Flink 连接流详解
连接流
1 Union
最简单的合流操作,就是直接将多条流合在一起,叫作流的“联合”(union)。联合操作要求必须流中的数据类型必须相同,合并之后的新流会包括所有流中的元素,数据类型不变。这种合流方式非常简单粗暴,就像公路上多个车道汇在一起一样。
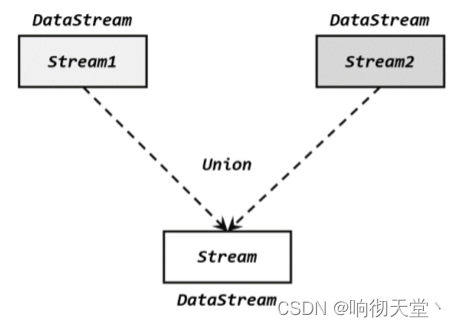
在代码中,我们只要基于 DataStream 直接调用.union()方法,传入其他 DataStream 作为参数,就可以实现流的联合了;得到的依然是一个 DataStream:
stream1.union(stream2, stream3, ...)
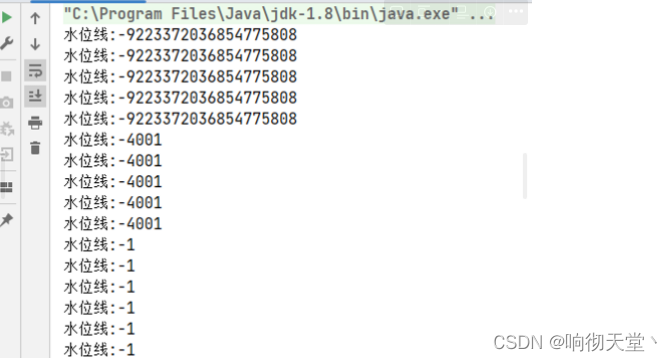
union()的参数可以是多个 DataStream,所以联合操作可以实现多条流的合并。这里需要考虑一个问题。在事件时间语义下,水位线是时间的进度标志;不同的流中可能水位线的进展快慢完全不同,如果它们合并在一起,水位线又该以哪个为准呢?还以要考虑水位线的本质含义,是“之前的所有数据已经到齐了”;所以对于合流之后的水位线,也是要以最小的那个为准,这样才可以保证所有流都不会再传来之前的数据。换句话说,多流合并时处理的时效性是以最慢的那个流为准的。我们自然可以想到,这与之前介绍的并行任务水位线传递的规则是完全一致的;多条流的合并,某种意义上也可以看作是多个并行任务向同一个下游任务汇合的过程。
package com.rosh.flink.combine;import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import com.rosh.flink.pojo.UserPojo;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.util.Collector;import java.time.Duration;public class UnionTest {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);// nc -lk 7777DataStreamSource<String> stream1 = env.socketTextStream("hadoop4", 7777);// nc -lk 7778DataStreamSource<String> stream2 = env.socketTextStream("hadoop4", 7778);//转换SingleOutputStreamOperator<UserPojo> user1DS = stream1.map(new MapFunction<String, UserPojo>() {@Overridepublic UserPojo map(String value) throws Exception {return getUserPojo(value);}}).assignTimestampsAndWatermarks(WatermarkStrategy.<UserPojo>forBoundedOutOfOrderness(Duration.ofSeconds(5)).withTimestampAssigner(new SerializableTimestampAssigner<UserPojo>() {@Overridepublic long extractTimestamp(UserPojo element, long recordTimestamp) {return element.getTimestamp();}}));SingleOutputStreamOperator<UserPojo> user2DS = stream2.map(new MapFunction<String, UserPojo>() {@Overridepublic UserPojo map(String value) throws Exception {return getUserPojo(value);}}).assignTimestampsAndWatermarks(WatermarkStrategy.<UserPojo>forBoundedOutOfOrderness(Duration.ofSeconds(3)).withTimestampAssigner(new SerializableTimestampAssigner<UserPojo>() {@Overridepublic long extractTimestamp(UserPojo element, long recordTimestamp) {return element.getTimestamp();}}));//联合DataStream<UserPojo> unionDS = user1DS.union(user2DS);SingleOutputStreamOperator<String> resultDS = unionDS.process(new ProcessFunction<UserPojo, String>() {@Overridepublic void processElement(UserPojo value, ProcessFunction<UserPojo, String>.Context ctx, Collector<String> out) throws Exception {out.collect("水位线:" + ctx.timerService().currentWatermark());}});resultDS.print();//执行env.execute("UnionTest");}/*** {"userId":1,"name":"rosh","uri":"/goods/1","timestamp":1000}* {"userId":1,"name":"rosh","uri":"/goods/1","timestamp":5000}*/private static UserPojo getUserPojo(String str) {JSONObject jsonObject = JSON.parseObject(str);Integer userId = jsonObject.getInteger("userId");String name = jsonObject.getString("name");String uri = jsonObject.getString("uri");Long timestamp = jsonObject.getLong("timestamp");return new UserPojo(userId, name, uri, timestamp);}}
2 连接(Connect)
流的联合虽然简单,不过受限于数据类型不能改变,灵活性大打折扣,所以实际应用较少出现。除了联合(union),Flink 还提供了另外一种方便的合流操作——连接(connect)。顾名思义,这种操作就是直接把两条流像接线一样对接起来。
为了处理更加灵活,连接操作允许流的数据类型不同。但我们知道一个 DataStream 中的数据只能有唯一的类型,所以连接得到的并不是 DataStream,而是一个“连接流”(ConnectedStreams)。连接流可以看成是两条流形式上的“统一”,被放在了一个同一个流中;事实上内部仍保持各自的数据形式不变,彼此之间是相互独立的。要想得到新的 DataStream,还需要进一步定义一个“同处理”(co-process)转换操作,用来说明对于不同来源、不同类型的数据,怎样分别进行处理转换、得到统一的输出类型。所以整体上来,两条流的连接就像是“一国两制”,两条流可以保持各自的数据类型、处理方式也可以不同,不过最终还是会统一到同一个 DataStream 中。
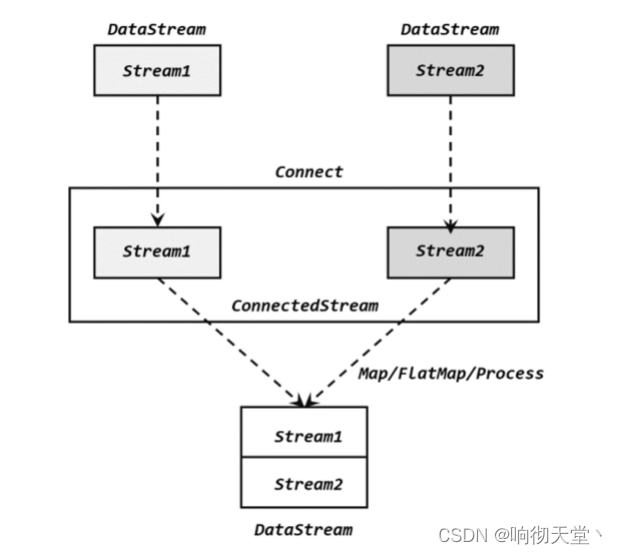
在代码实现上,需要分为两步:首先基于一条 DataStream 调用.connect()方法,传入另外一条 DataStream 作为参数,将两条流连接起来,得到一个 ConnectedStreams;然后再调用同处理方法得到 DataStream。这里可以的调用的同处理方法有.map()/.flatMap(),以及.process()方法。
两条流的连接(connect),与联合(union)操作相比,最大的优势就是可以处理不同类型的流的合并,使用更灵活、应用更广泛。当然它也有限制,就是合并流的数量只能是 2,而 union
可以同时进行多条流的合并。这也非常容易理解:union 限制了类型不变,所以直接合并没有问题;而 connect 是“一国两制”,后续处理的接口只定义了两个转换方法,如果扩展需要重新定义接口,所以不能“一国多制”。
package com.rosh.flink.test;import org.apache.flink.streaming.api.datastream.ConnectedStreams;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.CoMapFunction;public class ConnectTest {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);//创建流DataStreamSource<Integer> integerDS = env.fromElements(1, 2, 3, 4, 5);DataStreamSource<Long> longDS = env.fromElements(1L, 2L, 3L, 4L, 5L);//connectConnectedStreams<Integer, Long> connectDS = integerDS.connect(longDS);//mapSingleOutputStreamOperator<String> rsDS = connectDS.map(new CoMapFunction<Integer, Long, String>() {@Overridepublic String map1(Integer value) throws Exception {return "Integer:" + value;}@Overridepublic String map2(Long value) throws Exception {return "Long: " + value;}});//打印rsDS.print();env.execute("ConnectTest");}
}

