《Linux 内核设计与实现》12. 内存管理
文章目录
- 页
- 区
- 获得页
- 获得填充为 0 的页
- 释放页
- kmalloc()
- gfp_mask 标志
- kfree()
- vmalloc()
- slab 层
- slab 层的设计
- slab 分配器的接口
- 在栈上的静态分配
- 单页内核栈
- 高端内存的映射
- 永久映射
- 临时映射
- 每个 CPU 的分配
- 新的每个 CPU 接口
页
struct page 结构表示系统中的物理页,位于:include/linux/mm_types.h

- flag:页的状态。
- _count:页的引用次数。值为 -1 表示当前内核没有引用这一页,该页可分配。内核调用 page_count() 进行检查。
- virtual:页的虚拟地址。
区
由于硬件存在缺陷而引起的内存寻址问题:
- 一些硬件只能用某些特定的内存地址来执行 DMA。
- 一些体系结构的内存物理寻址范围比虚拟寻址范围大得多。这样,就有一些内存不能永久地映射到内核空间上。
因为存在这些约束,因此 Linux 主要使用了 4 种分区:
- ZONE_DMA —— 这个区包含的页能用来执行 DMA 操作。
- ZONE_DMA32 —— 和 ZOME_DMA 类似,该区包含的页面可以用来执行 DMA 操作;而和 ZONE_DMA 不同之处在于,这些页面只能被 32 位设备访问。在某些体系结构中,该区比 ZONE_DMA 更大。
- ZONE_NORMAL —— 这个区包含的都是正常能映射的页。
- ZONE_HIGHEM —— 这个区包含“高端内存”,其中的页并不能永久地映射到内核地址空间。
区的实际使用和分布都与体系结构有关。

- Linux 把系统的页划分为区,形成不同的内存池,这样就可以根据用途进行分配了。
- 注意,区的划分没有任何物理意义,这只不过是内核为了管理页而采取的一种逻辑上的分组。
获得页
以页为单位分配内存,分配 2 o r d e r 2^{order} 2order 个物理页,位于:include/linux/gfp.h
alloc_pages(gfp_t gfp_mask, unsigned int order) {return alloc_pages_current(gfp_mask, order);
}
将给定的页转为它的逻辑地址:
- include/linux/mm.h
- mm/highmem.c
/*** page_address - get the mapped virtual address of a page* @page: &struct page to get the virtual address of** Returns the page's virtual address.*/
void *page_address(struct page *page) {unsigned long flags;void *ret;struct page_address_slot *pas;if (!PageHighMem(page))return lowmem_page_address(page);pas = page_slot(page);ret = NULL;spin_lock_irqsave(&pas->lock, flags);if (!list_empty(&pas->lh)) {struct page_address_map *pam;list_for_each_entry(pam, &pas->lh, list) {if (pam->page == page) {ret = pam->virtual;goto done;}}}
done:spin_unlock_irqrestore(&pas->lock, flags);return ret;
}
上面函数返回一个指针,指向给定物理页当前所在的逻辑地址。若用不到 struct page,可以用:
路径:mm/page_alloc.c
/** Common helper functions.*/
unsigned long __get_free_pages(gfp_t gfp_mask, unsigned int order)
{struct page *page;/** __get_free_pages() returns a 32-bit address, which cannot represent* a highmem page*/VM_BUG_ON((gfp_mask & __GFP_HIGHMEM) != 0);page = alloc_pages(gfp_mask, order);if (!page)return 0;return (unsigned long) page_address(page);
}
EXPORT_SYMBOL(__get_free_pages);
获得填充为 0 的页
带有 zeroed 的函数,会将分配好的页都填充成 0。用户空间的页在返回之前,必须将分配的页填充为 0。

