需要几分钟时间(注意:也可以直接跨过) sudo yum update # 2、作用:安装需要的软件包, yum-util 提供yum-config-manager功能,另外两个是devicemapper驱动依赖的 sudo yum install -y yum-util…...

从零实现STL哈希容器:unordered_map/unordered_set封装详解
本篇文章是对C学习的STL哈希容器自主实现部分的学习分享 希望也能为你带来些帮助~ 那咱们废话不多说,直接开始吧! 一、源码结构分析 1. SGISTL30实现剖析 // hash_set核心结构 template <class Value, class HashFcn, ...> class hash_set {ty…...

多模态大语言模型arxiv论文略读(108)
CROME: Cross-Modal Adapters for Efficient Multimodal LLM ➡️ 论文标题:CROME: Cross-Modal Adapters for Efficient Multimodal LLM ➡️ 论文作者:Sayna Ebrahimi, Sercan O. Arik, Tejas Nama, Tomas Pfister ➡️ 研究机构: Google Cloud AI Re…...

ios苹果系统,js 滑动屏幕、锚定无效
现象:window.addEventListener监听touch无效,划不动屏幕,但是代码逻辑都有执行到。 scrollIntoView也无效。 原因:这是因为 iOS 的触摸事件处理机制和 touch-action: none 的设置有关。ios有太多得交互动作,从而会影响…...

Java多线程实现之Thread类深度解析
Java多线程实现之Thread类深度解析 一、多线程基础概念1.1 什么是线程1.2 多线程的优势1.3 Java多线程模型 二、Thread类的基本结构与构造函数2.1 Thread类的继承关系2.2 构造函数 三、创建和启动线程3.1 继承Thread类创建线程3.2 实现Runnable接口创建线程 四、Thread类的核心…...

在QWebEngineView上实现鼠标、触摸等事件捕获的解决方案
这个问题我看其他博主也写了,要么要会员、要么写的乱七八糟。这里我整理一下,把问题说清楚并且给出代码,拿去用就行,照着葫芦画瓢。 问题 在继承QWebEngineView后,重写mousePressEvent或event函数无法捕获鼠标按下事…...