****CoProcessFunction,****对于连接流 ConnectedStreams 的处理操作,需要分别定义对两条流的处理转换,因此接口中就会有两个相同的方法需要实现,用数字“1”“2”区分,在两条流中的数据到来时分别调
用。我们把这种接口叫作“协同处理函数”(co-process function)。与 CoMapFunction 类似,如果是调用.flatMap()就需要传入一个 CoFlatMapFunction,需要实现 flatMap1()、flatMap2()两个
方法;而调用.process()时,传入的则是一个 CoProcessFunction。抽象类 CoProcessFunction 在源码中定义如下:
public abstract class CoProcessFunction<IN1, IN2, OUT> extends AbstractRichFunction {...public abstract void processElement1(IN1 value, Context ctx, Collector<OUT> out) throws Exception;public abstract void processElement2(IN2 value, Context ctx, Collector<OUT> out) throws Exception;public void onTimer(long timestamp, OnTimerContext ctx, Collector<OUT> out) throws Exception {}public abstract class Context {...}...
}
我们可以看到,很明显 CoProcessFunction 也是“处理函数”家族中的一员,用法非常相似。它需要实现的就是 processElement1()、processElement2()两个方法,在每个数据到来时,会根据来源的流调用其中的一个方法进行处理。CoProcessFunction 同样可以通过上下文 ctx 来访问 timestamp、水位线,并通过 TimerService 注册定时器;另外也提供了.onTimer()方法,用于定义定时触发的处理操作。
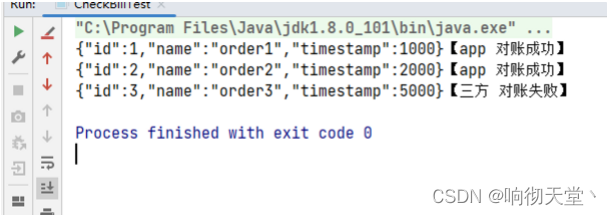
下面是 CoProcessFunction 的一个具体示例:我们可以实现一个实时对账的需求,也就是app 的支付操作和第三方的支付操作的一个双流 Join。App 的支付事件和第三方的支付事件将会互相等待 5 秒钟,如果等不来对应的支付事件,那么就输出报警信息。程序如下:
package com.rosh.flink.combine;import com.alibaba.fastjson.JSON;
import com.rosh.flink.pojo.OrderPojo;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.CoProcessFunction;
import org.apache.flink.util.Collector;public class CheckBillTest {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);//数据流SingleOutputStreamOperator<OrderPojo> appDS = env.fromElements(new OrderPojo(1L, "order1", 1000L),new OrderPojo(2L, "order2", 2000L)).assignTimestampsAndWatermarks(WatermarkStrategy.<OrderPojo>forMonotonousTimestamps().withTimestampAssigner(new SerializableTimestampAssigner<OrderPojo>() {@Overridepublic long extractTimestamp(OrderPojo orderPojo, long l) {return orderPojo.getTimestamp();}}));SingleOutputStreamOperator<OrderPojo> threeDS = env.fromElements(new OrderPojo(1L, "order1", 3000L),new OrderPojo(2L, "order2", 4000L),new OrderPojo(3L, "order3", 5000L)).assignTimestampsAndWatermarks(WatermarkStrategy.<OrderPojo>forMonotonousTimestamps().withTimestampAssigner(new SerializableTimestampAssigner<OrderPojo>() {@Overridepublic long extractTimestamp(OrderPojo orderPojo, long l) {return orderPojo.getTimestamp();}}));//connectSingleOutputStreamOperator<String> resultDS = appDS.connect(threeDS).keyBy(OrderPojo::getId, OrderPojo::getId).process(new OrderProcessFunction());resultDS.print();env.execute("CheckBillTest");}public static class OrderProcessFunction extends CoProcessFunction<OrderPojo, OrderPojo, String> {private ValueState<OrderPojo> appState;private ValueState<OrderPojo> threeState;@Overridepublic void open(Configuration parameters) throws Exception {appState = getRuntimeContext().getState(new ValueStateDescriptor<OrderPojo>("app-state", OrderPojo.class));threeState = getRuntimeContext().getState(new ValueStateDescriptor<OrderPojo>("three-state", OrderPojo.class));}/*** app逻辑*/@Overridepublic void processElement1(OrderPojo value, CoProcessFunction<OrderPojo, OrderPojo, String>.Context ctx, Collector<String> out) throws Exception {if (threeState.value() != null) {out.collect(JSON.toJSONString(value) + "【app 对账成功】");threeState.clear();} else {//更新状态appState.update(value);//注册5秒后定时器ctx.timerService().registerEventTimeTimer(value.getTimestamp() + 5000L);}}/*** 三方逻辑*/@Overridepublic void processElement2(OrderPojo value, CoProcessFunction<OrderPojo, OrderPojo, String>.Context ctx, Collector<String> out) throws Exception {if (appState.value() != null) {out.collect(JSON.toJSONString(value) + "【three 对账成功】");appState.clear();} else {threeState.update(value);//注册5秒后定时器ctx.timerService().registerEventTimeTimer(value.getTimestamp() + 5000L);}}@Overridepublic void onTimer(long timestamp, CoProcessFunction<OrderPojo, OrderPojo, String>.OnTimerContext ctx, Collector<String> out) throws Exception {if (appState.value() != null) {out.collect(JSON.toJSONString(appState.value()) + "【app 对账失败】");}if (threeState.value() != null) {out.collect(JSON.toJSONString(threeState.value()) + "【三方 对账失败】");}appState.clear();threeState.clear();}}}