释放页
void __free_pages(struct page *page, unsigned int order)
{if (put_page_testzero(page)) {if (order == 0)free_hot_cold_page(page, 0);else__free_pages_ok(page, order);}
}EXPORT_SYMBOL(__free_pages);void free_pages(unsigned long addr, unsigned int order)
{if (addr != 0) {VM_BUG_ON(!virt_addr_valid((void *)addr));__free_pages(virt_to_page((void *)addr), order);}
}EXPORT_SYMBOL(free_pages);
记住,分配完内存后,必须检测是否分配成功,否则会出现大问题。
kmalloc()
以字节为单位申请一块连续的内核空间。
位于:
-
include/linux/slab.h
-
include/linux/slab_def.h
static __always_inline void *kmalloc(size_t size, gfp_t flags) { ... }
gfp_mask 标志
行为修饰符:
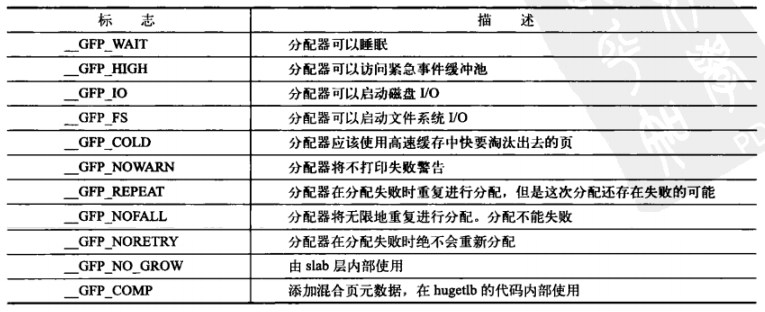
多个行为修饰符可以使用或运算符连接,如:
__GFP_WAIT | __GPT_IO | __GFP_FS
区修饰符:

指定从哪个区分配资源,若未指定任何标志,默认从 ZONE_DMA 或 ZONE_NORMAL 分配,优先从 ZONE_NORMAL 分配。
不能给 _get_free_pages() 或 kalloc() 指定 ZONE_HIGHMEM,因为这两个函数返回的都是逻辑地址,而不是 page 结构,这两个函数分配的内存当前有可能还没有映射到内核的虚拟地址空间,因此,也可能根本就没有逻辑地址。
类型标志:
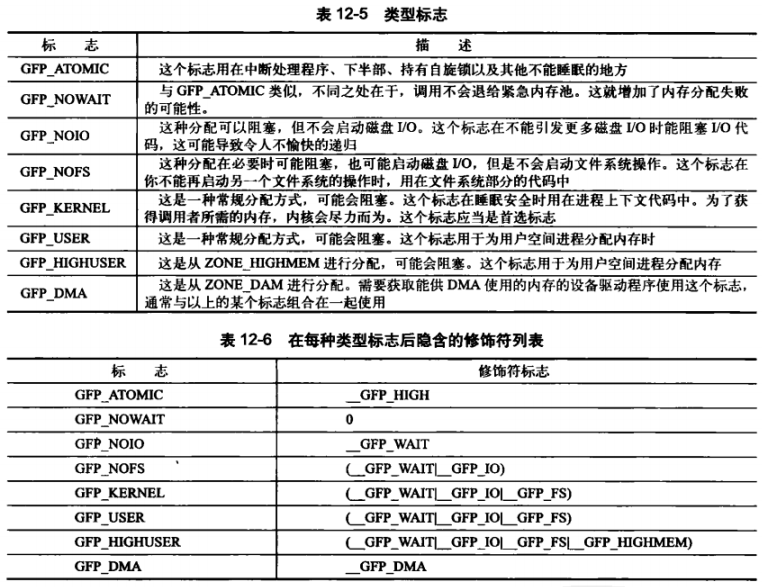
通常,要么用 GFP_KERNEL,要么是 GFP_ATOMIC。

kfree()
kmalloc() 所对应的内存释放函数 kfree()。
void kfree(const void *);
kfree() 只能释放由 kmalloc() 分配出来的内存资源。若想要释放的内存不是由 kmalloc() 申请的,或想要释放的内存早被释放了,再调用 kfree() 的话,就会导致很严重的后果。
和用户空间一样,申请和释放函数都是一对的。
vmalloc()
kmalloc() 确保页在物理地址上是连续的(虚拟地址自然也是连续的)。
vmalloc() 只确保页在虚拟地址是连续的。
硬件设备用到的任何内存区都必须是物理上连续的块,而不仅仅是虚拟地址连续上的块。应用程序所使用的内存块可以使用只有虚拟地址连续的内存块。
通过 vmalloc() 获得的页必须一个一个地进行映射(因为物理地址可以不连续),这就导致比直接内存映射大得多的 TLB 抖动。
对应释放:vfree()。
路径:
- include\linux\vmalloc.h
- mm\vmalloc.c
slab 层
空闲链表:便于数据的频繁分配和回收。当需要内存块时,就从空闲链表中取出一个,不用时就放回去,而不是释放它。
缺点:在内核中,空闲链表无法全局控制。当可用内存变得紧缺时,内核无法通知每个空闲链表,让其收缩缓存的大小以便释放出一些内存。
slab 层,即 slab 分配器来nibu缺陷。
slab 分配器在如下基本原则中寻求一种平衡:

