机器学习13(正则化)
文章目录
- 简介
- 正则化
- 经验风险和结构风险
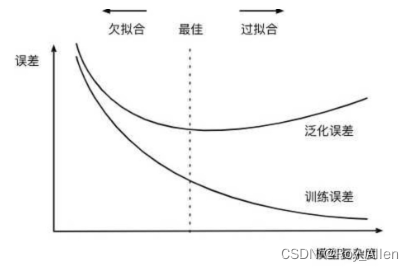
- 过拟合
- 正则化
- 建模策略
- 逻辑回归
- 逻辑回归评估器
- 练习
- 评估器训练与过拟合实验
- 评估器的手动调参
简介
- 这一节详细探讨关于正则化的相关内容,并就 sklearn 中逻辑回归(评估器)的参数进行详细解释
- 由于 sklearn 内部参数的一致性,许多参数不仅是逻辑回归的参数,也是大多数分类模型的通用参数
- 逻辑回归作为一个诞生时间较早并且拥有深厚统计学背景的模型,拥有非常多的变种应用方法,虽然之前就逻辑回归的基本原理、基础公式以及分类性能进行了探讨,但实际上逻辑回归算法的模型形态和应用方式远不止于此,在 sklearn 中,提供了非常丰富的逻辑回归的可选算法参数,相当于提供了一个集大成者的逻辑回归模型
- 第一个参数就是关于正则化的选项
正则化
- 可以看一下逻辑回归的参数选项
from sklearn.linear_model import LogisticRegression LogisticRegression? Init signature: LogisticRegression(penalty='l2',*,dual=False,tol=0.0001,C=1.0,fit_intercept=True,intercept_scaling=1,class_weight=None,random_state=None,solver='lbfgs',max_iter=100,multi_class='auto',verbose=0,warm_start=False,n_jobs=None,l1_ratio=None, ) penalty='l2'也就是 L2 正则化,接下来,就正则化的相关内容展开讨论- 机器学习中正则化(regularization)的外在形式非常简单,就是在模型的损失函数中加上一个正则化项(regularizer),有时也被称为惩罚项(penalty term)
- 如下方程所示,其中L为损失函数,J为正则化项
- 通常来说,正则化项往往是关于模型参数的 1-范数 或者 2-范数,当然也有可能是这两者的某种结合,例如sklearn的逻辑回归中的弹性网正则化项
- 模型加入 1-范数 的正则化也被称为 𝑙1 正则化,加入 2-范数 的正则化也被称为 𝑙2 正则化
1 N ∑ i = 1 N L ( y i , f ( x i ) ) + λ J ( f ) \frac{1}{N}\sum^{N}_{i=1}L(y_i,f(x_i))+\lambda J{(f)} N1i=1∑NL(yi,f(xi))+λJ(f) - 何时需要进行正则化呢?
- 正则化核心的作用是缓解模型过拟合倾向,此外,由于加入正则化项后损失函数的结构发生了变化,因此也会影响损失函数的求解过程,比如岭回归在加入了 𝑙1 正则化项之后会让损失函数的求解变得更加高效
- 对于逻辑回归来说,如果加入 𝑙2 正则化项,损失函数就会变成严格的凸函数
- 也就是说,如果模型出现了过拟合,就需要用正则化,在了解正则化的具体原理之前,需要引入两个非常重要的概念:经验风险和结构风险
经验风险和结构风险
- 在我们构建损失函数求最小值的过程,其实就是依据以往经验(训练数据)追求风险最小(以往数据上误差最小)的过程
- 而在给定一组参数(训练后的w)后计算得出的损失函数的损失值(使用测试数据),其实就是经验风险
- 而所谓结构风险,我们可以将其等价为模型复杂程度,模型越复杂,结构风险就越大
- 而正则化后的损失函数在进行最小值求解的过程中,其实是希望损失函数本身和正则化项都取得较小的值,即模型的经验风险和结构风险能够同时得到控制
- 换句话说就是,正则项能够进一步降低损失值,还能够简化模型结构
- 模型的经验风险需要被控制不难理解,因为我们希望模型能够尽可能的捕捉原始数据中的规律,但为何模型的结构风险也需要被控制?核心原因在于,尽管在一定范围内模型复杂度增加能够有效提升模型性能,但模型过于复杂可能会导致另一个非常常见的问题——过拟合
- 关于模型过拟合的概念稍后会进行更加详细的介绍,但总的来说,一旦模型过拟合了,尽管模型经验风险在降低、但模型的泛化能力会下降。因此,为了控制模型过拟合倾向,我们可以把模型结构风险纳入损失函数中一并考虑,当模型结构风险的增速高于损失值降低的收益时,我们就需要停止参数训练(迭代)
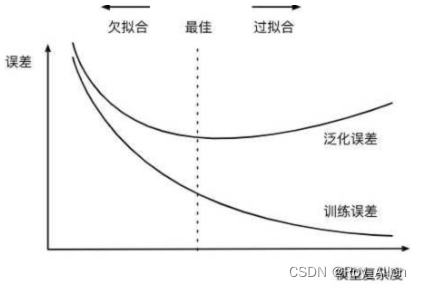
- 同时要求模型性能和模型复杂度都在一个合理的范围内,其实等价于希望训练得到一个较小的模型同时具有较好的解释数据的能力(捕捉全局规律的能力),这也符合奥卡姆剃刀原则
- 解释数据=捕捉数据全局规律
过拟合
- 前面探讨过关于机器学习建模有效性的问题,得出的结论是当训练数据和新数据具有规律的一致性时,才能够进行建模,而只有挖掘出贯穿始终的规律(同时影响训练数据和新数据的规律),模型才能够进行有效预测
- 不过,既然有贯穿始终的全局规律,那就肯定存在一些只影响了一部分数据的局部规律
- 一般来说,由于全局规律影响数据较多,因此更容易被挖掘,而局部规律只影响部分数据,更难被挖掘,因此从较为宽泛的角度来看,但伴随着模型性能提升,也是能够捕获很多局部规律的
- 但局部规律对于新数据的预测并不能起到正面的作用,反而会影响预测结果,此时就出现模型过拟合现象
- 也就是说,过拟合是指模型捕捉到了数据的局部规律,过拟合会对新数据的预测产生负面影响
- 通过如下实例进行说明
- x 是一个0到1之间等距分布20个点组成的 ndarray
# 设计随机数种子 np.random.seed(123)# 创建数据 n_dots = 20 x = np.linspace(0, 1, n_dots) # 从0到1,等宽排布的20个数 y = np.sqrt(x) + 0.2*np.random.rand(n_dots) - 0.1 # 根号x + 扰动项 - y = x + r y=\sqrt{x}+r y=x+r,r 是人为制造的随机噪声,在[-0.1,0.1]之间服从均匀分布
- 借助 numpy 的