3 窗口联结(Window Join)
基于时间的操作,最基本的当然就是时间窗口了。我们之前已经介绍过 Window API 的用法,主要是针对单一数据流在某些时间段内的处理计算。那如果我们希望将两条流的数据进行
合并、且同样针对某段时间进行处理和统计,又该怎么做呢?Flink 为这种场景专门提供了一个窗口联结(window join)算子,可以定义时间窗口,并将两条流中共享一个公共键(key)的数据放在窗口中进行配对处理。
窗口联结的调用:
窗口联结在代码中的实现,首先需要调用 DataStream 的.join()方法来合并两条流,得到一个 JoinedStreams;接着通过.where()和.equalTo()方法指定两条流中联结的 key;然后通过.window()开窗口,并调用.apply()传入联结窗口函数进行处理计算。通用调用形式如下:
stream1.join(stream2) .where(<KeySelector>) .equalTo(<KeySelector>) .window(<WindowAssigner>) .apply(<JoinFunction>)
上面代码中.where()的参数是键选择器(KeySelector),用来指定第一条流中的 key;而.equalTo()传入的 KeySelector 则指定了第二条流中的 key。两者相同的元素,如果在同一窗口中,就可以匹配起来,并通过一个“联结函数”(JoinFunction)进行处理了。
这里.window()传入的就是窗口分配器,之前讲到的三种时间窗口都可以用在这里:滚动窗口(tumbling window)、滑动窗口(sliding window)和会话窗口(session window)。而后面调用.apply()可以看作实现了一个特殊的窗口函数。注意这里只能调用.apply(),没有其他替代的方法。传入的 JoinFunction 也是一个函数类接口,使用时需要实现内部的.join()方法。这个方法有两个参数,分别表示两条流中成对匹配的数据。JoinFunction 在源码中的定义如下:
public interface JoinFunction<IN1, IN2, OUT> extends Function, Serializable {OUT join(IN1 first, IN2 second) throws Exception;}
这里需要注意,JoinFunciton 并不是真正的“窗口函数”,它只是定义了窗口函数在调用时对匹配数据的具体处理逻辑。当然,既然是窗口计算,在.window()和.apply()之间也可以调用可选 API 去做一些自定义,比如用.trigger()定义触发器,用.allowedLateness()定义允许延迟时间,等等。
JoinFunction 中的两个参数,分别代表了两条流中的匹配的数据。这里就会有一个问题:什么时候就会匹配好数据,调用.join()方法呢?接下来我们就来介绍一下窗口 join 的具体处理流程。
两条流的数据到来之后,首先会按照 key 分组、进入对应的窗口中存储;当到达窗口结束时间时,算子会先统计出窗口内两条流的数据的所有组合,也就是对两条流中的数据做一个笛卡尔积(相当于表的交叉连接,cross join),然后进行遍历,把每一对匹配的数据,作为参数(first,second)传入 JoinFunction 的.join()方法进行计算处理,得到的结果直接输出。所以窗口中每有一对数据成功联结匹配,JoinFunction 的.join()方法就会被调用一次,并输出一个结果。
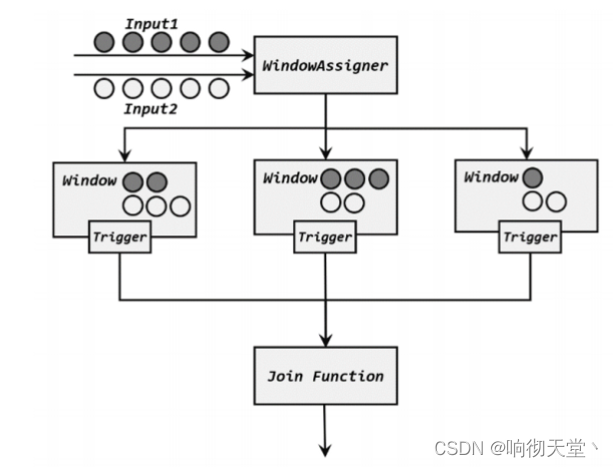
除了 JoinFunction,在.apply()方法中还可以传入 FlatJoinFunction,用法非常类似,只是内部需要实现的.join()方法没有返回值。结果的输出是通过收集器(Collector)来实现的,所以对于一对匹配数据可以输出任意条结果。其实仔细观察可以发现,窗口 join 的调用语法和我们熟悉的 SQL 中表的 join 非常相似:
SELECT * FROM table1 t1, table2 t2 WHERE t1.id = t2.id;
这句 SQL 中 where 子句的表达,等价于 inner join … on,所以本身表示的是两张表基于 id的“内连接”(inner join)。而 Flink 中的 window join,同样类似于 inner join。也就是说,最后
处理输出的,只有两条流中数据按 key 配对成功的那些;如果某个窗口中一条流的数据没有任何另一条流的数据匹配,那么就不会调用 JoinFunction 的.join()方法,也就没有任何输出了。
demo:
在电商网站中,往往需要统计用户不同行为之间的转化,这就需要对不同的行为数据流,按照用户 ID 进行分组后再合并,以分析它们之间的关联。如果这些是以固定时间周期(比如
1 小时)来统计的,那我们就可以使用窗口 join 来实现这样的需求。
package com.rosh.flink.combine;import com.alibaba.fastjson.JSON;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.JoinFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
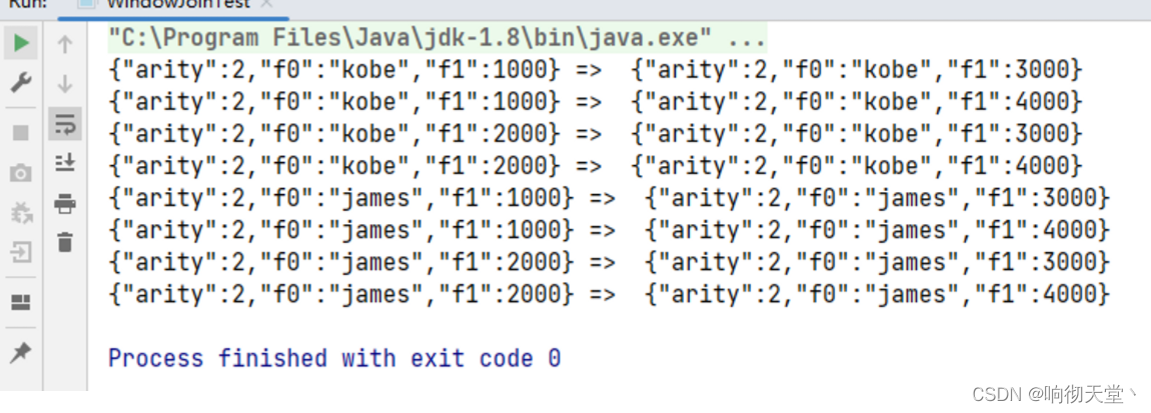
import org.apache.flink.streaming.api.windowing.time.Time;public class WindowJoinTest {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);SingleOutputStreamOperator<Tuple2<String, Long>> stream1 = env.fromElements(Tuple2.of("kobe", 1000L),Tuple2.of("james", 1000L),Tuple2.of("kobe", 2000L),Tuple2.of("james", 2000L)).assignTimestampsAndWatermarks(WatermarkStrategy.<Tuple2<String, Long>>forMonotonousTimestamps().withTimestampAssigner(new SerializableTimestampAssigner<Tuple2<String, Long>>() {@Overridepublic long extractTimestamp(Tuple2<String, Long> element, long recordTimestamp) {return element.f1;}}));SingleOutputStreamOperator<Tuple2<String, Long>> stream2 = env.fromElements(Tuple2.of("kobe", 3000L),Tuple2.of("james", 3000L),Tuple2.of("kobe", 4000L),Tuple2.of("james", 4000L)).assignTimestampsAndWatermarks(WatermarkStrategy.<Tuple2<String, Long>>forMonotonousTimestamps().withTimestampAssigner(new SerializableTimestampAssigner<Tuple2<String, Long>>() {@Overridepublic long extractTimestamp(Tuple2<String, Long> element, long recordTimestamp) {return element.f1;}}));DataStream<String> resultDS = stream1.join(stream2).where(t -> t.f0).equalTo(t -> t.f0).window(TumblingEventTimeWindows.of(Time.seconds(5))).apply(new JoinFunction<Tuple2<String, Long>, Tuple2<String, Long>, String>() {@Overridepublic String join(Tuple2<String, Long> first, Tuple2<String, Long> second) throws Exception {return JSON.toJSONString(first) + " => " + JSON.toJSONString(second);}});resultDS.print();env.execute("WindowJoinTest");}}
4 间隔联结(Interval Join)
在有些场景下,我们要处理的时间间隔可能并不是固定的。比如,在交易系统中,需要实时地对每一笔交易进行核验,保证两个账户转入转出数额相等,也就是所谓的“实时对账”。
两次转账的数据可能写入了不同的日志流,它们的时间戳应该相差不大,所以我们可以考虑只统计一段时间内是否有出账入账的数据匹配。这时显然不应该用滚动窗口或滑动窗口来处理—