slab 层的设计
一个高速缓存由多个 slab 组成,而一个 slab 由多个同类型对象。
slab 由一个或多个物理上连续的页组成。
slab 的三种状态:
- 满:没有空闲对象可分配。
- 部分满:有部分空闲对象可分配。
- 空:没有一个被分配的对象。
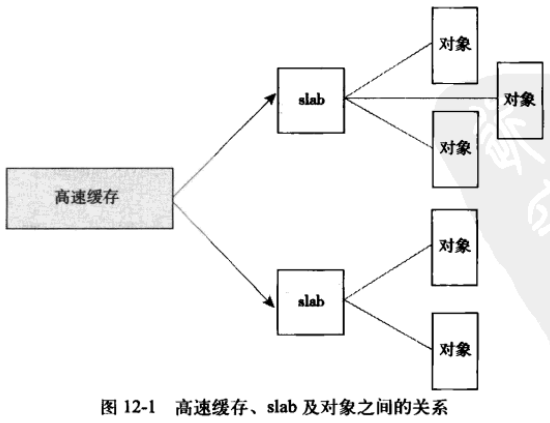
高速缓存的结构:
// include/linux/slab_def.h
struct kmem_cache {// ...struct kmem_list3 *nodelists[MAX_NUMNODES];// ...
}
// mm/slab.c
/** The slab lists for all objects.*/
struct kmem_list3 {struct list_head slabs_partial; /* partial list first, better asm code */struct list_head slabs_full;struct list_head slabs_free;// ...
}
slab 结构:
// mm/slab.c
/** struct slab** Manages the objs in a slab. Placed either at the beginning of mem allocated* for a slab, or allocated from an general cache.* Slabs are chained into three list: fully used, partial, fully free slabs.*/
struct slab {struct list_head list; // 三种状态的链表unsigned long colouroff; // slab 着色的偏移量void *s_mem; // 在 slab 中的第一个对象unsigned int inuse; // slab 中已分配的对象数kmem_bufctl_t free; // 第一个空闲对象unsigned short nodeid;
};
slab 描述符要么在 slab 之外另行分配,要么就放在 slab 自身开始的地方。
slab 分配器可以创建新的 slab,这通过 __get_free_pages() 低级内核页分配器进行。
// mm/slab.c
/** Interface to system's page allocator. No need to hold the cache-lock.** If we requested dmaable memory, we will get it. Even if we* did not request dmaable memory, we might get it, but that* would be relatively rare and ignorable.*/
static void *kmem_getpages(struct kmem_cache *cachep, gfp_t flags, int nodeid)
{struct page *page;int nr_pages;int i;#ifndef CONFIG_MMU/** Nommu uses slab's for process anonymous memory allocations, and thus* requires __GFP_COMP to properly refcount higher order allocations*/flags |= __GFP_COMP;
#endifflags |= cachep->gfpflags;if (cachep->flags & SLAB_RECLAIM_ACCOUNT)flags |= __GFP_RECLAIMABLE;page = alloc_pages_exact_node(nodeid, flags | __GFP_NOTRACK, cachep->gfporder);if (!page)return NULL;nr_pages = (1 << cachep->gfporder);if (cachep->flags & SLAB_RECLAIM_ACCOUNT)add_zone_page_state(page_zone(page),NR_SLAB_RECLAIMABLE, nr_pages);elseadd_zone_page_state(page_zone(page),NR_SLAB_UNRECLAIMABLE, nr_pages);for (i = 0; i < nr_pages; i++)__SetPageSlab(page + i);if (kmemcheck_enabled && !