polyfit函数来进行多项式拟合,polyfit函数会根据设置的多项式阶数,在给定数据的基础上利用最小二乘法进行拟合,并返回拟合后各阶系数,系数计算完成后,常用ploy1d函数逆向构造多项式方程,进而利用方程求解 y - 人为制造一个二阶多项式方程然后进行二阶拟合实验
y0 = x ** 2 np.polyfit(x, y0, 2) # 2阶 # array([ 1.00000000e+00, -2.00019564e-18, -3.29090297e-17]) p = np.poly1d(np.polyfit(x, y0, 2)) # 方程 print(p) # 1 x^2 - 2e-18 x - 3.291e-17 p(-1) # 1.0 - 接下来分别利用1阶x多项式、3阶x多项式和10阶x多项式来拟合y,并利用图形观察多项式的拟合度
- 首先定义一个辅助画图函数,方便后续将图形画于一张画布中,进而方便观察
def plot_polynomial_fit(x, y, deg):p = np.poly1d(np.polyfit(x, y, deg))t = np.linspace(0, 1, 200)# 原始数据红点,模型蓝曲线,真实规律红虚线(全局规律)plt.plot(x, y, 'ro', t, p(t), '-', t, np.sqrt(t), 'r--') # 测试 plot_polynomial_fit(x, y, 3)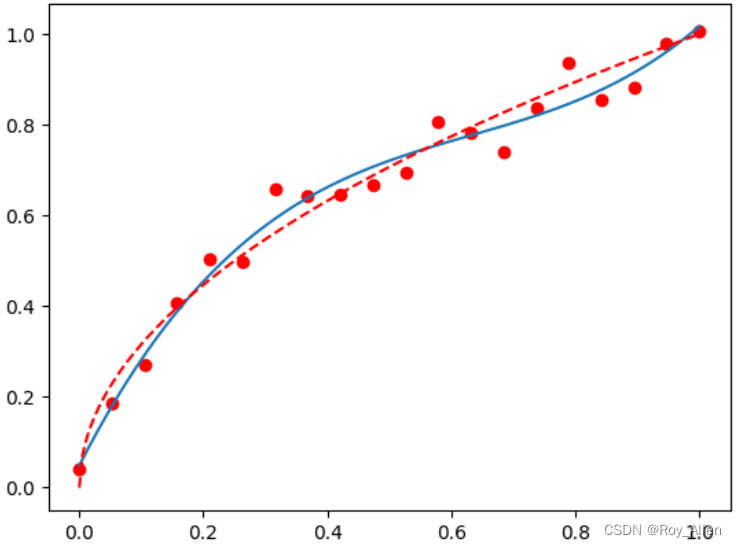
- 将三个拟合结果放在一张图中
plt.figure(figsize=(18, 4), dpi=200) titles = ['Under Fitting', 'Fitting', 'Over Fitting'] for index, deg in enumerate([1, 3, 10]):plt.subplot(1, 3, index + 1)plot_polynomial_fit(x, y, deg)plt.title(titles[index], fontsize=20)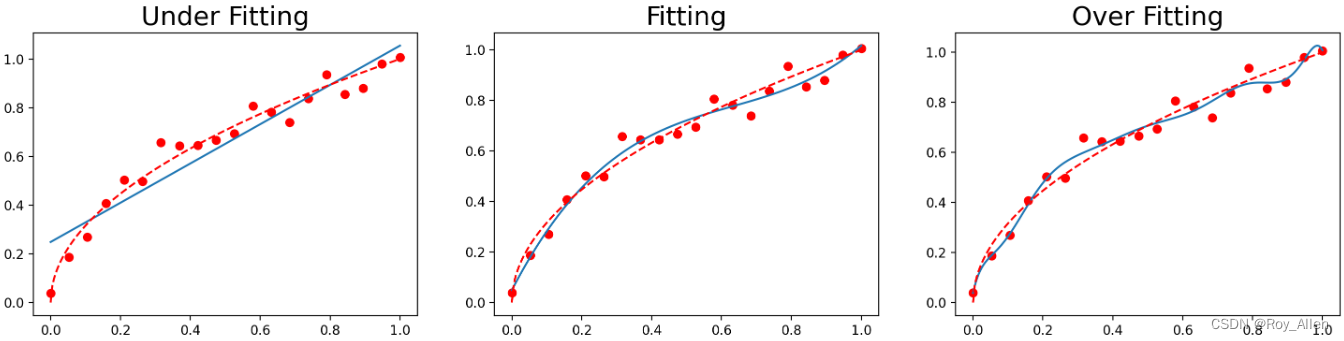
- 一阶多项式拟合的曲线即无法捕捉数据集的分布规律,离数据集背后客观规律也很远
- 三阶多项式在这两方面表现良好
- 十阶多项式则在数据集分布规律捕捉上表现良好(经过了大部分数据点),但同样偏离红色曲线较远
- 此时一阶多项式实际上就是欠拟合,而十阶多项式则过分捕捉了噪声数据的分布规律(局部规律),而噪声之所以被称作噪声,是因为其分布本身毫无规律可言,或者其分布规律毫无价值,因此就算十阶多项式在当前训练数据集上拟合度很高,但其捕捉到的无用规律无法推广到新的数据集上,因此该模型在测试数据集上执行过程将会有很大误差。即模型训练误差很小,但泛化误差(损失值)很大
- x 是一个0到1之间等距分布20个点组成的 ndarray
- 接下来回到正则化,看看它是如何降低风险的,或者说如何解决过拟合问题的
- 风险大的模型往往是过拟合的,所以从很大程度上来说,降低风险就是解决过拟合问题
- 而正则化核心的作用就是缓解模型过拟合倾向
- 至于如何提高预测的准确率就不是这里考虑的问题了,当然,风险大也有其他因素,需要用其他方法解决,这里先把握主要问题
正则化
- 尝试在模型中加入正则化项来缓解10阶多项式的过拟合倾向
- 为了更加符合 sklearn 的建模风格、从而能够使用sklearn的诸多方法,我们将上述10阶多项式建模转化为等价的另一种形式,即在原始数据中衍生出几个特征: x 2 x^2 x2、 x 3 x^3 x3、…、 x 10 x^{10} x10,然后代入线性回归方程进行建模
- 换句话说就是之前用一个特征拟合到10阶,现在用10个特征拟合,但这10个特征其实是由一个特征衍生(升次方)出来的,效果一样(每一阶/每个特征都有系数),转换形式而已
x_l = [] for i in range(10):x_temp = np.power(x, i+1).reshape(-1, 1) # 搞成一列x_l.append(x_temp) # 最终搞成10列(20行,20组训练数据),就是10个特征 x1...x10,开始训练得到 w1...w10 X = np.concatenate(x_l, 1) # 还要有个bias - 上述衍生过程也可以通过sklearn中的PolynomialFeatures类实现
from sklearn.preprocessing import PolynomialFeatures # 查看帮助文档 PolynomialFeatures? - 围绕特征衍生后的新数据来进行线性回归建模
from sklearn.linear_model import LinearRegression lr = LinearRegression() lr.fit(X, y) lr.coef_ # 查看过拟合时MSE from sklearn.metrics import mean_squared_error mean_squared_error(lr.predict(X), y) # 0.001172668222879593 # 观察建模结果 t = np.linspace(0, 1, 200) plt.plot(x, y, 'ro', x, lr.predict(X), '-', t, np.sqrt(t), 'r--') plt.title('10-degree') - 接下来,尝试在线性回归的损失函数中引入正则化,来缓解过拟合问题
- 根据前面的讨论我们知道,在线性回归中加入 l 2 l2 l2 正则化,实际上就是岭回归(Ridge),而加入 l 1 l1 l1 正则化,则变成了 Lasso
- 因此,我们分别考虑围绕上述模型进行岭回归和Lasso的建模