—因为匹配的两个数据有可能刚好“卡在”窗口边缘两侧,于是窗口内就都没有匹配了;会话窗口虽然时间不固定,但也明显不适合这个场景。 基于时间的窗口联结已经无能为力了。
为了应对这样的需求,Flink 提供了一种叫作“间隔联结”(interval join)的合流操作。顾名思义,间隔联结的思路就是针对一条流的每个数据,开辟出其时间戳前后的一段时间间隔,
看这期间是否有来自另一条流的数据匹配。
间隔联结具体的定义方式是,我们给定两个时间点,分别叫作间隔的“上界”(upperBound)和“下界”(lowerBound);于是对于一条流(不妨叫作 A)中的任意一个数据元素 a,就可以
开辟一段时间间隔:[a.timestamp + lowerBound, a.timestamp + upperBound],即以 a 的时间戳为中心,下至下界点、上至上界点的一个闭区间:我们就把这段时间作为可以匹配另一条流数据
的“窗口”范围。所以对于另一条流(不妨叫 B)中的数据元素 b,如果它的时间戳落在了这个区间范围内,a 和 b 就可以成功配对,进而进行计算输出结果。所以匹配的条件为:
a.timestamp + lowerBound <= b.timestamp <= a.timestamp + upperBound
这里需要注意,做间隔联结的两条流 A 和 B,也必须基于相同的 key;下界 lowerBound应该小于等于上界 upperBound,两者都可正可负;间隔联结目前只支持事件时间语义。
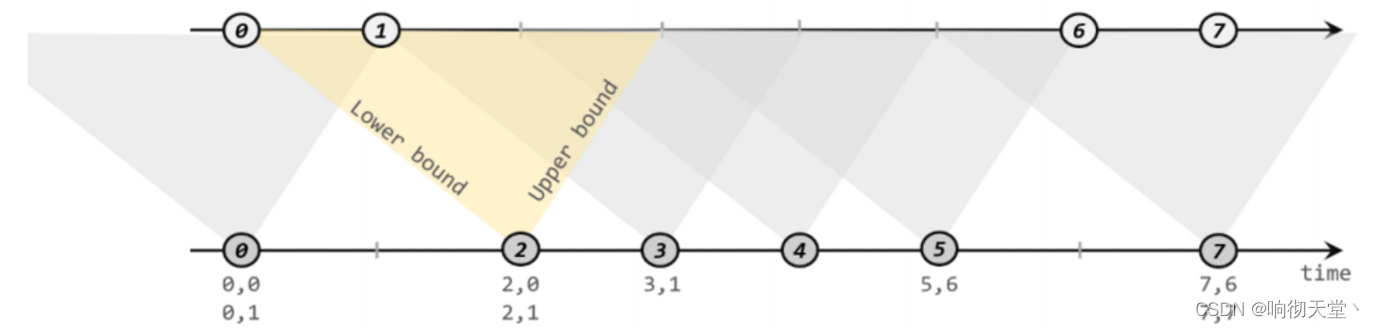
下方的流 A 去间隔联结上方的流 B,所以基于 A 的每个数据元素,都可以开辟一个间隔区间。我们这里设置下界为-2 毫秒,上界为 1 毫秒。于是对于时间戳为 2 的 A 中元素,它的
可匹配区间就是[0, 3],流 B 中有时间戳为 0、1 的两个元素落在这个范围内,所以就可以得到匹配数据对(2, 0)和(2, 1)。同样地,A 中时间戳为 3 的元素,可匹配区间为[1, 4],B 中只有时
间戳为 1 的一个数据可以匹配,于是得到匹配数据对(3, 1)。
所以我们可以看到,间隔联结同样是一种内连接(inner join)。与窗口联结不同的是,intervaljoin 做匹配的时间段是基于流中数据的,所以并不确定;而且流 B 中的数据可以不只在一个区
间内被匹配。
间隔联结在代码中,是基于 KeyedStream 的联结(join)操作。DataStream 在 keyBy 得到KeyedStream 之后,可以调用.intervalJoin()来合并两条流,传入的参数同样是一个 KeyedStream,
两者的 key 类型应该一致;得到的是一个 IntervalJoin 类型。后续的操作同样是完全固定的:先通过.between()方法指定间隔的上下界,再调用.process()方法,定义对匹配数据对的处理操
作。调用.process()需要传入一个处理函数,这是处理函数家族的最后一员:“处理联结函数”通用调用形式如下:
stream1 .keyBy(<KeySelector>).intervalJoin(stream2.keyBy(<KeySelector>)).between(Time.milliseconds(-2), Time.milliseconds(1)).process (new ProcessJoinFunction<Integer, Integer, String(){@Overridepublic void processElement(Integer left, Integer right, Context ctx, Collector<String> out) {out.collect(left + "," + right);}});
demo:
在电商网站中,某些用户行为往往会有短时间内的强关联。我们这里举一个例子,我们有两条流,一条是下订单的流,一条是浏览数据的流。我们可以针对同一个用户,来做这样一个
联结。也就是使用一个用户的下订单的事件和这个用户的最近十分钟的浏览数据进行一个联结查询。
package com.rosh.flink.combine;import com.rosh.flink.pojo.UserPojo;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.ProcessJoinFunction;
import org.apache.flink.streaming.api.windowing.time.Time;
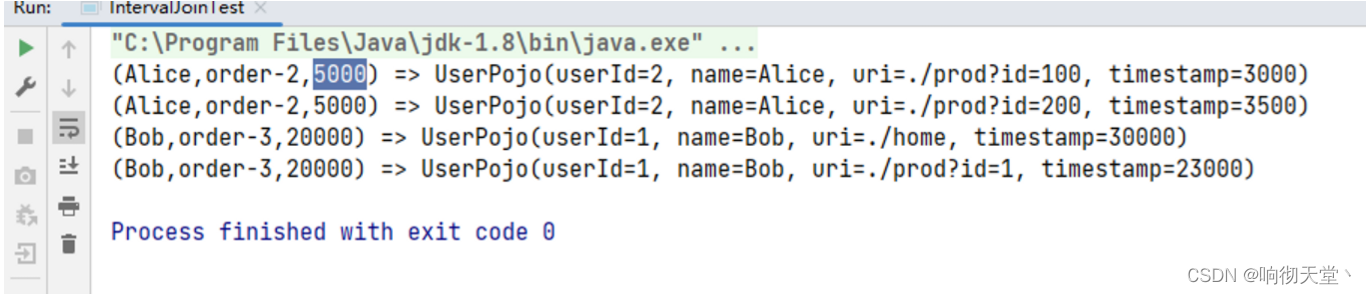
import org.apache.flink.util.Collector;public class IntervalJoinTest {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);//初始化流SingleOutputStreamOperator<Tuple3<String, String, Long>> orderDS =env.fromElements(Tuple3.of("Mary", "order-1", 5000L),Tuple3.of("Alice", "order-2", 5000L),Tuple3.of("Bob", "order-3", 20000L),Tuple3.of("Alice", "order-4", 20000L),Tuple3.of("Cary", "order-5", 51000L)).assignTimestampsAndWatermarks(WatermarkStrategy.<Tuple3<String, String, Long>>forMonotonousTimestamps().withTimestampAssigner(new SerializableTimestampAssigner<Tuple3<String, String, Long>>() {@Overridepublic long extractTimestamp(Tuple3<String, String, Long>element, long recordTimestamp) {return element.f2;}}));SingleOutputStreamOperator<UserPojo> clickDS = env.fromElements(new UserPojo(1, "Bob", "./cart", 2000L),new UserPojo(2, "Alice", "./prod?id=100", 3000L),new UserPojo(2, "Alice", "./prod?id=200", 3500L),new UserPojo(1, "Bob", "./prod?id=2", 2500L),new UserPojo(2, "Alice", "./prod?id=300", 36000L),new UserPojo(1, "Bob", "./home", 30000L),new UserPojo(1, "Bob", "./prod?id=1", 23000L),new UserPojo(1, "Bob", "./prod?id=3", 33000L)).assignTimestampsAndWatermarks(WatermarkStrategy.<UserPojo>forMonotonousTimestamps().withTimestampAssigner(new SerializableTimestampAssigner<UserPojo>() {@Overridepublic long extractTimestamp(UserPojo element, long recordTimestamp) {return element.getTimestamp();}}));//联合SingleOutputStreamOperator<String> resultDS = orderDS.keyBy(t -> t.f0).intervalJoin(clickDS.keyBy(UserPojo::getName)).between(Time.seconds(-5), Time.seconds(10)).process(new ProcessJoinFunction<Tuple3<String, String, Long>, UserPojo, String>() {@Overridepublic void processElement(Tuple3<String, String, Long> left, UserPojo right, ProcessJoinFunction<Tuple3<String, String, Long>, UserPojo, String>.Context ctx, Collector<String> out) throws Exception {out.collect(left + " => " + right);}});resultDS.print();env.execute("IntervalJoinTest");}}
相关文章:
Flink 连接流详解
连接流 1 Union 最简单的合流操作,就是直接将多条流合在一起,叫作流的“联合”(union)。联合操作要求必须流中的数据类型必须相同,合并之后的新流会包括所有流中的元素,数据类型不变。这种合流方式非常简…...