(cachep->flags & SLAB_NOTRACK)) {kmemcheck_alloc_shadow(page, cachep->gfporder, flags, nodeid);if (cachep->ctor)kmemcheck_mark_uninitialized_pages(page, nr_pages);elsekmemcheck_mark_unallocated_pages(page, nr_pages);}return page_address(page);
}
slab 层的管理就是在每个高速缓存的基础上,通过提供给整个内核一个简单的接口来完成的。通过接口就可以创建和撤销新的高速缓存,并在高速缓存内分配和释放对象。高速缓存及其内 slab 的复杂管理完全通过 slab 层的内部机制来处理。当你创建了一个高速缓存后,slab 层所起的作用就像一个专门的分配器,可以为具体的对象类型进行分配。
slab 分配器的接口
连续上了一个下午的讲座,头疼,不记了,艹!
在栈上的静态分配
单页内核栈
进程设置为单页内核栈的好处:
- 可以让每个进程减少内存消耗。
- 随着时间的推移,避免因为物理内存碎片化而造成给新进程分配两个未分配、连续的页变得困难。
中断栈:
- 中断栈为每个进程提供一个用于中断处理程序的栈。
- 这样中断处理程序就不用再和被中断的进程共享同一个内核栈了,它们可以使用自己的栈了。
高端内存的映射
在高端内存中的页不能永久映射到内核地址空间上。因此通过 alloc_pages() 以 __GFP_HIGHMEM 标志获得的页不可能有逻辑地址。
x86 的高端内存中的页被映射到 3GB~4GB。
永久映射
// linux/high.mem.h
// 将 page 映射到内核地址空间
void *kmap(struct page *page)
// 对应的解除映射
void kunmap(struct page *page)
- 高端或低端内存都可以使用。
- 若 page 对应低端那一页,返回该页虚拟地址。若是高端,则建立一个永久映射,返回物理地址。
- 该函数可休眠,因此只能用在进程上下文中。
临时映射
void *kmap_atomic(struct page *page, enum km_type type)
void *kunmap_atomic(struct page *kvaddr, enum km_type type)
- 该函数不可休眠。
- type 描述了临时映射的目的。
每个 CPU 的分配
- 支持 SMP 的现代操作系统使用每个 CPU 上的数据,对于给定的处理器其数据是唯一的。
- 一般来说,每个 CPU 的数据存放在一个数组中。数组中的每一项对应着系统上的一个处理器。
声明数据:
unsigned long my_percpu[NR_CPUS];
按照如下方式访问:
int cpu;
cpu = get_cpu(); // 获得当前处理器,并禁止内核抢占
my_percpu[cpu]++; // ...
printk("my_percpu on cpu=%d is %lu\n", cpu, my_percpu[cpu]);
put_cpu(); // 激活内核抢占
因为所操作的数据对当前处理器来说是唯一的。没有其它处理器可以访问到该数据,不存在并发访问的问题,因此当前处理器可以在不用锁的情况下安全访问它。
内核抢占引起的问题:
- 如果你的代码被其他处理器抢占被重新调度,那么这时 CPU 变量就会无效,因为它指向的是错误的处理器(通常,代码获得当前处理器后是不可休眠的)。
- 如果另一个任务抢占了你的代码,那么有可能在同一个处理器上发生并发访问 my_percpu 的情况,显然这属于一个竞争条件。
使用下面的方法来保护数据安全,就不需要自己手动禁止内核抢占:
- get_cpu():获得当前处理器号。该函数会禁止内核抢占。
- put_cpu():重新激活当前处理器号。
新的每个 CPU 接口
略…
相关文章:
《Linux 内核设计与实现》12. 内存管理
文章目录 页区获得页获得填充为 0 的页释放页 kmalloc()gfp_mask 标志kfree()vmalloc() slab 层slab 层的设计slab 分配器的接口 在栈上的静态分配单页内核栈 高端内存的映射永久映射临时映射 每个 CPU 的分配新的每个 CPU 接口 页 struct page 结构表示系统中的物理页&#x…...