# 导入岭回归和Lasso from sklearn.linear_model import Ridge,Lasso # alpha越大,惩罚力度越大 reg_rid = Ridge(alpha=0.005) reg_rid.fit(X, y) mean_squared_error(reg_rid.predict(X), y) # 0.0021197020660901986 # 观察惩罚效果 t = np.linspace(0, 1, 200) plt.subplot(121) plt.plot(x, y, 'ro', x, reg_rid.predict(X), '-', t, np.sqrt(t), 'r--') plt.title('Ridge(alpha=0.005)') plt.subplot(122) plt.plot(x, y, 'ro', x, lr.predict(X), '-', t, np.sqrt(t), 'r--') plt.title('LinearRegression')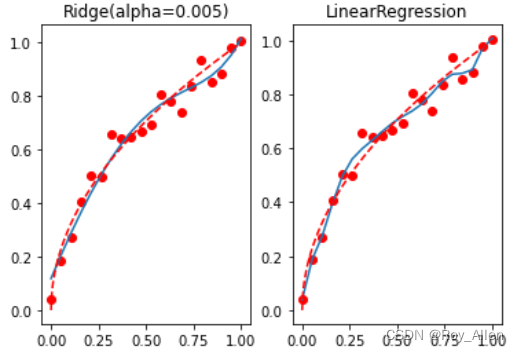
- 不难发现, l 2 l2 l2 正则化对过拟合倾向有较为明显的抑制作用
reg_las = Lasso(alpha=0.001) # 设置小一些 reg_las.fit(X, y) reg_las.coef_ # array([ 1.10845364, -0. , -0.37211179, -0. , -0. , # 0. , 0. , 0. , 0. , 0.05080217])mean_squared_error(reg_las.predict(X), y) # 0.004002917874293844 t = np.linspace(0, 1, 200) plt.subplot(121) plt.plot(x, y, 'ro', x, reg_las.predict(X), '-', t, np.sqrt(t), 'r--') plt.title('Lasso(alpha=0.001)') plt.subplot(122) plt.plot(x, y, 'ro', x, lr.predict(X), '-', t, np.sqrt(t), 'r--') plt.title('LinearRegression')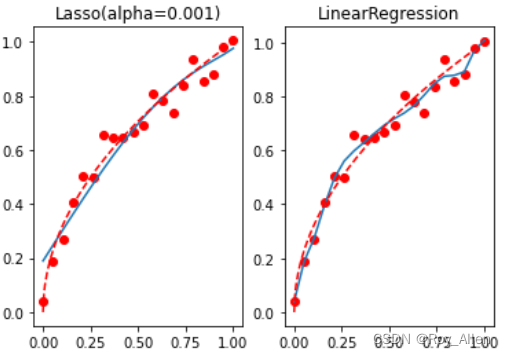
- 可以看到,Lasso 的惩罚力度更强,并且迅速将一些系数清零,而这些被清零的参数,则代表对应的特征在实际建模过程中并不重要,从而达到特征筛选的目的
- 在实际的建模过程中, l 2 l2 l2 正则化往往应用于缓解过拟合趋势,而 l 1 l1 l1 正则化往往被用于特征筛选
-
特征重要性和特征对应系数大小并没有太大的关系,判断特征是否重要的核心还是在于观察抛弃某些特征后,建模结果是否会发生显著影响
- l 1 l1 l1 正则化的运算结果说明,上述10个特征中,第一个、第三个和最后一个特征相对重要。而特征重要的含义,其实是代表哪怕带入上述3个特征建模,依然能够达到带入所有特征建模的效果
# 验证 # 挑选特征,构建新的特征矩阵 X_af = X[:, [0, 2, 9]] lr_af = LinearRegression() lr_af.fit(X_af, y) lr_af.coef_ # array([ 1.45261658, -0.93936141, 0.39449483]) mean_squared_error(lr_af.predict(X_af), y) # 0.0027510973386944155 lr_af.predict(X_af) # 画图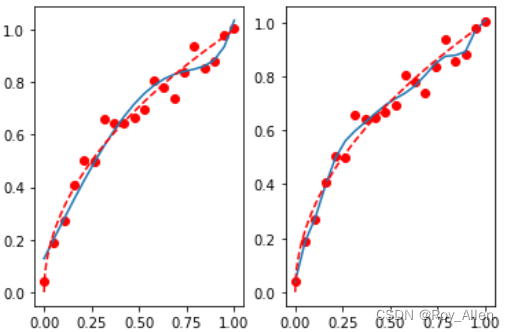
- 可以看到,哪怕删掉了70%的特征,最终建模结果仍然还是未收到太大的影响,从侧面也说明剩下70%的特征确实“不太重要”,过拟合的趋势也略微有所好转
- 继续加上 l 2 l2 l2 正则化呢
# 特征减少,可以适度放大alpha reg_rid_af = Ridge(alpha=0.05) reg_rid_af.fit(X_af, y) reg_rid_af.coef_ # array([ 1.02815296, -0.31070552, 0.06374435]) mean_squared_error(reg_rid_af.predict(X_af), y) # 0.004383156990375146 # 画图 t = np.linspace(0, 1, 200) plt.subplot(121) plt.plot(x, y, 'ro', x, reg_rid_af.predict(X_af), '-', t, np.sqrt(t), 'r--') plt.title('Ridge_af(alpha=0.05)') plt.subplot(122) # 和只使用Ridge相比 plt.plot(x, y, 'ro', x, reg_rid.predict(X), '-', t, np.sqrt(t), 'r--') plt.title('Ridge(alpha=0.005)')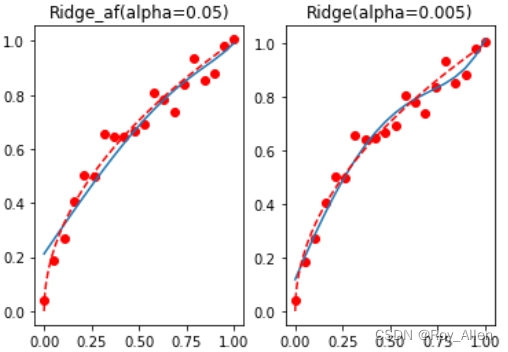
- 整体过拟合倾向被更进一步抑制,整体拟合效果较好
建模策略
- 小结一下
- 当模型效果(往往是线性模型,多项式方程)不佳时,可以考虑通过特征衍生的方式来进行数据的“增强”
- 如果出现过拟合趋势,则首先可以考虑进行不重要特征的筛选,过多的无关特征其实也会影响模型对于全局规律的判断,此时可以考虑使用 l 1 l1 l1 正则化配合线性方程进行特征重要性筛选,剔除不重要的特征
- 对于过拟合趋势的抑制,仅仅踢出不重要特征还是不够的,对于线性方程类的模型来说, l 2 l2 l2 正则化则是缓解过拟合非常好的方法,配合特征筛选,能够快速的缓解模型过拟合倾向
- 不进行特征筛选, l 2 l2 l2 正则化也可以帮助线性方程抑制过拟合,但特征太多其实会影响 l 2 l2 l2 正则化的参数取值范围,进而影响
alpha参数惩罚力度的有效性 - 上述参数的选取和过拟合倾向的判断,其实还是主观判断成分较多(选择,看图),一个更加严谨的流程是,先进行数据集的划分,然后选取更能表示模型泛化能力的评估指标,然后将特征提取(比如选 0/2/9)、 l 2 l2 l2 正则化后的线性方程组成一个 Pipeline,再利用网格搜索(遍历),确定一组最优的参数组合(下一节)
- 需要强调的是,并非所有模型都需要/可以通过正则化来进行过拟合修正,典型的可以通过正则化来进行过拟合倾向修正的模型主要有线性回归、逻辑回归、LDA、SVM 以及一些 PCA 衍生算法(如SparsePCA)。而树模型则不用通过正则化来进行过拟合修正
逻辑回归
- 官网给出的逻辑回归加入正则化后的损失函数表达式