分享112个HTML电子商务模板,总有一款适合您
分享112个HTML电子商务模板,总有一款适合您 112个HTML电子商务模板下载链接:https://pan.baidu.com/s/13wf9C9NtaJz67ZqwQyo74w?pwdzt4a 提取码:zt4a Python采集代码下载链接:采集代码.zip - 蓝奏云 有机蔬菜水果食品商城网…...
)
2023备战金三银四,Python自动化软件测试面试宝典合集(八)
马上就又到了程序员们躁动不安,蠢蠢欲动的季节~这不,金三银四已然到了家门口,元宵节一过后台就有不少人问我:现在外边大厂面试都问啥想去大厂又怕面试挂面试应该怎么准备测试开发前景如何面试,一个程序员成长之路永恒绕…...

J-Link RTT Viewer使用教程(附代码)
目录 RTT(Real Time Transfer)简介 使用教程 常用API介绍 RTT缓冲大小修改 使用printf重定向 官方例程 RTT(Real Time Transfer)简介 平常调试代码中使用串口打印log,往往需要接出串口引脚,比较麻烦,并且串口打印速度较慢,串…...
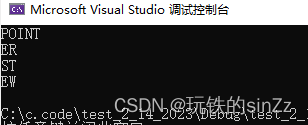
C语言——指针、数组的经典笔试题目
文章目录前言1.一维数组2.字符数组3.二维数组4.经典指针试题前言 1、数组名通常表示首元素地址,sizeof(数组名)和&数组名两种情况下,数组名表示整个数组。 2、地址在内存中唯一标识一块空间,大小是4/8字节。32位平台4字节,64位…...
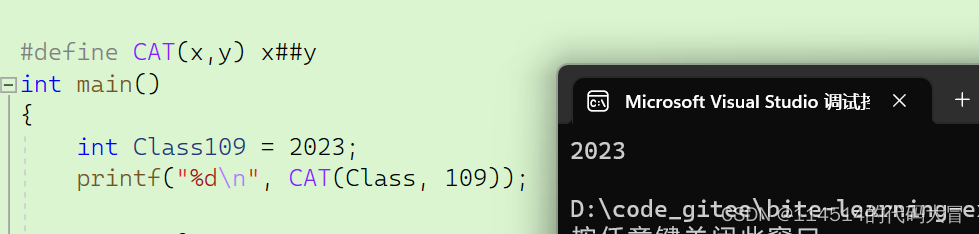
【C语言】程序环境和预处理|预处理详解|定义宏(上)
主页:114514的代码大冒险 qq:2188956112(欢迎小伙伴呀hi✿(。◕ᴗ◕。)✿ ) Gitee:庄嘉豪 (zhuang-jiahaoxxx) - Gitee.com 文章目录 目录 文章目录 前言 一、程序的翻译环境和执行环境 二、详解编译和链接 1.翻译环境 2.编…...