公司新来个卷王,让人崩溃...
最近内卷严重,各种跳槽裁员,相信很多小伙伴也在准备今年的面试计划。 在此展示一套学习笔记 / 面试手册,年后跳槽的朋友可以好好刷一刷,还是挺有必要的,它几乎涵盖了所有的软件测试技术栈,非常珍贵&#x…...
Docker 安全及日志管理
Docker 安全及日志管理 Docker 容器与虚拟机的区别隔离与共享性能与损耗 Docker 存在的安全问题Docker 自身漏洞Docker 源码问题Docker 架构缺陷与安全机制Docker 安全基线标准 容器相关的常用安全配置方法容器最小化Docker 远程 API 访问控制重启 Docker在宿主机的 firewalld …...

大厂面试必备 - MAC 地址 和 IP 地址分别有什么作用?
数据链路层 1、MAC 地址 和 IP 地址分别有什么作用? MAC 地址是数据链路层和物理层使用的地址,是写在网卡上的物理地址。MAC 地址用来定义网络设备的位置。IP 地址是网络层和以上各层使用的地址,是一种逻辑地址。IP 地址用来区别网络上的计…...

【sqlite】联查Join更新
系列文章 C#底层库–MySQLBuilder脚本构建类(select、insert、update、in、带条件的SQL自动生成) 本文链接:https://blog.csdn.net/youcheng_ge/article/details/129179216 C#底层库–MySQL数据库操作辅助类(推荐阅读࿰…...
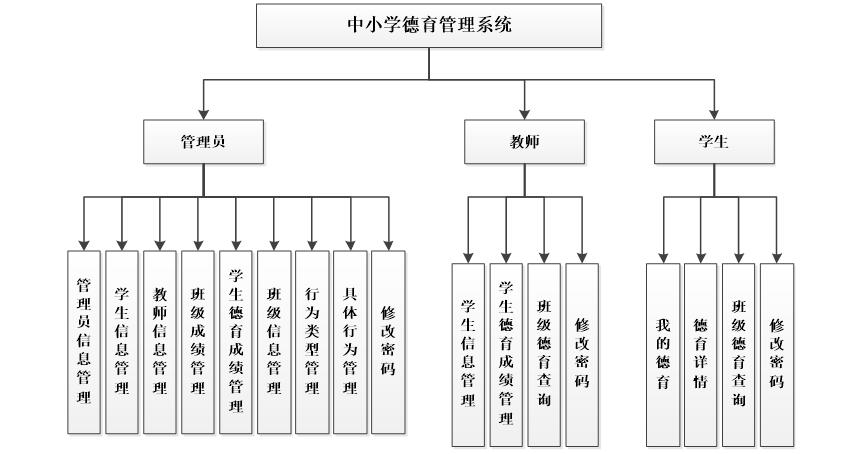