- 该表达式和此前推导的交叉熵损失函数的表达式略有差异,核心原因是 sklearn 在二分类时默认两个类别标签取值为 -1 和 1,而不是 0 和 1,可以参考前面的内容,练习推导过程
- 观察发现,正则化后的损失函数有两处发生了变化
- 在原损失函数基础上乘以了系数 C,也是超参数,需要人工输入,用于调整经验风险部分和结构风险部分的权重,C越大,经验风险部分权重越大,反之结构风险部分权重越大
- 加入了正则化项,在 l 2 l2 l2 正则化时,采用的 w T w 2 \frac{w^Tw}{2} 2wTw 表达式,其实相当于是各参数的平方和除以2,在求最小值时本质上和 w 的 2-范数 起到的作用相同,省去开平方是为了简化运算,而除以 2 则是为了方便后续求导运算
- 另外,sklearn 中还提供了弹性网正则化方法,通过 ρ \rho ρ 控制 l 1 l1 l1正则化和 l 2 l2 l2正则化惩罚力度的权重,是一个更加综合的解决方案。不过代价是增加了一个超参数 ρ \rho ρ,并且由于损失函数形态发生了变化,导致部分优化方法无法使用
逻辑回归评估器
- 进入正题,sklearn 中逻辑回归评估器的参数(函数形参)解释
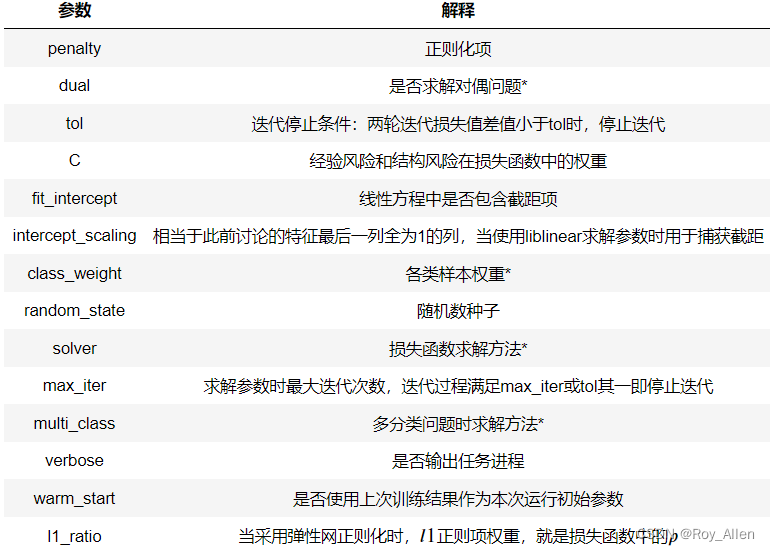
- 对偶问题是约束条件相反、求解方向也相反的问题,一般在数据集过小而特征较多时使用
- class_weight 代表各类样本在进行损失函数计算时的数值权重,例如一个二分类问题,0、1两类的样本比例是 2:1,此时可以输入一个字典类型对象用于说明两类样本在进行损失值计算时的权重,例如输入 {0:1, 1:3},则代表1类样本的每一条数据在进行损失函数值的计算时都会在原始数值上*3。而当我们将该参数选为balanced时,则会自动将这个比例调整为真实样本比例的反比,以达到平衡的效果
- 其实除了最小二乘法和梯度下降以外,还有非常多的关于损失函数的求解方法,由 solver 参数决定
- 当然,也不是随便选的,得看损失函数的形态
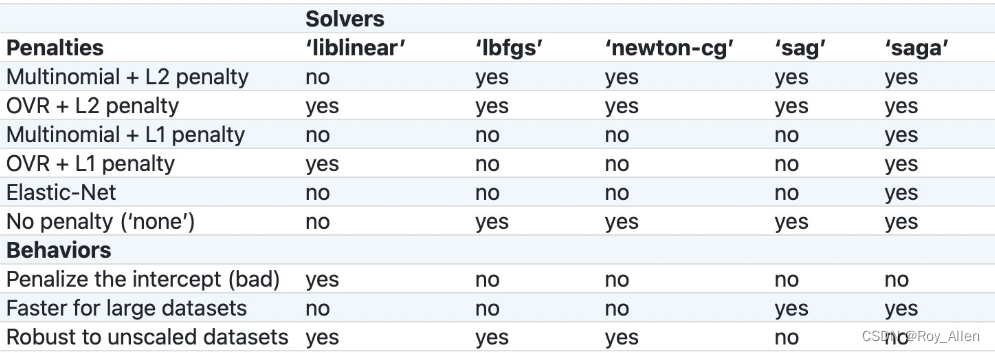
- liblinear,这是一种坐标轴下降法,并且该软件包中大多数算法都有C++编写,运行速度很快,支持OVR+L1或OVR+L2
- lbfgs,全称是L-BFGS,牛顿法的一种改进算法(一种拟牛顿法),适用于小型数据集,并且支持MVM+L2、OVR+L2以及不带惩罚项的情况
- newton-cg,同样也是一种拟牛顿法,和 lbfgs 适用情况相同
- sag,随机平均梯度下降,随机梯度下降的改进版,类似动量法,会在下一轮随机梯度下降开始之前保留一些上一轮的梯度,从而为整个迭代过程增加惯性,除了不支持L1正则化的损失函数求解以外(包括弹性网正则化)其他所有损失函数的求解
- saga,sag的改进版,修改了梯度惯性的计算方法,使得其支持所有情况下逻辑回归的损失函数求解
-
对于逻辑回归来说,决定损失函数形态的,就是多分类问题时采用的策略以及加入的惩罚项,所以大多数情况,会优先根据多分类问题的策略及惩罚项来选取优化算法,其次,如果还有多个算法可选,可以根据以下情况
- Penalize the intercept (bad),如果要对截距项也进行惩罚,那只能选取liblinear
- Faster for large datasets,如果需要对海量数据进行快速处理,则可以选取sag和saga
- Robust to unscaled datasets,如果未对数据集进行标准化,但希望维持数据集的鲁棒性(迭代平稳高效),则可以考虑使用liblinear、lbfgs和newton-cg三种求解方法
- 当然,也不是随便选的,得看损失函数的形态
- multi_class:选用何种方法进行多分类问题求解
- 可选 OVR 和 MVM,默认情况是 auto,此时模型会优先根据惩罚项和solver选择OVR还是MVM,但一般来说,MVM 效果会好于 OVR
- 对于这些参数更深层次的理解,则需要长期的积淀;接下来进行一次综合调参练习
练习
- 在补充了一系列关于正则化的基础理论以及 sklearn 中逻辑回归评估器的参数解释之后,我们可以尝试进行包含特征衍生和正则化过程的建模试验,同时探索模型经验风险和结构风险之间的关系
- 一方面巩固此前介绍的相关内容,同时也进一步加深对于Pipeline的理解和使用。也为后续的网格搜索调参做铺垫,总结出更好的调参策略
# 科学计算模块 import numpy as np import pandas as pd# 绘图模块 import matplotlib as mpl import matplotlib.pyplot as plt# 自定义模块 from ML_basic_function import *# Scikit-Learn相关模块 # 评估器类 from sklearn.preprocessing import StandardScaler from sklearn.preprocessing import PolynomialFeatures from sklearn.linear_model import LogisticRegression from sklearn.pipeline import make_pipeline# 实用函数 from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score - 准备数据集
- 逻辑回归的决策边界实际上就是逻辑回归的线性方程这一特性(线性模型=?)
- 创建一个满足分类边界为 y 2 = − x + 1.5 y^2=-x+1.5 y2=−x+1.5 的分布
np.random.seed(24) # 均值(中心),标准差(宽度),维度 X = np.random.normal(0, 1, size=(1000, 2)) # 从正态(高斯)分布中抽取随机样本,1000个坐标 y = np.array(X[:,0]+X[:, 1]**2 < 1.5, int) plt.scatter(X[:, 0], X[:, 1], c=y) np.shape(y) # (1000,) 一行,1000列,和 (4,3) 4行3列 相反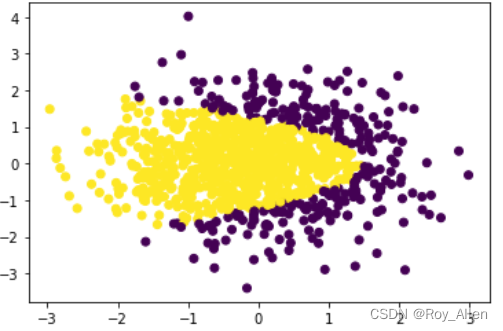
- 选取分类边界的哪一侧为正类哪一侧为负类(即不等号的方向),并不影响后续建模
- 再人为增加一些扰动项,即让两个类别的分类边界不是那么清晰
np.random.seed(24) for i in range(200):y[np.random.randint(1000)] = 1 # 一维数组y[np.random.randint(1000)] = 0 plt.scatter(X[:, 0], X[:, 1], c=y)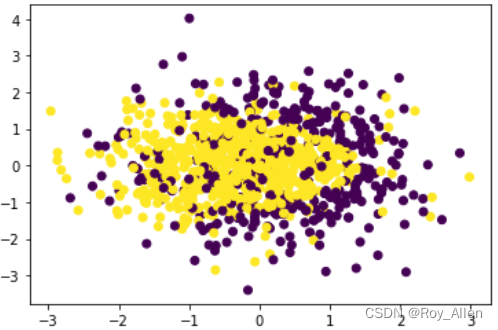
- 数据集切分
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.7, random_state = 42)
- 构建机器学习流
- 接下来,调用逻辑回归中的相关类,进行模型构建
- 很明显,面对上述曲线边界的问题,通过简单的逻辑回归无法达到较好的预测效果,因此需要借助此前介绍的 PolynomialFeatures 来进行特征衍生,或许能够提升模型表现
- 此外,我们还需要对数据进行标准化处理,增加训练过程稳定性及模型训练效率
- 还可以通过Pipeline将这些过程封装在一个机器学习流中,以简化调用过程