上海霄腾自动化装备盛装亮相2023生物发酵展
上海霄腾自动化携液体膏体粉剂颗粒等灌装生产线解决方案亮相2023生物发酵展BIO CHINA2023生物发酵展,作为生物发酵产业一年一度行业盛会,由中国生物发酵产业协会主办,上海信世展览服务有限公司承办,2023第10届国际生物发酵产品与技…...

python+flask开发mock服务
目录 什么是mock? 什么时候需要用到mock? 如何实现? pythonflask自定义mock服务的步骤 一、环境搭建 1、安装flask插件 2、验证插件 二、mock案例 1、模拟 返回结果 2、模拟 异常响应状态码 3、模拟登录,从jmeter中获取…...
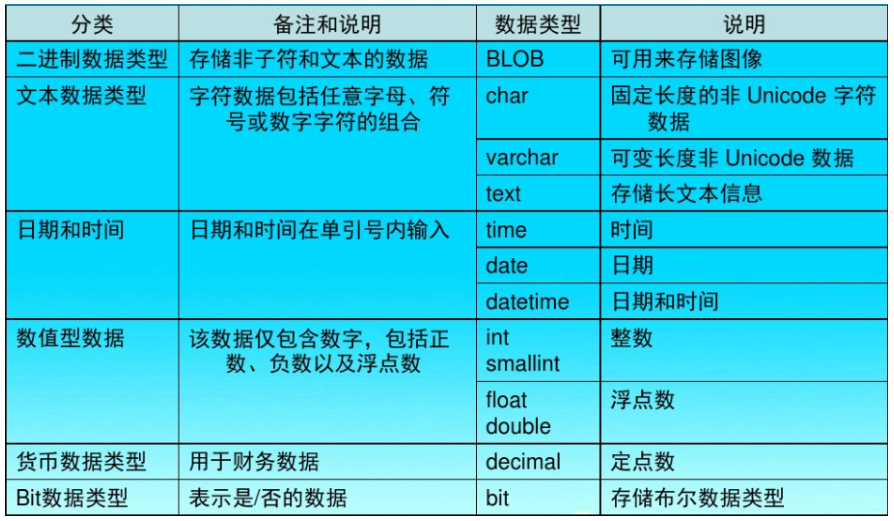
数据库(三)
第三章 MySQL库表操作 3.1 SQL语句基础 3.1.1 SQL简介 SQL:结构化查询语言(Structured Query Language),在关系型数据库上执行数据操作、数据检索以及数据维护的标准语言。使用SQL语句,程序员和数据库管理员可以完成如下的任务。 改变数据…...