如何配置一个sql server使得其它用户可以通过excel odbc获取数据
要让其他用户通过 Excel 使用 ODBC 连接到 SQL Server 获取数据,你需要完成以下配置步骤: ✅ 一、在 SQL Server 端配置(服务器设置) 1. 启用 TCP/IP 协议 打开 “SQL Server 配置管理器”。导航到:SQL Server 网络配…...
阿里云Ubuntu 22.04 64位搭建Flask流程(亲测)
cd /home 进入home盘 安装虚拟环境: 1、安装virtualenv pip install virtualenv 2.创建新的虚拟环境: virtualenv myenv 3、激活虚拟环境(激活环境可以在当前环境下安装包) source myenv/bin/activate 此时,终端…...
恶补电源:1.电桥
一、元器件的选择 搜索并选择电桥,再multisim中选择FWB,就有各种型号的电桥: 电桥是用来干嘛的呢? 它是一个由四个二极管搭成的“桥梁”形状的电路,用来把交流电(AC)变成直流电(DC)。…...
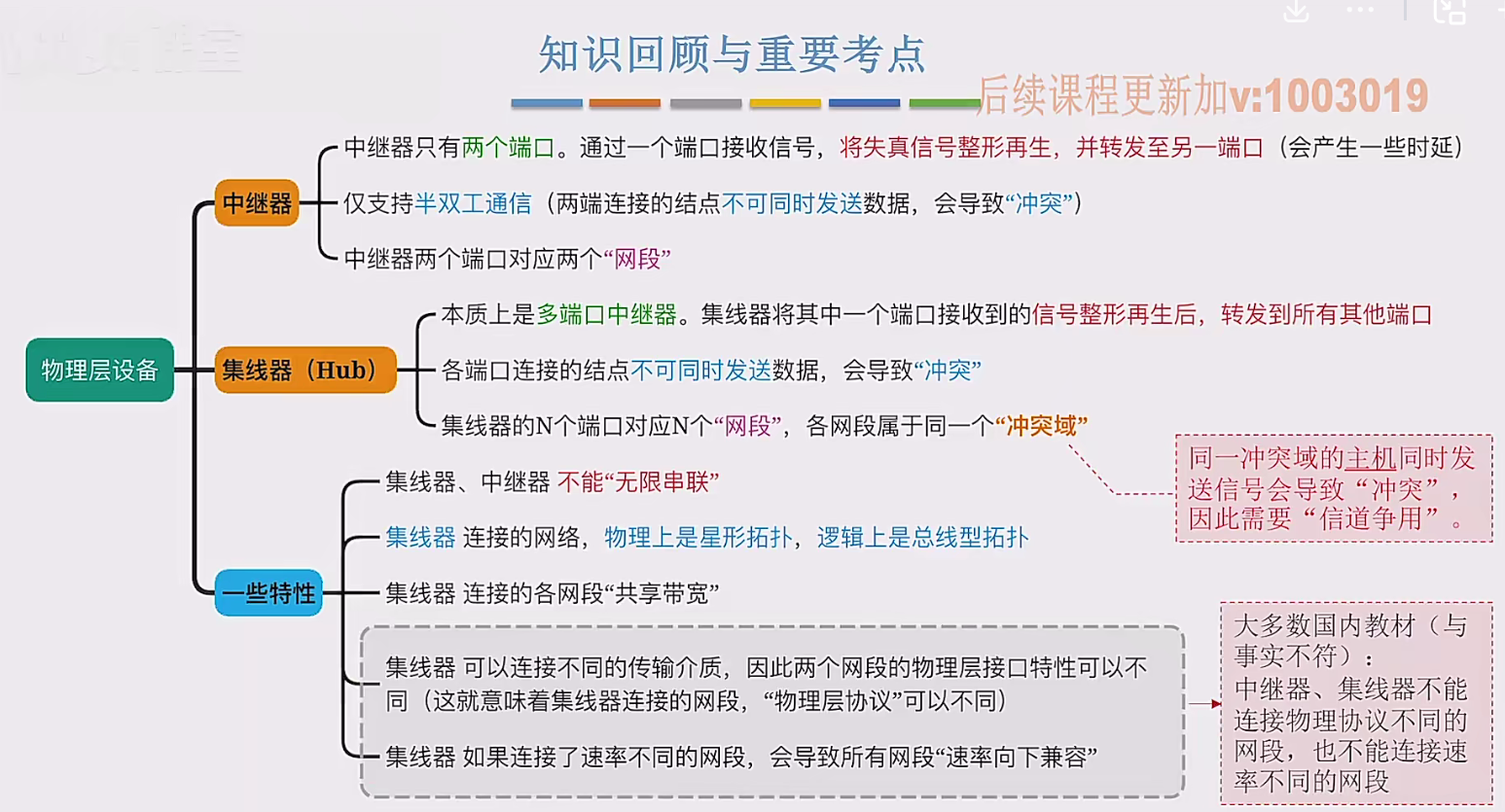
2.3 物理层设备
在这个视频中,我们要学习工作在物理层的两种网络设备,分别是中继器和集线器。首先来看中继器。在计算机网络中两个节点之间,需要通过物理传输媒体或者说物理传输介质进行连接。像同轴电缆、双绞线就是典型的传输介质,假设A节点要给…...
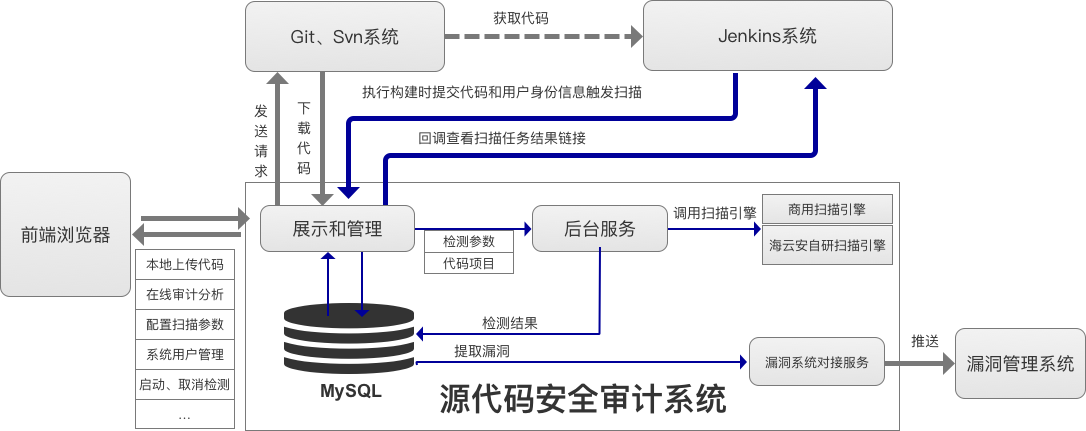
海云安高敏捷信创白盒SCAP入选《中国网络安全细分领域产品名录》
近日,嘶吼安全产业研究院发布《中国网络安全细分领域产品名录》,海云安高敏捷信创白盒(SCAP)成功入选软件供应链安全领域产品名录。 在数字化转型加速的今天,网络安全已成为企业生存与发展的核心基石,为了解…...