- 整个建模过程我们需要测试在不同强度的数据衍生下,模型是否会出现过拟合倾向,如果出现过拟合之后应该如何调整
- 我们将上述过程封装在一个函数中,可以非常便捷地进行核心参数的设置,同时也能够重复实例化不同的评估器以支持重复试验
# 构建学习流 def plr(degree=1, penalty='none', C=1.0):pipe = make_pipeline(PolynomialFeatures(degree=degree, include_bias=False), StandardScaler(), LogisticRegression(penalty=penalty, tol=1e-4, C=C, max_iter=int(1e6)))return pipe - degree 和数据增强的强度相关,决定了衍生特征的最高阶数
- penalty、C 是逻辑回归中控制正则化及惩罚力度的相关参数
- 有两点需要注意:首先,复杂模型的建模往往会有非常多的参数需要考虑,但一般来说我们会优先考虑影响最终建模效果的参数(如影响模型前拟合、过拟合的参数,这是根本),然后再考虑影响训练过程的参数(如调用几核心进行计算、采用何种迭代求解方法等,往往是效率问题);其次,上述实例化逻辑回归模型时,我们适当提高了最大迭代次数(1e6),这是一般复杂数据建模时都需要调整的参数
评估器训练与过拟合实验
- 手动调参,控制模型拟合度
pl1 = plr() # 查看模型参数 pl1.get_params() pl1.get_params()['polynomialfeatures__include_bias'] # 调整参数 # 调整PolynomialFeatures评估器中的include_bias参数 pl1.set_params(polynomialfeatures__include_bias=True) - 观察建模结果与决策边界函数
pr1 = plr() pr1.fit(X_train, y_train) # 效果并不好 pr1.score(X_train, y_train),pr1.score(X_test, y_test) # (0.79, 0.7733333333333333) - 绘制决策边界,更加直观
def plot_decision_boundary(X, y, model):"""决策边界绘制函数"""# 以两个特征的极值+1/-1作为边界,并在其中添加1000个点x1, x2 = np.meshgrid(np.linspace(X[:, 0].min()-1, X[:, 0].max()+1, 1000).reshape(-1,1),np.linspace(X[:, 1].min()-1, X[:, 1].max()+1, 1000).reshape(-1,1))# 将所有点的横纵坐标转化成二维数组X_temp = np.concatenate([x1.reshape(-1, 1), x2.reshape(-1, 1)], 1)# 对所有点进行模型类别预测yhat_temp = model.predict(X_temp)yhat = yhat_temp.reshape(x1.shape)# 绘制决策边界图像from matplotlib.colors import ListedColormapcustom_cmap = ListedColormap(['#EF9A9A','#90CAF9'])plt.contourf(x1, x2, yhat, cmap=custom_cmap)plt.scatter(X[(y == 0).flatten(), 0], X[(y == 0).flatten(), 1], color='red')plt.scatter(X[(y == 1).flatten(), 0], X[(y == 1).flatten(), 1], color='blue') plot_decision_boundary(X, y, pr1)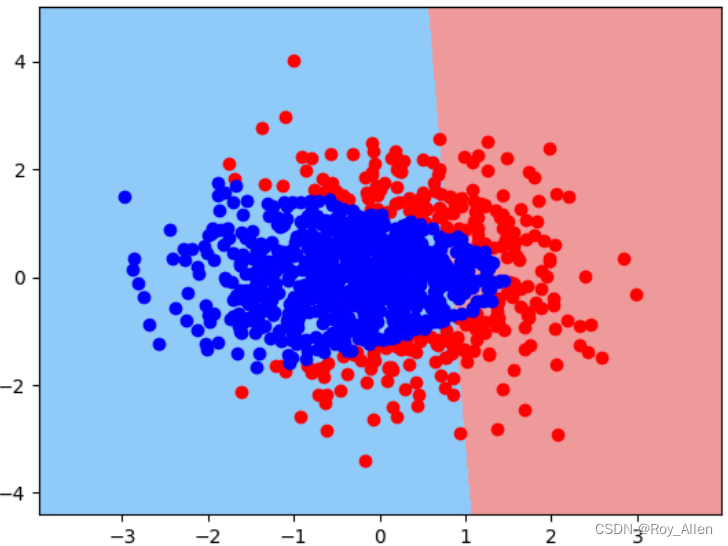
- 在不进行数据衍生的情况下,只能捕捉线性边界,当然这也是模型目前性能欠佳的核心原因
- 用直线将样本划开,就是线性的
- 线性模型可以是用曲线拟合样本,但是分类的决策边界一定是直线的
- 区分是否为线性模型,主要是看一个乘法式子中 x 前的系数 w,如果 w 只影响一个x,那么此模型为线性模型( x n x_n xn 只受 w n w_n wn 影响,才是线性)
- 尝试衍生特征,再进行建模
pr2 = plr(degree=2) # 允许交叉项 pr2.fit(X_train, y_train) pr2.score(X_train, y_train),pr2.score(X_test, y_test) # (1.0, 0.9933333333333333) plot_decision_boundary(X, y, pr2)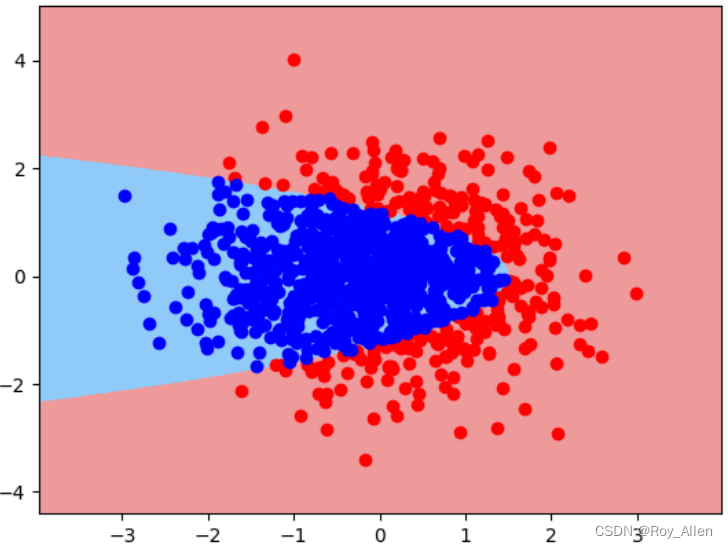
- 模型效果有了明显提升(非常接近自定义边界了)
# 可以列出当前实例化的所有评估器 pr2.named_steps # {'polynomialfeatures': PolynomialFeatures(include_bias=False), # 'standardscaler': StandardScaler(), # 'logisticregression': LogisticRegression(max_iter=1000000, penalty='none')} # 查看参数 pr2.named_steps['logisticregression'].coef_ # array([[-1201.44200673, -17.05785225, -20.11909011, 23.93051569, -1903.66861834]]) - 可以看到,模型总共5个参数,对应训练数据 5 个特征,说明最高次方为二次方、并且存在交叉项(当前5个特征为 x 1 x_1 x1、 x 1 2 x_1^2 x12、 x 2 x_2 x2、 x 2 2 x_2^2 x22、 x 1 x 2 x_1x_2 x1x2)
- 当我们在进行特征衍生的时候,就相当于将原始数据集投射到一个高维空间,而在高维空间内的逻辑回归模型,实际上是构建了一个高维空间内的超平面(高维空间的“线性边界”)在进行类别划分
- 而现在看到的原始特征空间的决策边界,实际上就是高维空间的决策超平面(截面)在当前特征空间的投影
- 由此我们也知道了特征衍生对于逻辑回归模型效果提升的实际作用,就是突破了逻辑回归在原始特征空间中的线性边界的束缚( x n x_n xn 不再只受 w n w_n wn 的影响,因为有交叉项,也因为特征衍生源于同一个特征项)
- 经过特征衍生的逻辑回归模型,也将在原始特征空间中呈现出非线性(不是直线)的决策边界的特性
- 如图所示,例如这种情况下,在三维空间中,两类样本的高度不同,从而确定了截面
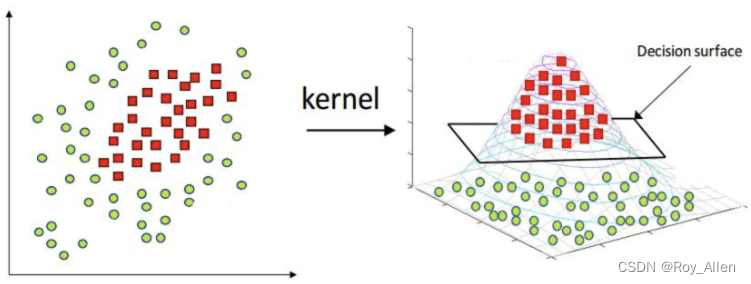
- 需要知道的是,尽管特征衍生看起来很强大,能够帮逻辑回归在原始特征空间中构建非线性的决策边界,但这种非线性边界其实也是受到特征衍生方式的约束的
- 无论是几阶的特征衍生,能够投射到的高维空间都是有限的,而我们最终也只能在这些有限的高维空间中寻找一个最优的超平面,再投影回来
- 过拟合实验
-
衍生到更高阶,可以看出模型已经过拟合了,偏离了我们定义的决策边界