2023软考纸质证书领取通知来了!
不少同学都在关注2022下半年软考证书领取时间,截止至目前,上海、湖北、江苏、南京、安徽、山东、浙江、宁波、江西、贵州、云南、辽宁、大连、吉林、广西地区的纸质证书可以领取了。将持续更新2022下半年软考纸质证书领取时间,请同学们在证书…...

Python requests模块
一、requests模块简介 requests模块是一个第三方模块,需要在python环境中安装: pip install requests 该模块主要用来发送 HTTP 请求,requests 模块比 urllib 模块更简洁。 requests模块支持: 自动处理url编码自动处理post请求…...

工业智能网关解决方案:物联网仓储环境监测系统
仓储是连接生产、供应和销售的中转系统,对于促进生产、提高效率有着重要的辅助作用。对于很多大型工厂或食品厂来说,需要对仓储环境进行严控的控制,以确保产品或食品的质量,避免不必要的产品损耗,提高产品存管的水平。…...
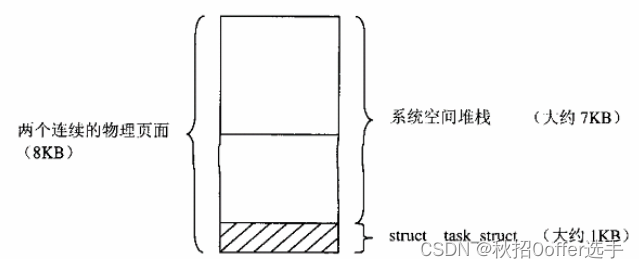
Linux进程线程管理
目录 存储管理 linux内存管理基本框架 系统空间管理和用户空间管理 进程与进程调度 进程四要素 用户堆栈的扩展 进程三部曲:创建,执行,消亡 系统调用exit(),wait() 内核中的互斥操作 存储管理 linux内存管理基本框架 系统空间管理…...

分享111个HTML电子商务模板,总有一款适合您
分享111个HTML电子商务模板,总有一款适合您 111个HTML电子商务模板下载链接:https://pan.baidu.com/s/1e8Wp1Rl9RaFrcW0bilIatg?pwdc97h 提取码:c97h Python采集代码下载链接:采集代码.zip - 蓝奏云 HTML5家居家具电子商务网…...

百度前端必会手写面试题整理
请实现一个 add 函数,满足以下功能 add(1); // 1 add(1)(2); // 3 add(1)(2)(3);// 6 add(1)(2, 3); // 6 add(1, 2)(3); // 6 add(1, 2, 3); // 6function add(...args) {// 在内部声明一个函数,利用闭包的特性保存并收集…...
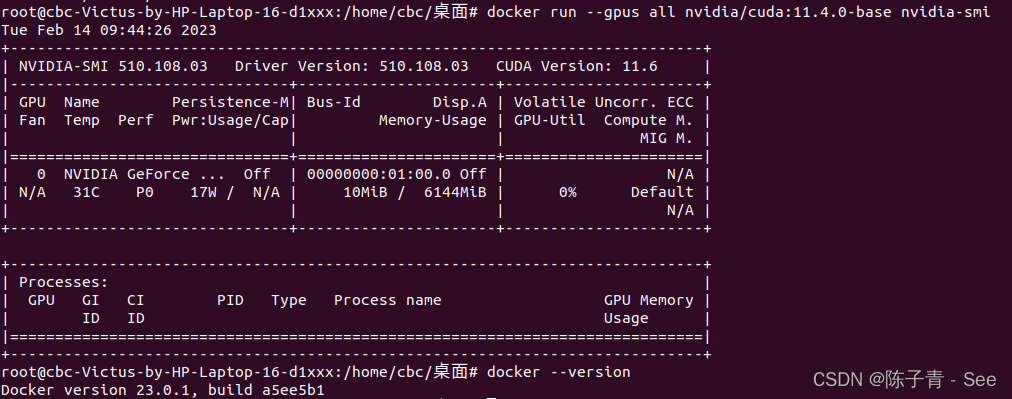
ubuntu 安装支持GPU的Docker详细步骤
安装依赖项 sudo apt-get update sudo apt-get install -y apt-transport-https ca-certificates curl gnupg-agent software-properties-common 添加 Docker GPG 密钥 curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add - sudo apt-key fingerpr…...
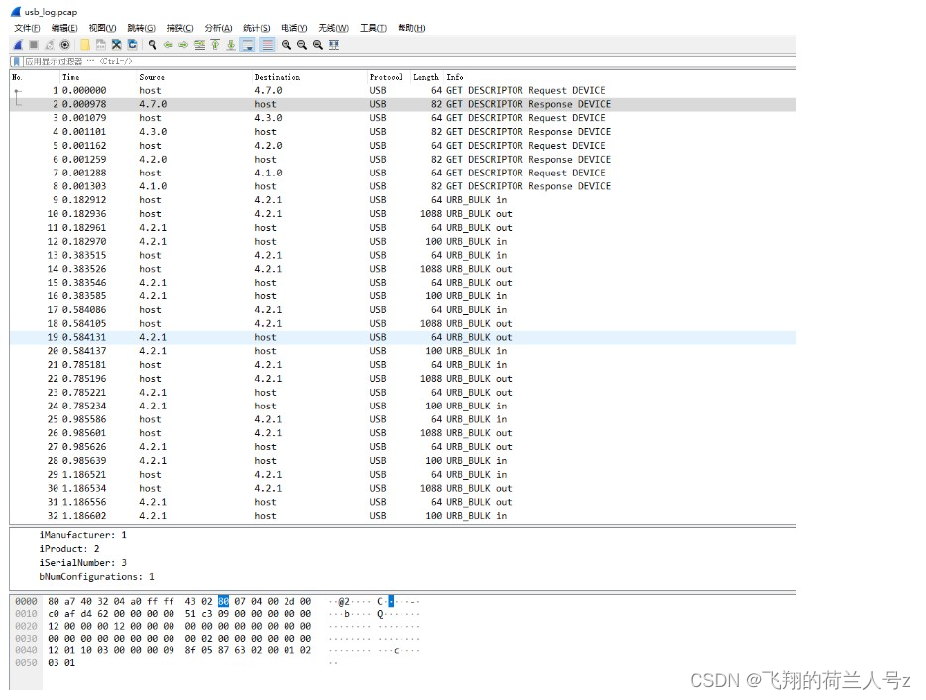
usbmon+tcpdump+wireshark USB抓包
文章目录usbmon抓包及配合wireshark解析usbmon抓包及配合wireshark解析 usbmon首先编译为内核模块,然后通过modprobe usbmon加载到linux sys文件系统中 rootroot-PC:~# modprobe usbmon 而后 linux系统下安装 tcpdump rootroot-PC:~# apt-get install tcpdump…...
【LeetCode】剑指 Offer 04. 二维数组中的查找 p44 -- Java Version
题目链接: https://leetcode.cn/problems/er-wei-shu-zu-zhong-de-cha-zhao-lcof/ 1. 题目介绍(04. 二维数组中的查找) 在一个 n * m 的二维数组中,每一行都按照从左到右 非递减 的顺序排序,每一列都按照从上到下 非递…...
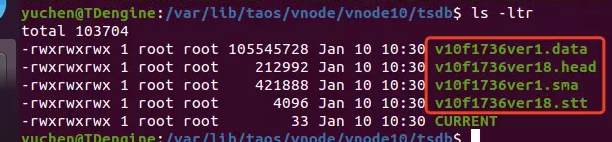
TDengine 3.0.2.5 查询再优化!揭秘索引文件的工作原理
TDengine 3.0 虽然对底层做了大规模的优化重构,但是相对于数据文件的工作逻辑和 2.0 相比是整体保持不变的。本系列文章的主旨在于帮助用户深入理解产品,并且拥有基本的性能调试思路,从而获得更好的产品体验。本期文章会在讲解 TDengine 时序…...