asp.net+C#德育课程分数统计管理系统
本中小学德育管理系统主要学校内部提供服务,系统分为管理员,教师和学生3个大模块。 本研究课题重点主要包括了下面几大模块:用户登录,管理员信息管理学生信息管理,教师信息管理,班级成绩管理,学…...
Figma中文网?比Figma更懂你的设计网站!
一个比 Figma 更懂你的设计网站的 Figma 中文网 —— 即时设计是一个非常有用的设计资源平台,它提供了大量的免费设计素材,包括来自各大厂商的 UI 组件库、精美的模板、插画设计和矢量图标素材等等。设计师可以从中学习到大师的设计技巧和规范࿰…...
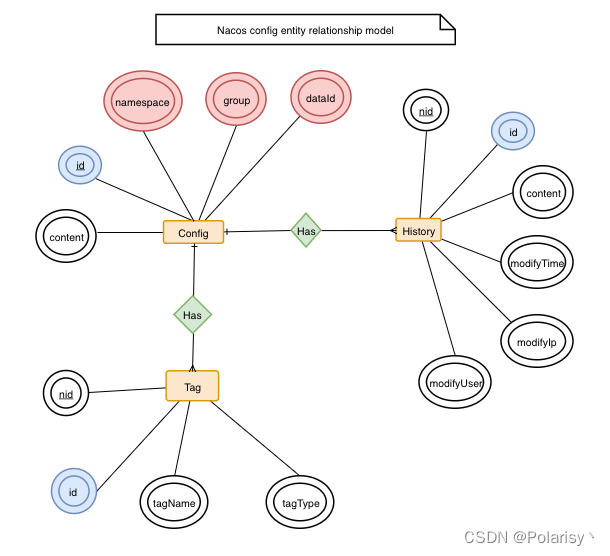
Nacos-01-Nacos基本介绍
背景 服务发现是⼀个古老的话题,当应用开始脱离单机运行和访问时,服务发现就诞生了。目前的网络架构是每个主机都有⼀个独立的 IP 地址,那么服务发现基本上都是通过某种方式获取到服务所部署的 IP 地址。DNS 协议是最早将⼀个网络名称翻译…...
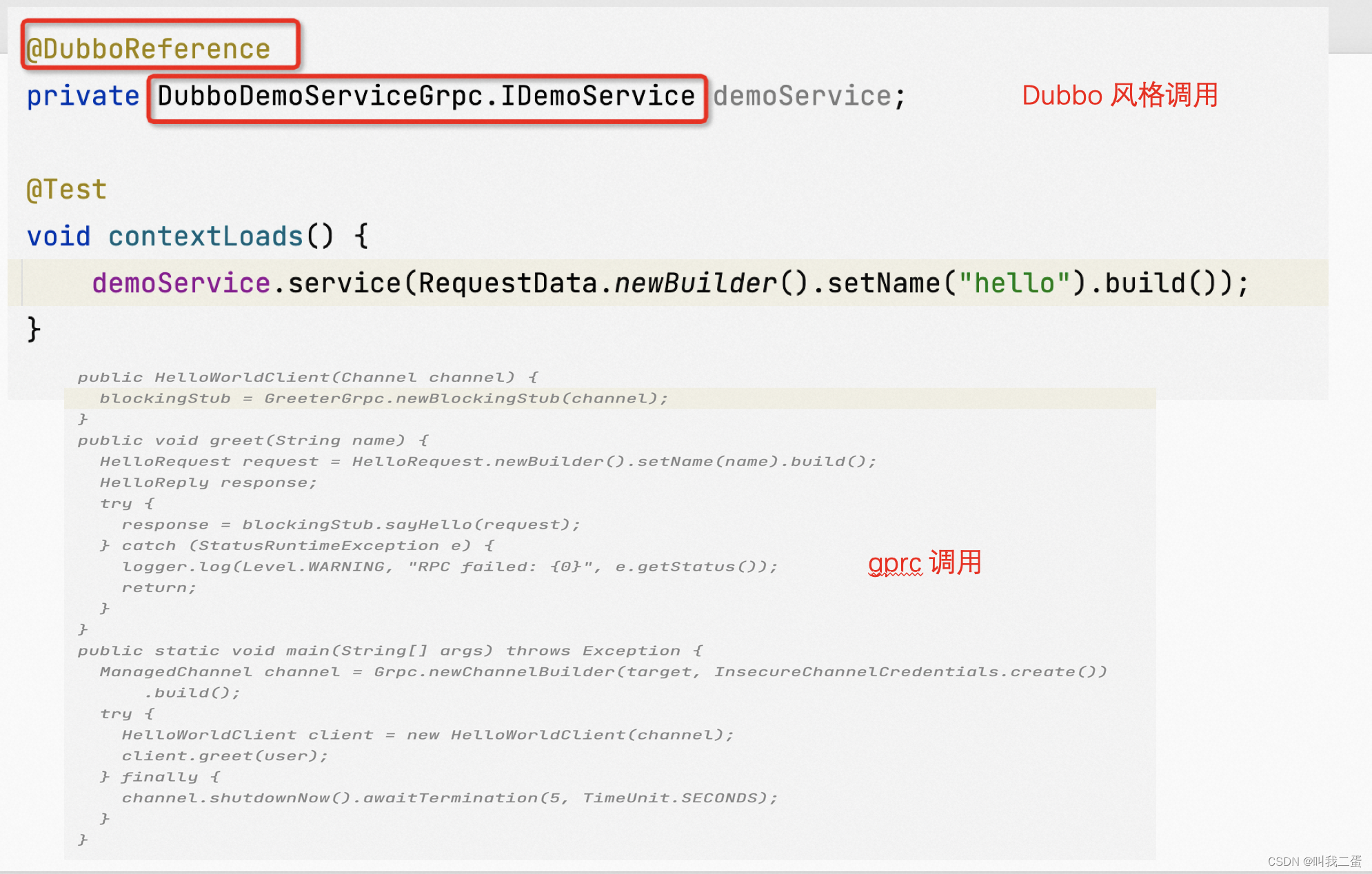
SpringBoot集成Dubbo启用gRPC协议
文章目录 前言项目结构代码示例父工程api moduleservice module 注意事项区别 本文记录下SpringBoot集成Dubbo启用gRPC协议,以及与原生 gRPC 在代码编写过程中的区别。 下面还有投票,帮忙投个票👍 前言 Dubbo 在 2.7.5 版本开始支持原生 gRP…...