pr3 = plr(degree=10) pr3.set_params(logisticregression__tol=1e-2) # 修改收敛条件 pr3 = plr(degree=10) pr3.set_params(logisticregression__tol=1e-2) # 放宽 pr3.fit(X_train, y_train) pr3.score(X_train, y_train),pr3.score(X_test, y_test) # (1.0, 0.9833333333333333) plot_decision_boundary(X, y, pr3)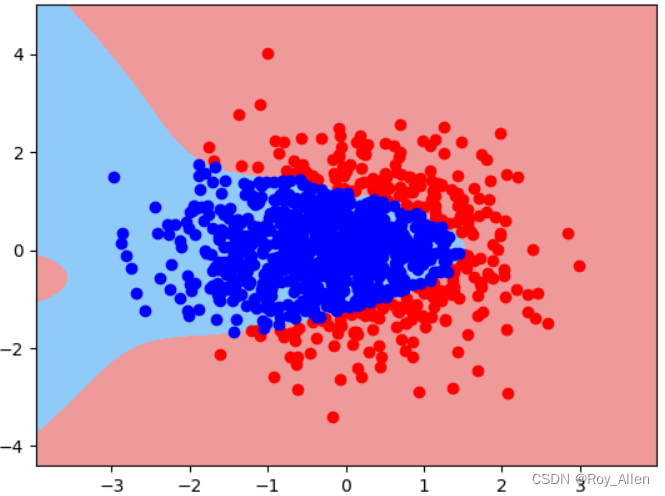
-
观察在提高模型复杂度的过程中训练误差和测试误差是如何变化的
# 用于存储不同模型 训练准确率 与 测试准确率 的列表 score_l = [] # 实例化多组模型,测试模型效果 for degree in range(1, 21):pr_temp = plr(degree=degree)pr_temp.fit(X_train, y_train)score_temp = [pr_temp.score(X_train, y_train),pr_temp.score(X_test, y_test)]score_l.append(score_temp) plt.plot(list(range(1, 21)), np.array(score_l)[:,0], label='train_acc') plt.plot(list(range(1, 21)), np.array(score_l)[:,1], label='test_acc') plt.legend(loc = 4)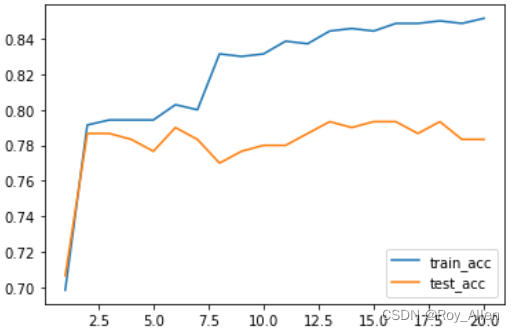
-
能够较为明显的看出,伴随着模型越来越复杂(特征越来越多),训练集准确率逐渐提升,但测试集准确率却在一段时间后开始下降
-
说明模型经历了由开始的欠拟合到拟合再到过拟合的过程,和上面说的 模型结构风险 伴随模型复杂度提升而提升的结论一致
-
评估器的手动调参
- 测试 l 1 l1 l1 正则化
pl1 = plr(degree=10, penalty='l1', C=1.0) pl1.fit(X_train, y_train) # 更换求解器为saga pl1.set_params(logisticregression__solver='saga') pl1.fit(X_train, y_train) pl1.score(X_train, y_train),pl1.score(X_test, y_test) # (0.9857142857142858, 0.9733333333333334) - 测试 l 2 l2 l2 正则化
pl2 = plr(degree=10, penalty='l2', C=1.0).fit(X_train, y_train) pl2.score(X_train, y_train),pl2.score(X_test, y_test) # 抑制了过拟合倾向 - 我们采用一个非常朴素的想法来进行调参,即使用degree、C和正则化选项(l1或l2)的不同组合来进行调参,试图从中选择一组能够让模型表现最好的参数
- l 1 l1 l1 正则化下最优特征衍生阶数,3 阶为最佳
- l 2 l2 l2 正则化下最优特征衍生阶数,15 阶为最佳
- 分别确定 C
# 用于存储不同模型训练准确率与测试准确率的列表 score_l1_3 = [] # 实例化多组模型,测试模型效果 for C in np.arange(0.5, 2, 0.1):pr_temp = plr(degree=3, penalty='l1', C=C)pr_temp.set_params(logisticregression__solver='saga')pr_temp.fit(X_train, y_train)score_temp = [pr_temp.score(X_train, y_train),pr_temp.score(X_test, y_test)]score_l1_3.append(score_temp) # 观察最终结果 plt.plot(list(np.arange(0.5, 2, 0.1)), np.array(score_l1_3)[:,0], label='train_acc') plt.plot(list(np.arange(0.5, 2, 0.1)), np.array(score_l1_3)[:,1], label='test_acc') plt.legend(loc = 4)# 用于存储不同模型训练准确率与测试准确率的列表 score_l2_15 = [] # 实例化多组模型,测试模型效果 for C in np.arange(0.5, 2, 0.1):pr_temp = plr(degree=15, penalty='l2', C=C)pr_temp.fit(X_train, y_train)score_temp = [pr_temp.score(X_train, y_train),pr_temp.score(X_test, y_test)]score_l2_15.append(score_temp) # 观察最终结果 plt.plot(list(np.arange(0.5, 2, 0.1)), np.array(score_l2_15)[:,0], label='train_acc') plt.plot(list(np.arange(0.5, 2, 0.1)), np.array(score_l2_15)[:,1], label='test_acc') plt.legend(loc = 4)
- 通过蛮力搜索,确定了一组能够让测试集准确率取得最大值的参数组合:degree=15, penalty=‘l2’, C=1.0,此时测试集准确率为0.9(可能会因为数据集而略有不同)
- 尽管上述过程能够帮助我们最终找到一组相对比较好的参数,最终建模结果略有提升,但上述手动调参过程存在三个问题:
(1) 过程不够严谨,诸如测试集中测试结果不能指导建模、参数选取及搜索区间选取没有理论依据等问题仍然存在;
(2) 执行效率太低,如果面对更多的参数(这是更一般的情况),手动执行过程效率太低,无法进行超大规模的参数挑选;
(3) 结果不够精确,一次建模结果本身可信度其实并不高,我们很难证明上述挑选出来的参数就一定在未来数据预测中拥有较高准确率 - 而要解决这些问题,需要了解关于机器学习调参的理论,以及掌握更多更高效的调参工具
- 正因如此,接下来会学习关于机器学习调参的基本理论以及 sklearn 中的网格搜索调参工具,而后我们再借助更完整的理论、更高效的工具解决这里的问题
- 小结
- 数据集准备——标准化——特征衍生——正则化——风险惩罚力度C
相关文章:
机器学习13(正则化)
文章目录 简介正则化经验风险和结构风险过拟合正则化建模策略 逻辑回归逻辑回归评估器 练习评估器训练与过拟合实验评估器的手动调参 简介 这一节详细探讨关于正则化的相关内容,并就 sklearn 中逻辑回归(评估器)的参数进行详细解释由于 skle…...
:原子数组、)
并发编程学习(十一):原子数组、
1、数组类型的原子类 原子数组类型,这个其实和AtomicInteger等类似,只不过在修改时需要指明数组下标。 CAS是按照来根据地址进行比较。数组比较地址,肯定是不行的,只能比较下标元素。而比较下标元素,就和元素的…...
递归到动态规划:省去枚举行为
如果在动态规划的过程中没有枚举行为,那严格位置依赖和傻缓存的方式并没有太大区别,但是当有枚举行为的时候(一个位置依赖于多个位置),那严格位置依赖是有优化空间的,枚举行为也许可以省去,题目…...