蓝牙耳机哪个品牌性价比高?性价比高的无线蓝牙耳机
现如今耳机已经十分普及,大多数人会随身佩戴蓝牙耳机,相较于传统耳机,无线耳机不仅携带方便,舒适度上也更加出色。不过市面上的无线耳机种类繁多,很多朋友不知道该如何挑选,所以小编特意整理了一期性价比高…...

在软件开发中正确使用MySQL日期时间类型的深度解析
在日常软件开发场景中,时间信息的存储是底层且核心的需求。从金融交易的精确记账时间、用户操作的行为日志,到供应链系统的物流节点时间戳,时间数据的准确性直接决定业务逻辑的可靠性。MySQL作为主流关系型数据库,其日期时间类型的…...

React 第五十五节 Router 中 useAsyncError的使用详解
前言 useAsyncError 是 React Router v6.4 引入的一个钩子,用于处理异步操作(如数据加载)中的错误。下面我将详细解释其用途并提供代码示例。 一、useAsyncError 用途 处理异步错误:捕获在 loader 或 action 中发生的异步错误替…...

<6>-MySQL表的增删查改
目录 一,create(创建表) 二,retrieve(查询表) 1,select列 2,where条件 三,update(更新表) 四,delete(删除表…...

day52 ResNet18 CBAM
在深度学习的旅程中,我们不断探索如何提升模型的性能。今天,我将分享我在 ResNet18 模型中插入 CBAM(Convolutional Block Attention Module)模块,并采用分阶段微调策略的实践过程。通过这个过程,我不仅提升…...

04-初识css
一、css样式引入 1.1.内部样式 <div style"width: 100px;"></div>1.2.外部样式 1.2.1.外部样式1 <style>.aa {width: 100px;} </style> <div class"aa"></div>1.2.2.外部样式2 <!-- rel内表面引入的是style样…...

【论文阅读28】-CNN-BiLSTM-Attention-(2024)
本文把滑坡位移序列拆开、筛优质因子,再用 CNN-BiLSTM-Attention 来动态预测每个子序列,最后重构出总位移,预测效果超越传统模型。 文章目录 1 引言2 方法2.1 位移时间序列加性模型2.2 变分模态分解 (VMD) 具体步骤2.3.1 样本熵(S…...

分布式增量爬虫实现方案
之前我们在讨论的是分布式爬虫如何实现增量爬取。增量爬虫的目标是只爬取新产生或发生变化的页面,避免重复抓取,以节省资源和时间。 在分布式环境下,增量爬虫的实现需要考虑多个爬虫节点之间的协调和去重。 另一种思路:将增量判…...

MySQL账号权限管理指南:安全创建账户与精细授权技巧
在MySQL数据库管理中,合理创建用户账号并分配精确权限是保障数据安全的核心环节。直接使用root账号进行所有操作不仅危险且难以审计操作行为。今天我们来全面解析MySQL账号创建与权限分配的专业方法。 一、为何需要创建独立账号? 最小权限原则…...

JVM虚拟机:内存结构、垃圾回收、性能优化
1、JVM虚拟机的简介 Java 虚拟机(Java Virtual Machine 简称:JVM)是运行所有 Java 程序的抽象计算机,是 Java 语言的运行环境,实现了 Java 程序的跨平台特性。JVM 屏蔽了与具体操作系统平台相关的信息,使得 Java 程序只需生成在 JVM 上运行的目标代码(字节码),就可以…...

libfmt: 现代C++的格式化工具库介绍与酷炫功能
libfmt: 现代C的格式化工具库介绍与酷炫功能 libfmt 是一个开源的C格式化库,提供了高效、安全的文本格式化功能,是C20中引入的std::format的基础实现。它比传统的printf和iostream更安全、更灵活、性能更好。 基本介绍 主要特点 类型安全:…...