Kali HTTrack演示-渗透测试察打一体(1)
HTTrack是一个免费并易于使用的线下浏览器工具,全称是HTTrack Website Copier for Windows,它能够让你从互联网上下载指定的网站进行线下浏览(离线浏览),也可以用来收集信息(甚至有网站使用隐藏的密码文件),一些仿真度极高的伪网站(为了骗取用户密码),也是使用类似工具做…...

ThreeJS进阶之使用后期处理
什么是后期处理? 很多three.js应用程序是直接将三维物体渲染到屏幕上的。 有时,你或许希望应用一个或多个图形效果,例如景深、发光、胶片微粒或是各种类型的抗锯齿。 后期处理是一种被广泛使用、用于来实现这些效果的方式。 首先,场景被渲染到一个渲染目标上,渲染目标表示…...

KubeEdge节点分组特性简介
01 边缘应用跨地域部署场景及问题 应用生命周期管理复杂导致运维成本提高 02 边缘节点分组管理 节点分组:将不同地区的边缘节点按照节点组的形式组织 边缘应用:将应用资源整体打包并满足不同节点组之间的差异化部署需求 流量闭环:将服务流量…...

论文笔记_2018_IEEE Access_评估地图用于车辆定位能力的因素
目录 基本情况 摘要 I. 引言 II. 相关工作 III. 地图评估标准的定义 A.地图的特...
YOLOv8 人体姿态估计(关键点检测) python推理 ONNX RUNTIME C++部署
目录 1、下载权重 2、python 推理 3、转ONNX格式 4、ONNX RUNTIME C 部署 1、下载权重 我这里之前在做实例分割的时候,项目已经下载到本地,环境也安装好了,只需要下载pose的权重就可以 2、python 推理 yolo taskpose modepredict model…...

AgilePLM 通用自动赋值程序 安装使用说明
功能概述 首先,简单介绍一下自动赋值的意思。就是程序根据给定的条件,给某一个数据对象的某个字段自动填值。 类似功能单独定制开发写程序也能实现。通用赋值程序只是赋值规则简化到了配置文件中。后续如果赋值规则变更,只需要修改配置文件…...

小数转整数的情况
小数转整数的情况 在程序开发中,经常会遇到需要将小数转为整数的情况。但是在转换时需要注意几个问题,本篇博客将详细阐述小数转整数的注意事项。 直接赋值 在C语言中,将一个小数赋值给整型变量时,会直接舍弃小数部分。比如&am…...

05-Docker安装Mysql、Redis、Tomcat
Docker 安装 Mysql 以安装 Mysql 5.7为例: docker pull mysql:5.7Mysql 单机 Mysql 5.7安装 启动 Mysql 容器,并配置容器卷映射: docker run -d -p 3306:3306 \--privilegedtrue \-v /app/mysql/log:/var/log/mysql \-v /app/mysql/data:…...
Docker Overlay2占用大量磁盘空间解决
问题 最近项目的jenkins编译时报错 FATAL: Unable to produce a script filejava.io.IOException: No space left on deviceat java.io.UnixFileSystem.createFileExclusively(Native Method)at java.io.File.createTempFile(File.java:2024)at hudson.FilePath$CreateTextTem…...
2023年免费自动养站程序
什么是养站?SEO是与搜索引擎建立信任的过程,养站不仅仅是建立一个网站,还需要我们不断的更新和维护,才能使网站长时间稳定运行并获得更好的排名。今天跟大家分享如何建站以及如何养站。 一、明确TDK 在设计网站时,我…...

86.qt qml-多种粒子特效按钮实现
截图如下所示: 动图如下所示: 支持黑白模式: 1.实现原理 配合之前我们学习的: 82.qt qml-2D粒子系统、粒子方向、粒子项(一)_诺谦的博客-CSDN博客 83.qt qml-初步学习2D粒子影响器(二)_诺谦的博客-CSDN博客 即可实现出来。 以按钮特效3按钮为例:...

DockerHub与私有镜像仓库在容器化中的应用与管理
哈喽,大家好,我是左手python! Docker Hub的应用与管理 Docker Hub的基本概念与使用方法 Docker Hub是Docker官方提供的一个公共镜像仓库,用户可以在其中找到各种操作系统、软件和应用的镜像。开发者可以通过Docker Hub轻松获取所…...

Oracle查询表空间大小
1 查询数据库中所有的表空间以及表空间所占空间的大小 SELECTtablespace_name,sum( bytes ) / 1024 / 1024 FROMdba_data_files GROUP BYtablespace_name; 2 Oracle查询表空间大小及每个表所占空间的大小 SELECTtablespace_name,file_id,file_name,round( bytes / ( 1024 …...