服务(第二十一篇)mysql高级查询语句(二)
①视图表: 视图表是虚拟表,用来存储SQL语句的定义 如果视图表和原表的字段相同,是可以进行数据修改的; 如果两者的字段不通,不可以修改数据。 语法: 创建:create view 试图表名 as ... 查…...

MYSQL高可用配置(MHA)
1、什么是MHA MHA(Master High Availability)是一套优秀的MySQL高可用环境下故障切换和主从复制的软件。 MHA 的出现就是解决MySQL 单点的问题。 MySQL故障切换过程中,MHA能做到0-30秒内自动完成故障切换操作。 MHA能在故障切换的过程中最大…...

单精度浮点数与十进制数据相互转换
一、float基础: Float类型占4个字节,也就是32bit,其中最高位是符号位,2~9位是指数位,后边的23bit是数值位.如下所示 大部分数据的二进制形式都可以用科学计数法表示,即1.m*2^n这种形式,只要知道m和n,就能确定一个数值 二、小数位如何转变为二进制: 下面…...

PMP敏捷-4大价值观、12原则
宣言及4大价值观 个体及互动 胜于 流程和工具 以人为本 工作的软件 胜于 完整的文档 以价值为导向 客户合作 胜于 合同谈判 合作共赢 应对变更 胜于 遵循计划 拥抱变化 12原则 工作原则:精益、至简,实现这种原则的方式是“定期反省”。9、10、12 …...
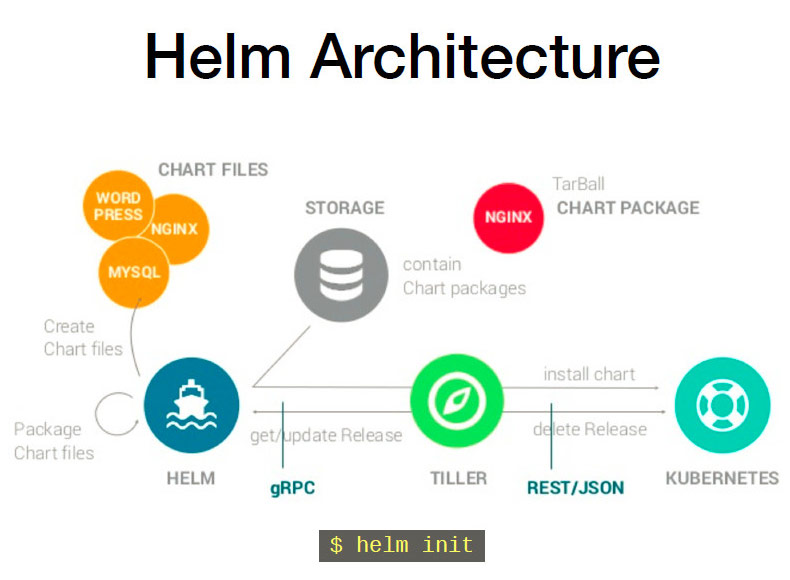
K8S—Helm
一、Helm介绍 helm通过打包的方式,支持发布的版本管理和控制,很大程度上简化了Kubernetes应用的部署和管理。 Helm本质就是让k8s的应用管理(Deployment、Service等)可配置,能动态生成。通过动态生成K8S资源清单文件&a…...

ALSA内部函数调用流程
ALSA内部函数调用流程 一直都有这样的一个疑问 就是在linux系统中我们调用snd_pcm_open后,就不知道alsa内部是怎么运行的了 用户的pcm_open()相当于先对ASoC各个驱动模块startup(),再做hw_params()。 pcm_open()pcm->fd open("/dev/snd/pcm…...

Python正则表达式详解,保姆式教学,0基础也能掌握正则
正则作为处理字符串的一个实用工具,在Python中经常会用到,比如爬虫爬取数据时常用正则来检索字符串等等。正则表达式已经内嵌在Python中,通过导入re模块就可以使用,作为刚学Python的新手大多数都听说”正则“这个术语。 今天来给…...

ChatGPT 接入飞书教程,创建自己的聊天机器人
ChatGPT 接入飞书教程,创建自己的聊天机器人 一、飞书进入开发者平台。点击创建应用。二、打开Aircode,点击创建应用,上面输入名字,下面选择Node.js v16三、配置环境,点击Environments,创建四个变量,全部要大写本教程收集于: AIGC从入门到精通教程 首先,准备三个账号…...
)
JS生成随机数(多种解决方案)
JS生成随机数 概述 随机数是编程语言中的重要组成部分。在JavaScript中,生成随机数是一项简单的任务。本文将介绍生成随机数的各种方法。 Math.random() Math.random()是JavaScript中生成随机数最常见的方法。该方法返回介于0和1之间的随机数。例如,…...

文件IO 函数 静态库和动态库的创建 5.11
5.11 文件IO函数 1.数据读写 ssize_t read(int fd,void *buf,size_t count); 功能: 从fd对应的文件中 读取前count个字节的数据到buf缓冲区中 头文件: #include <unistd.h> 参数: fd :文件描述符 buf…...

考研日语-详解ている、てある、ていく、てくる用法
目录 一、ている用法 1. 表示现在状态 2. 表示持续动作 3. 表示经验或习惯 4. 表示结果或效果 二、てある用法 1. 表示已经完成的动作 2. 表示现在状态 3. 表示被动 三、ていく用法 1. 表示未来的动作 2. 表示逐渐变化的过程 四、てくる用法 1. 表示过去到现在的…...

Spring Security 6.x 系列【36】授权服务器篇之OpenID Connect 1.0
有道无术,术尚可求,有术无道,止于术。 本系列Spring Boot 版本 3.0.4 本系列Spring Security 版本 6.0.2 本系列Spring Authorization Server 版本 1.0.2 源码地址:https://gitee.com/pearl-organization/study-spring-security-demo 文章目录 1. 前言2. OpenID Connect…...
【计算机视觉 | Pytorch】timm 包的具体介绍和图像分类案例(含源代码)
一、具体介绍 timm 是一个 PyTorch 原生实现的计算机视觉模型库。它提供了预训练模型和各种网络组件,可以用于各种计算机视觉任务,例如图像分类、物体检测、语义分割等等。 timm 的特点如下: PyTorch 原生实现:timm 的实现方式…...

轻博客Plume的搭建
什么是 Plume ? Plume 是一个基于 ActivityPub 的联合博客引擎。它是用 Rust 编写的,带有 Rocket 框架,以及 Diesel 与数据库交互。前端使用 Ructe模板、WASM 和SCSS。 反向代理 假设我们实际访问地址为: https://plume.laosu.ml…...

机器人关节电机PWM
脉冲宽度调制(Pulse width modulation,PWM)技术。一种模拟控制方式 机器人关节电机的控制通常使用PWM(脉冲宽度调制)技术。PWM是一种用于控制电子设备的技术,通过控制高电平和低电平之间的时间比例,实现对电子设备的控制。在机器人关节电机中,PWM信号可以控制电机的…...

MPU6050详解(含源码)
前言:MPU6050是一款强大的六轴传感器,需要理解MPU6050首先得有IIC的基础,MPU6050 内部整合了 3 轴陀螺仪和 3 轴加速度传感器,并且含有一个第二 IIC 接口,可用于连接外部磁力传感器,内部有硬件算法支持. 1…...

Vue入门学习笔记:TodoList(三):实例中的数据、事件和方法
目录: Vue入门学习笔记:TodoList(一):HelloWorld Vue入门学习笔记:TodoList(二):挂载点、模板、实例 Vue入门学习笔记:TodoList(三)&a…...

React 第五十五节 Router 中 useAsyncError的使用详解
前言 useAsyncError 是 React Router v6.4 引入的一个钩子,用于处理异步操作(如数据加载)中的错误。下面我将详细解释其用途并提供代码示例。 一、useAsyncError 用途 处理异步错误:捕获在 loader 或 action 中发生的异步错误替…...

如何在看板中体现优先级变化
在看板中有效体现优先级变化的关键措施包括:采用颜色或标签标识优先级、设置任务排序规则、使用独立的优先级列或泳道、结合自动化规则同步优先级变化、建立定期的优先级审查流程。其中,设置任务排序规则尤其重要,因为它让看板视觉上直观地体…...

FastAPI 教程:从入门到实践
FastAPI 是一个现代、快速(高性能)的 Web 框架,用于构建 API,支持 Python 3.6。它基于标准 Python 类型提示,易于学习且功能强大。以下是一个完整的 FastAPI 入门教程,涵盖从环境搭建到创建并运行一个简单的…...

1.3 VSCode安装与环境配置
进入网址Visual Studio Code - Code Editing. Redefined下载.deb文件,然后打开终端,进入下载文件夹,键入命令 sudo dpkg -i code_1.100.3-1748872405_amd64.deb 在终端键入命令code即启动vscode 需要安装插件列表 1.Chinese简化 2.ros …...

在QWebEngineView上实现鼠标、触摸等事件捕获的解决方案
这个问题我看其他博主也写了,要么要会员、要么写的乱七八糟。这里我整理一下,把问题说清楚并且给出代码,拿去用就行,照着葫芦画瓢。 问题 在继承QWebEngineView后,重写mousePressEvent或event函数无法捕获鼠标按下事…...

PHP 8.5 即将发布:管道操作符、强力调试
前不久,PHP宣布了即将在 2025 年 11 月 20 日 正式发布的 PHP 8.5!作为 PHP 语言的又一次重要迭代,PHP 8.5 承诺带来一系列旨在提升代码可读性、健壮性以及开发者效率的改进。而更令人兴奋的是,借助强大的本地开发环境 ServBay&am…...

n8n:解锁自动化工作流的无限可能
在当今快节奏的数字时代,无论是企业还是个人,都渴望提高工作效率,减少重复性任务的繁琐操作。而 n8n,这个强大的开源自动化工具,就像一位智能的数字助手,悄然走进了许多人的工作和生活,成为提升…...

Clickhouse统计指定表中各字段的空值、空字符串或零值比例
下面是一段Clickhouse SQL代码,用于统计指定数据库中多张表的字段空值情况。代码通过动态生成查询语句实现自动化统计,处理逻辑如下: 从系统表获取指定数据库(替换your_database)中所有表的字段元数据根据字段类型动态…...
跑通 TrackNet-Badminton-Tracking-tensorflow2 项目全记录
📝 跑通 TrackNet-Badminton-Tracking-tensorflow2 项目全记录 git clone https://github.com/Chang-Chia-Chi/TrackNet-Badminton-Tracking-tensorflow2.git TrackNet-Badminton-Tracking-tensorflow2 conda create --prefix /cloud/TrackNet-Badminton-Tracking-…...

ES海量数据更新及导入导出备份
一、根据查询条件更新字段 from elasticsearch import Elasticsearch import redis import json# 替换下面的用户名、密码和Elasticsearch服务器地址 username elastic password password es_host https://127.0.0.2:30674# 使用Elasticsearch实例化时传递用户名和密码 es…...