HTML 列表、表格、表单
1 列表标签 作用:布局内容排列整齐的区域 列表分类:无序列表、有序列表、定义列表。 例如: 1.1 无序列表 标签:ul 嵌套 li,ul是无序列表,li是列表条目。 注意事项: ul 标签里面只能包裹 li…...

基于当前项目通过npm包形式暴露公共组件
1.package.sjon文件配置 其中xh-flowable就是暴露出去的npm包名 2.创建tpyes文件夹,并新增内容 3.创建package文件夹...

基础测试工具使用经验
背景 vtune,perf, nsight system等基础测试工具,都是用过的,但是没有记录,都逐渐忘了。所以写这篇博客总结记录一下,只要以后发现新的用法,就记得来编辑补充一下 perf 比较基础的用法: 先改这…...

重启Eureka集群中的节点,对已经注册的服务有什么影响
先看答案,如果正确地操作,重启Eureka集群中的节点,对已经注册的服务影响非常小,甚至可以做到无感知。 但如果操作不当,可能会引发短暂的服务发现问题。 下面我们从Eureka的核心工作原理来详细分析这个问题。 Eureka的…...

【JVM面试篇】高频八股汇总——类加载和类加载器
目录 1. 讲一下类加载过程? 2. Java创建对象的过程? 3. 对象的生命周期? 4. 类加载器有哪些? 5. 双亲委派模型的作用(好处)? 6. 讲一下类的加载和双亲委派原则? 7. 双亲委派模…...
详细解析)
Caliper 负载(Workload)详细解析
Caliper 负载(Workload)详细解析 负载(Workload)是 Caliper 性能测试的核心部分,它定义了测试期间要执行的具体合约调用行为和交易模式。下面我将全面深入地讲解负载的各个方面。 一、负载模块基本结构 一个典型的负载模块(如 workload.js)包含以下基本结构: use strict;/…...

毫米波雷达基础理论(3D+4D)
3D、4D毫米波雷达基础知识及厂商选型 PreView : https://mp.weixin.qq.com/s/bQkju4r6med7I3TBGJI_bQ 1. FMCW毫米波雷达基础知识 主要参考博文: 一文入门汽车毫米波雷达基本原理 :https://mp.weixin.qq.com/s/_EN7A5lKcz2Eh8dLnjE19w 毫米波雷达基础…...
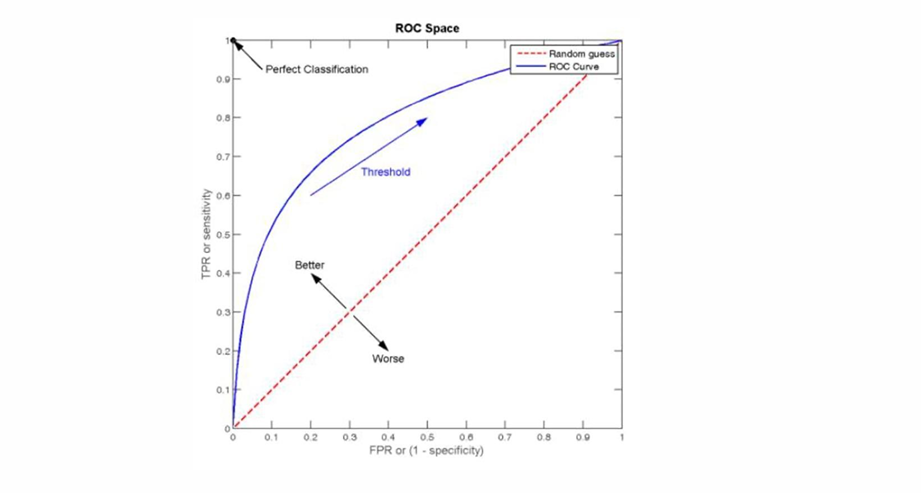
自然语言处理——文本分类
文本分类 传统机器学习方法文本表示向量空间模型 特征选择文档频率互信息信息增益(IG) 分类器设计贝叶斯理论:线性判别函数 文本分类性能评估P-R曲线ROC曲线 将文本文档或句子分类为预定义的类或类别, 有单标签多类别文本分类和多…...